
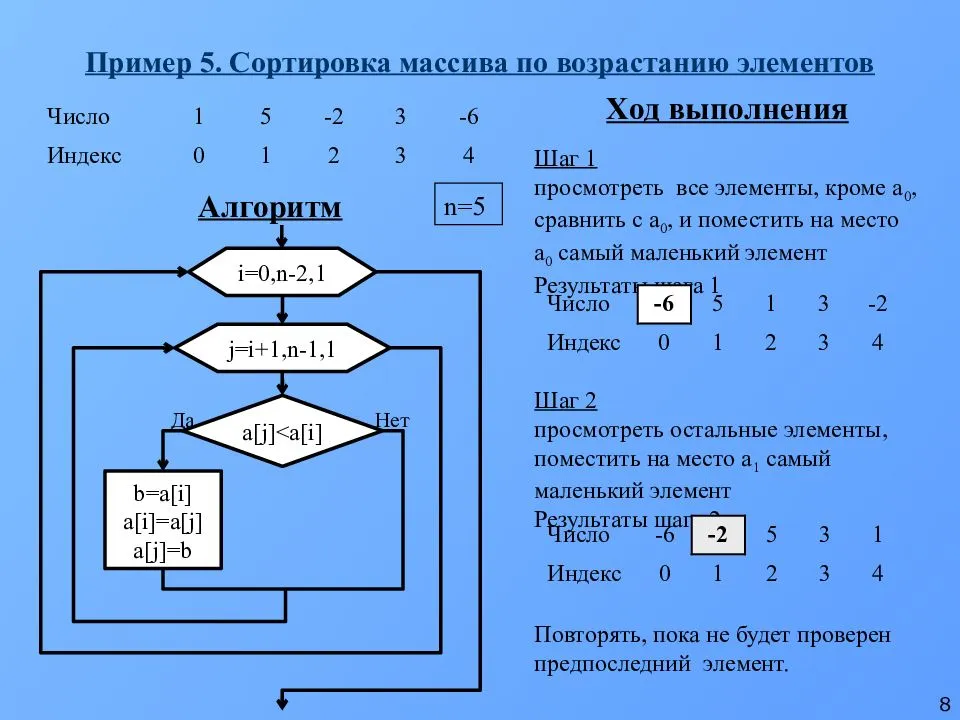
Сортировка настраиваемых объектов
Python обеспечивает гибкость для изменения алгоритма с помощью настраиваемого объекта. Мы создадим собственный класс и переопределим фактический параметр сравнения и постараемся сохранить тот же код, что и выше.
Нам потребуется перегрузить операторы, чтобы по-другому отсортировать объекты. Но мы можем передать другой аргумент функции insert_sort(), используя лямбда-функцию. Лямбда-функция удобна при вызове метода сортировки.
Давайте разберемся в следующем примере сортировки пользовательских объектов.
Сначала мы определяем класс Point.
Программа Python:
# Creating Point class
class Point:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return str.format("({},{})", self.a, self.b)
def insertion_sort(list1, compare_function):
for i in range(1, len(list1)):
Value = list1
Position = i
while Position > 0 and compare_function(list1, Value):
list1 = list1
Position = Position - 1
list1 = Value
U = Point(2,3)
V = Point(4,4)
X = Point(3,1)
Y = Point(8,0)
Z = Point(5,2)
list1 =
# We sort by the x coordinate, ascending
insertion_sort(list1, lambda x, y: x.a > y.a)
for point in list1:
print(point)
Выход:
The points are in the sorted order (2,3) (3,1) (4,4) (5,2) (8,0)
Используя приведенный выше код, мы можем отсортировать точки координат. Он будет работать для любого типа списка.
Некоторые общие алгоритмы сортировки
Некоторые из наиболее распространенных алгоритмов сортировки:
- Выбор Сортировка
- Пузырьковая сортировка
- Сортировка вставкой
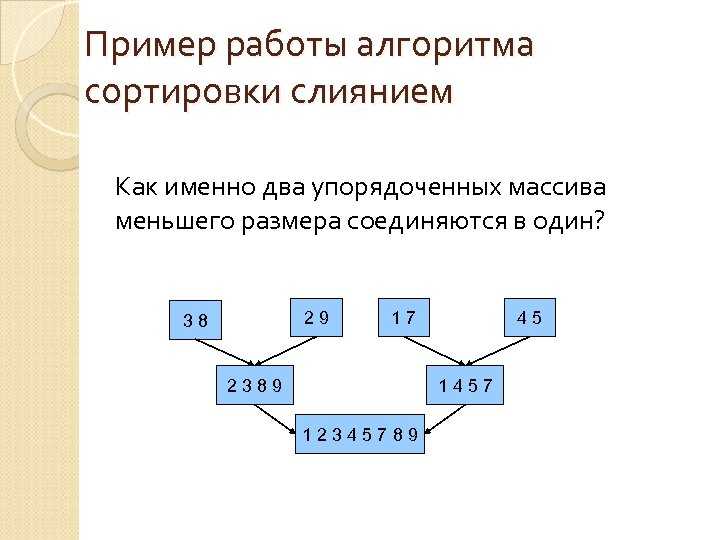
- Сортировка слиянием
- Быстрая сортировка
- Сортировка кучи
- Подсчет сортировки
- Радиксная сортировка
- Сортировка по ведру
Но прежде чем мы перейдем к каждому из них, давайте узнаем немного больше о том, что делает классифицирующим алгоритм сортировки.
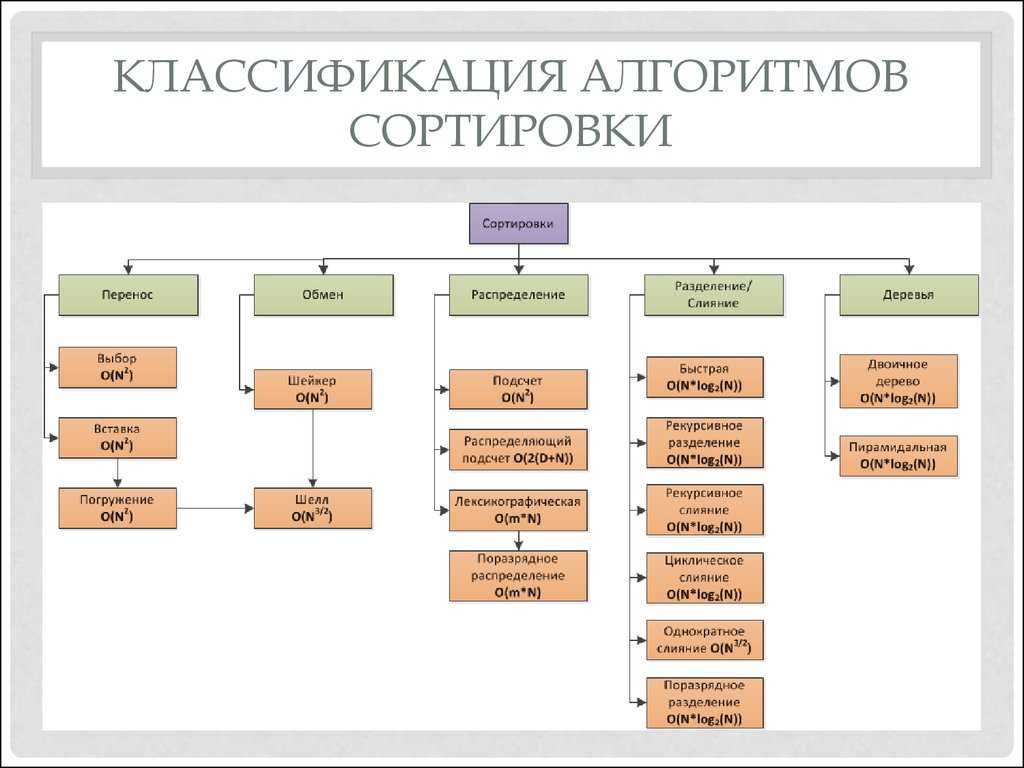
Классификация алгоритма сортировки
Алгоритмы сортировки можно разделить на категории по следующим параметрам:
- На основе количества замен или инверсии. Это количество раз, когда алгоритм меняет местами элементы для сортировки входных данных. требует минимального количества свопов.
- На основе количества сравнений Это количество раз, которое алгоритм сравнивает элементы для сортировки входных данных. В приведенных выше примерах алгоритмов сортировки, использующих нотацию Big-O, для большинства выходных данных требуются как минимум сравнения в лучшем случае и сравнения в худшем случае.
- На основе рекурсии или без рекурсии. Некоторые алгоритмы сортировки, например , используют рекурсивные методы для сортировки ввода. Другие алгоритмы сортировки, такие как или , используют нерекурсивные методы. Наконец, некоторый алгоритм сортировки, например , использует как рекурсивные, так и нерекурсивные методы для сортировки ввода.
- Алгоритмы, основанные на стабильности, называются такими, если алгоритм поддерживает относительный порядок элементов с одинаковыми ключами. Другими словами, два эквивалентных элемента остаются в отсортированном выводе в том же порядке, что и во вводе.
- , И являются стабильными
- и не стабильны
- Алгоритмы сортировки, основанные на требованиях к дополнительному пространству, называются, если им требуется постоянное дополнительное пространство для сортировки.
- и являются своим родом , как мы перемещаем элементы относительно оси поворота и на самом деле не использовать отдельный массив , который не имеет места в сортировках слияния , где размер входа должен быть выделен заранее , чтобы сохранить выход во время сортировки.
- является примером сортировки, поскольку для ее операций требуется дополнительное пространство памяти.
Оптимальная временная сложность для любой сортировки на основе сравнения
Любой алгоритм сортировки на основе сравнения должен выполнять как минимум nLog2n сравнения для сортировки входного массива, а Heapsort и merge sort являются асимптотически оптимальными сортировками сравнения. В этом легко убедиться, нарисовав древовидную диаграмму решений.
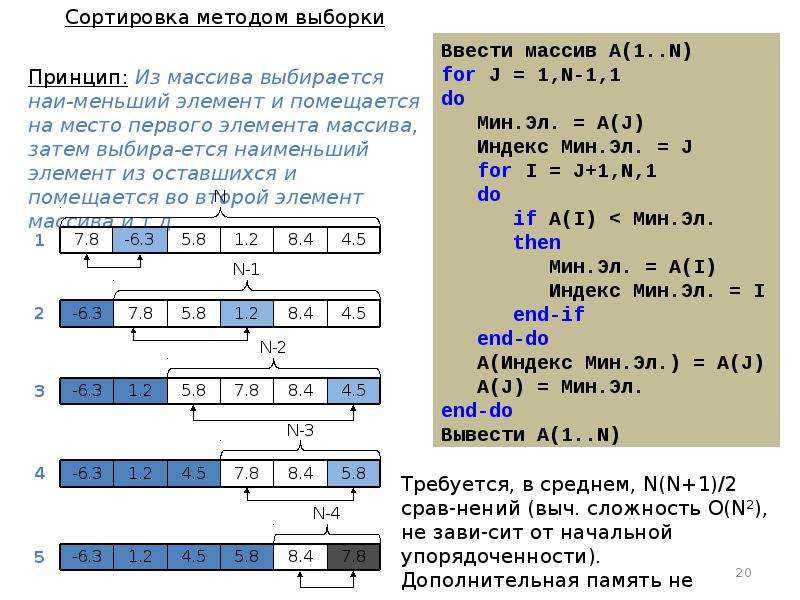
Демонстрация работы алгоритма
Рассмотрим приведенный ниже массив. В несортированном виде он выглядит следующим образом:
![]()
Сортировка выборки, начало
Во время первой итерации мы находим минимальный элемент массива (из {12, 7, 6, 16, 4}), который равен 4. Затем меняем местами arr с 4.
![]()
Сортировка выборки, итерация 1
В следующей итерации мы найдем минимальный элемент подмассива {7, 6, 16, 12}, который равен 6. Поменяем местами 6 и 7.
![]()
Сортировка выборки, итерация 2
Теперь переходим к следующему элементу обновленного массива и снова выполняем те же действия.
![]()
Сортировка выборки, итерация 3
Во время предыдущей итерации изменений не было, поскольку 7 — это минимальный элемент в оставшемся подмассиве.
![]()
Сортировка выборки, итерация 4
Мы достигли конца массива. Весь массив отсортирован!
Примеры блок-схем
В качестве примеров, построены блок-схемы очень простых алгоритмов сортировки, при этом акцент сделан на различные реализации циклов, т.к. у студенты делают наибольшее число ошибок именно в этой части.
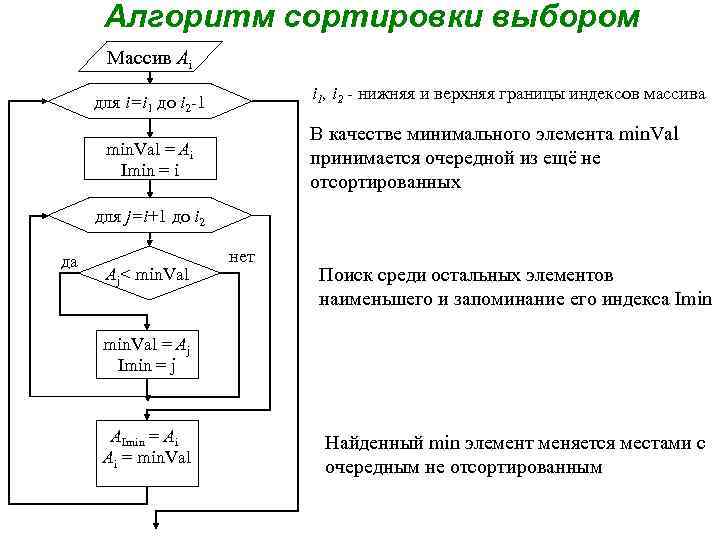
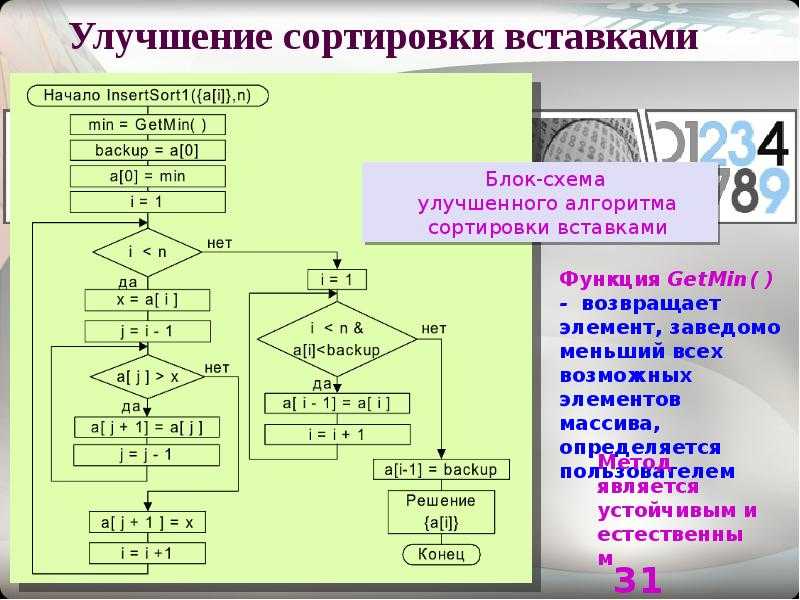
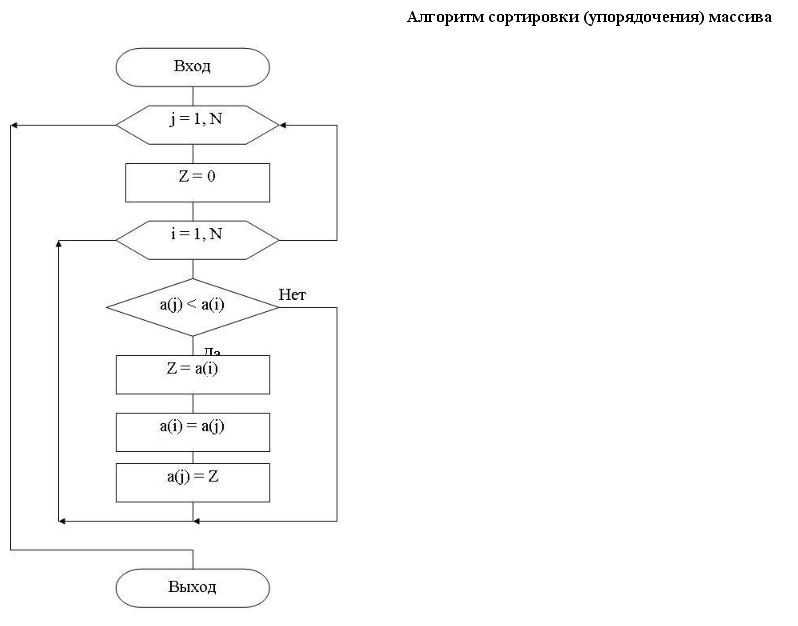
Сортировка вставками
Массив в алгоритме сортировки вставками разделяется на отсортированную и еще не обработанную части. Изначально отсортированная часть состоит из одного элемента, и постепенно увеличивается.
На каждом шаге алгоритма выбирается первый элемент необработанной части массива и вставляется в отсортированную так, чтобы в ней сохранялся требуемый порядок следования элементов. Вставка может выполняться как в конец массива, так и в середину. При вставке в середину необходимо сдвинуть все элементы, расположенные «правее» позиции вставки на один элемент вправо. В алгоритме используется два цикла — в первом выбираются элементы необработанной части, а во втором осуществляется вставка.
Блок-схема алгоритма сортировки вставками
В приведенной блок-схеме для организации цикла используется символ ветвления. В главном цикле (i < n) перебираются элементы необработанной части массива. Если все элементы обработаны — алгоритм завершает работу, в противном случае выполняется поиск позиции для вставки i-того элемента. Искомая позиция будет сохранена в переменной j в результате выполнения внутреннего цикла, осуществляющем сдвиг элементов до тех пор, пока не будет найден элемент, значение которого меньше i-того.
На блок-схеме показано каким образом может использоваться символ перехода — его можно использовать не только для соединения частей схем, размещенных на разных листах, но и для сокращения количества линий. В ряде случаев это позволяет избежать пересечения линий и упрощает восприятие алгоритма.
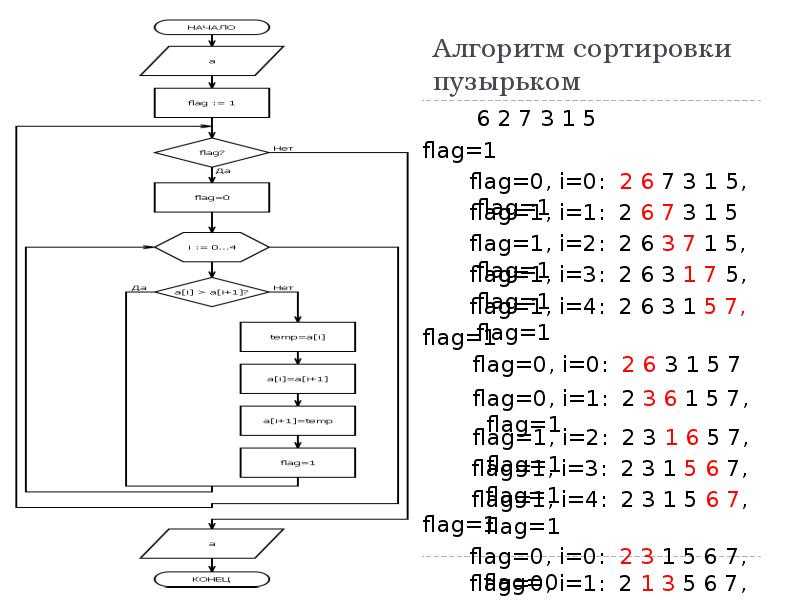
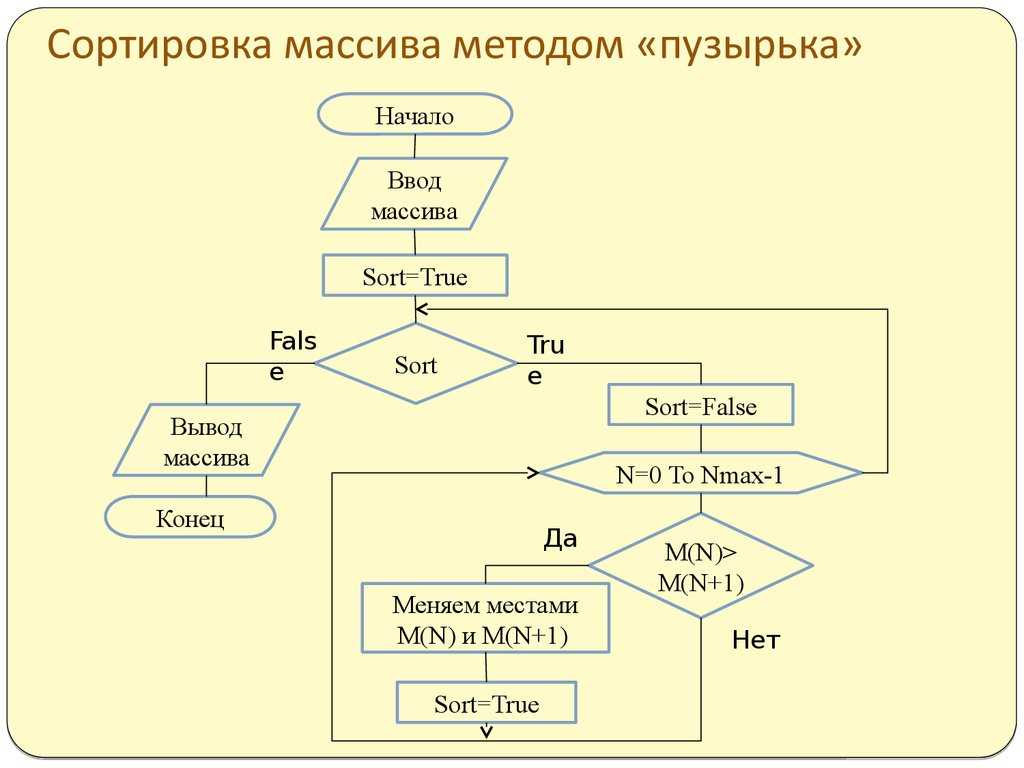
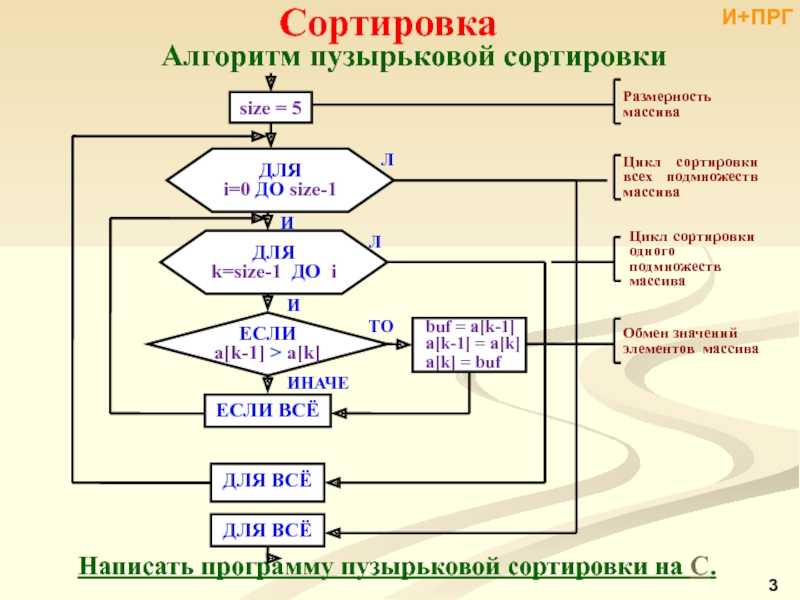
Сортировка пузырьком
Сортировка пузырьком, как и сортировка вставками, использует два цикла. Во вложенном цикле выполняется попарное сравнение элементов и, в случае нарушения порядка их следования, перестановка. В результате выполнения одной итерации внутреннего цикла, максимальный элемент гарантированно будет смещен в конец массива. Внешний цикл выполняется до тех пор, пока весь массив не будет отсортирован.
Блок-схема алгоритма сортировки пузырьком
На блок-схеме показано использование символов начала и конца цикла. Условие внешнего цикла (А) проверяется в конце (с постусловием), он работает до тех пор, пока переменная hasSwapped имеет значение true. Внутренний цикл использует предусловие для перебора пар сравниваемых элементов. В случае, если элементы расположены в неправильном порядке, выполняется их перестановка посредством вызова внешней процедуры (swap). Для того, чтобы было понятно назначение внешней процедуры и порядок следования ее аргументов, необходимо писать комментарии. В случае, если функция возвращает значение, комментарий может быть написан к символу терминатору конца.
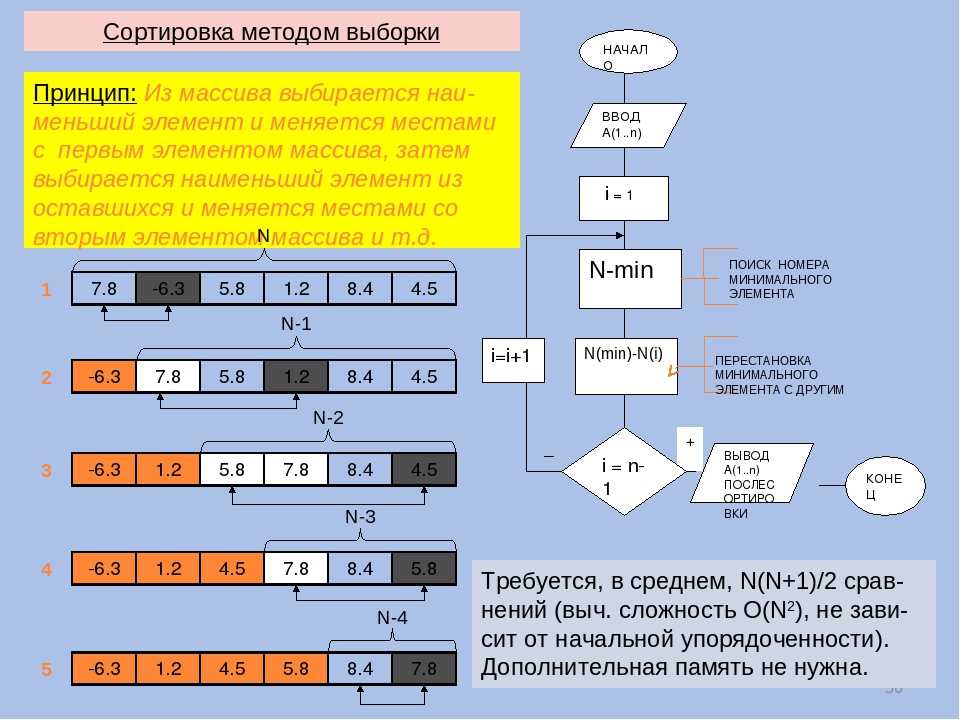
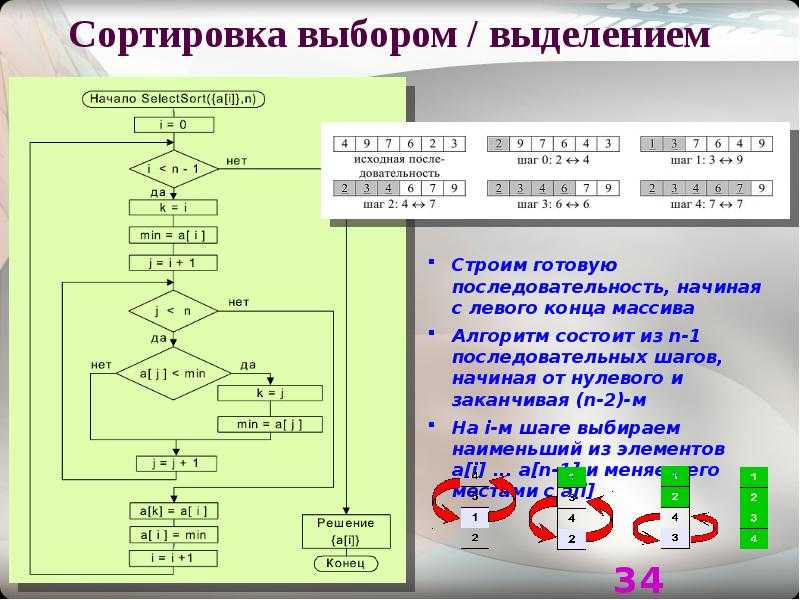
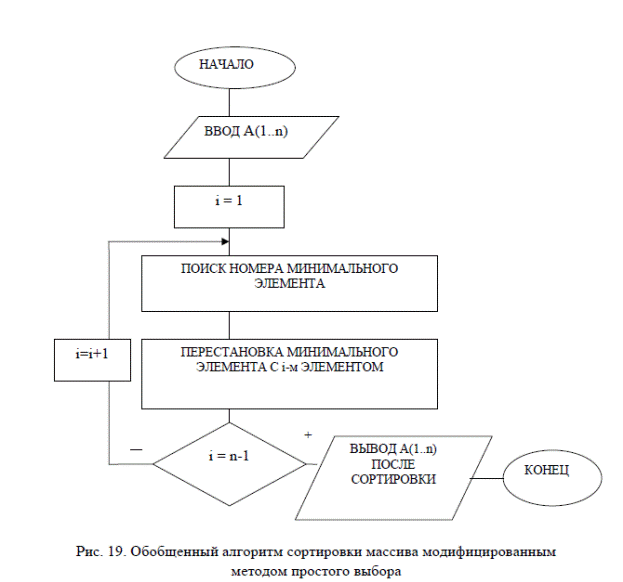
Сортировка выбором
В сортировке выбором массив разделяется на отсортированную и необработанную части. Изначально отсортированная часть пустая, но постепенно она увеличивается. Алгоритм производит поиск минимального элемента необработанной части и меняет его местами с первым элементом той же части, после чего считается, что первый элемент обработан (отсортированная часть увеличивается).
Блок-схема сортировки выбором
На блок-схеме приведен пример использования блока «подготовка», а также показано, что в ряде случаев можно описывать алгоритм более «укрупнённо» (не вдаваясь в детали). К сортировке выбором не имеют отношения детали реализации поиска индекса минимального элемента массива, поэтому они могут быть описаны символом вызова внешней процедуры. Если блок-схема алгоритма внешней процедуры отсутствует, не помешает написать к символу вызова комментарий, исключением могут быть функции с говорящими названиями типа swap, sort, … .
На блоге можно найти другие примеры блок-схем:
- блок-схема проверки правильности расстановки скобок арифметического выражения ;
- блок-схемы алгоритмов быстрой сортировки и сортировки слиянием .
Часть студентов традиционно пытается рисовать блок-схемы в Microsoft Word, но это оказывается сложно и не удобно. Например, в MS Word нет стандартного блока для терминатора начала и конца алгоритма (прямоугольник со скругленными краями, а не овал). Наиболее удобными, на мой взгляд, являются утилиты MS Visio и yEd , обе они позволяют гораздо больше, чем строить блок-схемы (например рисовать диаграммы UML), но первая является платной и работает только под Windows, вторая бесплатная и кроссплатфомренная. Все блок-схемы в этой статье выполнены с использованием yEd.
Хеш-таблицы в Python
Хеш-таблицы — это сложная структура данных, способная хранить большие объёмы информации и эффективно извлекать определённые элементы.
В этой структуре данных используются пары ключ / значение, где ключ — это имя желаемого элемента, а значение — это данные, хранящиеся под этим именем.
![]()
Каждый входной ключ проходит через хеш-функцию, которая преобразует его из начальной формы в целочисленное значение, называемое хешем. Хеш-функции всегда должны генерировать один и тот же хэш из одного и того же ввода, должны быстро вычислять и выдавать значения фиксированной длины. Python включает встроенную hash()функцию, ускоряющую реализацию.
Затем таблица использует хеш-код для нахождения общего местоположения желаемого значения, называемого корзиной хранения. После этого программе нужно будет искать нужное значение только в этой подгруппе, а не во всём пуле данных.
Помимо этой общей структуры, хеш-таблицы могут сильно отличаться в зависимости от приложения. Некоторые могут разрешать ключи из разных типов данных, в то время как некоторые могут иметь разные настройки сегментов или разные хеш-функции.
Вот пример хеш-таблицы в коде Python:
Преимущества:
- Может скрывать ключи в любой форме в целочисленные индексы.
- Чрезвычайно эффективен для больших наборов данных.
- Очень эффективная функция поиска.
- Постоянное количество шагов для каждого поиска и постоянная эффективность добавления или удаления элементов.
- Оптимизирован в Python 3.
Недостатки:
- Хэши должны быть уникальными, преобразование двух ключей в один и тот же хэш вызывает ошибку коллизии.
- Ошибки коллизии требуют полного пересмотра хэш-функции.
- Сложно построить для новичков.
Приложения:
- Используется для больших баз данных, в которых часто ведётся поиск.
- Системы поиска, использующие клавиши ввода.
Общие вопросы собеседования с хеш-таблицей в Python
- Создать хеш-таблицу с нуля (без встроенных функций).
- Формирование слова с помощью хеш-таблицы.
- Найдите два числа, которые в сумме дают «k».
- Реализовать открытую адресацию для обработки коллизий.
- Определите, является ли список циклическим, используя хеш-таблицу.
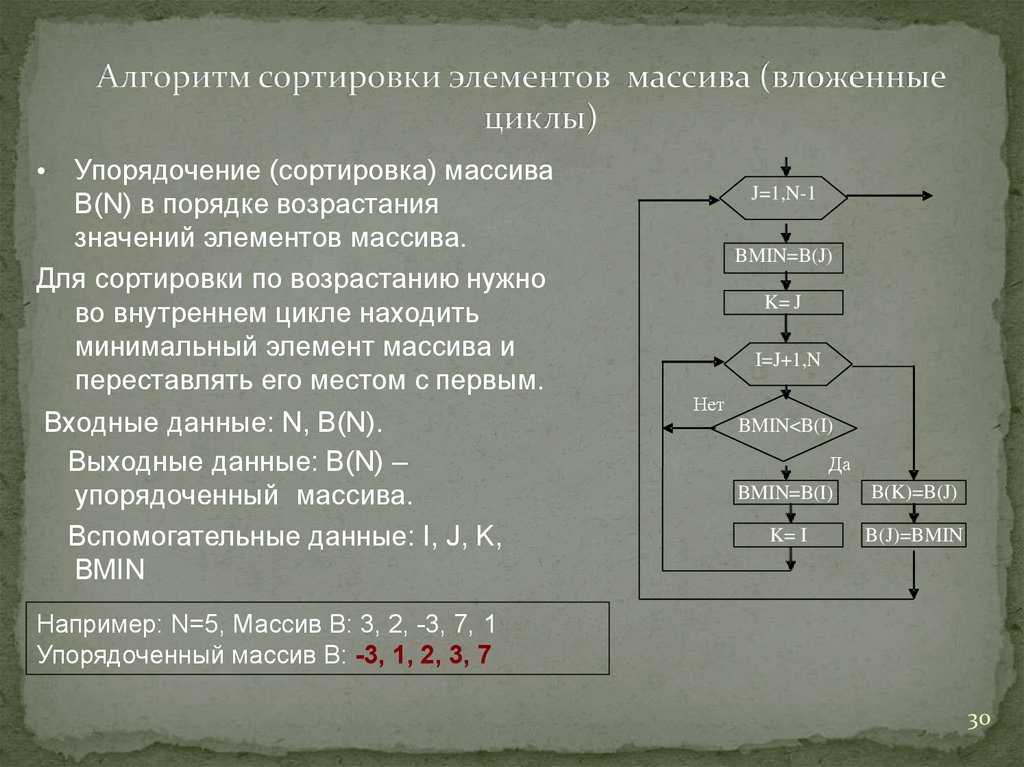
Сортировка массива в Python
Метод Пузырька
Сортировку массива в python будем выполнять :
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import random
from random import randint
mas = randint(1,10) for i in range(n)
for i in range(n):
print(masi,sep="")
print(" ")
for i in range(n-1):
for j in range(n-2, i-1 ,-1):
if masj+1 < masj:
masj, masj+1 = masj+1, masj
for i in range(n):
print(masi,sep="")
|
Задание Python 7_4:
Необходимо написать программу, в которой сортировка выполняется «методом камня» – самый «тяжёлый» элемент опускается в конец массива.
Быстрая сортировка массива
Данную сортировку еще называют или сортировка Хоара (по имени разработчика — Ч.Э. Хоар).




1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import random
from random import randint
# процедура
def qSort ( A, nStart, nEnd ):
if nStart >= nEnd: return
L = nStart; R = nEnd
X = A(L+R)//2
while L <= R:
while AL < X: L += 1 # разделение
while AR > X: R -= 1
if L <= R:
AL, AR = AR, AL
L += 1; R -= 1
qSort ( A, nStart, R ) # рекурсивные вызовы
qSort ( A, L, nEnd )
N=10
A = randint(1,10) for i in range(N)
print(A)
# вызов процедуры
qSort ( A, , N-1 )
print('отсортированный', A)
|
Задание Python 7_5:
Необходимо написать программу, которая сортирует массив (быстрой сортировкой) по возрастанию первой цифры числа.
Встроенные функции
- mas.reverse() — стандартный метод для перестановки элементов массива в обратном порядке;
- mas2 = sorted (mas1) — встроенная функция для сортировки массивов (списков);
Задание Python 7_6:
Напишите программу, которая, не изменяя заданный массив, выводит номера его элементов в возрастающем порядке значений этих элементов. Использовать вспомогательный массив номеров.
Пример:
результат: 0 2 3 1 4
Задание Python 7_7:
Напишите программу, которая сортирует массив и находит количество различных чисел в нём. Не использовать встроенные функции.Пример:
Введите количество: 10 Массив: Массив отсортированный: Количество различных элементов: 9
Задание Python 7_8:
Дан массив. Назовем серией группу подряд идущих одинаковых элементов, а длиной серии — количество этих элементов. Сформировать два новых массива, в один из них записывать длины всех серий, а во второй — значения элементов, образующих эти серии.Пример:
Введите количество элементов: 15 Массив: Элементы, создающие серии: Длины серий:
Задание Python 7_9:
Напишите вариант метода пузырька, который заканчивает работу, если на очередном шаге внешнего цикла не было перестановок. Не использовать встроенные функции.
Задание Python 7_10:
Напишите программу, которая сортирует массив, а затем находит максимальное из чисел, встречающихся в массиве несколько раз. Не использовать встроенные функции.
Пример:
Введите количество: 15 Массив исходный: Массив отсортированный: Максимальное из чисел, встречающихся в массиве несколько раз: 12
Программа сортировки массива C# выбором
По условию задачи пользователь может ввести любое количество целых чисел, разделенных запятыми. Нам необходимо прочитать эти числа, составить из полученных чисел массив, вывести его в консоль, отсортировать массив приведенным выше алгоритмом и вернуть в консоль отсортированный массив. Все эти шаги реализуются достаточно просто.
Собираем массив целых чисел
Console.WriteLine("Введите через запятую целые числа и нажмите Enter");
string[] nums = Console.ReadLine().Split(new char[] { ',' });
int[] intArray = new int;
for (int i = 0; i < nums.Length; i++)
{
intArray = int.Parse(nums);
}
В первой строке мы предлагаем пользователю ввести целые числа. После того, как пользователь введет любое количество чисел и нажмет Enter, программа переходит к следующему шагу — разделит полученную от пользователя строку на массив строк:
string[] nums = Console.ReadLine().Split(new char[] { ',' });
здесь — это .
Метод возвращает нам последнюю строку из консоли.
Метод — это метод для типа , который возвращает массив строк, созданный из исходной строки. В качестве аргумента этот метод принимает массив символов по которым будет делиться строка. Так как у нас, по условиям задачи, разделитель всего один — запятая, то и массив разделителей в методе содержит всего один элемент.
На следующем шаге мы целых чисел размер которого совпадает с размером массива .
int[] intArray = new int
Далее, в мы наполняем наш созданный массив числами, используя метод у типа данных , который возвращает нам целое число из строки.
for (int i = 0; i < nums.Length; i++)
{
intArray = int.Parse(nums);
}
Выводим неотсортированный массив в консоль
Вывести неотсортированный массив пользователю проще простого, если воспользоваться :
Console.WriteLine("Неотсортированный массив:");
foreach (int value in intArray)
{
Console.Write($"{value} ");
}
Сортируем массив, используя алгоритм «Сортировка выбором» и показываем результат
Для этого используем реализацию алгоритма, которая представленная выше. Чтобы вывести отсортированный массив пользователю снова используем цикл .
Console.WriteLine("\r\nОтсортированный массив:");
foreach (int value in intArray)
{
Console.Write($"{value} ");
}
так как для неосортированного массива мы использовали метод , которые не производит переход на следующую строку, то здесь, в методе мы использовали /r/n для перехода на новую строку и возврат каретки в начало строки.
Результат работы программы
В результате работы программы можно получить, например, вот такой вывод в консоли:
Введите через запятую целые числа и нажмите Enter
0,100,999,345,-100,1,0,9,7,6,5,4,3,2,1,67,88
Неотсортированный массив: 0 100 999 345 -100 1 0 9 7 6 5 4 3 2 1 67 88
Отсортированный массив: -100 0 0 1 1 2 3 4 5 6 7 9 67 88 100 345 999
Как видите, алгоритм успешно справляется с сортировкой массива и все заданные числа были отсортированы от меньшего к большему.
Почему важны алгоритмы сортировки
Поскольку сортировка часто может снизить сложность проблемы, это важный алгоритм в компьютерных науках. Эти алгоритмы имеют прямое применение в алгоритмах поиска, алгоритмах баз данных, методах разделения и владения, алгоритмах структуры данных и многом другом.
Компромиссы алгоритмов
При использовании разных алгоритмов необходимо задать несколько вопросов. Насколько велика сортировка коллекции? Сколько памяти можно использовать? Нужно ли коллекции расти?
Ответы на эти вопросы могут определить, какой алгоритм будет лучше всего работать в данной ситуации. Некоторым алгоритмам, таким как сортировка слиянием, может потребоваться много места для запуска, в то время как сортировка вставкой не всегда является самой быстрой, но для ее выполнения не требуется много ресурсов.
Вы должны определить, каковы требования к системе и ее ограничения, прежде чем решать, какой алгоритм использовать.
Пирамидальная сортировка
Также известна как сортировка кучей. Этот популярный алгоритм, как и сортировки вставками или выборкой, сегментирует список на две части: отсортированную и неотсортированную. Алгоритм преобразует второй сегмент списка в структуру данных «куча» (heap), чтобы можно было эффективно определить самый большой элемент.
Алгоритм
Сначала преобразуем список в Max Heap — бинарное дерево, где самый большой элемент является вершиной дерева. Затем помещаем этот элемент в конец списка. После перестраиваем Max Heap и снова помещаем новый наибольший элемент уже перед последним элементом в списке.
Этот процесс построения кучи повторяется, пока все вершины дерева не будут удалены.
С чего начать?
Изучаем концепции программирования
Прежде чем приступать к изучению алгоритмов, я бы порекомендовал освоить такие понятия программирования, как переменные, функции, классы и особенно понятия объектно-ориентированного программирования (ООП). Это будет вашим фундаментом для понимания более продвинутых концепций из области компьютерных наук.
Осваиваем алгоритмы и их принципы работы
Помимо материалов моего курса, я занимался также по учебнику «Алгоритмы: построение и анализ» Томаса Х. Кормена, Чарльза Э. Лейзерсона, Рональда Ривеста и Клиффорда Штайна. Можно начать с самых азов:
- анализа временной и пространственной сложности;
- терминов “O” большое и “o” малое;
- рекурсии;
- базовых структур данных, таких как массивы, матрицы, связные списки, стеки, очереди, деревья и т. д.;
- основных алгоритмов, таких как алгоритмы поиска и сортировки.
Анализ временной и пространственной сложности — это очень важная тема, которую необходимо освоить, чтобы анализировать алгоритмы. Затем можно перейти к более продвинутым алгоритмам, таким как алгоритмы на графах.
Самое важное — чётко понимать, что происходит внутри алгоритма. Раньше я брал простые примеры и применял алгоритм, чтобы посмотреть, что происходит на каждом его шаге
Проработка примеров помогала мне лучше понять, что происходит в алгоритме, причём мне никогда не приходилось эти алгоритмы запоминать. Если меня попросят написать псевдокод для алгоритма, я смогу легко связать его с примером и проработать его, вместо того чтобы запоминать каждый шаг.
Погружаемся в код с головой
На курсе нам предлагалось реализовать различные структуры данных с нуля, используя основные их операции. Например, двоичные деревья поиска (BST) в C++ с операциями вставки, удаления, поиска, обхода с предварительной выборкой, обхода с отложенной выборкой и обхода с порядковой выборкой. Приходилось создавать класс BST и реализовывать все эти операции в виде функций. Предлагалось даже сравнивать время выполнения определённых операций с различными размерами наборов данных. Это был отличный опыт. Я многому научился благодаря этим занятиям и стал лучше разбираться в операциях. Такой учебный процесс с практическими заданиями помог мне лучше понять концепцию алгоритмов.
Можно начать программировать с языков, поддерживающих ООП. Это легко с очень простыми в освоении языками:
- C++
- Java
- Python
Для новичков один из этих языков будет в самый раз.
Что означает “на месте” и “стабильно”?
- На месте: алгоритм на месте требует дополнительного пространства, не обращая внимания на размер ввода коллекции. После выполнения сортировки он перезаписывает исходные ячейки памяти элементов в коллекции.
- Стабильный: это термин, который управляет относительным порядком равных объектов в исходном массиве.
Что более важно, сортировка вставкой в Python не требует заранее знать размер массива, и она получает по одному элементу за раз. В сортировке вставкой замечательно то, что если мы вставляем больше элементов для сортировки, алгоритм размещает их в нужном месте, не выполняя полную сортировку
В сортировке вставкой замечательно то, что если мы вставляем больше элементов для сортировки, алгоритм размещает их в нужном месте, не выполняя полную сортировку.
Это более эффективно для массива небольшого (менее 10) размера. Теперь давайте разберемся с концепцией сортировки вставкой.
Концепция сортировки вставкой
Массив разделился практически на две части при сортировке вставками – несортированная часть и отсортированная часть.
Отсортированная часть содержит первый элемент массива, а другая несортированная часть содержит остальную часть массива. Первый элемент в несортированном массиве сравнивается с отсортированным массивом, чтобы мы могли поместить его в соответствующий подмассив.
Он фокусируется на вставке элементов путем перемещения всех элементов, если правое значение меньше левого.
Это будет повторяться до тех пор, пока весь элемент не будет вставлен в правильное место.
Ниже приведен алгоритм сортировки массива с помощью вставки.
- Разбить список на две части – отсортированный и несортированный.
- Итерировать от arr к arr по заданному массиву.
- Сравнить текущий элемент со следующим элементом.
- Если текущий элемент меньше, чем следующий элемент, сравнить с предыдущим элементом. Переместиться к большим элементам на одну позицию вверх, чтобы освободить место для замененного элемента.
Разберемся в следующем примере.
Рассмотрим первый элемент отсортированного массива.
Первый шаг к добавлению 10 в отсортированный подмассив.
Теперь берем первый элемент из несортированного массива – 4. Это значение сохраняем в новой переменной temp. Теперь мы видим, что 10> 4, перемещаем 10 вправо, и это перезаписывает 4, которые были ранее сохранены.




(темп = 4)
Здесь 4 меньше, чем все элементы в отсортированном подмассиве, поэтому мы вставляем его в первую позицию индекса.
У нас есть два элемента в отсортированном подмассиве.
Теперь проверьте число 25. Мы сохранили его во временной переменной. 25> 10, а также 25> 4, затем мы помещаем его в третью позицию и добавляем в отсортированный подмассив.
Снова проверяем цифру 1. Сохраняем в темп. 1 меньше 25. Он перезаписывает 25.
10> 1, затем перезаписывается снова
4> 1 теперь ставим значение temp = 1
Теперь у нас есть 4 элемента в отсортированном подмассиве. 5 <25, затем сместите 25 в правую сторону и передайте temp = 5 в левую сторону.
положите temp = 5
Теперь мы получаем отсортированный массив, просто помещая временное значение.
Данный массив отсортирован.
Своя сортирующая функция
Язык Python позволяет
создавать свои сортирующие функции для более точной настройки алгоритма
сортировки. Давайте для начала рассмотрим такой пример. Пусть у нас имеется вот
такой список:
a=1,4,3,6,5,2
и мы хотим,
чтобы вначале стояли четные элементы, а в конце – нечетные. Для этого создадим
такую вспомогательную функцию:
def funcSort(x): return x%2
И укажем ее при
сортировке:
print( sorted(a, key=funcSort) )
Мы здесь
используем именованный параметр key, который принимает ссылку на
сортирующую функцию. Запускаем программу и видим следующий результат:
Разберемся,
почему так произошло. Смотрите, функция funcSort возвращает вот
такие значения для каждого элемента списка a:
![]()
И, далее, в sorted уже
используются именно эти значения для сортировки элементов по возрастанию. То
есть, сначала, по порядку берется элемент со значением 4, затем, 6 и потом 2.
После этого следуют нечетные значения в порядке их следования: 1, 3, 5. В
результате мы получаем список:
А теперь,
давайте модифицируем нашу функцию, чтобы выполнялась сортировка и самих
значений:
def funcSort(x): if x%2 == : return x else: return x+100
Здесь четные
значения возвращаются такими как они есть, а к нечетным прибавляем 100. В
результате получим:
![]()
Здесь элементам
нашего списка ставятся в соответствие указанные числа, и по этим числам
выполняется их сортировка. То есть, эти числа можно воспринимать как некие
ключи, по которым и происходит сортировка элементов списка. Поэтому в Python
такую
сортировку называют сортировкой по ключам.
Конечно, здесь
вместо определения своей функции можно также записывать анонимные функции,
например:
print( sorted(a, key=lambda x: x%2) )
Получим ранее
рассмотренный результат:
Или, то же самое
можно делать и со строками:
lst = "Москва", "Тверь", "Смоленск", "Псков", "Рязань"
Отсортируем их
по длине строки:
print( sorted(lst, key=len) )
получим
результат:
Или по
последнему символу, используя лексикографический порядок:
print( sorted(lst, key=lambda x: x-1) )
Или, по первому
символу:
print( sorted(lst, key=lambda x: x) )
И так далее. Этот
подход часто используют при сортировке сложных структур данных. Допустим, у нас
имеется вот такой список из книг:
books = {
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
}
И нам нужно его
отсортировать по возрастанию цены (последнее значение). Это можно сделать так:
print( sorted(books, key=lambda x: x2) )
На выходе
получим список:
Вот так можно
выполнять сортировку данных в Python.
Заключение: какие из этого следуют выводы?
При попытке верифицировать Timsort нам не удалось установить инвариант объекта сортировки. Анализируя причины неудачи, мы обнаружили в реализации Timsort ошибку, которая приводит к ArrayOutOfBoundsException для определённых входных данных. Мы предложили исправление ошибочного метода (без ощутимого снижения производительности) и формально доказали, что исправление корректно и ошибки больше нет.
Из этой истории, помимо собственно найденной ошибки, можно сделать несколько наблюдений.
- Зачастую программисты считают формальные методы непрактичными и/или далёкими от реальных задач. Это не так: мы нашли и исправили ошибку в программном обеспечении, которым пользуются миллиарды пользователей каждый день. Как показал наш анализ, найти и исправить такой баг без формального анализа и инструмента для верификации было бы практически невозможно. Ошибка долгие годы жила в стандартной библиотеке языков Java и Python. Её проявления замечали ранее и даже думали, что исправили, но в действительности добились только того, что ошибка стала возникать реже.
- Хотя маловероятно, что такая ошибка возникнет случайно, легко представить, как можно её использовать для атаки. Вероятно, в стандартных библиотеках популярных языков программирования кроются и другие незамеченные ошибки. Может быть, стоит заняться их поиском до того как они причинят вред или будут использованы злоумышленниками?
- Реакция разработчиков Java на наш отчёт в некотором смысле разочаровывает. Вместо того, чтобы использовать нашу исправленную (и верифицированную!) версию mergeCollapse(), они предпочли увеличить выделенный размер runLen до «достаточного» размера. Как мы показали, вовсе не обязательно было так делать. Но теперь каждый, кто использует java.utils.Collection.sort() будет вынужден тратить больше памяти. Учитывая астрономическое число программ, использующих настолько базовую функцию, это приведёт к заметным дополнительным затратам энергии. Мы можем только догадываться, почему не было принято наше решение: возможно разработчики JDK не удосужились прочитать наш отчёт полностью и поэтому не поняли суть исправления и решили не полагаться на него. В конце концов, OpenJDK разрабатывает сообщество, в значительной степени состоящее из добровольцев, у которых не так много времени.
Какие из этого следуют выводы? Мы были бы счастливы, если бы наша работа послужила начальной точкой для более тесного взаимодействия между исследователями формальных методов и разработчиками открытых программных платформ. Формальные методы уже успешно применяются в
Amazon
и
. Современные языки формальной спецификации и инструменты формальной верификации
не являются
такими уж запутанными и суперсложными в изучении. Постоянно улучшается их юзабилити и автоматизация. Но нам нужно больше людей, которые бы пробовали, тестировали и использовали наши инструменты. Да, потребуются некоторые усилия, чтобы начать писать формальные спецификации и верифицировать код, но это не сложнее, чем, например, разобраться, как использовать компилятор или средство сборки проектов. Но речь идёт о днях или неделях, а не месяцах или годах. Ну как,




вы
принимаете вызов?
С наилучшими пожеланиями,
Стайн де Гув
,
Юриан Рот
,
Франк де Бур
,
Ричард Бубель
и
Райнер Хенле
Благодарности
Работа частично поддержана проектом седьмой рамочной программы Евросоюза FP7-610582 ENVISAGE:
Engineering Virtualized Services
Эта статья не была бы написана без поддержки и вежливых напоминаний
Амунда Твейта
! Также мы хотим поблагодарить Беруза Нобакта за то, что предоставил нам видео, демонстрирующее ошибку.



