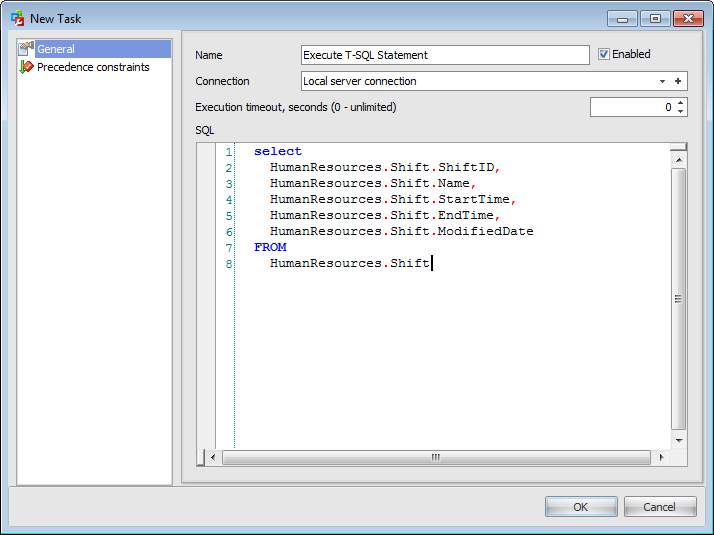
Содержание отчета
В отчете привести код процедур и функций, результаты выполнения, содержимое таблиц до и после (при необходимости) выполнения процедур и функций.
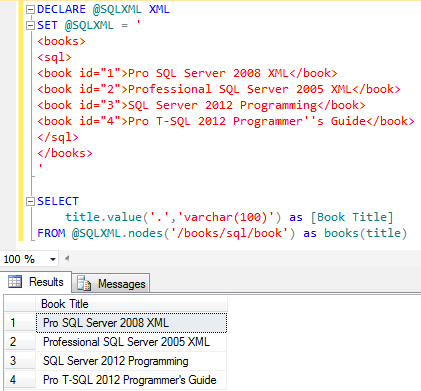
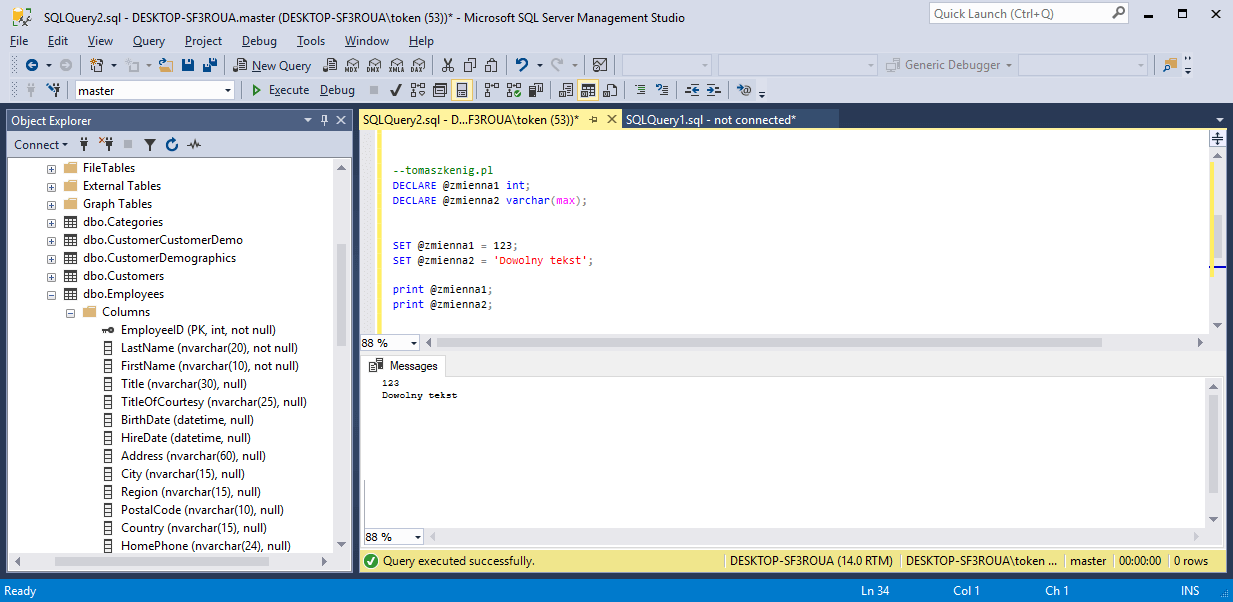
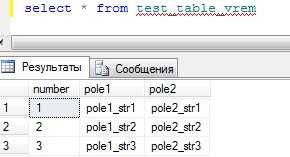
Пример реализации функции, которая возвращает количество различных городов, в которых находятся проекты, где используется определенная деталь (входной параметр):
CREATE FUNCTION Qty_of_Prj_Towns(S VARCHAR(20))
RETURNS INTEGER
BEGIN
DECLARE N INTEGER;
SELECT COUNT(*) INTO N FROM Towns WHERE Town_ID IN (SELECT Projects.Town_ID FROM Parts, Projects, Supply WHERE Parts.Part_ID= Supply.Part_ID AND Projects.Project_ID=Supply.Project_ID AND Parts.Part_name=S);
RETURN N;
END
![]()
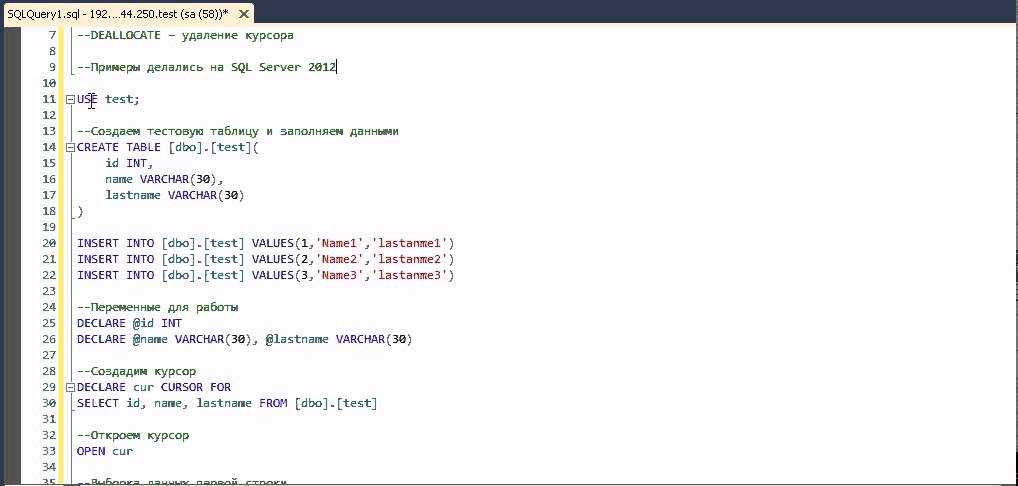
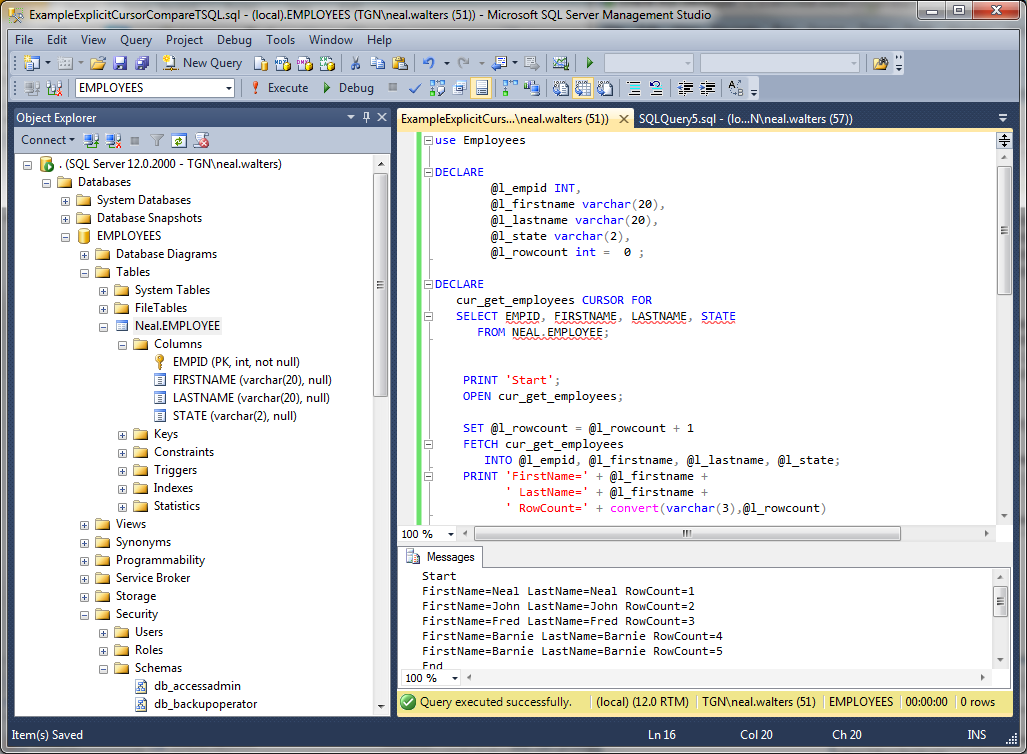
Working with MySQL cursor
First, declare a cursor by using the statement:
The cursor declaration must be after any variable declaration. If you declare a cursor before the variable declarations, MySQL will issue an error. A cursor must always associate with a statement.
Next, open the cursor by using the statement. The statement initializes the result set for the cursor, therefore, you must call the statement before fetching rows from the result set.
Then, use the statement to retrieve the next row pointed by the cursor and move the cursor to the next row in the result set.
After that, check if there is any row available before fetching it.
Finally, deactivate the cursor and release the memory associated with it using the statement:
It is a good practice to always close a cursor when it is no longer used.
When working with MySQL cursor, you must also declare a handler to handle the situation when the cursor could not find any row.
Because each time you call the statement, the cursor attempts to read the next row in the result set. When the cursor reaches the end of the result set, it will not be able to get the data, and a condition is raised. The handler is used to handle this condition.
To declare a handler, you use the following syntax:
The is a variable to indicate that the cursor has reached the end of the result set. Notice that the handler declaration must appear after variable and cursor declaration inside the stored procedures.
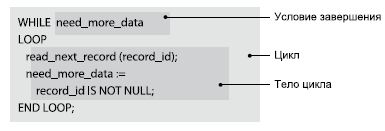
The following diagram illustrates how MySQL cursor works.
![]()
Триггеры
Триггеры — это особые хранимые процедуры, выполняемые в ответ на происходящие в базе данных события. Они относятся к числу наиболее важных элементов промышленных приложений базы данных. Основным назначением триггеров является поддержка ограничений целостности, которые не реализуются при помощи внешних ключей и ограничений, накладываемых на значение столбца (NOT NULL, CHEK и т.д.).



Триггеры уровня инструкций языка манипулирования данными (триггеры DML) запускаются после вставки, обновления или удаления строки конкретной таблицы. Это наиболее распространенный тип триггеров, особенно часто применяемый разработчиками.
Триггер BEFORE. Вызывается до внесения каких-либо изменений, в том числе до вставки записи (BEFORE INSERT).
Триггер AFTER. Выполняется после того, как производятся все изменения, в частности после операции вставки записи (AFTER INSERT).
Существуют, также, следующие виды триггеров:
Триггер уровня инструкции. Выполняется для отдельной SQL-инструкции, которая может обрабатывать одну или более записей базы данных.
Триггер уровня записи. Вызывается для отдельной записи, обрабатываемой SQL-инструкцией. Если, предположим, таблица books содержит 1000 строк, то следующая инструкция UPDATE модифицирует все эти строки: UPDATE books SET title = UPPER (title); И если для данной таблицы определен триггер уровня записи, он будет запущен 1000 раз.
Псевдозапись NEW. Структура данных с именем NEW, которая так же выглядит и обладает такими же свойствами, как и запись таблицы. Эта псевдозапись доступна только внутри триггеров обновления и вставки; она содержит значения модифицированной записи после внесения изменений.
Псевдозапись OLD. Структура данных с именем OLD, которая так же выглядит и обладает такими же свойствами, как и запись таблицы. Эта псевдозапись Доступна только внутри триггеров обновления и удаления; она содержит значения модифицируемой записи до внесения изменений.
Синтаксис оператора создания триггера:
CREATE TRIGGER <имя_триггера> {BEFORE | AFTER} <событие_БД>
ON <имя_таблицы> FOR EACH ROW
BEGIN
<операторы>
END
<событие_БД> — определение типа DML-инструкции, с которой связывается триггер: INSERT, UPDATE или DELETE. У каждой таблицы для каждого события может существовать только один триггер.
Триггер, осуществляющий проверку веса детали при добавлении ее в таблицу Parts (вес не должен превышать заданного значения)
CREATE TRIGGER Check_Weight BEFORE INSERT ON Parts FOR EACH ROW
BEGIN
DECLARE Wrong_weight CONDITION FOR SQLSTATE ‘45000’;
IF NEW.Weight > 1000 THEN
SIGNAL Wrong_weight SET MESSAGE_TEXT = ‘Вес детали превышает 1000!’;
END IF;
END
![]()
Триггер, осуществляющий проверку на совпадение наименований деталей:
CREATE TRIGGER Check_Part_Name BEFORE INSERT ON Parts FOR EACH ROW
BEGIN
DECLARE Duplicate_part_name CONDITION FOR SQLSTATE ‘45000’;
DECLARE N INTEGER;
SELECT COUNT(*) INTO N FROM Parts WHERE Part_name=NEW. Part_name;
IF N > 0 THEN
SIGNAL Duplicate_part_name SET MESSAGE_TEXT = ‘Такая деталь уже есть в базе!’;
END IF;
END
![]()
Триггер, который удаляет все детали, наименование которых совпадает с удаляемой деталью (не будет работать):
CREATE TRIGGER Delete_the_same_parts AFTER DELETE ON Parts FOR EACH ROW
BEGIN
DELETE FROM Parts WHERE Part_name=OLD.Part_name;
END
![]()
How to Write a Cursor in SQL Server
Creating a SQL Server cursor is a consistent process. Once you learn the
steps you are easily able to duplicate them with various sets of logic to loop
through data. Let’s walk through the steps:
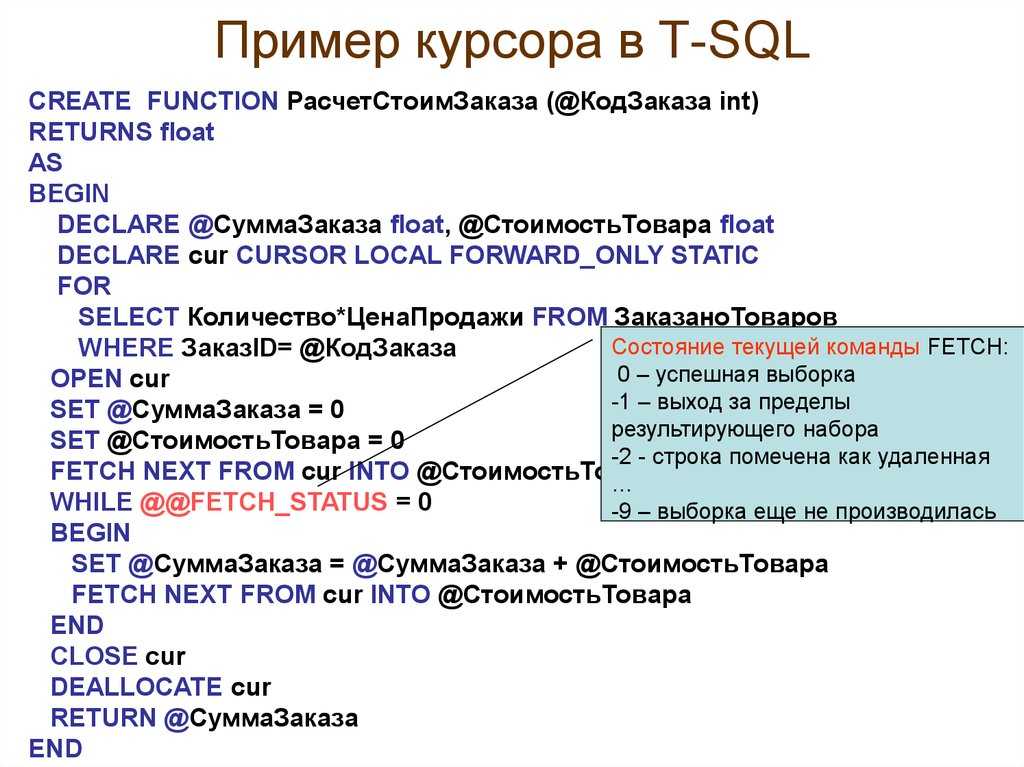

- Declare your variables (file names, database names, account numbers, etc.)
that you need in the logic and initialize the
variables. - Declare cursor with a specific name (i.e. db_cursor in this tip) that you will use
throughout the logic along with the business logic (SELECT statement) to populate the records
the cursor will need. The cursor name can be anything meaningful. This is immediately followed by opening the cursor. - Fetch a record from cursor to begin the data processing.
- The data process is unique to each set of logic.
This could be inserting, updating, deleting, etc. for each row of data that
was fetched. This is the most important set of logic during this process
that is performed on each row. - Fetch the next record from cursor as you did in step 3 and
then step 4 is repeated again by processing the selected data. - Once all of the data has been processed, then you close cursor.
- As a final and important step, you need to deallocate the cursor to
release all of the internal resources SQL Server is holding.
From here, check out the examples below to get started on knowing when to use
SQL Server cursors and how to do so.
When to Use a SQL Server Cursor
The analysis below is intended to serve as insight into various scenarios where
cursor-based logic may or may not be beneficial:
- Online Transaction Processing (OLTP) — In most OLTP environments, SET based
logic (INSERT, UPDATE or DELETE on applicable rows) makes the most sense for short transactions. Our team has run into
a third-party application that uses cursors for all of its processing, which
has caused issues, but this has been a rare occurrence. Typically, SET
based logic is more than feasible and cursors are rarely needed. - Reporting — Based on the design of the reports and the underlying design,
cursors are typically not needed. However, our team has run into reporting
requirements where referential integrity does not exist on the underlying database
and it is necessary to use a cursor to correctly calculate the reporting values.
We have had the same experience when needing to aggregate data for downstream
processes. A cursor-based approach was quick to develop and performed in an
acceptable manner to meet the need. - Serialized processing — If you have a need to complete a process in a serialized
manner, cursors are a viable option. - Administrative tasks — Many administrative tasks such as database
backups or Database Consistency Checks need to be executed in
a serial manner, which fits nicely into cursor-based logic. But other system-based objects exist to fulfill the need. In some of those circumstances,
cursors are used to complete the process. - Large data sets — With large data sets you could run into any one or more
of the following:- Cursor based logic may not scale to meet the processing needs.
- With large set-based operations on servers with a minimal amount of
memory, the data may be paged or monopolize the SQL Server which is time
consuming can cause contention and memory issues. As such, a cursor-based approach may meet the need. - Some tools inherently cache the data to a file under the covers, so
processing the data in memory may or may not actually be the case. - If the data can be processed in a staging SQL Server database, the impacts
to the production environment are only when the final data is processed.
All of the resources on the staging server can be used for the ETL processes
then the final data can be imported. -
SSIS supports batching sets
of data which may resolve the overall need to break-up a large data
set into more manageable sizes and perform better than a row by row approach
with a cursor. - Depending on how the cursor or SSIS logic is coded, it may be possible
to restart at the point of failure based on a
checkpoint or marking each
row with the cursor. However, with a set-based approach that may not
be the case until an entire set of data is completed. As such, troubleshooting
the row with the problem may be more difficult.
SQL Server Cursor Types
Simon Liew has written a detailed technical tip on five
Different Ways to Write a Cursor in SQL Server which includes the following:
- Most Common SQL Server Cursor Syntax
- SQL Server Cursor as a Variable
- SQL Server Cursor as Output of a Stored Procedure
- SQL Server Cursor Current Of Example
- SQL Server Cursor Alternative with a WHILE Loop
This tip provides sample code that can be used to expand your SQL Server
cursor options beyond the syntax in this tip.
Example SQL Server Cursor
Here is an example cursor from tip
Simple script to backup all SQL Server
databases where backups are issued in a serial manner:
DECLARE @name VARCHAR(50) — database name
DECLARE @path VARCHAR(256) — path for backup files
DECLARE @fileName VARCHAR(256) — filename for backup
DECLARE @fileDate VARCHAR(20) — used for file name
SET @path = «C:\Backup\»
SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112)
DECLARE db_cursor CURSOR FOR
SELECT name
FROM MASTER.dbo.sysdatabases
WHERE name NOT IN («master»,»model»,»msdb»,»tempdb»)
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
SET @fileName = @path + @name + «_» + @fileDate + «.BAK»
BACKUP DATABASE @name TO DISK = @fileName
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
DEALLOCATE db_cursor
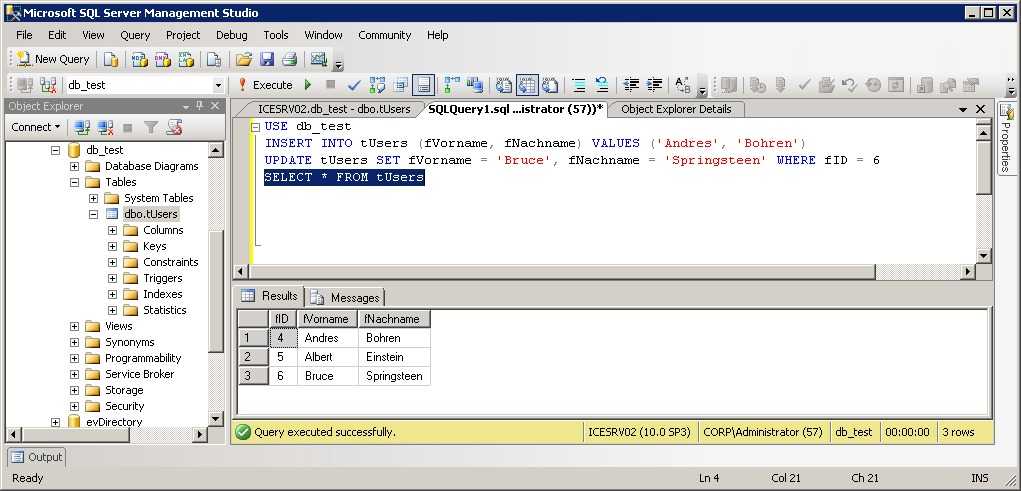
Что такое JOIN?
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Предназначен для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор.
Особенностями операции соединения являются следующее:
- в схему таблицы-результата входят столбцы обеих исходных таблиц (таблиц-операндов), то есть схема результата является «сцеплением» схем операндов;
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы-операнда со строкой второй таблицы-операнда;
- при необходимости соединения не двух, а нескольких таблиц, операция соединения применяется несколько раз (последовательно).
Предложение WITH RESULTS SETS инструкции EXECUTE
В SQL Server 2012 для инструкции EXECUTE вводится предложение WITH RESULTS SETS, посредством которого при выполнении определенных условий можно изменять форму результирующего набора хранимой процедуры.
Следующие два примера помогут объяснить это предложение. Первый пример является вводным примером, который показывает, как может выглядеть результат, когда опущено предложение WITH RESULTS SETS:
Процедура EmployeesInDept — это простая процедура, которая отображает табельные номера и фамилии всех сотрудников, работающих в определенном отделе. Номер отдела является параметром процедуры, и его нужно указать при ее вызове. Выполнение этой процедуры выводит таблицу с двумя столбцами, заголовки которых совпадают с наименованиями соответствующих столбцов таблицы базы данных, т.е. Id и LastName. Чтобы изменить заголовки столбцов результата (а также их тип данных), в SQL Server 2012 применяется новое предложение WITH RESULTS SETS. Применение этого предложения показано в примере ниже:
Результат выполнения хранимой процедуры, вызванной таким способом, будет следующим:
Как можно видеть, запуск хранимой процедуры с использованием предложения WITH RESULT SETS в инструкции EXECUTE позволяет изменить наименования и тип данных столбцов результирующего набора, выдаваемого данной процедурой. Таким образом, эта новая функциональность предоставляет большую гибкость в исполнении хранимых процедур и помещении их результатов в новую таблицу.
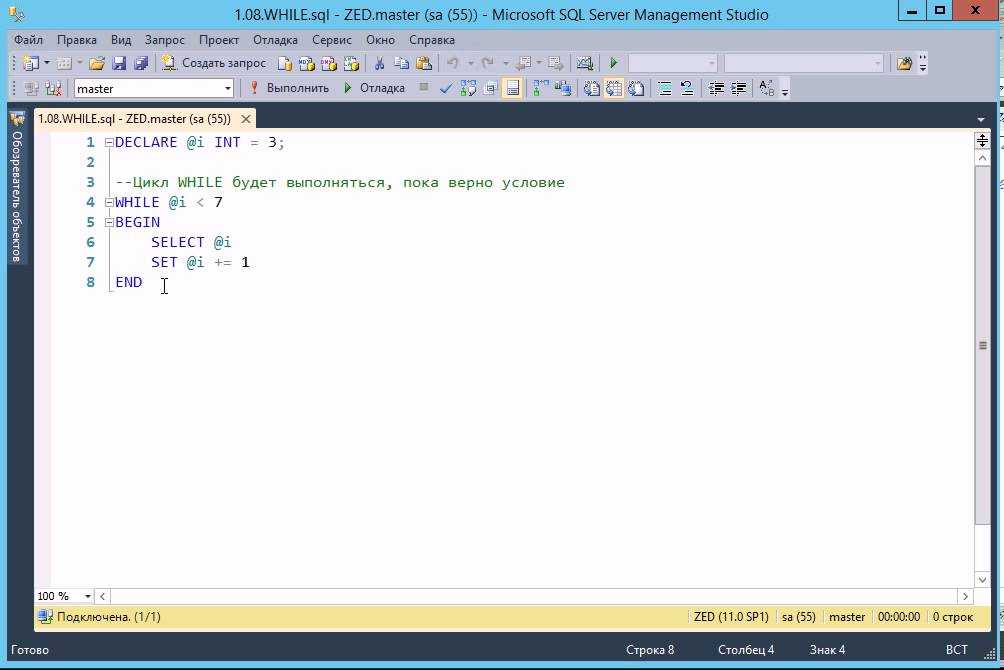
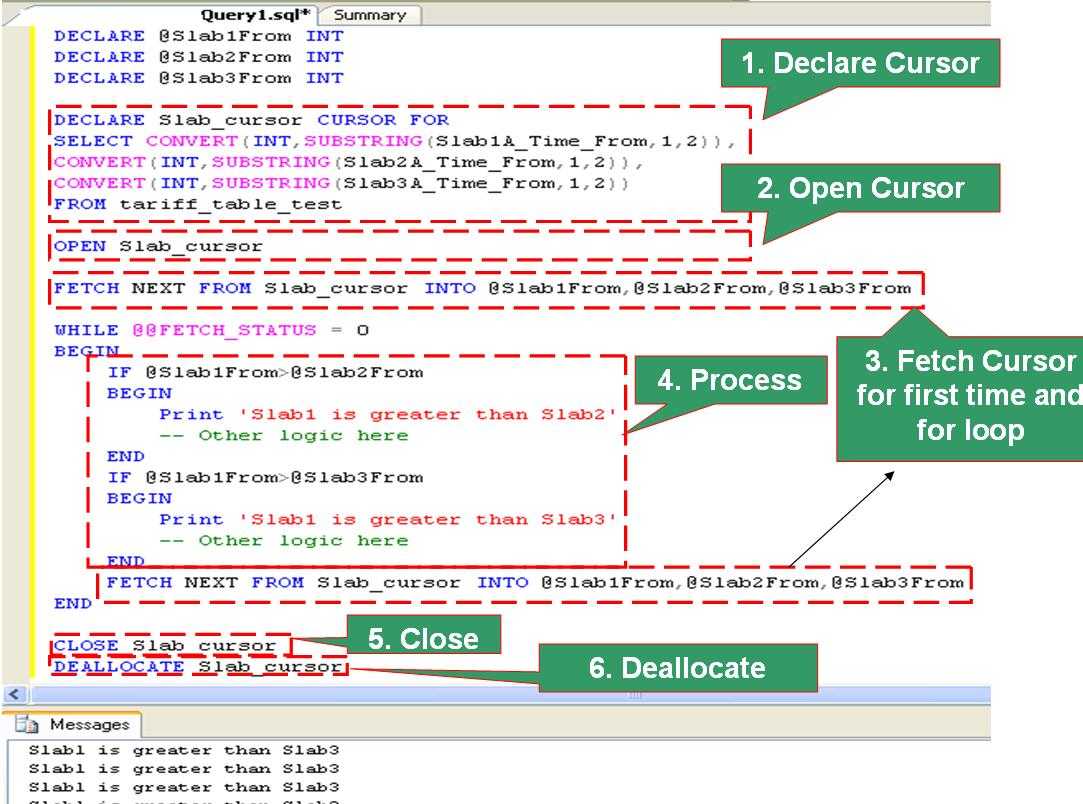
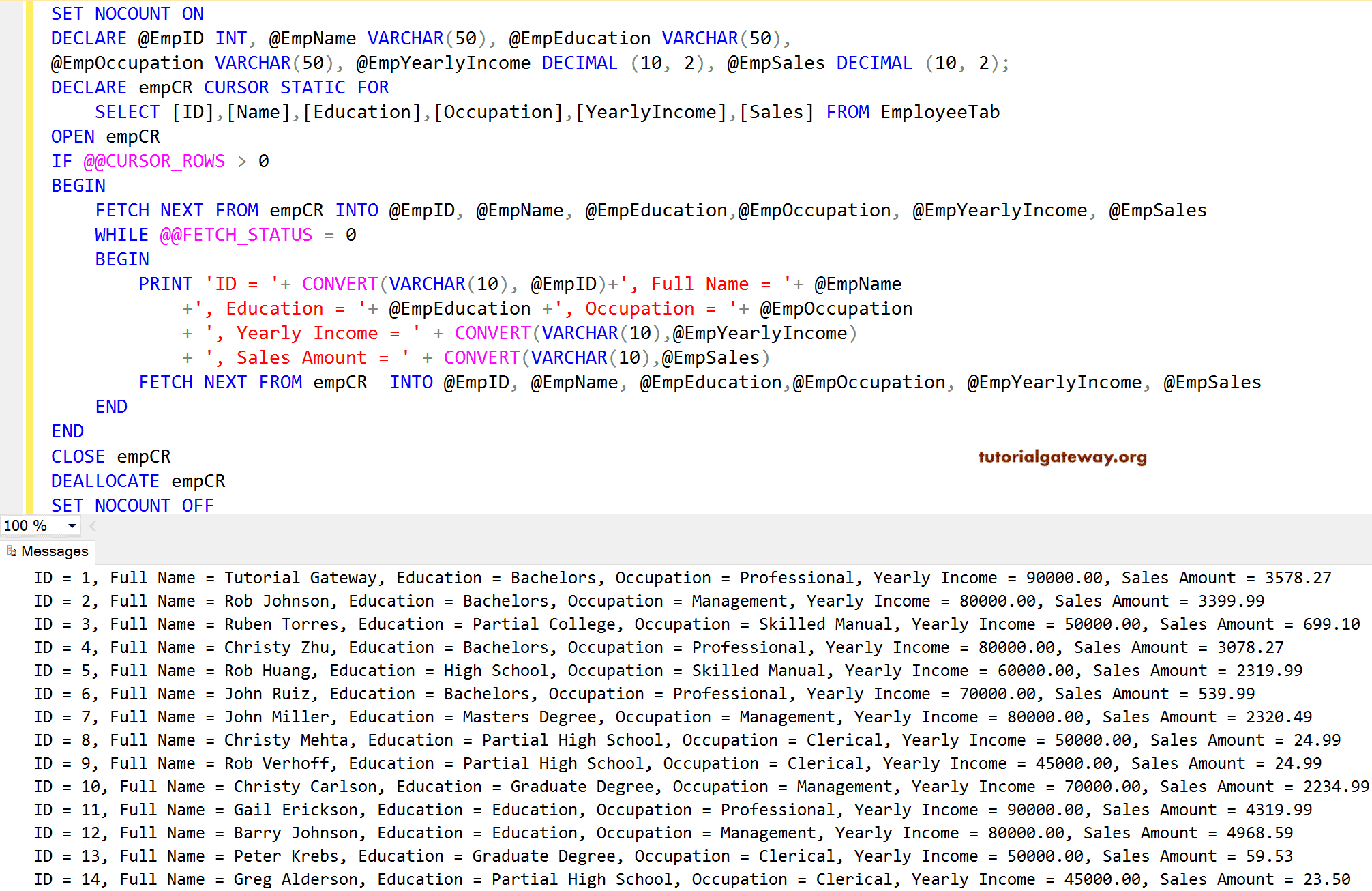
Как написать курсор в SQL Server
Создание курсора – процесс последовательный. Давайте проделаем эти шаги:
- Объявите ваши переменные (для имен файлов, имен баз данных, номеров счетов и т.д.), которые вам нужны для реализации логики, и присвойте им начальные значения. Эта логика будет меняться в зависимости от задачи.
Объявите курсор с конкретным именем (как db_cursor в этом примере), которое вы будете использовать на протяжении всей логики вместе с бизнес-логикой (оператор SELECT) для наполнения курсора требуемыми записями. Имя курсора может быть осмысленным. Сразу после этого следует открытие курсора. Эта логика будет меняться в зависимости от задачи.
Извлеките запись из курсора, чтобы начать обработку.Замечание. Число переменных, объявленных для курсора, число столбцов в операторе SELECT и число переменных в операторе FETCH одинаково. В рассматриваемом примере имеется только одна переменная для извлечения данных из единственного столбца. Однако если должно быть пять элементов данных в курсоре, то необходимо также указать пять переменных в операторе FETCH.
Обработка данных уникальна для каждого набора логики. Это может быть вставка, обновление, удаление и т.д. для каждой извлекаемой строки данных. Это самый важный набор логики в данном процессе, который выполняется для каждой строки. Эта логика будет меняться в зависимости от задачи.
Извлечение следующей записи из курсора, как это делалось на шаге 3, а затем шаг 4 снова повторяется при обработке выбранных данных.
По завершению обработки всех данных курсор закрывается.
На последнем и важном шаге вам необходимо освободить курсор, т.е. освободить все удерживаемые внутренние ресурсы SQL Server.
Теперь рассмотрим с этой точки зрения приведенные ниже примеры, чтобы узнать, когда использовать курсоры SQL Server и как это делать.
— 1 – Объявление переменных — * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * DECLARE @name VARCHAR(50) — имя базы данных DECLARE @path VARCHAR(256) — путь в файлам резервных копий DECLARE @fileName VARCHAR(256) — имя файла бэкапа DECLARE @fileDate VARCHAR(20) — используется для имени файла — Инициализация переменных — * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SET @path = ‘C:Backup’ SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112) — 2 – Объявление курсора DECLARE db_cursor CURSOR FOR — Наполнить курсор вашей логикой — * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SELECT name FROM MASTER.dbo.sysdatabases WHERE name NOT IN (‘master’,’model’,’msdb’,’tempdb’) — Открыть курсор OPEN db_cursor — 3 – Извлечь следующую запись из курсора FETCH NEXT FROM db_cursor INTO @name — Проверить состояние курсора WHILE @@FETCH_STATUS = 0 BEGIN — 4 – Начало настраиваемой бизнес-логики — * ЗДЕСЬ ЗАМЕНИТЬ НА ВАШ КОД * SET @fileName = @path + @name + ‘_’ + @fileDate + ‘.BAK’ BACKUP DATABASE @name TO DISK = @fileName — 5 – Извлечь следующую запись из курсора FETCH NEXT FROM db_cursor INTO @name END — 6 – Закрыть курсор CLOSE db_cursor — 7 – Освободить ресурсы DEALLOCATE db_cursor