
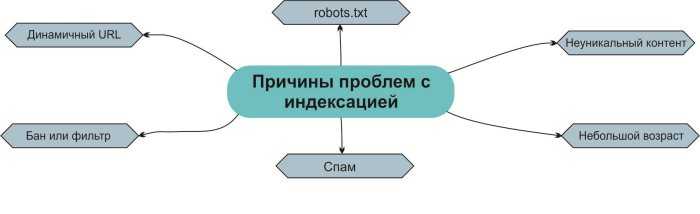
Какие данные рискуют попасть в поиск и почему
В прошлом году стало известно, что Google проиндексировал тексты, которые пользователи переводили с помощью облачного сервиса Translate.com. Среди них оказались внутренние документы крупной международной компании Statoil. Речь шла про данные контрактов, планы по сокращению штата, пароли. Translate.com рассказали, что сохраняли тексты пользователей для волонтеров (асессоров), которые обучали алгоритм онлайн-переводчика. К сожалению, сотрудники сервиса не позаботились о том, чтобы закрыть информацию от индексации. Угроза утечки данных через облачные сервисы существует, но гораздо чаще непубличная информация попадает в поисковики непосредственно с сайтов компаний. Например, сотрудники забывают закрыть страницы от индексации после переезда на новый сайт. Я бы хотел подробнее разобрать эту проблему ниже и заодно расскажу, как ее избежать.
Используем панель Вебмастера
Каждая поисковая система имеет свою панель инструментов, специально предназначенную для вебмастеров. С помощью этой панели можно увидеть общее количество проиндексированных страниц. Рассмотрим на примере самых популярных ПС (Яндекс и Google), как выполнять такую проверку.
Чтобы использовать панель инструментов Яндекс в данном контексте, нужно завести аккаунт (если его еще нет), зайти в панель и добавить в нее свой сайт. Там будет показано общее количество страниц, которые уже проиндексированы.
Для использования панели инструментов Google также нужно обзавестись аккаунтом, чтобы иметь возможность зайти в панель. В нее нужно добавить свой сайт и зайти на вкладку «Состояние / Статус индексирования». Здесь также будет показано количество проиндексированных страниц.
Нередко можно заметить, что панель Вебмастера Google может показать значительно большее количество проиндексированных страниц, чем панель инструментов Яндекс. Представим, что на сайте 70 уникальных страниц, которые проиндексировались. И, скажем, Яндекс насчитал приблизительно такое количество ссылок, а Гугл, например, 210. Получается, что Яндекс показал правильное число, а Гугл в 3 раза больше. Так в чем же дело? А дело в дублях страниц, генерируемых движком WordPress. Такие дубли поисковикам не по душе. Использование robots.txt позволяет игнорировать индексацию дублей страниц поисковыми системами. И если на Яндекс это действует, то с Гуглом в этом плане могут возникать проблемы, так как он может действовать по своему усмотрению.
Есть также специальный сервис Pr-cy.ru, позволяющий получить вебмастерам различные данные по сайтам – в том числе, число страниц, проиндексированных в Гугле и Яндексе. Чтобы узнать эту информацию, нужно посмотреть на две нижние колонки соответствующих поисковых систем.
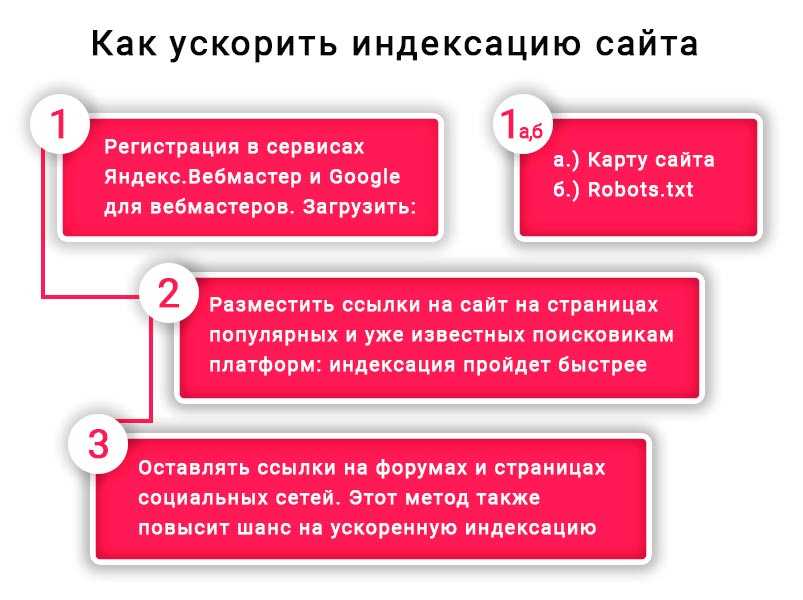
Что помогает ускорить индексацию сайта
Чтобы страницы быстрее индексировались, нужно придерживаться главных правил:
Регулярное размещение уникальных и оптимизированных статей. Поисковый робот возьмет себе за привычку регулярно посещать тот сайт, на котором с определенной периодичностью размещается качественный, полезный и интересный контент.
Анонсирование о размещении нового контента или полезных обновлениях на сайте через социальные сети. После того, как появилась статья, можно самостоятельно сообщить об этом в социальную сеть с помощью кнопки retweet. Поисковый бот отметит это и зайдет на сайт через социальную сеть значительно быстрее.
Поисковому роботу гораздо проще найти конкретную страницу с помощью ссылки, имеющейся на вашем сайте
То есть, не стоит забывать о важности внутренней перелинковки.
Добавив xml-карту в панель вебмастера, мы даем возможность поисковому боту пройти по ней. Также ее нужно добавить в robots.txt
Полезна и карта сайта (карта для человека), по которой бот отыщет все страницы сайта.
В материале мы рассмотрели основные способы, позволяющие проверить, попали ли страницы сайта в индекс различных поисковых систем. Некоторые из них более эффективные, а какие-то – менее, но каждый из них имеет право на существование и использование.
Читайте далее:
Методы ускорения индексации сайта в яндексе
Seo – проверка индексации текста и веса ссылок тест
Быстрая индексация сайта в Гугле
Проверить картинки на уникальность
Популярные бесплатные CMS системы
Как скрыть персональные данные в поисковых системах?
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
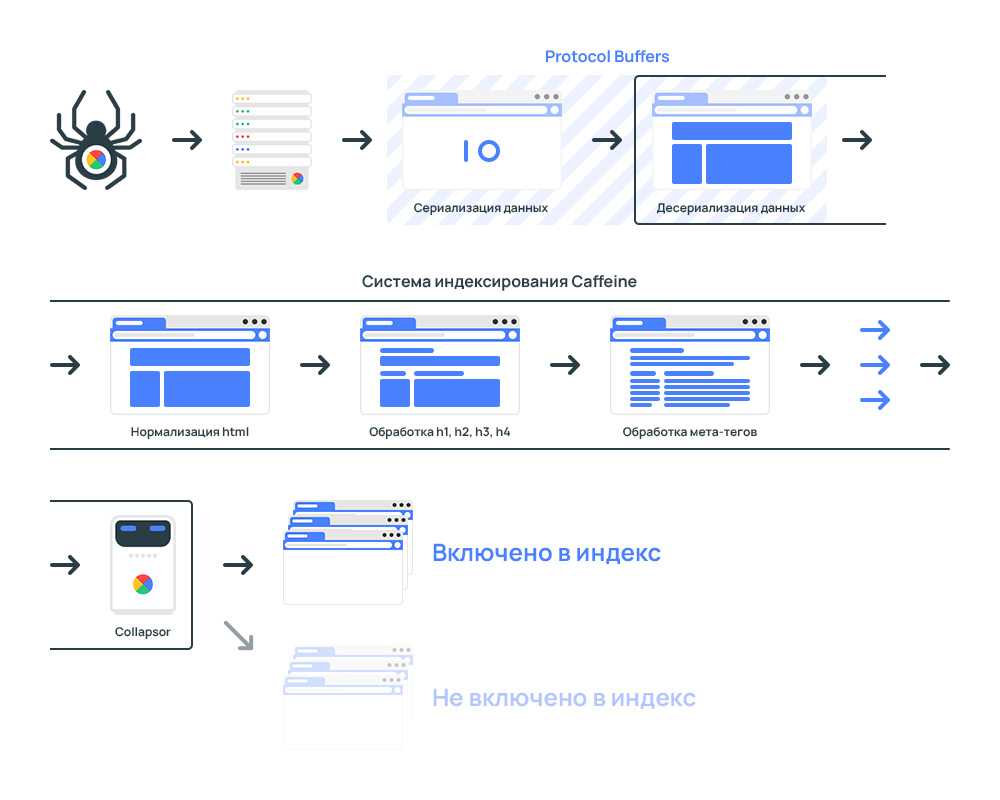
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
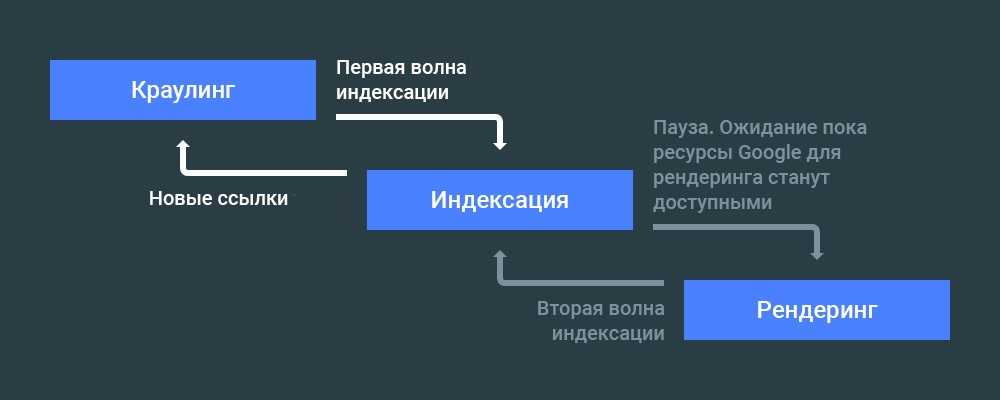
Как часто происходит индексация?
Индексация сайта в зависимости от ряда причин может занимать от нескольких часов до нескольких недель, вплоть до целого месяца. Обновление индексации, или апы поисковых систем происходят с различной периодичностью. По статистике в среднем Яндекс индексирует новые страницы и сайты за период от 1 до 4 недель, а Google справляется за период до 7 дней.
Но при правильной предварительной подготовке созданного ресурса эти сроки можно сократить до минимума. Ведь по сути все алгоритмы индексации ПС и логика их работы сводится к тому, чтобы дать наиболее точный и актуальный ответ на запрос пользователя. Соответственно, чем регулярнее на вашем ресурсе будет появляться качественный контент, тем быстрее он будет проходить индексацию.
Как проверить индексацию сайта в Google и Яндекс
Для проверки индексации сайта в поисковой системе можно воспользоваться одним из трех следующих методов:
- Панель вебмастера в конкретной поисковой системе. Если речь идет о Google, нужно использовать сервис для вебмастеров Search Console, в котором необходимо найти и открыть раздел «Индекс Google». В нем будет отображена информация касаемо вашего сайта — в блоке «Статус индексирования». Для проверки индексации веб-ресурса в Яндексе нужно воспользоваться Яндекс.Вебмастером. Открыв его, необходимо перейти по пути «Индексирование сайта» — «Страницы в поиске» (альтернативный вариант — «Индексирование сайта» — «История» — «Страницы в поиске»).
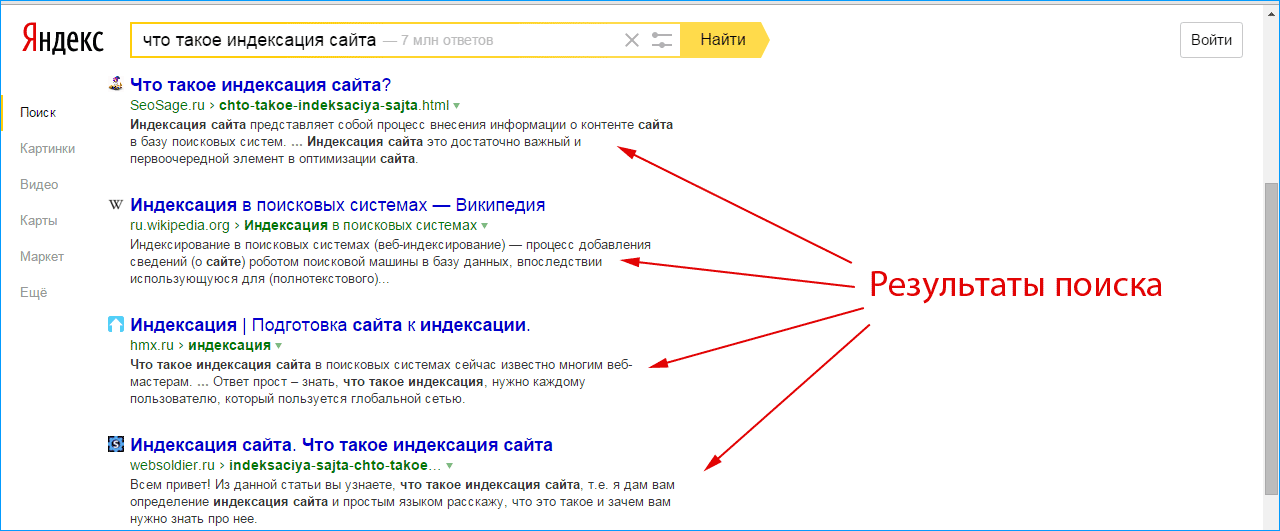
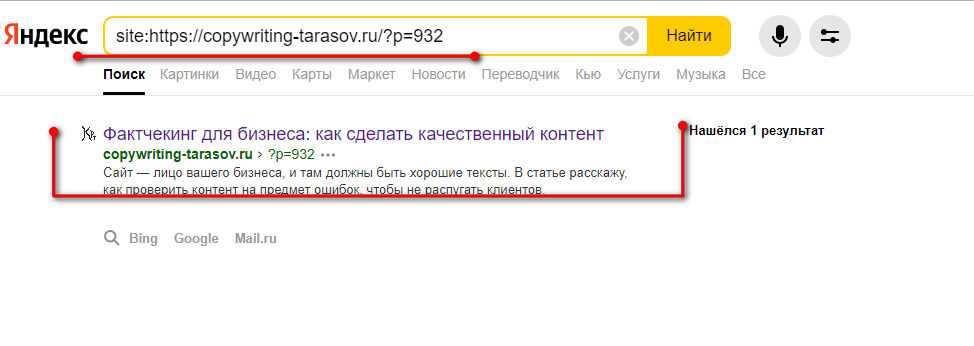
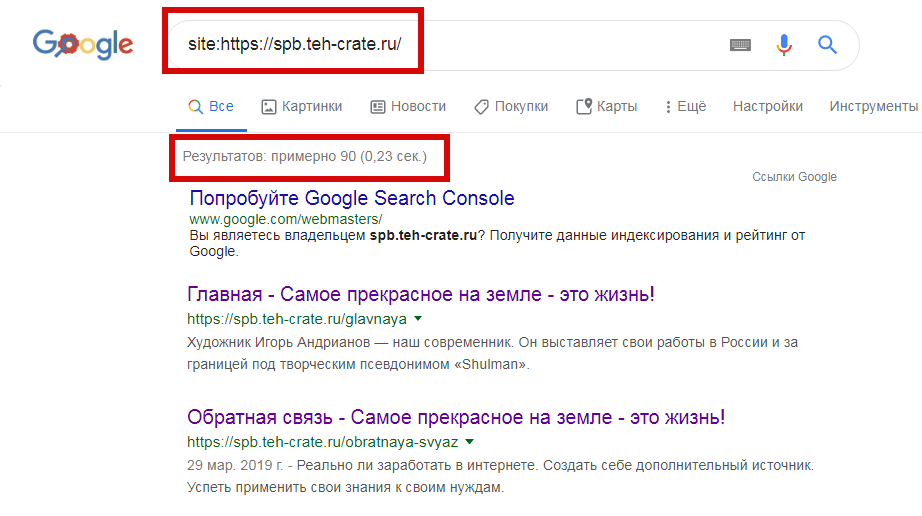
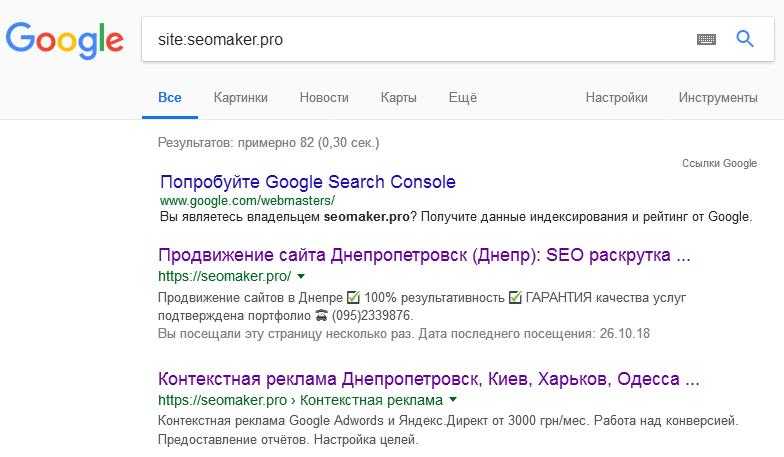
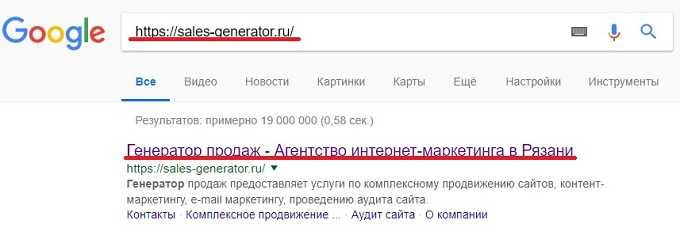
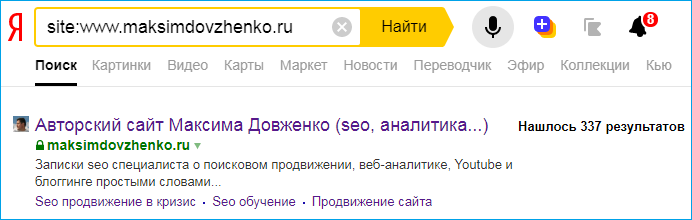
- Поиск по сайту с применением специальных операторов поиска. Чтобы использовать поиск по сайту со специальным оператором, нужно ввести в поисковой строке фразу «site:» и после двоеточия прописать адрес своего сайта. После этого нужно изучить выдачу и провести ее анализ, который поможет понять, сколько страниц есть в индексе, как они отображаются и т.д. При этом, если вы заметили расхождение в более, чем 80% в разных поисковиках, это может говорить о том, что один из поисковиков наложил на ваш сайт какой-либо фильтр (из-за которого определенное число страниц было удалено из индекса).
- Применение дополнительных плагинов или букмарклетов. Используя такие дополнительные инструменты в виде дополнений для браузеров, можно максимально быстро и удобно проверить число проиндексированных страниц. Здесь все зависит от функционала конкретного дополнения (например, большой популярностью пользуется RDS Bar).
Как убрать страницы из поиска
Самый простой способ – закрыть страницы от индексации в файле robots.txt.
Рекомендации по составлению файла robots.txt приведены в справках «Яндекса» и Google:
- https://yandex.ru/support/webmaster/controlling-robot/
- https://support.google.com/webmasters/answer/6062608?hl=ru
После корректировки файла, протестируйте его например, «Яндекс.Вебмастере» в разделе «Анализ Robots.txt». У Google есть аналогичный инструмент, но доступен он только после подтверждения прав на конкретный сайт.
Замечу, что robots.txt – это лишь набор правил для поисковых роботов, и иногда они могут не сработать. Тогда запрещенные для индексации страницы все равно попадут в поиск.
Поэтому лучше подстраховаться и запретить доступ к определенным разделам/директориям при помощи соответствующих кодов ответа сервера (например, ), то есть сделать разделы доступными только при авторизации.
Как подтвердить права сайта в Яндекс.Вебмастер
Это равнозначное понятие с запросом, как добавить сайт в Яндекс.Вебмастер или пройти верификацию. Для этого необходимо воспользоваться следующей ссылкой. Сервис откроется при условии, что вы авторизированы в аккаунте Яндекса. Проще говоря, у вас зарегистрирована почта на Яндекс.
- через размещение специального HTML-файла в корневой папке сайта на хостинге,
- через добавление мета-тега в код главной страницы сайта,
- через DNS-запись.
На мой взгляд для новичков проще всего воспользоваться первым вариантом: скачать предложенный файл на сервисе и загрузить в корневую папку сайта на хостинг. Обычно эта папка называется public_html. Повторяться, как это сделать, я не буду, т.к. у меня уже есть статья с пошаговой инструкцией, .
Второй вариант использовать тоже можно, при условии, что вы умеете работать с кодом веб-площадки. А вот про третий вариант нет информации даже в обучающем курсе самого Яндекса со ссылкой на то, что делать настройку через DNS сложно. Лично я всегда пользовалась вариантом №1.
Верификация сайта также позволяет показать Яндекс.Вебмастер, что вы действительно являетесь владельцем заявленной площадки.
Когда права подтверждены, самое время научиться пользоваться сервисом. Все возможности Вебмастера находятся в меню личного кабинета. Предлагаю рассмотреть их по порядку. Возможно, что вы читаете эту статью спустя какое-то время, и произошли изменения. Тем не менее основная информация всегда остается неизменной.




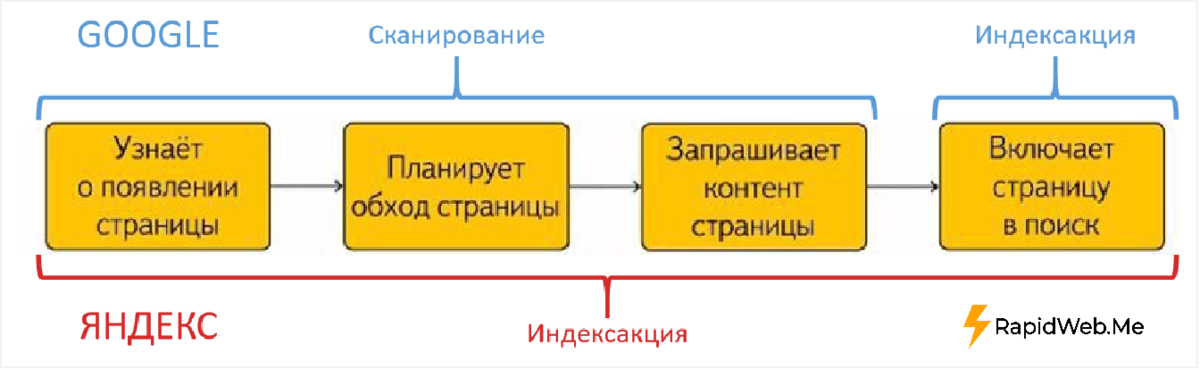

Нестандартные Директивы
Google не понимаю эту директиву. Указывает роботу, что URL страницы содержит GET-параметры, которые не нужно учитывать при индексировании. Такими параметрами могут быть идентификаторы сессий, пользователей, метки UTM, т.е. все то что не влияет на содержимое страницы.
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска. Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы, в которых параметр используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница:
example.com/dir/bookname?ref=site_1 example.com/dir/bookname?ref=site_2 example.com/dir/bookname?ref=site_3
Если указать директиву следующим образом:
User-agent: Yandex Clean-param: ref /dir/bookname
то робот Яндекса сведет все адреса страницы к одному:
example.com/dir/bookname
Пример очистки нескольких параметров сразу: и :
Clean-param: ref&sort /dir/bookname
Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. Если директив указано несколько, все они будут учтены роботом.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif
Google не понимает эту директиву. Таймаут его роботам можно указать в панели вебмастера.
Яндекс перестал учитывать Crawl-delay
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Для чего была нужна директива Crawl-delay
Когда робот сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты». Для этого можно использовать директиву Crawl-delay. Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Google Директиву Host никогда не поддерживал, а Яндекс полностью отказывается от неё. Host можно смело удалять из robots.txt. Вместо Host нужно настраивать 301 редирект со всех зеркал сайта на главный сайт (главное зеркало).
4.Работа с файлами Sitemap.xml и Robots.txt
Важно. Оба данных файла заполняются только для главных страниц сайта
Настройки будут распространяться на все страницы в подпапках, которые будут указаны в списке страниц Sitemap. Остальные страницы (которые не попали в список) могут быть индексированы как часть вашего основного сайта, как совершенно отдельный сайт или не быть проиндексированы совсем.Поддомен и страницы на нём распознаются системой как отдельный сайт. Поэтому для каждого поддомена необходимо составлять свой Sitemap.xml и Robots.txt.Для одностраничных сайтов заполнять Sitemap.xml и Robots.txt не обязательно,т.к. данные файлы созданы в первую очередь для работы с многостраничными сайтами.
Sitemap.xml
Sitemap помогает поисковикам определить список страниц сайта, время их последнего обновления, частоту обновления и важность относительно других страниц сайта для того, чтобы поисковики смогли более разумно провести индексацию
Подробную схему описания sitemap.xml можно найти на этой странице – https://www.sitemaps.org/ru/protocol.htmlЕсли у вас нет опыта в создании sitemap, или специалиста, который может это сделать — рекомендуем воспользоваться одним из бесплатных генераторов sitemap, который сделает это за вас
Обратите внимание, что карта генератором создаётся из ссылок, которые есть на главной странице. Если на основной странице нет ссылки на какую-то страницу в подпапке, то она может быть не включена в sitemap
Примеры генераторов: https://gensitemap.ru/ https://www.mysitemapgenerator.com/Инструкция по генератору mysitemapgenerator.com:
Введите полный адрес сайта, например, https://domen.ru/ и нажмите «Старт!»
Нажмите на кнопку «Скачать» и далее снова «Скачать»
Откройте скачанный файл через блокнот (обязательно данным способом, чтобы не появились сторонние символы)
Проверьте, что в файле есть все необходимые страницы. Адреса расположены между тегами ссылка
Скопируйте содержимое файла
Важно скопировать текст полностью, не пропустив ни символа. Пример:
![]()
При добавлении новой страницы к сайту необходимо ее прописывать в sitemap.xml вручную или создать файл заново через генератор, чтобы поисковые системы быстрее проиндексировали страницу и распознали её как часть сайта.После этого добавляем нашу созданную карту сайта и сохраняем изменения:
![]()
Robots.txt
Robots.txt —текстовый файл, ограничивающий поисковым роботам доступ к содержимому сайта.
Файл состоит из набора инструкций, при помощи которых можно указать страницы для запрета индексации, указать главное зеркало и sitemap.xml. Для правильной настройки рекомендуем использовать рекомендации от Яндекс () и Google (https://support.google.com/webmasters)
Если не существует файла robots.txt, то поисковые роботы будут индексировать ваш сайт полностью. Если же такой файл существует, то роботы будут руководствоваться правилами, которые в этом файле прописываются.
Некоторые сервисы для веб-мастеров, например, Яндекс, могут требовать наличие данного файла в обязательном порядке. Если вы планируете работать с поисковой выдачей, то желательно robots.txt заполнить.Пример стандартного содержимого файла при условии, что все страницы сайта открыты для индексации:
Прописать sitemap.xml и robots.txt можно в настройках страницы, на вкладке «Поисковая оптимизация»:
![]()
Особенности работы с поисковыми системами
Яндекс и Гугл – два наиболее популярных поисковика в России и СНГ. В основном люди, работающие с информационными проектами, стараются оптимизировать их именно под эти сервисы.
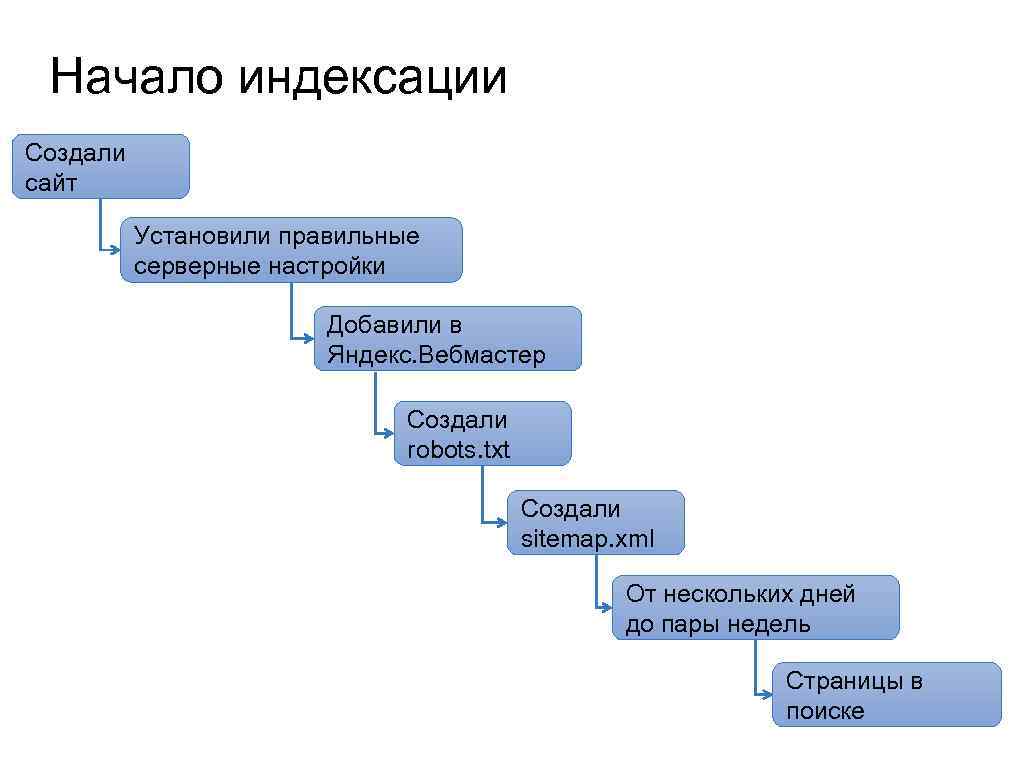
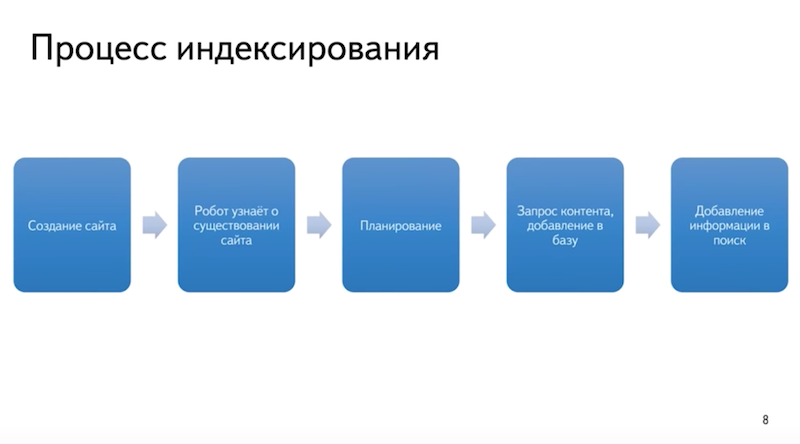
Когда вы только создаете свой сайт, то поисковые системы еще ничего не знают о нем. Поэтому для того, чтобы ресурс попал в поисковую выдачу, вы должны каким-то образом сообщить сервисам о том, что он существует.
Для этого можно использовать два способа:
Способ 1. Разместить ссылку на каких-то сторонних проектах.
В этом случае проект будет проиндексирован максимально быстро. Поисковик посчитает, что ваш сайт полезный и интересный, поэтому он сразу направит роботов для анализа содержимого.
Способ 2. Сообщить поисковикам о ресурсе при помощи специальных инструментов.
В Яндексе и Гугле есть специальные сервисы для вебмастеров. С их помощью вы сможете отслеживать состояние своих ресурсов относительно поисковых систем: смотреть статистику, количество показов, кликов, добавленные или удаленные страницы и т. д.
При добавлении сайта в эти инструменты вы сообщаете поисковикам о том, что проект существует. И если нет никаких запретов через Robots.txt или мета-теги, то он будет проиндексирован и добавлен в выдачу.
Срок добавления сайта в базу данных может быть разным: от нескольких дней до недели. Но обычно с этим не затягивают, особенно если ресурс добавлен в Yandex.Webmaster и Search Console.
Не забывайте, что добавление в базу данных – еще не означает, что материалы сайта сразу будут доступны по определенным запросам. Для этого может понадобиться дополнительное время. Роботы тщательно изучат содержимое проекта, и только после этого статьи будут доступны к показу по запросам.


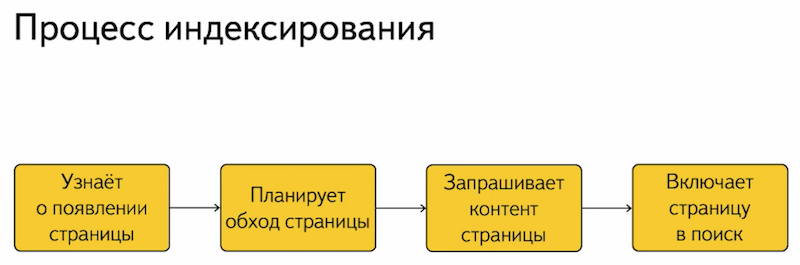


Если вы решите не открывать ресурс сразу, а подождать, пока он заполнится определенным количеством материалов, то после отправки на анализ может пройти чуть больше времени. То есть, чем больше информации на проекте, тем дольше придется ждать полной индексации.
В среднем между отправкой сайта в сервис и появлением статей в выдаче проходит 1 – 2 недели.
Помимо вышеописанных способов добавления ресурса в поисковую базу, существует еще один, менее эффективный. Вам просто нужно ввести в поисковую строку следующие команды:
- Для Яндекса: Host: Название + site.ru.
- Для Google: Site: Название + site.ru, где site.ru – ваш домен.
Также вы можете попробовать добавить ресурс при помощи автоматических сервисов. Какой будет результат – неизвестно. Но я полагаю, что эти сервисы просто воспользуются командами или размещением ссылки где-либо.
Директивы, использующиеся в создании robots.txt
* (звездочка) означает любое количество знаков. Иногда она ставится на месте пропущенных символов. Завершать код звездочкой нет необходимости. Ее нахождение там учитывается в любом случае.
После $ (знака доллара) символы уже не идут. Он всегда завершает код.
# (решетка) разделяет индексируемые роботом и неиндексируемые документы. Все, что после, поисковиком не определяется.
Disallow закрывает от индексации web-документы и разделы сайтов. Allow необходима для того, чтобы Yandex, Google или другой поисковик обязательно проиндексировал целевые страницы.
Disallow: *?s=
Disallow: /category/$
Не индексируемые URL:
http://name.com/?s=
http://name.com/?s=keyword
http://name.com/page/?s=keyword
http://name.com/category/
Индексируемые URL:
http://name.com/category/cat1/
http://name.com/category-folder/
Порядок указанных в файле директив не играет роли. Важнее местоположение директорий в коде.
Allow: *.css
Disallow: /template/
http://name.com/template/ — не определяется поисковиками
http://name.com/template/style.css — так же не видит поисковый робот
http://name.com/style.css — индексируется
http://name.com/theme/style.css — видно поисковому роботу
Есть ситуации, когда для индексирования необходимо указывать Allow в каждой папке, закрытой от поискового робота. Так стоит сделать для таблиц стилей, определяющих сайт уникальным.
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Если необходимо скрыть от поисковых роботов весь сайт, прописывается
User-agent: *
Disallow: /
Директива Sitemap включается в код файла для указания пути, ведущего к файлу Sitemap. Адрес страницы совпадает с указанным в строке браузера.
Sitemap: http://shop.com/sitemap.xml
В этом случае также не важно, где в файле robots.txt находится директива. Директива Host указывает, что является основным зеркалом ресурса
Она актуальна для определения в случае с вариантами, имеющими www или не содержащими www. Необходима для индексации поисковыми роботами Mail и Yandex. Для остальных поисковиков директива бесполезна. Основное зеркало при этом содержит https://, но не включает http://. Иногда требуется прописать порт сайта.
Директива Host указывает, что является основным зеркалом ресурса. Она актуальна для определения в случае с вариантами, имеющими www или не содержащими www. Необходима для индексации поисковыми роботами Mail и Yandex. Для остальных поисковиков директива бесполезна. Основное зеркало при этом содержит https://, но не включает http://. Иногда требуется прописать порт сайта.
Host: domen.com
Host: https://domen.com
Интервал, в течение которого поисковые машины скачивают страницы, определяет директива Crawl-delay. Необходима для больших магазинов или порталов, нагружающих работу сервера. Одностраничники могут обойтись без Crawl-delay. Не влияет на Google. Работает с Mail, Yahoo, Yandex, Bing. Поддерживается поисковыми машинами Яндекса, Mail.Ru, Bing, Yahoo. Время указывается в секундах. Может быть дробным.
Crawl-delay: 2
Crawl-delay: 1.5
Временной промежуток для скачивания страниц индивидуален для конкретного сайта. Чем больше стоит цифра, тем меньше страниц поисковик загрузит в течение одной сессии. Наиболее подходящее время подбирается для каждого сайта путем тестирования. Лучше начинать с маленьких значений — 0.1, 0.3, 0.4. Впоследствии можно их наращивать. Поисковые машины Mail.Ru, Bing и Yahoo сразу предполагают меньшие показатели. В связи с этим с самого начала для них стоит указывать большие цифры, чем для роботов Яндекса.
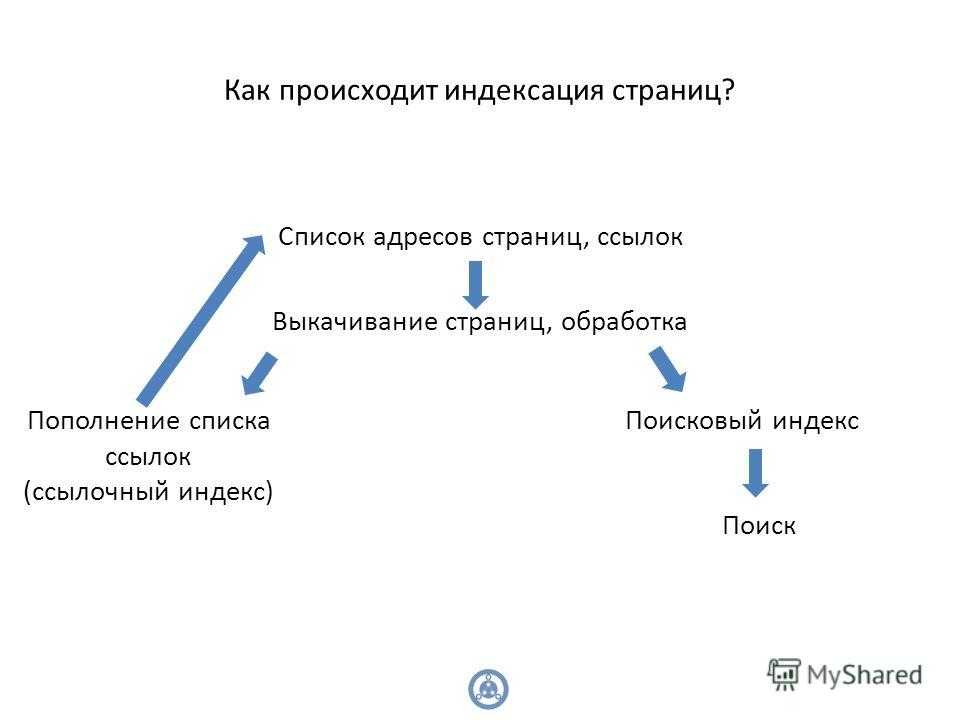



Директива Clean-param прописывается исключительно для роботов “Яндекса”. Включает параметр страниц и адреса разделов. Закрывает от индексации URL с обозначенными в коде признаками.
Clean-param: book_id http://name.com/documents/
Clean-param: book_id&sid http://name.com/documents/
Clean-param способна скрыть от поисковых машин идентификаторы сессий и UTM-метки.
Clean-Param: utm_file&utm_name&utm_campaign
Как закрыть сайт от индексации
Для этого мы можем использовать два способа:
Через Robots.txt
Просто нужно удалить все содержимое этого файла, добавив вместо него:
User-agent: *
Disallow: /
С помощью этой строчки вы скажете всем поисковым роботам, что ваш ресурс индексировать не нужно – ни одной странички. Если до этого какие-то материалы попали в ранжирование – они будут удалены.
Также можно запретить индексацию для роботов какой-то отдельной поисковой системы. Для этого вместо звездочки, в User-agent: вы должны ввести название этого робота. Например, Yandex – для Яндекса, Googlebot – для Google.
Когда вы передумаете, вам нужно будет просто удалить этот код и добавить вместо него нормальное содержимое файла.
С помощью мета-тегов
На каждой странице должны быть размещены следующие мета-теги:
<meta name=»robots» content=»noindex, nofollow»/>
<meta name=»Yandex» content=»noindex, nofollow»/> – если хотим закрыть для какой-то конкретной ПС, то в поле name вставляем имя робота.
Разместить такие мета-теги можно при помощи плагина Yoast SEO. В нем есть отдельные параметры, которые отвечают за индексацию. Можно закрыть как отдельную страницу, так и весь ресурс в целом.
Закрывать от индексации отдельные страницы при помощи мета-тегов считается хорошим тоном. Это и проще, и быстрее – не надо по многу раз дополнять файл robots.txt.
Принципы ранжирования в поисковых системах
Ранжирование
– это вывод сайтов на страницах поисковых систем в определенной
последовательности в ответ на какой-либо запрос пользователя. Принято выделять
внутренние и внешние принципы ранжирования. Рассмотрим каждую группу по
отдельности.
Внутренние
принципы ранжирования. Внутренние принципы ранжирования подчинены действиям владельца сайта. Они
учитывают:
- объем информации на странице
сайта; - количество, плотность и
расположение ключевых слов и фраз на странице интернет-ресурса; - стилистику представленного на
странице текста; - наличие ключевых слов в теге
Title и в ссылках; - содержание ключевых слов в
мета-тегах Description; - общее количество страниц сайта.
Внешние
принципы ранжирования учитывают:
- Индекс цитирования (оценивает
популярность сайта). - Ссылочный текст (внешние
ссылки, которые ведут на сайт). - Релевантность ссылающихся
страниц (оценка информации ссылающейся страницы). - Google PageRank (теоретическая
посещаемость страницы). - Тематический индекс цитирования
Яндекс (авторитетность сайта относительно других близких ему
интернет-ресурсов). - Добавление информации о сайте
(самбит) в каталоги общего назначения, каталог DMOZ, Каталог Яндекса. - Обмен ссылками между сайтами.
Таким
образом, мы представили некоторую информацию, касающуюся специфики работы
поисковых систем. Однако следует учесть тот факт, что алгоритм их работы
претерпевает различные изменения, поэтому информация о поисковых системах
является весьма динамичной и требует постоянного анализа со стороны
seo-специалистов.
Заключение
Для того, чтобы ваш сайт хорошо индексировался, вы должны соблюдать совсем несложные требования. Нужно просто добавить его в Яндекс Вебмастер и Search Console, следить за регулярным выходом качественных материалов, своевременно исправлять ошибки и не нарушать правил.
Все это гарант того, что ваш проект будет на хорошем счету у роботов. А это, в свою очередь, будет иметь материальное значение. Ваши статьи будут выше в выдаче, дохода будет больше.
Некоторым новичкам бывает очень сложно разобраться со всеми тонкостями SEO-оптимизации. Очень много разной информации и не всегда она правильная. Если вы один из таких новичков, то я рекомендую вам пройти курс Василия Блинова “Как создать сайт”.
Из материалов с этого курса вы сможете узнать о том, как создать собственный информационный проект под монетизацию. Там рассмотрены наиболее важные нюансы, которые должен учитывать каждый вебмастер.



