Использование директив CSP
CSP позволяет определять различные ограничения содержимого с помощью директив, обычно указанных в заголовках ответа HTTP. Вот пример добавления заголовков CSP на веб-сервер Apache:
Добавленный в файл httpd.conf или .htaccess, он установит политику по умолчанию, разрешающую только контент из текущего источника (подробности см. ниже).
При необходимости вы также можете указать желаемые директивы на уровне страницы, используя метатеги HTML. Вот пример, который устанавливает ту же политику, что и выше:
Каждая директива состоит из имени, за которым следует одно или несколько значений, и заканчивается точкой с запятой. Вы можете использовать подстановочный знак * для обобщения целых значений, поддоменов, схем и портов:
Этот заголовок позволяет использовать источники из любого субдомена example.com (но не самого example.com) по любой схеме (http, https и т.д.).
Официальная рекомендация W3C содержит полный список директив с более формальными определениями, но следующий обзор должен дать вам хорошее представление о наиболее часто используемых.
Воровство контента с сайтов и его виды
Думаю, можно выделить 4 вида этого явления.
1. Автоматическое копирование всего сайта
В этом случае специальными программами (т.н. грабберами) сайт полностью скачивается с сервера со всем его содержимым, структурой и оформлением. Т.е. создаётся практически не отличимая от источника копия (но, конечно, с другим доменным именем).
2. Вручную ворованный контент
Это наиболее распространённый вариант. Например, какой-нибудь сайтовладелец хочет наполнить свой проект по-быстрому статьями — идёт в поиск, вводит запрос, получает поисковую выдачу, из неё выбирает сайт, копирует тексты и размещает у себя. Обычно этим занимаются начинающие вебмастера, которые просто не знают, что делать так не надо.
3. Спарсенный контент
От английского слова «parsing» — «разбор». Имеется в виду, что специальный серверный скрипт с сайта (или вообще десктопное приложение с компьютера) обращается к URL-адресу вашего сайта, «вытягивает» всё, что там есть и получает текст статьи (т.е. отбрасываются блоки меню, сайдбар, футер и т.п.). В принципе, это просто автоматизация ручного воровства контента.
Кстати, в этом случае ваши статьи может «спасти» внутренняя перелинковка, т.к. при автоматическом парсинге скачиваются все ссылки внутри статьи — т.е. ссылки на другие материалы вашего ресурса. Конечно, данная особенность не решает все последствия копирования текста, но добавляет бэклинки — внешние ссылки на ваш сайт, а также может навести поисковых роботов на некоторые размышления.
4. Копирование статей с указанием авторства
На мой взгляд, это уже не нужно относить к ворованному контенту, потому как указана ссылка-источник. Правда, крайне желательно, чтобы такая ссылка не была закрыта от индексации поисковыми роботами, а иначе мы:
- не получим бэклинка;
- получим проблемы, если статья с «плохого» сайта влетит в индекс поисковой системы ранее нашей.
Но тут есть и обратный эффект: если очень некачественный сайт сошлётся на наш (оставив открытую ссылку), то нашему станет хуже. И наоборот — если трастовый сайт укажет на наш — то и нам хорошо.
В общем, в любом случае, от воровства контента больше вреда, чем пользы.
Почтовый фишинг
Возможно, будучи самым распространенным типом фишинга, он зачастую использует технику «spray and pray», благодаря которой хакеры выдают себя за некую легитимную личность или организацию, отправляя массовые электронные письма на все имеющиеся у них адреса электронной почты.
Такие письма содержат характер срочности, например, сообщая получателю, что его личный счет был взломан, а потому он должен немедленно ответить. Их цель заключается в том, чтобы своей срочностью вызвать необдуманное, но определенное действие от жертвы, например, нажать на вредоносную ссылку, которая ведет на поддельную страницу авторизации. Там, введя свои регистрационные данные, жертва, к сожалению, фактически передает свою личную информацию прямо в руки мошенника.
![]()
Пример почтового фишинга
The Daily Swig сообщила о фишинговой атаке, произошедшей в декабре 2020 года на американского поставщика медицинских услуг Elara Caring, которая произошла после несанкционированного компьютерного вторжения, нацеленного на двух его сотрудников. Злоумышленник получил доступ к электронной почте сотрудников, в результате чего были раскрыты личные данные более 100 000 пожилых пациентов, включая имена, даты рождения, финансовую и банковскую информацию, номера социального страхования, номера водительских прав и страховую информацию. Злоумышленник имел несанкционированный доступ в течение целой недели, прежде чем Elara Caring смогла полностью остановить утечку данных.
Несколько слов о веб-сервере Apache
Мы используем Apache httpd в качестве основного веб-сервера. Apache используется для организации большинства веб-серверов в мире и является самым массовым продуктом своего класса. Этот сервер обладает обширными возможностями конфигурации, является очень производительным и поддерживает все известные протоколы для работы веб-серверов. Специально для Apache созданы версии таких популярных языков программирования как Perl и PHP, а также этот сервер легко интегрируется с широко применяемыми СУБД (например, MySQL).
Пользователям мы предоставляем возможность самостоятельной конфигурации Apache путем использования соответствующих директив в файле . Таким образом можно решить большинство задач по конфигурации веб-сервера в условиях массового хостинга.
Редиректы
Самая часто используемая функция .htaccess — Redirect. Эта директива сообщает браузеру о том, что по указанному адресу необходимо загрузить другую страницу, в простонародье — сделать редирект.
Простой редирект оформляют по схеме:
Статус — необязательный параметр. Но часто он бывает важен для поисковых роботов. Возможные значения:
- 301 / permanent — документ перемещен постоянно
- 302 / temp — документ перемещен временно
- 303 / seeother — смотрите другой
- 410 / gone — убран
Подобный редирект не работает для адресов содержащих Query String (символы после ?). В таких случаях используют сочетание RewriteCond и RewriteRule.
- RewriteCond — определяет условие при котором происходит преобразование
- RewriteRule — правило для преобразования
Примеры редиректов
Перенаправить запросы со старого адреса страницы на новый
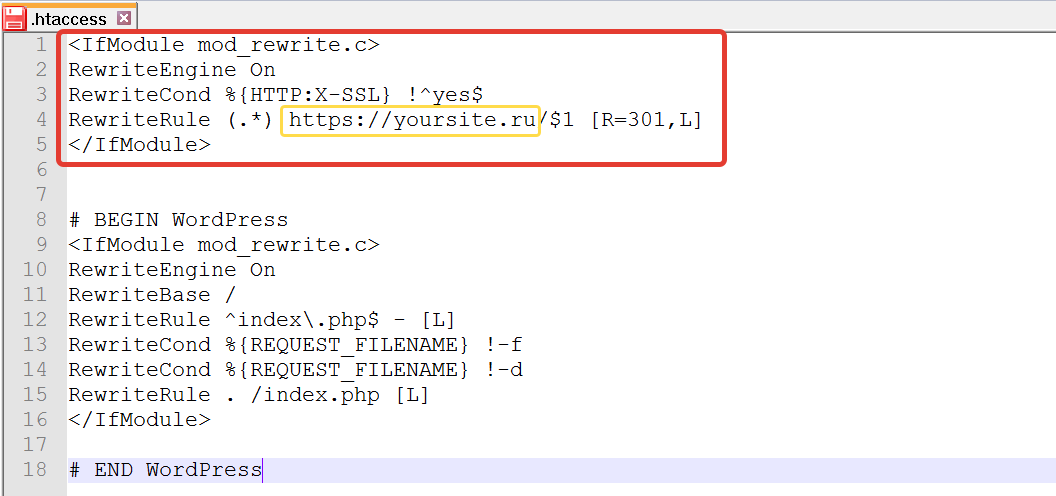
Перенаправить все запросы к страницам сайта на аналогичные страницы другого сайта с использованием redirect
Перенаправить все запросы к страницам сайта на аналогичные страницы другого сайта с использованием rewriteRule
Перенаправить запросы на domain.ru с любого из синонимов сайта
Перенаправить запросы на www.domain.ru с любого из синонимов сайта
Перенаправление всех запросов к странице /period/?test=123 на domain.ru
Со страниц без слеша на страницы со слешем
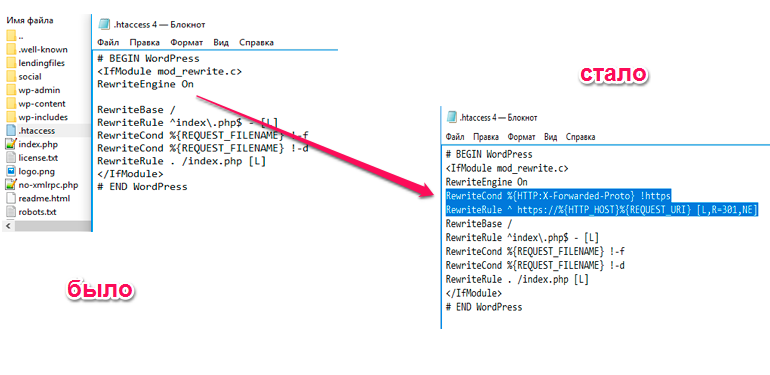
C http на https (актуален для timeweb)
Заголовки безопасности WordPress
HTTP Strict Transport Security (HSTS)
Заголовок безопасности HSTS сообщает браузеру, что все запросы к сайту WordPress должны выполняться через HTTPS.
Строка заголовка HTTP Strict Transport Security:
| 1 | Header always setStrict-Transport-Security»max-age=31536000″env=HTTPS |
Upgrade-Insecure-Requests
Заголовок безопасности Upgrade-Insecure-Requests является дополнительным методом принудительного выполнения запросов к сайту WordPress через HTTPS при обновлении.
Строка заголовка Upgrade-Insecure-Requests:
| 1 | Header always setContent-Security-Policy»upgrade-insecure-requests» |
X-XSS-Protection
Заголовок безопасности X-XSS-Protection останавливает загрузку страниц при обнаружении вредоносного кода межсайтового скриптинга (XSS).
Строка заголовка X-XSS-Protection:
| 1 | Header always setX-Content-Type-Options»nosniff» |
X-Content-Type-Options
Заголовок безопасности X-Content-Type-Options позволяет защитить сайт от атак с подменой типов MIME. Он указывает браузеру фильтровать передаваемые данные и передавать только те, которые по содержанию соответствуют расширению. Например, если расширение файла «.docx», браузер должен получить файл Word, а не какой-нибудь исполняемый файл, у которого расширение «.exe», «.bat» заменено на «.docx».
Строка заголовка X-Content-Type-Options:
| 1 | Header always setX-XSS-Protection»1; mode=block» |
Expect-CT (Certificate Transparency)
Заголовок безопасности Expect-CT (Certificate Transparency) сообщает браузеру, что он должен выполнить дополнительные проверки сертификата на подлинность по открытым журналам прозрачности сертификатов.
Строка заголовка Expect-CT (Certificate Transparency):
| 1 | Header always setExpect-CT»max-age=7776000, enforce» |
No Referrer When Downgrade
Заголовок безопасности No Referrer When Downgrade запрещает браузеру добавлять реферер при переходе на сайт с более низкой версией протокола (с HTTPS-сайта на HTTP-сайт).
Строка заголовка No Referrer When Downgrade:
| 1 | Header always setReferrer-Policy»no-referrer-when-downgrade» |
X-Frame-Options
Заголовок безопасности X-Frame-Options предотвращает загрузку сайта в iframe. Использование этого заголовка заблокирует отображение вашего сайта WordPress в iframe на других сайтах.
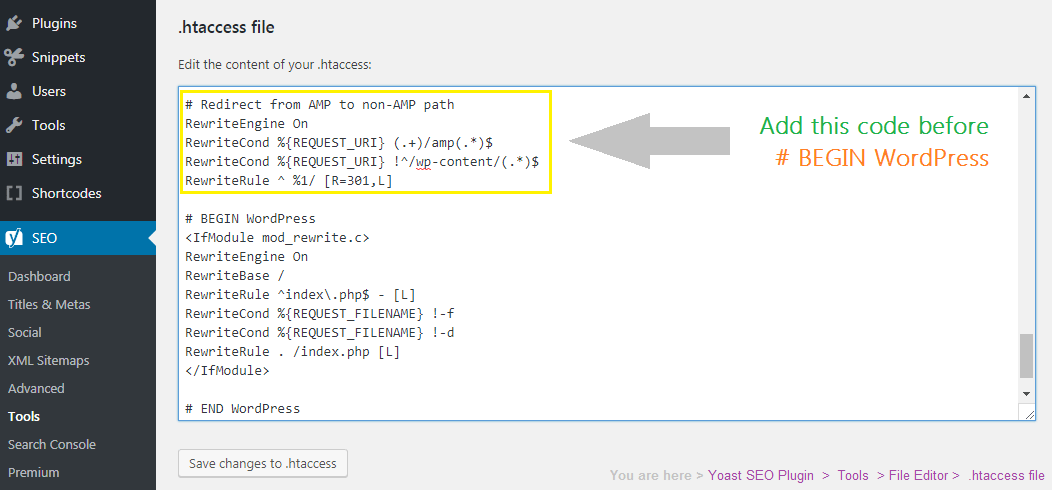
Строка заголовка X-Frame-Options:
| 1 | Header always setX-Frame-Options SAMEORIGIN |
Если вы хотите, чтобы ваш сайт отображался в iframe на других сайтах, удалите эту строку из списка заголовков безопасности.
А если на вашем хостинге установлен X-Frame-Options по умолчанию, но вы хотите чтобы ваш сайт отображался в iframe на других сайтах, добавьте в список заголовков безопасности следующую строку:
| 1 | Header always unsetX-Frame-Options |
Распространенные ошибки
3.1 Check robots.txt
Правила скрэпинга веб-сайтов можно найти в файле robots.txt. Вы можете найти его, написав слова «robots.txt» после имени домена, например так: . Эти правила определяют, какие части веб-сайтов не могут быть автоматически извлечены или как часто боту разрешено запрашивать данные со страницы. Большинство не заботятся об этих правилах, но все же постарайтесь хотя бы почитать их, даже если вы и не планируете следовать им.
3.2 HTML может быть злом
HTML-теги могут содержать идентификатор (id), класс или сразу оба этих элемента. Идентификатор (т.е. id) HTML описывает уникальный идентификатор, а класс HTML не является уникальным. Изменения в имени или элементе класса могут либо сломать ваш код, либо выдать вам неправильные результаты.
Есть два способа избежать, или, по крайней мере, предупредить это:
• Используйте конкретный идентификатор , а не , поскольку он с меньшей вероятностью будет изменен
Проверьте, не возвращается ли элемент значение None.
Однако, поскольку некоторые поля могут быть необязательными (например, в нашем HTML-примере), соответствующие элементы не будут отображаться в каждом списке. В этом случае вы можете подсчитать процентное соотношение частоты возврата None конкретным элементом в списке. Если это 100%, вы, возможно, захотите проверить, было ли изменено имя элемента.
3.3 Обмануть программу-агент
Каждый раз, когда вы посещаете веб-сайт, он получает информацию о вашем браузере через пользовательский агент. Некоторые веб-сайты не будут показывать вам какой-либо контент, если вы не предоставите им пользовательский агент. Кроме того, некоторые сайты предлагают разные материалы для разных браузеров. Веб-сайты не хотят блокировать разрешенных пользователей, но вы будете выглядеть подозрительно, если вы отправите 200 одинаковых запросов в секунду с помощью одного и того же пользовательского агента. Выход из этой ситуации может заключаться в том, чтобы сгенерировать (почти) случайного пользовательского агента или задать его самостоятельно.
3.4 Время ожидания запроса
По умолчанию Request будет продолжать ожидать ответ в течение неопределенного срока. Поэтому рекомендуется установить параметр таймаута.
3.5 Я заблокирован?
Частое появление кодов состояния, таких как 404 (не найдено), 403 (Запрещено), 408 (Тайм-аут запроса), может указывать на то, что вы заблокированы. Вы можете проверить эти коды ошибок и действовать соответственно.
Кроме того, будьте готовы обработать исключения из запроса.
3.6 Смена IP
Даже если вы рандомизировали своего пользовательского агента, все ваши запросы будут отправлены с одного и того же IP-адреса. Это вполне нормально, поскольку библиотеки, университеты, а также компании имеют всего несколько IP-адресов. Однако, если очень много запросов поступает с одного IP-адреса, сервер может это обнаружить.
Использование общих прокси, VPN или TOR может помочь вам стать незаметным;)
Если вы используете общий прокси-сервер, веб-сайт увидит IP-адрес прокси-сервера, а не ваш. VPN соединяет вас с другой сетью, а IP-адрес поставщика VPN будет отправлен на веб-сайт.
3.7 Ловушки для хакеров
Ловушки для хакеров — это средства для обнаружения сканеров или скреперов.
Такими средствами могут быть «скрытые» ссылки, которые не видны пользователям, но могут быть извлечены скреперами и/или вэб-спайдерами. Такие ссылки будут иметь набор стилей CSS, их можно смешивать, задачая цвет фона или даже перемещаясь из видимой области страницы. Как только ваша программа посещает такую ссылку, ваш IP-адрес может быть помечен для дальнейшего расследования или даже мгновенно заблокирован.
Безопасность
xxx.xxx.xxx.xxx — это ваш IP. Если вы замените последние три цифры, например, на 0/12, этим вы определите диапазон IP внутри этой сети и это оградит вас от проблемы перечислять по отдельности все разрешённые IP.
И, естественно, противоположная функция к этой:
Запретить доступ к скрытым файлам и директориям
Скрытые файлы и директории (те, чьи имена начинаются с точки .) должны в большинстве, если не все, быть недоступны для других. Например: .htaccess, .htpasswd, .git, .hg…
Как вариант, вы можете показывать ошибку Not Found (не найдено), чтобы не давать атакующему подсказку:
Запретить доступ к файлам
Эти файлы могут быть оставлены некоторыми редакторами text/html (вроде Vi/Vim) и представляют огромную дыру в безопасности, если станут общедоступными.
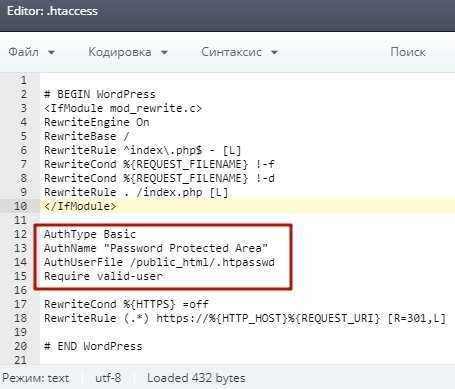
Защитить паролем директорию
Сначала нужно создать файл .htpasswd в определенной директории:
И потом использовать этот файл для аутентификации:
Запретить рендеринг сайта во фрейме
Эта команда запрещает отображение сайта во фрейме (например, в теге iframe), но разрешает отображение сайта во фрейме для определенных URI.
Перезапись URL с помощью .htaccess
Проблема дублирования ссылок: одна страница — несколько адресов
Часто бывает так, что одна и та же страница может быть доступна по нескольким URL. Другими словами, гиперссылки с другим адресов ведут на одну и ту же страницу (на английском языке это называется дублированием ссылок). Наиболее распространенным примером такого дублирования страниц является использование субдомена www вместе с основным доменом. Например, страницы адреса
https://ravechnost.ru/index.php и
https://www.ravechnost.ru/index.php
полностью идентичны — при вводе любого из двух вышеуказанных URL-адресов в адресную строку браузера отобразится та же страница.
Однако, поисковые системы различают URL для страниц. Это имеет свои нежелательные последствия — вместо того, чтобы сообщаться на странице, они распределяются по разным URL-адресам. Поскольку ценность страницы во многом определяется ее трафиком, очень популярная страница может выглядеть для поисковых систем как две или более довольно посредственные страницы.
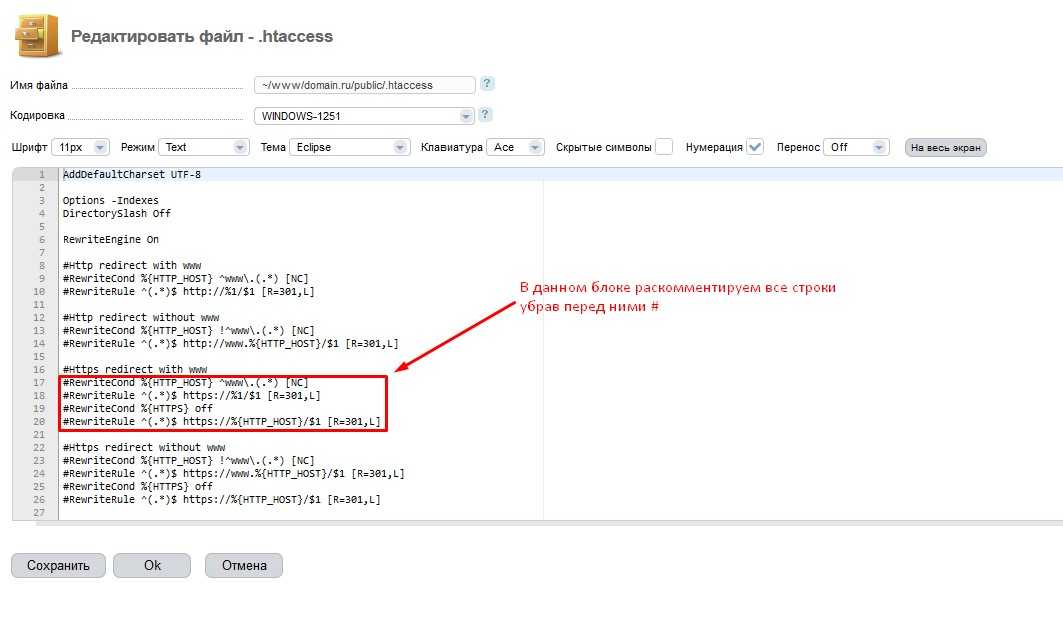
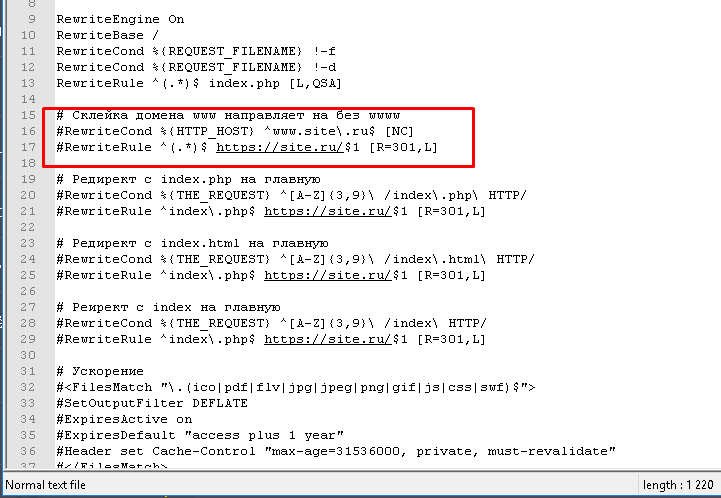
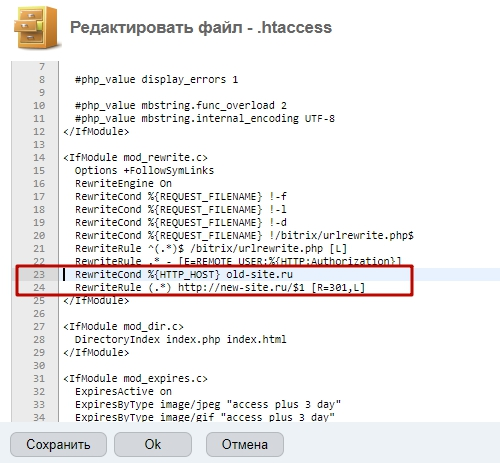
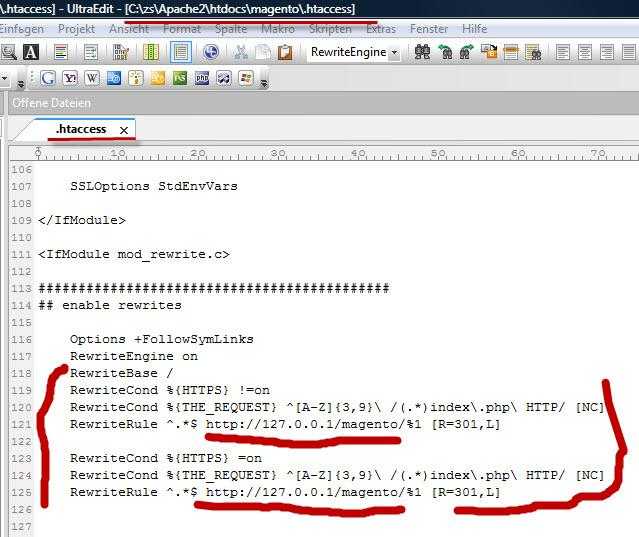
Одним из возможных решений проблемы дублирования ссылок является перезапись URL-адресов с помощью файла .htaccess. В следующем примере каждый запрос страницы ravechnost.ru будет переписан как запрос страницы от www.ravechnost.ru:
Первая строка, Options + FollowSymLinks, используется, если этого требует конфигурация сервера. Если вы получили сообщение об ошибке Server 500 error, удалите символ #, который является символом комментария и лишает законной силы команду, на которую он помещен.
Команда RewriteEngine on позволяет перезаписывать URL-адреса — по умолчанию механизм перезаписи выключен.
RewriteCond определяет условие для перезаписи адреса. В этом примере условие состоит в том, что имя хоста (доменное имя сайта) — ravechnost.ru. Это имя содержится в переменной HTTP-HOST, а символ «%» является именем переменной и всегда предшествует имени переменной. «^» — это символ начала строки. Знак «\» позволяет использовать символ, следующий за ним, не вызывая его особого значения. Поскольку точка (.) имеет особое значение, перед ней используется «\».
И что, этого достаточно?
Нет, но это ещё один уровень защиты сайта от злоумышленников и хакеров. Вот несколько других инструментов:
- безопасное соединение, чтобы между сервером и пользователем никто не смог заменить страницу;
- проверка и отключение инжектов на стороне сервера;
- безопасные пароли и защищённые страницы входа в панель администратора;
- двухфакторная авторизация для администраторов;
- мониторинг подозрительной активности пользователей.
И есть вещи, с которыми очень сложно бороться с помощью программирования, — например, фишинг и социальная инженерия. Но всё это темы для отдельных разговоров.
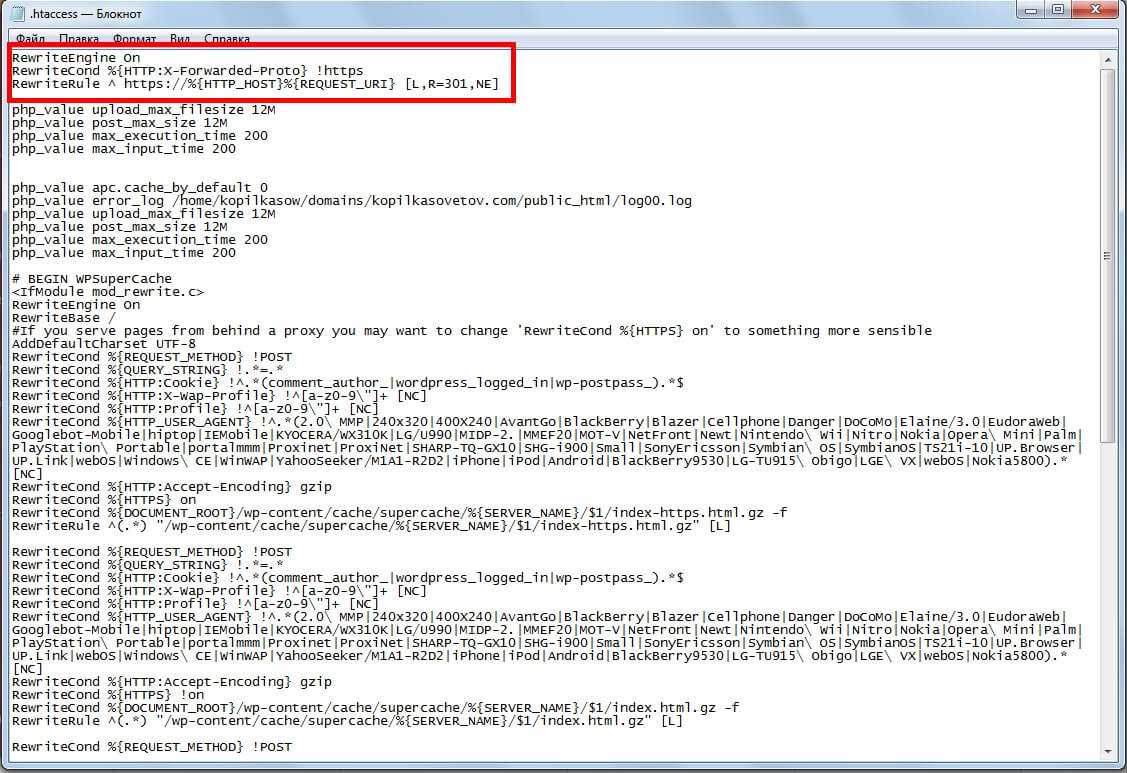
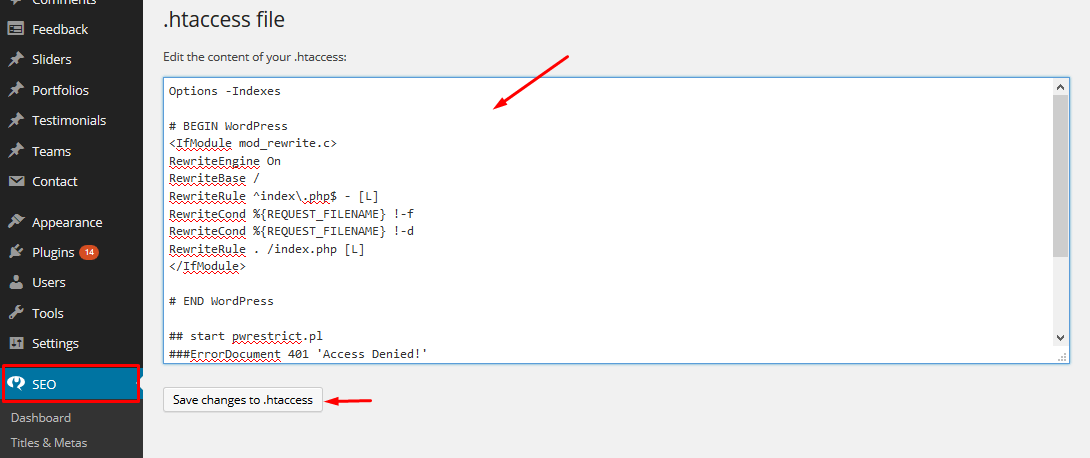
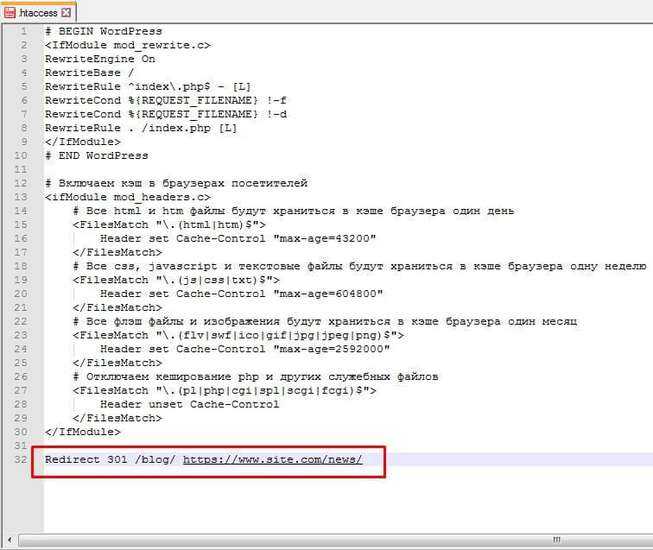
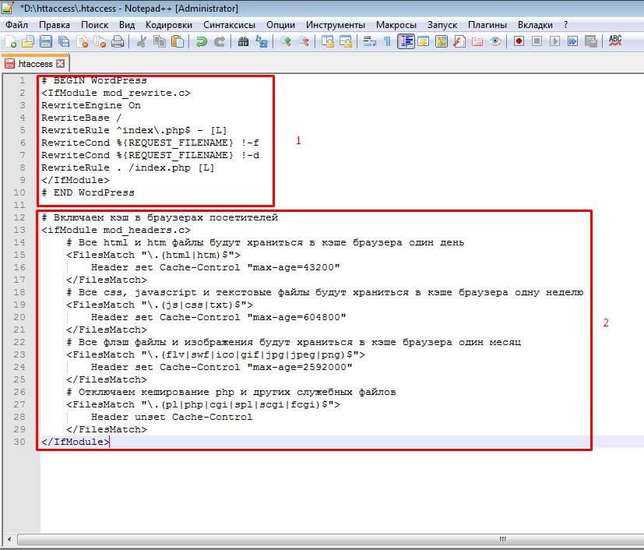
Включаем кеширование
Кеширование очень просто устанавливается и делает загрузку вашего сайта быстрее. Устанавливая дату обновления для ресурсов, которые редко изменяются, мы можем предотвратить многократную повторяющуюся загрузку той части содержания, которая остается неизменной.
Например:
ExpiresActive on ExpiresByType image/gif "access plus 1 month" ExpiresByType image/png "access plus 1 month" ExpiresByType image/jpg "access plus 1 month" ExpiresByType image/jpeg "access plus 1 month" ExpiresByType video/ogg "access plus 1 month" ExpiresByType audio/ogg "access plus 1 month" ExpiresByType video/mp4 "access plus 1 month" ExpiresByType video/webm "access plus 1 month"
Вы можете добавлять правила для любых типов содержания. Директива просто включает генерацию заголовка устарения ресурса. Данная директива зависит от наличия модуля mod_expires на сервере Apache.
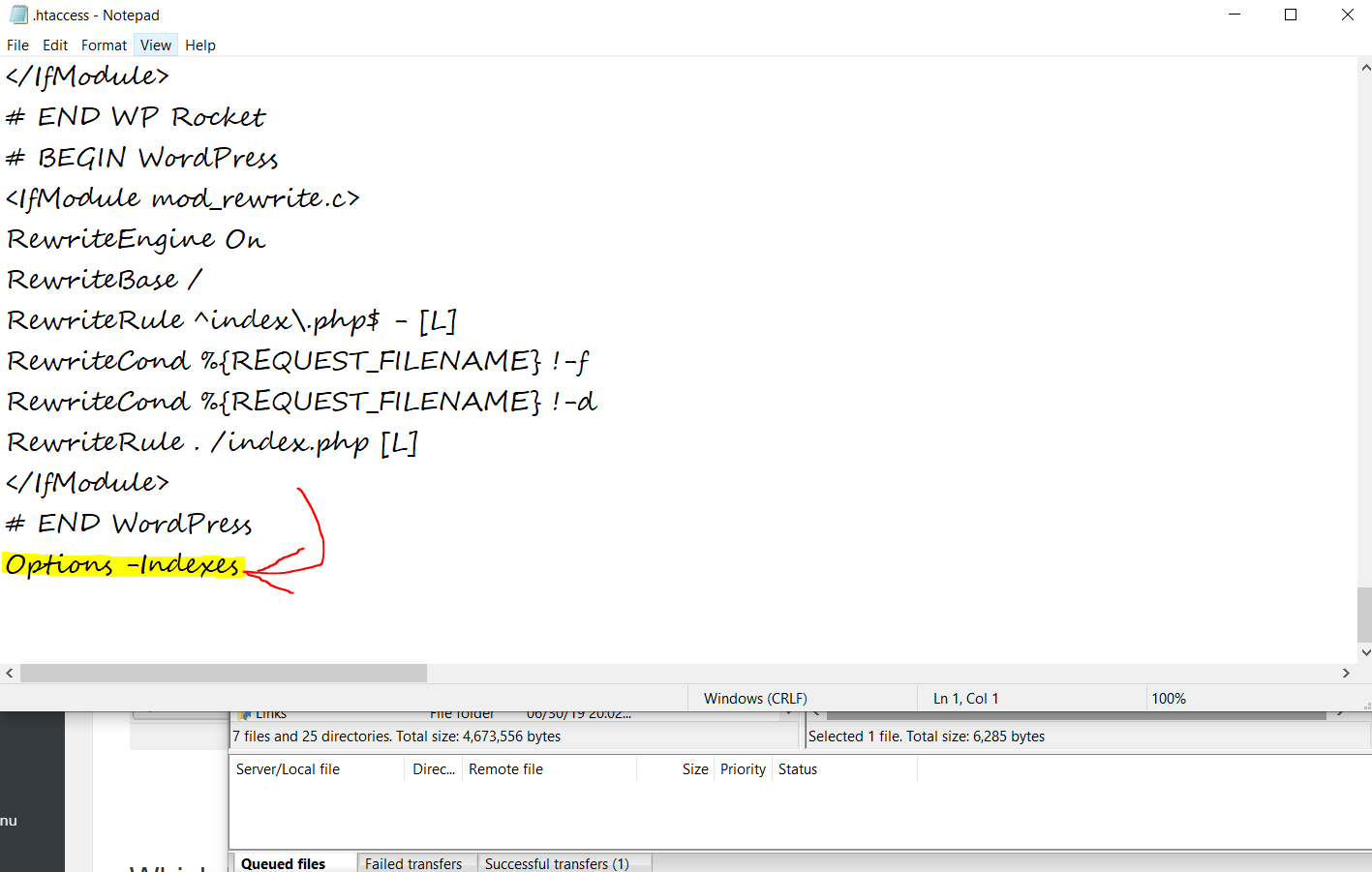
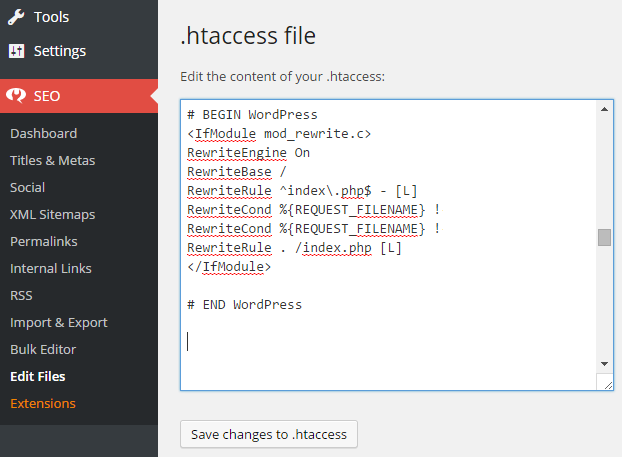
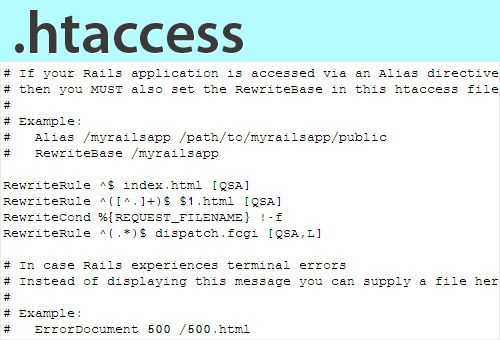
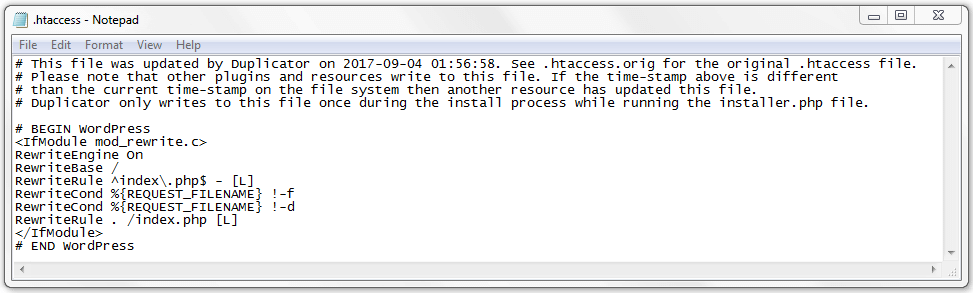
Стандартный .htaccess для WordPress
В большинстве случаев при установке WordPress на хостинг .htaccess создается в корневой директории сайта. Однако иногда этого не происходит и тогда нужно создать этот файл самостоятельно. Для этого выполните следующие действия:
- Подключитесь к хостингу по FTP, используя FileZilla или другой FTP-клиент, и перейдите в корневую директорию сайта.
- Кликните правой кнопкой мыши по правому окошку с файлами сайта и выберите «Создать новый файл».
- Введите .htaccess и нажмите OK.
Обратите внимание! Убедитесь, что ввели имя .htaccess (с точкой), а не htaccess (без точки). Другой способ создания файла .htaccess — через Консоль WordPress
Выберите в главном меню Настройки > Постоянные ссылки и, ничего не меняя на странице, нажмите кнопку «Сохранить изменения»
Другой способ создания файла .htaccess — через Консоль WordPress. Выберите в главном меню Настройки > Постоянные ссылки и, ничего не меняя на странице, нажмите кнопку «Сохранить изменения».
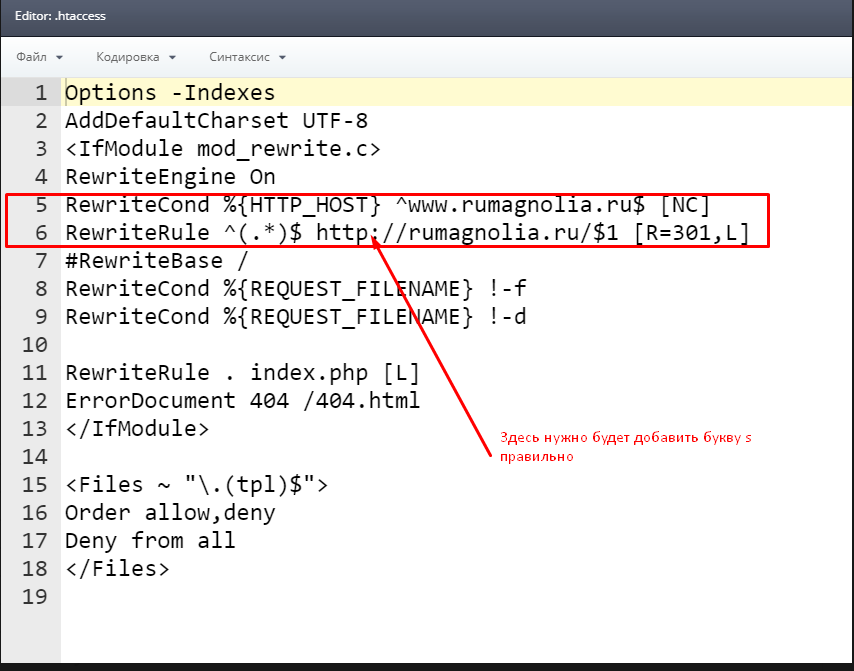
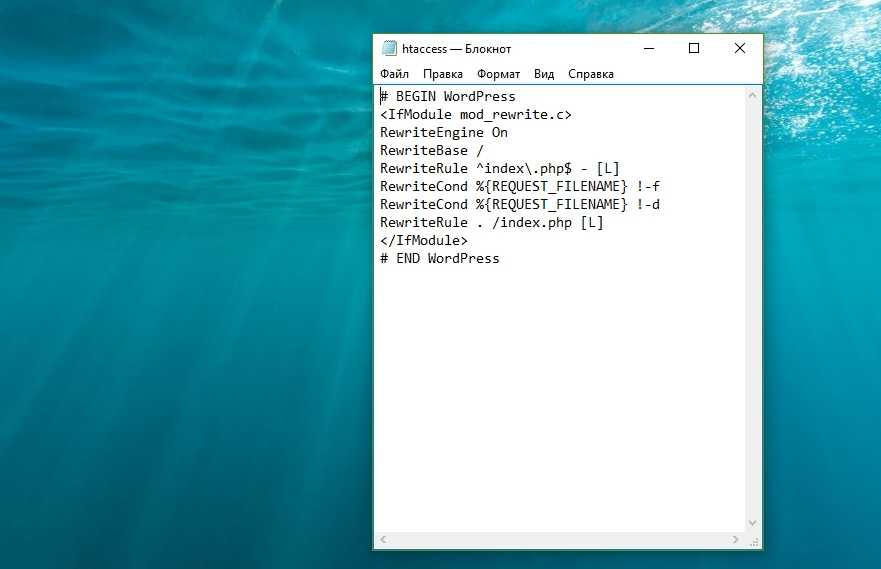
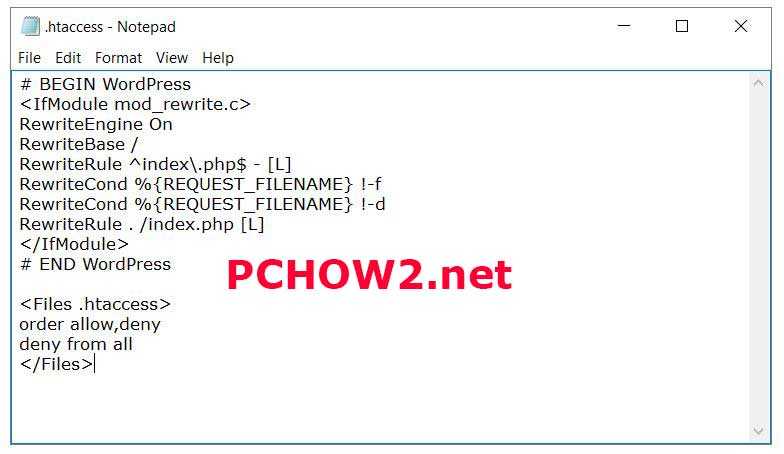
Стандартный .htaccess для WordPress выглядит следующим образом:
# BEGIN WordPress
RewriteEngine On
RewriteBase /
RewriteRule ^index\.php$ -
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php
# END WordPress
По умолчанию в .htaccess WordPress-сайта указаны только правила для корректного отображения постоянных ссылок записей и страниц. Однако, это легко изменить, добавив в файл дополнительные правила, которые и будут описаны далее.
Ускорение ‑ распараллеливание
Если вы решитесь на распараллеливание своей программы, будьте осторожны с реализацией, чтобы не “свалить” сервер. Обязательно прочитайте раздел «Распространенные ошибки», приведенный выше. Ознакомьтесь с определениями параллельного и последовательного выполнения, процессоров и потоков здесь и здесь.
Если вы извлекаете большое количество информации со страницы и выполняете некоторую предварительную обработку данных, количество повторных запросов в секунду, которое вы отправляете на страницу, может быть относительно низким.
В своем другом проекте я собирала цены на аренду квартиры и сделала для этого довольно сложную предварительную обработку данных, в результате чего мне удалось отправлять только один запрос в секунду. Чтобы собрать объявления размером в 4K, моя программа должна проработать около часа.
Чтобы отправлять запросы параллельно, вы можете воспользоваться пакетом multiprocessing.
Допустим, у нас есть 100 страниц, и мы хотим назначить каждому процессу равное количество страниц для обработки. Если — количество процессоров, то вы можете равномерно распределить все страницы на частей и назначить каждую часть отдельному процессору. Каждый процесс будет иметь свое имя, свою целевую функцию и свои аргументы для работы. После этого имя процесса можно использовать для включения записи данных в определенный файл.
Я назначила 1K страниц для каждого из 4-х процессоров, имевшихся у меня в распоряжении, в результате было создано 4 повторных запроса в секунду, что сократило время сбора данных моей программой до 17 минут.
Известные пакеты и инструменты
Для веб-скрэпинга нет универсального решения, поскольку способ, с помощью которого хранится на каждом из веб-сайтов обычно специфичны. На самом деле, если вы хотите собрать данные с сайта, вам необходимо понять структуру сайта и, либо создать собственное решение, либо воспользоваться гибким и перенастраиваемым вариантом уже готового решения.
Изобретать колесо здесь не нужно: существует множество пакетов, которые скорее всего, вам вполне подойдут. В зависимости от ваших навыков программирования и предполагаемого варианта использования вы можете найти разные более или менее полезные для себя пакеты.
1.1 Проверяем параметры
Чтобы вам было проще проверять HTML-сайт, воспользуйтесь опцией инспектора в вашем вэб-браузере.
![]()
Раздел веб-сайта, который содержит мое имя, мой аватар и мое описание, называется (любопытно, что Medium называет своих писателей героями:)). Класс <h1>, который содержит мое имя, называется , а описание содержится в описании героя <p> классом .
Вы можете более подробно познакомиться с HTML-тэгами и различиями между классами и id здесь.
1.2 Скрэпинг
Существует отдельная готовая к использованию библиотека для извлечения данных под названием Scrapy. Кроме извлечения HTML, этот пакет располагает большим количеством функций, таких как экспорт данных в различные форматы, создание лог-файлов и т.д. Это достаточно гибкий и настраиваемый вариант: запуск отдельных скрэперов на разных процессах , отключение cookies (некоторые сайты используют cookies для идентификации ботов) и установка задержек загрузки (веб-сайт может быть перегружен из-за огромного количества запросов на сканирование). Его также можно использовать для извлечения данных с помощью API. Однако для начинающих программистов пакет, скорее всего, будет несколько сложноват: вам придется прочитать руководства и разобраться с примерами, прежде чем вы сможете приступить к работе.
В моем случае я воспользовалась готовым методом «из коробки»: я просто хотела извлечь ссылки со всех страниц, получить доступ по каждой ссылке и извлечь из нее информацию.
1.3 BeautifulSoup с библиотекой Request
BeautifulSoup — это библиотека, позволяющая сделать синтаксический разбор (парсинг) HTML-кода. Кроме того, вам также потребуется библиотека Request , которая будет отображать содержимое URL-адреса. Однако, вы также должны позаботиться и о решении ряда прочих вопросов, таких как обработка ошибок, экспорт данных, распараллеливание и т.д.
Перенаправление страниц в .htaccess
При разработке сайта вы можете изменить URL-адрес одной или нескольких страниц — перенести в новые каталоги или даже на другой сайт. Вы можете легко обновить гиперссылки на эти страницы на своем собственном сайте, но у вас нет большого контроля над гиперссылками, которые хранятся на других сайтах, которые находятся в индексах поисковых систем или которые сохраняются отдельными пользователями.
Если вы хотите, чтобы пользователи, которые переходят по старым гиперссылкам, попадали на страницы, которые ищут, а не на страницу с ошибками, вам нужно автоматически перенаправлять их на новые адреса.
Существуют различные способы автоматического перенаправления страниц — одним из них является мета-тег http-equiv=»refresh», уже обсуждавшийся в статье HTML head:
Недостатком этого метода является необходимость написания команды отдельно для каждой страницы. Для сравнения, .htaccess позволяет вам перенаправлять как на отдельные страницы, так и на целые каталоги или непосредственно на весь сайт. Команда перенаправления страницы выглядит следующим образом:
301 — это код HTTP сообщения Moved permanently (страница на новом адресе). Старый адрес относится к основному каталогу сайта, а новый адрес является абсолютным — он включает в себя имя самого сайта. Это также позволяет перенаправлять страницы на совершенно другой сайт.
Один конкретный пример:
Страница rose.html, расположенная в корневом каталоге сайта, теперь находится по новому адресу — в подкаталоге flowers по адресу www.example.com с новым именем red_rose.html.
Таким же образом, содержимое всего каталога можно перенаправить:
или даже весь сайт:
Как автоматически добавить www к URL-адресу страницы (http://example.com/index.html, чтобы стать http://www.example.com/index.html) или наоборот — освободить URL-адреса страниц от www (http : //www.example.com/index.html, чтобы стать http://example.com/index.html), описывается далее.
Фишинг в поисковых системах
При использовании фишинга в поисковых системах хакеры создают свой собственный веб-сайт и индексируют его в легитимных поисковых системах. Эти сайты часто предлагают дешевые товары и невероятно заманчивые предложения, пытающиеся заманить ничего не подозревающих онлайн-покупателей, которые видят сайт на странице результатов поиска в Google или в других поисковиках. Если жертва нажимает в поисковике на ссылку для перехода на такой сайт, то, как правило, предлагается зарегистрировать аккаунт или ввести информацию о своем банковском счете для завершения покупки. Конечно, мошенники затем крадут эти личные данные, чтобы использовать их для извлечения финансовой выгоды в дальнейшем.
Пример фишинга в поисковых системах
В 2020 году сообщил, что ежедневно обнаруживается 25 миллиардов спам-сайтов и фишинговых веб-страниц. Кроме того, Wandera сообщила в 2020 году, что каждые 20 секунд запускается новый фишинговый сайт. Это означает, что каждую минуту в поисковых системах появляются три новых фишинговых сайта!
Минимизируйте CSS и JS файлы
Первое и самое простое, что можно сделать – это сжать JS и CSS файлы. Логика работы очень простая, из файлов убираются все «лишние» символы: пробелы, переносы строк, комментарии, переменные в JS приводятся к 1-2 символьному виду.
Если при разработке сайта на Битрикс вы подключали скрипты и стили правильно, то вам достаточно в настройках главного модуля проставить все галочки в блоке «Оптимизация CSS».
![]()
Что значит «правильно»? Это значит, что в коде шаблонов сайтов и компонентов у вас нет вставок <script></script>.
Что делать, если все подключено как попало? Переподключать!
Вот пример подключения на D7:
use Bitrix\Main\Page\Asset;
Asset::getInstance()->addJs('/js/jQuery.min.js'); - правильное подключение JS.
Asset::getInstance()->addCss('/css/bootstrap-grid.css'); - правильное подключение CSS.
Пробегитесь по шаблонам сайтов и компонентов и убедитесь, что у вас нет блоков <script></script> нигде. Исключением может быть разве что счетчики метрик, а лучше одного счетчика – Google Tag Manager.

Про подключение файлов на старом ядре я писал в этой статье.
Второй вариант минификации файлов – использование Grunt или Gulp. Мне больше нравится Grunt, но любители Gulp легко найдут аналоги грантовских тасков:
- grunt-contrib-cssmin – минифицирует CSS.
- grunt-contrib-uglify – минифицирует JS.
- grunt-contrib-concat – обычное объединение нескольких файлов в один.
Gruntfile.js:
module.exports = function(grunt) {
grunt.initConfig({
concat: {
dist: {
src: 'js/*.js',
dest: 'js/min/all.js'
}
},
uglify: {
dist: {
files: {
'js/min/all.min.js': ['js/min/all.js']
}
}
},
cssmin: {
target: {
files: ,
dest: 'css',
ext: '.min.css'
}]
}
}
});
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-cssmin');
grunt.loadNpmTasks('grunt-contrib-concat');
grunt.registerTask('default', );
};
Важно: сжатие скриптов и стилей с помощью стороннего софта не освобождают вас от правильного подключения в bitrix.
Поддельные сайты (фишинг)
За время пандемии многие сферы жизни перешли в онлайн, киберпреступники также активизировали свою деятельность в интернете. За первое полугодие 2020 года мошенники украли в интернете свыше 2 млрд руб., то есть более 50% из общего объема похищенных за этот период средств.
Способы мошенничества: мошенники могут создавать фишинговые сайты, предлагающие товары и услуги, например, авиа и ж/д билеты, по более низким ценам. «После выбора билета и формы оплаты пользователя просят ввести реквизиты своей банковской карты (номер карты, CVV-код). После согласия осуществить оплату происходит передача реквизитов кредитной карты злоумышленникам, о чем пользователь даже и не догадывается», — приводит пример Каргалев из CERT-GIB.
Также мошенники научились подделывать сайты банков, чтобы узнавать данные клиентов от их личного кабинета.
Еще одна новая волна мошенничества, которую выявил Group-IB, — это появление ресурсов, которые предлагают пострадавшим от интернет-преступников пользователям получить компенсацию за участие в популярных фейковых опросах, «недобросовестных» лотереях или компенсацию НДС, но вместо этого списывают деньги и похищают данные банковских карт.
Как защититься:
совершать покупки только на официальных сайтах;
не верить «фантастическим скидкам», «акциям» и «розыгрышам»;
проверять доменное имя ресурса
Если оно отличается от оригинального или просто кажется подозрительным — закрывать страницу;
при оплате товара необходимо обращать внимание на страницу платежной системы, на которую должен перенаправлять сайт продавца для ввода платежных данных. «Если продавец просит перевести деньги на карту или виртуальный кошелек, то это мошенник, так как компании не оформляют счета на физические лица», — объясняет Каргалев;
при входе в интернет-банк обращать внимание на наличие в адресной строке https:// и значка закрытого замка (это означает безопасное соединение).
Настройка доступа htaccess
Довольно часто htaccess используется для управления доступом к папке. Для управления доступом используются три команды:
- order — порядок;
- deny — запретить;
- allow — разрешить.
Сначала, с помощью опции order, нужно указать в каком порядке будут выполняться директивы, значение имеет только эта команда, и неважно в какой последовательности они расположены в файле. Затем с помощью директивы allow или deny мы разрешаем или запрещаем доступ к папке с определенных адресов
Например, чтобы запретить все необходимо добавить в htaccess:
Затем с помощью директивы allow или deny мы разрешаем или запрещаем доступ к папке с определенных адресов. Например, чтобы запретить все необходимо добавить в htaccess:
Но мы также можем разрешить доступ только с локальной сети:
Если указано deny,allow, то проверка будет выполняться в таком порядке. Сначала все директивы deny, затем все директивы allow, и если ни одно из условий не подошло, то запрос пропускается.При allow,deny такой запрос будет по умолчанию отклонен. Например, предыдущий пример можно написать так: