
Primary Key
Первичный ключ (primary key) — необходим для ОДНОЗНАЧНОГО поиска записи. Строки в реляционной базе данных неупорядочены: в таблице нет «первой», «последней»,»тридцать шестой» и «сорок третьей» строки . Возникает вопрос: каким же образом выбирать в таблице конкретную строку? Для этого в правильно спроектированной базе данных ДЛЯ каждой таблицы создается один или несколько столбцов, значения которых во всех строках различны. Такой столбец называется первичным ключом таблицы (PK — primary key). Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа, благодаря чему каждая строка таблицы обладает своим уникальным идентификатором.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).
Для логического задания первичного ключа необходимо выбрать в таблице столбец, который может однозначно установить уникальность записи. Если подходящих столбцов для естественного задания первичного ключа не находится, пользуются суррогатным ключом. Суррогатный ключ представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Даже если в базе данных содержится естественный первичный ключ, лучше использовать суррогатные ключи, поскольку их применение позволяет абстрагировать первичный ключ от реальных данных. Это облегчает работу с таблицами, поскольку суррогатные ключи не связаны ни с какими фактическими данными таблицы.
Команда SELECT
SELECT * | { <value expression>.,..}
FROM { <table name> }.,..
SELECT * | { < value expression >.,..}
FROM { <table name> } .,..
} ] ...;
Элементы, используемые в команде SELECT
- <value expression> Выражение, которое производит значение. Оно может включать в себя или содержать <column name>.
- <table name> Имя или синоним таблицы или представления
- <alias> Временный синоним для <table name>, определённый в этой таблице и используемый только в этой команде
- <predicate> Условие, которое может быть верным или неверным для каждой строки или комбинации строк таблицы в предложении FROM.
- <column name> Имя столбца в таблице.
- <integer> — число, которое отражает порядковый номер колонки запроса (поля таблицы) в запросе.
SELECT имя_поля1, имя_поля2, …. имя поляN FROM таблица1, таблица2, …таблицаN ;
Список использованной литературы
- Аладьев, В. В. Основы информатики: учебное пособие / В. В. Аладьев, Ю. Я. Хунт, М. Л. Шишаков. — М.: изд-во Алюф, 2019. — 97 с.
- Бойко, В. В. Проектирование баз данных информационных систем / В. В. Бойко, В. М. Савинков. — М.: Финансы и статистика, 2018. — 110 с.
- Дейт, К. Введение в системы баз данных / К. Дейт. — М.: Наука, 2018. — 112 с.
- Дейт, К Руководство по реляционной СУБД / К. Дейт. — М.: Финансы и статистика, 2019. — 120 с
- Ездов, А. А. Лабораторные работы по физике с использованием компьютерной модели / А. А. Ездов. — М.: Информатика и образование, 2016. — № 1. — 48 с.
- Ермаков, М. Г. Вопросы разработки тестирующих программ / М. Г. Ермаков, Л. Е. Андреева. — М.: Информатика и образование, 2017. — № 3. — 54 с.
- Жуков, А. А. Система контроля знаний TSTST / А. А. Жуков, Л. А. Федякина. — Информатика и образование, 2017. — № 2. — 56 с.
- Мейер, Д. Теория реляционных баз данных / Д. Мейер. — М.: Мир, 2017. — 210 с.
- Цикритизис, Д. Модели данных / Д. Цикритизис, Ф. Лоховски. — М.: Финансы и статистика, 2017. — 54 с.
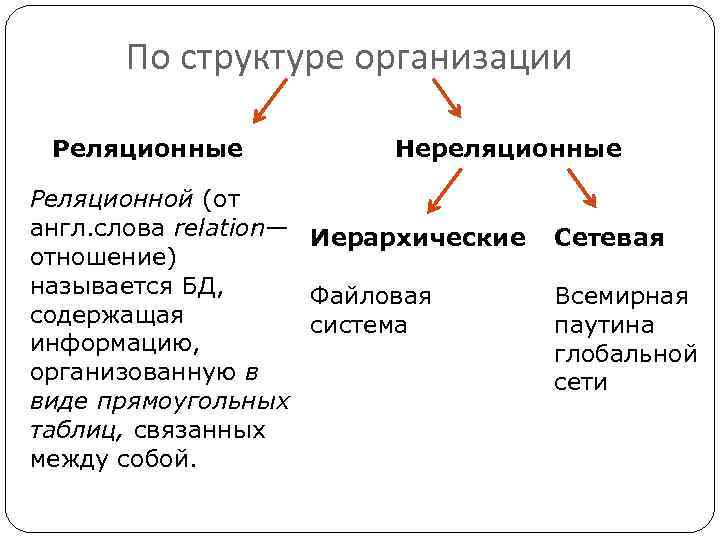
Примеры [ править ]
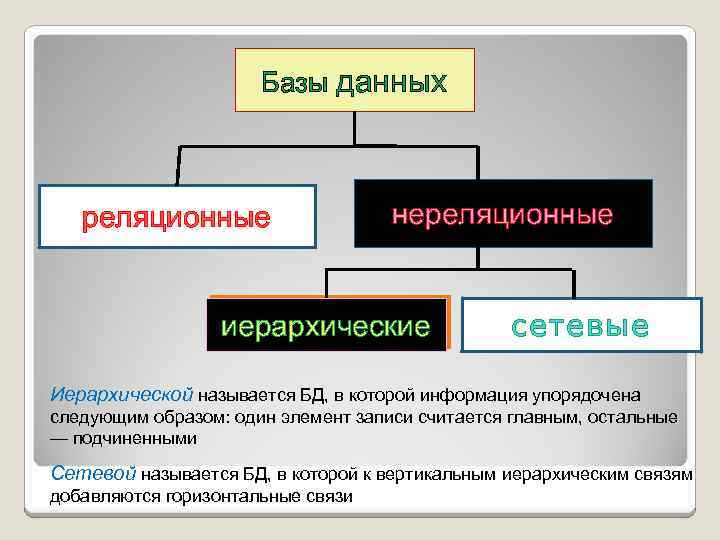
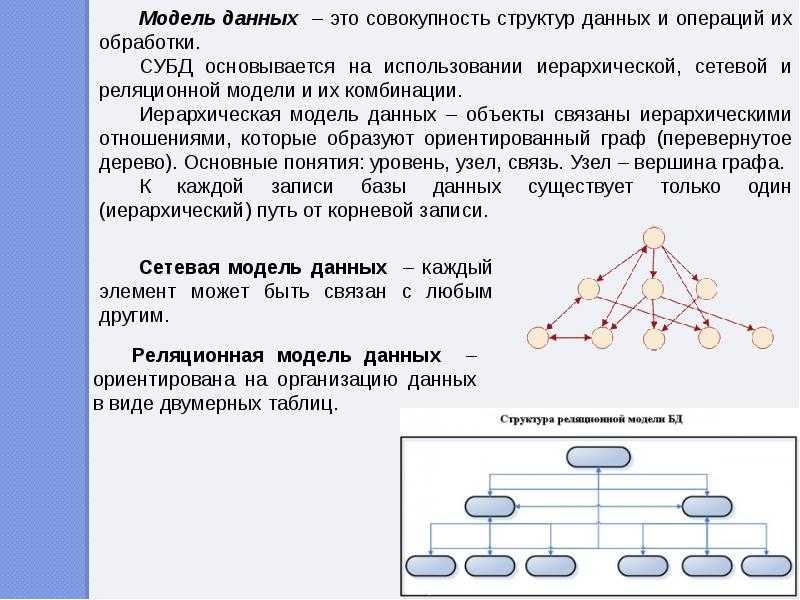
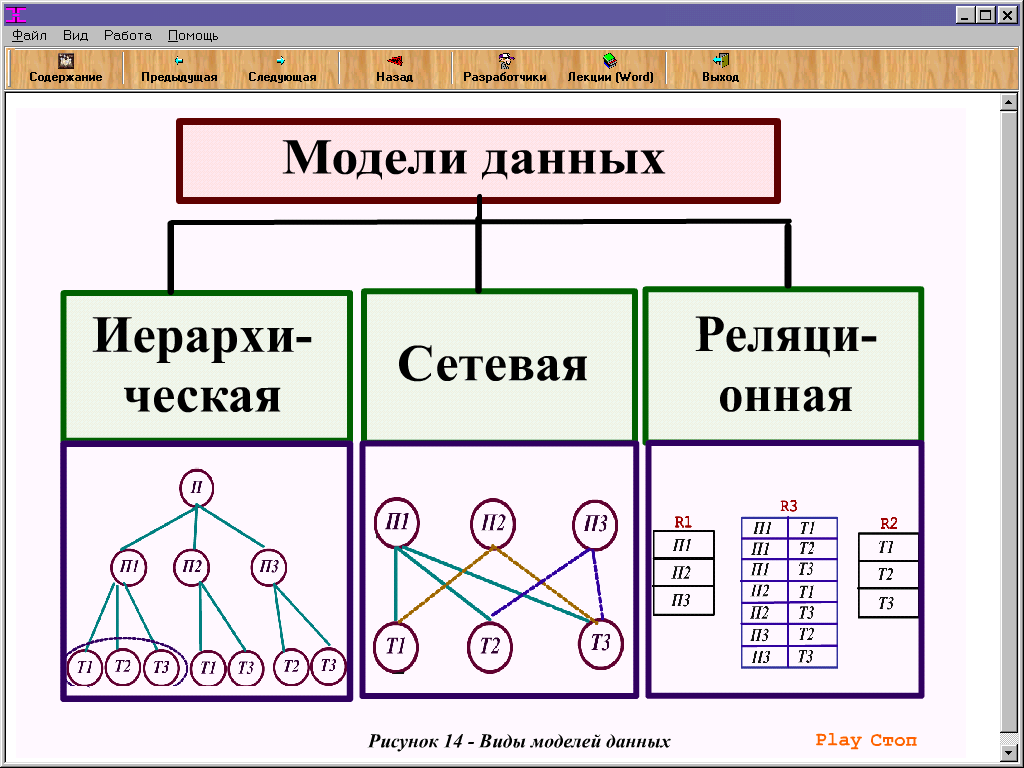
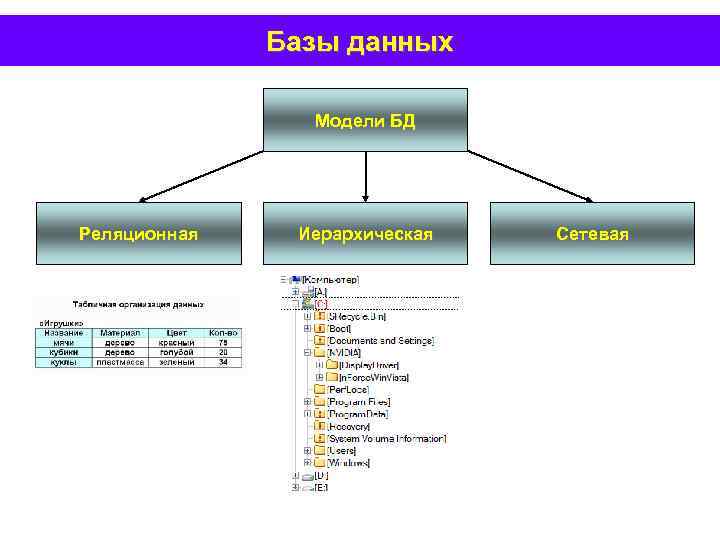
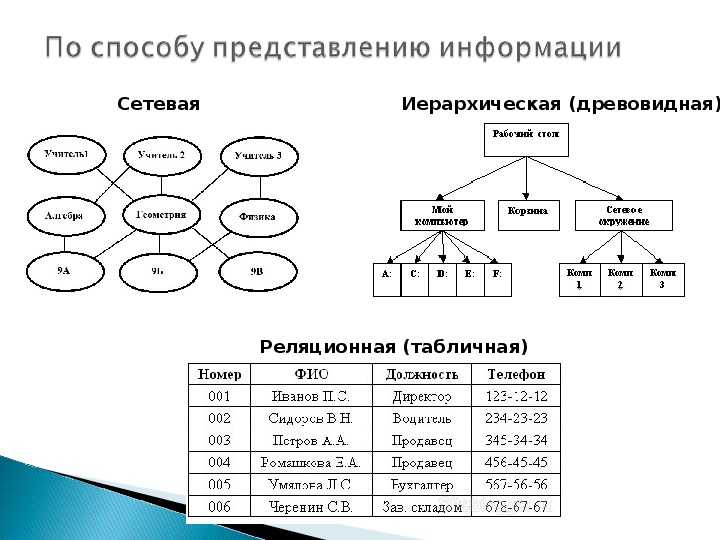
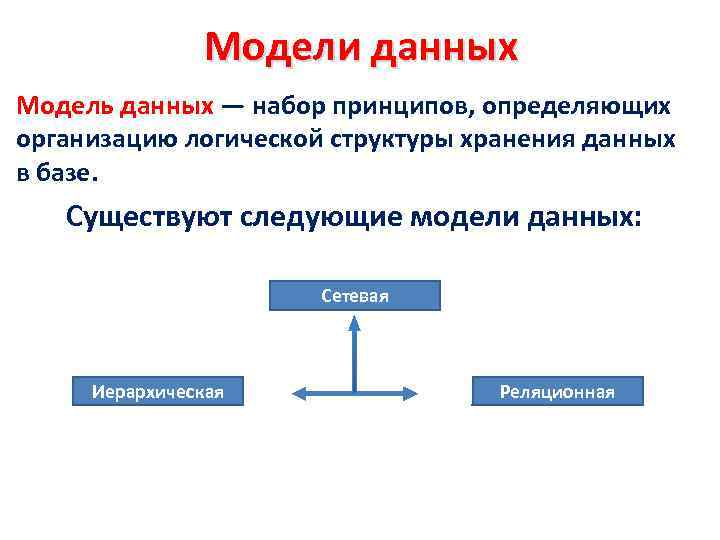
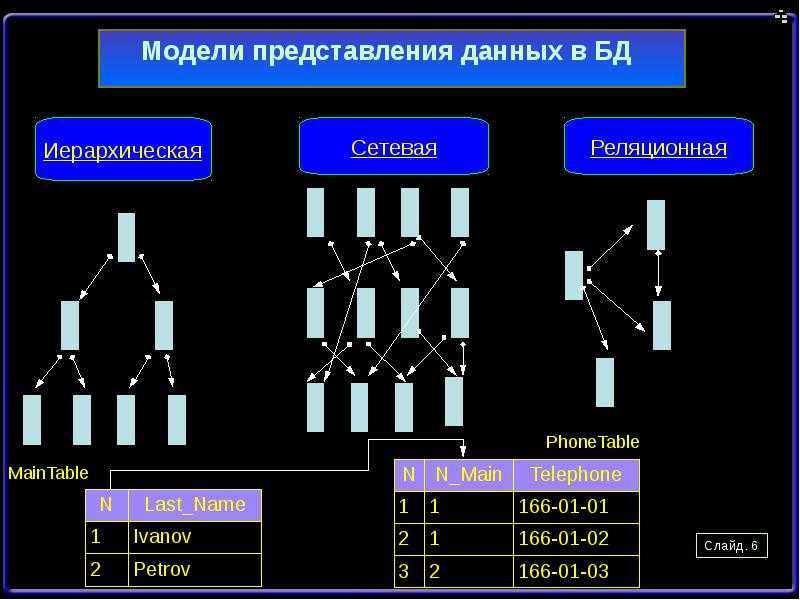
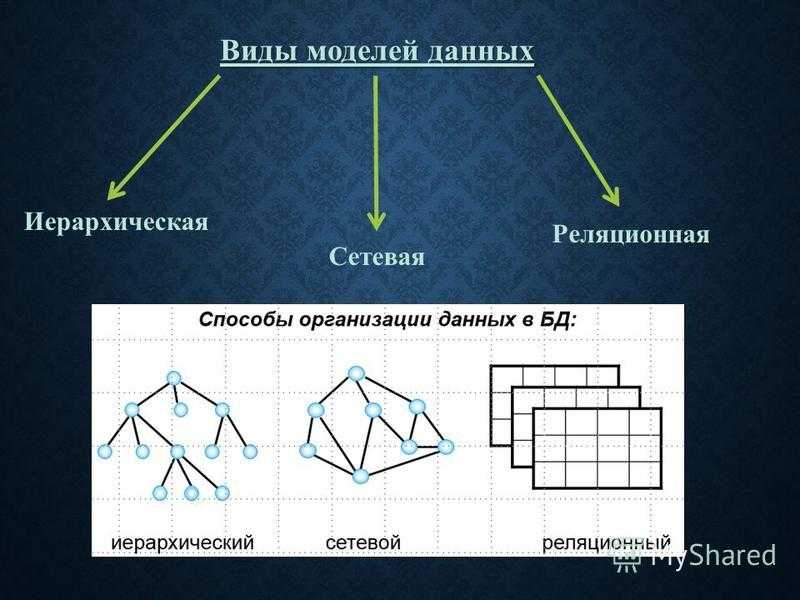
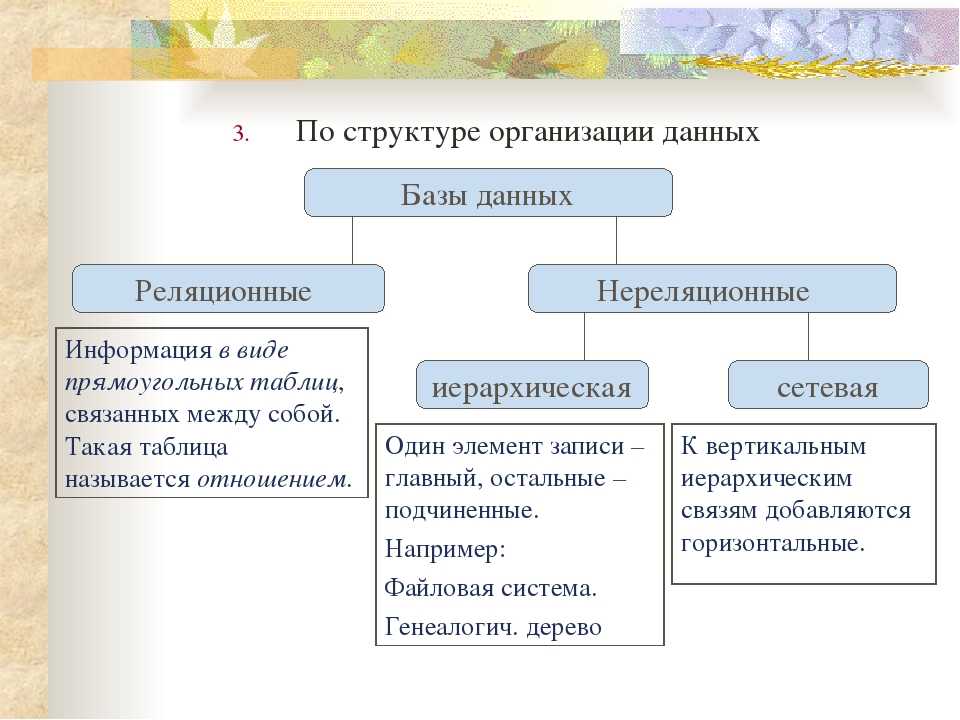
Общие логические модели данных для баз данных включают:
Иерархическая модель базы данных
- Это самая старая форма модели базы данных. Он был разработан IBM для IMS (система управления информацией). Это набор организованных данных в древовидной структуре. Запись БД — это дерево, состоящее из множества групп, называемых сегментами. Он использует отношения «один ко многим». Доступ к данным также предсказуем.
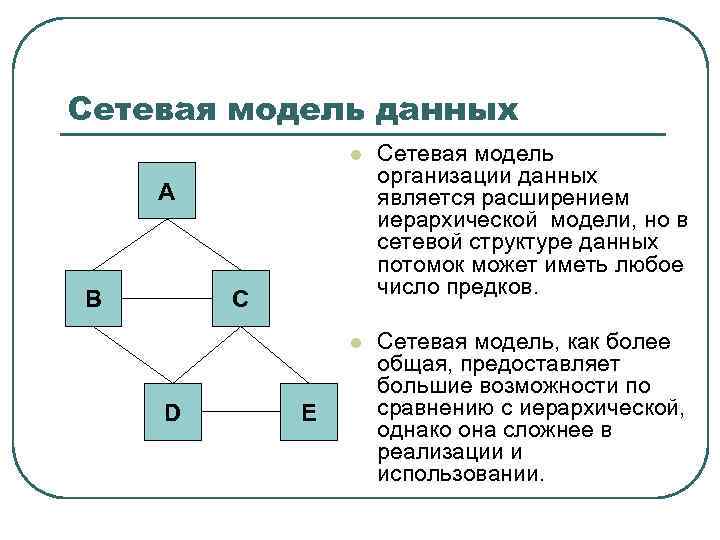
- Сетевая модель
- Реляционная модель
-
Модель сущность – отношения
Расширенная модель сущность – отношения
- Объектная модель
- Модель документа
- Модель сущность – атрибут – значение
- Схема звездочки
Объектно -реляционная база данных объединяет две связанные структуры.
К физическим моделям данных относятся:
- Инвертированный индекс
- Плоский файл
Другие модели включают:
- Ассоциативная модель
- Корреляционная модель
- Многомерная модель
- Многозначная модель
- Семантическая модель
- База данных XML
- Именованный граф
- Triplestore
Недостатки документных баз
- Обновление данных —медленный процесс в документной БД, потому что данные могут быть распределены между компьютерами и могут дублироваться.
- Атомарные транзакции по умолчанию не поддерживаются. Вы можете сами добавить их в код, используя механизм проверки и возврата, но, поскольку записи распределены между компьютерами, транзакция не может быть атомарной единицей, а значит, может возникнуть состояние гонки.
![]()
Шпаргалка
- Для кэширования используем БД типа ключ-значение.
- Для графов— графовые БД.
- Если удобно делать запросы по колонкам или характеристикам — колоночные БД.
- Для всех остальных случаев реляционные или документные базы данных.
- Шесть рекомендаций для начинающих специалистов по Data Science
- Почему за способностью объяснения модели стоит будущее Data Science
- Как составить Data Science портфолио? Часть 1
Мир объектов, систем и решений
Реальные объекты и действующие системы объединяются в области применения человеком, принимающим решения. Сам факт посещения ресурса, обращения к объекту, использование системы имеет цель и полученный результат.
Нет необходимости фантазировать об искусственном интеллекте, когда вполне достаточно накапливать практику принятия решений человеком и использовать ее. Совершенно не обязательно привязывать решения, принятые сотрудниками одной компании к работе этой структуры.
![]()
Сфера антивирусной защиты уже давно собирает вирусные угрозы со всех возможных направлений и обобщает их для использования в каждом конкретном случае. Чем выше объем захвата растущих угроз, тем эффективнее борьба с ними на конкретных рабочих местах.
Когда информационная система способна накапливать опыт принятия решений, это хорошее начало и свидетельство компетентности разработчиков, гарантия стабильности развития потребителей и общего успеха.
Разница между реляционной и нереляционной базой данных
Определение
Реляционная база данных — это база данных, основанная на реляционной модели данных, предложенной EF Codd в 1970 году. Нереляционная база данных, с другой стороны, представляет собой тип базы данных, которая обеспечивает механизм для хранения и извлечения данных, которые моделируются таким образом, кроме табличных отношений, используемых в реляционных базах данных.
Synonms
Реляционные базы данных также называются базами данных SQL, в то время как нереляционные базы данных также называются базами данных NoSQL.
присоединяется
Разница между реляционной и нереляционной базой данных заключается в том, что таблицы в реляционной базе данных могут быть объединены. С другой стороны, в нереляционной базе данных нет единой концепции.
Типы
Другое различие между реляционной и нереляционной базой данных состоит в том, что реляционные базы данных не могут быть классифицированы далее. Напротив, базы данных ключ-значение, документы, столбцы и графы являются типами нереляционных баз данных.
использование
Реляционные базы данных помогают выполнять сложные запросы. Кроме того, они обеспечивают гибкость и помогают анализировать данные. Нереляционные базы данных хорошо работают с большим количеством данных. Кроме того, они уменьшают задержку и улучшают пропускную способность. Следовательно, это еще одно различие между реляционной и нереляционной базой данных.
Примеры
MySQL, SQLite3 и PostgreSQL — это некоторые СУБД, использующие реляционные базы данных. Cassendra, Hbase, MongoDB и Neo4 — некоторые нереляционные базы данных.
Заключение
Основное различие между реляционной и нереляционной базой данных состоит в том, что реляционная база данных хранит данные в таблицах, в то время как нереляционная база данных хранит данные в формате ключ-значение, в документах или каким-либо другим способом без использования таблиц, таких как реляционная база данных.
С этим читают
Отношения и функции
Данная система управления базой данных может предоставлять одну или несколько моделей. Оптимальная структура зависит от естественной организации данных приложения и требований приложения, которые включают скорость транзакций (скорость), надежность, ремонтопригодность, масштабируемость и стоимость. Большинство систем управления базами данных построено на одной конкретной модели данных, хотя продукты могут предлагать поддержку более чем одной модели.
Различные физические модели данных могут реализовать любую заданную логическую модель. Большая часть программного обеспечения баз данных предлагает пользователю некоторый уровень контроля при настройке физической реализации, поскольку сделанный выбор оказывает значительное влияние на производительность.
Модель — это не просто способ структурирования данных: она также определяет набор операций, которые могут выполняться с данными. Например, реляционная модель определяет такие операции, как выбор ( проект ) и соединение . Хотя эти операции могут быть неявными в конкретном языке запросов , они обеспечивают основу, на которой построен язык запросов.
Иерархическая модель данных: история создания, пример
Первые сетевые и иерархические СУБД появились в 60-х годах. Причиной этому послужила потребность в управлении миллионами записей, которые были связаны друг с другом определенном иерархическим образом, в частности, при поддержке (информационной) лунного проекта под названием «Аполлон». Пример иерархической модели данных — система IMS компании IBM. В современное время она выступает самой распространенной СУБД среди всех остальных данного типа. Другой пример иерархической модели данных – TDMS компании Development Corporation, а также Mark IV Multi компании Control Data Corporation и др.
Далее необходимо уделить внимание графическому представлению данной модели
![]()
Что такое иерархическая база данных
Иерархическая база данных основана на иерархической модели. Он хранит данные в древовидной структуре. Здесь данные хранятся в виде записей, которые связаны друг с другом через ссылки. Также запись представляет собой набор полей. Каждое поле содержит только одно значение. Более того, иерархия начинается с корневых данных. Затем он расширяется подобно дереву, добавляя дочерние узлы к родительским узлам. Дочерний узел будет иметь только один родительский узел. Однако родительский узел может иметь один или несколько дочерних узлов.



![]()
Рисунок 2: Иерархическая модель
Например, предположим, университетский сценарий. Он делит данные на данные отдела и инфраструктуры. Вы можете разделить кафедру на курс, лектора и студента. Курс далее делится на теоретический и практический. Аналогично, данные организованы в древовидную структуру.
6) Хранилища данных и модели их представления
Хранилище данных: предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных, предназначенный для обеспечения принятия управленческих решений.
Основные модели представления данных в хранилищах данных:
- 1. Реляционная
- 2. Многомерная
- 3. Гибридная
- 4. Виртуальная
Реляционная модель хранилищ данных
В основе реляционных хранилищ данных лежит разделение данных на две группы – измерения и факты.
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе.
Примеры измерений: наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.Измерения качественно описывают исследуемый бизнес-процесс.Факты – это непрерывные по своему характеру данные (могут принимать бесконечное множество значений).
Примеры фактов: цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита и т. д.
Факты количественно описывают бизнес-процесс.
![]()
рис Схема построения реляционного хранилища данных «звезда»
Центральной является таблица фактов (Fact table), с которой связаны таблицы измерений (Dimension tables).
Преимущества схемы «звезда»:
- простота и логическая прозрачность модели
- более простая процедура пополнения измерений, поскольку
- приходится работать только с одной таблицей
Недостатки схемы «звезда»:
- медленная обработка измерений, поскольку одни и те же значения
- измерений могут встречаться несколько раз в одной и той же таблице высокая вероятность возникновения несоответствий в данных (в частности, противоречий), например, из-за ошибок ввода
![]()
Рис Схема построения реляционного хранилища данных «снежинка» (модификация схемы «звезда»)
![]()
Основное функциональное отличие схемы «снежинка» от схемы «звезда» – это возможность работы с иерархическими уровнями, определяющими
степень детализации данных.Преимущества схемы «снежинка»:
- она ближе к представлению данных в многомерной модели
- процедура загрузки из РХД в многомерные структуры более
- эффективна и проста, поскольку загрузка производится из отдельных таблиц
- намного ниже вероятность появления ошибок, несоответствия данных
- большая, по сравнению со схемой «звезда», компактность
- представления данных, поскольку все значения измерений упоминаются только один раз
Недостатки схемы «снежинка»:
- достаточно сложная для реализации и понимания структура данных
- усложненная процедура добавления значений измерений
Преимущества реляционных хранилищ данных:
- Практически неограниченный объем хранимых данных
- Поскольку реляционные СУБД лежат в основе построения многих систем оперативной обработки (OLTP), которые обычно являются главными источниками данных для ХД, использование реляционной модели позволяет упростить процедуру загрузки и интеграции данных в хранилище
- При добавлении новых измерений данных нет необходимости выполнять сложную физическую реорганизацию хранилища, в отличие, например, от многомерных ХД
- Обеспечиваются высокий уровень защиты данных и широкие возможности разграничения прав доступа
Главный недостаток реляционных хранилищ данных:
При использовании высокого уровня обобщения данных и иерархичности измерений в таких хранилищах начинают «размножаться» таблицы агрегатов. В результате скорость выполнения запросов реляционным хранилищем замедляется
2.2. Системы управления базами данных
По мере увеличения объемов и структурной сложности хранимой информации, а также расширения круга потребителей информации, определилась необходимость создания удобных и эффективных систем интеграции хранимых данных и управления ими. Теперь создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария — системы управления базами данных (СУБД).
Система управления базами данных (СУБД) — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Первые СУБД, поддерживающие opганизацию и ведение БД, появились в конце 60-х годов.
Использование СУБД обеспечивает лучшее управление данными, более совершенную организацию файлов и более простое обращение к ним по сравнению с обычными способами хранения информации.
Достоинства и недостатки реляционной модели данных
Достоинства реляционной модели:
- простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является «таблица»;
- строгие правила проектирования, базирующиеся на математическом аппарате;
- полная независимость данных. Изменения в прикладной программе при изменении реляционной БД минимальны;
- для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти.
Недостатки реляционной модели:
- далеко не всегда предметная область может быть представлена в виде «таблиц»;
- в результате логического проектирования появляется множество «таблиц». Это приводит к трудности понимания структуры данных;
- БД занимает относительно много внешней памяти;
- относительно низкая скорость доступа к данным.
Вступление
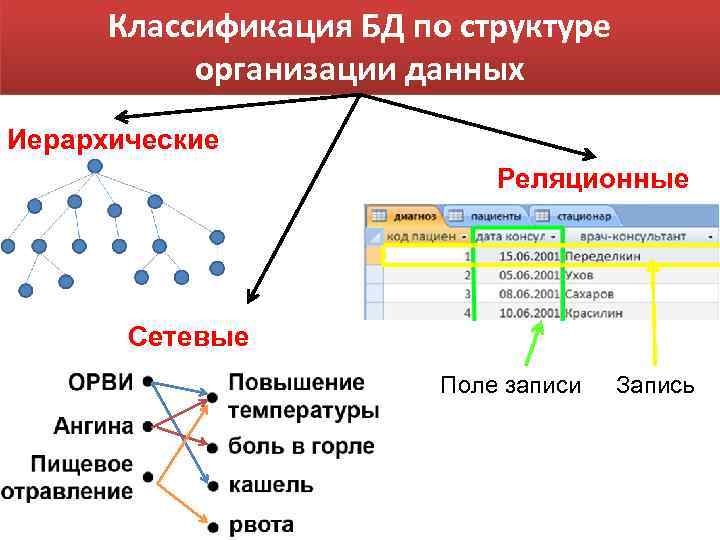
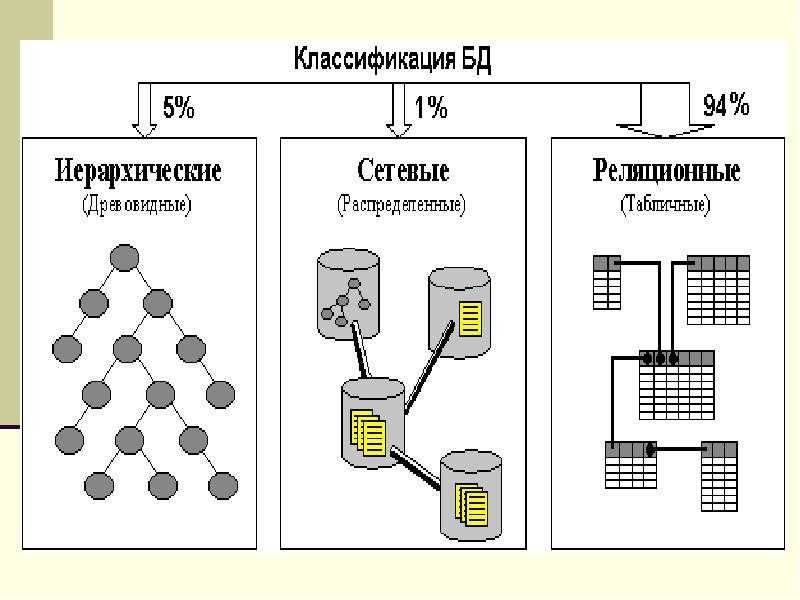
Напомню, что база данных это большой объем данных, которая в ней хранится, может обрабатываться, дополняться, удаляться, причем в удобной для пользователя форме. Также нужно четко понимать, что в БД хранится не всякая информация, а информация, которую можно организовать по тем или иным свойствам. Например, большое количество различных фотографий или документов это не данные, а информация. Но мы можем организовать фотографии, например по сути: фото людей, фото животных, фото городов и т.д. или организовать их по размеру: большие, средние, маленькие. Организованная, таким образом информация превращается в данные и пригодна для автоматической обработки с использованием баз данных. Переходим к классификации баз данных.
![]()
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
https://youtube.com/watch?v=oGHYKKC6gnk
4. Сравнение трёх моделей
также можно определитькоторых можно определить следующим образом:
- «Один к одному»;
- «Один ко многим»;
- «Многие ко многим».
Преимущества реляционной модели данных:
- простота использования;
- гибкость;
- независимость данных;
- безопасность;
- простота практического применения;
- слияние данных;
- целостность данных;
Недостатки:
- избыточность данных;
- низкая производительность;
- другие модели баз данных (ООСУБД).
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
ПримерыООСУБД
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
Состав реляционной модели данных
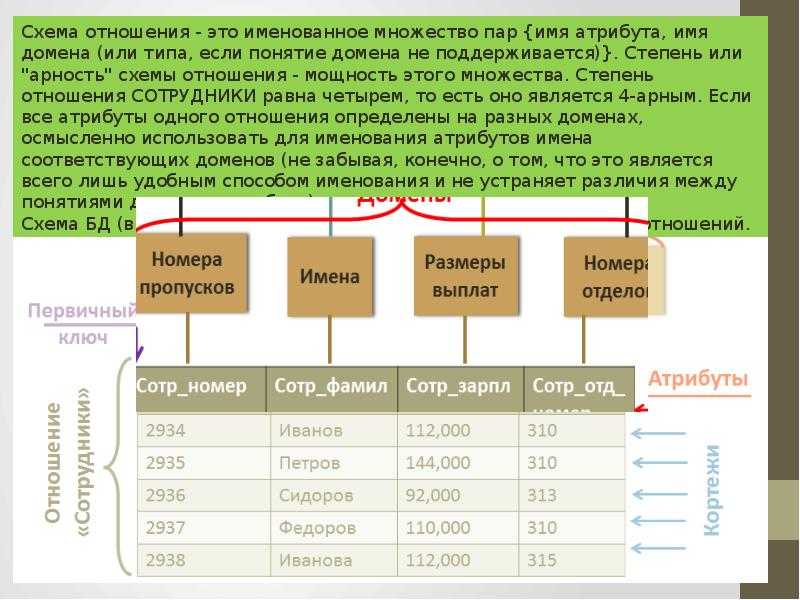
Кристофер Дейт определил три составные части реляционной модели данных:
- структурная
- манипуляционная
- целостная
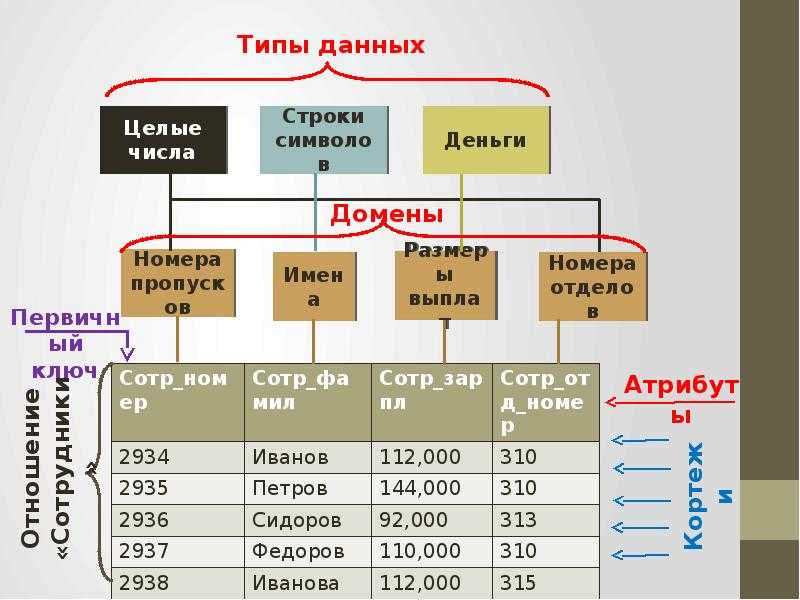
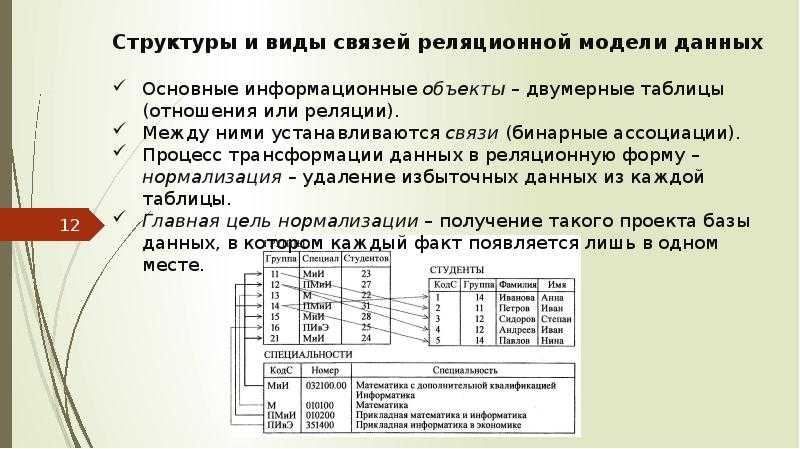
Структурная часть модели определяет, что единственной
структурой данных является нормализованное n-арное отношение.
Отношения удобно представлять в форме таблиц, где каждая строка есть
кортеж, а каждый столбец – атрибут, определенный на некотором домене.
Данный неформальный подход к понятию отношения дает более привычную для
разработчиков и пользователей форму представления, где реляционная база
данных представляет собой конечный набор таблиц.

Манипуляционная часть модели определяет два
фундаментальных механизма манипулирования данными – реляционная алгебра и
реляционное исчисление.
Основной функцией манипуляционной части реляционной модели является
обеспечение меры реляционности любого конкретного языка реляционных БД:
язык называется реляционным, если он обладает не меньшей
выразительностью и мощностью, чем реляционная алгебра или реляционное
исчисление.
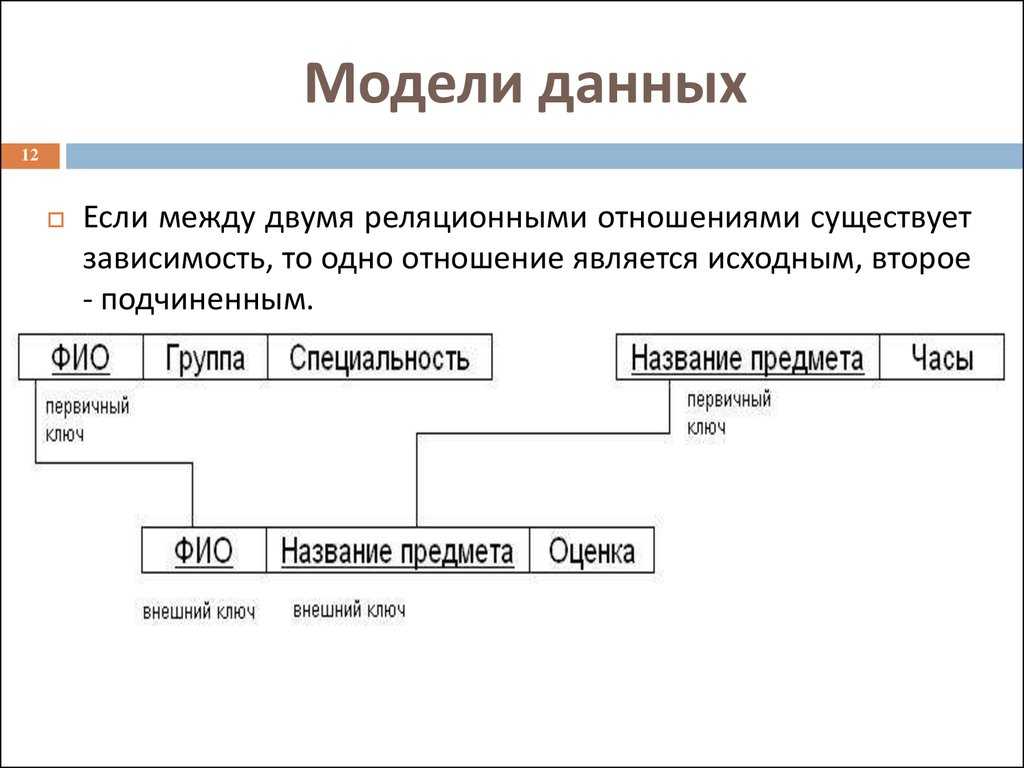
Целостная часть модели определяет требования целостности сущностей и целостности ссылок.
Первое требование состоит в том, что любой кортеж любого отношения
отличим от любого другого кортежа этого отношения, т.е. другими словами,
любое отношение должно обладать первичным ключом.
Требование целостности по ссылкам, или требование внешнего ключа
состоит в том, что для каждого значения внешнего ключа, появляющегося в
ссылающемся отношении, в отношении, на которое ведет ссылка, должен
найтись кортеж с таким же значением первичного ключа, либо значение
внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
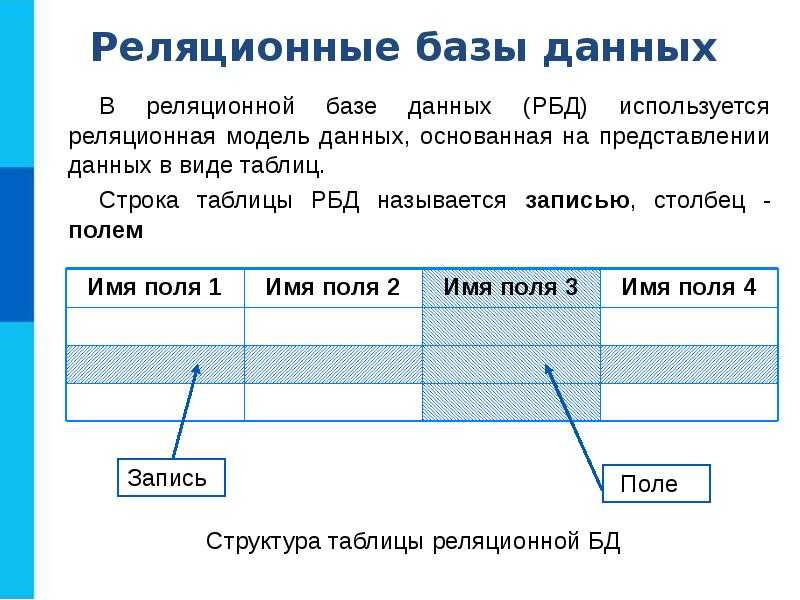
2.1. Структурные элементы базы данных
Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, файл (таблица).
Поле — элементарная единица логической организации данных, которая соответствует неделимой единице информации — реквизиту. Для описания поля используются следующие характеристики:
- имя, например. Фамилия, Имя, Отчество, Дата рождения;
- тип, например, символьный, числовой, календарный;
- длина, например, 15 байт, причем будет определяться максимально возможным количеством символов;
- точность для числовых данных, например два десятичных знака для отображения дробной части числа.
Запись — совокупность логически связанных полей. Экземпляр записи — отдельная реализация записи, содержащая конкретные значения ее полей.
Файл (таблица) — совокупность экземпляров записей одной структуры.
В структуре записи файла указываются поля, значения которых являются ключами первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей).
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
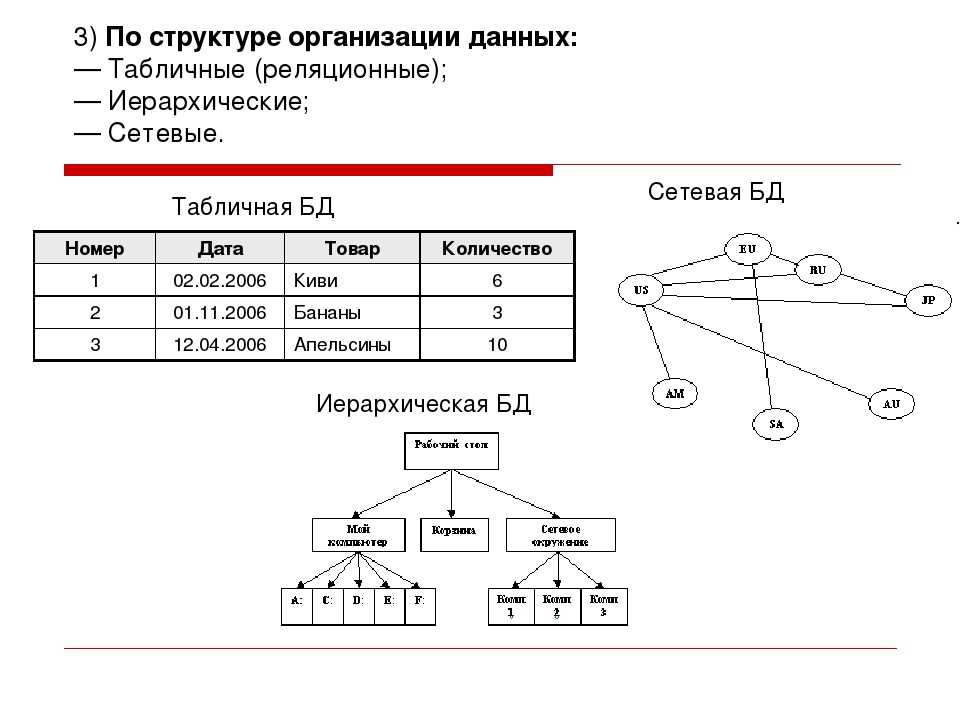
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Преимущества и ограничения реляционных баз данных
Учитывая организационную структуру, положенную в основу реляционных баз данных, давайте рассмотрим их некоторые преимущества и недостатки.
Сегодня как SQL, так и базы данных, которые ее используют, несколько отклоняются от реляционной модели Кодда. Например, модель Кодда предписывает, что каждая строка в таблице должна быть уникальной, а по соображениям практической целесообразности большинство современных реляционных баз данных допускают дублирование строк. Есть и те, кто не считает базы данных на основе SQL истинными реляционными базами данных, если они не соответствуют каждому критерию реляционной модели по версии Кодда. Но на практике любая СУБД, которая использует SQL и в какой-то мере соответствует реляционной модели, может быть отнесена к реляционным системам управления базами данных.
Хотя популярность реляционных баз данных стремительно росла, некоторое недостатки реляционной модели стали проявляться по мере того, как увеличивались ценность и объемы хранящихся данных. К примеру, трудно масштабировать реляционную базу данных горизонтально. Горизонтальное масштабирование или масштабирование по горизонтали — это практика добавления большего количества машин к существующему стеку, что позволяет распределить нагрузку, увеличить трафик и ускорить обработку. Часто это контрастирует с вертикальным масштабированием, которое предполагает модернизацию аппаратного обеспечения существующего сервера, как правило, с помощью добавления оперативной памяти или центрального процессора.
Реляционную базу данных сложно масштабировать горизонтально из-за того, что она разработана для обеспечения целостности, т.е. клиенты, отправляющие запросы в одну и ту же базу данных, всегда будут получать одинаковые данные. Если вы масштабируете реляционную базу данных горизонтально по всем машинам, будет трудно обеспечить целостность, т.к. клиенты могут вносить данные только в один узел, а не во все. Вероятно, между начальной записью и моментом обновления других узлов для отображения изменений возникнет задержка, что приведет к отсутствию целостности данных между узлами.
Еще одно ограничение, существующее в РСУБД, заключается в том, что реляционная модель была разработана для управления структурированными данными, или данными, которые соответствуют заранее определенному типу данных, или, по крайней мере, каким-либо образом предварительно организованы. Однако с распространением персональных компьютеров и развитием сети Интернет в начале 90-х годов появились неструктурированные данные, такие как электронные сообщения, фотографии, видео и пр.
Но все это не означает, что реляционные базы данных бесполезны. Напротив, спустя более 40 лет, реляционная модель все еще является доминирующей основой для управления данными. Распространенность и долголетие реляционных баз данных свидетельствуют о том, что это зрелая технология, которая сама по себе является главным преимуществом. Существует много приложений, предназначенных для работы с реляционной моделью, а также много карьерных администраторов баз данных, которые являются экспертами, когда дело доходит до реляционных баз данных. Также существует широкий спектр доступных печатных и онлайн-ресурсов для тех, кто хочет начать работу с реляционными базами данных.
Еще одно преимущество реляционных баз данных заключается в том, что почти все РСУБД поддерживают транзакции. Транзакция состоит из одного или более индивидуального выражения SQL, выполняемого последовательно, как один блок работы. Транзакции представляют подход «все или ничего», означающий, что все операторы SQL в транзакции должны быть действительными. В противном случае вся транзакция не будет выполнена. Это очень полезно для обеспечения целостности данных при внесении изменений в несколько строк или в таблицы.
Наконец, реляционные базы данных демонстрируют чрезвычайную гибкость. Они используются для построения широкого спектра различных приложений и продолжают эффективно работать даже с большими объемами данных. Язык SQL также обладает огромным потенциалом и позволяет вам добавлять или менять данные на лету, а также вносить изменения в структуру схем баз данных и таблиц, не влияя на существующие данные.
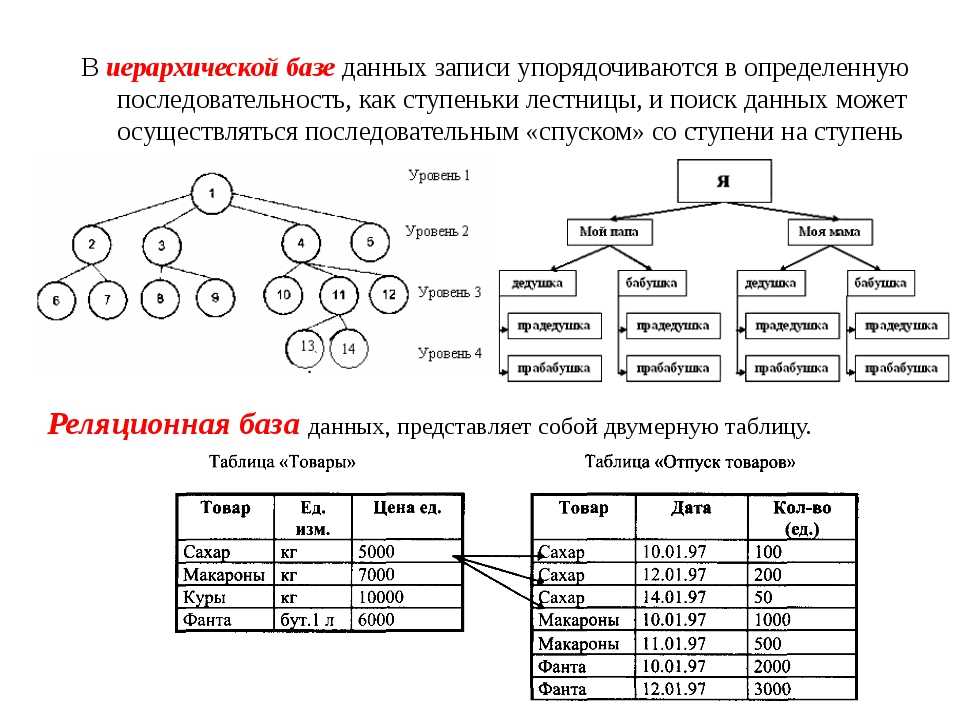
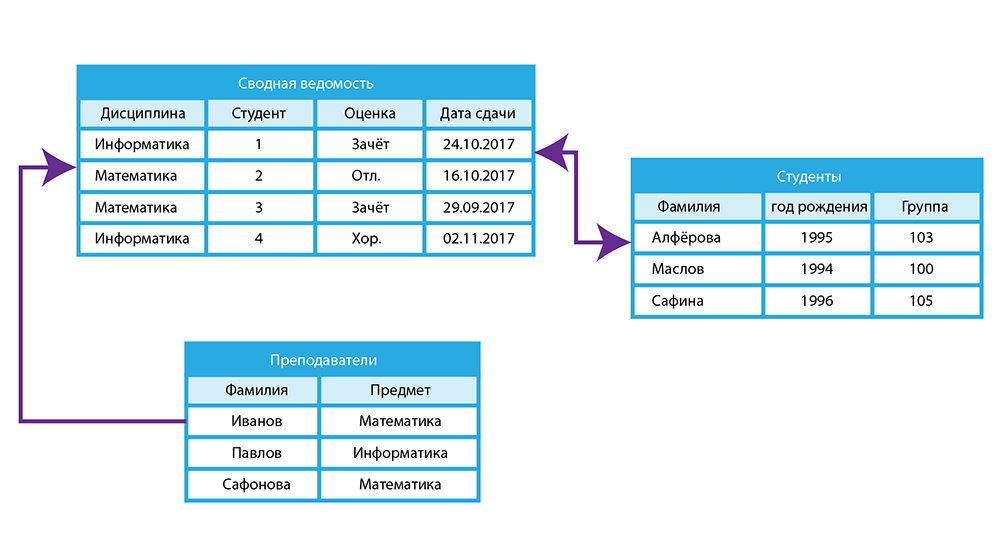
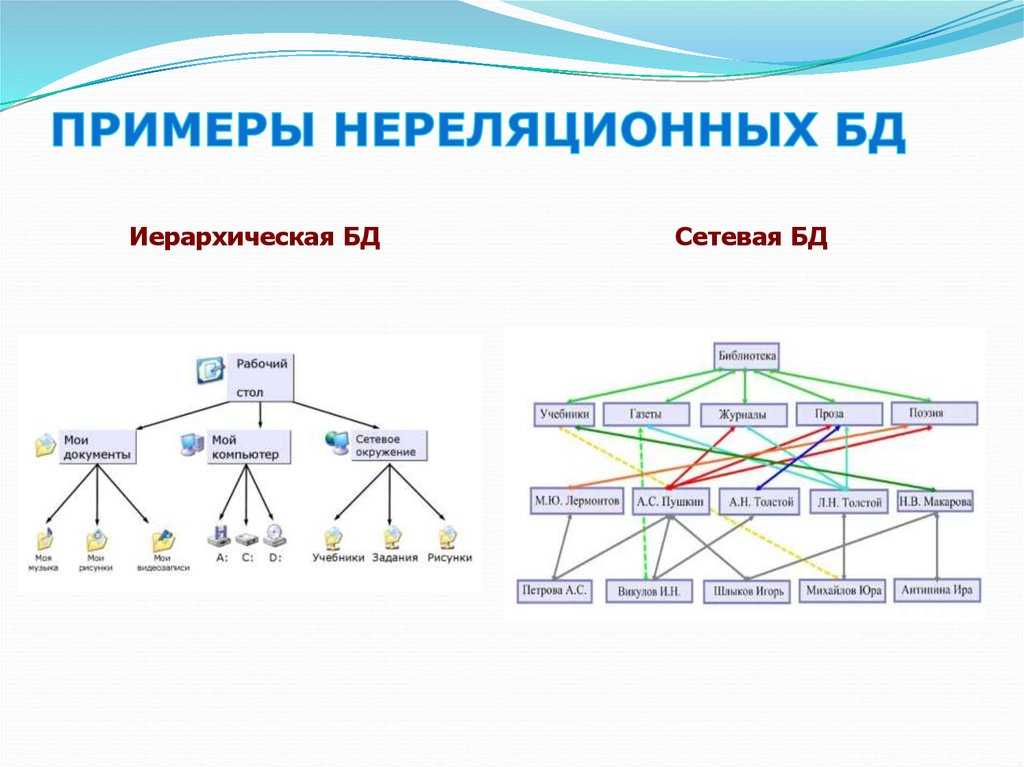
Иерархическая база данных — пример
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.
Плоская модель
Модель плоского файла
Модель плоской (или таблица) состоит из одного двумерного массива данных элементов, где предполагаются все члены данного столбца , чтобы быть аналогичные ценности, и все члены ряда предполагаются связанными друг с другом. Например, столбцы для имени и пароля, которые могут использоваться как часть базы данных безопасности системы. Каждая строка будет иметь конкретный пароль, связанный с отдельным пользователем. Столбцы таблицы часто имеют связанный с ними тип, определяющий их как символьные данные, информацию о дате или времени, целые числа или числа с плавающей запятой. Этот табличный формат является предшественником реляционной модели.
Недостатки реляционных баз
Поскольку каждый запрос выполняется к целой таблице, время выполнения запроса зависит от размера таблицы
Это важное ограничение, которое заставляет нас сохранять таблицы относительно небольшими и проводить оптимизацию БД для ее масштабирования.
Масштабирование осуществляется добавлением вычислительных мощностей к компьютеру, на котором установлена БД, этот метод называется вертикальное масштабирование. Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.
Не поддерживаются объекты на основе ООП, даже представление простых списков очень сложно.
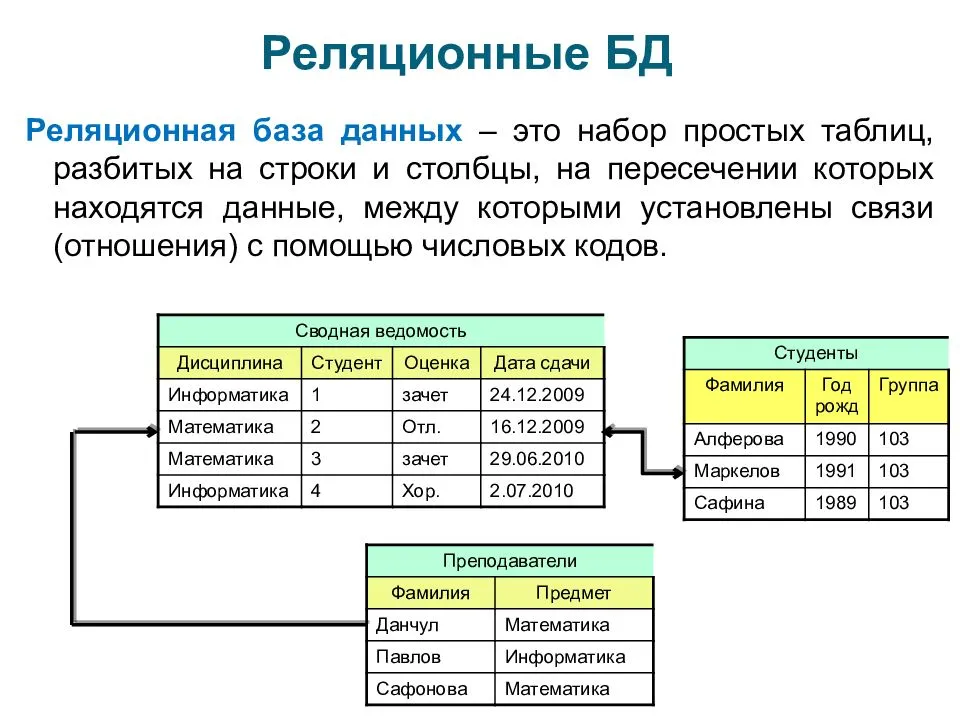
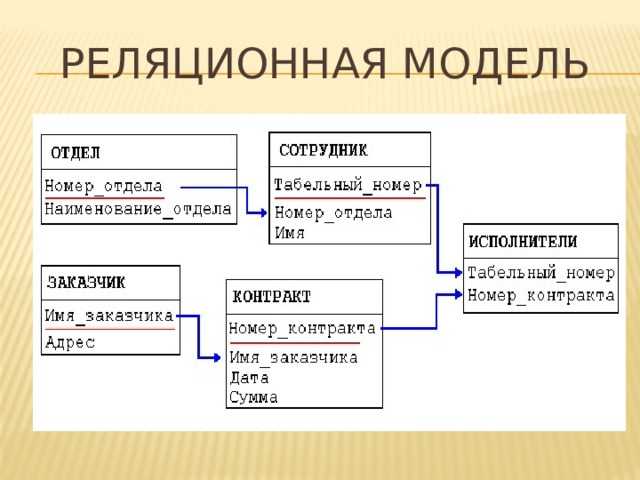
Что такое реляционная база данных
Модель базы данных определяет логический дизайн и структуру базы данных. Где реляционная база данных основана на реляционной модели и хранит данные в таблицах. Кроме того, строки представляют каждую сущность, в то время как столбцы представляют атрибуты.
![]()
Рисунок 1: Таблица в реляционной базе данных
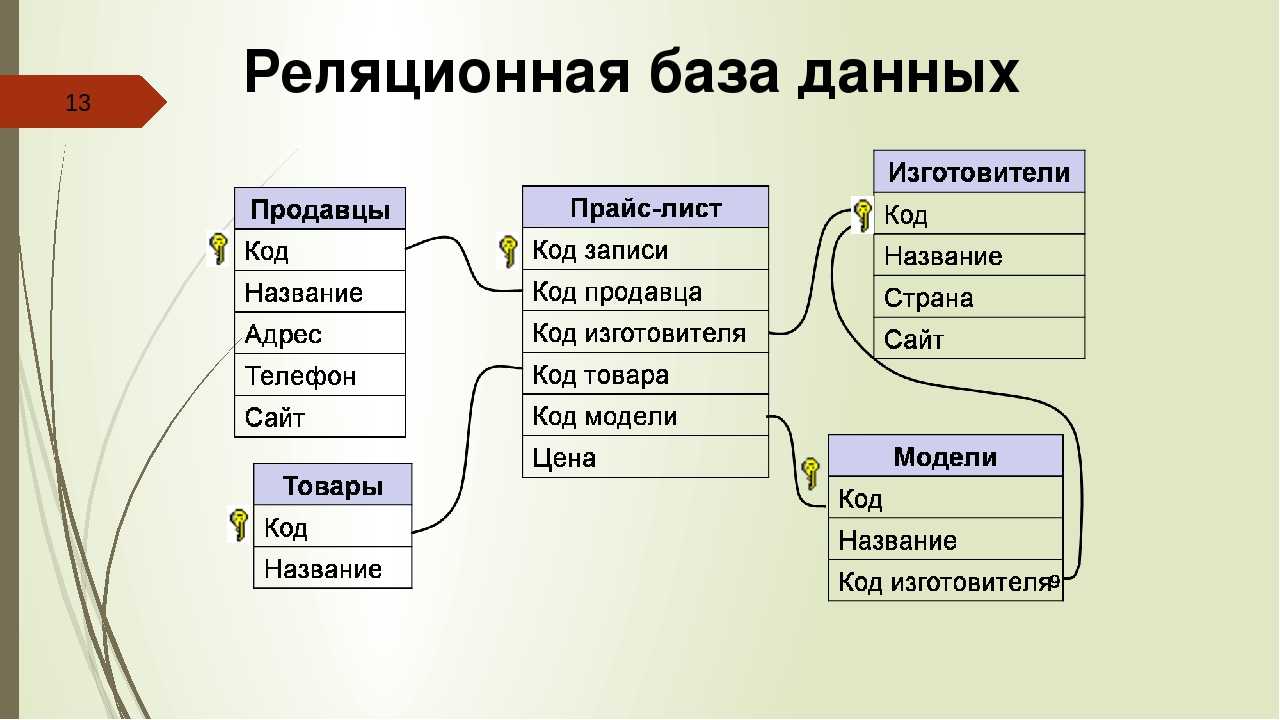
Например, предположим, что база данных в организации. Таблица сотрудников имеет атрибуты emp-id, имя, возраст и город. Здесь первичным ключом таблицы employee является emp-id. Другая таблица называется таблицей проекта и имеет атрибуты идентификатор проекта, имя проекта, продолжительность и идентификатор emp. Здесь первичным ключом таблицы проекта является идентификатор проекта. Emp-id в таблице employee является внешним ключом в таблице проекта. Эти две таблицы связаны между собой с помощью внешнего ключа. Поэтому таблицы в реляционной базе данных связаны друг с другом.
Язык структурированных запросов (SQL) используется для хранения и управления данными в реляционной базе данных. SQL далее делится на три основные категории: язык определения данных (DDL), язык манипулирования данными (DML) и язык управления данными (DCL). Кроме того, DDL меняет структуру таблиц. DML помогает манипулировать данными, в то время как DCL помогает предоставлять и отбирать полномочия у пользователя базы данных.



