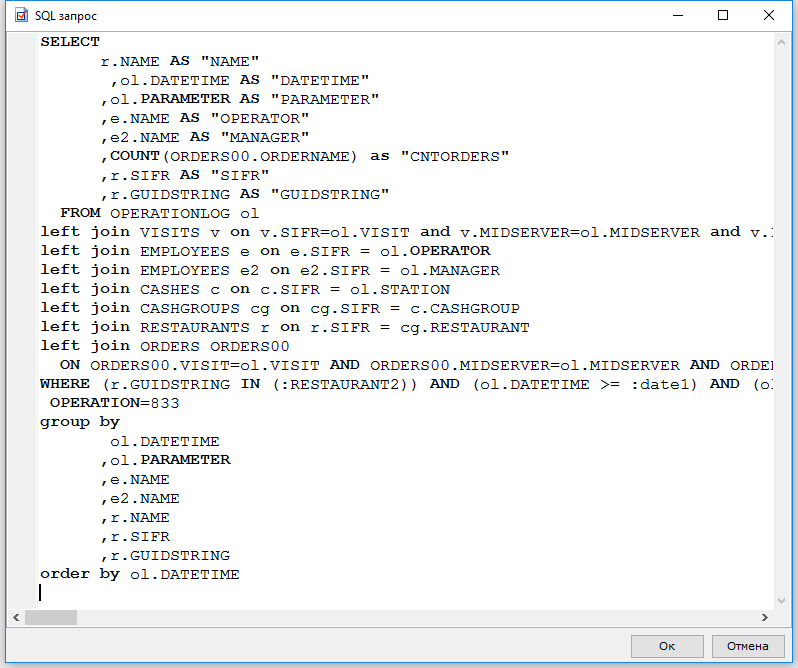
Введение
Эта статья – первая в серии из трёх статей, посвященных обработке ошибок и транзакций в SQL Server. Её цель – дать вам быстрый старт в теме обработки ошибок, показав базовый пример, который подходит для большей части вашего кода. Эта часть написана в расчете на неопытного читателя, и по этой причине я намеренно умалчиваю о многих деталях. В данный момент задача состоит в том, чтобы рассказать как без упора на почему. Если вы принимаете мои слова на веру, вы можете прочесть только эту часть и отложить остальные две для дальнейших этапов в вашей карьере.
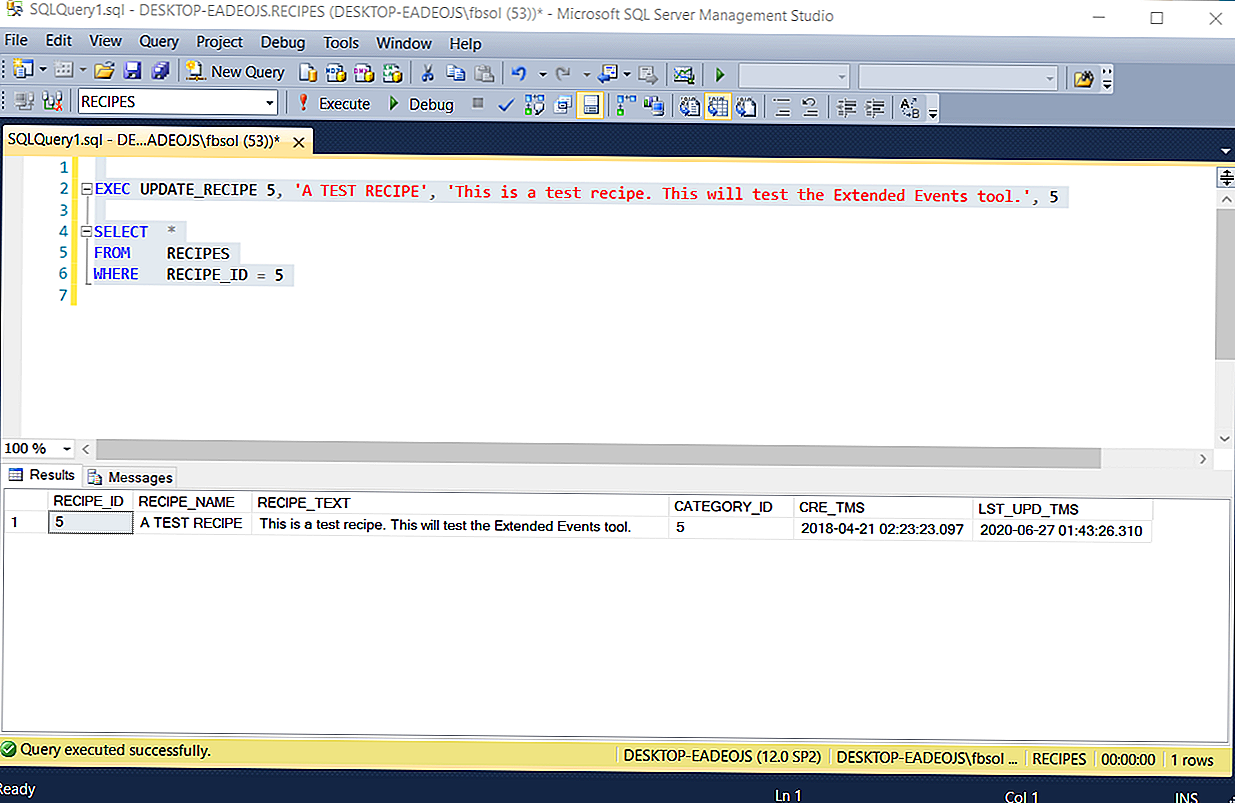
Все статьи описывают обработку ошибок и транзакций в SQL Server для версии 2005 и более поздних версий.
1.1 Зачем нужна обработка ошибок?
Почему мы обрабатываем ошибки в нашем коде? На это есть много причин. Например, на формах в приложении мы проверяем введенные данные и информируем пользователей о допущенных при вводе ошибках. Ошибки пользователя – это предвиденные ошибки. Но нам также нужно обрабатывать непредвиденные ошибки. То есть, ошибки могут возникнуть из-за того, что мы что-то упустили при написании кода. Простой подход – это прервать выполнение или хотя бы вернуться на этап, в котором мы имеем полный контроль над происходящим. Недостаточно будет просто подчеркнуть, что совершенно непозволительно игнорировать непредвиденные ошибки. Это недостаток, который может вызвать губительные последствия: например, стать причиной того, что приложение будет предоставлять некорректную информацию пользователю или, что еще хуже, сохранять некорректные данные в базе
Также важно сообщать о возникновении ошибки с той целью, чтобы пользователь не думал о том, что операция прошла успешно, в то время как ваш код на самом деле ничего не выполнил
Простые и системные переменные
Объявить переменную в хранимой подпрограмме можно в любом месте тела подпрограммы (внутри блока BEGIN .. END). Синтаксис оператора объявления переменной:
DECLARE имя … тип_данных
Объявить переменную в хранимой подпрограмме можно в любом месте тела подпрограммы. Если параметр DEFAULT отсутствует, то переменная инициализируется со значением NULL.
Для присвоения значения переменной может быть использован оператор SET. В следующем примере переменной S присваивается текстовое значение, которое затем выводится на экран:
CREATE PROCEDURE Hello_World()
BEGIN
DECLARE S VARCHAR(20);
SET S=‘Hello, world!’;
SELECT(S);
END
//
Результат вызова процедуры на выполнение:
![]()
Иногда бывает необходимо присвоить переменной значение, возвращаемое в результате запроса. Это можно сделать при помощи оператора SELECT..INTO. При этом запрос должен возвращать только одну строку. Если запрос возвращает пустой результат, это приведет к ошибке 1329 (No data). Если запрос содержит более одной строки, это приведет к ошибке 1172 (Result consisted of more than one row). Количество строк, возвращаемых запросом, можно ограничить опцией LIMIT оператора SELECT. Данная опция имеет два параметра. Первый параметр указывает смещение возвращаемого набора строк относительно начала, второй – количество возвращаемых строк. При использовании опции только с одним параметром он интерпретируется как количество возвращаемых строк от начала результата. Таким образом, совместно с оператором SELECT..INTO можно использовать опцию LIMIT 1. Следующая процедура выводит наименование самой тяжелой детали:
CREATE PROCEDURE Heavy()
BEGIN
DECLARE S VARCHAR(20);
SELECT weight INTO S FROM Parts ORDER BY Weight DESC LIMIT 1;
SELECT(S);
END
//
![]()
В процессе выполнения оператора SELECT..INTO выполняется неявное приведение типа возвращаемого запросом значения типу переменной:
CREATE PROCEDURE Parts_count()
BEGIN
DECLARE S VARCHAR(20);
SELECT count(*) INTO S FROM Parts;
SELECT(S);
END
//
![]()
Разница между простыми и системными переменными в том, что системные переменные доступны извне хранимой процедуры. Системную переменную не нужно инициализировать. Разница в простой и системной переменной пользовании префикса @ в имени системной переменной.



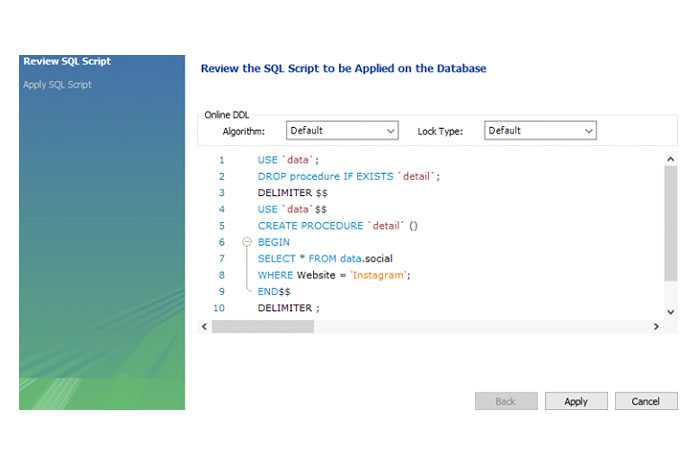
SET @S=‘Hello, world!’;
Значение системной переменной можно узнать после выполнения хранимой процедуры:
CREATE PROCEDURE Parts_count()
BEGIN
SELECT count(*) INTO @S FROM Parts;
END
//
![]()
Курсоры (MySQL Cursors)
Курсоры позволяют пройтись по всем полученным результатам запроса. На теории объяснить сложно, покажу на практике. Добавим еще одну таблицу к нашей базе данных — hits:
CREATE TABLE `tags` ( `id` INT NOT NULL AUTO_INCREMENT , `tag` VARCHAR(255) NOT NULL , PRIMARY KEY ( `id` ) ) ENGINE = MYISAM
Сюда мы будем записывать все тэги из всех тем. Хранимая процедура будет выглядеть примерно так:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE PROCEDURE `procedure3`()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE sTag VARCHAR(255);
DECLARE iCount INT DEFAULT 0;
DECLARE rCursor CURSOR FOR
SELECT `tag` FROM `threads` WHERE 1;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=1;
OPEN rCursor;
FETCH rCursor INTO sTag;
WHILE done = 0 DO
SELECT COUNT(*) INTO iCount FROM `tags` WHERE `tag` = sTag;
IF iCount = 0 THEN
INSERT INTO `tags` (`tag`) VALUES (sTag);
END IF;
FETCH rCursor INTO sTag;
END WHILE;
CLOSE rCursor;
END
|
Подробно. Процедура пройдет через каждую тему, каждый тег пробьет по таблице tags, и если данный тег отсутствует, то она его добавит.
Курсор для запроса SELECT, который выберет теги из всех тем (WHERE 1). После курсора объявляем что-то вроде исключения — что делать, когда результаты кончатся (SQLSTATE ‘02000′ означает это окончание). В этом случае мы в переменную done запишем 1, чтобы в последствии выйти из цикла.
Открываем курсор, и получаем первую запись. Дальше в цикле — Выбираем количество совпадений из таблицы тегов для текущего тега и помещаем результат в переменную iCount. Если результатов нет, то запросом INSERT вставляем новый тег.
В конце концов закрываем курсор и выходим из процедуры. Ну вот и всё.
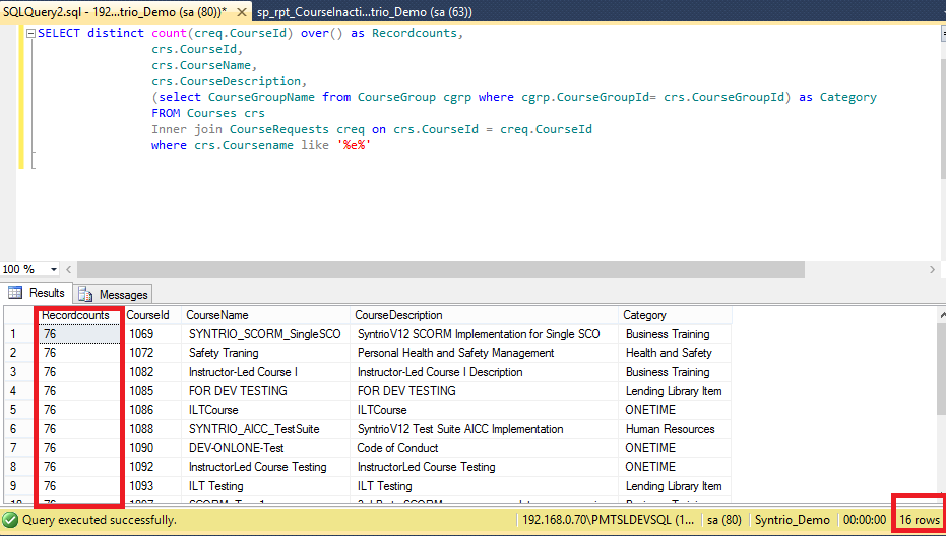
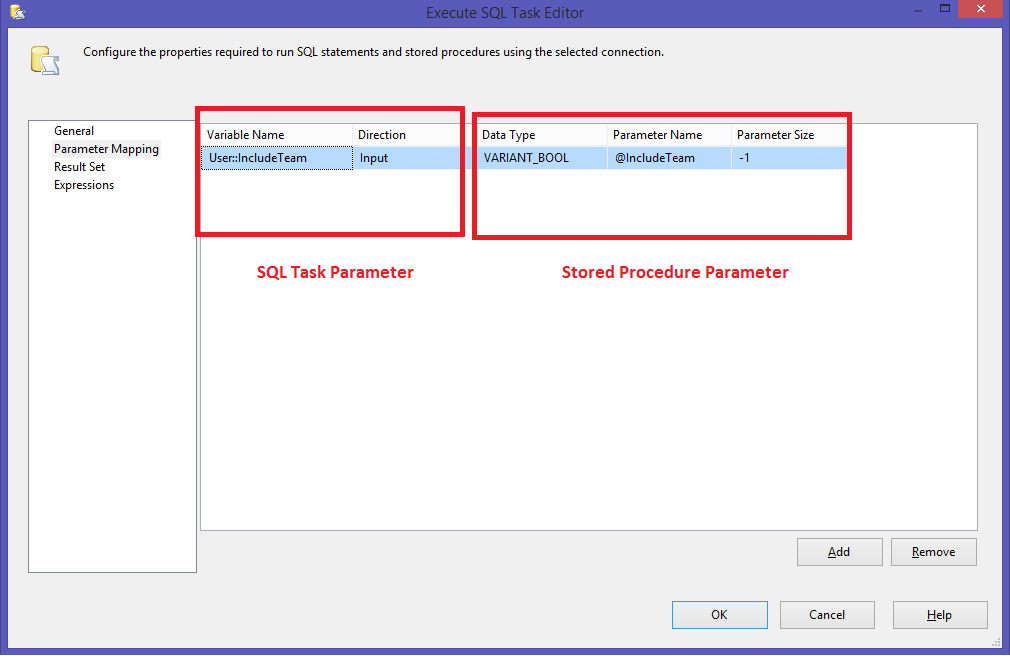
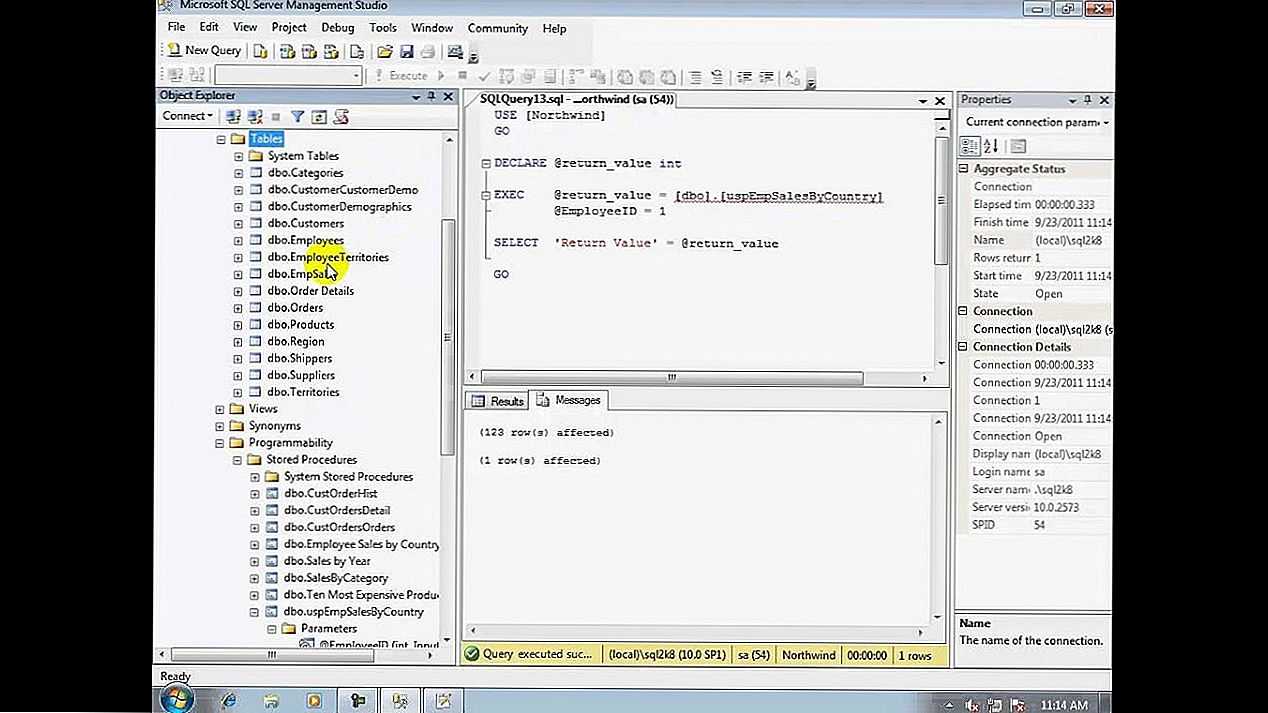
Working with Parameters
is a really simple stored procedureit simply displays the results of a statement. Typically stored procedures do not display results; rather, they return them into variables that you specify.
Variable A named location in memory, used for temporary storage of data.
Here is an updated version of (you’ll not be able to create the stored procedure again if you did not previously drop it):
CREATE PROCEDURE productpricing( OUT pl DECIMAL(8,2), OUT ph DECIMAL(8,2), OUT pa DECIMAL(8,2) ) BEGIN SELECT Min(prod_price) INTO pl FROM products; SELECT Max(prod_price) INTO ph FROM products; SELECT Avg(prod_price) INTO pa FROM products; END;
This stored procedure accepts three parameters: to store the lowest product price, to store the highest product price, and to store the average product price (and thus the variable names). Each parameter must have its type specified; here a decimal value is used. The keyword is used to specify that this parameter is used to send a value out of the stored procedure (back to the caller). MySQL supports parameters of types (those passed to stored procedures), (those passed from stored procedures, as we’ve used here), and (those used to pass parameters to and from stored procedures). The stored procedure code itself is enclosed within and statements as seen before, and a series of statements are performed to retrieve the values that are then saved into the appropriate variables (by specifying the keyword).
Parameter Datatypes The datatypes allowed in stored procedure parameters are the same as those used in tables.
Note that a recordset is not an allowed type, and so multiple rows and columns could not be returned via a parameter. This is why three parameters (and three statements) are used in the previous example.
To call this updated stored procedure, three variable names must be specified, as seen here:
CALL productpricing(@pricelow,
@pricehigh,
@priceaverage);
As the stored procedure expects three parameters, exactly three parameters must be passed, no more and no less. Therefore, three parameters are passed to this statement. These are the names of the three variables that the stored procedure will store the results in.
Variable Names All MySQL variable names must begin with .
When called, this statement does not actually display any data. Rather, it returns variables that can then be displayed (or used in other processing).
To display the retrieved average product price you could do the following:
SELECT @priceaverage;
+---------------+ | @priceaverage | +---------------+ | 16.133571428 | +---------------+
To obtain all three values, you can use the following:
SELECT @pricehigh, @pricelow, @priceaverage;
+------------+-----------+---------------+ | @pricehigh | @pricelow | @priceaverage | +------------+-----------+---------------+ | 55.00 | 2.50 | 16.133571428 | +------------+-----------+---------------+
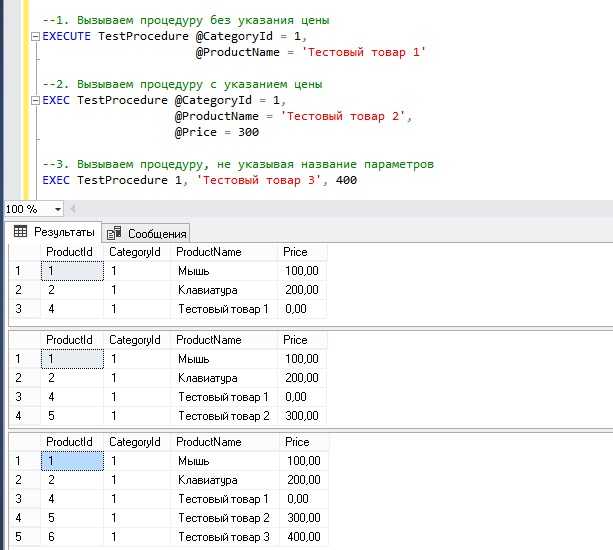
Here is another example, this time using both and parameters. accepts an order number and returns the total for that order:
CREATE PROCEDURE ordertotal( IN onumber INT, OUT ototal DECIMAL(8,2) ) BEGIN SELECT Sum(item_price*quantity) FROM orderitems WHERE order_num = onumber INTO ototal; END;
is defined as because the order number is passed in to the stored procedure. is defined as because the total is to be returned from the stored procedure. The statement used both of these parameters, the clause uses to select the right rows, and uses to store the calculated total.
To invoke this new stored procedure you can use the following:
CALL ordertotal(20005, @total);
Two parameters must be passed to ; the first is the order number and the second is the name of the variable that will contain the calculated total.
To display the total you can then do the following:
SELECT @total;
+--------+ | @total | +--------+ | 149.87 | +--------+
has already been populated by the statement to , and displays the value it contains.
To obtain a display for the total of another order, you would need to call the stored procedure again, and then redisplay the variable:
CALL ordertotal(20009, @total); SELECT @total;
Настройка клиентов syslog
Linux (rsyslog)
Для отправки syslog сообщений с linux-клиента, необходимо добавить в конфигурационный файл следующие строки:
# отправлять от любого источника (*) с любым приоритетом (*) по UDP на 10.0.0.1 *.* @10.0.0.1 # отправлять от любого источника (*) с любым приоритетом (*) по TCP на 10.0.0.1 *.* @@10.0.0.1
Ну и после этого — рестарт rsyslog. Если нужно настроить разграничение отправки сообщений по приоритетам, то нужно заменить *.* на свое значение в соответствии со статьей syslog, описывающей принципы сортировки.
Cisco
as53xx231#conf t Enter configuration commands, one per line. End with CNTL/Z. as53xx231(config)#logging 10.0.0.1 as53xx231(config)#exit
VMware ESXi
Для старенького гипервизора:
В /etc/syslog.conf необходимо добавить следующее:
*.* @10.0.0.1 # в файерволе необходимо разрешить syslog и сохранить это: esxcfg-firewall -o 514,udp,out,syslog esxcfg-firewall -l # перезапускаем syslog service syslog restart
В последних версиях гипервизора все делается через гуишного клиента. В настройках гипервизора Advansed -> Syslog -> remote указать адрес rsyslog сервера.


Исключения
Исключения — исключительные событие в PHP, в отличии от ошибок не просто констатируют наличие проблемы, а требуют от программиста дополнительных действий по обработке каждого конкретного случая.
К примеру, скрипт должен сохранить какие-то данные в кеш файл, если что-то пошло не так (нет доступа на запись, нет места на диске), генерируется исключение соответствующего типа, а в обработчике исключений принимается решение — сохранить в другое место или сообщить пользователю о проблеме.
В каких случаях стоит применять исключения:
Соответственно ловить данные исключения будем примерно так:
В данном примере приведен очень простой сценарий обработки исключений, когда у нас любая исключительная ситуация обрабатывается на один манер. Но зачастую, различные исключения требуют различного подхода к обработке, и тогда следует использовать коды исключений и задать иерархию исключений в приложении:
Теперь, если использовать эти исключения то можно получить следующий код:
Важно помнить, что Exception — это прежде всего исключительное событие, иными словами исключение из правил. Не нужно использовать их для обработки очевидных ошибок, к примеру, для валидации введённых пользователем данных (хотя тут не всё так однозначно)
При этом обработчик исключений должен быть написан в том месте, где он будет способен его обработать. К примеру, обработчик для исключений вызванных недоступностью файла для записи должен быть в методе, который отвечает за выбор файла или методе его вызывающем, для того что бы он имел возможность выбрать другой файл или другую директорию.
Чтобы избежать подобной ситуации следует использовать функцию set_exception_handler() и установить обработчик для исключений, которые брошены вне блока try-catch и не были обработаны. После вызова такого обработчика выполнение скрипта будет остановлено:
Ещё расскажу про конструкцию с использованием блока finally — этот блок будет выполнен вне зависимости от того, было выброшено исключение или нет:
Для понимания того, что это нам даёт приведу следующий пример использования блока finally :
Т. е. запомните — блок finally будет выполнен даже в том случае, если вы в блоке catch пробрасываете исключение выше (собственно именно так он и задумывался).
Для вводной статьи информации в самый раз, кто жаждет ещё подробностей, то вы их найдёте в статье Исключительный код
PHP7 — всё не так, как было раньше
Так, вот вы сейчас всю информацию выше усвоили и теперь я буду грузить вас нововведениями в PHP7, т. е. я буду рассказывать о том, с чем вы будете сталкиваться работая над современным PHP проектом. Ранее я вам рассказывал и показывал на примерах какой костыль нужно соорудить, чтобы отлавливать критические ошибки, так вот — в PHP7 это решили исправить, но? как обычно? завязались на обратную совместимость кода, и получили хоть и универсальное решение, но оно далеко от идеала. А теперь по пунктам об изменениях:
Сложно? Теперь на примерах, возьмём те, что были выше и слегка модернизируем:
В результате ошибку поймаем и выведем:
И чуть-чуть деталей:
TypeError — для ошибок, когда тип аргументов функции не совпадает с передаваемым типом:
ArithmeticError — могут возникнуть при математических операциях, к примеру когда результат вычисления превышает лимит выделенный для целого числа:
AssertionError — редкий зверь, появляется когда условие заданное в assert() не выполняется:
Полный список предопределённых исключений вы найдёте в официальном мануале, там же иерархия SPL исключений.
Шаг 5: Структуры управления потоками
MySQL поддерживает конструкции IF, CASE, ITERATE, LEAVE LOOP, WHILE и REPEAT для управления потоками в пределах хранимой процедуры. Мы рассмотрим, как использовать IF, CASE и WHILE, так как они наиболее часто используются.
Конструкция IF
С помощью конструкции IF, мы можем выполнять задачи, содержащие условия:
DELIMITER //
CREATE PROCEDURE `proc_IF` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
IF variable1 = 0 THEN
SELECT variable1;
END IF;
IF param1 = 0 THEN
SELECT 'Parameter value = 0';
ELSE
SELECT 'Parameter value <> 0';
END IF;
END //
Конструкция CASE
CASE — это еще один метод проверки условий и выбора подходящего решения. Это отличный способ замены множества конструкций IF. Конструкцию можно описать двумя способами, предоставляя гибкость в управлении множеством условных выражений.
DELIMITER //
CREATE PROCEDURE `proc_CASE` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
CASE variable1
WHEN 0 THEN
INSERT INTO table1 VALUES (param1);
WHEN 1 THEN
INSERT INTO table1 VALUES (variable1);
ELSE
INSERT INTO table1 VALUES (99);
END CASE;
END //
или:
DELIMITER //
CREATE PROCEDURE `proc_CASE` (IN param1 INT)
BEGIN
DECLARE variable1 INT;
SET variable1 = param1 + 1;
CASE
WHEN variable1 = 0 THEN
INSERT INTO table1 VALUES (param1);
WHEN variable1 = 1 THEN
INSERT INTO table1 VALUES (variable1);
ELSE
INSERT INTO table1 VALUES (99);
END CASE;
END //
Конструкция WHILE
Технически, существует три вида циклов: цикл WHILE, цикл LOOP и цикл REPEAT. Вы также можете организовать цикл с помощью техники программирования “Дарта Вейдера”: выражения GOTO. Вот пример цикла:
DELIMITER //
CREATE PROCEDURE `proc_WHILE` (IN param1 INT)
BEGIN
DECLARE variable1, variable2 INT;
SET variable1 = 0;
WHILE variable1 < param1 DO
INSERT INTO table1 VALUES (param1);
SELECT COUNT(*) INTO variable2 FROM table1;
SET variable1 = variable1 + 1;
END WHILE;
END //
Установка rsyslogd
Установка rsyslog (если по какой-то причине он не установлен по умолчанию) сводится к одной команде:
aptitude install rsyslog # в красной шляпе возможен вариант yum install rsyslog
Если, конечно, нет желания . Тогда необходимо прочитать. После установки в Debian, мы будем иметь (показаны наиболее важные):
# файл задает опции, передаваемые демону rsyslogd при запуске /etc/default/rsyslog # стартовый скрипт /etc/init.d/rsyslog # настройки /etc/logrotate.d/rsyslog # основной конфиг /etc/rsyslog.conf # библиотеки для работы сислога /usr/lib/rsyslog/* # бинарник демона, который работает в фоне /usr/sbin/rsyslogd # файлы документации /usr/share/doc/rsyslog/*
Как видно, все элементарно. rsyslog состоит из бинарника и файла конфигурации. Кроме указанных файлов, rsyslog так же использует:
/dev/log - unix сокет для получения локальных логов /var/run/rsyslogd.pid - pid файл для хранения id процесса rsyslogd
Пример обработчика MySQL в хранимых процедурах
В таблице article_tags хранятся связи между статьями и тегами. К каждой статье может относиться несколько тегов и наоборот.
В результате, мы все равно получили список тегов для статьи:
Теперь, мы можем попробовать добавить дубликат ключа, чтобы увидеть результат:
Приоритет обработчиков MySQL
В случае если у вас есть несколько обработчиков, которые имеют право обрабатывать ошибку, MySQL для обработки ошибки будет вызывать наиболее подходящий обработчик.
Предположим, что в хранимой процедуре insert_article_tags_3 мы объявляем три обработчика:
Теперь мы пробуем добавить в таблицу article_tags дубликат ключа через вызов хранимой процедуры:
Как видите, вызывается обработчик кода ошибки MySQL :
Использование проименованных условий ошибки
Начинаем с объявления обработчика ошибки:
Синтаксис оператора DECLARE CONDITION выглядит следующим образом:
Таким образом, мы можем переписать код, приведенный выше, следующим образом:
Этот код, очевидно, более удобен для чтения, нежели предыдущий. Отметим, что объявление условия должно размещаться перед объявлением обработчика или объявлением курсора.
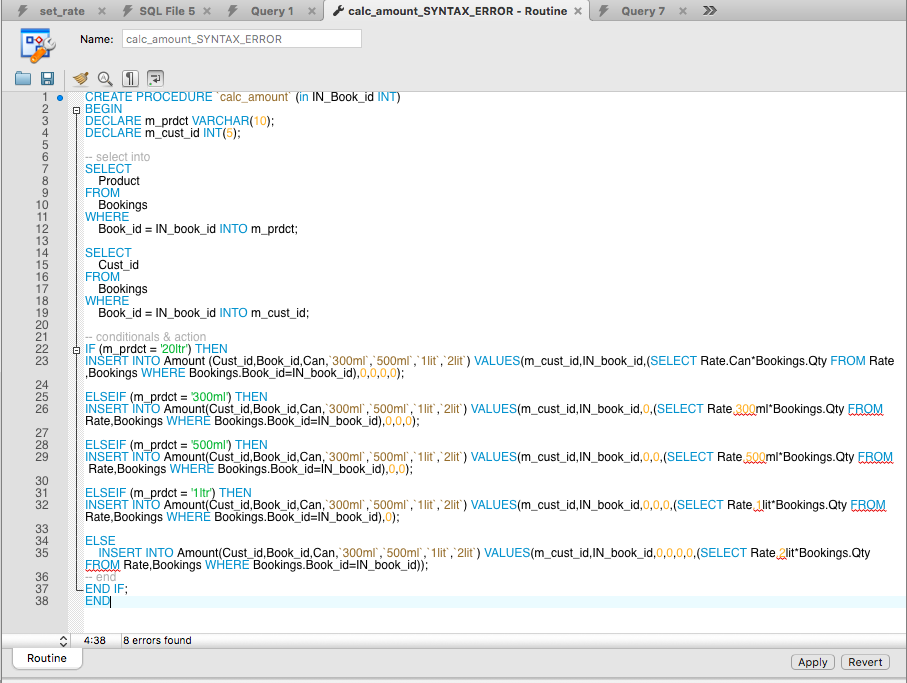
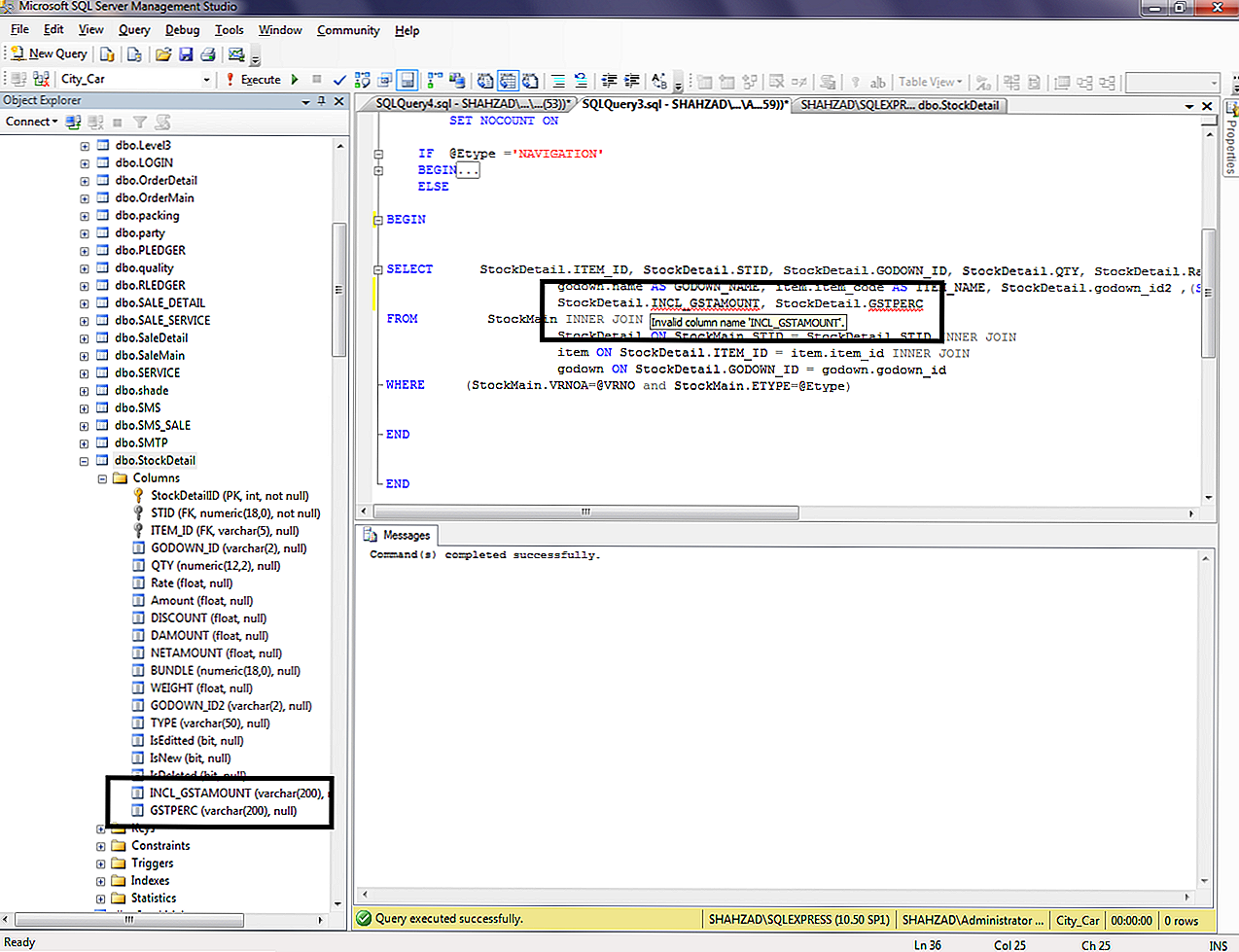
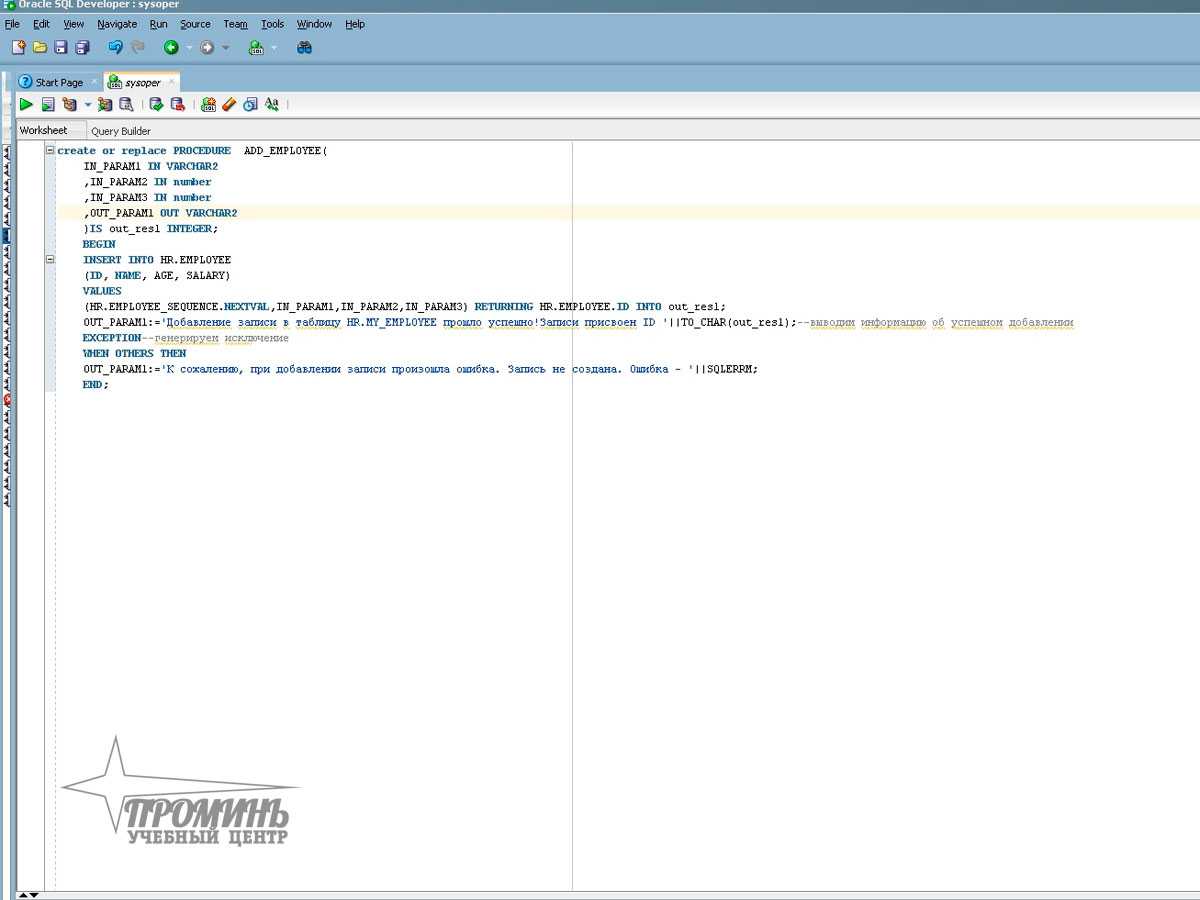
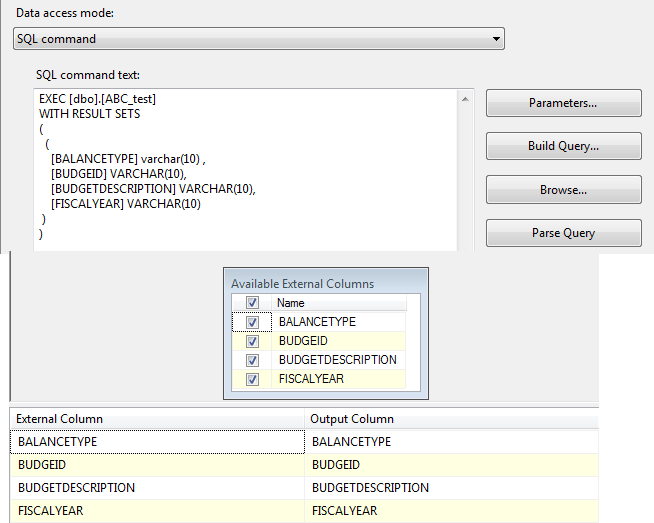
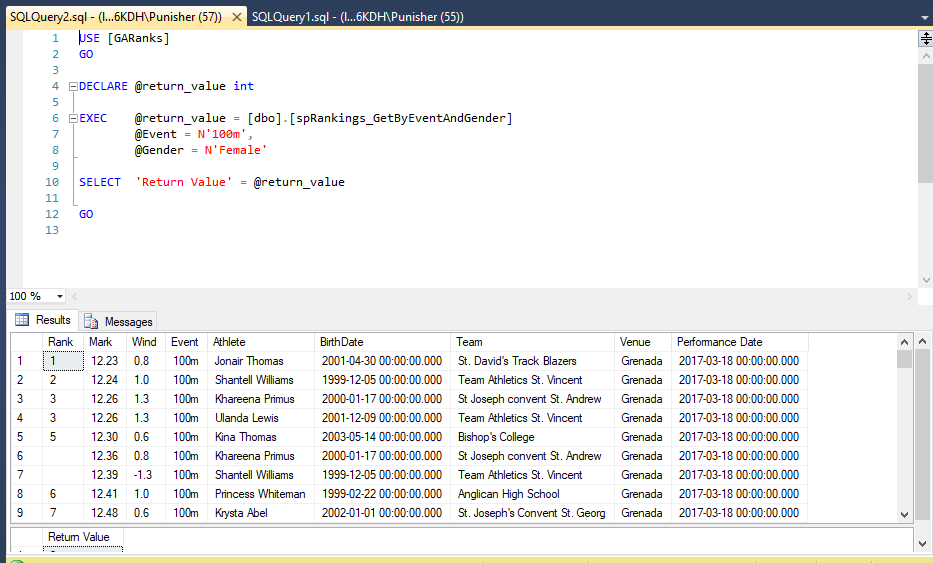
Конструкция TRY CATCH в T-SQL
TRY CATCH – это конструкция языка Transact-SQL для обработки ошибок. Все, что Вы хотите проверять на ошибки, т.е. код в котором могут возникнуть ошибки, Вы помещаете в блок TRY. Начало данного блока обозначается инструкцией BEGIN TRY, а окончание блока, соответственно, END TRY.
Все, что Вы хотите выполнять в случае появления ошибки, т.е. те инструкции, которые должны выполниться, если в блоке TRY возникла ошибка, Вы помещаете в блок CATCH, его начало обозначается BEGIN CATCH, а окончание END CATCH. Если никаких ошибок в блоке TRY не возникло, то блок CATCH пропускается и выполняются инструкции, следующие за ним. Если ошибки возникли, то выполняются инструкции в блоке CATCH, а после выполняются инструкции, следующие за данным блоком, иными словами, все инструкции, следующие за блоком CATCH, будут выполнены, если, конечно же, мы принудительно не завершили выполнение пакета в блоке CATCH.
Сам блок CATCH не передает никаких сведений об обнаруженных ошибках в вызывающее приложение, если это нужно, например, узнать номер или описание ошибки, то для этого Вы можете использовать инструкции SELECT, RAISERROR или PRINT в блоке CATCH.
Важные моменты про конструкцию TRY CATCH в T-SQL
- Блок CATCH должен идти сразу же за блоком TRY, между этими блоками размещение инструкций не допускается;
- TRY CATCH перехватывает все ошибки с кодом серьезности, большим 10, которые не закрывают соединения с базой данных;
- В конструкции TRY…CATCH Вы можете использовать только один пакет и один блок SQL инструкций;
- Конструкция TRY…CATCH может быть вложенной, например, в блоке TRY может быть еще одна конструкция TRY…CATCH, или в блоке CATCH Вы можете написать обработчик ошибок, на случай возникновения ошибок в самом блоке CATCH;
- Оператор GOTO нельзя использовать для входа в блоки TRY или CATCH, он может быть использован только для перехода к меткам внутри блоков TRY или CATCH;
- Обработка ошибок TRY…CATCH в пользовательских функциях не поддерживается;
- Конструкция TRY…CATCH не обрабатывает следующие ошибки: предупреждения и информационные сообщения с уровнем серьезности 10 или ниже, разрыв соединения, вызванный клиентом, завершение сеанса администратором с помощью инструкции KILL.
Функции для получения сведений об ошибках
Для того чтобы получить информацию об ошибках, которые повлекли выполнение блока CATCH можно использовать следующие функции:
- ERROR_NUMBER() – возвращает номер ошибки;
- ERROR_MESSAGE() — возвращает описание ошибки;
- ERROR_STATE() — возвращает код состояния ошибки;
- ERROR_SEVERITY() — возвращает степень серьезности ошибки;
- ERROR_PROCEDURE() — возвращает имя хранимой процедуры или триггера, в котором произошла ошибка;
- ERROR_LINE() — возвращает номер строки инструкции, которая вызвала ошибку.
Если эти функции вызвать вне блока CATCH они вернут NULL.
Пример использования конструкции TRY…CATCH для обработки ошибок
Для демонстрации того, как работает конструкция TRY…CATCH, давайте напишем простую SQL инструкцию, в которой мы намеренно допустим ошибку, например, попытаемся выполнить операцию деление на ноль.
--Начало блока обработки ошибок
BEGIN TRY
--Инструкции, в которых могут возникнуть ошибки
DECLARE @TestVar1 INT = 10,
@TestVar2 INT = 0,
@Rez INT
SET @Rez = @TestVar1 / @TestVar2
END TRY
--Начало блока CATCH
BEGIN CATCH
--Действия, которые будут выполняться в случае возникновения ошибки
SELECT ERROR_NUMBER() AS ,
ERROR_MESSAGE() AS
SET @Rez = 0
END CATCH
SELECT @Rez AS
![]()
В данном случае мы выводим номер и описание ошибки с помощью функций ERROR_NUMBER() и ERROR_MESSAGE(), а также присваиваем переменной с итоговым результатом значение 0, как видим, инструкции после блока CATCH продолжают выполняться.
У меня на этом все, надеюсь, материал был Вам полезен, пока!
Нравится15Не нравится1
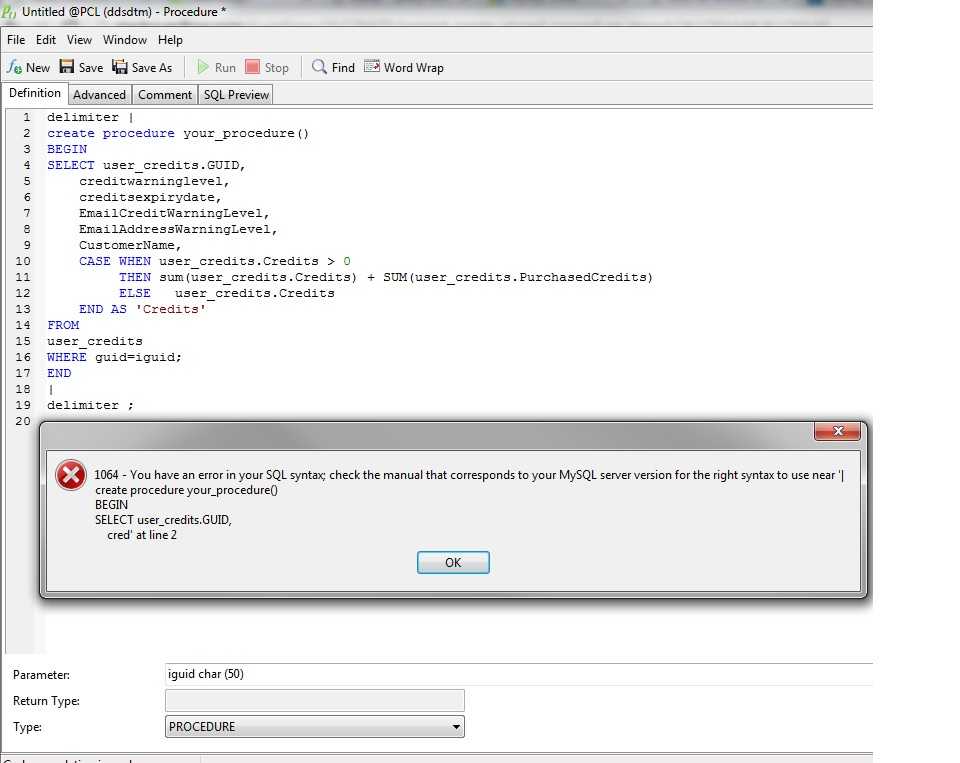
Первая хранимая процедура
Итак, открываем MySQL Administrator, подключаемся к серверу MySQL и создаем новую схему (базу данных): щелкните Catalogs, выберите Create New Schema в области Schemata (Ctrl+N). Назовите ее как-нибудь (например db). Откройте только что созданную схему, выберите вкладку Stored procedures и щелкните кнопку Create Stored Proc. Назовите свою процедуру procedure1. В тело процедуры (между BEGIN и END) впишите следующее:
SELECT "This is my stored procedure";
И нажмите Execute SQL — процедура создана. Откройте MySQL Query Browser, выберите свою схему (db) и впишите следующий запрос:
CALL procedure1();
Вуала! Поздравляю.
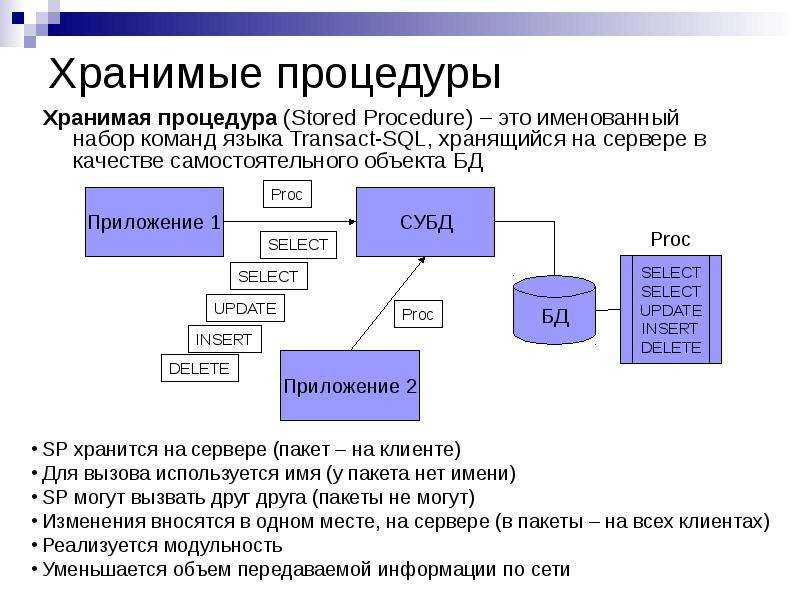
Stored procedures — что это?
Хранимые процедуры появились начиная с 5 версии MySQL. Они позволяют автоматизировать сложные процессы на уровне MySQL, нежели использовать для этого внешние скрипты. Это даёт нам наиболее высокую скорость выполнения, т.к. мы не гоняем большое количество запросов, а всего лишь один раз вызываем ту или иную процедуру (или функцию).
Что для этого нужно? Установите MySQL сервер версии 5 или выше (dev.mysql.com/downloads). Процедуры можно создавать как запросы, например через командную строку MySQL, но для удобства советую скачать MySQL GUI Tools (dev.mysql.com/downloads/gui-tools). Данный пакет включает в себя три программы — MySQL Administrator, MySQL Query Browser и MySQL Migration Toolkit. Нам понадобятся первые две. (Хотя можно обойтись одним MySQL Query Browser, но все эти $$ в хранимых процедурах иногда могут сбить с толку).