Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL. Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Дублирование страниц
К примеру, если в каталоге есть несколько позиций одного дивана, отличающиеся только цветом обивки, можно выбрать самый популярный вариант и указать его каноническим. Все варианты диванов будут доступны пользователям, но ссылочный вес и другие сигналы будут идти на страницу с основным вариантом.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Переключение страниц в каталоге рождает дубли. Иногда для всех страниц пагинации указывают первую страницу в качестве канонической — это советуют не делать, потому что тогда проиндексируется только первая страница.
![]() Пагинация на сайте www.petshop.ru
Пагинация на сайте www.petshop.ru
Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https://site.ru/category1/page-2 нужно прописать канонический URL:
Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site.ru/category1/page2 нужно указать каноническую ссылку:
Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
HTML-атрибуты
В HTML у тегов могут быть атрибуты. Когда браузер парсит HTML, чтобы создать DOM-объекты для тегов, он распознаёт стандартные атрибуты и создаёт DOM-свойства для них.
Таким образом, когда у элемента есть или другой стандартный атрибут, создаётся соответствующее свойство. Но этого не происходит, если атрибут нестандартный.
Например:
Пожалуйста, учтите, что стандартный атрибут для одного тега может быть нестандартным для другого. Например, атрибут является стандартным для элемента (), но не является стандартным для (). Стандартные атрибуты описаны в спецификации для соответствующего класса элемента.
Мы можем увидеть это на примере ниже:
Таким образом, для нестандартных атрибутов не будет соответствующих DOM-свойств. Есть ли способ получить такие атрибуты?
Конечно. Все атрибуты доступны с помощью следующих методов:
- – проверяет наличие атрибута.
- – получает значение атрибута.
- – устанавливает значение атрибута.
- – удаляет атрибут.
Эти методы работают именно с тем, что написано в HTML.
Кроме этого, получить все атрибуты элемента можно с помощью свойства : коллекция объектов, которая принадлежит ко встроенному классу со свойствами и .
Вот демонстрация чтения нестандартного свойства:
У HTML-атрибутов есть следующие особенности:
- Их имена регистронезависимы ( то же самое, что и ).
- Их значения всегда являются строками.
Расширенная демонстрация работы с атрибутами:
Пожалуйста, обратите внимание:
– здесь первая буква заглавная, а в HTML – строчная
Но это не важно: имена атрибутов регистронезависимы.
Мы можем присвоить что угодно атрибуту, но это станет строкой. Поэтому в этой строчке мы получаем значение .
Все атрибуты, в том числе те, которые мы установили, видны в .
Коллекция является перебираемой
В ней есть все атрибуты элемента (стандартные и нестандартные) в виде объектов со свойствами и .
Описание аттрибутов¶
- Дает подсказку для создания комбинации клавиш для текущего элемента. Этот атрибут содержит список разделенных пробелами символов. Браузер должен использовать первый имеющийся в раскладке клавиатуры символ из списка.
- Это список разделенных пробелами классов элемента. Классы позволяют CSS и JavaScript выбирать и получать доступ к конкретным элементам через селекторы по классу или через функции, такие как метод .
- Это перечислимый атрибут, указывающий, нужно ли предоставить пользователю возможность редактировать элемент. Если это так, браузер изменит свой виджет таким образом, чтобы позволить редактирование. Атрибут должен принимать одно из следующих значений:
- Это элемента , который следует использовать в качестве контекстного меню для данного элемента.
- Определяет группу атрибутов, называемых атрибутами пользовательских данных, позволяющих осуществлять обмен служебной информацией между HTML и его DOM представлением, что может быть использовано скриптами. Все такие пользовательские данные доступны через интерфейс элемента у которого установлен атрибут. Свойство предоставляет доступ к ним.
- Это перечислимый атрибут указывающий направление текста в элементе. Он может принимать одно из следующих значений:
- Это перечислимый атрибут, указывающий, можно ли перетаскивать элемент используя Drag and Drop API. Он может иметь одно из следующих значений:
- Это перечислимый атрибут, указывающий типы содержимого, которое можно перетащить в элемент с использованием Drag and Drop API. Он может иметь одно из следующих значений:
- Это логический атрибут, указывающий, что элемент уже (или еще) не актуален. Можно использовать этот атрибут, например для того, чтобы спрятать части страницы, которые не должны быть видны до завершения авторизации. Браузер не будет отображать такие элементы. Этот атрибут не должен использоваться, чтобы скрыть содержимое, которое может быть показано на законных основаниях.
- Определяет идентификатор (ID), который должен быть уникален для всего документа. Он предназначен для идентификации элемента при созданиии ссылок на него, исполнении скриптов или применении стилей (посредством CSS).
, , , ,
- Эти атрибуты относятся к определению микроданных.
- Участвует в определении языка элемента, языка написания нередактируемых элементов или языка, на котором должны быть написаны редактируемые элементы. Содержит единственное значение в формате, определенном в документе IETF BCP47. имеет приоритет над ним.
- Это перечислимый атрибут, определяющий, может ли содержимое элемента быть проверено на наличие орфорафических ошибок. Он может принимать одно из следующих значений:
- Содержит описание стилей CSS, которые должны быть применены к элементу. Учтите, что рекомендуется определять стили в отдельном файле или файлах. Этот атрибут, как и элемент , предназначен, в основном, для оперативного применения стилей, например в целях тестирования.
- Это числовой атрибут, указывающий, может ли элемент получать фокус, участвует ли он в последовательной навигации с клавиатуры, и если да, то в какой позиции. Может принимать одно из нескольких значений:
- Содержит текст, предоставляющий консультативную информацию об элементе. Эта информация может, но не обязательно, показываться пользователю в виде всплывающей подсказки.
- Это перечислимый атрибут, используемый для того, чтобы указать, следует ли переводить значения атрибутов элемента и его текстовое содержимое (содержимое узла Text) при локализации страницы. Этот атрибут может принимать следующие значения:
Улучшение с помощью CSSСкопировать ссылку
Что, если я использую немного CSS, чтобы визуализировать выбор раздела из моего оглавления? Конечно, это можно сделать при помощи псевдокласса .
Давая пользователям возможность раскрывать контент, мы превращаем наше оглавление во вкладки с помощью CSS. Поскольку скрывает контент от вспомогательных технологий, то это улучшение затрагивает пользователей скринридеров так же, как и всех остальных.

Возьмите ссылки из оглавления и выровняйте их по горизонтали: тогда этот небольшой CSS-эксперимент действительно приведёт к тому, что оглавление станет похожим на вкладки. Но в этом и заключается проблема.
Во второй главе своей книги «Resilient Web Design» Джереми Кит рассказывает о материальной честности (material honesty) следующее: «Один материал не должен использоваться в качестве замены другому». В этом случае мы делаем оглавление всего лишь похожим на список вкладок. Следует этого избегать. Пользователи, которые видят вкладки, ожидают определённого поведения, которого нет у простого списка ссылок.
По этой же причине элементы, по дизайну похожие на вкладки, не должны использоваться для навигации по всему сайту. По крайней мере, когда пользователь выбирает «вкладку», он не ожидает перехода на новую страницу!
Я встречал огромное количество полноценных вкладок, написанных на JavaScript и обвешанных атрибутами ARIA, для которых простые оглавления разделов страницы хорошо работали. Так даже лучше, ведь они более надёжны и эффективны. Но ради всего святого, пусть они выглядят как оглавления. Пусть семантика и поведение соответствуют тем ожиданиям, которые продиктованы визуальным дизайном интерфейса.
Размещение атрибутов
Пользователь может получать доступ к атрибутам, используя средства, предоставленные для этих целей файловой системой. Обычно разрешается читать значения любых атрибутов, а изменять — только некоторые. Например, пользователь может изменить права доступа к файлу (при условии, что он обладает необходимыми для этого полномочиями), но изменять дату создания или текущий размер файла ему не разрешается.
Значения атрибутов файлов могут непосредственно содержаться в каталогах, как это сделано в файловой системе MS DOS (см. рисунок 1). На рисунке представлена структура записи в каталоге, содержащая простое символьное имя и атрибуты файла. Здесь буквами обозначены признаки файла: R — только для чтения, А — архивный, Н — скрытый, S — системный.
![]() Рисунок 1 – Структура каталогов
Рисунок 1 – Структура каталогов
Способ размещения атрибутов UNIX
Другим вариантом является размещение атрибутов в специальных таблицах, когда в каталогах содержатся только ссылки на эти таблицы. Такой подход реализован, например, в файловой системе ufs ОС UNIX. В этой файловой системе структура каталога очень простая. Запись о каждом файле содержит короткое символьное имя файла и указатель на индексный дескриптор файла, так называется в ufs таблица, в которой сосредоточены значения атрибутов файла.В том и другом вариантах каталоги обеспечивают связь между именами файлов и собственно файлами. Однако подход, когда имя файла отделено от его атрибутов, делает систему более гибкой. Например, файл может быть легко включен сразу в несколько каталогов. Записи об этом файле в разных каталогах могут содержать разные простые имена, но в поле ссылки будет указан один и тот же номер индексного дескриптора.
Адаптивный дизайнСкопировать ссылку
Адаптивный дизайн — это инклюзивный дизайн. Он не только совместим с максимальным числом устройств, но также чувствителен к пользовательским настройкам увеличения страницы. За масштабирование всей страницы отвечает точно так же, как и за уменьшение области просмотра — вьюпорта.
Для вкладок нужен брейкпоинт, на котором недостаточно места для размещения всех вкладок по горизонтали. Самый быстрый способ исправить это — перестроить контент в один столбец.
![]()
С визуальной точки зрения это нельзя больше считать вкладками, так как они больше не выглядят как вкладки. Это не обязательно проблема, если выбранная вкладка (или опция) чётко обозначена. Не визуально, с точки зрения скринридеров, такой элемент выглядит и ведёт себя точно так же.
Аккордеоны для небольших вьюпортов?Скопировать ссылку
Некоторые пытаются превратить вкладки в аккордеоны на небольших вьюпортах. Учитывая, что последние структурированы, реализованы и управляются совершенно иначе, чем вкладки, я бы не рекомендовал так делать.
Аккордеоны имеют свои преимущества: они объединяют заголовок и кнопку с их контентом, что, возможно, лучше подходит для одной колонки. Но адаптивный гибрид вкладок и аккордеона просто не стоит того с точки зрения производительности.
Там, где много вкладок или их количество заранее не известно, аккордеон безопаснее всего для всех размеров экранов. Одноколоночная раскладка адаптивна вне зависимости от количества контента. Проще простого.
![]()
Различия в атрибутах
Существует ряд атрибутов, которые работают по-разному в React и HTML:
checked
Атрибут поддерживается компонентами типа или . Вы можете использовать его, чтобы установить, отмечен ли компонент. Это полезно для создания контролируемых компонентов. — это неконтролируемый эквивалент, который устанавливает, отмечен ли компонент, когда он впервые примонтирован.
className
Чтобы указать класс CSS, используйте атрибут . Это относится ко всем обычным элементам DOM и SVG, таким как , и др.
Если вы используете React с веб-компонентами (Web Components), что редко встречается, используйте вместо этого атрибут .
dangerouslySetInnerHTML
— это замена React для использования в браузере DOM. В целом, установка HTML из кода является рискованным, потому что легко непреднамеренно подвергнуть ваших пользователей атаке «межсайтовый скриптинг» (cross-site scripting, XSS). Таким образом, вы можете задать HTML напрямую из React, использовав и передать объект с помощью ключа для напоминая самому себя, что это опасно. Например:
onChange
Событие ведёт себя так, как вы ожидали: каждый раз, когда изменяется поле формы, вызывается данное событие. Мы специально не используем существующее поведение браузера, потому что является ошибочным для его поведения, и React полагается на это событие для обработки ввода пользователем в режиме реального времени.
selected
Атрибут поддерживается компонентами . Вы можете использовать его, чтобы указать, выбран ли компонент. Это полезно для создания контролируемых компонентов.
style
Атрибут принимает объект JavaScript со свойствами в стиле написания camelCase, а строку с CSS. Это соответствует свойству JavaScript DOM , что более эффективно и предотвращает дыры в безопасности при атак типа XSS. Например:
Обратите внимание, что к стилям не добавляются браузерные префиксы. Чтобы поддерживать старые браузеры, вам необходимо задать соответствующие свойства для стиля:. Ключи стилей пишутся в стиле camelCase для совместимости с доступом к свойствам на DOM-узлах с JS-кода (например, )
Префиксы браузеров кроме начинаются с прописной буквы. Вот почему у заглавная буква «W»
Ключи стилей пишутся в стиле camelCase для совместимости с доступом к свойствам на DOM-узлах с JS-кода (например, ). Префиксы браузеров кроме начинаются с прописной буквы. Вот почему у заглавная буква «W».
React автоматически добавит суффикс «px» к определённым числовым встроенным свойствам стиля. Если вы хотите использовать единицы, отличные от «px», укажите значение в виде строки с нужным единицей измерения. Например:
Однако не все свойства стиля преобразуются в строки с уже заданными пикселями. Некоторые из них остаются без каких-либо единиц (например, ,, ). Полный список свойств, не имеющих единиц, можно посмотреть .
suppressContentEditableWarning
Как правило, появляется предупреждение, когда элемент с дочерними элементами также помечен как , поскольку он не будет работать. Этот атрибут скрывает это предупреждение. Не используйте его, если вы не создаёте такую библиотеку, как Draft.js, которая управляет вручную.
suppressHydrationWarning
Если вы используете отрисовку React на стороне сервера, обычно появляется предупреждение, когда сервер и клиент отрисовывают разное содержимое. Однако в некоторых редких случаях очень сложно или невозможно гарантировать точное соответствие. Например, ожидается, что метки времени будут отличаться на сервере и на клиенте.
Если вы установите на значение, React не будет предупреждать вас о несоответствиях в атрибутах и о содержимом этого элемента. Он работает только на один уровень вложенности и предназначен для использования в качестве запасного варианта. Не злоупотребляйте им. Вы можете больше узнать о гидратации в .


value
Атрибут поддерживается компонентами и . Вы можете использовать его для установки значения компонента. Это полезно для создания контролируемых компонентов. — это неконтролируемый эквивалент, который устанавливает значение компонента при его первом монтировании.
О компоненте Tabs
Tabs – это js-компонент фреймворка Bootstrap, предназначенный для добавления на страницу вкладок.
Табы состоят из 2 частей: самих вкладок и контента.
Вкладки используются, когда контент нужно показывать не сразу весь целиком, а определёнными порциями. Переключение между этими порциями осуществляется посредством вкладок.
Что дают вкладки для сайта? Во-первых, они улучшают организацию данных на странице и её внешний вид. Доступ к информации становится более простым и понятным. Во-вторых, занимая определённую часть страницы они позволяют разместить на ней намного больше информации. Страница становится более компактной и в ней намного проще ориентироваться.
spellcheck
Атрибут указывает, разрешается ли проверять содержимое элемента на наличие орфографических ошибок. Атрибут может принимать одно из следующих значений:
- — указывает, что содержимое элемента должно быть, по возможности, проверено на наличие орфографических ошибок.
- — указывает, что элемент не должен проверяться на наличие орфографических ошибок.
Атрибут является . Это значит, что требуется явное указание значения атрибута. Добавление атрибута без значения запрещено:
<!-- правильное добавление атрибута --> <textarea spellcheck="false"> <!-- неправильное добавление атрибута --> <textarea spellcheck>
Атрибут определяет лишь рекомендацию для браузера: браузеры не должны иметь возможность проверки на орфографические ошибки. Обычно не редактируемые элементы не проверяются на наличие ошибок, даже если для атрибута установлено значение , а браузер поддерживает проверку.
Схема горячего кодирования
Учитывая, что у нас есть числовое представление любого категориального атрибута смметки (после преобразования), схема горячего кодирования, кодирует или преобразует атрибут вмдвоичные признаки, которые могут содержать только значение 1 или 0. Таким образом, каждое наблюдение в категориальном признаке преобразуется в вектор размерамтолько с одним из значений как1(указывая это как активный). Давайте возьмем подмножество нашего набора данных покемонов с двумя интересными атрибутами.
poke_df].iloc
![]()
Подмножество нашего набора данных покемонов
Атрибуты интереса покемонови ихположение дел. Первым шагом являетсяпреобразованиеэти атрибуты в числовые представления на основе того, что мы узнали ранее.
from sklearn.preprocessing import OneHotEncoder, LabelEncoder# transform and map pokemon generationsgen_le = LabelEncoder()gen_labels = gen_le.fit_transform(poke_df)poke_df = gen_labels# transform and map pokemon legendary statusleg_le = LabelEncoder()leg_labels = leg_le.fit_transform(poke_df)poke_df = leg_labelspoke_df_sub = poke_df]poke_df_sub.iloc
![]()
Атрибуты с преобразованными (числовыми) метками
Особенностиа такжеТеперь изобразите числовые представления наших категориальных функций. Давайте теперь применим схему быстрого кодирования к этим функциям.
# encode generation labels using one-hot encoding schemegen_ohe = OneHotEncoder()gen_feature_arr = gen_ohe.fit_transform( poke_df]).toarray()gen_feature_labels = list(gen_le.classes_)gen_features = pd.DataFrame(gen_feature_arr, columns=gen_feature_labels)# encode legendary status labels using one-hot encoding schemeleg_ohe = OneHotEncoder()leg_feature_arr = leg_ohe.fit_transform( poke_df]).toarray()leg_feature_labels = leg_features = pd.DataFrame(leg_feature_arr, columns=leg_feature_labels)
В общем, вы всегда можете кодировать обе функции вместе, используяфункция, передав ему двумерный массив из двух объектов вместе (Проверьтедокументация!). Но мы кодируем каждую функцию в отдельности, чтобы было проще понять. Помимо этого, мы также можем создать отдельные фреймы данных и соответствующим образом пометить их. Давайте теперь объединим эти фреймы и посмотрим на конечный результат.
poke_df_ohe = pd.concat(, axis=1)columns = sum(, gen_feature_labels, , leg_feature_labels], [])poke_df_ohe.iloc
![]()
Функции быстрого кодирования для генерации покемонов и легендарного статуса
Таким образом, вы можете видеть, что6фиктивные переменные или двоичные объекты были созданы дляа также2длятак как это общее количество различных категорий в каждом из этих атрибутов соответственно.активныйсостояние категории обозначается1значение в одной из этих фиктивных переменных, что вполне очевидно из приведенного выше фрейма данных.
Предположим, что вы построили эту схему кодирования на ваших тренировочных данных и создали некоторую модель, и теперь у вас есть некоторые новые данные, которые должны быть спроектированы для функций перед предсказаниями, как показано ниже.
new_poke_df = pd.DataFrame(, ], columns=)new_poke_df
Образец новых данных
Вы можете использоватьотличный API здесь, позвонивфункция ранее построеннойа такжеобъекты на новые данные. Помните наш рабочий процесс, сначала мы делаемпреобразование,
new_gen_labels = gen_le.transform(new_poke_df)new_poke_df = new_gen_labelsnew_leg_labels = leg_le.transform(new_poke_df)new_poke_df = new_leg_labelsnew_poke_df]
![]()
Категориальные атрибуты после трансформации
Получив числовые метки, давайте применим схему кодирования сейчас!
new_gen_feature_arr = gen_ohe.transform(new_poke_df]).toarray()new_gen_features = pd.DataFrame(new_gen_feature_arr, columns=gen_feature_labels)new_leg_feature_arr = leg_ohe.transform(new_poke_df]).toarray()new_leg_features = pd.DataFrame(new_leg_feature_arr, columns=leg_feature_labels)new_poke_ohe = pd.concat(, axis=1)columns = sum(, gen_feature_labels, , leg_feature_labels], [])new_poke_ohe
![]()
Категориальные атрибуты после однократного кодирования
Таким образом, вы можете легко применить эту схему к новым данным, используямощный API.
Вы также можете легко применить схему горячего кодирования, используяфункция от,
gen_onehot_features = pd.get_dummies(poke_df)pd.concat(], gen_onehot_features], axis=1).iloc
![]()
Горячие закодированные функции, используя панд
Вышеупомянутый кадр данных изображает схему горячего кодирования, примененную катрибут и результаты такие же, как ожидалось, по сравнению с более ранними результатами.
Именование атрибутов
Каждый атрибут должен иметь ясное, точное и непротиворечивое имя. Имя атрибута не должно конфликтовать с его описанием. Имя атрибута должно указывать на значения, собираемые для экземпляров атрибута. Имя атрибута должно быть понятным и общепринятым в корпорации.
Вероятно, что у вас в корпорации есть набор соглашений об именовании атрибутов, разработанные в вашей корпорации или при формировании корпоративной модели данных, которыми вы руководствуетесь. Использование соглашений именования атрибутов гарантирует, что имена конструируются единообразно в рамках корпорации, вне зависимости от того, кто конструирует имя.
Соглашения об именовании атрибутов важны, вне зависимости от того, в маленькой или большой организации вы работаете. Однако, в большой организации с несколькими командами разработчиков и большим количеством пользователей, соглашения об именовании существенно помогают при взаимодействии и понимании элементарных данных. В идеале, вы должны разработать и сопровождать соглашения об именовании атрибутов централизованно и затем документально оформить и опубликовать их для всей корпорации.
Ниже представлены некоторые положения для формирования начального набора соглашений об именовании атрибутов, просто на случай, если в вашей организации пока такой набор не разработан:
- Имя атрибута должно быть достаточно описательным. Подумайте об использовании словосочетаний на основе существительных в форме объект/ модификатор/ класс.
- По возможности имя атрибута должно включать имя сущности. Используйте «Имя для персоны» вместо просто «Имя».
- Имя атрибута должно указывать на значения конкретных экземпляров атрибута. Использование одинаковых имен для атрибутов, содержащих различные данные, или разных имен для атрибутов, содержащих одинаковые данные, будет без необходимости вводить в заблуждение разработчиков и конечных пользователей.
- Имя атрибута должно использовать язык бизнеса вместо языка технических описаний.
- Имя атрибута не должно содержать специальных символов (таких как !, @, #, $, %, л, &, * и тому подобных) или указывать на принадлежность (Имя, принадлежащее персоне).
- Имя атрибута не должно содержать акронимов или аббревиатур, если только они не являются частью принятых соглашений именования.
Разработчикам моделей предпочтительно использовать хорошие соглашения именования, если таковые существуют, или разработать их, если таких соглашений нет.
Схема подсчета бинов
Схемы кодирования, которые мы обсуждали до сих пор, работают достаточно хорошо с категориальными данными в целом, но они начинают вызывать проблемы, когда число отдельных категорий в любой функции становится очень большим. Необходим для любой категориальноймотдельные ярлыки, вы получитемотдельные функции. Это может легко увеличить размер набора функций, вызывая такие проблемы, как хранение, проблемы с обучением модели в отношении времени, пространства и памяти. Помимо этого, мы также имеем дело с тем, что в народе называется«Проклятие размерности»где, в основном, с огромным количеством функций и недостаточно репрезентативными образцами, на производительность модели часто влияют перегрузки.
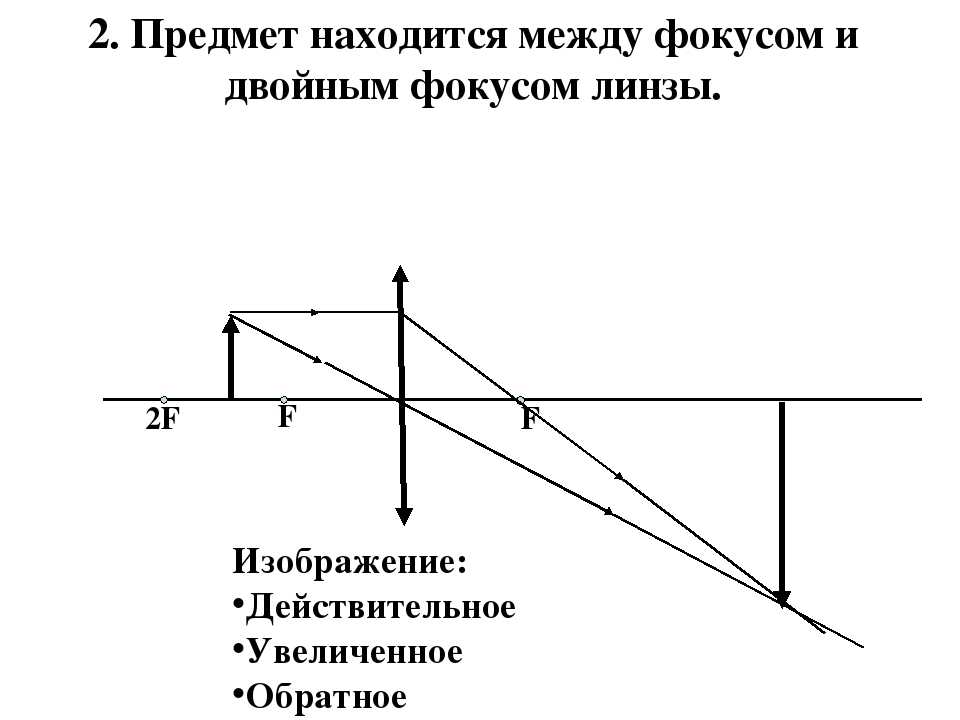

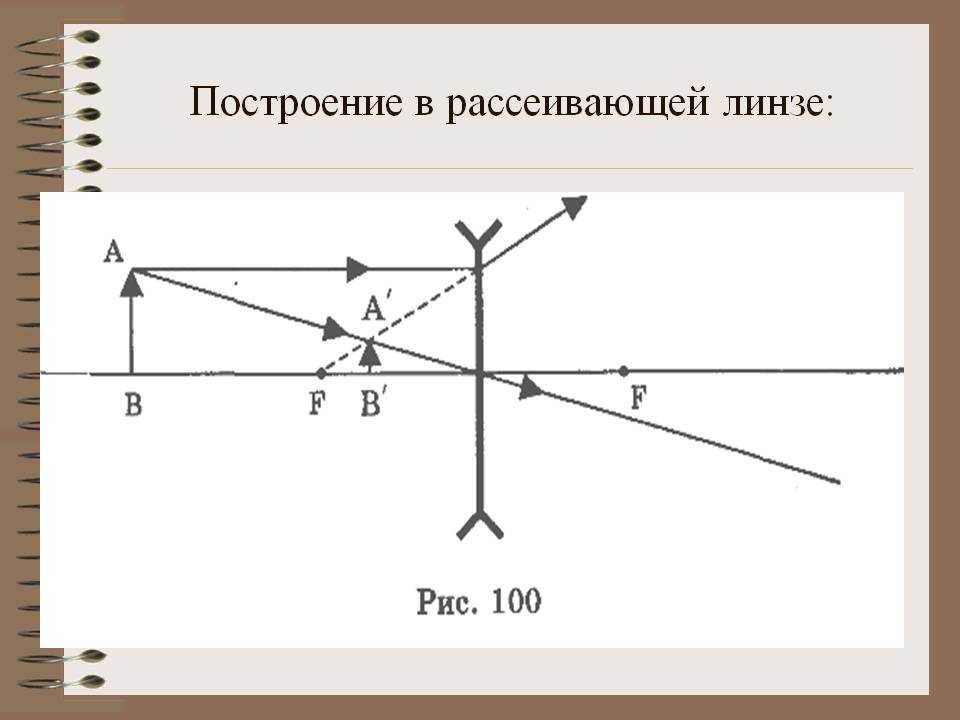
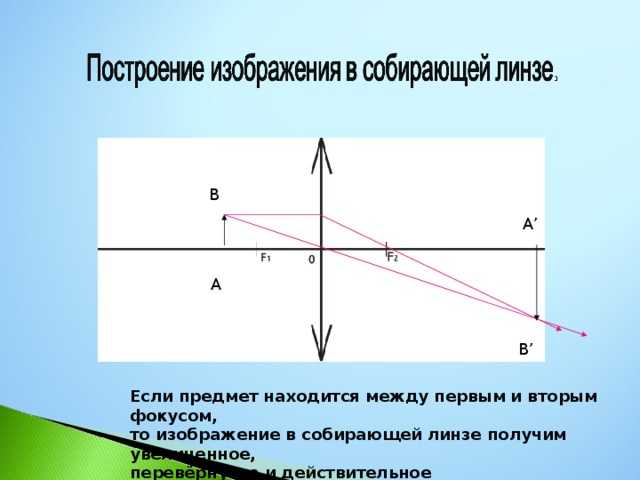
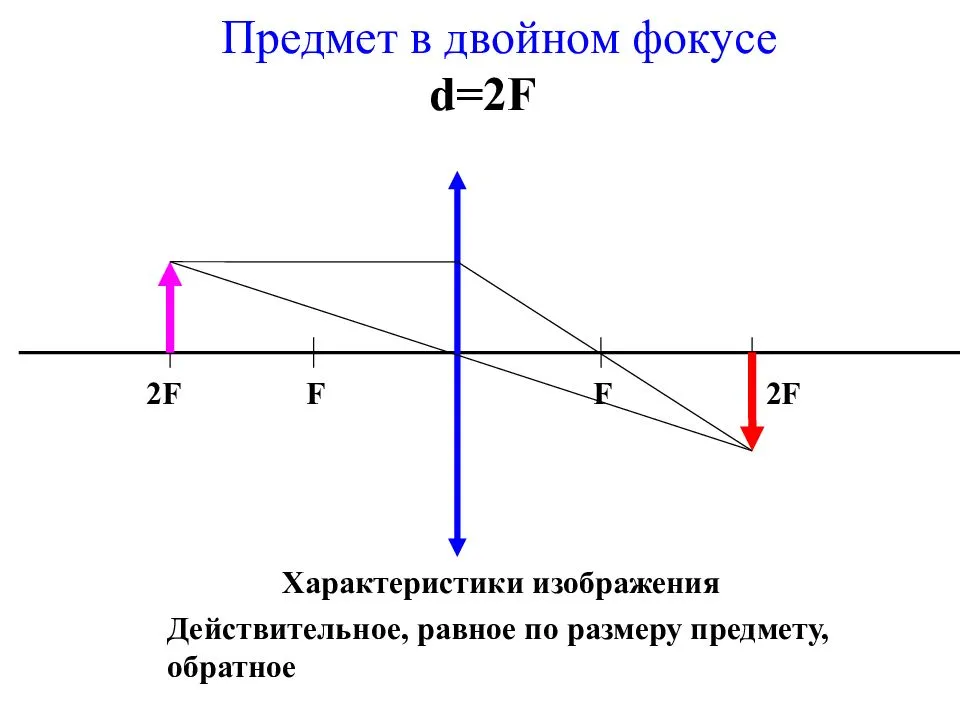
![]()
Следовательно, нам нужно обратиться к другим категориальным схемам проектирования функций данных для функций, имеющих большое количество возможных категорий (таких как IP-адреса). Схема подсчета бинов — полезная схема для работы с категориальными переменными, имеющими много категорий. В этой схеме вместо использования фактических значений меток для кодирования мы используем основанную на вероятности статистическую информацию о значении и фактическом целевом значении или значении отклика, которое мы стремимся предсказать в наших усилиях по моделированию. Простой пример будет основан на прошлых исторических данных для IP-адресов и тех, которые использовались в DDOS-атаках; мы можем построить значения вероятности для DDOS-атаки, вызванной любым из IP-адресов. Используя эту информацию, мы можем закодировать функцию ввода, которая показывает, что, если тот же IP-адрес появится в будущем, какова вероятность вероятности атаки DDOS. Эта схема требует исторических данных в качестве предварительного условия и является сложной. Описать это полным примером в настоящее время было бы трудно здесь, но есть несколько ресурсов онлайн, к которым вы можете обратиться за тем же.
Стандартные атрибуты
Стандартные атрибуты также известны как глобальные атрибуты и работают с большим количеством элементов. Они включают в себя основные стандартные атрибуты: к ним относятся accesskey, class, contenteditable, contextmenu, data, dir, hidden, id, lang, style, tabindex, title . Есть и экспериментальные. Оба xml: lang и xml: base устарели. Множественные aria- * атрибуты улучшения доступности. Атрибуты обработчика событий перечислены позже.
Технически все стандартные атрибуты должны приниматься всеми элементами, хотя они не будут работать с некоторыми элементами. В таблице ниже перечислены некоторые общие стандартные атрибуты и некоторые элементы, с которыми они могут работать.
| Элемент | я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex |
|---|---|---|---|---|---|---|---|---|---|
| я бы | |||||||||
| реж | язык | xml: lang | |||||||
| реж | язык | xml: lang | |||||||
| реж | язык | xml: lang | |||||||
| реж | язык | xml: lang | |||||||
| заглавие | реж | язык | xml: lang | ||||||
| я бы | класс | стиль | заглавие | ||||||
| я бы | класс | стиль | заглавие | ||||||
| я бы | класс | стиль | заглавие | ||||||
| я бы | класс | стиль | заглавие | ||||||
| я бы | класс | стиль | заглавие | ||||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | ||||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| , , , , , | я бы | класс | стиль | заглавие | реж | язык | xml: lang | ||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | |||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | ||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | ||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | tabindex | ||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | tabindex | ||
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex | |
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex | |
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex | |
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex | |
| я бы | класс | стиль | заглавие | реж | язык | xml: lang | ключ доступа | tabindex |
Использование неудачных имен для атрибутов
Неясные, неоднозначные или неточные имена атрибутов усложняют для новых пользователей и команд разработчиков повторное использование или развитие существующей модели.
Не используйте аббревиатур или акронимов в качестве части имени атрибута. Аббревиатуры и акронимы открыты для неправильной интерпретации и даже могут иметь разное значение в разных предметных областях.
Не используйте имена собственные, указывающие на значение для конкретного экземпляра. Имя атрибута, использующее имя собственное — индикатор серьезных проблем при моделировании, заключающихся не только в неудачном выборе имени. Не включайте месторасположение в качестве части имени атрибута. Если значение существует для одного месторасположения, оно определенно существует и для другого месторасположения. Имя атрибута с указанием расположения является признаком того, что вы моделируете конкретный экземпляр вместо класса.
Виды атрибутов для Windows
В Windows существует несколько атрибутов файлов, в том числе:
- Атрибут архивного файла.
- Атрибут каталога.
- Скрытый атрибут файла.
- Атрибут файла только для чтения.
- Атрибут системного файла.
- Атрибут метки тома
Для Windows с NTFS
Следующие атрибуты файлов были впервые доступны для операционной системы Windows с файловой системой NTFS , то есть они недоступны в старой файловой системе FAT :
- Атрибут сжатого файла.
- Шифрованный атрибут файла.
- Индексированный атрибут файла.
Редкие атрибуты
Вот несколько дополнительных, хотя и более редких, атрибутов файлов, распознаваемых Windows:
- Атрибут файла устройства.
- Атрибут файла целостности.
- Не индексированный атрибут файла содержимого.
- Нет атрибута файла scrub.
- Автономный атрибут файла.
- Атрибут разреженного файла.
- Атрибут временного файла.
- Атрибут виртуального файла.