
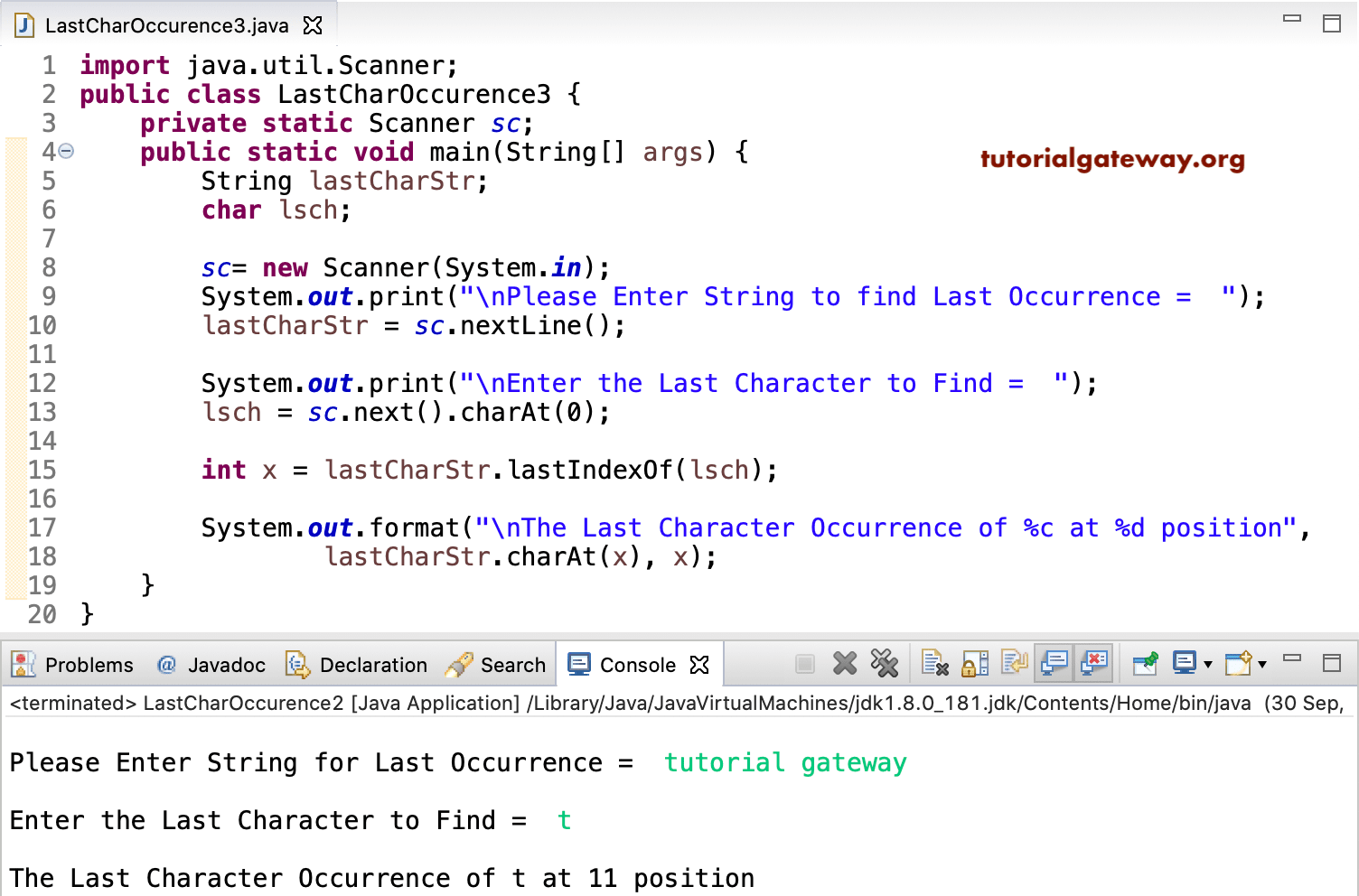
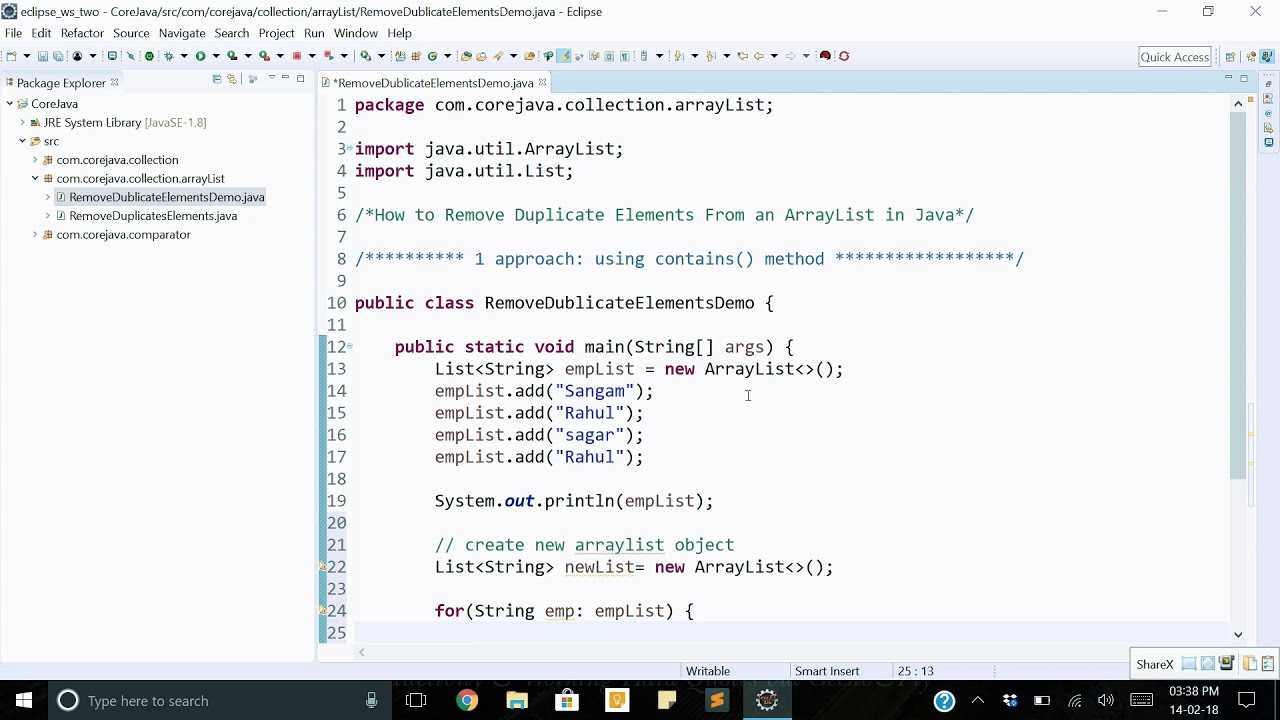
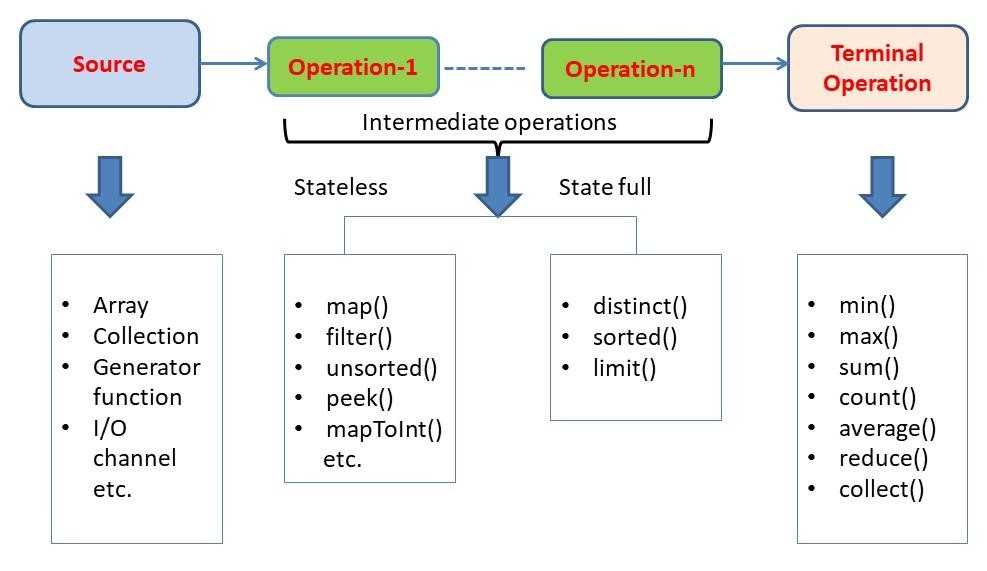
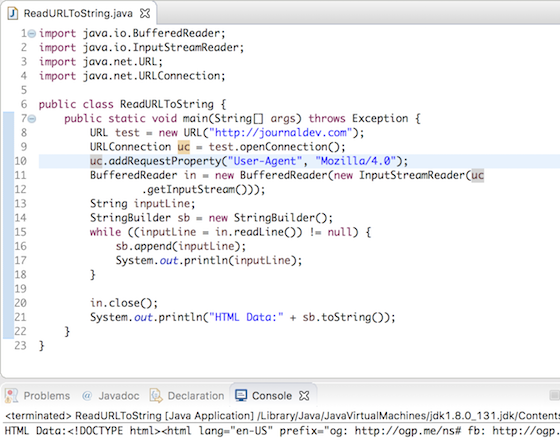
Для фильтрации — filter()
Метод фильтрует стрим согласно переданному в метод условию-предикату. Позволяет записать условие в одну строчку без громоздких конструкций if-else.
Задача
Снова нужно получить список рассылки. Но на этот раз включаем в него только адреса читателей, которые согласились на рассылку. Дополнительно нужно проверить, что читатель взял из библиотеки больше одной книги.
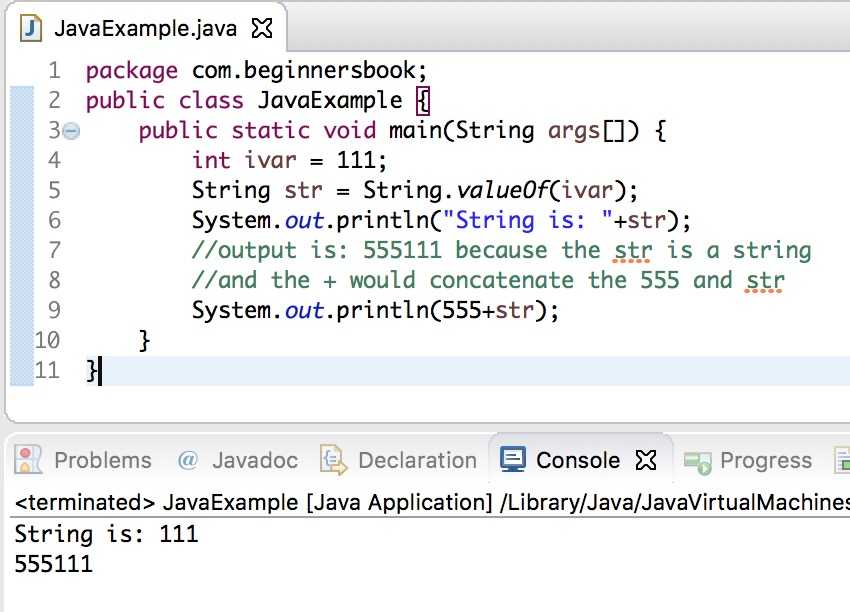
С лямбдами
На первом шаге (первое использование filter()) сокращаем число читателей: работаем со списком тех, кто дал согласие на рассылку.
На втором шаге из этого ограниченного числа читателей выбираем тех, кто взял более одной книги.
Критика Java Stream API
Поработав с другими API потоковой передачи данных, такими как Apache Kafka Streams API. Я немного критикую Java Stream API. Которым поделюсь с вами. Это не большие, важные критические замечания, но их полезно иметь в голове. Когда вы начинаете заниматься потоковой обработкой.
Пакетная, Не Потоковая
Несмотря на свое название. Java Stream API на самом деле не является API обработки потока. Терминальные операции Java Stream API возвращают конечный результат итерации по всем элементам потока и предоставления этим элементам нетерминальных и терминальных операций. Результат терминальной операции возвращается после обработки последнего элемента в потоке.
Возврат конечного результата после обработки последнего элемента потока возможен только в том случае, если вы знаете. Какой элемент является последним в потоке. Единственный способ узнать, является ли данный элемент последним элементом в потоке, — это если вы обрабатываете пакет, который имеет последний элемент. Напротив, истинный поток не имеет последнего элемента Вы никогда не знаете. Является ли данный элемент последним или нет. Поэтому невозможно выполнить терминальную операцию над потоком. Лучшее, что вы можете сделать , это собрать временные результаты после обработки данного элемента, но это будет выборка, а не конечный результат.
Цепочка, А Не Граф
API Java Stream разработан таким образом. Что экземпляр может быть обработан только один раз. Другими словами, вы можете добавить только одну нетерминальную операцию к a , что приведет к созданию нового объекта. Вы можете добавить еще одну нетерминальную операцию к полученному объекту. Но не к первому. Полученная структура нетерминальных экземпляров образует цепочку.
В истинном потоковом API обработки корневой поток и прослушиватели событий обычно образуют граф, а не просто цепочку. Несколько слушателей могут прослушивать корневой поток. И каждый слушатель может обрабатывать элементы в потоке по-своему и в результате пересылать преобразованный элемент. Таким образом, каждый слушатель (нетерминальная операция) может, как правило, действовать как сам поток. Который другие слушатели могут слушать результаты. Именно так спроектирован Apache Kafka Streams. Каждый слушатель (промежуточный поток) также может иметь несколько слушателей. Результирующая структура образует граф слушателей со слушателями со слушателями и т. Д.
С графом потоковой обработки. А не цепочкой. В графе нет ни одной конечной операции. Под конечной операцией я подразумеваю операцию, которая гарантированно будет последней в технологической цепочке. Вместо этого может быть несколько конечных операций. Каждый
Когда ваша структура обработки потока может представлять собой график с несколькими конечными операциями. Stream API не может легко поддерживать терминальные операции. Как это делает Java Stream API. Чтобы легко поддерживать терминальные операции. Должна быть одна заключительная операция. Из которой возвращается конечный результат. API потоковой обработки на основе графа может вместо этого поддерживать операцию
Внутренняя, А Не Внешняя Итерация
Java Stream API преднамеренно разработан. Чтобы иметь внутреннюю итерацию элементов в a . Итерация запускается при вызове терминальной операции . Фактически, для того. Чтобы терминальные операции могли возвращать результат. Терминальная операция должна инициировать итерацию элементов в .
Некоторые API потоковой обработки на основе графов также предназначены для того. Чтобы как бы скрыть итерацию элементов от пользователя API (например. Apache Kafka Streams и RxJava). Однако лично я предпочитаю дизайн, в котором каждый узел потока (корневой поток и слушатели) может иметь элементы. Переданные им через вызов метода. И этот элемент должен быть передан через полный граф для обработки. Такой дизайн облегчил бы тестирование каждого слушателя в графике. Так как вы можете настроить график и протолкнуть элементы через него позже. И, наконец. Проверить результат (выборочное состояние графика). Такая конструкция также позволила бы графу потоковой обработки иметь элементы. Помещенные в него через несколько узлов в графе. А не только через корневой поток.
Задание
Необходимо получить список книг со статусом (Срок возврата истек) и проверить, числятся ли какие-нибудь из них за Jordan:
boolean result = libraryRepo.stream().filter(b -> b.getStatus().equalsIgnoreCase("Expired")). anyMatchList(b -> b.getBorrower().equalsIgnoreCase("Jordan"));
У нас есть библиотека, предоставляющая список книг. Из них были отобраны () все те, срок возврата которых истек. Затем мы проверили, а брал ли какие-либо из них . Если да, то возвращается , в противном случае — .
- Когда параллелизм превосходит конкурентность
- Незаслуженно забытый ForkJoinPool
- Очереди с приоритетом в Java
Читайте нас в Telegram, VK и
Используем Set
Set — это новый тип данных, представленный в ES6.
Значения Set могут присутствовать только в одном экземпляре, тем самым этот тип данных подразумевает наличие только уникальных элементов.
Соответственно, если мы передадим Array в Set, то мы получим объект только с уникальными значениями.
Перейдем к коду:
- Первое, что необходимо сделать — это передать массив в сет.
- Второе — используя spread оператор, преобразовать сет обратно в массив. Так же spread можно заменить на .
Теперь давайте максимально укоротим код для того, чтобы оценить количество строк.
Плюсы:
-
Производительность. Этот вариант самый производительный.
Согласно нотации Big O, сложность алгоритма будет равна O(2n), что в действительности является O(n), а значит производительность максимальная. - Краткость. Самая короткая запись из всех возможных вариантов.
Минусы:
Обработка только примитивных типов данных. Данный способ не работает, если в массиве будут присутствовать объекты.
Внешняя итерация
При работе с Java Collections мы используем внешнюю итерацию.
Во внешней итерации мы используем for или for каждого цикла или получаем итератор для коллекции и технологических элементов коллекций в последовательности.
Следующий код вычисляет сумму квадратов всех нечетных чисел в списке.
Он использует для каждого цикла, чтобы получить доступ к каждому отдельному элементу в списке, для того чтобы фильтровать нечетные целые числа.
После этого она вычисляет квадрат и хранит сумму квадрата в переменной.
Java
//nookery.ru
import java.util.Arrays;
import java.util.List;
public class Test {
public static void main(String[] args) {
List<Integer> num = Arrays.asList(1, 2, 3, 4, 5);
int result= 0;
for (int n : num) {
if (n % 2 == 1) {
int square = n * n;
result = result + square;
}
}
System.out.println(result);
}
}
|
1 |
//nookery.ru importjava.util.Arrays; importjava.util.List; publicclassTest{ publicstaticvoidmain(Stringargs){ List<Integer>num=Arrays.asList(1,2,3,4,5); intresult=; for(intnnum){ if(n%2==1){ intsquare=n*n; result=result+square; } } System.out.println(result); } } |
Результатом работы программы будет: 35
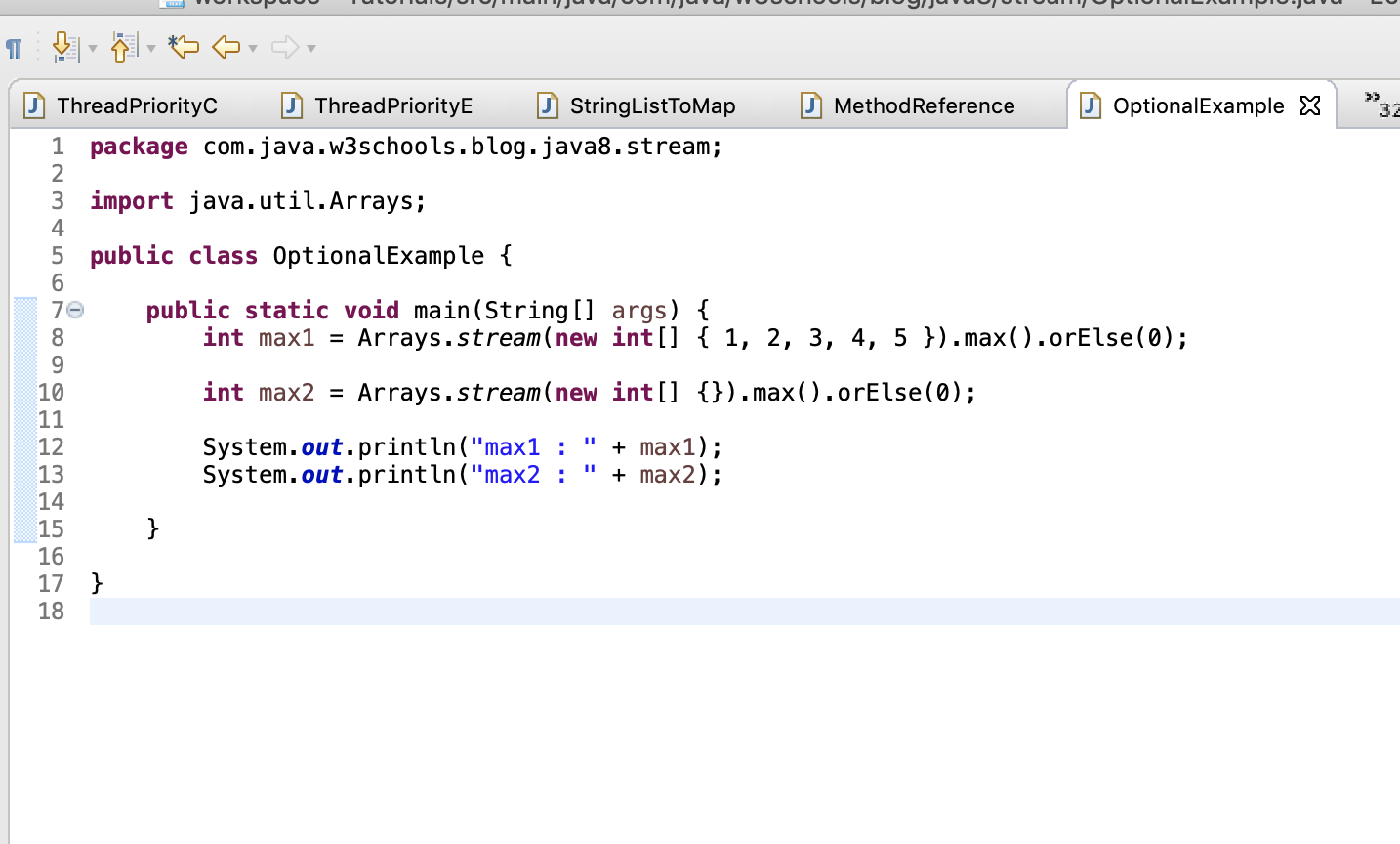
max()
max() возвращает самый большой элемент в потоке. Наибольший элемент определяется реализацией Comparator, которую мы передаем методу max().
List<String> stringList = new ArrayList<String>();
stringList.add("abc");
stringList.add("def");
Stream<String> stream = stringList.stream();
Optional<String> max = stream.max((val1, val2) -> {
return val1.compareTo(val2);});
String maxString = max.get();
System.out.println(maxString);
Возвращает необязательный параметр, который может содержать или не содержать результат. Если поток пустой, дополнительный метод get() будет генерировать исключение NoSuchElementException.
Для сортировки — sorted()
Этот метод используется для сортировки элементов стрима. По умолчанию применяется сортировка по возрастанию (с числами всё понятно, а вот заглавные и строчные буквы рассматриваются отдельно).
Примечание. Метод подходит только для сортировки объектов, которые реализуют интерфейс Comparable.
Если же классы наших объектов не реализуют этот интерфейс или нужна иная логика сортировки, то можно передать в качестве аргумента свой алгоритм сравнения элементов.
В результате работы метода получается новый стрим.
Без лямбд
У интерфейса List есть метод для сортировки — sort(). В него тоже можно передать алгоритм сравнения. До появления лямбд для этого создавали свои классы, реализующие интерфейс Comparator, или анонимные классы:
Метод sort() не возвращает результат, он преобразует исходную коллекцию. Поэтому в нашем примере пришлось вынести сортировку в отдельный метод, чтобы не менять текущий порядок книг.
С лямбдами
Для передачи алгоритма сравнения элементов в метод sorted() используется лямбда-выражение Comparator.comparing(Book: :getIssueYear).
Оно равносильно анонимному классу в примере выше: означает, что книги сравниваются по году издания.
Метод collect(Collectors.toList()) замыкает стрим в список (List).
Создавать отдельный метод для сортировки не пришлось. И в целом код выглядит компактнее.
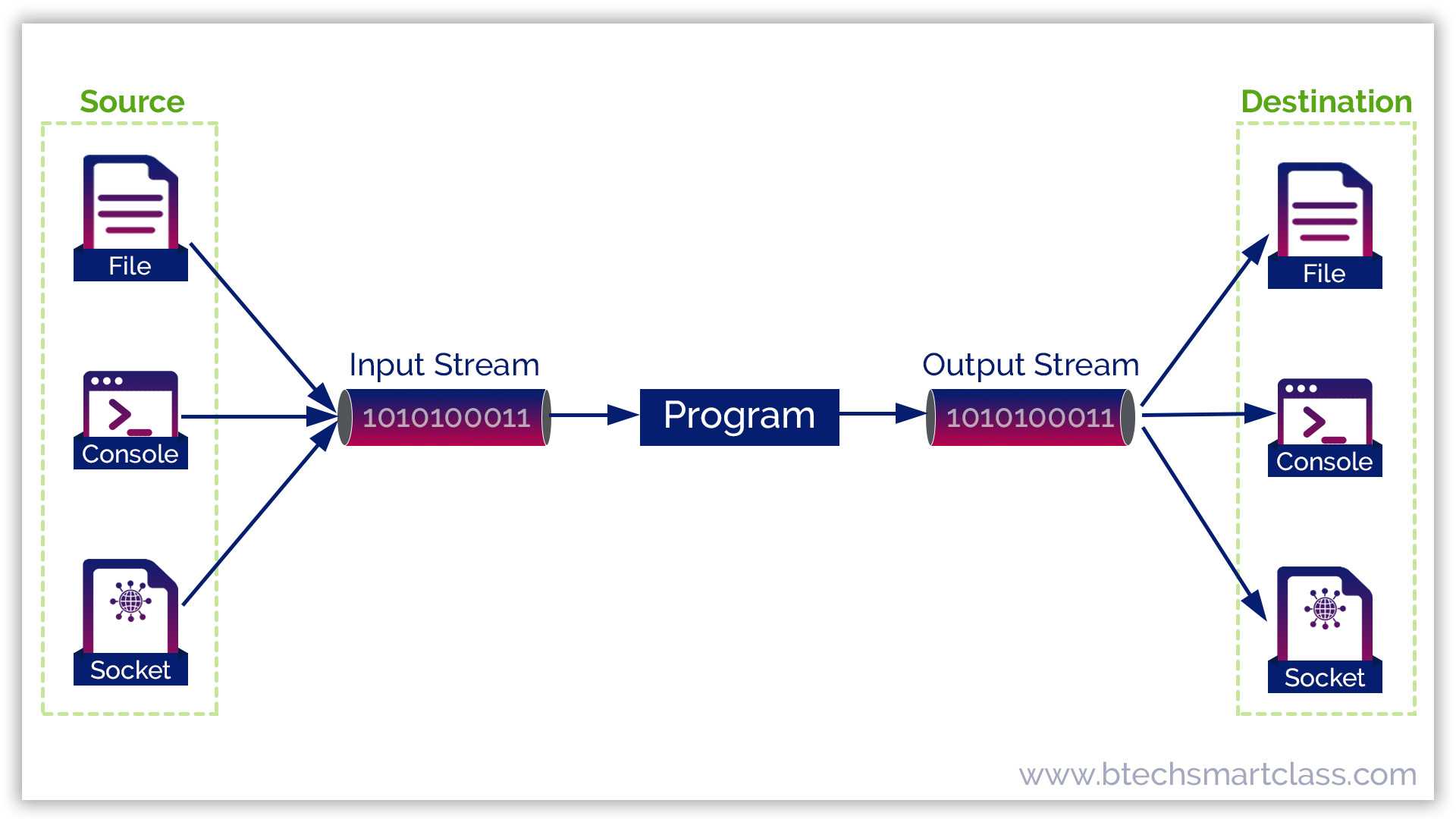
Коллекции против Потоков
Java Collections сосредоточены на том, чтобы хранить элементы данных для эффективного доступа.
Java потоки сосредоточены на совокупных операций на элементах данных из источника данных.
Потоки (Streams)
Java Streams имеют свои особенности.
Java Streams не имеют места хранения.
Коллекция представляет собой структуру данных в оперативной памяти, которая хранит все его элементы.
Поток не имеет памяти. Поток тянет элементы из источника данных по требованию и передает их в трубопровод операций по переработке.


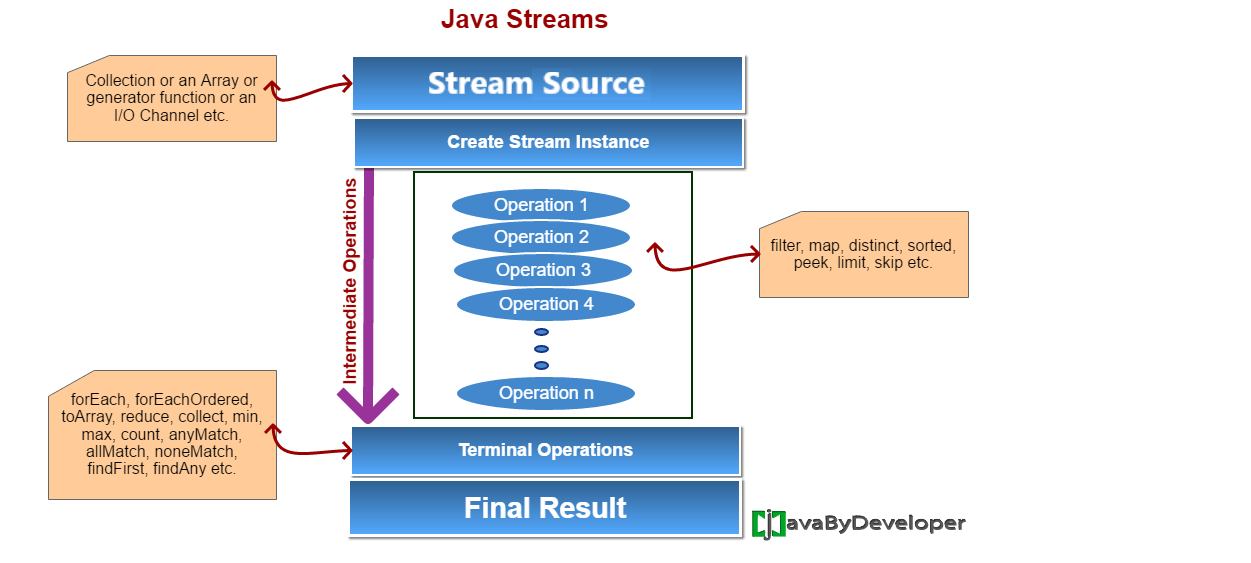
Для коллекции мы говорим о хранении или как элементы данных хранятся, как получить доступ к элементам данных.
Потока сконцентрировано внимание на операциях, например, как подводить поток
Пакетный, не потоковый
Несмотря на свое название, Stream API не является действительно API потоковой обработки. Терминальные операции возвращают конечный результат итерации по всем элементам в потоке и предоставляют нетерминальные и терминальные операции элементам. Результат возвращается после того, как последний элемент в потоке был обработан.
Возврат окончательного результата после обработки последнего элемента потока возможен, только если вы знаете, какой элемент является последним в потоке. Единственный способ узнать, является ли данный элемент последним элементом в потоке, – это если вы обрабатываете пакет с последним элементом. Напротив, истинный поток не имеет последнего элемента. Вы никогда не знаете, является ли данный элемент последним или нет. Поэтому невозможно выполнить терминальную операцию над потоком. Лучшее, что вы можете сделать, это собрать временные результаты после обработки данного элемента, но это будет выборка, а не окончательный результат.
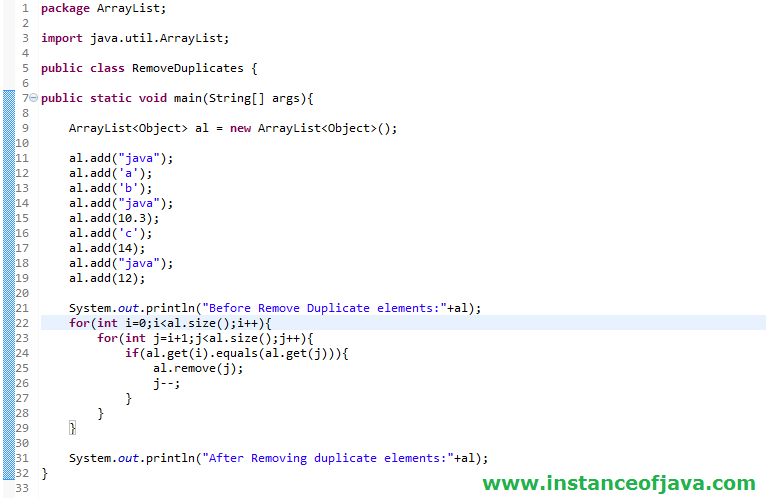
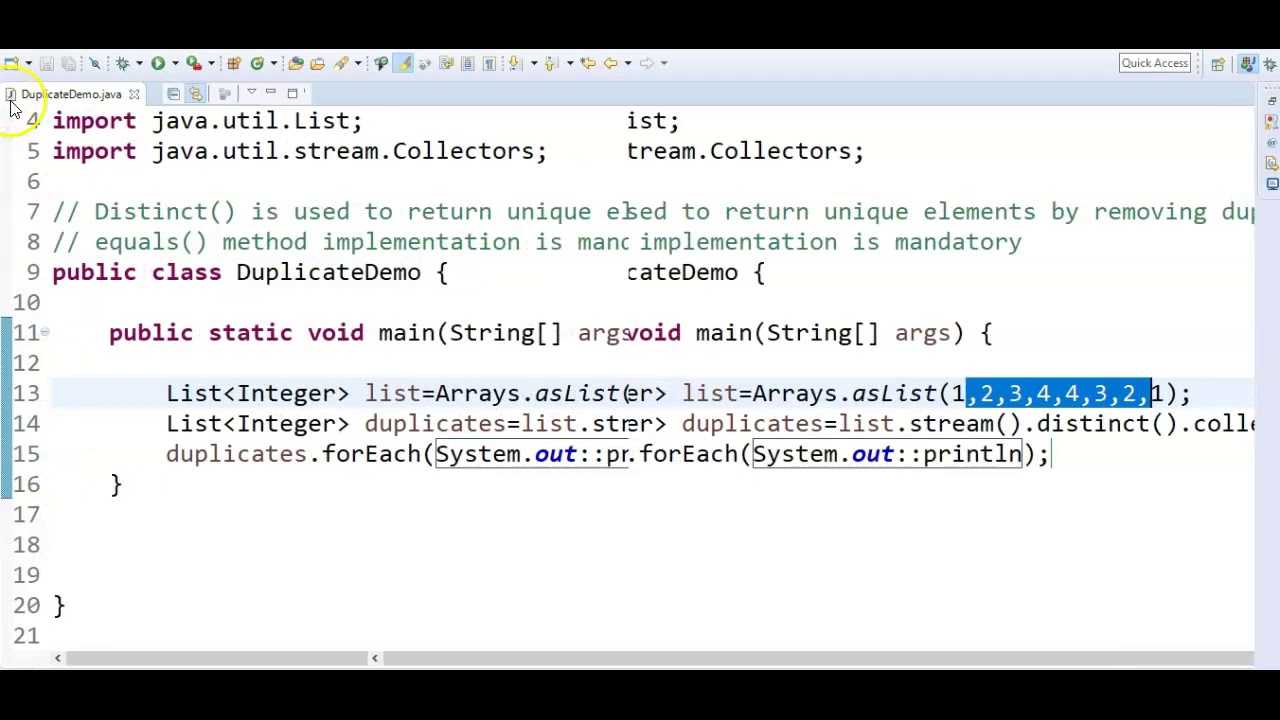
Поиск дубликатов с помощью Set
Сначала инициализируем вспомогательный Set, с помощью которого мы будем проверять, является ли следующий элемент стрима дубликатом:
Set<T> elements = new HashSet<>();
Затем в стриме будем добавлять каждый элемент из коллекции в Set с помощью метода add(). Этот метод возвращает true в том случае, если этот элемент ранее не был добавлен в Set:
collection.stream()
.filter(e -> !elements.add(e))
.collect(Collectors.toSet());
Таким образом, мы отфильтруем те элементы, которые встречаются в коллекции более одного раза.
Таким образом, полный код нашего метода может выглядеть следующим образом:
public static <T> Set<T> findDuplicates(Collection<T> collection) {
Set<T> elements = new HashSet<>();
return collection.stream()
.filter(e -> !elements.add(e))
.collect(Collectors.toSet());
}
Проверим его с помощью тестовых данных:
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Alice", "Carl", "Don", "Eugene", "Carl");
System.out.println("Все элементы: " + names);
Set<String> duplicates = findDuplicates(names);
System.out.println("Дубликаты: " + duplicates);
}
В результате мы выведем на экран дублирующиеся элементы:
![]()
Поиск дубликатов с помощью Set наиболее быстрый вариант из предложенных в данной статье.
reduce()
reduce() может свести все элементы в потоке к одному элементу. Посмотрите на реализацию:
List<String> stringList = new ArrayList<String>();
stringList.add("One flew over the cuckoo's nest");
stringList.add("To kill a muckingbird");
stringList.add("Gone with the wind");
Stream<String> stream = stringList.stream();
Optional<String> reduced = stream.reduce((value, combinedValue) -> {
return combinedValue + " + " + value;});
System.out.println(reduced.get());
Обратим внимание на необязательный параметр, возвращаемый методом reduce(). Этот необязательный параметр содержит значение (если оно есть), возвращаемое лямбда-выражением, переданным методу reduce()
Мы получаем значение, вызывая метод Optionalget().
2 ответа
14
Лучший ответ
Всякий раз, когда вы переопределяете , вам также необходимо переопределить метод , который будет использоваться в реализации .
В этом случае вы можете просто использовать
…, который будет работать нормально.
12 янв. 2015, в 23:16
Поделиться
3
Альтернативный подход
06 март 2017, в 12:50
Поделиться
Ещё вопросы
- XPath-запрос для всех ‘ocrx_word’
- 1Контролировать бета-версию Google Music из моего приложения?
- ng-show не работает с логическими значениями
- 1Как я могу заменить свой курсор на круг вместо того, чтобы рисовать его на холсте в p5.js?
- 1Конечные переменные в анонимных классах
- 1Как я могу получить Xstream для объединения событий мыши?
- 1Поддерживать страницу входа, когда пользователь нажимает кнопку «Назад»
- 1почему новый Integer (i) .hashCode () возвращает i?
- Игнорировать клики, которые выпадают: перед частью элемента заголовка (jQuery)
- 1Использовать пользовательский цвет в SolidColorBrush
- 1Android: seekcompleteListener для использования с VideoView
- Как заставить эту галерею AngularJs работать?
- 1Python: заменить все экземпляры буквенно-цифровой подстроки, за исключением номеров более высокого порядка
- Не удалось отправить запрос HTTP из-за CORS
- 1Сделать обязательное свойство пустым, но не неопределенным с помощью Vue.js
- Используя карту STL, неверное количество аргументов шаблона?
- 1андроид приложение скорость / частота кадров?
- переменные в JQuery против Javascript
- Использование одного div для очистки поплавка
- ‘sqrt’: неоднозначный вызов перегруженной функции .. \ assimp \ vector3.inl
- 1Заставить убить бегущую нить
- 1Как найти курс обмена между двумя валютами с помощью PHP
- Как перенаправить страницу с помощью jquery
- 1Ошибка сегментации с Homebrew php56-xdebug
- 1Расширение NHibernate для запроса не сопоставленного свойства
- как установить fancybox iframe высоту и ширину
- 1mstest.exe отсутствует в папке установки VS2013
- 1Размеры основного макета Android
- 1Методы перегрузки
- DB2 SQL Найдите идентификатор поставщиков, которые предоставляют определенный цвет
- 1Определите, произошел ли объект PDOStatement из PDO :: query () или PDO :: prepare ()
- jQuery UI — слайдер отвязывается после одного использования
- 1Несоответствие типов: невозможно преобразовать из класса <capture # 1-of?> В класс <?> []
- Не удается установить соединение с БД при развертывании файла .war на Tomcat7
- POST-запрос через HTTPS — какая библиотека?
- Почему я не могу переместить мои 3D кубы? OpenGL
- 1Запуск одного сервера и двух клиентов с использованием ANT
- Создание приложений AngluarJS, но не имеет серверной опции для SEO-дружественных URL-адресов. Будет ли это работать?
- 1Невозможно получить свойство навигации (данные внешнего ключа) из-за LazyLoading
- 1Картографическое построение точек неправильно с ортогональной проекцией
- заполнить несколько скрытых полей на замену выпадающего
- 1Остановите Facebook, исследующий сайт на предмет содержания с помощью PHP
- 1Как изменить порядок отображения свойств в объекте, переданном методу (WCF)
- Как разместить массив по одному входному углу
- Вызов метода Android из HTML всегда указывает на «другое»
- Добавить внешний ключ в Rails
- 1Анимация изображений в JavaScript против Java
- 1Удалить запись БД в Symfony
- 1Drupal 7 — ошибка схемы файла module.install
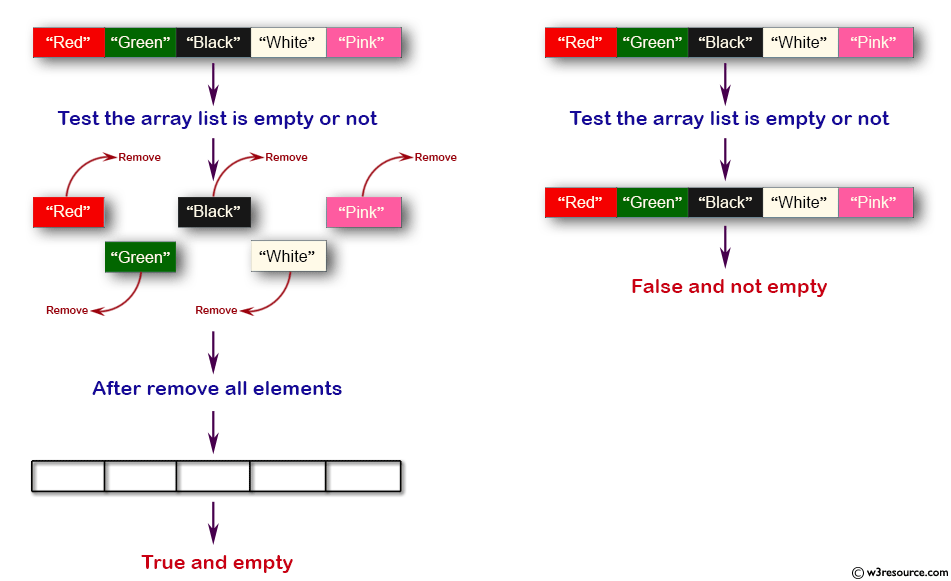
Использование итерации
Чтобы удалить дубликаты элементов из списка в Python, мы можем вручную повторить через список и добавить элемент в новый список, если оно нет. В противном случае мы пропускаем этот элемент.
Код показан ниже:
a =
b = []
for i in a:
# Add to the new list
# only if not present
if i not in b:
b.append(i)
print(b)
Выход
Один и тот же код может быть написан, используя понимание списка для уменьшения количества строк кода, хотя оно по существу то же самое, что и раньше.
a = b = [] print(b)
Проблема с таким подходом состоит в том, что она немного медленно, поскольку для каждого элемента выполняется сравнение для каждого элемента в новом списке, пока уже итерацией через наш оригинальный список.
Это вычислительно дорого, и у нас есть другие методы для решения этой проблемы. Вы должны использовать это только в том случае, если размер списка не очень большой. В противном случае обратитесь к другим методам.
Внутренняя итерация
Мы можем переписать код, указанный выше, используя поток. Он делает то же самое.
Java
//nookery.ru
import java.util.Arrays;
import java.util.List;
public class Test {
public static void main(String[] args) {
List<Integer> num = Arrays.asList(1, 2, 3, 4, 5);
int result = num.stream()
.filter(n -> n % 2 == 1)
.map(n -> n * n)
.reduce(0, Integer::sum);
System.out.println(result);
}
}
|
1 |
//nookery.ru importjava.util.Arrays; importjava.util.List; publicclassTest{ publicstaticvoidmain(Stringargs){ List<Integer>num=Arrays.asList(1,2,3,4,5); intresult=num.stream() .filter(n->n%2==1) .map(n->n*n) .reduce(,Integer::sum); System.out.println(result); } } |
В коде выше мы не использовали оператор цикла для итерации по списку. Мы сделали петлю внутри потока.
Для расчета нечетного мы использовали лямбда-выражения. Сначала мы сделали фильтр, затем карту, затем уменьшили.
Результатом работы программы будет: 35
Чтобы остался только один — reduce()
Метод reduce() берёт стрим и редуцирует (сокращает) его до одного значения. Для этого в метод передаются начальное значение (необязательный параметр) и функция-аккумулятор с двумя параметрами.
Сначала эта функция применяется к начальному значению и первому элементу стрима, затем к полученному на этом шаге результату и следующему элементу стрима — и так до последнего элемента стрима.
Есть и более сложные варианты редукции, когда нужен третий параметр — функция комбинирования. Она полезна при распараллеливании задач или несовпадении типов аргументов функции-аккумулятора и результата этой функции.
![]()
Вычисление максимального значения с помощью reduce ()
Без лямбд
На старте принимаем за максимум наименьшее возможное число книг у каждого читателя, то есть 0. Потом перебираем всех читателей, смотрим, сколько у кого книг, и при необходимости обновляем максимум.
С лямбдами
На первом шаге с помощью map() соотносим с каждым читателем число взятых им книг, а затем с помощью reduce() находим максимальный элемент в этом новом стриме.
Это важно. При каждом вызове функции-аккумулятора создаётся новый объект
Если вы хотите, чтобы на выходе reduce() оказался сложный объект — например, коллекция, и ходите в функции-аккумуляторе добавлять в неё значения, то на каждом шаге будет создаваться новая коллекция.
Это плохо сказывается на производительности. В таких случаях лучше использовать collect().
Overview
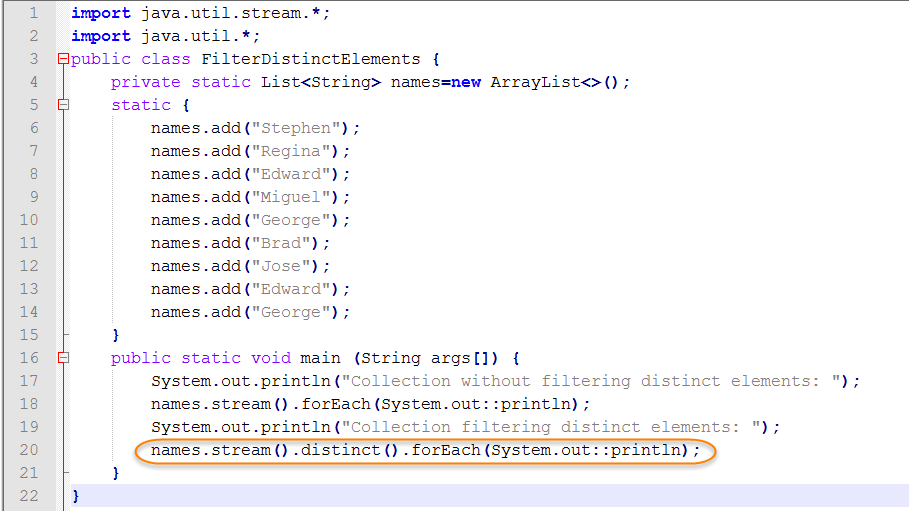
In this tutorial, you’ll learn How to get the distinct values from collection using java 8 stream api method.
Read more on
In other words, how to remove the duplicates from list or collection using java 8 streams. This is a common tasks to avoid duplicates in the list. After java 8 roll out, it has become simple filtering using functional programming language.
Java 8 stream api is added with a unique distinct() method to remove the duplicate objects from stream.
distinct() is an intermediate operation that means it returns Stream<T> as output.
Next, let us jump into examples programs using Strings and Custom objects.
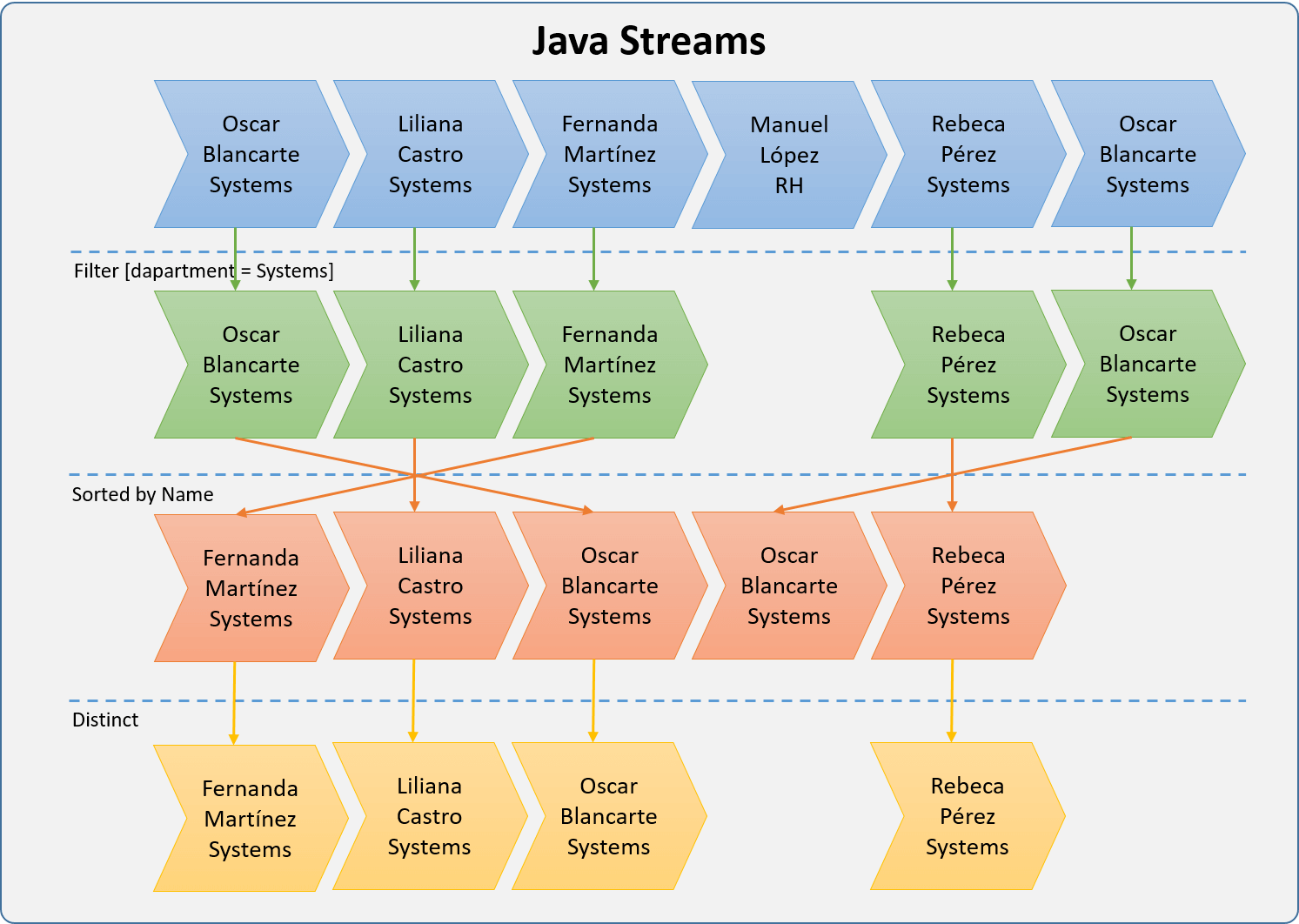
Промежуточные операции
Мы ранее уже знакомились с операцией фильтр, она позволяет нам написать выражение, которое будет проверятся для каждого элемента и если выражение истинно, то элемент может проходить дальше.
Но на нашем заводе мы делаем намного больше чем просто фильтруем бревна. Для того, чтобы дерево превратилось в мебель его нужно преобразовать.
Для этого пригодится самая популярная функция —
Возьмем наш пример выше и попробуем преобразовать
Функция map принимает реализацию функционального интерфейса .
На вход мы получаем объект типа T, а возвращаем объект типа R. То есть наш стрим, который был типизирован объектом Log становится типизирован объектом, который возвращает . Мы получаем набор строк с названиями деревьев.
Промежуточные операции можно конкатенировать между собой, то есть мы можем добавить еще несколько преобразований:
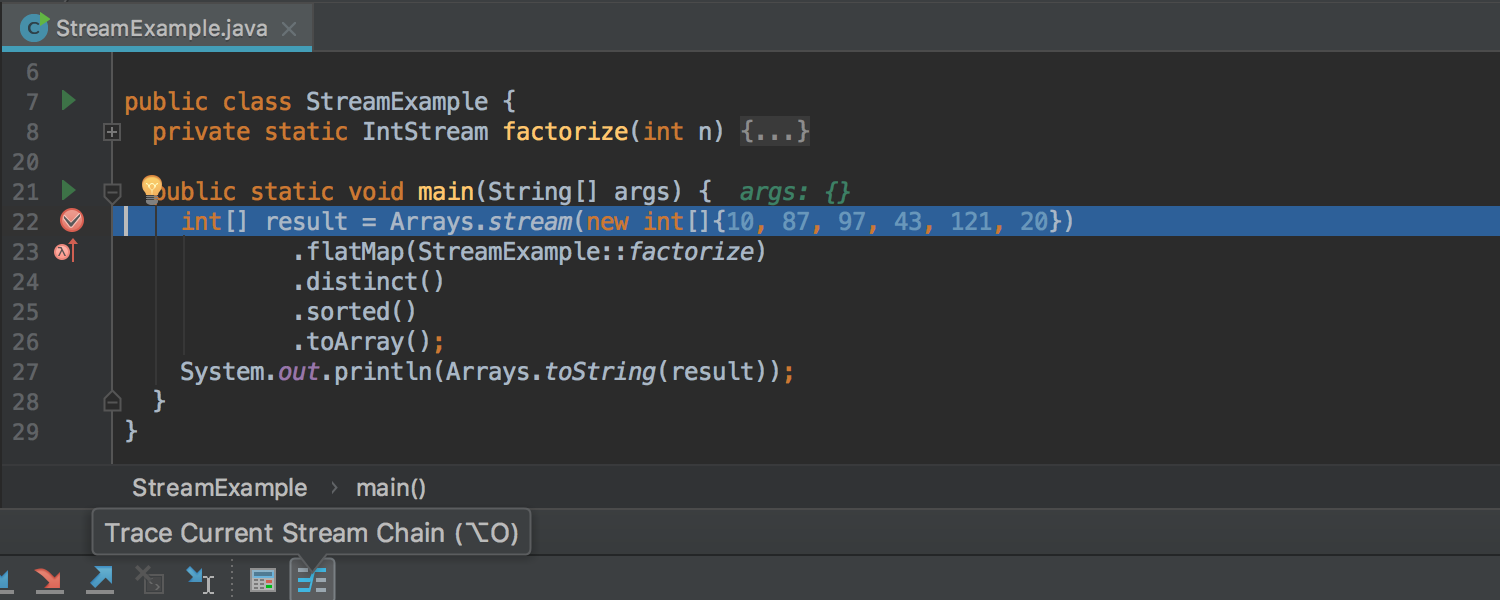
Во втором преобразовании мы разбили каждую строку на массив строк. Но если мы запустим приложение, мы увидим, что на экран не вывелись строки, а вывелось массивов. Нам хочется чтобы стрим был плоский — то есть только из объектов, а не из других стримов/массивов в которых есть объекты. Для этого авторы Java Stream API придумали еще одну промежуточную операцию — flatMap. Вот как она позволит изменить нам наш стрим (для более краткой записи я заменил прошлые операции на метод референс):
На вход flatMap() поступает функция, задача которой получить из объекта стрим и конкатенировать его с другими. Таким образом, мы создаем стримы из массивов строк и соединяем их вместе. Попробуем теперь получить список всех букв, которые встречаются в нашем стриме. Для этого воспользуемся методом . Метод класса String возвращает стрим примитивов IntStream. Каждому символу в строке она сопоставляет int значение.
Но запустив пример выше мы получили стрим стримов —
Но так с ним работать не удобно, а обычный flatMap не сработает, поэтому для примитивных стримов существуют специальные операции для их преобразований:
Значение функции выше говорит нам о том, что для того чтобы склеить наши стримы нам не нужно никаких дополнительных преобразований. В терминальной операции forEach мы привели значение x1 к символьной записи.
В итоге предыдущий пример вывел нам на экран побуквенно каждое название типа дерева. Что делать, если мы хотим вывести на экран только по одной букве, убрав повторяющиеся буквы? Для этого мы можем воспользоваться промежуточной операцией . Сама по себе операция очень похожа на фильтр, только разница в том, что она в себе запоминает все числа, которые через нее прошли и в следующий раз «пропускает» только те объекты, которые еще не прошли.
Для того чтобы отсортировать буквы воспользуемся операцией :
Стоит отметить, что операция таит в себе некоторые проблемы. Так для того чтобы отсортировать объекты, поступающие из стрима, она должна аккумулировать в себе все объекты, которые есть в стриме и только потом приступить к сортировке. Но что делать, если стрим бесконечный либо в стриме огромное количество элементов? Вызов такой операции приведет к OutOfMemoryException.
Для того, чтобы ограничить бесконечные операции существует операция . В нее в качестве аргумента мы можем передать число элементов, которых мы хотим взять из стрима.
В примере выше мы с помощью функции limit ограничили наш стрим до трех элементов, которые уже позже попали в .
Противоположная операция называется . Она принимает в качестве параметра число элементов, которые надо пропустить. То есть если логика нашей программы говорит нам начать обрабатывать элементы только после какого-то.
Порой это не особо удобно, а порой невозможно указать заранее сколько элементов пропустить или поглотить. Поэтому в стримы были добавлены дополнительные промежуточные операции, которые принимают предикат: и .
Простой пример приведен ниже:
Стрим будет генерировать новые значения, пока остаток от деления на 7 сгенерированного значения не будет равен 0.
И последняя операция, которую хотелось бы описать — это boxed. Ее стоит применять в том случае, если мы хотим превратить наш стрим примитивов в объектный стрим. То есть в примере выше, если добавить ее, то наш стрим перестанет быть IntStream, а станет .
Есть еще несколько промежуточных операций, но я расскажу только об одной, на мой взгляд, самой важной. Это операция
Разместив ее в любом месте нашего стрима мы волшебным образом запускаем очень сложный механизм внутри JVM. Мы получаем возможность многопоточной обработки нашего стрима. То есть Stream API постарается максимально эффективно выполнить все операции на разных ядрах процессора.
Что такое «ссылка на метод»?
Если существующий в классе метод уже делает все, что необходимо, то можно воспользоваться механизмом method reference (ссылка на метод) для непосредственной передачи этого метода. Такая ссылка передается в виде:
- для статического метода;
- для метода экземпляра;
- для конструктора.
Результат будет в точности таким же, как в случае определения лямбда-выражения, которое вызывает этот метод.
Ссылки на методы потенциально более эффективны, чем использование лямбда-выражений. Кроме того, они предоставляют компилятору более качественную информацию о типе и при возможности выбора между использованием ссылки на существующий метод и использованием лямбда-выражения, следует всегда предпочитать использование ссылки на метод.
Java 8 distinct() example — Strings Values in List
First, create a simple list with duplicate string values. Now, we want to get only the unique values from it.
For this, we need to convert the list into stream using stream() method and next call distinct() method. Here, this distinct() method eliminates the duplicate string values.
Finally, invoke the Collectors.toList() method to take the distinct values into List.
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class DistinctStringExample {
public static void main(String[] args) {
// create a list with string values
List<String> strings = new ArrayList<>();
// adding values to list
strings.add("ABC");
strings.add("XYZ");
strings.add("ABC");
strings.add("MNO");
strings.add("ABC");
strings.add("MNO");
strings.add("PQR");
// Getting the distinct values from stream using distinct() method
List<String> uniqueStrings = strings.stream().distinct().collect(Collectors.toList());
//printing the values
System.out.println("Original list : "+strings);
System.out.println("Unique values list : "+uniqueStrings);
}
}
Output:
Original list : Unique values list :
Сравнение: containing, startsWith, greaterThan
Мы уже использовали ключевое слово containing, что означало «поле содержит строку». Есть также startingWith:
List<User> findByNameIsStartingWith(String str);
А для чисел есть GreaterThan. Найдем пользователей, у которых сумма счета превышает заданное число:
List<User> findDistinctByAccounts_AmountIsGreaterThan(long n);
Генерируемый SQL:
select distinct user0_.id as id1_1_, user0_.name as name2_1_
from user user0_
left outer join account accounts1_
on user0_.id=accounts1_.user_id
where accounts1_.amount>?
Тест:
@Test
void t6() {
List<User> users = userDao.findDistinctByAccounts_AmountIsGreaterThan(15);
Assertions.assertEquals(2, users.size());
}
Без ключевого слова Distinct в этом тесте появляются дубликаты, потому что join генерирует одну запись для Ivan и целых 3 записи для John (у которого три аккаунта более 15).
Другие ключевые слова .
Логические условия or, and
Можно соединять условия для полей символами or, and. Например, найдем пользователей с заданным именем, либо (еще) тех у которых имеется счет с суммой больше заданной:
List<User> findDistinctByNameOrAccounts_AmountIsGreaterThan(String name, long amount);
Генерируемый SQL:
select distinct user0_.id as id1_1_, user0_.name as name2_1_ from user user0_ left outer join account accounts1_ on user0_.id=accounts1_.user_id where user0_.name=? or accounts1_.amount>?
Iterable как параметр
Можно задать список в качестве параметра:
List<User> findByNameIn(Iterable name);
Пример использования:
@Test
void t8() {
List<User> users = userDao.findByNameIn(Arrays.asList("Ivan", "Petr"));
Assertions.assertEquals(2, users.size());
}
Желательно параметр делать именно Iterable, а не Set и List, чтобы при вызове метода не требовалось лишних преобразований.
Pagination
Можно создавать запросы для постраничного извлечения сущности:
Page<User> findByName(String name, Pageable pageable);
Ниже пример использования: в запросе передается PageRequest.of(0,2) с номером страницы и количеством элементов на странице:
@Test
void t10() {
Page<User> userPage = userDao.findByName("John",PageRequest.of(0,2));
Assertions.assertEquals(2, userPage.getTotalElements());
}
Страницы нумеруются с 0.
Генерируемый SQL:
Hibernate: select user0_.id as id1_1_, user0_.name as name2_1_ from user user0_ where user0_.name=? limit ? Hibernate: select count(user0_.id) as col_0_0_ from user user0_ where user0_.name=?
Стоит отметить, что метод постраничного получения всех подряд сущностей уже есть в PagingAndSortingRepository:
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
...
Page<T> findAll(Pageable pageable);
...
}
Сортировка: orderBy и Sort
Найти пользователей, что имя содержит заданную строку и упорядочить результат по имени:
List<User> findByNameContainingOrderByNameAsc(String str);
Или передать в параметре объект Sort:
List<User> findByNameContaining(String str, Sort sort);
Пример использования второго метода:
@Test
void t12() {
Sort sort = Sort.by(Sort.Direction.ASC, "name");
List<User> users= userDao.findByNameContaining("e", sort);
Assertions.assertEquals(2,users.size());
Assertions.assertEquals("Artem",users.get(0).getName());
}
Оба метода генерируют одинаковый SQL:
select user0_.id as id1_1_, user0_.name as name2_1_ from user user0_ where user0_.name like ? escape ? order by user0_.name asc
Подсчет количества: count
Есть еще ключевое слово count для подсчета строк. Например, найти количество пользователей с заданным именем:
int countAllByName(String name);
Spring Data генерирует следующий SQL:
select count(user0_.id) as col_0_0_ from user user0_ where user0_.name=?
Найти количество пользователей с названием аккаунта, содержащим строку:
int countDistinctUserByAccounts_NameContaining(String str);
Удаление сущности: remove и delete
Наконец, можно писать и методы удаления сущности с помощью ключевых слов remove и delete:
int deleteByName(String name); void removeUserByName(String name);
Какое ключевое слово выбрать значения не имеет. А вот возвращаемый тип int вернет количество удаленных строк.

Генерируемый SQL:
select user0_.id as id1_1_, user0_.name as name2_1_ from user user0_ where user0_.name=? delete from user where id=?
Цепь, а не график
Stream API разработан таким образом, что к экземпляру можно обращаться только один раз. Другими словами, вы можете добавить только одну нетерминальную операцию в Stream, что приведет к созданию нового объекта Stream. Вы можете добавить еще одну нетерминальную операцию к результирующему объекту, но не к первому. Результирующая структура нетерминальных экземпляров Stream образует цепочку.
В истинном API обработки потока корневой поток и прослушиватели событий обычно могут образовывать график, а не просто цепочку. Несколько слушателей могут прослушивать корневой поток, и каждый из них – обрабатывать элементы в потоке по-своему, и в результате – пересылать преобразованный элемент. Таким образом, каждый слушатель (нетерминальная операция) обычно может действовать как сам поток, который другие слушатели прослушивают. Так устроен Apache Kafka Streams. Каждый слушатель (промежуточный поток) также может иметь несколько слушателей. Полученная структура формирует график слушателей со слушателями и т. д.
С графом потоковой обработки, а не цепочкой, в графе нет ни одной последней операции. Под конечной операцией подразумевается операция, которая гарантированно будет последней в цепочке обработки. Вместо этого может быть несколько заключительных операций. Каждый «лист» на графике является конечной операцией.
Когда ваша структура потоковой обработки может быть графом с несколькими заключительными операциями, потоковый API не может легко поддерживать терминальные операции, как это делает Stream API. Чтобы добиться этого, должна быть одна, последняя операция, из которой возвращается конечный результат. API обработки потоков на основе графа может вместо этого поддерживать «примерную» операцию, где у каждого узла в графе обработки потоков запрашивается любое значение, которое он может содержать внутри (например, сумма), если таковые имеются (чисто преобразовывающие узлы слушателя не будут иметь никакого внутреннего состояния).



