
str.match(regexp)
Метод ищет совпадения с в строке .
У него есть три режима работы:
-
Если у регулярного выражения нет флага , то он возвращает первое совпадение в виде массива со скобочными группами и свойствами (позиция совпадения), (строка поиска, равна ):
-
Если у регулярного выражения есть флаг , то он возвращает массив всех совпадений, без скобочных групп и других деталей.
-
Если совпадений нет, то, вне зависимости от наличия флага , возвращается .
Это очень важный нюанс. При отсутствии совпадений возвращается не пустой массив, а именно . Если об этом забыть, можно легко допустить ошибку, например:
Если хочется, чтобы результатом всегда был массив, можно написать так:
Проверка наличия совпадения
Регулярные выражения используются для описания текста, который требуется найти в строке (и возможно, подвергнуть дополнительной обработке). Давайте вернемся к примеру, который приводился ранее в этом блоге:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Aaron,Jeff';
Допустим, мы хотим определить на программном уровне, содержит ли строка список имен, разделенных запятыми. Для этого мы воспользуемся функцией , обнаруживающей совпадения шаблона в строке:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
BEGIN
--Поиск по шаблону
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$');
--Вывод результата
DBMS_OUTPUT.PUT_LINE(
CASE comma_delimited
WHEN true THEN 'Обнаружен список с разделителями!'
ELSE 'Совпадение отсутствует.'
END);
END;
Результат:
Обнаружен список с разделителями
Чтобы разобраться в происходящем, необходимо начать с выражения, описывающего искомый текст. Общий синтаксис функции выглядит так:
REGEXP_LIKE (исходная_строка, шаблон )
Здесь — символьная строка, в которой ищутся совпадения; шаблон — регулярное выражение, совпадения которого ищутся в исходной_строке; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Если функция находит совпадение шаблона в , она возвращает логическое значение ; в противном случае возвращается .
Процесс построения регулярного выражения выглядел примерно так:
- Каждый элемент списка имен может состоять только из букв и пробелов. Квадратные скобки определяют набор символов, которые могут входить в совпадение. Диапазон a–z описывает все буквы нижнего регистра, а диапазон A–Z — все буквы верхнего регистра. Пробел находится между двумя компонентами выражения. Таким образом, этот шаблон описывает один любой символ нижнего или верхнего регистра или пробел.
- * Звездочка является квантификатором — служебным символом, который указывает, что каждый элемент списка содержит ноль или более повторений совпадения, описанного шаблоном в квадратных скобках.
- *, Каждый элемент списка должен завершаться запятой. Последний элемент является исключением, но пока мы не будем обращать внимания на эту подробность.
- *,) Круглые скобки определяют подвыражение, которое описывает некоторое количество символов, завершаемых запятой. Мы определяем это подвыражение, потому что оно должно повторяться при поиске.
- ]*,)+ Знак + — еще один квантификатор, применяемый к предшествующему элементу (то есть к подвыражению в круглых скобках). В отличие от * знак + означает «одно или более повторений». Список, разделенный запятыми, состоит из одного или нескольких повторений подвыражения.
- ( В шаблон добавляется еще одно подвыражение: (*). Оно почти совпадает с первым, но не содержит запятой. Последний элемент списка не завершается запятой.
- Мы добавляем квантификатор {1}, чтобы разрешить вхождение ровно одного элемента списка без завершающей запятой.
- ^ Наконец, метасимволы ^ и привязывают потенциальное совпадение к началу и концу целевой строки. Это означает, что совпадением шаблона может быть только вся строка вместо некоторого подмножества ее символов.
Функция анализирует список имен и проверяет, соответствует ли он шаблону. Эта функция оптимизирована для простого обнаружения совпадения шаблона в строке, но другие функции способны на большее!
Наборы и диапазоны
Наборы и диапазоны могут пригодиться, когда нужно указать специальные символы набора или их диапазон.
/* Набор или диапазон - Значение */ - любой один из символов в скобках. — любой символ, за исключением символов в скобках. - любой символ в диапазоне от "a" до "z". - любой символ не из диапазона от "a" до "z".(x) - "x", значение запоминается для дальнейшего использования.(?<name>x) - создание именованной скобочной группы, к которой можно обратиться по указанному имени.(?:x) - "x", значение не запоминается, поэтому совпадение невозможно извлечь из итогового массива элементов.
Примеры:
// - Любой один из символов в скобках.const myPattern = //console.log(myPattern.test('aei'))// true (есть a, e, i)console.log(myPattern.test('form'))// false (нет a, e или i)// - Любой символ, за исключением символов в скобках.const myPattern = //console.log(myPattern.test('aei'))// false (нет других символов, кроме a, e и i)console.log(myPattern.test('form'))// true (есть другие символы, кроме a, e и i)// - Любой символ в диапазоне от "a" до "z".const myPattern = //console.log(myPattern.test('bcd'))// true (есть символы в диапазоне от 'b' до 'g')console.log(myPattern.test('jklm'))// false (нет символов в диапазоне от 'b' до 'g')// - Любой символ не из диапазона от "a" до "z".const myPattern = //console.log(myPattern.test('bcd'))// false (нет других символов, кроме входящих в диапазон от 'b' до 'g')console.log(myPattern.test('jklm'))// true (есть другие символы, кроме входящих в диапазон от 'b' до 'g')// (x) - "x", значение запоминается для дальнейшего использования.const myPattern = /(na)da\1/console.log(myPattern.test('nadana'))// true - \1 запоминает и использует совпадение 'na' из первого выражения в скобках.console.log(myPattern.test('nada'))// false// (?<name>x) - Создание именованной скобочной группы, к которой можно обратиться по указанному имени.const myPattern = /(?<foo>is)/console.log(myPattern.test('Work is created.'))// trueconsole.log(myPattern.test('Just a text'))// false// (?:x) - "x", значение не запоминается.const myPattern = /(?:war)/console.log(myPattern.test('warsawwar'))// trueconsole.log(myPattern.test('arsaw'))// false
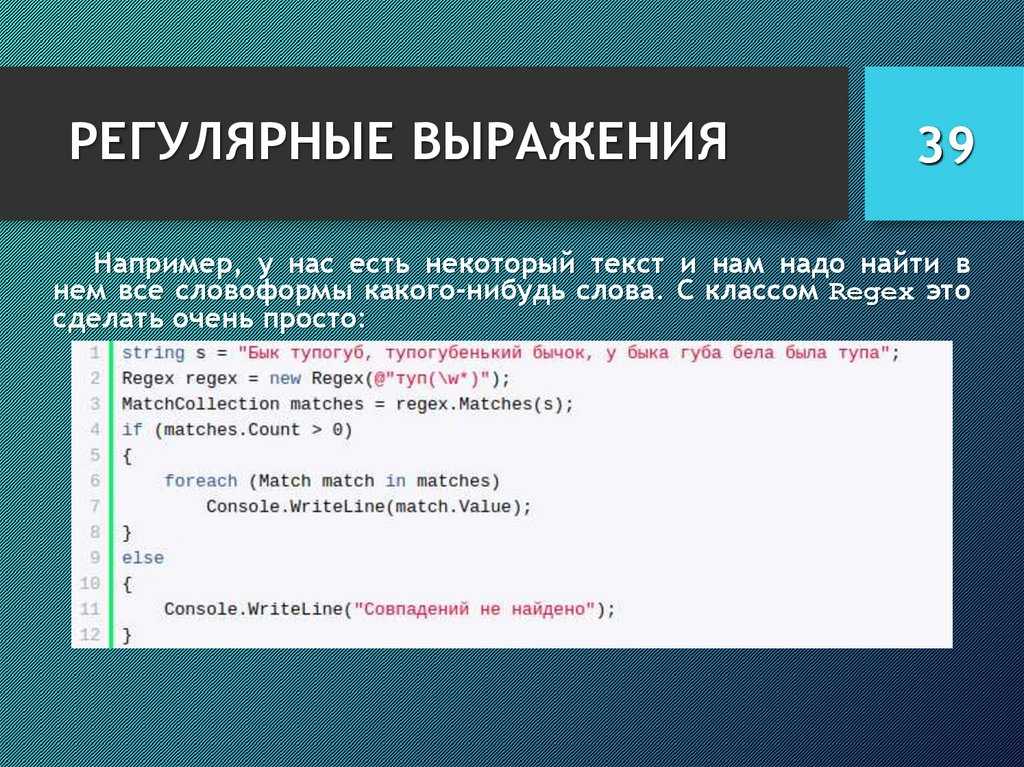
Разделители¶
Разделители строк
| Метасимвол | Находит |
|---|---|
| любой символ в строке, может включать разделители строк | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| похож на но совпадает перед разделителем строки, а не сразу после него, как |
Примеры:
| RegEx | Находит |
|---|---|
| только если он находится в начале строки | |
| , только если он в конце строки | |
| только если это единственная строка в строке | |
| , , и так далее |
Метасимвол совпадает с точкой начала строки (нулевой длины). — в конце строки. Если включен , они совпадают с началами или концами строк внутри текста.
Обратите внимание, что в последовательности нет пустой строки. Примечание
Примечание
Если вы используете , то / также соответствует , , , или .
Метасимвол совпадает с точкой нулевой длины в начале строки, — в конце (после символов завершения строки). Модификатор на них не влияет. тоже самое что но совпадает с точкой перед символами завершения строки (LF and CR LF).
Метасимвол по умолчанию соответствует любому символу, но если вы выключите , то не будет совпадать с разделителями строк внутри строки.
Обратите внимание, что выражение не соответствует точке между , потому что это неразрывный разделитель строк. Но оно соответствует пустой строке в последовательности , поэтому из-за неправильного порядка кодов он не воспринимается как разделитель строк и считается просто двумя символами
Примечание
Многострочная обработка может быть настроена с помощью свойств и .
Таким образом, вы можете использовать разделители стиля Unix или стиль DOS / Windows или смешивать их вместе (как описано выше по умолчанию).
Если вы предпочитаете математически правильное описание, вы можете найти его на сайте www.unicode.org.





![[урок 6] . регулярные выражения в javascript. основы. - nagibaka.ru](https://luxe-host.ru/wp-content/uploads/a/0/8/a08ae33898ee2151eb9e9d1db7e3a2de.jpeg)



Regular expression syntax
Regular expressions typically specify characters (or character classes) to seek out, possibly with information about repeats and location within the string. This is accomplished with the help of metacharacters that have specific meaning: . We will use some small examples to introduce regular expression syntax and what these metacharacters mean.
Escape sequences
There are some special characters in R that cannot be directly coded in a string. For example, apostrophes. Apostrophes can be used in R to define strings (as well as quotation marks). For example will return an error. When we want to use an apostrophe as an apostrophe and not a string delimiter, we need to use the “escape” character . You would have to “escape” the single quote in the pattern, by preceding it with , so it’s clear it is not part of the string-specifying machinery. So will work. Let’s search the country names for those with an apostrophe:
There are other characters in R that require escaping, and this rule applies to all string functions in R, including regular expressions:
- : single quote. You don’t need to escape single quote inside a double-quoted string, so we can also use in the previous example.
- : double quote. Similarly, double quotes can be used inside a single-quoted string, i.e. .
- : newline.
- : carriage return.
- : tab character.
Quantifiers
Quantifiers specify how many repetitions of the pattern.
- : matches at least 0 times.
- : matches at least 1 times.
- : matches at most 1 times.
- : matches exactly n times.
- : matches at least n times.
- : matches between n and m times.
Run the following while taking the time to understand the logic:
Exercise
Using quantifiers find all countries with , but not , in its name
Position of pattern within the string
- : matches the start of the string.
- : matches the end of the string.
- : matches the empty string at either edge of a word. Don’t confuse it with which marks the edge of a string.
- : matches the empty string provided it is not at an edge of a word.
For the last example, is not a recognized escape character, so we need to double slash it .
Exercise
Find the string of country names that
- Start with “South”
- End in “land”
- Have a word in its name that starts with “Ga”
Character classes
Character classes allows to – surprise! – specify entire classes of characters, such as numbers, letters, etc. There are two flavors of character classes, one uses and around a predefined name inside square brackets and the other uses and a special character. They are sometimes interchangeable.
- or : digits, 0 1 2 3 4 5 6 7 8 9, equivalent to .
- : non-digits, equivalent to .
- : lower-case letters, equivalent to .
- : upper-case letters, equivalent to .
- : alphabetic characters, equivalent to or .
- : alphanumeric characters, equivalent to or .
- : word characters, equivalent to or .
- : not word, equivalent to .
- : hexadecimal digits (base 16), 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f, equivalent to .
- : blank characters, i.e. space and tab.
- : space characters: tab, newline, vertical tab, form feed, carriage return, space.
- : space, ` `.
- : not space.
- : punctuation characters, ! » # $ % & ’ ( ) * + , — . / : ; < = > ? @ ^ _ ` { | } ~.
- : graphical (human readable) characters: equivalent to .
- : printable characters, equivalent to .
- : control characters, like or , .
Note:
- has to be used inside square brackets, e.g. .
- itself is a special character that needs escape, e.g. . Do not confuse these regular expressions with R escape sequences such as .
Exercise
- Find all countries that use punctuation in its name
- Rewrite the function from HW04 that takes in a string and
- keeps only alpha-numeric characters
- removes all spaces
- converts to lower case and returns it the newly formatted string. For example should return
Конструктор регулярных выражений
Первый способ — использование конструктора. Это громкое слово на самом деле означает функцию-конструктор объекта RegExp. Конструктор принимает два параметра. Первый — шаблон, который вы хотите описать. Это обязательный параметр. В конце концов, зачем вообще создавать регулярное выражение, если нет шаблона?
Второй параметр — строка с флагами (). Не волнуйтесь, скоро мы с ними познакомимся. Этот параметр необязательный. Стоит запомнить одно: после создания регулярного выражения флаги уже нельзя будет добавить или убрать. Поэтому, если хотите использовать флаг, добавьте его на этапе создания выражения.
// Синтаксис конструктора регулярных выраженийnew RegExp(pattern)// Создание регулярного выражения// с помощью конструктора// без флаговconst myPattern = new RegExp('')// Создание регулярного выражения// с помощью конструктора// с одним флагомconst myPattern = new RegExp('', 'g')
Реализации[править]
- NFA (Nondeterministic Finite State Machine; Недетерминированные Конечные Автоматы) используют «жадный» алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA, выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (Deterministic Finite-state Automaton; Детерминированные Конечные Автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть, не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
Разбить число на разряды
Задача: Разбить число на разряды например запятыми. Формально задача выглядит так «вставить запятые во всех позициях, у которых количество цифр справа кратно трем, а слева есть хотя бы одна цифра»
Второе требование выполняется при помощи ретроспективной проверки. Одной цифры слева достаточно для выполнения этого требования, а этот критерий задается выражением (?⇐\d).
Группа из трех цифр определяется выражением \d\d\d. Заключим ее в конструкцию (…)+, чтобы совпадение могло состоять из нескольких групп, и завершим метасимволом $, чтобы гарантировать отсутствие символов после совпадения. Само по себе выражение (\d\d\d)+$ совпадает с группами из трех цифр, следующими до конца строки, но в конструкции опережающей проверки (?=…) оно совпадает с позицией, справа от которой до конца строки следуют группы из трех цифр. Однако перед первой цифрой запятая не ставится, поэтому совпадение дополнительно ограничивается ретроспективной проверкой (?⇐\d).
Чтобы выражение стало более эффективным можно добавить несохраняющие скобки ?: в (?:\d\d\d), в этом случае подсистема регулярных выражений не будет тратить ресурсы на сохранение текста в круглых скобках.
Реализация PHP (PCRE библиотека регулярных выражений):<?php $n = «7500400300222»;
//$n = preg_replace(‘/(?<=\d)(?=(\d\d\d)+$)/’, ‘,’, $n);
$n = preg_replace(‘/(?<=\d)(?=(?:\d\d\d)+$)/’, ‘,’, $n);
echo «$n\n»;
?>
Ссылки
- Джеффри Фридл — «Регулярные выражения» 3-е издание ISBN-13: 978-5-93286-121-9 ISBN-10: 5-93286-121-5
-
Библиотека регулярных выражений
-
Google Analytics Регулярные выражения
Поиск от заданной позиции
Можно заставить regexp.exec начать поиск с данной позиции, установив вручную lastIndex:
let str = 'A lot about JavaScript at https://javascript.info'; let regexp = /javascript/ig; regexp.lastIndex = 30; alert( regexp.exec(str).index ); // 34, поиск начинается с 30-й позиции
Флаг «y»
Флаг y значит, что поиск должен найти совпадение на позиции, указанной в свойстве regexp.lastIndex, и только там.
Другими словами, обычно поиск идет по всей строке: /javascript/ ищет подстроку “javascript”. Но когда JavaScript RegExp содержит флаг y, оно ищет только совпадение на позиции, указанной в regexp.lastIndex(по умолчанию — 0).
Например:
let str = "I love JavaScript!"; let reg = /javascript/iy; alert( reg.lastIndex ); // 0 (по умолчанию) alert( str.match(reg) ); // null, не найдено на позиции 0 reg.lastIndex = 7; alert( str.match(reg) ); // JavaScript (это слово начинается на позиции 7) // для любого другого индекса reg.lastIndex результат - null
Регулярное выражение /javascript/iy может быть найдено, только если установить reg.lastIndex=7, так как из-за флага y программа пытается найти его только в одном месте внутри строки — на позиции reg.lastIndex.
Так в чем же смысл? В производительности.
Флаг y отлично работает для парсеров – программ, которым нужно «читать» текст и строить в памяти синтаксическую структуру или производить на ее основании действия. Для этого мы двигаемся по тексту и применяем регулярные выражения, чтобы увидеть, что находится дальше: строка, число или что-то еще.
Флаг y позволяет применять регулярное выражение (или несколько одно за другим) именно на заданной позиции. И когда мы поймем, что там, то сможем двигаться дальше, шаг за шагом исследуя текст.









Без флага y регулярное выражение всегда ищет до конца текста, что занимает время, особенно если текст большой. Тогда наш парсер будет медленным. Флаг y — это то, что нужно в подобном случае.
Область применения регулярных выражений
В прошлом уроке мы разбирали работу со строками и там было несколько функций для поиска и извлечения искомых подстрок. Может возникнуть вопрос, а зачем придумывать что-то еще, если у нас уже есть достаточно богатый функционал для раздербанивания и анализа строк? Отвечаю, при работе с огромным количество текста, особенно, который генерируется динамически, можно проследить некоторые паттерны(повторяющиеся фрагменты и структура текста в-целом). Допустим, нам нужно выдрать из таблички все названия товаров и цены, а сколько данных будет в таблице — нам не известно. Можно в цикле использовать и, но код получится громоздким и не очень надежным. Регулярные выражения очень удобно использовать для валидации данных, например для электронной почты, номера телефона, даты и т.д.
Помните задачку из прошлого урока «Определение баланса биткойн-крана»? Там мы находили определенный тэг и из него извлекали текст, после чего получали оттуда цифру. Если мы попытались бы использовать тот же скрипт на другом кране — не факт, что он заработал бы, поскольку сведения о балансе могли находится в совершенно другом тэге с другим классом и другими атрибутами.
При помощи регулярных выражений мы можем сделать универсальный скрипт, который будет искать баланс крана не по тэгу, а в тексте страницы.
Алгоритм такой:
- Мы получаем содержимое всей страницы в текстовом формате
- Составляем паттерн на основе строки Balance: 145335 satoshi. Логически это выглядит примерно так
- Ищем в тексте все совпадения с нашим паттерном и при успехе, вытаскиваем значение из 1-9 цифр.
Выглядеть это будет так:
var str = window.document.querySelector('body').textContent;
var re = /Balance:\s{0,}(\d{1,9})\s{0,}satoshi/igm;
var result = re.exec(str);
window.console.log(result); //
window.console.log(result); // 145335 - это баланс нашего крана
Я пока не буду подробно разбирать этот код, все подробности ниже.Что действительно круто, регулярные выражения работают очень быстро и позволяют просто с хирургической точностью вытаскивать нужные данные и мы можем легко проанализировать все совпадения с заданным паттерном.
regexp.test(str)
Метод ищет совпадение и возвращает , в зависимости от того, находит ли он его.
Например:
Пример с отрицательным ответом:
Если регулярное выражение имеет флаг , то ищет, начиная с и обновляет это свойство, аналогично .
Таким образом, мы можем использовать его для поиска с заданной позиции:
Одно и то же регулярное выражение, использованное повторно на другом тексте, может дать другой результат
Если мы применяем одно и то же регулярное выражение последовательно к разным строкам, это может привести к неверному результату, поскольку вызов обновляет свойство , поэтому поиск в новой строке может начаться с ненулевой позиции.
Например, здесь мы дважды вызываем для одного и того же текста, и второй раз поиск завершается уже неудачно:
Это именно потому, что во втором тесте не равен нулю.
Чтобы обойти это, можно присвоить перед новым поиском. Или вместо методов на регулярном выражении вызывать методы строк , они не используют .
Конструктор или литерал?
Конструктор и литерал выполняют одну функцию, но есть одно важное различие. Регулярное выражение, созданное при помощи конструктора, компилируется при выполнении программы, литерал — на этапе загрузки скрипта
Это значит, что литерал нельзя изменить динамически, в то время как конструктор — можно.
Таким образом, если вам нужно (или может понадобиться) изменить шаблон на лету, создавайте регулярное выражение с помощью конструктора. Также конструктор будет лучшим решением, если шаблон нужно создавать динамически. С другой стороны, если вам не понадобится менять или создавать шаблон, вы можете воспользоваться литералом.
Как использовать регулярные выражения с методами объекта RegExp?
Прежде чем приступить к созданию шаблонов, давайте кратко рассмотрим, как они используются. С помощью описанных ниже методов мы сможем в дальнейшем применять разные способы создания шаблонов.
В теории формальных языков[править]
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно. На данном конечном алфавите Σ определены следующие константы:
- (пустое множество) ∅ обозначает ∅
- (пустая строка) ε обозначает множество {ε}
- (строка) a в Σ обозначает множество {a}
и следующие операции:
- (связь, конкатенация) RS обозначает множество { αβ | α из R и β из S }. Пример: {«ab», «c»}{«d», «ef»} = {«abd», «abef», «cd», «cef»}.
- (перечисление) R|S обозначает объединение R и S.
- (замыкание Клини, звезда Клини) R* обозначает минимальное надмножество из R, которое содержит ε и закрыто связью строк. Это есть множество всех строк, которые могут быть получены связью нуля или более строк из R. Например, {«ab», «c»}* = {ε, «ab», «c», «abab», «abc», «cab», «cc», «ababab», … }.
Многие книги используют символы ∪, + или ∨ для перечисления вместо вертикальной черты.
Question mark meta character
The question mark (?) meta character is a quantifier that matches the
previous element zero or one time.
question_mark_meta.js
let words = ;
let pattern = /.?even/;
words.forEach(word => {
if (pattern.test(word)) {
console.log(`the ${word} matches`);
}
});
In the example, we add a question mark after the dot character. This means that
in the pattern we can have one arbitrary character or we can have no character
there.








$ node question_mark_meta.js the seven matches the even matches the prevent matches the revenge matches the eleven matches the event matches
This time the even and event words, which do not have a preceding character,
match as well.
Window
Window Object
alert()
atob()
blur()
btoa()
clearInterval()
clearTimeout()
close()
closed
confirm()
console
defaultStatus
document
focus()
frameElement
frames
history
getComputedStyle()
innerHeight
innerWidth
length
localStorage
location
matchMedia()
moveBy()
moveTo()
name
navigator
open()
opener
outerHeight
outerWidth
pageXOffset
pageYOffset
parent
print()
prompt()
resizeBy()
resizeTo()
screen
screenLeft
screenTop
screenX
screenY
scrollBy()
scrollTo()
scrollX
scrollY
sessionStorage
self
setInterval()
setTimeout()
status
stop()
top
Window Console
assert()
clear()
count()
error()
group()
groupCollapsed()
groupEnd()
info()
log()
table()
time()
timeEnd()
trace()
warn()
Window History
back()
forward()
go()
length
Window Location
assign()
hash
host
hostname
href
origin
pathname
port
protocol
reload()
replace()
search
Window Navigator
appCodeName
appName
appVersion
cookieEnabled
geolocation
javaEnabled()
language
onLine
platform
product
taintEnabled()
userAgent
Window Screen
availHeight
availWidth
colorDepth
height
pixelDepth
width
The new .matchAll() method
Now that you know all about the method, it’s worth pointing out that the method was recently introduced.
Unlike the method which returns an array or , requires the global search flag (), and returns either an iterator or an empty array:
While it seems like just a more complicated method, the main advantage that offers is that it works better with capture groups.
Here’s a simple example:
While that just barely scratches the surface, keep in mind that it’s probably better to use if you’re using the flag and want all the extra information that provides for a single match (index, the original string, and so on).



