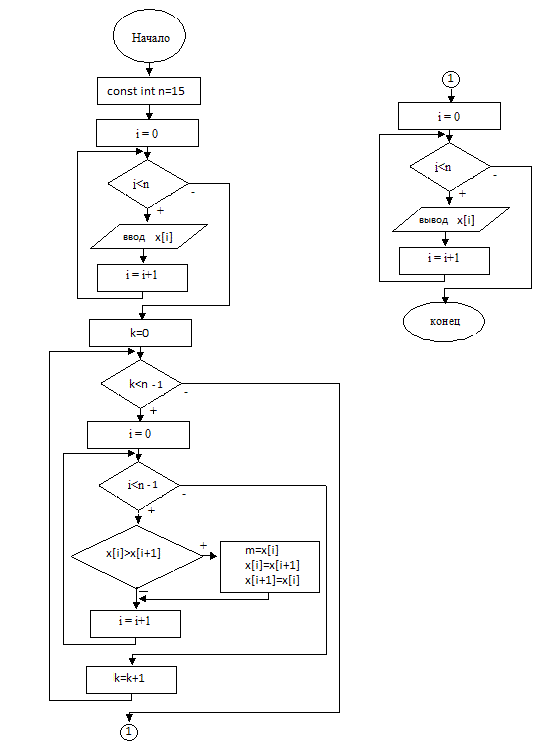
Сортировка слиянием
Используется метод “разделяй и властвуй”: массив разбивается пополам, каждая из частей рекурсивно сортируется, затем отсортированные части объединяются.
Рекурсия очевидно имеет конечную глубину, т.к. массив 1 элемента тривиально отсортирован.
Оценим сложность вычислений. Пусть сортировка массива размера \(n\) имеет сложность \(t(n)\). На каждом уровне рекурсии тогда требуется \(2t(n/2)+q(n),\) где \(q(n)\) – сложность объединения . \(q(n) = \mathcal O(n) = c\cdot n\). Тогда имеем
\[t(n) = 2t(n/2)+c\cdot n\] \
Тогда
\[t(n) = 2(2t(n/2^2)+c\cdot n/2)+c\cdot n = 2^2 t(n/2^2)+2c\cdot n\] \[t(n) = 2^2 (2t(n/2^3)+c\cdot n/4)+2c\cdot n = 2^3t(n/2^3)+3c\cdot n\] \ \
Можно показать (сделаем это позже), что сортировка, основанная на бинарном сравнении, не может иметь сложность ниже \(\mathcal O(n\log n).\)
Как работает алгоритм сортировки расчёской
На первом шаге мы находим длину массива (например, 10 элементов) и делим её на 1,247. Допустим, после округления у нас получилось число 8. Теперь мы проходим первый цикл пузырьковой сортировки, только сравнивая не 1 и 2, 2 и 3, а сразу 1 и 8, 2 и 9, 3 и 10. Это отправит самые большие числа, если они есть в начале, в самый конец. Всего на первом шаге будет три сравнения.
На втором шаге мы берём число 8 из предыдущего этапа и снова делим его на 1,247, получая число 6. Теперь мы снова проходим весь массив и сравниваем так:
1 и 6
2 и 7
3 и 8
4 и 9
5 и 10
Уже получилось 5 перестановок и снова крупные числа улетели поближе к концу массива.
Так мы уменьшаем размер шага до тех пор, пока он не станет меньше единицы — к этому моменту массив будет полностью отсортирован.
Сортировка расчёской называется так из-за того, что мы как бы расчёсываем массив сначала широким гребнем (большой шаг), потом гребнем поменьше (шаг поменьше). В конце шаг равен единице, как в пузырьковой сортировке.
Оптимальный порядок слияния
С отдельными слияниями разобрались, но что с сортировкой в целом? Первое, что стоит сделать, это улучшить случай отсортированного массива. Для этого необходимо не просто разрезать массив на подмассивы одинаковой длинны \(2^j\), а выбирать максимально длинные отсортированные части. Кроме того можно выбирать не только подмассивы, отсортированные в нужном нам порядке, но и обратно отсортированные, меняя для них направление итератора. Таким образом можно получить список подмассивов оригинального массива, для каждого подмассива необходима пара чисел: начало и конец. При этом, если начало больше конца, значит подмассив обратно отсортирован.
И тут возникает следующий вопрос: в каком порядке сливать полученные подмассивы? Для того, чтобы более наглядно фиксировать порядок слияния, будем использовать дерево слияния.
graph TD
ABCD
ABCD—AB
AB—A
AB—B
ABCD—CD
CD—C
CD—D
style A fill:LightCoral
style B fill:SpringGreen
style C fill:SkyBlue
style D fill:MediumPurple
style AB fill:Yellow
style CD fill:Cyan
style ABCD fill:White
Рис. 1.
Ниже в узлах дерева будем записывать только размеры подмассивов.
graph TD
ABCD((24))
ABCD—AB((18))
AB—A((2))
AB—B((16))
ABCD—CD((6))
CD—C((3))
CD—D((3))
style A fill:LightCoral
style B fill:SpringGreen
style C fill:SkyBlue
style D fill:MediumPurple
style AB fill:Yellow
style CD fill:Cyan
style ABCD fill:White
Рис. 2.
В данном случае это минимальное по глубине дерево. Такое дерево легко получить при обработке подмассивов в порядке расположения. Однако, это не всегда выигрышный подход, как и в этом примере. Надо помнить, что сложность функции слияния зависит от размеров сливаемых частей. И это дерево не является оптимальным, потому что самый большой подмассив, состоящий из \(16\) элементов мы сливали дважды. Более оптимальным в данном случае будет следующее дерево слияния:
graph TD
ABCD((24))
ABCD—ACD((8))
ACD—AC((5))
AC—A((2))
AC—C((3))
ACD—D((3))
ABCD—B((16))
style A fill:LightCoral
style B fill:SpringGreen
style C fill:SkyBlue
style D fill:MediumPurple
style AC fill:#b666d2
style ACD fill:#df00ff
style ABCD fill:White
Рис. 3.
Лучшим деревом слияния будет то, где каждый раз сливаются массивы минимальной длинны из оставшихся. Для его построения воспользуемся следующей леммой:
- Лемма
-
Пусть \(X = ( x_i \colon i < k )\) конечная последовательность натуральных чисел. Будем строить последовательность \(Y\) следующим образом:
- выберем и вычеркнем из \(X \cup Y\) два минимальных числа \(a\) и \(b\);
- добавим в \(Y\) число \(a + b\);
- повторяем до тех пор, пока \(|X \cup Y| \geqslant 2\).
Тогда на каждом шаге \(a + b \geqslant \max Y\).
Доказательство достаточно тривиально и оставляется на откуп читателю ().
Куда труднее эту лемму применить. Для оптимального слияния необходимо правильно расположить начальные подмассивы друг относительно друга так, чтобы всегда сливались соседние. Расположить подмассивы просто в порядке возрастания их длин неверное решение, например, если у нас есть подмассивы длин \((1, 2, 2, 2, 3)\), то последний подмассив надо перенести в середину:
graph TD
ABCDE((10))
ABCDE—ABE((6))
ABE—AB((3))
AB—A((1))
AB—B((2))
ABCDE—CD((4))
CD—C((2))
CD—D((2))
ABE—E((3))
style E fill:pink
Рис. 4.
Релизация подобной перестановки оставляется читателю.
Базовый алгоритм
Mergesort является двойственным к быстрой сортировке и относится к классу алгоритмов «Разделяй и властвуй». Основной функцией этого алгоритма является функция слияния, которая получает на вход два отсортированных массива и возвращает их отсортированное объединение. В простейшем варианте её можно записать так:
Имея такую функцию можно построить функцию сортировки двумя путями.
Top-Down и Bottom-Up
Например, можно поступить как в быстрой сортировке: делить массив пополам до тех пор, пока не получатся подмассивы длины \(1\). Такие подмассивы всегда отсортированы, поэтому к ним можно применить функцию слияния:
Конечно, в отличии от быстрой сортировки, глубина стека этой рекурсивной реализации гарантированно будет \(\log n\), но можно решить эту задачу вообще не используя рекурсию.
То есть пойти снизу вверх, от одноэлементных массивов через массивы длинны \(k = 2^j\) до тех пор, пока сливаемая часть не будет содержать весь исходный массив.
Эти два подхода к решению задачи, как не трудно догадаться, носят названия Top-Down (сверху вниз) и Bottom-Up (снизу вверх). Подход сверху вниз обычно является рекурсивным. Но, если для какого-то алгоритма есть решение рекурсивное и нерекурсивное, однозначно никогда не нужно использовать рекурсивное. Собственно и здесь рекурсивное решение приведено исключительно как дань уважения быстрой сортировке.
В текущей реализации получаем следующие оценки сложности:
| Sorted | Random | Reversed |
|---|---|---|
| \(O(n\log n)\) | \(O(n\log n)\) | \(O(n\log n)\) |
И по памяти: \(S(n) = 2n\).
Бинарный поиск в упорядоченном массиве
В случае если массив упорядочен (скажем, по возрастанию), линейный поиск неэффективен: действительно, сравнив “средний” элемент массива мы можем сразу отсечь половину значений.
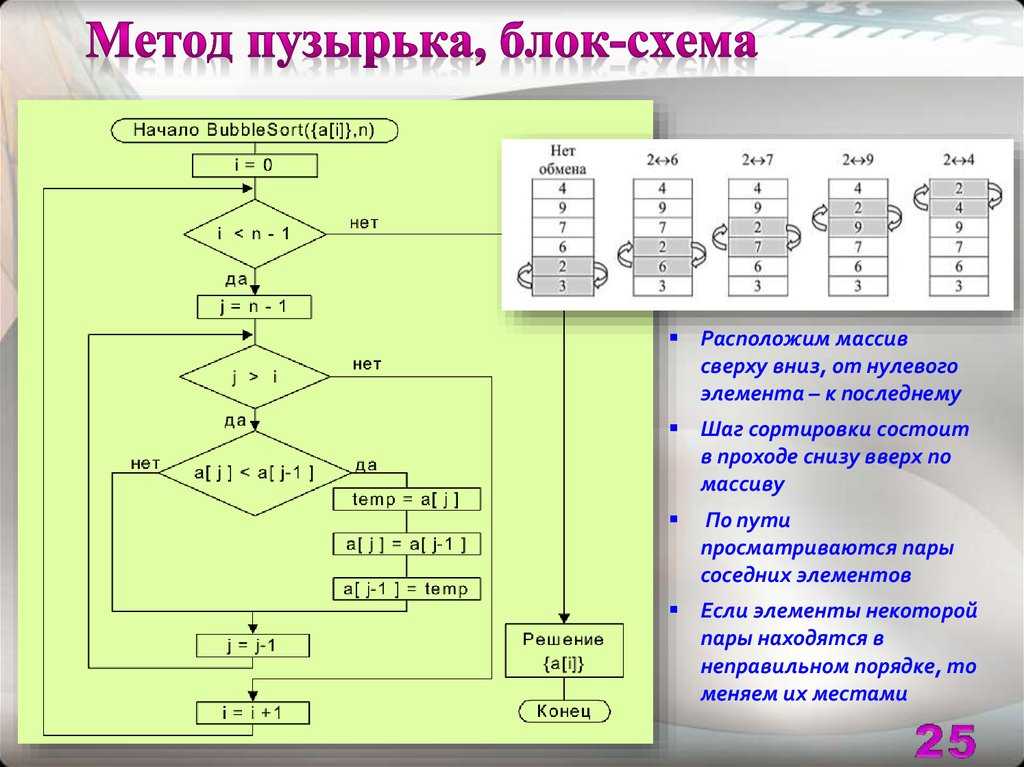
Имеется упорядоченный по возрастанию массив \(a\) размера \(n\) (индексация с 1), найти индекс элемента равного \(P\)
Алгоритм:
- Установить \(k:=1\), \(m:=n\)
- Если \(m<k\), алгоритм завершён неудачно
- \(p:=\floor{(n+k)/2}\)
- Если \(a_p < P\), то \(k:=p+1\), если \(a_p > P\), то \(m:=p-1\); иначе, \(a_p=P\), вывести \(p\), алгоритм завершён удачно
- перейти к шагу 2
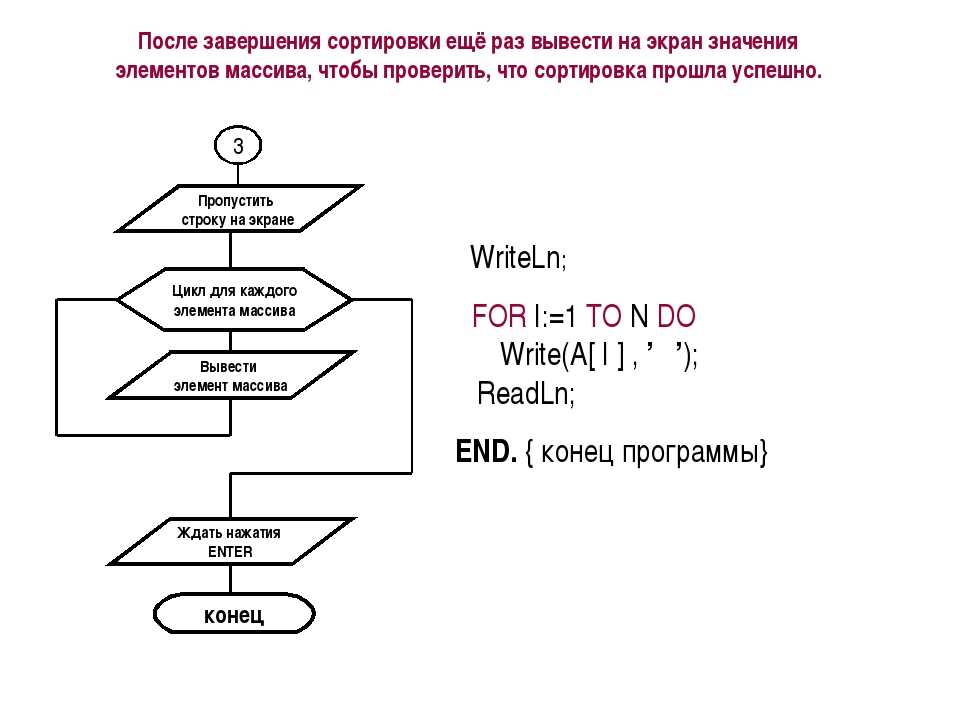
Блок-схема алгоритма
Алгоритмы сортировки
Общая постановка: упорядочить произвольный массив \(n\) элементов по возрастанию (точнее, неубыванию). Полагается, что для элементов корректно определены операции \(<\), \(>\) и \(=\).







Оптимизируем по времени
В текущей реализации функция для двух списков \(A\) и \(B\) длин \(n\) и \(m\) соответственно имеет линейную сложность, то есть \(O(n+m)\). Это можно оптимизировать несколькими очевидными способами, но прежде чем это делать, давайте определимся с функцией, к которой будем стремиться. Теоретически можно оценить функцию слияния двух отсортированных массивов способом похожим на доказательство минимальной сложности сортировки.
Немного теории
Итак, пусть у нас есть два отсортированных массива:
\
Заметим, что в результирующем массиве \(a_i\) будет стоять левее \(a_{i+1}\) и аналогично с элементами \(B\). Таким образом это сводится к задаче Шаров и перегородок. То есть всевозможных результатов слияния будет
\
Если на каждом шаге алгоритма мы делаем бинарный выбор и дерево выбора идеально сбалансированно, то его глубина будет \(\log k\). Следовательно минимальное число сравнений необходимое для слияния двух списков:
\
Применив формулу Стирлинга и упростив выражение по \(O\), получим следующую оценку:
\
При этом без ограничения общности можем считать, что \(n < m\).
Эта оценка совпадает с наивной в крайних случаях:
\
То есть при \(n = 1\) это можно свести к бинарному поиску места вставки одного элемента в массив \(B\). А для списков равной длины получаем линейную сложность.
А на практике как?
Можно ли получить подобную оценку на практике? Можно. Для этого нам понадобится немного видоизменить бинарный поиск. Пусть нам даны отсортированный массив \(B = ( b_i \colon i < m )\) и элемент \(x\). Надо найти \(i < m\) такое, что \(b_i \leqslant x\) и \(x \leqslant b_{i+1}\), если \(i+1 < m\).
Вместо того, чтобы делать 2 указателя и итеративно их сближать, сделаем следующим образом:
- \(k = 0\);
- пока \(2^k — 1 < m\) и \(b_{2^k-1} < x\) увеличиваем \(k\) на \(1\);
- если \(2^k — 1 \geqslant m\), то \(l = m — 1\), иначе \(l = 2^k — 1\);
- пока \(l \geqslant 0\) и \(b_l > x\) уменьшаем \(l\) на \(1\);
- \(l + 1\) — искомая позиция;
Асимптотически такой поиск будет иметь логарифмическую сложность, при этом нетрудно заметить, что \(T\) будет равно не \(O(\log m)\), а \(O(\log i)\). Ведь мы не рассматриваем элементы правее \(2^{\lceil \log i \rceil}\).
Также надо помнить про то, что мы будем последовательно искать места для вставки элементов монотонной последовательности, так что начинать поиск надо не с начала массива \(B\), а с места предыдущей вставки. Таким образом для вставки \(n\) элементов между \(m\) элементами потребуется:
\
где \(i_j\) — места для вставки \(j\)-го элемента.
Теперь поделим всё на \(n\) и вспомним, что функция \(\log\) выпукла вверх, а значит можно применить неравенство Йенсена:
\
\
\
В получившейся формуле есть один недостаток: при \(n = m\) мы получаем \(\log 1\) равный \(0\). Ноль это несколько излишне оптимистичная оценка, поэтому добавим \(1\) на этот случай (). Домножим обратно на \(n\) и получим нашу теоретическую оценку:
\
Такое слияние называется галопирование (galloping). Но ближе к коду. В данном примере копировать в дополнительную память будем \(A\), а проходить массивы будем слева направо.
Чем плоха пузырьковая сортировка
Главный недостаток пузырьковой сортировки — её скорость и полный перебор всех элементов массива. Скорость работы алгоритма зависит не от количества сравнений (они выполняются быстро), а от количества перестановок (на них как раз и тратится много процессорного времени).
Получается, что если у нас в массиве в начале будет много больших элементов, которые нужно отправить в конец массива, то каждый раз нам придётся менять их местами с соседями, по одной перестановке за раз. Можно представить, что мы несем куда-то не слишком тяжёлый ящик, но после каждого шага ставим этот ящик на пол, потом поднимаем, делаем шаг, снова ставим, снова поднимаем. Процедуры простые, но из-за устройства алгоритма мы делаем эти процедуры слишком много раз.
Поразрядная сортировка (radix sort)
Поразрядная сортировка основана на сортировке подсчётом и том факте, что для сортировки чисел, представленных в \(P\)-ичной системе счисления, достаточно последовательно отсортировать числа по каждому разряду. Это позволяет применить сортировку подсчётом к каждому разряду. Тогда для некоторого \(P,\) сложность поразрядной сортировки составит примерно \(\mathcal O(N\log_P \overline x)=\mathcal O(N).\)
Рассмотрим алгоритм более подробно. Пусть – число \(P\)-ичных разрядов в числе.
Сложность алгоритма таким образом \(\mathcal O(K\cdot(P+N)) = \mathcal O((P+N)\ceil{\log_P \overline x}).\) Положив \(\overline x\) и \(P\) константными, получаем сложность \(\mathcal O(N)\), однако понятно, что использование алгоритма осмысленно только если \(N\gg P\) и \(\ceil{\log_P \overline x}\) не слишком велико (т.е. \(\overline x \ll N\)).
Отметим также что алгоритм требует \(\mathcal O(N+P)\) дополнительной памяти.
Часто в качестве \(P\) выбирается степень двойки, например \(2^8\), \(2^{16}\), в основном в силу того, что получение разряда числа в таком случае сводится к битовым операциям.
Классы сложности алгоритмов
Выделяются определенные классы сложности: это категории, которые имеют схожую сложность.
Выделяют следующие основные классы сложности:
- DTIME
- Машина Тьюринга находит решение задачи за конечное время (количество шагов). Часто уточняется асимптотика алгоритма, так, скажем, если порядок роста времени работы \(T(n) = \mathcal{O}(f(n))\), то указывают \(DTIME(f(n))\).
- P
- Машина Тьюринга находит решение задачи за полиномиальное время (количество шагов), т.е. \(T(n) = \mathcal{O}(n^k)\), где \(k\in \mathbb{N}\). \(P=DTIME(n^k)\)
- EXPTIME
- Машина Тьюринга находит решение задачи за экспоненциальное время (количество шагов), т.е. \(T(n) = \mathcal{O}(2^{n^k})\), где \(k\in \mathbb{N}\). \(EXPTIME=DTIME(2^{n^k})\).
- DSPACE
- Машина Тьюринга находит решение задачи, используя конечное количество дополнительной памяти (ячеек). Часто уточняется асимптотика алгоритма, так, скажем, если порядок роста потребления памяти \(S(n) = \mathcal{O}(f(n))\), то указывают \(DSPACE(f(n))\).
- L
- Машина Тьюринга находит решение задачи c логарифмической пространственной сложностью, то есть \(S(n) = \mathcal{O}(\log n)\). \(L=DSPACE(\log n)\).
- PSPACE
- Машина Тьюринга находит решение задачи c полиномиальной пространственной сложностью, то есть \(S(n) = \mathcal{O}(n^k)\), где \(k\in \mathbb{N}\). \(PSPACE=DSPACE(n^k)\).
- EXPSPACE
- Машина Тьюринга находит решение задачи c экспоненциальной пространственной сложностью, то есть \(S(n) = \mathcal{O}(2^{n^k})\), где \(k\in \mathbb{N}\). \(EXPSPACE=DSPACE(2^{n^k})\).
Кроме того, существуют теоретические классы сложности, которые оперируют понятием недетерменированной машины Тьюринга (НМТ). Их определения совпадают с вышеприведенными, с заменой машины Тьюринга на НМТ, а названия имеют префикс N (например NP), кроме NTIME и NSPACE, где D заменяется на N.
НМТ – это чисто теоретическое построение, которое по принципам действия аналогично МТ, с тем отличием, что для каждого из состояний может быть несколько возможных действий. При этом, НМТ всегда выбирает из возможных действий то, которое приводит к решению за минимально возможное число шагов. Эквивалентно, НМТ производит вычисления всех ветвей и выбирает ту ветвь, которая приводит к решению за минимально возможно число шагов.
Иногда можно услышать, что квантовые компьютеры являются реализацией НМТ. Хотя это может казаться верным в некоторых случаях, в общем случае НМТ является более мощной системой, чем квантовый компьютер.
Известно, что \(P \subseteq NP \subseteq PSPACE \subseteq EXPTIME \subseteq NEXPTIME \subseteq EXPSPACE\)
Кроме того, \(P \subsetneq EXPTIME\), \(NP \subsetneq NEXPTIME\), \(PSPACE \subsetneq EXPSPACE\)
Так же известно, что если \(P = NP\), то \(EXPTIME = NEXPTIME\).
Вопрос равенства P и NP является одним из главных нерешенных вопросов современной информатики.
В чём хитрость сортировки расчёской
Раз у нас большие элементы могут тормозить весь процесс, то можно их перекидывать не на соседнее место, а подальше. Так мы уменьшим количество перестановок, а с ними сэкономим и процессорное время, нужное на их обработку.
Но отправлять каждый большой элемент сразу в конец массива будет недальновидно — мы же не знаем, насколько этот элемент большой по сравнению с остальными элементами. Поэтому в сортировке расчёской сравниваются элементы, которые отстоят друг от друга на каком-то расстоянии. Оно не слишком большое, чтобы сильно не откидывать элементы и возвращать потом большинство назад, но и не слишком маленькое, чтобы можно было отправлять не на соседнее место, а чуть дальше.
Опытным путём программисты установили оптимальное расстояние между элементами — это длина массива, поделённая на 1,247 (понятное дело, расстояние нужно округлить до целого числа). С этим числом алгоритм работает быстрее всего.
Написание кода для алгоритма слияния
Заметное различие между этапом слияния, описанным выше, и тем, который используется для merge sort, состоит в том, что функция слияния выполняется только для последовательных подмассивов. Вот почему нужен только массив, первая позиция, последний индекс первого подмассива (можно вычислить первый индекс второго подмассива) и последний индекс второго подмассива.
Наша задача состоит в объединении двух подмассивов A и A, чтобы создать отсортированный массив A. Таким образом, входными данными функции являются A, p, q и r.
Функция слияния работает следующим образом:
- Создает копии подмассивов L <- A и M <- A.
- Создает три указателя i, j и k:
- i сохраняет текущий индекс L, начиная с 1;
- j сохраняет текущий индекс M, начиная с 1;
- k сохраняет текущий индекс A, начиная с p.
- Пока не будет достигнут конец L или M, выбираем те, что больше среди элементов из L и M и помещаем их в нужной позиции в A
- Когда заканчиваются элементы в L или M, выбираем оставшиеся элементы и помещаем в A
В коде реализации merge sort алгоритма это будет выглядеть следующим образом:
void merge(int A[], int p, int q, int r)
{
/* Создать L <- A and M <- A */
int n1 = q - p + 1;
int n2 = r - q;
int L, M;
for (i = 0; i < n1; i++)
L = A;
for (j = 0; j < n2; j++)
M = A;
/* Сохранить текущий индекс подмассивов и основной массив */
int i, j, k;
i = 0;
j = 0;
k = p;
/*Пока не будет достигнут конец L или M, выбираем те, что больше среди элементов из L и M, и помещаем их в нужной позиции в A */
while (i < n1 && j < n2)
{
if (L <= M)
{
arr = L;
i++;
}
else
{
arr = M;
j++;
}
k++;
}
/* Когда заканчиваются элементы в L или M, выбираем оставшиеся элементы и помещаем в A */
while (i < n1)
{
A = L;
i++;
k++;
}
while (j < n2)
{
A = M;
j++;
k++;
}
}
.2 Основные способы и алгоритмы сортировки массивов
В этой курсовой работе будет рассмотрена только сортировку массивов,
которая имеет три основных способа:
· сортировка обменом;
· сортировка выбором;
· сортировка вставкой.
Пусть на столе лежит колода карт. Для сортировки обменом их необходимо
разложить лицевой стороной вверх и затем менять местами те карты, которые
расположены в неправильном порядке, делая это до тех пор, пока колода карт не
станет упорядоченной.
Для сортировки выбором вы должны разложить карты на столе, выбрать самую
младшую карту и взять ее в свою руку. Затем вы должны из оставшихся на столе
карт вновь выбрать наименьшую по значению карту и поместить ее позади той
карты, которая уже имеется у вас в руке.






Этот процесс вы должны продолжать до тех пор, пока все карты не окажутся
у вас в руках. Поскольку каждый раз вы выбираете наименьшую по значению карту из
оставшихся на столе, по завершению такого процесса карты у вас в руке будут
отсортированы.
Для сортировки вставкой вы должны держать карты в своей руке, поочередно
снимая карту с колоды. Каждая взятая вами карта помещается в новую колоду на
столе, причем она ставится на соответствующее место. Колода будет
отсортирована, когда у вас в руке не окажется ни одной карты.
Для каждого способа сортировки имеется много алгоритмов. Каждый алгоритм
имеет свои достоинства, но в целом оценка алгоритма сортировки зависит от
ответов, которые будут получены на следующие вопросы:
· с какой средней скоростью этот алгоритм сортирует
информацию?;
· какова скорость для лучшего случая и для худшего случая?;
· поведение алгоритма является естественным или является не
естественным?;
· выполняется ли перестановка элементов для одинаковых ключей?
Для алгоритма большое значение имеет скорость сортировки. Скорость, с
которой массив может быть упорядочен, прямо зависит от числа сравнений и числа
необходимых операций обмена, причем операции обмена занимают большое время.
Время работы алгоритма для лучшего и худшего случаев важно учитывать,
когда ожидается их частое появление. Часто сортировка имеет хорошую среднюю
скорость, но очень плохую скорость для худшего случая, и наоборот
Считается поведение алгоритма сортировки естественным, если время
сортировки наименьшее при упорядоченном списке элементов, время сортировки
увеличивается при менее упорядоченном списке элементов и время сортировки
становится наихудшим, когда список элементов упорядочен в обратном порядке.
Время сортировки зависит от числа операций сравнения и операций обмена.
В информатике сортировка является основополагающей операцией (во многих
программах она используется в качестве промежуточного шага), в результате чего
появилось большое количество хороших алгоритмов сортировки. Выбор наиболее
подходящего алгоритма зависит от многих факторов, в том числе от количества
сортируемых элементов, от их порядка во входной последовательности, от
возможных ограничений, накладываемых на члены последовательности, а также от
того, какое устройство используется для хранения последовательности: основная
память, магнитные диски или накопители на магнитных лентах.
Наиболее известной (и наиболее «бесславной») является
сортировка пузырьковым методом. Ее популярность объясняется запоминающимся
названием и простотой алгоритма. Однако эта сортировка является одной из самых
худших среди всех когда-либо придуманных сортировок. Сортировка пузырьковым
методом использует метод обменной сортировки. Она основана на выполнении в
цикле операций сравнения и при необходимости обмена соседних элементов.
Сортировка вставкой является последней из класса простых алгоритмов
сортировки. При сортировке вставкой сначала упорядочиваются два элемента массива.
Затем делается вставка третьего элемента в соответствующее место по отношению к
первым двум элементам. Затем делается вставка четвертого элемента в список из
трех элементов. Этот процесс повторяется до тех пор, пока все элементы не будут
упорядочены.
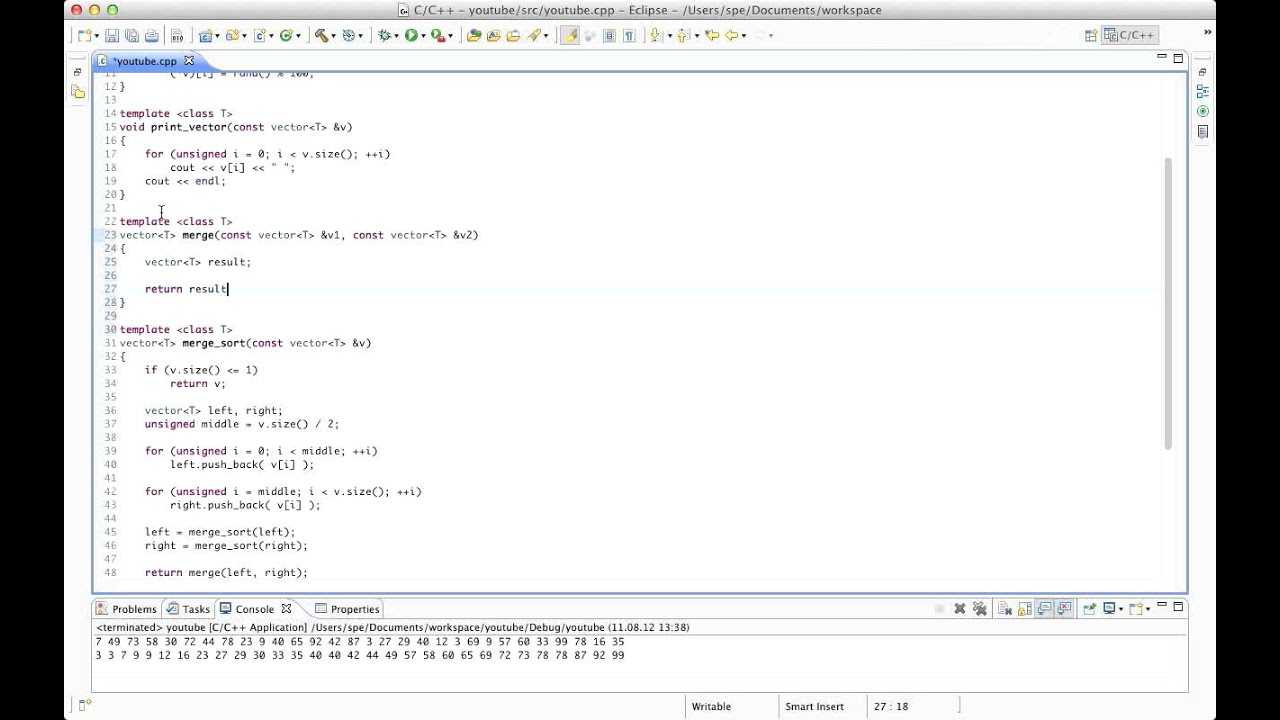
Реализовать сортировку слиянием для контейнера std::vector в C++
Сортировка слиянием использует стратегию для достижения эффективности, и ее можно использовать в качестве универсального алгоритма сортировки для больших списков. Идея алгоритма состоит в том, чтобы разделить входной вектор на несколько меньших векторов, а затем отсортировать каждый из этих векторов. Как только меньшие векторы созданы, мы можем объединить их в один список, что оказывается относительно более простой операцией
Обратите внимание, что в следующем примере кода этот метод реализуется с использованием рекурсии, поскольку он оптимально подходит для этого решения. Рекурсивный процесс используется для деления исходного вектора несколько раз, пока мы не получим двухэлементные векторы, в которых будет вызвана функция сравнения
Когда каждая пара сортируется, они объединяются в четырехэлементные векторы и так далее, пока не вернется последний уровень рекурсии.
Функция — это основная часть рекурсивного процесса. Он принимает ссылку на вектор в качестве единственного аргумента и проверяет, меньше ли размер единицы. Если это так, вектор считается отсортированным, и функция возвращается. Когда вектор содержит два или более элемента, он разбивается на два отдельных векторных объекта, и для каждого из них вызывается функция
Обратите внимание, что последняя часть заставляет сортировку начинаться с самых маленьких подвекторов. Как только рекурсия достигает такого уровня, обе функции возвращаются, и начинается выполнение следующего кода
Сначала очищается вектор , а затем вызывается функция . Функция реализована с помощью итеративного процесса, который можно понять при внимательном наблюдении. В общем, последний шаг объединяет самые маленькие отсортированные векторы в один векторный объект.
Выход:
В качестве альтернативы можно было бы переписать предыдущий код, используя алгоритм STL , который мог бы упростить код для чтения
Обратите внимание, что функция заменяет нашу реализацию , а слияние векторов может быть выполнено с помощью одного оператора в теле функции. Когда последний уровень рекурсии возвращает два вектора при первом вызове , последний вызов сохранит отсортированное содержимое в исходном объекте , который можно наблюдать из функции
.
2.2 Реализация на языке программирования
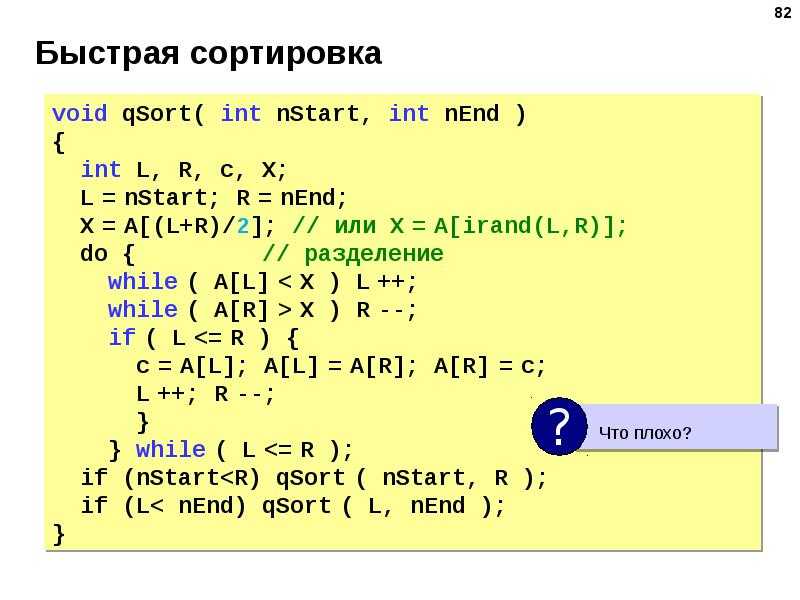
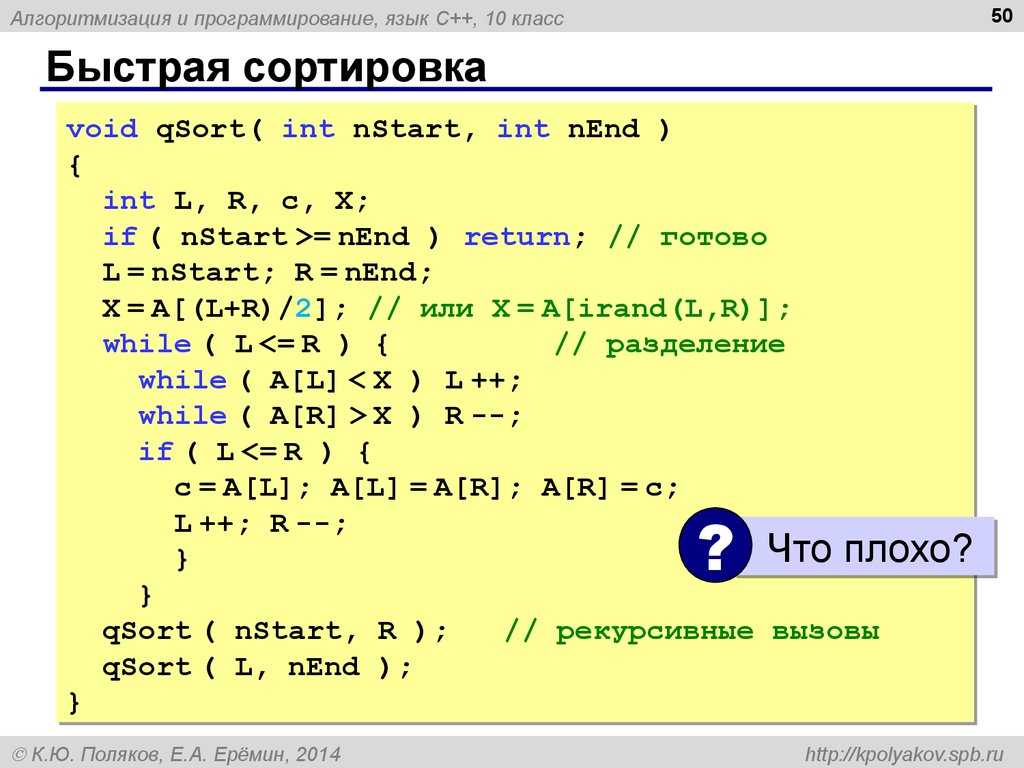
Мы рассмотрели алгоритм «быстрой сортировки», который описали на
повседневном языке, понятном почти всем. А для реализации данного алгоритма был
выбран язык программирования Pascal.
Причина такого выбора заключается в том, что он был изначально разработан в
учебных целях, прост и эффективен. Перевод программы на язык программирования
подразумевает довольно глубокие знания того языка, на котором пишется
программа. Вот еще одна причина, по которой был выбран язык Pascal.
Рассмотрим базовые процедуры и функции, которые использовались при
написании программы.
Процедуры read и write используются для ввода и вывода
данных.
Reset
— процедура, открывающая файл для чтения.
Assign
— процедура, предназначенная для связывания файловой переменной с файлом на
диске.
Rewrite
— процедура, открывающая файл для записи. Если файла не существует, то она
создает его.
Close
— процедура, закрывающая открытый файл.
Теперь мы рассмотрим более подробно структуру программы. В первую очередь
назовем программу «Q123». Затем
введем константу, которая определяет величину массива (в нашем случае n=10). Так же нам необходимо описать
переменные и сам массив, которые будут использоваться в данной программе:
Для ввода массива создадим специальный файл «input.txt»,
в который будем вводить сам массив. Например: 5 4 2 9 6 1 4 2 9 5.И файл, в
который будем выводить отсортированный массив «output.txt».
assign (input,’input.txt’); reset (input);(output,’output.txt’);
rewrite (output);
С помощью оператора For
прочтем массив из файла.
for k:=1 to n do read (A);
Теперь мы опишем саму процедуру Quicksort, которая также будет включать свои переменные.
procedure QuickSort(p,r:integer);
var q:integer;
Эта переменная будет являться тем средним значением, которое мы получим в
результате функции Part (ее опишем
ниже). Затем процедура Quicksort вызывает саму себя уже для подмассивов и .
Но это все будет выполняться, если будет выполняться условие p<r:
if p<r then begin:=Part(p,r);(p,q);(q+1,r);
end;
В этой процедуре используется функция Part, которая так же имеет свои переменные:
function Part(p,r:integer):integer;c,x,j,i,q:integer;
Эта функция сортирует массив с помощью нескольких операторов. Но для
начала нам необходимо ввести два накопителя, которые сразу пусты. И введем
некоторое значение x.




i:=p-1;:=r+1;:=A;
С помощью оператора while
мы будем повторять следующие действия.
while true do begin
И так, для начала мы будем уменьшать j, пока A>=x:
repeat:=j-1
until A<=x;
И увеличивать i , пока A>=x:
repeat:=i+1A>=x;
Проверим условие i<j и если оно справедливо, то меняем местами A и A. Если же нет, то покидаем цикл.
if (i<j) then begin
c:=A;:=A;:=c;
else break;
После этого мы присваиваем значение j самой функции Part.
В конце самой программы мы выводим отсортированный массив в раннее
созданный файл «output.txt». Всю программу можно увидеть в
приложении 1.
Глава 3.
Анализ быстрой сортировки
Анализ алгоритма заключается в том, чтобы предсказать требуемые для его
выполнения ресурсы. Иногда оценивается потребность в таких ресурсах, как
память, пропускная способность сети или необходимое аппаратное обеспечение, но
чаще всего определяется время вычисления. Путем анализа нескольких алгоритмов,
предназначенных для решения одной и той же задачи, можно без труда выбрать
наиболее эффективный. Но нам необходимо сделать анализ только одного алгоритма
быстрой сортировки.
Простые сортировки
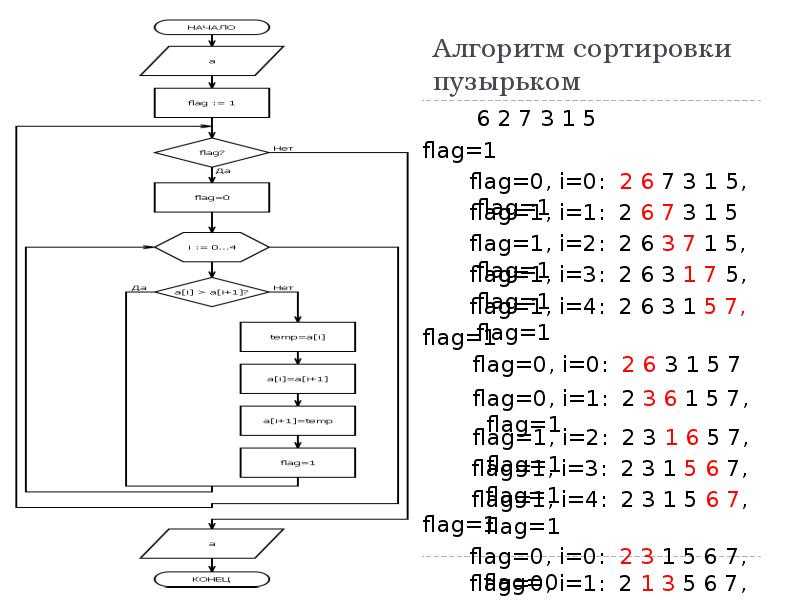
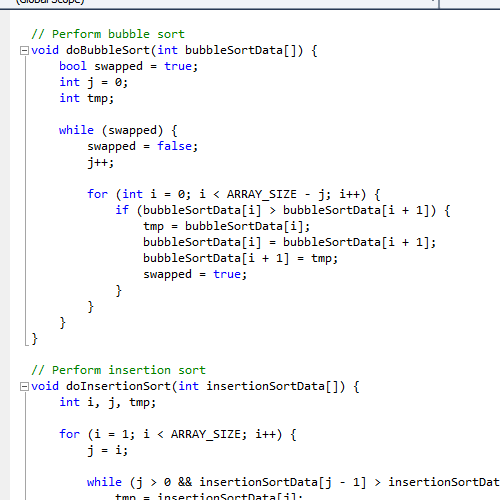
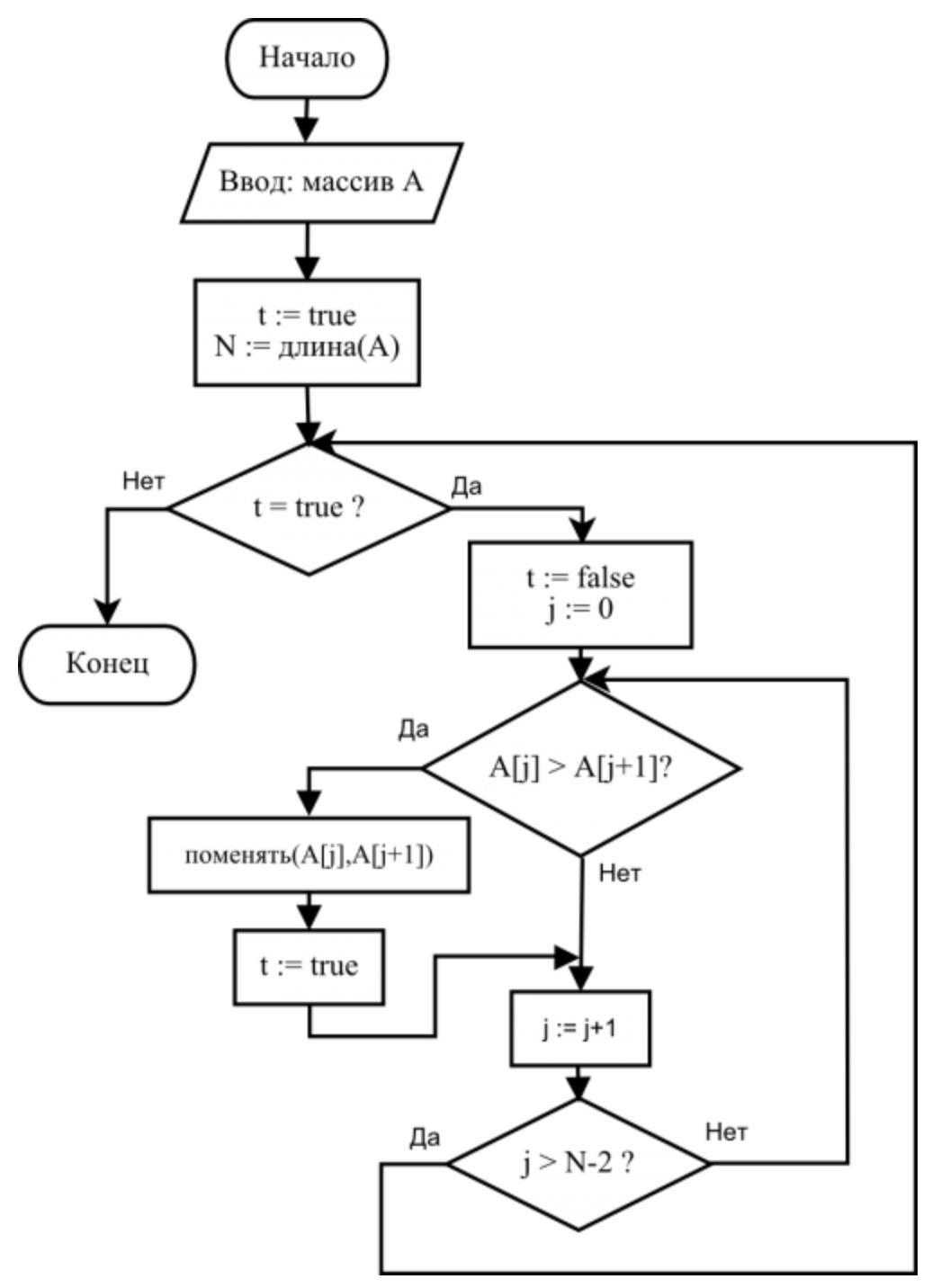
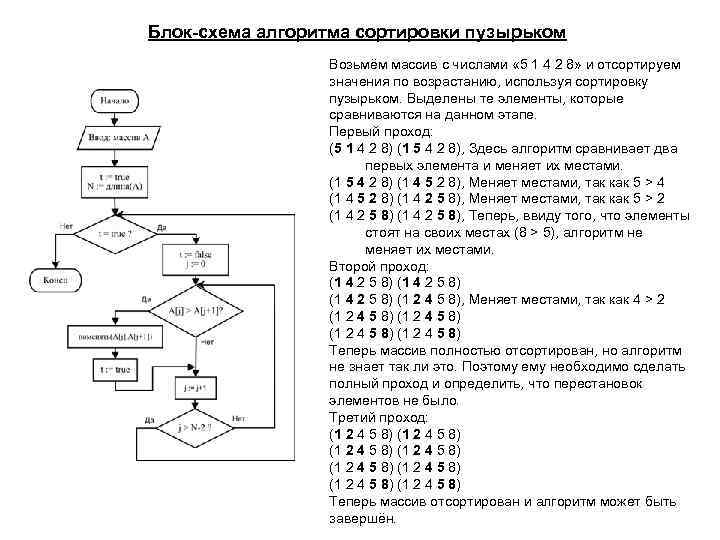
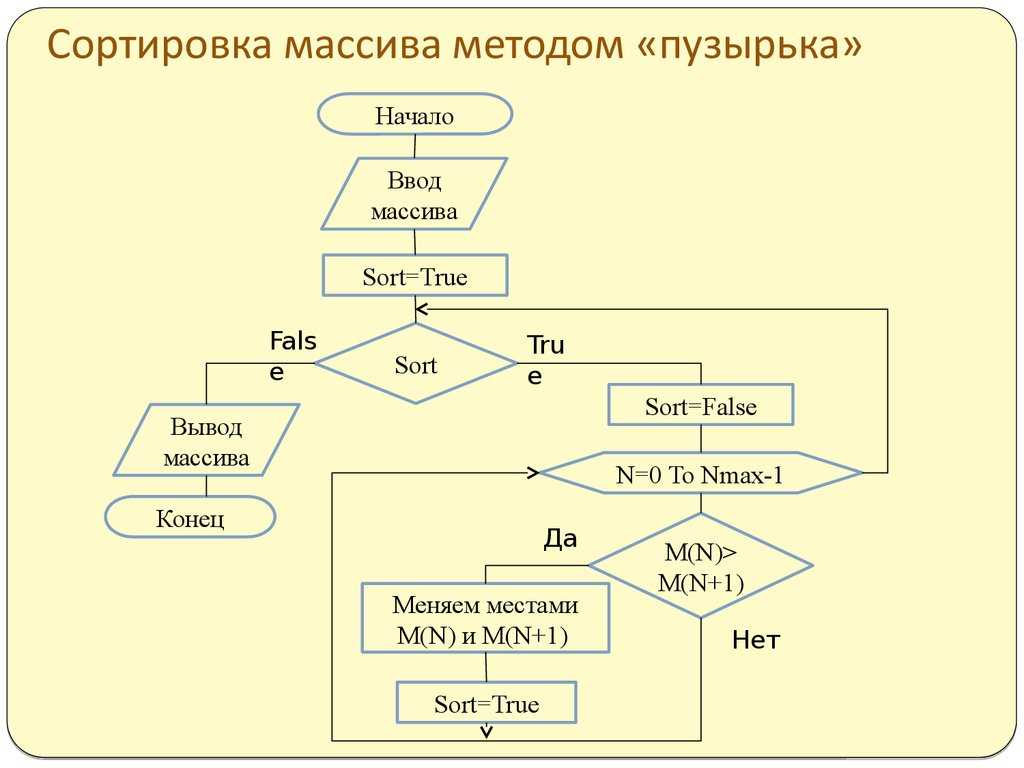
Сортировка “пузырьком”
Простейшая идея:
Оптимизация: раннее завершение если массив не отсортирован
Сложность: в лучшем случае \(n-1\) операций сравнения (если массив отсортирован). В худшем случае \(n-1+n-2+n-3+\ldots = n(n-1)/2 = \mathcal O(n^2).\) Максимально \(n(n-1)/2 = \mathcal O(n^2).\) обменов.
Сортировка вставками
Сортировка вставками сортирует массив с начала. На каждой итерации алгоритм ищет подходящее место для вставки следующего элемента в уже отсортированную часть.
В приведённой реализации сложность по сравнениям \(1+2+\ldots+n-1 = n(n-1)/2 = \mathcal O(n^2)\), сложность по присваиваниям \(\mathcal O(n^2)\).
Если вместо массива использовать структуру данных, позволяющую \(\mathcal O(1)\) вставку (например, список), сложность по присваиваниям можно улучшить до \(\mathcal O(n)\). Если использовать бинарный поиск в отсортированной части, сложность по сравнениям можно улучшить до \(\mathcal O(n\log n)\). Увы, скомбинировать эти подходы не получится: для эффективного бинарного поиска необходим случайный доступ к элементам, что не поддерживается структурами данных с эффективной (\(\mathcal O(1)\)) вставкой.