
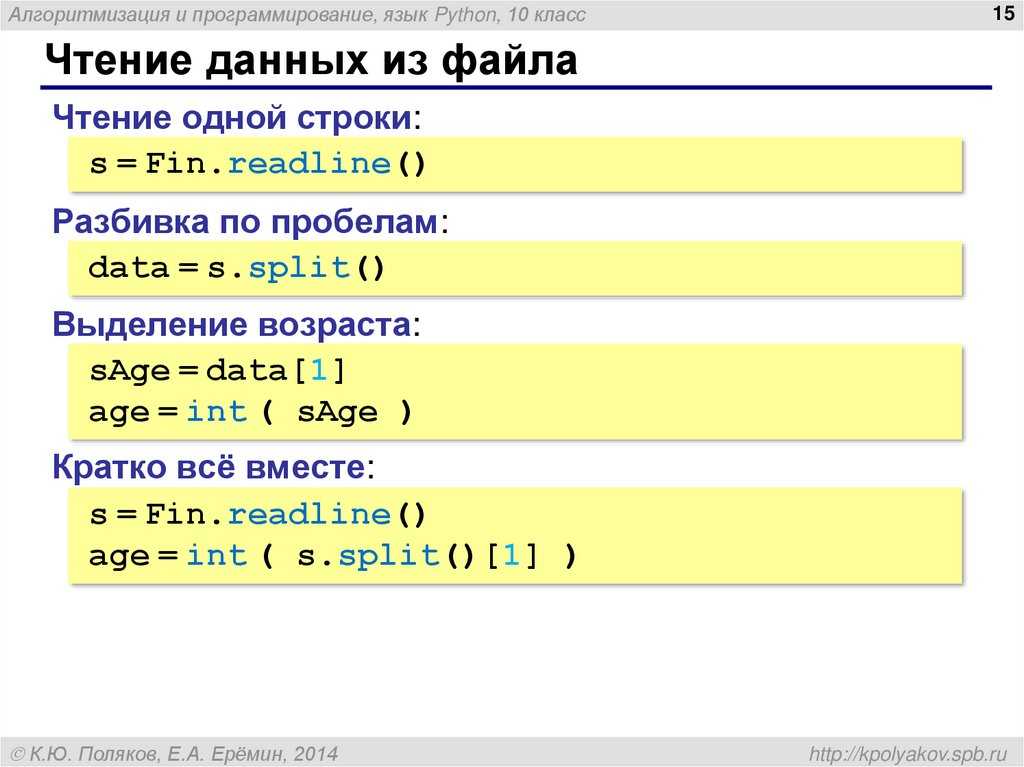
Чтение
Для чтения информации из файла в Python 3, следует вызывать метод read через объект, который ссылается на существующий документ. Также необходимо не забывать указывать «r» в качестве второго параметра функции open при открытии текстового файла.
В следующем примере read возвращает информацию из test.txt в метод print, который затем выводит сведения на экран. Как и прежде, программа завершается закрытием документа при помощи метода close. Метод read также может принимать целочисленный параметр, который используется для передачи количества символов для чтения. К примеру, введя 5, программа прочитает только hello.
try:
file = open("test.txt", "r")
print(file.read())
file.close()
except FileNotFoundError:
print('Not found')
except IOError:
print('Something else')
Обратите внимание, что при открытии может возникнуть ошибка. Например, если указанный файл не найден
Поэтому нам пришлось обработать исключение. В Python можно воспользоваться конструкцией with, в таком случае не надо будет обрабатывать исключения и даже закрывать файл. Её рассмотрим ниже.
Есть еще один момент: нельзя делать закрытие в секции finally блока try. Если произойдет исключение при открытии файла, то в секции finally будет ошибка.
Чтение бинарных данных
В случае, если данные бинарного вида — следует использовать «rb» в функции open. Рассмотрим пример:
try:
f = open("test.dat", "rb")
b = f.read(1)
str = ""
while True:
b = f.read(1)
if b == b'':
break
str += b.hex()
print(str)
f.close()
except IOError:
print('error')
81d182d180d0bed0bad0b0
Здесь побайтно читается файл. Каждый байт приводит к строковому виду в шестнадцатеричном представлении. С помощью функции print выводится результирующая строка.
Режим открытия
Ранее были упомянуты специальные символы, которые используются в языке Python при открытии файла. Они задают режим открытия файла. Указывают программе, как именно нужно открывать. Все они представлены в следующей таблице, которая содержит их сигнатуру и короткое описание назначения.
| Символ | Значение |
| «r» | открытие для чтения (по умолчанию) |
| «w» | открытие для записи, а если его не существует по заданному пути, то создается новый |
| «x» | открытие для записи, но только если его еще не существует, иначе будет выдано исключение |
| «a» | открытие на дополнительную запись, чтобы информация добавлялась в конец документа |
| «b» | открытие в двоичном режиме |
| «t» | открытие в текстовом режиме (по умолчанию) |
| «+» | открытие одновременно на чтение и запись |
Пользуясь вторым аргументом метода open, можно комбинировать различные режимы работы с файлами, указывая, к примеру, «rb» для чтения записанных данных в двоичном режиме.
Еще один пример: отличие «r+» и «w+» заключается в том, что во втором случае создастся новый файл, если такого нет. В первом же случае возникнет исключение. При использовании «r+» и «w+» файл будет открыт и на чтение и на запись. Пример обработки исключения разберем, когда будем рассматривать чтение файла.
2 Word XML document structure
For a basic document that consists of paragraphs of text with some
styles/formatting applied, the XML structure is fairly straightforward.
Here’s the example document:
![]()
And here’s the resulting xml in word/document.xml (you can get this by
simply doing
etree.tostring(xmltree, pretty_print=True)
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mo="http://schemas.microsoft.com/office/mac/office/2008/main" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:mv="urn:schemas-microsoft-com:mac:vml" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="00192975" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:pPr>
<w:pStyle w:val="Heading1"/>
</w:pPr>
<w:r>
<w:t>Test</w:t>
</w:r>
</w:p>
<w:p w:rsidR="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:r>
<w:t>The quick brown fox jumped over the lazy dog.</w:t>
</w:r>
</w:p>
<w:p w:rsidR="00450526" w:rsidRPr="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="00450526" w:rsidRPr="00450526" w:rsidSect="00192975">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>
Some salient points:
- The top tag is <w:document>, followed by the <w:body> tag
- The body is then split up into paragraphs, demarcated by <w:p>
- Each paragraph may contain paragraph styles
- Within each paragraph, there also exist runs of content <w:r>
- These runs then end up having text blocks inside them, with the text
enclosed by <w:t> tags - Multiple pieces of text can be contained within a run <w:r> tag
Пишем скрипт для рисования
В данном примере мы напишем скрипт, который будет рисовать дерево. Для работы с графикой в открытом доступе существует специальная Python-библиотека simple_draw. Чтобы установить ее, необходимо открыть командную строку (cmd) и прописать в ней команду pip install simple_draw.
![]()
Для начала давайте представим, из чего состоит структура дерева. Это ствол и ветки. В нашей программе дерево будет строиться из векторов — направленных отрезков. Попробуем нарисовать вектор. Перейдем в редактор, создадим новый файл draw.py и пропишем следующий код:
Для начала мы указываем, что хотим импортировать в нашу программу библиотеку simple_draw. Затем задаем разрешение окна для отрисовки — 1200 на 600 пикселей.
Далее создаем переменную point (точка) и с помощью метода (функции) get_point задаем начальную точку, из который будет выходить вектор, — 600 пикселей от левого края экрана и 5 пикселей от низа экрана.
Чтобы создать объект Vector, нужно задать ему такие параметры, как точка начала вектора — point, угол отклонения — angle (90 градусов), длина — length (100 пикселей) и толщина линии — width (3 пикселя). Как видно из кода, все эти переменные можно записать в одну строчку.
Переменная vector_1 будет содержать в себе объект — вектор, а чтобы отрисовать его в окне, применим к нему метод draw (рисовать). Сохраним и запустим скрипт.
![]()
Представим, что мы отрисовали ствол дерева. Теперь попробуем создать еще несколько векторов, чтобы нарисовать ветви. У дерева может быть огромное количество веток, поэтому придется создавать и большое количество векторов. Такой код будет слишком громоздким и длинным. Чтобы этого избежать, автоматизируем процесс рисования векторов и создадим функцию branch, принимающую на вход параметры point, angle, length и width, которая и будет рисовать ветви.
Данная функция создает вектор с теми параметрами, которые ей передаются в скобках, отрисовывает его, а затем возвращает конечную точку отрисованного вектора (vector.end_point), угол отклонения, который на30 градусов меньше предыдущего (angle –30), длину вектора, немного меньшую исходной (length*0.8) и ширину (width). Попробуем с ее помощью создать несколько новых ветвей.
![]()
Мы нарисовали 4 вектора. Каждый последующий вектор исходит от конца предыдущего и отличается длиной и углом отклонения, тем самым формируя изгиб ветви дерева. Но если мы снова представим реальное дерево, то чтобы отрисовать его, потребуется еще множество векторов. Задача программиста — написать как можно более компактный, универсальный и красивый код.
Поэтому сейчас пора освоить такую важную вещь, как рекурсия. Рекурсия — это когда функция внутри своего тела вызывает саму себя. Сократим немного код и перепишем функцию.
Чтобы функция до бесконечности не вызывала саму себя, нужно установить ей условие, при котором она будет останавливать выполнение. То есть мы указываем, что когда длина вектора при очередном вызове окажется меньше 10 пикселей, то функция завершит свое выполнение и дальше ветви рисовать не будет.
Теперь сделаем так, чтобы с конца каждой ветви дерева исходили вправо и влево другие ветви, меньшего размера. Для этого в тело функции нужно добавить еще один вызов самой себя, в котором параметр angle будет увеличиваться на 30 градусов. Таким образом ветви будут отрисовываться и вправо (angle –30), и влево (angle +30).
Добавим немного красоты нашему дереву и сделаем так, чтобы цвет каждой ветви генерировался случайным образом. Для этого внутри функции vector.draw() в скобках укажем параметр simple_draw.random_color() — это функция, которая возвращает случайный цвет.
Таким образом, конечный код выглядит следующим образом:
Запустим на выполнение и получим красивое, разноцветное дерево.
![]()
Как видите, небольшая функция за нас сделала всю работу. Изменив ее параметры и немного «поиграв» с кодом, можно добиться различных форм и видов деревьев.
Ответ 3
Посмотрите, как работает формат doc, и создайте документ Word с помощью PHP в Linux. Первый вариант особенно полезен. Abiword — рекомендуемый мною инструмент. Однако здесь есть свои ограничения: «если в документе есть сложные таблицы, текстовые поля, встроенные электронные таблицы и так далее, то он может работать не так, как ожидается. Разработка хороших фильтров для MS Word — очень сложный процесс, поэтому, пожалуйста, потерпите, пока мы работаем над тем, чтобы документы Word открывались правильно. Если у вас есть документ Word, который не загружается, пожалуйста, откройте сообщение об ошибке и укажите документ, чтобы мы могли улучшить импортер.
Функции, применяемые для осуществления файловых операций
| Функция | Краткое описание |
|---|---|
| FileClose | Закрытие файла, ранее открытого функцией FileOpen(). |
| FileDelete | Удаление указанного файла. Файлы могут быть удалены только в том случае, если они расположены в папке каталог_терминала\experts\files (каталог_терминала\tester\files в случае тестирования эксперта) или ее подпапках. |
| FileFlush | Сброс на диск всех данных, оставшихся в файловом буфере ввода-вывода. |
| FileIsEnding | Возвращает TRUE, если файловый указатель находится в конце файла, иначе возвращает FALSE. В случае достижения конца файла в процессе чтения функция GetLastError() вернет ошибку ERR_END_OF_FILE (4099) |
| FileIsLineEnding | Возвращает TRUE, если файловый указатель находится в конце строки файла формата CSV, иначе возвращает FALSE. |
| FileOpen | Открывает Файл для ввода и/или вывода. Возвращает файловый описатель открытого файла или -1 в случае неудачи. |
| FileOpenHistory | Открывает файл в текущей папке истории (каталог_терминала\history\server_name) или ее подпапках. Возвращает описатель файла или -1 в случае неудачи. |
| FileReadArray | Функция читает указанное число элементов из двоичного файла в массив. Перед чтением данных массив должен быть достаточного размера. Функция возвращает количество фактически прочитанных элементов. |
| FileReadDouble | Функция читает число двойной точности с плавающей точкой (double) из текущей позиции бинарного файла. Размер числа может быть 8 байтов (double) или 4 байта (float). |
| FileReadInteger | Функция читает целое число из текущей позиции бинарного файла. Размер целого числа может быть 1, 2 или 4 байта. Если размер числа не указан, система пытается прочитать как 4-байтовое целое число. |
| FileReadNumber | Чтение числа с текущей позиции файла CSV до разделителя. Применяется только для файлов CSV. |
| FileReadString | Функция читает строку с текущей позиции файла. Применяется как к CSV, так и к двоичным файлам. Для текстовых файлов строка будет прочитана до разделителя. Для бинарных файлов в строку будет прочитано указанное количество символов. |
| FileSeek | Функция перемещает файловый указатель на новую позицию, которая является смещением в байтах от начала, конца или текущей позиции файла. Следующее чтение или запись происходят с новой позиции. Если перемещение файлового указателя прошло успешно, функция возвращает TRUE, иначе возвращает FALSE. |
| FileSize | Функция возвращает размер файла в байтах. |
| FileTell | Функция возвращает смещение текущей позицию файлового указателя от начала файла. |
| FileWrite | Функция предназначена для записи данных в файл CSV, разделитель между данными включается автоматически. После записи в файл добавляется признак конца строки «\r\n». При выводе числовые данные преобразуются в текстовый формат. Возвращает количество записанных символов или отрицательное значение, если происходит ошибка. |
| FileWriteArray | Функция записывает массив в бинарный файл. |
| FileWriteDouble | Функция записывает число с плавающей запятой в двоичный файл. |
| FileWriteInteger | Функция записывает значение целого числа в двоичный файл. |
| FileWriteString | Функция записывает строку в двоичный файл с текущей позиции. Возвращает число фактически записанных байтов или отрицательное значение в случае ошибки. |
Для получения подробного описания этих и других функций необходимо обратиться к
справочной документации на MQL4.community, сайте MetaQuotes Ltd. или к разделу «Справка» в редакторе MetaEditor.
Дата и времяМассивы и таймсерии
Задания для самоподготовки
1. Выполните
считывание данных из текстового файла через символ и записи прочитанных данных
в другой текстовый файл. Прочитывайте так не более 100 символов.
2. Пользователь
вводит предложение с клавиатуры. Разбейте это предложение по словам (считать,
что слова разделены пробелом) и сохраните их в столбец в файл.
3. Пусть имеется
словарь:
d = {«house»:
«дом», «car»: «машина»,
«tree»:
«дерево», «road»: «дорога»,
«river»:
«река»}
Необходимо
каждый элемент этого словаря сохранить в бинарном файле как объект. Затем,
прочитать этот файл и вывести считанные объекты в консоль.
Видео по теме
#1. Первое знакомство с Python Установка на компьютер
#2. Варианты исполнения команд. Переходим в PyCharm
#3. Переменные, оператор присваивания, функции type и id
#4. Числовые типы, арифметические операции
#5. Математические функции и работа с модулем math
#6. Функции print() и input(). Преобразование строк в числа int() и float()
#7. Логический тип bool. Операторы сравнения и операторы and, or, not
#8. Введение в строки. Базовые операции над строками







#9. Знакомство с индексами и срезами строк
#10. Основные методы строк
#11. Спецсимволы, экранирование символов, row-строки
#12. Форматирование строк: метод format и F-строки
#13. Списки — операторы и функции работы с ними
#14. Срезы списков и сравнение списков
#15. Основные методы списков
#16. Вложенные списки, многомерные списки
#17. Условный оператор if. Конструкция if-else
#18. Вложенные условия и множественный выбор. Конструкция if-elif-else
#19. Тернарный условный оператор. Вложенное тернарное условие
#20. Оператор цикла while
#21. Операторы циклов break, continue и else
#22. Оператор цикла for. Функция range()
#23. Примеры работы оператора цикла for. Функция enumerate()
#24. Итератор и итерируемые объекты. Функции iter() и next()
#25. Вложенные циклы. Примеры задач с вложенными циклами
#26. Треугольник Паскаля как пример работы вложенных циклов
#27. Генераторы списков (List comprehensions)
#28. Вложенные генераторы списков
#29. Введение в словари (dict). Базовые операции над словарями
#30. Методы словаря, перебор элементов словаря в цикле
#31. Кортежи (tuple) и их методы
#32. Множества (set) и их методы
#33. Операции над множествами, сравнение множеств
#34. Генераторы множеств и генераторы словарей
#35. Функции: первое знакомство, определение def и их вызов
#36. Оператор return в функциях. Функциональное программирование
#37. Алгоритм Евклида для нахождения НОД
#38. Именованные аргументы. Фактические и формальные параметры
#39. Функции с произвольным числом параметров *args и **kwargs
#40. Операторы * и ** для упаковки и распаковки коллекций
#41. Рекурсивные функции
#42. Анонимные (lambda) функции
#43. Области видимости переменных. Ключевые слова global и nonlocal





#44. Замыкания в Python
#45. Введение в декораторы функций
#46. Декораторы с параметрами. Сохранение свойств декорируемых функций
#47. Импорт стандартных модулей. Команды import и from
#48. Импорт собственных модулей
#49. Установка сторонних модулей (pip install). Пакетная установка
#50. Пакеты (package) в Python. Вложенные пакеты
#51. Функция open. Чтение данных из файла
#52. Исключение FileNotFoundError и менеджер контекста (with) для файлов
#53. Запись данных в файл в текстовом и бинарном режимах
#54. Выражения генераторы
#55. Функция-генератор. Оператор yield
#56. Функция map. Примеры ее использования
#57. Функция filter для отбора значений итерируемых объектов
#58. Функция zip. Примеры использования
#59. Сортировка с помощью метода sort и функции sorted
#60. Аргумент key для сортировки коллекций по ключу
#61. Функции isinstance и type для проверки типов данных
#62. Функции all и any. Примеры их использования
#63. Расширенное представление чисел. Системы счисления
#64. Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операторы
#65. Модуль random стандартной библиотеки
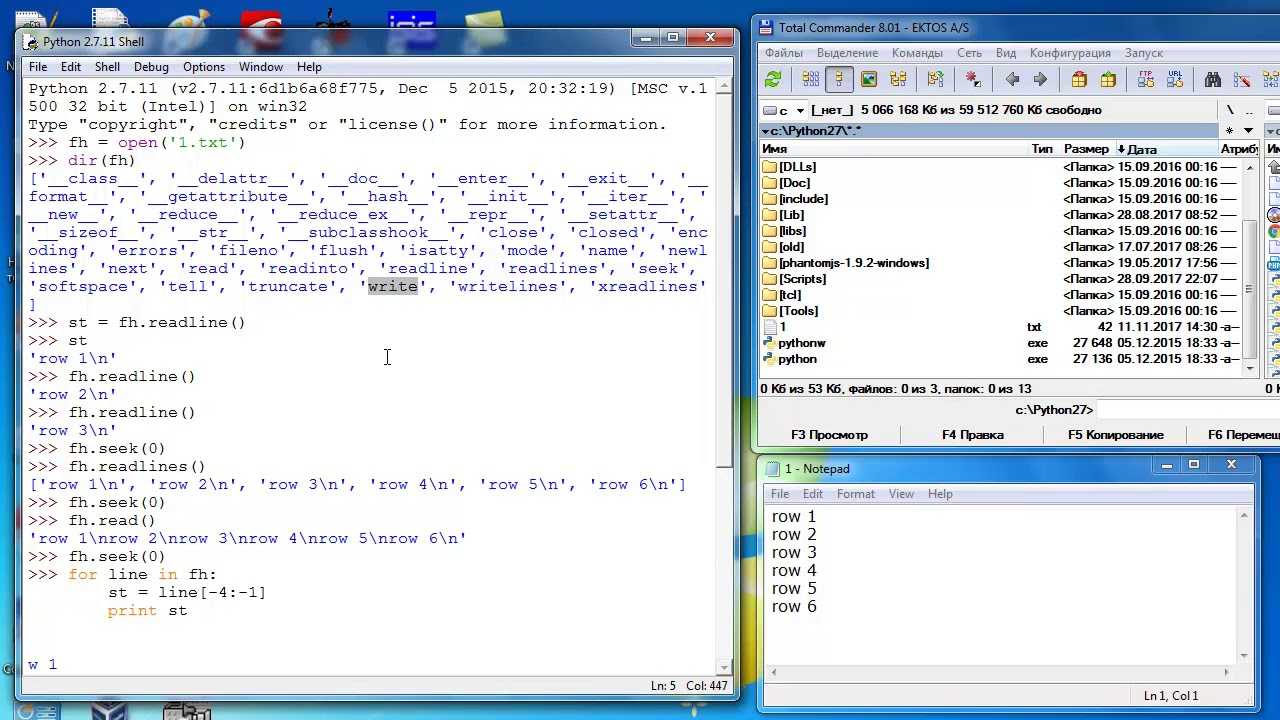
Чтение файла
С помощью файлового метода можно прочитать файл целиком или только определенное количество байт. Пусть у нас имеется файл data.txt с таким содержимым:
one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V
Откроем его и почитаем:
>>> f1 = open('data.txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'>
Сначала считываются первые десять символов. Последующий вызов считывает весь оставшийся текст. После этого объект файлового типа f1 становится пустым.
Заметим, что метод возвращает строку, и что конец строки считывается как .
Для того, чтобы читать файл построчно существует метод :
>>> f1 = open('data.txt')
>>> f1.readline()
'one - 1 - I\n'
>>> f1.readline()
'two - 2 - II\n'
>>> f1.readline()
'three - 3 — III\n'
Метод считывает сразу все строки и создает список:
>>> f1 = open('data.txt')
>>> f1.readlines()
Объект файлового типа относится к итераторам. Из таких объектов происходит последовательное извлечение элементов. Элементами в данном случае являются строки-линии файла. Поэтому считывать данные из них можно сразу в цикле без использования методов чтения:
>>> for i in open('data.txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>>
Здесь выводятся лишние пустые строки, потому что функция преобразует в переход на новую строку. К этому добавляет свой переход на новую строку. Создадим список строк файла без :
>>> nums = []
>>> for i in open('data.txt'):
... nums.append(i)
...
>>> nums
Переменной i присваивается очередная строка файла. Мы берем ее срез от начала до последнего символа, не включая его. Следует иметь в виду, что это один символ, а не два.
Готовим рабочее окружение
Как убедиться, что вы все делаете хорошо? Проверить рабочее окружение!
Когда вы работаете в терминале, вы можете сначала перейти в каталог, в котором находится ваш файл, а затем запустить Python. Убедитесь, что файл лежит именно в том каталоге, к которому вы обратились.
Возможно, вы уже начали сеанс Python и у вас нет подсказок о каталоге, в котором вы работаете. Тогда можно выполнить следующие команды:
Круто, да?
Вы увидите, что эти команды очень важны не только для загрузки ваших данных, но и для дальнейшего анализа. А пока давайте продолжим: вы прошли все проверки, вы сохранили свои данные и подготовили рабочее окружение.
Можете ли вы начать с чтения данных в Python?
Ответ 4
Если вы намерены использовать исключительно модули Python без вызова подпроцесса, вы можете использовать zip-файл Python module.
content = «»
# Загрузка DocX из zipfile
docx = zipfile.ZipFile(‘/home/whateverdocument.docx’)


# Распаковка zipфайла
unpacked = docx.infolist()
# Найдите файл /word/document.xml в пакете и присвойте его переменной
if item.orig_filename == ‘word/document.xml’:
content = docx.read(item.orig_filename)
else:
pass
Однако ваша строка содержимого нуждается в очистке. Один из способов сделать это:
# Очистите строку содержимого от xml-тегов для лучшего поиска
fullyclean = []
halfclean = content.split(‘<‘)
for item in halfclean:
if ‘>’ in item:
bad_good = item.split(‘>’)
if bad_good != »:
fullyclean.append(bad_good)
else:
pass
else:
pass
# Соберите новую строку со всем чистым содержимым
content = » «.join(fullyclean)
Но наверняка существует более элегантный способ очистки строки, возможно, с помощью модуля «re». Надеюсь, это поможет.
Запись данных в файл с помощью Python
Если вам нужно записать данные в файл, следует сделать три главных шага:
- Открыть файл
- Записать в него данные
- Закрыть файл
В общем-то, это точно такая же последовательность шагов, которую вы используете при написании кода, редактировании фотографий или выполнении практически любых операций на компьютере. Сначала вы открываете документ, который хотите отредактировать, затем вносите некоторые изменения, а затем закрываете документ.
В Python данный процесс будет выглядеть следующим образом:
f = open('example.txt', 'w')
f.write('hello world')
f.close()
В этом примере первая строка открывает файл в режиме записи. Файл представлен как переменная , что является произвольным выбором. Мы используем , потому что это общепринятая практика в написании кода на Python. Однако любое другое допустимое имя переменной работает так же.
Есть разные режимы, в которых вы можете открыть файл:
- — для записи данных
- — для чтения и записи
- — только для добавления данных
Вторая строка в нашем коде записывает данные в файл. Данные, записанные в этом примере, представляют собой обычный текст, но вы можете записывать что угодно.
Последней строкой мы закрываем файл.
Запись данных с использованием конструкции with
Существует более короткий способ записи данных в файл, и этот метод может быть полезен для быстрого взаимодействия с файлами. Он не оставляет файл открытым, поэтому вам не нужно вызывать функцию после того, как вы выполнили все действия с файлом. Этот способ записи данных предполагает использование конструкции :
with open('example.txt', 'a') as f:
f.write('hello pythonist')



