
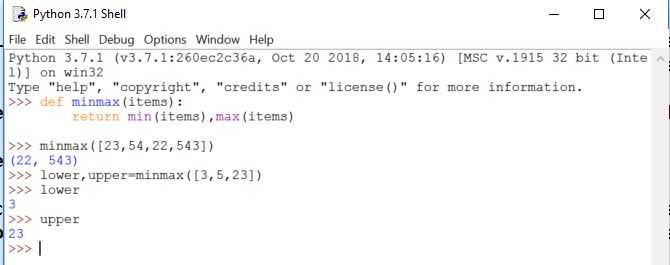
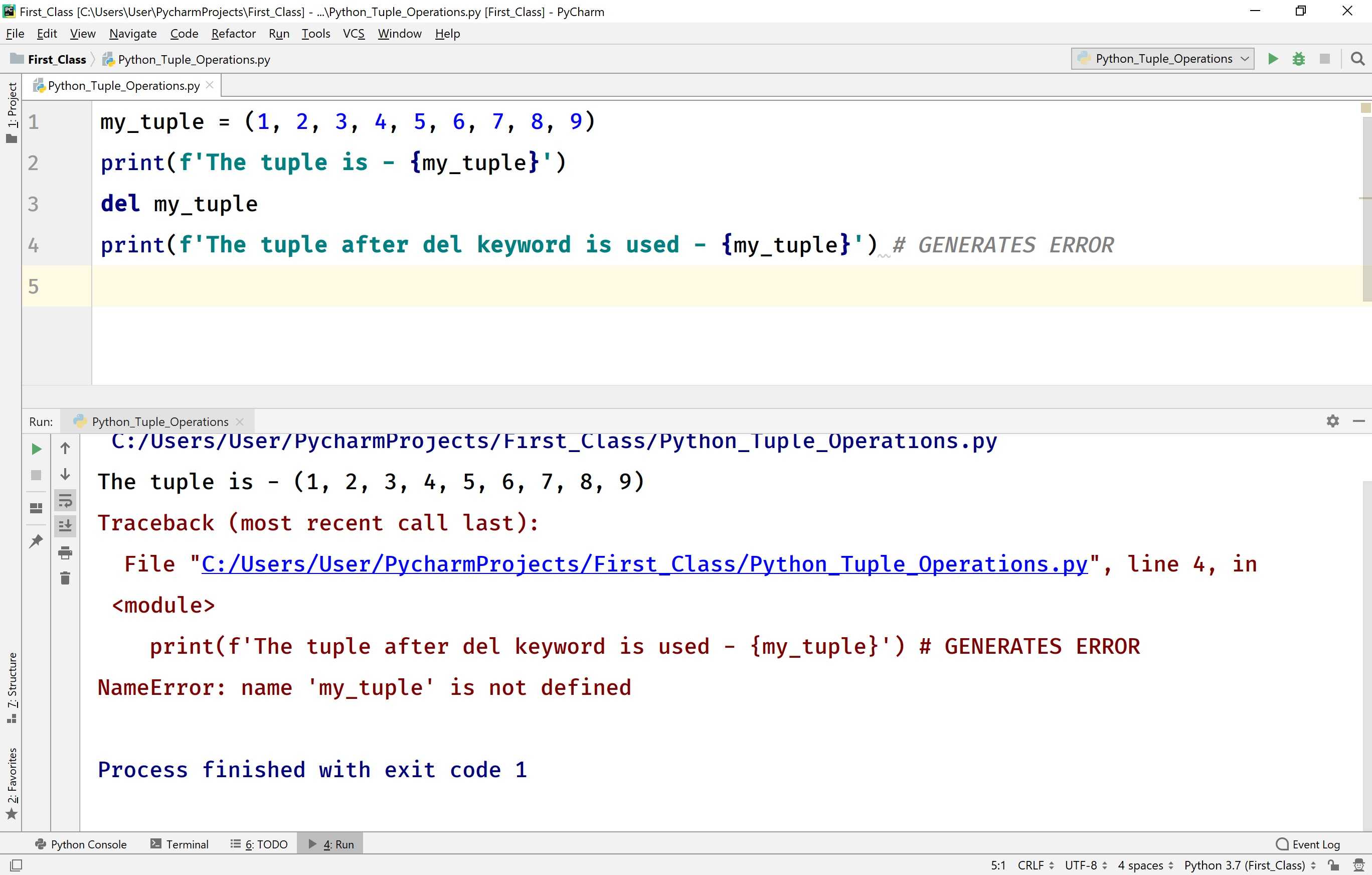
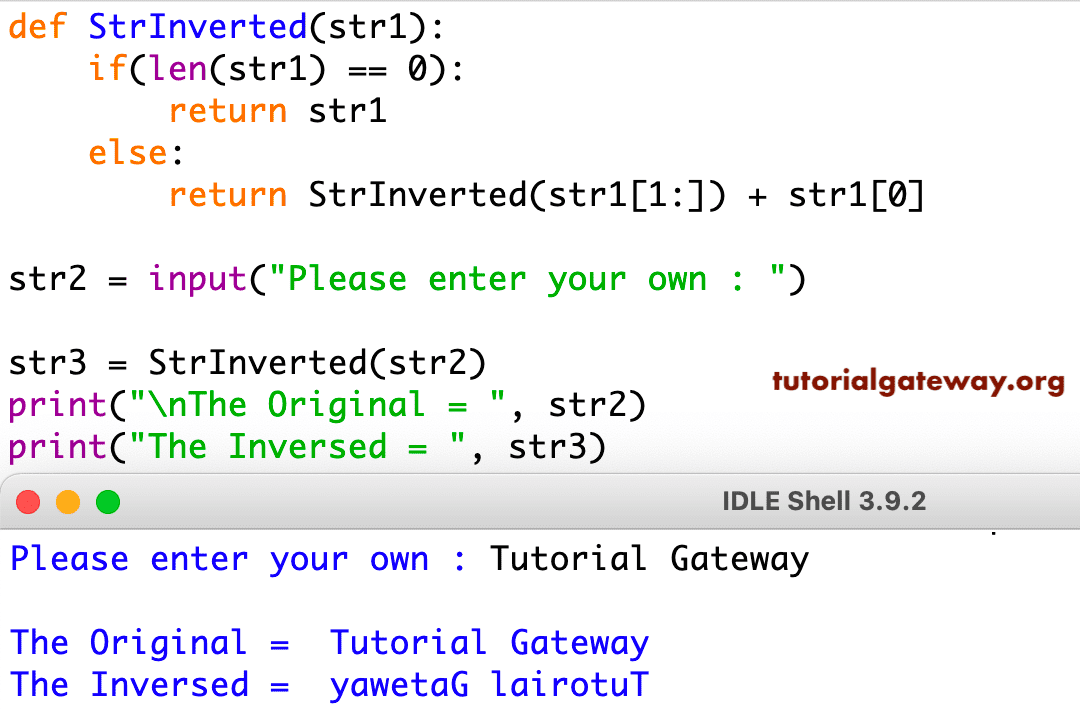
Удаление элементов из списка
Метод принимает один аргумент и удаляет из списка первый элемент со значением, соответствующим аргументу:
Если элемент с данным значением не существует, возникает исключение :
Метод принимает один аргумент и удаляет элемент с индексом, соответствующим аргументу, из списка:
Аргумент является необязательным. По умолчанию используется значение «-1», которое является последним элементом списка. Возвращаемое значение метода — удаленный элемент. Вот пример:
Ключевое слово в сочетании с обозначением среза позволяет удалить более одного элемента. Например, чтобы удалить первые два элемента из списка, вы должны использовать следующее:
Чтобы удалить все элементы, используйте метод , который очищает список и не принимает никаких аргументов:
Индексирование
Что же такое индексирование? Это загадочное слово обозначает операцию обращения к элементу по его порядковому номеру ( ( ・ω・)ア напоминаю, что нумерация начинается с нуля). Проиллюстрируем это на примере:
fruits =
print(fruits[])
print(fruits)
print(fruits)
>>> Apple
>>> Grape
>>> Orange
Списки в Python являются изменяемым типом данных. Мы можем изменять содержимое каждой из ячеек:
fruits =
fruits[] = ‘Watermelon’
fruits = ‘Lemon’
print(fruits)
>>>
Индексирование работает и в обратную сторону. Как такое возможно? Всё просто, мы обращаемся к элементу списка по отрицательному индексу. Индекс с номером -1 дает нам доступ к последнему элементу, -2 к предпоследнему и так далее.
fruits =
print(fruits)
print(fruits)
print(fruits)
print(fruits)
>>> Orange
>>> Banan
>>> Peach
>>> Grape
Создание списка
Пусть даны два числа: количество строк и количество столбцов
. Необходимо создать список размером ×, заполненный нулями.
Очевидное решение оказывается неверным:
A = * m ] * n
В этом легко убедиться, если присвоить элементу
значение , а потом вывести значение другого элемента — оно тоже будет равно 1! Дело в том, что
возвращает ccылку на список из нулей.
Но последующее повторение этого элемента создает список из
элементов, которые являются ссылкой на один и тот же список (точно
так же, как выполнение операции для списков не создает
новый список), поэтому все строки результирующего списка на самом деле
являются одной и той же строкой.
Таким образом, двумерный список нельзя создавать при помощи операции
повторения одной строки. Что же делать?
Первый способ: сначала создадим список из элементов
(для начала просто из нулей). Затем сделаем каждый
элемент списка ссылкой на другой одномерный список из
элементов:
A = * n
for i in range(n):
A = * m
Другой (но похожий) способ: создать пустой список, потом
раз добавить в него новый элемент, являющийся списком-строкой:
A = []
for i in range(n):
A.append( * m)
Но еще проще воспользоваться генератором: создать список из
элементов, каждый из которых будет списком,
состоящих из нулей:
A = * m for i in range(n)]
Доступ к элементам списка
На элемент списка можно ссылаться по его индексу. Индексы являются целыми числами и начинаются от до где — количество элементов:
В Python индексы заключаются в квадратные скобки:
Например, для доступа ко второму элементу списка вы должны использовать:
Если вы ссылаетесь на несуществующий индекс, исключение :
Для доступа к элементам во вложенном списке используйте несколько индексов:
Python также позволяет вам получать доступ к элементам списка, используя отрицательные индексы. Последний элемент обозначается как , второй последний элемент — как и так далее:
Например, чтобы получить доступ ко второму элементу с конца, вы должны использовать:
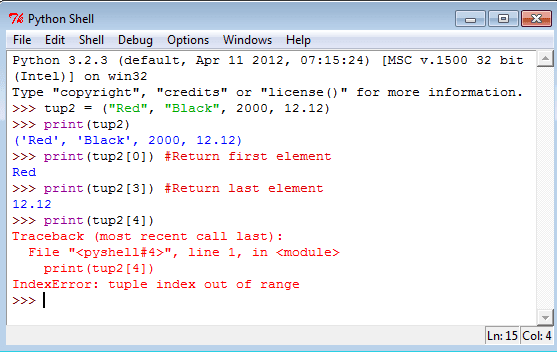
Python – найти индекс или положение элемента в списке
Чтобы найти индекс первого вхождения элемента в данном списке Python, вы можете использовать индекс () метод списка класса с элементом, пройденным в качестве аргумента.
index = mylist.index(element)
Метод Index () Возвращает целое число, которое представляет индекс первого совпадения указанного элемента в списке.
Вы также можете предоставить начальные и конец позиции списка, где поиск должен произойти в списке.
Ниже приведен синтаксис индекса () функции с начальными и торцевыми позициями.
index = mylist.index(x, ])
Параметр необязательный. Если вы предоставляете значение для Тогда не является обязательным.
Мы посмотрим на примеры, где мы проходим через каждый из этих сценариев подробно.
Пример 1. Найти индекс элемента в списке
В следующем примере мы взяли список с номерами. Использование метода Index () Мы найдем индекс товара в списке.
Python Program
mylist = item = 8 #search for the item index = mylist.index(item) print('The index of', item, 'in the list is:', index)
Выход
The index of 8 in the list is: 2
Элемент присутствует на 3-й позиции, поэтому Функция возвращена 2.
Пример 2: Найти индекс элемента в списке – начало, конец
В следующем примере мы взяли список с номерами. Использование метода Index () Мы найдем индекс товара в списке. Кроме того, мы будем проходить начало и конец. Функция index () рассматривает только те элементы в списке, начиная с Индекс, до позиция в Отказ
Python Program
mylist =
item = 8
start=2
end=7
#search for the item
index = mylist.index(item, start, end)
print('The index of', item, 'in the list is:', index)
Выход
The index of 8 in the list is: 4
Объяснение
mylist =
----------------- only this part of the list is considered
^ index finds the element here
0 1 2 3 4 => 4 is returned by index()
Пример 3: Найти индекс элемента – элемент имеет несколько вхождений в списке
Список Python может содержать несколько вхождений элемента. В таких случаях возвращается только индекс первого вхождения указанного элемента в списке.
Python Program
mylist =
item = 52
#search for the item
index = mylist.index(item)
print('The index of', item, 'in the list is:', index)
Выход
The index of 52 in the list is: 3
Элемент присутствует два раза, но только индекс первого вхождения возвращается методом индекса ().
Давайте понять, как работает метод индекса (). Функция сканирует список от начала. Когда элемент соответствует аргументу, функция возвращает этот индекс. Последние вхождения игнорируются.
Пример 4: Найти индекс элемента в списке – товар отсутствует
Если элемент, который мы ищем в списке, нет, вы получите с сообщением Отказ
В следующей программе мы предприняли список и постараемся найти индекс элемента, который отсутствует в списке.
Python Program
mylist =
item = 67
#search for the item/element
index = mylist.index(item)
print('The index of', item, 'in the list is:', index)
Выход
Traceback (most recent call last): File "example.py", line 5, in index = mylist.index(item) ValueError: 67 is not in list
В качестве индекса () можно бросить ValueError, используйте Python Try – за исключением при использовании индекса (). В следующем примере мы узнаем, как использовать оператор TRY – кроме, для обработки этого ValueError.
Python Program
mylist =
item = 67
try:
#search for the item
index = mylist.index(item)
print('The index of', item, 'in the list is:', index)
except ValueError:
print('item not present')
Выход
item not present
Элемент, индекс которого мы пытаемся найти, нет в списке. Поэтому бросает valueError. Блок ловит эту ошибку, а соответствующий блок выполнен.
Резюме
В этом учебном пособии Python мы узнали, как найти индекс элемента/элемента в списке, с помощью хорошо подробных примеров.
Удалить элемент из списка
Как и в примере с добавление элементов, мы так же можем удалить один или несколько элементов из списка. Для удаление используется ключевое слово del.

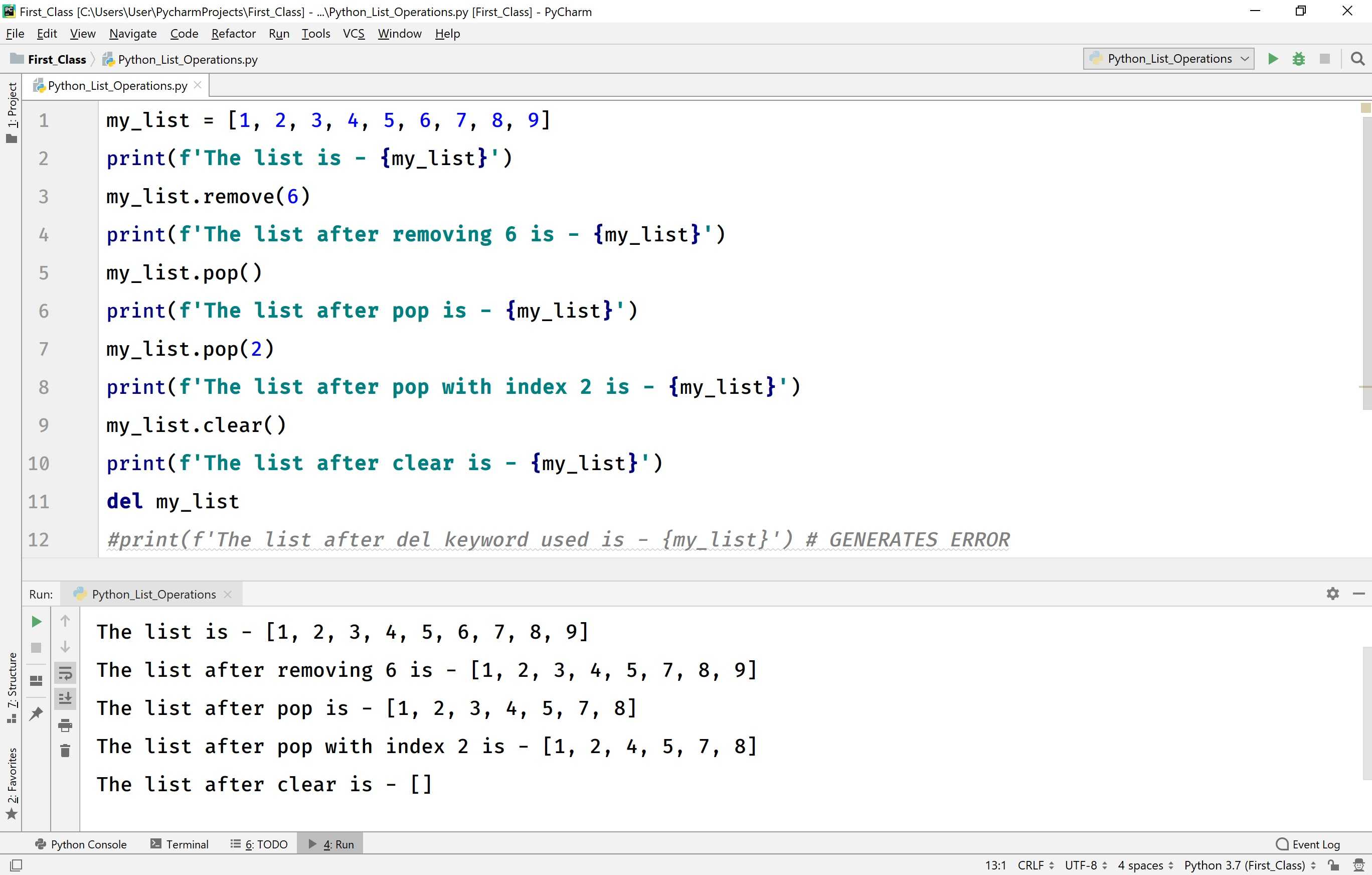


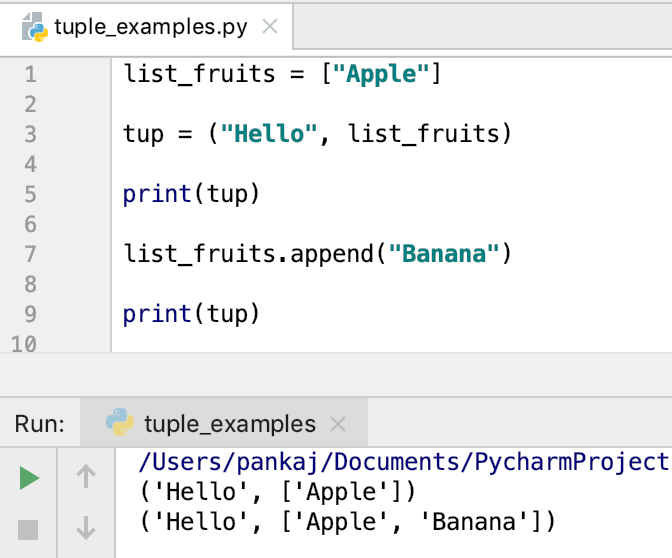
# Удаление элементов списка my_list = # Удаление одного элемента del my_list print(my_list) # Удаление диапазона элементов del my_list print(my_list) # Удаление всего списка del my_list
По мимо вышеописанного, мы так же можем воспользоваться методами списка. Метод remove(), для удаление элемента, или метод pop() для удаления элемента с заданным индексом.
Метод pop() удаляет и возвращает последний элемент если не указан индекс. Так же для очистки всего списка, мы можем воспользоваться методом clear().
list =
list.remove('p')
print(list)
# Результат
print(list.pop(1))
#Результат o
print(list)
# Результат
print(list.pop())
#Результат m
list.clear() print(list)
#Результат []
Методы списков
Давайте теперь
предположим, что у нас имеется список из чисел:
a = 1, -54, 3, 23, 43, -45,
и мы хотим в
конец этого списка добавить значение. Это можно сделать с помощью метода:
a.append(100)
И обратите
внимание: метод append ничего не возвращает, то есть, он меняет
сам список благодаря тому, что он относится к изменяемому типу данных. Поэтому
писать здесь конструкцию типа
a = a.append(100)
категорически не
следует, так мы только потеряем весь наш список! И этим методы списков
отличаются от методов строк, когда мы записывали:
string="Hello" string = string.upper()
Здесь метод upper возвращает
измененную строку, поэтому все работает как и ожидается. А метод append ничего не
возвращает, и присваивать значение None переменной a не имеет
смысла, тем более, что все работает и так:
a = 1, -54, 3, 23, 43, -45, a.append(100)
Причем, мы в методе
append можем записать
не только число, но и другой тип данных, например, строку:
a.append("hello")
тогда в конец
списка будет добавлен этот элемент. Или, булевое значение:
a.append(True)
Или еще один
список:
a.append(1,2,3)
И так далее. Главное,
чтобы было указано одно конкретное значение. Вот так работать не будет:
a.append(1,2)
Если нам нужно
вставить элемент в произвольную позицию, то используется метод
a.insert(3, -1000)
Здесь мы
указываем индекс вставляемого элемента и далее значение самого элемента.
Следующий метод remove удаляет элемент
по значению:
a.remove(True)
a.remove('hello')
Он находит
первый подходящий элемент и удаляет его, остальные не трогает. Если же
указывается несуществующий элемент:
a.remove('hello2')
то возникает
ошибка. Еще один метод для удаления
a.pop()
выполняет
удаление последнего элемента и при этом, возвращает его значение. В самом
списке последний элемент пропадает. То есть, с помощью этого метода можно
сохранять удаленный элемент в какой-либо переменной:
end = a.pop()
Также в этом
методе можно указывать индекс удаляемого элемента, например:
a.pop(3)
Если нам нужно
очистить весь список – удалить все элементы, то можно воспользоваться методом:
a.clear()
Получим пустой
список. Следующий метод
a = 1, -54, 3, 23, 43, -45, c = a.copy()
возвращает копию
списка. Это эквивалентно конструкции:
c = list(a)
В этом можно
убедиться так:
c1 = 1
и список c будет отличаться
от списка a.
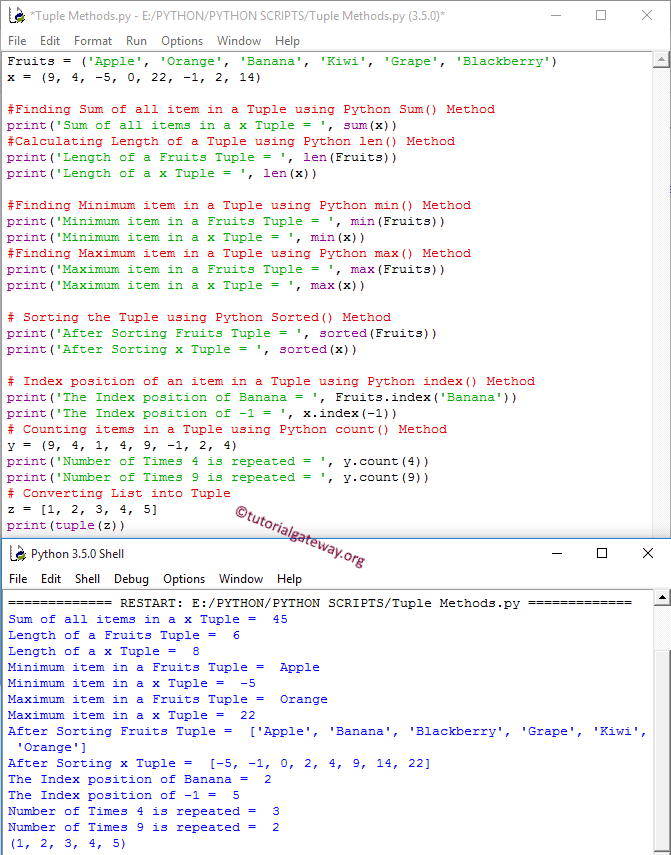
Следующий метод count позволяет найти
число элементов с указанным значением:
c.count(1) c.count(-45)
Если же нам
нужен индекс определенного значения, то для этого используется метод index:
c.index(-45) c.index(1)
возвратит 0,
т.к. берется индекс только первого найденного элемента. Но, мы здесь можем
указать стартовое значение для поиска:
c.index(1, 1)
Здесь поиск
будет начинаться с индекса 1, то есть, со второго элемента. Или, так:
c.index(23, 1, 5)
Ищем число 23 с
1-го индекса и по 5-й не включая его. Если элемент не находится
c.index(23, 1, 3)
то метод
приводит к ошибке. Чтобы этого избежать в своих программах, можно вначале
проверить: существует ли такой элемент в нашем срезе:
23 in c1:3
и при значении True далее уже
определять индекс этого элемента.
Следующий метод
c.reverse()
меняет порядок
следования элементов на обратный.
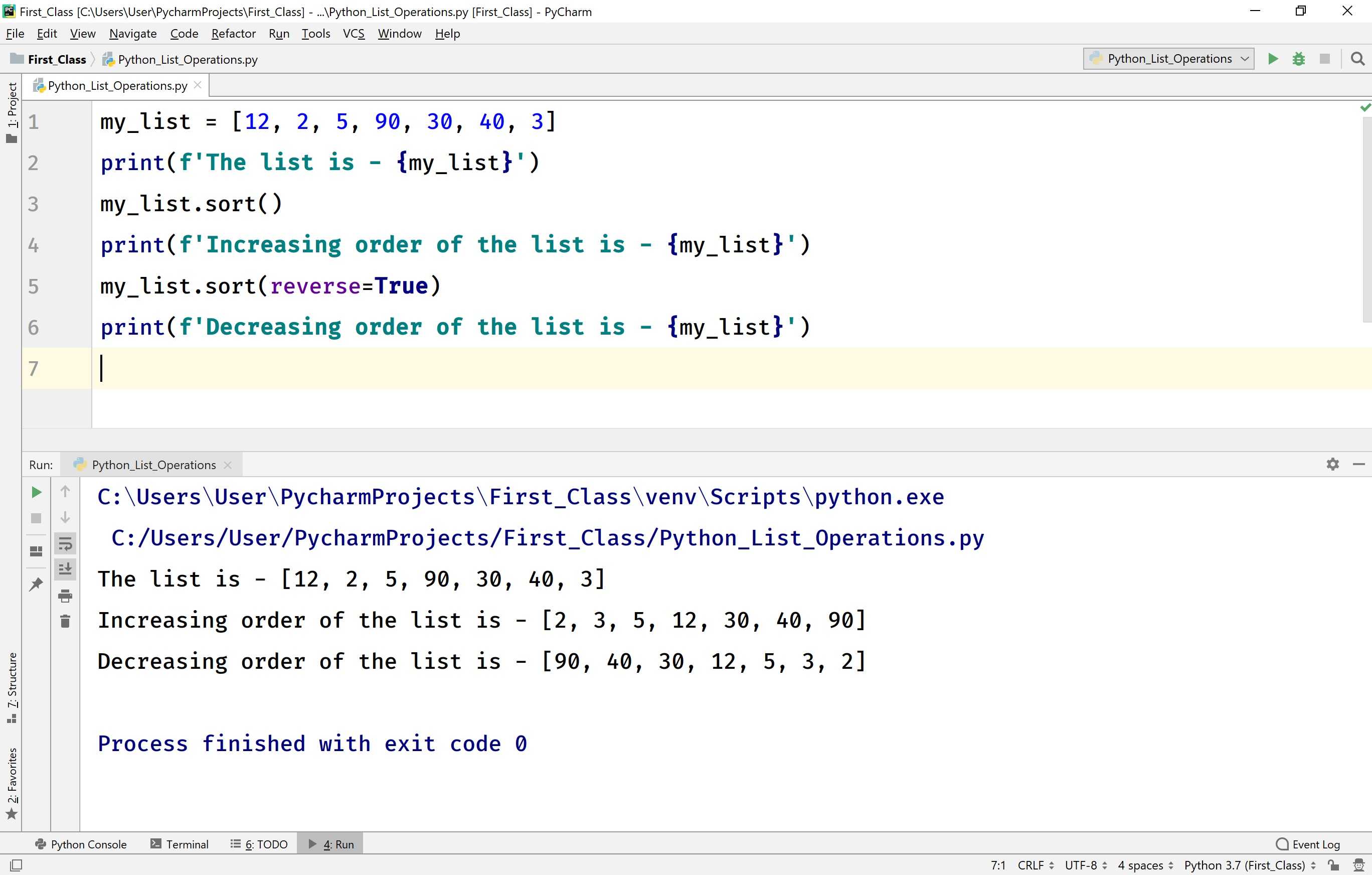
Последний метод,
который мы рассмотрим, это
c.sort()
выполняет
сортировку элементов списка по возрастанию. Для сортировки по убыванию, следует
этот метод записать так:
c.sort(reverse=True)
Причем, этот
метод работает и со строками:
lst = "Москва", "Санкт-Петербург", "Тверь", "Казань" lst.sort()
Здесь
используется лексикографическое сравнение, о котором мы говорили, когда
рассматривали строки.
Это все основные
методы списков и чтобы вам было проще ориентироваться, приведу следующую
таблицу:
|
Метод |
Описание |
|
append() |
Добавляет |
|
insert() |
Вставляет |
|
remove() |
Удаляет |
|
pop() |
Удаляет |
|
clear() |
Очищает |
|
copy() |
Возвращает |
|
count() |
Возвращает |
|
index() |
Возвращает |
|
reverse() |
Меняет |
|
sort() |
Сортирует |
Бинарный поиск
Бинарный поиск следует методологии «разделяй и властвуй». Это быстрее, чем линейный поиск, но требует сортировки массива перед выполнением алгоритма.

Предполагая, что мы ищем значение val в отсортированном массиве, алгоритм сравнивает его со значением среднего элемента массива, который мы назовем mid:
- Если mid – это элемент, который мы ищем (в лучшем случае), мы возвращаем его индекс.
- Если нет, мы определяем, какая сторона mid val с большей вероятностью будет лежать в основе, в зависимости от того, больше или меньше val, чем mid, и отбрасываем другую сторону массива.
- Затем мы рекурсивно или итеративно выполняем jump, выбирая новое значение для mid, сравнивая его с val и отбрасывая половину возможных совпадений на каждой итерации алгоритма.
Алгоритм двоичного поиска может быть написан рекурсивно или итеративно. Рекурсия в Python обычно выполняется медленнее, поскольку требует выделения новых кадров стека.
Поскольку хороший алгоритм поиска должен быть максимально быстрым и точным, давайте рассмотрим итеративную реализацию двоичного поиска:
def BinarySearch(lys, val):
first = 0
last = len(lys)-1
index = -1
while (first <= last) and (index == -1):
mid = (first+last)//2
if lys == val:
index = mid
else:
if val<lys:
last = mid -1
else:
first = mid +1
return index
Если мы используем функцию для вычисления:
>>> BinarySearch(, 20)
Получаем результат:
1
Это индекс значения, которое мы ищем.
Действие, которое алгоритм выполняет следующим на каждой итерации, является одной из нескольких возможных:
- Возврат индекса текущего элемента.
- Поиск в левой половине массива.
- Поиск по правой половине массива.
Мы можем выбрать только одну возможность на итерацию, и наш пул возможных совпадений делится на два на каждой итерации. Это делает временную сложность двоичного поиска равной O (log n).
Одним из недостатков бинарного поиска является то, что если в массиве несколько вхождений элемента, он возвращает не индекс первого элемента, а скорее индекс элемента, ближайшего к середине:
>>> print(BinarySearch(, 4))
Запуск этого фрагмента кода приведет к получению индекса среднего элемента:
1
Для сравнения выполнение линейного поиска в том же массиве вернет:
Это индекс первого элемента. Однако мы не можем категорически сказать, что двоичный поиск не работает, если массив содержит один и тот же элемент дважды – он может работать так же, как линейный поиск и в некоторых случаях возвращать первое вхождение элемента.
Если мы выполним двоичный поиск, например, в массиве и найдем 4, в результате мы получим 3.
Двоичный поиск довольно часто используется на практике, поскольку он эффективен и быстр по сравнению с линейным поиском. Однако у него есть некоторые недостатки, такие как использование оператора //. Есть много других алгоритмов поиска «разделяй и властвуй», которые являются производными от бинарного поиска, давайте рассмотрим некоторые из них далее.
Индекс списка
Счет индекса в списках, в целом как и в программировании начинается с 0, таким образом список который имеет 5 элементов, будет иметь индекс от 0 до 4.
Оператором для получения нужного элемента являются квадратные скобки []. Если мы обратимся к несуществующему индексу, то получим ошибку IndexError. Индекс — это всегда целое число, и никак иначе. Доступ к вложенным спискам, так же осуществляется с помощью вложенной индексации, и так, поехали обкатывать теорию.
my_list = #Наш список от 0 до 4 print(my_list) # Первый элемент p print(my_list) #Третий элемент o print(my_list) # Пятый элемент e n_list = ]#Смешанный список print(n_list) # Второй элемент из первого списка a print(n_list) # Четвертый элемент из второго списка 5 print(my_list) # Будет ошибка, так как индекс не является целым числом
Так же в Python есть и отрицательная индексация.
my_list = print(my_list) # последний элемент списка e print(my_list) # Первый элемент списка p
Вопрос 9. Чем список отличается от других структур?
Сложность: (> ⌒ <)
Такие вопросы надо отбивать особенно чётко. Если спрашивающий не услышит конкретные ключевые слова, его подозрительность повысится, а ваши шансы, наоборот, снизятся.
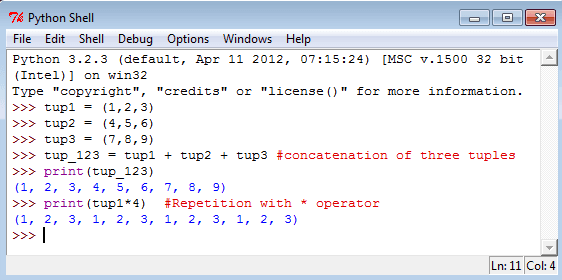
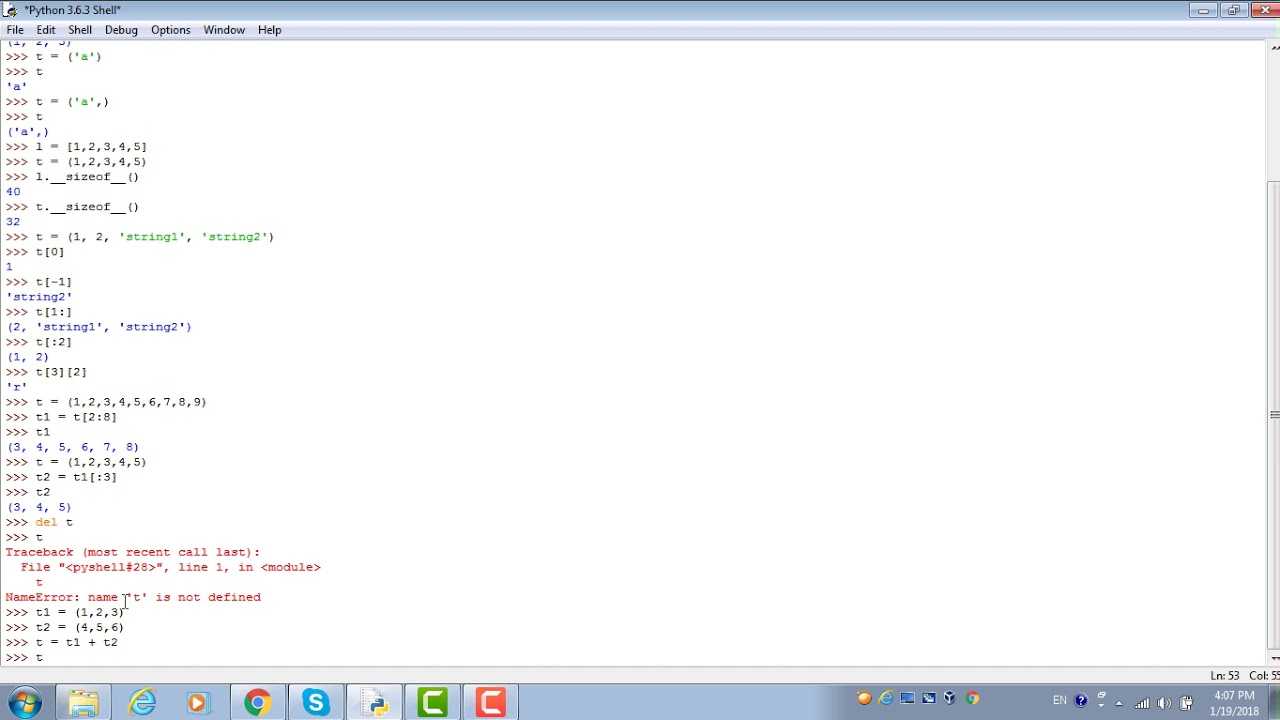
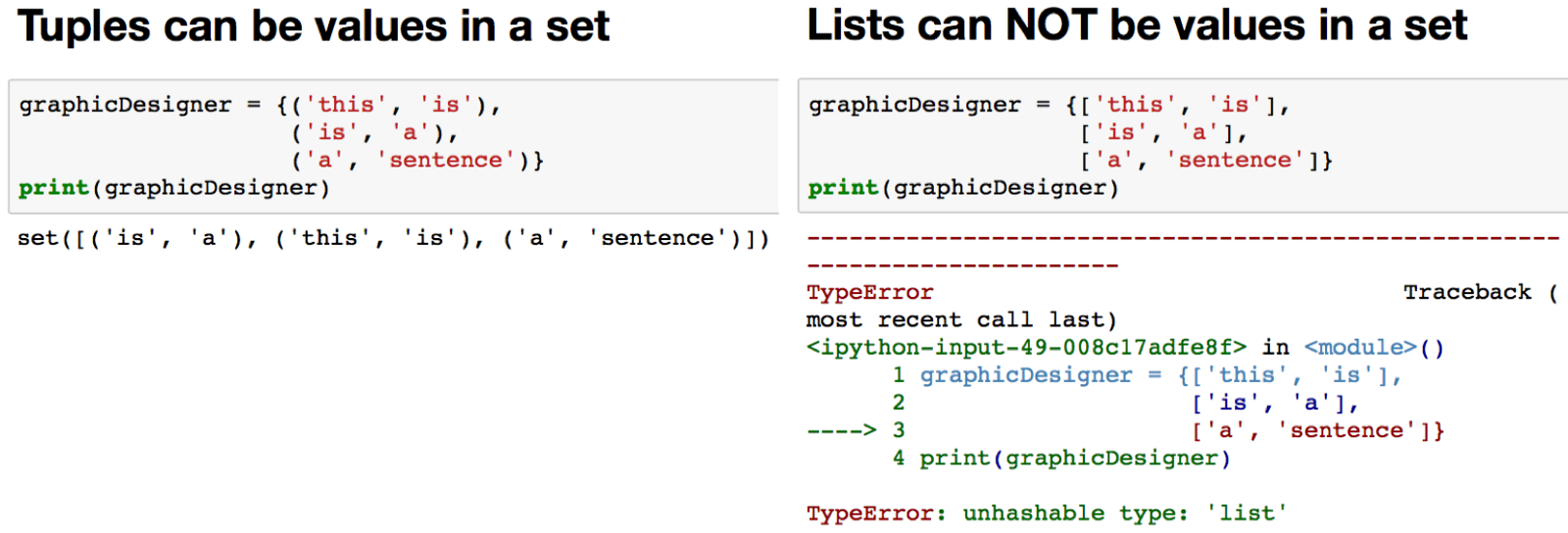
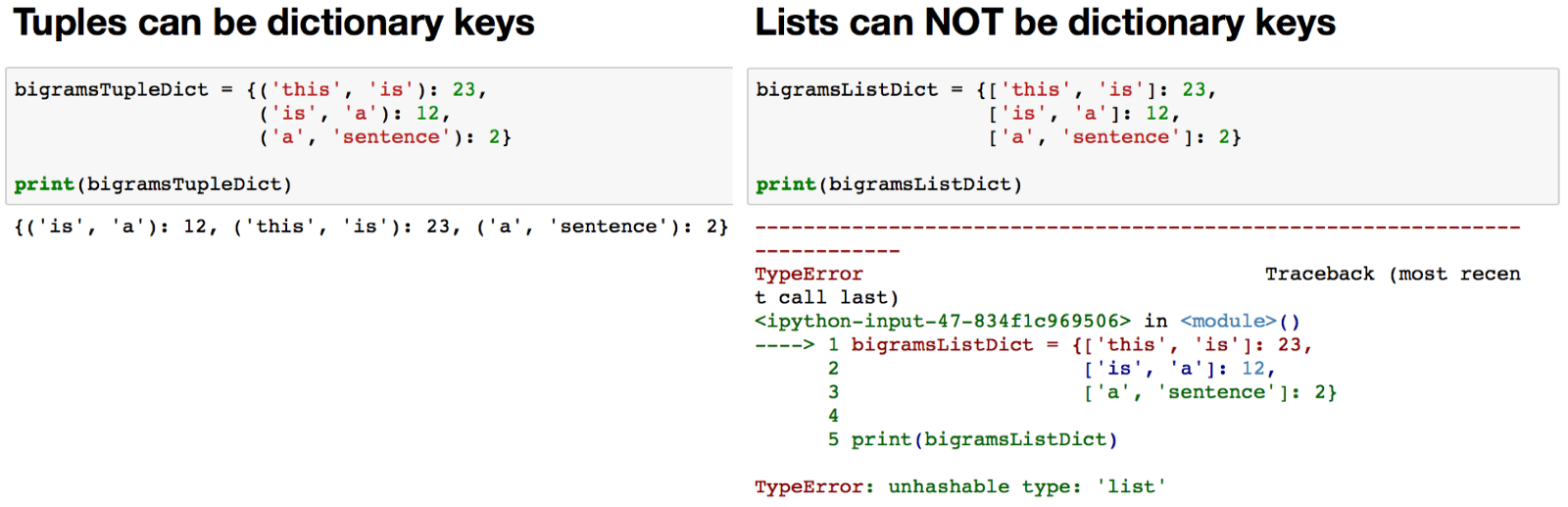
Список и кортеж (tuple)
Список можно менять после создания (например, с помощью функции append()), а кортеж нет: он защищает данные от изменений после создания. По этой причине кортеж можно использовать в качестве ключа в словарях, а список нельзя. Кроме того, кортеж обрабатывается интерпретатором Python чуть быстрее.
Список и множество (set)
Список упорядочен: каждый элемент списка имеет индекс, а элемент множества — нет. Список может содержать одинаковые значения, а во множестве каждое значение уникально. Проверка, принадлежит ли элемент множеству, выполняется быстрее, чем такая же проверка элемента списка.
Список и словарь (dictionary)
Словарь состоит из пар «ключ-значение», а список может состоять и из одиночных элементов, и из пар, и из троек — если элементами будут другие списки или кортежи. Ключи у словаря должны быть уникальными и иметь неизменяемый тип, у списка таких ограничений нет. Поиск по словарю быстрее, чем по списку.
Список и массив (array)
Для использования массива нужно вызывать библиотеку array, а списки встроены в Python. В массиве могут содержаться элементы только одного типа. Массив не может содержать другие массивы или списки. Массив занимает меньше памяти и поэтому быстрее, чем одномерный список.
numpy.unique() для создания списка с уникальными элементами
Модуль NumPy имеет встроенную функцию с именем numpy.unique для извлечения уникальных элементов данных из массива numpy.
Чтобы получить уникальные элементы из списка Python, нам нужно будет преобразовать список в массив NumPy, используя следующую команду.
Синтаксис:
numpy.array(list-name)
Затем мы будем использовать метод numpy.unique() для извлечения уникальных элементов данных из массива numpy и, наконец, распечатаем получившийся список.
Синтаксис:
numpy.unique(numpy-array-name)
Пример:
import numpy as N
list_inp =
res = N.array(list_inp)
unique_res = N.unique(res)
print("Unique elements of the list using numpy.unique():\n")
print(unique_res)
Вывод:
Unique elements of the list using numpy.unique():
Как перейти к поиску?
Поиск с переходом похож на двоичный поиск в том, что он работает с отсортированным массивом и использует аналогичный подход «разделяй и властвуй» для поиска по нему.
Его можно классифицировать как улучшение алгоритма, поскольку он зависит от линейного поиска для выполнения фактического сравнения при поиске значения.
Для отсортированного массива вместо постепенного поиска по элементам массива мы ищем скачкообразно. Итак, в нашем входном списке lys, если у нас есть размер jump, наш алгоритм будет рассматривать элементы в порядке lys , lys , lys , lys и т.д.
При каждом переходе мы сохраняем предыдущее значение и его индекс. Когда мы находим набор значений, где lys <element <lys , мы выполняем линейный поиск с lys , как крайний левый элемент и lys , как крайний правый элемент в нашем поисковом наборе:
import math
def JumpSearch (lys, val):
length = len(lys)
jump = int(math.sqrt(length))
left, right = 0, 0
while left < length and lys <= val:
right = min(length - 1, left + jump)
if lys <= val and lys >= val:
break
left += jump;
if left >= length or lys > val:
return -1
right = min(length - 1, right)
i = left
while i <= right and lys <= val:
if lys == val:
return i
i += 1
return -1
Поскольку это сложный алгоритм, давайте рассмотрим пошаговое вычисление поиска перехода с этим входом:
>>> print(JumpSearch(, 5))
- Поиск перехода сначала определит размер перехода путем вычисления math.sqrt (len (lys)). Поскольку у нас 9 элементов, размер jump будет √9 = 3.
- Затем мы вычисляем значение переменной right, которое является минимумом длины массива минус 1, или значение left + jump, которое в нашем случае будет 0 + 3 = 3. Поскольку 3 меньше 8 мы используем 3 как значение права.
- Теперь мы проверяем, находится ли наш элемент поиска 5 между lys и lys . Поскольку 5 не находится между 1 и 4, мы идем дальше.
- Затем мы снова выполняем вычисления и проверяем, находится ли наш элемент поиска между lys и lys , где 6 – это 3 + jump. Поскольку 5 находится между 4 и 7, мы выполняем линейный поиск элементов между lys и lys и возвращаем индекс нашего элемента как:
4
Временная сложность поиска с переходом составляет O (√n), где √n – размер перехода, а n – длина списка, что с точки зрения эффективности помещает поиск с переходом между алгоритмами линейного и двоичного поиска.
Единственное наиболее важное преимущество поиска с переходом по сравнению с двоичным поиском состоит в том, что он не полагается на оператор деления (/).
В большинстве процессоров использование оператора деления обходится дорого по сравнению с другими основными арифметическими операциями (сложение, вычитание и умножение), поскольку реализация алгоритма деления является итеративной.
Стоимость сама по себе очень мала, но когда количество элементов для поиска очень велико и количество операций деления, которые нам нужно выполнить, увеличивается, стоимость может увеличиваться постепенно. Поэтому поиск с переходом лучше, чем двоичный поиск, когда в системе большое количество элементов, где даже небольшое увеличение скорости имеет значение.
Чтобы ускорить поиск с переходом, мы могли бы использовать двоичный поиск или другой внутренний поиск с переходом для поиска по блокам вместо того, чтобы полагаться на гораздо более медленный линейный поиск.
Срезы
В начале статьи что-то говорилось о «срезах». Давайте разберем подробнее, что это такое. Срезом называется некоторая подпоследовательность. Принцип действия срезов очень прост: мы «отрезаем» кусок от исходной последовательности элемента, не меняя её при этом. Я сказал «последовательность», а не «список», потому что срезы работают и с другими итерируемыми типами данных, например, со строками.
fruits =
part_of_fruits = fruits
print(part_of_fruits)
>>>
Детально рассмотрим синтаксис срезов:
итерируемая_переменная
Обращаю ваше внимание, что мы делаем срез от начального индекса до конечного индекса — 1. То есть i = начальный_индекс и i. Больше примеров!
Больше примеров!
fruits =
print(fruits)
# Если начальный индекс равен 0, то его можно опустить
print(fruits)
print(fruits)
print(fruits)
print(fruits)
# Если конечный индекс равен длине списка, то его тоже можно опустить
print(fruits)
print(fruits)
>>>
>>>
>>>
>>>
>>>
>>>
>>>
Самое время понять, что делает третий параметр среза — длина шага!
fruits =
print(fruits)
print(fruits)
# Длина шага тоже может быть отрицательной!
print(fruits)
print(fruits)
print(fruits)
>>>
>>>
>>>
>>>
>>>
А теперь вспоминаем всё, что мы знаем о циклах. В Python их целых два! Цикл for и цикл while Нас интересует цикл for, с его помощью мы можем перебирать значения и индексы наших последовательностей. Начнем с перебора значений:
fruits =
for fruit in fruits:
print(fruit, end=’ ‘)
>>> Apple Grape Peach Banan Orange
Выглядит несложно, правда? В переменную fruit объявленную в цикле по очереди записываются значения всех элементов списка fruits
А что там с перебором индексов?
for index in range(len(fruits)):
print(fruits, end=’ ‘)
Этот пример гораздо интереснее предыдущего! Что же здесь происходит? Для начала разберемся, что делает функция range(len(fruits))
Мы с вами знаем, что функция len() возвращает длину списка, а range() генерирует диапазон целых чисел от 0 до len()-1.
Сложив 2+2, мы получим, что переменная index принимает значения в диапазоне от 0 до len()-1. Идем дальше, fruits — это обращение по индексу к элементу с индексом index списка fruits. А так как переменная index принимает значения всех индексов списка fruits, то в цикле мы переберем значения всех элементов нашего списка!
Как получить доступ к элементам из списка?
Существуют различные способы доступа к элементам списка.
Доступ по индексу
блок 1
Для доступа к элементу списка можно использовать оператор индекса []. Индекс начинается с 0. Итак, список из 5 элементов будет иметь индексы от 0 до 4.
Попытка получить доступ к элементу, который не существует, вызовет ошибку IndexError. Индекс должен быть целым числом. Нельзя использовать float или другие типы данных в качестве индекса, это приведет к ошибке TypeError.
Доступ к вложенному списку осуществляется с помощью дополнительных индексов.
my_list = # Вывод первого элемента: p print(my_list) # Вывод третьего элемента: o print(my_list) # Вывод последнего (пятого) элемента: e print(my_list) # Ошибка, индексом может быть только целое число # my_list # Пример вложенного списка n_list = ] # Индексы вложенных списков # Вывод второго символа первого элемента списка: a print(n_list) # вывод четвертого элемента второго вложенного списка: 5 print(n_list)
Отрицательные индексы списка
Python допускает отрицательную индексацию для элементов списка. Индекс -1 выведет последний элемент, -2 — второй элемент с конца и т.д.
my_list = # Вывод последнего элемента: e print(my_list) # Вывод последнего элемента с конца (первого): p print(my_list)
Срезы списков в Python
Вы можете получить доступ к ряду элементов в списке, используя оператор среза (двоеточие).
my_list = # Элементы с 3го по 5й print(my_list) # Элементы с начала до 4го print(my_list) # Элементы с 6го до последнего print(my_list) # Элементы с первого до последнего print(my_list)
Срез списка Python
Как и любой другой подобный объект, список может возвращать не только всю последовательность элементов, а лишь определенные, начиная одним и заканчивая другим.
Чтобы это сделать, необходимо воспользоваться символом : в индексе.
my_list =
print(my_list)
Тут случае будет возвращено значение со словами «два» и «три».Возможно еще оставить либо первое число среза, либо последнее. В первом случае программист задает, с какого места стартует то или иное значение. Во втором же задается конец среза. Еще можно оставить только двоеточие. Но это тождественно выводу всех частей списка в консоль.Разработчик может редактировать списки, и поэтому также реальна замена компонентов через оператор среза.
my_list =
my_list =
print(my_list)
Предварительные сведения
Списки в Python это на редкость популярная тема как для начинающих свой путь программировании, так и для опытных экспертов в языке Python. Если верить Google Trends, то интерес к этой теме растет из года в год.
Если вы регулярно посещаете форумы, где можно задать вопросы по программированию на Python, например Stack Overflow, Quora или Reddit, то наверняка понимаете причину такой популярности этой темы.
На этих форумах постоянно появляется множество вопросов про списки, за них голосуют, и наиболее интересные продолжают обсуждать, находя разные решения.
В данной статье мы кратко пройдемся по самым распространенным вопросам на тему списков в языке Python.
Обработка и вывод вложенных списков
Часто в задачах приходится хранить прямоугольные таблицы с данными.
Такие таблицы называются матрицами или двумерными массивами. В языке
программирования Питон таблицу можно представить в виде списка строк,
каждый элемент которого является в свою очередь списком, например, чисел.
Например, создать числовую таблицу из двух строк и трех столбцов можно так:
A = , ]
Здесь первая строка списка является списком из чисел
. То есть
A == 1, A == 2, A == 3 A == 4, A == 5, A == 6
Для обработки и вывода списка как правило используется два вложенных
цикла. Первый цикл по номеру строки, второй цикл по элементам внутри строки.
Например, вывести двумерный числовой список на экран построчно,
разделяя числа пробелами внутри одной строки, можно так:
for i in range(len(A)):
for j in range(len(A):
print(A, end = ' ')
print()
То же самое, но циклы не по индексу, а по значениям списка:
for row in A:
for elem in row:
print(elem, end = ' ')
print()
Естественно для вывода одной строки можно воспользоваться
методом :
for row in A:
print(' '.join(list(map(str, row))))
Используем два вложенных цикла для подсчета суммы всех
чисел в списке:
S = 0
for i in range(len(A)):
for j in range(len(A)):
S += A
Или то же самое с циклом не по индексу, а по значениям строк:



