
Обратный проход
C D B E G F A.
Пример:
-
int backPrintNodes (Node * current){ -
if (!current->hasChildren())
-
return 1;
-
int sum = ;
-
for (Int i= ; I < current->getCountChildren(); i++)
-
sum+= backPrintNodes (current->getChildAtPosition(i));
-
if (sum % 2 != )
-
printf (“element %s” , current->getStringPresentation() );
-
return 1 + sum;
-
}
* hasChildren – метод возвращает логическую величину – признак того есть ли у текущего узла поддеревья. * getCountChildren – возвращается количество подчиненных узлов. * getChildAtPosition – получение поддерева по порядковому номеру. * getStringPresentation – метод который возвращает строку представляющую (описывающую) текущий узел.
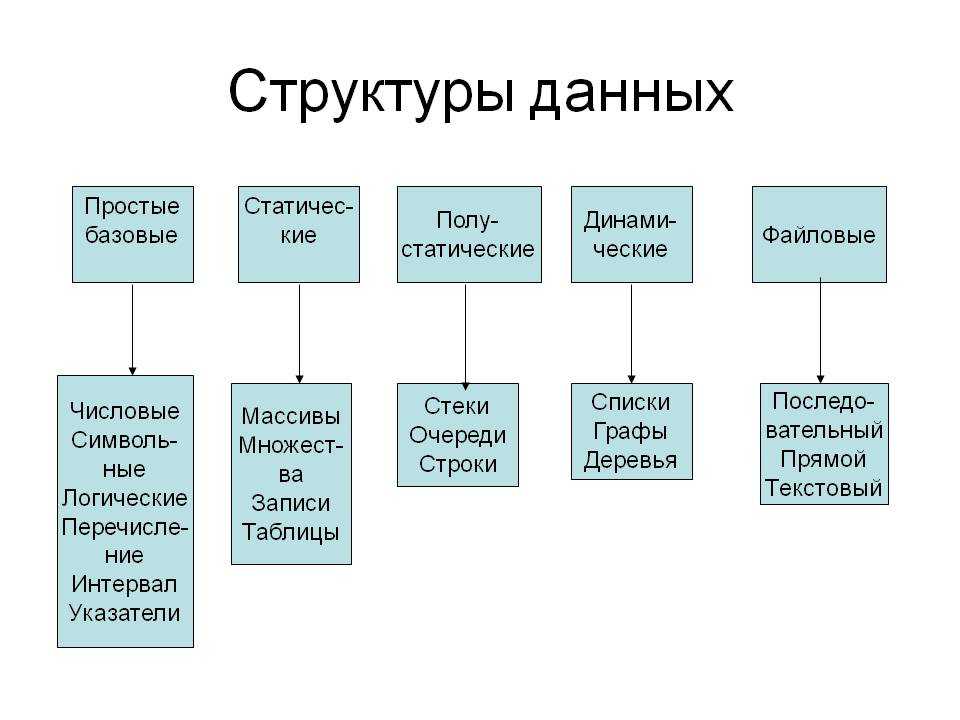
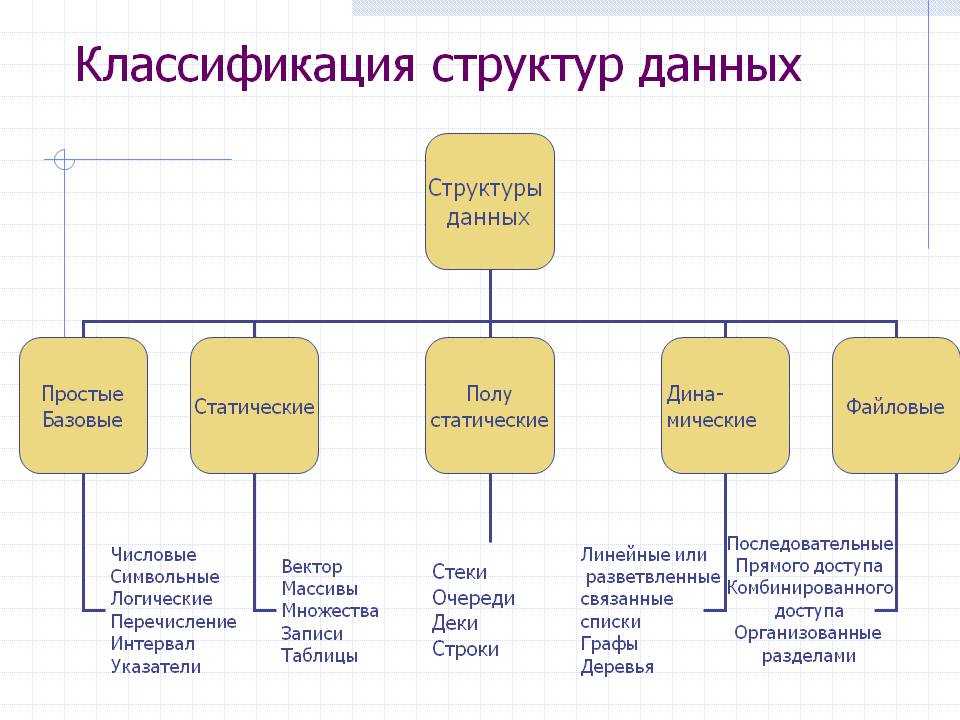
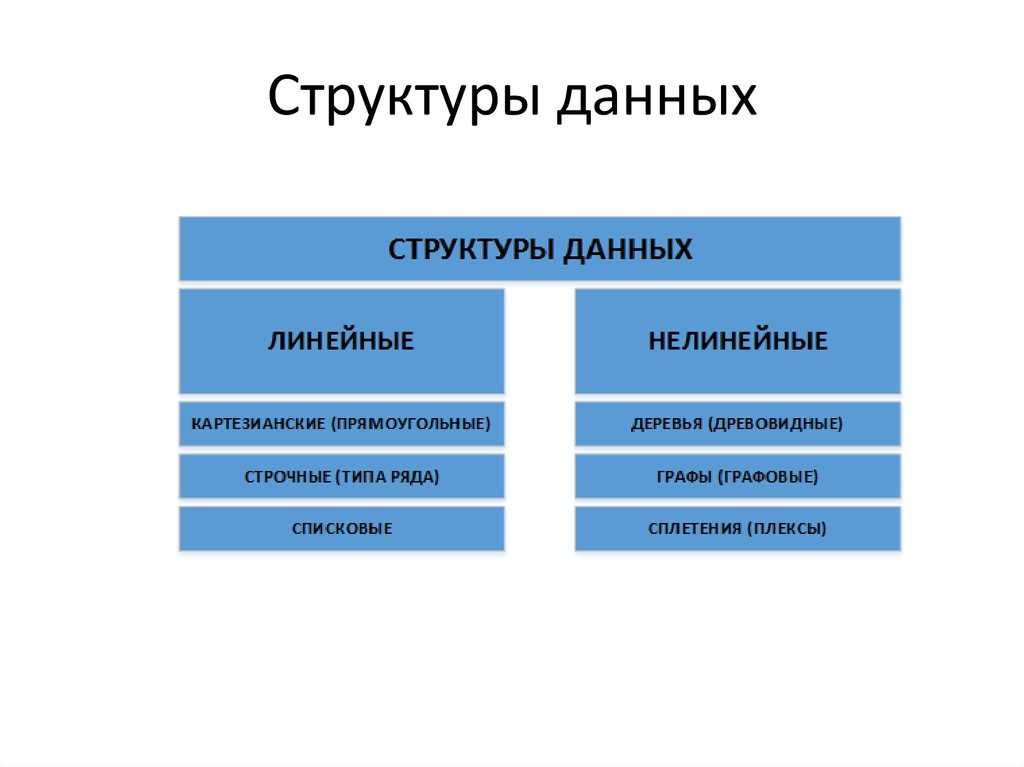
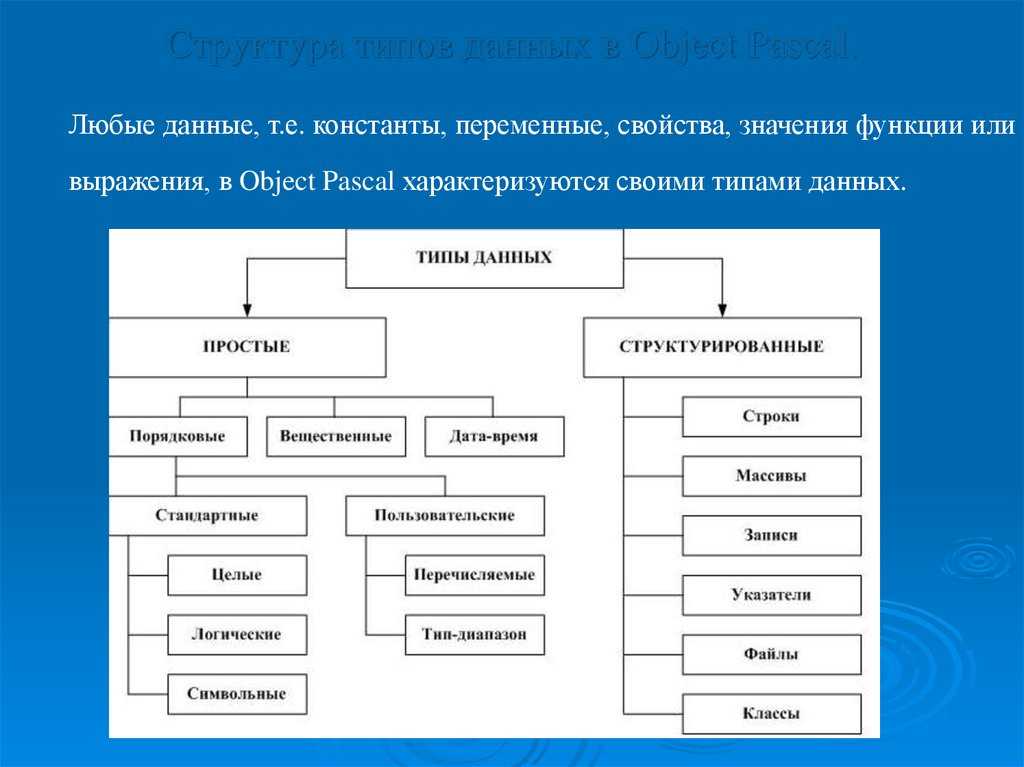
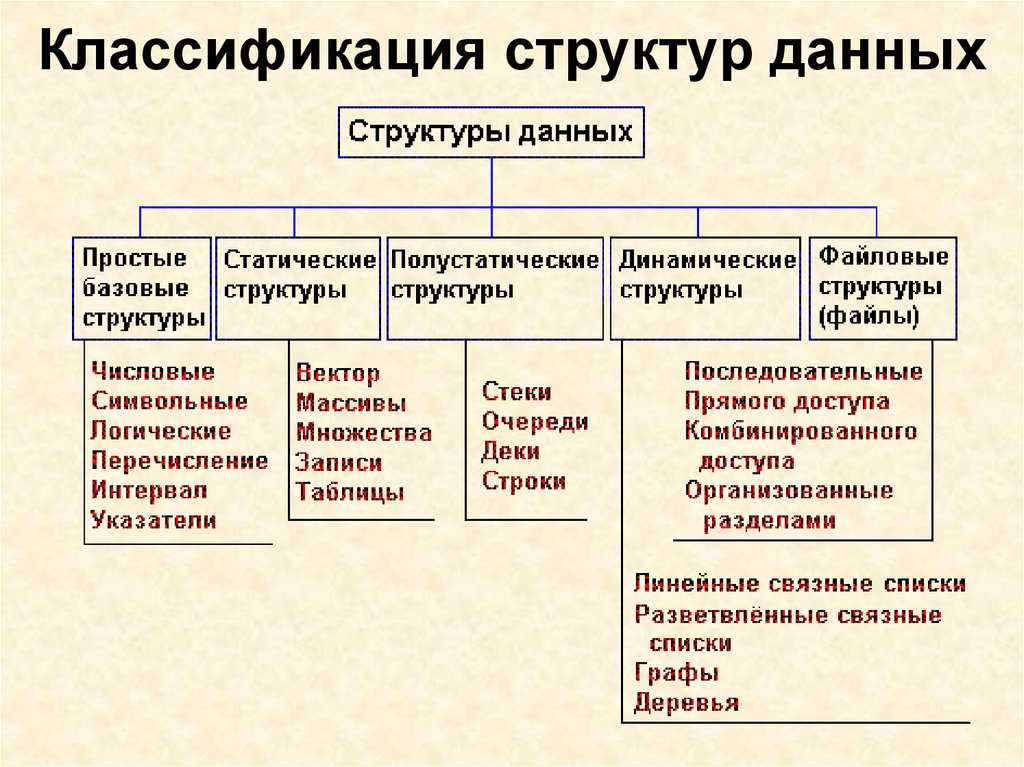
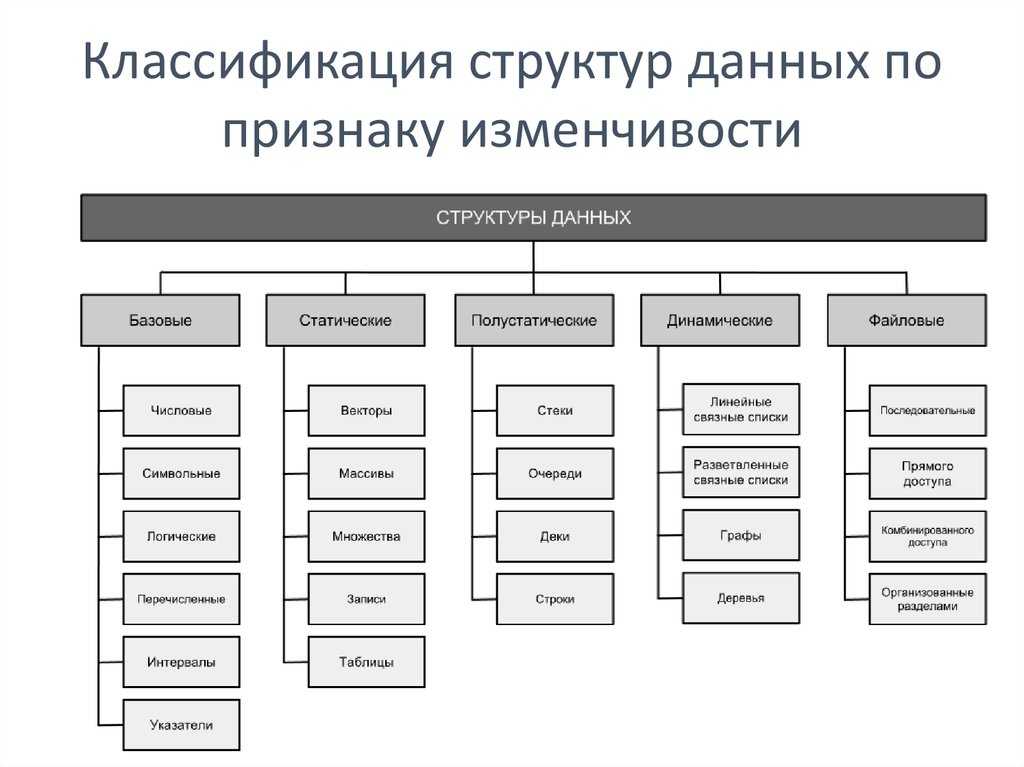
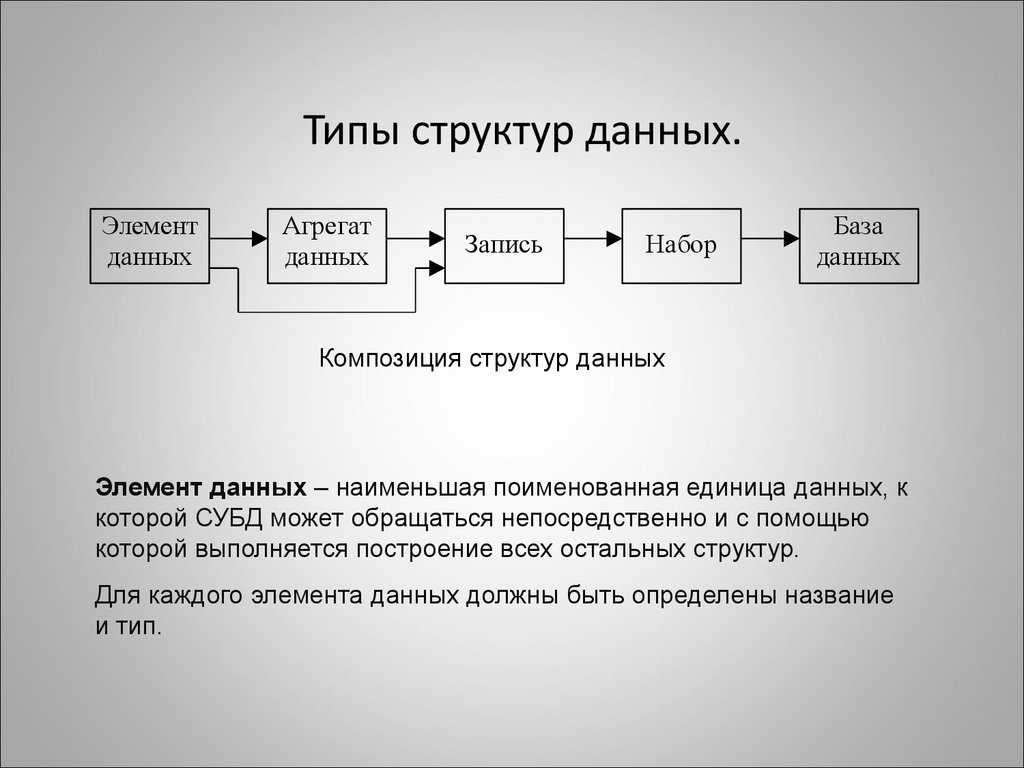
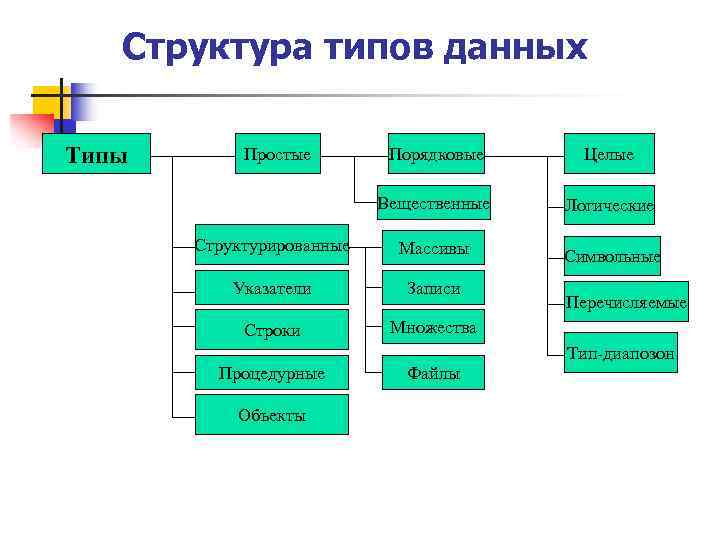
Сортировка структуры данных
Сортировка пузырьком
Сортировка пузырьком осуществляется
путем постоянной перемены местами
больших значений с меньшими. В результате
самое большое значение «пузырьком»
всплывает кверху.
Итак, предположим, что ваша коллекция
начинается с индекса 0. Вы меняете местами
содержимое элемента с текущим индексом
(i) с содержимым элемента, имеющего
следующий индекс (i + 1), если индекс (i)
имеет более высокое значение. Затем вы
переходите к следующей паре индексов
(i + 1 и i + 2), и так далее.
В какой-то момент вы доберетесь до
ячейки с наибольшим значением в вашей
коллекции. Ее содержимое будет все время
перемещаться вперед, как пузырек воздуха
– вверх. Проходы по всей коллекции
продолжаются, пока вся она не будет
отсортирована от самого низкого до
самого высокого значения содержимого
ячеек.
Поскольку при каждой итерации последняя
ячейка будет иметь самое большое
значение, в каждой следующей итерации
последние ячейки исключаются и больше
не сравниваются.
Сортировка выбором
Сортировка выбором осуществляется
путем непрерывного выбора наименьшего
значения и перемещения его к одному
концу.
В этом случае вы проходите всю коллекцию в поисках наименьшего значения. Найдя его, вы меняете местами содержимое этой ячейки с содержимым ячейки, имеющей наименьший индекс (изначально – 0). Процесс повторяется, но поскольку наименьшее значение уже заняло свою позицию, остальные пересматриваются, начиная с ячейки со следующим индексом (1).
С каждой итерацией длина участка массива, который нужно пройти, уменьшается на единицу. Все это продолжается, пока вся коллекция не будет отсортирована по степени возрастания значений, от наименьшего к наибольшему.
Сортировка вставками
Сортировка вставками это упорядочивание
коллекции путем вставки каждого
встреченного значения на правильную
позицию.
![]()
В этом случае мы не проходим всю
коллекцию при каждой итерации (как в
сортировке пузырьком и выбором). Вместо
этого мы начинаем со сравнения значений
элементов с индексами 0 и 1. Если последнее
значение меньше первого, они меняются
местами. После этого мы перемещаемся к
элементу с индексом 2 и сравниваем его
значение со значениями двух предыдущих
элементов (сначала с индексом 1, потом
с индексом 0).
Каждый раз, находя более высокое
значение, вы размещаете его правее.
Найдя правильную позицию, вы вставляете
содержимое ячейки с индексом 2 в ячейку
на нужной позиции.
Это как будто вы вынимаете содержимое
следующей ячейки и возвращаетесь с ним
к предыдущей. Если содержимое предыдущей
ячейки имеет больше значение, что то,
которое вы «держите», вы перемещаете
содержимое предыдущей ячейки в следующую.
Это продолжается, пока вы не найдете
подходящую ячейку, куда можно поместить
значение, находящееся у вас «в руках».
Как посмотреть и оценить структуру сайта конкурента
Не секрет, что владельцы интернет-проектов анализируют конкурентов для продвижения собственных сайтов. Тогда почему бы не оценить одновременно и схему других подобных ресурсов? Если вы поймете, каким образом соперник сумел достичь успеха, то сможете не только использовать его находки, но и избежать его ошибок.
Структуру стороннего ресурса можно проверить вручную.
Прежде всего, откройте проект конкурента и оцените его визуально. Посмотрите, какие записи и разделы там присутствуют
Обратите внимание на URL-адреса страниц, чтобы понять, имеют ли визуальные элементы какую-либо иерархию. Например, наличие у страницы «Двери» в меню подстраницы «Установка дверей» вовсе не означает, что вторая страница подчиняется первой
Визуальные элементы могут быть расположены любым образом и не являются показателем, хотя зачастую структура отображается в визуальной части ресурса.
В данном случае следует посмотреть на адрес страницы «Установка дверей». Если заметите в нем папку «Двери» (site.ru/dveri/ustanovka-dverei), то подчинение действительно есть. А URL типа site.ru/ ustanovka-dverei показывает, что рассматриваемая страница существует сама по себе. И это неправильно.
Помимо самостоятельного изучения структуры сайта можно пользоваться специальными программами и сервисами
Только делайте это осторожно, ведь не все из них работают корректно
Шаг 5. Скрытие-раскрытие
Для скрытия-раскрытия добавим два CSS-правила.
.ExpandOpen .Container {
display: block;
}
.ExpandClosed .Container {
display: none;
}
Как всегда, важен порядок. идет после , поэтому имеет больший приоритет, и вложенные закрытые узлы отображаются закрытыми.
Для скрытия-раскрытия javascript-функция всего лишь меняет класс узла. Остальное делает CSS.
Чтобы в дереве поддерживалось скрытие-раскрытие — достаточно повесить обработчик на самый внешний .
И для красоты — обязательно поправить курсор при наведении на иконки скрытия/раскрытия:
.ExpandOpen .Expand, .ExpandClosed .Expand {
cursor: pointer; /* иконки скрытия-раскрытия */
}
.ExpandLeaf .Expand {
cursor: auto; /* листовой узел */
}
Обязательно задать определение для листового узла тоже, иначе курсор на нем тоже станет (почему? — из-за вложенности ‘ов).
Root
-
Item 1
-
Item 1.1
Item 1.1.2
-
Item 1.2
-
-
Item 2title long yeah
Item 2.1
-
Item 3
Item 3.1
<div onclick="tree_toggle(arguments)">
<div>Root</div>
<ul class="Container">
<li class="Node IsRoot ExpandClosed">
<div class="Expand"></div>
<div class="Content">Item 1</div>
<ul class="Container">
<li class="Node ExpandClosed">
<div class="Expand"></div>
<div class="Content">Item 1.1</div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<div class="Content">Item 1.1.2</div>
</li>
</ul>
</li>
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<div class="Content">Item 1.2</div>
</li>
</ul>
</li>
<li class="Node IsRoot ExpandClosed">
<div class="Expand"></div>
<div class="Content">Item 2<br/>title long yeah</div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<div class="Content">Item 2.1</div>
</li>
</ul>
</li>
<li class="Node ExpandOpen IsRoot IsLast">
<div class="Expand"></div>
<div class="Content">Item 3</div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<div class="Content">Item 3.1</div>
</li>
</ul>
</li>
</ul>
</div>
А вот и сам обработчик события . После правил CSS делать ему осталось всего ничего:
- Определить, произошел ли клик на иконке , используя
- Получить узел для иконки
- Если узел — не лист, то поменять класс
function tree_toggle(event) {
event = event || window.event
var clickedElem = event.target || event.srcElement
if (!hasClass(clickedElem, 'Expand')) {
return // клик не там
}
// Node, на который кликнули
var node = clickedElem.parentNode
if (hasClass(node, 'ExpandLeaf')) {
return // клик на листе
}
// определить новый класс для узла
var newClass = hasClass(node, 'ExpandOpen') ? 'ExpandClosed' : 'ExpandOpen'
// заменить текущий класс на newClass
// регексп находит отдельно стоящий open|close и меняет на newClass
var re = /(^|\s)(ExpandOpen|ExpandClosed)(\s|$)/
node.className = node.className.replace(re, '$1'+newClass+'$3')
}
function hasClass(elem, className) {
return new RegExp("(^|\\s)"+className+"(\\s|$)").test(elem.className)
}
Структура
Дерево является графом у которого есть единственный
узел, называемый корнем. Рёбрами он связан с другими узлами (непосредственными потомками корня).
Эти потомки, в свою очередь, имеют собственных потомков и т.д.
Перемещаясь от корня по узлам дерева, можно попасть в любой узел, причём единственным образом.
Деревья широко используются в различных задачах поиска решений. В этом документе
обсуждаются способы визуального представления деревьев.
К алгоритмам обработки деревьев мы вернёмся в дальнейшем.



Дерево будем задавать объектом: { nm, ar },
где nm — имя узла, а ar — массив ветвей (ближайших потомков).
Так, следующий объект tree описывает бинарное дерево глубины 2, изображенное справа на рисунке:
var tree = {
nm:"root",
ar: },
{nm: "b2", ar: },
]
};
терминальныелистьями{ nm: «root» }y
JavaScriptJSON.stringify
JSON.stringify(tree)JSON{«nm»:»root»,»ar»:…регулярным выражением
Tree.getJSON = function (tr)
{
return JSON.stringify(tr).replace(/"(\w+)":/g, "$1:");
}
JavaScriptreplace
replace\w+\w(\w+)$1replaceg
Функция getJSON является статической и не требует создания экземпляра
класса Tree при помощи new.
Можно просто написать: document.write( Tree.getJSON(tree) ), что даст строку:
В классе Tree все статические функции продублированы как «динамические»,
при помощи указателя prototype:
function Tree(tr)
{
if(tr){
this.nm = tr.nm;
this.ar = tr.ar;
}
}
Tree.prototype.getJSON = function ()
{
return Tree.getJSON(this);
}
Treetreevart = new Tree(tree); document.write( t.getJSON() )
Требования к структуре сайта
![]()
Кем формируются требования к содержанию и структуре сайта? Разумеется, поисковыми системами. Ведь вебмастера всегда стараются подстроиться именно под них. Хотя не стоит забывать, что интернет-площадки в первую очередь создаются для пользователей, а не для роботов.
Чтобы проанализировать структуру ресурса, поисковики оценивают его URL. Строго говоря, его конструкция – это и есть схема URL. Но в разговоре проще не использовать аббревиатуру URL.
Давайте посмотрим, какие же требования поисковые системы выдвигают к структуре организации сайта.
«Яндекс»
С подробным описанием всех требований «Яндекса» можно ознакомиться в разделе «поддержка» на сайте поисковика. Здесь же мы перечислим лишь самые важные пункты:
- Корректность symlink-ов – при переходе по интернет-ресурсу не должны добавляться аналогичные URL (например: example.com/vasya/vasya/vasya/vasya/).
- Четкая схема ссылок. Каждая запись должна относиться к соответствующему блоку (категории, разделу). На каждую страницу должна ссылаться хотя бы одна другая.
- Наличие текстовых ссылок на другие записи (разделы). Поисковику так проще анализировать контент.
- Наличие карты ресурса (xml-карты), которая ускоряет его индексацию.
- Единственный и уникальный URL-адрес для каждой записи. На разные записи должны вести разные URL, и наоборот – одна запись должна иметь единственный адрес.
- Ограничение индексирования служебной информации (наличие файла robots.txt).
Как мы видим, «Яндекс» предъявляет немало критериев и требований как к схеме ресурса, так и к нему самом. Но это официальная информация, так что придется подстраиваться.
Рекомендуемые статьи по данной теме:
- Разработка веб-сайтов: способы, инструменты и проблемы
- Внутренняя оптимизация сайта: пошаговый разбор
- Разработка дизайна сайта: от выбора стиля до получения макета
«Google»
![]()
Его рекомендации достаточно просты и понятны. Они умещаются всего в один абзац:
- Избегать чересчур сложных и длинных url-адресов.
- Создавать простую структуру официального сайта.
- Использовать некоторые знаки пунктуации в url (в частности дефис «-«).
- Создавать понятную логическую схему url-адресов.
- Использовать не идентификаторы, а слова.
Стеки
Всем известна знаменитая опция «Отмена», предусмотренная почти во всех приложениях. Задумывались когда-нибудь, как она работает? Смысл такой: в программе сохраняются предшествующие состояния вашей работы (количество сохраняемых состояний ограничено), причем, они располагаются в памяти в таком порядке: последний сохраненный элемент идет первым. Одними массивами такую задачу не решить. Именно здесь нам пригодится стек.
Так выглядит стек, содержащий три элемента данных (1, 2 и 3), где 3 находится сверху — поэтому будет убран первым:
Стэк
Простейшие операции со стеком:
- Push — Вставляет элемент в стек сверху
- Pop — Возвращает верхний элемент после того, как удалит его из стека
- isEmpty — Возвращает true, если стек пуст
- Top — Возвращает верхний элемент, не удаляя его из стека
Вопросы о стеке, часто задаваемые на собеседованиях
- Вычислить постфиксное выражение при помощи стека
- Отсортировать значения в стеке
- Проверить сбалансированные скобки в выражении
Зачем это нужно
Trie часто используют в работе со словарями. С помощью дерева работает, например, Т9. Пользователь вводит набор цифр, а программа смотрит, какие ключи можно для такого набора получить. А потом выбирает самый популярный и подставляет его. Так из комбинации 5-6-4-2-3-6 получается «привет».
Ещё Trie помогает в подсказках в поиске. Вот что про это говорит Роман Халкечев, руководитель отдела аналитики в «Яндекс.Лавке» и «Яндекс.Еде», который несколько лет разрабатывал подсказки:
«Префиксное дерево лежит в основе быстрого поиска строк, начинающихся на префикс — символ или несколько символов, которые вводит пользователь.
В подсказках мы пользуемся модификацией этой структуры данных, которая оптимизирована по памяти и по скорости поиска. Мы заранее складываем большое количество запросов в такую структуру данных, а когда пользователь вводит префикс, мы его получаем и первым этапом ищем запросы, начинающиеся с того, что набрал пользователь. Затем уже ранжируем кандидатов и выбираем, что показать пользователю.
То есть, пользователь начинает вводить запрос, мы идём вниз по дереву и смотрим, какие запросы так начинаются. А затем сортируем их по актуальности, контексту и ещё куче параметров. И в итоге предлагаем пользователю то, что ему может быть нужно».
Эксперт
Роман Халкечев
Текст и иллюстрации
Слава Уфимцев
Редактор
Максим Ильяхов
Корректор
Ирина Михеева
Художник
Даня Берковский
Вёрстка
Мария Дронова
Разнёс весть
Виталий Вебер
Древо данных, дай нам сил.
1.10.1. Классификация
— это класс, способный выполнять мультиклассовую классификацию набора данных.
Как и в случае с другими классификаторами, принимает в качестве входных данных два массива: массив X, разреженный или плотный, формы (n_samples, n_features), содержащий обучающие образцы, и массив Y целочисленных значений, формы (n_samples,), содержащий метки классов для обучающих образцов:
>>> from sklearn import tree >>> X = , ] >>> Y = >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
После подбора модель можно использовать для прогнозирования класса образцов:
>>> clf.predict(]) array()
В случае, если существует несколько классов с одинаковой и самой высокой вероятностью, классификатор предскажет класс с самым низким индексом среди этих классов.
В качестве альтернативы выводу определенного класса можно предсказать вероятность каждого класса, которая представляет собой долю обучающих выборок класса в листе:
>>> clf.predict_proba(]) array(])
поддерживает как двоичную (где метки — ), так и мультиклассовую (где метки — ) классификацию.
Используя набор данных Iris, мы можем построить дерево следующим образом:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> X, y = iris.data, iris.target >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, y)
После обучения вы можете построить дерево с помощью функции:
>>> tree.plot_tree(clf)
![]()
Мы также можем экспортировать дерево в формат Graphviz с помощью экспортера. Если вы используете Conda менеджер пакетов, то Graphviz бинарные файлы и пакет питон может быть установлен .




В качестве альтернативы двоичные файлы для graphviz можно загрузить с домашней страницы проекта graphviz, а оболочку Python установить из pypi с помощью .
Ниже приведен пример экспорта graphviz вышеуказанного дерева, обученного на всем наборе данных радужной оболочки глаза; результаты сохраняются в выходном файле :
>>> import graphviz
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = graphviz.Source(dot_data)
>>> graph.render("iris")
Экспортер также поддерживает множество эстетических вариантов, в том числе окраски узлов их класс (или значение регрессии) и используя явные имена переменных и классов , если это необходимо. Блокноты Jupyter также автоматически отображают эти графики встроенными:
>>> dot_data = tree.export_graphviz(clf, out_file=None, ... feature_names=iris.feature_names, ... class_names=iris.target_names, ... filled=True, rounded=True, ... special_characters=True) >>> graph = graphviz.Source(dot_data) >>> graph
![]()
![]()
В качестве альтернативы дерево можно также экспортировать в текстовый формат с помощью функции . Этот метод не требует установки внешних библиотек и более компактен:
>>> from sklearn.datasets import load_iris >>> from sklearn.tree import DecisionTreeClassifier >>> from sklearn.tree import export_text >>> iris = load_iris() >>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2) >>> decision_tree = decision_tree.fit(iris.data, iris.target) >>> r = export_text(decision_tree, feature_names=iris) >>> print(r) |--- petal width (cm) <= 0.80 | |--- class: 0 |--- petal width (cm) > 0.80 | |--- petal width (cm) <= 1.75 | | |--- class: 1 | |--- petal width (cm) > 1.75 | | |--- class: 2
Примеры
- Постройте поверхность принятия решений дерева решений на наборе данных радужной оболочки глаза
- Понимание структуры дерева решений
Определения
Чтобы начать понимание деревьев, вы должны ознакомиться со следующими понятиями:
- Узел Каждый элемент дерева, содержащий значение. Подумайте о них как капсулы, связанные друг с другом.
- Root это первый узел дерева.
- Край Является ли линия, которая соединяет 2 узла.
- Ребенок это узел, который имеет родительский узел.
- Родительский узел Это тот, который содержит детей, нижние узлы.
- Листья У узлов, у которых нет ребенка, последние узлы в дереве.
- Высота это длина (начиная с 1) самого длинного пути к листу.
- Глубина это длина пути к корню. По сути, меньшая высота для конкретного элемента, чтобы вы могли сказать «Пункт 5 на глубине 7». Мы будем использовать его для создания алгоритмов для наших деревьев.
Двоичное дерево
Двоичное дерево-это рекурсивная структура данных, в которой каждый узел может иметь не более 2 дочерних элементов.
Распространенным типом двоичного дерева является двоичное дерево поиска , в котором каждый узел имеет значение, которое больше или равно значениям узлов в левом поддереве и меньше или равно значениям узлов в правом поддереве.
Вот краткое визуальное представление этого типа двоичного дерева:
Для реализации мы будем использовать вспомогательный класс Node , который будет хранить значения int и сохранять ссылку на каждый дочерний элемент:
class Node {
int value;
Node left;
Node right;
Node(int value) {
this.value = value;
right = null;
left = null;
}
}
Затем давайте добавим начальный узел нашего дерева, обычно называемый root:
public class BinaryTree {
Node root;
// ...
}
Создать таблицу с помощью JavaScript
Чтобы создать элемент HTML с помощью JavaScript, мы должны использовать метод под названием , который принимает имя тега, которое является строкой в качестве параметра. Например, мы хотим создать таблицу, поэтому передадим строку в качестве входных данных в метод .
Давайте теперь создадим приведенную ниже таблицу, полностью используя JavaScript.
| Старший Нет. | Имя | Компания |
|---|---|---|
| 1. | Джеймс Клерк | Netflix |
| 2. | Адам Уайт | Microsoft |
В приведенной выше таблице 4 строки. Первая строка содержит весь заголовок, а следующие три строки содержат данные.
Ниже у нас есть код HTML, CSS и JS. Внутри нашего тега у нас изначально ничего нет. Мы создадим нашу таблицу внутри JavaScript, и в конце мы добавим всю таблицу в тег , чтобы она была видна на веб-странице. Внутри тега мы придали нашей таблице базовый стиль.
Чтобы создать таблицу, сначала создадим тег . Затем мы сохраним этот тег в переменной , чтобы потом использовать. Таким же образом мы создадим теги и и сохраним их внутри переменных. Затем мы добавляем и к тегу .
Вы должны добавить или добавить ту таблицу, которую вы создали в JavaScript, в тег . Сначала нам нужно получить тег тела HTML, используя его , а затем мы добавим таблицу, используя так называемый метод . Поскольку мы уже сохранили нашу таблицу внутри переменной , нам просто нужно добавить таблицу, которую мы создали как дочернюю, к этому элементу тела.
На данный момент так выглядит структура нашей таблицы.
Чтобы добавить строки и данные в нашу таблицу, мы создадим теги строк таблицы (), заголовка таблицы () и данных таблицы () с помощью метода , а затем добавить данные внутри этих элементов с помощью свойства .
После вставки данных с помощью свойства мы добавим эти данные в соответствующие строки. Например, сначала мы добавляем заголовки (например, , , ) в . Затем мы добавляем нашу первую строку, то есть , к тегу в качестве дочернего элемента.
Точно так же мы создаем еще 2 строки, то есть и , а затем добавляем переменные (, , ) и (, , ) соответственно к этим 2 ряда. И в конце мы добавляем эти 2 строки к тегу как к дочернему.
Вот так таблица и ее структура HTML выглядят в консоли разработчика.
Слева у нас есть таблица, а справа код, созданный браузером. Вы можете настроить код js в зависимости от того, как должна выглядеть таблица. Для этого мы использовали только 3 метода JavaScript (, , ).
Шаг 7. Дополнительные возможности
Вы можете пожелать добавить в дерево дополнительные элементы. Например, чекбоксы или иконки с типом узла.
Для добавления, например, чекбокса после иконки , нужно для начала вставить его в структуру сразу после иконки открытия/закрытия.
Указываем размеры, отступ и :
/* Общий размер 14+2+2 = 18 - такой же как Expand */
.Node input {
width: 14px;
height: 14px;
float: left;
margin: 2px;
}
Теперь, сохраняя двухколоночную верстку, нужно отодвинуть вправо уже не на 18, а на общую ширину двух ‘ов — 36px.
После того как сдвинулся заголовок — естественно сдвинуть и сам узел , чтобы структурная линия шла от заголовка.
Все это осуществляется добавлением пары правил:
/* подвинем за оба float'а Node, Content */
.Node, .Content {
margin-left: 36px;
}
/* заново переопределим .IsRoot */
.IsRoot { margin-left: 0; }
Root
-
Item 1
-
Item 1.1
Item 1.1.2
-
Item 1.2
-
-
Item 2title long yeah
Item 2.1
-
Item 3
Item 3.1
<div onclick="tree_toggle(arguments)">
<div>Root</div>
<ul class="Container">
<li class="Node IsRoot ExpandOpen">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 1</div>
<ul class="Container">
<li class="Node ExpandOpen">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 1.1 </div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 1.1.2</div>
</li>
</ul>
</li>
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 1.2</div>
</li>
</ul>
</li>
<li class="Node IsRoot ExpandOpen">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 2<br/>title long yeah</div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 2.1</div>
</li>
</ul>
</li>
<li class="Node ExpandOpen IsRoot IsLast">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 3</div>
<ul class="Container">
<li class="Node ExpandLeaf IsLast">
<div class="Expand"></div>
<input type="checkbox"/>
<div class="Content">Item 3.1</div>
</li>
</ul>
</li>
</ul>
</div>
Что такое технологии веб-разработки
Технологии веб-разработки относятся к множеству языков программирования и инструментам, которые используются для создания динамических и полнофункциональных веб-сайтов и приложений.
Здесь поговорим про интерфейсные и серверные технологии.
Давайте сначала определим каждый из этих терминов.
Front-end (интерфейсные) технологии
Интерфейсные технологии предназначены для «клиентской стороны» вашего веб-сайта или приложения. Они используются для разработки интерактивных компонентов вашего сайта и создания элементов, которые пользователи видят и с которыми взаимодействуют. Сюда входят цвета и стили текста, изображения, кнопки и меню навигации.

Back-end (серверные) технологии
Внутренние технологии предназначены для «серверной части» вашего сайта или приложения. Они хранят и упорядочивают данные и следят за тем, чтобы на интерфейсе всё работало. Например, когда пользователь предоставляет учетные данные для входа в приложение социальной сети, используются внутренние технологии для проверки правильности этих учетных данных. После проверки учетных данных сервер отправит обратно имя профиля, изображение и другую связанную информацию.
Back-end технологии также используются для оптимизации основных бизнес-процессов. В случаях, когда у вас есть много данных, которые необходимо обработать, вы можете запустить скрипт в серверной части, чтобы создать содержательный отчет во внешней части.
Вы также можете отправлять автоматические электронные письма группам пользователей. Электронные письма могут быть отправлены в определенные даты, например, по истечении срока действия бесплатной пробной версии веб-сайта пользователя.
Первые две технологии, которые мы обсудим, – это интерфейсные технологии.
Итого
Термины:
- Рекурсия – это термин в программировании, означающий вызов функцией самой себя. Рекурсивные функции могут быть использованы для элегантного решения определённых задач.Когда функция вызывает саму себя, это называется шагом рекурсии. База рекурсии – это такие аргументы функции, которые делают задачу настолько простой, что решение не требует дальнейших вложенных вызовов.
- Рекурсивно определяемая структура данных – это структура данных, которая может быть определена с использованием самой себя.Например, связанный список может быть определён как структура данных, состоящая из объекта, содержащего ссылку на список (или null).Деревья, такие как дерево HTML-элементов или дерево отделов из этой главы, также являются рекурсивными: они разветвляются, и каждая ветвь может содержать другие ветви.Как мы видели в примере , рекурсивные функции могут быть использованы для прохода по ним.



