
Заголовки для кеширования
Когда веб-сервер отдаёт какой-нибудь файл: картинку, css, js или контент страницы, то он должен сказать сколько можно хранить эти данные в кеше.
Картинки можно хранить там вечно, они никогда не изменяются. Многие любят выдавать запрет на кеширование в виде заголовков:
Cache-Control: no-cache,no-store,max-age=0,must-revalidate Expires: -1 Expires: Thu, 19 Nov 1981 08:52:00 GMT Pragma: no-cache
На самом деле, смысла в этом никакого нет для большинства данных, только нагрузка на сервер. И не надо бояться сказать, что файл или страницу сайта можно закешировать.
Во-первых, потому что браузер при следующем обращении к этому контенту при условии, что время хранения кеша просрочено спросит: «а не изменился ли ресурс с момента последнего моего запроса».
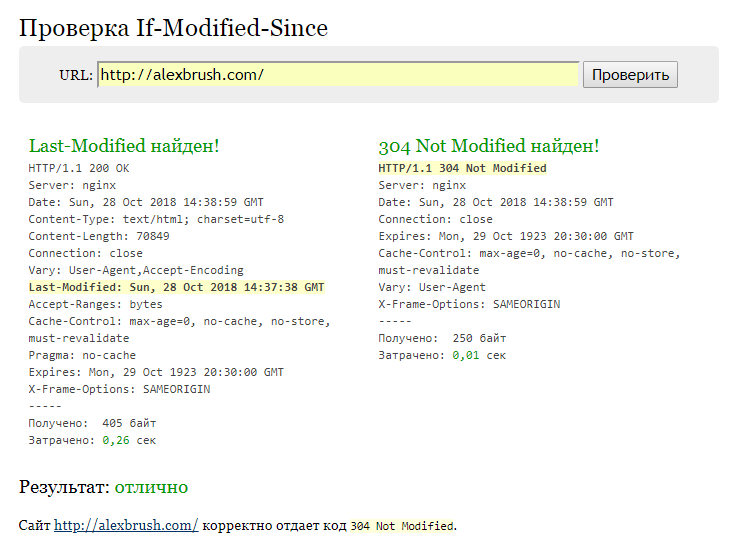
И если не изменился, то веб-сервер должен вернуть заголовок 304 Not Modified и не отправлять запрашиваемый файл.
Во-вторых, пользователь всегда может нажать обновить страницу и принудительно послать запрос к серверу не уточняя изменился ресурс или нет.
Важно только правильно определить время хранения кеша. В решение этого вопроса можно исходить из того как часто обновляются данные и насколько это важные данные.
Что случится, если посетитель увидит обновление с опозданием
Какое это разумное опоздание? Подавляющее большинство страниц в интернете чаще умирает, чем обновляется.
Обновляются ленты новостей, а страница с конкретной новостью живёт вечно. Поэтому для подобных страниц можно смело выставить время жизни веша сутки или неделю, т.е. то
разумное время в которое посетитель может вернуться на эту страницу или ваш сайт.
Итак, давайте рассмотрим как браузер спросит не изменился ли запрашиваемый ресурс. Для этого есть два варианта.
Первый — отправить в запросе If-Modified-Since с датой предыдущего запроса.
Второй — отправить в запросе If-None-Match с меткой ETag, которую он получил при предыдущем обращении.
При ответе веб-серве посылает следующие заголовки:
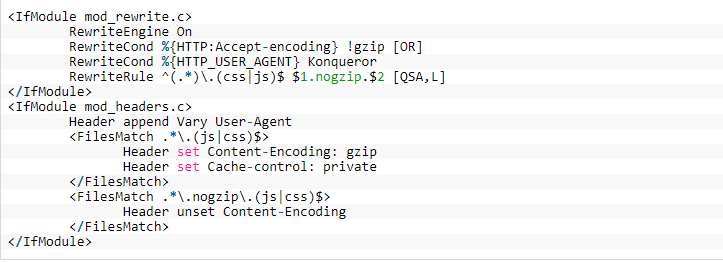
ETag: "1722-59d1cd83fc41f" Cache-Control: max-age=31536000, public
ETag — является уникальной меткой, а Cache-Control сообщает можно ли хранить кеш на промежуточных прокси-сервера и сколько его можно хранить.
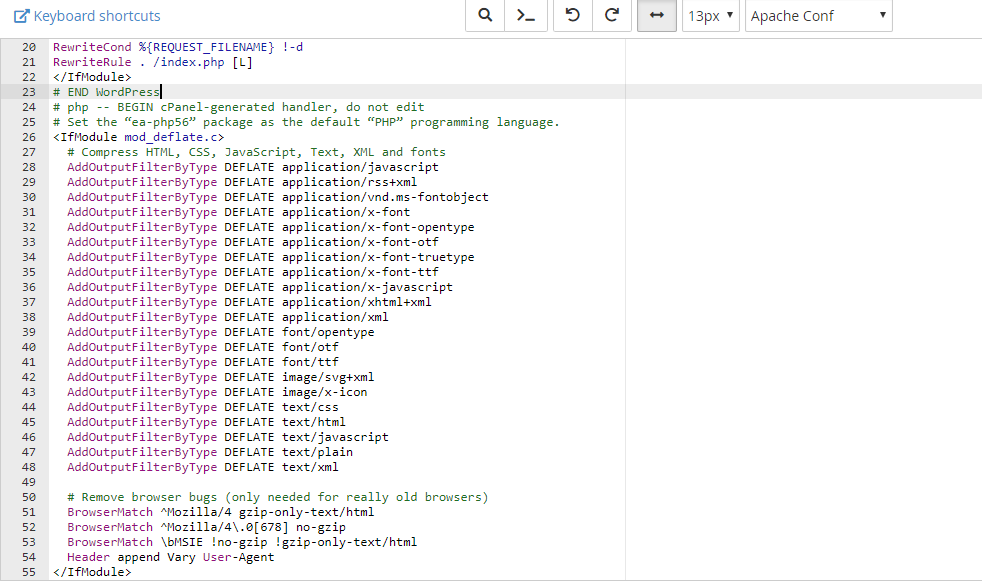
В .htaccess укажите:
Header set Cache-Control "max-age=31536000, public"
В заголовой php-скрипта добавьте следующий код если он не обращается к базе и не зависит от других сервисов.
Про аутентификацию и авторизацию
Если посмотреть на структуру HTTP запросов и ответов становится понятно, что каждый запрос для веб-сервера является изолированным и не сохраняет состояния. То есть если вы сделаете два одинаковых запроса с одного браузера, веб-сервер обработает их так, будто они были присланы разными пользователями.
В жизни это ограничение обходят двумя путями:
- хранят уникальный идентификатор сессии в куках (cookies), которые браузер по требованию сервера сохраняет локально и затем прикрепляет к каждому запросу в виде заголовка «Cookie». Cервер при каждом запросе разбирает заголовок с куками и по сохранённому там идентификатору «узнаёт» пользователя.
- через заголовок Authorization браузер посылает серверу в каждом запросе токен (форматы могут быть разными), по которому сервер определяет пользователя аналогично сессиям. Этот способ чаще всего используется в API.
Поскольку http протокол передаёт все данные в незащищённом виде, то ни один из этих способов не является безопасным, а идентификатор сессии или токен могут быть легко перехвачены злоумышленником. В качестве решения проблемы следует использовать более безопасного брата HTTP — HTTPS.
The right way to rotate User-Agents in any program
Most of the techniques above just rotates the User-Agent header, but we already saw that it is easier for bot detection tools to block you when you are not sending the other correct headers for the user agent you are using.
To get better results and less blocking, we should rotate a full set of headers associated with each User-Agent we use. We can prepare a list like that by taking a few browsers and going to https://httpbin.org/headers and copy the set headers used by each User-Agent. (Remember to remove the headers that start with in HTTPBin)
Browsers may behave differently to different websites based on the features and compression methods each website supports. A better way is
- Open an incognito or a private tab in a browser, go to the Network tab of each browsers developer tools, and visit the link you are trying to scrape directly in the browser.
-
Copy the curl command to that request –
-
Paste into CurlConverter hosted here http://curl.trillworks.com and just take the value of the variable and paste into a list
Things to keep in mind while rotating User Agents and corresponding headers
In order to make your requests from web scrapers look as if they came from a real browser:
- Have the right headers for the browser you are using and the website you are scraping
- Send headers in the right order as the real browser would send. Although HTTP spec says that the order of the HTTP headers does not matter, some bot detection tools check that too. They have a huge database of the combination of headers that are sent by specific versions of a browser on different operating systems and websites. There isn’t a straight forward way to order the HTTP requests using Python Requests. The code below uses a workaround.
- Have a Referer header with the previous page you visited or Google, to make it look real
- There is no point rotating the headers if you are logging in to a website or keeping session cookies as the site can tell it is you without even looking at headers
- We advise you to use proxy servers when making a large number of requests and use a different IP for each browser or the other way
Having said that, let’s get to the final piece of code
Before you go
Rotating user agents can help you from getting blocked by websites that use intermediate levels of bot detection, but advanced anti-scraping services has a large array of tools and data at their disposal and can see past your user agents and IP address.
- If you are using proxies that were already detected and flagged by bot detection tools, rotating headers isn’t going to help.
- The SSL/TLS fingerprint of Python Requests or Scrapy is going to be very different from that of the browser whose User-Agent you were faking. Not a lot of tools do this, but it may be the reason this technique may not have worked for you.
For reference, every request we made to a server with Python Requests had the JA3 fingerprint no matter what HTTP Headers we sent. While real Chrome 83 on Mac had the fingerprint . You can see your browsers JA3 fingerprint in ja3er. Bypassing such blocking is too complicated to fit into the scope of this article.
You can learn more on this topic here How do websites detect web scrapers and other bots.
Disclaimer:Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.
Роботы Яндекс и Google
У популярнейших поисковых систем присутствует большое количество роботов, и все они выполняют определенные функции. Благодаря robots.txt вы можете контролировать действия каждого из них. Но некоторые роботы держатся в секрете поисковыми системами. Ниже перечислены все публичные роботы Яндекса и Гугла с кратким описанием.
Роботы Яндекс:
- YandexBot. Это основной индексирующий робот Яндекса. Он работает с органической выдачей поисковика.
- YandexDirect. Робот, отвечающий за контекстную рекламу. Посещает сайты и оценивает их на основе того, в каком месте располагается контекстная реклама.
- YandexDirectDyn. Выполняет похожие функции, что и предыдущий бот, но с тем лишь отличием, что оценивает динамические объявления.
- YandexMedia. Индексирует мультимедийные файлы. Сканирует, загружает и оценивает видео, аудио.
- YandexImages. Обрабатывает изображения и контролирует раздел поисковика “Картинки”.
- YandexNews. Новостной бот, отвечающий за раздел Яндекса “Новости”. Индексирует все, что связано с изданиями новостных сайтов.
- YandexBlogs. Занимается постами, комментариями, ответами и прочим контентом в блогах.
- YandexMetrika. Как понятно из названия, это робот Яндекс Метрики, анализирующей трафик сайтов и их поведенческие факторы.
- YandexPagechecker. Отвечает за распознание микроразметки на сайте и ее индексацию.
- YandexCalendar. Бот, индексирующий все, что связано с Календарем Яндекса.
- YandexMarket. Робот сервиса Яндекс.Маркет, добавляющий в индекс товары, описания к ним, цены и прочую информацию, полезную для Маркета.
Роботы Google:
- Googlebot. Это основной робот поискового гиганта, индексирующий главный текстовый контент страниц и обеспечивающий формирование органической выдачи.
- GoogleBot (Google Smartphone). Главный индексирующий бот Гугла для смартфонов и планшетов.
- Googlebot-News. Робот, индексирующий новостные публикации сайта.
- Googlebot-Video. Включает в поисковую выдачу видеофайлы.
- Googlebot-Image. Робот, занимающийся графическим контентом веб-ресурсов.
- AdsBot-Google. Проверяет качество целевых страниц – скорость загрузки, релевантность контента, удобство навигации и так далее.
- AdsBot-Google-Mobile-Apps. Оценивает качество мобильных приложений по тому же принципу, что и предыдущий бот.
- Mediapartners-Google. Робот контекстной рекламы, включающий сайт в индекс и оценивающий его для дальнейшего размещения рекламных блоков.
- Mediapartners-Google (Google Mobile AdSense). Аналогичный предыдущему бот, только отвечает за размещение релевантной рекламы для мобильных устройств.
Зачастую в файле Robots прописывают директории сразу для всех роботов поисковиков Google и Яндекс. Но для специфических задач оптимизаторы дают указания роботам разных поисковых систем отдельно.
HTTP в практике веба
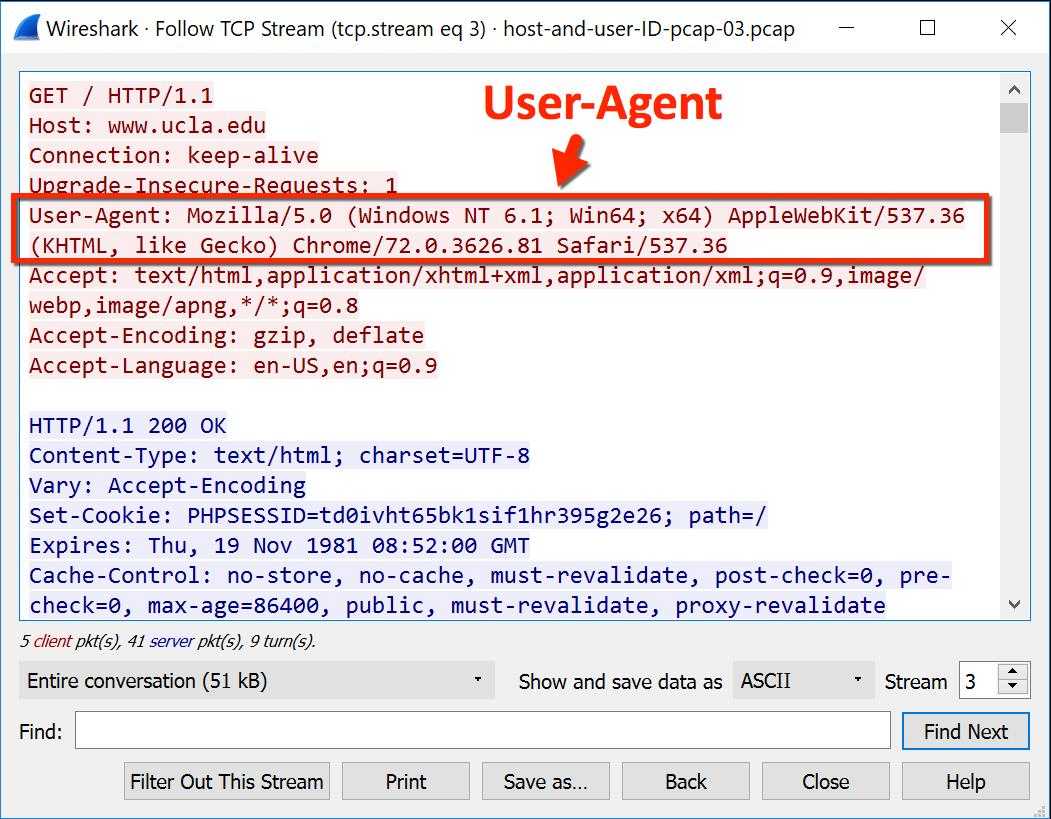
Поскольку сценарии использования протокола HTTP в современном вебе достаточно сложные, запросы и ответы HTTP содержат, кроме идентификаторов методов и адресов документов, много дополнительной служебной информации. Самым известным примером здесь является поле User-Agent, в котором клиент указывает свой тип, название, версию. В частности, поле User-Agent позволяет веб-серверу определить тип браузера, который отправил запрос. User-Agent в классическом HTTP представляет собой текстовую строку, состоящую из идентификатора (собственно, «User-Agent») и значения, разделённых символом «:» (двоеточие). Так же записываются и другие HTTP-заголовки.
Дополнительные поля передаются и клиентом, и севером. Все эти поля представляют собой сочетание текстового имени поля и текстового же значения. Именно эти дополнительные поля в HTTP-ответе сервера и принято называть HTTP-заголовками, а идентификаторы — используются в качестве имён, по которым на конкретный заголовок ссылаются. Так, о поле с описанием типа браузера говорят как об «HTTP-заголовке User-Agent».
Как уже упоминалось выше, протокол HTTP — это протокол типа «клиент-сервер»: клиент отправляет запросы, а сервер выполняет их (при возможности) и отправляет ответы. Клиентом, в типичной ситуации, выступает браузер, а сервер — это веб-сервер. Сессия работы с современным веб-сайтом включает множество HTTP-запросов и HTTP-ответов, которые могут направляться как последовательно, так и параллельно.
Веб-сервер использует HTTP-заголовки для того, чтобы передать клиенту расширенные сведения о настройках сервера в контексте HTTP, о правилах обработки HTTP-соединений, принятых на стороне сервера. Заголовки также позволяют отправить рекомендации по дальнейшему взаимодействию с сервером. Заголовки содержат и другую техническую информацию о соединении, например, cookie-файлы, используемые для авторизации. Другими словами, набор HTTP-заголовков сервера представляет собой небольшой текстовый справочник, при помощи которого клиент, в автоматическом режиме, определяет сценарий дальнейшей работы с данным веб-сервером.
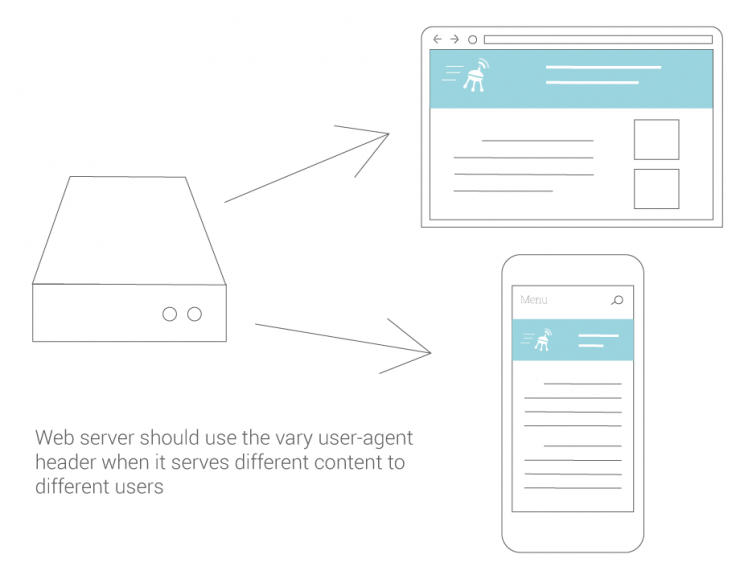
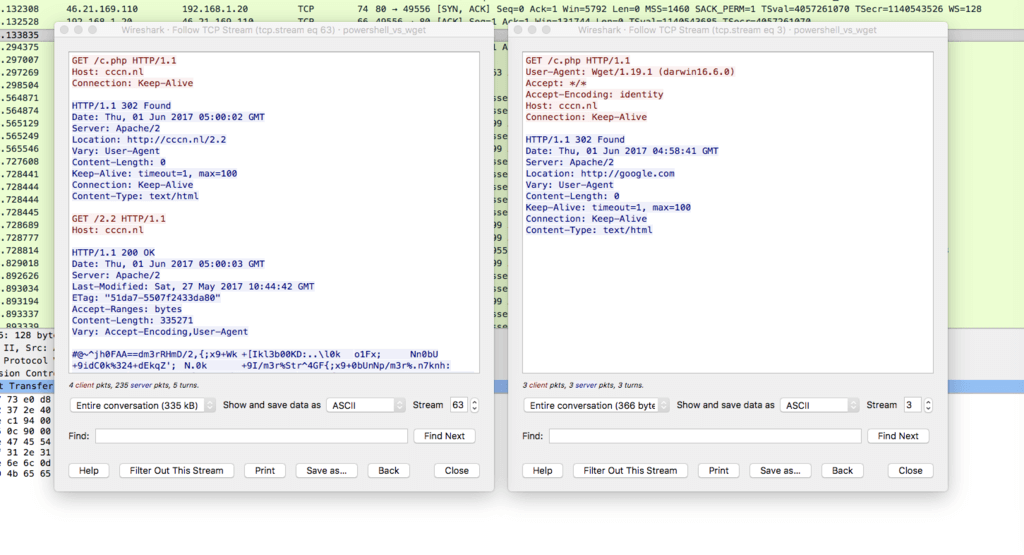
До момента первого соединения с сервером, клиент, в общем случае, не может узнать, какие дополнительные параметры будут переданы сервером в заголовках, поэтому руководствуется настройками по умолчанию; однако после ответа сервера на первый запрос — клиент получает возможность скорректировать последующие запросы в соответствии с рекомендациями сервера, а также изменить способ интерпретации только что полученных от сервера данных. Последний аспект, в частности, позволяет заблокировать большие классы атак, направленных на пользовательские браузерные сессии, потому что браузер может преобразовать и отфильтровать данные до того, как отобразит страницу или её элемент для пользователя.
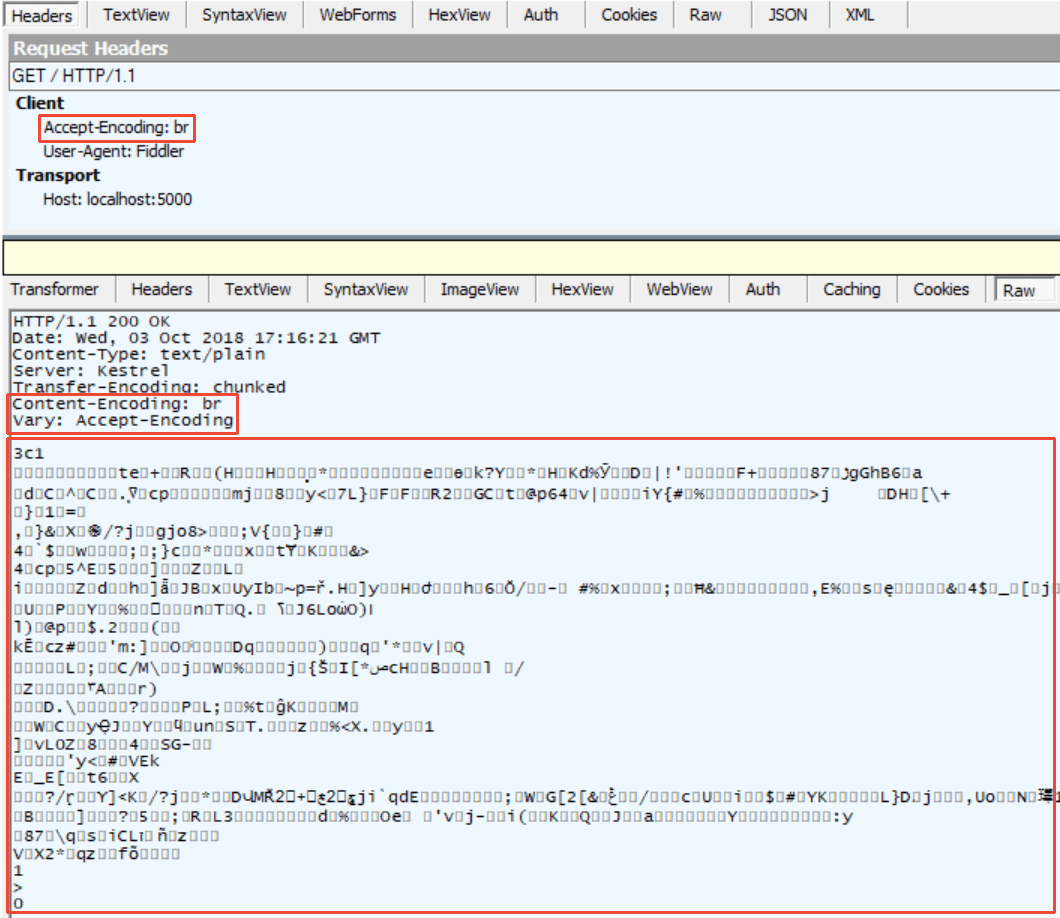
Безопасная версия HTTP – HTTPS – использует TLS (протокол Transport Layer Security) для защиты информации. HTTPS, с точки зрения части HTTP, работает полностью аналогично открытой версии, однако, так как канал защищён криптографическими методами, клиент и сервер получают механизмы проверки подлинности и целостности переданных данных. Такая проверка проводится за пределами HTTP. HTTPS существенно усиливает значение HTTP-заголовков, и многие из этих заголовков актуальны только в случае HTTPS.
Итак, HTTP-заголовки — это представленные в текстовом формате сведения о различных параметрах HTTP-сессии. Заголовки позволяют веб-серверу информировать браузер о настройках, которые следует применять для данного адреса и данного сайта. Эти настройки могут относиться как к текущей сессии, так и к последующим. Рассмотрим элементарный пример запроса и ответа HTTP (с заголовками):
Запрос (это GET-запрос, он отправляется клиентом в адрес сервера, в данном случае — обозначает извлечение индексного документа из корневой директории на сервере, «HTTP/1.1» — указывает на версию, используемую клиентом):
(Здесь Host: — это служебный HTTP-заголовок _запроса_, обозначающий имя сервера, к которому обращается клиент: www.google.com, в данном случае.)
Ответ (HTTP-ответ с кодом статуса 200, обозначающим успешное выполнение — код статуса указан в первой строке):
Здесь нужно обратить внимание на две нижних строки, которые начинаются с обозначений X-XSS-Protection и X-Frame-Options. Это примеры _серверных_ HTTP-заголовков безопасности.
Как выжать максимум из пользовательского контента
Стараться применять его где только можно. Главное, дать пользователям стимул создавать новый контент. Процент людей, пишущих отзывы просто от скуки или из чистого альтруизма исчезающе мал.
- Просите людей высказаться, оставить свое мнение, поучаствовать в опросе или похвалиться покупкой.
- Пригодятся и все стандартные «материальные стимулы»: скидки за отзывы, конкурсы и все такое.
- Не забывайте про визуальный контент. Правильное фото вызывает больше отклика, чем самый лучший текст. Пользуйтесь этим.
- Максимально упростите процесс, например, прикрутить к сайту авторизацию через соцсети и кнопки «поделиться».
Теперь разберемся подробнее.
SMM
Начнем со святая святых – отзывов. Работать с ними можно по-разному:
- Побуждать пользователей на фотографироваться с продуктом.И тут тоже несколько подходов: можно просить делать фото с хэштегами (самое то для Instagram), можно завести отдельный альбом и выкладывать фото оттуда на главную. В любом случае, вы получаете живые снимки живых людей, а они ценятся выше, чем постановочные и отфотошопленные изображения на карточках товаров. Главный минус – фотоотзывы подходят не для всех тематик, потому что некоторые вещи даже потрогать нельзя. Что фотографировать, если вы продаете, скажем, ПО? Но в остальных случаях это отличный вариант.
- Текстовые отзывы. Здесь то же самое – можно выделить специальное обсуждение, а можно просто публиковать все отзывы на главной странице группы. Причем не обязательно работать исключительсно с отзывами из соцсетей. Если вам сыпется шквал благодарностей на e-mail или сайт, публикуйте отзывы оттуда. Главное, без заказухи – фейковые посты сразу видно.
Остальные типы user generated content тоже лучше всего раскрываются в соцсетях. Там проще всего задать вопрос, написать комментарий к посту или поучаствовать в опросе. Пользуйтесь этим – проводите конкурсы и акции, поощряйте активность подписчиков и не ограничивайтесь одной соцсетью. Это окупается.
UGC на сайте: какой контент вам нужен
Здесь возможностей меньше, но они есть. Обязательная программа – отзывы. Они нужны, чтобы потенциальные клиенты могли оценить опыт других людей и просто убедиться в том, что у вас покупают. Если есть возможность, прикрутите к сайту расширенную систему рейтинга, а не просто стандартные звездочки. Если, к примеру, торгуете техникой, предложите людям оценить дизайн, функциональность, надежность и соотношение цена/качества. Это даст людям подсказки, о чем можно писать, если возникло такое желание.
Ну и стандартная схема со мини-скидками за отзыв тоже не повредит – так у людей появится дополнительный стимул к созданию контента.
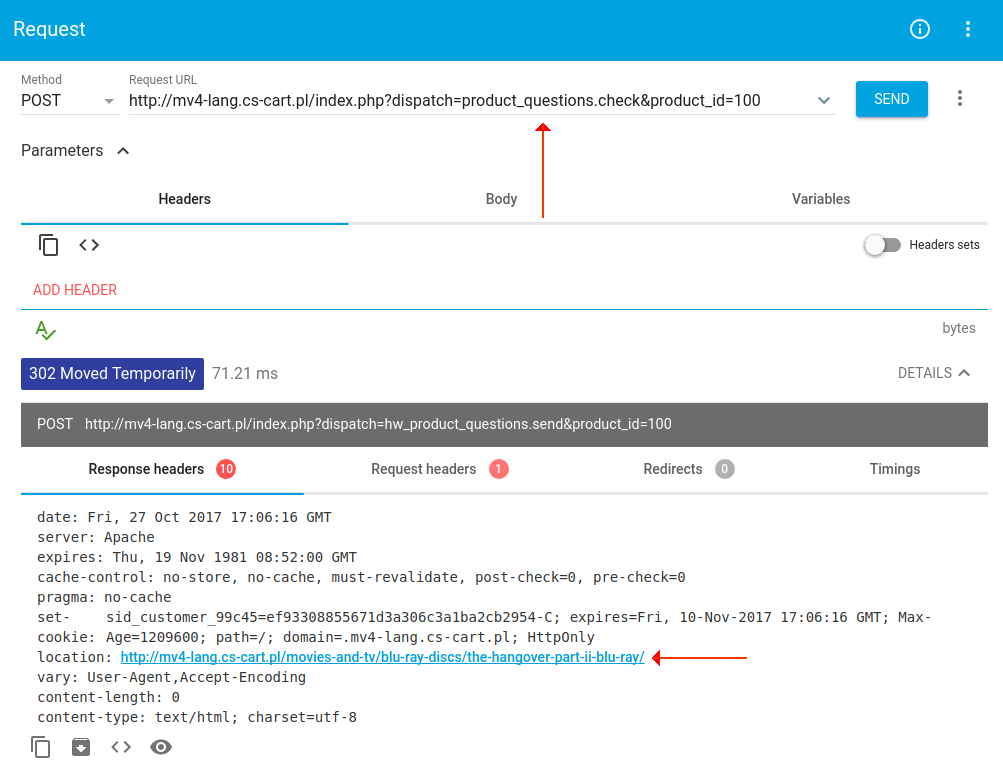
User Agent и поисковые роботы
Поисковый гигант Google создал огромное количество роботов, отвечающих за индексацию контента различного вида, содержащегося на сайтах, а также устройств, с которых пользователи пользуются интернетом.
Главным поисковым ботом Google является Googlebot. Если вам нужно полностью заблокировать сайт от индексации в поисковой системе, в файле Robots агентом пользователя для Googlebot нужно указать условие, скрывающее ресурс от ботов поисковика.
Еще можно скрыть определенную часть контента. Для этого необходимо прописать правило для агента, индексирующего контент. К примеру, желая закрыть от индексации изображения на сайте, условие указывается для Googlebot-Image. Вот пример, как данная операция смотрится в файле Robots:
User-agent: Googlebot Disallow: (строка пустая, потому что основному боту индексация разрешена) User-agent: Googlebot-Image Disallow: /personal (запрещает боту сканировать изображения в личном каталоге)
Вы также можете скрыть от робота весь сайт, кроме определенного типа контента, к примеру, видео. Тогда запретите Googlebot индексировать ресурс целиком, а агентом, которому индексация разрешена, пропишите Googlebot Video.
Нет нужды вносить какие-либо изменения в robots.txt, если вы хотите, чтобы сайт был открыт для сканирования поисковыми ботами полностью.
User-Agent и аналитика
Чтобы понимать, что происходит на сайте или в web-приложении и как улучшить его использование, полезно в том числе знать на каких платформах аудитория пользуется им. Если подключена одна из систем ведения аналитики, например Яндекс.Метрика или Google Аналитика, то при посещении ресурса пользователем, система помимо прочих метрик залогирует браузер (или приложение), версию, устройство и операционную систему клиента. Как вы уже догадались эта информация берется из строки User-Agent.
![]()
Информацию об используемых браузерах можно использовать, например для определения списка поддерживаемых платформ. Это поможет ответить на вопрос, стоит ли тратить на них ресурсы, если доля пользователей таких платформ невелика.
Что такое User-Agent?
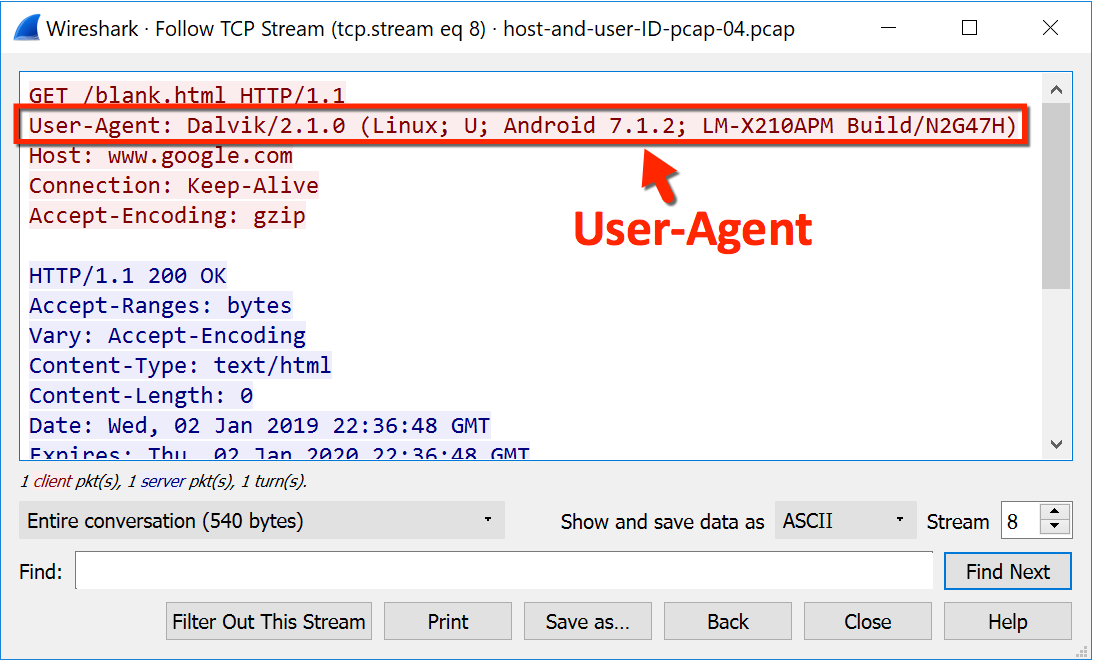
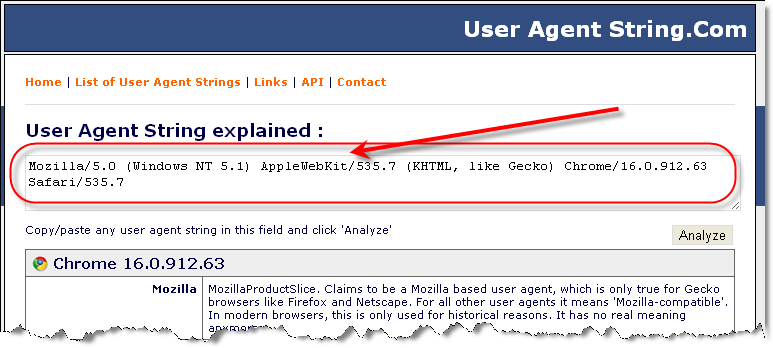
User-Agent – это текстовая строка, являющаяся частью HTTP-запроса, идентифицирующая браузеры, приложения или операционные системы, которые подключаются к серверу.
Юзер-агенты присутствуют не только в браузерах, но и в ботах, сканерах, таких как Googlebot, Google AdSense и т.д.
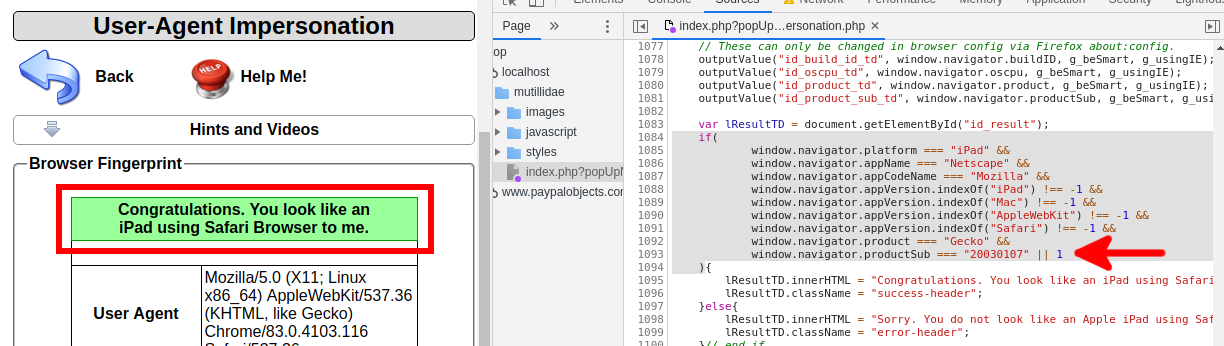
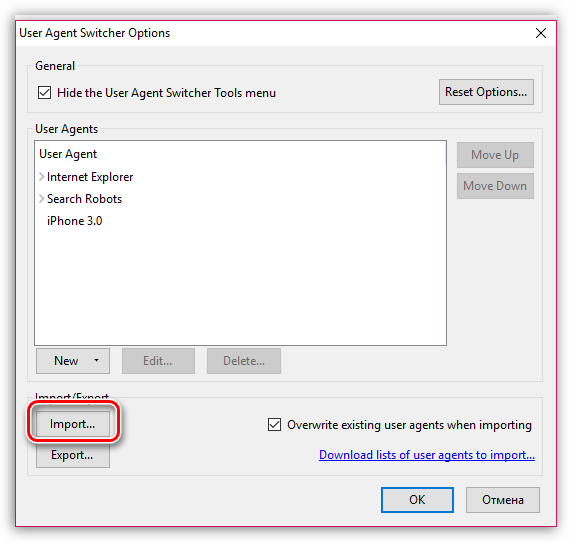
Не вдаваясь в технические дебри, перейдём сразу к тому, как изменить юзерагент вашего браузера. Процесс называется спуфингом пользовательского агента.
User-agent spoofing – это когда браузер или любой другой клиент отправляет отличный от первоначального HTTP-заголовок пользовательского агента, подделывает его. Это полностью безопасная процедура, не вызывающая никаких проблем.
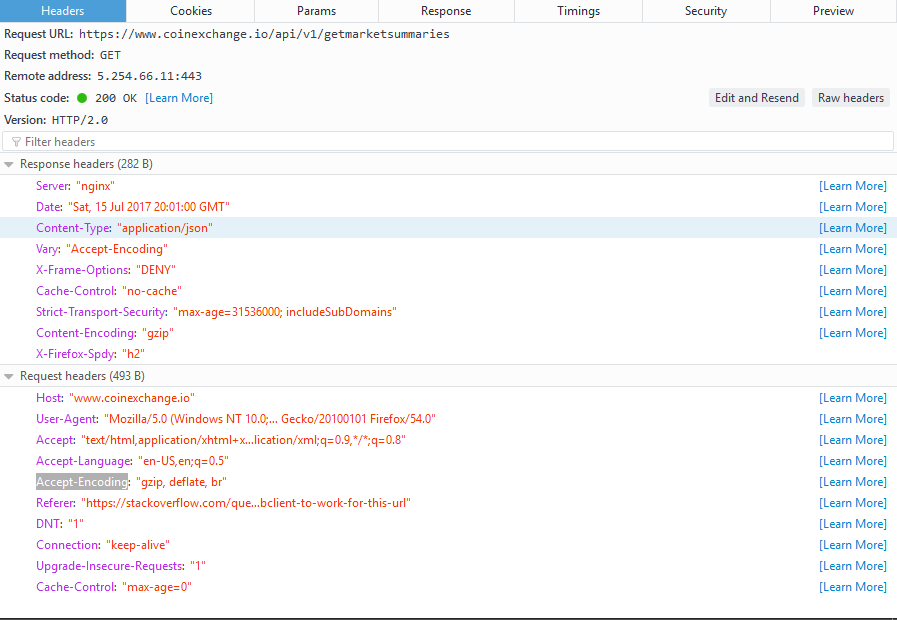
Why should you use a User-Agent
Most websites block requests that come in without a valid browser as a User-Agent. For example here are the User-Agent and other headers sent for a simple python request by default while making a request.
Ignore the as it is not sent by Python Requests, instead generated by Amazon Load Balancer used by HTTPBin.
Any website could tell that this came from Python Requests, and may already have measures in place to block such user agents. User-agent spoofing is when you replace the user agent string your browser sends as an HTTP header with another character string. Major browsers have extensions that allow users to change their User-agent.

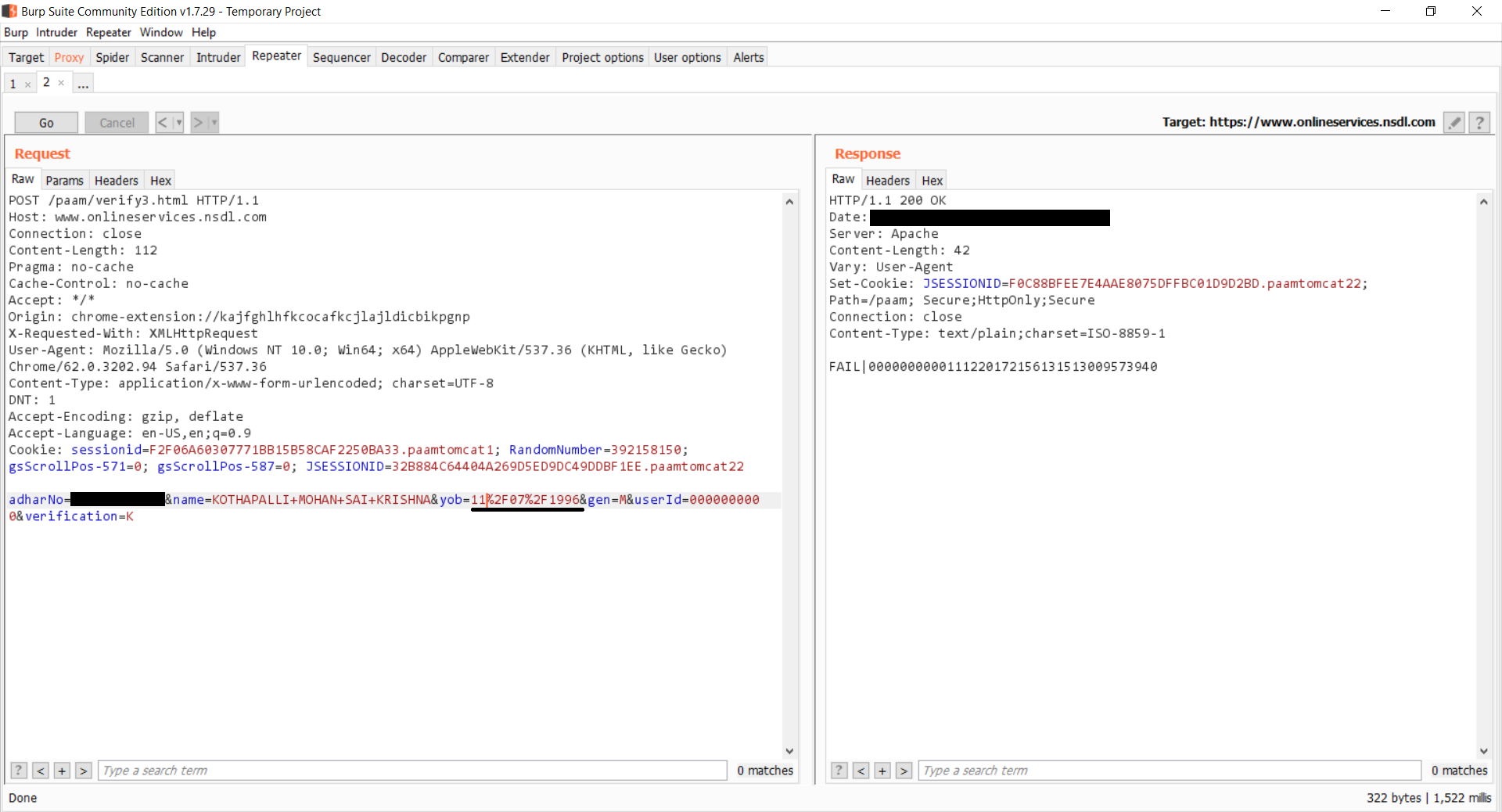


We can fake the user agent by changing the User-Agent header of the request and bypass such User-Agent based blocking scripts used by websites.
Что из себя представляет User-agent?
User-agent есть в любом браузере и мобильном устройстве. Эта строка содержит множество сведений о компьютере, операционной системе, версии браузера. Прописанные в файле Robots.txt, строки с описанием User-agent влияют на работу поисковых систем на сайте. С их помощью можно скрыть от поисковиков (от всех или каких-то определённых) находящуюся на сайте информацию – какую-то страницу или весь сайт, конкретный тип файлов. Ограничивая индексацию по типу файлов, к примеру, можно сделать видимыми только картинки, только тексты или, наоборот, исключить из индексации конкретный тип файла.
Ограничение видимости можно прописать для бота конкретной поисковой системы или для всех роботов. Инструкции прописываются для каждого робота, для которого известно написание User-agent.
https://youtube.com/watch?v=TJuzlkupL94
Из строки, содержащей описание User-agent можно узнать следующие сведения:
- Наименование основного браузера, его версию;
- Версию операционной системы;
- Какое специфическое программное обеспечение установлено на устройстве;
- Вид устройства, с которого осуществляется выход в интернет.
Изменение User-agent может понадобиться не только для того чтобы редактировать параметры индексации сайта, но и чтобы скрывать нежелательную для отслеживания информацию: например, вид устройства для аккаунтов Google, VK. Также с помощью редактирования User-agent можно сделать актуальным устаревший браузер, перестать получать предложения об установке того или иного браузера. Изменение данной строки в разных браузерах и устройствах происходит по-своему. Следует искать инструкции для конкретного браузера или типа операционной системы (Android, iOS).
Проверка с помощью инструментов разработчика в браузере
1. Откройте любой интернет-браузер (например, Google Chrome).
2. Откройте ваш сайт.
3. Нажмите кнопку F12 (откроется панель разработчика).
4. Выберите вкладку «Сеть» (Network).
5. Обновите страницу (клавиша F5).
6. Вы получите список всех файлов, которые были загружены с вашего сайта.
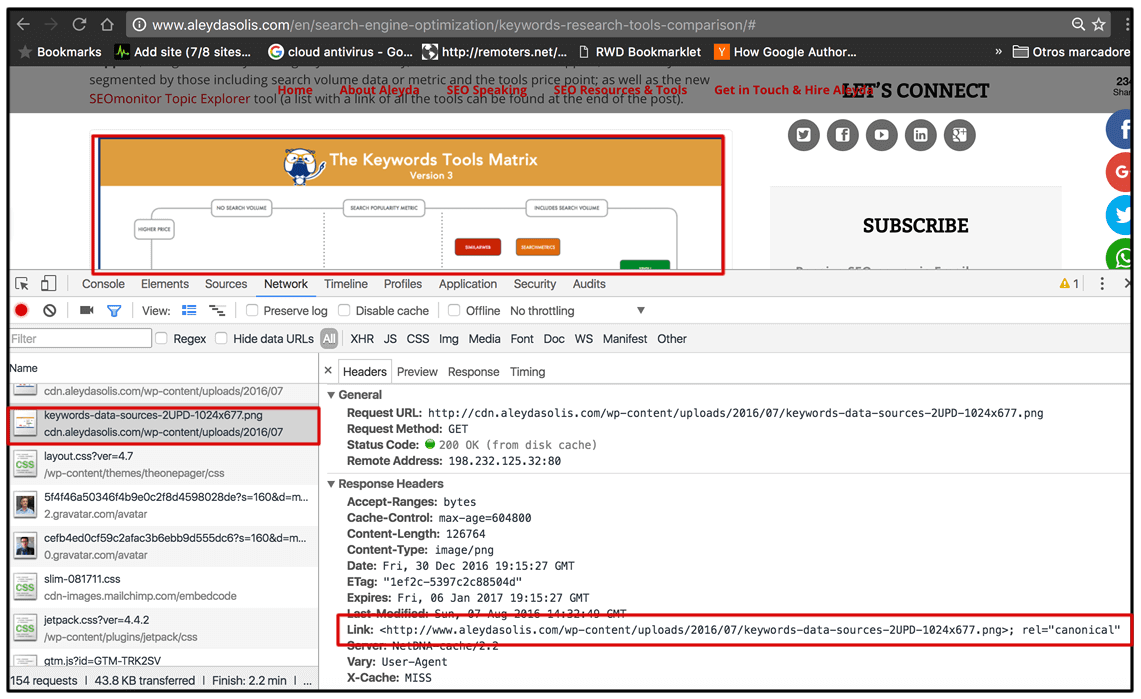
7. Найдите необходимый файл (например: jpeg, png, img), интегрированный с CDN и нажмитенанего. Дляболееудобногопоискаможетевоспользоватьсяфильтром в левомуглупанели.
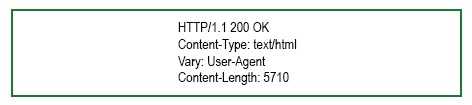
8. На вкладке «Headers» справа вы увидите заголовки, которые настроены на вашем сервере.
![]() 9. Проанализируйте их,если в ответевыувиделизаголовок «Access-Control-Allow-Origin»,заголовок CORS настроен.
9. Проанализируйте их,если в ответевыувиделизаголовок «Access-Control-Allow-Origin»,заголовок CORS настроен.
Предпечатные запросы
Для некоторых запросов CORS браузер отправляет запрос на дополнительные Параметры перед выполнением фактического запроса. Этот запрос называется предпечатным запросом. Браузер может пропустить Предпечатный запрос, если выполняются все перечисленные ниже условия.
- Метод запроса — GET, HEAD или POST.
- Приложение не устанавливает заголовки запроса, кроме, , , или .
- Заголовок, если он задан, имеет одно из следующих значений:
Правило для заголовков запросов, заданных для запроса клиента, применяется к заголовкам, которые устанавливаются приложением путем вызова для объекта. Спецификация CORS вызывает заголовки заголовков. Правило не применяется к заголовкам, которые может задать браузер, например , или .
Ниже приведен пример ответа, аналогичного предпечатному запросу, выполненному с помощью кнопки в разделе этого документа.
Предпечатный запрос использует метод http Options . Он может включать следующие заголовки:
- Access-Control-Request-Method— метод HTTP, который будет использоваться для фактического запроса.
- Access-Control-request-headers. список заголовков запросов, которые приложение устанавливает на основе фактического запроса. Как упоминалось ранее, в него не входят заголовки, заданных браузером, например .
- Access-Control — Allow-Methods
Если Предпечатный запрос отклонен, приложение возвращает ответ, но не задает заголовки CORS. Поэтому браузер не пытается выполнить запрос между источниками. Пример запрещенного запроса на предпечатную версию см. в разделе » » этого документа.
С помощью средств F12 консольное приложение отображает ошибку, аналогичную одной из следующих в зависимости от браузера.
- Firefox: запрос на перекрестное происхождение заблокирован: одна и та же политика происхождения запрещает чтение удаленного ресурса в . (Причина: запрос CORS не выполнен). Подробнее
- Chromium на основе: доступ к выборке в » https://cors1.azurewebsites.net/api/TodoItems1/MyDelete2/5 » из источника » https://cors3.azurewebsites.net » заблокирован политикой CORS: ответ на предварительный запрос не проходит проверку контроля доступа: в запрошенном ресурсе отсутствует заголовок «Access-control-Allow-origin». Если этот непрозрачный ответ вам подходит, задайте для режима запроса значение «no-cors», чтобы извлечь ресурс с отключенным параметром CORS.
Чтобы разрешить определенные заголовки, вызовите WithHeaders :
Чтобы разрешить все , вызовите :
Браузеры не согласуются с тем, как они заданы . Если:
- Для заголовков заданы любые значения, отличные от
- AllowAnyHeader вызывается: включите как минимум , , и , а также любые пользовательские заголовки, которые требуется поддерживать.
Код автоматического предпечатного запроса
Когда применяется политика CORS, выполните одно из следующих действий.
- Глобально путем вызова в .
- С помощью атрибута.
ASP.NET Core отвечает на запрос параметров предварительной проверки.
Включение CORS для отдельных конечных точек с помощью в настоящее время поддерживает автоматические предпечатные запросы.
Это поведение демонстрируется в разделе в этом документе.
Атрибут для предпечатных запросов
когда cors включается с соответствующей политикой, ASP.NET Core обычно отвечает на запросы на предпечатную cors автоматически. В некоторых сценариях это может быть не так. Например, использование .
В следующем коде атрибут используется для создания конечных точек для запросов Options:
Инструкции по тестированию приведенного выше кода см. в статьях .






Задать срок действия предпечатного срока
Заголовок указывает время, в течение которого может быть кэширован ответ на Предпечатный запрос. Чтобы задать этот заголовок, вызовите SetPreflightMaxAge :
Формат запроса
Запрос выглядит примерно так:
Request-Line = Method SP URI SP HTTP-Version CRLF
Method = "OPTIONS"
| "HEAD"
| "GET"
| "POST"
| "PUT"
| "DELETE"
| "TRACE"
SP — это разделитель между токенами. Версия HTTP указывается в HTTP-Version. Реальный запрос выглядит так:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Список возможных заголовков запроса:
request-header = Accept
| Accept-Charset
| Accept-Encoding
| Accept-Language
| Authorization
| Expect
| From
| Host
| If-Match
| If-Modified-Since
| If-None-Match
| If-Range
| If-Unmodified-Since
| Max-Forwards
| Proxy-Authorization
| Range
| Referer
| TE
| User-Agent
В заголовке Accept определяется поддерживаемые mime типы, язык, кодировку символов. Заголовки From, Host, Referer и User-Agent содержат информацию о клиенте. Префиксы If- предназначены для создания условий. Если условие не прошло, то возникнет ошибка 304 Not Modified.
Заключение
User-agent легко подменить. Даже начинающий вебмастер может использовать, описанные выше инструменты, чтобы сделать это.
Эта функция полезна для тестирования веб-приложений на разных устройствах, особенно если у них разный HTML-код для мобильных и настольных девайсов. Вам не придётся их приобретать или прибегать к помощи сторонних сервисов.
Незаменимый инструмент для веб-разработчика. Я им активно пользуюсь при редактировании и адаптации WordPress-шаблонов. Также он помогает, когда возникают проблемы с подменой контента.
Пользуйтесь на здоровье!
ПОНРАВИЛСЯ ПОСТ? ПОДЕЛИСЬ ССЫЛКОЙ С ДРУЗЬЯМИ!
СТАТЬИ ИЗ РУБРИКИ:
Тематика: SEM, Кодинг
(некоторые ответы перед публикацией проверяются модератором)
Выводы
- Файл robots.txt — это рекомендация роботам, какие страницы сканировать, а какие нет.
- С помощью robots.txt запрет индексации настроить нельзя, но можно увеличить шансы сканирования или игнорирования роботом определенных документов или файлов.
- Скрытие малополезного содержимого сайта с помощью директивы disallow позволяет экономить краулинговый бюджет. Это актуально и для многостраничных, и для небольших сайтов.
- Для создания файла robots.txt достаточно простого текстового редактора, а для проверки — Google Search Console и Яндекс.Вебмастер.
- Название файла robots.txt должно состоять из маленьких букв и не превышать в размере 500 Кб.
Шпаргалка: Список роботов для вашего файла robots.txt
8 850
Анна Чудная
Анна – фрилансер в сфере продвижения сайтов, который также пишет статьи для тех, кто хочет лучше разбираться в теме SEO и интернет-маркетинга. Последние 2 года Аня работает удаленно и ведет образ жизни «цифрового кочевника», пробуя жить понемногу в разных городах и странах. Также ее вдохновляет природа, пешие и велосипедные прогулки.



