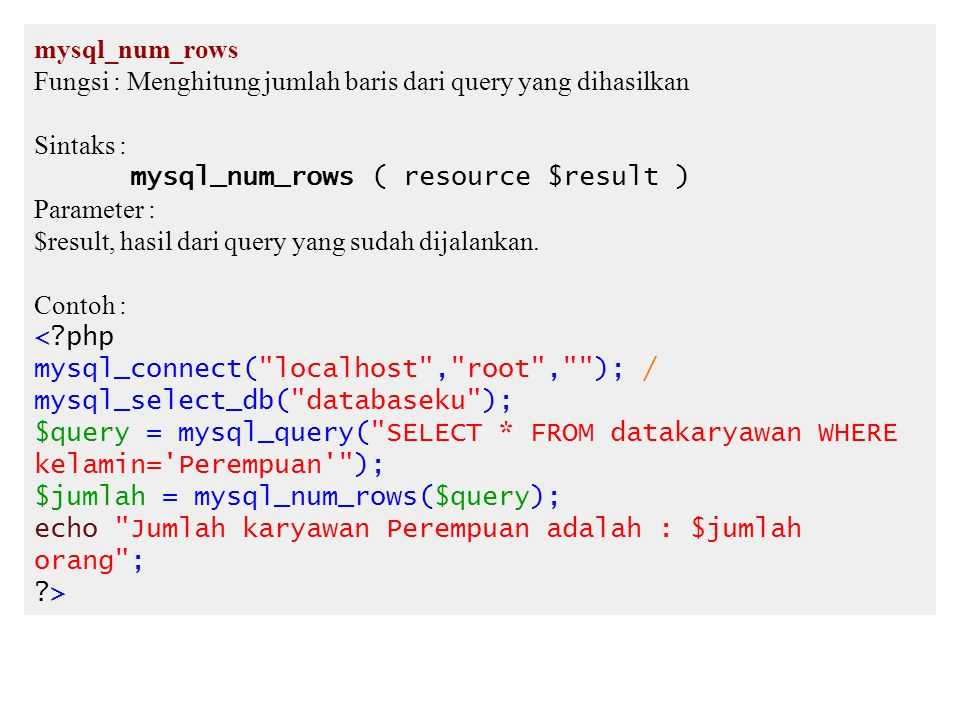
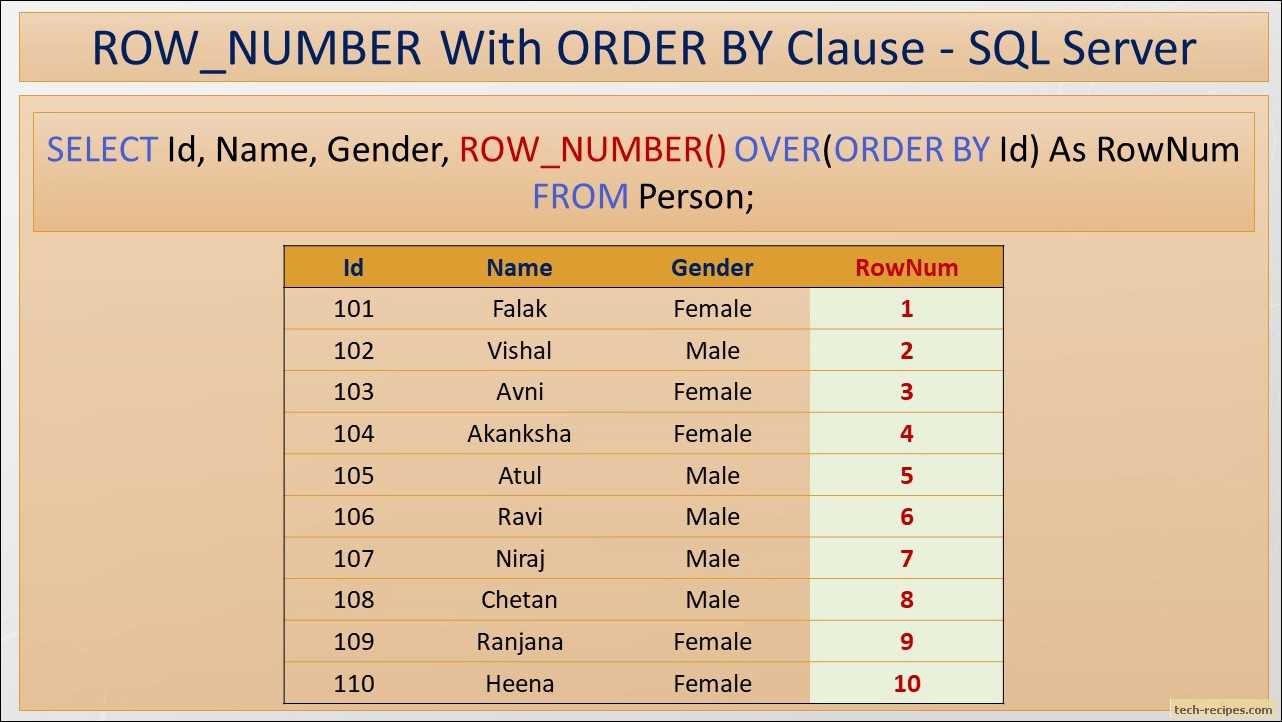
Using ROW_NUMBER() in MySQL with Example
In this section, we will look into how to use the row_number() function in MySQL. It is generally used when we want to select a row corresponding to its sequence number or if we want to limit our result set in the output.
We will be looking into two examples to demonstrate its usage:
Row_Number() usage Example 1 :
Get the latest customer_id inserted for customer_name =”Henric”
Observe the below query for the solution.
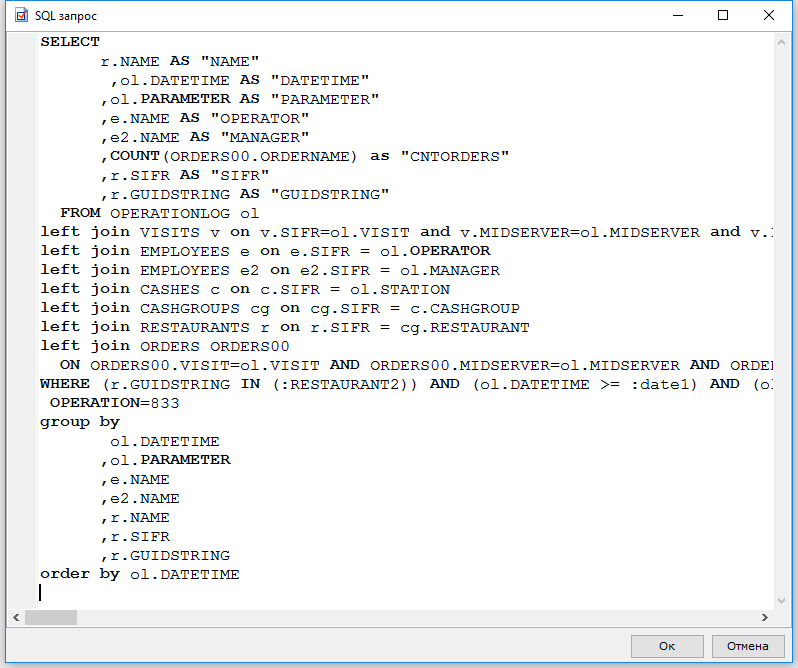
SELECT cd.customer_id, cd.customer_name, cd.customer_address FROM ( SELECT customer_id, customer_name, customer_address, ROW_NUMBER() OVER(PARTITION BY customer_name ORDER BY customer_id DESC) row_num FROM customer_details ) cd WHERE cd.row_num =1 and customer_name = "Henric";
Action Message Output Response:-
1 row(s) returned.
Output:-
![]() Figure 6
Figure 6
Here we have partitioned the table based on customer_name and ordered by descending customer_id. Hence the row with customer_id ‘8’ is assigned with row number 1. Finally, the query filters the result to get rows with row_num = 1 and customer_name = “Henric.”
Row_Number() usage Example 2 :
Get first five records from table customer_details ordered by customer_name.
Observe the below query for the solution.
SELECT *
FROM
(SELECT customer_id, customer_name ,
customer_address,
row_number()
OVER (order by customer_name) AS row_num
FROM customer_details) t
WHERE row_num BETWEEN 1 AND 5;
Output:-
![]() Figure 7
Figure 7
Here we are getting the first 5 records from the customer_details table when ordered by customer_name.
We hope this tutorial helps in understanding the concept of ROW_NUMBER() in MySQL. Good Luck !!!
Пример — ВЫБОРКА ОТДЕЛЬНЫХ ПОЛЕЙ ИЗ ОДНОЙ ТАБЛИЦЫ
Вы также можете использовать MySQL оператор SELECT для выбора отдельных полей из таблицы.
Например:
MySQL
SELECT order_id, quantity, unit_price
FROM order_details
WHERE quantity < 300
ORDER BY quantity ASC, unit_price DESC;
|
1 |
SELECTorder_id,quantity,unit_price FROMorder_details WHEREquantity<300 ORDER BYquantityASC,unit_priceDESC; |
В этом MySQL примере SELECT возвращает только поля order_id, quantity и unit_price из таблицы order_details, где количество меньше 300. Результаты сортируются по quantity в порядке возрастания, а затем unit_price в порядке убывания.
MySQL Функции даты
| Функция | Описание |
|---|---|
| ADDDATE | Добавляет интервал времени/даты к дате, а затем возвращает дату |
| ADDTIME | Добавляет временной интервал к времени/дате времени, а затем возвращает время/дату времени |
| CURDATE | Возвращает текущую дату |
| CURRENT_DATE | Возвращает текущую дату |
| CURRENT_TIME | Возвращает текущее время |
| CURRENT_TIMESTAMP | Возвращает текущую дату и время |
| CURTIME | Возвращает текущее время |
| DATE | Извлекает дату из datetime выражение |
| DATEDIFF | Возвращает количество дней между двумя значениями даты |
| DATE_ADD | Добавляет интервал времени/даты к дате, а затем возвращает дату |
| DATE_FORMAT | Форматирование даты |
| DATE_SUB | Вычитает интервал времени/даты из даты, а затем возвращает дату |
| DAY | Возвращает день месяца для заданной даты |
| DAYNAME | Возвращает название дня недели для заданной даты |
| DAYOFMONTH | Возвращает день месяца для заданной даты |
| DAYOFWEEK | Возвращает индекс дня недели для заданной даты |
| DAYOFYEAR | Возвращает день года для заданной даты |
| EXTRACT | Извлекает часть из заданной даты |
| FROM_DAYS | Возвращает дату из числового значения даты |
| HOUR | Возвращает часовую часть для заданной даты |
| LAST_DAY | Извлекает последний день месяца для заданной даты |
| LOCALTIME | Возвращает текущую дату и время |
| LOCALTIMESTAMP | Возвращает текущую дату и время |
| MAKEDATE | Создает и возвращает дату на основе значения года и количества дней |
| MAKETIME | Создает и возвращает время, основанное на часе, минуте и втором значении |
| MICROSECOND | Возвращает микросекундную часть время/даты-время |
| MINUTE | Возвращает минутную часть время/даты-время |
| MONTH | Возвращает часть месяца для заданной даты |
| MONTHNAME | Возвращает название месяца для заданной даты |
| NOW | Возвращает текущую дату и время |
| PERIOD_ADD | Добавляет к периоду заданное количество месяцев |
| PERIOD_DIFF | Возвращает разницу между двумя периодами |
| QUARTER | Возвращает квартал года для заданного значения даты |
| SECOND | Возвращает секундную часть времени/даты-время |
| SEC_TO_TIME | Возвращает значение времени, основанное на указанных секундах |
| STR_TO_DATE | Возвращает дату на основе строки и формата |
| SUBDATE | Вычитает интервал времени/даты из даты, а затем возвращает дату |
| SUBTIME | Уменьшает интервал времени из DateTime и возвращает время/дата-время |
| SYSDATE | Возвращает текущую дату и время |
| TIME | Извлекает время от данный момент времени |
| TIME_FORMAT | Форматирует время по заданному формату |
| TIME_TO_SEC | Преобразует значение времени в секунды |
| TIMEDIFF | Возвращает разницу между двумя выражениями время/дата-время |
| TIMESTAMP | Возвращает значение datetime значение даты или типа datetime |
| TO_DAYS | Возвращает количество дней между датой и датой «0000-00-00» |
| WEEK | Возвращает номер недели для заданной даты |
| WEEKDAY | Возвращает номер дня недели для заданной даты |
| WEEKOFYEAR | Возвращает номер недели для заданной даты |
| YEAR | Возвращает часть года для заданной даты |
| YEARWEEK | Возвращает номер года и недели для заданной даты |
ROW_NUMBER() in MySQL Syntax
Let us look into the syntax for ROW_NUMBER() function.
ROW_NUMBER() OVER (<partition_specification> <order_specification>)
Syntax for <partition_specification>
PARTITION BY clause is optional.
PARTITION BY <expression> ,
Syntax for <order_specification>
ORDER BY clause is mandatory. ASC is the default value.
ORDER BY <expression> ,
The row_number() function assigns a designated number to the current row corresponding to the partition.
Row numbers assigned to each row range between 1 to the number of partition rows.
The order by clause decides the arrangement for the sequence given to each row. Hence, in case the order is changed, the sequential number assigned to each row changes.
Дополнительно о SELECT
Теперь, когда мы научились делать простые запросы с и , можно ненадолго снова вернуться к .
Агрегатные функции
В операторе можно использовать агрегатные функции, которые дают единственное значение для целой группы строк в таблице.
Агрегатная функция записывается в следующем виде:
Пользователю доступны следующие агрегатные функции:
- ‑ вычисляет сумму множества значений указанного столбца;
- ‑ вычисляет количество значений указанного столбца;
- / ‑ определяет минимальное/максимальное значение в указанном столбце;
- ‑ вычисляет среднее арифметическое значение множества значений столбца;
- / ‑ определяет первое/последнее значение в указанном столбце.
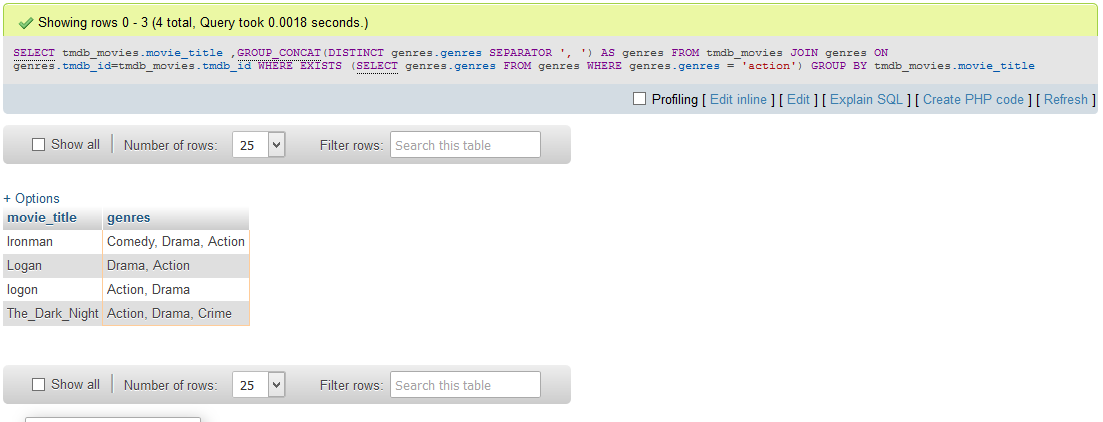
Пример 15.Определить общий объем поставляемых деталей.
| Expr1000 |
|---|
| 2000 |
Вычисляемые столбцы
Столбцы результирующей таблицы, которых не существовало в исходных таблицах, называются вычисляемыми. Таким столбцам СУБД присваивает системные имена, что не всегда является удобным.
При вычислении результатов любой агрегатной функции СУБД сначала исключает все -значения, после чего требуемая операция применяется к оставшимся значениям.
Для функции возможен особый вариант использования — . Его назначение состоит в подсчете всех строк в результирующей таблице, включая -значения.
Следует запомнить, что агрегатные функции нельзя вкладывать друг в друга. Такая конструкция работать не будет: `MAX(SUM(VOLUME))`
Переименование столбца
Язык SQL позволяет задавать новые имена столбцам результирующей таблицы, для чего используется операция . Переименование также используют для изменения сложных имен столбцов таблицы.
Например, присвоить новое имя вычисляемому столбцу в предыдущем примере позволит выполнение следующего запроса.
| Sum |
|---|
| 2000 |
Пример 16.Определить количество поставщиков, которые поставляют детали в настоящее время.
| Count |
|---|
| 6 |
Несмотря на то, что реальное число поставщиков деталей в таблице PD равно 3, СУБД возвращает число 6
Такой результат объясняется тем, что СУБД подсчитывает все строки в таблице PD, не обращая внимание на то, что в строках есть одинаковые значения
Операция
Если до применения агрегатной функции необходимо исключить дублирующиеся значения, следует перед именем столбца указать ключевое слово .
| Count |
|---|
| 3 |
можно задать только один раз для одного предложения .
Противоположностью является операция . Она имеет противоположное действие «показать все строки таблицы» и предполагается по умолчанию.
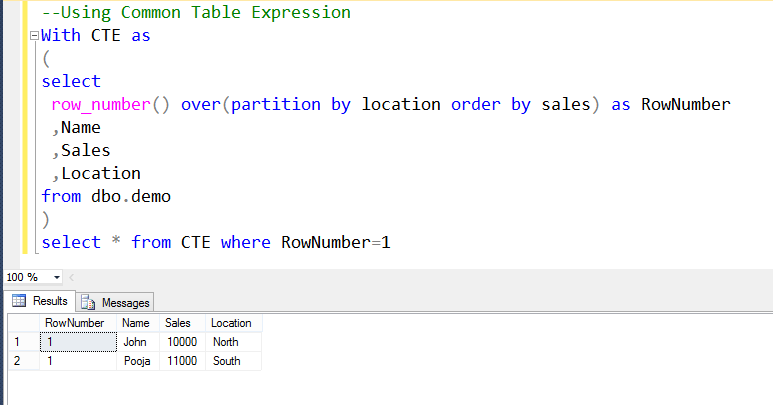
ROW_NUMBER
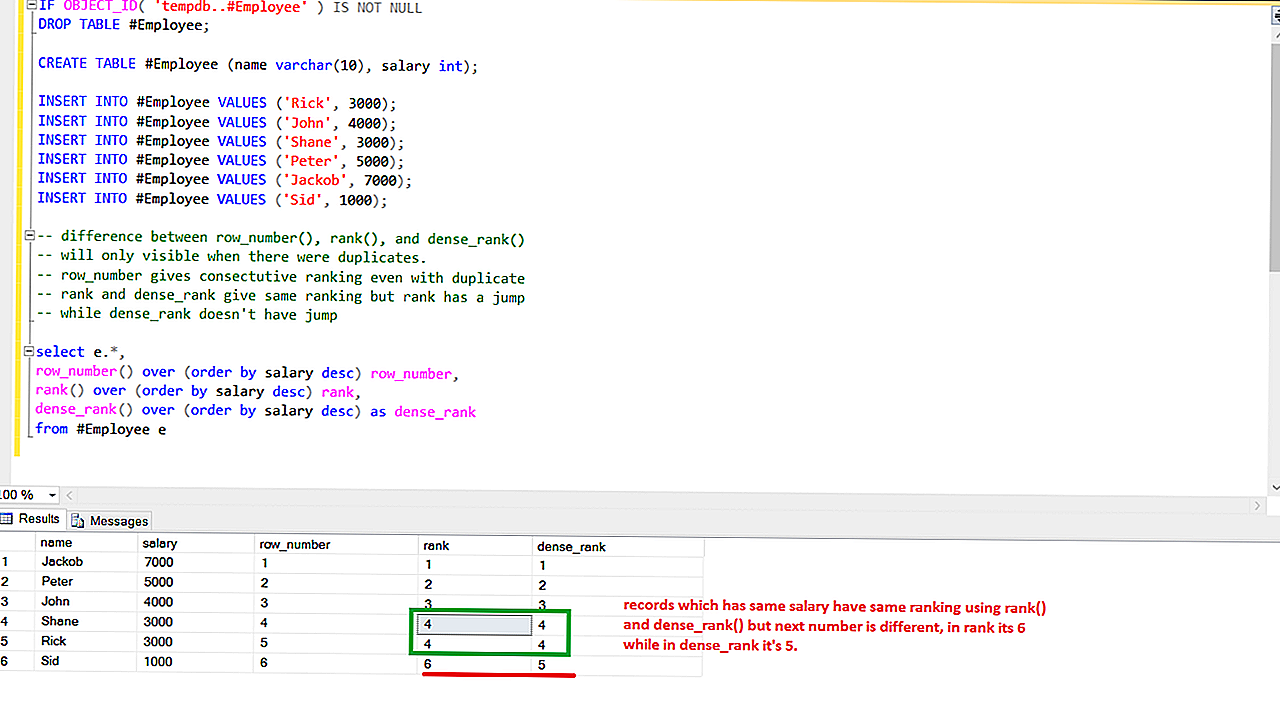
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
ROW_NUMBER () OVER ( ORDER BY столбец сортировки)
где, partition by — это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
![]()
![]()
Как видите, здесь уже нумерация идет в каждой категории.
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
![]()
![]()
Demo
In this section, we’ll take a look at the SQL ROW_NUMBER function. For the entire demo, I’ve used AdventureWorks2016 database.
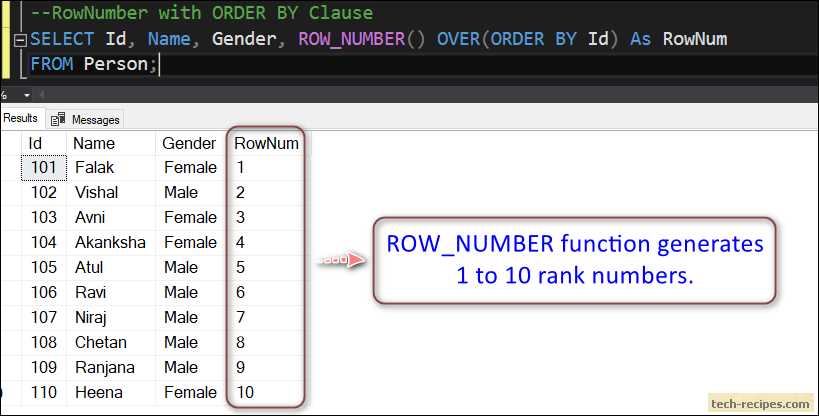
How to use ROW_NUMBER in SQL Query
The following examples, we’ll see the use of OVER clause.
Let us get the list of all the customers by projecting the columns such as SalesOrderID, OrderDate, SalesOrderNumber, SubTotal, TotalDue and RowNum. The Row_Number function is applied with the order of the CustomerID column. The temporary value starts from 1 assigned based on the order of the CustomerID, and the values are continued till the last rows of the table. The order of CustomerID is not guaranteed because we don’t specify the ORDER BY clause in the query.
|
1 |
USEAdventureWorks2016; GO SELECTROW_NUMBER()OVER( ORDERBYCustomerID)ASRowNum, CustomerID, SalesOrderID, OrderDate, SalesOrderNumber, SubTotal, TotalDue FROMSales.SalesOrderHeader; |
![]()
How to use Order by clause
The following example uses the ORDER BY clause in the query. The ORDER BY clause in the query applied on the SalesOrderID column. We can see that the rows in output are still ordered and returned. The Row_Number is still applied to the CustomerID. The output indicates that the ORDER BY of the query and the ORDER BY of the OVER Clause are independent of the output.
|
1 |
USEAdventureWorks2016; GO SELECTROW_NUMBER()OVER( ORDERBYCustomerID)ASRowNum, CustomerID, SalesOrderID, OrderDate, SalesOrderNumber, SubTotal, TotalDue FROMSales.SalesOrderHeader ORDERBYSalesOrderID; |
![]()
How to use multiple columns with the OVER clause
The following example you can see that we have listed customerID and OrderDate in the ORDER BY clause. This gives the customer details with the most recent order details along with the sequence of numbers assigned to the entire result-set.
|
1 |
USEAdventureWorks2016; GO SELECTROW_NUMBER()OVER(ORDERBYCustomerID,OrderDateDESC)ASRowNum, CustomerID, SalesOrderID, OrderDate, SalesOrderNumber, SubTotal, TotalDue FROMSales.SalesOrderHeader |
![]()
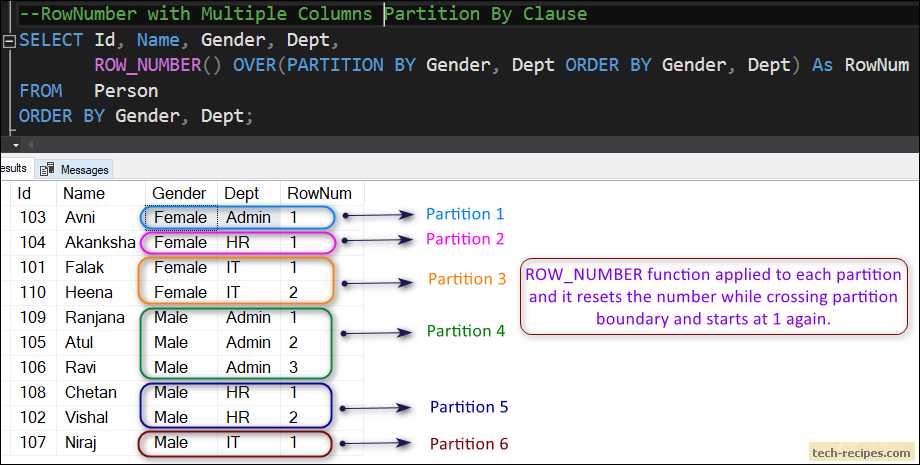
How to use the SQL ROW_NUMBER function with PARTITION
The following example uses PARTITION BY clause on CustomerID and OrderDate fields. In the output, you can see that the customer 11019 has three orders for the month 2014-Jun. In this case, the partition is done on more than one column.
The partition is a combination of OrderDate and CustomerID. The Row_Number will start over for each unique combination of OrderDate and CustomerID. In this way, it’s easy to find the customer who has placed more than one order on the same day.
|
1 |
USEAdventureWorks2016; GO SELECTROW_NUMBER()OVER(PARTITIONBYCustomerID, DATEADD(MONTH,DATEDIFF(MONTH,,OrderDate),) ORDERBYSubTotalDESC)ASMonthlyOrders, CustomerID, SalesOrderID, OrderDate, SalesOrderNumber, SubTotal, TotalDue FROMSales.SalesOrderHeader; |
![]()
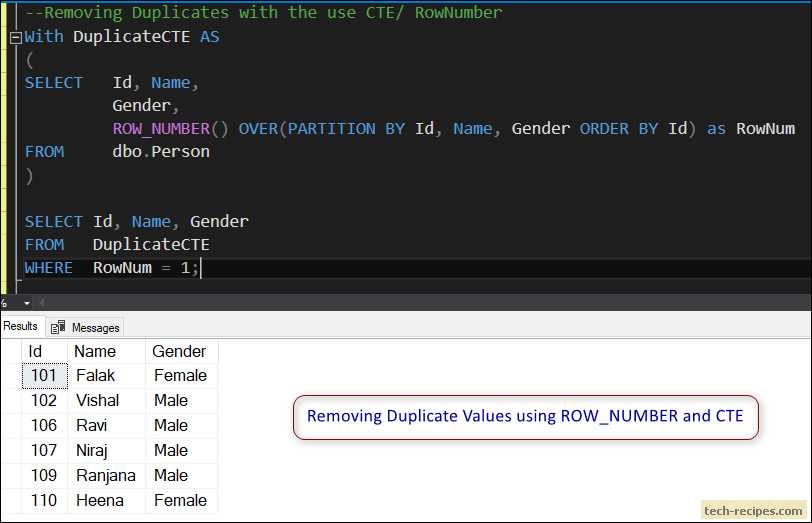
How to return a subset of rows using CTE and ROW_NUMBER
The following example we are going to analyze SalesOrderHeader to display the top five largest orders placed by each customer every month. Using the Month function, the orderDate columns is manipulated to fetch the month part. In this way, the sales corresponding to specific month (OrderDate) along with customer (CustomerID) is partitioned.
To list the five largest orders in each month for each customer, a CTE is used. A window is created on the partition data and it is assigned with the values and then the CTE is being called to fetch the largest orders.
|
1 |
WITHcte AS(SELECTROW_NUMBEROVER(PARTITIONBYcustomerID,MONTH(OrderDate)ORDERBYSubTotalDESC,TotalDueDESC)ASROW_NUM, CustomerID, MONTH(OrderDate)Month, SubTotal, TotalDue, OrderDate FROMSales.SalesOrderHeader ) SELECT* FROMcte WHEREROW_NUM<=5 |
![]()
Решение на основе ранжирующих функций
Ранжирующие функции — ROW_NUMBER, RANK, DENSE_RANK и NTILE появились в составе SQL Server, начиная с версии 2005. Их появление в языке SQL было вызвано потребностью выполнять упорядоченные вычисления. Собственно, наше упражнение как раз и относится к этому классу задач. И теперь у нас есть возможность оценить данное приобретение. :
Для решения нашей задачи воспользуемся функцией RANK. Эта функция позволяет разбить все строки, возвращаемые запросом, на группы и вычислить ранг каждой строки в группе в соответствии заданной сортировкой. Поскольку мы будем сортировать по уникальному номеру модели, то ранг фактически будет совпадать с номером строки в группе. Итак, решение
Собственно, все делается в подзапросе. Внешний запрос служит лишь для того, чтобы ограничить выборку тремя моделями по каждой группе. Говоря другими словами, мы оставляем только те строки, у которых ранг не превышает трех.
Экономно, не так ли. Однако давайте разберем более детально конструкцию
Предложение PARTITION BY type формирует группы; в одну группу у нас попадают строки, имеющий один и тот же тип продукции (одно и то же значение в столбце type).
Предложение ORDER BY model задает сортировку строк в группе (по возрастанию номера модели).
Наконец, RANK() присваивает ранг каждой строке в группе на основе заданной сортировки, т.е. первая строка в группе получает ранг 1, следующая, если она имеет отличный номер модели, ранг 2 и т.д. Как я уже сказал, поскольку номер модели уникальный, то каждая строка в группе будет иметь отличный ранг. В противном случае, строки с одинаковым номером модели имели бы одинаковый ранг.
Подробное описание функций ранжирования выходит за рамки данной статьи, но, возможно, я напишу нечто подобное для Учебника по SQL.
Назад | | Вперед
| Начало | Упражнения SELECT (рейтинговые этапы) | Упражнения DML | Разработчики |
Курсоры
Курсор представляет собой временную таблицу, получаемую в результате запроса, которая служит для построчной обработки данных. Курсор позволяет в цикле «перебирать» строки, выполняя над ними необходимые действия. Таки образом, курсор является таблицей, возможности которой выходят за рамки классической реляционной модели (в классическом отношении отсутствует понятие порядка следования строк – строки представляют собой множество).
Для объявления курсора используется следующий оператор:
DECLARE <имя_курсора> CURSOR FOR <SQL-выражение>;
Прежде чем курсор может быть использован, его необходимо открыть:
OPEN <имя_курсора>;
После открытия указатель курсора устанавливается на первую строку. Для доступа к текущей строке открытого курсора используется оператор:
FETCH <имя_курсора> INTO <имя_переменной> …
Этот оператор помещает значения строки курсора в переменные, количество и типы данных которых соответствуют схеме (столбцам) курсора. После выполнения оператора FETCH происходит автоматическое продвижение на следующую строку курсора. Если более нет доступных строк (достигнута последняя строка) происходит изменение значения переменной SQLSTATE в 02000. Для обработки этого события необходимо установить обработчик: HANDLER FOR SQLSTATE ‘02000’.
Следующий оператор закрывает курсор:
CLOSE <имя_курсора>;
Если оператор закрытия курсора не указан явно, то курсор закрывается автоматически при закрытии соответствующего блока подпрограммы.
Для примера создадим процедуру, которая изменяет имя всех деталей с определенным именем на имя, формируемое как «Имя-N», где N – порядковый номер в списке всех деталей «Gasket» в порядке возрастания веса детали. Имя детали передается в качестве параметра.
CREATE PROCEDURE Parts_rename(PName VARCHAR(20))
BEGIN
DECLARE Done INT DEFAULT 0;
DECLARE S VARCHAR(20);
DECLARE N,I INTEGER;
DECLARE Cur1 CURSOR FOR SELECT Part_ID, Part_name FROM Parts WHERE Part_name=PName ORDER BY WEIGHT;
DECLARE CONTINUE HANDLER FOR SQLSTATE ‘02000’ SET done = 1;
OPEN Cur1;
SET I=1;
REPEAT
FETCH Cur1 INTO N,S;
IF Done=0 THEN UPDATE Parts SET Part_name=CONCAT(S,’-’,I) WHERE Part_ID=N;
END IF;
SET I=I+1;
UNTIL Done END REPEAT;
CLOSE Cur1;
END
Содержимое таблицы до выполнения процедуры:
![]()
Содержимое таблицы после выполнения процедуры:
![]()
UNION
Ключевое слово используется для объединения результатов нескольких запросов в одну таблицу. Каждый оператор , используемый в запросе , должен иметь одинаковое количество столбцов, а для каждого столбца требуется одинаковый тип данных. Имена столбцов из первого запроса используются в качестве столбцов для возвращаемых результатов.
Например, приведем пример таблицы сотрудников Employee:
|
employee_id |
name |
city |
postal_code |
country |
|
1 |
Robert |
Berlin |
12209 |
Germany |
|
2 |
Mac |
Mexico D.F. |
5021 |
Mexico |
|
3 |
Patel |
Mexico D.F. |
5023 |
Mexico |
Далее приведем пример таблицы подрядчиков Contractor:
|
contractor_id |
name |
city |
postal_code |
country |
|
1 |
Dave |
Berlin |
12209 |
Germany |
|
2 |
Robert |
Mexico D.F. |
5021 |
Mexico |
|
3 |
Patel |
Mexico D.F. |
5023 |
Mexico |
Как показано в следующем ниже примере, имена столбцов из первого запроса используются в качестве столбцов для возвращаемых результатов:
Следующий ниже пример объединения удаляет повторяющиеся строки из результата; если мы не хотим удалять повторяющиеся строки, можно применить ключевое слово :
Этот запрос возвращает две строки из предыдущей таблицы — Germany и Mexico. Чтобы получить все строки из обеих таблиц, можно использовать ключевое слово следующим образом:
Подзапрос
Оператор внутри оператора называется подзапросом. Этот подзапрос может применяться для выбора столбца или в условных предложениях. Подзапрос также может быть вложен в другой запрос типа , или .


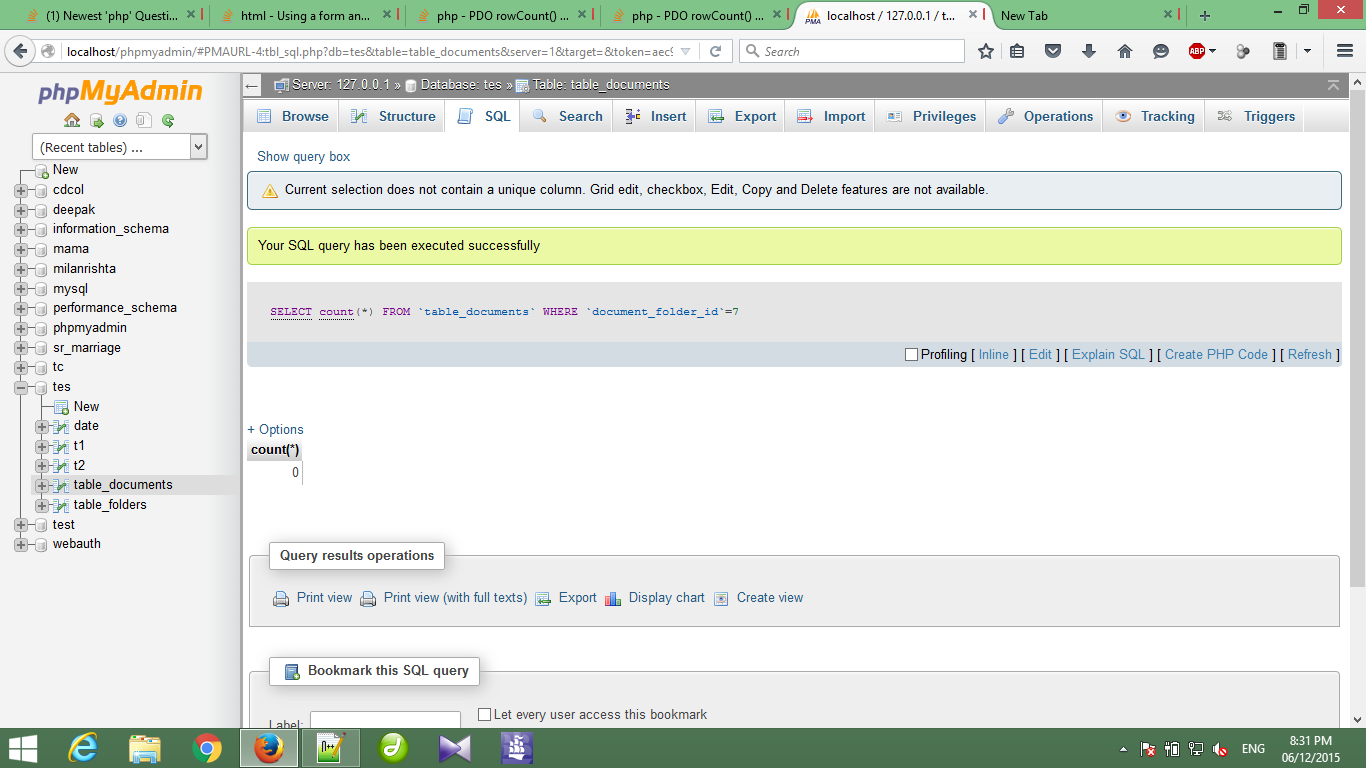

Следующий ниже запрос возвращает множество пользователей, которые находятся в Ahmedabad, используя вложенный запрос:
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
![]()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) ,
ROW_NUMBER() over (order by price desc) as
FROM selling
![]()
Текст запроса
SELECT NameProduct, price, category,
rank() over (partition by category order by price desc) ,
ROW_NUMBER() over (partition by category order by price desc) as
FROM selling
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии