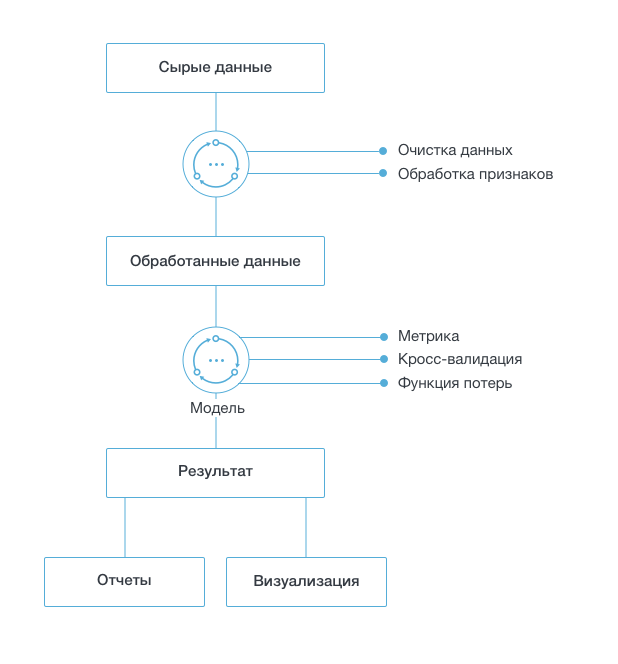
Строковые типы данных
| Тип данных | Объем памяти | Максимальный размер | Описание |
| CHAR (M) | M символов | М символов | Позволяет хранить строку фиксированной длины М. Значение М — от 0 до 65535.Примеры: CHAR (8) — хранит строки из 8 символов и занимает 8 байтов. Например, любое из следующих значений: », ‘Иван’,’Ирина’, ‘Сергей’ будет занимать по 8 байтов памяти. А при попытке ввести значение ‘Александра’, оно будет усечено до ‘Александ’, т.е. до 8 символов. |
| VARCHAR (M) | L+1 символов | М символов | Позволяет хранить переменные строки длиной L. Значение М — от 0 до 65535.Примеры: VARCHAR (3) — хранит строки максимум из 3 символов, но пустая строка » занимает 1 байт памяти, строка ‘a’ — 2 байта, строк ‘aa’ — 3 байта, строка ‘aaa’ — 4 байта. Значение более 3 символов будет усечено до 3. |
| BLOB, TEXT | L+2 символов | 216-1 символов | Позволяют хранить большие объемы текста. Причем тип TEXT используется для хранения именно текста, а BLOB — для хранения изображений, звука, электронных документов и т.д. |
| MEDIUMBLOB, MEDIUMTEXT | L+3 символов | 224-1 символов | Аналогично предыдущему, но с большим размером. |
| LONGBLOB, LONGTEXT | L+4 символов | 232-1 символов | Аналогично предыдущему, но с большим размером. |
| ENUM (‘value1’, ‘value2′, …,’valueN’) | 1 или 2 байта | 65535 элементов | Строки этого типа могут принимать только одно из значений указанного множества.Пример: ENUM (‘да’, ‘нет’) — в столбце с таким типом может храниться только одно из имеющихся значений. Удобно использовать, если предусмотрено, что в столбце должен храниться ответ на вопрос. |
| SET (‘value1’, ‘value2′, …,’valueN’) | до 8 байт | 64 элемента | Строки этого типа могут принимать любой или все элементы из значений указанного множества.Пример: SET (‘первый’, ‘второй’) — в столбце с таким типом может храниться одно из перечисленных значений, оба сразу или значение может отсутствовать вовсе. |
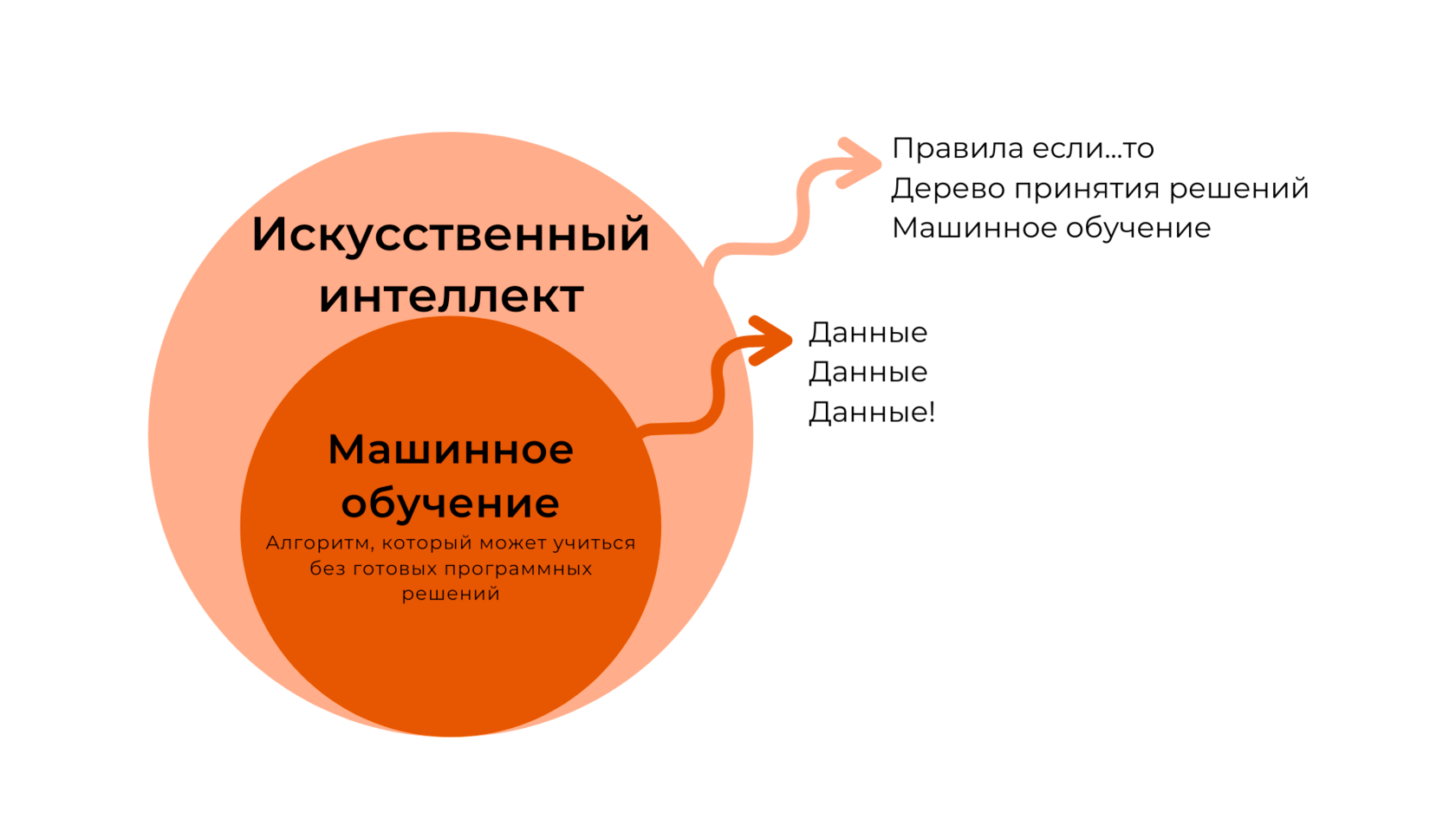
Примитивные типы данных
Примитивные типы данных — это базовые типы данных языка программирования. Их ключевая особенность в том, что данные в них, в отличие от ссылочных типов, располагаются непосредственно на участке памяти компьютера в котором находится переменная. Перечислим и опишем основные примитивные типы данных в программировании.
- Логический тип данных или булевый. Переменные данного вида могу принимать лишь два значения: истина (true, либо 1) или ложь (false, либо 0). В различных языках программирования булевы переменные объявляются с помощью ключевого слова bool либо boolean. Логический тип данных имеет широчайшее применение (как собственно и другие типы). Например, он фигурирует в условных операторах ветвления (if) и операторах цикла (for, while, do-while).
-
Целочисленный тип данных. Обычно объявляется ключевым словом int или integer. Переменные данного типа могут принимать только целочисленные значения. Часто тип int занимает четыре байта (232 = 4294967296), следовательно переменные могут принимать значения от — 2 147 483 648 и до 2 147 483 647 в случае, когда целый тип учитывает знак числа. Если использовать беззнаковый целый тип данных (unsigned int), то его диапазон значений от 0 до 4294967295. В языке программирования Java целый тип всегда 4 байта. В языках Си и C# предполагаемый размер также 4 байта, но на деле — всё зависит от конкретной реализации языка на программной платформе.
Данный тезис относится не только к типу int. Размер каждого примитивного типа данных в любой реализации языка Java всегда строго определен и одинаков. В C-подобных языках это не так. - Целочисленный тип byte. Исходя из названия типа, он занимает в памяти один байт, то есть восемь бит. 28 = 256 — такое количество значений он может в себя вместить. Если говорить конкретно, то в случае, если тип byte со знаком, то диапазон от -128 до 127 (не забываем, что есть еще число ноль); когда byte беззнаковый, то от 0 до 255.
- Короткий целый тип short. В памяти для него выделено 2 байта = 16 бит (216 = 65536). Диапазон принимаемых значений типом short со знаком — это .
- Длинный целый тип long. Длинный целый тип занимает в памяти 8 байт, то есть 64 бита. 264 = 1,8446744 × 1019. Диапазон допустимых значений очень велик: в случае знакового типа, это . Кроме того, модификатор long можно использовать в сочетании с другими типами (long пишется перед названием типа, например: long double), расширяя, тем самым, диапазон допустимых значений типа согласно спецификации конкретного языка программирования.
- Число с плавающей запятой. Этот тип обозначается ключевым словом float, также же этот тип называют вещественным типом одинарной точности. float — это ни что иное, как десятичная дробь (привычная нам на письме), но в памяти компьютера она представляется в виде экспоненциальной записи: состоит из мантиссы и показателя степени. Например: 0,0506 = 506,0 ⋅ 10-4, где 506 — мантисса, а -4 — показатель степени десяти. Размер типа данных float в спецификации языка Си четко не определен.
- Число с плавающей запятой двойной точности — это тип double. Данный тип схож с типом float, единственное их различие — это размер в памяти и, соответственно, диапазон принимаемых значений. Естественно тип double больше; но всё зависит от реализации языка, говоря строго: тип double по крайней мере должен быть не меньше, чем float.
- Символьный тип данных занимает в памяти один байт — если используется кодировка ASCII и два байта — если установлена кодировка Unicode. Данный тип по сути является целым числом. Цифра, хранящаяся в переменной символьного типа — это номер символа в таблице кодировки. Обычно объявляется с помощью ключевого слова char. Нужно четко представлять себе, что char — это число, и работать с ним, как с числом, в некоторых случаях очень удобно и эффективно.
![]()
Ключевая особенность примитивных типов данных в том, что они передаются по значению. Это значит, что при передачи переменной в качестве аргумента функции (или методу) она копируется туда. Следовательно манипуляции, производимые с переменной в вызванной функции, никак не повлияют на значение переменной в вызывающей функции.
Примечание: модификатор unsigned (то есть беззнаковый) применим к любому целочисленному типу (в том числе и к символьному), а long (длинный) применим практически к любому типу, за исключением логического.
Что такое динамическая типизация
Прежде, чем мы приступим к рассмотрению наиболее употребляемых типов данных в Python, проведём небольшую параллель с другими языками программирования. Всё их множество можно разделить на две составляющие:
- типизированные языки;
- нетипизированные (бестиповые) языки.
Нетипизированные языки в основной своей массе сосредоточены на низком уровне, где большинство программ напрямую взаимодействует с железом. Так как компьютер «мыслит» нулями и единицами, различия между строкой и, допустим, классом для него будут заключаться лишь в наборах этих самых 0 и 1. В связи с этим, внутри бестиповых языков, близких к машинному коду, возможны любые операции над какими угодно данными. Результат на совести разработчика.
Python же — язык типизированный. А, раз в нём определено понятие «типа», то должен существовать и процесс распознавания и верификации этих самых «типов». В противном случае вероятны ситуации, когда логика кода окажется нарушенной, а программа выполнится некорректно.
Таким процессом и является типизация. В ходе её выполнения происходит подтверждение используемых типов и применение к ним соответствующих ограничений. Типизация может быть статической и динамической. В первом случае, проверка выполняется во время компиляции, во втором — непосредственно во время выполнения программного кода.
Python — язык с динамической типизацией. И здесь, к примеру, одна и та же переменная, при многократной инициализации, может являть собой объекты разных типов:
В языке со статической типизацией такой фокус не пройдёт:
Адепты и приверженцы разных языков часто спорят о том, что лучше: динамическая типизация или статическая, но, само собой, преимущества и недостатки есть и там, и там.
К плюсам динамической типизации можно отнести:
1. Создание разнородных коллекций.
Благодаря тому, что в Python типы данных проверяются прямиком во время выполнения программного кода, ничто не мешает создавать коллекции, состоящие их элементов разных типов. Причём делается это легко и просто:
2. Абстрагирование в алгоритмах.
Создавая на Питоне, предположим, функцию сортировки, можно не писать отдельную её реализацию для строк и чисел, поскольку она и так корректно отработает на любом компарируемом множестве.
3. Простота изучения.
Не секрет, что изучать Питон с нуля гораздо легче, чем, например, Java. И такая ситуация будет наблюдаться не только для этой пары. Языки с динамической типизацией в большинстве своём лучше подходят в качестве учебного инструмента для новичков в программировании.
К минусам же динамической проверки типов можно отнести такие моменты, как:
1. Ошибки.
Ошибки типизации и логические ошибки на их основе. Они достаточно редки, однако зачастую весьма сложно отлавливаемые. Вполне реальна ситуация, когда разработчик писал функцию, подразумевая, что она будет принимать числовое значение, но в результате воздействия тёмной магии или банальной невнимательности, ей на вход поступает строка и …функция отрабатывает без ошибок выполнения, однако её результат, — ошибка, сам по себе. Статическая же типизация исключает такие ситуации априори.
2. Оптимизация.
Статически типизированные языки обычно работают быстрее своих динамических братьев, поскольку являются более «тонким» инструментом, оптимизация которого, в каждом конкретном случае, может быть настроена более тщательно и рационально.
Так или иначе, сказать, что «одно лучше другого» нельзя. Иначе «другого» бы не было. Динамически типизированные языки экономят уйму времени при кодинге, но могут обернуться неожиданными проблемами на этапе тестирования или, куда хуже, продакшена. Однако вряд ли кто-то будет спорить с тем, что динамический Python куда более дружелюбный для новичков, нежели статический C++.
Почему вы предпочитаете сильную слабую или наоборот?
Сильные языки — это строгие языки. Опять же, они удостоверяются, что точно знают, что намерен делать программист. Если возникает ошибка, чаще всего это ошибка программиста, не понимающего операций. Эти ошибки также потенциально указывают на непонимание проблемы. Если вы пытаетесь добавить 5число к «5«строке, то, возможно, вы не понимаете, почему это не имеет смысла для компьютера. Это заставляет вас прийти к истине об операции и прямо говорит компьютеру, что вы хотите сделать (обычно с помощью некоторой формы механизма преобразования / преобразования). Это, как правило, приводит к созданию более надежного и менее подверженного ошибкам кода в производственной среде, но добавляет время и препятствия для перепрыгивания во время разработки.
Слабые языки, опять же, больше полагаются на гибкость и выразительность, убирая строгую строгость сильного языка и позволяя программисту запустить свой код и запустить его. Но обратная сторона заключается в том, что компьютер делает предположения, которых программист, возможно, не предполагал.
JavaScript, язык со слабой типизацией (который также бывает динамическим), снова был усилен TypeScript, чтобы сделать его сильнее. Обработка типов данных в TypeScript позволяет программисту писать JavaScript с использованием явных типов и получать преимущества строго типизированного языка. Он обнаруживает множество ошибок во время компиляции и помогает предотвратить попадание расплывчатых предположений JavaScript в производственные системы. Но опять же, это происходит за счет более формального и строгого формата кодирования во время разработки. Даже редакторы кода, знающие TypeScript, могут помечать ошибки по мере их написания. VS Code — отличный тому пример.
Синонимы типов данных в Microsoft SQL Server
В MS SQL Server для совместимости со стандартом ISO существуют синонимы системных типов данных. Эти синонимы можно использовать в инструкциях языка Transact-SQL точно также как и соответствующие системные типы данных, единственный момент, что после создания объекта (таблицы, процедуры) синониму назначается базовый тип данных, связанный с этим синонимом, иными словами, каких-либо признаков, что в инструкции использовался синоним, нет.
Синонимы и соответствующие им системные типы данных представлены в таблице ниже:
| Системный тип данных | Синоним типа |
| varbinary | Binary varying |
| varchar | char varying |
| char | character |
| char(1) | character |
| char(n) | character( n ) |
| varchar(n) | character varying( n ) |
| decimal | Dec |
| float | Double precision |
| real | float; n = 1-7 |
| float | float; n = 8-15 |
| int | Integer |
| nchar(n) | national character( n ) |
| nchar(n) | national char( n ) |
| nvarchar(n) | national character varying( n ) |
| nvarchar(n) | national char varying( n ) |
| ntext | national text |
| rowversion | timestamp |
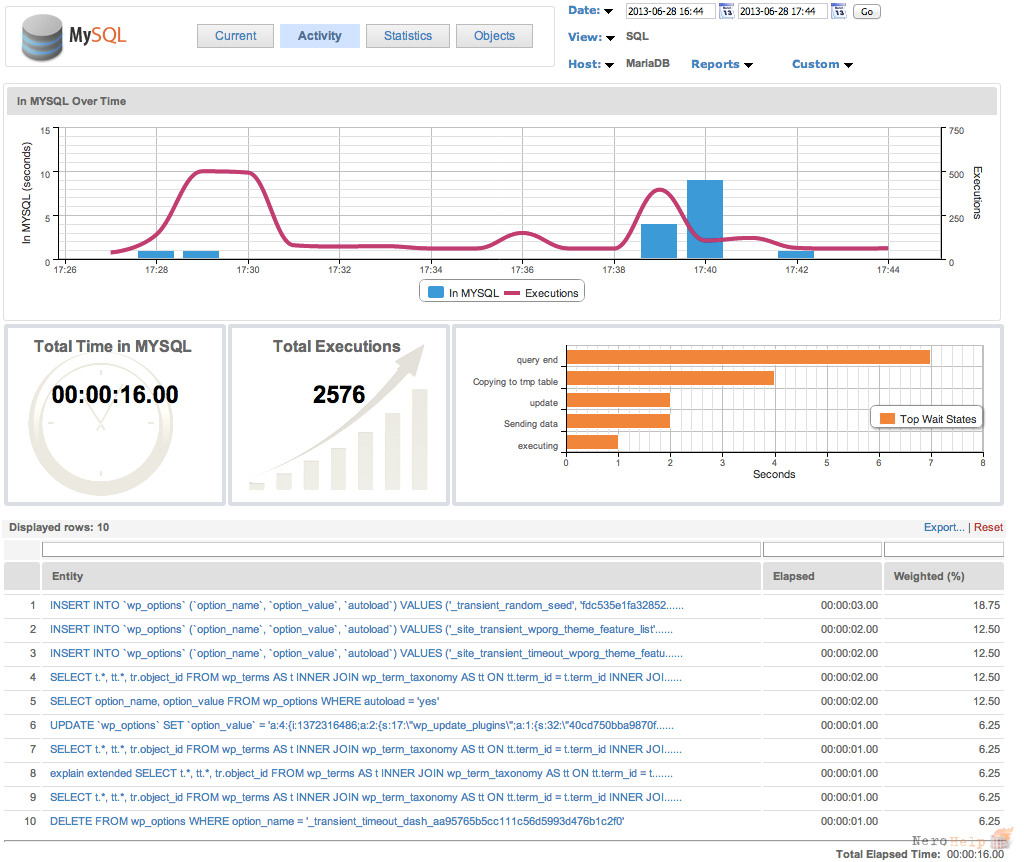
Объемы данных в мире
2020: Объем созданных данных достиг 64,2 Зб, из них сохранено менее 2% — IDC
В 2020 году в мире было создано 64,2 зеттабайт данных, однако к 2021 году было сохранено менее 2% новых данных, то есть большая часть из них была временно создана или реплицирована для использования, а затем удалена или перезаписана новыми данными. Об этом свидетельствуют результаты исследования IDC.
По сообщению IDC, объем созданных, потребляемых и передаваемых данных в 2020 году значительно вырос из-за резкого увеличения числа людей, которые на фоне ограничений из-за пандемии COVID-19 вынуждены работать и учиться дистанционно. В связи с глобальной пандемией также увеличился объем передаваемого мультимедийного контента.
![]() Объем созданных данных в 2020 году достиг 64,2 Зб, из них сохранено менее 2%
Объем созданных данных в 2020 году достиг 64,2 Зб, из них сохранено менее 2%
Исследователи утверждают, что Интернет вещей является самым быстрорастущим сегментом на рынке данных, не принимая во внимание данные, полученные от систем видеонаблюдения. За ним следуют социальные сети
Данные, созданные в облаке, не демонстрирует такой же быстрый рост, как данные, хранящиеся в облаке, однако создание данных на периферии развивается такими же быстрыми темпами, как и в облаке. В IDC также отмечают, что корпоративная «датасфера» (DataSphere) растет в два раза быстрее, чем потребительская, из-за возрастающей роли облака для хранения и потребления.
| Установленная база емкости «хранилищесферы» (StorageSphere) достигла 6,7 зеттабайт данных в 2020 году и неуклонно растет, но с более медленными темпами годового роста, чем у «датасферы», что означает, что мы сохраняем меньше данных, которые мы создаем каждый год, — сказал вице-президент по исследованиям DataSphere в IDC. |
IDC определила три причины, по которым человечество должно хранить больше данных, которые оно создает. Во-первых, данные имеют решающее значение для усилий любой организации по обеспечению цифровой устойчивости — способности организации быстро адаптироваться к сбоям в работе бизнеса за счет использования цифровых возможностей не только для восстановления бизнес-операций, но и для извлечения выгоды из изменившихся условий. Во-вторых, компании, прошедшие цифровую трансформацию, используют данные для разработки новых инновационных решений для будущего предприятия. В-третьих, компании должны следить за ритмом своих сотрудников, партнеров и клиентов, чтобы поддерживать высокий уровень доверия и сочувствия, обеспечивающий удовлетворенность и лояльность клиентов. Данные являются источником для отслеживания этих метрик.
Двоичная куча
Двоичная куча — ещё одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.


![]()
Так устроены минимальная и максимальная кучи
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче всё устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне. На иллюстрации видно, что в минимальной куче на третьем уровне значения идут не по порядку: 10, 6 и 12.
Временная сложность двоичной кучи
![]()
https://youtube.com/watch?v=dM_JHpfFITs
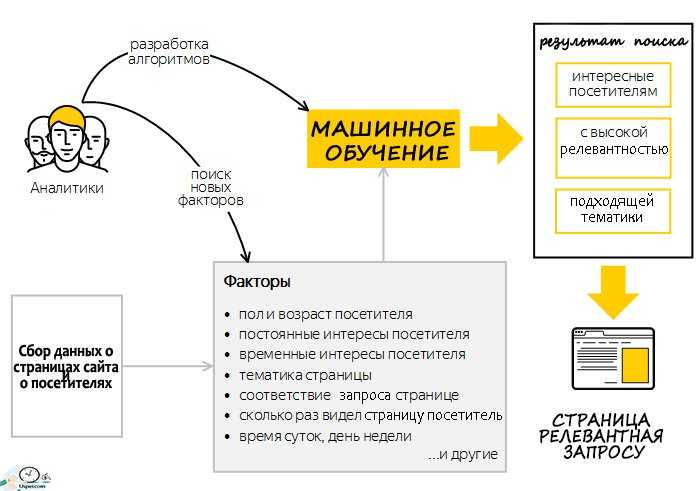
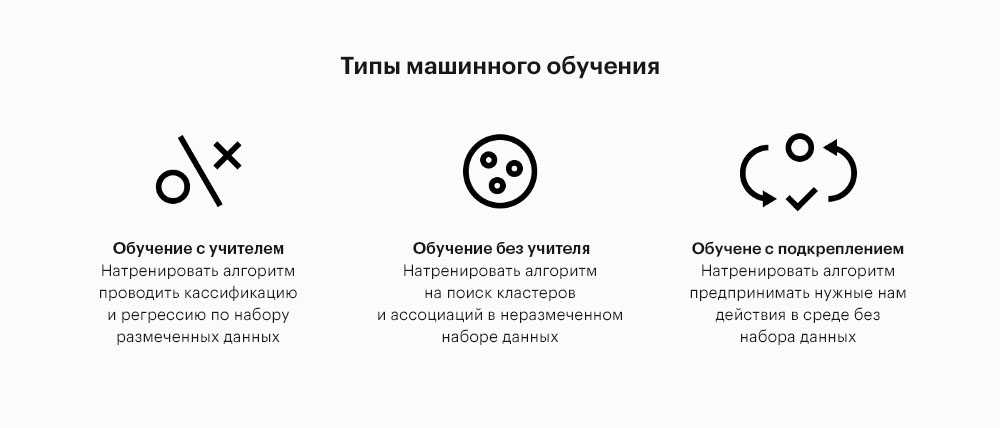
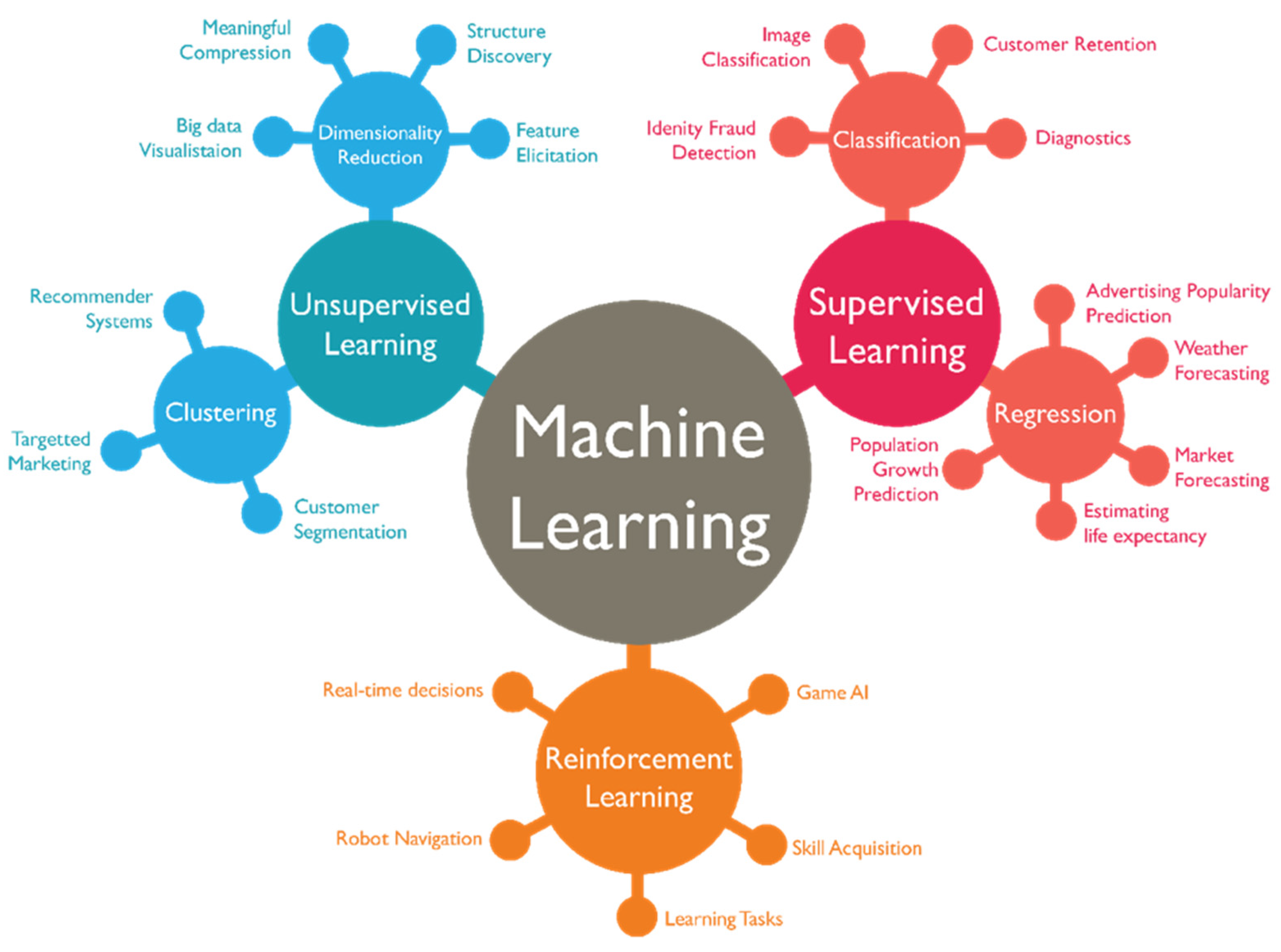
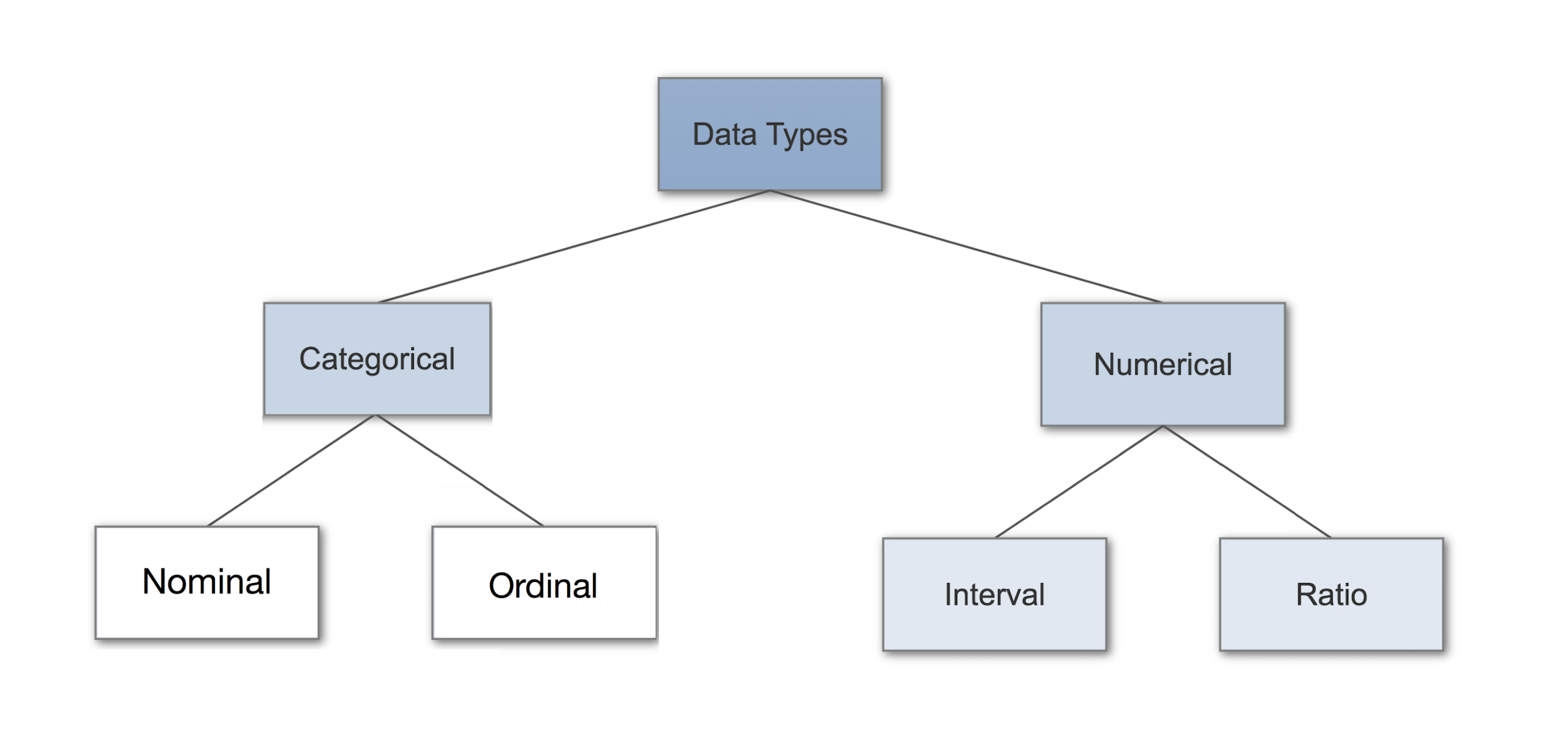
Классификация типов данных
Изначально, типы данных делятся на простые и составные. Простой — это тип данных, объекты (переменные или постоянные) которого не имеют доступной программисту внутренней структуры. Для объектов составного типа данных, в противовес простому, программист может работать с элементами внутренней его структуры.
Числовой тип данных разработан для хранения естественно чисел. Символьный — для хранения одного символа. Логический тип имеет два значения: истина и ложь. Перечислимый тип может хранить только те значения, которые прямо указаны в его описании.
Для простых типов данных определяются границы диапазона и количество байт, занимаемых ими в памяти компьютера.
В большинстве языков программирования, простые типы жестко связаны с их представлением в памяти компьютера. Компьютер хранит данные в виде последовательности битов, каждый из которых может иметь значение 0 и 1. Фрагмент данных в памяти может выглядеть следующим образом
Данные на битовом уровне (в памяти) не имеют ни структуры, ни смысла. Как интерпретировать данные, как целочисленное число, или вещественное, или символ, зависит от того, какой тип имеют данные, представленные в этой и последующих ячейках памяти.
Двоичное дерево поиска
![]()
Двоичное дерево поиска
Дерево — это структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов, и так далее.
У двоичного дерева поиска есть два дополнительных свойства:
- Каждый узел имеет до двух дочерних узлов (потомков).
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Временная сложность двоичного дерева поиска
![]()
https://youtube.com/watch?v=5cU1ILGy6dM
https://youtube.com/watch?v=Aagf3RyK3Lw
Упражнения от freeCodeCamp
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Интервал
Интервальные данные имеют равные промежутки между числами и не представляют временную структуру. Примеры включают проценты, температуры и доход.
![]()
Интервальные данные являются наиболее точными и очень распространенными. Хотя каждое значение является дискретным числом, например, 3,1 мили, для целей машинного обучения, как правило, не имеет значения, является ли это непрерывной шкалой (например, возможны бесконечно меньшие размеры измерений), а также не имеет значения, существует ли абсолютный ноль.
С данными интервалов, как правило, легко работать, но вы можете создать ячейки, чтобы сократить количество диапазонов.
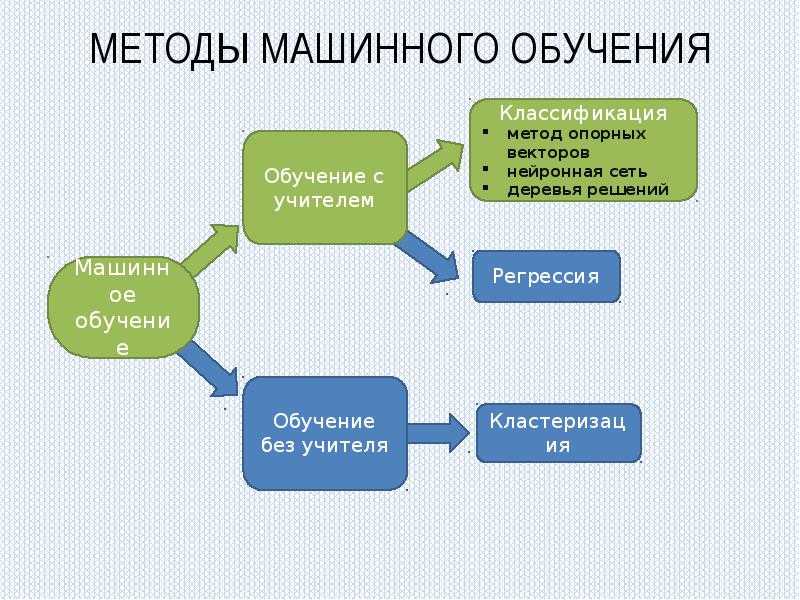
И вот у вас есть 7 типов данных.
- Бесполезный
- номинальный
- двоичный
- порядковый
- подсчитывать
- Время
- интервал
Несмотря на то, что многие опытные специалисты по машинному обучению, безусловно, по-разному думают о некоторых типах данных, описанных с помощью этих ярлыков, четкой таксономии для этой области не хватает. Я полагаю, что использование таксономии выше поможет людям быстрее оценить варианты кодирования, вменения и анализа своих данных.
Обратите внимание, что большинство из этих семи категорий могут отображаться в ваших необработанных данных практически в любой форме. Мы не говорим о float64 против bool: тип Python или (Numpy или Pandas dtype) не совпадает стипданных, обсуждаемых здесь
Это правильные семь категорий?
Типологии были придуманы для обсуждения ![]()
При создании 7 типов данных я спрашивал себя, действительно ли полезно отделять данные подсчета от интервальных данных. В конце концов, я считаю, что это потому, что текстовые данные являются такой распространенной формой данных подсчета и потому что данные подсчета действительно имеют некоторыеобщие разные статистические методы,
Аналогично, двоичные данные могут рассматриваться как подтип всех типов более высоких масштабов. Тем не менее, двоичные данные довольно часто встречаются в машинном обучении, а двоичные переменные результата имеют некоторые потенциальные алгоритмы машинного обучения, которых нет в других задачах мульти-классификации. Вам также не нужно предпринимать дополнительные действия по кодированию двоичных данных.

ОБНОВЛЕНИЕ 7 декабря 2018 года:
Потратив больше времени на глубокое изучение и рассмотрение комментариев читателей, я бы добавил еще четыре конкретных типа данных, чтобы довести общее число полезных типов данных для машинного обучения до 11.
8. Имидж
9. Видео
10. Аудио
11. Текст
Эти четыре типа данных имеют уникальные характеристики и функции библиотеки, созданные специально для них. Я думаю, что комплексная таксономия типов данных для машинного обучения требует их включения.
Как я буду помнить эти 7̶ — сделать это 11 — Типы данных?
- Бесполезный
- номинальный
- двоичный
- порядковый
- подсчитывать
- Время
- интервал
- Образ
- видео
- аудио
- Текст
Запоминание является ключом к обучению.RNBOCTIне совсем скатывается с языка.
![]()
Одна из восьми или девяти планет
Принимая сигнал от9 планет мнемоническихДавайте сделаем мнемонику, чтобы помочь запомнить 7 типов данных.
Гадкие шумные бонобо и старые кошки берут лед?
или
Uppity Noisy Boys часто не могут получить инструкции
или
Под новыми кроватями превращаются старые коровы
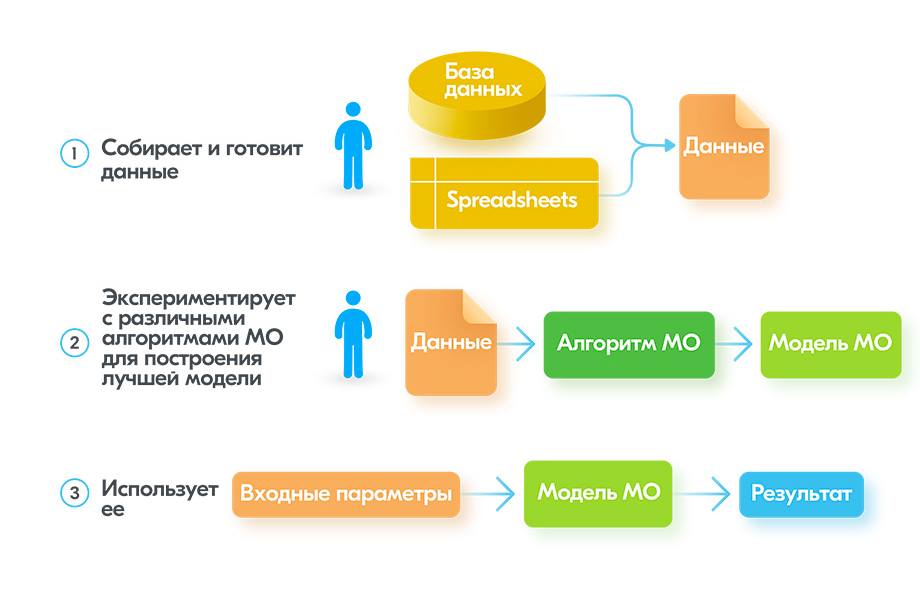
Должен ли я распространять информацию о типах данных?
Определенно.
В этой статье я рассмотрел классификацию типов данных как одну из одиннадцати категорий, чтобы создать более последовательную лексику для размышлений о данных и обмена ими в науке о данных. Эти категории имеют практическое применение для размышлений о вариантах кодирования и стратегиях вменения, которые я расскажу в следующих статьях.
Когда мы все используем одни и те же термины, чтобы обозначать одно и то же, мы экономим время на изучение и передачу знаний. Разве это не звучит замечательно? Если вы согласны, пожалуйста, поделитесь и хлопайте. Спасибо за чтение.
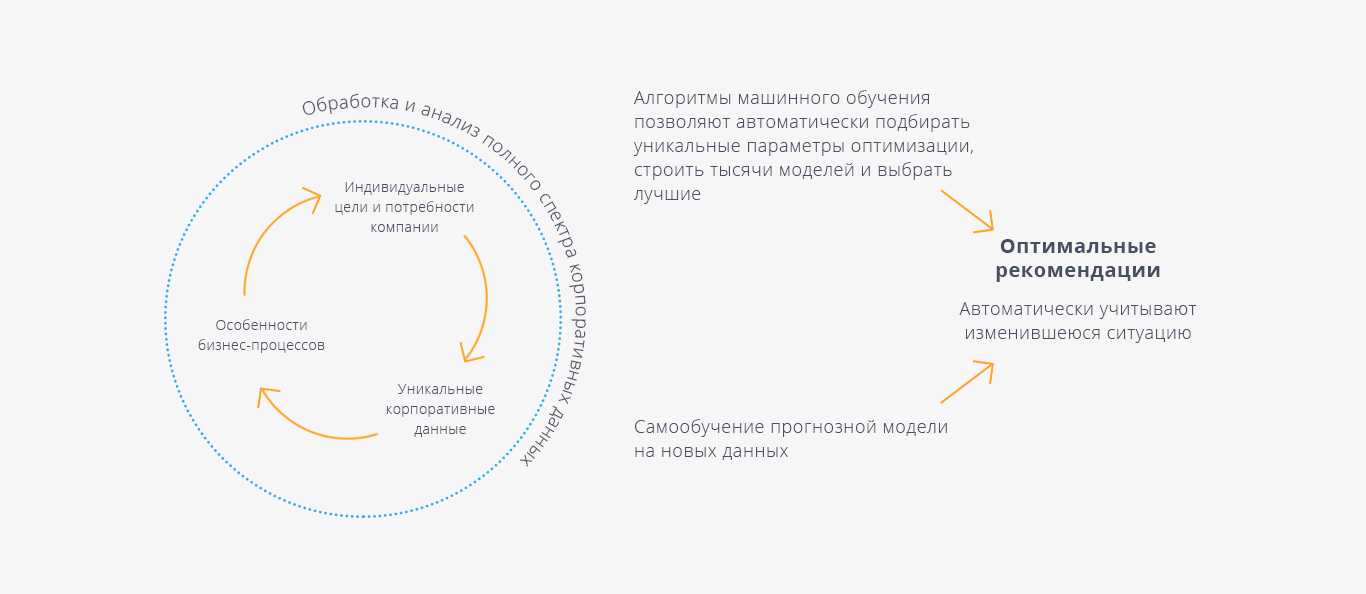
И снова про бизнес-процессы: живой опыт без теории
«Вы не любите кошек? Вы просто не умеете их готовить» (к/ф «Альф»)
Есть разные подходы к тому, как выделять и классифицировать бизнес-процессы, есть с десяток разных нотаций, в которых их можно описывать, есть целый ряд правил, по которым следует выявлять зоны неоптимальности и предлагать улучшения. По сути, мы с вами получаем в руки ящик с инструментами. А профессионализм аналитика заключается в выборе того, инструмента, который лучше всего подойдет для конкретной бизнес-задачи конкретного предприятия. В статье я хочу поделиться результатами осмысления собственных проектов и теми правилами, которые считаю важным и нужным учитывать при анализе и оптимизации бизнес-процессов.
1.6 Стандартные типы пользователя
1.6.1 Перечисляемый
Перечисляемый тип определяется конечным набором значений, представленных списком идентификаторов в объявлении типа. Значениям из этого набора присваиваются номера в соответствии с той последовательностью, в которой перечислены идентификаторы. Формат
объявления перечисляемого типа таков:
TYPE<имя> = (<список>);
<список>:= <идентификатор>,
Если идентификатор указан в списке значений перечисляемого типа, он считается именем константы, определенной в том блоке, где объявлен перечисляемый тип. Порядковые номера значений в объявлении перечисляемого типа определяются их позициями в списке идентификаторов, причем у первой константы в списке порядковый номер равен нулю. К данным перечисляемого типа относится, например, набор цветов:
TYPE <Цвет> = (Красный, Зеленый, Синий)
Операции те же, что и для символьного типа.
1.6.2 Диапазонный или интервальный
В любом порядковом типе можно выделить подмножество значений, определяемое минимальным и максимальным значениями, в которое входят все значения исходного типа, находящиеся в этих границах, включая сами границы. Такое подмножество определяет диапазонный тип. Он задаётся указанием минимального и максимального значений, разделенных двумя точками.
TYPE T=
TYPE <Час>=
Минимальное значение при определении такого типа не должно быть больше максимального.
2) Количественные данные
Информация записывается в виде чисел и представляет объективное измерение или подсчёт. Температура, вес, количество транзакций — вот примеры количественных данных. Аналитики также называют такие данные числовыми.
2.1) Дискретные данные
Дискретные количественные данные — это подсчёт случаев наличия характеристики, результата, предмета, деятельности. Эти измерения невозможно поделить на более мелкие части без потери смысла. Например, у семьи может быть 1 или 2 машины, но их не может быть 1,6. Таким образом, существует конечное число возможных значений, которые можно зарегистрировать в процессе наблюдений.
У дискретных переменных можно подсчитать и оценить интенсивность потока событий или сводное количество (медиана, мода, среднеквадратичное отклонение). К примеру, в 2014 году у каждой американской семьи было, в среднем, по 2,11 транспортных средства.
Обычный способ графического представления дискретных переменных — столбчатые диаграммы, где каждый отдельный столбик представляет отдельное значение, а высота столбика означает его пропорцию к целому.
![]()
Столбчатая диаграмма, отражающая количество автомобилей в калифорнийских семьях
2.2) Непрерывные данные
Непрерывные данные могут принимать практически любое числовое значение и могут быть разделены на меньшие части, включая дробные и десятичные значения. Непрерывные переменные часто измеряют по шкале. Когда вы измеряете высоту, вес, температуру, вы имеете дело с непрерывными данными.
Например, средний рост в Индии составляет 5 футов 9 дюймов (~ 175 см.) для мужчин и 5 футов 4 дюйма (~ 162 см.) для женщин.
Непрерывные данные подразделяются на 2 типа:
а) Интервальные данные
Интервальные значения представлены упорядоченными единицами, которые имеют одинаковое отличие друг от друга. Таким образом, мы говорим об интервальных данных, когда есть переменная, которая содержит упорядоченные числовые значения, и нам известны точные отличия этих значений. Примером может служить температура в заданном месте:

![]()
Положительные и отрицательные интервалы температуры
Проблема со значениями интервальных данных в том, что у них нет “абсолютного нуля”.
б) Данные соотношения
Данные соотношения также представляют собой упорядоченные единицы с одинаковыми отличиями друг от друга. Это практически то же самое, что и интервальные данные, однако данные соотношения имеют “абсолютный ноль”. Подходящие примеры — высота, вес, длина и т. д.
![]()
Длина стола в дюймах
При работе с непрерывными данными можно использовать практически все методы: процентиль, медиану, межквартильный размах, среднее арифметическое, моду, среднеквадратичное отклонение, амплитуду.
Методы визуализации:
Для визуализации непрерывных данных можно воспользоваться гистограммой или диаграммой размаха. С помощью гистограммы можно определить среднее значение и крутость распределения, изменчивость и модальность. Имейте в виду, что гистограмма не показывает выбросы — для этого нужно использовать диаграмму размаха.
![]()
Диаграмма размаха и гистограмма для анализа непрерывных данных
Заключение
Из этой статьи вы узнали о различных типах данных, используемых в статистике, о разнице между дискретными и непрерывными данными, а также о том, что собой представляют номинальные, порядковые, бинарные, интервальные данные и данные соотношения. Кроме того, теперь вы знаете, какие статистические измерения и методы визуализации можно применять для разных типов данных и как преобразовать категориальные переменные в числовые. Это позволит вам провести большую часть разведочного анализа на представленном наборе данных.
- Продвинутый взгляд на рекурсию
- Не учите машинное обучение
- Инновационный алгоритм глубокого обучения в Google Translate
Читайте нас в Telegram, VK и
Как теряют бизнес. Реальные истории от бизнес-консультанта. Промо
Поговорить о том, какие причины способствуют гибели существующего и часто даже успешного на определенном этапе бизнеса, я планировал давно, но все не доходили руки. Но недавно я услышал о банкротстве моего, теперь уже, клиента. Именно этот факт стал для меня неким толчком
Я осознал, что именно сейчас, в условиях кризиса очень важно понимать, почему бизнес может окончиться крахом и учиться избегать подобных ситуаций
Как известно, когда в экономике кризис, любой бизнес ослаблен. Если сравнивать с человеческим организмом, то кризис для экономики – как ослабление иммунитета. Когда человек здоров, то мелкие болезни проходят незамеченными. Организм сам справляется с проблемами, а в случае ослабления иммунитета, любая инфекция может привести к серьезным заболеваниям или даже стать фатальной.
Так происходит и в бизнесе. Если в период подъема экономики какие-то недостатки конкретного бизнеса сглаживаются, остаются незамеченными и даже не слишком мешают работать, то в периоды экономического спада они становятся теми самыми «тонкими местами», которые приводят к снижению прибыли, к определенным проблемам, а иногда даже к полному краху всего бизнеса.