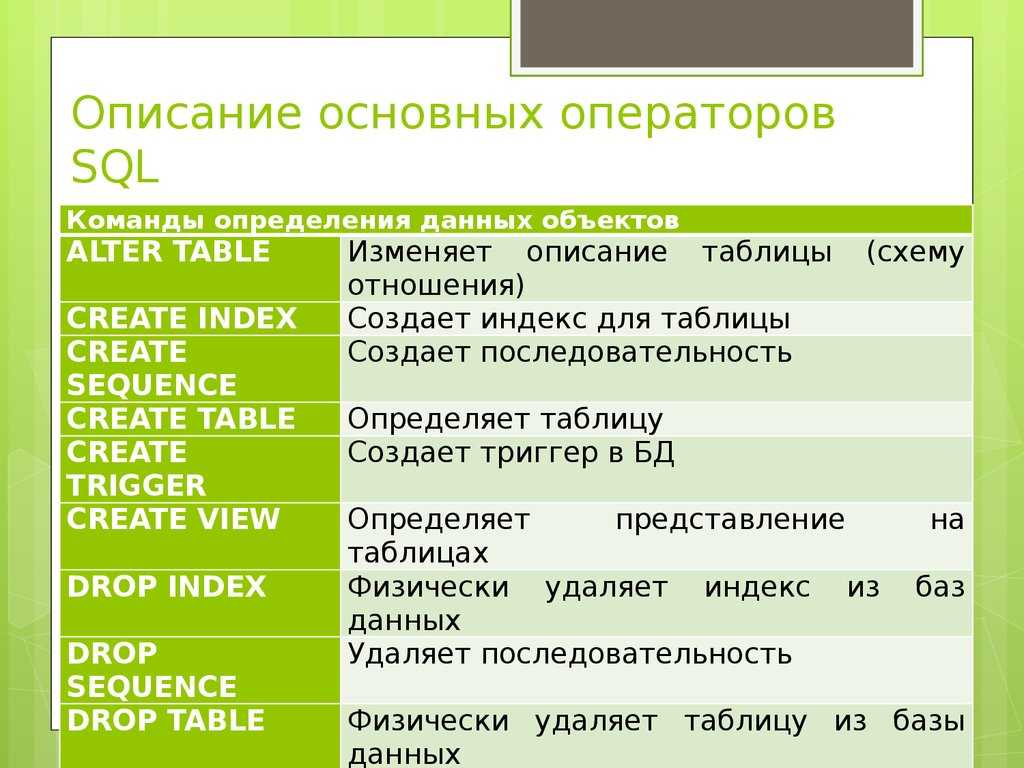
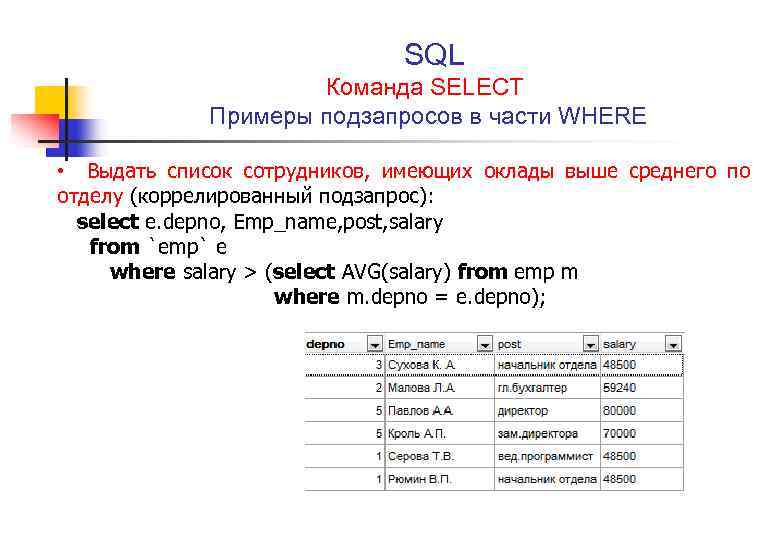
Синтаксис идентификаторов MySQL CREATE TABLE
CREATE TABLE database_name.table_name
CREATE TABLE database_name.schema_name.table_name
MySQL использует обратные кавычки вместо квадратных скобок в именах таблиц и столбцов
![]()
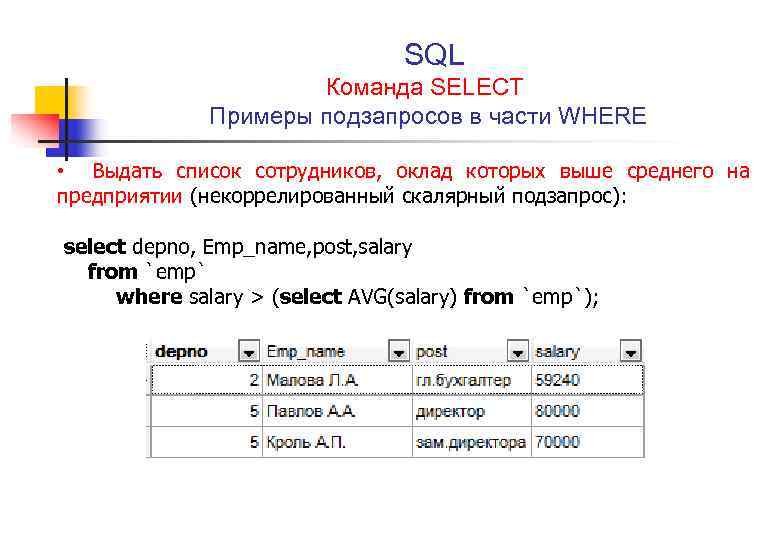
-- MySQL CREATE TABLE CREATE TABLE `testdatabase`.`person` ( `BusinessEntityID` INT NOT NULL, `PersonType` NCHAR(2) NOT NULL, `Title` VARCHAR(8) NULL, `FirstName` NVARCHAR(50) NOT NULL, `MiddleName` VARCHAR(50) NULL, `LastName` VARCHAR(50) NOT NULL, `Suffix` NVARCHAR(10) NULL, `EmailPromotion` INT NOT NULL, `ModifiedDate` DATETIME NOT NULL DEFAULT NOW(), PRIMARY KEY (`BusinessEntityID`));
-- T-SQL CREATE TABLE CREATE TABLE ..( NOT NULL, (2) NOT NULL, (8) NULL, (50) NOT NULL, (50) NULL, (50) NOT NULL, (10) NULL, NOT NULL, NOT NULL DEFAULT GETDATE(), CONSTRAINT PRIMARY KEY ( ASC ) ) ON
MySQL использует «TEMPORARY» вместо ‘#’ для временных таблиц
-- Временная таблица в MySQL CREATE TEMPORARY TABLE `MyTempTable`
-- Временная таблица в T-SQL CREATE TABLE #MyTempTable
Таблица базы данных
База данных чаще всего содержит одну или несколько таблиц.
Каждая таблица идентифицируется по имени (например, «клиенты» или «заказы»).
Таблицы содержат записи (строки) с данными.
В этом уроке мы будем использовать хорошо известный образец базы данных Northwind (входит в MS Access и MS SQL Server).
Ниже приведен выбор из таблицы «клиенты»:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Obere Str. 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
| 4 | Around the Horn | Thomas Hardy | 120 Hanover Sq. | London | WA1 1DP | UK |
| 5 | Berglunds snabbköp | Christina Berglund | Berguvsvägen 8 | Luleå | S-958 22 | Sweden |
Приведенная выше таблица содержит пять записей (по одной для каждого клиента)
и семь столбцов (CustomerID, CustomerName, ContactName, Address, City, PostalCode и Country).
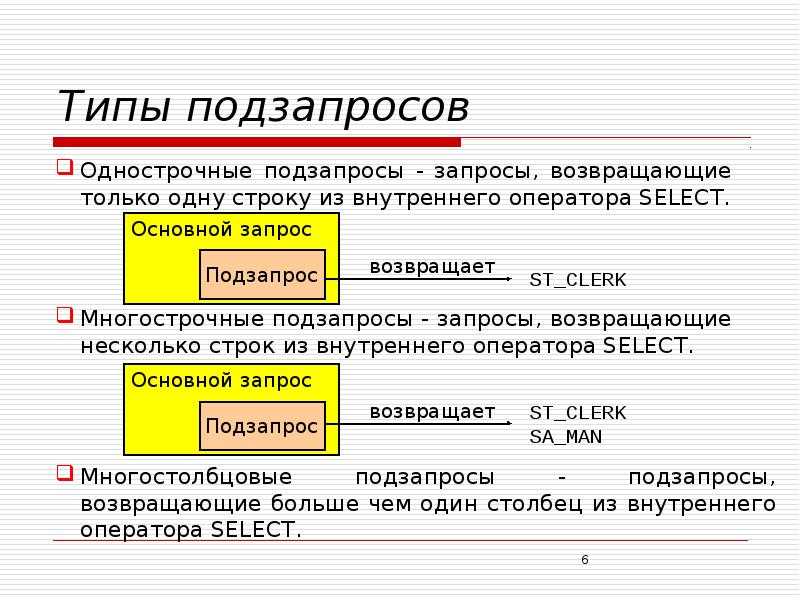
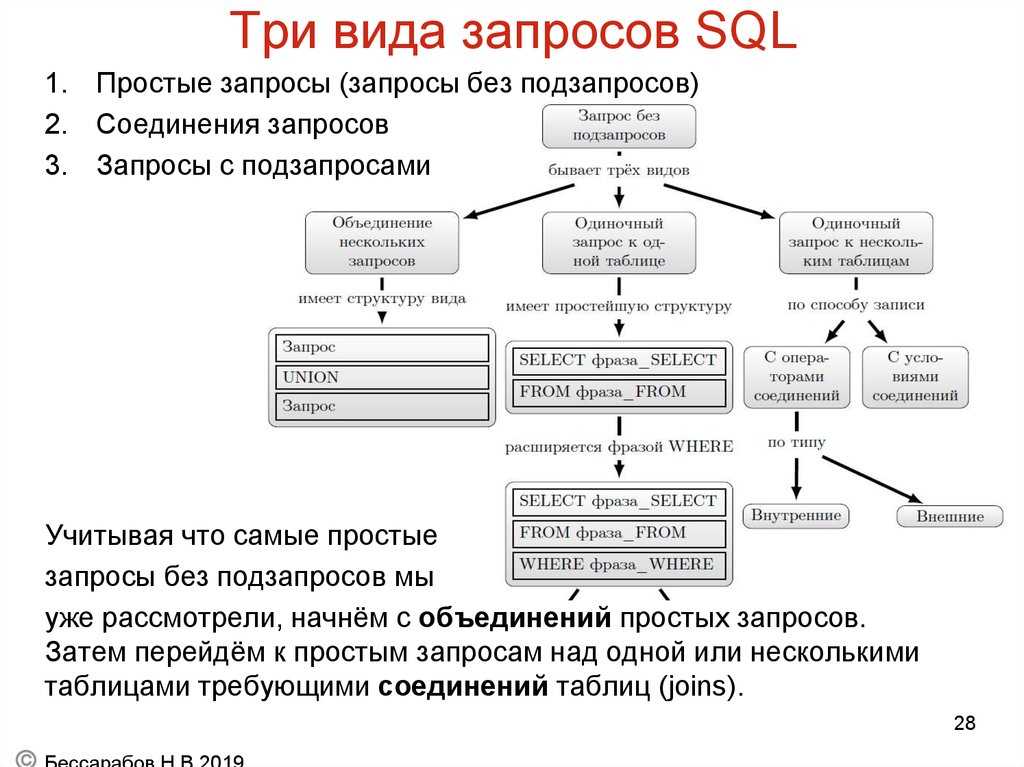
Предложение GROUP BY
Использование позволяет разбивать таблицу на логические группы и применять агрегатные функции к каждой из этих групп. В результате получим единственное значение для каждой группы.
Обычно предложение применяют, если формулировка задачи содержит фразу «для каждого…», «каждому..» и т.п.
Пример 18.Определить суммарный объем деталей, поставляемых каждым поставщиком.
| pnum | sum |
|---|---|
| 1 | 600 |
| 2 | 400 |
| 3 | 1000 |
Выполнение запроса можно описать следующим образом: СУБД разбивает таблицу PD на три группы, в каждую из групп помещаются строки с одинаковым значением номера поставщика. Затем к каждой из полученных групп применяется агрегатная функция SUM, что дает единственное итоговое значение для каждой группы.
Рассмотрим два похожих примера.
В примере 1 определяется минимальный объем поставки каждого поставщика. В примере 2 определяется объем минимальной поставки среди всех поставщиков.
Пример 1:
Пример 2:
Результаты запросов представлены в следующей таблице:
| pnum | min | max |
|---|---|---|
| 1 | 100 | 100 |
| 2 | 150 | |
| 3 | 1000 |
Следует обратить внимание, что в первом примере мы можем вывести номера поставщиков, соответствующие объемам поставок, а во втором примере – не можем.
Все имена столбцов, перечисленные после ключевого слова SELECT должны присутствовать и в предложении GROUP BY, за исключением случая, когда имя столбца является аргументом агрегатной функции.
Однако в предложении могут быть указаны имена столбцов, не перечисленные в списке вывода после ключевого слова .
Если предложение расположено после предложения , то группы создаются из строк, выбранных после применения .
Пример 19.Для каждой из деталей с номерами 1 и 2 определить количество поставщиков, которые их поставляют, а также суммарный объем поставок деталей.
Результат запроса:
| dnum | COUNT | SUM |
|---|---|---|
| 1 | 3 | 1250 |
| 2 | 2 | 450 |
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO <table> (<fields>) VALUES (<values>)
Синтаксис 2:
> INSERT INTO <table> VALUES (<values>)
* где table — имя таблицы, в которую заносим данные; fields — перечисление полей через запятую; values — перечисление значений через запятую.
* первый вариант позволит сделать вставку только по перечисленным полям — остальные получат значения по умолчанию. Второй вариант потребует вставки для всех полей.
1. Вставка нескольких строк одним запросом:
> INSERT INTO cities (`name`, `country`) VALUES (‘Москва’, ‘Россия’), (‘Париж’, ‘Франция’), (‘Фунафути’ ,’Тувалу’);
* в данном примере мы одним SQL-запросом добавим 3 записи.
2. Вставка из другой таблицы (копирование строк, INSERT + SELECT):
Синтаксис при копировании строк из одной таблицы в другую выглядит так:
> INSERT INTO <table1> SELECT * FROM <table2> WHERE <условие для select>;
* где table1 — куда копируем; table2 — откуда копируем.
а) скопировать все без разбора:
> INSERT INTO cities-new SELECT * FROM cities;
* в данном примере мы скопируем все строки из таблицы cities в таблицу cities-new.
б) скопировать определенные столбцы строк с условием:
> INSERT INTO cities-new (`name`, `country`) SELECT `name`, `country` FROM cities WHERE name LIKE ‘М%’;
* извлекаем все записи из таблицы cities, названия которых начинаются на «М» и заносим в таблицу cities-new.
в) копирование с обновлением повторяющихся ключей.
Если копировать таблицы несколько раз, то может возникнуть проблема повторения первичного ключа. В базах данных значения таких ключей должны быть уникальными и при попытке вставить повтор мы получим ошибку «Duplicate entry ‘xxx’ for key ‘PRIMARY’». Чтобы новые строки вставить, а повторяющиеся обновить (если есть изменения), используем «ON DUPLICATE KEY UPDATE»:
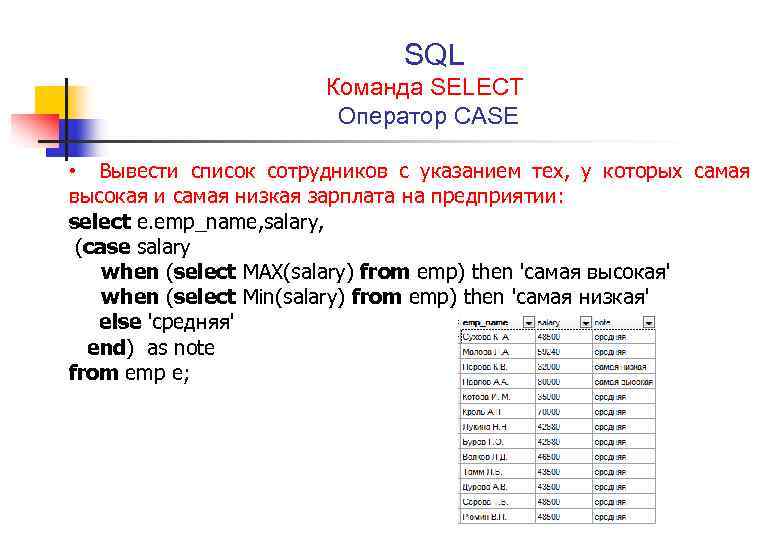






> INSERT INTO cities-new SELECT * FROM cities ON DUPLICATE KEY UPDATE `name`=VALUES(`name`), `country`=VALUES(`country`);
* в данном примере, как и в предыдущих, мы копируем данные из таблицы cities в таблицу cities-new. Но при совпадении значений первичного ключа мы будем обновлять поля name и country.
SELECT раздел ORDER BY
ORDER BY используется для того, чтобы упорядочить строки, извлекаемые запросом.
В предложении ORDER BY SQL можно задавать несколько выражений. Сначала сортируются строки, основываясь на их значениях для первого выражения. Строки с одним и тем же значением для первого выражения затем сортируются по второму выражению и так далее. NULL- значения располагает после всех других при упорядочивании в порядке возрастания и перед всеми другими при сортировке в убывающем порядке.
ORDER BY подчинено следующим ограничениям:
- Если в утверждении SELECT используются и оператор ORDER BY и оператор DISTINCT, то предложение ORDER BY не может ссылаться на столбцы, не упоминаемые в списке выбора выбираемых столбцов.
- Предложение ORDER BY не может появляться в подзапросах внутри других утверждений.
Пример. ORDER BY в возрастающем (ASC по умолчанию ) и убывающем (DESC) порядке. Выбрать из таблицы peers записи, упорядоченные сначала по возрастанию данных в столбце code, а затем по убыванию данных в столбце sale:
SELECT ename, deptno, sal FROM peers ORDER BY code ASC, sale DESC;
При задании в операторе ORDER BY числовой константы сортировка осуществляется по столбцу с за данным в списке SELECT порядковым номером. Когда в ORDER BY задается функция, сортировке подвергается результат, возвращаемый функцией для каждой строки.
Соглашения о наименовании
Общее
-
Убедитесь в том, что имя уникально и его нет в
. -
Ограничивайте длину имени 30 байтами (это 30 символов, если не
используется многобайтный набор символов). - Начинайте имена с буквы и не заканчивайте их символом подчёркивания.
- Используйте в именах только буквы, цифры и символ подчёркивания.
- Избегайте нескольких подряд идущих символов подчёркивания.
-
Используйте символ подчёркивания там, где вы бы поставили пробел в
реальной жизни (например, станет ). -
Избегайте сокращений. Если их всё же нужно использовать, убедитесь в
том, что они общепонятны.
Таблицы
-
Используйте собирательные имена или, что менее предпочтительно, форму
множественного числа. Например, и (в порядке убывания
предпочтения). -
Не используйте описательные префиксы вида и венгерскую нотацию в
целом. -
Не допускайте совпадений названия таблицы с названием любого из её
столбцов. - По возможности избегайте объединения названий двух таблиц для построения
таблицы отношений. Например, вместо названия лучше подойдёт
.
Столбцы
- Названия всегда давайте в единственном числе.
- По возможности не используйте в качестве первичного идентификатора
таблицы. - Не создавайте в таблице столбцов с таким же названием, как у неё самой.
- Названия всегда пишите со строчной буквы. Могут быть исключения,
например использование имени собственного.
Псевдонимы/корреляции
-
Должны так или иначе быть связаны с объектами или выражениями,
псевдонимом которых они являются. - Имя корреляции обычно составляется из первых букв каждого слова в имени
объекта. - Добавьте цифру к имени, если такое уже существует.
- Всегда используйте ключевое слово для лучшей читаемости.
- Для вычислимых данных ( или ) используйте такие имена,
которые вы бы дали, будь они столбцами в таблице.
Универсальные суффиксы
Приведённые ниже суффиксы универсальны, что гарантирует простоту понимания
значения столбцов из кода SQL.
- — уникальный идентификатор, например первичный ключ.
- — флаг или любой статус, например .
- — общее количество или сумма значений.
- — поле, содержащее число.
- — любое имя, например .
- — непрерывная последовательность значений.
- — колонка, содержащая дату.
- — счётчик.
- — размер или величина чего-либо, например размер файла.
- — физический или абстрактный адрес, например .
Вопросы и задания
- Модифицируйте сценарий этого урока. Необходимо также записывать в таблицу имя оператора и время начала соединения абонента с оператором.
- Реализуйте сценарий сбора статистики по пропущенным звонкам, пользуясь статьей: Задача по обработке пропущенных
- Создайте IVR-сценарий, при звонке на который вам на почту будет отправляться информация из таблицы по всем соединениям за день. Воспользуйтесь статьей Построковая обработка sql выборки в сценарии
- Модифицируйте сценарий исходящей маршрутизаций. Необходимо записывать всю информацию по исходящим звонкам (время звонка, набираемый номер, имя пользователя, внутренний или внешний номер).
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Понимание операторов SELECT
Как упоминалось во введении, SQL-запросы почти всегда начинаются с оператора . SELECT используется в запросах, чтобы указать, какие столбцы из таблицы должны быть возвращены в наборе результатов. Запросы также почти всегда включают , который используется для указания таблицы, к которой будет обращаться оператор.
Как правило, SQL-запросы следуют этому синтаксису:
Например, следующий оператор вернет весь столбец из таблицы:
Вы можете выбрать несколько столбцов из одной таблицы, разделяя их имена запятыми, например:
Вместо того, чтобы называть конкретный столбец или набор столбцов, вы можете следовать за оператором со звездочкой (), которая служит заполнителем, представляющим все столбцы в таблице. Следующая команда возвращает каждый столбец из таблицы :
WHERE используется в запросах для фильтрации записей, которые удовлетворяют указанному условию, и любые строки, которые не удовлетворяют этому условию, исключаются из результата. Предложение обычно соответствует следующему синтаксису:
Оператор сравнения в предложении WHERE определяет способ сравнения указанного столбца со значением. Вот некоторые распространенные операторы сравнения SQL:
| Оператор | Что он делает |
|---|---|
| = | тесты для равенства |
| != | тесты для неравенства |
| тесты для меньше, чем | |
| > | тесты для больше |
| тесты для менее чем или равный к | |
| >= | тесты для больше чем или равный к |
| BETWEEN | проверяет лежит ли в заданном диапазоне |
| IN | проверяет содержатся ли строки в наборе значений |
| EXISTS | тесты на соответствие строки существует при заданных условиях |
| LIKE | проверяет совпадает ли значение с указанной строкой |
| IS NULL | тесты для `NULL` значения |
| IS NOT NULL | тесты для всех других значений, чем `NULL` |
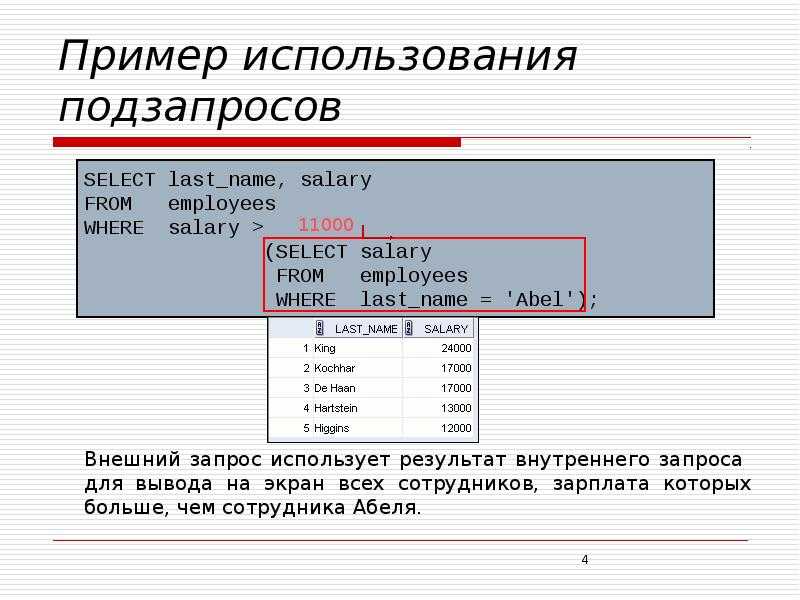
Например, если вы хотите найти размер обуви Ирмы, вы можете использовать следующий запрос:
SQL допускает использование подстановочных знаков, и это особенно удобно при использовании в предложениях WHERE. Знаки процента () представляют ноль или более неизвестных символов, а подчеркивания () представляют один неизвестный символ. Они полезны, если вы пытаетесь найти конкретную запись в таблице, но не уверены, что эта запись. Чтобы проиллюстрировать это, скажем, что вы забыли любимое блюдо нескольких своих друзей, но вы уверены, что это конкретное блюдо начинается с буквы «t». Вы можете найти его имя, выполнив следующий запрос:
Основываясь на вышеприведенном выводе, мы видим, что блюдо — это тофу.
Могут быть случаи, когда вы работаете с базами данных, в которых есть столбцы или таблицы с относительно длинными или трудно читаемыми именами. В этих случаях вы можете сделать эти имена более читабельными, создав псевдоним с ключевым словом . Псевдонимы, созданные с помощью , являются временными и существуют только на время запроса, для которого они созданы:
Здесь мы сказали SQL отображать столбец как, столбец как, а столбец как .
Примеры, которые мы рассмотрели до этого момента, включают в себя некоторые из наиболее часто используемых ключевых слов и предложений в запросах SQL. Они полезны для базовых запросов, но они бесполезны, если вы пытаетесь выполнить вычисление или получить скалярное значение (одно значение, а не набор из нескольких различных значений) на основе ваших данных. Это где агрегатные функции вступают в игру.
Создание образца базы данных
Прежде чем мы сможем начать делать запросы в SQL, мы сначала создадим базу данных и пару таблиц, а затем заполним эти таблицы некоторыми примерами данных. Это позволит вам получить практический опыт, когда вы начнете делать запросы позже.
Для примера базы данных, которую мы будем использовать в этом руководстве, представьте следующий сценарий:
Вы и несколько ваших друзей празднуете свои дни рождения друг с другом. В каждом случае члены группы направляются в местный боулинг, участвуют в дружеском турнире, а затем все направляются к вам, где вы готовите любимое блюдо для именинника.
Теперь, что эта традиция продолжается некоторое время, вы решили начать отслеживать записи с этих турниров. Кроме того, чтобы упростить планирование обедов, вы решаете создать запись о днях рождения ваших друзей и их любимых блюдах, сторонах и десертах. Вместо того чтобы хранить эту информацию в физической книге, вы решаете использовать свои навыки работы с базами данных, записав ее в базу данных MySQL.
Если вы создали сервер в NetAngels на основе образа Ubuntu 18.04 Bionic LAMP, то откройте приглашение MySQL выполнив от пользователя root команду:
mysql
Примечание: Если зайти в MySQL таким образом не удается, то для аутентификации с использованием пароля используйте команду:
mysql -u root -p
Затем создайте базу данных, запустив:
Затем выберите эту базу данных, набрав:
Затем создайте две таблицы в этой базе данных. Мы будем использовать первую таблицу, чтобы отслеживать записи ваших друзей в боулинге. Следующая команда создаст таблицу под названием «tourneys» со столбцами для «name» каждого из ваших друзей, количества турниров, которые они выиграли («wins»), их лучший результат за все время и каков размер обувь для боулинга, которую они носят ():





![Sql [айти бубен]](https://luxe-host.ru/wp-content/uploads/0/d/1/0d19bb267297f0f68c17a2766059589b.jpeg)
Как только вы запустите команду и заполните ее заголовками столбцов, вы получите следующий вывод:
Заполните таблицу ‘tourneys’ некоторыми примерами данных:
Вы получите такой вывод:
После этого создайте еще одну таблицу в той же базе данных, которую мы будем использовать для хранения информации о любимых блюдах ваших друзей на день рождения. Следующая команда создает таблицу с именем dinners и столбцами для«имя» каждого из ваших друзей, их «дата рождения», их любимое «блюдо», их любимое «гарнир» и их любимый «десерт»:
Аналогично для этой таблицы вы получите отзыв, подтверждающий успешное выполнение команды:
Заполните эту таблицу также некоторыми примерами данных:
Как только эта команда завершится успешно, вы закончили настройку базы данных. Далее мы рассмотрим основную структуру команд запросов SELECT.
Операторы управления схемой данных
Операторы создания элементов схемы в общем называются .
Операторы создания
Создание базы данных
Создание таблицы
Здесь может иметь следующие значения (или их комбинации):
- – не может быть “пустым”
- – значение уникально
- – комбинация первых двух
- – указание внешнего ключа
- – значение должно удовлетворять условию
- – значение по умолчанию
Присутствуют некоторые разночтения в разных реализациях.
Если первичный ключ состоит из нескольких столбцов, необходимо выносить его после объявления столбцов в виде
где – уникальное название ограничения.
Во многих реализациях, часть можно опустить. В таком случае имя будет сгенерировано автоматически.
Внешний ключ в любом случае объявляется после объявления колонок.
Синтаксис:
где – уникальное название ограничения, – названия колонок данной таблицы, входящих во внешний ключ, – таблица, для которой указанный внешний ключ является первичным, – названия соответствующих колонок в . и определяют, как БД реагирует на изменение и удаление записей из , и могут принимать одно из значений:
- – ссылающиеся колонки устанавливается в NULL
- – если есть записи, ссылающиеся на обновляемое/удаляемое значение, обновление/удаление завершается ошибкой
- – обновляет/удаляет все ссылающиеся записи
- – ничего не делать
Во многих реализациях, часть можно опустить. В таком случае имя будет сгенерировано автоматически.
Создание индекса
Индексы ускоряют выборку по индексированным колонкам, но замедляют добавление и удаление записей.
Операторы удаления элементов схемы в общем называются .
Удаление базы данных
Удаление таблицы
Удаление индекса
Операторы изменения
Изменение таблицы
Здесь может быть одним из:
- – позволяет указать или убрать значение по умолчанию
- – позволяет переименовать, и изменить определение
- – позволяет изменить определение
- и т.д.