
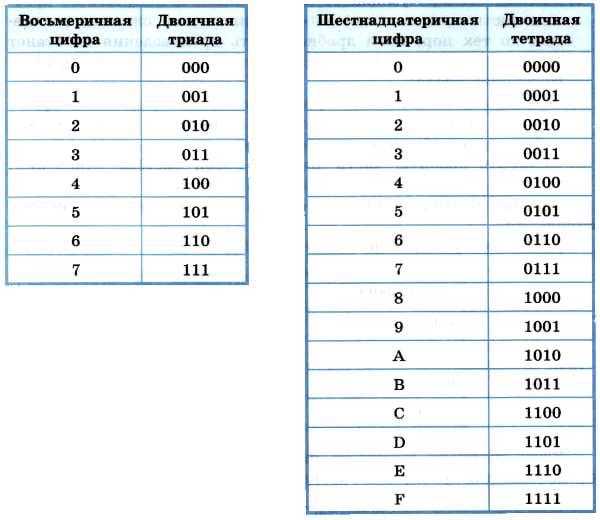
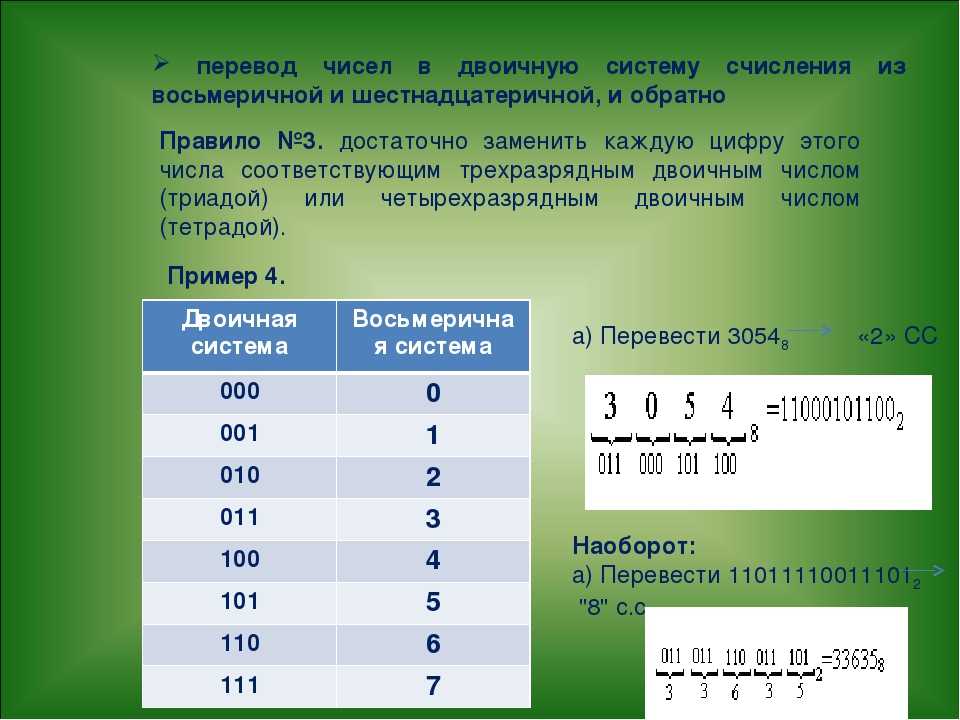
Использование функции stoi ()
Функция atoi () используется для возврата числа путем преобразования строкового значения в целое число. Первый аргумент этой функции является обязательным, а остальные аргументы — необязательными. Синтаксис этой функции приведен ниже.
Синтаксис:
Создайте файл C ++ со следующим кодом для преобразования строки в целое число с помощью функции stoi (). После выполнения кода входное значение, полученное от пользователя, будет преобразовано в число и распечатано, если входное значение является допустимым числом. Если входное значение содержит какой-либо алфавитный или нечисловой символ, будет сгенерировано исключение invalid_argument и будет напечатано сообщение об ошибке.
Выход:
Следующий вывод появится, если после выполнения кода в качестве входных данных будет выбрано 4577.
![]()
Следующий вывод появится, если после выполнения кода будет принято приветствие в качестве ввода.
![]()
Stream на примере простой задачи
Для наглядности посмотрим на примере использование стримов в сравнении со старым решением аналогичной задачи.
Задача — найти сумму нечетных чисел в коллекции.
Решение с методами стрима:
Integer odd = collection.stream().filter(p -> p % 2 != 0).reduce((c1, c2) -> c1 + c2).orElse(0);
Здесь мы видим функциональный стиль. Без стримов эту же задачу приходится решать через использование цикла:
Integer oldOdd = 0;
for(Integer i: collection) {
if(i % 2 != 0) {
oldOdd += i;
}
}
Да, на первый взгляд цикл выглядит более понятным. Но это вопрос опыта взаимодействия со стримами. Очень быстро привыкаешь к тому, что можно обрабатывать данные без использования циклов.
java.util.Scanner
Класс java.util.Scanner предназначен для разбиения форматированного ввода на токены и конвертирования токенов в соответствующий тип данных.
По умолчанию сканер использует пробельные символы (пробелы, табуляторы, разделители линий) для разделения токенов. Рассмотрите следующий код:
Java
import java.io.*;
import java.util.Scanner;
public class ScanXan {
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(new FileReader(«xanadu.txt»)));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
|
1 |
importjava.io.*; importjava.util.Scanner; publicclassScanXan{ publicstaticvoidmain(Stringargs)throwsIOException{ Scanners=null; try{ s=newScanner(newBufferedReader(newFileReader(«xanadu.txt»))); while(s.hasNext()){ System.out.println(s.next()); } }finally{ if(s!=null){ s.close(); } } } } |
Если файл «xanadu.txt» содержит следующий текст:
In Xanadu did Kubla Khan
A stately pleasure-dome decree:
Where Alph, the sacred river, ran
Through caverns measureless to man
Down to a sunless sea.
|
1 |
In Xanadu did Kubla Khan A stately pleasure-dome decree: Where Alph, the sacred river, ran Through caverns measureless to man Down to a sunless sea. |
То результатом работы программы будет вывод:
In
Xanadu
did
Kubla
Khan
A
stately
pleasure-dome
…
|
1 |
In Xanadu did Kubla Khan A stately pleasure-dome … |
Чтобы использовать другой разделитель токенов используйте метод
useDelimiter, в который передаётся регулярное выражение. Например, предположим, что мы хотим использовать в качестве разделителя запятую, после которой может идти, а может не идти пробел:
Java
s.useDelimiter(«,\\s*»);
| 1 | s.useDelimiter(«,\\s*»); |
Класс
java.util.Scanner поддерживает все примитивные типы Java,
java.math.BigInteger и
java.math.BigDecimal.
Scanner использует экземпляр
java.util.Locale для преобразования строк в эти типы данных. Пример:
ScanSum.java
Java
import java.io.FileReader;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Scanner;
import java.util.Locale;
public class ScanSum {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader(«usnumbers.txt»)));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
|
1 |
importjava.io.FileReader; importjava.io.BufferedReader; importjava.io.IOException; importjava.util.Scanner; importjava.util.Locale; publicclassScanSum{ publicstaticvoidmain(Stringargs)throwsIOException{ Scanners=null; doublesum=; try{ s=newScanner(newBufferedReader(newFileReader(«usnumbers.txt»))); s.useLocale(Locale.US); while(s.hasNext()){ if(s.hasNextDouble()){ sum+=s.nextDouble(); }else{ s.next(); } } }finally{ s.close(); } System.out.println(sum); } } |
Цикл статей «Учебник Java 8».
Следующая статья — «Java 8 консоль».
Предыдущая статья — «Java 8 дата и время».
Шаблонные строки
Базовые шаблонные строки
Шаблонные строки позволяют объединять переменные и текст в новую строку с использованием более удобочитаемого синтаксиса.
Вебинар «Как попасть в IT без опыта и остаться там»
12 марта в 16:00, Онлайн, Беcплатно
tproger.ru
События и курсы на tproger.ru
Вместо двойных или одинарных кавычек заключите строку в обратные кавычки и вставьте переменные, используя синтаксис ${variableName}
До
После
Вы также можете включать выражения в шаблонные строки:
Сейчас браузеры очень хорошо поддерживают работу с шаблонными строками в JavaScript.
Chrome: 41+
Edge: 13+
Firefox: 34+
Safari: 9.1+
Opera: 29+
Объединение строк
Конкатенация строк
Вы можете объединить (или «конкатенировать») несколько строк, чтобы создать новую, используя символ +:
Этот подход также можно использовать для разделения создания строки на несколько строк для удобства чтения:
Вы также можете объединять строки с переменными (нестроковые переменные будут преобразованы в строки):
Чтобы создать новую строку, добавив ее в конец существующей, используйте +=:
Повторение строки
Метод repeat() в JavaScript возвращает новую строку, содержащую исходную строку, повторяющуюся несколько раз.
Вы можете использовать string.repeat() в следующих браузерах:
Chrome: 41+
Edge: 12+
Firefox: 24+
Safari: 9+
Opera: 28+
Объединение строк
Вы можете объединить массив строк в одну, используя метод .join() для массива.
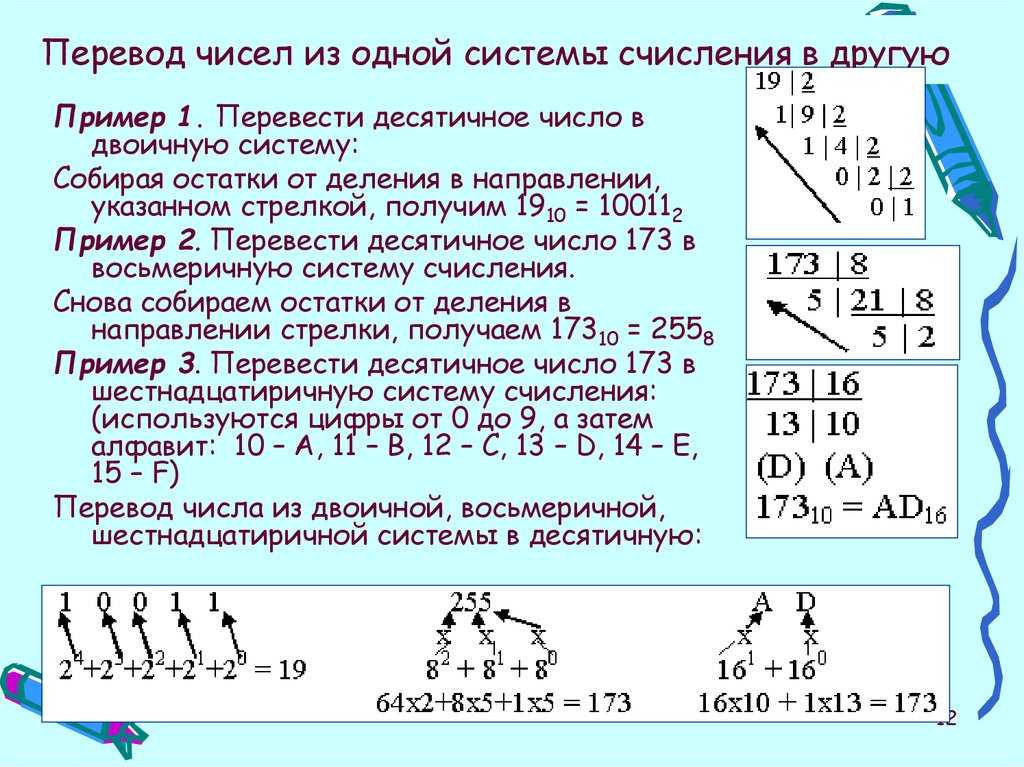
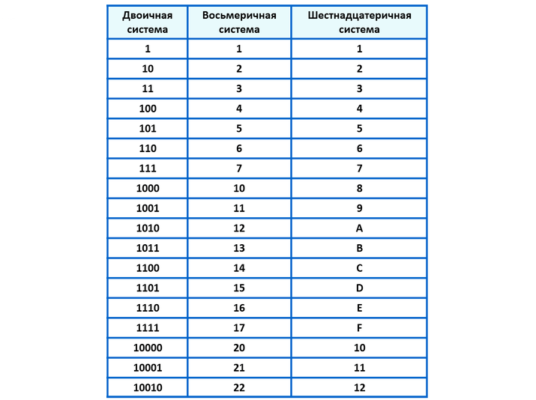
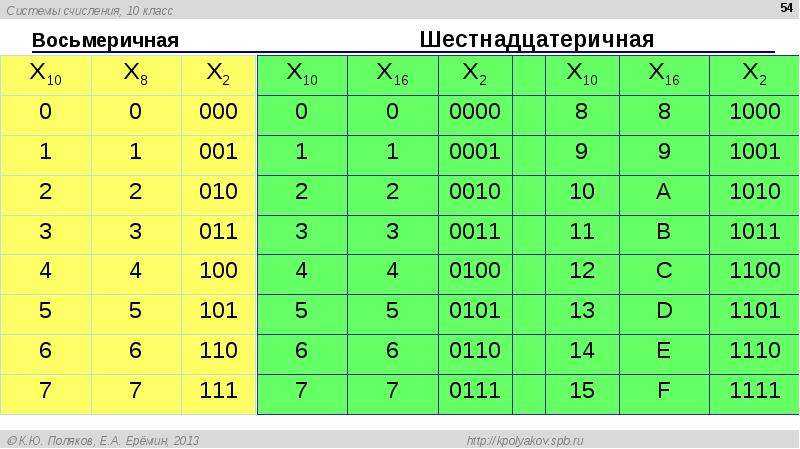
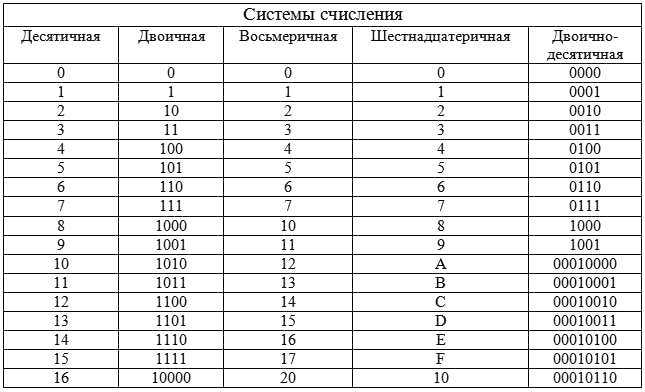
По умолчанию элементы разделяются запятой:
Вы также можете указать строку, используемую для разделения элементов:
Передача пустой строки в string.join объединит элементы, между которыми ничего нет:
Когда toString() используется в массиве, он также возвращает список строк, разделенных запятыми.
Разделение строки
Вы можете разделить строку на массив с помощью метода split().
Типичные варианты использования:
Превращаем предложение в массив слов, разбивая его по пробелам:
… или разделение многострочной строки на отдельные строки:
Вы также можете ограничить количество элементов, которые вы хотите вернуть из split(), передав необязательный второй параметр:
В современных браузерах вместо этого можно использовать spread-оператор:
Поиск в строке
Метод indexOf() находит
индекс первого вхождения подстроки в строку, а метод lastIndexOf() — индекс
последнего вхождения. Если подстрока не будет найдена, то оба
метода возвращают -1:
String str = "Hello world";
int index1 = str.indexOf('l'); // 2
int index2 = str.indexOf("wo"); //6
int index3 = str.lastIndexOf('l'); //9
System.out.println(index1+" "+index2+" "+index3);
Метод startsWith() позволяют
определить начинается ли строка с определенной подстроки, а метод endsWith() позволяет
определить заканчивается строка на определенную подстроку:
String str = "myfile.exe";
boolean start = str.startsWith("my"); //true
boolean end = str.endsWith("exe"); //true
System.out.println(start+" "+end);
Как найти подстроку
includes
Проверяет, содержит ли строка указанную подстроку. Возвращает значение true или false. Вторым параметром можно указать позицию в строке, с которой следует начать поиск.
indexOf
Возвращает индекс первого найденного вхождения указанного значения. Поиск ведётся от начала до конца строки. Если совпадений нет, возвращает -1. Вторым параметром можно передать позицию, с которой следует начать поиск.
lastIndexOf
Возвращает индекс последнего найденного вхождения указанного значения. Поиск ведётся от конца к началу строки. Если совпадений нет, возвращает -1. Вторым параметром можно передать позицию, с которой следует начать поиск.
endsWith
Проверяет, заканчивается ли строка символами, заданными первым параметром. Возвращает true или false. Есть второй необязательный параметр — ограничитель по диапазону поиска. По умолчанию он равен длине строки.
startsWith
Проверяет, начинается ли строка с указанных символов. Возвращает true или false. Вторым параметром можно указать индекс, с которого следует начать проверку.
Спецификаторы формата Java
Вот краткий справочник по всем поддерживаемым спецификаторам.
| Спецификатор | Тип | Вывод |
| %a | floating point (except BigDecimal) | Шестнадцатеричный вывод числа с плавающей запятой |
| %b | Any type | “true” если не 0, “false” если 0 |
| %c | character | Юникод |
| %d | integer (incl. byte, short, int, long, bigint) | Десятичное целое |
| %e | floating point | десятичное число в научной записи |
| %f | floating point | десятичное число |
| %g | floating point | десятичное число, возможно, в научных обозначениях в зависимости от точности и значения. |
| %h | any type | Шестнадцатеричная строка значения из метода hashCode (). |
| %n | none | Специфичный для платформы разделитель строк. |
| %o | integer (incl. byte, short, int, long, bigint) | Восьмеричное число |
| %s | any type | Строковое значение |
| %t | Date/Time (incl. long, Calendar, Date and TemporalAccessor) | % t – это префикс для преобразования даты / времени. |
| %x | integer (incl. byte, short, int, long, bigint) | Шестнадцатеричная строка. |
https://youtube.com/watch?v=O2NiLjzkvn0
Метасимволы
В приведенных выше примерах использовались очень простые шаблоны. Метасимволы позволяют нам выполнять более сложные сопоставления с образцом, например проверять правильность адреса электронной почты. Давайте теперь посмотрим на часто используемые метасимволы.
| Метасимвол | Описание | Пример |
|---|---|---|
| . | Соответствует любому отдельному символу, кроме новой строки | /./ соответствует всему, что имеет один символ |
| ^ | Соответствует началу или строке/исключает символы | /^PH/ соответствует любой строке, начинающейся с PH |
| $ | Соответствует шаблону в конце строки | /ru$/ соответствует it-blog.ru и т.д. |
| * | Соответствует любому нулю (0) или более символов | /com*/ соответствует computer, communication и т. д. |
| + | Требуется, чтобы предшествующие символы появлялись хотя бы раз | /yah+oo/ соответствует yahoo |
| \ | Используется для экранирования метасимволов | /yahoo+\.com/ трактует точку как буквальное значение |
| Символы внутри скобках | // соответствует abc | |
| a-z | Соответствует строчным буквам | /a-z/ соответствует cool, happy и т.д. |
| A-Z | Соответствует заглавным буквам | /A-Z/ соответствует WHAT, HOW, WHY и т.д. |
| 0-9 | Соответствует любому числу от 0 до 9 | /0-4/ соответствует 0,1,2,3,4 |
Приведенный выше список содержит только наиболее часто используемые метасимволы в регулярных выражениях.
Давайте теперь рассмотрим довольно сложный пример, который проверяет действительность адреса электронной почты.
<?php
$my_email = "name@company.com
";
if (preg_match("/^+@+\.{2,5}$/", $my_email)) {
echo "$my_email это действительный адрес электронной почты";
}
else
{
echo "$my_email это не действительный адрес электронной почты";
}
?>
![]()
Метод 2: Использование метода join()
В следующей программе мы увидим, как метод join() помогает нам сделать то же самое. Метод join() берет элементы и объединяет их в строку.
Следующая программа показывает, как это можно сделать:
def convert_tuple(c_tuple):
str=''.join(c_tuple)
return str
c_tuple=('P','y','t','h','o','n','a','t','J','T','P')
c_string=convert_tuple(c_tuple)
print(c_string)
Выход:
PythonatJTP
Давайте разберемся, что произошло в приведенной выше программе.
- Мы создали функцию, которая преобразует элемент из кортежа в строку.
- В определении программы мы упомянули, что метод join() возьмет элементы из c_tuple и объединит их с пустой строкой. Эта функция наконец вернет результирующую строку.
- Вне функции мы объявили наш кортеж с именем c_tuple, а затем передали его в нашу функцию.
- При выполнении этой программы отображается ожидаемый результат.
Явное и неявное преобразование
Преобразование типов данных может быть явным и неявным. Так как JavaScript – это слабо типизированный или динамический язык программирования, значения могут быть конвертированы между различными типами автоматически. Это называют неявным приведением типов. Обычно неявное преобразование происходит, когда в выражениях используют значения различных типов.
Явное преобразование – это когда преобразование типов данных выполняет сам программист. Явное преобразование иначе называют приведением типов:
Выполнить код »
Скрыть результаты
Для явного преобразования в примитивные типы данных в JavaScript используются следующие функции: Boolean(), Number(), String(). При неявном преобразования интерпретатор JavaScript автоматически использует те же самые функции, что используются и для явного преобразования.
Вместо функций для явного преобразования типов данных можно использовать операторы. Например, если один из операндов оператора сложения является строкой, то другой операнд также преобразуется в строку. Операции инкремента или декремента над строкой приведут её к числу. Унарный оператор плюс преобразует свой операнд в число, а унарный оператор отрицания преобразует операнд в логическое значение и инвертирует его:
Выполнить код »
Скрыть результаты
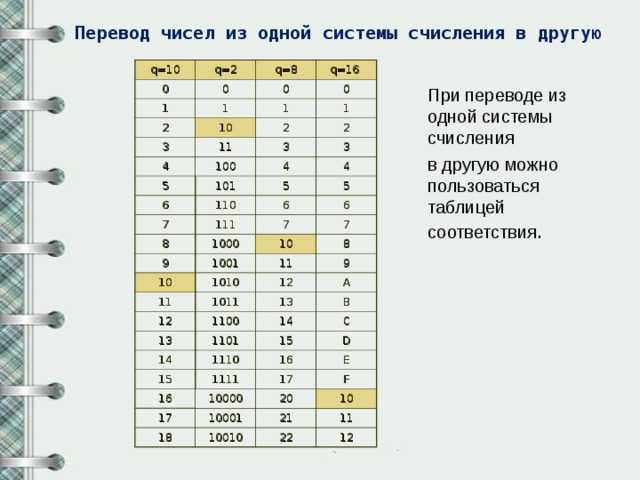
6.3.5. Дискретность
Дискретизация (также известная как квантование или биннинг) обеспечивает способ разделения непрерывных функций на дискретные значения. Определенные наборы данных с непрерывными объектами могут выиграть от дискретизации, потому что дискретизация может преобразовать набор данных с непрерывными атрибутами в набор только с номинальными атрибутами.
Дискретизированные признаки, закодированные одним горячим способом (One-hot encoded), могут сделать модель более выразительной, сохраняя при этом интерпретируемость. Например, предварительная обработка с помощью дискретизатора может внести нелинейность в линейные модели.
6.3.5.1. Дискретизация K-бинов
дискретизирует функции в бункеры:
>>> X = np.array(, ... , ... ]) >>> est = preprocessing.KBinsDiscretizer(n_bins=, encode='ordinal').fit(X)
По умолчанию выходные данные быстро кодируются в разреженную матрицу (см. ), и это можно настроить с помощью параметра. Для каждого объекта границы интервалов вычисляются во время и вместе с количеством интервалов они определяют интервалы. Следовательно, для текущего примера эти интервалы определены как:
- особенность 1: ${[-\infty, -1), [-1, 2), [2, \infty)}$
- особенность 2: ${[-\infty, 5), [5, \infty)}$
- особенность 3: ${[-\infty, 14), [14, \infty)}$
На основе этих интервалов бинов преобразуется следующим образом:
>>> est.transform(X)
array(,
,
])
Результирующий набор данных содержит порядковые атрибуты, которые в дальнейшем можно использовать в файле .
Дискретизация аналогична построению гистограмм для непрерывных данных. Однако гистограммы фокусируются на подсчете объектов, которые попадают в определенные интервалы, тогда как дискретизация фокусируется на присвоении значений признаков этим интервалам.
реализует различные стратегии биннинга, которые можно выбрать с помощью параметра. «Равномерная» стратегия использует ячейки постоянной ширины. Стратегия «квантилей» использует значения квантилей, чтобы иметь одинаково заполненные ячейки в каждой функции. Стратегия «k-средних» определяет интервалы на основе процедуры кластеризации k-средних, выполняемой для каждой функции независимо.
Имейте в виду, что можно указать настраиваемые интервалы, передав вызываемый объект, определяющий стратегию дискретизации . Например, мы можем использовать функцию Pandas :
>>> import pandas as pd
>>> import numpy as np
>>> bins =
>>> labels =
>>> transformer = preprocessing.FunctionTransformer(
... pd.cut, kw_args={'bins': bins, 'labels': labels, 'retbins': False}
... )
>>> X = np.array()
>>> transformer.fit_transform(X)
Categories (5, object):
Примеры:
- Использование KBinsDiscretizer для дискретизации непрерывных объектов
- Дискретизация функций
- Демонстрация различных стратегий KBinsDiscretizer
6.3.5.2. Бинаризация функций
Бинаризация функций — это процесс определения пороговых значений числовых функций для получения логических значений . Это может быть полезно для последующих вероятностных оценок, которые предполагают, что входные данные распределены согласно многомерному распределению Бернулли . Например, это касается .
В сообществе обработки текста также распространено использование двоичных значений признаков (вероятно, для упрощения вероятностных рассуждений), даже если нормализованные подсчеты (также известные как частоты терминов) или функции, оцениваемые по TF-IDF, часто работают немного лучше на практике.
Что касается класса утилиты, он предназначен для использования на ранних этапах . Метод не делает ничего , поскольку каждый образец обрабатывают независимо от других:
>>> X = ,
... ,
... ]
>>> binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer()
>>> binarizer.transform(X)
array(,
,
])
Есть возможность настроить порог бинаризатора:
>>> binarizer = preprocessing.Binarizer(threshold=1.1)
>>> binarizer.transform(X)
array(,
,
])
Что касается класса, модуль предварительной обработки предоставляет вспомогательную функцию, которая будет использоваться, когда API-интерфейс преобразователя не нужен.
Обратите внимание, что это похоже на то, когда k = 2 и когда край ячейки находится на значении . Редкий ввод
Редкий ввод
и принимать как плотные, похожие на массивы, так и разреженные матрицы из scipy.sparse в качестве входных данных .
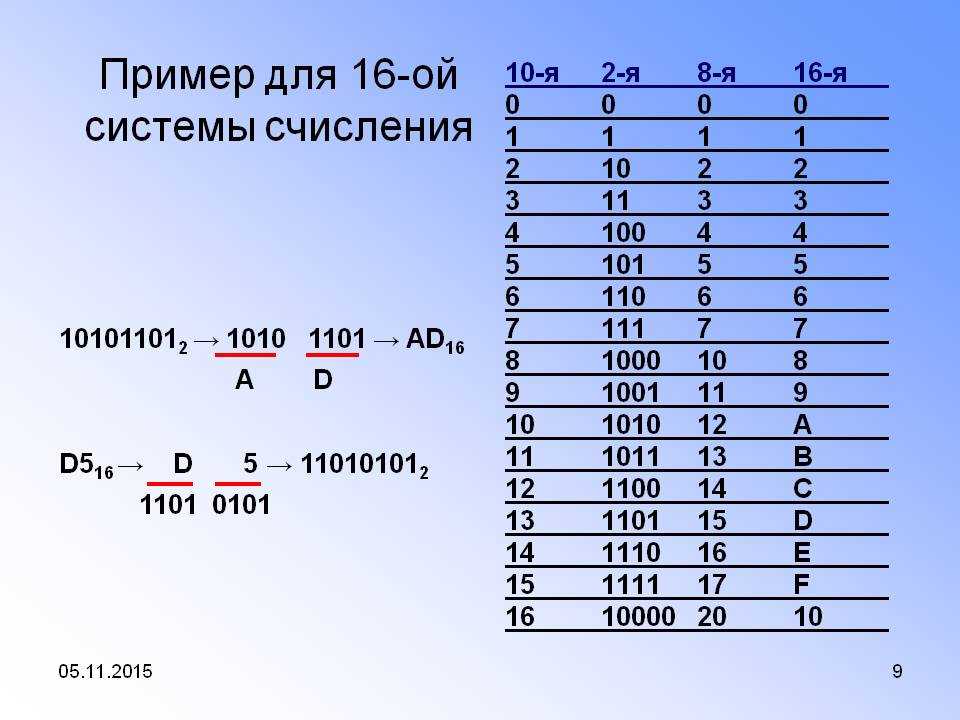
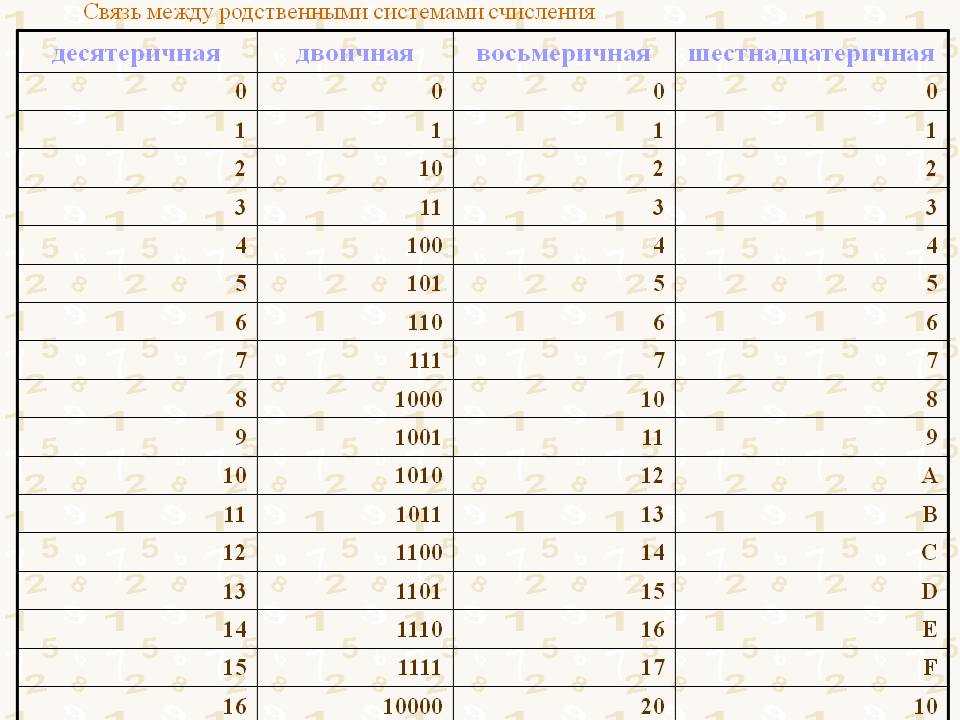
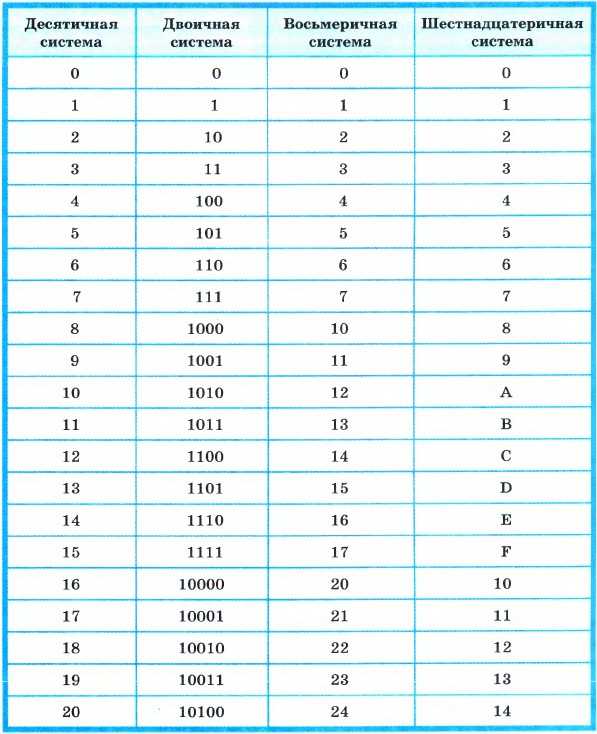
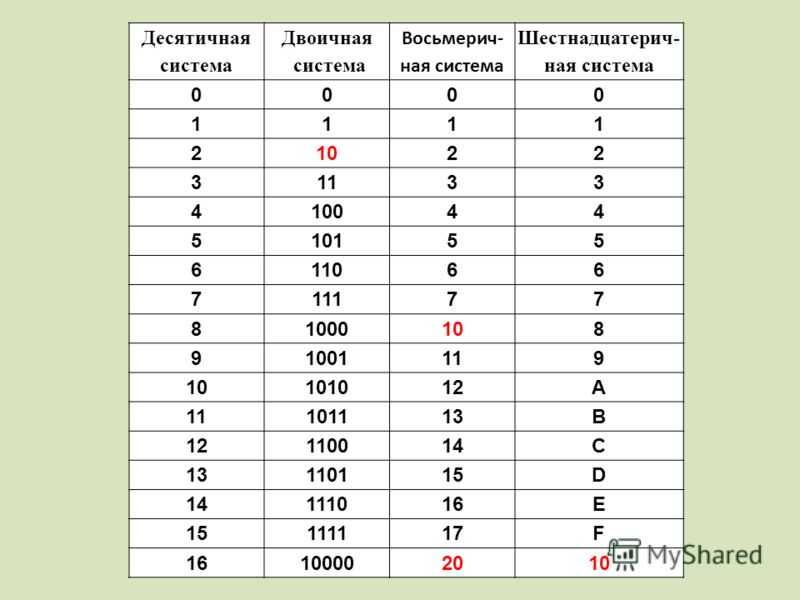
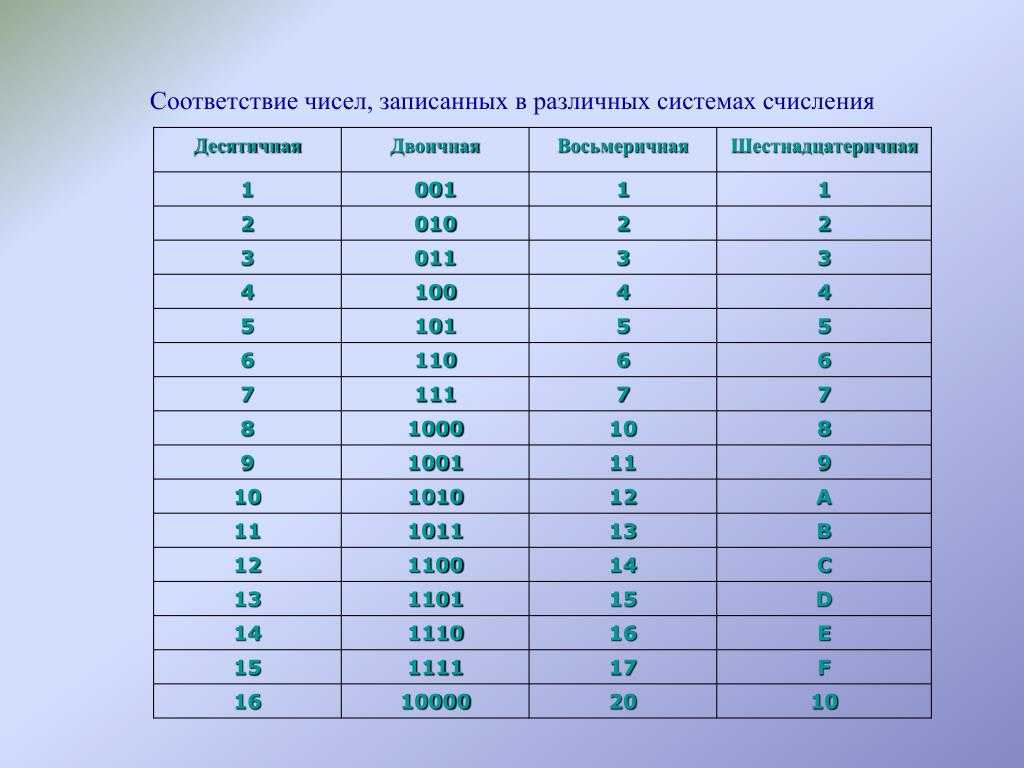


Для разреженного ввода данные преобразуются в представление сжатых разреженных строк (см . Раздел «Ресурсы» ). Чтобы избежать ненужных копий памяти, рекомендуется выбирать представление CSR в восходящем направлении.
Метод 1: Использование цикла for
В первом методе мы будем использовать цикл for для преобразования кортежа Python в строку. В этой программе цикл for поможет нам взять каждый итератор из кортежа и применить к нему функцию.
Следующая программа показывает, как это можно сделать.
Пример:
def convert_tuple(c_tuple):
str=''
for i in c_tuple:
str=str+i
return str
c_tuple=('P','y','t','h','o','n','a','t','J','T','P')
c_string=convert_tuple(c_tuple)
print(c_string)
Выход:
PythonatJTP
Давайте разберемся, что произошло в приведенной выше программе.
- Мы создали функцию, которая преобразует элемент из кортежа в строку.
- В определении программы мы упомянули, что каждый итератор берет элемент и объединяет его с объявленной пустой строкой. Эта функция наконец вернет результирующую строку.
- Вне функции мы объявили наш кортеж с именем c_tuple, а затем передали его в нашу функцию.
- При выполнении этой программы отображается ожидаемый результат.
6.3.8. Трансформаторы на заказ
Часто вам может потребоваться преобразовать существующую функцию Python в преобразователь для помощи в очистке или обработке данных. Вы можете реализовать преобразователь из произвольной функции с помощью . Например, чтобы создать преобразователь, который применяет преобразование журнала в конвейере, выполните:
>>> import numpy as np
>>> from sklearn.preprocessing import FunctionTransformer
>>> transformer = FunctionTransformer(np.log1p, validate=True)
>>> X = np.array(, ])
>>> transformer.transform(X)
array(,
])
Вы можете убедиться, что и являются противоположностью друг другу, установив и вызвав раньше . Обратите внимание, что появляется предупреждение, которое может быть преобразовано в ошибку с помощью :
>>> import warnings
>>> warnings.filterwarnings("error", message=".*check_inverse*.",
... category=UserWarning, append=False)
Полный пример кода, демонстрирующий использование a для извлечения функций из текстовых данных, см. В разделе Преобразователь столбцов с гетерогенными источниками данных.
Преобразование чисел в строки
С помощью глобального метода можно преобразовать числа в строки.
Он может быть использован для любого типа чисел, литералов, переменных или выражений:
Пример
String(x) // возвращает строку из числовой переменной x
String(123) // возвращает строку из числового литерала 123
String(100 + 23) // возвращает строку из числа из выражения
Метод Чисел делает то же самое.
Пример
x.toString()(123).toString()(100 + 23).toString()
В главе Методы чисел, вы найдете больше методов, которые можно использовать для преобразования чисел в строки:
| Метод | Описание |
|---|---|
| toExponential() | Возвращает строку с округленным и записанным числом с использованием экспоненциальной записи. |
| toFixed() | Возвращает строку с округленным числом и записанным с указанным количеством десятичных знаков. |
| toPrecision() | Возвращает строку с числом, записанным с указанной длиной |
Преобразование значений в строки
Чтобы явно преобразовать значение в строку, вызовите метод String() или n.toString().
Попробуйте преобразовать логическое значение true в строку с помощью String().
Это вернет строковый литерал «true».
Также можно попробовать передать функции число:
Она вернет строковый литерал:
Теперь попробуйте использовать String() с переменной. Присвойте числовое значение переменной odyssey и используйте оператор typeof, чтобы проверить тип.
На данный момент переменной odyssey присвоено числовое значение 2001. Оператор typeof подтверждает, что значение является числом.
Теперь присвойте переменной odyssey ее эквивалент внутри функции String(), а затем используйте typeof, чтобы убедиться, что значение переменной успешно преобразовано из числа в строку.
Как видите, теперь переменная odyssey содержит строку.
Функция n.toString() работает аналогичным образом. Замените n переменной.
Переменная blows будет содержать строку.
Вместо переменной можно поместить значение в круглых скобках:
String() и n.toString() явно преобразовывают логические и числовые значения в строки.
Численное преобразование
Численное преобразование происходит в математических функциях и выражениях, а также при сравнении данных различных типов (кроме сравнений === , !== ).
Для преобразования к числу в явном виде можно вызвать Number(val) , либо, что короче, поставить перед выражением унарный плюс «+» :
| Значение | Преобразуется в. |
|---|---|
| undefined | NaN |
| null | |
| true / false | 1 / 0 |
| Строка | Пробельные символы по краям обрезаются.Далее, если остаётся пустая строка, то 0 , иначе из непустой строки «считывается» число, при ошибке результат NaN . |
Сравнение разных типов – значит численное преобразование:
При этом строка » 0″ преобразуется к числу, как указано выше: начальные и конечные пробелы обрезаются, получается строка «0» , которая равна 0 .
С логическими значениями:
Здесь сравнение «==» снова приводит обе части к числу. В первой строке слева и справа получается 0 , во второй 1 .
Специальные значения
Посмотрим на поведение специальных значений более внимательно.
Интуитивно, значения null/undefined ассоциируются с нулём, но при преобразованиях ведут себя иначе.
Специальные значения преобразуются к числу так:
| Значение | Преобразуется в. |
|---|---|
| undefined | NaN |
| null |
Это преобразование осуществляется при арифметических операциях и сравнениях > >= , но не при проверке равенства == . Алгоритм проверки равенства для этих значений в спецификации прописан отдельно (пункт 11.9.3). В нём считается, что null и undefined равны «==» между собой, но эти значения не равны никакому другому значению.
Это ведёт к забавным последствиям.
Например, null не подчиняется законам математики – он «больше либо равен нулю»: null>=0 , но не больше и не равен:
Значение undefined вообще «несравнимо»:
Для более очевидной работы кода и во избежание ошибок лучше не давать специальным значениям участвовать в сравнениях > >= .
Используйте в таких случаях переменные-числа или приводите к числу явно.
Теговые шаблоны
Теговые шаблоны позволяют создать функцию, которая парсит шаблонную строку.
Это может быть действительно мощным инструментом и наиболее наглядно демонстрируется на примере:
Представьте, что у нас есть функция censor(), которая удаляет любые оскорбительные слова в строке, введенной пользователем.
Когда мы хотим подвергнуть строку цензуре, мы можем вручную вызвать censor() для каждого введенного пользователем значения:
Или мы могли бы использовать теговые шаблоны.
Это позволяет нам написать функцию, которая принимает строковые значения из шаблонной строки и все выражения, используемые в шаблоне:
Обратите внимание, что в последней строке мы «тегаем» строку нашей функцией, добавляя ее перед шаблонной строкой, а не явно вызывая функцию censorStrings(). Это означает, что теперь мы можем управлять шаблонной строкой и значениями внутри неё
Это означает, что теперь мы можем управлять шаблонной строкой и значениями внутри неё.
Теперь у нас есть доступ к шаблонной строке и отдельным аргументам. Мы можем отслеживать каждую переменную, используемую в строке:
Наконец, наша теговая функция должна вернуть обработанную строку.
Для этого мы просто объединяем исходный массив строк и массив (измененных) входных данных в новый массив.
Здесь мы делаем это с помощью .reduce():
Наша теговая функция теперь готова, и ее можно использовать везде, где нам нужно цензурировать вводимые пользователем данные:
Raw-строки в JavaScript
String.raw — это предопределенная теговая функция.

Она позволяет вам получить доступ к строке без обработки каких-либо значений после обратного слэша.
Например, при использовании строки, содержащей \ n с String.raw, вместо получения новой строки вы получите фактические символы \ и n:
Это может быть полезно (помимо прочего) для написания строк, в которых вам обычно приходится избегать большого количества символов обратного слэша, таких как пути к файлам:
При использовании string.raw символ \ экранирует последнюю обратную кавычку.
Это означает, что вы не можете заканчивать raw-строку символом \ следующим образом:



