
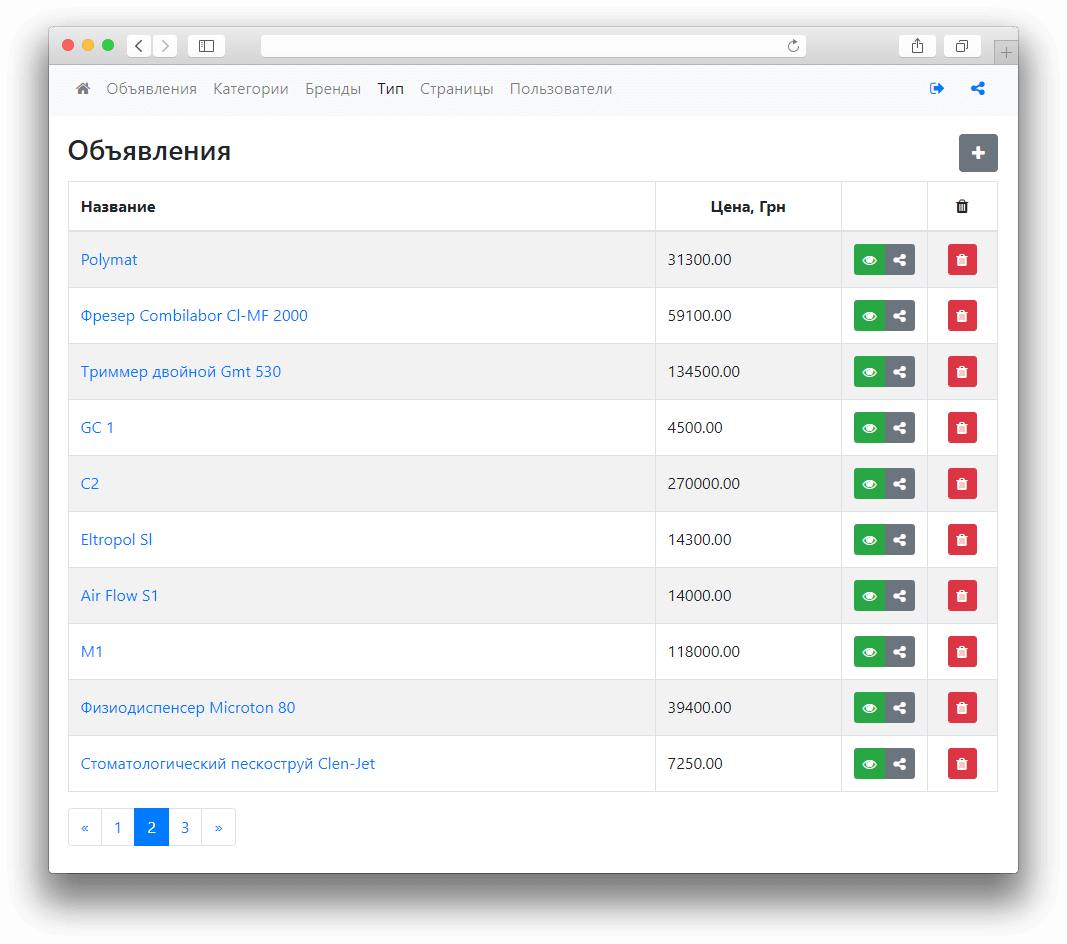
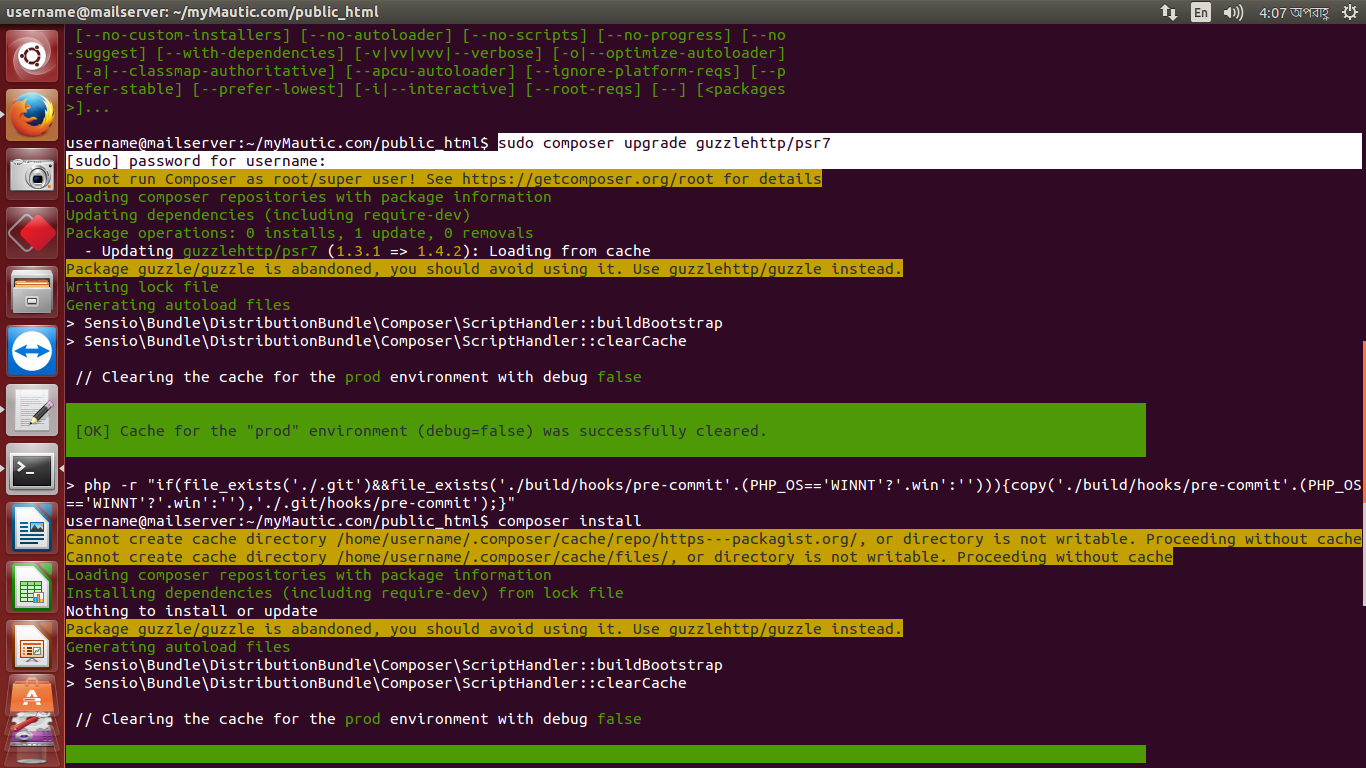
Типы запросов Oracle
| SELECT | извлекает записи из одной или нескольких таблиц |
| FROM | указывает список таблиц и любых присоединений |
| WHERE | используется для фильтрации результатов |
| ORDER BY | используется для сортировки записей |
| GROUP BY | группирует результаты одного или нескольких столбцов |
| HAVING | используется в сочетании с GROUP BY, чтобы ограничить группы возвращаемых строк |
| DISTINCT | удаляет дубликаты из результирующего набора SELECT |
| EXISTS | используется в сочетании с подзапросом (subquery) |
| INSERT | используется для вставки одной записи или несколько записей в таблицу Oracle |
| INSERT ALL | используется для добавления нескольких строк с помощью одного оператора INSERT |
| UPDATE | используется для обновления существующих записей в таблице в базе данных Oracle |
| DELETE | используется для удаления одной или нескольких записей из таблицы в Oracle |
| TRUNCATE TABLE | используется для удаления всех записей из таблицы в Oracle |
| UNION | удаляет повторяющиеся строки между запросами SELECT |
| UNION ALL | возвращает все строки из запроса и не удаляет повторяющиеся строки |
| INTERSECT | возвращает пересечение 2-х наборов результатов |
| MINUS | возвращает один набор данных минус другой набора данных |
| PIVOT | используется для поворота строк в столбцы |
| Subqueries | подзапросы |
Что такое базы данных
База данных — это организованная структура для хранения, изменения информации и взаимодействия с ней.
Они бывают двух видов:
- нереляционные. Такие БД имеют специфическую структуру: например, данные хранятся в формате ключ-значение или в виде дерева;
- реляционные. В таких БД данные хранятся в виде связанных таблиц.
Каждая таблица обычно содержит данные, относящиеся к похожим объектам. У каждой таблицы есть название: оно соотносится с тем, какая информация хранится в таблице.
Таблицы состоят из строк и столбцов. Каждый столбец имеет уникальное название, которое также отмечает вид хранимой информации. В каждой строке находится информация об одном объекте. Таблица содержит конкретное число столбцов, но может иметь любое количество строк.
В таблице ниже представлена информация о клиентах: имя, адрес, выручка и др., — разбитая на столбцы и строки.
![]()
Пример реляционной БД
Для связи данных в разных таблицах часто используют ID — уникальный идентификатор строки. Имя или какой-либо признак с этой целью не используются, поскольку они могут быть неуникальными.
Обращаться с таким хранилищем намного сложнее, чем с обычной таблицей. Число записей может исчисляться миллионами. Чтение информации вручную практически невозможно, поэтому для работы с БД используется особый язык программирования. Он называется SQL, и ему посвящена отдельная статья. Там же подробно рассказано про особенности хранения информации в базах.
Изменяем файл скрипта
После клонирования репозитория
и запуска
нужно изменить аргументы, передаваемые в конструктор OciConfig (файл index.php).
-
Аргументы 1–5 (region, user, tenancy, fingerprint, path to private key) следует взять из текстового поля во время генерации ключей (начало статьи).
-
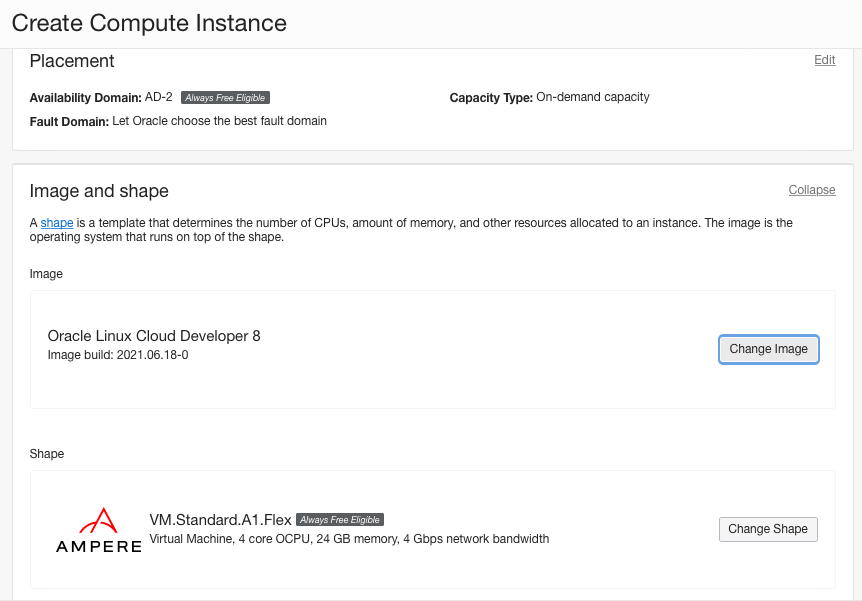
Для получения аргументов 6–8 (availabilityDomain, subnetId, imageId) следует инициировать создание экземпляра из веб-браузера (консоли) Oracle Cloud (Menu -> Compute -> Instances -> Create Instance).
Поменяйте образ и тип (shape), убедитесь, что домен доступности (Availability Domain) – с плашкой “Always Free Eligible”.
Измените также секцию «Networking» — установите чекбокс «Do not assign a public IPv4 address»
Важно: если вы ранее не создавали экземпляр M.Standard.E2.1.Micro, сделайте это прямо сейчас, перед всем этим (две штуки оных предоставляются бесплатно) – нам нужны существующие VNC, subnet, route table, security list и т.д
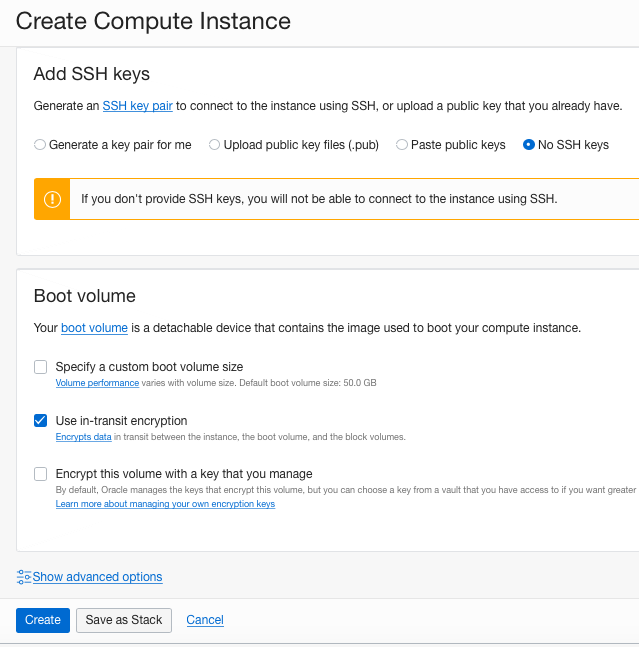
Секция “Add SSH keys” нас здесь пока не интересует. До клика по кнопке “Create”…
…откройте инструменты разработчика в браузере (вкладка «Сеть»). Теперь жмите “Create” и подождите немного — получите ошибку “Out of capacity”. Найдите вызов конечной точки /instances (красный)…
кликните по нему правой кнопкой мыши и выберите «скопировать как curl». Вставьте содержимое в любой текстовый редактор, посмотрите на параметр —data-binary. Найдите availabilityDomain, subnetId, imageId. Используйте их как аргументы 6,7 and 8, соответственно – конструктора OciConfig.
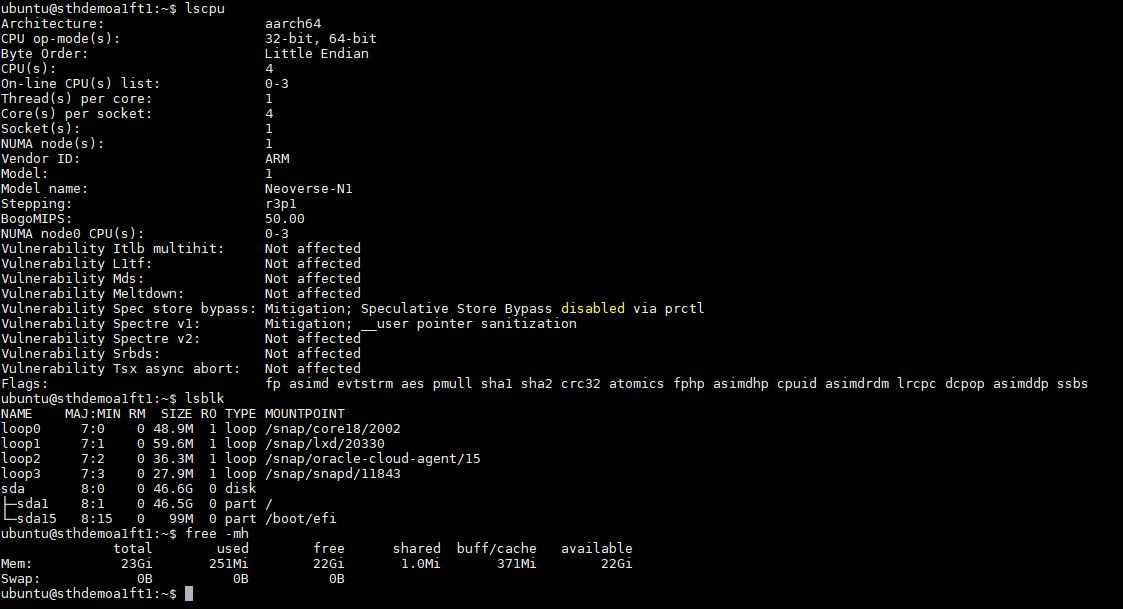
OciConfig также имеет два последних опциональных аргумента – ocpus и memoryInGBs соответственно. По умолчанию они равны 4 и 24. Разумеется, можете их изменить. Возможные варианты значений – 1/6, 2/12, 3/18 and 2/24
В случае использования образа Oracle Linux Cloud Developer обратите внимание, что он требует как минимум 8 ГБ ОЗУ
3. Чтобы иметь безопасный зашифрованный доступ к экземпляру, нужно иметь сгенерированную пару ключей ~/.ssh/id_rsa и ~/.ssh/id_rsa.pub. Имя файла второго из них (публичного) должно быть передано в команду ниже. В сети достаточно инструкций, чтобы выполнить их генерацию, здесь мы опустим эту часть.
Oracle FETCH clause syntax
The following illustrates the syntax of the row limiting clause:
clause
The clause specifies the number of rows to skip before the row limiting starts. The clause is optional. If you skip it, then offset is 0 and row limiting starts with the first row.
The offset must be a number or an expression that evaluates to a number. The offset is subjected to the following rules:
- If the offset is negative, then it is treated as 0.
- If the offset is NULL or greater than the number of rows returned by the query, then no row is returned.
- If the offset includes a fraction, then the fractional portion is truncated.
clause
The clause specifies the number of rows or percentage of rows to return.
For the semantic clarity purpose, you can use the keyword instead of , instead of . For example, the following clauses behavior the same:
The returns exactly the number of rows or percentage of rows after (or ).
The returns additional rows with the same sort key as the last row fetched. Note that if you use , you must specify an clause in the query. If you don’t, the query will not return the additional rows.



Основы синтаксиса: переменные, условия, циклы
Перейдём сразу к практике и посмотрим, как выглядит шаблон, взяв для примера немного упрощенную версию HTML-кода сайта webew.ru:
<html><head>
/* Многострочные комментарии — как в C или PHP */
<title>{*title*}</title>
<base href=»{*=BASEHREF*}»> /* константа */
/* условные конструкции: */
{?*keywords*}
<meta name=»keywords» content=»{*keywords*}»>
{?}
{?*description*}
<meta name=»description» content=»{*description*}»>
{?}
/* условие с негативной частью */
<link rel=»stylesheet» href=» {?*default_css*} default.css {?!} special.css {?} «> </head><body>
<div id=»logo»>
<a href=»»><img src=»{*logo.image*}» alt=»{*logo.alt*}»></a>
</div>
<div id=»menu»>
/* цикл: */
{%*menu*}
<a href=»{*menu:url*}»>{*menu:title*}</a>
{%}
</div>
<div id=»content»>
{*content*}
</div>
<div id=»footer»>
webew.ru © {*year*}
</div></body></html>
А вот соответствующий код PHP:
ini_set(‘pcre.backtrack_limit’, 1024*1024); // (см. ниже)$DATA’title’ = ‘Webew: теория и практика веб-технологий ‘;define(‘BASEHREF’, ‘http://webew.ru/’);$DATA’logo’ = array(
‘image’ => ‘i/logo.gif’,
‘alt’ => ‘Логотип webew.ru’
);$DATA’menu’ = array(
array(‘url’ => ‘css’, ‘title’ => ‘CSS’),
array(‘url’ => ‘php’, ‘title’ => ‘PHP’),
array(‘url’ => ‘seo’, ‘title’ => ‘Интернет-маркетинг’),
array(‘url’ => ‘c’, ‘title’ => ‘C/C++’)
);$DATA’content’ = ‘Приветствуем вас на webew.ru!’;require_once ‘websun.php’; // подключаем файл с шаблонизатором$tpl = ‘templates/main.tpl’; // путь к шаблону$html = websun_parse_template_path($DATA, $tpl); // запуск шаблонизатораecho $html; // получили обработанный шаблон, отдаем клиенту результат
Несмотря на то, что переменные $DATA’keywords’ и $DATA’description’ не установлены, при обработке шаблона не возникнет никаких ошибок или предупреждений.
Условная конструкция вида {?*keywords*} что-то {?} означает «вставить что-то, если в переменной, переданной шаблону (в данном случае $DATA) присутствует элемент keywords и при этом он не является пустой строкой, нулём, FALSE, NULL или пустым массивом». Соответственно, конструкция {?!*keywords*} … {?} срабатывает, если какое-нибудь из этих условий не выполняется.
Шаблонизатор не генерирует ошибок или предупреждений в том случае, если какой-либо из запрошенных переменных или констант вообще не существует (вместо них молчаливо будет вставлена пустая строка) поэтому формат передаваемых данных может быть нестрогим.
В цикле ключи массива указываются через двоеточие — {*menu:title*}, а вне цикла через точку — {*logo.image*}.
Можно также обращаться к переменным глобальной области видимости, в т.ч. суперглобальным массивам. Для этого перед именем переменной нужно поставить знак доллара. Например, подстановка в шаблон переменной $_GET’foo’ выглядит так: {*$_GET.foo*}.
Внедрение 1С: Комплексной автоматизации 2 на небольшом машиностроительном заводе – первая очередь
В статье ведется речь о небольшом машиностроительном заводе, в чем-то даже типичном для многих предприятий России, «дотянувших» до наших времен с эпохи Советского Союза. Завод расположен в центральном регионе России, он производит небольшие, но достаточно важные агрегаты для двигателей внутреннего сгорания. Предприятие осуществляет поставки продукции нескольким традиционным заказчикам-производителям, а также дилерам торговых сетей, снабжающих ремонтные службы запасными частями.
Первая очередь проекта предполагала модернизацию и автоматизацию операционной системы управления.
Особенности мигрируемой БД
Приложение у нас, как я называю «backend-центрированное», что означает:
- Используется ORM (hibernate);
- В БД не так много процедурного кода (почти нет);
- Используется не так много «изысков» SQL, как могло бы. Хотя, как выяснилось, так казалось на первый взгляд. Вообще, язык SQL очень хорошо стандартизирован и, казалось бы, должен «практически одинаково» работать на всех СУБД, которые заявляют совместимость со стандартом SQL-XX (здесь XX – это год выпуска стандарта). В реальной жизни все совсем иначе, разницу диалектов SQL можно (шутливо) проиллюстрировать следующей картинкой:
- В коде вперемежку встречается «native SQL» и «Hibernate QL». Также используется QueryDSL.
Создание БД PG
Раз уж существует инструмент ora2pg, то им и попробуем воспользоваться. Написан он, похоже, аж на Perl’е, что впрочем его не портит. Были какие-то мелкие заморочки с его установкой, но в целом он вполне работает.
Было решено с его помощью преобразовать только таблицы, представления же создать руками. Пакетов и процедур — минимум, их тоже руками.
В целом инструмент отработал вполне достойно, выдав рабочий скрипт создания таблиц. Из минусов — все первичные ключи он мне сделал как numeric(22), пришлось переделывать на int8 (он же bigint, примерно он же bigserial).
И вот здесь возникает первая большая сложность
Стоит крайне пристально обратить внимание на типы полей. Лучше даже вообще составить таблицу по типам «было» — «стало» и ее придерживаться
Основные проблемы возникают с number — float — numeric. Также надо запомнить разницу в датах — в Oracle в дате есть время, в pg нет. Доступно про типы описано здесь: https://habr.com/ru/post/335716/
Важный организационный момент — всем объектом устроили ревизию, т. е. как минимум все таблицы и представления было решено снабдить комментарием, что это и зачем. Если комментария нет, то значит, что мы не знаем, что это за объект и как используется. Эта работа была сделана командой линейного развития проекта.
Таблицы создали, надо наполнять их данными. Напомню, система живая, каждый день в ней появляются данные, основных потоков три — интеграционный, расчетный и пользовательский ввод.
Здесь посчитали важным реализовать репликацию ora → pg, чтобы в каждый момент времени БД pg была максимально близка к БД ora (максимально — значит каждый день). Так родился модуль репликации.
Структура базы данных Oracle
База данных Oracle включает в себя:
— табличные пространства;
— управляющие файлы;
— журналы;
— архивные журналы;
— файлы трассировки изменения блоков;
— ретроспективные журналы;
— файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов:
• control files — управляющие файлы;
• data files — файлы данных;
• redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация:
• имя базы данных Oracle;
• время создания БД;
• имена и местонахождение журнальных файлов и файлов данных;
• информация о табличных пространствах;
• информация об архивных журналах;
• история журналов, порядковый номер текущего журнала;
• информация о файлах данных в автономном режиме;
• информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Вот, к примеру, как выглядит список обязательных параметров инициализации для СУБД Oracle Database 11g:
1. Местонахождение управляющих файлов — CONTROLFILES.
2. Локальное имя БД — DB_NAME.
3. Имя домена БД Oracle — DBDOMAIN.
4. Местонахождение архивного журнала — LOGARCHIVEDEST.
5. Параметр, который включает архивирование журналов — LOG_ARCHIVE_DEST_STATE.
6. Местонахождение области быстрого восстановления — DBRECOVERYFILEDEST.
7. Наибольший размер области быстрого восстановления БД Oracle в байтах —DBRECOVERYFILEDESTSIZE.
8. Размер блока БД в байтах — DBBLOCKSIZE.
9. Наибольшее количество процессов ОС, которые обслуживают одновременный доступ к СУБД Oracle — PROCESSES.
10. Наибольшее число сеансов работы с БД — SESSIONS.
11. Наибольшее количество открытых курсоров в базе данных — OPEN_CURSORS.
12. Наименьшее количество разделяемых серверов базы данных Oracle — SHARED_SERVERS.
13. Имя удалённого прослушивателя — REM O TE_LI S TENER.
14. Версия СУБД Oracle, с которой должна поддерживаться совместимость — COMPATIBLE.
15. Размер области памяти, которая автоматически выделяется для PGA и SGA экземпляра — MEMORY_TARGET.
16. Время ожидания возможности установить монопольную блокировку до отправки сообщения об ошибке (для команд DDL) — DDLLOCKTIMEOUT.
17. Язык, который определён в подсистеме поддержки национальных языков для базы данных Oracle — NLS_LANGUAGE.
18. Территория, которая определена в подсистеме поддержки национальных языков для БД — NLS_TERRITORY.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Какие преимущества предоставляет PHP?
-
Каждая из наиболее распространенных операционных систем (Windows, MacOS, Linux) имеет свои версии пакетов разработок на языке PHP, а значит, изучив PHP, вы сможете создавать свои веб-сайты на любой из операционных систем.
-
PHP умеет работать с разными веб-серверами: Apache, Nginx, IIS.
-
PHP прост и легок в освоении. Имея небольшой первоначальный опыт в программировании на PHP, вы сможете создавать небольшие веб-сайты
-
PHP похож на язык Си и, если вы знаете Си или подобный язык с сиподобным синтаксисом, вам будет проще овладеть PHP.
-
PHP поддерживает работу с множеством систем баз данных (MySQL, MSSQL, Oracle, Postgre, MongoDB и другие)
-
Высокая производительность. PHP-программы работают быстрее, чем ASP.
-
Цена. PHP абсолютно бесплатен.
-
Язык PHP постоянно совершенствуется, и ему наверняка обеспечено долгое доминирование в области языков веб-программирования, по крайней мере, в ближайшее время.
Программные единицы PL/SQL
- Процедура — это подпрограмма, которая выполняет специфическое действие (CREATE PROCEDURE).
- Функция — это подпрограмма, которая вычисляет значение (CREATE FUNCTION).
- PL/SQL пакеты — это объект базы данных, который группирует логически связанные типы, программные объекты и подпрограммы PL/SQL. Пакеты обычно состоят из двух частей — спецификации и тела. Спецификация пакета — это интерфейс с вашими приложениями, она объявляет типы, переменные, константы, исключения, курсоры и подпрограммы, доступные для использования в пакете. Тело пакета полностью определяет курсоры и подпрограммы, тем самым реализуя спецификацию пакета (CREATE PACKAGE и CREATE PACKAGE BODY).
-
Динамический SQL
- Native Dynamic SQL (NDS)
- DBMS_SQL
- Триггеры — это хранимая процедура особого типа, которую пользователь не вызывает непосредственно, а исполнение которой обусловлено действием по модификации данных. В Oracle различают следующие виды триггеров: BEFORE INSERT, AFTER INSERT, BEFORE UPDATE, AFTER UPDATE, BEFORE DELETE, AFTER DELETE (CREATE TRIGGER).
- Опции компилятора
- Управление зависимостями
- Хинты или подсказки (Oracle Hints) — средство, позволяющее явным образом влиять на план запроса. Хинты определяют общие цели и подходы для оптимизации плана выполнения запроса, включая правила и методы доступа к данным — указание порядка соединения таблиц, указание метода соединения таблиц, указание конкретного индекса для доступа к таблице.
Итак, что же может PHP?
Благодаря обширному сообществу, широкому спектру функций, большому набору фреймворков, PHP подвластно практически все. Сбор данных, скриптирование серверной части, динамическая генерация контента — всего лишь некоторые сферы его применения. PHP может использоваться практически на всех операционных системах, включая Microsoft Windows, Linux, большинство Unix вариантов и macOS. Он также имеет поддержку для большинства серверов и баз данных.
По этим причинам PHP — хороший выбор для создания успешных проектов. Долгое время PHP не рассматривался в качестве достаточно серьезного языка для разработки больших веб-приложений и преимущественно был известен как хороший вариант для небольших проектов. В последнее время ситуация существенно изменилась. Фреймворки PHP (Symfony, Laravel, CakePHP, Zend и т.д.) расширяют способности языка.
.
Внедрение программного продукта. Особенности работы бизнес-консультанта. Часть II Промо
Говорить о внедрении программного продукта можно очень долго, тема это обширная, а нюансов в работе бизнес-консультанта очень много. В статье Внедрение программного продукта. Особенности работы бизнес-консультанта. Часть I я раскрыл только некоторые общие понятия, пояснил, чем работа бизнес-консультанта для малого и среднего бизнеса отличается от работы обычных внедренцев. Также я рассказал о тех базовых принципах, на которых я строю свою работу по внедрению программного обеспечения.
Сейчас я предлагаю перейти к подробному обсуждению процесса работы бизнес-консультанта при внедрении ПО.
Пример использования команды include
В предыдущей статье я рассказывал о блочной вёрстке сайта и приводил в пример простейшую страницу (документ index.html и привязанный к нему файл style.css).
Сейчас мы разделим документ index.html на несколько файлов, каждый из которых будет содержать свою часть страницы, что поможет ещё сильней разделить код, улучшить структуру шаблона и, по сути, сделать страницу динамической. Для этой цели мы будем использовать язык PHP, а точнее лишь одну его директиву — функцию include(), которая включает один файл в другой.
1. Смените разрешение созданного в статье о блочной вёрстке файла index с .html на .php, чтобы документ назывался index.php. Тип файла .PHP указывает серверу, что документ был написан или использует вставки на одноимённом языке программирования.
2. В папке со страницей создайте директорию blocks.
3. Всю вспомогательную информацию (верх, низ, навигацию и боковую панель сайта) вынесем в отдельные файлы, которые разместим в папке blocks.
Итак, создайте в каталоге blocks четыре файла: header.php, navigation.php, sidebar.php и footer.php. Заполните файлы кодом.
header.php:
<div id="header"> <h2>header (шапка сайта)</h2> </div>
navigation.php
<div id="navigation"> <h2>Блок навигации</h2> </div>
sidebar.php
<div id="sidebar"> <h2>Левая панель</h2> </div>
footer.php
<div id="clear"> </div> <div id="footer"> <h2>footer (низ сайта)</h2> </div>
4. Проверьте структуру папки шаблона. В корне должны находиться файлы index.php, style.css и директория blocks.
Структура папки blocks должна быть такой.
5. В файле index.php удалите существующий код и напишите новый:

<!DOCTYPE html>
<html>
<head>
<title>Блочная вёрстка</title>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="container">
<?php include ("blocks/header.php");?>
<?php include ("blocks/navigation.php");?>
<?php include ("blocks/sidebar.php");?>
<div id="content">
<h2>Основной контент страницы</h2>
</div>
<?php include ("blocks/footer.php");?>
</div>
</body>
</html>
В браузере файл index.php выглядит точно так же, как и раньше, но структура шаблона при этом полностью изменилась. О том, что получилось, поговорим потом, а сейчас ответим на вопрос о загадочных командах вида <?php include («имя_файла»);?>.
Как и HTML-код, код PHP тоже имеет своё обозначение начала и конца. Так вот начинать PHP-вставку нужно командой <?php, а заканчивать строкой ?>. Между этими командами пишется основной код. В нашем случае это всего лишь одна команда — include.
Функция include() вставляет в файл код из другого файла, давая возможность хранить разные части страницы в разных документах, тем самым надёжно отделяя их друг от друга.
В результате выполненных действий мы получили динамическую страницу index.php, части которой подгружаются из разных файлов. Благодаря этому можно создавать другие страницы, точно так же подгружая в них вспомогательные элементы из файлов папки blocks.
Такой подход хорош тем, что если вы захотите на сайте в 20-30 страниц изменить, скажем, название пункта меню, то в шаблоне с только что созданной структурой понадобится внести правки только в один файл — blocks/navigation.php, и меню изменится сразу на всех страницах, в которые он включен. Если же сайт был бы статическим, то для смены названия одного пункта меню вам пришлось бы вносить изменения в каждую из 20-30 страниц. Разница очевидна.
Дата размещения/обновления информации: 29.04.2021 г.
Сообщить об ошибке
Подходы к миграции
Настало время поговорить о подходах. Будем честны, опыта такой миграции в нашей команде еще не было. Зато появилась хорошая экспертиза на PG, так как последние проекты разрабатываем на нем. Поэтому для начала надо оглядеться, как люди это делают, почитать, поспрашивать. Здесь нам повезло, как раз не так давно мы были на pgConf, на котором было несколько очень качественных докладов на тему миграции. Вот они, например, от 2020 года — доступны всем желающим: https://pgconf.ru/2020/talks-and-tutorials. Если не смотрели, начните например, с Анатолия Афиногенова (РЖД) — просто, доступно и познавательно. Но там и другие очень интересные.
В процессе гугления интернета был найден очень интересный фолиант — Oracle to Azure Database for PostgreSQL Migration Guide. Пусть вас слово «Azure» не отпугнет, там все по делу и все про PostgreSQL. Очень подробно, 313 страниц на английском языке.
Технически же пойдем таким путем:
- Организуем схожую продуктивной площадку серверов (в качестве операционки была выбрана наша «родная» RedOS 7.2 «Муром»);
- Устанавливаем все «схожим образом». В качестве СУБД взяли самую свежую на сегодняшний момент PostgresPro Standard 13.
Выполняемая секция
Выполняемая секция начинается с ключевого слова BEGIN и заканчивается либо ключевым словом EXCEPTION, если присутствует секция исключений, либо ключевым словом END, за которым следуют необязательное имя функции или процедуры и точка с запятой. Выполняемая секция содержит один и более PL/SQL-операторов, выполняемых при передаче управления данному блоку. Структура выполняемой секции показана ниже.
BEGIN
один и более PL/SQL-операторов
END ;
|
1 |
BEGIN секцияисключений ENDимяфункцииилипроцедуры; |
В выполняемом коде PL/SQL чаще всего встречается оператор присваивания (:=). Он указывает, что нужно вычислить выражение справа и поместить результат в переменную слева.



