
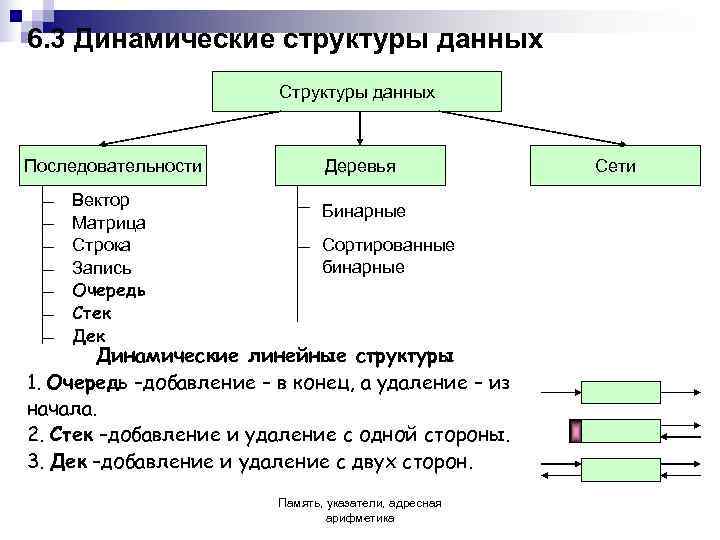
Графы
Граф — это множество узлов, соединенных друг с другом в виде сети. Узлы также называются вершинами. Пара (x,y) называется ребром, это означает, что вершина x соединена с вершиной y. Ребро может иметь вес/стоимость — показатель, характеризующий, насколько затратен переход от вершины x к вершине y.
Графы
Типы графов:
- Неориентированный граф
- Ориентированный граф
В языке программирования графы могут быть двух видов:
- Матрица смежности
- Список смежности
Распространенные алгоритмы обхода графа:
- Поиск в ширину
- Поиск в глубину
Вопросы о графах, часто задаваемые на собеседованиях:
- Реализуйте поиск в ширину и поиск в глубину
- Проверьте, является граф деревом или нет
- Подсчитайте количество ребер в графе
- Найдите кратчайший путь между двумя вершинами
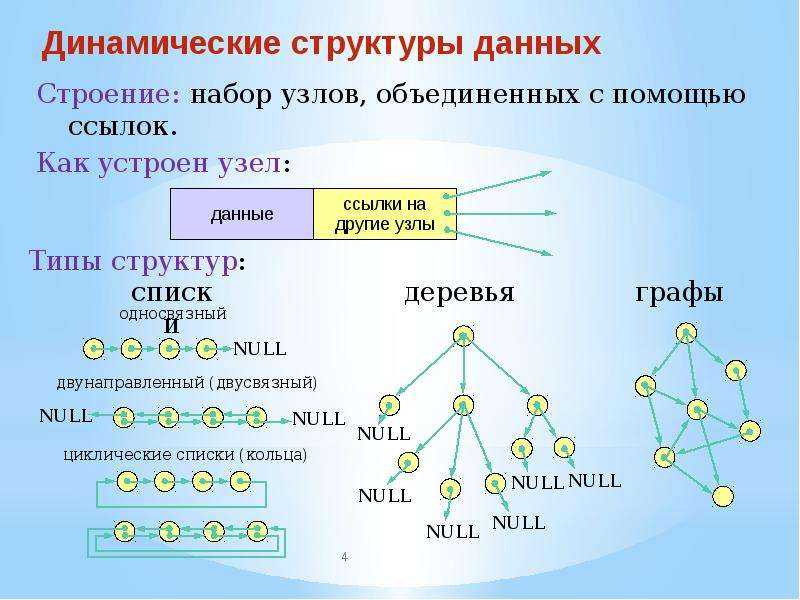
Односвязный список
Односвязный список (односвязный список) — это разновидность связанного списка.Его характерно то, что направление ссылки связанного списка одностороннее, и доступ к связанному списку начинается с головы путем последовательного чтения.
вставить
Чтобы вставить узел в односвязный список, необходимо изменить предыдущий узел (предшественник), чтобы он указывал на только что добавленный узел, а вновь добавленный узел указывает на узел, на который указывает исходный предшественник.
удалять
Чтобы удалить элемент из односвязного списка, необходимо указать узел-предшественник удаляемого элемента на узел-преемник удаляемого элемента, и в то же время указать для удаленного элемента значение null.
Concatenating singly linked lists
You might occasionally need to concatenate a singly linked list to another singly linked list. For example, suppose you have a list of words that start with letters A through M and another list of words starting with letters N through Z, and you want to combine these lists into a single list. The following pseudocode describes an algorithm for concatenating one singly linked list to another:
In the trivial case, there is no -referenced list, and so is assigned ‘s value, which would be if there was no -referenced list.
This operation has a time complexity of O(1) in the trivial case and a time complexity of O(n) otherwise. However, if you maintain a reference to the last node, there’s no need to search the list for this node; the time complexity changes to O(1).
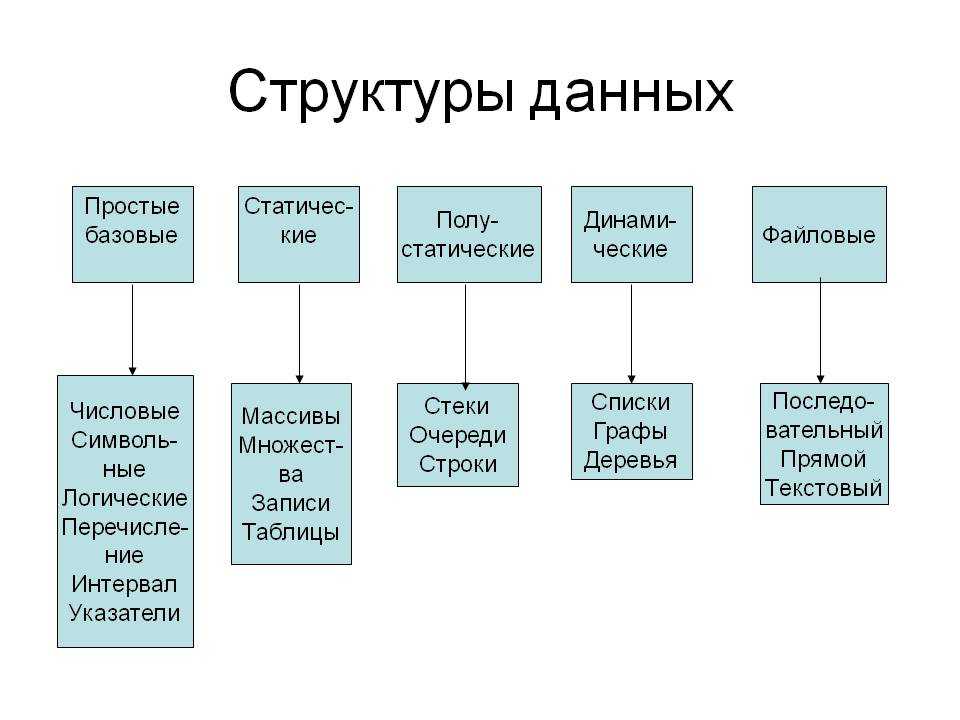
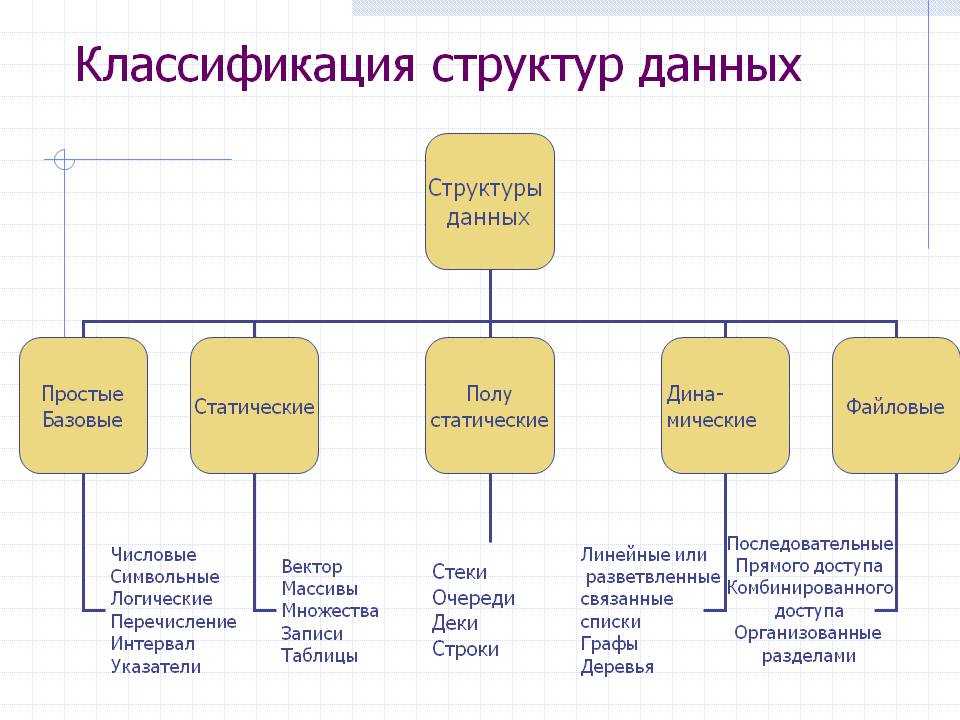
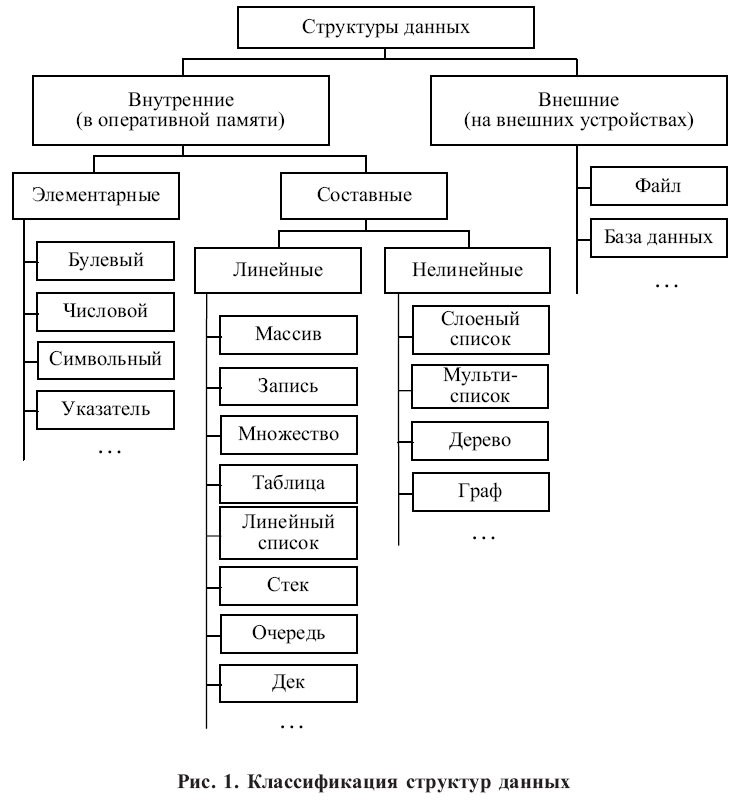
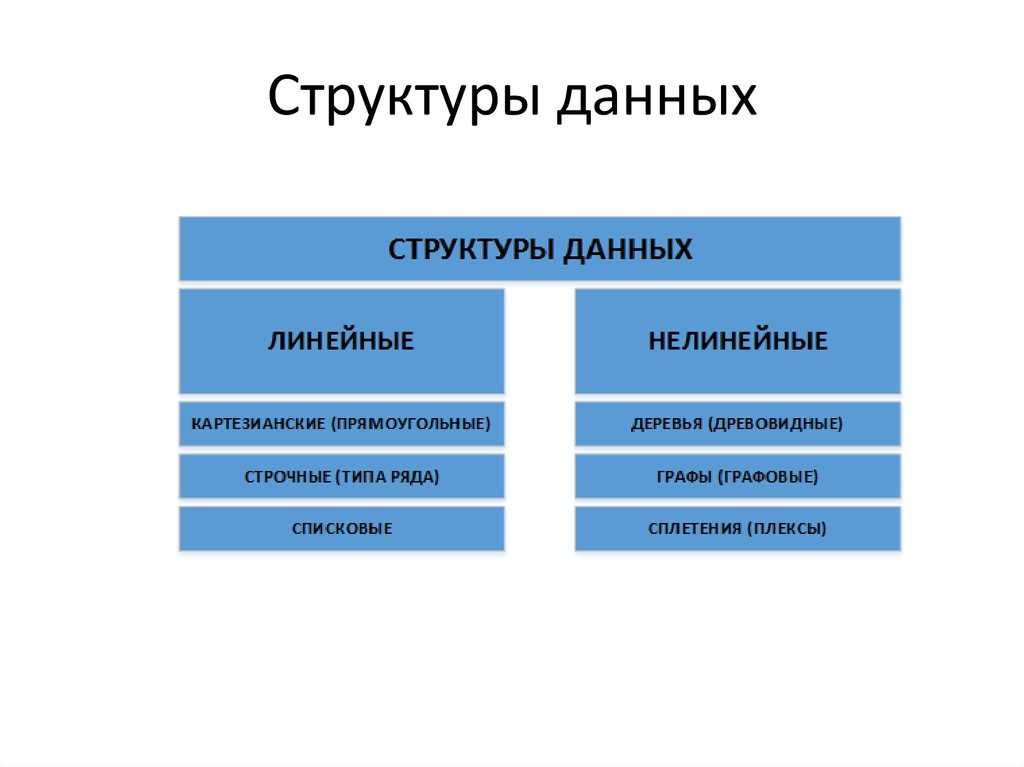
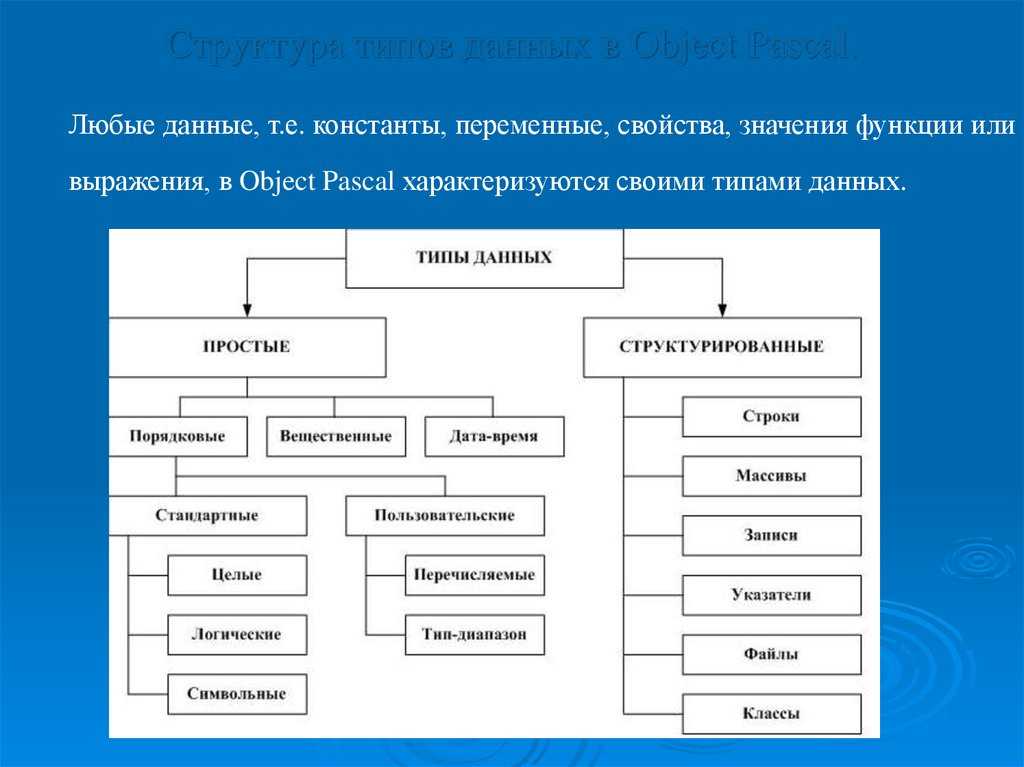
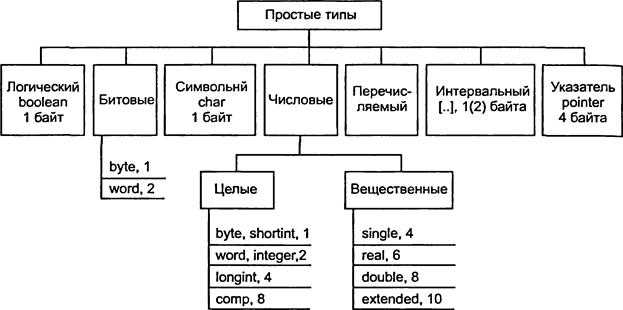
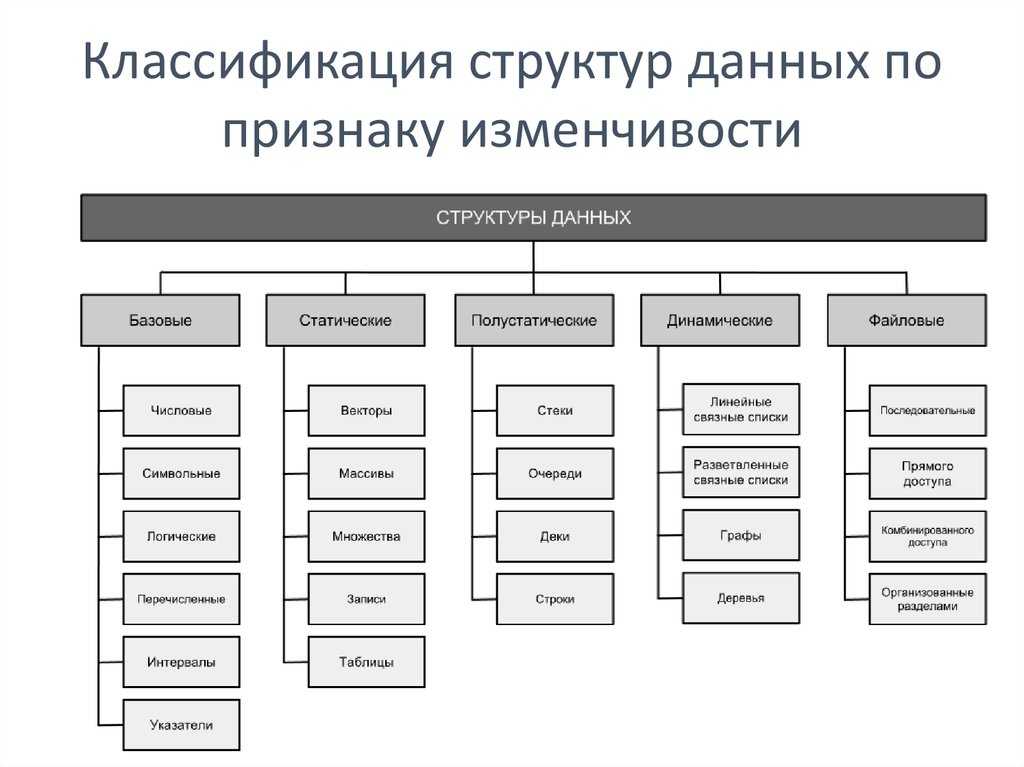
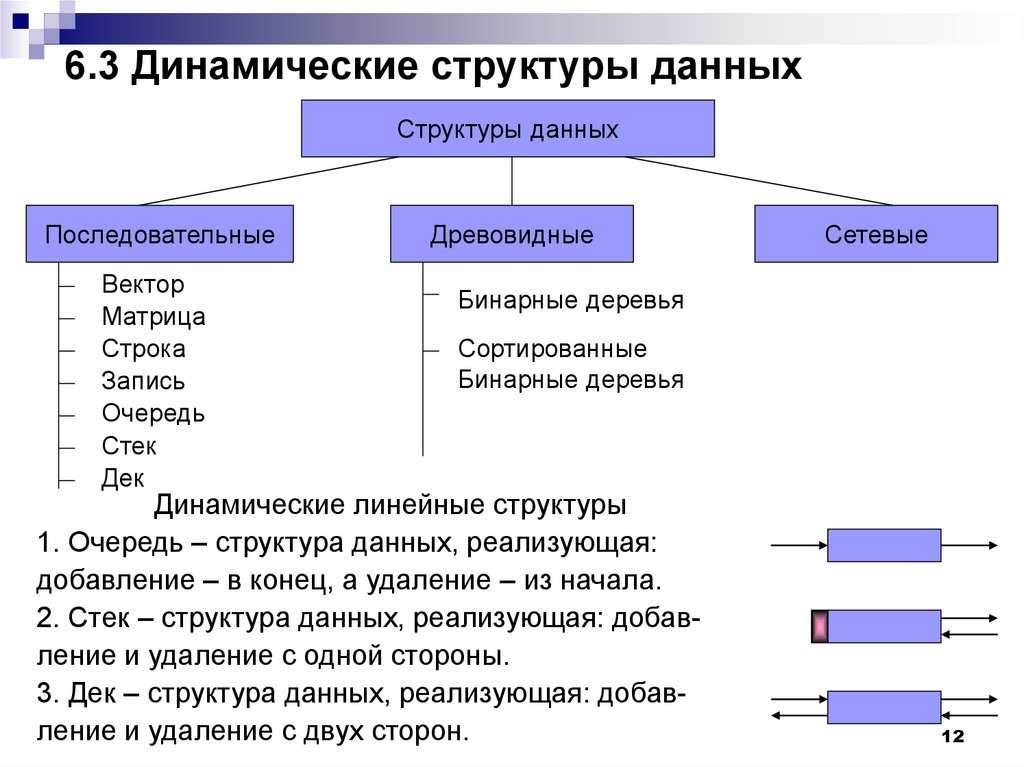
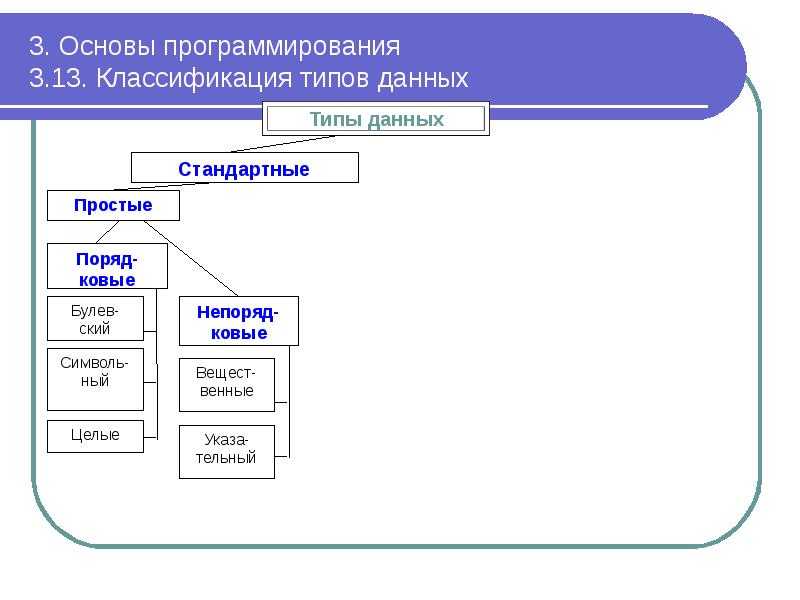
Типы данных
Примитивные типы
- Логическое , истина или ложь.
- символ
- Числа с плавающей запятой , аппроксимация вещественных чисел с ограниченной точностью .
- Числа с фиксированной точкой
- Целочисленные , целочисленные значения или значения с фиксированной точностью.
- Ссылка (также называемая указателем или дескриптором), небольшое значение, относящееся к адресу другого объекта в памяти, возможно, гораздо большему.
- Перечислимый тип , небольшой набор значений с уникальными именами.
- Дата Время , значение, относящееся к дате и времени
Составные типы или непримитивные типы
- Массив (например, String, представляющий собой массив символов)
- Запись (также называемая ассоциативным массивом, картой или структурой )
- Объединение ( объединение с тегами — это подмножество, также называемое вариантом , вариантной записью, размеченным объединением или непересекающимся объединением)
Абстрактные типы данных
- Контейнер
- Список
- Кортеж
- Multimap
- Задавать
- Мультисет (сумка)
- Стек
- Очередь (пример очереди с приоритетом )
- Двусторонняя очередь
- График (пример Tree , Heap )
Некоторые свойства абстрактных типов данных:
| Состав | порядок | Уникальный |
|---|---|---|
| Список | да | нет |
| Ассоциативный массив | нет | да |
| Задавать | нет | да |
| Стек | да | нет |
| Multimap | нет | нет |
| Мультисет (сумка) | нет | нет |
| Очередь | да | нет |
Порядок означает, что последовательность вставки имеет значение. Уникальный означает, что повторяющиеся элементы не допускаются на основании некоторых встроенных или, альтернативно, определяемых пользователем правил для сравнения элементов.
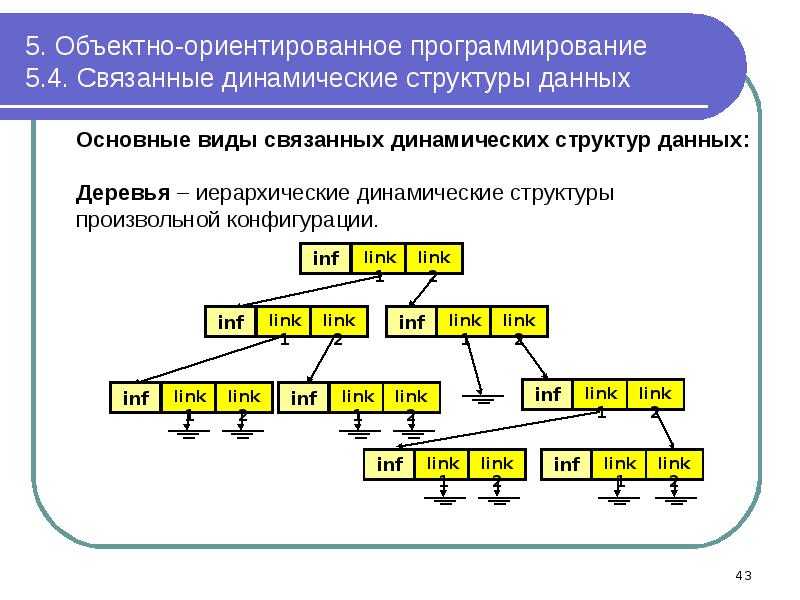
Двоичное дерево поиска
Двоичное дерево поиска
Дерево — это структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов, и так далее.
У двоичного дерева поиска есть два дополнительных свойства:
- Каждый узел имеет до двух дочерних узлов (потомков).
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Временная сложность двоичного дерева поиска
https://youtube.com/watch?v=5cU1ILGy6dM
https://youtube.com/watch?v=Aagf3RyK3Lw
Упражнения от freeCodeCamp
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Очереди
Идеальный реалистичный пример очереди — это и есть очередь покупателей в билетную кассу. Новый покупатель становится в самый хвост очереди, а не в начало. Тот же, кто стоит в очереди первым, первым приобретет билет и первым ее покинет.
Вот изображение очереди с четырьмя элементами данных (1, 2, 3 и 4), где 1 идет первым и первым же покинет очередь:
Очереди
Простейшие операции с очередью
- Enqueue() — Добавляет элемент в конец очереди
- Dequeue() — Удаляет элемент из начала очереди
- isEmpty() — Возвращает true, если очередь пуста
- Top() — Возвращает первый элемент в очереди
Вопросы об очередях, часто задаваемые на собеседованиях
- Реализуйте стек при помощи очереди
- Обратите первые k элементов в очереди
- Сгенерируйте двоичные числа от 1 до n при помощи очереди
Проверяем наш связный список
Давайте все это проверим. Начнем с создания нового объекта Node. Назовем его (две латинские буквы «l» в нижнем регистре как сокращение Linked List). Назначим ему значение 1.
Поскольку мы написали такой классный метод , мы можем вызывать его для добавления в наш список новых узлов.
Как нам увидеть, как выглядит наш список? Теоретически, выглядеть он должен следующим образом:
Но нет способа вывести его именно в таком виде. Нам нужно пройти список, выводя каждое значение. Вы же помните, как проходить список? Мы только что это делали. Повторим:
- Создаем переменную, указывающую на .
- Если есть следующий узел, перемещаемся к этому узлу.
И просто выводим в каждом узле. Мы начинаем с шага № 1: создаем новую переменную и назначаем ее головным элементом списка.
Далее мы выводим первый узел. Почему мы не начали с цикла while? Цикл while проитерируется только дважды, потому что только у двух узлов есть (у последнего узла его нет). В информатике это называется ошибкой на единицу (когда нужно сделать что-то Х раз плюс 1). Это можно представить в виде забора. Вы ставите столб, затем секцию забора, и чередуете пару столько раз, сколько нужно по длине.
![]()
Но вы не можете оставить последнюю секцию забора висящей в воздухе. Ограда должна закончиться столбом, а не секцией. Поэтому вам приходится либо добавлять еще один столб в конце, либо (что в информатике более распространено) начать с постановки столба, а затем добавлять пары . Это мы и сделаем.
Для начала мы выведем первый узел, а затем запустим цикл while для вывода всех последующих узлов.
node = ll
print(node.data)
while node.next:
node = node.next
print(node.data)
Запустив это для нашего предыдущего списка, мы получим в консоли:
Ура! Наш связный список работает.
Приложения
Как следует из названия, списки можно использовать для хранения списка элементов. Однако, в отличие от традиционных массивов , списки могут расширяться и сжиматься и динамически хранятся в памяти.
В вычислительной технике списки реализовать проще, чем наборы. Конечное множество в математическом смысле может быть реализовано в виде списка с дополнительными ограничениями; то есть повторяющиеся элементы запрещены, и порядок не имеет значения. Сортировка списка ускоряет определение того, находится ли данный элемент уже в наборе, но для обеспечения порядка требуется больше времени для добавления новой записи в список. Однако в эффективных реализациях наборы реализуются с использованием самобалансирующихся двоичных деревьев поиска или хэш-таблиц , а не списка.




Списки также составляют основу для других абстрактных типов данных, включая очередь , стек и их варианты.
Важные принципы
Все значения примитивов ― неизменны
Осторожно с приведением типов
Здесь нет места статической типизации т.е. Движок JavaScript сам определяет типы
Почему Null это объект?
Документация причисляет Null к примитивам, тем не менее оператор возвращает значение .
По сути, это баг, который не исправили, потому что существующий код перестанет работать. Этот баг присутствовал ещё с первой версии JavaScript, он пришёл из функции в исходниках JS. Я покажу это с помощью псевдокода:
![]() Псевдокод
Псевдокод
Улавливаете? Они не проверили …
Подробней о причинах отказа исправлять баг, читайте здесь. А здесь, та часть исходника JS о которой я говорил.
Почему не number стало number?
Если коротко, то определён как числовой тип, но это не настоящее число. ― это результат неких математических операций, который не может считаться числом.
Или ещё короче, потому что эксперты так сказали
Хеш-таблица
Хеширование — это процесс, применяемый для уникальной идентификации объектов и сохранения каждого объекта по заранее вычисленному индексу, именуемому его «ключом». Таким образом, объект хранится в виде «ключ-значение», а коллекция таких объектов называется «словарь». Каждый объект можно искать по его ключу. Существуют разные структуры данных, построенные по принципу хеширования, но чаще всего из таких структур применяется хеш-таблица.
Как правило, хеш-таблицы реализуются при помощи массивов.
Производительность хеширующей структуры данных зависит от следующих трех факторов:
- Хеш-функция
- Размер хеш-таблицы
- Метод обработки коллизий
Ниже показано, как хеш отображается на массив. Индекс этого массива вычисляется при помощи хеш-функции.
Хеш-таблица
Вопросы о хешировании, часто задаваемые на собеседованиях:
- Найдите симметричные пары в массиве
- Отследите полную траекторию пути
- Найдите, является ли массив подмножеством другого массива
- Проверьте, являются ли массивы непересекающимися
Выше описаны восемь важнейших структур данных, которые определенно нужно знать, прежде чем идти на собеседование по программированию.
Удачи и интересного обучения!
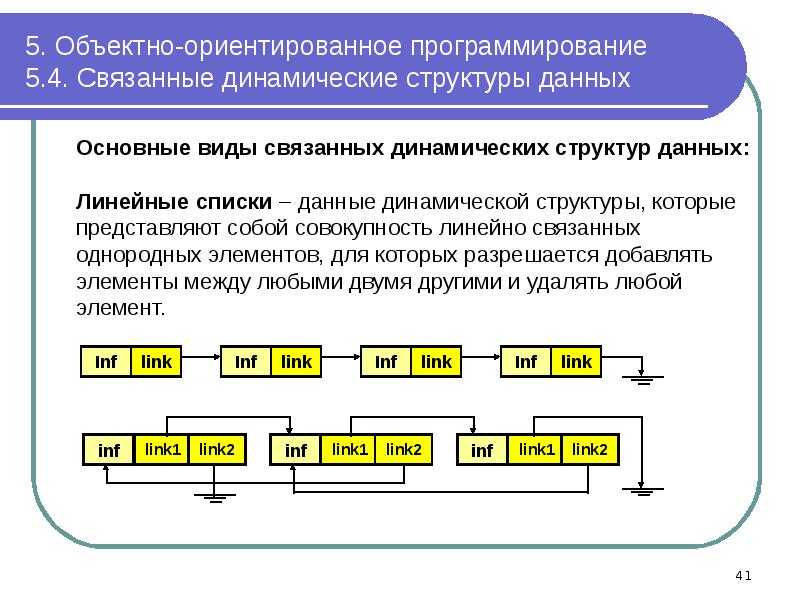
Связанный список
Массивы не всегда являются лучшей структурой данных, потому что во многих языках программирования длина массива фиксирована.Если массив заполнен данными, очень сложно добавлять новые элементы. Более того, для операций удаления и добавления массива другие элементы в массиве обычно необходимо переводить вперед или назад, что также очень утомительно.
js массивы реализованы как объекты, что намного неэффективно по сравнению с массивами на других языках.
Помимо произвольного доступа к данным, связанные списки можно использовать практически везде, где можно использовать одномерные массивы.
Связанный список — это набор из серии узлов, каждый из которых использует ссылку на объект, чтобы указать на своего преемника, а ссылка на другой узел называется цепочкой.
О языках программирования
Языком программирования считают формальные правила и их наборы, необходимые для создания софта. Своеобразный элемент, посредством которого пользователь «общается» с компьютером и приложениями. Аналогичным образом техника «разговаривает» с программным обеспечением.
У каждого языка программирования имеется лексика – функции и операторы, при помощи которых согласно синтаксисным принципам составляются всевозможные выражения. Чтобы создать приложение, нужно выбрать язык и набрать исходный код. Кодификаций очень много. Одним из самых популярных является некий Java.
Java – определение
Java – способ «общения» пользователя с компьютером. Относится к объектно-ориентированному программированию и предусматривает строгую типизацию. Многофункциональный, универсальный.
Джава используется для написания:
- Android-приложений;
- компьютерного софта;
- банковских утилит;
- научных программ;
- программного обеспечения, предназначенного для Big Data;
- веб-утилит;
- корпоративного ПО;
- строенных систем (и маленькие чипы, и спецкомпьюетры).
Среди недостатков выделяют следующие черты:
- невысокую скорость работы;
- высокие требования к памяти устройства;
- отсутствие поддержки низкоуровневого программирования;
- обновления 2019 года для бизнеса и коммерции – платные;
- составление новой утилиты отнимает большое количество времени.
Но Java может оказаться полезным. Это – объектно-ориентированная среда, функциональная и с простым синтаксисом. Надежный и независимый. Элементы, написанные на Джаве, запускаются на всех поддерживающих «языковую раскладку» девайсах.
В процессе составления кода приложения используются односвязные списки и другие составляющие синтаксиса. Этот элемент является крайне важным в программировании.
Односвязные
Односвязные списки – такие объекты, которые включают в себя «маркеры»-указатели на следующий узел. Из точки А можно попасть лишь в точку Б. Так пользователь будет двигаться в самый конец перечня. То есть, пошагово, последовательно.
Вследствие происходит образование потоков, текущих в одном заданном направлении. Полем указателя последнего элемента служит нулевое значение. То есть, NULL.
Основные манипуляции, осуществляемые посредством ОЛС:
- инициализация;
- добавление новых элементов в перечень;
- удаление узлов и корней;
- вывод составляющих списка;
- взаимообмен нескольких «частей» перечня.
Далее будут рассмотрены все эти операции с примерами кодов для большей наглядности.
Инициализация
Операция необходима для того, чтобы создавать корневые узлы списков, у которых поля с указателями на следующие составляющие обладают нулевым значением:
Это – самый простой вариант развития событий. Но в процессе работы пригодятся и другие манипуляции.
Добавление
При добавлении элементов в списки функциям присваиваются следующие аргументы:
- информация для добавляемой составляющей;
- непосредственный указатель на задействованный элемент.
Проводится в несколько этапов. Сначала создается добавляемый узел и заполняются его поля информации. Затем переустанавливаются предыдущие указатели на тот, что хочется внедрить. Завершающим этапом является установка указателей добавляемого элемента туда, куда «показывал» прошлый узел.
Адрес добавленного узла – возвращаемое значение задействованной функции.
Удаление
При удалении элементов ОЛС функциями аргументов служат указатели на подлежащий стиранию «объект», а также «маркер» его корня. Функции возвращают указатель на элемент, который следует за удаленным.



Тоже проводится в несколько шагов:
- постановка указателя предыдущей составляющей на следующий за тем, что подлежит деинсталляции;
- высвобождение памяти устройства.
Код будет примерно следующим:
В случае со стиранием корней ситуация обстоит иначе:
Функции удаления корней в списках в виде аргументов получают указатели на текущие корни перечней. Возвращаемое значение – новый корень. А именно – узел, на который указывал удаленный.
Вывод
Отобразить элемент списка можно следующим макаром:
Аргументом в функции вывода становится указатель на корень списка, а сама функция последовательно обходит все элементы перечня с последующим их выводом (значений).
Обеспечение взаимообмена
При подобных обстоятельствах кодификация, используемая для реализации поставленной задачи будет иметь примерно следующее представление:
В этом случае работа связных списков основывается на обмене узлового характера. Аргументы функций ОЛС – это два указателя на обмениваемые узлы, а также указатели корня списка. Функция отвечает за возврат корневого «объекта» списка.
Могут рассматриваться разные ситуации:
- заменяемые «частицы» находятся по соседству;
- обрабатываемые узлы – не соседние.
Когда маркеры переустанавливаются, требуется проверка на причастность к корню списка. Если заменяемая составляющая является таковой, все нормально. В противном случае узел, предшествующий корневому, будет отсутствовать.
HTML код
Практически идентичен прошлому примеру.
Мы подключаем библиотеку jQuery и класс — TSEL, создающий связанные списки. TSEL работает с двумя HTML контейнерами, идентификаторы которых мы передадим при инициализации TSEL. Третьим параметром будет url к файлу сервера для обработки ajax запросов.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″ />
<script type=»text/javascript» src=»https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js»></script>
<script type=»text/javascript» src=»tsel.js»></script>
</head>
<body>
<div id=»selector»>
<!— Здесь будут выпадающие списки —>
</div>
<div id=»result»>
<!— Здесь будет описание ед. вооружения —>
</div>
<script type=»text/javascript»>
//получаем экземпляр, управляющего списками класса
//попутно инициализируем его
$(function () {
var TS = new TSEL({
selectorID: «selector»,
resultID: «result»,
ajaxUrl: «/ajax.php»});
});
</script>
</body>
</html>
|
1 |
<!DOCTYPE html> <html> <head> <meta http-equiv=»Content-Type»content=»text/html; charset=utf-8″/> <script type=»text/javascript»src=»https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js»></script> <script type=»text/javascript»src=»tsel.js»></script> </head> <body> <div id=»selector»> <!—Здесьбудутвыпадающиесписки—> </div> <div id=»result»> <!—Здесьбудетописаниеед.вооружения—> </div> <script type=»text/javascript»> //получаем экземпляр, управляющего списками класса $(function(){ varTS=newTSEL({ selectorID»selector», resultID»result», ajaxUrl»/ajax.php»}); }); </script> </body> </html> |
Связный список
Связный список — еще одна важная линейная структура данных, на первый взгляд напоминающая массив. Однако, связный список отличается от массива по выделению памяти, внутренней структуре и по тому, как в нем выполняются базовые операции вставки и удаления.
Связный список напоминает цепочку узлов, в каждом из которых содержится информация: например, данные и указатель на следующий узел в цепочке. Есть головной указатель, соответствующий первому элементу в связном списке, и, если список пуст, то он направлен просто на null (ничто).
При помощи связных списков реализуются файловые системы, хеш-таблицы и списки смежности.
Вот так можно наглядно изобразить внутреннюю структуру связного списка:
Связный список
Существуют такие типы связных списков:
- Односвязный список (однонаправленный)
- Двусвязный список (двунаправленный)
Простейшие операции со связными списками:
- InsertAtEnd — Вставляет заданный элемент в конце связного списка
- InsertAtHead — Вставляет заданный элемент в начале (с головы) связного списка
- Delete — Удаляет заданный элемент из связного списка
- DeleteAtHead — Удаляет первый элемент в связном списке
- Search — Возвращает заданный элемент из связного списка
- isEmpty — Возвращает true, если связный список пуст
Вопросы о связных списках, часто задаваемые на собеседованиях:
- Обратите связный список
- Найдите петлю в связном списке
- Возвратите N-ный узел с начала связного списка
- Удалите из связного списка дублирующиеся значения
Абстрактное определение
Тип абстрактного списка L с элементами некоторого типа E ( мономорфный список) определяется следующими функциями:
ноль: () → L
минусы: E × L → L
сначала: L → E
отдых: L → L
с аксиомами
first (cons ( e , l )) = e
остаток (cons ( e , l )) = l
для любого элемента e и любого списка l . Подразумевается, что
минусы ( д , л ) ≠ л
минусы ( е , л ) ≠ е
cons ( e 1 , l 1 ) = cons ( e 2 , l 2 ), если e 1 = e 2 и l 1 = l 2
Обратите внимание, что first (nil ()) и rest (nil ()) не определены. Эти аксиомы эквивалентны аксиомам абстрактного типа данных стека
Эти аксиомы эквивалентны аксиомам абстрактного типа данных стека .
В теории типов приведенное выше определение проще рассматривать как индуктивный тип, определяемый в терминах конструкторов: nil и cons . В алгебраических терминах, это можно представить как преобразование 1 + Е × L → L . first и rest затем получаются путем сопоставления с образцом в конструкторе cons и отдельной обработки случая nil .
Монада списка
Тип списка образует монаду со следующими функциями (с использованием E * вместо L для представления мономорфных списков с элементами типа E ):
где добавление определяется как:
В качестве альтернативы, монада может быть определена в терминах операций return , fmap и join с помощью:
Обратите внимание, что fmap , join , append и bind четко определены, поскольку они применяются к более глубоким аргументам при каждом рекурсивном вызове. Тип списка — это аддитивная монада, где nil является монадическим нулем, а добавление — монадической суммой
Тип списка — это аддитивная монада, где nil является монадическим нулем, а добавление — монадической суммой.
Зачем использовать связный список
Основное преимущество связных списков состоит в том, что они могут содержать произвольное количество значений, используя необходимый объем памяти
Сохранение памяти было очень важно на старых компьютерах, где мало памяти. Для массивов требовалось резервировать необходимый обьем памяти под элементы и можно было легко исчерпать доступную память или наоборот, не использовать то, что было зарезервировано
Связные списки были созданы, чтобы обойти эту проблему.
Связные списки стали популярными, когда разработчики не знали, сколько элементов в конечном итоге будет содержать массив. Было гораздо проще использовать связный список и добавлять значения по мере необходимости, чем точно угадывать максимальное количество значений, которое может содержать массив. Такие связные списки часто используются в качестве основы для встроенных структур данных в различных языках программирования.




Встроенный тип не реализован как связный список, хотя его размер динамический и всегда является лучшим вариантом для начала. Мы можем пройти всю свою карьеру без необходимости в использовании связных списков в JavaScript, но они по-прежнему являются хорошим способом узнать о создании собственных структур данных.
Компиляция 2
Давайте выполним компиляцию и используем методы класса LinkedList:
![]()
В этом коде мы используем метод display, и наш связный список будет выглядеть так:
Удаление узла
Теперь создадим метод, куда будет передаваться значение элемента, который нужно удалить, и назовём этот метод delete_node.
![]()
В этом методе сначала мы проверяем список на наличие элементов. Если он окажется пуст, тогда в консоль выводится LinkedList is Empty. Следующее условие проверяет, является ли удаляемый элемент firstNode. Если да, то удаляется первый узел.
Если же оба условия окажутся неверны, тогда придётся перебрать весь список, чтобы найти удаляемый элемент.



