
Содержание
User Contributed Notes 35 notes
Please note that all the discussion about mb_str_replace in the comments is pretty pointless. str_replace works just fine with multibyte strings:
= ‘漢字はユニコード’ ; $needle = ‘は’ ; $replace = ‘Foo’ ;
?>
The usual problem is that the string is evaluated as binary string, meaning PHP is not aware of encodings at all. Problems arise if you are getting a value «from outside» somewhere (database, POST request) and the encoding of the needle and the haystack is not the same. That typically means the source code is not saved in the same encoding as you are receiving «from outside». Therefore the binary representations don’t match and nothing happens.
PHP can input and output Unicode, but a little different from what Microsoft means: when Microsoft says «Unicode», it unexplicitly means little-endian UTF-16 with BOM(FF FE = chr(255).chr(254)), whereas PHP’s «UTF-16» means big-endian with BOM. For this reason, PHP does not seem to be able to output Unicode CSV file for Microsoft Excel. Solving this problem is quite simple: just put BOM infront of UTF-16LE string.
SOME multibyte encodings can safely be used in str_replace() and the like, others cannot. It’s not enough to ensure that all the strings involved use the same encoding: obviously they have to, but it’s not enough. It has to be the right sort of encoding.
UTF-8 is one of the safe ones, because it was designed to be unambiguous about where each encoded character begins and ends in the string of bytes that makes up the encoded text. Some encodings are not safe: the last bytes of one character in a text followed by the first bytes of the next character may together make a valid character. str_replace() knows nothing about «characters», «character encodings» or «encoded text». It only knows about the string of bytes. To str_replace(), two adjacent characters with two-byte encodings just looks like a sequence of four bytes and it’s not going to know it shouldn’t try to match the middle two bytes.
While real-world examples can be found of str_replace() mangling text, it can be illustrated by using the HTML-ENTITIES encoding. It’s not one of the safe ones. All of the strings being passed to str_replace() are valid HTML-ENTITIES-encoded text so the «all inputs use the same encoding» rule is satisfied.
The text is «x = ‘x ; mb_internal_encoding ( ‘HTML-ENTITIES’ );
?>
Even though neither ‘l’ nor ‘;’ appear in the text «x y» and in the other it broke the encoding completely.
One more reason to use UTF-8 if you can, I guess.
Yet another single-line mb_trim() function
PHP5 has no mb_trim(), so here’s one I made. It work just as trim(), but with the added bonus of PCRE character classes (including, of course, all the useful Unicode ones such as \pZ).
Unicode
Решить проблему в рамках 8-битных (где символ занимает 1 байт) кодировок было нельзя. Число разных символов было больше, чем 256. Потому при разработке нового стандарта Unicode решили отказаться от идеи «1 символ = 1 байт» и просто присваивать символам номера по порядку (эти номера называются codepoint), не ограничиваясь каким-либо числом. Таким образом, получается единая таблица кодов символов, которую не придется менять, и можно добавлять новые коды в конец таблицы.
Первые 128 символов с кодами 0-127 повторяют таблицу ASCII, а далее идут символы и буквы различных алфавитов. Цель Юникода — присвоить код всем существующим и существовавшим когда-либо символам. Юникод включает даже буквы умерших алфавитов вроде древнеегипетского, а также современные значки вроде эмодзи. Сейчас Юникод содержит около 110 000 символов.
Кроме обычных символов, Юникод содержит символы-модификаторы. Они печатаются поверх предыдущего символа. Это позволяет, например, добавить кружочек или черточку сверху к любому символу. С другой стороны, это немного усложняет работу с текстом, так как один символ на печати кодируется несколькими кодами (символ + модификаторы). Например, текстовый редактор должен уметь воспринимать такую комбинацию как один символ.
Я советую посмотреть, какие виды символов есть в Юникоде:
Казалось бы, с приходом Юникода проблема разных кодировок исчезнет, но не тут-то было.
В UTF-16 символы с кодами менее 55296 (D800 в 16-чной системе счисления) кодируются 2 байтами, и символы с кодами выше (которые появились в UCS-4) кодируются как суррогатная пара, 4 байтами, как будто это 2 обычных символа с кодами больше 55296.
Переход на Юникод требовал полной переделки программ. Библиотеки для операций со строками считали, что один символ занимает 1 байт, и не могли даже посчитать число символов в юникодной строке, не говоря о более сложных операциях. Майкрософт, проделав огромный объем работы, сделала поддержку UTF-16 в Windows, и ей пришлось сделать по 2 варианта каждой системной функции — для старых программ с 1-байтными кодировками, и для новых, юникодных. Появившийся в то время язык Java тоже решил использовать UTF-16 для хранения строк.
Но многие разработчики не хотели переделывать код. Также, англоязычным разработчикам не нравилась необходимость тратить в 2 раза больше места на хранение строк. Потому был придуман еще один способ кодирования Юникода — UTF-8. В этой кодировке символы с кодами 0-127 (из ASCII) кодируются одним байтом, и текст из ASCII-символов кодируется одинаково и в ASCII и в UTF-8. Таким образом, старая программа может обрабатывать UTF-8 текст, если он содержит только латиницу.
Другие символы Юникода в UTF-8 кодируются большим числом байт — от 1 до 6, чем больше код символа, тем больше байт требуется. Кириллица, например, требует 2 байта на символ. Старые программы воспримут символ кириллицы как 2 отдельных символа и могут повредить строку, например, отрезав один байт из двух.
Таким образом, есть как минимум 5 вариантов записи кодов Юникода в памяти: UTF-32 LE/BE, UTF-16 LE/BE, UTF-8. Вот их преимущества и недостатки:
- в UTF-32 каждый символ занимает ровно 4 байта, что позволяет делать операции со строками быстрее. Ну например, чтобы перейти к 500-му символу, нам достаточно умножить 500 на 4 и пропустить 2000 байт от начала строки. В кодировках вроде UTF-8 с разным размером символов нам придется просматривать байты от начала строки, отсчитывая эти 500 символов, что делает любые операции со строками намного медленее. С другой стороны, строки обычно не очень большие по размеру, а процессоры — быстрые, так что в большинстве случаев это не влияет на производительность программы.
- текст на латинице в UTF-32 занимает в 4 раза больше памяти и места на диске, чем в UTF-8
- в UTF-16 символ занимает ровно 2 байта при отказе от суррогатных пар (они кодируют редко используемые символы и не всегда нужны), что экономнее, при этом работа со строками оптимизируется. С другой стороны, символы эмодзи (смайлики) кодируются именно суррогатными парами, и для их поддержки приходится отказываться от оптимизаций.
- UTF-8 позволяет использовать старые библиотеки при условии обработки текстов на латинице и строка в этой кодировке, как правило, занимает меньше места, чем UTF-16 и UTF-32. Но операции со строками становятся медленнее.
На практике в большинстве случаев используют UTF-8. Windows, Java и Javascript внутри используют UTF-16.
Стоит помнить, что текст в памяти или в файле — это лишь набор байт. Чтобы понять, каким символам они соответствуют, надо знать кодировку текста.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
Настройка PowerShell
В PowerShell кодировка по умолчанию зависит от версии:
- В PowerShell 6+ кодировка по умолчанию на всех платформах — UTF-8 без метки порядка байтов.
- В Windows PowerShell кодировка по умолчанию — обычно Windows-1252, расширение latin-1, которое также называется ISO 8859-1.
В PowerShell 5 + можно определить кодировку по умолчанию так:
Следующий скрипт может использоваться для определения кодировки, которую ваш сеанс PowerShell выводит для скрипта, где нет метки порядка байтов.
Можно настроить PowerShell так, чтобы использовать заданную кодировку в более общем виде с помощью параметров профиля.
См. следующие статьи:
- (https://stackoverflow.com/a/40098904).
- (https://rkeithhill.wordpress.com/2010/05/26/handling-native-exe-output-encoding-in-utf8-with-no-bom/).
Заставить PowerShell использовать конкретную кодировку для входных данных невозможно. В PowerShell 5.1 и более ранних версий в Windows с языковым стандартом en-US по умолчанию используется кодировка Windows-1252, если отсутствует метка порядка байтов. Другие параметры языкового стандарта могут использовать другую кодировку. Для обеспечения совместимости лучше сохранять скрипты в Юникоде с меткой порядка байтов.
Важно!
Любые другие имеющиеся у вас инструменты для работы со скриптами PowerShell могут зависеть от выбранных параметров кодировки или преобразовывать скрипты в другую кодировку.
Существующие скрипты
Скрипты, которые уже находятся в файловой системе, могут нуждаться в повторном кодировании в указанную вами кодировку. В нижней строке VS Code вы увидите метку UTF-8. Щелкните ее, чтобы открыть панель действий, и выберите команду Сохранить с кодировкой. Теперь вы можете выбрать новую кодировку для этого файла. Подробные инструкции см. в разделе .
Если вам нужно повторно кодировать несколько файлов, можно использовать следующий скрипт:
Интегрированная среда сценариев (ISE) PowerShell
При редактировании скриптов с помощью интегрированной среды сценариев PowerShell необходимо синхронизировать здесь параметры кодировки.
Интегрированная среда сценариев должна учитывать метку порядка байтов, но можно также использовать отражение для задания кодировки.
Обратите внимание, что это значение не сохраняется между запусками
Система управления версиями
Некоторые системы управления версиями, например git, игнорируют кодировки; git отслеживает только байты. Поведение других, например Azure DevOps или Mercurial, может отличаться. Даже некоторые средства, основанные на git, полагаются на декодирование текста.




Если это так, убедитесь, что вы:
- Настроили кодировку в системе управления версиями в соответствии с вашей конфигурацией VS Code.
- Сделали так, что все файлы добавляются в систему управления версиями в соответствующей кодировке.
- Остерегайтесь изменять кодировки, полученные через систему управления версиями. Ключевым признаком здесь будет разностный файл, который указывает, что изменения отсутствуют (так как изменены байты, но не символы).
Среды других участников
Настроив систему управления версиями, убедитесь также, что параметры других участников, работающих над теми файлами, к которым вы предоставляете общий доступ, не переопределяют кодировку путем повторного кодирования файлов PowerShell.
Другие программы
Все другие программы, которые считывают или записывают скрипты PowerShell, могут перекодировать их.
Некоторые примеры.
- Использование буфера обмена для копирования и вставки скрипта. Такое часто встречается в следующих случаях:
- Копирование скрипта в виртуальную машину.
- Копирование скрипта из электронной почты или с веб-страницы.
- Копирование скрипта через документ Microsoft Word или PowerPoint.
- Другие текстовые редакторы, например:
- Блокнот;
- vim;
- любой другой редактор скриптов PowerShell.
- Служебные программы редактирования текста, например:
- //
- Операторы перенаправления PowerShell, такие как и .
- Программы передачи файлов, такие как:
- Веб-браузер при скачивании скриптов.
- Общий файловый ресурс.
Некоторые из этих средств работают с байтами, а не с текстом, но другие позволяют настраивать кодировки. В случаях, когда необходимо настроить кодировку, используйте те же параметры, что и в вашем редакторе, чтобы предотвратить возникновение проблем.
Определение кодировки текста
На первый взгляд, определить кодировку, имея текстовый файл, невозможно, так как она в нем не задана. Но если человек попробует просматривать этот файл в различных кодировках, он скорее всего сможет сказать, какая из них правильная. Ведь например текст на русском языке состоит в основном из букв кириллицы, а не из случайных символов. В разных кодировках эти буквы кодируются разными байтами, и посчитав частоту, с которой каждый байт встречается в тексте, можно сделать выводы о вероятности, что текст закодирован в той или иной кодировке.
К примеру, в кодировке Windows-1251 байты с кодами 192-255 кодируют русские буквы, а байты с кодами 128-191 — различные редковстречающиеся символы и буквы вроде ¤ или Љ. Если в тексте часто встречаются коды 192-255, и редко — 128-191, то, возможно этот текст использует кодировку Windows-1251. И наоборот, если текст содержит в основном байты 128-191, кодировка скорее всего другая.
Также, можно анализировать сочетания (пары или тройки) букв. В русском языке часто встречаются сочетания вроде «кот», но не встречаются тройки вроде «бзщ».
Еще можно анализировать частоту появления букв. Буква «а» встречается гораздо чаще, чем буква «щ».
Сопоставив процент правильных и неправильных сочетаний, можно получить вероятность того, что текст закодирован в данной кодировке.
Также, можно анализировать особенности кодировки. Например, в UTF-8 не могут встречаться определенные последовательности байт. Если их много, то текст скорее всего в другой кодировке.
Ascii
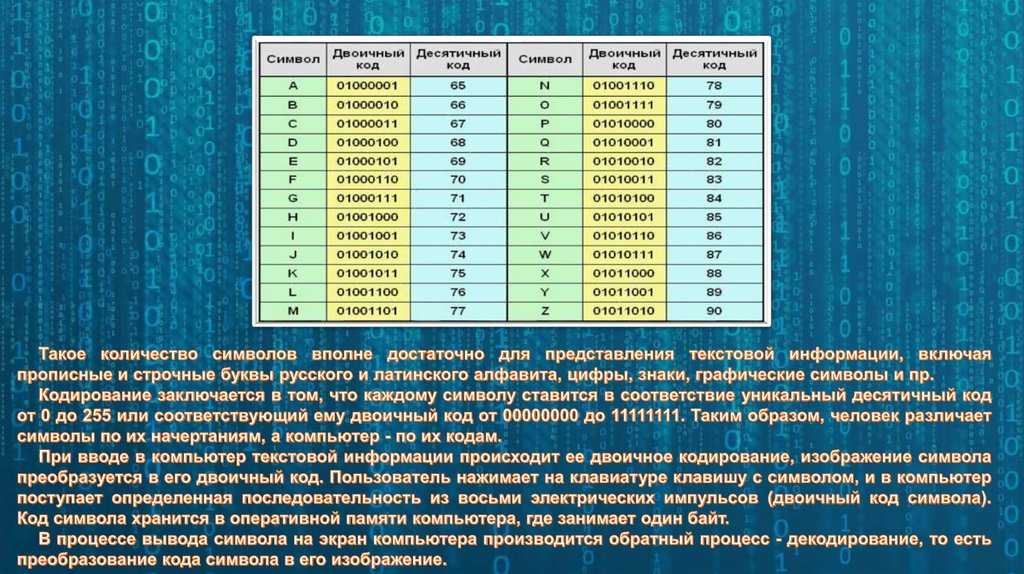
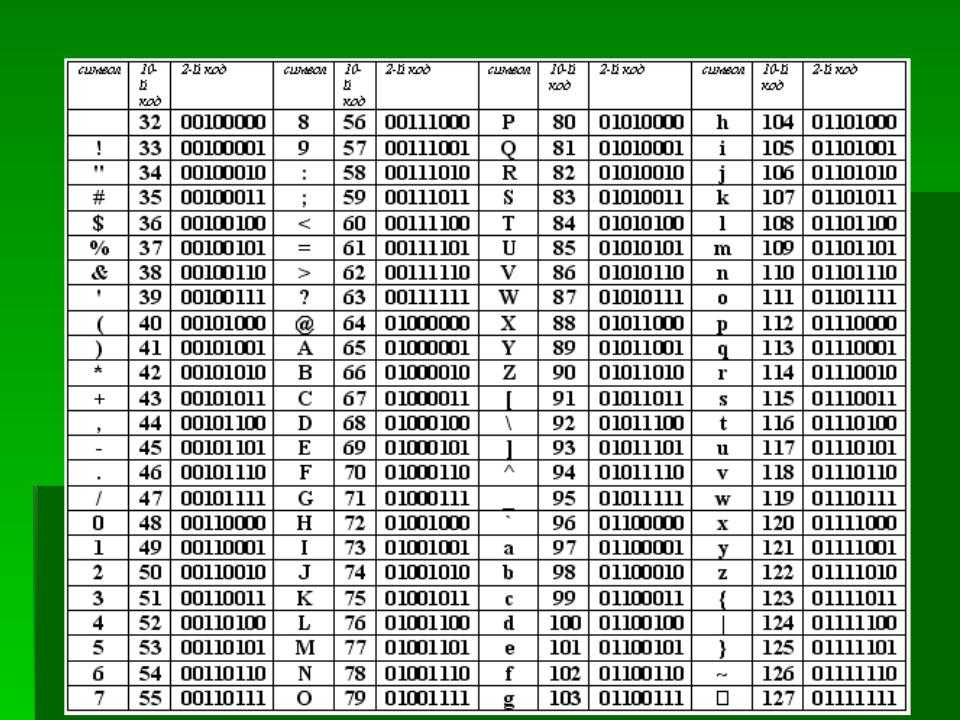
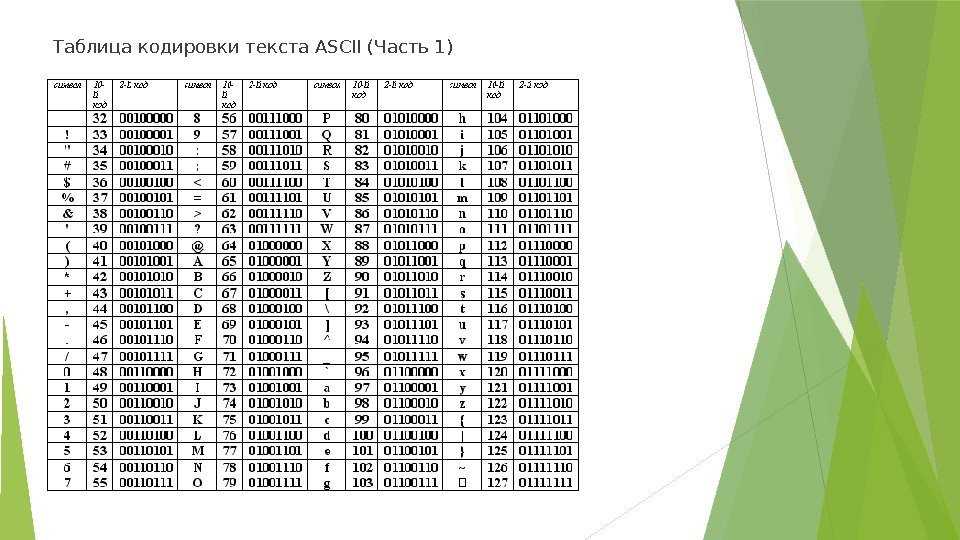
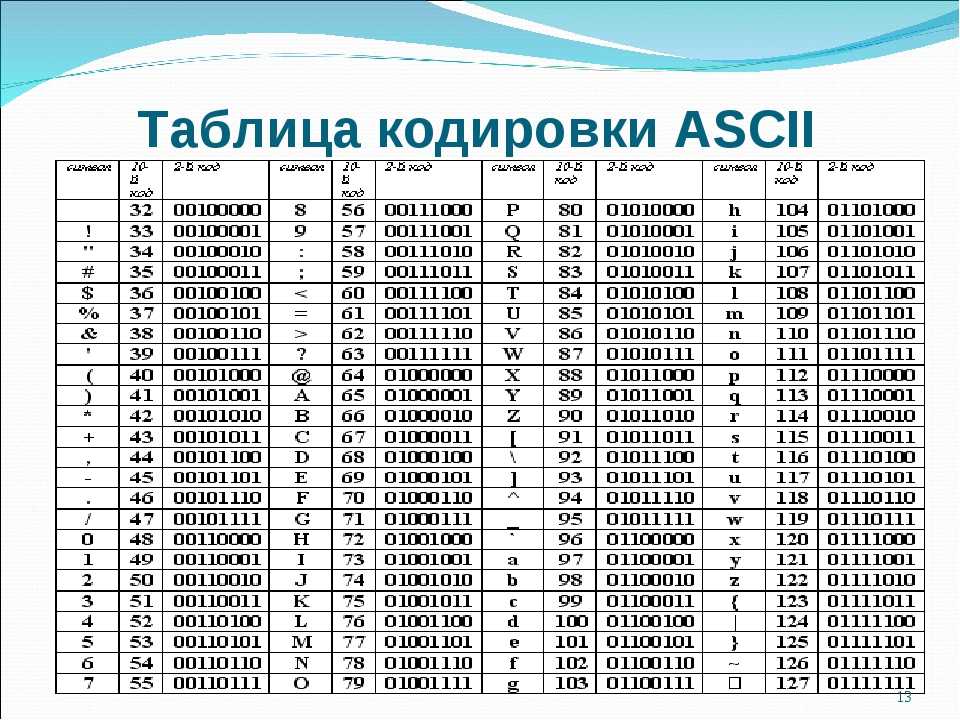
Первые компьютеры разрабатывались в западных странах, где используется латиница. Текст разбивался на символы, каждому символу соответствовало какое-то число, и эти числа записывалось в память. Таблица, которая отражает соответствие символов и цифр, называется кодировка (charset).
Одна из самых древних кодировок — это ascii (американский стандартный код для обмена информацией), придуманная еще в 1963 году. Ascii содержит 96 видимых символов и 32 невидимых, управляющих символов. Управляющие символы — это символы вроде «перевод строки», которые не вызывают печать символов, а управляют выводом текста на экран или печать.
Каждый символ кодируется ровно 1 байтом (вообще-то, в Ascii 128 символов, и для их кодирования достаточно 7, а не 8 бит, но удобнее, когда каждый символ хранится в своей ячейке. Оставшийся ненужным бит иногда использовался для других целей, например, обозначения конца текста).
Вот таблица кодов Ascii:
| +0 | +1 | +2 | +3 | +4 | +5 | +6 | +7 | +8 | +9 | +10 | +11 | +12 | +13 | +14 | +15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0+ | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 16+ | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 32+ | ! | « | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | ||
| 48+ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 64+ | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 80+ | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 96+ | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 112+ | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Чтобы определить код символа, надо сложить числа слева и сверху от этого символа. Ну например, символ имеет код 64 + 5 = 69. А строка кодируется 3 байтами с значениями , , .
Как видно, кодировка Ascii содержит такие виды символов:
- заглавные и прописные латинские буквы
- цифры
- математические знаки (звездочка обозначает умножение, а косая черта — деление), скобки трех видов (), знаки препинания, кавычки , апостроф и дополнительные символы вроде
- пробел (код 32)
- управляющие, невидимые символы с кодами 0-31 и 127 (обозначенные сокращениями вроде или )
На кнопках стандартной компьютерной клавиатуры представлены все видимые символы ASCII.
Большинство управляющих символов сейчас не используется, а те, что стоит знать, я выделил жирным. Вот они:
-
В языках программирования вроде PHP и Javascript вставить символ табуляции в строку можно специальной последовательностью , например:
-
LF (код 10), line feed, перевод строки. Переставляет курсор на начало новой строки. В языках программирования PHP, Javascript и многих других обозначается последовательностью .
В текстовых файлах обозначает конец строки (однако, под Windows по историческим причинам принято обозначать конец строки двумя идущими подряд символами, (коды 13 и 10). Когда создавали MS-DOS, в Макинтошах для обозначения конца строки использовался , а в Юниксе . Майкрософт решила использовать сразу оба символа, чтобы тексты отображались корректно в других системах. В наше время Маки перешли на символ , как и Юникс/Линукс).
-
CR (код 13), carriage return, переставляет курсор в начало строки. Используется в текстовых файлах под Windows совместно с LF, чтобы обозначить конец строки. В коде часто пишется как .
В старых языках программирования (вроде Си) также использовался символ (код 0) для обозначения конца строки в памяти. В современных языках вроде PHP или Javascript обычно длина строки хранится в памяти отдельно и обозначать ее конец не требуется, и строка может содержать внутри символы NUL, не имеющие специального значения. В PHP и JS вставить в строку символ можно с помощью последовательности символов
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Что такое кодировка и почему она важна?
VS Code управляет интерфейсом ввода строки символов в буфер пользователем и чтения-записи блоков байтов в файловой системе. При сохранении файла в VS Code используется кодирование текста для определения того, какие байты получит каждый символ. Подробные сведения см. в статье О шифровании символов.
Аналогичным образом, когда оболочка PowerShell запускает скрипт, ей необходимо преобразовать байты из файла в символы для преобразования файла в программу PowerShell. Так как VS Code записывает файл, а PowerShell считывает файл, этим средствам необходимо использовать одну и ту же систему кодировки. Этот процесс синтаксического анализа скрипта PowerShell идет так: байты -> символы -> лексемы -> дерево абстрактного синтаксиса -> выполнение.
И VS Code, и PowerShell устанавливаются с подходящей конфигурацией кодировки по умолчанию. Тем не менее кодировка по умолчанию, используемая PowerShell, была изменена с выпуском PowerShell 6. Чтобы избежать проблем с PowerShell и расширениями PowerShell в VS Code, необходимо настроить параметры VS Code и PowerShell должным образом.
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
header('Content-Type: charset=utf-8');
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
header('Content-Type: text/html; charset=utf-8');
Ещё один вариант для RSS ленты:
header('Content-type: text/xml; charset=utf-8');
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.

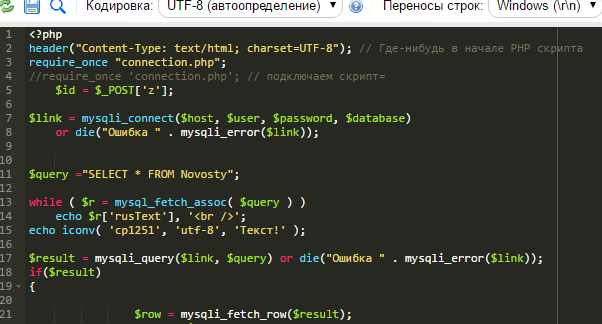

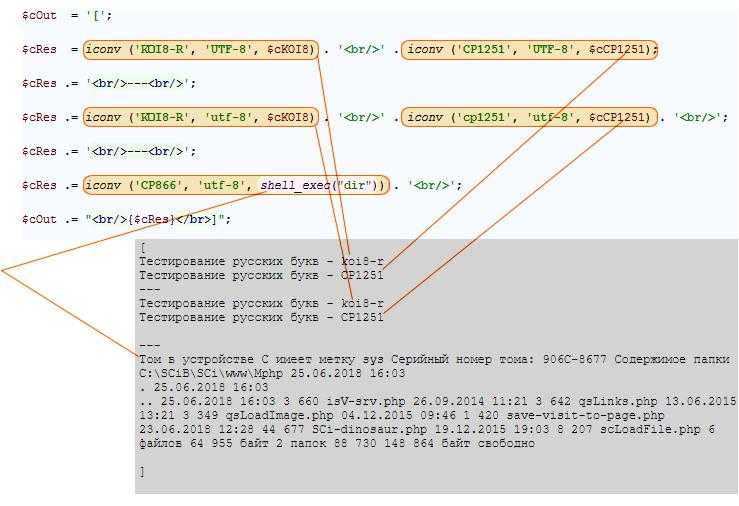


Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8
Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Кодировка windows 1251 в сайтостроении
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft:
Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866). Однако у 1251-кодировки имеются и весомые недостатки:
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8, CP866.
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде):
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:
Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:
Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка
Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename); if ($this->mysqli->connect_error) { $this->errorHandler_c->logError(1, ‘Connect Error (‘ . $this->mysqli->connect_errno . ‘) ‘ . $this->mysqli->connect_error, $_SERVER ); } $this->mysqli->query(«SET NAMES UTF8»); $this->mysqli->query(«SET CHARACTER SET UTF8»); $this->mysqli->query(«SET character_set_client = UTF8»); $this->mysqli->query(«SET character_set_connection = UTF8»); $this->mysqli->query(«SET character_set_results = UTF8»);



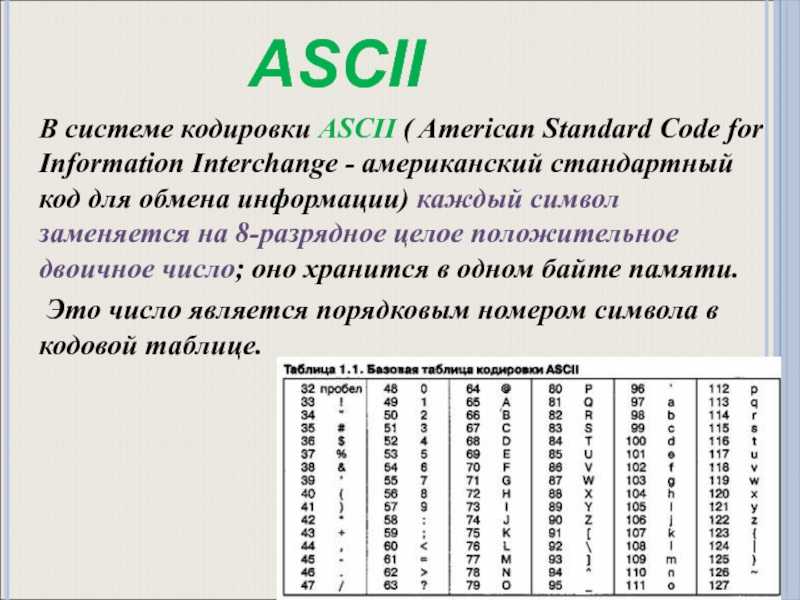



Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Определение кодировки текста в PHP вместо mb_detect_encoding
Иногда появляется необходимость определить кодировку текста. И в PHP даже функция для этого есть:
но как писал m00t в статье Определение кодировки текста в PHP — обзор существующих решений плюс еще один велосипед
Я протестировал функцию определения кодировки по кодам символов, результат меня удовлетворил и я использовал эту функцию пару лет.
Недавно решил переписать проект где использовал эту функцию, нашел готовый пакет на packagist.org cnpait/detect_encoding, в котором кодировка определяется методом m00t
При этом указанный пакет был установлен более 1200 раз, значит не у меня одного периодически возникает задача определения кодировки текста.
Мне бы установить этот пакет и успокоиться, но я решил «заморочиться».
В общем, сделал свой пакет: onnov/detect-encoding.
Как его использовать написано в README.md
А о его тестировании и сравнении с пакетом cnpait/detect_encoding напишу.
Методика тестирования
Берем большой текст: Tolstoy — Anna Karenina Всего — 1’701’480 знаков
Убираем все лишнее, оставляем только кириллицу:
Осталось 1’336’252 кирилистических знаков.
В цикле берем часть текста (5, 15, 30,… символов) преобразуем в известную кодировку и пытаемся определить кодировку скриптом. Затем сравниваем правильно или нет.
Вот таблица в которой слева кодировки, сверху количество символов по которому определяем кодировку, в таблице результат достоверности в %%
| letters -> | 5 | 15 | 30 | 60 | 120 | 180 | 270 |
|---|---|---|---|---|---|---|---|
| windows-1251 | 99.13 | 98.83 | 98.54 | 99.04 | 99.73 | 99.93 | 100.0 |
| koi8-r | 99.89 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 99.27 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 |
| ibm866 | 99.81 | 99.99 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| mac-cyrillic | 12.79 | 47.49 | 73.48 | 92.15 | 99.30 | 99.94 | 100.0 |
Наихудшая точность с мак-кириллицей, вам нужно как минимум 60 символов, чтобы определить эту кодировку с точностью 92,15%. Кодировка Windows-1251 также имеет очень низкую точность. Это связано с тем, что номера их символов в таблицах сильно пересекаются.
К счастью, кодировки mac-cyrillic и ibm866 не используются для кодирования веб-страниц.
Попробуем без них:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 99.40 | 99.69 | 99.86 | 99.97 | 100.0 |
| koi8-r | 99.89 | 99.98 | 99.98 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 96.41 | 99.27 | 99.98 | 100.0 |
Точность определения высока даже в коротких предложениях от 5 до 10 букв. А для фраз из 60 букв точность определения достигает 100%. А еще, определение кодировки выполняется очень быстро, например, текст длиной более 1 300 000 символов кириллицы проверяется за 0 00096 секунд. (на моем компьютере)
А какие результаты покажет статистический способ описанный m00t:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 88.75 | 96.62 | 98.43 | 99.90 | 100.0 |
| koi8-r | 85.15 | 95.71 | 97.96 | 99.91 | 100.0 |
| iso-8859-5 | 88.60 | 96.77 | 98.58 | 99.93 | 100.0 |
Как видим результаты определения кодировки хорошие. Скорость работы скрипта высокая, особенно на коротких текстах, на огромных текстах скорость значительно уступает. Текст длиной более 1 300 000 символов кириллицы проверяется за 0 32 секунд. (на моем компьютере).



