
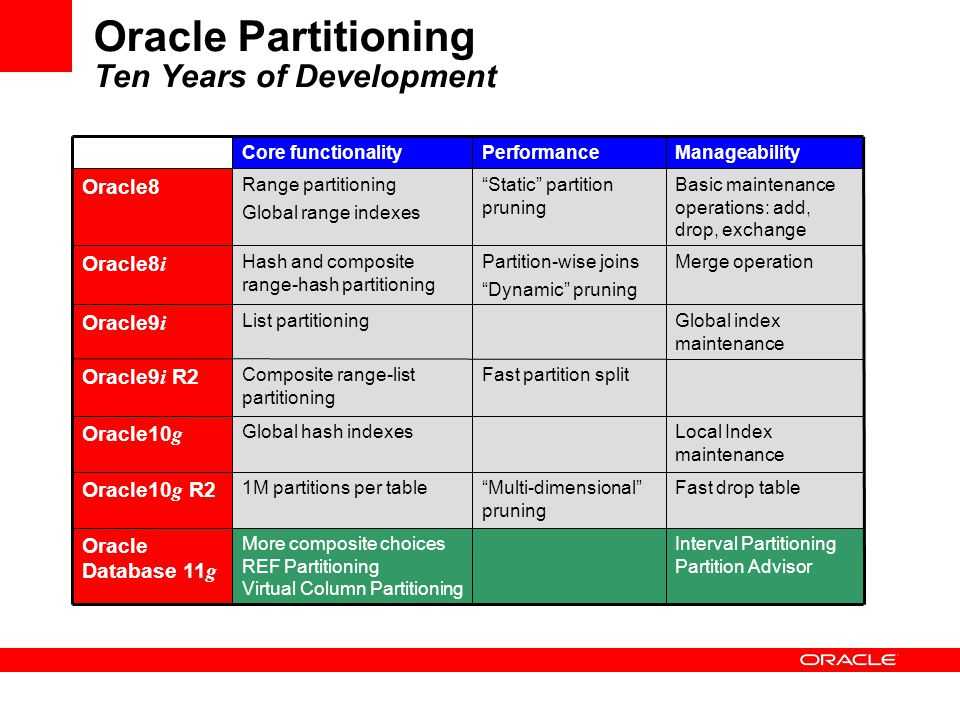
Пробелы в именах объектов базы данных
У тебя может возникнуть вопрос – а что, а можно создавать имена таблица или колонок из нескольких слов и как тогда MySQL будет работать с пробелами? Создавать объекты с пробелами можно, но в этом случае имя нужно окружить специальными символами, которые зависят от базы данных, в MySQL это символ ` который находится слева от цифры 1 на большинстве клавиш.
Так что теоретически наш запрос может выглядеть так:
SELECT `Adress id`, Name FROM `Address Table`
Обратите внимание, что колонка Address id содержит пробел, поэтому вначале и в конце стоит символ `. У колонки Name нет пробелов, поэтому ничего добавлять не нужно
У имени таблицы так же есть пробел.
Если в имени объекта есть пробел, то ` является обязательным, если пробела нет, то можно поставить, а можно и опустить. Это значит, следующие запросы одинаково корректны:
SELECT `cityname` FROM `city`; SELECT cityname FROM `city`; SELECT `cityname` FROM city; SELECT cityname FROM city;
Все они корректны и все будут работать.
Хотя все примеры мы рассматриваем и тестируем под MySQL, почти все они будут работать и в других базах данных, но вот разделитель в разных базах может отличаться. В MS SQL Server это квадратные скобки:
SELECT FROM ;
Очень часто программисты стараются создавать таблицы и колонки без пробелов, поэтому не так часто можно увидеть запросы, в которых используются символы, которыми окружаются имена объектов.
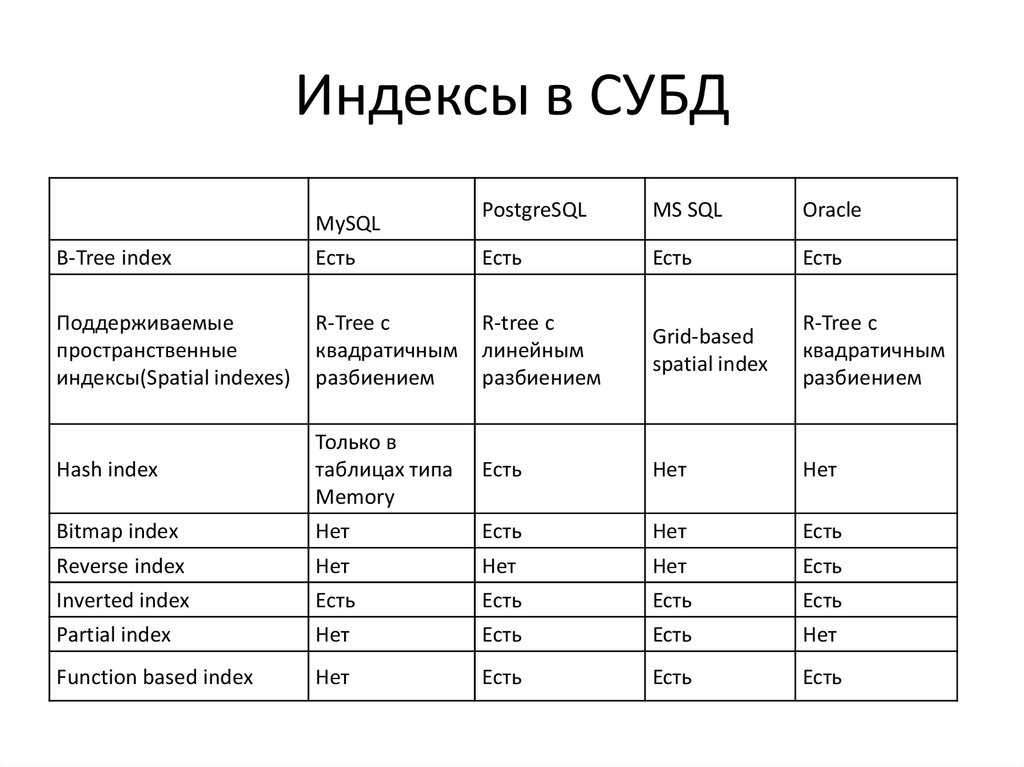
Что такое индексы в sql server
Разберемся в понятии индексов (indexes) – это особые таблицы, используемые поисковыми системами для поиска данных. Их активное использование играет важнейшую роль в повышении производительности sql серверов.
Словно указатель в грамотно составленной книге, индекс помогает быстро получить доступ к строкам требуемых данных в таблице, соответствующих запросу. Таким образом, их использование позволяет ускорить выполнение требуемого запроса.
К примеру, для получения всех страниц в книге, касающихся выбранной тематики, сначала нужно обратиться к перечню тем, а затем выбрать нужные страницы. Для этого следует создать индекс по выбранной теме. На ее основе и будут выбираться ссылки на страницы книги по затронутой теме. Используя значения, заданные первичным ключом, sql server найдет нужный индекс и с его помощью быстро выберет все строки с необходимыми данными. Если не использовать индекс, то для поиска информации будет произведено сканирование каждой строки таблицы. Это значительно понизит производительность и увеличит время поиска.
Благодаря индексу процесс поиска данных сокращается за счет их упорядочивания как физического, так и логического. Таким образом, он выглядит как набор ссылок на данные, которые упорядочены по выбранному столбцу таблицы. Такой столбец называется индексированным. Индексы находятся в таблице и по сути выступают полезными внутренними механизмами системы sql-сервера, которые помогают сделать доступ к данным наиболее оптимальным.
Создать стандартный индекс можно на всех столбцах данных, кроме:
- столбцов, которые используются для хранения данных объектов, имеющих большие размеры, (LOB): TEXT, IMAGE, VARCHAR (MAX);
- представленных в XML. Для работы с данными, представлены в таком формате используются xml-index, которые отличаются от стандартных. О них рассказано ниже.
Производительность лейкопластыря
![]()
SELECT pp.BusinessEntityID , pp.FirstName , pp.LastName , sp. , sp. , sp. , sp. AS , sp. , cr. , cr. AS , pbe.AddressTypeID , pp.AdditionalContactInfo , pp.Demographics FROM . sp INNER JOIN . cr ON RTRIM(LTRIM(sp.)) = RTRIM(LTRIM(cr.)) INNER JOIN Person.Address pa ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID)) INNER JOIN Person.BusinessEntityAddress pbe ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID)) INNER JOIN Person.Person pp ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID)) WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2;
Уникальный INDEX
Чтобы создать уникальный индекс в таблице, вам нужно указать ключевое слово UNIQUE при создании индекса. Опять же, это можно сделать с помощью оператора CREATE TABLE или оператора CREATE INDEX.
Например:
MySQL
CREATE TABLE contacts
( contact_id INT(11) NOT NULL AUTO_INCREMENT,
last_name VARCHAR(30) NOT NULL,
first_name VARCHAR(25),
birthday DATE,
CONSTRAINT contacts_pk PRIMARY KEY (contact_id),
UNIQUE INDEX contacts_idx (last_name, first_name)
);
|
1 |
CREATETABLEcontacts last_nameVARCHAR(30)NOT NULL, first_nameVARCHAR(25), birthdayDATE, CONSTRAINTcontacts_pkPRIMARY KEY(contact_id), UNIQUEINDEXcontacts_idx(last_name,first_name) |
ИЛИ
MySQL
CREATE TABLE contacts
( contact_id INT(11) NOT NULL AUTO_INCREMENT,
last_name VARCHAR(30) NOT NULL,
first_name VARCHAR(25),
birthday DATE,
CONSTRAINT contacts_pk PRIMARY KEY (contact_id)
);
CREATE UNIQUE INDEX contacts_idx
ON contacts (last_name, first_name);
|
1 |
CREATETABLEcontacts last_nameVARCHAR(30)NOT NULL, first_nameVARCHAR(25), birthdayDATE, CONSTRAINTcontacts_pkPRIMARY KEY(contact_id) CREATEUNIQUEINDEXcontacts_idx ONcontacts(last_name,first_name); |
Оба эти примера создавали бы уникальный индекс для полей last_name и first_name, так что комбинация этих полей всегда должна содержать уникальное значение без дубликатов. Это отличный способ обеспечить целостность вашей базы данных, если вам нужны уникальные значения в столбцах, которые не являются частью вашего первичного ключа.
Исчезающий закон
SELECT o.name AS ObjName , i.name AS IdxName , SUM(ps.page_count) AS page_count , SUM(ps.record_count) AS record_count , SUM(ps.page_count) / 128.0 AS SizeMB FROM sys.indexes i INNER JOIN sys.objects o ON i.object_id = o.object_id INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'detailed') ps ON ps.object_id = o.object_id WHERE o.name LIKE 'vperson%' GROUP BY o.name , i.name;
![]()
ALTER VIEW . WITH SCHEMABINDING AS SELECT pp.BusinessEntityID , pp.FirstName , pp.LastName , sp. , sp. , sp. , sp. AS , sp. , cr. , cr. AS , pbe.AddressTypeID FROM . sp INNER JOIN . cr ON RTRIM(LTRIM(sp.)) = RTRIM(LTRIM(cr.)) INNER JOIN Person.Address pa ON RTRIM(LTRIM(sp.StateProvinceID)) = RTRIM(LTRIM(pa.StateProvinceID)) INNER JOIN Person.BusinessEntityAddress pbe ON RTRIM(LTRIM(pbe.AddressID)) = RTRIM(LTRIM(pa.AddressID)) INNER JOIN Person.Person pp ON RTRIM(LTRIM(pp.BusinessEntityID)) = RTRIM(LTRIM(pbe.BusinessEntityID)) WHERE RTRIM(LTRIM(pbe.AddressTypeID)) = 2;
SELECT o.name AS ObjName , i.name AS IdxName , SUM(ps.page_count) AS page_count , SUM(ps.record_count) AS record_count , SUM(ps.page_count) / 128.0 AS SizeMB FROM sys.indexes i INNER JOIN sys.objects o ON i.object_id = o.object_id INNER JOIN sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'detailed') ps ON ps.object_id = o.object_id WHERE o.name LIKE 'vperson%' GROUP BY o.name , i.name;
Индексирование таблиц MySQL
Использование индексирования таблиц MySQL имеет свои особенности:
- Индексировать есть смысл только определенные поля таблицы. Нередки случаи, когда неопытные пользователи индексируют всю БД. На практике такой шаг может привести к обратному результату: в MySQL индексы негативно влияют на скорость вставки и обновления данных, так как при этих операциях возникает необходимость изменять данные в информационной части индекса.
- Операции индексирования полей таблиц БД должна быть проделана работа по анализу наиболее частых запросов к БД. Только в этом случае использование индексов позволит оптимизировать работу БД. Выявить наиболее медленные запросы к БД поможет slow log (сохраняет в специальный файл запросы, время выполнения которых превысило заданное пользователем значение). Включить его в MySQL можно, отредактировав конфигурационный файл.
- Использование одного составного индекса вместо нескольких односоставных для ускорения наиболее активно использующихся запросов также ускорит скорость работы с БД.
- Покрывающие индексы позволяют получать результат вообще без обращения к таблице БД. Иногда добавление дополнительного проиндексированного поля позволяет существенно сократить время обработки запросов.
- В MySQL индексы с низкой селективностью (чем больше различных значений принимает параметр, тем выше его селективность) зачастую оказываются неэффективными.
- В запросах, где используется LIKE %, индексы не используются, даже если поле проиндексировано. Например, при таком запросе:LIKE(SELECT Name FROM Persons WHERE Points LIKE ‘%10’)
Определившись с назначением и особенностями использования индексов СУБД, перейдем к основным операциям с ними.
Создание индекса в MySQL
Для операции создания индекса MySQL предусматривает такой синтаксис:CREATE INDEX <уникальное имя индекса> ON <имя таблицы> (<имя столбца> ,… )
где:
<имя столбца> — уникальный идентификатор индекса. Если это поле не определено, ему будет присвоено имя первого подлежащего индексации столбца.

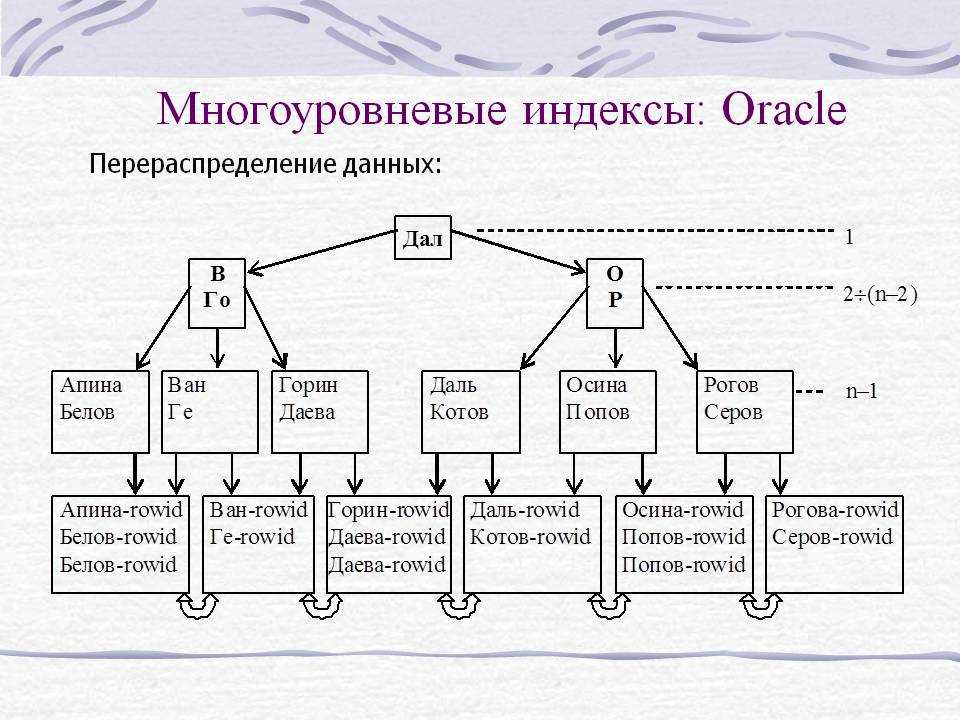
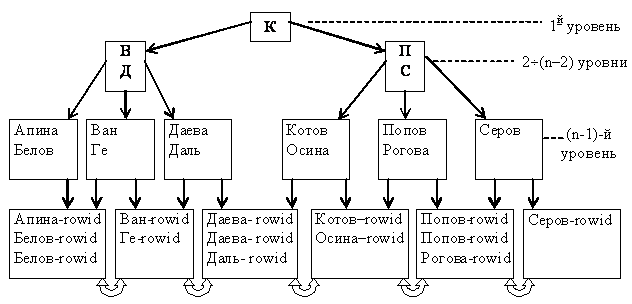

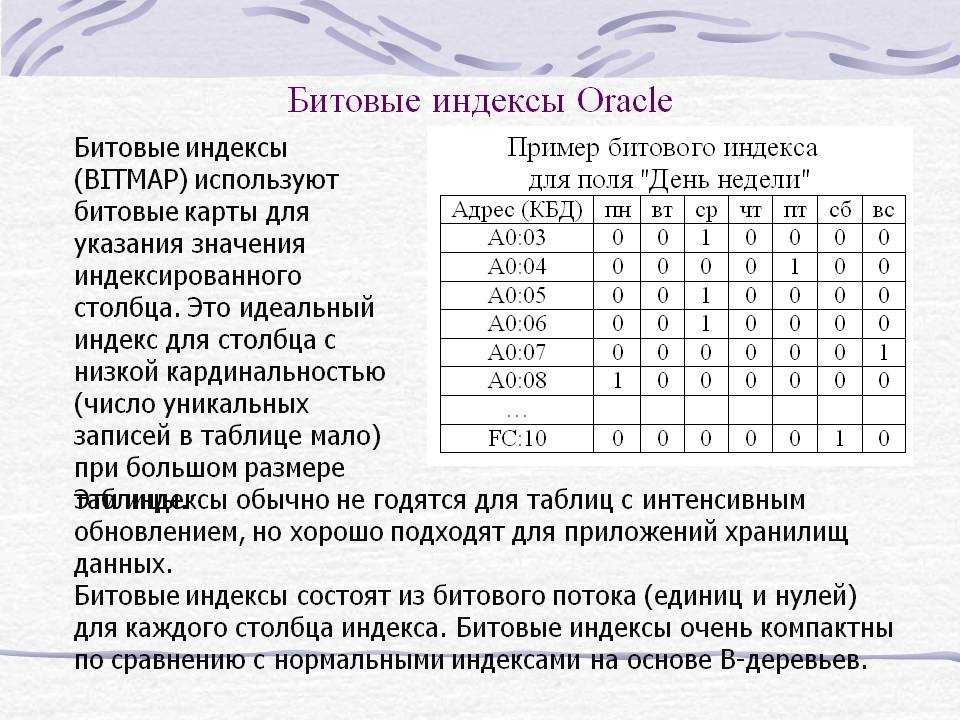
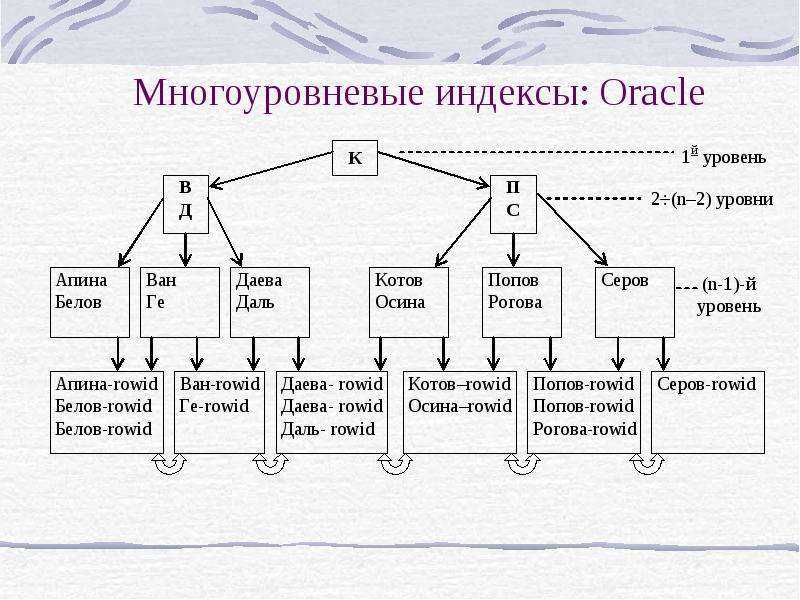




В версиях MySQL младше 3.22 эта команда не активна, а в более поздних – в плане создания индексов работает аналогично команде ALTER TABLE. При работе с ALTER TABLE добавление записей происходит при помощи команды ADD INDEX, MySQL при помощи этой команды позволяет создавать индексы PRIMARY KEY (создать индекс такого типа при помощи CREATE INDEX нельзя).
Предостережение
Обратите внимание. что первичный ключ не может быть невидимым
Оптимизатору необходимо знать — имеет ли таблица первичный ключ. Это также справедливо для ситуации, когда нет первичного ключа, но есть уникальный ключ. В этом случае первый уникальный ключ рассматривается в качестве первичного ключа, и, следовательно, не может быть невидимым.
Спасибо, что выбрали MySQL!
Функциональность очень удобная, но пока имеет недостатки: если в запросе указано FORCE INDEX(`индекс, объявленный невидимым`), то всегда будет полный скан таблицы даже при наличии других индексов, подходящих для запроса.
Вызывает удивление, что FORCE INDEX(`индекс, объявленный невидимым`) не генерирует предупреждение. Это было бы удобно, чтобы не пропустить такие запросы при оценке производительности, когда объявляем индекс невидимым.
Все права на данную статью принадлежат порталу SQLInfo.ru. Перепечатка в интернет-изданиях разрешается только с указанием автора и прямой ссылки на оригинальную статью. Перепечатка в бумажных изданиях допускается только с разрешения редакции.
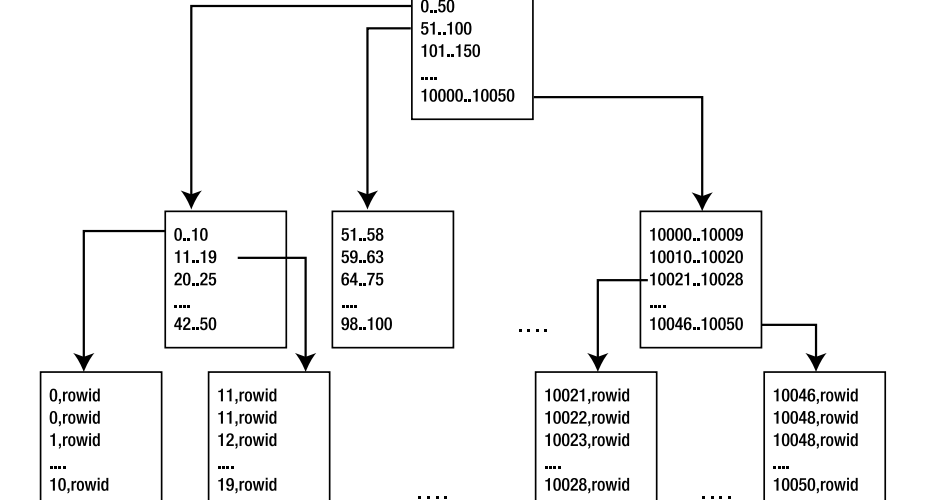
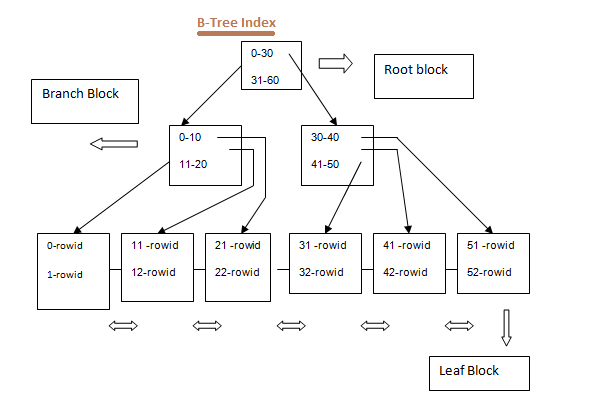
Алгоритмы построения индексов
В основном, MySQL поддерживает построение индексов по алгоритму сбалансированного двоичного дерева, B-Tree. Таблицы кроме того поддерживают построение индексов по hash-таблицам.
B-Tree-индексы могут использоваться для поиска с различными опреаторами сравнения, включая , , , , , . Так же работает для оператора с постоянной строкой, не начинающейся на .
Hash-индексы могут использоваться только с операторами и , но эта операция гораздо быстрее, чем в случае с B-Tree-индексами.
B-Tree индексы могут использоваться для ускорения работы , в то время как hash-индексы – нет.
Hash-индексы крайне удобно использовать для организации временных Key-Value хранилищ, например, для хранения промежуточных результатов. По сути, это позволяет использовать MySQL в качестве .
ARCHIVE
Этот тип таблиц позволяет хранить “архивные” данные в сжатом виде. Не поддерживает не только транзакции и внешние ключи, но и даже индексы и операции обновления (UPDATE) и удаления (DELETE).
Хранится на диске в виде трех файлов, , содержащим схему таблицы, , содержащий сжатые данные и , содержащий метаданные.
По большому счету, поддерживаются только операции типа и , причем всегда использует полное сканирование таблицы, и, как следствие, работает достаточно медленно.
Тем не менее, этот тип таблиц достаточно удобен для хранения информации, доступ к которой нужен не слишком часто. Например, информации о деятельности предприятия в прошлые отчетные периоды.
Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
![]()
Рассмотрим такой запрос:
Нам следует создать составной индекс на обе колонки:
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значений всех входящих колонок сразу. Для таблицы с такими данными:
id | name | age | gender
1 | Den | 29 | male 2 | Alyona | 15 | female 3 | Putin | 89 | tsar 4 | Petro | 12 | male
значения составного индекса будут такими:
age_gender
12male 15female 29male 89tsar
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
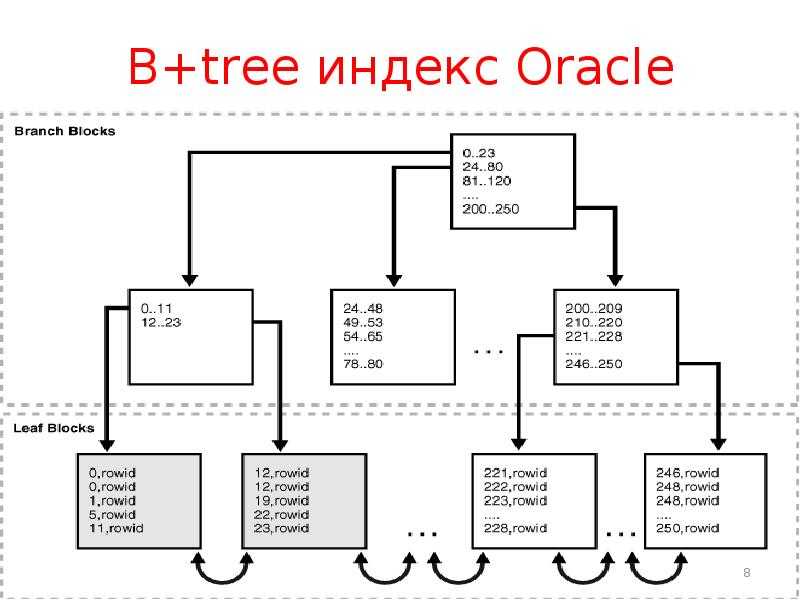

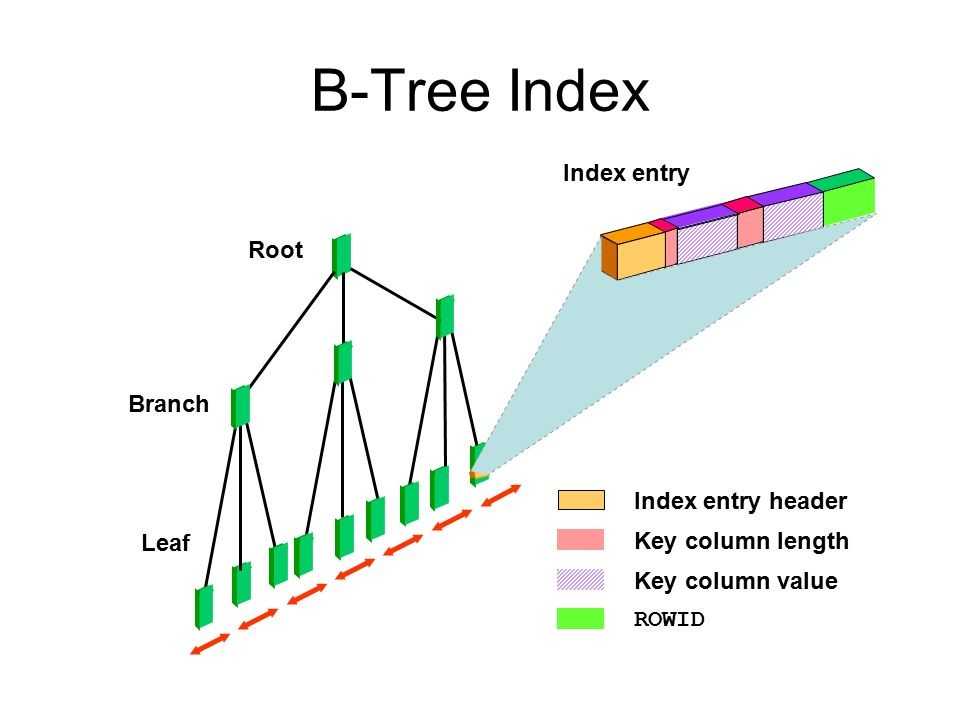
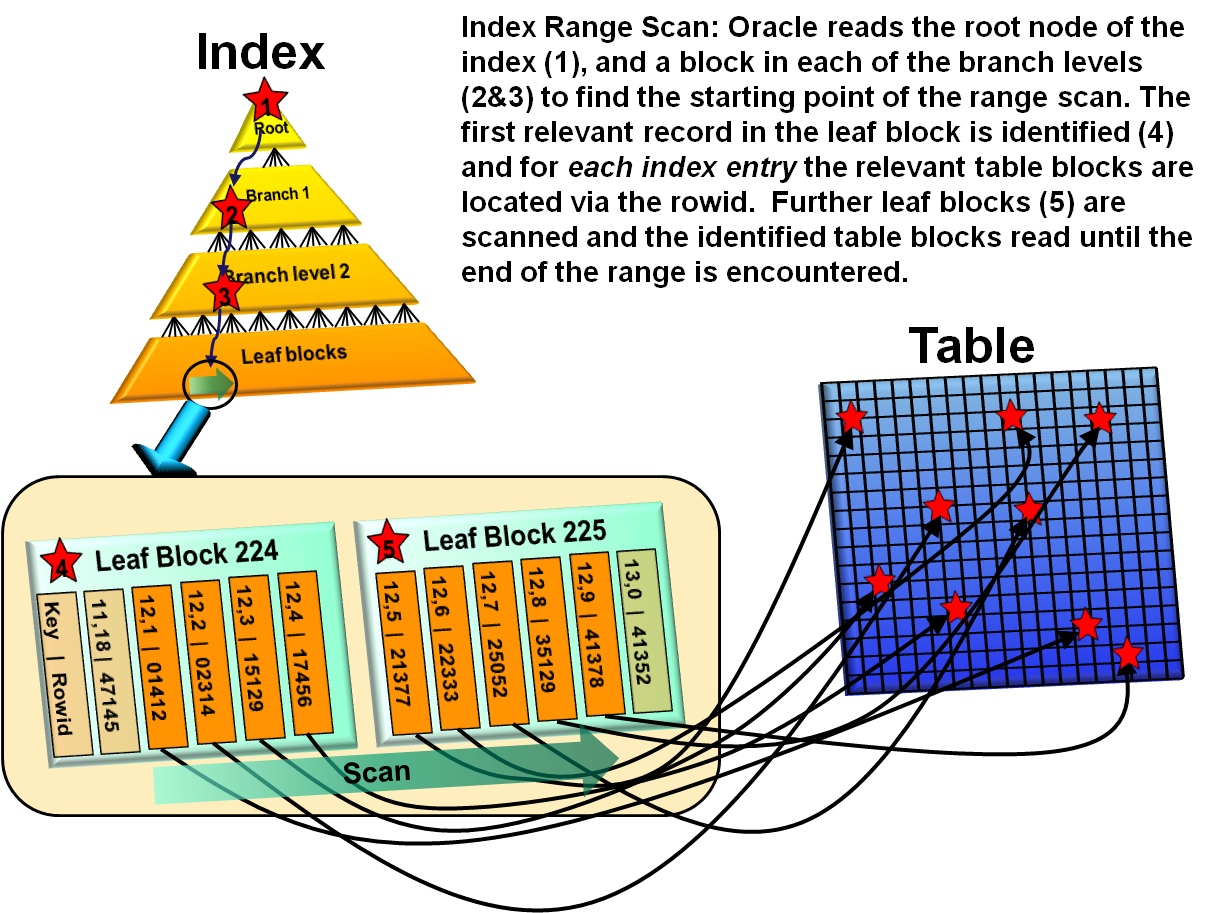
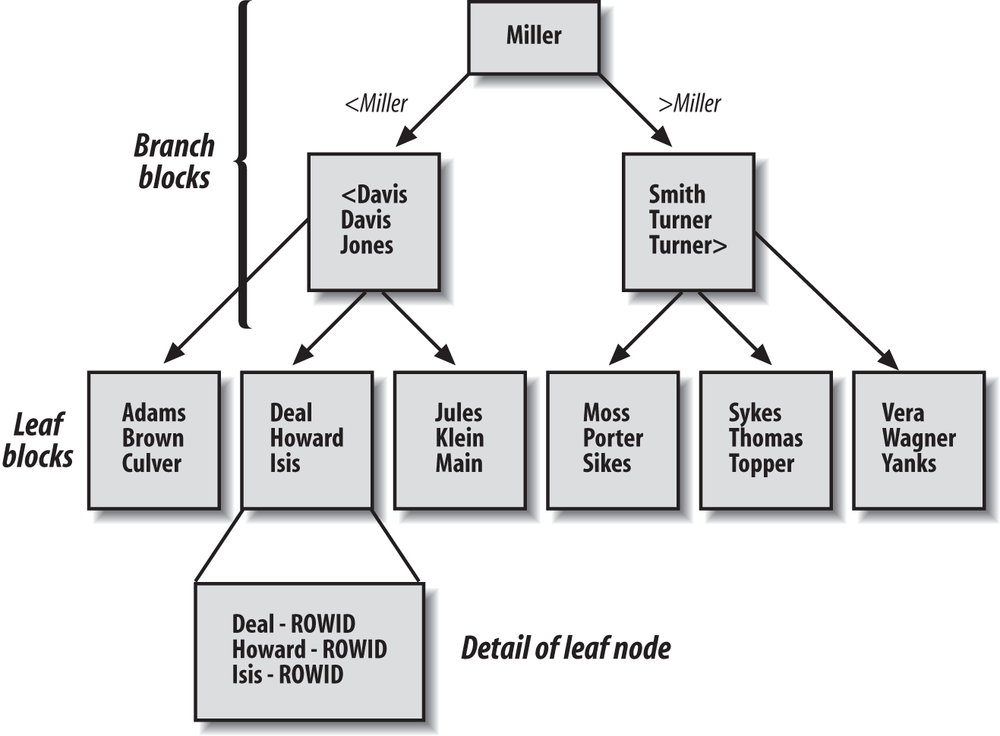

Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
age_gender
12male 15female 29male 89tsar
Сначала будут отфильтрованы все данные, которые подходят под условие age <= 29. Затем, поиск по значению «male» будет произведен без использования индекса.
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
В этом случае следует создать такой индекс:
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
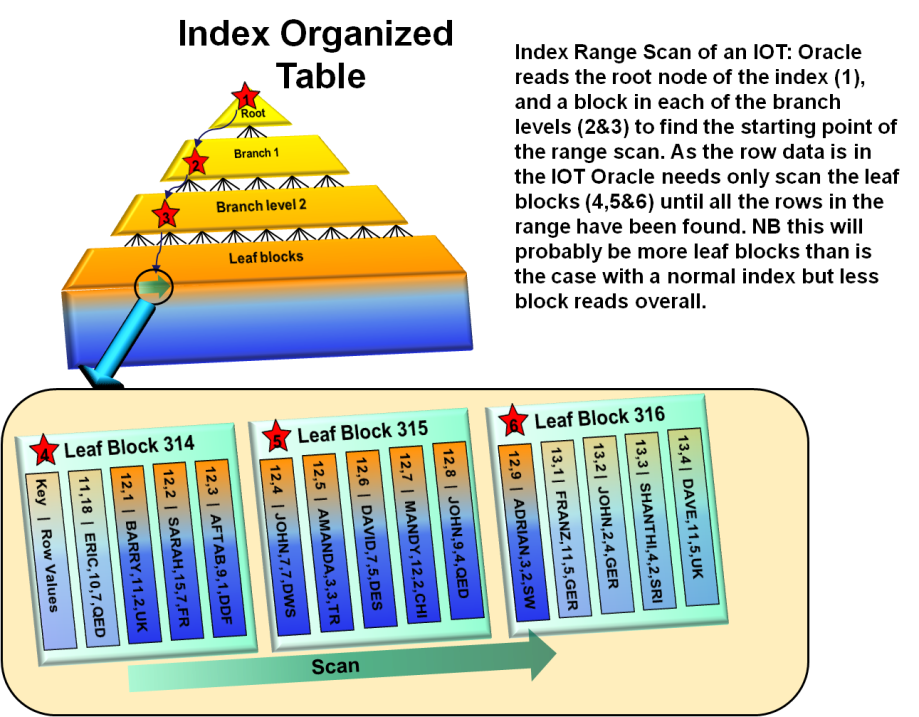
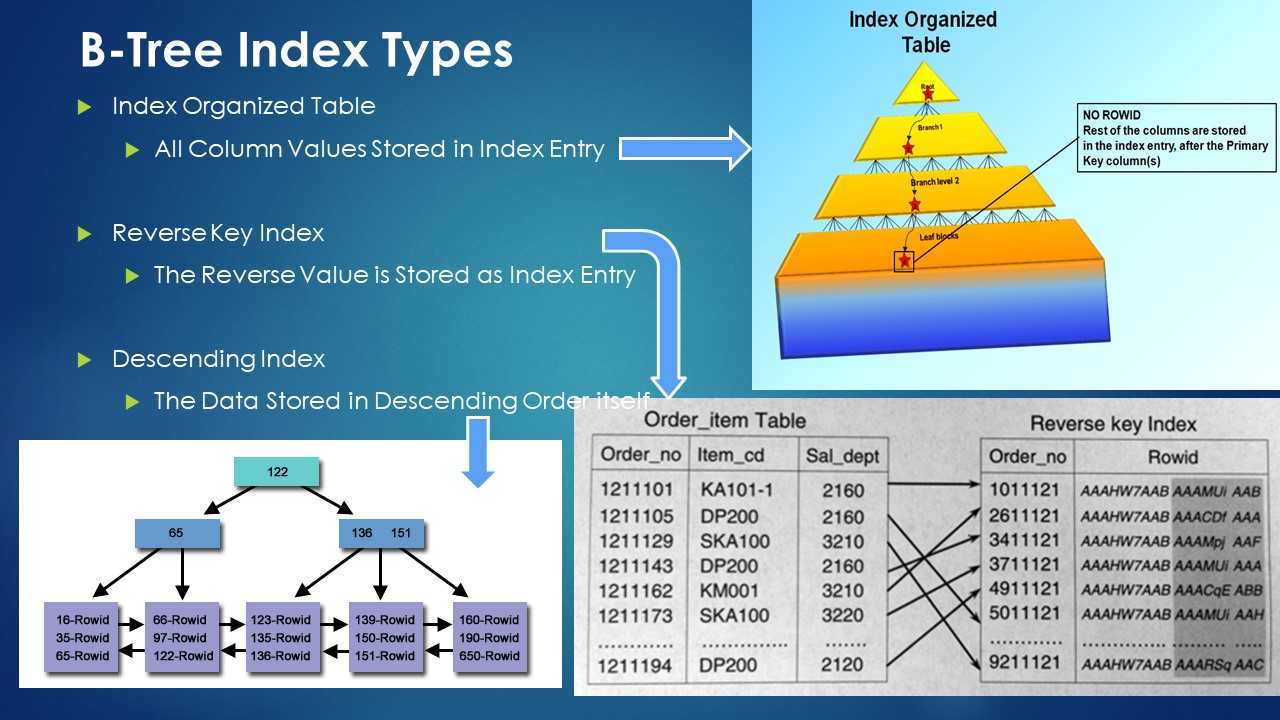
InnoDB и индекс дерева B +
Для InnoDB наиболее распространенным типом индекса является индекс B + Tree, который хранит элементы в отсортированном порядке. Кроме того, вам не нужно обращаться к реальной таблице, чтобы получить индексированные значения, что ускоряет возврат запроса.
«Проблема» в этом типе индекса заключается в том, что вам нужно запросить самое левое значение для использования индекса. Итак, если ваш индекс имеет два столбца, скажем last_name и first_name, порядок, который вы запрашиваете для этих полей , имеет значение.
Итак, учитывая следующую таблицу:
В этом запросе будет использоваться индекс:
Но следующий не будет
Потому что вы сначала запрашиваете столбец , а не самый левый столбец в индексе.
Этот последний пример еще хуже:
Потому что теперь вы сравниваете правую часть самого правого поля в индексе.
Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
|
1 |
CREATETABLE`users`( `id`int(10)unsignedNOTNULLAUTO_INCREMENT, `email`varchar(128)NOTNULL, `name`varchar(128)NOTNULL, <b>PRIMARYKEY(`id`)</b>, )ENGINE=InnoDBAUTO_INCREMENT=1DEFAULTCHARSET=utf8 |
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
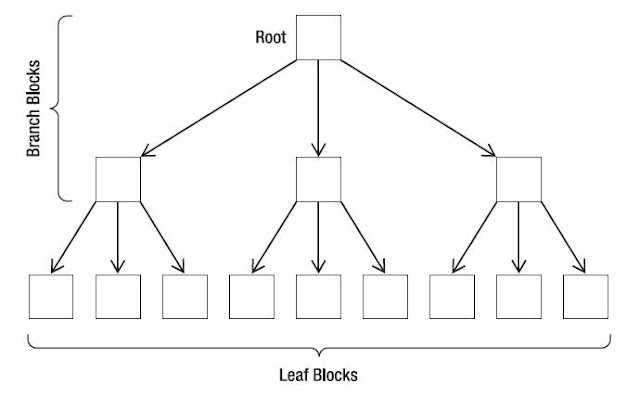
Кластерные индексы
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
![]()
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.
![]()
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Когда создавать индексы?
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды, являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Что такое индексы в базе данных?
![]()
Индекс — это объект базы данных, который представляет собой структуру данных, состоящую из ключей, построенных на основе одного или нескольких столбцов таблицы или представления, и указателей, которые сопоставляются с местом хранения заданных данных. Индексы предназначены для более быстрого получения строк из таблицы, другими словами, индексы обеспечивают быстрый поиск данных в таблице, что значительно повышает производительность запросов и приложений. Индексы также могут быть использованы и для обеспечения уникальности строк таблицы, гарантируя тем самым целостность данных.
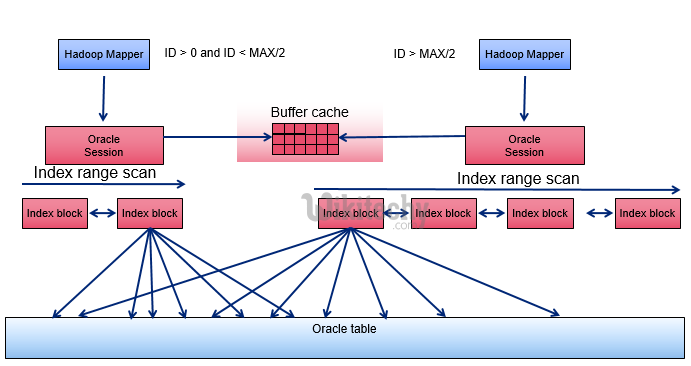

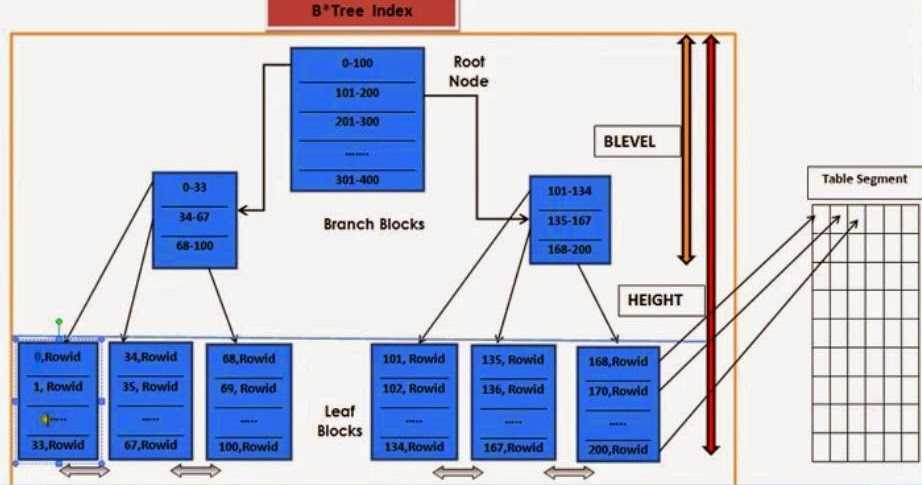
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных,следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индексация имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4–5% данных таблицы. Альтернативой использованию индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного ключа Oracle автоматически создает индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, состоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы только с высокой селективностью. То есть индексируйте таблицы, в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец с максимальной селективностью.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса; например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Виды индексов Oracle Database
Индексы Oracle могут относиться к нескольким видам, наиболее важные из которых перечислены ниже.
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце — обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы — это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы — это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы. Составные индексы — это индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Индексы и ключи
Часто можно встретить взаимозаменяемое употребление терминов “индекс” и “ключ”. Тем не менее, эти две сущности на самом деле отличаются друг от друга. Индекс — это физическая структура, хранящаяся в базе данных. Индекс можно создавать, изменять и уничтожать; в основном он служит для ускорения доступа к данным таблицы. С другой стороны, ключи — полностью логическая концепция. Ключи, с другой стороны, являются чисто логическим концепциями. Они представляют ограничения целостности, создаваемые для реализации бизнес-правил. Путаница между индексами и ключами обычно возникает потому, что база данных часто использует индекс для обеспечения ограничения целостности. Просто помните, что эти две вещи — не одно и то же.
Поиск данных в MySQL
Таблицы MySQL — это обычные файлы. Выполним запрос такого вида:
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные:
![]()
Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
Тестирование производительность InnoDB и MyIASM
Наибольший интерес для web-разработчика составляют innodb и myisam.
Сейчас мы проведем сравнительный тест производительности этих типов
таблиц. Для этого сначала создадим две одинаковые по структуре таблицы,
но с разным типом движка хранения:
CREATE TABLE `inno` ( `id` BIGINT(20) NOT NULL AUTO_INCREMENT, `data` VARCHAR(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; CREATE TABLE `myisam` ( `id` BIGINT(20) NOT NULL AUTO_INCREMENT, `data` VARCHAR(255) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM;
Напишем небольшой скрипт который будет выполнять 3 теста: запись данных
(insert), выборка по ключу, выборка по не ключевому полю.
<?php
// ...
class timer{
public $value=;
public function start(){
$this->value = microtime(true);
}
public function end(){
return microtime(true) - $this->value;
}
}
$timer = new timer();
mysql_connect('localhost','root');
mysql_select_db('test');
$data = array();
$select_query = 'SELECT data FROM myisam WHERE id = :val:';
for ($i = ; $i <= 10000; $i++){
$result = mysql_query(str_replace(':val:', $i, $select_query));
$tmp = mysql_fetch_array($result);
$data[] = $tmp];
}
echo '<br/>MyISAM select<br/>';
$select_query = 'SELECT * FROM myisam WHERE data = :val:';
$timer->start();
foreach ($data as $one){
mysql_query(str_replace(':val:', $one, $select_query));
}
echo $timer->end() . ' s<br/>';
echo '<br/>InnoDB select<br/>';
$select_query = 'SELECT * FROM inno WHERE data = :val:';
$timer->start();
foreach ($data as $one){
mysql_query(str_replace(':val:', $one, $select_query));
}
echo $timer->end() . ' s<br/>';
/*
$data = array();
for ($i = 0; $i <= 10000; $i++){
$data[] = mt_rand(0, 100500);
}
echo '<br/>MyISAM select by key<br/>';
$select_query = 'SELECT * FROM myisam WHERE id = :val:';
$timer->start();
for ($i = 0; $i <= 10000; $i++){
mysql_query(str_replace(':val:', $i, $select_query));
}
echo $timer->end() . ' s<br/>';
echo '<br/>InnoDB select by key<br/>';
$select_query = 'SELECT * FROM inno WHERE id = :val:';
$timer->start();
for ($i = 0; $i <= 10000; $i++){
mysql_query(str_replace(':val:', $i, $select_query));
}
echo $timer->end() . ' s<br/>';
*/
/*
$data = array();
for ($i = 0; $i <= 10000; $i++){
$data[] = mt_rand(0, 100500);
}
echo '<br/>MyISAM insert<br/>';
$insert_query = 'INSERT INTO myisam VALUES (NULL,\':val:\')';
$timer->start();
foreach ($data as $one){
mysql_query(str_replace(':val:', $one, $insert_query));
}
echo $timer->end() . ' s<br/>';
echo 'InnoDB insert<br/>';
$insert_query = 'INSERT INTO inno VALUES (NULL,\':val:\')';
$timer->start();
foreach ($data as $one){
mysql_query(str_replace(':val:', $one, $insert_query));
}
echo $timer->end() . ' s<br/>';
*/
Для того что-бы выполнить тест, нужно раскоментить один соответствующий
блок кода. И собственно, то что у меня получилось в результате
тестирования:
| Тест | InnoDB | MyISAM |
|---|---|---|
| Вставка данных(insert) | 15.697 с | 1.591 с |
| Выборка по ключу | 1.678 с | 1.603 с |
| Выборка по не ключевому полю | 149.961 c | 95.984 c |
Как мы видим myisam работает значительно быстрее, особенно это заметно
при вставке данных. Хотя innodb и дает ряд новых возможностей и
преимуществ, такая медлительность не позволяет ему конкурировать с
myisam, особенно в web-приложениях.



