
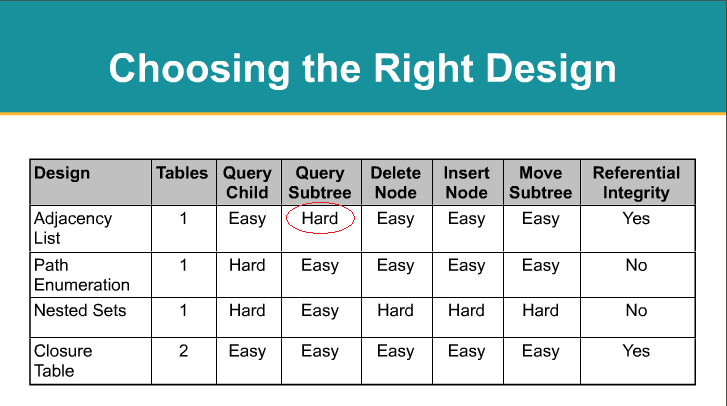
Мотивация
Стандарт реляционная алгебра и реляционное исчисление, а SQL операции, основанные на них, не могут напрямую выразить все желаемые операции над иерархиями. Модель вложенных множеств — решение этой проблемы.
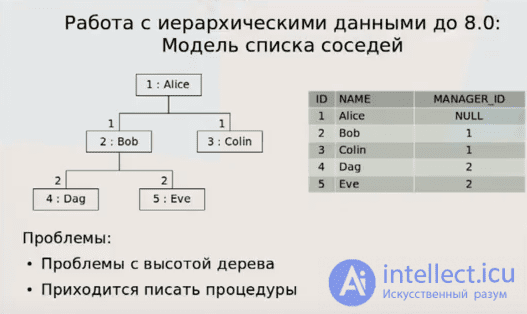
Альтернативным решением является выражение иерархии как отношения родитель-потомок. Celko назвал это модель списка смежности. Если иерархия может иметь произвольную глубину, модель списка смежности не позволяет выполнять такие операции, как сравнение содержимого иерархий двух элементов или определение того, находится ли элемент где-нибудь в подиерархии другого элемента. Когда иерархия имеет фиксированную или ограниченную глубину, операции возможны, но дороги из-за необходимости выполнения одной за уровень. Это часто называют ведомость материалов проблема.[нужна цитата]
Иерархии можно легко выразить, переключившись на база данных графов. В качестве альтернативы существует несколько решений для реляционной модели, которые доступны в качестве обходного пути в некоторых системы управления реляционными базами данных:
- поддержка выделенного тип данных иерархии, например, в SQL иерархический запрос объект;
- расширение реляционного языка с помощью манипуляций с иерархией, например, в вложенная реляционная алгебра.
- расширение реляционного языка с помощью переходное закрытие, например, оператор SQL CONNECT; это позволяет использовать отношение родитель-потомок, но выполнение остается дорогостоящим;
- запросы могут быть выражены на языке, который поддерживает итерацию и охватывает реляционные операции, такие как PL / SQL, T-SQL или язык программирования общего назначения
Когда эти решения недоступны или неосуществимы, необходимо использовать другой подход.
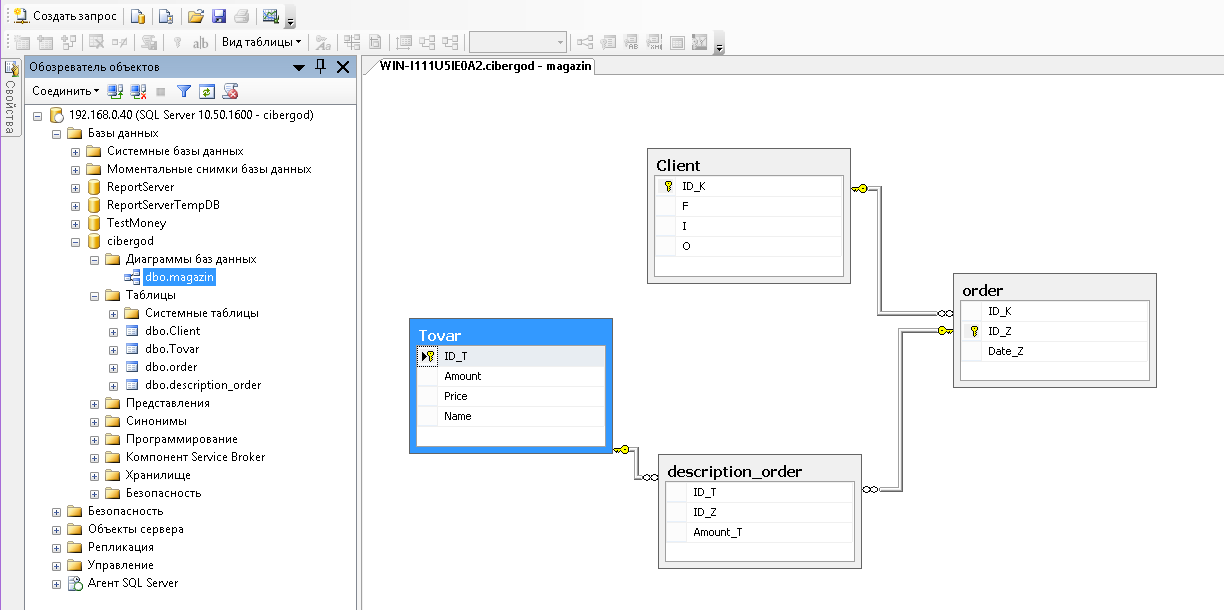
Как хранить в БД древовидные структуры
Древовидные структуры — это такие структуры, где есть родители и дети, например, каталог товаров:
Типичные задачи, которые встречаются при работе с такими структурами:
- выбрать всех детей элемента
- выбрать всех потомков (детей и их детей) элемента
- выбрать цепочку предков элемента (родитель, его родитель, и так далее)
- переместить элемент (и его потомков) из одной группы в другую
- удалить элемент из таблицы (со всеми потомками)
У каждой записи есть идентификатор — уникальное число, он на схеме написан в скобках (думаю, это ты и так знаешь). Рассмотрим способы хранения таких данных.
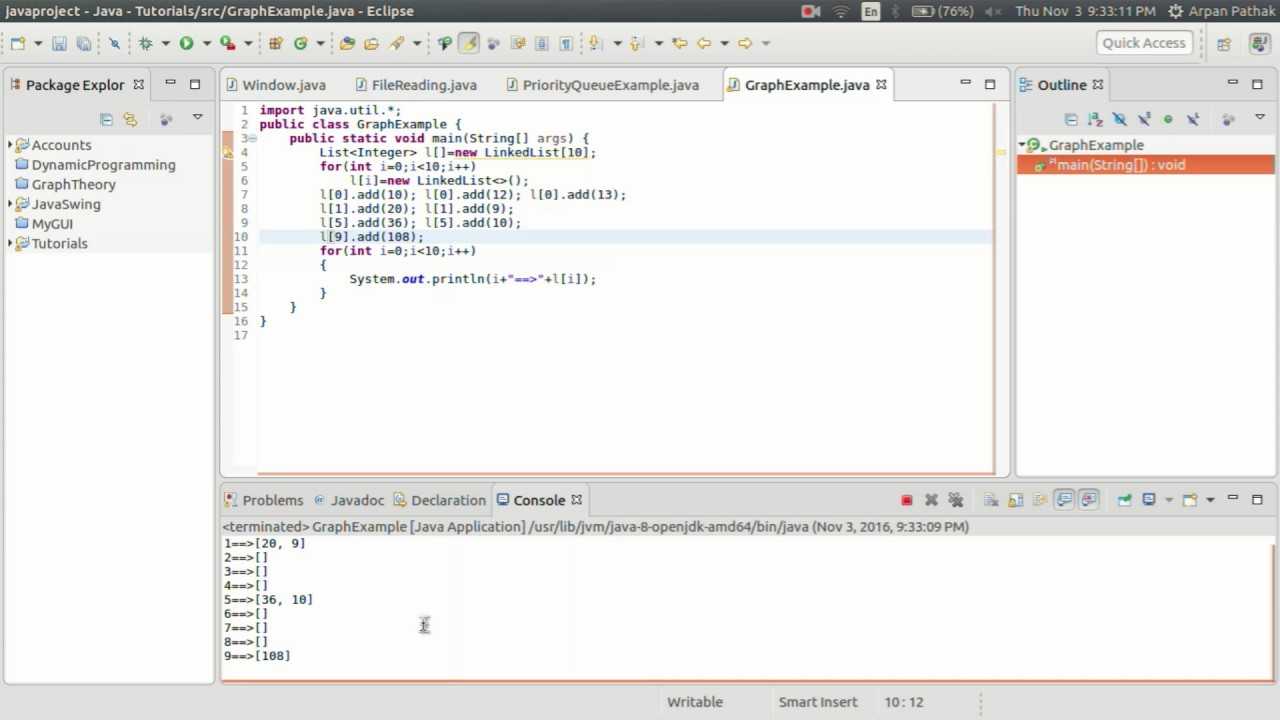
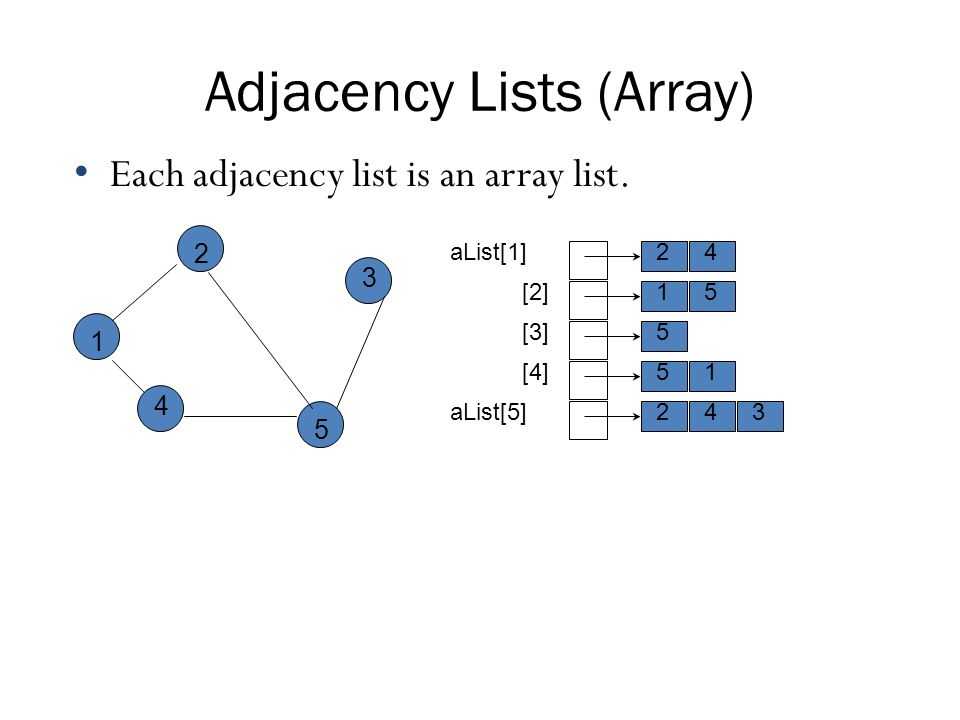
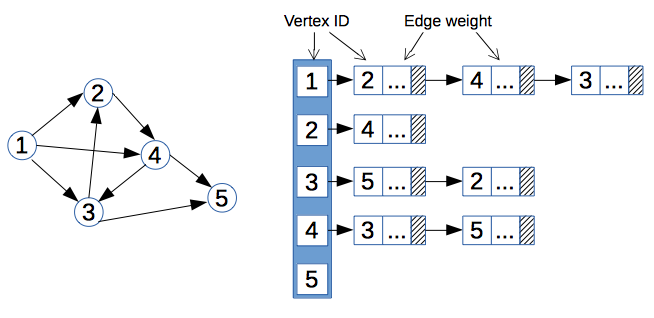
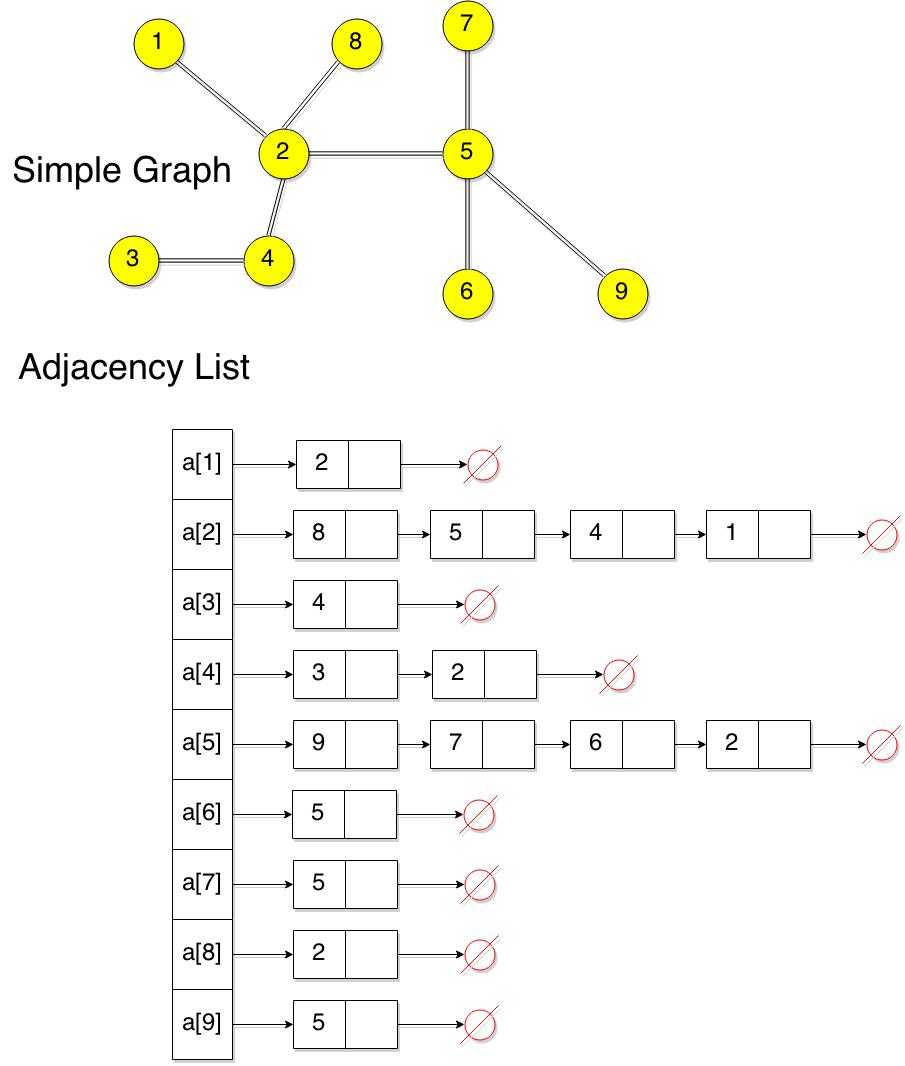
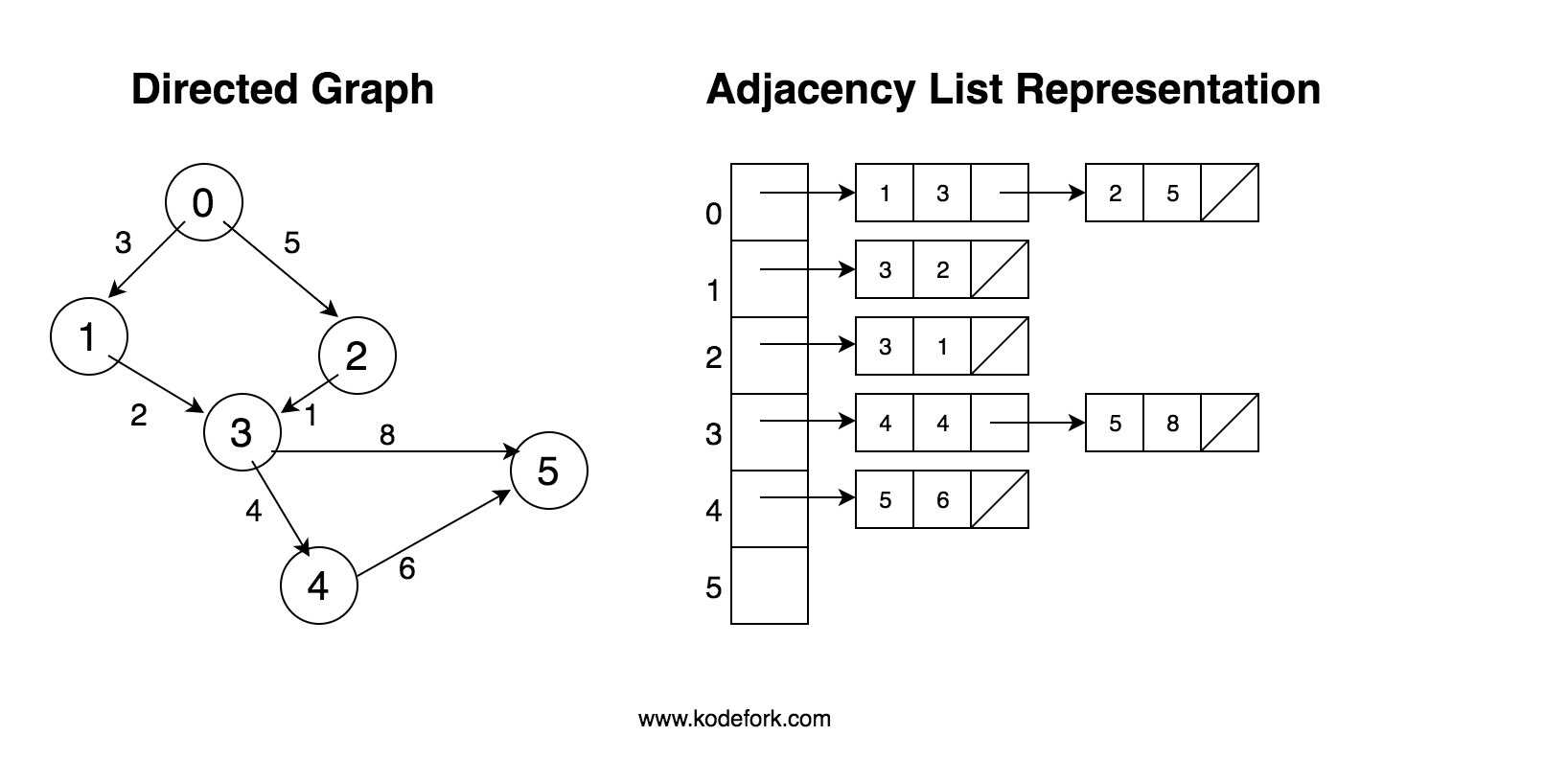
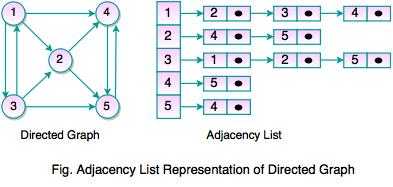
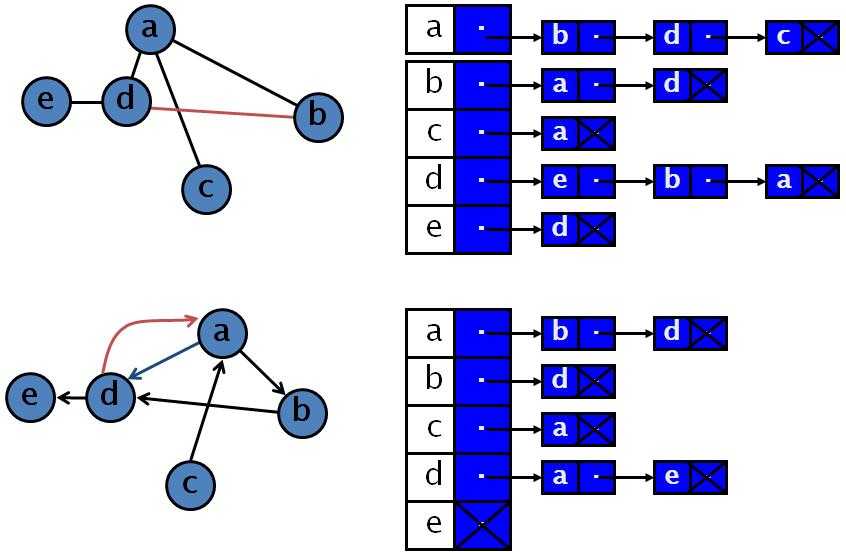
1) Добавить колонку parent_id (метод Adjacency List)
Мы добавляем к каждой записи колонку (и индекс на нее), которая хранит id родительской записи (если родителя нет — NULL). Это самый простой, но самый неэффективный способ. Вот как будет выглядеть вышеприведенное дерево:
Выбрать всех детей просто: , но другие операции требуют выполнения нескольких запросов и на больших деревьях особо неэффективны. Например, выбор всех потомков элемента с идентификатором
- выбрать список детей :id ()
- выбрать список их детей ()
- выбрать список детей детей ()
И так, пока мы не дойдем до самого младшего ребенка. После этого надо еще отсортировать и объединить результаты в дерево.
Плюсом, впрочем, является быстрая вставка и перемещение веток, которые не требуют никаких дополнительных запросов, и простота реализации. Если можно эффективно кешировать выборки, это в общем-то нормальный и работающий вариант (например, для меню сайта). Это может быть годный вариант для часто меняющихся данных.
Иногда еще добавляют поле , указывющее глубину вложенности, но его надо не забыть обновлять при перемещении ветки.
2) Closure table — усовершенствование предыдущего способа
В этом способы мы так же добавляет поле , но для оптимизации рекурсивных выборок создаем дополнительную таблицу, в которой храним всех потомков (детей и их детей) и их глубину относительно родителя каждой записи. Поясню. Дополнительная таблица выглядит так:
Чтобы узнать всех потомков записи, мы (в отличие от предыдущего способа), делаем запрос к дополнительной таблице: , получаем потомков и выбираем их их основной таблицы: . Если таблицы хранятся в одной БД, запросы можно объединить в один с использованием JOIN.
Данные потом надо будет вручную отсортировать в дерево.
Узнать список предков можно тоже одним запросом к таблице связей:
Минусы метода: нужно поддерживать таблицу связей, она может быть огромной (размер посчитайте сами), при вставке новых записей и при перемещении веток нужны сложные манипуляции. Если таблица часто меняется, это не лучший способ.
Плюсы: относительная простота, быстрота выборок.
3) Nested sets
Идея в том, что мы добавляем к каждой записи поля , , , и выстраиваем записи хитрым образом. После этого выборка всех потомков (причем уже отсортированных в нужном порядке) делаетсяпростым запросом вида
Минусы: необходимость пересчитывать / при вставке записей в середину или удалении, сложное перемещение веток, сложность в понимании.
Плюсы: скорость выборки
В общем-то, годный вариант для больших таблиц, которые часто выбираются, но меняются нечасто (например, только через админку, где не критична производительность).
4) Materialized Path
Идея в том, что записи в пределах одной ветки нумеруются по порядку и в каждую запись добавляется поле path, содержащее полный список родителей. Напоминает способ нумерации глав в книгах. Пример:
При этом способе path хранится в поле вроде TEXT или BINARY, по нему делается индекс. Выбрать всех потомков можно запросом , который использует индекс.
Плюс: записи выбираются уже отсортированными в нужном порядке. Простота решения и скорость выборок высокая (1 запрос). Быстрая вставка.
Минусы: при вставке записи в середину надо пересчитывать номера и пути следующих за ней. При удалении ветки, возможно тоже. При перемещении ветки надо делать сложные расчеты. Глубина дерева и число детей у родителя ограничены выделенным дял них местом и длиной path
Этот способ отлично подходит для древовидных комментариев.
Теория: google it
5) Использовать БД с поддержкой иерархии
Я в этом не разбираюсь, может кто-то расскажет, какие есть возможности в БД для нативной поддержки деревьев. Вроде что-то такое есть в MSSQL и Oracle. Только хотелось бы услышать, как именно это оптимизируется и какой метод хранения используется, а не общие слова.
Двоичное дерево поиска
Двоичное дерево поиска
Дерево — это структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов, и так далее.
У двоичного дерева поиска есть два дополнительных свойства:
- Каждый узел имеет до двух дочерних узлов (потомков).
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Временная сложность двоичного дерева поиска
https://youtube.com/watch?v=5cU1ILGy6dM
https://youtube.com/watch?v=Aagf3RyK3Lw
Упражнения от freeCodeCamp
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Что это такое?
О проблемах хранения деревьев в SQL базах данных вопрос можно не поднимать, просто сказать, что они есть.
Одним из методов хранения древовидных структур является Nested Sets (Вложенные множества).
Прежде всего посмотрим как выглядят деревья Nested Sets, как они организованы и в чем удобство их использования.
![]()
На схеме представлено дерево, описанное по всем правилам метода «Вложенных множеств». Квадратами обозначены узлы дерева, синие цифры в верхнем правом и верхнем левом углах узла — уровень и уникальный идентификатор соответственно, а красные цифры в нижних углах — это левый и правый ключ. Именно в этих двух цифрах — левом и правом ключе заложена вся информация о дереве. И если информацию о ключах занести в базу данных, то работа с деревом намного упрощается
Обратите внимание на то, в каком порядке проставлены эти ключи. Если мысленно пройтись по порядку от 1 до 32, то вы обойдете все узлы дерева слева направо
Фактически это путь обхода всех узлов дерева слева направо.
При использовании такой структуры дерева каталогов, очень сильно упрощается выборка определенных элементов, таких как родительская ветка, подчиненные узлы, вообще вся «ветка» в которой участвует наш узел. В общем все гораздо проще увидеть на практике:
Создадим таблицу, где мы будем хранить наше дерево (1):
Где:
- left_key — Левый ключ узла. Указывает на точку отсчета начала ветки. Так же является полем сортировки дерева;
- right_key — Правый ключ узла. Указывает на точку останова конца ветки. Так же используется для посчета дочерних узлов ветки;
- level — Уровень узла. Так же показывает количество родителей узла;
Мотивация
Стандартная реляционная алгебра и реляционное исчисление , а также операции SQL, основанные на них, не могут напрямую выразить все желаемые операции над иерархиями. Модель вложенных множеств — решение этой проблемы.
Альтернативным решением является выражение иерархии в виде родительско-дочерних отношений. Celko назвал это моделью списка смежности . Если иерархия может иметь произвольную глубину, модель списка смежности не позволяет выполнять такие операции, как сравнение содержимого иерархий двух элементов или определение того, находится ли элемент где-то в подиерархии другого элемента. Когда иерархия имеет фиксированную или ограниченную глубину, операции возможны, но дороги из-за необходимости выполнять одно на каждом уровне. Это часто называют проблемой ведомости материалов .
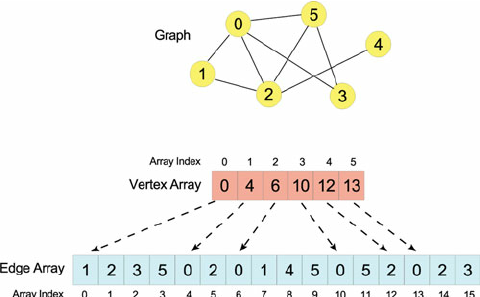
Иерархии можно легко выразить, переключившись на базу данных графов . В качестве альтернативы существует несколько решений для реляционной модели, которые доступны в качестве обходного пути в некоторых системах управления реляционными базами данных :
- поддержка выделенного типа данных иерархии , например, в SQL- средстве иерархических запросов ;
- расширение реляционного языка с помощью манипуляций с иерархией, например, во вложенной реляционной алгебре .
- расширение реляционного языка с помощью транзитивного замыкания , такого как оператор CONNECT в SQL; это позволяет использовать отношение родитель-потомок, но выполнение остается дорогостоящим;
- запросы могут быть выражены на языке, который поддерживает итерацию и охватывает реляционные операции, например PL / SQL , T-SQL или язык программирования общего назначения.
Когда эти решения недоступны или неосуществимы, необходимо использовать другой подход.
Ниже описаны подходы к индексированию иерархических данных:
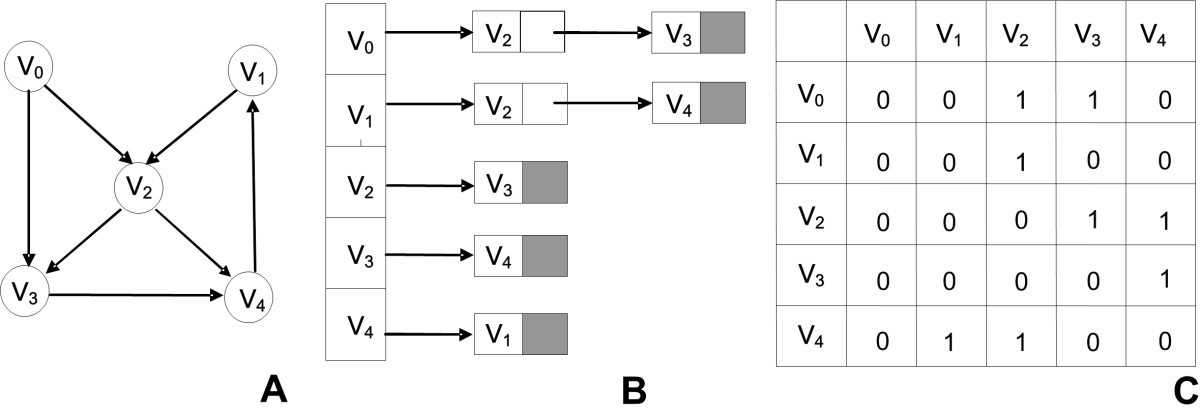
Есть два подхода к индексированию иерархических данных:
-
В глубину
В индексе преимущественно в глубину строки поддерева хранятся рядом друг с другом. Например, записи всех сотрудников, в цепи подчиненности которых есть данный руководитель, хранятся рядом с записью руководителя.
В индексе преимущественно в глубину все узлы поддерева узла хранятся вместе. Поэтому индекс преимущественно в глубину эффективен для обработки запросов по поддеревьям. Например, «найти все файлы в этой папке и ее подкаталогах».
-
-
В ширину
Если используется индексирование в ширину, строки одного уровня иерархии хранятся вместе. Например, записи всех сотрудников, напрямую подчиненных одному и тому же руководителю, хранятся рядом друг с другом.
В индексе преимущественно в ширину все прямые потомки узла хранятся в одном месте. Поэтому индекс преимущественно в ширину эффективен для запросов по прямым потомкам. Например: «найти всех прямых подчиненных этого начальника».
Выбор стратегии индексирования (в глубину, в ширину или обе) и ключа кластеризации зависит от того, какие из вышеуказанных типов запросов обрабатываются чаще и какие операции более важны (SELECT или DML). Пример использования стратегий индексирования см. в разделе Tutorial: Using the hierarchyid Data Type.
Создание индексов
Для организации данных в ширину можно использовать метод GetLevel(). В следующем примере создаются оба типа индекса: преимущественно в глубину и преимущественно в ширину.
Вариант 2. Симбиоз двух методов «Closure Table» и «Adjacency List»
Давайте ещё раз посмотрим на метод «Closure Table». В плоском списке связей иерархической структуры, который мы получаем всего одним запросом, нам, очевидно, не хватает информации о связи каждого элемента со своим родителем, для того, чтобы мы смогли построить отсортированное дерево. Поэтому, давайте добавим поле idNearestAncestor в таблицу commentsTree и будем сохранять там ссылку на элемент, который является ближайший предком.
![]()
Таким образом, мы получили симбиоз двух методов «Closure Table» и «Adjacency List». Теперь формирование правильно отсортированной иерархической структуры — тривиальная задача. И самое главное, мы нашли решение, которое полностью отвечает требованиям.
Следующим запросом мы получим необходимые для построения дерева данные:
SELECT `tableData`.`idEntry`, `tableData`.`content`, `tableTree`.`idAncestor`, `tableTree`.`idDescendant`, `tableTree`.`idNearestAncestor`, `tableTree`.`level`, `tableTree`.`idSubject` FROM `comments` AS `tableData` JOIN `commentsTree` AS `tableTree` ON `tableData`.`idEntry` = `tableTree`.`idDescendant` WHERE `tableTree`.`idAncestor` = 1
Недостатки
Вариант использования динамической бесконечной древовидной иерархии базы данных встречается редко. Модель вложенного набора подходит, когда элемент дерева и один или два атрибута являются единственными данными, но это плохой выбор, когда для элементов в дереве существуют более сложные реляционные данные. Учитывая произвольную начальную глубину для категории «Транспортные средства» и дочернего элемента «Машины» с дочерним элементом «Мерседес», должна быть установлена связь таблицы внешних ключей, если только древовидная таблица изначально не нормализована. Атрибуты вновь созданного элемента дерева могут не разделять все атрибуты с родителем, дочерним элементом или даже братом или сестрой. Если для таблицы атрибутов «Растения» установлена таблица внешнего ключа, то данные дочернего атрибута «Деревья» и его дочернего элемента «Дуб» не целостны. Следовательно, в каждом случае, когда элемент вставлен в дерево, таблица внешних ключей атрибутов элемента должна создаваться для всех случаев, кроме самых тривиальных.
Если не ожидается, что дерево будет часто меняться, правильно нормализованная иерархия таблиц атрибутов может быть создана в первоначальном проекте системы, что приведет к более простым и переносимым операторам SQL; особенно те, которые не требуют произвольного количества исполняемых, программно созданных или удаленных таблиц для изменения дерева. Для более сложных систем иерархия может быть разработана с помощью реляционных моделей, а не неявной числовой древовидной структуры. Глубина элемента — это просто еще один атрибут, а не основа всей архитектуры БД. Как указано в SQL Antipatterns :
Модель не позволяет использовать несколько родительских категорий. Например, «Дуб» может быть потомком «Тип дерева», но также и «Тип дерева». Чтобы учесть это, необходимо установить дополнительные теги или таксономию, что опять же приведет к созданию более сложного дизайна, чем простая фиксированная модель.
Вложенные наборы очень медленны для вставки, потому что для этого требуется обновить значения левого и правого домена для всех записей в таблице после вставки. Это может вызвать сильную нагрузку на базу данных, поскольку многие строки перезаписываются и индексы перестраиваются. Однако, если можно хранить в таблице лес маленьких деревьев вместо одного большого дерева, накладные расходы могут быть значительно сокращены, поскольку необходимо обновлять только одно маленькое дерево.
Плюсы и минусы
- Сложность чтения в большинстве случаев постоянна. В модели списка смежности усилия линейно зависят от глубины обрабатываемого узла. В свою очередь, изменение дерева в модели вложенных множеств занимает гораздо больше времени, чем в модели списка смежности. Поэтому он лучше подходит для структур, которые не изменяются часто, но очень часто читаются.
- Представление в виде количеств лучше подходит для количественно-ориентированного мира баз данных. С языком запросов SQL легче работать с наборами, чем с иерархическими структурами.
- Запрашивать прямые дочерние узлы сложно.
- Порядок дочерних узлов сохраняется.
Вариант 1. Заставим СУБД сортировать дерево
Существует довольно оригинальный способ, при помощи которого можно получить из базы данных сразу отсортированную древовидную иерархию, причём всего одним запросом. Известный разработчик Билл Карвин (Bill Karwin) предложил весьма изящный вариант решения задачи извлечения отсортированного дерева:
SELECT `tableData`.`idEntry`, `tableData`.`content`, `tableTree`.`level`, `tableTree`.`idAncestor`, `tableTree`.`idDescendant`, GROUP_CONCAT(`tableStructure`.`idAncestor`) AS `structure` FROM `comments` AS `tableData` JOIN `commentsTree` AS `tableTree` ON `tableData`.`idEntry` = `tableTree`.`idDescendant` JOIN `commentsTree` AS `tableStructure` ON `tableStructure`.`idDescendant` = `tableTree`.`idDescendant` WHERE `tableTree`.`idAncestor` = 1 GROUP BY `tableData`.`idEntry` ORDER BY `structure`
В результате мы получим, то что нам нужно:
![]()
Но, как не сложно заметить, такой способ будет корректно работать только в случае, когда длина идентификаторов idAncestor у всех строк, отвечающих условию запроса, одинаковая
Обратите внимание на следующий фрагмент SQL-запроса: «GROUP_CONCAT(tableStructure.idAncestor ORDER BY tableStructure.level DESC) AS structure». Сортировка строк содержащих множества «12,14,28» и «13,119,12» будет некорректной с точки зрения нашей задачи
То есть, если все идентификаторы в запрашиваемой части дерева одинаковой длинны, то сортировка верная, а в случае если это не так, то структура дерева будет нарушена. Уменьшить количество неправильных сортировок можно, задав начало отсчёта идентификаторов с большого целого числа, например 1000000, указав в SQL запросе при создании таблицы AUTO_INCREMENT=1000000.
Для того чтобы полностью избавится от этой проблемы, можно указать для столбца идентификатора idAncestor параметр ZEROFILL, в этом случае СУБД будет автоматически добавлять атрибут UNSIGNED и идентификаторы буду выглядеть примерно так: 0000000004, 0000000005, 0000000194.
Для некоторых задач, без сомнений, можно использовать этот способ. Но давайте всё-таки постараемся избежать использования двух JOIN’ов при работе с двумя таблицами, функции GROUP_CONCAT(), да ещё и параметра ZEROFILL.
Заключительное слово
Хотя я надеюсь, что информация в данной статье, будет полезна для вас, концепция вложенных множеств в SQL была вокруг в течение более десяти лет, и есть много дополнительной информации, имеющейся в книгах и в интернете. На мой взгляд, наиболее полным источником информации об управлении иерархической информации является книга под названием Деревья Джо Celko и иерархии в SQL для Smarties, написанная очень уважаемым автором в области передовых SQL, Джо Celko. Джо Celko часто приписывают модель вложенных множеств и на сегодняшний день является самым плодовитым автором по этому вопросу. Я нашел книгу Celko, чтобы быть бесценным ресурсом в своих исследованиях и очень рекомендую его. В книге рассматриваются сложные вопросы, которые я не в этой статье, а также предоставляет дополнительные методы для управления иерархическими данными в дополнение к списку смежности и вложенные модели Set.
Мотивация
Стандарт реляционная алгебра и реляционное исчисление, а SQL операции, основанные на них, не могут напрямую выразить все желаемые операции над иерархиями. Модель вложенных множеств — решение этой проблемы.
Альтернативным решением является выражение иерархии как отношения родитель-потомок. Celko назвал это модель списка смежности. Если иерархия может иметь произвольную глубину, модель списка смежности не позволяет выполнять такие операции, как сравнение содержимого иерархий двух элементов или определение того, находится ли элемент где-нибудь в подиерархии другого элемента. Когда иерархия имеет фиксированную или ограниченную глубину, операции возможны, но дороги из-за необходимости выполнения одной за уровень. Это часто называют ведомость материалов проблема.[нужна цитата]
Иерархии можно легко выразить, переключившись на база данных графов. В качестве альтернативы существует несколько решений для реляционной модели, которые доступны в качестве обходного пути в некоторых системы управления реляционными базами данных:
- поддержка выделенного тип данных иерархии, например, в SQL иерархический запрос объект;
- расширение реляционного языка с помощью манипуляций с иерархией, например, в вложенная реляционная алгебра.
- расширение реляционного языка с помощью переходное закрытие, например, оператор SQL CONNECT; это позволяет использовать отношение родитель-потомок, но выполнение остается дорогостоящим;
- запросы могут быть выражены на языке, который поддерживает итерацию и охватывает реляционные операции, такие как PL / SQL, T-SQL или язык программирования общего назначения
Когда эти решения недоступны или неосуществимы, необходимо использовать другой подход.
Двоичная куча
Двоичная куча — ещё одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.

Так устроены минимальная и максимальная кучи
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче всё устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне. На иллюстрации видно, что в минимальной куче на третьем уровне значения идут не по порядку: 10, 6 и 12.
Временная сложность двоичной кучи
https://youtube.com/watch?v=dM_JHpfFITs
Класс Set
Класс реализует интерфейс и принимает аргумент типа, который является наследником , так как для работы алгоритмов нужна проверка элементов на равенство.
Элементы нашего множества будут храниться в экземпляре стандартного класса .NET , но на практике для хранения обычно используются древовидные структуры, например, двоичное дерево поиска. Выбор внутреннего представления будет влиять на сложность алгоритмов работы с множеством. К примеру, при использовании списка метод будет выполняться за O(n) времени, в то время как множество, реализованное с помощью дерева, будет работать в среднем за O(log n) времени.
Кроме методов для работы с множеством класс также имеет конструктор, который принимает с начальными элементами.
public class Set : IEnumerable
where T: IComparable
{
private readonly List _items = new List();
public Set()
{
}
public Set(IEnumerable items)
{
AddRange(items);
}
public void Add(T item);
public void AddRange(IEnumerable items);
public bool Remove(T item);
public bool Contains(T item);
public int Count
{
get;
}
public Set Union(Set other);
public Set Intersection(Set other);
public Set Difference(Set other);
public Set SymmetricDifference(Set other);
public IEnumerator GetEnumerator();
System.Collections.IEnumerator
System.Collections.IEnumerable.GetEnumerator();
}
Метод Add
- Поведение: Добавляет элементы в множество. Если элемент уже присутствует в множестве, бросается исключение .
- Сложность: O(n)
При реализации метода необходимо решить, будем ли мы разрешать дублирующиеся элементы. К примеру, если у нас есть мнжество:
Если пользователь попытается добавить число 3, в результате получится:
В некоторых случаях это допустимо, но в нашей реализации мы не будем поддерживать дубликаты. Если представить, например, множество студентов колледжа, было бы нелогичным добавлять в него одного и того же студента дважды. На самом деле, попытка добавить элемент, который уже присутствует — скорее всего ошибка, и наша реализация класса воспринимает ее именно так.
Метод использует метод , который будет рассмотрен далее.
public void Add(T item)
{
if (Contains(item))
{
throw new InvalidOperationException(
"Item already exists in Set"
);
}
_items.Add(item);
}
Метод AddRange
- Поведение: Добавляет несколько элементов в множество. Если какой-либо из добавляемых элементов присутствует в множестве, или в добавляемых элементах есть дублирующиеся, выбрасывается исключение .
- Сложность: O(m·n), где m — количество вставляемых элементов и n — количество элементов множества.
public void AddRange(IEnumerable items)
{
foreach (T item in items)
{
Add(item);
}
}
Метод Remove
- Поведение: Удаляет указанный элемент из множества и возвращает . В случае, если элемента нет, возвращает .
- Сложность: O(n)
public bool Remove(T item)
{
return _items.Remove(item);
}
Метод Contains
- Поведение: Возвращает , если множество содержит указанный элемент. В противном случае возвращает .
- Сложность: O(n)
public bool Contains(T item)
{
return _items.Contains(item);
}
Метод Count
- Поведение: Возвращает количество элементов множества или 0, если множество пусто.
- Сложность: O(1)
public int Count
{
get
{
return _items.Count;
}
}
Метод GetEnumerator
- Поведение: Возвращает итератор для перебора элементов множества.
- Сложность: Получение итератора — O(1), обход элементов множества — O(n).
public IEnumerator GetEnumerator()
{
return _items.GetEnumerator();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return _items.GetEnumerator();
}



