
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
всем текстомвсего текстастрочкой текста
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Начало всего текста или начало строчки текста, если |
|||
| Конец всего текста или конец строчки текста, если |
|||
| Строго начало всего текста | |||
| Строго конец всего текста | |||
| Начало или конец слова (слева пусто или не-буква, справа буква и наоборот) | вал, перевал, Перевалка | ||
| Не граница слова: либо и слева, и справа буквы, либо и слева, и справа НЕ буквы |
перевал, вал, Перевалка | ||
| перевал, вал, Перевалка |
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
|
lookahead assertion, соответствует каждой позиции, сразу после которой начинается соответствие шаблону … |
Isaac Asimov, Isaac other | ||
|
negative lookahead assertion, соответствует каждой позиции, сразу после которой НЕ может начинаться шаблон … |
Isaac Asimov, Isaac other | ||
|
positive lookbehind assertion, соответствует каждой позиции, которой может заканчиваться шаблон … Длина шаблона должна быть фиксированной, то есть и — это ОК, а и — нет. |
abcdef, bcdef | ||
|
negative lookbehind assertion, соответствует каждой позиции, которой НЕ может заканчиваться шаблон … |
abcdef, bcdef |
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
lookaround на примере королей и императоров Франции
— Людовик, за которым идёт VI
| Шаблон | Комментарий | Применяем к тексту |
|---|---|---|
| Цифра, окружённая не-цифрами | Text ABC 123 A1B2C3! | |
| Текст от #START# до #END# | text from #START# till #END# | |
| Цифра, после которой идёт ровно одно подчёркивание | 12_34__56 | |
| Строка, в которой нет boo (то есть нет такого символа, перед которым есть boo) |
a foo and boo and zooand others |
|
| Строка, в которой нет ни boo, ни foo | a foo and boo and zoo and others |
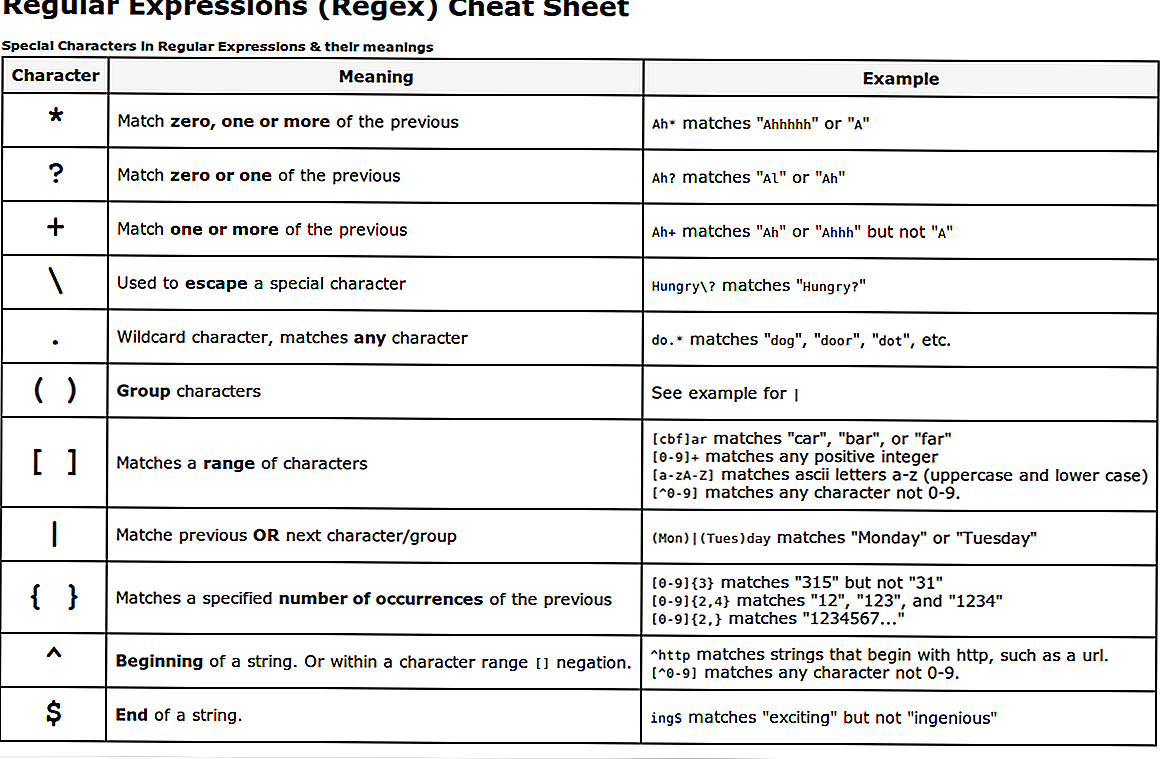
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
| . | Один символ кроме новой строки |
| \. | Просто точка , обратный слеш убирает магию всех специальных символов. |
| \d | Одна цифра |
| \D | Один символ кроме цифры |
| \w | Один буквенный символ, включая цифры |
| \W | Один символ кроме буквы и цифры |
| \s | Один пробельный (включая таб и перенос строки) |
| \S | Один не пробельный символ |
| \b | Границы слова |
| \n | Новая строка |
| \t | Табуляция |
Модификаторы
| $ | Конец строки |
| ^ | Начало строки |
| ab|cd | Соответствует ab или de. |
| Один символ: a, b, c, d | |
| Любой символ, кроме: a, b, c, d | |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| {2} | 2 непрерывных появления a или b |
| {2,5} | от 2 до 5 непрерывных появления a или b |
| {2,} | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
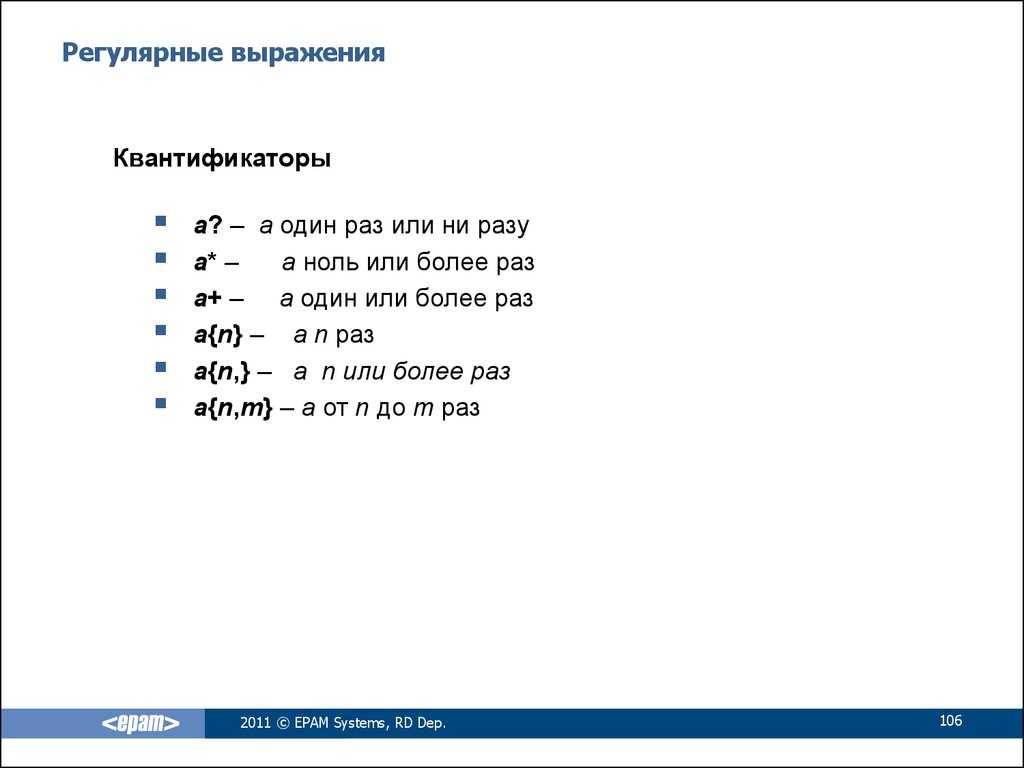
Основной синтаксис регулярных выражений в PHP
Чтобы использовать регулярные выражения, сначала вам нужно изучить синтаксис шаблонов. Мы можем сгруппировать символы внутри шаблона следующим образом:
- Обычные символы, которые следуют один за другим, например,
- Индикаторы начала и окончания строки в виде и
- Индикаторы подсчета, такие как , ,
- Логические операторы, такие как
- Группирующие операторы, такие как , ,
Пример шаблона регулярного выражения для проверки правильности адреса электронного ящика выглядит следующим образом:
^+@+\.{2,5}$
Код PHP для проверки электронной почты с использованием Perl-совместимого регулярного выражения выглядит следующим образом:
<?php
$pattern = "/^+@+\.{2,5}$/";
$email = "some-email@test.com";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Теперь давайте посмотрим на подробный разбор синтаксиса шаблона при регулярном выражении:
| Регулярное выражение (шаблон) | Проходит проверку (объект) | Не проходит проверку (объект) | Комментарий |
| Hello world | Hello Ivan | Проходит, если шаблон присутствует где-либо в объекте | |
| world class | Hello world | Проходит, если шаблон присутствует в начале объекта | |
| Hello world | world class | Проходит, если шаблон присутствует в конце объекта | |
| This WoRLd | Hello Ivan | Выполняет поиск в нечувствительном к регистру режиме | |
| world | Hello world | Строка содержит только «world» | |
| worl, world, worlddd | wor | Присутствует 0 или больше «d» после «worl» | |
| world, worlddd | worl | Присутствует по крайней мере одна «d» после «worl» | |
| worl, world, worly | wor, wory | Присутствует 0 или 1 «d» после «worl» | |
| world | worly | Присутствует одна «d» после «worl» | |
| world, worlddd | worly | Присутствует одна или больше «d» после «worl» | |
| worldd, worlddd | world | Присутствует 2 или 3 «d» после «worl» | |
| wo, world, worldold | wa | Присутствует 0 или больше «rld» после «wo» | |
| earth, world | sun | Строка содержит «earth» или «world» | |
| world, wwrld | wrld | Содержит любой символ вместо точки | |
| world, earth | sun | Строка содержит ровно 5 символов | |
| abc, bbaccc | sun | В строке есть «a», или «b» или «c» | |
| world | WORLD | В строке есть любые строчные буквы | |
| world, WORLD, Worl12 | 123 | В строке есть любые строчные или прописные буквы | |
| earth | w, W | Фактический символ не может быть «w» или «W» |
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.
Группирующие скобки (…) и match-объекты в питоне
Match-объекты
| Метод | Описание | Пример |
|---|---|---|
| , | Подстрока, соответствующая шаблону | |
| Индекс в исходной строке, начиная с которого идёт найденная подстрока | ||
| Индекс в исходной строке, который следует сразу за найденной подстрока |
Группирующие скобки
Если в шаблоне регулярного выражения встречаются скобки без , то они становятся группирующими. В match-объекте, который возвращают , и , по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует , а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок , то вывод был бы таким:
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
Группы и
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки .
Группы и
Если в шаблоне нет группирующих скобок, то работает очень похожим образом на . А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
Символ «точка»
Точка используется для поиска любого одиночного символа, за исключением символа перевода строки. Передадим такому регулярному выражению файл
myfile, содержимое которого приведено ниже:
$ awk ‘/.st/{print $0}’ myfile
| 1 | $awk’/.st/{print $0}’myfile |
![]()
Использование точки в регулярных выражениях
Как видно по выведенным данным, шаблону соответствуют лишь первые две строки из файла, так как они содержат последовательность символов «st», предварённую ещё одним символом, в то время как третья строка подходящей последовательности не содержит, а в четвёртой она есть, но находится в самом начале строки.
Скобки
Скобки ([]) имеют особое значение при использовании в контексте регулярных выражений. Они используются для поиска диапазона символов.








| # | Значение | Описание |
|---|---|---|
| Он соответствует любой десятичной цифре от 0 до 9. | ||
| Он соответствует любому символу от нижнего регистра a до нижнего регистра z. | ||
| Он соответствует любому символу в верхнем регистре A в верхнем регистре Z. | ||
| Он соответствует любому символу от нижнего регистра a до верхнего регистра Z. |
Диапазоны, показанные выше, являются общими; вы также можете использовать диапазон для соответствия любой десятичной цифре в диапазоне от 0 до 3 или диапазону , чтобы соответствовать любому строчному символу в диапазоне от b до v.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk:
$ echo «This is a test» | sed -n ‘/test/p’
$ echo «This is a test» | awk ‘/test/{print $0}’
|
1 |
$echo»This is a test»|sed-n’/test/p’ $echo»This is a test»|awk’/test/{print $0}’ |
![]()
Поиск текста по шаблону в sed
![]()
Поиск текста по шаблону в awk
Можно заметить, что поиск заданного шаблона выполняется без учёта точного места нахождения текста в строке. Кроме того, не имеет значение и количество вхождений. После того, как регулярное выражение найдёт заданный текст в любом месте строки, строка считается подходящей и передаётся для дальнейшей обработки.
Работая с регулярными выражениями нужно учитывать то, что они чувствительны к регистру символов:
$ echo «This is a test» | awk ‘/Test/{print $0}’
$ echo «This is a test» | awk ‘/test/{print $0}’
|
1 |
$echo»This is a test»|awk’/Test/{print $0}’ $echo»This is a test»|awk’/test/{print $0}’ |
![]()
Регулярные выражения чувствительны к регистру
Первое регулярное выражение совпадений не нашло, так как слово «test», начинающееся с заглавной буквы, в тексте не встречается. Второе же, настроенное на поиск слова, написанного прописными буквами, обнаружило в потоке подходящую строку.
В регулярных выражениях можно использовать не только буквы, но и пробелы, и цифры:
$ echo «This is a test 2 again» | awk ‘/test 2/{print $0}’
| 1 | $echo»This is a test 2 again»|awk’/test 2/{print $0}’ |
![]()
Поиск фрагмента текста, содержащего пробелы и цифры
Пробелы воспринимаются движком регулярных выражений как обычные символы.
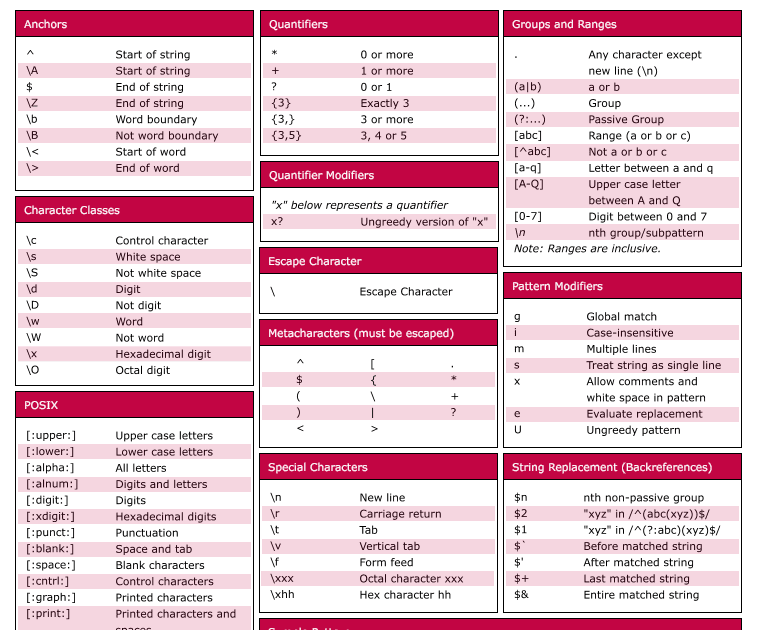
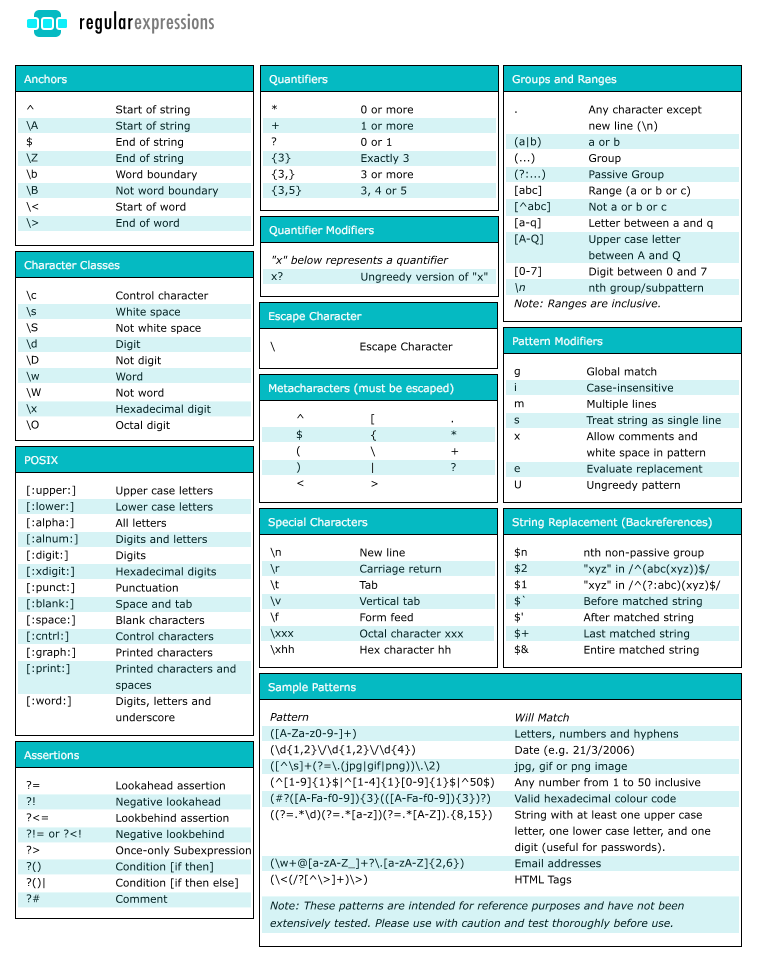
2.8 Якоря
Понятие якорей в регулярных выражениях используется для обозначения проверок, является ли
соответствующий символ начальным или конечным символом входной строки. Якоря бывают двух типов:
Первый тип — Каретка , проверяет, является ли соответствующий символ начальным символом в тексте.
Второй тип — Доллар , проверяет, является ли соответствующий символ последним символом входной строки.
2.8.1 Каретка
Символ каретки используется для проверки, является ли соответствующий символ первым символом входной строки.
Если мы применяем следующее регулярное выражение (если a является начальным символом) для строки ,
совпадение будет соответствовать букве . Если же мы используем регулярное выражение на той же строке,
мы не получим совпадения, поскольку во входящей строке «b» не является первым символом. Рассмотрим другое
регулярное выражение: , обозначающее заглавную или строчную как первый символ, за которым следуют
символы букв и . Cоответственно:
"(T|t)he" => car is parked in garage.
"^(T|t)he" => car is parked in the garage.
2.8.2 Доллар
Символ доллара используется для проверки, является ли соответствующий символ
последним символом входной строки. Например, регулярное выражение последовательность из
строчной , строчной , и точки , ключевой момент в том, что благодаря доллару этот шаблон будет
находить совпадения только в том случае, если будет наблюдаться в конце строки. Например:
"(at\.)" => The fat c s on the m
"(at\.)$" => The fat cat. sat. on the m
Когда можно использовать регулярные выражения?
Типовых задач, в которых регулярные выражения действительно могут пригодиться, не так много. Среди них:
- Поиск или замена подстроки в строке с «плавающими» (неизвестными) данными. Самая распространённая задача — найти в тексте ссылки и адреса электронной почты и сделать их кликабельными.
- Валидация данных формы и ограничение ввода. Например, валидация номера телефона, электронной почты, данных паспорта гражданина РФ и другой информации.
- Получение части строки или формирование новых структур данных из строк. Например, нужно найти количество вхождений ключевых слов в тексте без учёта падежных окончаний, составить из них массив с данными для дальнейшего использования.
Чаще всего фронтенд-разработчики встречаются с регулярными выражениями в задачах, связанных с валидацией данных. И чаще всего такие задачи решаются поиском нужного выражения в интернете и вставкой его кода в проект — по крайней мере, у начинающих специалистов.
В контексте поиска и замены текста регулярные выражения используют редко, а в сложных кейсах по работе с текстом — ещё меньше. Но они могут помочь, если задача связана с обработкой текста.
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
2.2 Набор символов.
Набор символов также называется классом символов. Квадратные скобки используются
для определения набора символов. Дефис используется для указания диапазона символов.
Порядок следования символов, заданный в квадратных скобках, не важен. Например,
регулярное выражение обозначает заглавную или строчную , за которой следуют буквы и .







"he" => car parked in garage.
Точка внутри набора символов, однако, обозначает непосредственно точку, как символ.
Регулярное выражение обозначает строчную , за которой следует , за которой следует (символ точки).
"ar" => A garage is a good place to park a c
2.2.1 Отрицание набора символов
Знак вставки обозначает начало строки, однако, когда вы вписываете его после открытия квадратных скобок, он отрицает набор символов.
Например, регулярное выражение обозначает любой символ, кроме , за которым следуют буквы и .
"ar" => The car ked in the age.
Статичные регэкспы
В некоторых реализациях javascript регэкспы, заданные коротким синтаксисом /…/ — статичны. То есть, такой объект создается один раз в некоторых реализациях JS, например в Firefox. В Chrome все ок.
function f() {
// при многократных заходах в функцию объект один и тот же
var re = /lalala/
}
По стандарту эта возможность разрешена ES3, но запрещена ES5.
Из-за того, что при глобальном поиске меняется, а сам объект регэкспа статичен, первый поиск увеличивает , а последующие — продолжают искать со старого , т.е. могут возвращать не все результаты.
При поиске всех совпадений в цикле проблем не возникает, т.к. последняя итерация (неудачная) обнуляет .
Функции для обработки строк в PHP
Начиная с этого урока мы с вами открываем главу посвященную функциям для обработки строковых данных. С помощью этих фукнций можно, например, обрезать строку, дописывать строку, заменить часть строки и много другое. Это очень полезный инструмент и вы частенько будете использовать все эти функции при разработке своих скриптов.
Все функции для обработки строк перечислены ниже:
| chr | Возвращает символ по его коду ASCII |
| chunk_split | Разбивает строку на подстроки заданной длины |
| crypt | Зашифровывает строку с использованием одного из алгоритмов |
| echo | Выводит одну или несколько строк |
| explode | Разбивает строку на подстроки, ограниченные заданным разделителем, и форматирует из них массив |
| html_entity_decode | Декодирует все HTML-представления в соответствующие символы. Функция обратно по отношению к htmlentites |
| htmlentites | Кодирует все специальные символы в их HTML-представление |
| htmlspecialchars | Кодирует все символы в их HTML-представление |
| implode | Формирует строку из элементов массива |
| ltrim | Удаляет начальные пробелы из строки |
| rtrim | Удаляет конечные пробелы из строки |
| number_format | Представляет число в виде строки в различных форматах |
| ord | Возвращает ASCII-код символа |
| parse_str | Разбивает строку URL и присваивает значение переменным |
| Выводит строку | |
| printf | Выводит строку с форматированием |
| sprintf | Возвращает строку с форматированием |
| setlocale | Устанавливает информацию о кодовой странице |
| similar_text | Вычисляет степень похожести двух строк |
| sscanf | Разбивает строку по шаблону и присваивает полученные значения переменным |
| str_ireplace | То же самое, что и str_replace, но без учета различий в регистре символов |
| str_pad | Дополняет строку до заданной длины другой строкой |
| str_repeat | Повторяет строку заданное количество раз |
| str_replace | Ищет в строке все вхождения подстроки и меняет на заданную строку |
| str_shuffle | Случайным образом перемешивает все символы в строке |
| str_split | Формирует массив из символов строки |
| str_word_count | Подсчитывает количество слов в строке |
| strcasecmp | Выполняет побайтовое сравнение строк без учета регистра символов |
| strcht | То же самое что strstr |
| strcmp | Выполняет побайтовое сравнение строк с учетом регистра символов |
| strip_tags | Удаляет из строки все HTML-и PHP-теги |
| stripos | Ищет первое вхождение подстроки в строке без учета регистра символов |
| stristr | То же самое что strstr, но без учета регистра символов |
| strlen | Возвращает длину строки |
| strnatcasecmp | То же самое что strnatcmp, но без учета регистра символов |
| strncmp | Выполняет побайтовое сравнение первых n символов строк |
| strpos | Ищет первое вхождение подстроки в строке |
| strrchr | Ищет последнее вхождение символа в строке |
| strrev | Инвертирует строку — прочитывает ее справа налево |
| strripos | Ищет последнее вхождение подстроки в строке без учета регистра символов |
| strrpos | Ищет последнее вхождение подстроки в строке |
| strspn | Возвращает длину участка строки, состоящего из заданных символов |
| strstr | Возвращает часть строки от первого вхождения подстроки до конца |
| strtolower | Преобразует прописные буквы в строчные |
| strtoupper | Преобразует строчные буквы в прописные |
| strtr | Преобразует заданные символы в строке |
| substr_compare | Сравнивает две строки, начиная с заданного смещения |
| substr_count | Подсчитывает, сколько раз заданная подстрока встречается в строке |
| substr_replace | Ищет в заданном участке строки все вхождения подстроки и меняет на другую строку |
| substr | Возвращает заданную часть исходной строки |
| trim | Удаляет начальные и конечные пробелы из строки |
| ucfirst | Преобразует первую букву строки в прописную |
Более подробную информацию про все строковые функции вы можете найти на странице официальной документации.
Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста
- удаление пунктуации
- всех символов, кроме букв и цифр
Но бывают случаи, когда необходима реальная замена — например, когда нужно заменить буквы с хвостиками/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:
![]()
Диакритические символы и их английские эквиваленты
Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка, она как раз и обозначает любой символ
![]()
Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
А так будет выглядеть процесс на практике:
![]()
Разбиваем текст на цифры и нецифровые символы (буквы и знаки препинания) с помощью регулярного выражения
Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры:
Эту задачу можно решить также с помощью функции ПОДСТАВИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению. В отличие от обычной процедуры замены, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:
![]()
Заменяем первый пробел с помощью замены по регулярному выражению
Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в 2 клика готовой процедурой в меню «Изменить слова«, но можно воспользоваться и несложным выражением для замены:
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое «ИЛИ».
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — «удалить лишние пробелы» или «Удалить символы в начале / конце ячейки«.
![]()
Вставка символа после каждого слова с помощью регулярного выражения
Группирующие скобки (…) и match-объекты в питоне
Match-объекты
Если функции , не находят соответствие шаблону в строке, то они возвращают , функция возващает пустой итератор.
Однако если соответствие найдено, то возвращается -объект.
Эта штука содержит в себе кучу полезной информации о соответствии шаблону.
В отличие от предыдущих функций, возвращает «простой и понятный» список соответствий.
Полный набор атрибутов -объекта можно посмотреть в , а здесь приведём самое полезное.
| Метод | Описание | Пример |
|---|---|---|
| Подстрока, соответствующая всему шаблону | ||
| Индекс в исходной строке, начиная с которого идёт найденная подстрока | ||
| Индекс в исходной строке, который следует сразу за найденной подстрока |
Группирующие скобки
Если в шаблоне регулярного выражения встречаются скобки без , то они становятся группирующими.
В match-объекте, который возвращают , и , по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует , а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.






import re
pattern = r'\s*(+)(\d+)\s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match.group(0)}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match.group(1)}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match.group(2)}< с позиции {match.start(2)} до {match.end(2)}')
###
# Найдена подстрока > Опять45 < с позиции 3 до 16
# Группа букв >Опять< с позиции 6 до 11
# Группа цифр >45< с позиции 11 до 13
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия.
Например, если бы в примере выше квантификаторы были снаружи от скобок , то вывод был бы таким:
Найдена подстрока > Опять45 < с позиции 3 до 16 Группа букв >ь< с позиции 10 до 11 Группа цифр >5< с позиции 12 до 13
Внутри группирующих скобок могут быть и другие группирующие скобки.
В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
import re
pattern = r'((\d)(\d))((\d)(\d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match.group(0)}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, match.groups()+1):
print(f'Группа №{i} >{match.group(i)}< с позиции {match.start(i)} до {match.end(i)}')
###
Найдена подстрока >1234< с позиции 0 до 4
Группа №1 >12< с позиции 0 до 2
Группа №2 >1< с позиции 0 до 1
Группа №3 >2< с позиции 1 до 2
Группа №4 >34< с позиции 2 до 4
Группа №5 >3< с позиции 2 до 3
Группа №6 >4< с позиции 3 до 4
Группы и
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки .
import re print(re.findall(r'(+)(\d*)', r'foo3, im12, go, 24buz42')) # ->
Группы и
Если в шаблоне нет группирующих скобок, то работает очень похожим образом на .
А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
import re print(re.split(r'(\s*)([+*/-])(\s*)', r'12 + 13*15 - 6')) # ->



