
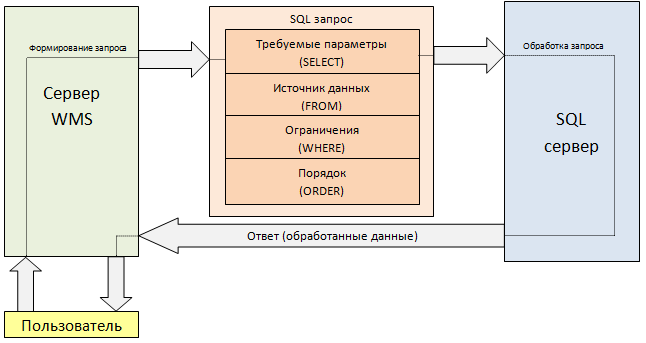
Агрегатные функции в SQL
Для получения итоговых значений и вычисления выражений используются агрегатные функции в sql:
| Функция | Описание |
|---|---|
| (*) | Возвращает количество строк таблицы. |
| (имя поля) | Возвращает количество значений в указанном столбце. |
| (имя поля) | Возвращает сумму значений в указанном столбце. |
| (имя поля) | Возвращает среднее значение в указанном столбце. |
| (имя поля) | Возвращает минимальное значение в указанном столбце. |
| (имя поля) | Возвращает максимальное значение в указанном столбце. |
Все агрегатные функции возвращают единственное значение.
Функции , и применимы к любым типам данных.
Важно: при работе с агрегатными функциями в SQL используется служебное слово AS
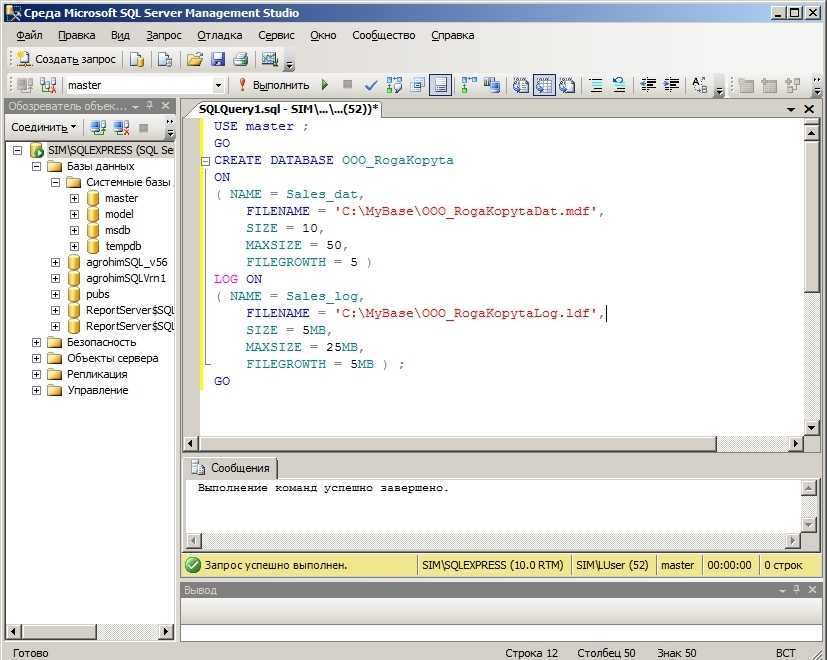
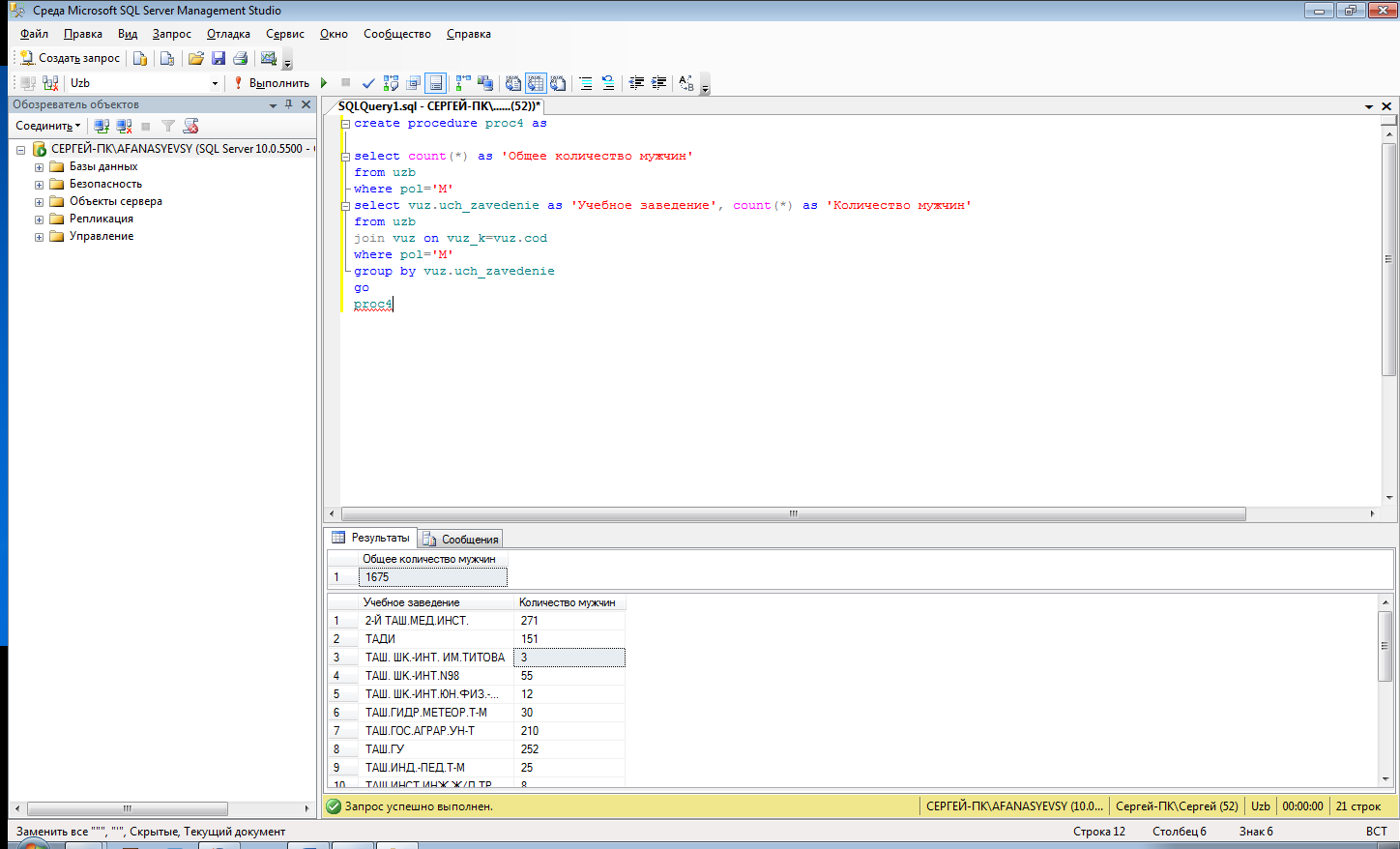
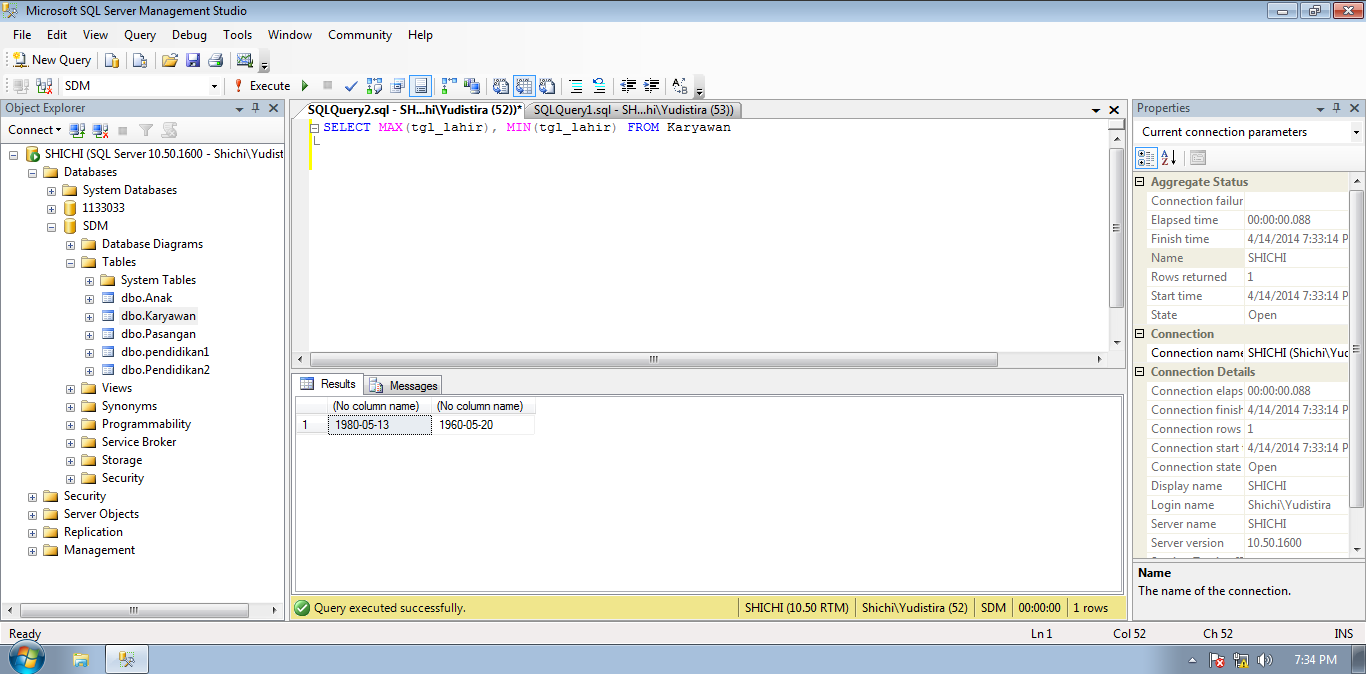
Пример БД «Институт»: Получить значение самой большой зарплаты среди учителей, вывести итог как «макс_зп»
Решение:
SELECT MAX(zarplata) AS макс_зп FROM teachers; |
Результаты:
Рассмотрим более сложный пример использования агрегатных функций в sql.
Пример: БД . Найти имеющееся в наличии количество компьютеров, выпущенных производителем Америка
Решение:
1 2 3 4 5 6 7 8 |
SELECT COUNT( * ) FROM `pc` WHERE `Номер` IN ( SELECT `Номер` FROM product WHERE Производитель = "Америка" ) |
SQL As 2_3. . Вывести общее количество продуктов, странами-производителями которых является Россия
SQL As 2_4. . Вывести среднюю цену на ноутбуки
Agr func 2_2. . Вывести минимальную и максимальную зарплату учителей
Agr func 2_3. . Выберите название курса, уроки по которому не проводились и не запланированы проводиться. Дополните код:
1 2 3 4 5 6 |
SELECT `title` FROM `courses` WHERE `title` NOT IN ( ... ) |
Agr func 2_4. . Измените предыдущее задание: Посчитайте количество тех курсов, уроки по которым не проводились и не запланированы проводиться. Выводите результат с именем «нет_уроков»
Задание 2_3. . Вывести год рождения самого младшего студента, назвать поле «Младший»
Задание 2_4. . Посчитать количество всех студентов группы 101. Назвать поле «Группа101»
Предложение GROUP BY в SQL
Оператор в sql обычно используется совместно с агрегатными функциями.
Агрегатные функции выполняются над всеми результирующими строками запроса. Если запрос содержит оператор , каждый набор строк, заданных в предложении GROUP BY, составляет группу, и агрегатные функции выполняются для каждой группы отдельно.
Рассмотрим пример с таблицей :
Пример:
- Выдавать количество проведенных уроков учителем Иванов из таблицы (порядковый номер Иванова ()).
SELECT COUNT(tid) AS Иванов FROM lessons WHERE tid=1 |
Результат:
Выдавать количество проведенных уроков учителем Иванов по разным курсам из таблицы
SELECT course, COUNT( tid ) AS Иванов FROM lessons WHERE tid =1 GROUP BY course |
Результат:
Важно: Таким образом, в результате использования все выходные строки запроса разделяются на группы, характеризуемые одинаковыми комбинациями значений в этих столбцах (т.е. агрегатные функции выполняются для каждой группы отдельно)
При этом стоит учесть, что при группировке по полю, содержащему -значения, все такие записи попадут в одну группу.
SQL group by 2_5. . Для различных типов принтеров определить их среднюю стоимость и количество (т.е. отдельно по лазерным, струйным и матричным). Использовать агрегатные функции . Результат должен выглядеть так:
![]()
SQL group by 2_5. . Посчитать количество уроков, проведенных одним и тем же учителем. Результат должен выглядеть так:
Задание 2_5. . Вывести количество человек в каждой группе и количество человек на каждом курсе из таблицы . Назвать вычисляемые поля «кол_во_в_гр» и «кол_во_на_курс»
Оператор Having SQL
Предложение в SQL необходимо для проверки значений, которые получены с помощью агрегатной функции после группировки (после использования ). Такая проверка не может содержаться в предложении WHERE.
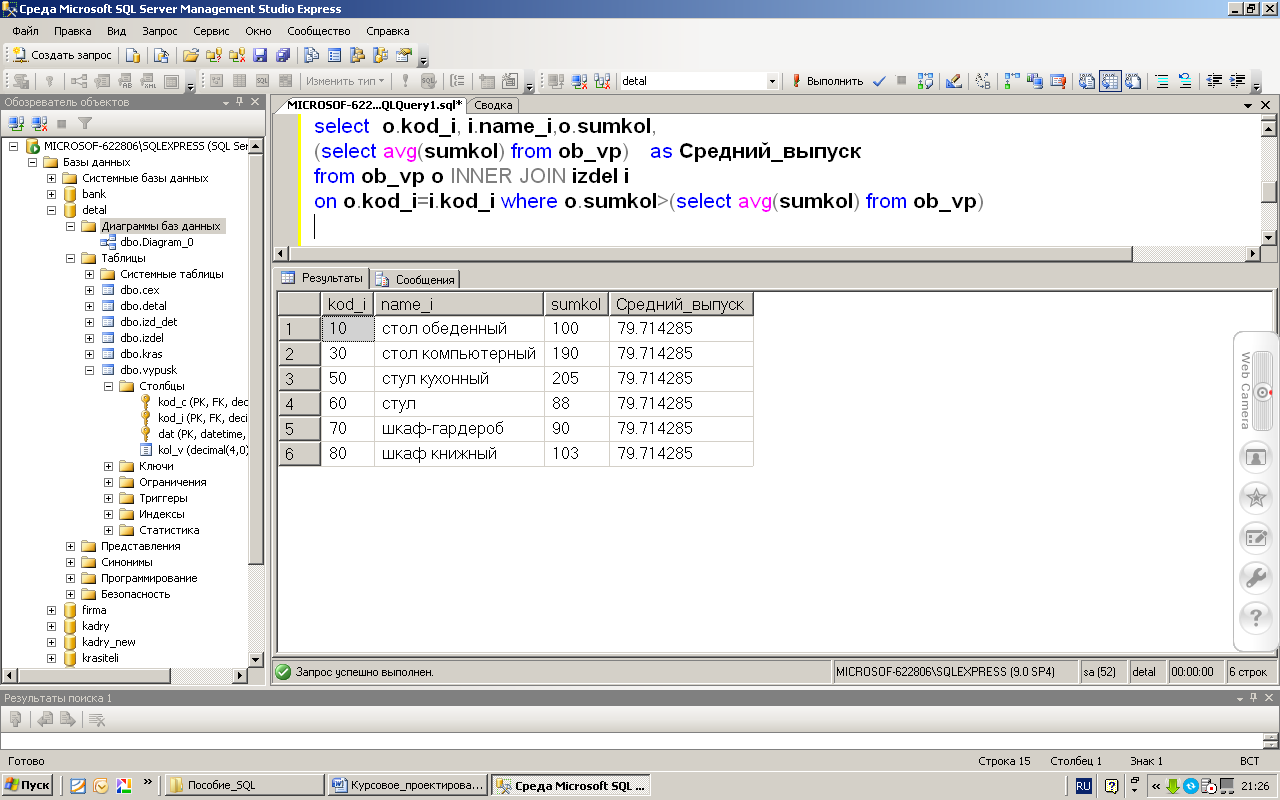
Пример: БД Компьютерный магазин. Посчитать среднюю цену компьютеров с одинаковой скоростью процессора. Выполнить подсчет только для тех групп, средняя цена которых меньше 30000.
Решение:
SELECT AVG(`Цена`) ,`Скорость` FROM `pc` GROUP BY `Скорость` HAVING AVG(`Цена`) <30000 |
Результат:
Важно: В операторе нельзя использовать псевдоним (например, сред_цена), используемый для именования значений агрегатной функции.
Having SQL 2_6
Для различных типов принтеров определить их среднюю стоимость (т.е. отдельно по лазерным, струйным и матричным). Вести подсчет только если средняя стоимость
Having SQL 2_6.
Посчитать количество уроков, проведенных одним и тем же учителем. Выдавать значение только для тех учителей, у которых уроков больше двух.
Задание 2_6. . Получить количество учеников каждой группы при условии, что курс не меньше 3-го
Далее
Преобразование строк в несколько столбцов с помощью оператора Pivot
Чтобы преобразовать несколько строк в несколько столбцов, выполните следующие действия:
Осуществите выборку данных с помощью следующего запроса:
/* Получение данных из таблицы */ WITH cte_result AS( SELECT m.movieid, m.title, ROUND(r.rating,0) AS rating, u.gender FROM .. r JOIN .. m ON m.movieid=r.movieid JOIN .. u ON u.userid=r.userid WHERE r.movieid < = 5 ) SELECT movieid,title,CAST(SUM(rating) AS FLOAT) AS rating,CAST(COUNT(*) AS FLOAT) AS nofuser,CAST(AVG(rating) AS FLOAT) avgr,gender FROM cte_result GROUP BY movieid,title,gender ORDER BY movieid,title,gender
![]()
Строки могут быть преобразованы в несколько столбцов с помощью применения обоих операторов (UNPIVOT и PIVOT).
Используйте оператор UNPIVOT, чтобы извлечь значения столбцов rating, nofuser и avgr и преобразовать их в один столбец с несколькими строками:
/* Получение агрегированных данных, используя Unpivot, и преобразование столбца в строку */ WITH cte_result AS( SELECT m.movieid, m.title, ROUND(r.rating,0) AS rating, u.gender FROM .. r JOIN .. m ON m.movieid=r.movieid JOIN .. u ON u.userid=r.userid WHERE r.movieid < = 5 ) SELECT movieid,title,gender+'_'+col AS col,value FROM ( SELECT movieid,title,CAST(SUM(rating) AS FLOAT) AS rating,CAST(COUNT(*) AS FLOAT) AS nofuser,CAST(AVG(rating) AS FLOAT) avgr,gender FROM cte_result GROUP BY movieid,title,gender) rt unpivot ( value FOR col in (rating,nofuser,avgr))unpiv ORDER BY movieid
Поля, преобразованные в один столбец, показаны на следующей диаграмме:
![]()
Оператор PIVOT применяется к полученному результату, чтобы преобразовать полученный столбец в несколько строк.
Получите агрегированные данные, используя оператор pivot, и преобразуйте несколько полей в несколько столбцов:
/* Получение агрегированных данных, используя Pivot, и преобразование нескольких полей в несколько столбцов */ WITH cte_result AS( SELECT m.movieid, m.title, ROUND(r.rating,0) AS rating, u.gender FROM .. r JOIN .. m ON m.movieid=r.movieid JOIN .. u ON u.userid=r.userid WHERE r.movieid < = 5 ) SELECT movieid,title, ,, ,, , FROM ( SELECT movieid,title,gender+'_'+col AS col,value FROM ( SELECT movieid,title,CAST(SUM(rating) AS FLOAT) AS rating,CAST(COUNT(*) AS FLOAT) AS nofuser,CAST(AVG(rating) AS FLOAT) avgr,gender FROM cte_result GROUP BY movieid,title,gender) rt unpivot ( value FOR col in (rating,nofuser,avgr))unpiv )tp pivot ( SUM(value) FOR col in (,,,,,)) piv ORDER BY movieid
Несколько полей, преобразованные в несколько столбцов, показаны на следующей диаграмме:
![]()
Преобразованные рейтинги фильмов и их пользователи, графически представленные в MS Excel:
![]()
Вычисляемые столбцы в таблицах
Вычисляемый столбец – это виртуальный столбец таблицы, который вычисляется на основе выражения, в этих выражениях могут участвовать другие столбцы этой же таблицы. Такие столбцы физически не хранятся, их значения рассчитываются каждый раз при обращении к ним. Это поведение по умолчанию, но можно сделать так, чтобы вычисляемые столбцы физически хранились, для этого нужно указать ключевое слово PERSISTED при создании подобного столбца. В данном случае значения данного столбца будут обновляться, когда будут вноситься любые изменения в столбцы, входящие в вычисляемое выражение.
Вычисляемые столбцы нужны для того, чтобы было проще и надежней получить результат каких-то постоянных вычислений. Например, при обращении к таблице, Вы всегда в SQL запросе применяете какую-нибудь формулу (один столбец перемножаете с другим или что-то в этом роде, хотя формула может быть и сложней), так вот, если в таблице определить вычисляемый столбец, указав в его определении нужную формулу, Вам больше не нужно будет каждый раз писать эту формулу в SQL запросе в инструкции SELECT. Вам достаточно обратиться к определенному столбцу (вычисляемому столбцу), который автоматически при выводе значений применяет эту формулу. При этом этот столбец можно использовать в запросах также как обычный столбец, например, в секциях WHEHE (в условии) или в ORDER BY (в сортировке).
Также важно понимать, что вычисляемый столбец не может быть указан в инструкциях INSERT или UPDATE в качестве целевого столбца
Универсальный генератор строк для оператора Unpivot в Oracle11g
(Flexible Row Generator with Oracle 11g Unpivot Operator, by Lucas Jellema)
Генератор
строк — очень полезный механизм для многих (полу-) продвинутых SQL-запросов. В
предыдущих статьях мы обсудили различные методы генерации строк.
Тому примерами являются оператор CUBE, табличные функции (Table Functions)
и фраза «Connect By Level < #» количества подходящих записей, не говоря уже о старом добром UNION ALL
с многократным «select from dual». Эти приемы разнятся по гибкости и компактности. CUBE
и Connect By обеспечивают легкую генерацию большого количества строк как с незначительным, так и
сложным управлением значениями в таких строках, в то время как UNION ALL сложен и громоздок, даже при том, что он
предоставляет большие возможности управления точными значениями.
Оператор Unpivot в Oracle11g предоставляет нам новый способ
сгенерировать строки с великолепными возможностями управления над значениями в
строках и более компактный и изящный синтаксис, чем альтернатива UNION ALL.
Давайте рассмотрим простой пример.
Предположим, что нам нужен набор строк с определенными значениями, возможно, для использования в качестве встроенного представления
внутри нашего сложного запроса или в качестве автономного представления. В этом примере я взял шесть довольно бесполезных величин, но он излагает концепцию,
что значение имеет.
Единственным select-предложением выборки из DUAL, а не шестью запросами из DUAL, которые по
UNION ALL вместе, мы выбираем шесть требуемых значений, как из индивидуальных столбцов – от a
до f. Оператор UNPIVOT, который мы затем применяем к этому результату, берет единственную строку с шестью столбцами и превращает ее в шесть строк с двумя
столбцами, один из которых содержит имя исходного столбца исходной строки, а другой — значение в том исходном столбце:
select * from ( ( select ‘value1′ a , ‘value27′ b , ‘value534′ c , ‘value912′ d , ‘value1005′ e , ‘value2165′ f from dual ) unpivot > ( value for value_type in ( a,b,c,d,e, f) ) ) /
Результат этого запроса таков:
:
V VALUE - ——— A value1 B value27 C value534 D value912 E value1005 F value2165 6 rows selected.
Замечание:
в ситуациях, где требуется прямая генерация большого количества строк, прием strong>«CONNECT BY» все
еще будет превалирующим. Например, чтобы сгенерировать алфавит, следует использовать предложение типа:
1 select chr(rownum+64) letter 2 from (select level 3 from dual 4 connect 5 by level<27 6* )
Однако, чтобы сгенерировать поднабор, скажем, все гласные из алфавита, подход с применением оператора strong>UNPIVOT
может оказаться полезным.
select vowel from ( ( select ‘a’ v1 , ‘e’ v2 , ‘i’ v3 , ‘o’ v4 , ‘u’ v5 from dual ) unpivot ( vowel for dummy in ( v1,v2,v3,v4,v5) ) ) /
Группировка с агрегатными функциями
Агрегатные функции COUNT, SUM, AVG, MAX, MIN служат для вычисления соответствующего агрегатного значения ко всему
набору строк, для которых некоторый столбец — общий.
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
SELECT Author, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Author
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
SELECT Customer_ID, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Customer_ID
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору IN,
предикату EXISTS и функциям
CONCAT, COALESCE.
На сайте есть более подробный материал об агрегатных функциях и их совместном
использовании с оператором GROUP BY.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Рекомендации по использованию наборов столбцов
При использовании наборов столбцов следует учитывать следующие рекомендации.
-
Разреженные столбцы и набор столбцов могут быть созданы в рамках одной и той же инструкции.
-
Набор столбцов не может быть добавлен в таблицу, если в ней уже содержатся разреженные столбцы.
-
Набор столбцов нельзя изменять. Чтобы изменить набор столбцов, нужно удалить его, после чего создать разреженные столбцы и набор столбцов.
-
Набор столбцов может быть добавлен в таблицу, если в ней нет разреженных столбцов. Если впоследствии в таблицу будут добавлены разреженные столбцы, они появятся в наборе столбцов.
-
В таблице может содержаться только один набор столбцов.
-
Набор столбцов является дополнительной функцией, он не требуется для использования разреженных столбцов.
-
Для набора столбцов нельзя определить ограничения или значения по умолчанию.
-
Вычисляемые столбцы не могут содержать столбцы набора столбцов.
-
Распределенные запросы не поддерживаются в таблицах, содержащих наборы столбцов.
-
Репликация не поддерживает наборы столбцов.
-
Система отслеживания измененных данных не поддерживает наборы столбцов.
-
Набор столбцов не может быть частью никакого вида индексов. Это касается XML-индексов, полнотекстовых индексов и индексированных представлений. Набор столбцов не может быть добавлен как включенный столбец в любой индекс.
-
Набор столбцов не может быть использован в критерии фильтра фильтруемого индекса или статистике фильтрации.
-
Если представление содержит набор столбцов, в представлении он будет отображен как XML-столбец.
-
Набор столбцов не может быть включен в определение индексированного представления.
-
Секционированные представления, включающие таблицы, в которых содержатся наборы столбцов, могут быть обновлены, если секционированные представления упоминают разреженные столбцы по именам. Секционированное представление не может быть обновлено, если оно ссылается на набор столбцов.
-
Не допускается использование уведомлений о запросах, ссылающихся на наборы столбцов.
-
Предел размера XML-данных — 2 ГБ. Если суммарный размер данных в строке во всех разреженных столбцах, содержащих значения, отличные от NULL, превышает этот предел, запрос или операция DML завершатся с ошибкой.
-
Сведения о данных, возвращаемых функцией , см. в разделе Использование разреженных столбцов.
Как добавить новую колонку с помощью ALTER TABLE
Чтобы добавить новый столбец, вам сначала нужно выбрать таблицу с помощью ALTER TABLE имя_таблицы, а затем написать имя нового столбца и его тип данны вместе с операторомо ADD. В совокупности код выглядит так:
Например у нас есть база данных пользователей, как показано ниже:
| id | name | age | state | |
|---|---|---|---|---|
| 1 | Paul | 24 | Michigan | paul@example.com |
| 2 | Molly | 22 | New Jersey | molly@example.com |
| 3 | Robert | 19 | New York | robert@example.com |
Настал момент, когда нам нужно сохранить номера документов, удостоверяющих личность наших пользователей, поэтому нам нужно добавить для этого новый столбец.
Чтобы добавить новый столбец в нашу таблицу пользователей, нам нужно выбрать таблицу с ALTER TABLE users, а затем указать имя нового столбца и его тип данных с помощью оператора ADD id_number TEXT. Все вместе выглядит так:
Таблица с новым столбцом будет выглядеть следующим образом:
| id | name | age | state | id_number | |
|---|---|---|---|---|---|
| 1 | Paul | 24 | Michigan | paul@example.com | NULL |
| 2 | Molly | 22 | New Jersey | molly@example.com | NULL |
| 3 | Robert | 19 | New York | robert@example.com | NULL |
Вам нужно будет использовать оператор UPDATE, чтобы добавить недостающую информацию для уже существующих пользователей, как только она будет предоставлена.
Изменение таблицы
Последнее обновление: 09.07.2017
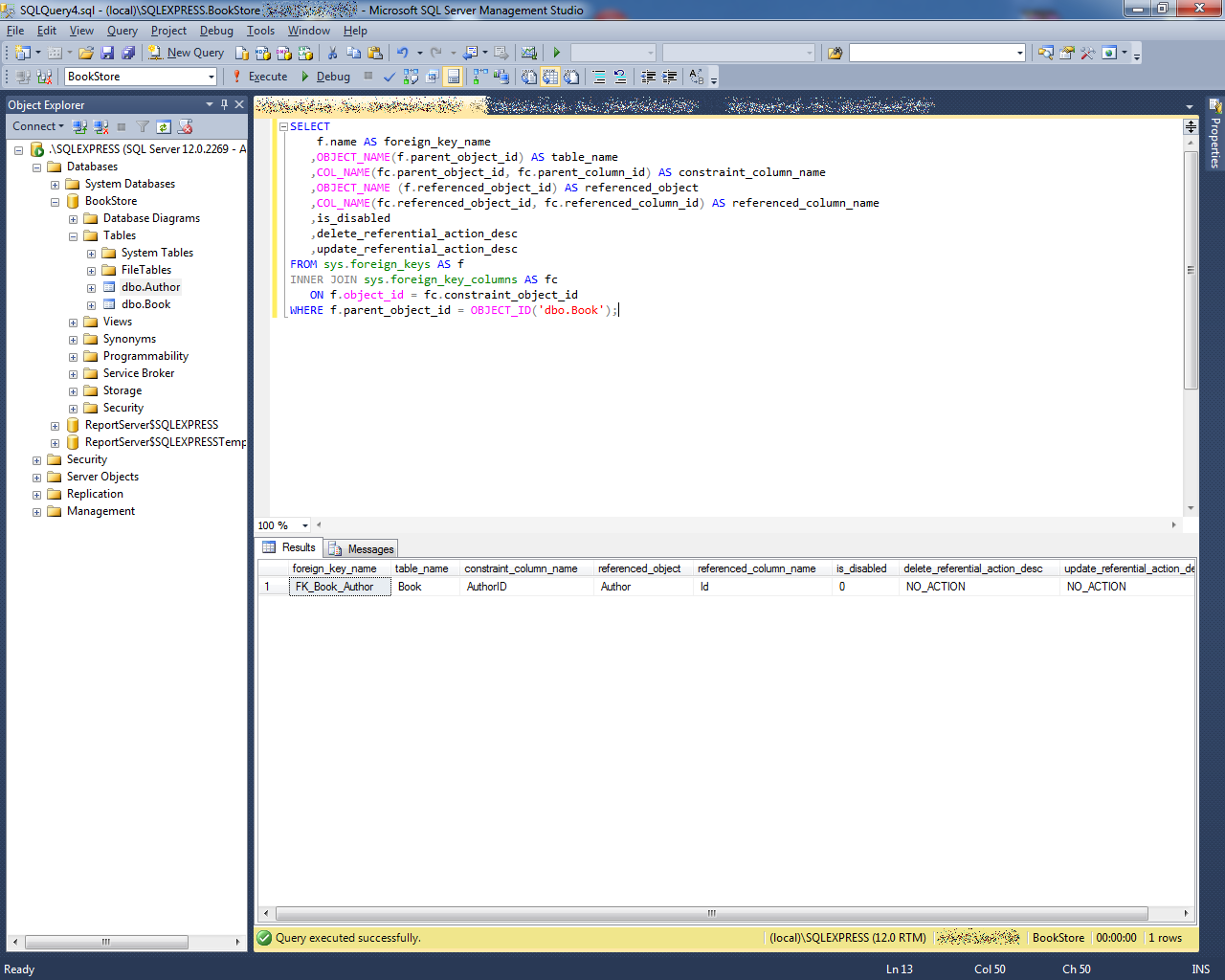
Возможно, в какой-то момент мы захотим изменить уже имеющуюся таблицу. Например, добавить или удалить столбцы, изменить тип столбцов, добавить или удалить ограничения.
То есть потребуется изменить определение таблицы. Для изменения таблиц используется выражение ALTER TABLE.
Общий формальный синтаксис команды выглядит следующим образом:
ALTER TABLE название_таблицы
{ ADD название_столбца тип_данных_столбца |
DROP COLUMN название_столбца |
ALTER COLUMN название_столбца тип_данных_столбца |
ADD определение_ограничения |
DROP имя_ограничения}
Таким образом, с помощью мы можем провернуть самые различные сценарии изменения таблицы. Рассмотрим некоторые из них.
Добавление нового столбца
Добавим в таблицу Customers новый столбец Address:
ALTER TABLE Customers ADD Address NVARCHAR(50) NULL;
В данном случае столбец Address имеет тип NVARCHAR и для него определен атрибут NULL. Но что если нам надо добавить столбец, который не должен принимать
значения NULL? Если в таблице есть данные, то следующая команда не будет выполнена:
ALTER TABLE Customers ADD Address NVARCHAR(50) NOT NULL;
Поэтому в данном случае решение состоит в установке значения по умолчанию через атрибут DEFAULT:
ALTER TABLE Customers ADD Address NVARCHAR(50) NOT NULL DEFAULT 'Неизвестно';
В этом случае, если в таблице уже есть данные, то для них для столбца Address будет добавлено значение «Неизвестно».
Удалим столбец Address из таблицы Customers:
ALTER TABLE Customers DROP COLUMN Address;
Изменение типа столбца
Изменим в таблице Customers тип данных у столбца FirstName на :
ALTER TABLE Customers ALTER COLUMN FirstName NVARCHAR(200);
Добавление ограничения CHECK
При добавлении ограничений SQL Server автоматически проверяет имеющиеся данные на соответствие добавляемым ограничениям. Если данные не соответствуют
ограничениям, то такие ограничения не будут добавлены. Например, установим для столбца Age в таблице Customers ограничение Age > 21.
ALTER TABLE Customers ADD CHECK (Age > 21);
Если в таблице есть строки, в которых в столбце Age есть значения, несоответствующие этому ограничению, то sql-команда завершится с ошибкой.
Чтобы избежать подобной проверки на соответствие и все таки добавить ограничение, несмотря на наличие несоответствующих ему данных,
используется выражение WITH NOCHECK:
ALTER TABLE Customers WITH NOCHECK ADD CHECK (Age > 21);
По умолчанию используется значение WITH CHECK, которое проверяет на соответствие ограничениям.
Добавление внешнего ключа
Пусть изначально в базе данных будут добавлены две таблицы, никак не связанные:
CREATE TABLE Customers ( Id INT PRIMARY KEY IDENTITY, Age INT DEFAULT 18, FirstName NVARCHAR(20) NOT NULL, LastName NVARCHAR(20) NOT NULL, Email VARCHAR(30) UNIQUE, Phone VARCHAR(20) UNIQUE ); CREATE TABLE Orders ( Id INT IDENTITY, CustomerId INT, CreatedAt Date );
Добавим ограничение внешнего ключа к столбцу CustomerId таблицы Orders:
ALTER TABLE Orders ADD FOREIGN KEY(CustomerId) REFERENCES Customers(Id);
Добавление первичного ключа
Используя выше определенную таблицу Orders, добавим к ней первичный ключ для столбца Id:
ALTER TABLE Orders ADD PRIMARY KEY (Id);
Добавление ограничений с именами
При добавлении ограничений мы можем указать для них имя, используя оператор CONSTRAINT, после которого указывается имя ограничения:
ALTER TABLE Orders
ADD CONSTRAINT PK_Orders_Id PRIMARY KEY (Id),
CONSTRAINT FK_Orders_To_Customers FOREIGN KEY(CustomerId) REFERENCES Customers(Id);
ALTER TABLE Customers
ADD CONSTRAINT CK_Age_Greater_Than_Zero CHECK (Age > 0);
Удаление ограничений
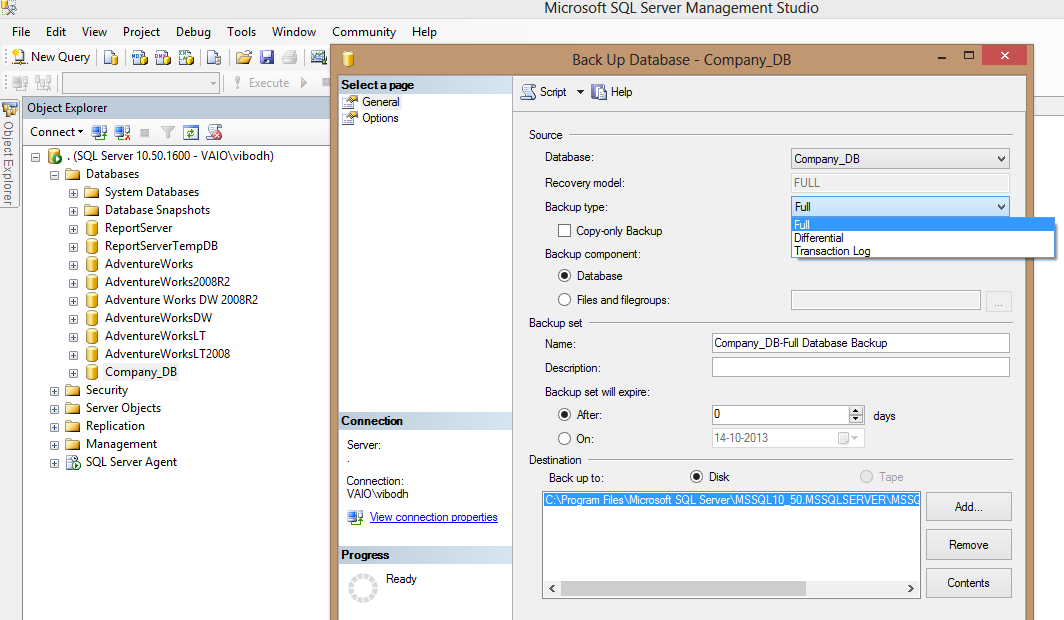
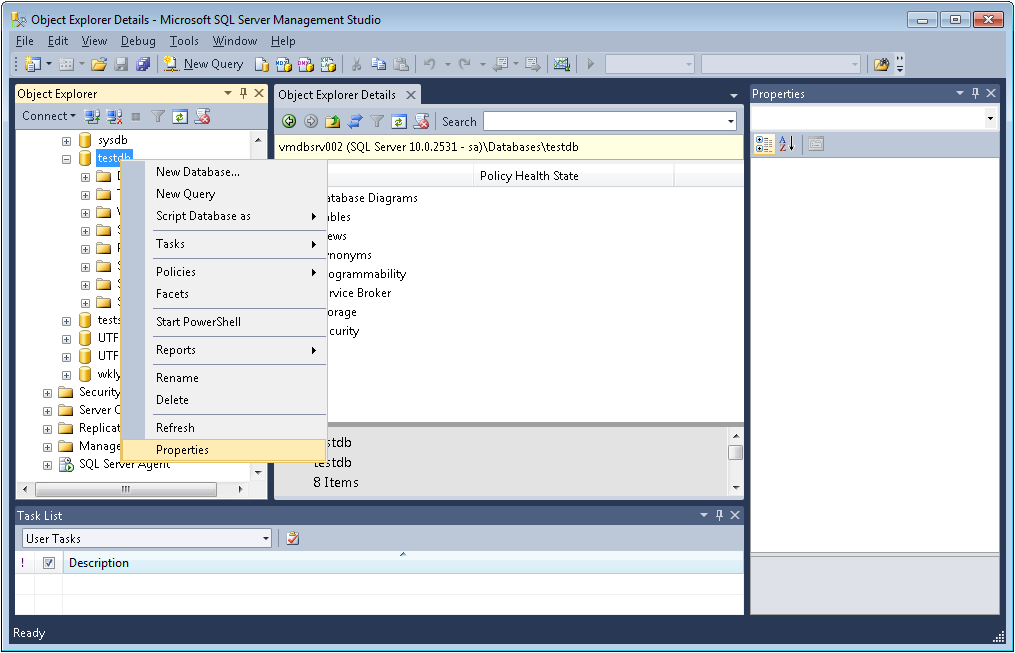
Для удаления ограничений необходимо знать их имя. Если мы точно не знаем имя ограничения, то его можно узнать через SQL Server Management Studio:
Раскрыв узел таблиц в подузле Keys можно увидеть названия ограничений первичного и внешних ключей. Названия ограничений внешних ключей
начинаются с «FK». А в подузле Constraints можно найти все ограничения CHECK и DEFAULT. Названия ограничений CHECK начинаются с «CK»,
а ограничений DEFAULT — с «DF».
Например, как видно на скриншоте в моем случае имя ограничения внешнего ключа в таблице Orders называется «FK_Orders_To_Customers».
Поэтому для удаления внешнего ключа я могу использовать следующее выражение:
ALTER TABLE Orders DROP FK_Orders_To_Customers;
НазадВперед
SQL Group By
Предложение SQL GROUP BY сопоставляет строки. Предложения GROUP BY часто встречаются в запросах, использующих агрегатные функции, такие как MIN и MAX. Оператор GROUP BY сообщает SQL, как агрегировать информацию в любом неагрегированном столбце, который вы запросили.
Синтаксис оператора GROUP BY:
Мы использовали агрегатную функцию в нашем запросе и указали другой столбец.
В любом запросе это так, нам нужно использовать оператор GROUP BY. Оператор GROUP BY сообщает SQL, как отображать данные ветки, даже если они находятся за пределами агрегатной функции. Вам нужно сгруппировать по таблице, которой нет в агрегатной функции.
Предложение GROUP BY используется только в операторах SQL SELECT.
Давайте посмотрим на пример предложения GROUP BY в SQL.
SQL Group By по нескольким столбцам
Если бы мы хотели, мы могли бы выполнить GROUP BY для нескольких столбцов. Например, предположим, что мы хотели получить список сотрудников с определёнными должностями в каждом филиале. Мы могли бы получить эти данные, используя следующий запрос:
Наш набор результатов запроса показывает:
| ответвляться | заглавие | считать |
| Стэмфорд | Сотрудник по продажам | 1 |
| Олбани | Вице-президент по продажам | 1 |
| Сан-Франциско | Сотрудник по продажам | 1 |
| Сан-Франциско | Старший специалист по продажам | 1 |
| Олбани | Директор по маркетингу | 1 |
| Бостон | Сотрудник по продажам | 2 |
(6 рядов)
Наш запрос создаёт список титулов, которыми владеет каждый сотрудник. Мы видим количество людей, обладающих этим титулом. Наши данные сгруппированы по отраслям, в которых работает каждый сотрудник, и их должностям.
Таблицы и представления
Таблицы и представления — это те объекты, к которым Вы, наверное, чаще всего будете обращаться, ведь данные из базы данных следует извлекать, а они хранятся в таблицах, имена которых будут использоваться и в представлениях, и в процедурах, и в функциях, тем самым, от того, насколько удачным будет имя таблицы, включая представление, ведь с помощью представления мы также получаем доступ к данным, будет зависеть удобочитаемость всех Ваших инструкций, а также, насколько сложно Вам будет писать все эти инструкции, так как писать код с использованием «неудобных» имен гораздо сложней, чем с использованием понятных и корректных имен.
Здесь я собрал правила, которым следует придерживаться при именовании таблиц и представлений, эти объекты в базе данных в Microsoft SQL Server подчинены примерно одинаковым правилам.
Не используйте единственное число
Таблица сама по себе является множеством, набором данных, поэтому ее никак нельзя называть в единственном числе, например, «Заказ» (Order) или «Автомобиль» (Car). Согласитесь, когда мы говорим «Автомобиль», в голове мы так и представляем один автомобиль, но, если мы говорим «Автомобили», мы уже представляем себе много автомобилей.
Поэтому всегда при названии таблиц или представлений используйте существительные во множественном числе.
В качестве исключения.
Таблица может быть названа в единственном числе, только если в ней действительно будет присутствовать одна строка.
Не используйте похожие имена
Не нужно называть таблицы или представления так, чтобы Вы, или другой программист, могли их спутать. К примеру, если Вам нужно назвать таблицу, которая будет содержать более детализированные данные заказов, а при этом таблица с названием OrderDetails уже есть, не нужно создавать таблицу с названием Order_Details, лучше добавьте дополнительное описательное слово, которое будет характеризовать конкретную детализацию, например, OrderDetailsMoney, по названию которой можно легко понять, что таблица содержит какие-то детализированные сведения о заказах в части денежных средств.
Временные таблицы подчиняются тем же правилам, что и обычные таблицы
Временные таблицы стоит называть с учетом тех же правил, что и обычные таблицы, ведь это такой же набор данных. Иными словами, у нее также должно быть хорошее имя во множественном числе, по которому сразу понятно, что содержит эта таблица.
Не нужно в названии временной таблицы использовать префикс, допустим, tmp или temp или любой другой, по символу #, который используется для создания временных таблиц, и так сразу понятно, что это таблица временная.
Разбиение строки в массив в SQL Server
Подход на основе таблицы чисел означает, что вы должны вручную создать таблицу, содержащую достаточно строк, чтобы самая длинная строка, которую вы разбиваете, не превысила их число.
IF EXISTS ( SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'dbo.NumbersTest') ) BEGIN DROP TABLE NumbersTest; END; CREATE TABLE NumbersTest (Number INT NOT NULL); DECLARE @RunDate datetime = GETDATE() DECLARE @i INT = 1; WHILE @i BEGIN INSERT INTO dbo.NumbersTest(Number) VALUES (@i); SELECT @i = @i + 1; END; CREATE UNIQUE CLUSTERED INDEX n ON dbo.NumbersTest(Number) WITH (DATA_COMPRESSION = PAGE); GO
сжатие индекса может использоваться только в Enterprise версии SQL Server.
CREATE FUNCTION dbo.Split_Numbers ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) )
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.NumbersTest
WHERE Number
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter);
С другой стороны, если мы используем метод CTE, он не потребует таблицы чисел. Вместо нее будет использоваться рекурсивное CTE для извлечения каждой части строки из «остатка» после предыдущей части.
CREATE FUNCTION dbo.Split_CTE ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) )
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
= 1,
= COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll),
= SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll) - 1)
UNION ALL
SELECT
= CONVERT(INT, ) + @ld,
= COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, + @ld), 0), @ll),
= SUBSTRING(@List, + @ld, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, + @ld), 0), @ll)--@ld)
FROM a
WHERE
)
INSERT @Items SELECT
FROM a
WHERE LEN() > 0
OPTION (MAXRECURSION 0);
RETURN;
END
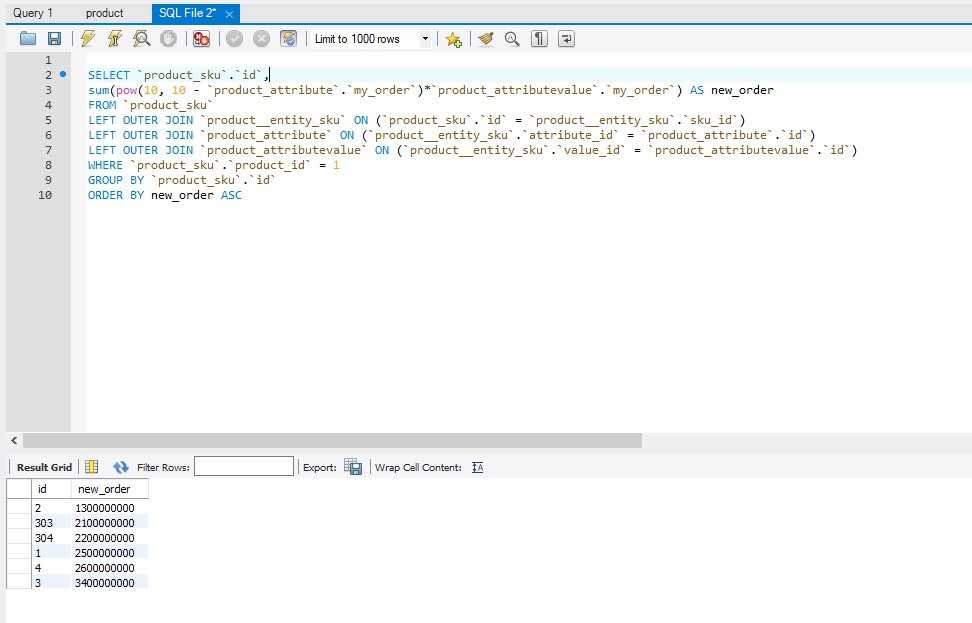
DECLARE @Values NVARCHAR(MAX) =N'Value 1,Value 2,Value 3,Value 4,Value 5'; SELECT Item AS NumSplit FROM dbo.Split_Numbers (@Values, N','); SELECT Item AS CTESplit FROM dbo.Split_CTE (@Values, N',');
![]()
CREATE TABLE dbo.TestData ( string_typ INT, string_val NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.TestData(string_len); CREATE TABLE #Temp(st NVARCHAR(MAX)); INSERT #Temp SELECT N'a,va,val,value,value1,valu,va,value12,,valu,value123,value1234'; GO INSERT dbo.TestData SELECT 1, st FROM #Temp; GO 10000 INSERT dbo.TestData SELECT 2, REPLICATE(st,10) FROM #Temp; GO 1000 INSERT dbo.TestData SELECT 3, REPLICATE(st,100) FROM #Temp; GO 100 INSERT dbo.TestData SELECT 4, REPLICATE(st,1000) FROM #Temp; GO 10 INSERT dbo.TestData SELECT 5, REPLICATE(st,10000) FROM #Temp; GO DROP TABLE #Temp; GO -- убираем концевую запятую UPDATE dbo.TestData SET string_val = SUBSTRING(string_val, 1, LEN(string_val)-1) + 'x';
SELECT func.Item FROM dbo.TestData AS tst CROSS APPLY dbo.Split_CTE(tst.string_val, ',') AS func WHERE tst.string_typ = 1; -- Значения string_typ от 1-5 SELECT func.Item FROM dbo.TestData AS tst CROSS APPLY dbo.Split_Numbers(tst.string_val, ',') AS func WHERE tst.string_typ = 1; -- Значения string_typ от 1-5
![]()
Вставка или изменение данных в наборе столбцов
Управлять данными в разреженных столбцах можно с помощью имен индивидуальных столбцов либо ссылаясь на имя набора столбцов и указывая значения набора столбцов, используя XML-формат набора столбцов. Разреженные столбцы могут быть расположены в XML-столбце в любом порядке.
При вставке или обновлении значений разреженных столбцов с помощью набора XML-столбцов производится неявное преобразование значений, вставляемых в лежащие в основе разреженные столбцы, из типа данных xml . Для числовых столбцов пустые значения в XML-столбцах преобразуются в пустые строки. Поэтому в числовые столбцы вставляются значения 0, как это показано в следующем примере.
В этом примере для столбца не было указано значение, однако было вставлено значение .
Советы по оптимизации хранимых процедур и SQL пакетов
Инкапсулируйте ваш код в хранимых процедурах
Для обработки данных используйте хранимые SQL процедуры.
Когда хранимая процедура выполняется в первый раз (и у нее не определена опция WITH RECOMPILE), она оптимизируется, для нее создается план выполнения запроса, который кешируется SQL сервером. Если та же самая хранимая процедура вызывается снова, она будет использовать кешированный план выполнения запроса, что экономит время и увеличивает производительность.
Всегда включайте в ваши хранимые процедуры инструкцию «SET NOCOUNT ON». Если Вы не включите эту инструкцию, тогда каждый раз при выполнении запроса SQL сервер отправит ответ клиенту, указывающему число строк, на которые воздействует запрос.
Избегайте использования курсоров
По возможности выбирайте быстрый forward-only курсор
При использовании серверного курсора, старайтесь использовать как можно меньший рекордсет. Для этого выбирайте только те столбцы и строки, которые необходимы клиенту для решения его текущей задачи.
Когда Вы закончили использовать курсор, как можно раньше не только ЗАКРОЙТЕ (CLOSE) его, но и ОСВОБОДИТЕ (DEALLOCATE).
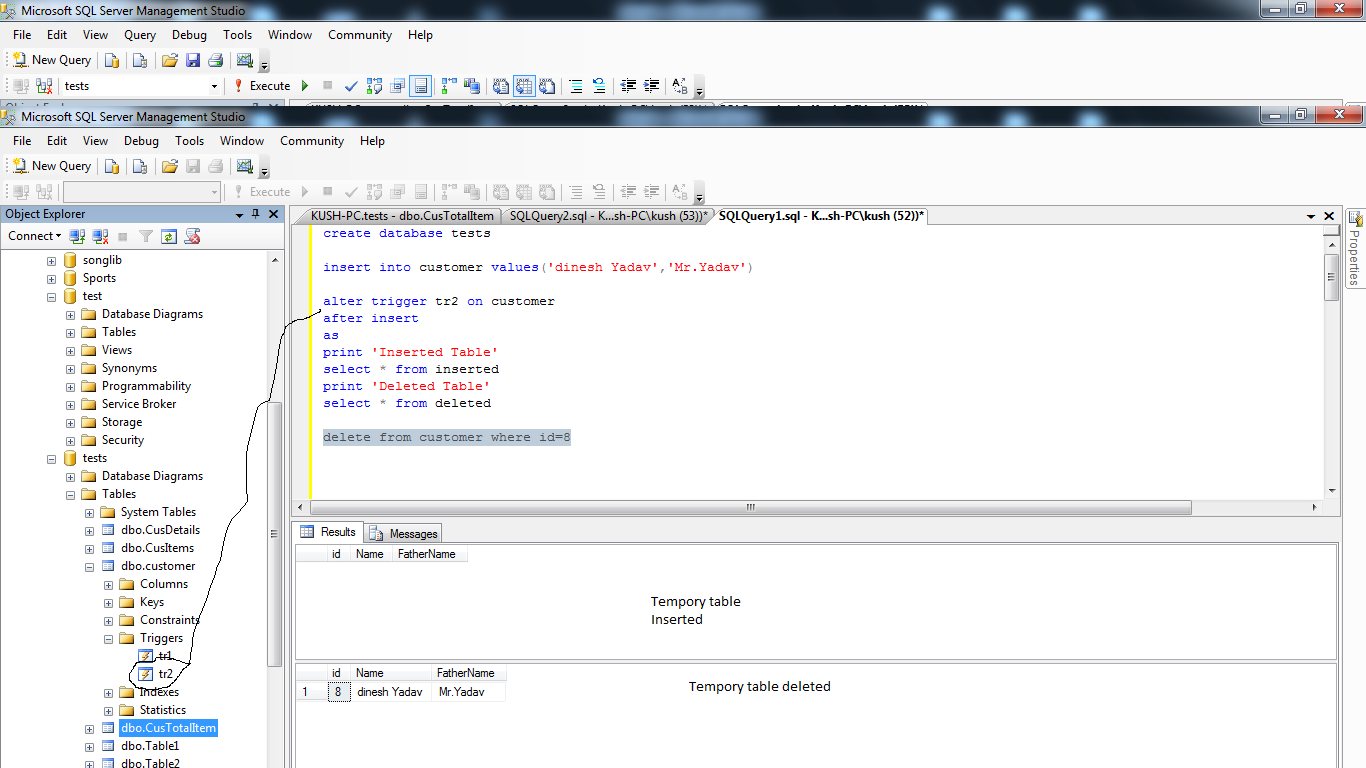
Используйте триггеры c осторожностью
Триггеры — это усложнение логики работы приложения, неявное неожиданное выполнение дополнительных действий.
Триггеры усложняют интерфейс хранимых процедур. Поместите все необходимые проверки и действия в рамки хранимых процедур.
Временные таблицы для больших таблиц, табличные переменные — для малых (меньше 1000)
Если вам требуется хранить промежуточные данные в таблицах, то используйте табличные переменные (@t1) для малых таблиц, а временные таблицы (#t1) — для больших.
Подробнее:
При определении временной таблицы имеет смысл проверить ее на существование:
Также для улучшения быстродействия используйте для временной таблицы первичный ключ и индексы.



