
Вступление
Cache API является частью спецификации Service Worker и представляет собой отличный способ повысить эффективность кэширования ресурсов.
Это позволяет вамкешировать ресурсы с URL-адресом, что означает ресурсы, веб-страницы, ответы HTTP API.
Этонетпредназначен для кэширования отдельных фрагментов данных, что является задачейIndexedDB API.
В настоящее время он доступен в Chrome> = 40, Firefox> = 39 и Opera> = 27.
Safari и Edge недавно представили его поддержку.
Internet Explorer его не поддерживает.
Мобильная поддержка хороша на Android, поддерживается в Android Webview и в Chrome для Android, тогда как в iOS она доступна только пользователям Opera Mobile и Firefox Mobile.
Что такое Кэш (Cache)?
Для начала, давайте глянем значение этого слова в англо-русском словаре.
Cache – тайник, тайный склад, запас провианта.
Но если говорить про сache сайта, то определение будет несколько другим. Cache сайта – это программный или аппаратный компонент, который содержит данные сайта, для дальнейшего ускоренного обращения к сайту.
![]()
Разделяют две основные техники кэширования: полностраничное кэширование, и частичное кэширование (фрагментарное). Оба эти названия, говорят сами за себя, в одном из них, сохраняется вся страница, в другом, только фрагменты страницы, например, тяжелые картинки.
Вообще, скорость загрузки сайтов, это один из важный параметров SEO оптимизации сайтов. Подробнее о том, что такое скорость сайта, и как она влияет на продвижение сайтов, читайте здесь.
И один из главных инструментов, для ускорения сайта, это использование кэша. Если вы правильно настроите кэширование, то ваш сайт будет загружаться быстрее, а ваши посетители, будут довольны, что в конечном итоге, приведет к более высоким позициям в поисковой выдаче.
А теперь, давайте посмотрим на два основных типа кеширования, которые применяются для ускорения сайтов.
Подогревание
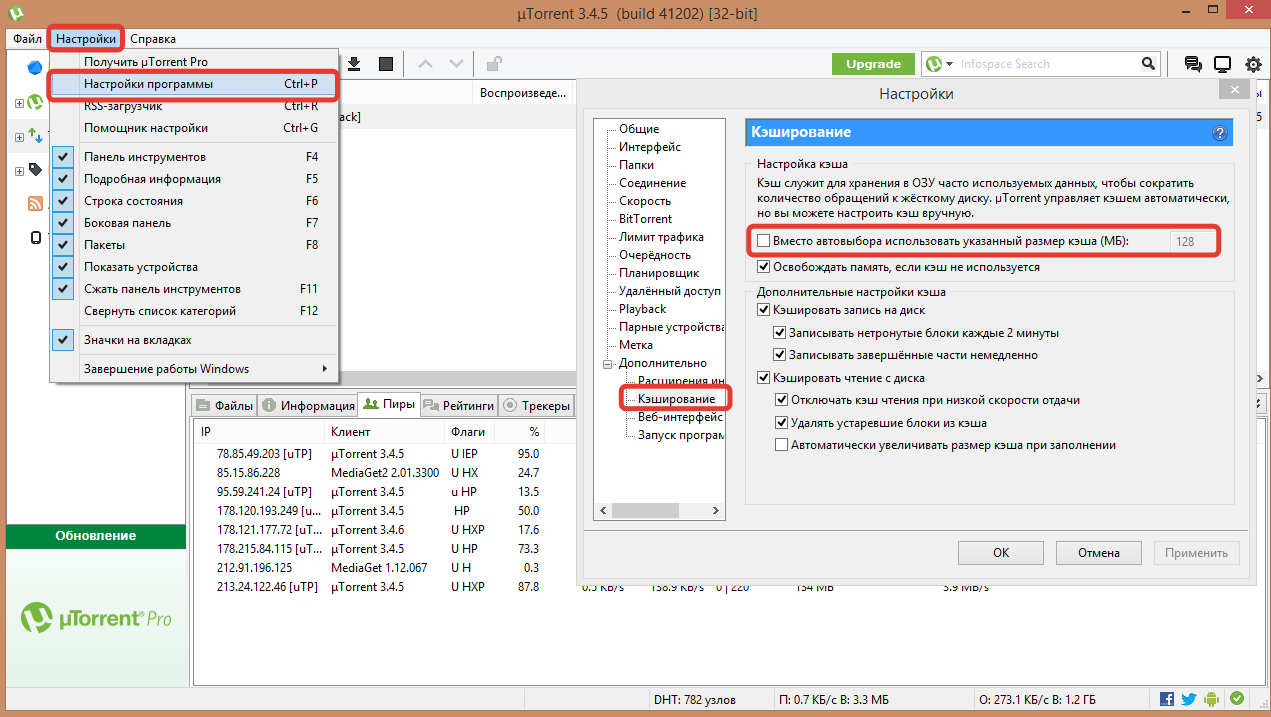
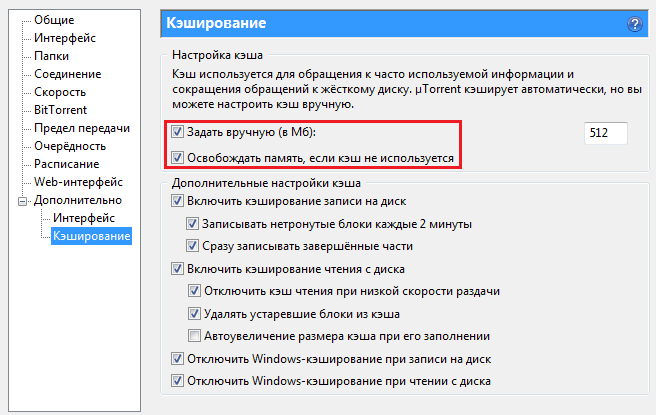
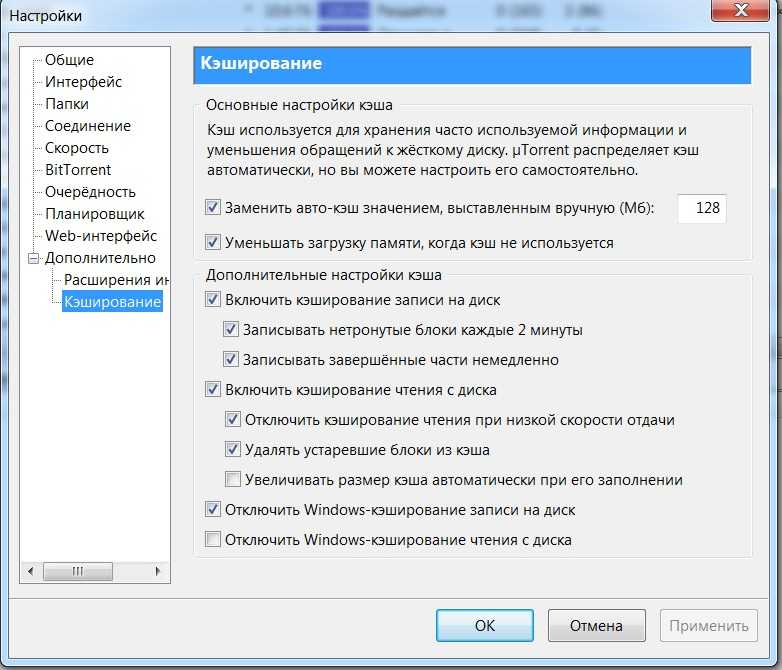
При обновлении особенно тяжелых данных следует использовать не сброс кэша, а прямое обновление данных в нем:
memcache_connect('localhost', 11211);
function get_rss($id)
{
if ( !$data = memcache_get('rss') )
{
$data = file_get_contents('http://rss.com/rss');
memcache_set('rss', $data, 60*60);
}
return $data;
}
function update_rss_feed($id, $data)
{
# операции по обновлению внешних ресурсов
$data = file_get_contents('http://rss.com/rss');
memcache_set('rss', $data, 60*60);
}
Это позволит избежать дополнительной нагрузки при выполнении тяжелых выборок, когда ключ удаляется. Такую методику обычно используют в cron задачах, чтобы периодически обновлять результаты очень тяжелых выборок.Время жизни (ttl)
ttl (время жизни) — это время, после которого, данные будут удалены из кэша. В Memcache устанавливается в секундах:
Установка ttl на 1 час
Чаще всего ttl ставят от нескольких минут до нескольких дней. Не используйте значение 0 (бесконечное хранение), это может засорить память.LRU
Любой кэш работает по принципу вытеснения если ему не хватает памяти. Т.е. если Memcache может использовать максимум 1G памяти, а Вы пытаетесь сохранить ключей на 2G, то половину из этих данных Memcache удалит. Для определения, какие именно ключи удалять, используется алгоритм LRU (Least Recently Used):Memcache постарается удалить прежде всего те данные, которые запрашивались очень давно (т.е. менее популярные удалит, а более популярные оставит).
Простое кеширование ETag
Самый простой способ кеширования статических ресурсов — использование .
Достаточно включить соответствующую настройку сервера (для Apache включена по умолчанию) — и к каждому файлу в заголовках будет даваться — хеш, который зависит от времени обновления, размера файла и (на inode-based файловых системах) inode.
Браузер кеширует такой файл и при последующих запросах указывет заголовок с ETag кешированного документа. Получив такой заголовок, сервер может ответить кодом 304 — и тогда документ будет взят из кеша.
Выглядит это так:
- Первый запрос к серверу (кеш чистый)
-
GET /misc/pack.js HTTP/1.1 Host: javascript.ru
Вообще, браузер обычно добавляет еще пачку заголовоков типа User-Agent, Accept и т.п. Для краткости они порезаны.
- Ответ сервера
- Сервер посылает в ответ документ c кодом 200 и ETag:
HTTP/1.x 200 OK Content-Encoding: gzip Content-Type: text/javascript; charset=utf-8 Etag: "3272221997" Accept-Ranges: bytes Content-Length: 23321 Date: Fri, 02 May 2008 17:22:46 GMT Server: lighttpd
- Следующий запрос браузера
-
При следующем запросе браузер добавляет : (кешированный ):
GET /misc/pack.js HTTP/1.1 Host: javascript.ru If-None-Match: "453700005"
- Ответ сервера
-
Сервер смотрит — ага, документ не изменился. Значит можно выдать код 304 и не посылать документ заново.
HTTP/1.x 304 Not Modified Content-Encoding: gzip Etag: "453700005" Content-Type: text/javascript; charset=utf-8 Accept-Ranges: bytes Date: Tue, 15 Apr 2008 10:17:11 GMT
Альтернативный вариант — если документ изменился, тогда сервер просто посылает 200 с новым .
Аналогичным образом работает связка + :
- сервер посылает дату последней модификации в заголовке (вместо )
- браузер кеширует документ, и при следующем запросе того же документа посылает дату закешированной версии в заголовке (вместо )
- сервер сверяет даты, и если документ не изменился — высылает только код 304, без содержимого.
Эти способы работают стабильно и хорошо, но браузеру в любом случае приходится делать по запросу для каждого скрипта или стиля.
Функции API низкого уровня для кэширования
Для более тонкой
настройки и использования механизма кэширования в Django имеются весьма
полезные функции, которые составляют уровень API для
кэширования. Основные из них, следующие:
-
cache.set() –
сохранение произвольных данных в кэш по ключу; -
cache.get() – выбор
произвольных данных из кэша по ключу; -
cache.add() –
заносит новое значение в кэш, если его там еще нет (иначе данная операция
игнорируется); -
cache.get_or_set()
– извлекает данные из кэша, если их нет, то автоматически заносится значение по
умолчанию; -
cache.delete() –
удаление данных из кэша по ключу; - cache.clear() –
полная очистка кэша.
Давайте
воспользуемся этим функционалом и закэшируем данные рубрик. Откроем файл women/utils.py, где сначала
импортируем модуль:
from django.core.cache import cache
А, затем, в
классе DataMixin будем делать
выборку категорий из кэша с помощью функции get():
cats = cache.get('cats')
if not cats:
cats = Category.objects.annotate(Count('women'))
cache.set('cats', cats, 60)
Далее, мы
проверяем, если данные из кэша не были получены (это значит, что они туда либо
не были помещены, либо истекло время кэша), то выполняем чтение из БД и заносим
данные в кэш с помощью функции set().
Вот так,
достаточно просто можно использовать кэширование страниц, их фрагментов и
отдельных данных во фреймворке Django. Но, имейте в виду, этот
инструмент следует включать на конечном этапе разработки сайта, чтобы в
процессе программирования мы могли отслеживать все нагрузки, которые происходят
при формировании ответов к серверу. Кэширование может скрывать от разработчика
какие-либо SQL-запросы и
вводить в заблуждение. Чтобы этого не было, кэш подключается в самую последнюю
очередь.
Видео по теме
#1. Django — что это такое, порядок установки
#2. Модель MTV. Маршрутизация. Функции представления
#3. Маршрутизация, обработка исключений запросов, перенаправления
#4. Определение моделей. Миграции: создание и выполнение
#5. CRUD — основы ORM по работе с моделями
#6. Шаблоны (templates). Начало




#7. Подключение статических файлов. Фильтры шаблонов
#8. Формирование URL-адресов в шаблонах
#9. Создание связей между моделями через класс ForeignKey
#10. Начинаем работу с админ-панелью
#11. Пользовательские теги шаблонов
#12. Добавляем слаги (slug) к URL-адресам
#13. Использование форм, не связанных с моделями
#14. Формы, связанные с моделями. Пользовательские валидаторы
#15. Классы представлений: ListView, DetailView, CreateView
#16. Основы ORM Django за час
#17. Mixins — убираем дублирование кода
#18. Постраничная навигация (пагинация)
#19. Регистрация пользователей на сайте
#20. Делаем авторизацию пользователей на сайте
#21. Оптимизация сайта с Django Debug Toolbar
#22. Включаем кэширование данных
#23. Использование капчи captcha
#24. Тонкая настройка админ панели
#25. Начинаем развертывание Django-сайта на хостинге
#26. Завершаем развертывание Django-сайта на хостинге
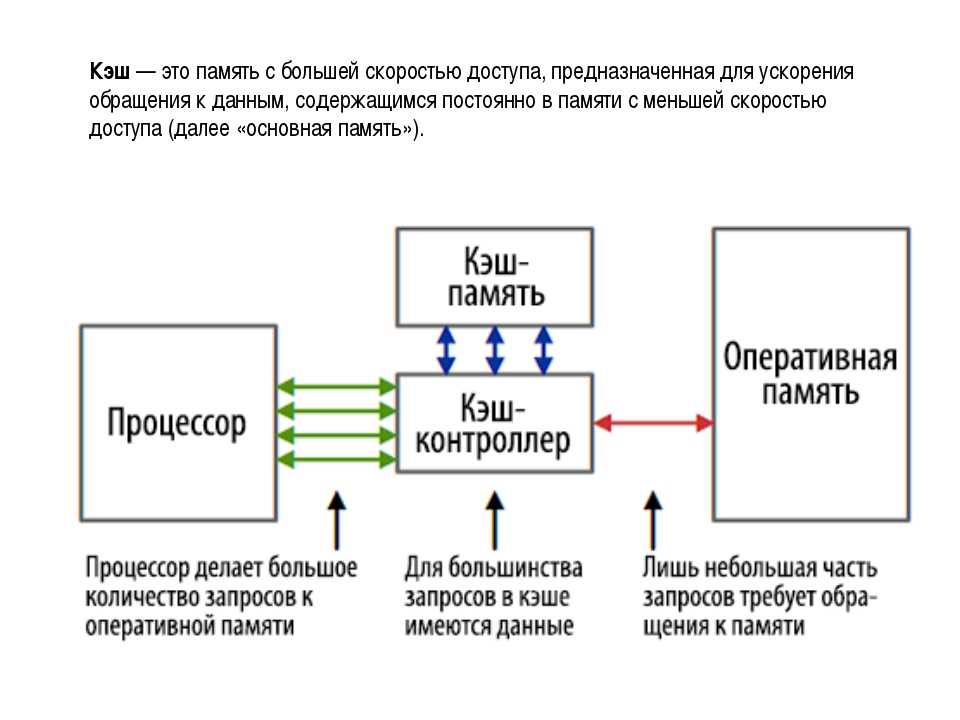
Что такое кэш
Кэш — это данные, которые компьютер уже получил и использовал один раз, а потом сохранил на будущее. Смысл кэша в том, чтобы в следующий раз взять данные не с далёкого и медленного сервера, а из собственного быстрого кэша. То же самое, что закупиться продуктами на неделю и потом ходить не в магазин, а в холодильник.
В случае с браузером это работает так:
- Браузер сделал запрос на сервер.
- Сервер в ответ прислал страницу, скрипты и все картинки.
- ️ Браузер сохранил всё это в память ← это и есть кэш.
Дальше происходит так:
4. Если вкладкой или браузером долго не пользовались, операционная система выгружает из оперативной памяти все страницы, чтобы освободить место для других программ.5. Если переключиться назад на браузер, он моментально сходит в кэш, возьмёт оттуда загруженную страницу и покажет её на экране.
Получается, что если браузер будет брать из кэша только постоянные данные и скачивать с сервера только что-то новое, то страница будет загружаться гораздо быстрее. Выходит, главная задача браузера — понять, какой «срок годности» у данных в кэше и через какое время их надо запрашивать заново.
Например, браузер может догадаться, что большая картинка на странице вряд ли будем меняться каждые несколько секунд, поэтому имеет смысл подержать её в кэше и не загружать с сервера при каждом посещении. Поэтому в кэше часто хранятся картинки, видеоролики, звуки и другие декоративные элементы страницы.
Для сравнения: браузер понимает, что ответ сервера на конкретный запрос пользователя кэшировать не надо — ведь ответы могут очень быстро меняться. Поэтому ответы от сервера браузер не кэширует.
Изменяющиеся ответы
Заголовок HTTP-ответа определяет, как по заголовкам будущих запросов понять, может ли быть использована копия из кеша, или нужно запросить новые данные у сервера.
Если кеш получает запрос, который можно удовлетворить сохранённым в кеше ответом с заголовком , то использовать этот ответ можно только при совпадении всех указанных в полей заголовка исходного (сохранённого в кеше) запроса и нового запроса.
Это может быть полезно, например, при динамическом предоставлении контента. При использовании заголовка кеширующие сервера, принимая решение об использовании страницы из кеша, должны учитывать агент пользователя. Так можно избежать ситуации, когда пользователи мобильных устройств по ошибке получат десктопную версию вашего сайта. Вдобавок, это может помочь Google и другим поисковым системам обнаружить мобильную версию страницы, и может также указать им на то, что здесь нет никакой подмены контента с целью поисковой оптимизации (Cloaking).

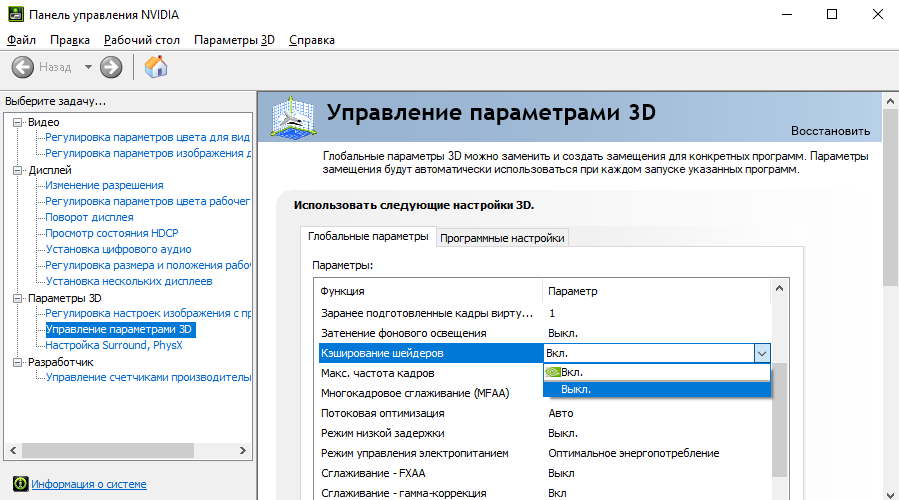
Vary: User-Agent
Поскольку значение заголовка различается («varies») у мобильных и десктопных клиентов, закешированный мобильный контент не будет по ошибке отсылаться пользователям десктопов и наоборот.
Установка демона Memcached
Установить сервер memcached могут только владельцы виртуальных и физических серверов. Если у вас обычных хостинг, то самостоятельно эту процедуру вы выполнить не сможете. Впрочем на многих хостинг-площадках memcached уже включен, либо его можно использовать опционально, иногда за дополнительные деньги.
Если вы владелец сервера с операционной системой Debian , то для установки memcached выполните следующую команду в консоли от имени администратора:
apt install memcached
В CentOS должно быть не сложнее.
После установки сервер Memcached запустится сразу. Конфигурация сервера находится в файле /etc/memcached.conf, в нем вы можете настраивать такие параметры как память, адрес и порт. Эти данные вам потребуются при конфигурации плагина для WordPress.
Если вы что-то будете менять, то не забудьте перезапустить демон memcached:
service memcached restart
Заголовки директив кэша
Важно!
По умолчанию конечная точка Azure CDN, оптимизированная для DSA, игнорирует заголовки директив кэша и обходит кэширование. Для профилей Azure CDN уровня «Стандартный» от Verizon и Azure CDN уровня «Стандартный» от Akamai можно настроить способ обработки этих заголовков конечной точкой Azure CDN, воспользовавшись правилами кэширования CDN для включения кэширования. Только для профилей Azure CDN уровня «Премиум» от Verizon для включения кэширования используется обработчик правил.
Azure CDN поддерживает следующие заголовки директив кэша HTTP, которые определяют длительность кэширования и совместное использование кэша.
Cache-Control:
- Представлен в HTTP 1.1, чтобы дать веб-издателям больше возможностей управления своим содержимым и устранить ограничения заголовка .
- Переопределяет заголовок , если определен этот заголовок и заголовок .
- Если указан в HTTP-запросе от клиента к POP сети CDN, все профили Azure CDN по умолчанию игнорируют его.
- при использовании в HTTP-ответе от сервера-источника к точке подключения CDN:
- Azure CDN standard/Premium от Verizon и Azure CDN standard от корпорации майкрософт поддерживают все директивы.
- Azure CDN Standard/Premium от Verizon и Azure CDN Standard от корпорации Майкрософт учитывает поведение кэширования для директив Cache-Control в .
-
Azure CDN Standard из Akamai поддерживает только следующие директивы. все остальные игнорируются:
- . Содержимое может храниться в кэше в течение указанного количества секунд. Например, . Эта директива задает максимальное время, в течение которого содержимое будет считаться актуальным.
- . Кэширует содержимое, но проверяет содержимое каждый раз перед его доставкой из кэша. Эквивалент .
- . Никогда не кэширует содержимое. Удалите контент, если он был ранее сохранен.
Expires:
- Устаревший заголовок, представленный в HTTP 1.0. Поддерживается для обеспечения обратной совместимости.
- Использует дату окончания срока действия со вторым уровнем точности.
- Аналогично .
- Используется, если нет.
Pragma:
- По умолчанию не учитывается Azure CDN.
- Устаревший заголовок, представленный в HTTP 1.0. Поддерживается для обеспечения обратной совместимости.
- Используется в качестве заголовка запроса клиента со следующей директивой: . Эта директива предписывает серверу предоставить новую версию ресурса.
- равно .
Что нужно знать, прежде чем начинать новую жизнь
Держу пари, что это не первая ваша попытка начать жить заново. Наверняка вы, как и большинство людей, хоть раз давали себе обещание кардинально измениться и начать новую жизнь, не оставив в ней места былым вредным привычкам, порокам, недостаткам. За гипотетическое начало этой самой «новой» жизни мог приниматься следующий понедельник, первый день нового года, начало отпуска и т. п.
В день «икс» вы честно пытались свой замысел осуществить, но что-то шло не так – то будильник не прозвенел, и вы проспали пробежку, то соседка предательски заманила вас вкусным тортом и диету пришлось отложить, то телевизор загипнотизировал и приковал вас к дивану, не дав возможности спокойно заниматься английским. И вот уже новая жизнь, где вы красивый, умный и успешный, отодвигается на неопределенный срок.
Запомните, новая жизнь – это не та крепость, которую нужно брать штурмом. Не стоит пытаться кардинально изменить себя и свою жизнь одним махом. Очень многие люди совершают эту досадную ошибку и терпят неудачу за неудачей. Упущенных понедельников становится все больше, а мотивации поменяться – все меньше.
Хотя кажется, что вы все сделали правильно: купили абонемент в спортзал, записались на курсы испанского, запаслись здоровым питанием, выкинули сигареты – и все это в первый день вашей новой жизни. Вот только похож он почему-то оказался на день открытых дверей в аду. Вам было неприятно и некомфортно, вы устали и при этом ничего не успели. После такой демо-версии новой жизни старая покажется не такой уж плохой.
![]()
Почему так получилось? Все дело в том, что наш мозг представляет собой сложную динамическую систему, которая всегда стремится к равновесию с окружающей средой. Годами отработанные привычки и шаблоны поведения укореняются и закрепляются в виде нейронных цепей. Нейронная цепь – путь, по которому электрический импульс проходит быстро и легко, затрачивая минимальное количество энергии.
Когда вы пытаетесь совершить квантовый скачок из привычной унылой и безрадостной жизни в светлое продуктивное будущее, вашему мозгу сложно сразу перестроиться. Новые нейронные цепи еще не сформировались, а старые не распались. Импульсы проходят очень медленно, блуждая в лабиринтах незнакомых клеток, на их передачу тратится большое количество энергии. Поэтому вы можете чувствовать себя опустошенным и разбитым.
Чтобы процесс изменений проходил легко и гладко, нужно постепенно перестраивать свой мозг, формируя новые нейронные цепи. Делается это посредством закрепления новых привычек, многократного повторения полезных действий и отказа от вредных.
Для наглядности посмотрите это видео.
https://youtube.com/watch?v=Sg4Y2gyh3wY
Узнаем пропускную способность роутера
При тестировании беспроводных сетей важно учесть, что пропускная способность зависит в первую очередь от помех и препятствий между роутером и ноутбуком. Поэтому важно разместить устройство недалеко от маршрутизатора (в той же комнате)
Также проследите, чтобы уровень сигнала Wifi был максимальным.
Если имеются радиочастотные помехи, перегородки между приемником/передатчиком беспроводного сигнала, показатель не будет точным.Просканируйте ПК на вредоносные программы (к примеру, приложением DrWebCureIt). Они часто занимают довольно много трафика, снижая общую скорость передачи данных.
Несколько способов измерения пропускной способности Wifi.
- Запуск копирования объемного потока данных. Удобно рассчитывается скорость, с которой происходит трансляция.
- Использование утилиты LAN Speed Test, NetStress, NetMeter. При этом отключите торренты, программы загрузки, мессенджеры, почтовый клиент. Закройте ненужные вкладки браузера.
- Администраторская клиент-сервисная программа Iperf или графическая оболочка Jperf.
Тестирование лучше повторить несколько раз в разное время суток. Результат будет варьироваться, что зависит от сервера, кэширования, трафика веб-сайта, прочего.
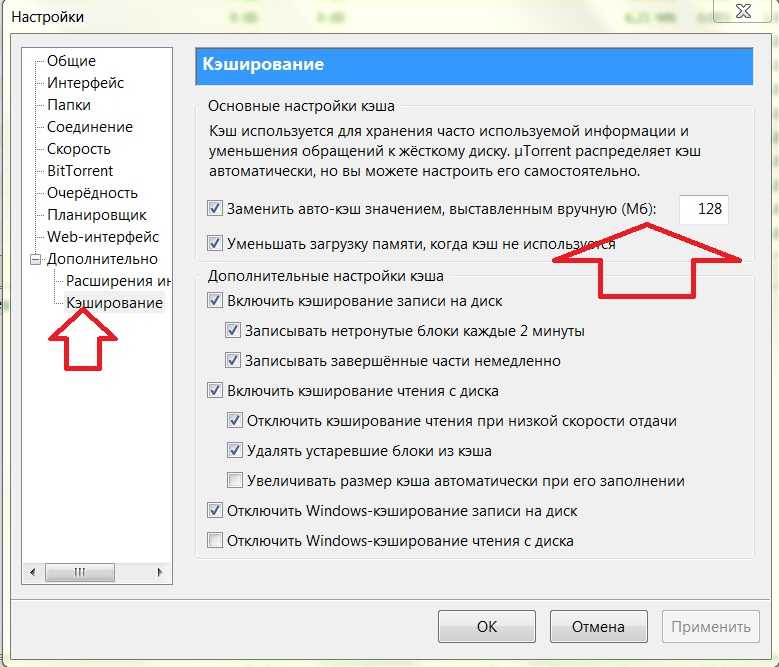
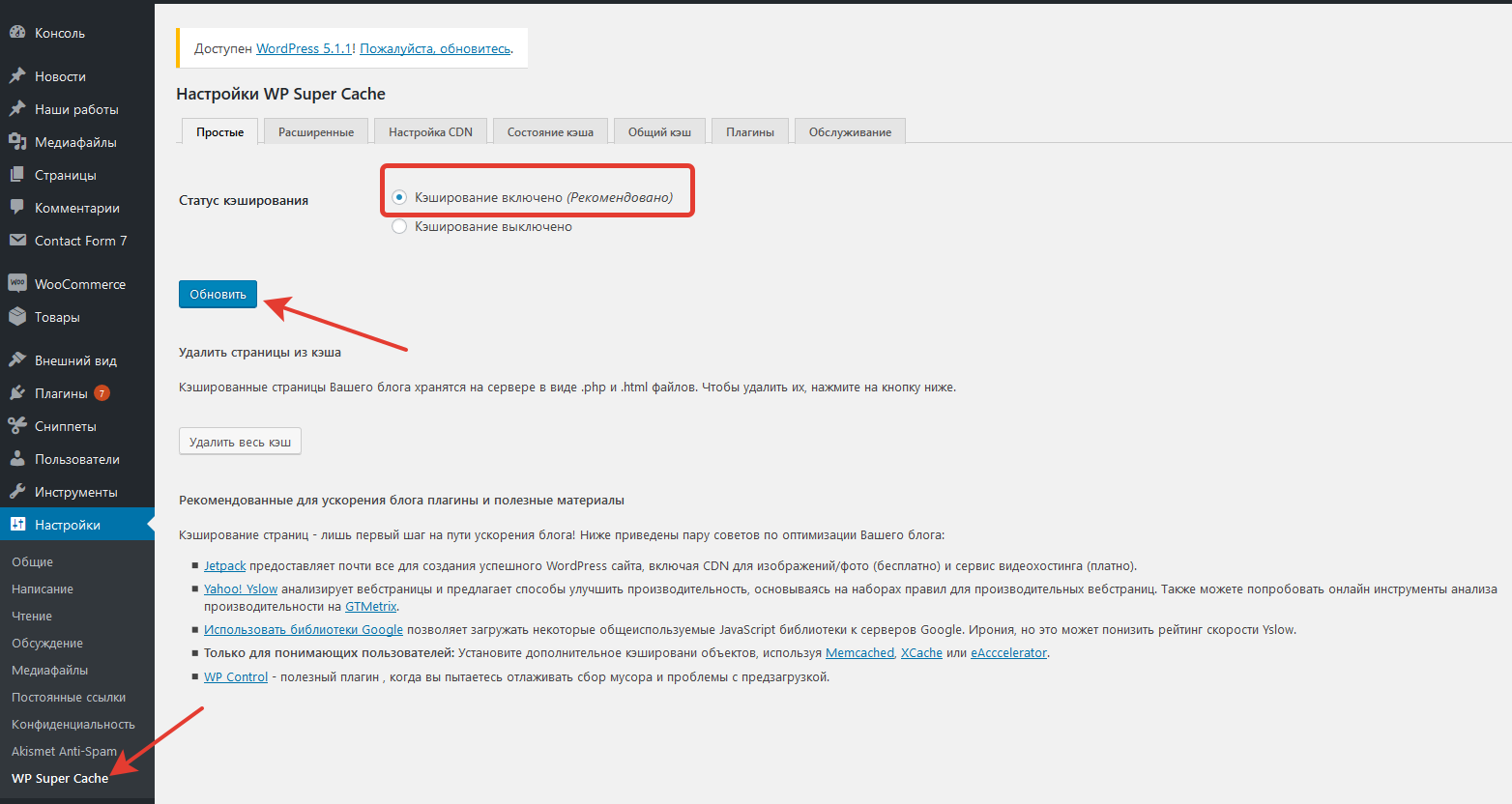
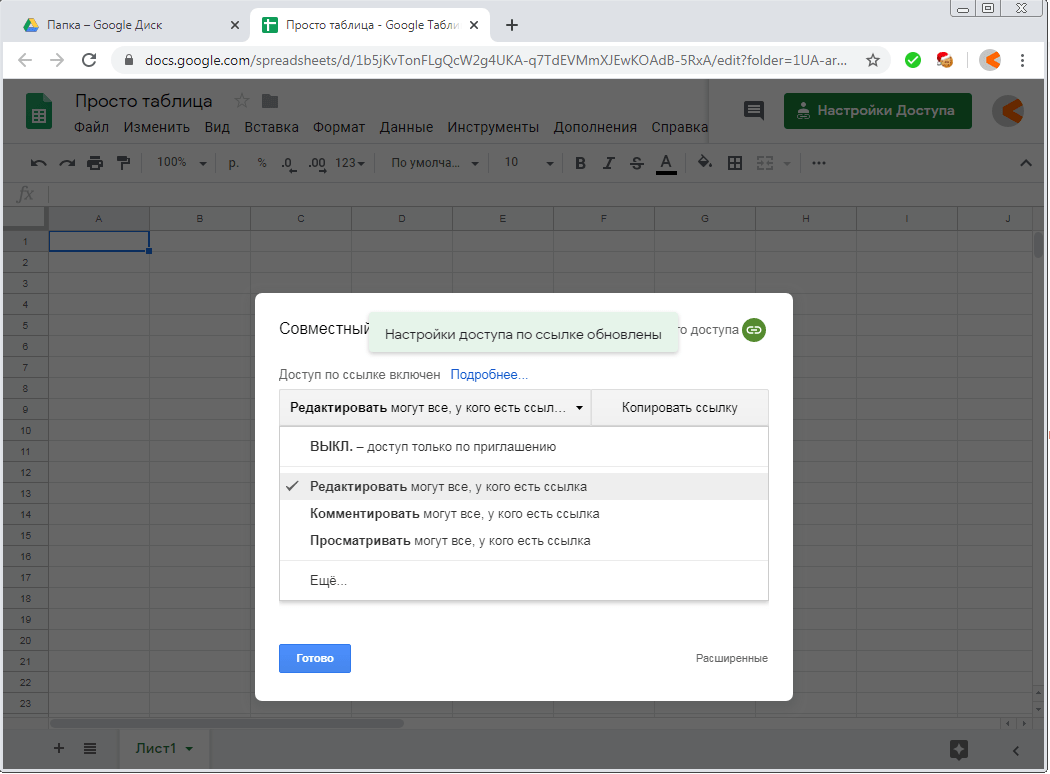
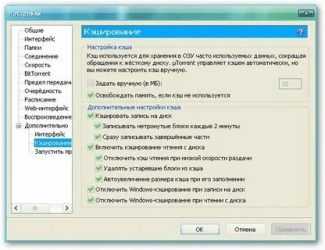
Настройка системы кэширования
![]()
Как вы уже поняли, данный процесс является очень полезным и при его правильной настройке можно оптимизировать результаты работы и загрузки веб-сервиса.
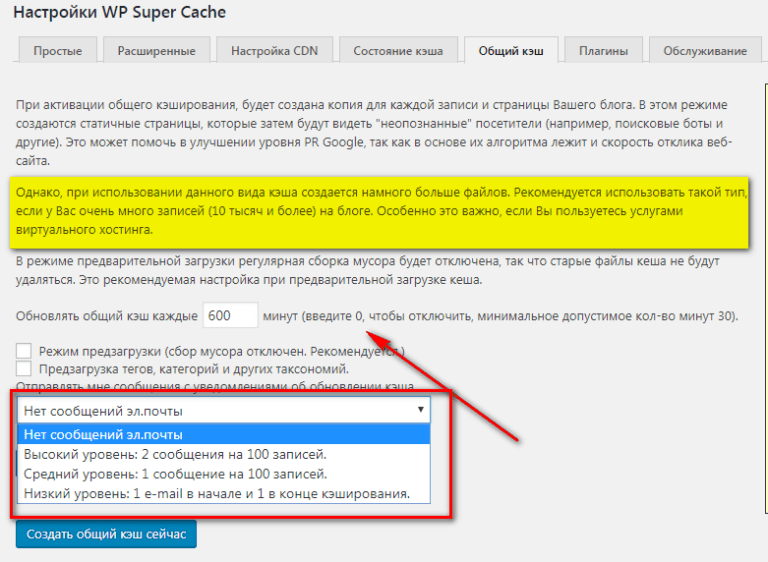
Так, например, известные движки имеют свои встроенные процессы. Начну с WordPress.
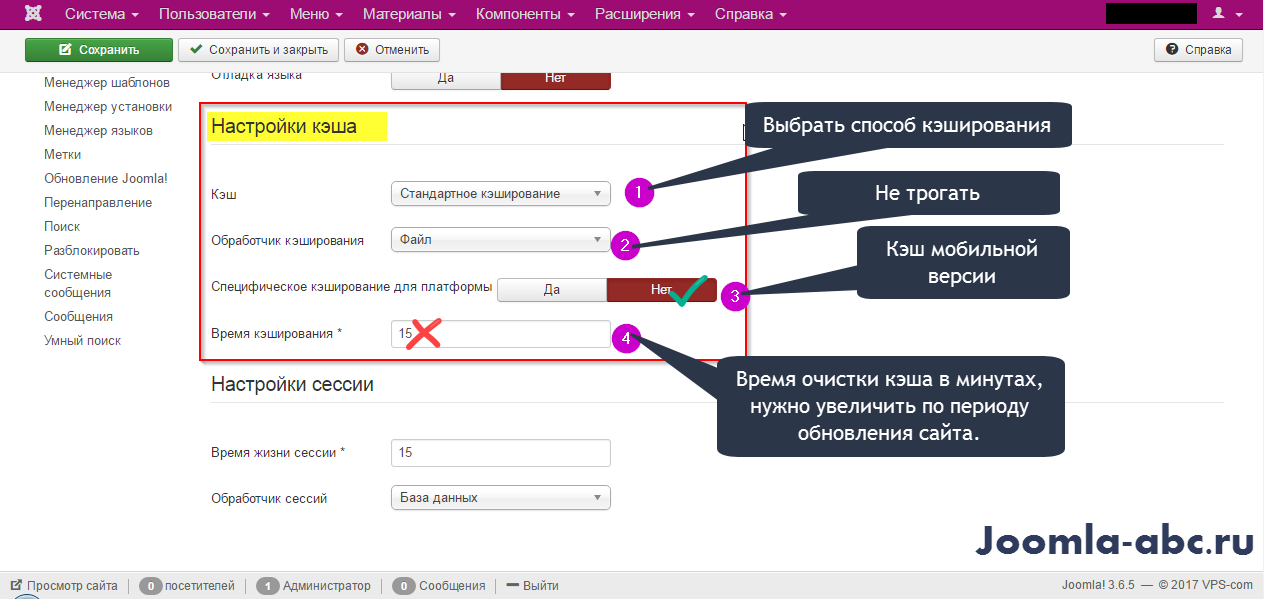
Первый режим позволяет сохранять веб-страницы в полном объеме и после по запросу выдавать результат. Второй кэширует данные произвольного типа. И, наконец, третий. Он похож на предыдущий, однако сохраняет определенное состояние объектов некий промежуток времени.
Названные режимы можно спокойно использовать для конкретного проекта. А также можно воспользоваться одним из популярных плагинов. Это W3 Total Cache и WP Super Cache
Теперь перейдем к Joomla 3. Данный движок также имеет три режима работы, однако их названия несколько отличаются, как и реализация. Так, существует отключение кэширования, подключение стандартного и прогрессивного хранения копий. Обычно используется второй режим. Конечно же и для этой CMS существуют соответствующие плагины.
Ну а теперь я хочу рассказать вам о более общих способах настройки. К ним относится указание плавил кэширования через документ .htaccess и веб-сервер nginx.
.htaccess
В архивах блога вы можете найти несколько статей, посвященных детальному объяснению работы названного файла-конфигуратора. А сейчас займемся решением конкретной задачи.
Чтобы ускорить загрузку сайта, можно добавить в кэш статическую информацию, т.е. те ресурсы, которые практически не изменяются или меняются очень редко. Для этого следует воспользоваться модулем под названием headers, вписав в конфигурационный документ следующие строки:
При этом виды расширений вы можете изменять под свои нужды. Соответственно если вы хотите запретить принудительное кэширование указанных расширений, то вместо команды set пропишите unset.
Nginx
Для начала вам стоит знать, что это веб-сервер, который функционирует на Unix-подобных ОС. Т.е. сюда входят Linux, Mac OS X, Solaris и другие. А также с выпуском версии 0.7.52 nginx стал работать и под Microsoft Windows.
Для работы с ним, вам необходимо найти конфигурационный файл nginx.conf. После открытия документа найдите в нем раздел с названием server. А вот теперь в него добавьте следующие строки:
1 2 3 4 5 6 7 |
location ~* \.(jpg|jpeg|gif|png|swf|tiff|swf|flv)$ {
root $webroot;
#Все копии файлов с указанными расширениями будут сохранены на 4 месяца
expires 4M;
#А теперь кэшируем данные с двух сторон: на клиентской и на прокси
add_header Cache-Control public;
}
|
Если вам не нравятся предложенные варианты решения поставленной задачи, то вы можете воспользоваться встроенными средствами языка php.
Если данная статья оказалась для вас полезной, то вступайте в ряды моих дорогих подписчиков, а также делитесь ссылкой на этот блог с друзьями. До новых встреч! Пока-пока!
Прочитано: 297 раз
Валидация кеша
Валидация кеша запускается при нажатии пользователем кнопки перезагрузки. Кроме того, она может выполняться в ходе обычного просмотра страниц, если кешированный ответ включает заголовок «Cache-control: must-revalidate». Другим фактором являются настройки кеширования браузера — можно потребовать принудительной валидации при каждой загрузке документа.
При истечении срока годности документа он либо проходит валидацию, либо повторно доставляется с сервера. Валидация может выполняться только если на сервере реализован сильный валидатор или слабый валидатор.
Заголовок ответа является непрозрачным для клиентского приложения (агента) значением, которое можно использовать в качестве сильного валидатора. Суть в том, что клиент, например, браузер, не знает, что представляет эта строка и не может предсказать, каким будет её значение. Если в ответе присутствует заголовок , клиент может транслировать его значение через заголовок If-None-Match (en-US) будущих запросов для валидации кешированного ресурса.
Заголовок ответа можно использовать в качестве слабого валидатора. Слабым он считается из-за того, что имеет 1-секундное разрешение. Если в ответе присутствует заголовок , то для валидации кешированного документа клиент может выводить в запросах заголовок .




При запросе на валидацию сервер может либо проигнорировать валидацию и послать стандартный ответ , либо вернуть ответ (с пустым телом), тем самым указывая браузеру взять копию из кеша. В последнем случае в ответ могут входить также заголовки для обновления срока действия кешированного ресурса.
Проблемы с кэшированием
В процессе создания и работы кэширующей системы может возникнуть набор разные проблем и вопросы, такие как:
- Деление данных между кэширующими серверами.
- Параллельные запросы на обновление данных.
- “Холодный” старт приложения.
Деление данных между кэширующими серверами
Для повышения надежности и производительности системы кеширования приходится разделять ее на несколько серверов. Поэтому возникает вопрос как делить данные между серверами.
Вариант 1. Использовать хеширование ключей. В таком случае данные разделяются по серверам в зависимости от ключа кэширования. Для этого используется хеш функция, которая на вход принимает ключ и возвращает номер сервера.
Проблема такого подхода заключается в том, что в случае падения сервера мы теряем почти 80% данных из-за изменения месторасположения ключей.
Вариант 2. Логическое разделение данных на основе какого-то признака. Например мы можем разделять данные на основании пользователя. Так данные одного пользователя будут лежать рядом на одном сервере.
Примеры проблем и их решения отлично описаны в статье “Проблемы при работе с кэшем и способы их решения”
Параллельные запросы на обновление данных
Время от времени данные в кеше протухают и удаляются. В таком случае их необходимо обновить. Обычно это происходит, когда запрос обращается в кэш, видит, что данных нет, идет за ними в БД после чего обновляет кэш. Может возникнуть ситуация, когда таких запросов нескольколько, тогда все они пойдут в базу данных и нагрузят систему.
Решение 1. Блокировка перед обновлением кеша. Первый запрос получает уникальную блокировку на загрузку данных в кэш, все остальные ожидают блокировку. Это решает проблему с обновлением, но порождает новые: как обрабатывать таймауты, как правильно подобрать время блокировки и т. д.
Решение 2. Фоновое обновление кэша. Приложение всегда читает данные из кеша и никогда не ходит в базу данных. Данные в кеше обновляет специальный скрипт или программа, которая работает в фоне. В таком случае никогда не наступит параллельного обновления кеша. Но возникает проблема с временем реакции на изменение данных в БД.
Решение 3. Вероятностное обновление данных. Обновляем не только данные, которых нет в кэше, но и с какой-то вероятностью те что уже есть. Это позволит обновить данные, до того как они протухнут и будут удалены.
Решение 4. Дублирование ключей. В системе есть два ключа, где второй имеет время жизни немного больше чем первый. В таком случае после того как исчезнет первый ключ мы обновляем его данные, но остальные запросы на чтение могут взять данные из второго ключа.
«Холодный» старт приложения
В момент запуска приложения данных в кэше может не быть. Как только пойдут запросы от пользователей все они пойдут массово в базу данных и начнуть одновременно обновлять кэш. Такая ситуация может привести к резкому падению производительности всей системы.
Решение. Можно прибегнуть к технике «прогревания» кеша. В таком случае при старте приложения мы также наполняем кэш данными, которые активно используются.
Когда изменения необходимы
Вы чувствуете, что из жизни постепенно уходит радость и нарастает тревожность, что ваши повседневные дела совсем не приносят удовольствия, а только забирают энергию? Это сигнал, что живете вы неправильно. Если на этом этапе не свернуть с проторенной дорожки, она заведет вас в дебри глубокой депрессии, выбраться из которой будет очень сложно.
Иногда жизнь распоряжается за нас и буквально насильно заставляет начать все с чистого листа. Так происходит после смерти очень близкого человека, утраты ценного имущества, развода, потери работы. В таких ситуациях нам ничего не остается, как собраться с силами и построить жизнь с нуля. К сожалению, не у всех хватает сил справиться с тяжелыми потрясениями, некоторые люди “ломаются”. Поэтому лучше не дожидаться серьезных проблем и начать менять жизнь к лучшему уже сегодня.
Кэширование в теории и на практике
Прежде чем раскрыть всю суть, отмечу, что эта статья — продолжение нашего цикла про архитектуру highload-систем, где главным героем будет кэширование. Ранее, в материале «Big Data с «кремом» от LinkedIn: инструкция о том, как правильно строить архитектуру системы», я вскользь коснулся вопроса кэширования данных, как способа снижения нагрузки на СУБД, а значит, повышения производительности нашего приложения. Суть кэширования очень простая – не надо каждый запрос приземлять на СУБД. Как же это реализовать? Давайте разберёмся и начнём с определений и классификации.
Кэширование – это подход, который, при правильном (!) использовании значительно ускоряет работу и снижает нагрузку на вычислительные ресурсы. Если ещё проще, кэширование — это метод оптимизации хранения и/или доступа к данным, при котором операции с этими данными производятся эффективнее, чем на источнике.
Теперь о классификации — в рамках этой статьи я хочу подробнее остановиться на двух подходах: LRU-кэширование и кэширование в Redis.
Least Recently Used (Вытеснение давно неиспользуемых)
LRU — это алгоритм, при котором в первую очередь вытесняется неиспользованный дольше всех элемент.
Кэш, реализованный посредством стратегии LRU, упорядочивает элементы в порядке хронологии их использования. Каждый раз, когда мы обращаемся к записи, алгоритм LRU перемещает её в верхнюю часть кэша. Таким образом, алгоритм может быстро определить запись, которая дольше всех не использовалась, проверив конец списка.
В модуле стандартной библиотеки Python functools реализован декоратор @lru_cache, дающий возможность кэшировать результат выполнения функций, используя стратегию LRU.
Декоратор @lru_cache под капотом использует словарь. Результат выполнения функции кэшируется под ключом, который соответствует вызову функции и её аргументам. О чём это говорит? Самые догадливые уже сообразили: чтобы декоратор работал, — аргументы должны быть хешируемыми.
Вот пример:
Нам нужно пробежаться по журналу событий (audit_log), где каждый элемент имеет атрибут user_id — уникальный идентификатор пользователя, подтверждающий определённое действие пользователем в информационной системе. При этом, один и тот же пользователь обычно совершает множественные действия в системе, а значит, событий с одинаковыми used_id будет больше 1. Но идентификатор пользователя нам ни о чём не говорит. Это просто UUID и если вы не вундеркинд, который запоминает 100 знаков после запятой в числе π, то вам проще оперировать фамилией, именем и отчеством (ФИО). А где лежит ФИО? Правильно — в СУБД, в табличке с пользователями. И что теперь каждый раз делать запрос в СУБД по одному и тому же user_id, чтобы получить ФИО? Конечно, нет!
Применим LRU декоратор уже на конкретном примере:
Одна строчка кода, которая декорирует функцию get_fio_by_id() и мы уже прикрутили LRU кэш + существенно повысили производительность приложения!



