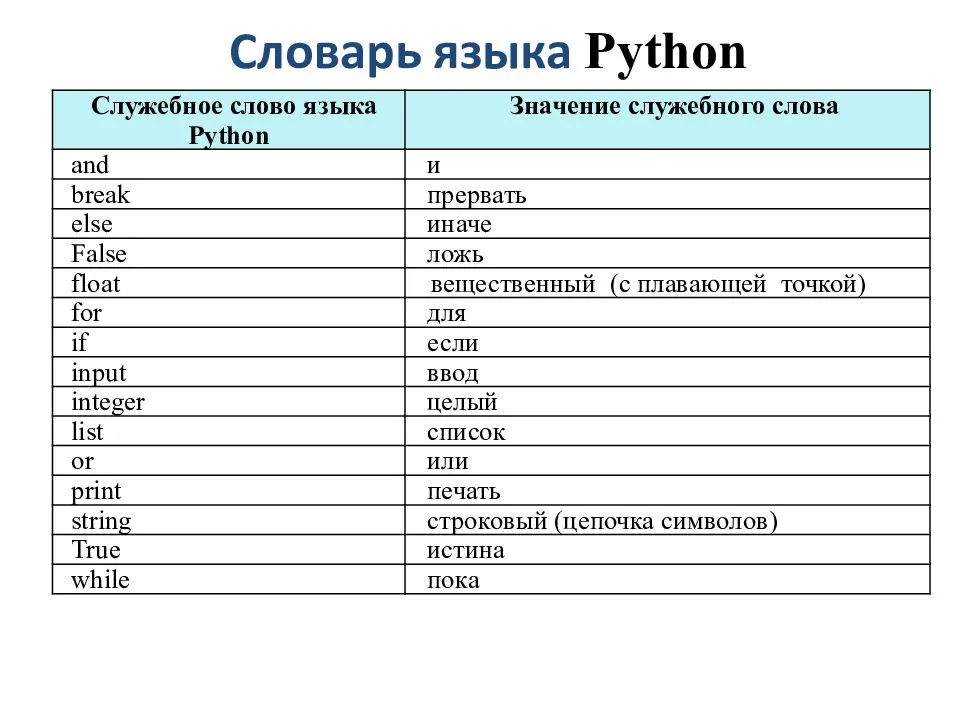
Использование метода keys
Словари в Python имеют удобный метод, который позволяет нам легко перебирать все инициализированные ключи.
Имейте в виду, что начиная с Python 3 этот метод не возвращает список, а возвращает объект представления. Объект представления — это возвращаемое значение исходного объекта, изменения которого не влияют на исходный объект. Для внесения изменений и сохранения данных в измененном объекте представления необходимо присвоить его какой-либо переменной.
Давайте посмотрим, как это работает:
# В качестве словаря используем рейтинг популярности языков программирования TIOBE
tiobe_index = {
"C": 17.38,
"Java": 11.96,
"Python": 11.72,
"C++": 7.56,
"C#": 3.95,
}
# Выведем на экран список ключей словаря и тип объекта возвращаемый выполнением метода keys
print(f"Key view: {tiobe_index.keys()}")
print(f"Type: {type(tiobe_index.keys())}")
Результат выполнения кода
Key view: dict_keys() Type: <class 'dict_keys'>
Итерация словаря по ключу в цикле for с указанием индекса элемента
for k in tiobe_index.keys():
print(f"{k}: {tiobe_index}")
Результат выполнения кода
C: 17.38 Java: 11.96 Python: 11.72 C++: 7.56 C#: 3.95
При использовании ключевого слова in в цикле for словарь вызывает свой метод iter. Затем этот метод возвращает итератор, который используется для неявного просмотра ключей предоставленного словаря.
Как сортировать словари в Python
Поскольку мы загрузили в словарь реальный набор данных, мы можем выполнить его базовый анализ. Если нас интересуют слова, которые связаны с негативным отношением к роману, можно провести низкоуровневый анализ настроений. Для этого можно составить частотный список слов в негативных отзывах (оценка 1,0).
Нам нужно немного обработать текст отзыва, удалив HTML-теги и переведя слова в верхнем регистре в нижний.
Теги мы удалим при помощи регулярного выражения: . Регулярные выражения — очень полезный инструмент при работе с текстовыми данными. Подробнее о них можно почитать в статье «Регулярные выражения в Python». В данном случае мы захватываем части строки, которые начинаются с символа <, за которым следует (или не следует) любое количество других символов, за которыми идет символ >.Части строки, соответствующие этому шаблону, удаляются путем замены «ничем» (пустые кавычки).
Также в Python есть встроенная функция для перевода букв в нижний регистр. К интересующей нас строке нужно просто добавить .
Затем мы создаем частотный словарь, используя вместо обычного словаря. Это гарантирует, что каждый «ключ» будет инициализирован, и мы сможем просто увеличить частоту на 1.
Без при попытке обратиться к несуществующему ключу (чтобы увеличить счетчик) Python выдал бы ошибку. Это можно обойти, сначала проверив, есть ли ключ в словаре. Однако это решение куда менее элегантно, чем использование .
import re
# Import defaultdict
from collections import defaultdict
freqdict = defaultdict(int)
for item in lowscores:
review = reviews
cleantext = re.sub(r'<.*?>', '', review).strip().split() # Удаляем HTML-теги и делим обзор на слова (разделенные пробелами)
for word in cleantext:
# Переводим все в нижний регистр
word = word.lower()
# Увеличиваем счетчик на единицу
freqdict += 1
print(freqdict)
После того, как частотный словарь готов, нам все еще нужно отсортировать ключи по значению в порядке убывания. Это нужно для того, чтобы быстро увидеть, какие слова являются наиболее частотными.
Поскольку обычные словари (в том числе ) не могут быть упорядочены, нам нужен другой класс. Для этой цели отлично подойдет . Он хранит словарь в порядке добавления элементов. То есть нужно сперва отсортировать элементы, а затем сохранить их в новом .
Сортировка с помощью sorted()
Функция принимает 3 аргумента. Первый — это объект, который вы хотите отсортировать, т.е. наш частотный словарь. Помните, однако, что доступ к парам ключ-значение в словаре возможен только через функцию . Если вы забудете об этом, Python вернет первый попавшийся ключ. Другими словами: если вы перебираете словарь и ваш код ведет себя странно, проверьте, добавили ли вы функцию .
Второй аргумент указывает, какая часть первого аргумента должна использоваться для сортировки: . Первая часть говорит сама за себя: вы хотите, чтобы ключи были отсортированы.
Лямбда-функция — это анонимная функция, которую нельзя вызывать извне. Это альтернативный способ перебрать весь диапазон объектов с помощью одной функции. В этом случае она просто использует значение словаря (, при этом является ключом) в качестве аргумента для сортировки.
Последний аргумент, , указывает, должна ли сортировка проходить по возрастанию или по убыванию. В этом случае мы хотим видеть наиболее часто встречающиеся слова вверху. Поэтому мы должны явно указать, что .
Если бы вы сейчас посмотрели на верхнюю часть отсортированных элементов, вы были бы разочарованы словами, которые доминируют в этом частотном списке. Это были бы просто «служебные слова», такие как «the», «and», «a» и т.д. В английском (и, конечно, многих других языках) полно этих слов. Однако они в основном используются для связки слов и сами по себе совершенно бессмысленны.
В текстовой аналитике используются так называемые стоп-листы, чтобы исключить из анализа эти часто встречающиеся слова. Мы применим более простой подход, проигнорировав первые 10% слов и рассматривая только те слова, которые входят в 90% наиболее часто встречающихся.
Вы увидите, что в верхней части этого списка есть более интересные негативно окрашенные слова, такие как “uncomfortable” (неудобно) и “frustrating” (разочаровывает). Однако есть и позитивные слова, такие как “captivating” (захватывающий) и “wonderfully” (замечательно).
Вы можете сами поэкспериментировать с нарезкой, чтобы увидеть, в каких частях данных сможете найти интересные слова.
from collections import OrderedDict # Создаем упорядоченный словарь ordict = OrderedDict(sorted(freqdict.items(), key=lambda item: item, reverse=True)) # Игнорируем верхние 10% top10 = int(len(ordict.keys())/10) # Выводим первые 100 слов из оставшихся 90% print(list(ordict.items()))
Альтернативы словарям
Есть такой модуль, который называется . В нем представлены альтернативные словарям типы данных: , и . Они близки словарям по сути, но имеют несколько расширенный функционал.
OrderedDict
OrderedDict, можно сказать, является обычным словарем, который, однако, запоминает порядок добавления в него ключей. А, значит, у метода появляется возможность, через присвоение параметру значений или , указывать какой элемент нужно удалить: первый или последний.
defaultdict
Это подмножество словарей также, на первый взгляд, очень похоже на обычный dict. Но и тут есть свои тонкости. В частности, , при отсутствии ключа, всегда присваивает значение по умолчанию, если его пытаются извлечь. Соответственно, KeyError вы больше не увидите.
Counter
— подтип словаря, подсчитывающий и хранящий количество совпадающих неизменяемых элементов последовательности. Однако обладает и своими небезынтересными методами:
- — метод возвращает список элементов в лексикографическом порядке;
- — возвращает num элементов, которые встречаются в последовательности чаще всего;
- — метод вычитает количество элементов, присутствующих в итерируемом или map объекте из вычисляемого объекта.
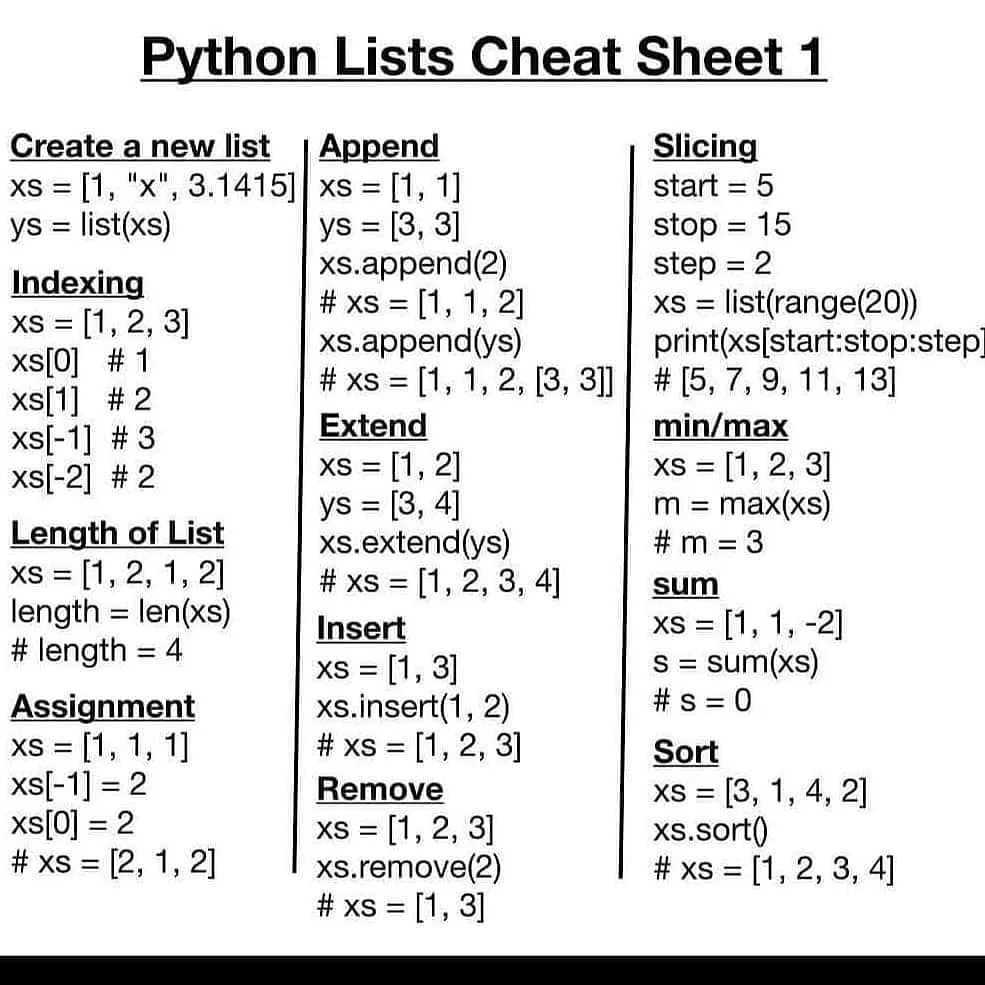
Наверно вы заметили, что словари и списки (о которых, кстати, вы можете почитать в нашей предыдущей статье «Списки в Python») схожи как, внешне, так и в том, что могут изменять свой размер по необходимости.
Вообще говоря, и списки и словари — это изменяемые объекты, однако операции, провоцирующие изменения для этих типов данных, различны. Различаются они ещё и тем, что элементы словарей сохраняются по ключам, а не по позициям. Так или иначе, оба типа коллекций входят в число наиболее важных и часто применяемых на практике в языке Python.
self
Рассотрим пример. Пусть у нас есть объект мяч — ball , обладающий атрибутами и методами.
Атрибуты мяча могут быть:
ball.color - цвет, например, красныйball.size - размер, например, маленькийball.price – стоимость мяча
Методы нашего объекта могут выглядеть следующим образом:
ball.Move( ) - перемещение мячаball.Show( ) – вывести характеристики (атрибуты) мяча на экран
Переменная self указывает на конкретный объект экземпляра класса. Доступ к атрибутам и методам осуществляется через переменную self. Это главное назначение переменной self.
Предположим мы создали три мяча — экземпляры класса Ball: ball1, ball2, ball3.Мячи могут иметь разные характеристики, например, как в таблице.
|
Объект |
Self |
Color |
Size |
Price |
|
|
имя объекта |
адрес объекта |
||||
|
ball1 |
адрес 1 |
адрес 1 |
Красный |
Маленький |
10 |
|
ball2 |
адрес 2 |
адрес 2 |
Синий |
Средний |
20 |
|
ball3 |
адрес 3 |
адрес 3 |
Белый |
Большой |
30 |
Переменная self представляет ссылку на экземпляр класса, т.е. содержит адрес объекта. Всем методам класса автоматически передается эта ссылка.




Предположим в классе Ball имеется метод Show( ) – вывести характеристики мяча.
Приведение Python-словарей к другим типам
dict to json
Чтобы сериализовать словарь в json формат, сперва необходимо импортировать сам модуль json:
Теперь можно развлекаться. Существует два схожих метода:
- позволит вам конвертировать питоновские словари в json объекты и сохранять их в файлы на вашем компьютере. Это несколько напоминает работу с csv.
- запишет словарь в строку Python, но согласно json-формату.
dict to list
Для конвертации dict в list достаточно проитерировать словарь попарно с помощью метода , и, на каждой итерации, добавлять пару ключ:значение к заранее созданному списку. На выходе получим список списков, где каждый подсписок есть пара из исходного словаря.
dict to string
Как указывалось выше, привести словарь к строке (str) можно при помощи модуля . Но, если словарь не слишком большой, то эквивалентного результата можно добиться, используя стандартную функцию
Модули, библиотеки, import
Язык Python хорош тем, что в него встроено большое количество модулей и библиотек по умолчанию. Более того, их можно дополнительно установить из официального репозитория при помощи команды «pip install название_модуля» в терминале проекта.
Модули (один файл) и библиотеки (несколько файлов с обязательным наличием документа __init__.py) расширяют возможности программистов и упрощают работу. Не нужно создавать велосипед заново, так как его уже кто-то сделал ранее для вас. Нужно лишь им воспользоваться, чтобы добраться из точки А в точку Б.
В нашем коротком курсе мы рассмотрим абсолютный импорт и все его варианты. Имеется и относительный, но он понадобится позже, когда вы начнете разрабатывать сложные проекты.
Итак, в стандартном наборе модулей имеется random, используемый для работы со случайными числами и генерацией оных, выборкой рандомных значений и т.п. Дополнительных установок не потребуется.
Перечислим все способы абсолютного импортирования в Питоне:
Сначала указываем модуль, а потом функцию через точку.
Модуль указывать не требуется.
Модуль указывать не надо, но остальные его функции и переменные недоступны.
Определение функции Python 3
Вы можете задать функции для реализации нужной вам функциональности. Вот простые правила для определения функции в Python.
- Ключевое слово для определения функции: def, за которым следуют имя функции и круглые скобки () с параметрами.
- Любые входные параметры или аргументы должны быть помещены в эти круглые скобки.
- В качестве первой команды может быть необязательная конструкция — строка документации функции (эта часть функции — пояснение зачем функция создана, очень рекомендуется использовать для облегчения понимания кода при работе в команде или при повторном возвращении к коду через длительный промежуток времени).
- Блок кода в каждой функции начинается с двоеточия и имеет отступ.
- Оператор return возвращает результат из функции. Оператор return без аргументов аналогичен return None. Функции всегда возвращают значение, хотя бы None.
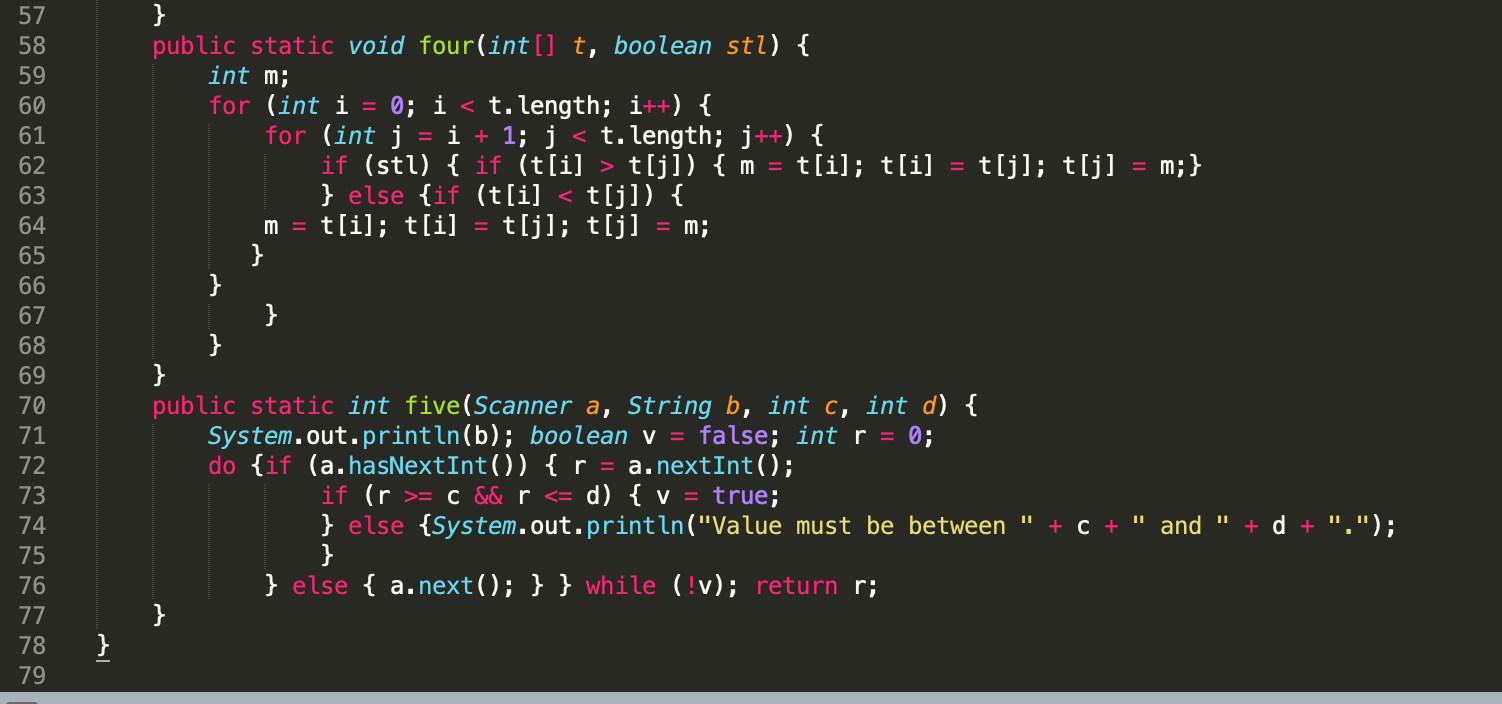
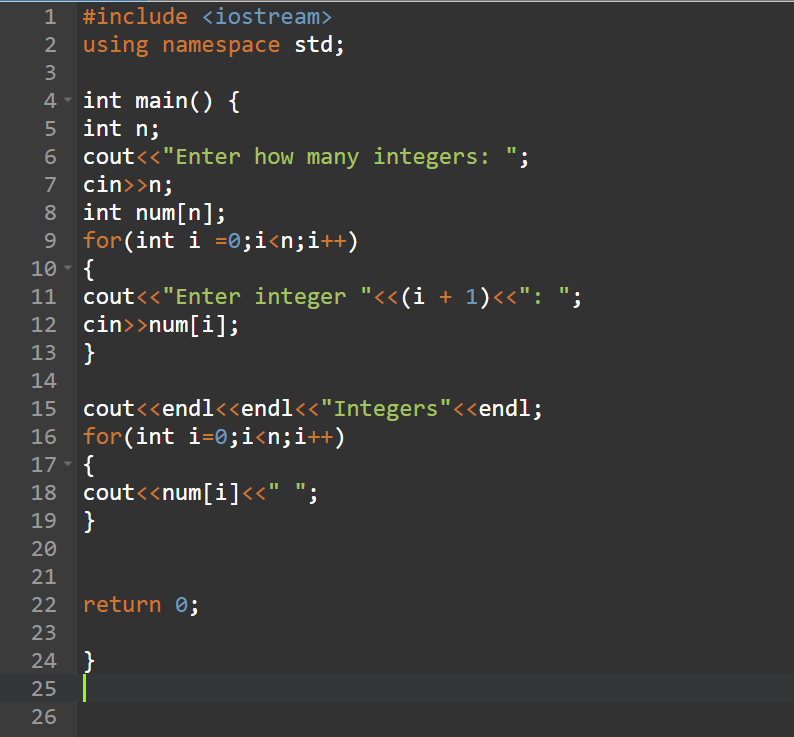
Сортировка списка объектов
Сортировка по умолчанию работает с числами и строками. Но это не будет работать со списком настраиваемых объектов. Посмотрим, что произойдет, когда мы попытаемся запустить сортировку по умолчанию для списка объектов.
class Employee:
def __init__(self, n, a, gen):
self.name = n
self.age = a
self.gender = gen
def __str__(self):
return f'Emp'
# List uses __repr__, so overriding it to print useful information
__repr__ = __str__
e1 = Employee('Alice', 26, 'F')
e2 = Employee('Trudy', 25, 'M')
e3 = Employee('Bob', 24, 'M')
e4 = Employee('Alexa', 22, 'F')
emp_list =
print(f'Before Sorting: {emp_list}')
try:
emp_list.sort()
except TypeError as te:
print(te)
Вывод:
Before Sorting: , Emp, Emp, Emp] '<' not supported between instances of 'Employee' and 'Employee'
В этом случае мы должны в обязательном порядке предоставить ключевую функцию для указания поля объектов, которое будет использоваться для сортировки.
# sorting based on age
def sort_by_age(emp):
return emp.age
emp_list.sort(key=sort_by_age)
print(f'After Sorting By Age: {emp_list}')
Вывод:
After Sorting By Age: , Emp, Emp, Emp]
Мы также можем использовать модуль functools для создания пользовательской логики сортировки для элементов списка.
С чего лучше начать обучение языку программирования Python
Разработка на любом языке программирования начинается с изучения синтаксиса и возможностей самого языка. “Питон” славится своим низким порогом вхождения для новичков: синтаксис его ясен и легко запоминается (чего нельзя сказать, например, о С).
Поэтому, если запастись терпением и усердием, любой желающий сможет освоить этот язык. Новички будут нуждаться лишь в грамотных советах.
Часто путь начинающего питониста бывает таким: человек, ранее далёкий от разработки и помнящий, в лучшем случае, фамилию основателя Microsoft, гуглит запросы “как выучить Python”, “основы языка программирования Python”, и т. п.. На первых позициях выдачи он натыкается на статьи, рекомендующие вначале прочесть классические труды Марка Саммерфилда и Марка Лутца.
Но это неправильный подход.
С чего лучше начать обучение языку программирования Python
Учить язык программирования по этим книгам, особенно новичку, будет сложно. Вообще странно предлагать человеку, который ещё не знаком с азами, сразу прочесть большую книгу. В ней он обнаружит:
- историю создания языка программирования Python на первых сорока страницах;
- затем рассказ об интерпретаторе ещё на сотню страниц;
- наконец, автор добирается до базовых типов и повествует о них на прядении ещё ста страниц.
К этому моменту новичок просто устаёт читать (тем более что текст действительно излишне академичен и нуден) и решает, что Python — не для него.
Имейте в виду, что авторов наподобие Саммерфилда и Лутца (несомненно, весьма компетентных и полезных) лучше оставить до того момента, когда вы уже станете более или менее ориентироваться в языке. Начинать с такого сложного чтива просто бессмысленно.
Знакомство с Python должно быть другим. Главное — сохранить интерес к программированию и увлечённость, а не вызубрить все базовые типы.
Знать все тонкости интерпретации кода на Python тоже незачем, если вы только начинаете свой путь в программировании на этом языке. А вот самостоятельное написание “hello world” — это серьёзный шаг вперёд.
Словарь vs. список Python, массив NumPy и Pandas DataFrame
Словари являются важной структурой данных, встроенной в Python. Они позволяют нам помещать данные в объекты Python для их дальнейшей обработки
Словари, наряду со списками и кортежами, — одна из основных и наиболее мощных и гибких структур данных, которые может предложить Python. Однако в последнее время большая часть функциональности словаря может быть заменена Pandas. Это библиотека Python, которая позволяет выполнять большую часть обработки и анализа данных.
Если есть готовые библиотеки, зачем утруждать себя пониманием того, на что способны словари?
Что ж, всегда полезно научиться ходить, прежде чем пытаться бегать.
Такие библиотеки, как Pandas, позволяют работать с данными быстрее и эффективнее. С ними не приходится беспокоиться о том, как хранятся данные. Однако Pandas также использует словари (наряду с другими расширенными структурами данных, такими как массив NumPy) для хранения своих данных. Поэтому, прежде чем начинать работать с Pandas, все же полезно узнать, как работает словарь.



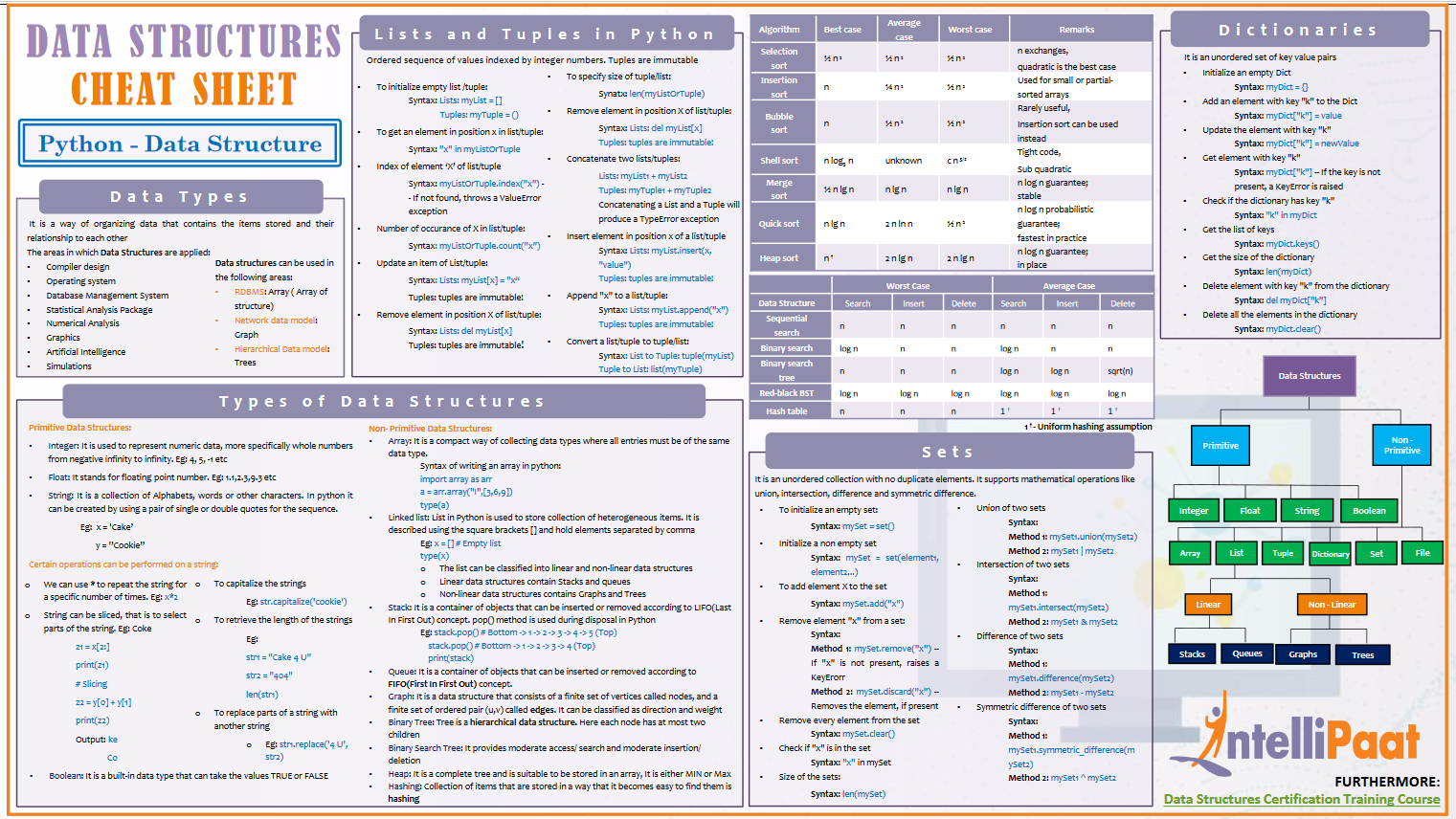



Даже при использовании Pandas иногда рекомендуется использовать словари. Например, когда значения необходимо просто сопоставить, использование объекта Pandas будет неэффективным и излишним.
Наконец, Pandas содержит функции для преобразования словаря в Pandas DataFrame и наоборот. Кроме того, датафреймы могут содержать словари. И то, и другое — очень полезные инструменты для работы с данными.
Основные операторы
Оператор
Краткое описание
+
Сложение (сумма x и y)
—
Вычитание (разность x и y)
*
Умножение (произведение x и y)
Деление
Внимание! Если x и y целые, то результат всегда будет целым числом! Для получения вещественного результата хотя бы одно из чисел должно быть вещественным. Пример: 40/5 → 8, а вот 40/5.0 → 8.0
=
Присвоение
+=
y+=x; эквивалентно y = y + x;
-=
y-=x; эквивалентно y = y — x;
*=
y*=x; эквивалентно y = y * x;
/=
y/=x; эквивалентно y = y / x;
%=
y%=x; эквивалентно y = y % x;
==
Равно
!=
не равно
>
Больше
=
больше или равно
Часть после запятой отбрасывается
4 // 3 в результате будет 125 // 6 в результате будет 4
**
Возведение в степень
5 ** 2 в результате будет 25
and
логическое И
or
логическое ИЛИ
not
логическое отрицание НЕ
Dict comprehension
Dictionary comprehension, как и в случае со , позволяет превратить один словарь в другой. В процессе этого превращения, элементы исходного словаря могут быть изменены или отобраны на основе какого-либо условия.
Основной целью использования как list, так и dict comprehension является упрощение и повышение читаемости кода.
Приведем базовую схему dict comprehension.
![]()
Посмотрим на два несложных примера.
|
1 |
# создадим еще один несложный словарь source_dict={‘k1’2,’k2’4,’k3’6} |
В первом примере умножим каждое значение на два.
| 1 | {kv*2for(k,v)insource_dict.items()} |
| 1 | {‘k1’: 4, ‘k2’: 8, ‘k3’: 12} |
Во втором примере сделаем символы всех ключей заглавными с помощью метода .upper().
| 1 | {k.upper()vfor(k,v)insource_dict.items()} |
| 1 | {‘K1’: 2, ‘K2’: 4, ‘K3’: 6} |
Теперь предположим, мы хотим отсортировать те пары, в которых значение больше двух, но меньше шести.
| 1 | {kvfor(k,v)insource_dict.items()ifv>2ifv<6} |
| 1 | {‘k2’: 4} |
Если бы мы выполняли эту задачу с помощью цикла for, то использовали бы оператор И.
|
1 |
new_dict={} fork,vinsource_dict.items() ifv>2andv<6 # если условия верны, записываем ключ и значение в новый словарь new_dictk=v |
| 1 | {‘k2’: 4} |
Как и в случае list comprehension, применение условия if-else несколько меняет изначальную схему. Предположим, мы хотим определить, какие из значений четные, а какие нечетные.
| 1 | {k(‘even’ifv%2==else’odd’)for(k,v)insource_dict.items()} |
| 1 | {‘k1’: ‘even’, ‘k2’: ‘even’, ‘k3’: ‘even’} |
Dict comprehension можно использовать вместо метода .fromkeys().
|
1 |
# создадим кортеж из ключей keys=(‘k1′,’k2′,’k3’) {kforkinkeys} |
| 1 | {‘k1’: 0, ‘k2’: 0, ‘k3’: 0} |
Наследование классов
Вместо того, чтобы начинать с нуля, вы можете создать класс, выведя его из ранее существовавшего класса, перечислив родительский класс в скобках после имени нового класса.
Дочерний класс наследует атрибуты своего родительского класса, и вы можете использовать эти атрибуты, как если бы они были определены в дочернем классе. Дочерний класс также может переопределять элементы данных и методы родительского класса.
Синтаксис
Производные классы объявляются так же, как их родительский класс; однако список базовых классов для наследования дается после имени класса
class SubClassName (ParentClass1): 'Optional class documentation string' class_suite
Пример
#!/usr/bin/python class Parent: # define parent class parentAttr = 100 def __init__(self): print "Calling parent constructor" def parentMethod(self): print 'Calling parent method' def setAttr(self, attr): Parent.parentAttr = attr def getAttr(self): print "Parent attribute :", Parent.parentAttr class Child(Parent): # define child class def __init__(self): print "Calling child constructor" def childMethod(self): print 'Calling child method' c = Child() # instance of child c.childMethod() # child calls its method c.parentMethod() # calls parent's method c.setAttr(200) # again call parent's method c.getAttr() # again call parent's method
Когда приведенный выше код выполняется, он дает следующий результат
Calling child constructor Calling child method Calling parent method Parent attribute : 200
Аналогичным образом вы можете управлять классом из нескольких родительских классов следующим образом:
class A: # define your class A ..... class B: # define your class B ..... class C(A, B): # subclass of A and B .....
Вы можете использовать функции issubclass () или isinstance (), чтобы проверить отношения двух классов и экземпляров.
- Issubclass ( к югу, вир) функция булева возвращает истину , если данный подкласс суб действительно подкласс суперкласса вир .
- Isinstance (объект, класс) Функция булева возвращает истину , если OBJ является экземпляром класса Class или является экземпляром подкласса класса
Список в словаре Python.
В словарь Python можно также поместить список. Например, есть словарь с опросами посетителей на сайте, какая марка автомобиля им больше нравится. У одного человека может быть несколько ответов, как раз их можно поместить в список.
>>> favorite_cars = {
… ‘alex’: ‘bmw’, ‘audi’, ‘mersedes’,
… ‘artem’: ‘audi’,
… ‘phil’: ‘ford’, ‘porshe’,
… ‘jon’: ‘lada’
… }
>>> for name, cars in favorite_cars.items():
… print(«{name.title()} любит автомобили марки:»)
… for car in cars:
… print(«{car.title()}»)
…
Alex любит автомобили марки:
Bmw
Audi
Mersedes
Artem любит автомобили марки:
Audi
Phil любит автомобили марки:
Ford
Porshe
Jon любит автомобили марки:
Lada
В процессе перебора словаря имя сохраняется в переменной name, а список в переменную cars. Выводим сообщение с помощью f-строки с именем опрашиваемого, затем с помощью цикла for перебираем элементы списка и выводим названия брендов с новой строки.
Методы словарей в Python
Перечислим основные словарные методы, которые помогут вам при работе с этим типом данных.
- — очищает заданный словарь, приводя его к пустому.
- — отдаёт значение словаря по указанному ключу. Если ключ не существует, а в качестве дополнительного аргумента передано значение по умолчанию, то метод вернет его. Если же значение по умолчанию опущено, метод вернет None.
- — возвращает словарные пары ключ:значение, как соответствующие им кортежи.
- — возвращает ключи словаря, организованные в виде списка.
- — подобным образом, возвращает список значений словаря.
- — удалит запись словаря по ключу и вернет её значение.
- — выбрасывает пару ключ:значение из словаря и возвращает её в качестве кортежа. Такие пары возвращаются в порядке LIFO.
- — реализует своеобразную операцию конкатенации для словарей. Он объединяет ключи и значения одного словаря с ключами и значениями другого. При этом если какие-то ключи совпадут, то результирующим значением станет значение словаря, указанного в качестве аргумента метода update.
- — создает полную копию исходного словаря.
Примеры:
Пишем универсальный шаблон для декоратора
Лично я нахожу излишним и обременительным то, что нам нужно использовать три слоя вложенных функций для определения более совершенного декоратора, который мы можем использовать с аргументами или без. Дэвид Бизли в своей книге Python Cookbook предлагает отличный способ для определения универсальных декораторов без использования трех уровней вложенных функций. Для этого используется функционал модуля . Ниже приведен пример кода, который можно использовать для определения универсальных декораторов более элегантным способом:
import functools
def decorator(func=None, foo="spam"):
if func is None:
return functools.partial(decorator, foo=foo)
@functools.wraps(func)
def wrapper(*args, **kwargs):
# Тут вы можете что-то сделать с `func` или `foo`
pass
return wrapper
# Применяем декоратор без параметров
@decorator
def f(*args, **kwargs):
pass
# Применяем декоратор с параметрами
@decorator(foo="buzz")
def f(*args, **kwargs):
pass
Давайте перепишем наш декоратор , используя этот шаблон кода.
import functools
def retry(func=None, n_tries=4):
if func is None:
return functools.partial(retry, n_tries=n_tries)
@functools.wraps(func)
def wrapper(*args, **kwargs):
tries = 0
while True:
resp = func(*args, **kwargs)
if resp.status_code == 500 or resp.status_code == 404 and tries < n_tries:
print(f"retrying... ({tries})")
tries += 1
continue
break
return resp
return wrapper
@retry
def getdata(url):
resp = requests.get(url)
return resp
@retry(n_tries=2)
def getdata_(url):
resp = requests.get(url)
return resp
resp1 = getdata("https://httpbin.org/get/1")
print("-----------------------")
resp2 = getdata_("https://httpbin.org/get/1")
>>> retrying... (0)
retrying... (1)
retrying... (2)
retrying... (3)
-----------------------
retrying... (0)
retrying... (1)
И так, теперь нам не нужно писать три уровня вложенных функций, функция позаботится об этом. Метод может быть использован для создания новых производящих функций, которым передаются некоторые входные параметры для инициализации. При этом будет выполнять следующий код:
def partial(func, *part_args):
def wrapper(*extra_args):
args = list(part_args)
args.extend(extra_args)
return func(*args)
return wrapper