
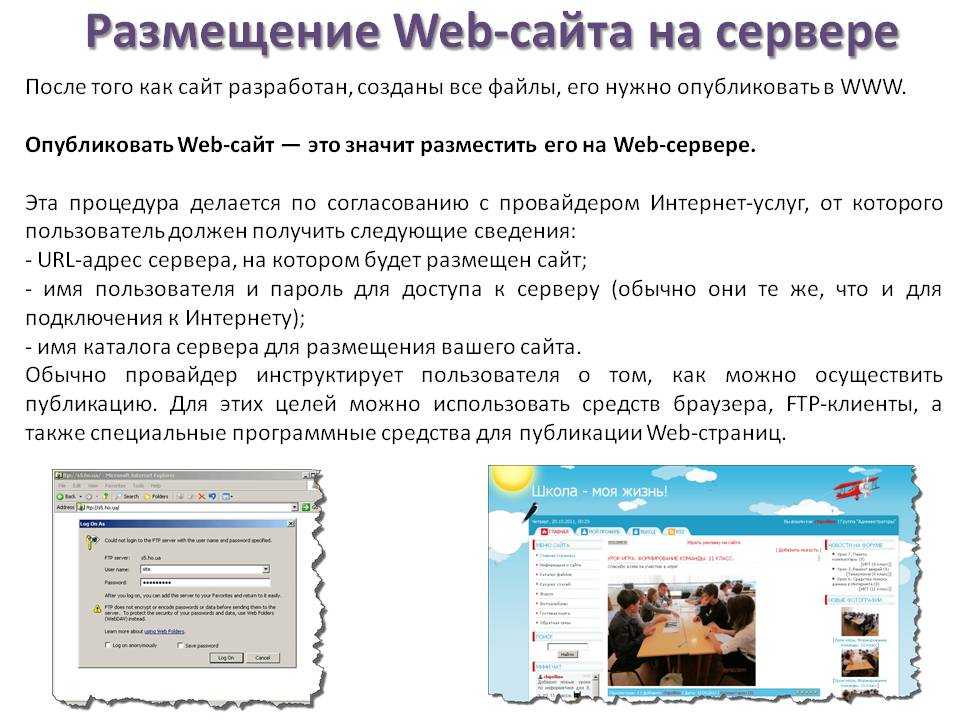
2.3. PDF в браузере Mozilla Firefox
Оптимальные настройки PDF-принтера предусматривает и печать на борту Mozilla Firefox.
- Кликаем кнопку «Открыть меню» (1 на рис. 11),
- затем – «Печать» (2 на рис. 11):
Рис. 11. «Открыть меню» – «Печать» в Мозилле
В окне «Печать» можно задать параметры для сохранения веб-страницы в PDF (рис. 12):
- количество необходимых страниц,
- масштаб,
- книжная или альбомная ориентация
- и очень полезная опция «Упростить страницу», которая убирает лишние элементы навигации с веб-страницы. В итоге pdf-документ выглядит аккуратным, «причесанным».
Рис. 12. Сохранение странички в PDF-формате с помощью Мозиллы
Если в Мозилле, опция «Печать» есть название принтера (на рис. 13 – это HP LaserJet M1005), но отсутствует PDF, тогда надо
- кликнуть по маленькому треугольничку (1 на рис. 13),
- в выпадающем списке выбрать PDF (2 на рис. 13).
Рис. 13. Поиск PDF-формата в Мозилле
Причины возникновения дублей на сайте
Ошибка контент-менеджера
Самая банальная ситуация —когда контент добавили на сайт дважды, то есть созданы одинаковые страницы. К счастью, таких ситуаций легко можно избежать.
Если у вас сайт с преимущественно текстовым наполнением, вам стоит вести контент-план, с помощью которого вы сможете следить за своими публикациями. В любом случае необходимо периодически делать ревизию контента и следить за посадочными страницами, чтобы избежать проблем с каннибализацией и дублями.
Если контент добавлен и проиндексирован, необходимо определить основную страницу и оставить только ее. Для этого воспользуйтесь инструкциями ниже в секции «Выбор основной версии страницы».
URL с параметрами
Чаще всего именно параметры становятся причиной дублирования контента и траты краулингового бюджета на страницы, не представляющие ценности.
Параметры и дубли страниц могут появляться при:
Классическим решением является использование тега canonical. В таком случае все страницы с параметрами указывают на страницу без параметров как на каноническую. Например: https://seranking.ru/?sort=desc содержит <link rel=»canonical» href=»https://seranking.ru/»/>.
Второй классический вариант решения проблемы — использование метатега robots либо X-Robots-Tag с директивой noindex для предотвращения индексации страниц.
В случае страниц с параметрами лично мне больше нравится решение с canonical
Но важно помнить, что canonical является для поисковиков только рекомендацией. . Для решения проблем фильтрации я рекомендую заменять теги на для тех фильтров, которые заведомо создают страницы-дубли или страницы, которые вы не планируете индексировать
Это более сложное решение, которое экономит краулинговый бюджет, но требует постановки задачи разработчику.
Для решения проблем фильтрации я рекомендую заменять теги <a> на <span> для тех фильтров, которые заведомо создают страницы-дубли или страницы, которые вы не планируете индексировать. Это более сложное решение, которое экономит краулинговый бюджет, но требует постановки задачи разработчику.
Однотипные товары с различными вариантами продукта
Я приверженец практики, когда для практически одинаковых товаров — например, футболок разных цветов — используют одну и ту же карточку товара, а нужный вам вариант можно выбрать при заказе. Таким образом минимизируется число дублей — карточек товара с одинаковым продуктом, а пользователь всегда попадает именно на тот товар, который он ищет. Такое решение также позволяет сэкономить краулинговый бюджет и избежать каннибализации.
Региональные версии сайтов
Для сайтов услуг проблема решается проще. Если вы создаете страницы под разные города, пишите уникальный локальный контент для конкретной локации.
Использование hreflang помогает решить проблему с частичными дублями, но использовать этот инструмент нужно аккуратно и обязательно отслеживать ситуацию.
Последняя ситуация, которая встречается реже, — использование региональных доменов с одинаковым контентом, т.е. когда каждый регион\область\штат имеет свой сайт на отдельном домене, но при этом используют одинаковый либо похожий контент. В таком случае стоит, опять-таки, уникализировать контент с учетом особенностей каждой локации и правильно настроить теги hreflang.
Доступность товара в разных категориях
https://site.com/t-shirt/nike/t-shirt-best.html и https://site.com/t-shirt/red/t-shirt-best.html
Эту проблему можно решить, исправив логику работы CMS, чтобы для товаров в разных категориях всегда использовался один URL. На мой взгляд, это оптимальное решение проблемы. Также можно использовать тег canonical.
Технические проблемы
Одна из самых популярных проблем дублирования — техническая. Особенно часто проблема встречается в самописных или малопопулярных CMS, но грешат этим и более именитые системы. Поэтому SEO-специалист всегда должен быть на чеку и контролировать параметры, которые приводят к дублированию: настроено ли главное зеркало, обрабатываются ли завершающие слеши и т.д. Полный список возможных технических проблем, из-за которых на сайте появляются полные дубли, я приводил выше.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью
Front-end Frameworks
![]()
Front-end Frameworks
Front-end frameworks обычно состоят из пакета, который содердит файлы и папоки, такие как HTML, CSS, JavasScript и т. д. Также существует множество автономных фреймворков.
- Bootstrap: HTML, CSS и JS фреймворк для разработки интерактивных и мобильных проектов.
- Foundation: это мощный CSS-фреймворк, который продолжительное время пребывал в тени Twitter Bootstrap, и только в последнее время пробивший себе дорогу в мир WordPress-тем.
- Semantic UI: это фреймворк для создания переносимых интерфейсов, который поможет повторно использовать элементы UI в своих проектах.
- uikit: это легкая, модульная платформа (фреймворк) для разработки быстрых и мощных веб-интерфейсов.
Используем поиск Google
Если в Яндексе копия уже изменена и не открывается в виде до изменений, можно попробовать поискать ту же информацию в другой поисковой системе. Есть вероятность что другой поисковик не успел внести изменения.
Чтобы найти удаленную страницу при помощи другого поисковика необходимо:
- Зайти на удаленный аккаунт Вконтакте и скопировать адрес.
- Вставить скопированный элемент в поисковую систему, например, Гугл.
- Навести курсор на выпадающее меню и выбрать сохраненную копию.
Сохраненную копию можно просмотреть, если оригинальную удалили не так давно. Если пользователь удалил профиль, например, год назад, то осуществить просмотр таким способом не представляется возможным.
Четвёртый метод — использование графического редактора
А именно — Photoshop. Самый трудоёмкий, но зато самый надёжный способ сделать копию понравившегося дизайна на свой ресурс. Опять же, если вы не обладаете навыками работы в этой программе, а также не умеете верстать готовый шаблон, то без помощи специалиста не обойтись.
Честно, я даже не знаю, сколько стоит подобная услуга у дизайнера. Найти точный ценник можно на какой-нибудь бирже фриланса. Используя этот метод, вы можете быть уверены в том, что получите качественную копию, и поставить её на свой сайт не составит труда.
Для самостоятельного изучения Фотошопа могу порекомендовать замечательный курс Зинаиды Лукьяновой — «Фотошоп с нуля в видеоформате 3.0».
Главное преимущество заключается в том, что здесь не играет роли CMS понравившегося проекта. Скопированный шаблон можно будет установить на WP, DLE, Opencart и любые другие платформы.





Снижаем негативное влияние копирования контента
Суть метода заключается не в том, чтобы полностью ограничить возможность копирования контента, но уменьшить негативное влияние от сего действия. А в некоторых случаях даже изымать эффект.
Для этого будем использовать сервис tynt.com, который к скопированной части текста будет добавлять ссылку на источник. На практике это выглядит следующим образом.
Если текст размещается на раскрученном ресурсе, то нам от такой ссылки может быть только плюс. Во-первых ссылка кликабельна, что будет давать трафик по ней, если площадка посещаемая. Во-вторых, на конце ссылки размещается идентификатор сервиса, который будет отслеживать статистику (рассмотрим далее).
Для начала стоит зарегистрироваться в сервисе, введя свою почту, адрес сайта и пароль дважды.
![]()
![]()
После регистрации вам перекинет на страницу, где необходимо обязательно заполнить данные о сайте.
![]()
Далее будет страниц благодарности с ссылкой на страницу, где можно взять код для размещения на сайте.
![]()
Именно данный скрипт и будет вставлять ссылку к скопированному тексту.
![]()
Скрипт можно скопировать, как с области, где объясняется, куда его нужно разместить. Можно также нажать на кнопку «Copy script to clipboard», которая находится в самом верху. Ее я пометил стрелкой. После копирования скрипта в буфер мы его размещаем на сайте.
Сервис предлагает разместить скрипт в секции между открывающим и закрывающим тегами head. Но я предлагаю его закинуть в область footer перед закрывающим тегом body. Только что проверил и скрипт там работает.
![]()
Далее на странице со скриптом мы жмем на кнопку «Continue tu Publisher Dashboard», после чего нас перекинет на домашнюю страницу сервиса, где будет статистика. Вы можете смотреть:
- Сколько раз скопировали контент;
- Количество ссылок, которые имеют SEO эффект;
- Трафик по ссылкам со скопированного контента.
![]()
Последним шагом я предлагаю сделать человеческий вид ссылки, а именно заменить английскую стандартную надпись «Read more» на «Источник». В примере выше я давал пример уже замененной фразы.
Для этого стоит зайти в настройки аккаунта и во соответствующем поле заменить стандартную надпись перед ссылкой. Также можно выбрать вид ссылки. В общем, смотрите скрин ниже.
![]()
По поводу вида ссылки, то я рекомендую оставить стандартный вариант, так как при большом количество воровства контента с вашего сайта, ссылочная масса будет на вас формироваться более естественная, чем ссылка в виде названия страницы (вариант 2). Третий вариант выводит и простую ссылку и ссылку с анкором в виде названия страницы.
После нажатия на кнопку сохранения будет предложено подтвердить его с текстом, что настройки вступят в силу немедленно.
![]()
Далее рекомендуется подождать 10 минут, чтобы все данные обработались и перед тестированием работы новых настроек очистить кэш сайта.
Итак, друзья. Вот какие методы борьбы с защитой текста на сайте от копирования можно применять.
Если ваш ресурс сугубо информационный, где вы только что-то объясняете и не даете поводов копировать контент для личного употребления, то можно использовать и сервис. Он вполне справится со своей задачей.
Копии данных в поисковых системах
Каждый из нас пользуется Яндексом и Гуглом. У поисковых систем есть одна полезная функция, которая может помочь нам с нашей задачей. Поисковики сохраняют в своем кеше данные обо всех найденных страницах. И мы всегда можем его просмотреть. Если нам повезет, то может получиться найти копию удаленной страницы пользователя, и увидеть искомые данные.
Здесь нам снова нужна ссылка на страницу. Вбиваем ее в поисковую строку, и работаем с результатами.
Сначала в Яндекс
Если в резултатах поиска есть искомая страница, обратите внимание на строку с Url адресом. Здесь откройте выпадающее меню, и выберите пункт «Сохраненная копия»
Вы перейдете на нужную страницу.
Здесь интерфейс более удобен. Можно просматривать графические материалы в полном разрешении. Если Вам нужно было найти фотку с удаленной страницы, вы можете открыть и сохранить ее.
Намного удобнее. Но, к сожалению, здесь редко сохраняются данные с давно удаленных страниц.
Теперь в Гугл
Здесь процесс аналогичен. Ищем страницу по адресу. Если она существует, просматриваем сохраненную копию.
Ну и напоследок еще один рабочий метод.
Как сохранить страницу в PDF в Firefox
Подобным способом в Mozilla Firefox выполняется сохранение веб-страницы в файл формата PDF.
Пройдите следующее:
- В окне открытого сайта в браузере Mozilla Firefox нажмите на кнопку «Открыть меню приложения».
- В открывшемся контекстном меню щелкните по пункту «Печать…».
- В свойствах печати, в опции «Получать» установите «Сохранить в PDF».
- Если потребовалось, измените настройки печати.
- Нажмите на кнопку «Сохранить».
- В окне «Сохранить как», в поле «Тип файла:» выбран формат — PDF.
- Нажимайте на кнопку «Сохранить», чтобы получить готовый файл на своем компьютере.
Как скопировать веб-страницу если там установлена защита от копирования
Сохранение картинок и шрифтов
Помимо сервисов онлайн для скачивания интернет-сайтов, существуют и специальные программы для этого. Как и сервисы, они требуют наличия интернет соединения, но для работы им необходим только адрес сайта.
HTTrack WebSite Copier
Бесплатная программа с поддержкой русского языка, операционных систем, не относящихся к семейству Windows, а главное – бесплатная. В меню установки доступен только английский, однако уже при первом запуске в настройках есть возможность установить русский или любой другой. По умолчанию создает на системном разделе папку «Мои сайты», куда и будут сохраняться все загруженные интернет-порталы. Имеет возможность дозагрузить сайт, если по какой-то причине загрузка прервалась.
Главное окно программы HTTrack WebSite Copier
Также есть ряд настраиваемых параметров:
- тип контента – позволяет задавать доступность изображений, видео и прочих медийных составляющих;
- максимальная глубина скачивания – доля доступного функционала. Большинству сайтов подходит глубина – 3-4 уровня;
- очередность скачиванию – задает приоритет загрузки текста или медиа-файлов.
Возможно вас заинтересует: Как расшарить файлы и папки в локальной сети и интернет (общие папки)
К недостаткам можно отнести частично утративший актуальность интерфейс.
Использование:
- Скачать программу из надежного источника.
Скачиваем программу из официального источника
- Кликнуть «Далее», чтобы создать новый проект.
Нажимаем «Далее»
- Ввести имя, под которым будет находиться сохраненный сайт, выбрать путь для загрузки файла, нажать «Далее».
Вводим имя, под которым будет находиться сохраненный сайт, выбираем путь для загрузки, нажимаем «Далее»
- Задать адрес сайта и тип содержимого, которое будет загружаться.
Задаем адрес сайта и тип содержимого
- Настроить глубину загрузки — количество подразделов сайта, щелкнув по опции «Задать параметры».
Щелкаем по опции «Задать параметры»
- Во вкладке «Прокси» оставить настройки по умолчанию или убрать галочку с пункта «Использовать прокси…».
Во вкладке «Прокси» оставляем все по умолчанию
- В закладке «Фильтры» отметить флажками пункты, которые нужно исключить.
Во вкладке «Фильтры» отмечаем нужные пункты
- Перейти во вкладку «Ограничения» в полях задать максимум и минимум, как на скриншоте.
Во вкладке «Ограничения» выставляем значения максимальное и минимальное, как на фото
- Во вкладке «Линки» отметьте пункты, как на фото.
Отмечаем пункты, как на скриншоте
- Перейти во вкладку «Структура», в разделе «Тип структуры…» выбрать параметр «Структура сайта (по умолчанию)», нажать «ОК».
Во вкладке «Структура» выбираем в параметре «Тип…» структуру сайта по умолчанию, нажимаем «ОК»
- Выбрать тип соединения, при необходимости — выключение компьютера после завершения. Нажать «Готово».
Выставляем настройки, как на скриншоте, нажимаем «Готово»
- Дождаться завершения процесса скачивания.
Процесс скачивания сайта, ожидаем завершения
Teleport Pro
Программа с простым и понятным интерфейсам, дружелюбным даже для новичка. Способна искать файлы с определенным типом и размером, а также выполнять поиск, использую ключевые слова. При поиске формирует список из всех файлов со всех разделов ресурса. Однако, у нее хватает и недостатков. Главный из них – платная лицензия. 50 долларов далеко не каждому по карману.



Возможно вас заинтересует: Как поменять мак адрес компьютера
Интерфейс программы Teleport Pro
Кроме того в настройках отсутствует русский язык, что сделает еще более сложным пользование людям, не владеющим английским. Также эта программа несовместима с «альтернативными» ОС для обычных компьютеров (не «маков»), и в завершении «минусов» программы – она обладает очень старым интерфейсом, что может не понравиться людям, привыкшим работать на последних версиях Windows.
Offline explorer Pro
Интерфейс программы Offline explorer Pro
Еще одна лицензионная программа. По сравнению с упомянутыми выше, функционал значительно расширен: можно загружать даже потоковое видео, интерфейс более привычен для современных операционных систем. Может обрабатываться до 500 сайтов одновременно, включая запароленные. Программа имеет собственный сервер, что делает ее гораздо автономней прочих программ, не говоря уже об онлайн-сервисах. Позволяет переносить сайты прямиком из браузера.
Главный недостаток большая цена: 60 долларов за стандартную версию, 150 – за профессиональную и целых 600 – за корпоративную. Такие цены делают ее доступной только для узкого круга пользователей.
Как скопировать защищенный Google документ?
Для этого нажимаем на клавиатуре клавиши Ctrl + P или Print PrtScr в любом браузере. В Хроме (Google Chrome ) и Опере (Opera) после нажатия горячих клавиш откроется окно предварительного просмотра, настройки и отправки на печать в файл нужной вам страницы через виртуальный принтер.
Как скопировать с Гугл таблицы?
Копирование и вставка в Google Документах, Таблицах и Презентациях
- Откройте файл в приложении «Google Документы», «Google Таблицы» или «Google Презентации» на устройстве iOS.
- Только в Документах: нажмите на значок .
- Выделите нужный фрагмент.
- Нажмите Копировать.
Как скопировать защищенный текст со страницы?
Как скопировать текст с сайта, который как бы «защищен»
- Копируем из браузера адрес «защищенной» странички:
- Открываем Microsoft Office Word.
- Нажимаем Файл –> Открыть
- Вставляем в окно открытия адрес этой странички и нажимаем кнопку .
- Если Word показывает предупреждения, нажимаем кнопки
- Вуаля! Копируем любые тексты! PROFIT.
Как скопировать документ Если он защищен от копирования?
Переходим в раздел меню «Вставка», находим «Вставить объект», нажимаем на маленькую стрелочку возле него и кликаем по «Текст из файла…». Выбираем нужный файл и нажимаем кнопку «Вставить». После этой процедуры мы можем начинать работу с текстом.
Как скопировать с Гугл документа?
На компьютере перейдите на сайт Google Документов, Таблиц, Презентаций или Форм. Откройте нужный файл. Создать копию. Введите название копии и выберите, где ее сохранить.
Как скопировать диаграмму из Гугл таблицы?
Как сохранить диаграмму на компьютере
- Откройте файл в Google Таблицах на компьютере.
- Нажмите на диаграмму.
- В правом верхнем углу диаграммы нажмите «Ещё» Скачать как.
- Выберите тип файла.
Как перенести данные из одной Гугл таблицы в другую?
Перенести данные из одной «Google Таблицы» в другую можно простой операцией «Ctrl+с — Ctrl+v». Однако когда нужно, чтобы при изменении данных в исходной таблице, цифры в новой тоже менялись автоматически, этот вариант не подойдет.
Как скопировать весь текст на сайте?
Способ 1 – Ctrl + U
Защита от копирования в Интернете всегда делается однотипно – пользователю запрещается при чтении пользоваться правой кнопкой мыши и контекстным меню, выделять и копировать.
Как скопировать защищенный текст в ворде?
Кликните по импровизированной стрелке рядом с инструментом и в появившемся меню выберите опцию «Текст из файла». В окне Проводника укажите путь к защищённому документу и нажмите кнопку «Вставить». В зависимости от размера документа копирование займет от долей секунды до нескольких секунд.
Как скопировать текст из PDF с защитой?
Перейдите в папку с созданным документом и дважды щелкните по нему, чтобы открыть. Он откроется в программе для просмотра PDF-документов; при этом документ защищен не будет. Скопируйте текст. Наведите указатель на начало текста, удерживайте кнопку мыши и переместите указатель в конец текста, чтобы выделить его.
Как скопировать текст в PDF в браузере?
Для этого откройте PDF-файл в браузере, щелкнув правой кнопкой мыши файл и выбрав « Открыть с помощью»> (выберите браузер) или перетащите его в открытое окно браузера. Выберите текст, который вы хотите. Нажмите CTRL + C, чтобы скопировать текст и вставить его в другой документ, используя CTRL + V.
Как скопировать гугл документ на флешку?
Шаги Войдите в ваш аккаунт Gmail и откройте Google Docs. Найдите документ, который вы хотите скопировать на флешку. Откройте документ и нажмите «File» — «Download As».
Как скопировать файлы с гугл диска на флешку?
Найдите на Google Диске папку, содержащую все файлы, которые вы хотите поместить на флэш-диск. Шаг 3. . Выберите файл, который хотите загрузить, нажав на него. Если вам нужно несколько файлов, удерживайте клавишу CTRL, затем щелкните все файлы, которые вы хотите поместить на флэш-диск.
Бесплатные способы восстановления
Ручной
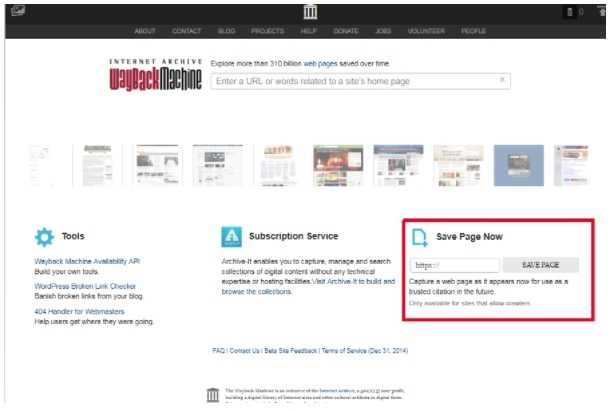
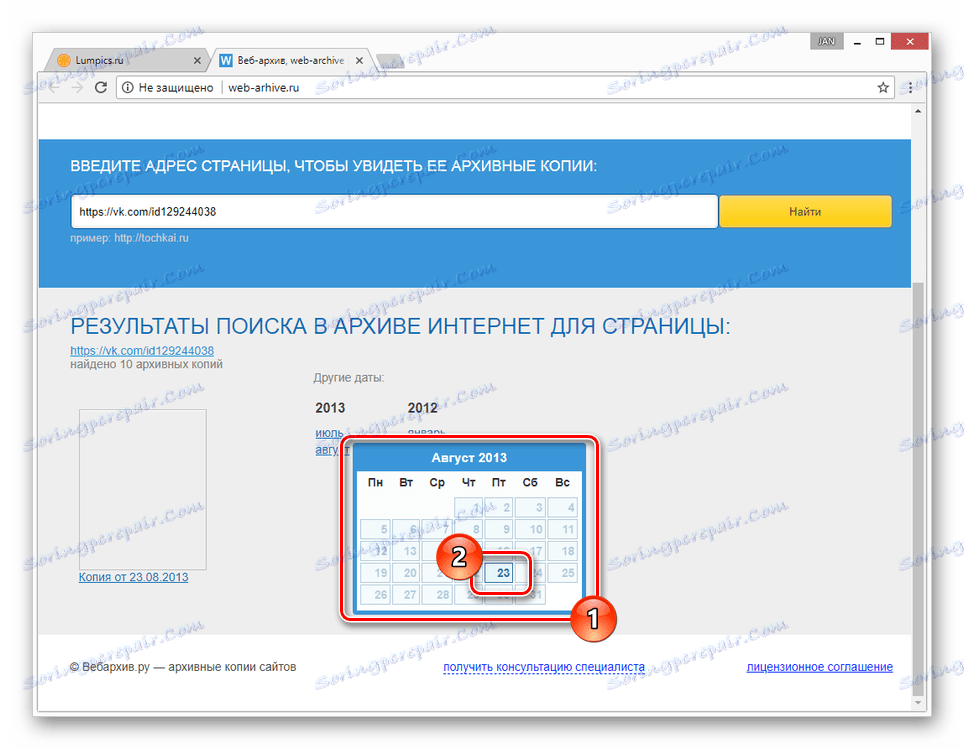
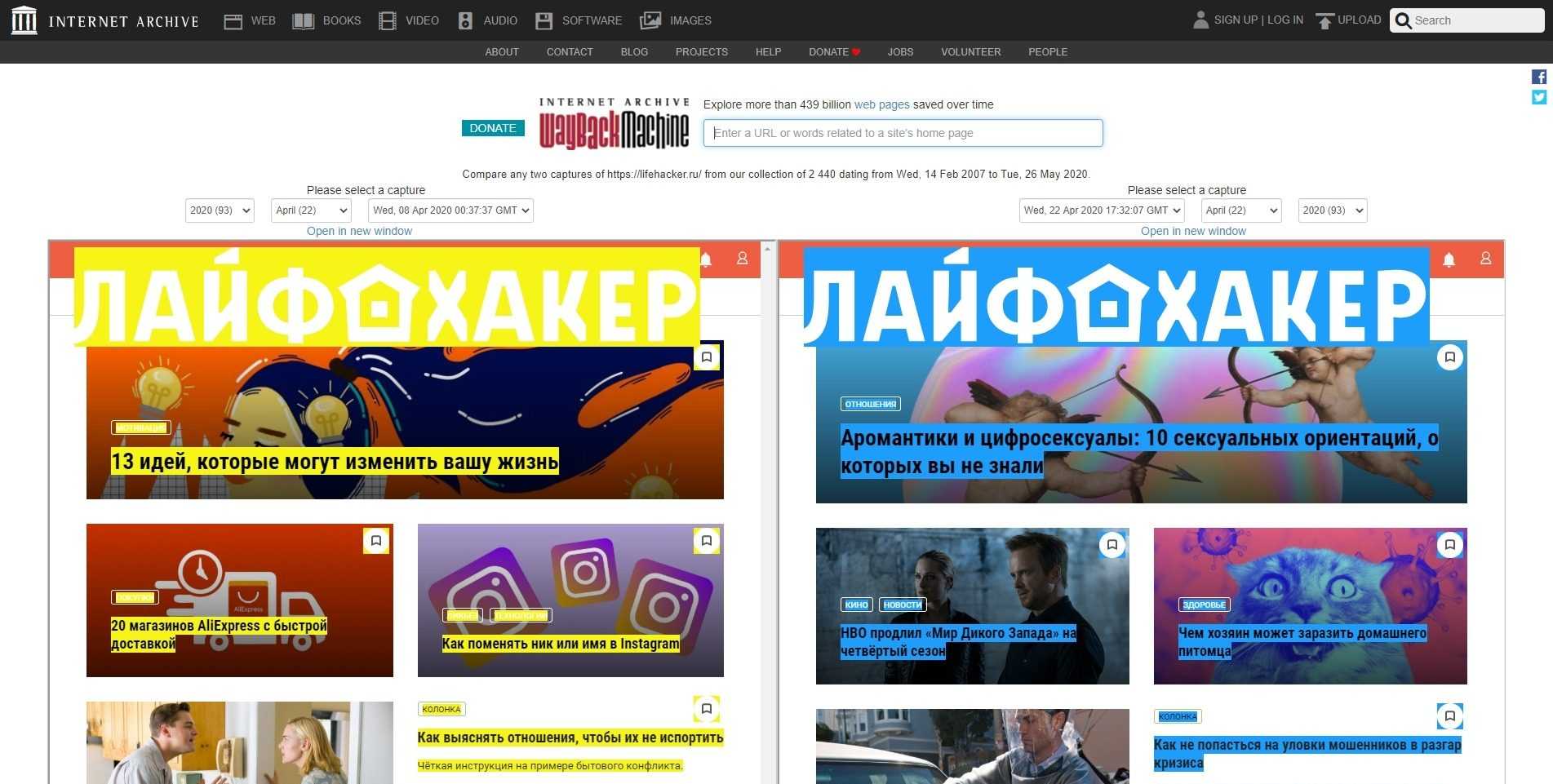
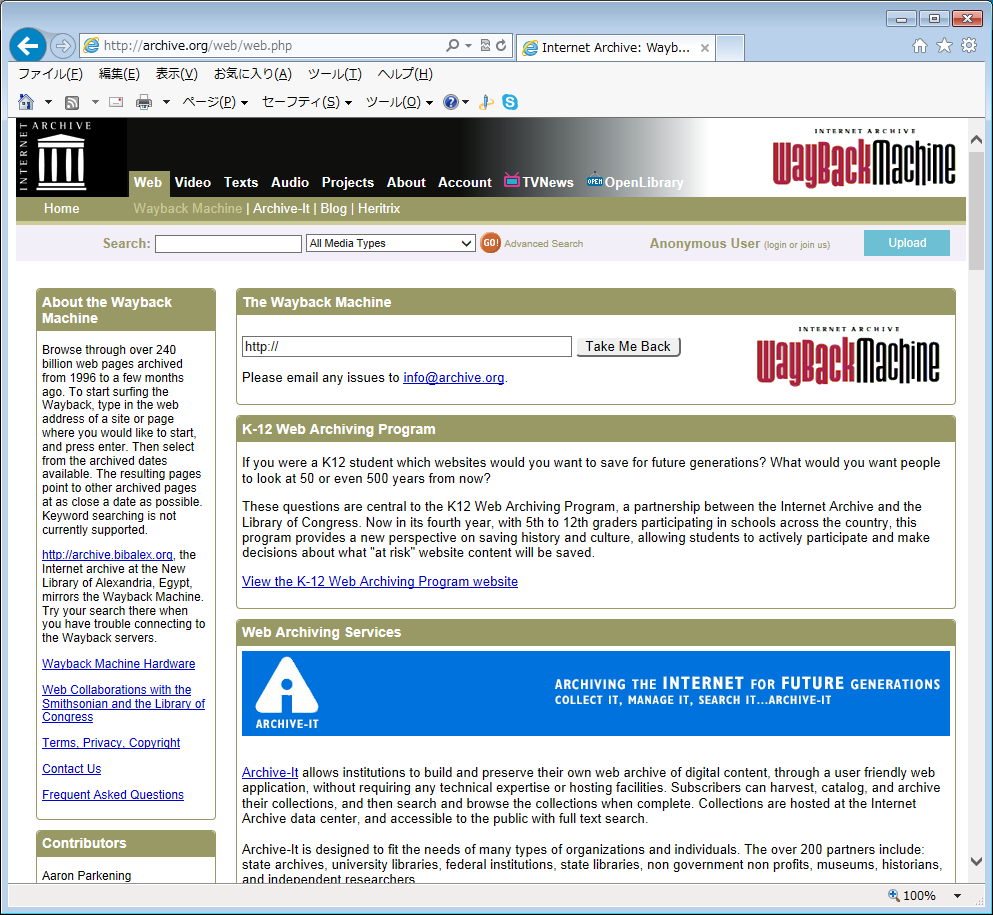
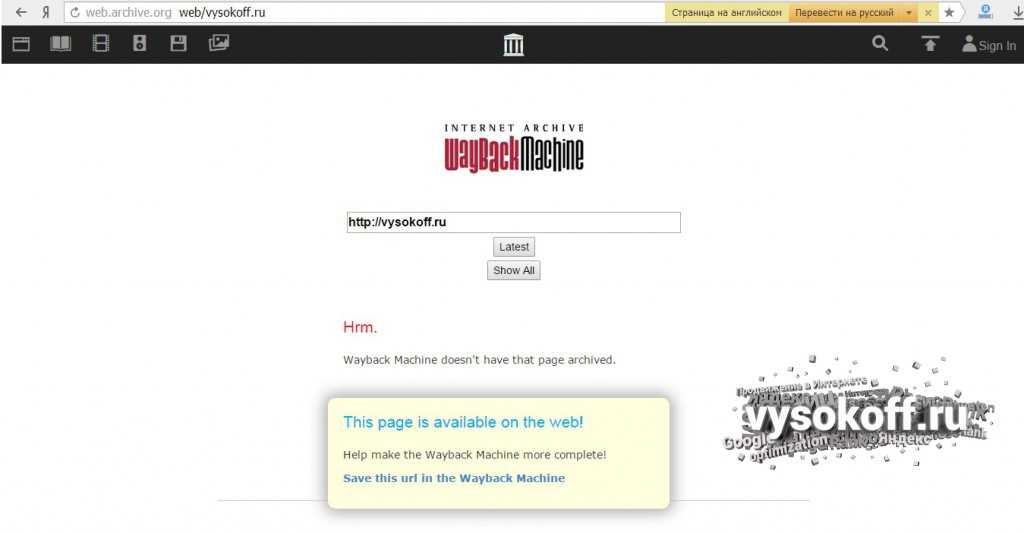
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.
Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.
«История» в мобильном приложении
Подавляющее большинство пользователей сидит в ВК именно с мобильного приложения на телефоне или планшете. Чтобы запросить архив данных своего профиля в телефоне, придерживайтесь следующих указаний.
- Кликните по профилю.
- В верхнем правом углу нажмите три черточки.
- Ищите пункт «Помощь».
- Далее переходите на него и вбивайте в поисковый запрос «Архив данных»
- Выбирайте первый раздел. В тексте объяснения вы увидите гиперссылку, по которой следует тапнуть.
- В открывшемся новом окне внимательно прочитайте всю хранившуюся информацию.
- Войдите через этот веб-браузер.
- Кликните «Запросить архив».
Теперь вы в курсе, как посмотреть исходные данные профиля , пользуясь разными сервисами. Внимательно читайте данную инструкцию.
Обычный способ
Перед сохранением интернет-страницы следует перейти на неё. То есть обозреватель сохранит полностью всё, что там находится: картинки, текст, анимацию. Вся информация будет распределена в папке. Однако сам файл с расширением html будет выведен отдельно.
Сохранить страницу можно несколькими способами.
- Нажмите одновременно кнопки Ctrl + S.
- Жмем правой кнопкой мыши на любую часть веб-страницы. Из списка выбираем «Сохранить как…».
- При сохранении указывается путь и подтверждается.
- Открывается меню и нажимаем «Сохранить как…».
Чтобы сохранить полностью все данные, следует выбрать в поле «Тип файла» пункт «Веб-страница полностью».
Редактирование сохранённых страниц
Откройте скачанную веб-страницу из панели ScrapBook, а затем воспользуйтесь иконкой ScrapBook в строке состояния браузера в правом нижнем углу. При нажатии на эту иконку появится выпадающее меню, в котором можно выбрать команду «Панель редактирования ScrapBook». На панели редактирования можно:
- задать имя веб-страницы, как оно будет отображено в панели ScrapBook;
- задать комментарий для веб-страницы, в том числе многострочный;
- отметить выделенный на веб-странице текст одним из четырёх маркеров; маркеры настраиваются в панели ScrapBook, через меню «Инструменты» — «Настройки расширения…», на вкладке «Изменение»;
- создать «быстрое примечание»; этот инструмент вставляет в код веб-страницы тег «div», позволяя создать характерно оформленную рамку с (многострочным) текстом в нужном месте документа; размер рамки регулируется мышью и может быть изменён в любой момент, также, как и сам текст примечания; в любой момент существующее примечание можно удалить;
- создать комментарий к выделенному фрагменту текста; фрагмент выделяется специальным подчёркиванием, а при наведении на него курсора мыши комментарий отобразится во всплывающей подсказке; в любой момент существующий комментарий можно изменить или удалить; в версии ScrapBook 1.3.3.7 этот инструмент доступен при нажатии на стрелочку рядом с иконкой карандаша в панели редактирования, пункт выпадающего меню «Присоединить файл к выделенному фрагменту»; вероятно, такое название пункта меню является ошибкой и будет исправлено в следующих версиях;
- присоединить файл к выделенному фрагменту текста веб-страницы, при этом будет выдан диалог для выбора произвольного файла; выбранный файл будет скопирован в каталог этой веб-страницы и вставлен как ссылка к выделенному фрагменту текста; этот инструмент доступен при нажатии на стрелочку рядом с иконкой карандаша в панели редактирования, пункт выпадающего меню «Присоединить файл к выделенному» (можно спутать с инструментом комментария, о котором было сказано чуть выше);
- присоединить ссылку к выделенному фрагменту текста веб-страницы, указав при этом произвольный URL;
- удалить все теги SCRIPT, IFRAME, все типы подсветок, подсветку в выделенном фрагменте текста или просто выделенный фрагмент документа;
- удалить произвольный фрагмент документа с помощью инструмента «DOM-очистка страницы»; когда используется этот инструмент, при наведении мыши на какой-либо фрагмент документа он обрамляется специальной рамкой, а щелчок мыши удаляет этот фрагмент.
Специальной кнопкой на панели редактирования можно сохранить сделанные изменения. Также есть кнопка для команды «Undo» (откат последнего действия). И наконец, кнопка «<<» позволяет быстро найти открытый документ в дереве на панели ScrapBook.
Когда скачанная веб-страница открыта, можно воспользоваться иконкой ScrapBook в строке состояния браузера в правом нижнем углу. При нажатии на эту иконку появится выпадающее меню, в котором можно выбрать команду «Показывать индикаторы ссылок». Эта команда отмечает специальным маркером все ссылки документа, которые ведут на локальные веб-страницы, то есть сохранённые ScrapBook’ом в результате захвата с «Уровнем глубины захвата ссылок» больше нуля. Это очень удобно, так как явно показывает ссылки, при переходе по которым не будет обращения к Интернет.
Вы можете отредактировать веб-страницу и перед её захватом. Когда веб-страница по какому-то URL открыта, воспользуйтесь иконкой ScrapBook в строке состояния браузера в правом нижнем углу. При нажатии на эту иконку появится выпадающее меню, в котором можно выбрать команду «Редактирование перед сохранением».
Попытка найти копию данных в кеше браузера
Этот способ представляю Вам больше для полного понимания доступных способов. Он не так актуален, как предыдущие, но иногда позволяет получить доступ к медиафайлам с удаленной страницы.
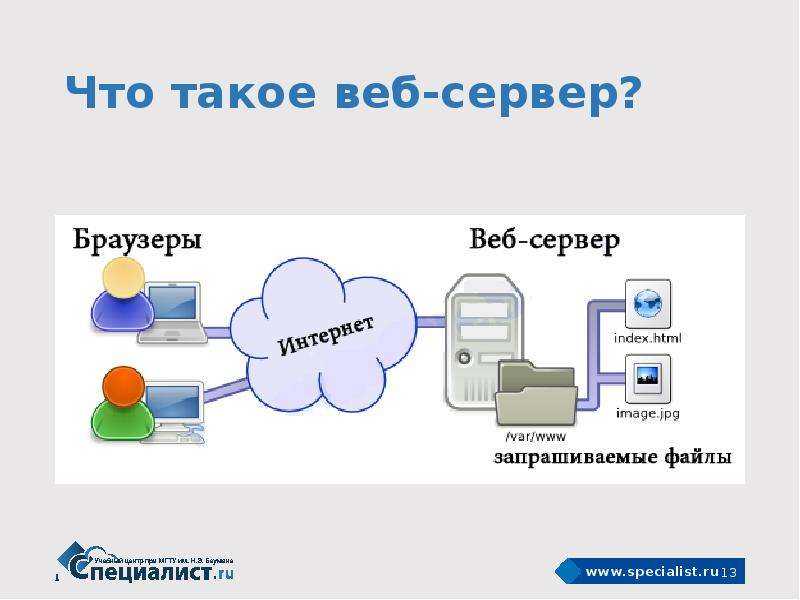




Работает только в том случае, если вы заходили на нужный адрес через ваш браузер.
Смысл в том, чтобы просмотреть кеш, и попытаться там найти копию данных.
Вам понадобится программа CacheView. Прямая ссылка для скачивания ниже.
Откройте полученный архив, и запустите программу. Будет запущен автоматический анализ существующего кеша из всех браузеров. В меню нужно открыть раздел «Опции», и отметить галочкой пункт «Отображать файлы изображений».
После окончания анализа, ищем существующие данные с сайта Вконтакте. Для этого нажимаем Ctrl+F, и в строке поиска пишем «Vk.com». Просматриваем найденные строки, дважды щелкая по ним курсором мыши. Если хотим увидеть данные, копируем ссылку на файл, и переходим по ней.
В том случае, когда удалось найти нужное изображение или фото, его можно сохранить.
Инструменты для веб-архивирования
здесь
Архивирование целых сайтов
- Archive-It: курируемая служба веб-архивирования. Предлагает годовую подписку на доступ к своему веб-приложению с различными услугами: полнотекстовый поиск, краулинг контента с различной частотой, выдача отчётов и т. д.
- ArchiveWeb.page: десктопная программа и расширение для Chrome для создания веб-архивов. Расширение можно поставить на «запись», то есть на автоматическое сохранение всех страниц, которые открывались в браузере или в конкретной вкладке. Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page
- Brozzler: опенсорсная утилита, которая для скачивания контента использует настоящий браузер (Chrome или Chromium), а также youtube-dl и rethinkdb
- Crawler
- Crawler4j: опенсорсный краулер на Java с простым интерфейсом
- grab-site: предварительно сконфигурированный опенсорсный граббер сайтов, граф ссылок хранит на диске, а не в памяти, поэтому может успешно скачать сайт даже с 10 млн страниц. Результат записывает в формате WARC
- gecco
- Heritrix
- HTTrack
- ItSucks (не поддерживается с 2010 года)
- NetarchiveSuite: разработка Датской королевской библиотеки
- Nutch: краулер с локальным поиском изначально создавался как альтернатива аналогичному корпоративному продукту Google
- Octoparse: проприетарная платная программа, работает только под Windows
- PageFreezer: ещё одна проприетарная система, веб-приложение, специализируется на автоматической архивации сайтов и соцсетей для юридических целей
- simplecrawler: простой API для краулера, не поддерживается
- Squidwarc: ещё один краулер, который работает через браузер (Chrome или Chromium), поэтому умеет выполнять скрипты и извлекать оттуда ссылки для краулинга
- StormCrawler: опенсорсный SDK для построения распределённых, масштабируемых краулеров на Apache Storm
- WAIL (Electron): Web Archiving Integration Layer (WAIL) — графический интерфейс работает поверх многих веб-архиваторов, чтобы упростить пользователям процесс сохранения и последующего просмотра веб-страниц
- WAIL (py): версия на Python
- WebMagic: масштабируемый фреймворк
- Conifer (бывш. WebRecorder.io): выделил пользовательскую утилиту WebRecorder в отдельный опенсорсный проект, сам продвигает услугу облачного веб-архивирования с бесплатным лимитом 5 ГБ
- wget: популярная утилита из набора GNU тоже умеет сохранять на диске веб-архивы в виде файлов WARC
- wpull: wget-совместимый веб-архиватор, написанный на Python
Архивирование отдельных страниц
- Archive.is: общедоступный сервис для съёмки снапшотов страниц, которые получают новые URL, сохраняются в архиве для всеобщего просмотра
- curl: известная утилита командной строки для скачивания страничек
- FreezePage: веб-интерфейс для скачивания страничек, сохранять их можно в облаке или на диске
- Paparazzi!: маленькая утилита под macOS, которая делает графические скриншоты страниц
- Perma.cc: сокращатель ссылок и веб-архиватор позиционируется как инструмент для школьников, студентов, юристов и всех остальных, кто хочет получить надёжную ссылку на документ с гарантией, что он не исчезнет и не изменится
- WARCreate: расширение Google Chrome, которое сохраняет любую страницу в формате Web ARChive (WARC)
- webkit2png: утилита командной строки для сохранения скриншотов простой командой типа
Системы скрапинга данных
- Import.io: платная корпоративная система для скрапинга преимущественно финансовой информации с интеграцией собранных данных в сторонний софт
- iRobotSoft.com: персональный «менеджер», который автоматизирует рутинные ежедневные задачи в интернете: созданные «роботы» могут в том числе ходить по сайтам, кликать по ссылкам и собирать данные с веб-страниц
- morph.io: инструментарий для написания скраперов на Ruby, Python, PHP, Perl и Node.js, коллекция более 10 800 публичных скраперов
- Zyte (бывш. Scrapinghub): платный сервис дата-скрапинга через Extraction API
- WebScraper.io: расширение Chrome и Firefox для удобного скрапинга, экспорт в CSV, XLSX и JSON. Поддерживает работу в облаке по расписанию, через API, с продвинутым парсингом и т. д.Выбор данных для скрапинга в расширении Chrome
- Web Scraper Plus+: платный парсер под Windows, давно не поддерживается и даже не совместим с Windows 7
LinkAceWallabagLinkAce (платная)
Выводы статьи
Чтобы сохранить необходимую информацию из Интернета, пользователи применяют различные методы. Один из самых распространенных вариантов — сохранение веб-страниц в качестве файла в формате PDF, который можно просматривать на любом устройстве. В этом случае, на помощь пользователю придут различные инструменты: виртуальный принтер на компьютере или в браузере, расширение для браузера или онлайн сервис.
Как сохранить веб-страницу сайта в PDF (видео)
Похожие публикации:
- Как вставить PDF в документ Word — 6 способов
- Лучшие онлайн сервисы для сравнения документов
- Как скрыть текст в Word
- Чем открыть RTF — 10 способов
- Как сжать PDF онлайн — 6 сервисов



