
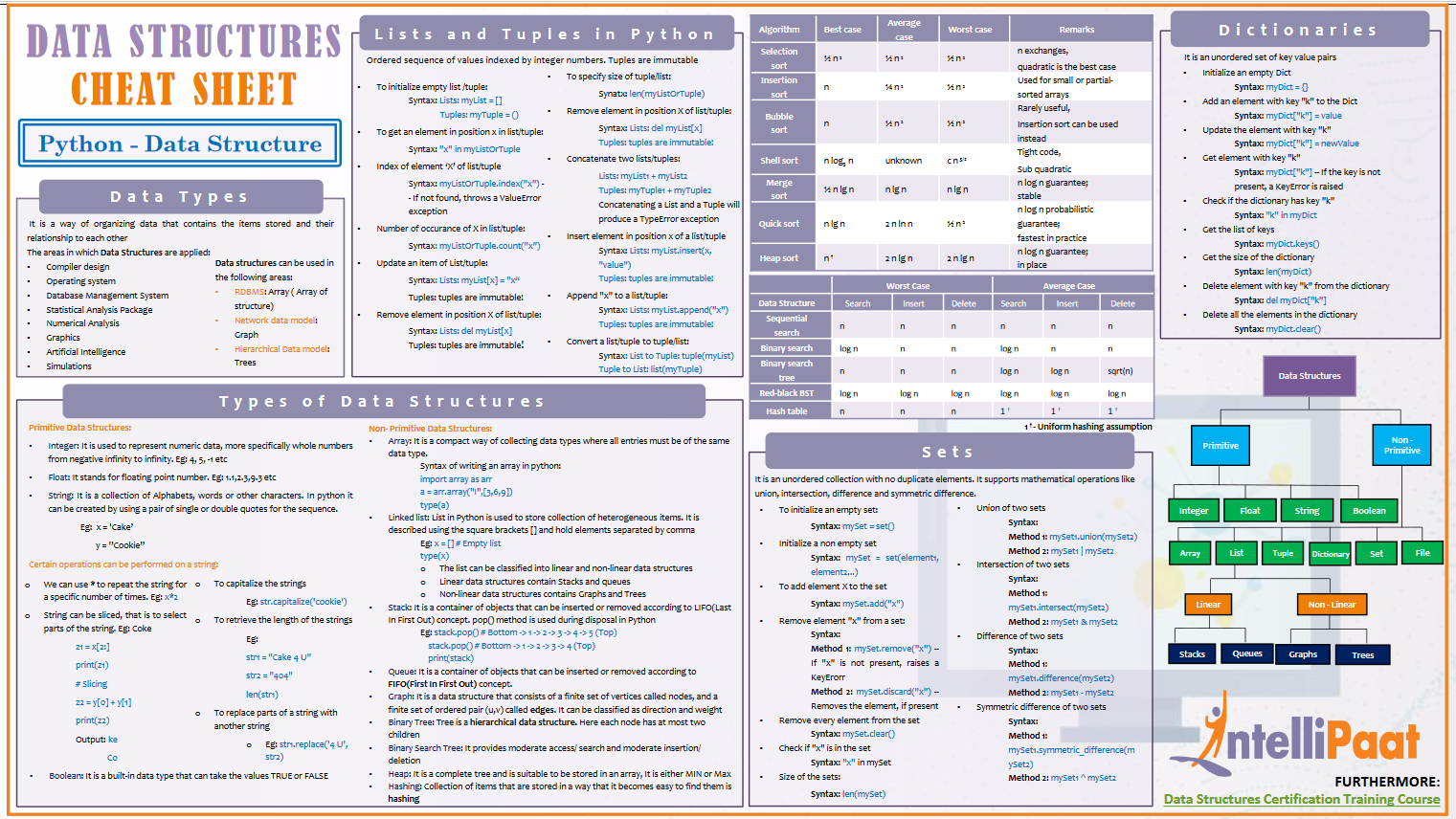
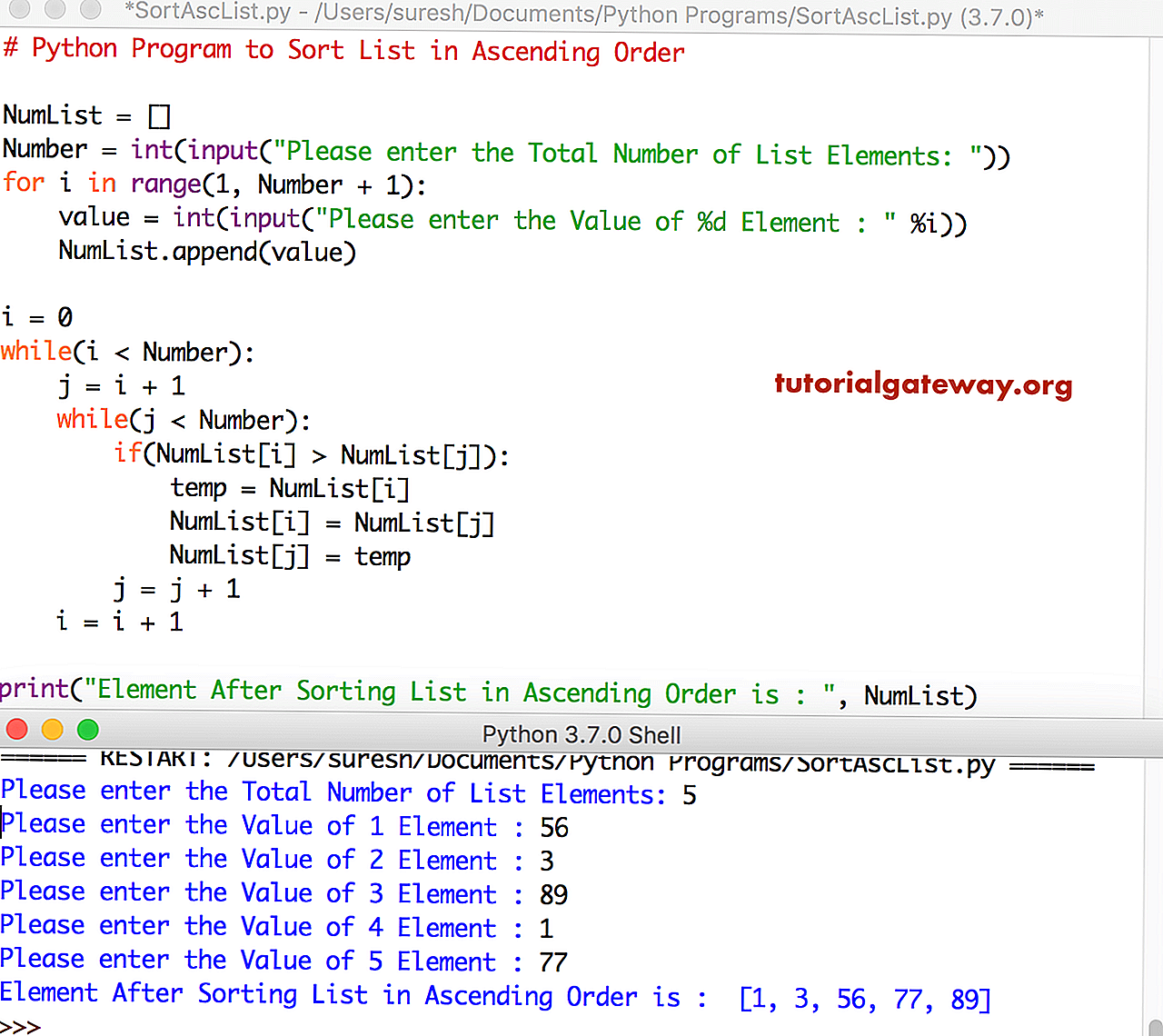
Python Programming
Python Programs
Python Programs
Python Linked Lists
Python Stacks & Queues
Python Searching & Sorting
Python Trees
Python Graphs
Simple Python Programs
Sum of Digits of Number in Python
Average of Numbers in Python
Reverse of Number in Python
Identity Matrix in Python
Python — Mathematical Functions
Leap Year Program in Python
Prime Factors Program in Python
Sum of Digits in Python
Armstrong Number in Python
Pascal Triangle in Python
Perfect Number in Python
Strong Number in Python
GCD in Python
LCM Program in Python
Area of Triangle in Python
Python Program to Check Prime Number
Sum of N Numbers in Python
Python – Lists
Largest Number in Python
Second Largest Number in Python
Merge Sort in Python
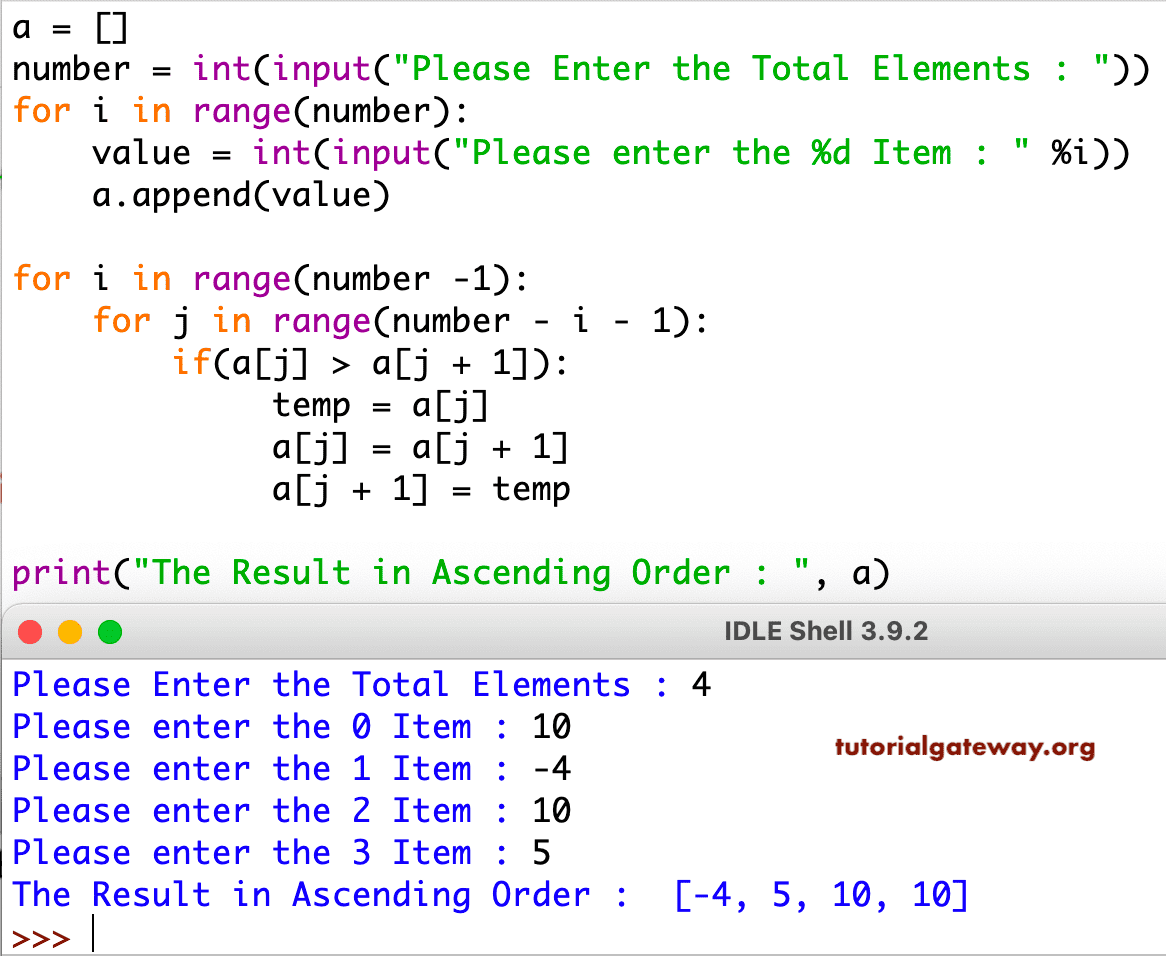
Sorting in Python
Bubble Sort in Python
Python Sets Intersection Program
Python Union Set Operations Program
Python Swapping Program
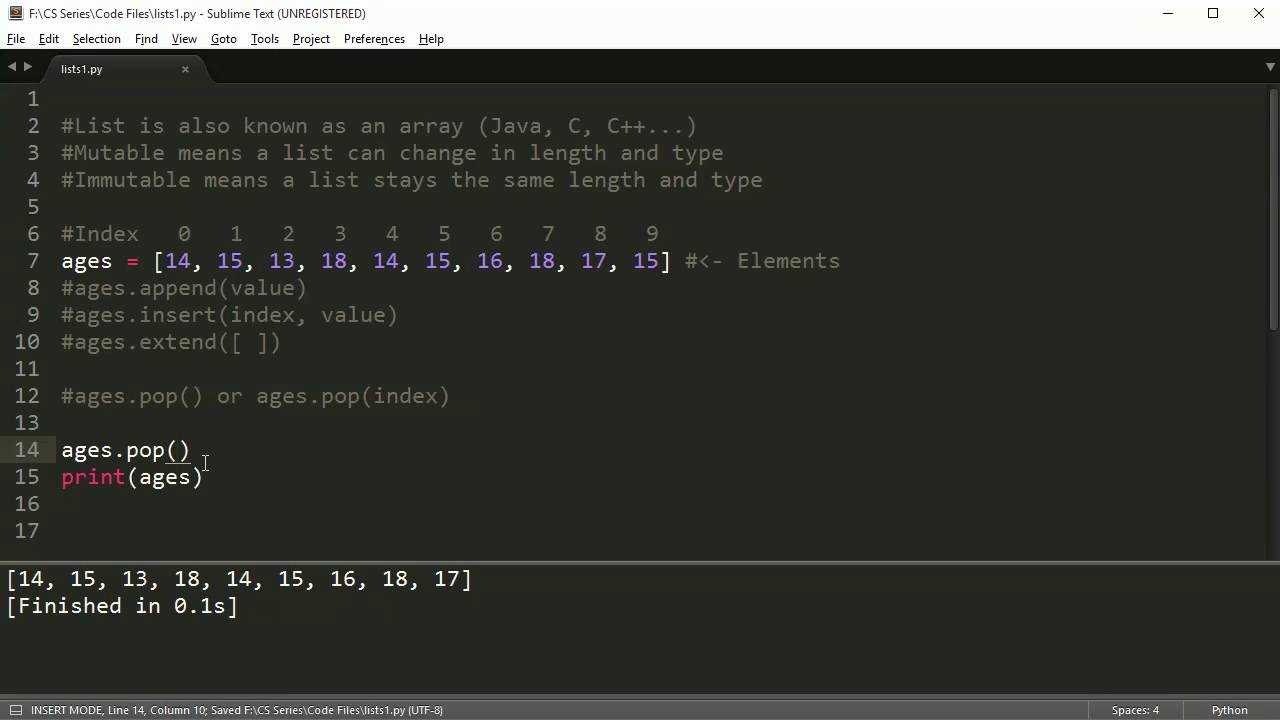
Remove Duplicates from List in Python
Maximum Subarray Problem in Python
Python – Strings
Anagram Program in Python
String Length in Python
Python Palindrome Program
Pangram in Python
Substring in Python
Permutations in Python
Python – Dictionary
Key Value Pair in Python
Python Concatenate Program
Remove Key from Dict in Python
Map Two Lists in Python
Count Vowels in Python
Python – Recursions
Fibonacci Series in Python
Factorial Program in Python
Binary Equivalent in Python
Sum of Digits in Python
LCM in Python
GCD in Python
Prime Number in Python
Exponential in Python
Python Palindrome
Python Reverse a String
Fibonacci Series in Python without Recursion
Factorial in Python without Recursion
Python – File Handling
Count Words in Python
Appending String in Python
Python – Classes & Objects
Appending Lists in Python
Python Subsets
Python – Linked Lists
Singly Linked List in Python
Doubly Linked List in Python
Remove Duplicates from List in Python
Python – Stacks & Queues
Stack in Python
Queue in Python
Python Dequeue
Python Palindrome using Stack Program
Queues using Stacks in Python
Graph in Python
Python – Searching & Sorting
Linear Search in Python
Binary Search in Python
Bubble Sort in Python
Selection Sort in Python
Insertion Sort in Python
Python Program to Implement Merge Sort
Quicksort in Python
Heapsort in Python
Python Radix Sort
Bucket Sort in Python
Python Shell Sort
Python Binary Search Tree
Python – Trees
Binary Heap in Python
Special Python Programs
Tower of Hanoi in Python
n-Queen Problem in Python
Fractional Knapsack Problem in Python
Interval Scheduling Problem in Python
Dynamic Programming in Python
Python Resources
1000 Python MCQ
Python Internship
Best Python Programming Books
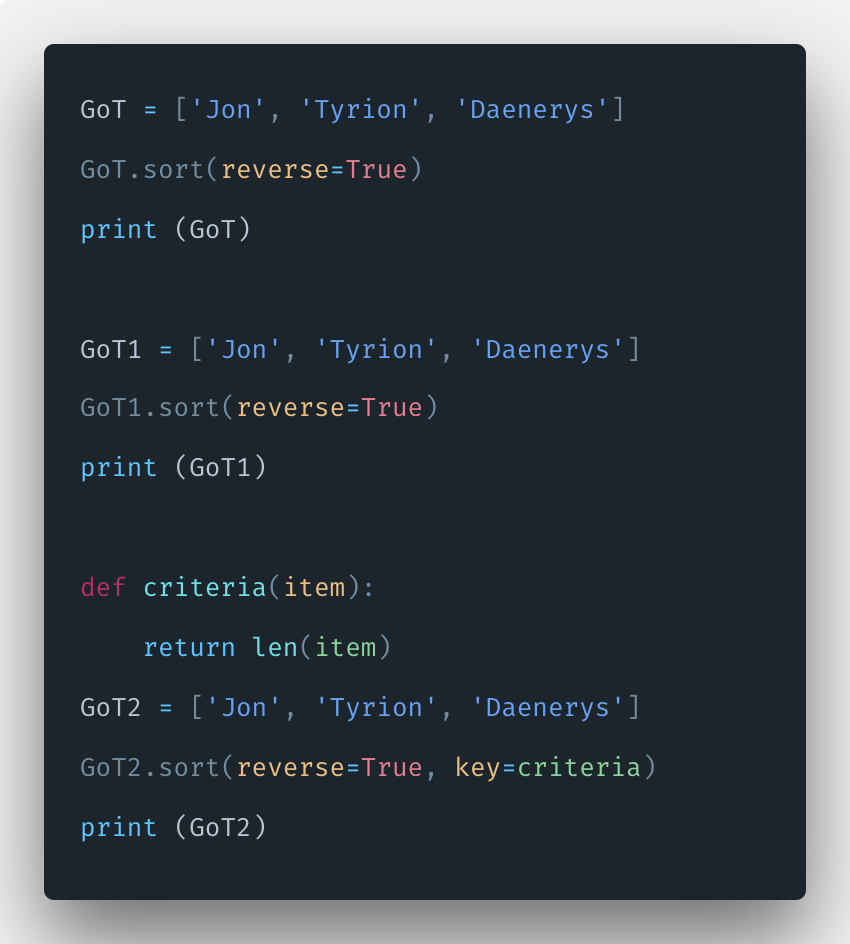
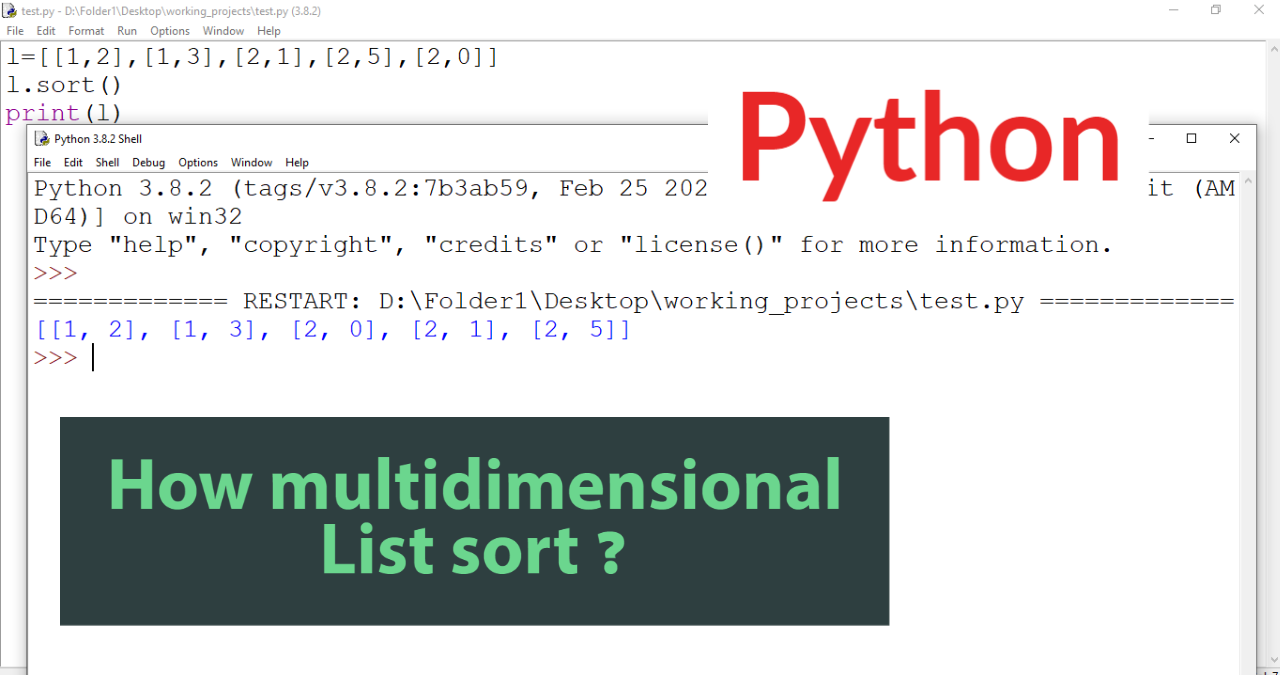
Пользовательская логика для сортировки списка
Мы также можем реализовать вашу собственную логику для сортировки элементов списка.
В последнем примере мы использовали возраст как ключевой элемент для сортировки нашего списка.
Но есть такая поговорка: «Сначала дамы!». Итак, мы хотим отсортировать наш список таким образом, чтобы женский пол имел приоритет над мужским. Если пол двух человек совпадает, младший получает более высокий приоритет.
Итак, мы должны использовать ключевой аргумент в нашей функции сортировки. Но функцию сравнения нужно преобразовать в ключ.
Итак, нам нужно импортировать библиотеку под названием functools. Мы будем использовать функцию cmp_to_key(), чтобы преобразовать compare_function в key.
import functools
def compare_function(person_a, person_b):
if person_a == person_b: # if their gender become same
return person_a - person_b # return True if person_a is younger
else: # if their gender not matched
if person_b == 'F': # give person_b first priority if she is female
return 1
else: # otherwise give person_a first priority
return -1
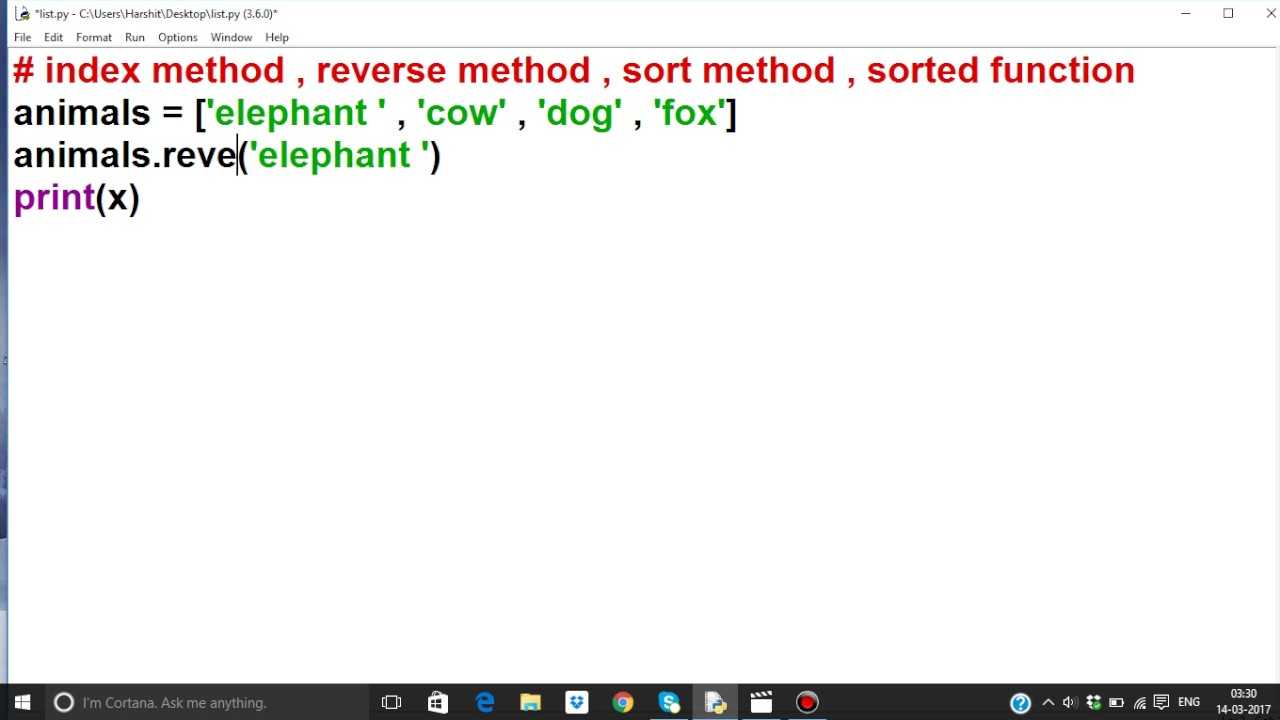
persons = , , , ]
print(f'Before sorting: {persons}')
persons.sort(key=functools.cmp_to_key(compare_function))
print(f'After sorting: {persons}')
Вывод:
Before sorting: , , , ] After sorting: , , , ]
Список сначала сортируется по полу. Затем он сортируется по возрасту людей.
Сортировка вложенного списка
Если мы вызываем функцию списка sort() для вложенного списка, для сортировки используются только первые элементы из элементов списка. Давайте разберемся в этом примере.
numbers = , , , , ]
print(f'Before sorting: {numbers}')
numbers.sort()
print(f'After sorting: {numbers}')
Вывод:
Before sorting: , , , , ] After sorting: , , , , ]
Понятно, что сортировка производится по первому элементу вложенного списка. Но иногда нам нужно отсортировать вложенный список по позициям разных элементов.
Допустим, вложенный список содержит информацию об имени, возрасте и поле человека. Давайте посмотрим, как отсортировать этот вложенный список по возрасту, который является вторым элементом вложенного списка.
def custom_key(people):
return people # second parameter denotes the age
persons = , , , ]
print(f'Before sorting: {persons}')
persons.sort(key=custom_key)
print(f'After sorting: {persons}')
Вывод:
Before sorting: , , , ] After sorting: , , , ]
Мы используем ключевой аргумент, чтобы указать элемент, который будет использоваться для целей сортировки. Функция custom_key возвращает ключ для сортировки списка.
Выполняет сортировку последовательности по возростанию/убыванию.
Параметры:
- — объект, поддерживающий итерирование
- — пользовательская функция, которая применяется к каждому элементу последовательности
- — порядок сортировки
Описание:
Функция вернет новый отсортированный t-list] из итерируемых элементов. Функция имеет два необязательных аргумента, которые должны быть указаны в качестве аргументов ключевых слов.
Аргумент принимает функцию, например . Переданная функция вычисляет результат для каждого элемента последовательности, который используется для сравнения элементов при сортировке. Значением по умолчанию является , т.е. сравнивать элементы напрямую (как есть).
Аргумент имеет логическое значение. Если установлено значение , то элементы списка сортируются в обратной последовательности (по убыванию).
Используйте для преобразования функции, использующей cmp (старый стиль) в использующую key (новый стиль).
Встроенная функция sorted() является гарантированно стабильной. Это означает, что когда несколько элементов последовательности имеют равные значения, их первоначальный порядок сохраняется. Такое поведение полезно при сортировке в несколько проходов.
Примеры различных способов сортировки последовательностей.
Сортировка слов в предложении без учета регистра:
line = 'This is a test string from Andrew' x = sorted(line.split(), key=str.lower) print(x) #
Сортировка сложных объектов с использованием индексов в качестве ключей :
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по возрасту student
x = sorted(student, key=lambda student student2])
print(x)
#
Тот же метод работает для объектов с именованными атрибутами.
class Student
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
student =
Student('john', 'A', 15),
Student('jane', 'B', 12),
Student('dave', 'B', 10),
x = sorted(student, key=lambda student student.age)
print(x)
#
Сортировка по убыванию:
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по убыванию возраста student
x = sorted(student, key=lambda i i2], reverse=True)
print(x)
#
Стабильность сортировки и сложные сортировки:
data = x = sorted(data, key=lambda data data]) print(x) #
Обратите внимание, как две записи (‘blue’, 1), (‘blue’, 2) для синего цвета сохраняют свой первоначальный порядок. Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам
Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым
Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам. Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым.
student =
('john', 15, 4.1),
('jane', 12, 4.9),
('dave', 10, 3.9),
('kate', 11, 4.1),
# По средней оценке
x = sorted(student, key=lambda num num2])
# По убыванию возраста
y = sorted(x, key=lambda age age1], reverse=True)
print(y)
#
А еще, для сортировок по нескольким ключам, удобнее использовать модуль . Функции модуля допускают несколько уровней сортировки. Например, как в предыдущем примере успеваемость будет первым ключом, возраст вторым.Только сортировать будем все по возрастанию:
from operator import itemgetter x = sorted(student, key=itemgetter(2,1)) print(x) #
Key Functions¶
Both and have a key parameter to specify a
function (or other callable) to be called on each list element prior to making
comparisons.
For example, here’s a case-insensitive string comparison:
>>> sorted("This is a test string from Andrew".split(), key=str.lower)
The value of the key parameter should be a function (or other callable) that
takes a single argument and returns a key to use for sorting purposes. This
technique is fast because the key function is called exactly once for each
input record.
A common pattern is to sort complex objects using some of the object’s indices
as keys. For example:
>>> student_tuples =
... ('john', 'A', 15),
... ('jane', 'B', 12),
... ('dave', 'B', 10),
...
>>> sorted(student_tuples, key=lambda student student2]) # sort by age
The same technique works for objects with named attributes. For example:
Псевдокод
function bucket-sort(A, n) is
buckets ← новый массив из n пустых элементов
for i = 0 to (length(A)-1) do
вставить A в конец массива buckets, k)]
for i = 0 to n - 1 do
next-sort(buckets)
return Конкатенация массивов buckets, ..., buckets
На вход функцииbucket-sortподаются сортируемый массив (список, коллекция и т.п.)Aи количество блоков —n.
Массивbucketsпредставляет собой массив массивов (массив списков, массив коллекций и т.п.), подходящих по природе к элементамA.
Функцияmsbits(x,k)тесно связана с количеством блоков —n(возвращает значение от 0 до n), и, в общем случае, возвращаетkнаиболее значимых битов изx(floor(x/2^(size(x)-k))). В качествеmsbits(x,k)могут быть использованы разнообразные функции, подходящие по природе сортируемым данным и позволяющие разбить массив A на n блоков. Например, для символов A-Z это может быть сопоставление номерам букв 0-25, или возврат кода первой буквы (0-255) для ASCII набора символов; для чисел[0, 1)это может быть функцияfloor(n*A), а для произвольного набора чисел в интервале[a, b)— функцияfloor(n*(A-a)/(b-a)).
Функцияnext-sortтакже реализует алгоритм сортировки для каждого созданного на первом этапе блока. Рекурсивное использованиеbucket-sortв качествеnext-sortпревращает данный алгоритм впоразрядную сортировку. В случаеn = 2соответствуетбыстрой сортировке(хотя и с потенциально плохим выбором опорного элемента).
Сортировать с помощью настраиваемой функции с помощью клавиши
Если вам нужна собственная реализация для сортировки, метод sort() также принимает ключевую функцию в качестве необязательного параметра.
По результатам ключевой функции вы можете отсортировать данный список.
list.sort(key=len)
В качестве альтернативы для сортировки:
sorted(list, key=len)
Здесь len ‒ это встроенная функция Python для подсчета длины элемента.
Список сортируется по длине каждого элемента от наименьшего количества к наибольшему.
Мы знаем, что кортеж по умолчанию сортируется по первому параметру. Давайте посмотрим, как настроить метод для сортировки с использованием второго элемента.
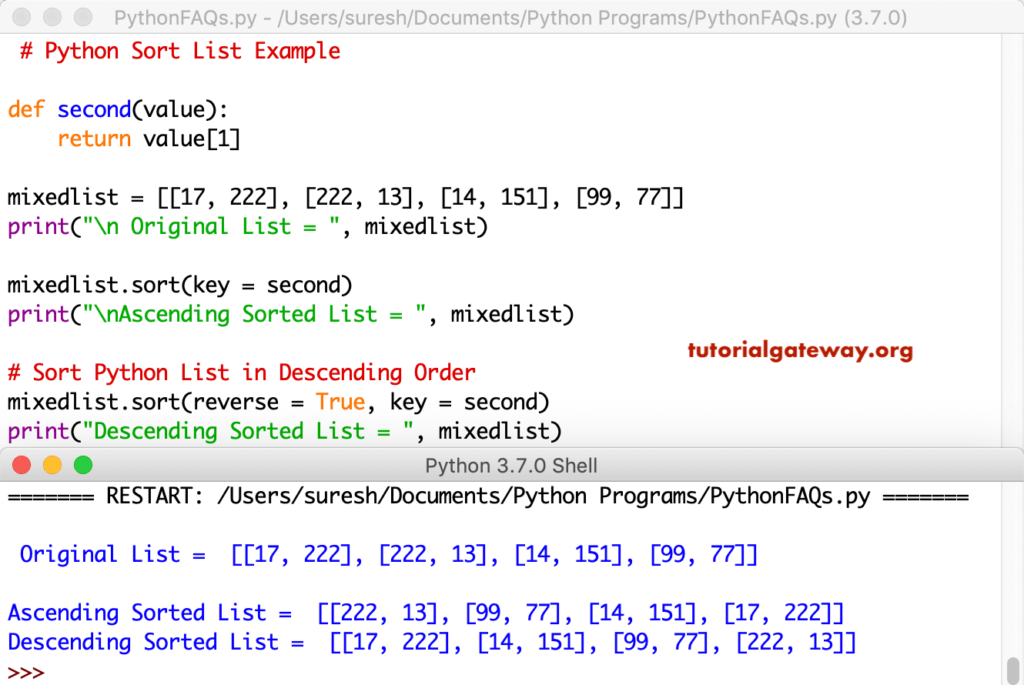

key¶
С помощью параметра key можно указывать, как именно выполнять
сортировку. Параметр key ожидает функцию, с помощью которой должно быть
выполнено сравнение.
Например, таким образом можно отсортировать список строк по длине
строки:
In 14]: list_of_words = 'one', 'two', 'list', '', 'dict' In 15]: sorted(list_of_words, key=len) Out15]: '', 'one', 'two', 'list', 'dict'
Если нужно отсортировать ключи словаря, но при этом игнорировать регистр
строк:
In 16]: dict_for_sort = {
... 'id' 1,
... 'name''London',
... 'IT_VLAN'320,
... 'User_VLAN'1010,
... 'Mngmt_VLAN'99,
... 'to_name' None,
... 'to_id' None,
... 'port''G1/0/11'
... }
In 17]: sorted(dict_for_sort, key=str.lower)
Out17]:
'id',
'IT_VLAN',
'Mngmt_VLAN',
'name',
'port',
'to_id',
'to_name',
'User_VLAN'
Параметру key можно передавать любые функции, не только встроенные.
Также тут удобно использовать анонимную функцию lambda.
С помощью параметра key можно сортировать объекты не по первому
элементу, а по любому другому. Но для этого надо использовать или
функцию lambda, или специальные функции из модуля operator.
Например, чтобы отсортировать список кортежей из двух элементов по
второму элементу, надо использовать такой прием:
Оценка сложности
Оценим сложность алгоритма блочной сортировки для случая, при котором в качестве алгоритма сортировки блоков (next-sortиз псевдокода) используетсясортировка вставками.
Для оценки сложности алгоритма введёмслучайную величинуni, обозначающую количество элементов, которые попадут в карман. Время работы сортировки вставками равно
{\displaystyle O\left(n^{2}\right)}
.
Время работы алгоритма карманной сортировки равно
{\displaystyle T(n)=\Theta (n)+\sum _{i=0}^{n-1}O(n_{i}^{2})}
Вычислимматематическое ожиданиеобеих частей равенства:
{\displaystyle M\left(T(n)\right)=M\left(\Theta (n)+\sum _{i=0}^{n-1}O(n_{i}^{2})\right)=\Theta (n)+\sum _{i=0}^{n-1}O\left(M(n_{i}^{2})\right)}
Найдем величину
{\displaystyle M(n_{i}^{2})}
.
Введем случайную величину
{\displaystyle X_{ij}}
, которая равна1, еслипопадает вi-й карман, ив противном случае:
{\displaystyle n_{i}=\sum _{j=1}^{n}X_{ij}}
{\displaystyle {\begin{matrix}M\left(n_{i}^{2}\right)=&M\left=M\left=\\\ &\sum _{j=1}^{n}M\left+\sum _{1\leq j\leq n}\ \sum _{1\leq k\leq n,k\neq j}M\left\end{matrix}}}
{\displaystyle M\left=1\cdot {\frac {1}{n}}+0\cdot \left(1-{\frac {1}{n}}\right)={\frac {1}{n}}}
Еслиk ≠ j, величиныXijиXikнезависимы, поэтому:
{\displaystyle M\left=M\leftM\left={\frac {1}{n^{2}}}}
Таким образом
{\displaystyle M\left(n_{i}^{2}\right)=\sum _{j=1}^{n}{\frac {1}{n}}+\sum _{1\leq j\leq n}\ \sum _{1\leq k\leq n,k\neq j}{\frac {1}{n^{2}}}=2-{\frac {1}{n}}}
Итак, ожидаемое время работы алгоритма карманной сортировки равно
{\displaystyle \Theta (n)+n\cdot O(2-1/n)=\Theta (n)}
Post Views:
2 506
Сортировка DataFrame по нескольким столбцам
Во время анализа данных мы иногда хотим отсортировать данные на основе значений нескольких столбцов. Предположим, у нас есть набор данных с именами и фамилиями людей. И мы хотим отсортировать его по имени, а затем по фамилии людей. Чтобы у людей было одинаковое имя, которое можно расположить в алфавитном порядке по их фамилиям.


В следующем примере мы отсортируем DataFrame по одному столбцу с именем city08. MPG в городских условиях является существенным фактором, который может определить приоритет автомобилей. И предположим, что мы также хотим посмотреть на количество миль на галлон для условий шоссе в дополнение к MPG в городских условиях. Для сортировки DataFrame по двум ключам мы можем передать список меток столбцов по параметрам.
Пример:
df.sort_values( ... by = ... )]
Вывод:
Здесь, указав список меток столбцов city08 и highway08, мы отсортировали два столбца с помощью sort_values().
В следующем примере мы объясним, как мы можем указать порядок сортировки и почему пользователям важно обращать внимание на список используемых ими меток столбцов
В порядке возрастания
Для сортировки DataFrame по нескольким столбцам мы должны предоставить список меток столбцов. Предположим, для сортировки DataFrame по марке и модели. Мы должны создать следующий список, а затем передать его в sort_values().
Пример:
df.sort_values(
by =
)]
Вывод:
Теперь наш DataFrame отсортирован в порядке возрастания по столбцу make. Если есть два или более одинаковых производителя, то DataFrame будет отсортирован по столбцу модели. DataFrame будет отсортирован в соответствии с порядком меток столбцов, которые мы указали в нашем списке.
Изменение порядка
Поскольку мы сортируем DataFrame, используя несколько столбцов, мы также можем указать порядок, в котором мы хотим, чтобы наши столбцы сортировались. Если мы хотим изменить порядок сортировки нашего DataFrame из последнего примера, то мы можем изменить порядок меток столбцов в списке, который мы передали параметру by.
Пример:
df.sort_values(
by =
)]
Вывод:
Вот, теперь наш DataFrame отсортирован в порядке возрастания по столбцам модели, если есть две и более одинаковых модели, то DataFrame будет отсортирован по столбцу make. Мы можем заметить, что когда мы меняем порядок столбцов, то меняется и порядок, в котором сортируются значения.
В порядке убывания
До сих пор мы отсортировали несколько столбцов в порядке возрастания. В следующем примере мы отсортируем несколько столбцов в порядке убывания. Для сортировки DataFrame в порядке убывания мы установим возрастающее значение False.
Пример:
df.sort_values(
by = ,
ascending = False
Вывод:
Здесь мы можем заметить, что в DataFrame столбец марки отсортирован в обратном алфавитном порядке, а значения столбца модели отсортированы в порядке убывания для любых автомобилей той же марки.
Сортировка чувствительна к текстовым данным, что означает, что текст, набранный заглавными буквами, будет отображаться первым в порядке возрастания и последним в порядке убывания.
Разный порядок
С Pandas в Python мы можем сортировать, используя несколько столбцов и имея эти столбцы, используя разные возрастающие аргументы, и это тоже всего за один вызов функции. Если пользователь хочет отсортировать столбцы в порядке возрастания, а некоторые столбцы в порядке убывания, то он должен передать список логических значений в порядке возрастания.
В следующем примере мы отсортируем наш DataFrame по столбцам make, model и city08, причем первые два столбца должны быть отсортированы в порядке возрастания, а столбец city08 — в порядке убывания. Для этого мы будем передавать список меток столбцов по параметрам и список логических значений по возрастанию.
Пример:
с
df.sort_values( ... by = , ... ascending = ... )]
Вывод:
![]()
Вот, теперь наш DataFrame отсортирован по столбцам марки и модели в порядке возрастания, а столбец city08 отсортирован в порядке возрастания. Это полезно, так как эта группа автомобилей находится в категорическом порядке, и сначала отображаются автомобили с наибольшим количеством миль на галлон.
Разделение
Класс Java String содержит метод split(), который можно использовать для разделения String на массив объектов String:
String source = "A man drove with a car.";
String[] occurrences = source.split("a");
После выполнения этого кода Java массив вхождений будет содержать экземпляры String:
"A m" "n drove with " " c" "r."
Исходная строка была разделена на символы a. Возвращенные строки не содержат символов a. Символы a считаются разделителями для деления строки, а разделители не возвращаются в результирующий массив строк.
Параметр, передаваемый методу split(), на самом деле является регулярным выражением Java, которые могут быть довольно сложными. Приведенное выше соответствует всем символам, даже буквам нижнего регистра.
Метод String split() существует в версии, которая принимает ограничение в качестве второго параметра — limit:
String source = "A man drove with a car.";
int limit = 2;
String[] occurrences = source.split("a", limit);
Параметр limit устанавливает максимальное количество элементов, которое может быть в возвращаемом массиве. Если в строке больше совпадений с регулярным выражением, чем заданный лимит, то массив будет содержать совпадения с лимитом — 1, а последним элементом будет остаток строки из последнего среза — 1 совпадением. Итак, в приведенном выше примере возвращаемый массив будет содержать эти две строки:
"A m" "n drove with a car."
Первая строка соответствует регулярному выражению. Вторая — это остальная часть строки после первого куска.
Выполнение примера с ограничением 3 вместо 2 приведет к тому, что эти строки будут возвращены в результирующий массив String:
"A m" "n drove with " " car."
Обратите внимание, что последняя строка по-прежнему содержит символ в середине. Это потому, что эта строка представляет остаток строки после последнего совпадения (a после ‘n водил с’). Выполнение приведенного выше примера с пределом 4 или выше приведет к тому, что будут возвращены только строки Split, поскольку в String есть только 4 совпадения с регулярным выражением a
Выполнение приведенного выше примера с пределом 4 или выше приведет к тому, что будут возвращены только строки Split, поскольку в String есть только 4 совпадения с регулярным выражением a.
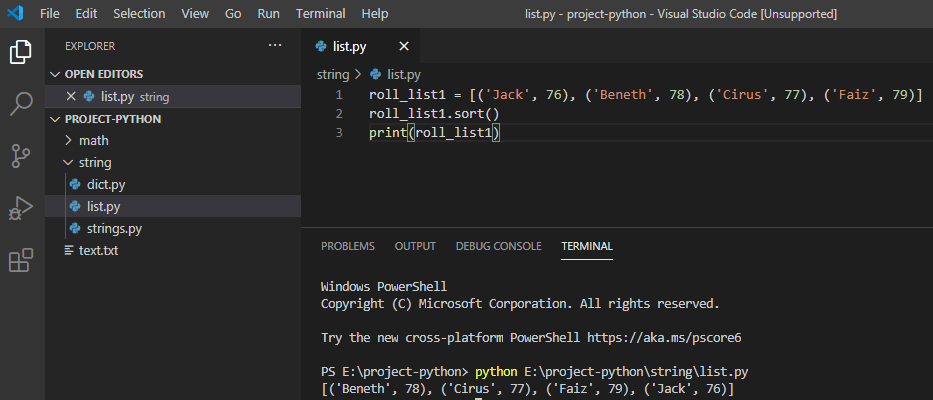
Синтаксис и параметры метода sort()
Синтаксис метода sort():
В качестве альтернативы методу sort(), так же можно использовать встроенный метод в python , который в принципе выполняет ту же функцию.
Между этими двумя методами есть небольшое различие. Метод sort() отсортирует список напрямую, и не возвращает никаких значений, а метод sorted() не изменяет оригинальный список, а возвращает отсортированный список.

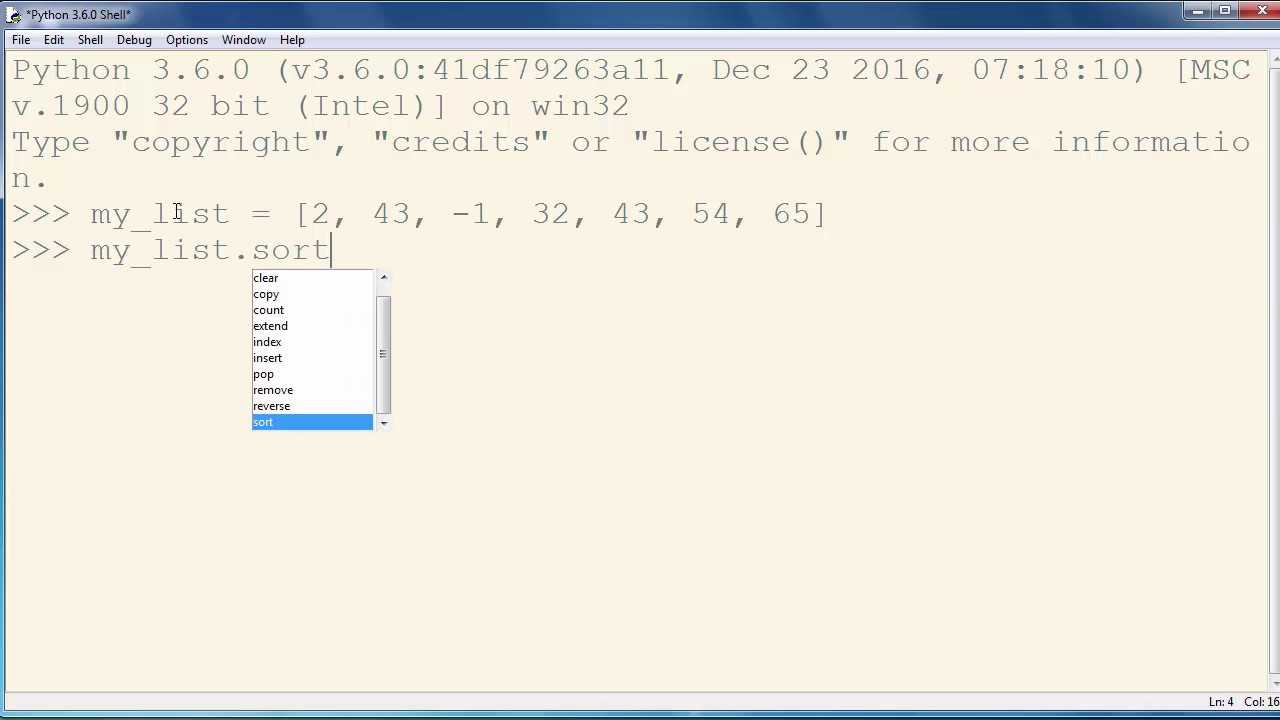
Параметры метода sort()
Метод sort() изначально не требует никаких параметров, но в то же время, у данного метода есть два дополнительных параметра:
- reverse — Если значение True, отсортированный список идет в обратном порядке, либо сортировка выполнена в порядке убывания.
- key — Данный параметр можно указать в качестве ключа для сравнения сортировки
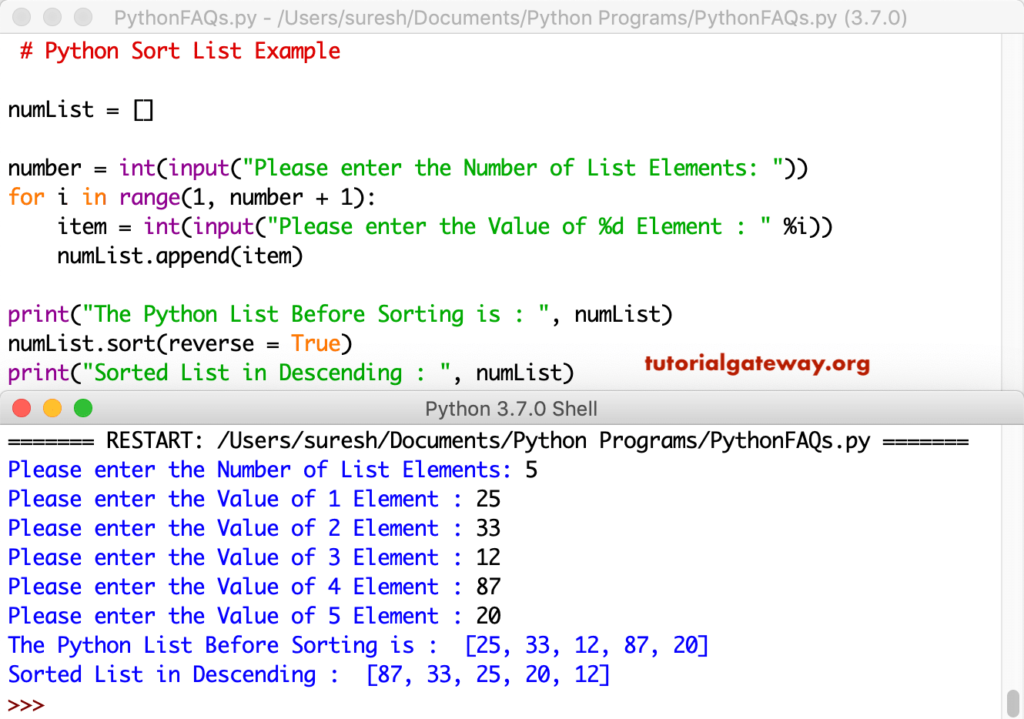
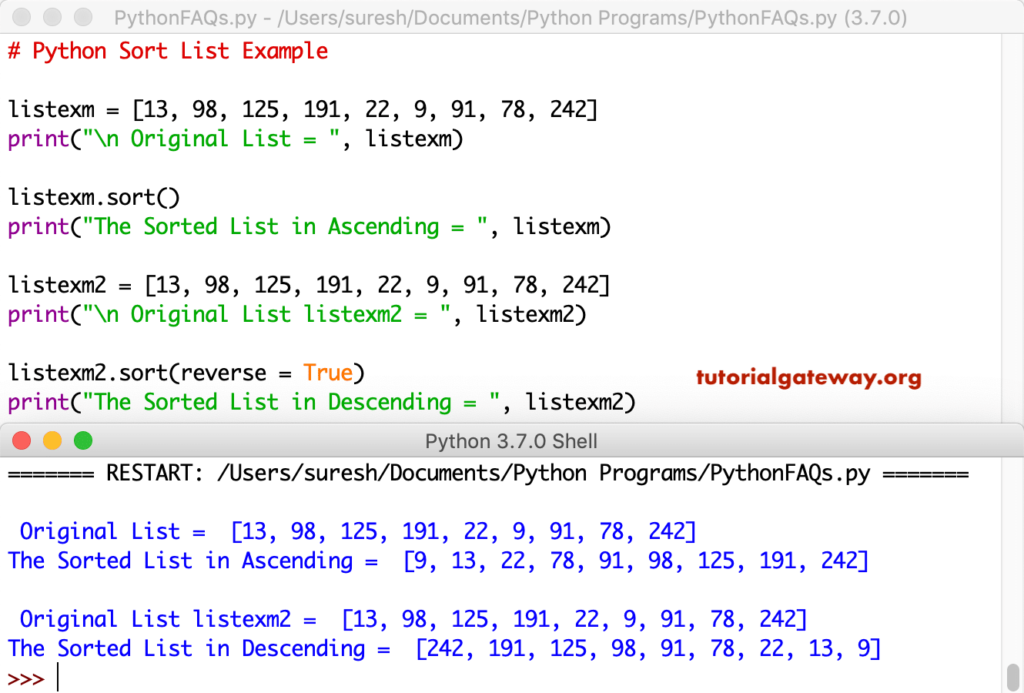
Пример 1. Сортировка списка
Сортировка списка в порядке убывания
Как мы уже говорили, у метода sort() есть необязательный аргумент reverse. Если мы установим метода reverse=True, то список будет отсортирован в порядке убывания.
Так же можно воспользоваться альтернативным решением, и использовать встроенную функцию в Python, sorted().
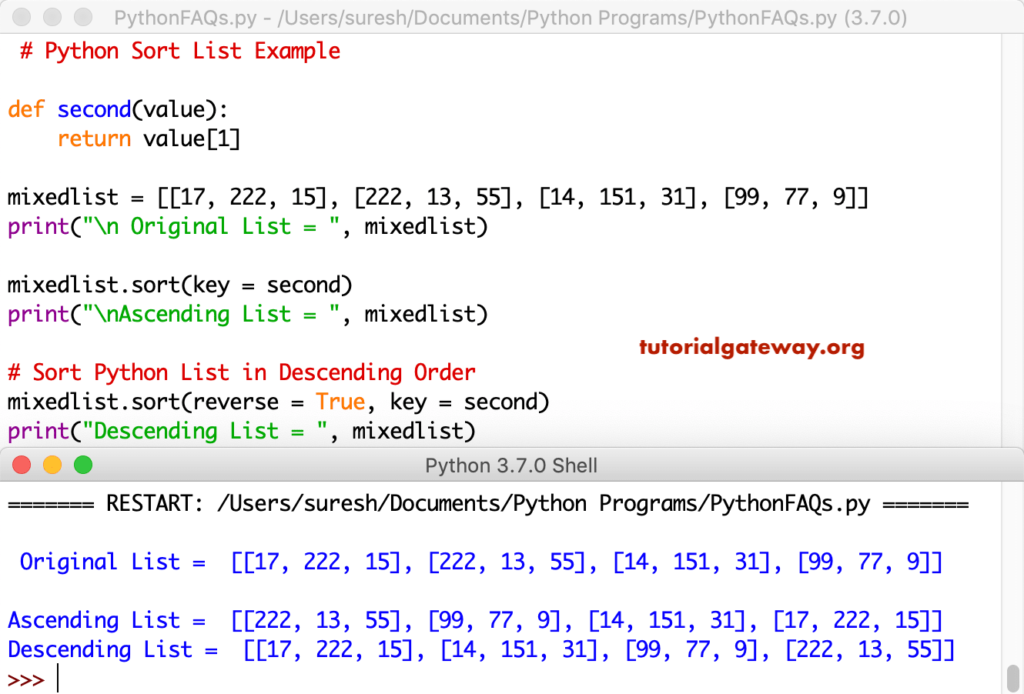
Пользовательская сортировка списка с помощью ключа
Представим себе ситуацию, где нам необходимо реализовать свой собственный метод сортировки. В таком случае, метод sort() принимает в качестве необязательного параметра аргумент key.
Альтернативный вариант с использованием метода sorted().
В данном случае, len() — это встроенная функция Python, которая применяется для подсчета длины каждого элемента. После того, как у нас есть длина каждого элемента, мы можем отсортировать этот список от наименьшего до наибольшего, или наоборот.
Пример 3. Сортировка списка с помощью ключа
Как видите ключ прекрасно выполнил свою задачу, мы отсортировали данный список по второму элементу. Для более ясного понимания, как все это дело работает, предлагаю рассмотреть еще один пример, чуть по сложнее. Представим себе, что у нас есть список сотрудников компании, каждый элемент данного списка будет являться словарем. Вначале я приведу весь листинг кода вместе с результатом, а затем мы разберем, как это работает.
- В первом случае, наша функция возвращает нам имена сотрудников. Так как имя у нас является строкой, то соответственно Python сортирует его в алфавитном порядке.
- Второй случай возвращает нам возраст, тип данных которого int(), и сортируется в порядке возрастания
- В третьем случае, функция возвращает зарплату, и ее тип данных тоже int(), в данном случае используется дополнительный параметр reverse со значением True, и сортируется в порядке убывания.
Вышеприведенный код, можно сократить используя lambda функции, такое решение позволит нам свести функцию в одну строку. Соответственно, вышеприведенный код можно переписать следующим образом:
Реализация
Python предоставляет встроенные функции для сортировки элементов с использованием сортировки по куче. Функции приведены ниже.
- heappush(list, item) – используется для добавления элемента кучи и его повторной сортировки.
- heappop(список) – нужна для удаления и возврата элемента.
- heapfy() – используется для превращения данного списка в кучу.
Рассмотрим следующий пример сортировки кучей.
Пример –
from heapq import heappop, heappush
def heapsort(list1):
heap = []
for ele in list1:
heappush(heap, ele)
sort = []
# the elements are lift in the heap
while heap:
sort.append(heappop(heap))
return sort
list1 =
print(heapsort(list1))
Выход:
Объяснение:
В приведенном выше коде мы импортировали модуль heapq, который состоит из методов heappop() и heappush(). Мы создали метод Heapsort Heapsort(), который принимает list1 в качестве аргумента. Цикл for выполняет итерацию по списку 1 и помещает элементы в пустую кучу. Мы использовали цикл while и добавили отсортированный элемент к пустой сортировке.
Мы вызвали функцию Heapsort Heapsort() и передали список. Он вернул отсортированный список.
Использовать
Пузырьковая сортировка, алгоритм сортировки, который непрерывно просматривает список, обмен элементы, пока они не появятся в правильном порядке. Список был построен в декартовой системе координат, каждая точка (Икс, у), указывая, что значение у хранится в индексе Икс. Затем список будет отсортирован пузырьковой сортировкой по значению каждого пикселя
Обратите внимание, что сначала сортируется самый большой конец, а меньшим элементам требуется больше времени, чтобы переместиться в правильное положение.
Хотя пузырьковая сортировка является одним из самых простых алгоритмов сортировки для понимания и реализации, ее О(п2) сложность означает, что его эффективность резко снижается для списков, состоящих из более чем небольшого числа элементов. Даже среди простых О(п2) алгоритмы сортировки, такие алгоритмы, как вставка сортировки обычно значительно более эффективны.
Из-за своей простоты пузырьковая сортировка часто используется для ознакомления с концепцией алгоритма или алгоритма сортировки. Информатика студенты. Однако некоторые исследователи, такие как Оуэн Астрахан приложили все усилия, чтобы осудить пузырьковую сортировку и ее неизменную популярность в образовании по информатике, рекомендуя даже не преподавать ее.
В Файл жаргона, который классно называет Богосорт «архетипичный извращенно ужасный алгоритм» также называет пузырьковую сортировку «общим плохим алгоритмом».Дональд Кнут, в Искусство программирования, пришел к выводу, что «пузырьковой сортировке, похоже, нечего рекомендовать, кроме запоминающегося названия и того факта, что это приводит к некоторым интересным теоретическим проблемам», некоторые из которых он затем обсуждает.
Сортировка пузырьков асимптотически эквивалентно по времени работы сортировке вставкой в худшем случае, но эти два алгоритма сильно различаются по количеству необходимых замен. Экспериментальные результаты, такие как результаты Astrachan, также показали, что сортировка вставкой работает значительно лучше даже в случайных списках. По этим причинам многие современные учебники алгоритмов избегают использования алгоритма пузырьковой сортировки в пользу сортировки вставкой.
Пузырьковая сортировка также плохо взаимодействует с современным оборудованием ЦП. Он производит как минимум вдвое больше записей, чем сортировка вставкой, в два раза больше промахов в кеш и асимптотически больше. неверные предсказания ветвей.[нужна цитата] Эксперименты Астрахана по сортировке строк в Ява показывать пузырьковую сортировку примерно на одну пятую быстрее, чем сортировка вставкой, и на 70% быстрее, чем сортировка выбора.
В компьютерной графике пузырьковая сортировка популярна благодаря своей способности обнаруживать очень маленькую ошибку (например, замену всего двух элементов) в почти отсортированных массивах и исправлять ее с линейной сложностью (2п). Например, он используется в алгоритме заливки многоугольника, где ограничивающие линии сортируются по их Икс координаты на определенной строке сканирования (линия, параллельная Икс оси) и с приращением у их порядок меняется (меняются местами два элемента) только на пересечении двух линий. Пузырьковая сортировка — это стабильный алгоритм сортировки, как и сортировка вставкой.
Odd and Ends¶
-
For locale aware sorting, use for a key function or
for a comparison function. -
The reverse parameter still maintains sort stability (so that records with
equal keys retain the original order). Interestingly, that effect can be
simulated without the parameter by using the builtin function
twice:>>> data = >>> standard_way = sorted(data, key=itemgetter(), reverse=True) >>> double_reversed = list(reversed(sorted(reversed(data), key=itemgetter()))) >>> assert standard_way == double_reversed >>> standard_way
-
The sort routines are guaranteed to use when making comparisons
between two objects. So, it is easy to add a standard sort order to a class by
defining an method:>>> Student.__lt__ = lambda self, other self.age < other.age >>> sorted(student_objects)
-
Key functions need not depend directly on the objects being sorted. A key
function can also access external resources. For instance, if the student grades
are stored in a dictionary, they can be used to sort a separate list of student
names:>>> students = 'dave', 'john', 'jane' >>> newgrades = {'john' 'F', 'jane''A', 'dave' 'C'} >>> sorted(students, key=newgrades.__getitem__)



