
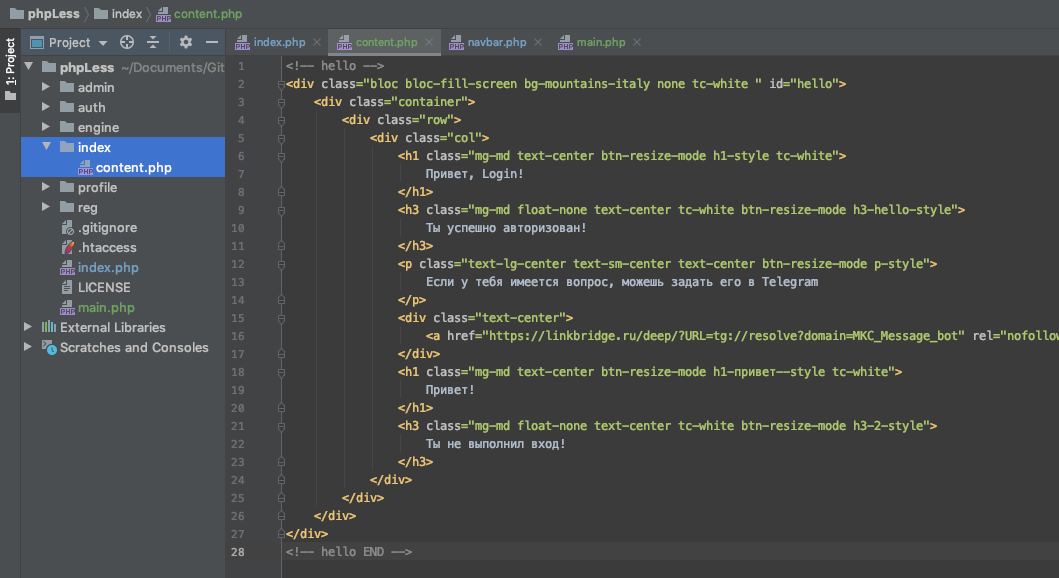
Задача
В этой статье я напишу простой WEB-парсер информации о фильме с Кинопоиска, который будет получать детали этого фильма: ![]()
Почему я использую ReactPHP для выполнения асинхронных запросов? Если кратко — это быстрее. Если представить, что мы хотим спарсить все фильмы с первой страницы популярных фильмов, то для получения данных о всех фильмах понадобится выполнить 1 запрос на получение списка, и 200 запросов на получение подробной информации о каждом фильме отдельно. В итоге, 201 запрос, выполняя его в синхронном режиме, последовательно друг за другом может занять достаточно много времени.
И в противовес этому, представьте, что есть возможность запустить обработку всех этих запросов одновременно. И в этом случае, данные будут скопированы на порядок быстрее. Давайте попробуем.
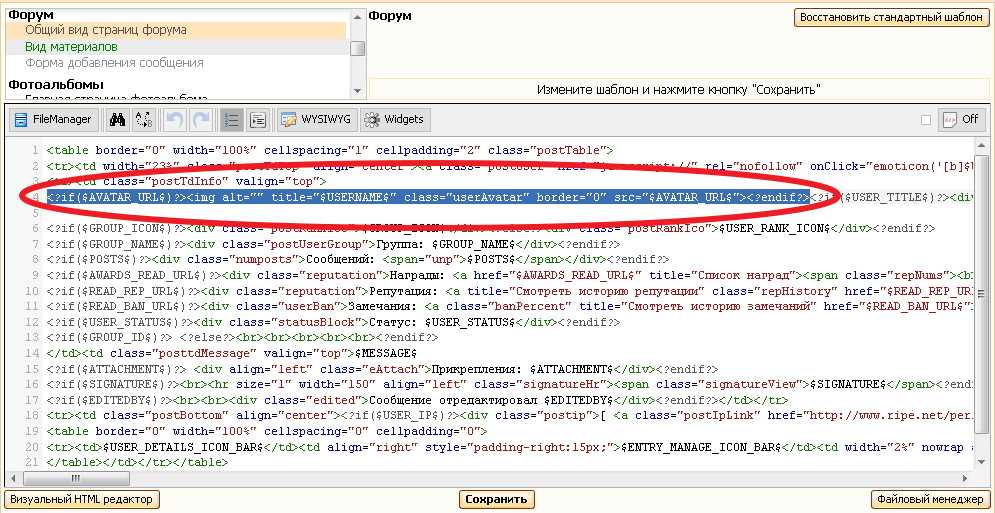
Шаг 5. Находим ту информацию, которая нам нужна
![]()
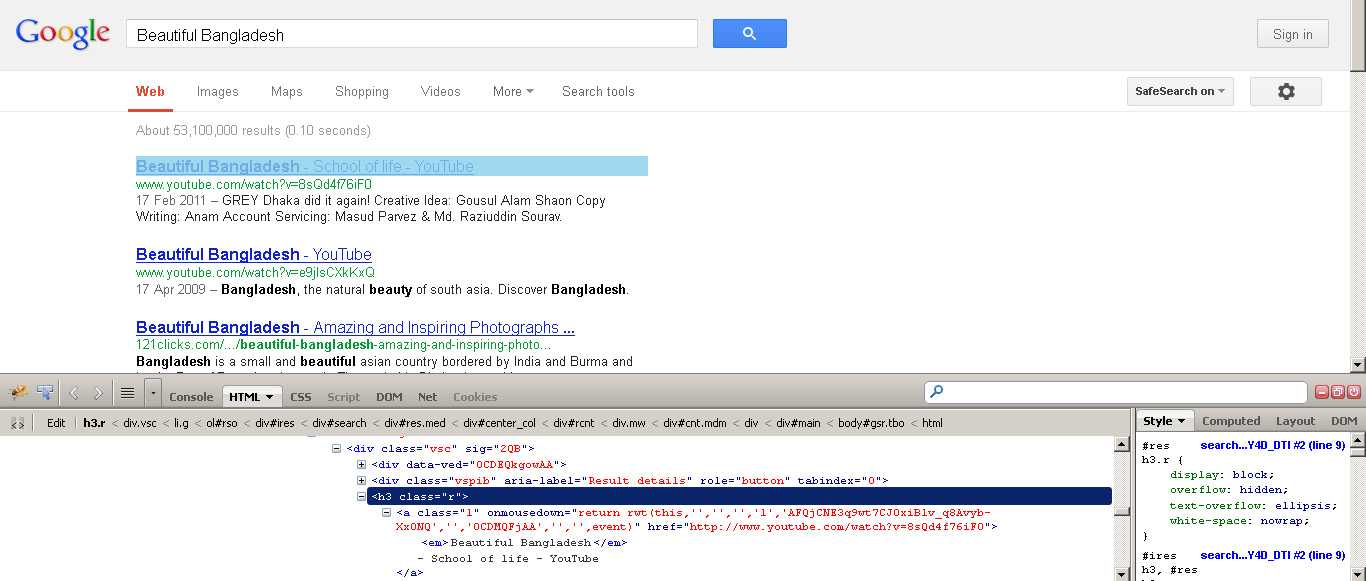
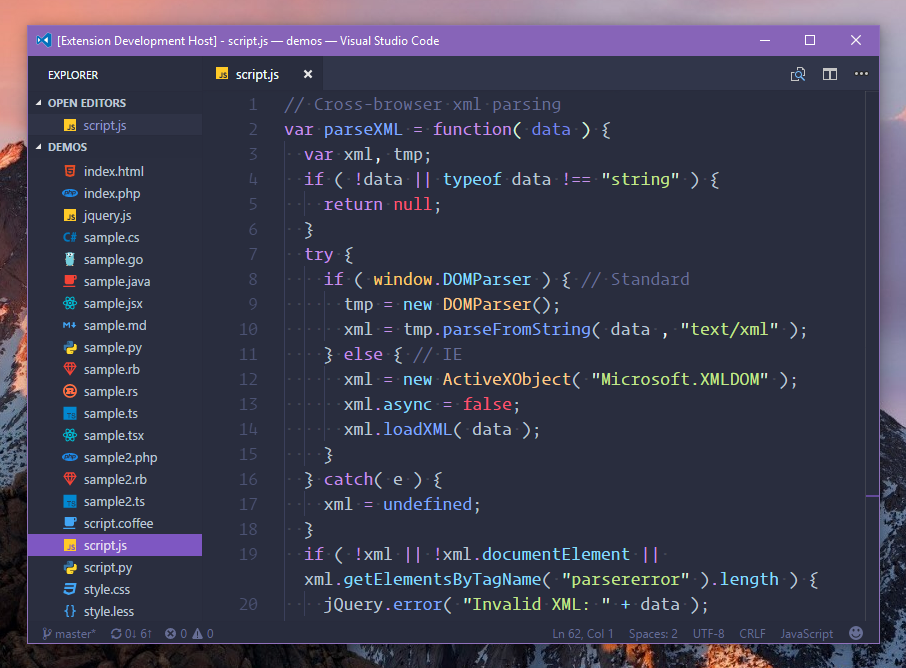
Это суть функции getArticles. Нужно разобраться более детально, чтобы понять, что происходит.
Строка 1: Создаем массив элементов – тег div с классом preview. Теперь у нас есть коллекция статей, сохраненная в $items.
Строка 4: $post теперь ссылается на единичный div класса preview. Если мы взглянем в оригинальный HTML, то увидим, что третий элемент потомок — это тег H1, который содержит заголовок статьи. Мы берем его и присваиваем $articles.
Помните о начале отсчета с 0 и учете комментариев исходного кода, когда будете определять правильный индекс узла.
Строка 5: Шестой потомок $post — это <div class=”text”>. Нам нужен текст описания из него, поэтому мы используем outertext – в описание будет включен тег параграфа. Единичная запись в массиве статей будет выглядеть примерно так:
Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
#Блокируем плохих ботов и роботов SetEnvIfNoCase user-Agent ^FrontPage SetEnvIfNoCase user-Agent ^Java.* SetEnvIfNoCase user-Agent ^Microsoft.URL SetEnvIfNoCase user-Agent ^MSFrontPage SetEnvIfNoCase user-Agent ^Offline.Explorer SetEnvIfNoCase user-Agent ^ebandit SetEnvIfNoCase user-Agent ^Zeus <limit get="" post="" head=""> Order Allow,Deny Allow from all Deny from env=bad_bot </limit>
Список User Agent браузеров, роботов и пауков поисковых машин, веб-каталогов, менеджеров закачек, спам-ботов и плохих ботов можно найти на сайте List of User-Agents.
Защищаем паролем папки и файлы
Вы можете включить проверку пароля для доступа в любую папку или файл на вашем сервере, используя этот код:
#защита паролем файла <files secure.php=""> AuthType Basic AuthName "Prompt" AuthUserFile /pub/home/.htpasswd Require valid-user </files> #защита паролем папки resides AuthType basic AuthName "This directory is protected" AuthUserFile /pub/home/.htpasswd AuthGroupFile /dev/null Require valid-user
Для того, чтобы организовать доступ к файлу по паролю, необходимо создать файл .htpasswd и внести в него пару логин-пароль в формате user:password.
Однако в этом случае пароли будут хранится в открытом виде, что не слишком хорошо с точки зрения безопасности. Поэтому оптимальнее пароль зашифровать. Для этого воспользуйтесь сервисами генерации записей в файлы .htpasswd. Например, вот таким.
В нашем примере файл с паролями доступа лежит в корневой директории сайта и называется .htpasswd. Директория указывается от корня сервера и если путь будет некорректным — Apache, не получив доступа к файлу, откажет в доступе к папке любому пользователю — в том чилсе и тому, который ввел правильную пару логин:пароль.
5) Конвертируйте WWW ЧПУ в без-WWW или наоборот¶
Ранее мы упоминали одно изменение, которое вы всегда должны вносить в файл , когда у вас работают ЧПУ. Это касается URL, которые начинаются с ‘www’ (или нет). Пользователь может получить доступ к большинству сайтов с доменным именем или доменным именем, перед которым стоит ‘www’»’. Вы всегда должны конвертировать URL в один или другой. Причины сложны, но если вы этого не сделаете, на вашем сайте могут произойти странные вещи. Например, пользователи, которые вошли в систему, могут внезапно потерять этот статус.
Исправить это действительно легко. В приведенном выше коде файла вы увидите два раздела, оба закомментированы. Один меняет не-www URL-адреса на www-URL-адреса, а другой — наоборот. Решите, какой из них вы хотите, и просто раскомментируйте раздел, который делает это, удалив знак ‘#’ в начале каждой строки. Будьте осторожны, вы будете раскомментировать только три строки.
Например, чтобы удалить ‘www.’ Из всех запросов на сайт с доменом ‘yoursite.com’ измените этот раздел:
он должен в итоге выглядеть так:
Обратите внимание, что мы не раскомментировали первую строку. Здесь указан настоящий комментарий
Раскомментирование заставит сервер обращаться с ним как с кодом, и это может привести к сбою сервера.
Сервер может быть довольно чувствительным к тому, что находится в файле . Всегда делайте резервную копию рабочего файла перед его изменением. Таким образом, если ваша работа приводит к сбою сервера, вы можете просто скопировать сохраненную версию обратно в и начать заново.
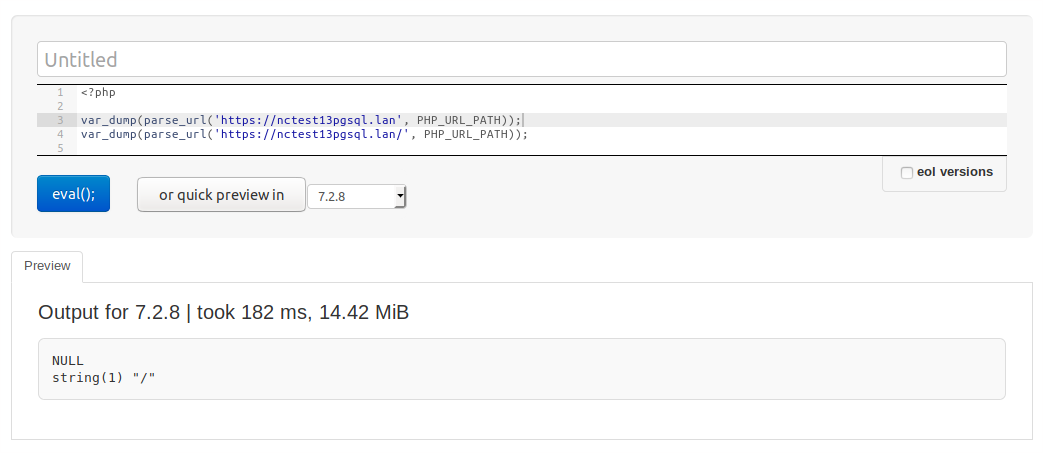
Structured Parse Results¶
The result objects from the , and
functions are subclasses of the type.
These subclasses add the attributes listed in the documentation for
those functions, the encoding and decoding support described in the
previous section, as well as an additional method:
- ()
-
Return the re-combined version of the original URL as a string. This may
differ from the original URL in that the scheme may be normalized to lower
case and empty components may be dropped. Specifically, empty parameters,
queries, and fragment identifiers will be removed.For results, only empty fragment identifiers will be removed.
For and results, all noted changes will be
made to the URL returned by this method.The result of this method remains unchanged if passed back through the original
parsing function:>>> from urllib.parse import urlsplit >>> url = 'HTTP://www.Python.org/doc/#' >>> r1 = urlsplit(url) >>> r1.geturl() 'http://www.Python.org/doc/' >>> r2 = urlsplit(r1.geturl()) >>> r2.geturl() 'http://www.Python.org/doc/'
The following classes provide the implementations of the structured parse
results when operating on objects:
- class (url, fragment)
-
Concrete class for results containing
data. The method returns a
instance.New in version 3.2.
- class (scheme, netloc, path, params, query, fragment)
-
Concrete class for results containing
data. The method returns a
instance.
- class (scheme, netloc, path, query, fragment)
-
Concrete class for results containing
data. The method returns a
instance.
The following classes provide the implementations of the parse results when
operating on or objects:
- class (url, fragment)
-
Concrete class for results containing
data. The method returns a
instance.New in version 3.2.
-
- class (scheme, netloc, path, params, query, fragment)
-
Concrete class for results containing
data. The method returns a
instance.New in version 3.2.
Случайный лес
Случайный лес — модель, состоящая из множества деревьев решений. Вместо того,чтобы просто усреднять прогнозы разных деревьев (такая концепция называется просто «лес»), эта модель использует две ключевые концепции, которые и делают этот лес случайным.
- Случайная выборка образцов из набора данных при построении деревьев.
- При разделении узлов выбираются случайные наборы параметров.
Случайная выборка тренировочных образцов
В процессе тренировки каждое дерево случайного леса учится на случайном образце из набора данных. Выборка образцов происходит с возмещением (в статистике этот метод называется бутстреппинг, bootstrapping). Это даёт возможность повторно использовать образцы одним и тем же деревом. Хотя каждое дерево может быть высоковариативным по отношению к определённому набору тренировочных данных, обучение деревьев на разных наборах образцов позволяет понизить общую вариативность леса, не жертвуя точностью.
При тестировании результат выводится путём усреднения прогнозов, полученных от каждого дерева. Подход, при котором каждый обучающийся элемент получает собственный набор обучающих данных (с помощью бутстреппинга), после чего результат усредняется, называется бэггинг (bagging, от bootstrap aggregating).
Случайные наборы параметров для разделения узлов
Вторая базовая концепция случайного леса заключается в использовании определённой выборки параметров образца для разделения каждого узла в каждом отдельном дереве. Обычно размер выборки равен квадратному корню из общего числа параметров. То есть, если каждый образец набора данных содержит 16 параметров, то в каждом отдельном узле будет использовано 4. Хотя обучение случайного леса можно провести и с полным набором параметров, как это обычно делается при регрессии. Этот параметр можно настроить в реализации случайного леса в Scikit-Learn.
Случайный лес сочетает сотни или тысячи деревьев принятия решений, обучая каждое на отдельной выборке данных, разделяя узлы в каждом дереве с использованием ограниченного набора параметров. Итоговый прогноз делается путём усреднения прогнозов от всех деревьев.
Чтобы лучше понять преимущество случайного леса, представьте следующий сценарий: вам нужно решить, поднимется ли цена акций определённой компании. У вас есть доступ к дюжине аналитиков, изначально не знакомых с делами этой компании. Каждый из аналитиков характеризуется низкой степенью погрешности, так как не делает каких-либо предположений. Кроме того, они могут получать новые данные из новостных источников.
Трудность задачи в том, что новости, помимо реальных сигналов, могут содержать шум. Поскольку предсказания аналитиков базируются исключительно на данных — обладают высокой гибкостью — они могут быть искажены не относящейся к делу информацией. Аналитики могут прийти к разным заключениям, исходя из одних и тех же данных. Кроме того, каждый аналитик старается делать прогнозы, максимально коррелирующие с полученными отчётами (высокая вариативность) и предсказания могут значительно различаться при разных наборах новостных источников.
Поэтому нужно не опираться на решение какого-то одного аналитика, а собрать вместе их прогнозы. Более того, как и при использовании случайного леса, нужно разрешить каждому аналитику доступ только к определённым новостным источникам, в надежде на то, что эффекты шумов будут нейтрализованы выборкой. В реальной жизни мы полагаемся на множество источников (никогда не доверяйте единственному обзору на Amazon). Интуитивно нам близка не только идея дерева решений, но и комбинирование их в случайный лес.
Как не стать жертвой ошибки выжившего
Дмитрий Ковпак:
«Когнитивным искажениям подвержены в той или иной степени все люди. Это систематические отклонения в восприятии, мышлении и поведении, тесно связанные с предубеждениями или так называемыми ограничивающими убеждениями, ошибочными стереотипами. Чаще всего они не осознаются самим носителем и требуют специальных навыков для их обнаружения и коррекции. Если человек думает, что никакого из когнитивных искажений у него нет, то это тоже своего рода когнитивное искажение.
Что касается «ошибки выжившего», то больше всего им подвержены люди, которые живут и действуют на автомате, не задумываются, что из их мыслей, предположений и ожиданий верно, а что нет, не анализируют и не проверяют факты, то есть редко пользуются критическим мышлением, логикой и анализом опыта».
Когда человек знает об «ошибке выжившего», ему гораздо проще не попасться в эту когнитивную ловушку. Кроме этого, избежать последствий влияния этой ошибки можно, если подходить к принятию решения критически.
Экономика образования
Что такое критическое мышление?
Копайте глубже
Не доверяйте поверхностным суждениям и скоропалительным выводам, убедитесь, что у вас достаточно информации для принятия решения. Задавайте вопросы, которые помогут увидеть картину целиком. Например:
- Откуда я это знаю?
- Вся ли это информация по теме?
- Какие данные подтверждают эту версию/гипотезу?
- При каких условиях были собраны данные?
- Могу ли я отделить факты от субъективного мнения и впечатлений?
- Та информация, которая есть, составляет полную картину или только ее часть?
Изучайте разные точки зрения
Воспринимайте любую историю успеха как одну из версий развития событий, а не как истину в последней инстанции. Найдите неудачную статистику или истории провала и посмотрите, что в них пошло не так.
Дмитрий Ковпак:
«Многие любят публичные выступления людей, которые преодолели превратности судьбы и выжили всему вопреки. Книги наподобие «Секретов успеха от Джона Смита» также страдают «ошибкой выжившего»: это значит лишь то, что дело Джона Смита не разорилось. Куда полезнее было бы узнать, какие ошибки допустили его разорившиеся конкуренты.
Если вам пришла идея открыть ресторан в своем городе исходя из факта, что здесь много прибыльных ресторанов, вы проигнорировали то, что видите только уцелевшие и ставшие успешными точки общепита, победившие в конкурентной борьбе. Может быть, 90% всех открытых заведений в вашем городе разорились за первые два года. Но вы этого не знаете, потому что для вас они не существуют. Как писал Нассим Талеб в своей книге «Черный лебедь», на кладбище закрытых ресторанов очень тихо».
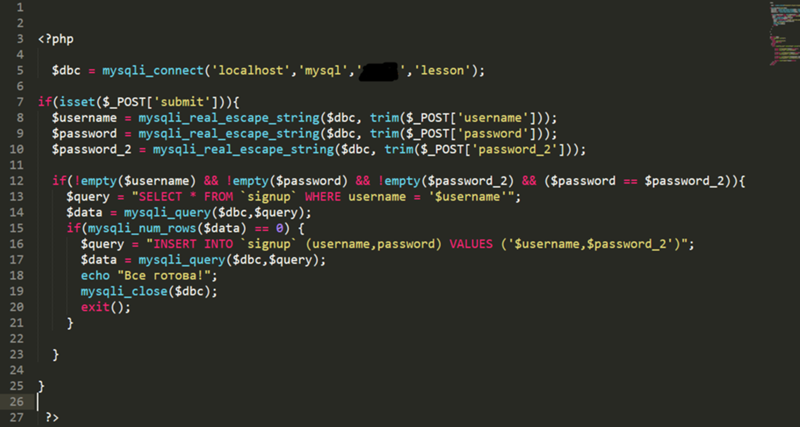
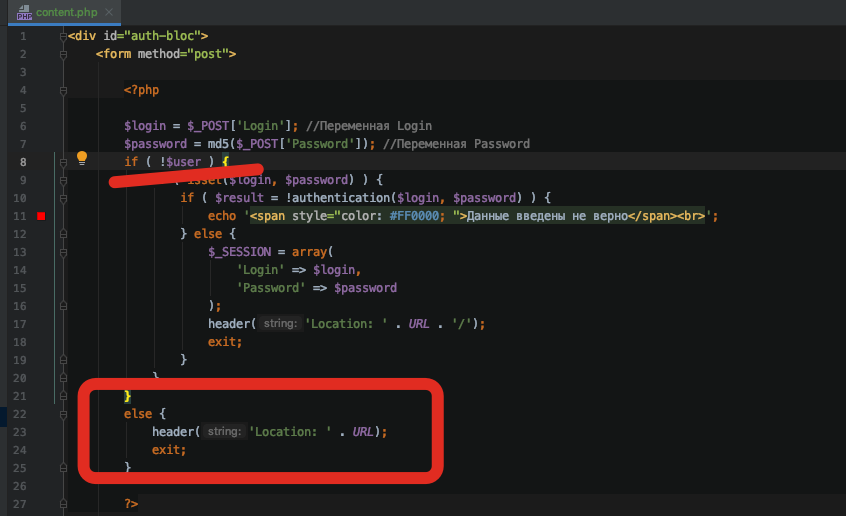
Делаем запросы
Интерфейс класса достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода :
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра . В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
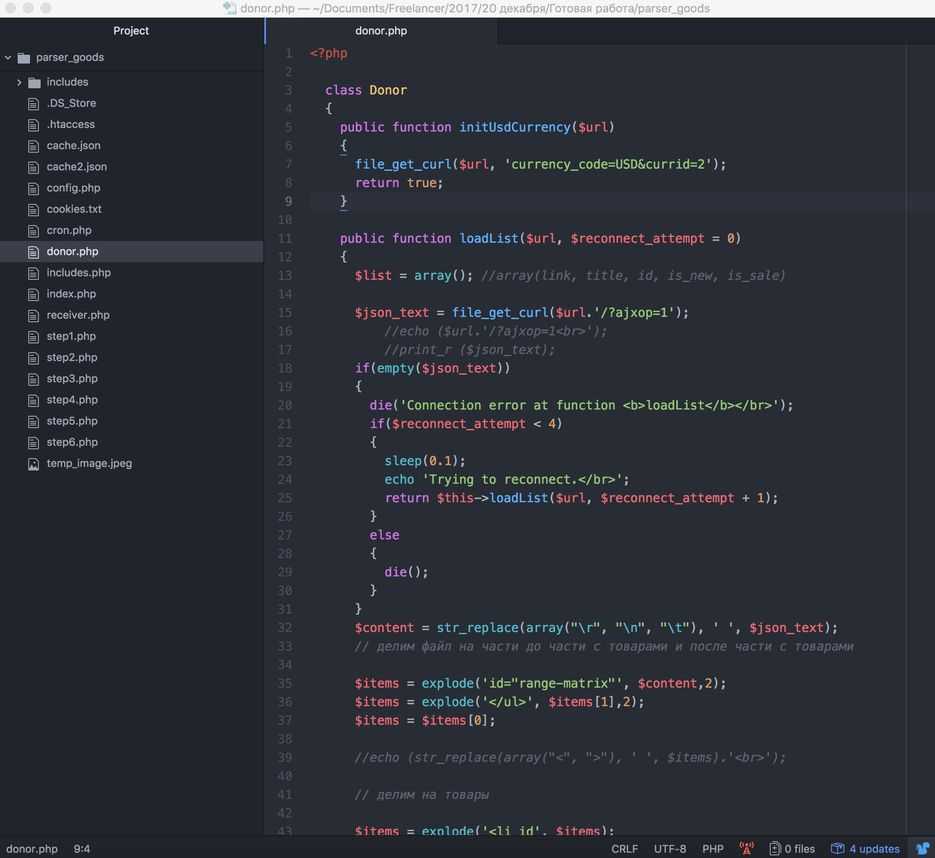
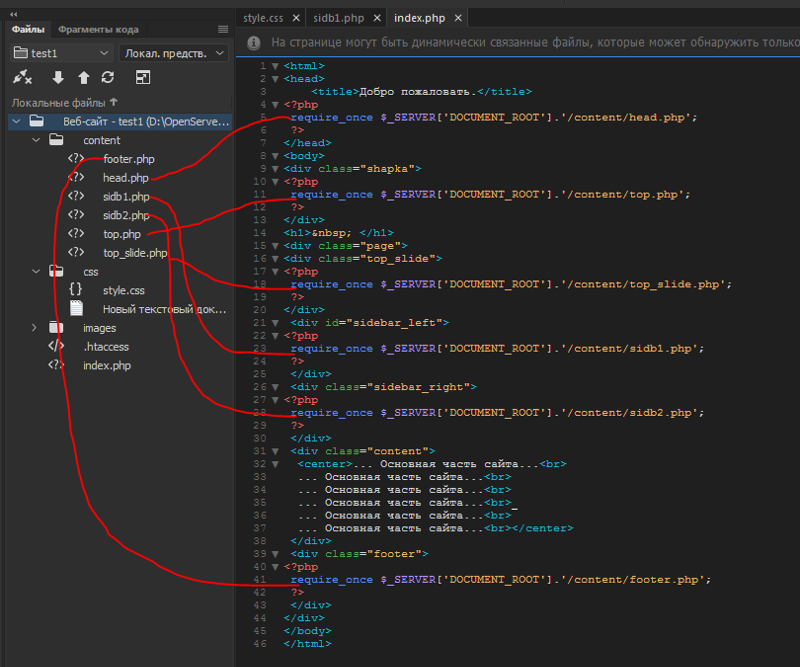
Простой роутинг
Если единая точка входа настроена правильно, то при заходе по любому несуществующему URL-адресу, например /test должен запуститься файл index.php.
URL текущей страницы находится в переменной $_SERVER
Теперь мы можем написать очень простой роутер, который смотрит на текущий URL и подключает соответствующий скрипт:
Внесём ещё пару доработок. Во-первых, зачастую URL-адреса должны работать вне зависимости от наличия GET-параметров, поэтому вырежем их из URI:
Кроме этого, часто требуется получить доступ к определённой части URL. Для этого разобьём URL на части по слешу:
В переменной $segments для URL /products/15 будет лежать массив вида .
Теперь мы можем легко добавить маршруты для админки:
Это самый простой вариант роутинга. Не идеальный, конечно, но и не требующий знания регулярных выражений (хотя никто не мешает их использовать) и подключения сторонних библиотек.

При хранении URL адресов в базе данных роутинг будет выглядеть примерно так (реальный код зависит от библиотеки, которую вы используете для взаимодействия с БД):
4.Удаление чисел.
Для привлекательности, многие статьи содержат в своих заголовках цифру. Например, статья с названием 55 идей для постов в блог.
Это совершенно нормально, потому что название легко изменить. Если мы однажды обновим статью и добавим ещё 5 идей, то мы легко сможем изменить заголовок страницы.
![]()
Если изменить название статьи, это не проблема, то вот изменить URL-адрес страницы, это совсем другая история.
Вам придется либо оставить URL страницы прежним, и получить разницу в поиске
![]()
Либо делать 301 редирект, со всеми вытекающими отсюда последствиями. То есть, рискуя тем, что страница может значительно просесть в поисковой выдаче.
Поэтому, лучше вообще изначально убрать цифры из URL страницы, и тогда мы получим следующий адрес.
![]()
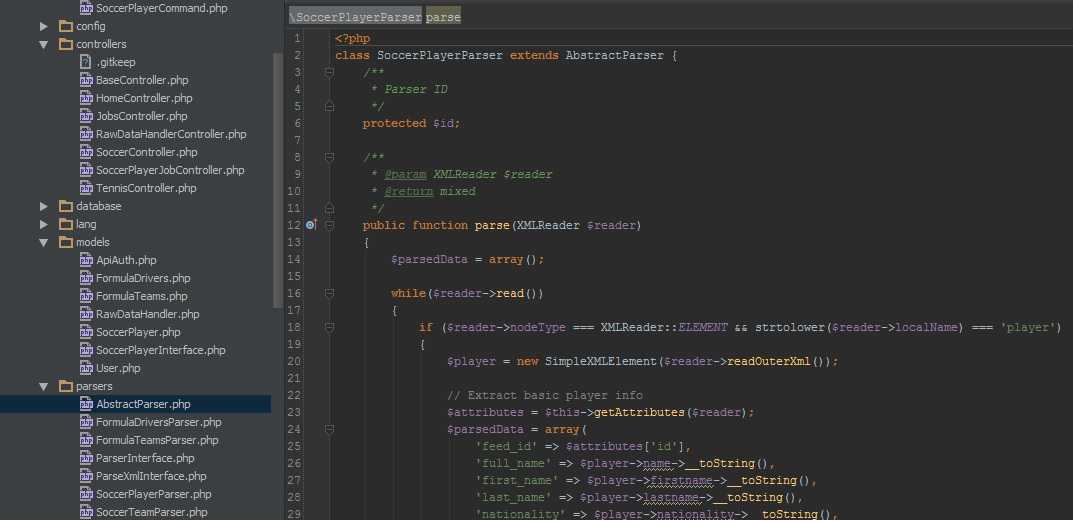
Шаг 2. Основы парсинга
Данную библиотеку очень просто использовать, но есть несколько основных моментов, которые следует изучить до того, как вы начнете приводить ее в действие.
Загрузка HTML
Вы можете создать исходный объект загрузив HTML либо из строки, либо из файла. Загрузка из файла может быть выполнена либо через указание URL, либо из вашей локальной файловой системы.
Примечания: Метод load_file() делегирует работу функции PHP file_get_contents. Если allow_url_fopen не установлен в значение true в вашем файле php.ini, то может отсутствовать возможность открывать удаленные файлы таким образом. В этом случае вы можете вернуться к использованию библиотеки CURL для загрузки удаленных страниц, а затем прочитать с помощью метода load().
Доступ к информации
![]()
Как только у вас будет объект DOM, вы сможете начать работать с ним, используя метод find() и создавая коллекции. Коллекция — это группа объектов, найденных по селектору. Синтаксис очень похож на jQuery.
В данном примере HTML мы собираемся разобраться, как получить доступ к информации во втором параграфе, изменить ее и затем вывести результат действий.
Строки 2-4: Загружаем HTML из строки, как объяснялось выше.
Строка 6: Находим все тэги <p> в HTML, и возвращаем их в массив. Первый параграф будет иметь индекс 0, а последующие параграфы индексируются соответственно.
Строка 8: Получаем доступ ко второму элементу в нашей коллекции параграфов (индекс 1), добавляем текст к его атрибуту innertext. Атрибут innertext представляет содержимое между тэгами, а атрибут outertext представляет содержимое включая тэги. Мы можем заменить тэг полностью, используя атрибут outertext.
Теперь добавим одну строку и модифицируем класс тэга нашего второго параграфа.
Окончательный вид HTML после команды save будет иметь вид:
Другие селекторы
Несколько других примеров селекторов. Если вы использовали jQuery, все покажется вам знакомым.
Первый пример требует пояснений. Все запросы по умолчанию возвращают коллекции, даже запрос с ID, который должен вернуть только один элемент. Однако, задавая второй параметр, мы говорим “вернуть только первый элемент из коллекции”.
Это означает, что $single — единичный элемент, а не не массив элементов с одним членом.
Остальные примеры достаточно очевидны.
Добавление, удаление и замена элементов
Вы также можете внести изменения в загруженный HTML-документ, используя различные методы, предоставляемые библиотекой. Например, вы можете добавлять, заменять или удалять элементы из дерева DOM с помощью методов , и .
Библиотека также позволяет создавать собственные HTML-элементы, чтобы добавлять их в исходный HTML-документ. Вы можете создать новый объект Element, используя .
Имейте в виду, что вы получите сообщение об ошибке Uncaught Error: Class ‘Element’ not found, если ваша программа не содержит строку перед созданием объекта элемента.
После того, как у вас есть элемент, вы можете либо добавить его к другим элементам DOM с помощью метода , либо использовать метод для использования вновь созданного элемента в качестве замены некоторого старого элемента HTML в документе. Следующий пример должен помочь в дальнейшем разъяснении этой концепции.
Первоначально в нашем документе нет элемента h2 с классом test-heading. Поэтому мы будем получать ошибку, если попытаемся получить доступ к такому элементу.
После проверки того, что такого элемента нет, мы создаем новый элемент h2 и меняем значение его атрибута class на test-heading.
После этого мы заменим первый элемент h1 в документе на наш недавно созданный элемент h2. Повторное использование метода в нашем документе, чтобы найти заголовок h2 с классом test-heading, теперь вернет элемент.
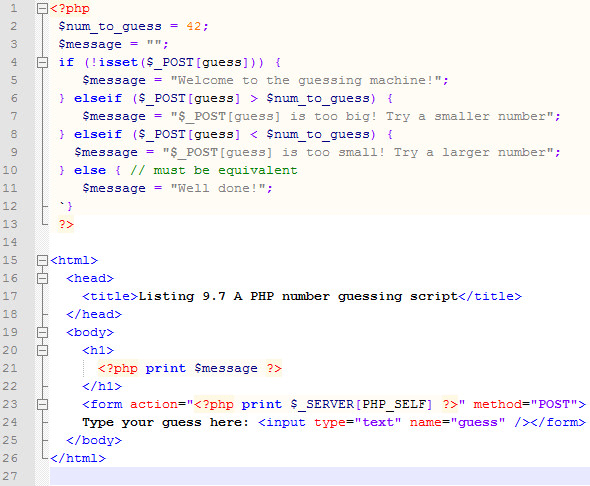

Шаблоны и параметры замены для преобразования в ЧПУ ссылки
Пример, который мы рассмотрели выше позволяет перенаправлять запросы для одного URL адреса. Но мощь режима mod_rewrite заключается в том, что он позволяет преобразовывать целые группы запросов URL адресов сверяя их с шаблоном, который записан в правиле. Предположим, что нужно изменить все URL адреса сайта. Возьмем пример из первой части статьи. У нас имеется URL адрес сайта:
http://www.softmaker.kz.php?id=2
И мы хотим преобразовать его к следующему виду:
http://www.softmaker.kz/id/2
Чтобы не писать правило для каждой статьи id необходимо написать правило, чтобы управлять всеми cтатьями. Поэтому нужно изменить правило к следующему виду:
http://www.softmaker.kz.php?id={номер}
Нужно изменить этот URL адрес так:
http://www.softmaker.kz/id/{номер}/
Чтобы сделать это нужно использовать регулярные выражения. Они являются шаблонами (паттернами, от англ. pattern), определёнными в формате, который сервер может понимать. Вот обычный паттерн, который определяет число:
+
Квадратные скобки содержат в себе определенный диапазон сиволов и «0-9» указывает на все числа. Симвлол плюс «+» указывает, что в шаблоне может быть одно или более чисел, стоящих перед знаком «+». Этот шаблон подходит для нашей задачи по поиску числовых категорий в URL адресе PHP сайта. Шаблон этого правила рассматривается как регулярное выражение по умолчанию, поэтому нет надобности где-либо указывать, что он включен или активирован.
RewriteRule ^id/(+)/?$ articles.php?id=$1 # Управление запросом по категориям
Первое, что можно отметить, так это шаблон взятый в круглые скобки. Он позволяет нам получить обратную ссылку для параметра замены. Выражение «$1» в параметре замены указывает серверу Apache брать из URL адреса всё то, что в скобках шаблона. Можно задать множество обратных ссылок и они будут пронумерованы в порядке появления в шаблоне. Итак, это правило означает, что сервер Apache переправит все запросы для
softmaker.kz/id/{номер}/ на articles.php?id={тот же номер}.
Резюме
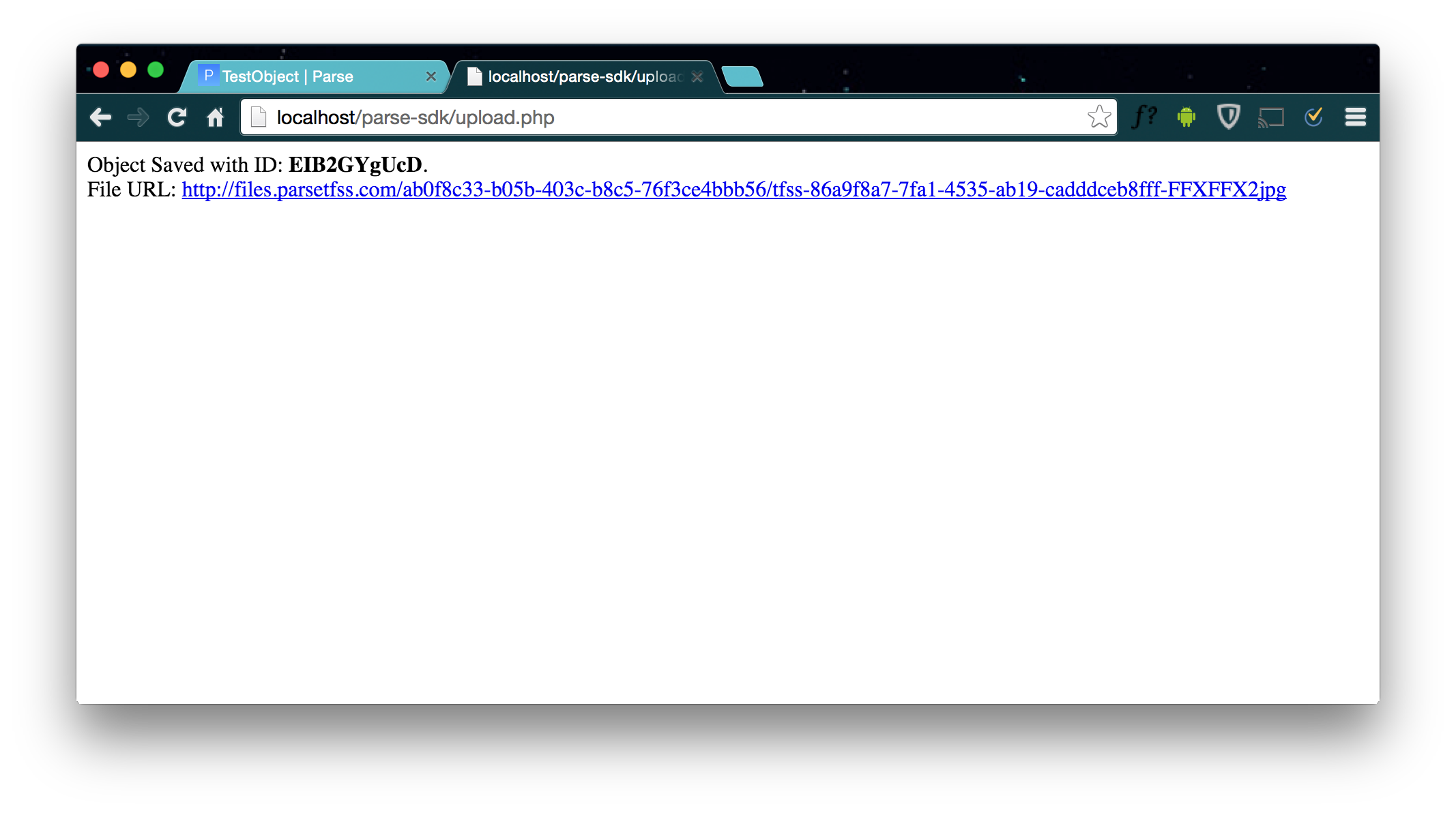
В этой статье я показал, как работать с ReactPHP, показал примеры работы с ним, реализовав пример простого php парсера кинопоиска. Так же, в этой статье было рассмотрено, как парсить html на php, с помощью php dom парсера DiDOM, который является лучшим DOM-парсером на PHP. К слову, DiDOM — это отличная замена всем известного php simple dom parser-а. Надеюсь, что теперь вы без проблем сможете написать парсер контента собственными руками на php. И, полностью освоив материал этой статьи, выполняя запросы асинхронно, вы значительно прибавите в скорости и качестве парсеров.
Хорошего парсинга.
5) Конвертируйте WWW ЧПУ в без-WWW или наоборот¶
Ранее мы упоминали одно изменение, которое вы всегда должны вносить в файл , когда у вас работают ЧПУ. Это касается URL, которые начинаются с ‘www’ (или нет). Пользователь может получить доступ к большинству сайтов с доменным именем или доменным именем, перед которым стоит ‘www’»’. Вы всегда должны конвертировать URL в один или другой. Причины сложны, но если вы этого не сделаете, на вашем сайте могут произойти странные вещи. Например, пользователи, которые вошли в систему, могут внезапно потерять этот статус.
Исправить это действительно легко. В приведенном выше коде файла вы увидите два раздела, оба закомментированы. Один меняет не-www URL-адреса на www-URL-адреса, а другой — наоборот. Решите, какой из них вы хотите, и просто раскомментируйте раздел, который делает это, удалив знак ‘#’ в начале каждой строки. Будьте осторожны, вы будете раскомментировать только три строки.
Например, чтобы удалить ‘www.’ Из всех запросов на сайт с доменом ‘yoursite.com’ измените этот раздел:
он должен в итоге выглядеть так:
Обратите внимание, что мы не раскомментировали первую строку. Здесь указан настоящий комментарий
Раскомментирование заставит сервер обращаться с ним как с кодом, и это может привести к сбою сервера.
Сервер может быть довольно чувствительным к тому, что находится в файле . Всегда делайте резервную копию рабочего файла перед его изменением. Таким образом, если ваша работа приводит к сбою сервера, вы можете просто скопировать сохраненную версию обратно в и начать заново.



