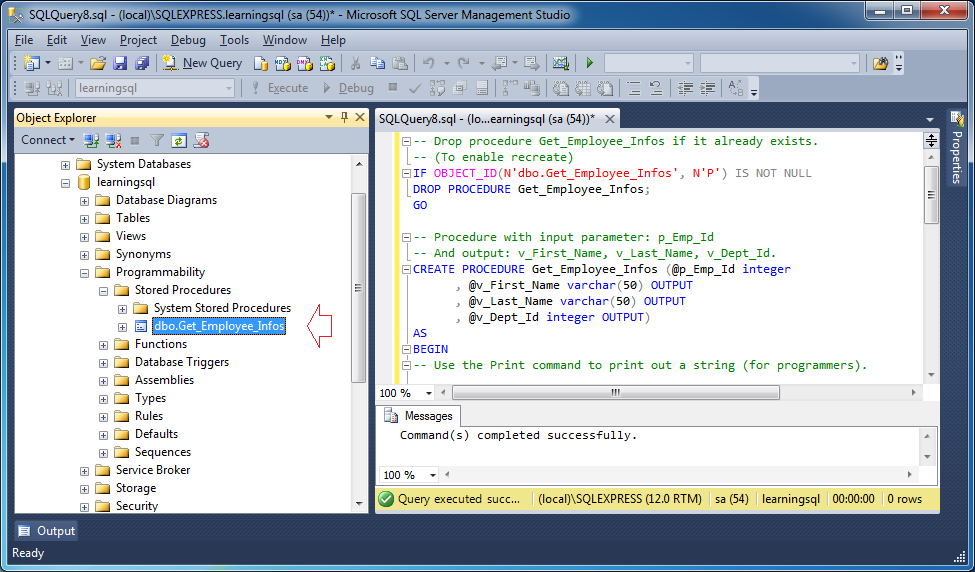
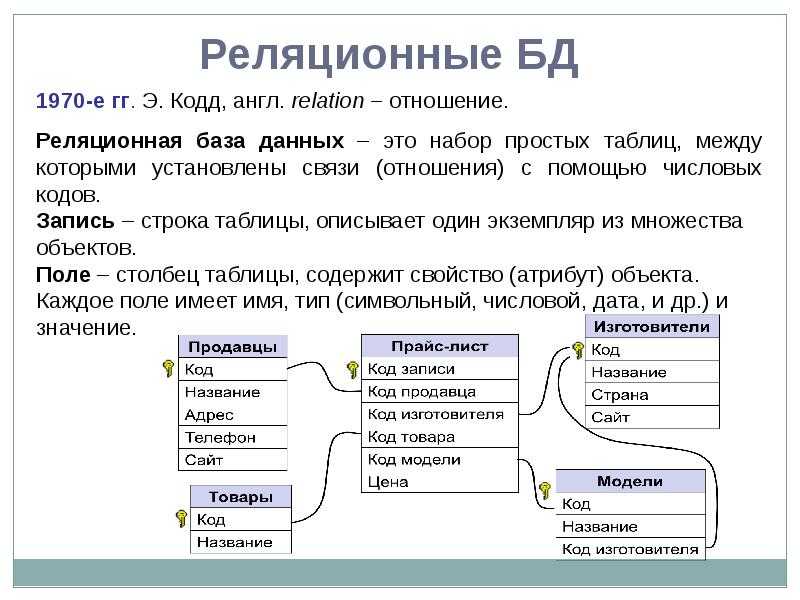
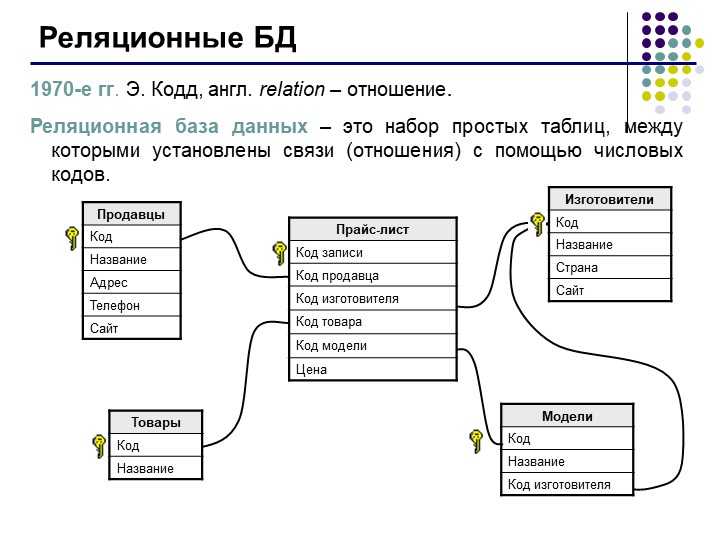
№45 Реляционная модель данных. Понятия таблица, ключ, кортеж, атрибут, домен
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой.
В упомянутой статье Е.Ф. Кодда утверждается, что «реляционная модель
предоставляет средства описания данных на основе только их естественной
структуры, т.е. без потребности введения какой-либо дополнительной
структуры для целей машинного представления». Другими словами,
представление данных не зависит от способа их физической организации.
Это обеспечивается за счет использования математической теории отношений
(само название «реляционная» происходит от английского relation –
«отношение»).
В состав реляционной модели данных обычно включают теорию нормализации.
Реляционная система управления базой данных (РСУБД)
Реляционная система управления базой данных (РСУБД) — СУБД, управляющая реляционными базами данных.
Доступ к реляционным базам данных осуществляется через реляционные системы управления базами данных (РСУБД).
Почти все системы баз данных, которые мы используем, являются реляционными, такие как Oracle, SQL Server, MySQL, Sybase, DB2, TeraData и так далее.
Причины такого доминирования неочевидны. На протяжении всего существования реляционных БД они постоянно предлагали наилучшую смесь простоты, устойчивости, гибкости, производительности, масштабируемости и совместимости в сфере управлении данными.
Например, простой SELECT запрос может иметь сотни потенциальных путей выполнения, которые оптимизатор оценит непосредственно во время выполнения запроса. Все это скрыто от пользователей, однако внутри РСУБД создает план выполнения, основывающийся на вещах вроде алгоритмов оценки стоимости и наилучшим образом отвечающий запросу.
Однако чтобы обеспечить все эти особенности, реляционные хранилища невероятно сложны внутри.
Реляционная система управления базой данных содержит:
- командный язык;
- язык программирования с ориентацией на обработку таблиц;
- интерпретирующую и/или компилирующую систему; и
- пользовательскую оболочку.
Как реляционные базы данных структурируют данные
Теперь, когда у вас есть общее понимание истории реляционной модели, давайте более подробно рассмотрим, как данная модель структурирует данные.
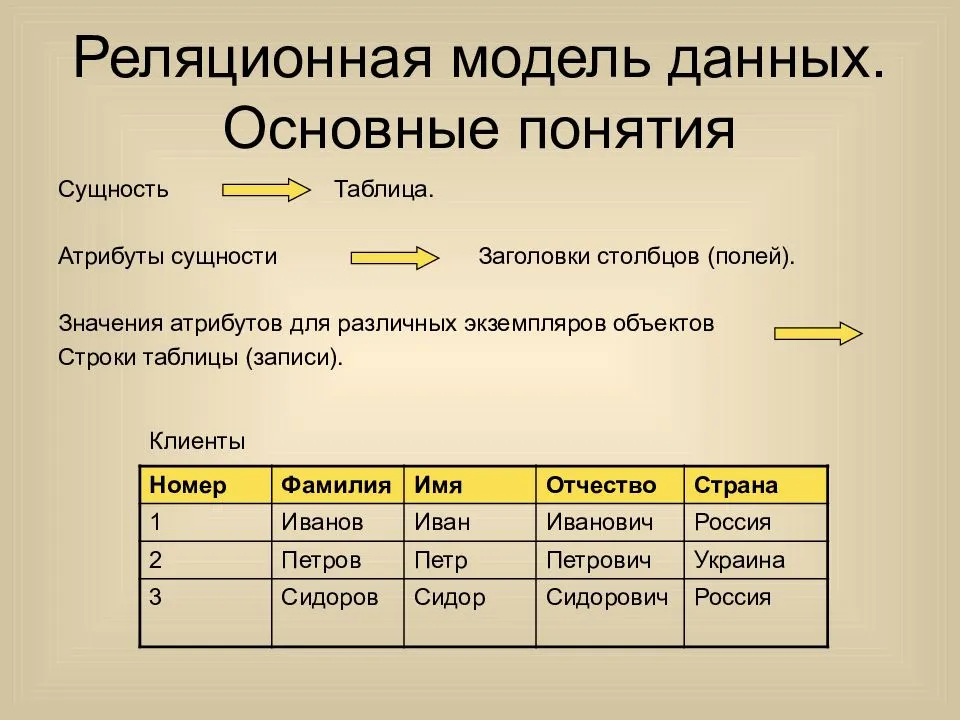
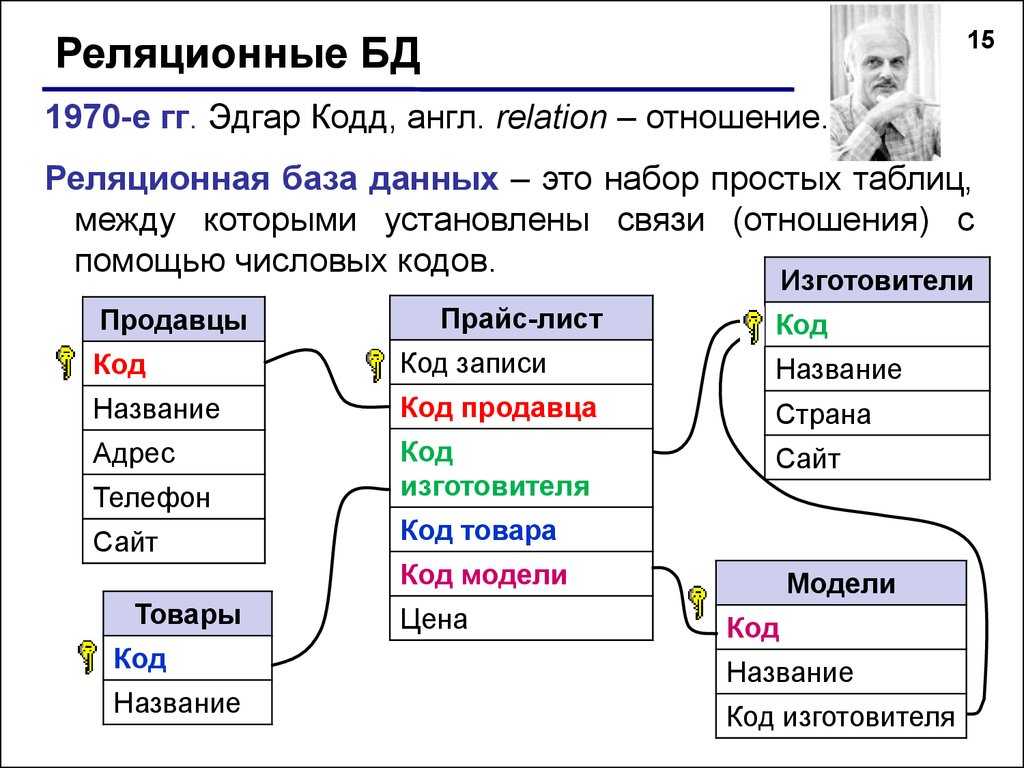
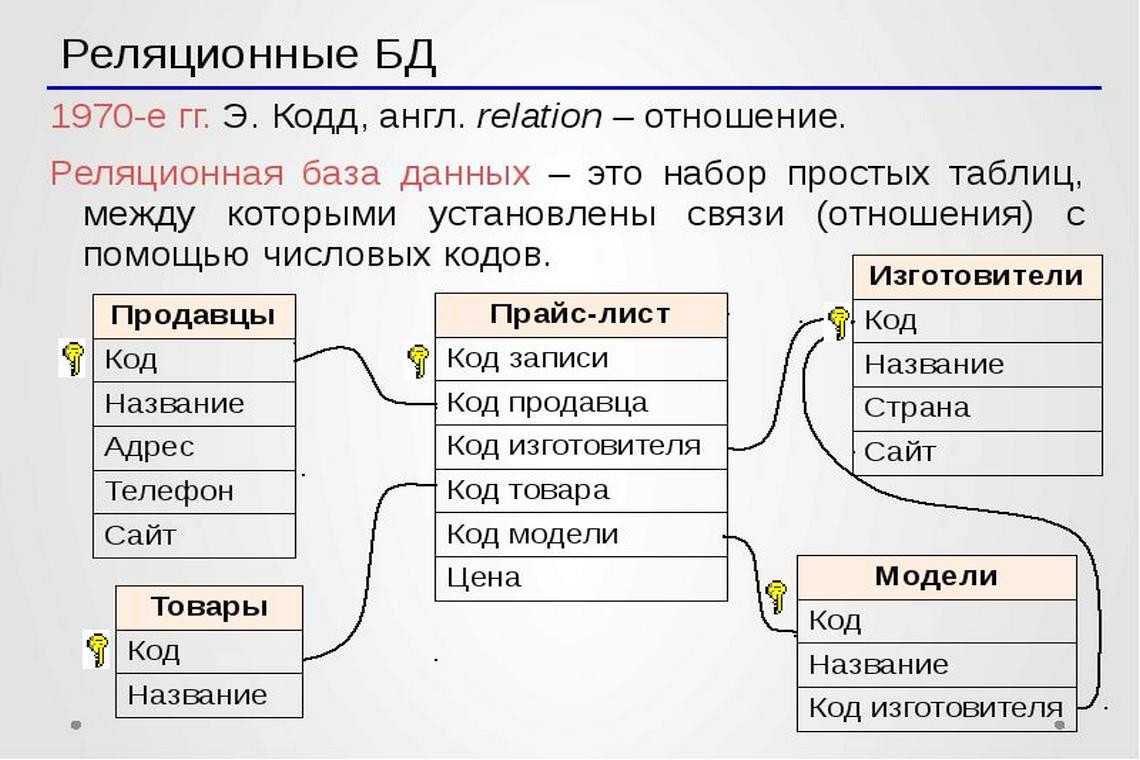
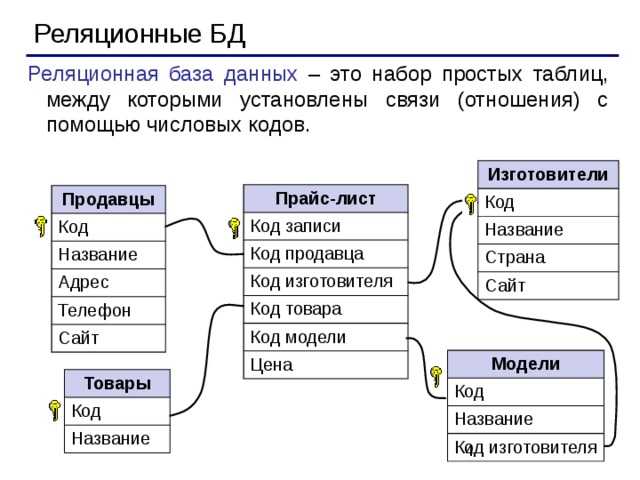
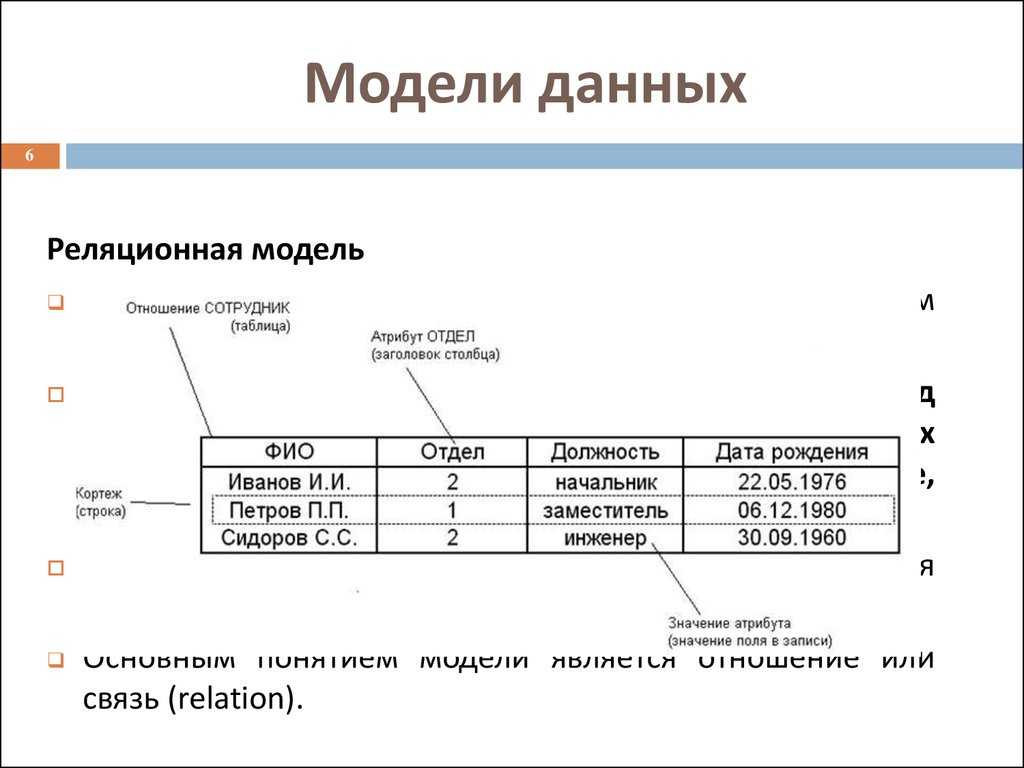
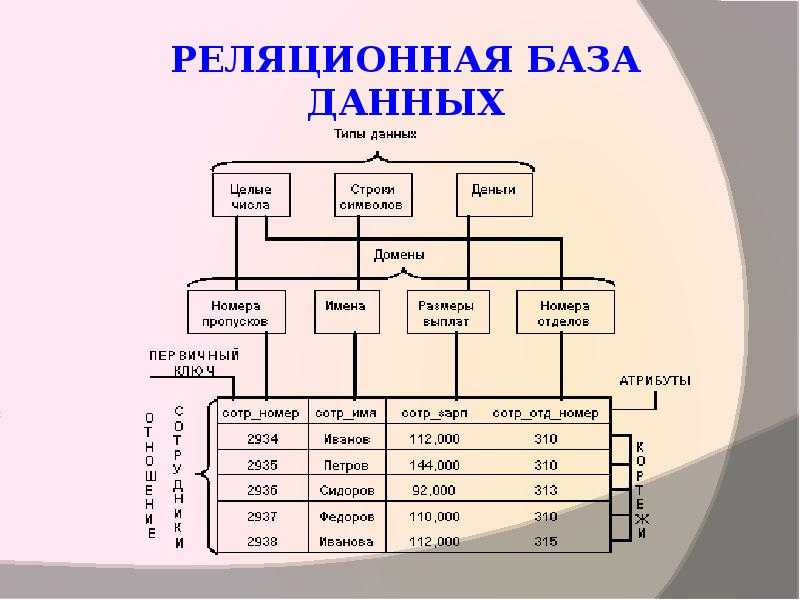
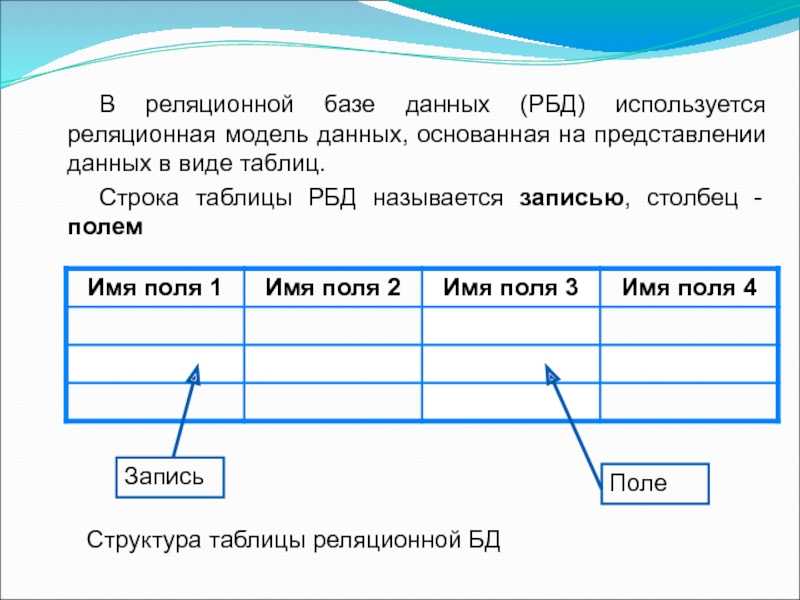
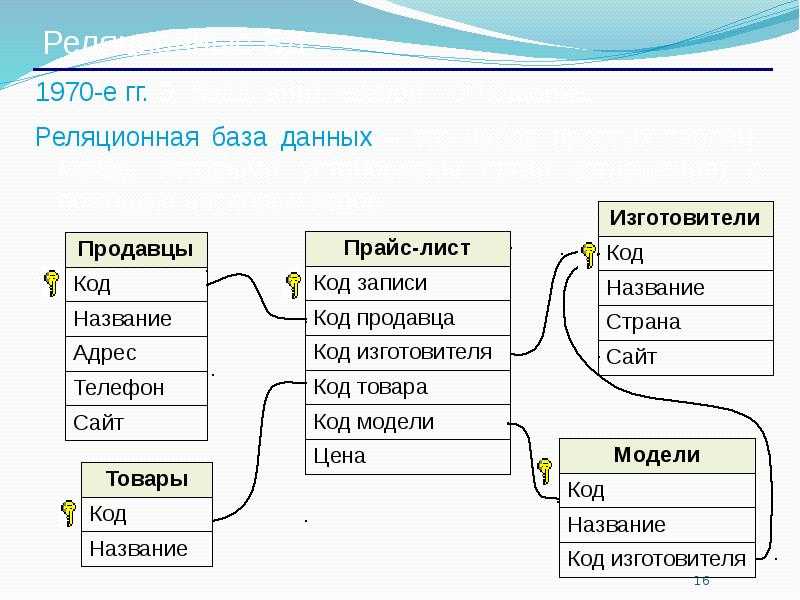
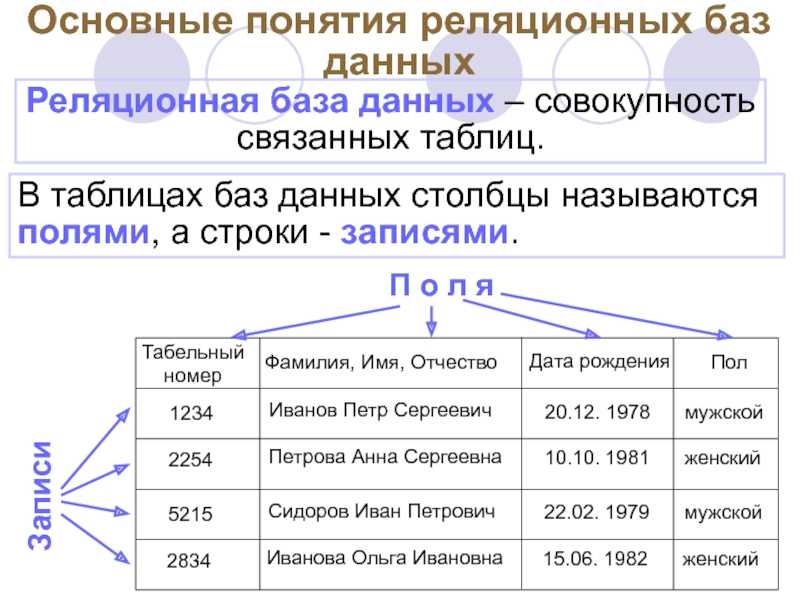
Наиболее значимыми элементами реляционной модели являются отношения, которые известны пользователям и современным РСУБД как таблицы. Отношения — это набор кортежей, или строк в таблице, где каждый кортеж имеет набор атрибутов, или столбцов:
![]()
Столбец — это наименьшая организационная структура реляционной базы данных, представляющая различные ячейки, которые определяют записи в таблице. Отсюда происходит более формальное название — атрибуты. Вы можете рассматривать каждый кортеж в качестве уникального экземпляра чего-либо, что может находиться в таблице: категории людей, предметов, событий или ассоциаций. Такими экземплярами могут быть сотрудники компаний, продажи в онлайн-бизнесе или результаты лабораторных тестов. Например, в таблице с трудовыми записями учителей в школе кортежи могут иметь такие атрибуты, как , , и т. д.
При создании столбцов вы указываете тип данных, определяющий, какие записи могут вноситься в данный столбец. РСУБД часто используют свои собственные уникальные типы данных, которые могут не быть напрямую взаимозаменяемы с аналогичными типами данных из других систем. Некоторые распространенные типы данных включают даты, строки, целые числа и логические значения.
В реляционной модели каждая таблица содержит по крайней мере один столбец, который можно использовать для уникальной идентификации каждой строки. Он называется первичным ключом
Это важно, поскольку это означает, что пользователям не нужно знать, где физически хранятся данные на компьютере. Их СУБД может отслеживать каждую запись и возвращать ее в зависимости от конкретной цели
В свою очередь, это означает, что записи не имеют определенного логического порядка, и пользователи могут возвращать данные в любом порядке или с помощью любого фильтра по своему усмотрению.
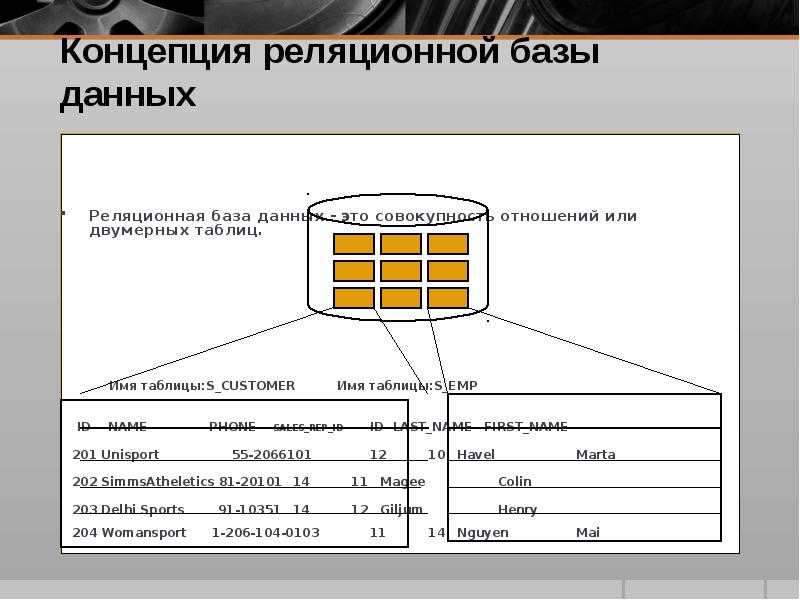
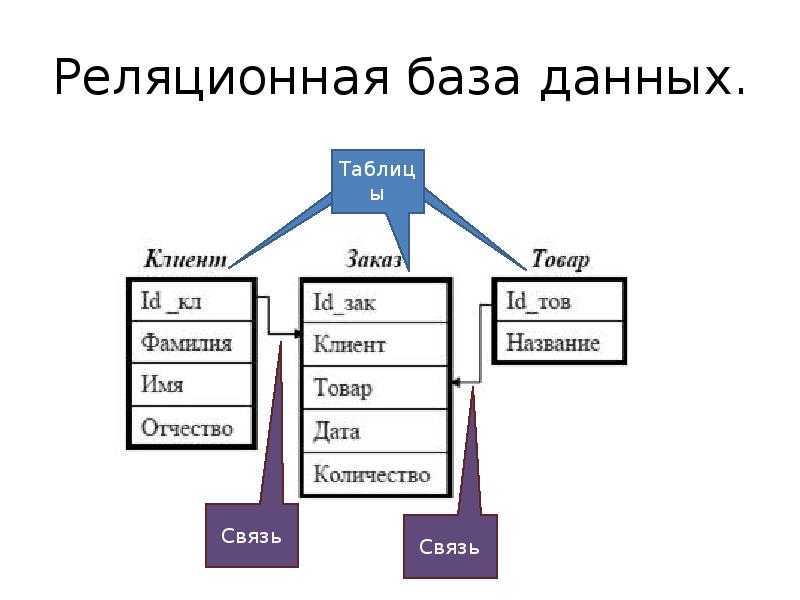
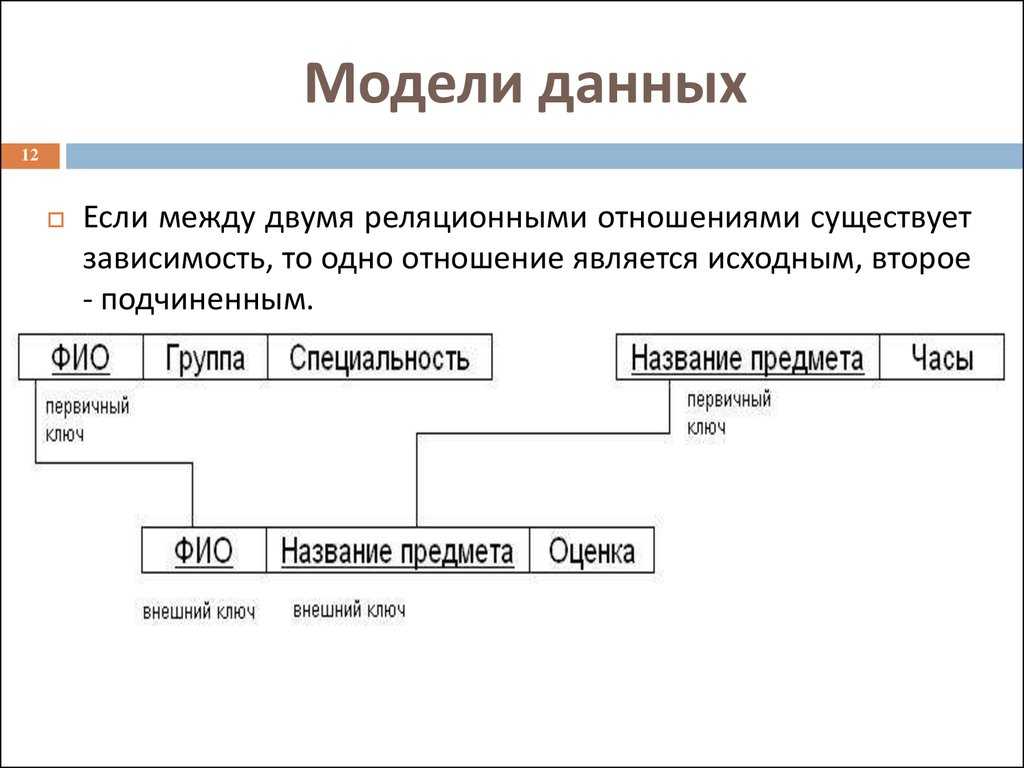
Если у вас есть две таблицы, которые вы хотите связать друг с другом, можно сделать это с помощью внешнего ключа. Внешний ключ — это, по сути, копия основного ключа одной таблицы (таблицы «предка»), вставленная в столбец другой таблицы («потомка»). Следующий пример показывает отношения между двумя таблицами: одна используется для записи информации о сотрудниках компании, а другая — для отслеживания продаж компании. В этом примере первичный ключ таблицы используется в качестве внешнего ключа таблицы :
![]()
Если вы попытаетесь добавить запись в таблицу «потомок», и при этом значение, вводимое в столбец внешнего ключа, не существует в первичном ключе таблицы «предок», вставка будет недействительной. Это помогает поддерживать целостность уровня отношений, поскольку ряды в обеих таблицах всегда будут связаны корректно.
Структурные элементы реляционной модели помогают хранить данные в структурированном виде, но хранение имеет значение только в том случае, если вы можете извлечь эти данные. Для извлечения информации из РСУБД вы можете создать запрос, т. е. структурированный запрос на набор информации. Как уже упоминалось ранее, большинство реляционных баз данных используют язык SQL для управления данными и отправки запросов. SQL позволяет фильтровать результаты и обрабатывать их с помощью различных пунктов, предикатов и выражений, позволяя вам контролировать, какие данные появятся в результате.
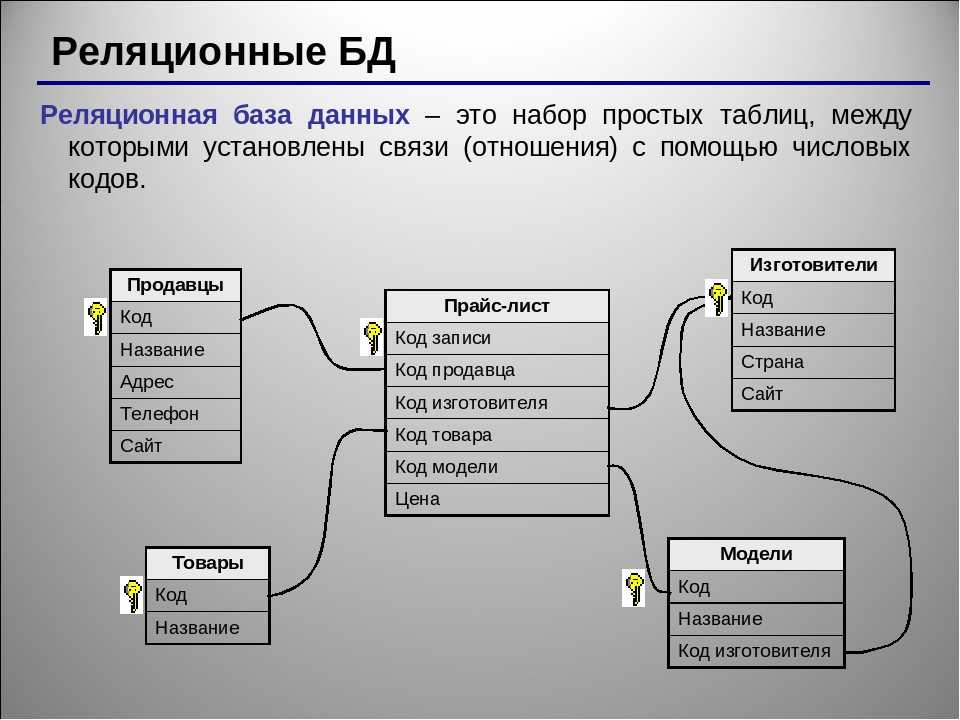

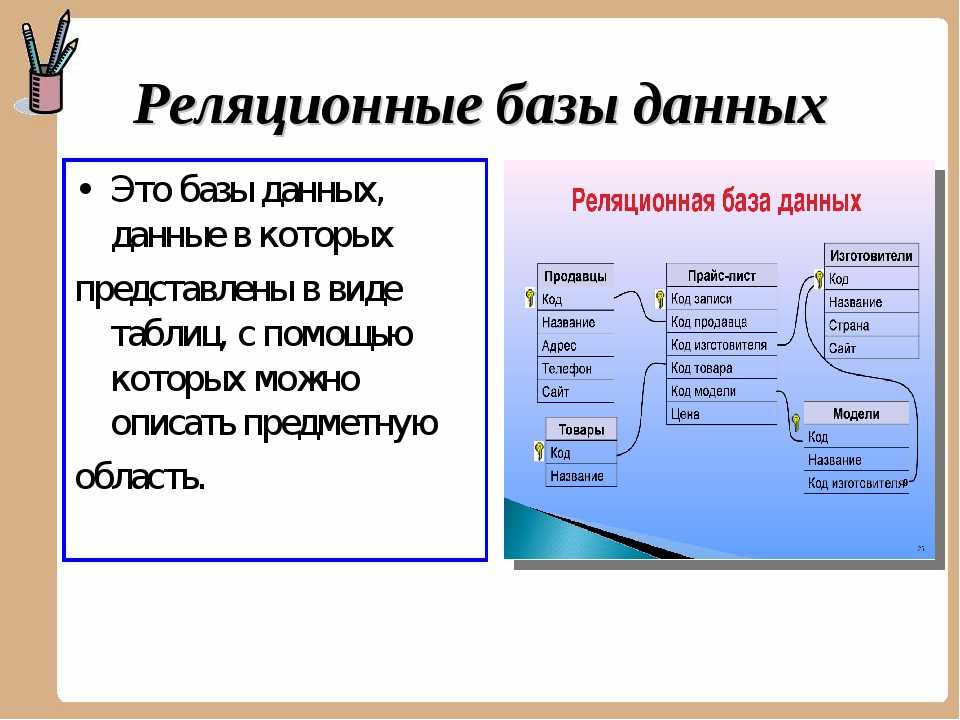

Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
![]()
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.
- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
https://youtube.com/watch?v=hH1k9zSmVt0
Ключи [ править ]
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций. [ необходима цитата ]
Часть этой обработки включает в себя постоянную возможность выбрать или изменить одну и только одну строку в таблице. Следовательно, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другие, более естественные ключи также могут быть идентифицированы и определены как альтернативные ключи.(АК). Часто для формирования AK требуется несколько столбцов (это одна из причин, почему один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Дополнительные технологии могут применяться для обеспечения уникального идентификатора во всем мире, глобального уникального идентификатора , когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда PK переносится в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять отношения « один-к-одному» или « один-ко-многим» . Большинство проектов реляционных баз данных решают проблему » многие ко многим»отношения путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей — отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы — вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе множества других типов столбцов.
Отношения править
Отношения — это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.



Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Ключи отношения в реляционной модели данных
Ключи отношения могут быть следующми:
- суперключ;
- потенциальный ключ;
- первичный ключ;
- внешний ключ;
- суррогатный ключ.
Ключ отношения — это подсхема исходной схемы отношения, состоящая из одного или
нескольких атрибутов, для которых декларируется условие уникальности значений в кортежах отношений.
При объявлении схемы базового отношения могут быть заданы объявления нескольких ключей.
Ключ отношения может быть простым или составным. Простой ключ – это ключ,
состоящий из одного и не более атрибута. Составной ключ -ключ, состоящий из двух и более атрибутов.
Суперключ — это атрибут или множество атрибутов, которое единственным
образом идентифицирует кортеж данного отношения. Он может включать дополнительные атрибуты. Суперключ
не обладает свойством неизбыточности.
Потенциальный ключ — это подмножество атрибутов отношения, удовлетворяющее требованиям
уникальности и неизбыточности. Он обладает следующими свойствами. Уникальность: в таблице нет двух разных
строк с одинаковыми значениями в нашем потенциальном ключе. Неизбыточность: нельзя убрать один из
столбцов из ключа, так, чтобы он не потерял уникальности. В отношении может быть больше одного
потенциального ключа.
Первичный ключ (primary key, PK) — это один из потенциальных ключей отношения,
выбранный в качестве основного ключа. Допустимо объявление одного и только одного первичного ключа.
Атрибуты первичного ключа не могут принимать значения Null.
Внешний ключ (foreign key, FK) — это ключ, объявленный в базовом отношении,
который при этом ссылается на первичный того же самого или какого-то другого базового отношения.
Суррогатный ключ — это служебный атрибут, добавленный к уже имеющимся информационным
атрибутам отношения. Предназначение суррогатного ключа — служить первичным ключом отношения. Значение
этого атрибута генерируется искусственно.
Пример 2. Есть база данных сети аптек. В ней есть таблица «Аптеки», в
которую занесены все аптеки сети, и есть таблица «Препараты». Кроме того, есть таблица «Наличие», в которую
заносятся данные о наличии препаратов в каждой аптеке. В таблице наличие есть поля: «Аптека» (в ней —
идентификаторы аптек), «Препарат» (в ней — идентификаторы препаратов), «Количество». Возникает проблема:
в случае поступления в аптеку некоторого количества препарата можно не заметить, что в той же аптеке тот
же препарат уже содержится в некотором количестве и сделать новую записись в таблице, в которой аптека и
препарат будут повторяться. Как на уровне ключей избежать этой проблемы?
Решение. Можно объявить первичным ключём таблицы «Наличие» составной ключ, состоящий
из идентификатора аптеки и идентификатора препарата. Тогда в таблице невозможно повторение в разных записях
сочетания аптеки и прапарата. Первичный ключ может быть не только простым, но и
составным.
Модель ACID¶
Большинство реляционных баз данных реализует транзакционную модель. Акроним ACID содержит основные принципы такого подхода.
Атомарность (Atomicity)
Атомарность гарантирует, что никакая транзакция не будет зафиксирована в
системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни
одной. Поскольку на практике невозможно одновременно и атомарно выполнить всю
последовательность операций внутри транзакции, вводится понятие «отката»
(rollback): если транзакцию не удаётся полностью завершить, результаты всех её
до сих пор произведённых действий будут отменены и система вернётся во «внешне
исходное» состояние — со стороны будет казаться, что транзакции и не было.
Сигнал завершения транзакции называется «фиксация» (commit).
Согласованность (Consistency)
Транзакция достигающая своего нормального завершения (EOT — end of transaction,
завершение транзакции) и, тем самым, фиксирующая свои результаты, сохраняет
согласованность базы данных. Другими словами, каждая успешная транзакция по
определению фиксирует только допустимые результаты. Это условие является
необходимым для поддержки четвёртого свойства.
Согласованность является более широким понятием. Например, в банковской системе
может существовать требование равенства суммы, списываемой с одного счёта,
сумме, зачисляемой на другой. Это бизнес-правило и оно не может быть
гарантировано только проверками целостности, его должны соблюсти программисты
при написании кода транзакций. Если какая-либо транзакция произведёт списание,
но не произведёт зачисление, то система останется в некорректном состоянии и
свойство согласованности будет нарушено.
Наконец, ещё одно замечание касается того, что в ходе выполнения транзакции
согласованность не требуется. В нашем примере, списание и зачисление будут,
скорее всего, двумя разными подоперациями и между их выполнением внутри
транзакции будет видно несогласованное состояние системы. Однако не нужно
забывать, что при выполнении требования изоляции, никаким другим транзакциям
эта несогласованность не будет видна. А атомарность гарантирует, что транзакция
либо будет полностью завершена, либо ни одна из операций транзакции не будет
выполнена. Тем самым эта промежуточная несогласованность является скрытой.
Изолированность (Isolation)
Во время выполнения транзакции параллельные транзакции не должны оказывать
влияние на её результат. Изолированность — требование дорогое, поэтому в
реальных БД существуют различные уровни изоляции.
- Read uncommitted. Низший (нулевой) уровень изоляции. Он гарантирует только отсутствие потерянных обновлений Если несколько параллельных транзакций пытаются изменять одну и ту же строку таблицы, то в окончательном варианте строка будет иметь значение, определенное последней успешно выполненной транзакцией. При этом возможно считывание не только логически несогласованных данных, но и данных, изменения которых ещё не зафиксированы.
- Read committed. На этом уровне обеспечивается защита от чернового, «грязного» чтения, тем не менее, в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы. В итоге первая транзакция будет работать с другим набором данных.
- Repeatable Read. Уровень, при котором читающая транзакция «не видит» данные, которые были изменены но еще не зафиксированы другой транзакцией. При этом никакая другая транзакция не может изменять данные читаемые текущей транзакцией, пока та не окончена.
- Serializable. Самый высокий уровень изолированности; транзакции полностью изолируются друг от друга, каждая выполняется так, как будто параллельных транзакций не существует. Только на этом уровне параллельные транзакции не подвержены эффекту «фантомного чтения» (ситуация, когда при повторном чтении в рамках одной транзакции одна и та же выборка дает разные множества строк).
Надежность (Durability)
Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или
сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией,
должны остаться сохранёнными после возвращения системы в работу. Другими
словами, если пользователь получил подтверждение от системы, что транзакция
выполнена, он может быть уверен, что сделанные им изменения не будут отменены
из-за какого-либо сбоя.


Когда выбрать SQL, а когда NOSQL?
SQL будет оптимальной при обработке большого числа сложных запросов, кропотливого, рутинного анализа информации. Если нужна надежная, стабильная и продуктивная обработка транзакций с сохранением ссылочной ценности, стоит отдать предпочтения SQL.
Нереляционная база данных – это выбор тех, кто будет работать с большими объемами различных данных. Здесь нет четких структурированных механизмов, благодаря чему процесс загрузки и обработки проходит максимально быстро. К тому же такие БД намного сложнее взломать: доступ к ним ограничен. Если вам необходимо хранить информацию в объектах JSON, если требуется горизонтальное масштабирование, если сведения находятся в коллекциях с разными атрибутами и полями, стоит сделать выбор в пользу NoSQL.
Более подробную информацию о том, что такое реляционные и нереляционные базы данных, сферах и особенностях их применения предоставят специалисты компании «Xelent». Большой опыт позволяет им находить решения, которые будут оптимальны именно для вашего бизнеса по надежности, продуктивности работы и стоимости. Для связи воспользуйтесь телефоном или онлайн-формой.
Популярные услуги
Облачные технологии в логистике
Облачные технологии в логистике применяются последние 5 лет. Они упрощают взаимодействие поставщиков, перевозчиков, потребителей между собой, упрощают рабочий процесс.Одним из направлений работы нашей компании является предоставление логистическим предприятиям в аренду облачных серверов, программного обеспечения (SaaS), ИТ-инфраструктуры с соблюдением требований к персональной защите информации.
Платформа облачных сервисов Cloud.Xelent
Оптимальные тарифы для облачных решений!
Полный аналог «железного» сервера в виртуальной среде.
Реализовано на VMware.
Удаленные рабочие места (VDI)
Переведите офис на удаленную работу в течение 1 дня. Облако VMware с площадками в Санкт-Петербурге, Москве, Алма-Ате и Минске.
Особенности нереляционных баз данных
NoSQL – аналог реляционной базы данных, в которой информация хранится без строгой структуры и явной связи между другими сведениями. Данные здесь могут храниться не только в табличной, но и текстовой, в графической, аудио-, видео- и любой другой форме. На практике широкое применение такие БД получили в компьютерных приложениях, мобильных софтах. Они используются тогда, когда в приоритете не четкое структурирование данных, а гибкая, масштабируемая база с высоким уровнем производительности. Здесь нет никаких ограничений ни при хранении, ни при использовании данных.
Нереляционные БД наделены рядом весомых преимуществ:
- Высокая гибкость. Это свойство положительным образом сказалось на оперативности разработок. Работы можно разбивать на отдельные этапы, привлекая к их выполнению нескольких специалистов. Также высокая гибкость позволяет работать как с неструктурированными, так и со структурированными данными. Можно создавать документы, заранее не устанавливая их структуру. К тому же она может быть своя для каждого файла. Может отличаться и синтаксис, а новые поля можно будет добавлять даже в рабочем процессе.
- Отличная эффективность. Базу, созданную на основе нереляционной системы можно легко оптимизировать под хранение определенных данных или готовых шаблонов. Такое решение позволяет существенно повысить производительность в сравнении с реляционными аналогами.·
- Хорошая масштабируемость. В NOSQL базах данных предусмотрена горизонтальная масштабируемость. Предусмотрено несколько кластеров, которые применяются для разделения информации и добавления любого количества серверов: как квартал, который можно расширять, достраивая новые здания. Чтобы сохранить на максимально высоком уровне управляемость, операции по созданию облачных решений можно выполнять в фоновом режиме. Благодаря масштабируемости нереляционная база данных стала оптимальным вариантом для часто меняющихся масштабных хранилищ.