
Setting base URLs
Suppose you are only using one API hosted at api.org. You’ll end up repeating
the protocol and domain for every http call:
requests.get('https://api.org/list/')
requests.get('https://api.org/list/3/item')
You can save yourself some typing by using
.
This allows you to specify the base url for the HTTP client and to only specify
the resource path at the time of the request.
from requests_toolbelt import sessions
http = sessions.BaseUrlSession(base_url="https://api.org")
http.get("/list")
http.get("/list/item")
Note that the requests toolbelt isn’t
included in the default requests installation, so you’ll have to install it
separately.
Использование Translate API
Теперь перейдем к чему-то более интересному. Мы используем API Яндекс.Перевод (Yandex Translate API) для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, нужно предварительно войти в систему. После входа в систему перейдите к Translate API и создайте ключ API. Когда у вас будет ключ API, добавьте его в свой файл в качестве константы. Далее приведена ссылка, с помощью которой вы можете сделать все перечисленное: https://tech.yandex.com/translate/
script.py
Ключ API нужен, чтобы Яндекс мог проводить аутентификацию каждый раз, когда мы хотим использовать его API. Ключ API представляет собой облегченную форму аутентификации, поскольку он добавляется в конце URL запроса при отправке.
Чтобы узнать, какой URL нам нужно отправить для использования API, посмотрим документацию Яндекса.
Там мы найдем всю информацию, необходимую для использования их Translate API для перевода текста.
![]()
Если вы видите URL с символами амперсанда (&), знаками вопроса (?) или знаками равенства (=), вы можете быть уверены, что это URL запроса GET. Эти символы задают сопутствующие параметры для URL.
Обычно все, что размещено в квадратных скобках ([]), будет необязательным. В данном случае для запроса необязательны формат, опции и обратная связь, но обязательны параметры key, text и lang.
Добавим код для отправки на этот URL. Замените первый созданный нами запрос на следующий:
script.py
Существует два способа добавления параметров. Мы можем прямо добавить параметры в конец URL, или библиотека Requests может сделать это за нас. Для последнего нам потребуется создать словарь параметров. Нам нужно указать три элемента: ключ, текст и язык. Создадим словарь, используя ключ API, текст и язык , т. к. нам требуется перевод с английского на испанский.
Другие коды языков можно посмотреть здесь. Нам нужен столбец 639-1.
Мы создаем словарь параметров, используя функцию , и передаем ключи и значения, которые хотим использовать в нашем словаре.
script.py
Теперь возьмем словарь параметров и передадим его функции .
script.py
Когда мы передаем параметры таким образом, Requests автоматически добавляет параметры в URL за нас.
Теперь добавим команду печати текста ответа и посмотрим, что мы получим в результате.
script.py
![]()
Мы видим три вещи. Мы видим код состояния, который совпадает с кодом состояния ответа, мы видим заданный нами язык и мы видим переведенный текст внутри списка. Итак, мы должны увидеть переведенный текст .
Повторите эту процедуру с кодом языка en-fr, и вы получите ответ .
script.py
![]()
Посмотрим заголовки полученного ответа.
script.py
![]()
Разумеется, заголовки должны быть другими, поскольку мы взаимодействуем с другим сервером, но в данном случае мы видим тип контента application/json вместо text/html. Это означает, что эти данные могут быть интерпретированы в формате JSON.
Если ответ имеет тип контента application/json, библиотека Requests может конвертировать его в словарь и список, чтобы нам было удобнее просматривать данные.
Для обработки данных в формате JSON мы используем метод на объекте response.
Если вы распечатаете его, вы увидите те же данные, но в немного другом формате.
script.py
![]() Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Допустим, нам нужно получить доступ к тексту. Поскольку сейчас это словарь, мы можем использовать ключ текста.
script.py
![]() Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
script.py
![]()
Теперь мы видим только переведенное слово.
Разумеется, если мы изменим параметры, мы получим другие результаты. Изменим переводимый текст с на , изменим язык перевода на испанский и снова отправим запрос.




script.py
![]() Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
Custom Headers¶
If you’d like to add HTTP headers to a request, simply pass in a to the
parameter.
For example, we didn’t specify our user-agent in the previous example:
>>> url = 'https://api.github.com/some/endpoint'
>>> headers = {'user-agent' 'my-app/0.0.1'}
>>> r = requests.get(url, headers=headers)
Note: Custom headers are given less precedence than more specific sources of information. For instance:
-
Authorization headers set with headers= will be overridden if credentials
are specified in , which in turn will be overridden by the
parameter. Requests will search for the netrc file at ~/.netrc, ~/_netrc,
or at the path specified by the NETRC environment variable. -
Authorization headers will be removed if you get redirected off-host.
-
Proxy-Authorization headers will be overridden by proxy credentials provided in the URL.
-
Content-Length headers will be overridden when we can determine the length of the content.
Furthermore, Requests does not change its behavior at all based on which custom headers are specified. The headers are simply passed on into the final request.
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать
с помощью параметра timeout
Перейдите на
раздел — / #/ Dynamic_data / delete_delay__delay_
и изучите документацию — если делать запрос на этот url можно выставлять время, через которое
будет отправлен ответ.
Создайте файл timeout_demo.py следующего содержания
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
python3 tiemout_demo.py
<Response >
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
python3 tiemout_demo.py
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request
six.raise_from(e, None)
File «<string>», line 3, in raise_from
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request
httplib_response = conn.getresponse()
File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse
response.begin()
File «/usr/lib/python3.8/http/client.py», line 307, in begin
version, status, reason = self._read_status()
File «/usr/lib/python3.8/http/client.py», line 268, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1»)
File «/usr/lib/python3.8/socket.py», line 669, in readinto
return self._sock.recv_into(b)
File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into
raise timeout(«The read operation timed out»)
socket.timeout: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send
resp = conn.urlopen(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen
retries = retries.increment(
File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment
raise six.reraise(type(error), error, _stacktrace)
File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise
raise value
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen
httplib_response = self._make_request(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «timeout_demo.py», line 4, in <module>
r = requests.get(‘https://httpbin.org/delay/7’, timeout=3)
File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если такая обработка исключений не вызывает у вас восторга — измените код используя try except
python3 tiemout_demo.py
Response is taking too long.
Асинхронность
Как объяснялось ранее, requests полностью синхронен. Он блокирует приложение в ожидании ответа сервера, замедляя работу программы. Создание HTTP-запросов в потоках является одним из решений, но потоки имеют свои собственные накладные расходы, и это подразумевает параллелизм, который не всегда каждый рад видеть в программе.
Начиная с версии 3.5, Python предлагает асинхронность внутри своего ядра, используя aiohttp. Библиотека aiohttp предоставляет асинхронный HTTP-клиент, построенный поверх asyncio. Эта библиотека позволяет отправлять запросы последовательно, но не дожидаясь первого ответа, прежде чем отправлять новый. В отличие от конвейерной передачи HTTP, aiohttp отправляет запросы по нескольким соединениям параллельно, избегая проблемы, описанной ранее.
Использование aiohttp
import aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return response
loop = asyncio.get_event_loop()
coroutines = [get("http://example.com") for _ in range(8)]
results = loop.run_until_complete(asyncio.gather(*coroutines))
print("Results: %s" % results)
Все эти решения (с использованием Session, thread, futures или asyncio) предлагают разные подходы к ускорению работы HTTP-клиентов. Но какая между ними разница с точки зрения производительности?
Получение списка заголовков из ответа
Заголовки получаемого из ответа обычно также содержат важную информацию о типе данных, отправляемых обратно с сервера, а также о статусе ответа. Мы можем получить список заголовков из самого объекта ответа. Давайте посмотрим на фрагмент кода, который представляет собой немного измененную версию последней программы:
import http.client
import pprint
connection = http.client.HTTPSConnection("www.journaldev.com")
connection.request("GET", "/")
response = connection.getresponse()
headers = response.getheaders()
pp = pprint.PrettyPrinter(indent=4)
pp.pprint("Headers: {}".format(headers))
Посмотрим на результат этой программы:
![]()
Тело сообщения
В соответствии со спецификацией HTTP, , , и менее распространенные запросы передают свои данные через тело сообщения , а не через параметры в строке запроса. Используя , вы передадите полезную нагрузку параметру соответствующей функции .
принимает словарь, список кортежей, байтов или файлоподобный объект. Вы захотите адаптировать данные, которые вы отправляете в теле запроса, к конкретным потребностям службы, с которой вы взаимодействуете.
Например, если тип контента вашего запроса – , вы можете отправить данные формы в виде словаря:
Вы также можете отправить те же данные в виде списка кортежей:
Однако если вам необходимо отправить данные JSON, вы можете использовать этот параметр. Когда вы передадите данные JSON через , сериализует ваши данные и добавит правильный заголовок для вас.
httpbin.org большой ресурс , созданный автором – Kenneth Reitz . Это сервис, который принимает тестовые запросы и отвечает данными о запросах. Например, вы можете использовать его для проверки основного запроса:
Из ответа вы можете видеть, что сервер получил данные вашего запроса и заголовки по мере их отправки. также предоставляет эту информацию вам в форме .








Retry on failure
Network connections are lossy, congested and servers fail. If we want to build
a truly robust program we need to account for failures and have a retry
strategy.
Add a retry strategy to your HTTP client is straightforward. We create a
HTTPAdapter and pass our strategy to the adapter.
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
retry_strategy = Retry(
total=3,
status_forcelist=429, 500, 502, 503, 504],
method_whitelist="HEAD", "GET", "OPTIONS"
)
adapter = HTTPAdapter(max_retries=retry_strategy)
http = requests.Session()
http.mount("https://", adapter)
http.mount("http://", adapter)
response = http.get("https://en.wikipedia.org/w/api.php")
The default Retry class offers sane defaults, but is highly configurable so
here is a rundown of the most common parameters I use.
The parameters below include the default parameters the requests library uses.
total=10
The total number of retry attempts to make. If the number of failed requests or
redirects exceeds this number the client will throw the
exception. I vary this parameter based on
the API I’m working with, but I usually set it to lower than 10, usually 3
retries is enough.
status_forcelist=413, 429, 503
The HTTP response codes to retry on. You likely want to retry on the common
server errors (500, 502, 503, 504) because servers and reverse proxies don’t
always adhere to the HTTP spec. Always retry on 429 rate limit exceeded because
the urllib library should by default incrementally backoff on failed requests.
method_whitelist="HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"
The HTTP methods to retry on. By default this includes all HTTP methods except
POST because POST can result in a new insert. Modify this parameter to
include POST because most API’s I deal with don’t return an error code and
perform an insert in the same call. And if they do, you should probably issue a
bug report.
backoff_factor=
This is an interesting one. It allows you to change how long the processes will
sleep between failed requests. The algorithm is as follows:
{backoff factor} * (2 ** ({number of total retries} - 1))
For example, if the backoff factor is set to:
- 1 second the successive sleeps will be .
- 2 seconds —
- 10 seconds —
The value is exponentially increasing which is a sane default
implementation for retry
strategies.
This value is by default 0, meaning no exponential backoff will be set and
retries will immediately execute. Make sure to set this to 1 in to avoid
hammering your servers!.
The full documentation on the retry module is
.
Combining timeouts and retries
Since the HTTPAdapter is comparable we can combine retries and timeouts like
so:
retries = Retry(total=3, backoff_factor=1, status_forcelist=429, 500, 502, 503, 504])
http.mount("https://", TimeoutHTTPAdapter(max_retries=retries))
Pip install Requests into a Virtual Directory
You should always work in a virtual environment to prevent conflicts. You can use pip to install a specific version of the Requests module into a Virtualenv environment for Python 2 or Venv for Python 3 projects.
Syntax
Assuming that you are working in Python 3, you can set up a virtual directory for a project with the following command:
python3 -m venv <path_to_env>
venv will create a virtual Python installation in the <env_name> folder.
Activate <env_name> with the following command:
Linux:
source <env_name>/bin/activate
Windows:
.\env\Scripts\activate
You can pip install Requests into your virtual environment with the following command:
python -m pip install requests
Ограничения urllib.request¶
-
В настоящее время поддерживаются только следующие протоколы: HTTP (версии 0.9
и 1.0), FTP, локальные файлы и URL-адреса данных.Изменено в версии В: 3.4 добавлена поддержка data URL.
-
Функция кэширования была отключена до тех пор, пока кто-
нибудь не найдет время, чтобы взломать правильную обработку заголовков
времени истечения срока действия. -
Должна быть функция для запроса, есть ли конкретный URL-адрес в кеше.
-
Для обратной совместимости, если URL-адрес указывает на локальный файл, но
файл не открывается, URL-адрес повторно интерпретируется с использованием
протокола FTP. Иногда это может вызывать сбивающие с толку сообщения об
ошибках. -
Функции и могут вызывать сколь угодно
большие задержки при ожидании установки сетевого подключения. Это означает,
что сложно создать интерактивный веб-клиент, использующий эти функции, без
использования потоков. -
Данные, возвращаемые или , являются
необработанными данными, возвращаемыми сервером. Это могут быть двоичные
данные (например, изображение), простой текст или (например) HTML. Протокол
HTTP предоставляет информацию о типе в заголовке ответа, который можно
проверить, просмотрев заголовок Content-Type. Если возвращенные
данные представляют собой HTML, вы можете использовать модуль
для их анализа. -
Код, обрабатывающий протокол FTP, не может различать файл и каталог. Это
может привести к неожиданному поведению при попытке прочитать URL-адрес,
указывающий на недоступный файл. Если URL-адрес заканчивается на ,
предполагается, что он относится к каталогу и будет обработан соответствующим
образом. Но если попытка прочитать файл приводит к ошибке 550 (это означает,
что URL-адрес не может быть найден или недоступен, часто по причинам
разрешения), то путь обрабатывается как каталог, чтобы обработать случай,
когда каталог указан. по URL-адресу, но конечный был опущен. Это может
привести к ошибочным результатам при попытке получить файл, права на чтение
которого делают его недоступным; код FTP попытается прочитать его, выдаст
ошибку 550, а затем выполнит список каталогов для нечитаемого файла. Если
требуется детальный контроль, рассмотрите возможность использования модуля
, создания подкласса или изменения
_urlopener в соответствии с вашими потребностями.
Проверка вашего запроса
Когда вы делаете запрос, библиотека подготавливает запрос перед фактической отправкой его на целевой сервер. Подготовка запроса включает в себя такие вещи, как проверка заголовков и сериализация содержимого JSON.
Вы можете просмотреть , зайдя в :
Проверка дает вам доступ ко всей информации о выполняемом запросе, такой как полезная нагрузка, URL, заголовки, аутентификация и многое другое.
До сих пор вы делали много разных видов запросов, но у них всех было одно общее: это неаутентифицированные запросы к публичным API. Многие службы, с которыми вы можете столкнуться, захотят, чтобы вы каким-то образом проходили аутентификацию.
Производительность
Ниже приведен фрагмент HTTP-клиента, отправляющего запросы на httpbin.org, HTTP-API, который обеспечивает (среди прочего) конечную точку, имитирующую длинный запрос. Этот пример реализует все методы, перечисленные выше.
Программа для сравнения производительности использования различных запросов
import contextlib
import time
import aiohttp
import asyncio
import requests
from requests_futures import sessions
URL = "http://httpbin.org/delay/1"
TRIES = 10
@contextlib.contextmanager
def report_time(test):
t0 = time.time()
yield
print("Time needed for `%s' called: %.2fs"
% (test, time.time() - t0))
with report_time("serialized"):
for i in range(TRIES):
requests.get(URL)
session = requests.Session()
with report_time("Session"):
for i in range(TRIES):
session.get(URL)
session = sessions.FuturesSession(max_workers=2)
with report_time("FuturesSession w/ 2 workers"):
futures =
for f in futures:
f.result()
session = sessions.FuturesSession(max_workers=TRIES)
with report_time("FuturesSession w/ max workers"):
futures =
for f in futures:
f.result()
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await response.read()
loop = asyncio.get_event_loop()
with report_time("aiohttp"):
loop.run_until_complete(
asyncio.gather(*))
Запуск этой программы дает следующий вывод:
Time needed for `serialized' called: 12.12s Time needed for `Session' called: 11.22s Time needed for `FuturesSession w/ 2 workers' called: 5.65s Time needed for `FuturesSession w/ max workers' called: 1.25s Time needed for `aiohttp' called: 1.19s
Не удивительно, что более медленный результат приходит с сериализованной версией, поскольку все запросы выполняются один за другим без повторного использования соединения — 12 секунд на 10 запросов.
Использование объекта Session и, следовательно, повторное использование соединения означает экономию 8% времени, что уже является большим и легким выигрышем. Как минимум, вы всегда должны использовать Session.
Если ваша система и программа допускают использование потоков, рекомендуется использовать их для распараллеливания запросов. Однако у потоков есть некоторые накладные расходы, и они не менее весовые. Они должны быть созданы, запущены и затем присоединены.
Если вы не используете старые версии Python, то, без сомнения, использование aiohttp должно быть вашим выбором, если вы хотите написать быстрый и асинхронный HTTP-клиент. Это самое быстрое и масштабируемое решение, поскольку оно может обрабатывать сотни параллельных запросов.
Как передать параметры в URL?
Нередко приходится передавать параметры, используя URL-адрес. Если настройка осуществляется непосредственно в нем, то данные передаются по следующему образцу: httpbin.org/get?key=val. То есть, записывается метод запроса, потом пишется ключ, а затем – его значение.
Ничего не напоминает? Правильно, словарь Python, где информация хранится в таком же виде. Для этого применяется аргумент params. Например, нам требуется передать такие ключи ресурсу httpbin.org/get : key1=value1, key2=value2.






Чтобы это сделать, используется такой код.
payload = {‘key1’: ‘value1’, ‘key2’: ‘value2’}
r = requests.get(‘https://httpbin.org/get’, params=payload)
print(r.url)
Этот код формирует словарь с описанными выше ключами, потом передает их указанному серверу. Ну и, наконец, программа выводит получившийся адрес в консоль. Это нужно сделать, например, для проверки, все ли правильно выводится.
Список также можно передавать в качестве значения. Для этого нужно в соответствующее место словаря поставить квадратные скобки с перечисленными значениями через запятую.
Передача параметров в GET
В некоторых случаях вам нужно будет передавать параметры вместе с вашими запросами GET, которые принимают форму строк запроса. Для этого нам нужно передать эти значения в параметре params, как показано ниже:
import requests
payload = {'user_name': 'admin', 'password': 'password'}
r = requests.get('http://httpbin.org/get', params=payload)
print(r.url)
print(r.text)
Здесь мы присваиваем значения наших параметров переменной полезной нагрузки, а затем – запросу GET через params. Приведенный выше код вернет следующий результат:
http://httpbin.org/get?password=passworduser_name=admin
{"args":{"password":"password","user_name":"admin"},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Host":"httpbin.org","User-Agent":"python-requests/2.9.1"},"origin":"103.9.74.222","url":"http://httpbin.org/get?password=passworduser_name=admin"}
Как видите, библиотека Reqeusts автоматически превратила наш словарь параметров в строку запроса и прикрепила ее к URL-адресу.
Обратите внимание, что вам нужно быть осторожным, какие данные вы передаете через запросы GET, поскольку полезная нагрузка видна в URL-адресе, как вы можете видеть в выходных данных выше.
Customize requests in Python
We can access headers and cookies that servers send back to us and . At the same time we can send our own custom cookies and headers using requests in Python. In the following sections we will discuss how we can customize sending requests in python.
Inserting cookies into requests
To add HTTP cookies to a request, we can simply pass them in a dict to the cookies parameter.
See the example below which demonstrates how to send cookies and headers. We can print out cookies using .
Output:
b'{\n "cookies": {\n "my_cookie": "cookie_value"\n }\n}\n'
Inserting headers into requests
We can send cookies in a similar way as we did for cookies. To add HTTP cookies to a request, we can simply pass them in a dict to the cookies parameter.
See the example below. We can use to print headers.
Output:
b'{\n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "My-Headers": "headers_values", \n "User-Agent": "python-requests/2.20.0", \n "X-Amzn-Trace-Id": "Root=1-6103a3d3-106a9e8d135974dd6b963b0a"\n }\n}\n'
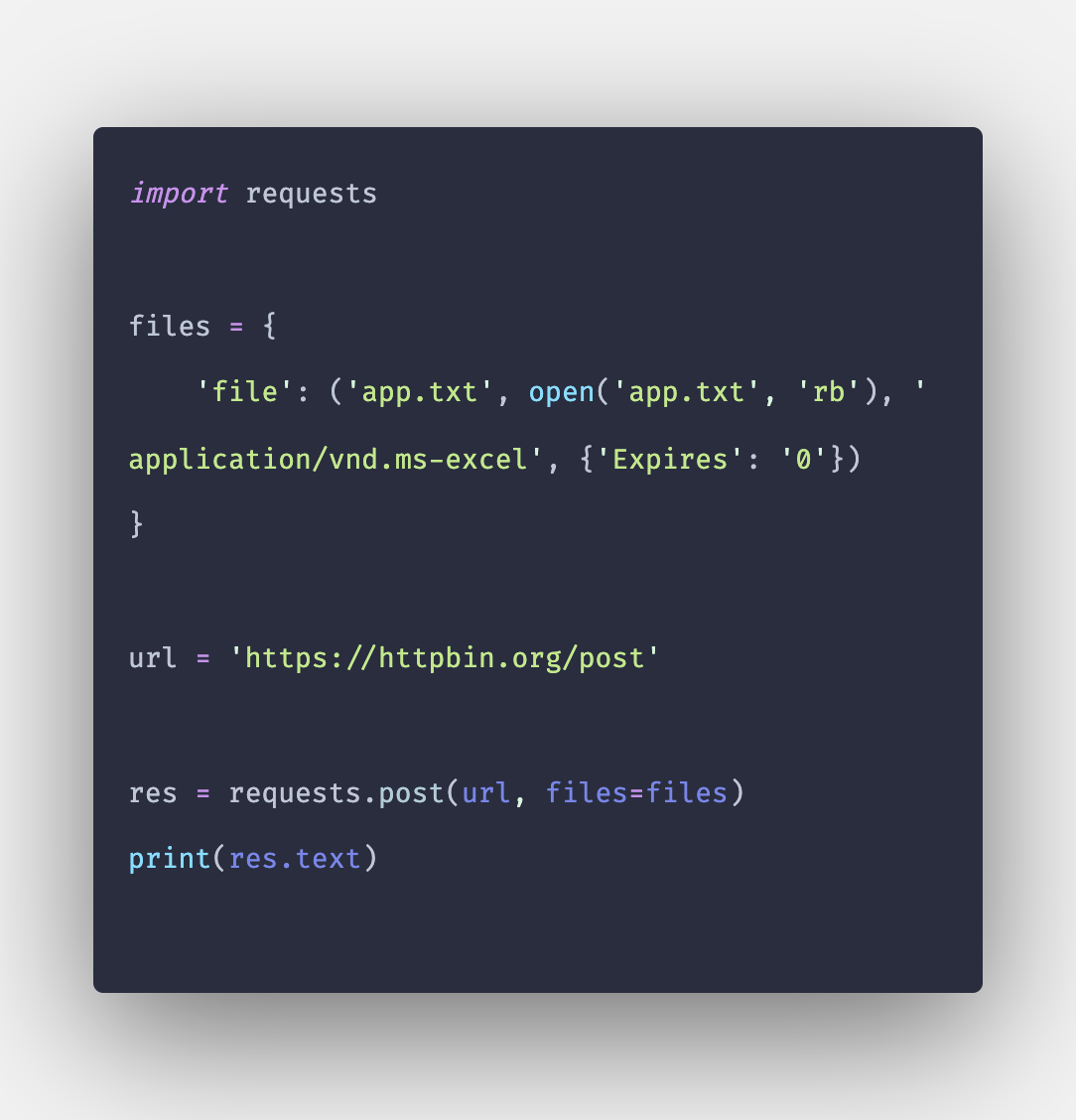
Отправка файлов
Иногда нам нужно отправить на сервер один или несколько файлов одновременно. Например, если пользователь отправляет форму, она включает в себя различные поля формы для загрузки файлов, такие как изображение профиля пользователя, резюме пользователя и т.д. Запросы могут обрабатывать несколько файлов в одном запросе. Этого можно добиться, поместив файлы в список кортежей, как показано ниже:
import requests
url = 'http://httpbin.org/post'
file_list = [
('image', ('image1.jpg', open('image1.jpg', 'rb'), 'image/png')),
('image', ('image2.jpg', open('image2.jpg', 'rb'), 'image/png'))
]
r = requests.post(url, files=file_list)
print(r.text)
Кортежи, содержащие информацию о файлах, имеют форму (field_name, file_information).
Python requests head method
The method retrieves document headers.
The headers consist of fields, including date, server, content type,
or last modification time.
head_request.py
#!/usr/bin/env python
import requests as req
resp = req.head("http://www.webcode.me")
print("Server: " + resp.headers)
print("Last modified: " + resp.headers)
print("Content type: " + resp.headers)
The example prints the server, last modification time, and content type
of the web page.
$ ./head_request.py Server: nginx/1.6.2 Last modified: Sat, 20 Jul 2019 11:49:25 GMT Content type: text/html
This is the output of the program.



