
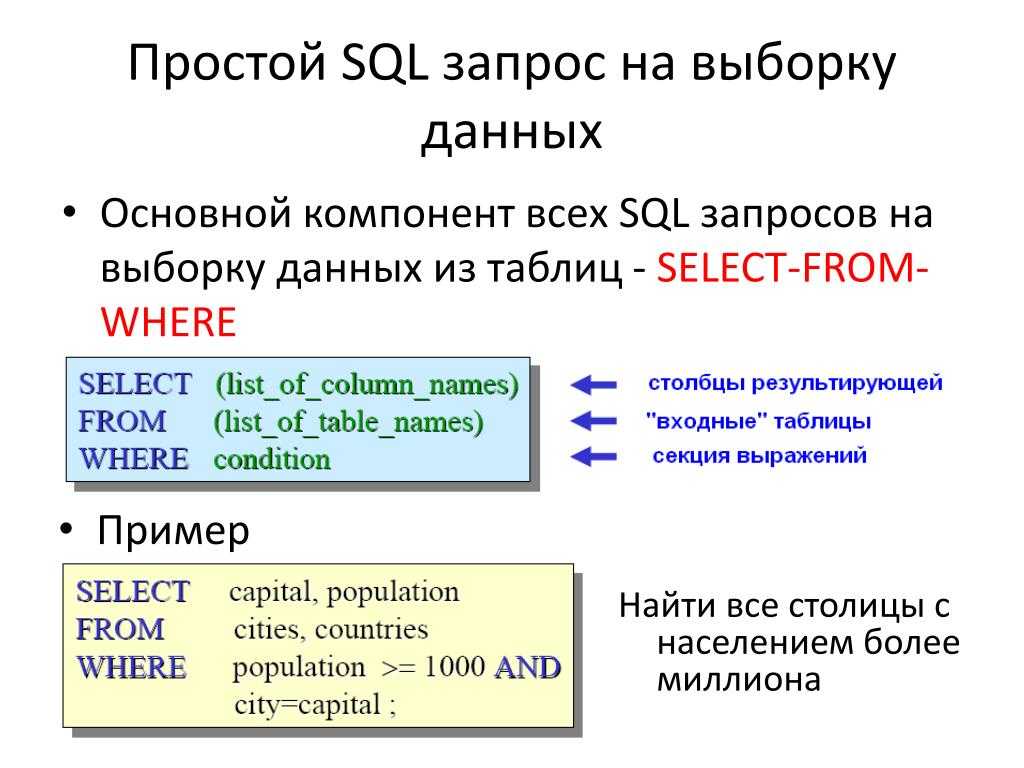
Никакого капса
В давние времена, когда редакторы кода не имели возможности подсвечивать синтаксис, было принято писать ключевые слова заглавными буквами. С тех пор эта привычка крепко укоренилась в головах некоторых разработчиков и они продолжают следовать этой традиции. Некоторые пошли ещё дальше, и стали писать капсом вообще всё: имена таблиц, стобцов и пр. На деле же, любой современный редактор кода имеет подстветку ситнаксиса (в т. ч. и для встроенных языков, если вы пишете запрос внутри другого языка)
, , навряд ли помогут вам понять суть запроса, а вот внимание на себя отвлекать однозначно будут.
За 5 лет что я пишу SQL запросы, я редко встречал те которые можно назвать «образцовыми»: где все ключевые слова выделены капсом, а не ключевые нет. Зато смешивание этих стилей попадается сплошь и рядом
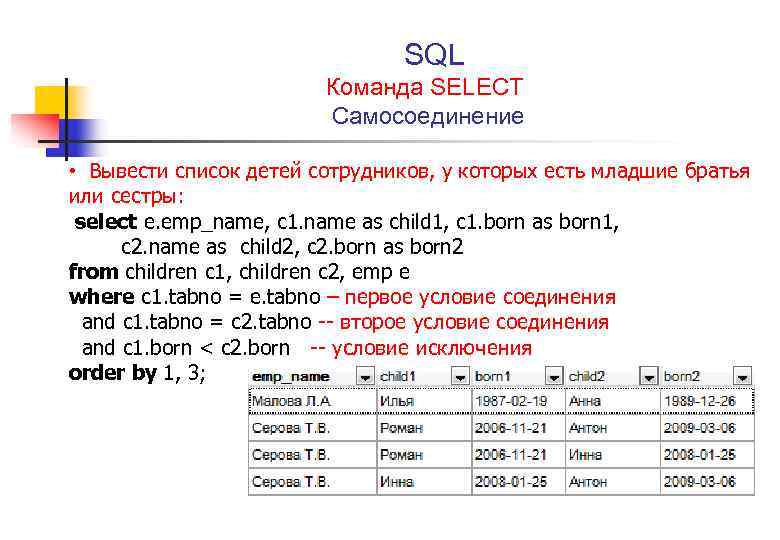
Задачи на оконные функции
№ 1. Найти идентификатор с максимальным значением
Контекст: Допустим, у нас есть таблица с данными об отделах и зарплате сотрудников в следующем формате:
Задача: написать запрос, чтобы получить с самой высокой зарплатой. Убедитесь, что ваше решение обрабатывает случаи одинаковых зарплатами!
Решение:
Альтернативное решение с использованием :
Часть 1
Контекст: допустим, у нас есть таблица в таком формате:
Задача: написать запрос, который возвращает ту же таблицу, но с новым столбцом, в котором указана средняя зарплата по департаменту. Мы бы ожидали таблицу в таком виде:
Решение:
Часть 2
Задача: напишите запрос, который добавляет столбец с позицией каждого сотрудника в табели на основе его зарплаты в своём отделе, где сотрудник с самой высокой зарплатой получает позицию 1. Мы бы ожидали таблицу в таком виде:
Решение:
Время выполнения SQL запросов
Итак, нам нужно засечь время, потраченное на выполнение SQL запросов ? Это не очень легко, но и не сложно. Начнем с определения задачи. Необходимо выдать полное время, затраченное на генерацию страницы и время, затраченное на выполнения SQL запросов, еще было бы здорово вывести процент от общего времени.
Сначала напишем функцию, которая выдает время, затраченное на выполнение своего кода:
функция do_something ()
{
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ tstart = $ mtime;
// здесь код для выполнения
//………
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ тендер = $ mtime;
$ tpassed = ($ тендер — $ tstart);
возврат ($ tpassed);
}
Для конкретно нашей задачи, нужно модифицировать эту функцию так, чтобы выполнялись SQL запросы:
//запрос передается как аргумент
функция do_query ($ query)
{
//подсоединяем две глобальные переменные
глобальный результат в $;
глобальный $ qnum;
//счетчик запросов
$ Qnum ++;
//засекаем время старта
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ tstart = $ mtime;
//выполняем запрос
$ result = MYSQL_QUERY ($ query);
//засекаем время окончания
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ тендер = $ mtime;
$ tpassed = ($ тендер — $ tstart);
//возвращаем время, затраченное на запрос
возврат ($ tpassed);
}
Теперь у нас есть функция, которая считает запросы и выдает время экзекуции ![]() Вот как она должна быть использована:
Вот как она должна быть использована:
//Не забудьте где-нибудь в начале скрипта объявить эти две переменные:
$ Результат = 0;
$ Qnum = 0;
//…
//Вызов функции:
$ sql_time + = do_query («SELECT * FROM SOME_TABLE»);
//Теперь можно разбирать полученные данные:
while ($ row = mysql_fetch_array ($ result))
{
печать ($ строки );
}
В окончательном скрипте нужно еще засечь полное время выполнения, таким же способом, что использовался в функции. Внизу код такого скрипта, который заработает, если вы вставите реальные SQL запросы и подсоединитесь к базе данных.
<?
//Засекаем время старта
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ tstart = $ mtime;
//Коннектимся к базе:
включите ‘connect.php’;
//Объявляем переменные
$ Результат = 0;
$ Qnum = 0;
//Объявляем нашу функцию
функция do_query ($ query)
{
глобальный результат в $;
глобальный $ qnum;
$ Qnum ++;
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ tstart = $ mtime;
$ result = MYSQL_QUERY ($ query);
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ тендер = $ mtime;
$ tpassed = ($ тендер — $ tstart);
возврат ($ tpassed);
}
//Далее тело скрипта
$ sql_time + = do_query («SELECT * FROM SOME_TABLE»);
//Обрабатываем данные
while ($ row = mysql_fetch_array ($ result))
{
печать ($ строки );
}
//Пример еще одного запроса
$ sql_time + = do_query («ВЫБРАТЬ * ИЗ ДРУГОГО»);
//Обрабатываем данные
$ row = mysql_fetch_array ($ result);
печать ($ строки );
//Засекаем время окончания
$ mtime = microtime ();
$ mtime = explode («», $ mtime);
$ mtime = $ mtime + $ mtime ;
$ тендер = $ mtime;
$ total = ($ тендер — $ tstart);
//Выдаем время:
printf(«SQL запросов: $qnum, время mysql: %f, всего затрачено: %f секунд !», $sql_time, $total);
//Вычисляем процент времени:
$ sqlpercent = ($ sql_time * 100) / $ всего;
print(‘Процент времени на MySQL: ‘. round($sqlpercent, 2) . ‘%’);
?>
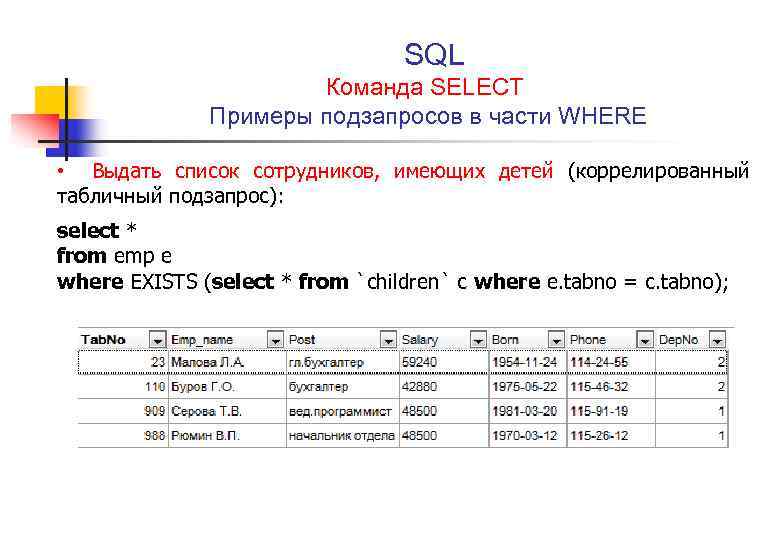
Идентификация проблем поиска закладок
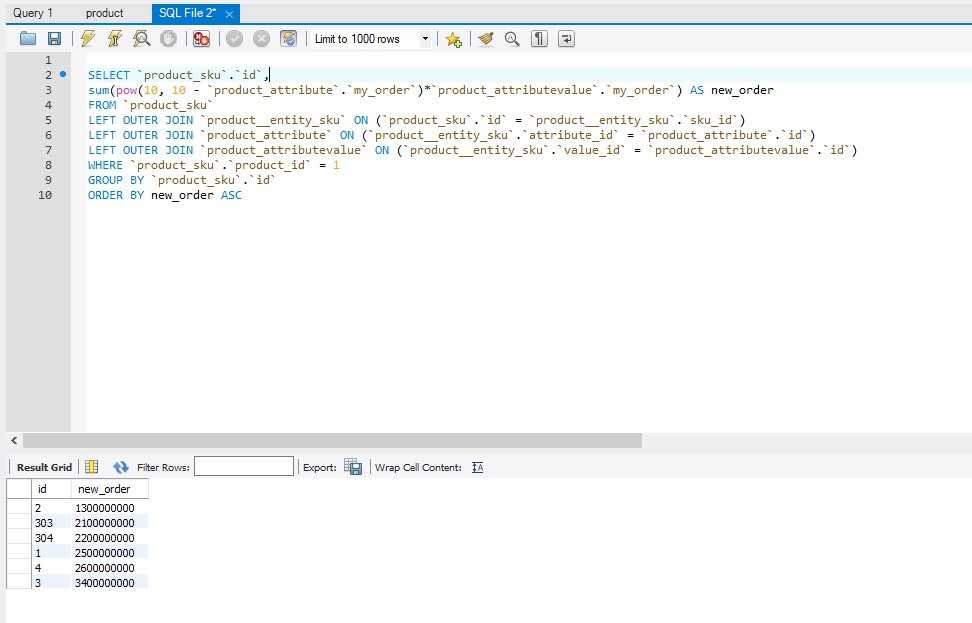
select db_name(database_id),max(user_lookups) bigger, avg(user_lookups) average from sys.dm_db_index_usage_stats group by db_name(database_id) order by average desc
use adventureworks2012 /* <<<<<------- вам нужно изменить имя базы данных */
select object_name(c.object_id) as ,
c.name as ,user_lookups,
case a.index_id
when 1 then 'CLUSTERED'
else 'NONCLUSTERED'
end as type
from sys.dm_db_index_usage_stats a
inner join sys.indexes c
on c.object_id=a.object_id and c.index_id=a.index_id
and database_id=DB_ID('AdventureWorks2012') /* <<<<<--измените имя базы данных */
order by user_lookups desc
![]() Adventureworks2012 также имеет проблемы с закладками
Adventureworks2012 также имеет проблемы с закладками
lookupIndexScan
select qp.query_plan,qt.text, plan_handle,query_plan_hash from
sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
AWMI="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//AWMI:IndexScan/AWMI:Object"]')=1
quantityactualcost![]()
Мы видим причину закладки
Важность MS SQL запросов
Аббревиатура SQL расшифровывается – Structured Query Language (язык структурированных запросов). Его конструкции выступают непроцедурным декларативным языком. SQL позволяет сохранять информацию в базах данных (БД) в удобном для использования виде, а также манипулировать данными. Используется для управления данными в системе реляционных баз данных (RDBMS).
БД, в том числе и реляционная модель, основывается на теории множеств. Она подразумевает возможность объединения различных объектов в единое целое, которым в БД выступает таблица
Данное утверждение имеет важное значение, т.к. SQL основывается на работе с множествами, наборами данных, которые по сути и являются таблицами
SQL запросы важны для всех веб-проектов в Интернете, обрабатывающих большие объемы информации. Все они вынуждены сохранять ее в различных видах БД. Многие проекты хранят информацию в БД реляционного типа (записи осуществляются в разных табличных подобиях). С помощью различных конструкций MS SQL запросов производится внесение новых и обращение к имеющимся записям.
Говоря простым языком, SQL выступает набором принятых стандартов, которые используются для создания обращений к БД. Стандарты языка SQL не являются статичными. Они постоянно видоизменяются, обновляются, расширяются.
Вопрос 1. Уровень: Junior
Есть категория «хитрых» вопросов, которые особенно любят задавать Junior-специалистам. Хотя чего уж там, любым специалистам.
Один из таких видов — вопросы по темам, на которые в повседневной жизни не обращаешь внимания и о которых не задумываешься. Просто делаешь на автомате, а на собеседовании это стреляет. Ну или на проекте, когда код начинает работать неправильно. Но это другая история…
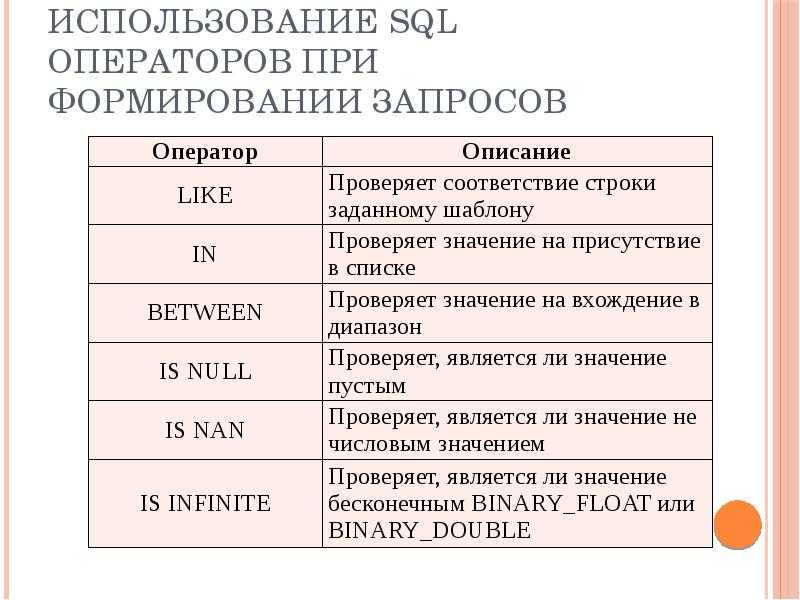
Вопрос: Как оператор обрабатывает поля с NULL?
Если Вы не знаете ответ на этот вопрос, то после прочтения ответа обязательно проверьте свои проекты — может у вас где-то закралась ошибка?
Учитывая, что NULL в SQL — просто отсутствие значения, то все значения NULL при группировке попадают в одну группу. Например, пусть есть таблица:
Тогда запрос даст:
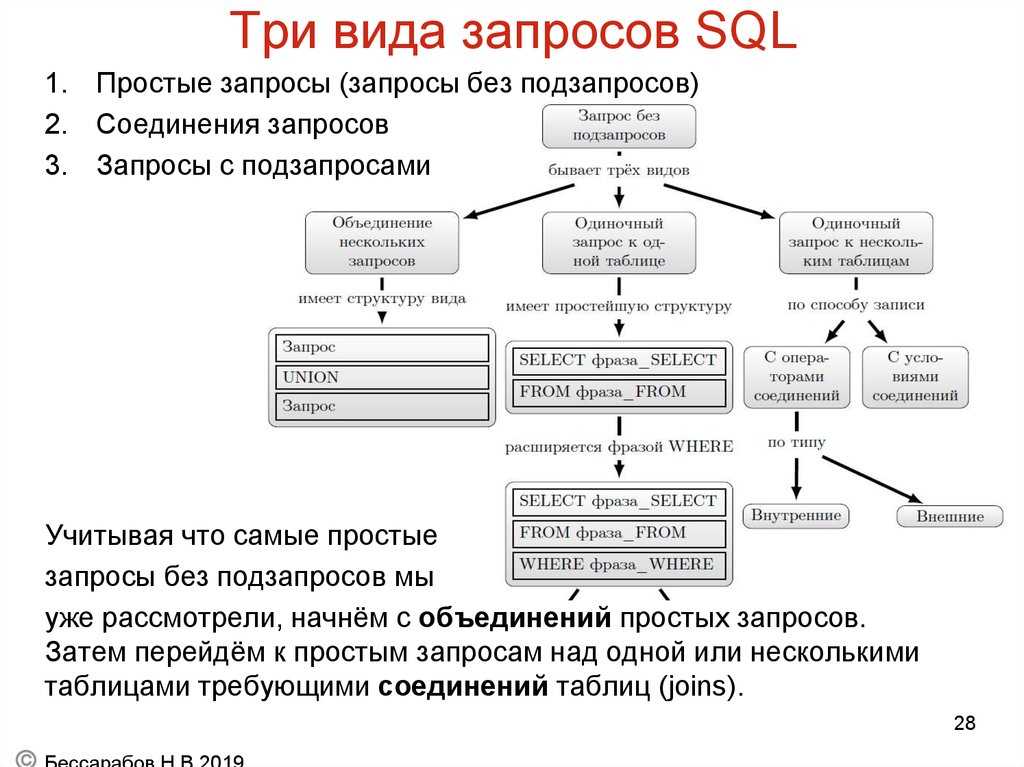
Соединения
Тема соединений таблиц всегда была очень болезненной. Когда-то и я перечислял имена таблиц через запятую, а все соединения наряду с предикатами делал в блоке используя вместо . Но, такая запись трудна для восприятия человеком, читающим этот запрос. Основных аргументов в её пользу, которые мне доводилось слышать, два: 1) ANSI соединения в оракле работают медленнее (на данный момент это уже не актуально); 2) глазам не приходится бегать по всему запросу, т. к. все условия находятся в одном месте. Аргумент 2 не выдерживает никакой критики, скорее это закостенелая привычка от которой сложно изавиться людям давно использующим такой синтаксис. Когда все условия собраны в , это больше похоже на месиво в котором чёрт ногу сломит. Напротив, при использовании ANSI соединений, запрос выглядит опрятным, каждое такое соединение и его уточнение сосредоточено сразу под именем таблицы, а в блоке находится лишь окончательный предикат глядя на который становится видно саму суть.
Обратите внимание, что в условии соединения столбец текущей таблицы стоит слева, а столбец внешней таблицы стоит справа от знака равенства. Нередко авторы запросов заключают в скобки условия соединений:
Нередко авторы запросов заключают в скобки условия соединений:
Сути это не меняет, а определённый шум вносит, поэтому лучше обойтись без них.
Вступление
За последние пять лет мне довелось поработать в трёх разных компаниях, но ни в одной из них я не встречал SQL запросы, которые выглядели бы опрятно и легко читались (не считая редких исключений). Как правило попадаются запросы написанные как попало: в них случайным образом скачут отступы и меняется регистр, они плохо структурированы и непоследовательны, зачастую ещё и написаны не очень эффективно. Открывая такой запрос приходится потратить немалое время, чтобы начать хоть что-то в нём понимать. А через месяц, встретив этот же запрос снова, придётся опять в нём разбираться. Многие люди вообще относятся к сиквелу как к второсорному языку, не проявляя к нему никакого уважения. Но уважения они не проявляют не только к языку, но и к другим разработчикам, которым в будущем приходится читать и поддерживать такие запросы.
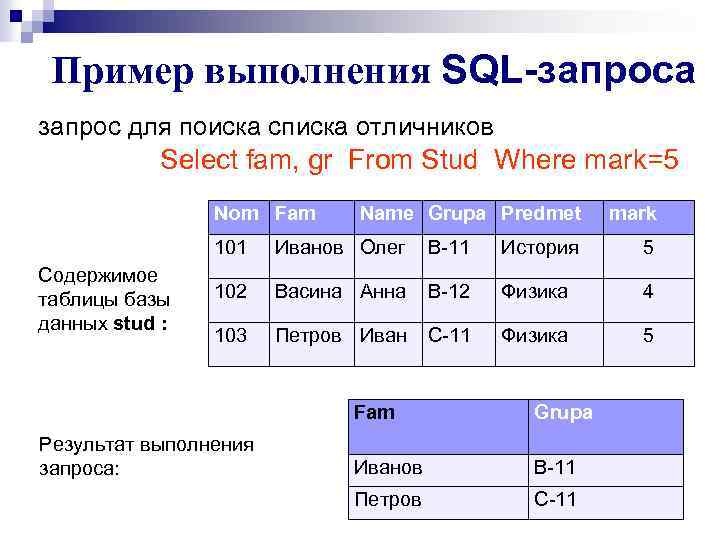
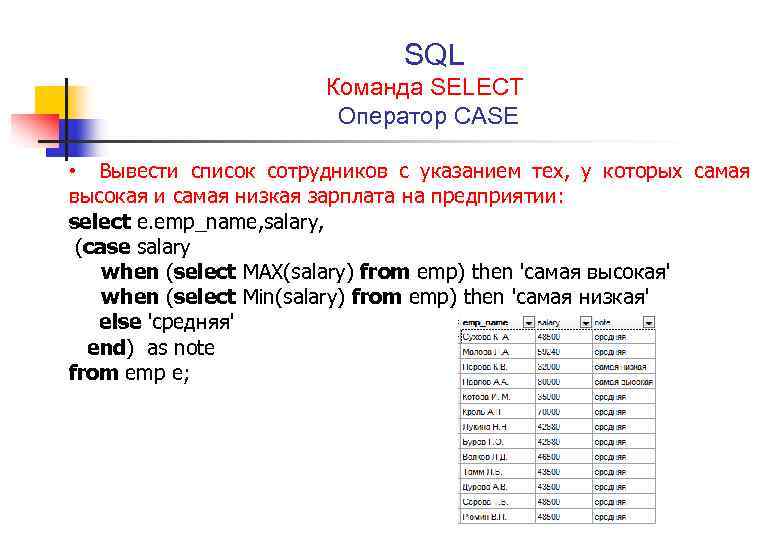
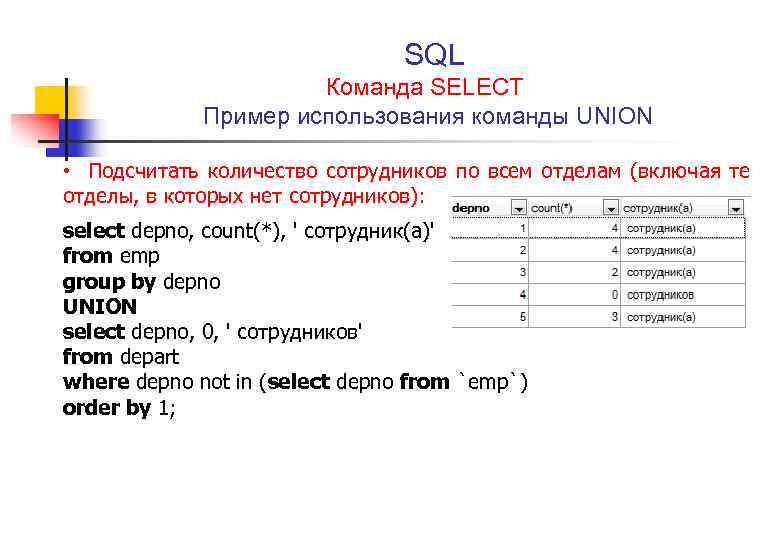

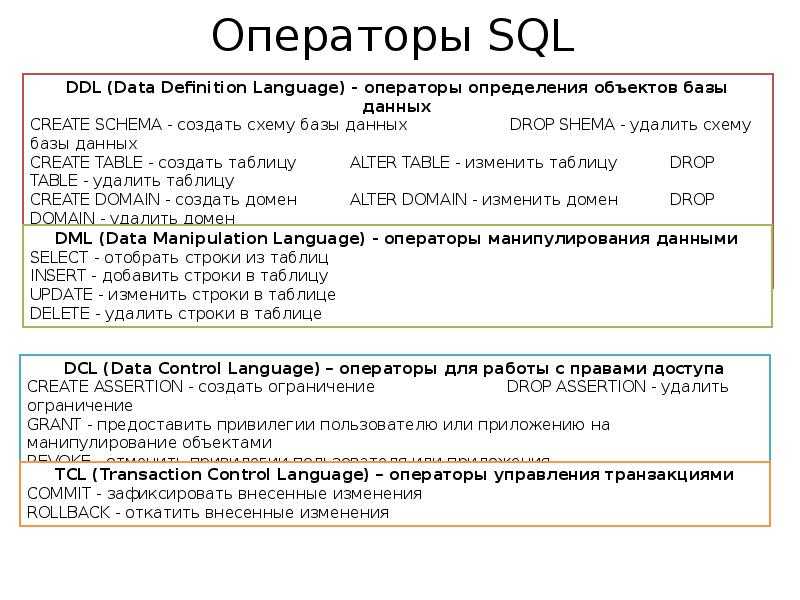



Ниже я привожу 8 простых правил основанных на личном опыте. Следуя им, ваши запросы будут легко читаемыми и простыми для понимания другими разработчиками.
Ограничьте свои результаты
В тех случаях, когда вам не удается избежать фильтрации в инструкции , вы можете ограничить свои результаты другими способами. Ниже приведены другие подходы, такие как оператор и преобразования типов данных.
Вы можете добавить оператор или к своим запросам, чтобы установить максимальное число выбираемых в результате строк. Вот некоторые примеры:
SELECT TOP 3 * FROM Drivers;
Обратите внимание, что вы можете дополнительно указать , например, если вы измените первую строку запроса с помощью
SELECT driverslicensenr, name FROM Drivers LIMIT 2;
Кроме того, вы также можете добавить оператор , что эквивалентно использованию в запросе:
SELECT * FROM Drivers WHERE driverslicensenr = 123456 AND ROWNUM <= 3;
Вы всегда должны использовать самые эффективные, то есть самые маленькие, типы данных. Всегда существует риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако, когда вы добавляете преобразование типа данных в свой запрос, вы увеличиваете время выполнения.
Альтернатива заключается лишь в том, чтобы стараться избегать преобразования типа данных, насколько это возможно
Обратите также внимание, что не всегда возможно удалить или опустить преобразование типа данных из запросов, но вы должны определенно стремиться быть осторожным в их использовании, а в случае использования, советуем проверять эффект применения преобразования типа перед запуском запроса
Журнал медленных запросов
Если определить тяжелые запросы «на глаз» не получается, нужно собрать более обширную статистику. В этом поможет журнал медленных запросов (slow query log).
Для включения журнала в MySQL, начиная с версии 5.1.29, задайте переменной slow_query_log значение 1 или ON; для отключения журнала — 0 или OFF. В более старых версиях используется log-slow-queries = /var/db/mysql/slow_queries.log (путь можно задать другой).
Вторая важная настройка — long_query_time — порог времени выполнения, при превышении которого запрос считается медленным и записывается в журнал. Начиная с MySQL 5.1.21 может задаваться в микросекундах и может быть равен нулю.
Пара полезных дополнительных настроек:
- log-queries-not-using-indexes – запись в журнал запросов, не использующих индексы.
- slow_query_log_file – имя файла журнала. По умолчанию host_name-slow.log
Пример для записи в журнал всех запросов, выполняющихся дольше 50 миллисекунд:
Пример для старых версий MySQL, все запросы дольше 1 секунды:
Для анализа журнала используются утилиты mysqldumpslow, mysqlsla и mysql_slow_log_filter. Они парсят журнал и выводят агрегированную информацию о медленных запросах.
mysqldumpslow – утилита из состава MySQL. Вызывается таким образом: . Пример:
Reading mysql slow query log from /usr/local/mysql/data/mysqld51-apple-slow.log
Count: 1 Time=4.32s (4s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t2 select * from t1
Count: 3 Time=2.53s (7s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t2 select * from t1 limit N
Count: 3 Time=2.13s (6s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t1 select * from t1
Count – сколько раз был выполнен запрос данного типа. Time – среднее время выполнения запроса, дальше в скобках – суммарное время выполнения всех запросов данного типа.
Некоторые параметры mysqldumpslow:
- -t N – отображать только первые N запросов.
- -g pattern — анализировать только запросы, которые соответствуют шаблону (как grep).
- -s sort_type — как сортировать вывод. Значения sort_type: t или at — сортировать по суммарному или среднему времени выполнения запросов, c — по количеству выполненных запросов данного типа.
mysqlsla – еще одна утилита для анализа логов MySQL с аналогичной функциональностью. Пример использования:
Подробности в документации.mysql_slow_log_filter — perl-скрипт с похожей функциональностью. Пример использования:
Эта команда в реальном времени покажет запросы, выполняющиеся дольше 0,5 секунды или сканирующие больше 1000 строк.
Выявленные медленные запросы дальше можно оптимизировать, используя .
Вторая часть статьи будет посвящена тонкой настройке MySQL. Материал находится в разработке.
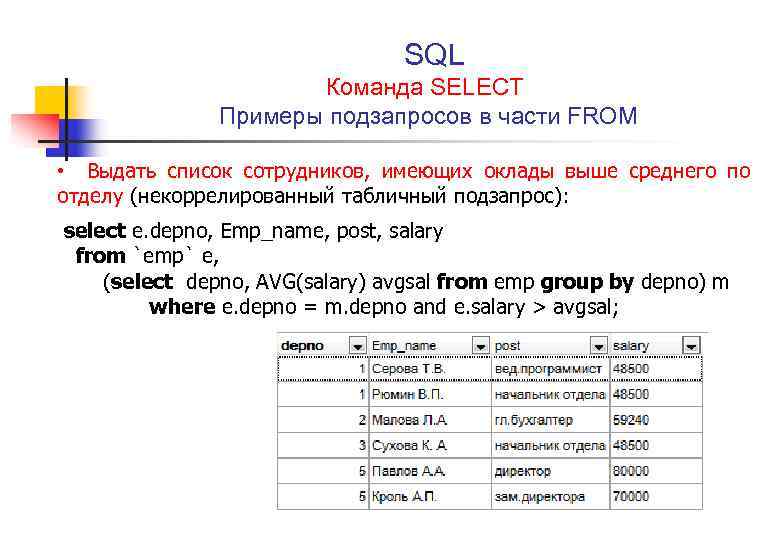
№ 2. Среднее значение и ранжирование с оконной функцией (несколько частей)
Часть 1
Контекст
depname | empno | salary | -----------+-------+--------+ develop | 11 | 5200 | develop | 7 | 4200 | develop | 9 | 4500 | develop | 8 | 6000 | develop | 10 | 5200 | personnel | 5 | 3500 | personnel | 2 | 3900 | sales | 3 | 4800 | sales | 1 | 5000 | sales | 4 | 4800 |
Задача:
depname | empno | salary | avg_salary | -----------+-------+--------+------------+ develop | 11 | 5200 | 5020 | develop | 7 | 4200 | 5020 | develop | 9 | 4500 | 5020 | develop | 8 | 6000 | 5020 | develop | 10 | 5200 | 5020 | personnel | 5 | 3500 | 3700 | personnel | 2 | 3900 | 3700 | sales | 3 | 4800 | 4867 | sales | 1 | 5000 | 4867 | sales | 4 | 4800 | 4867 |
Решение:
Часть 2
Задача:
depname | empno | salary | salary_rank | -----------+-------+--------+-------------+ develop | 11 | 5200 | 2 | develop | 7 | 4200 | 5 | develop | 9 | 4500 | 4 | develop | 8 | 6000 | 1 | develop | 10 | 5200 | 2 | personnel | 5 | 3500 | 2 | personnel | 2 | 3900 | 1 | sales | 3 | 4800 | 2 | sales | 1 | 5000 | 1 | sales | 4 | 4800 | 2 |
Решение:
Подготовка
Суть примера заключается в том чтобы получить ожидание на блокировке СУБД. Для этого нам потребуется тестовая база данных, а также информация об имени таблицы в базе для составления SQL-запроса. С помощью обработки выполним запись в регистр и встанем на ожидании, не завершив транзакцию. В Management Studio выполним запрос чтения данных из регистра. Поскольку в предлагаемом примере уровень изоляции Read Committed, запрос на чтение будет ожидать освобождения ресурса, который заблокирован транзакцией записи.





Создание базы данных
Создадим базу данных, в которой установим режим управления блокировкой «Управляемый», основной режим запуска «Обычное приложение», режим использования модальных окон в «Использовать», режим совместимости «8.2.13». Добавим в базу регистр сведений «ТекущиеИсполняемыеЗапросы» (непериодический, независимый). В регистре добавим измерение: «Измерение1» (тип Число) и ресурс: «Ресурс1» (тип Число). Также создадим обработку «ЗаписьВРегистрВТранзакции» со следующим кодом:
НачатьТранзакцию();
НаборЗаписей = РегистрыСведений.ТекущиеИсполняемыеЗапросы.СоздатьНаборЗаписей();
НаборЗаписей.Отбор.Измерение1.Установить(1);
НоваяЗапись = НаборЗаписей.Добавить();
НоваяЗапись.Измерение1 = 1;
НоваяЗапись.Ресурс1 = 1;
НаборЗаписей.Записать(Истина);
Предупреждение(«Ожидание»);
ЗафиксироватьТранзакцию();
|
1 |
НачатьТранзакцию(); НаборЗаписей= РегистрыСведений.ТекущиеИсполняемыеЗапросы.СоздатьНаборЗаписей(); НаборЗаписей.Отбор.Измерение1.Установить(1); НоваяЗапись= НаборЗаписей.Добавить(); НоваяЗапись.Измерение1= 1; НоваяЗапись.Ресурс1= 1; НаборЗаписей.Записать(Истина); Предупреждение(«Ожидание»); ЗафиксироватьТранзакцию(); |
SQL-запрос
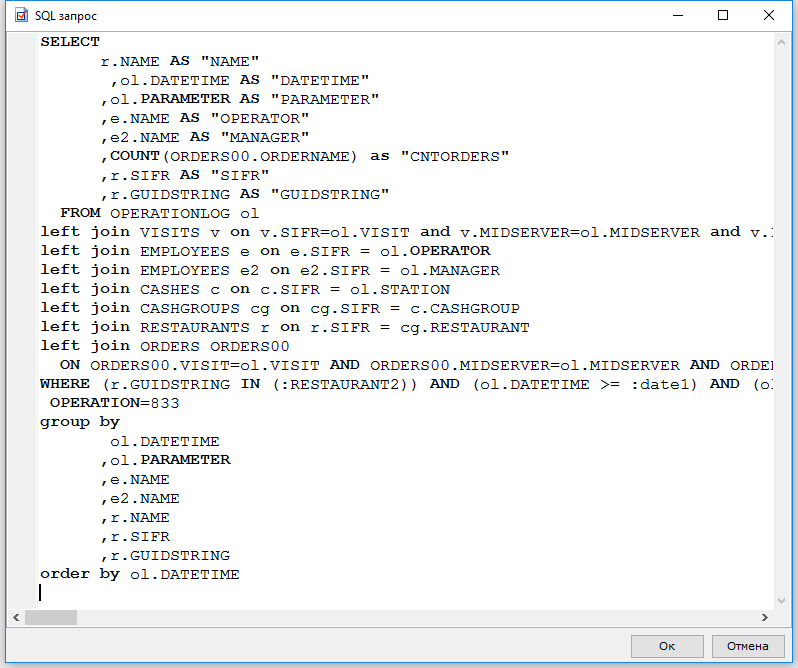
Для составления SQL-запроса нам потребуется имя таблицы базы данных, соответствующее регистру сведений. Для этого воспользуемся обработкой из статьи «Получение информации о структуре хранения базы данных в терминах 1С:Предприятие и СУБД». В моей базе данных имя этой таблицы: «_InfoRg243», напишем следующий запрос выборки всех данных из таблицы:
SELECT
*
FROM
dbo._InfoRg243
|
1 |
SELECT * FROM dbo._InfoRg243 |
Пишите запросы как можно проще
Преобразования типов данных приводят вас к следующему: вы не должны чрезмерно усложнять свои запросы. Старайтесь сохранять их простыми и эффективными. Этот совет может показаться слишком простым или глупым, особенно потому, что запросы могут быть и сложными.
Тем не менее, вы увидите на наших примерах в следующих разделах, действительно можно легко начать делать простые запросы более сложными, гораздо сложнее, чем это необходимо на самом деле.
Когда вы используете оператор в запросе, вероятно, вы не можете воспользоваться индексом.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но она имеет свою стоимость: для поддержания индексной структуры данных необходимы дополнительные записи и дополнительное пространство для хранения. Индексы используются для быстрого поиска или поиска данных без необходимости поиска к каждой строке базы данных каждый раз, когда обращается к таблице баз данных. Индексы могут быть созданы на основе одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, имеющиеся в базе данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора в запросе.
Рассмотрим следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;
Вы можете заменить оператор на:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr IN (123456, 678910, 345678);
Два оператора с .
Совет. Здесь вам нужно быть осторожным, и излишне не прибегать к использованию операции объединения , потому что в этом случае вы проходите одну и ту же таблицу несколько раз. С другой стороны, вы должны понимать, что при использовании в запросе время выполнения увеличивается. Альтернативой операции является переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию или с использованием вместо .
Совет. Помните также, что, хотя и другие операторы, которые будут упомянуты в следующих разделах, вероятно, не используют индекс, индексные запросы не всегда предпочтительны!
Когда ваш запрос содержит оператор , вероятно, индекс не используется, как и для оператора . А это неизбежно замедлит выполнение вашего запроса. Если вы не понимаете, что мы подразумеваем, рассмотрите следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE NOT (year > 1980);
Этот запрос определенно будет работать медленнее, чем вы могли бы ожидать, главным образом потому, что он сформулирован намного сложнее, чем это могло бы быть: в таких случаях, как этот, лучше искать альтернативу. Рассмотрите возможность замены операторами сравнения, такими как , или . Этот пример запроса действительно может быть переписан примерно в таком виде:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
Это уже выглядит аккуратно, не так ли?
Оператор – это другой оператор, который не использует индекс и тоже может замедлить выполнение вашего запроса, особенно если он используется слишком сложным и неэффективным способом, как в примере ниже:
SELECT driverslicensenr, name FROM Drivers WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос и использовать оператор :
SELECT driverslicensenr, name FROM Drivers WHERE year BETWEEN 1960 AND 1980;
Кроме того, операторы и ‑ это такие операторы, с которыми нужно обращаться очень осторожно, потому что, включение их приводит к отказу от использования индекса. Альтернативными вариантами, которые могут здесь пригодится, являются функции агрегации, такие как или
Совет. В тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать, что все функции агрегации, такие как , , , во многих строках, могут привести к повышению времени выполнения запроса. В этих случаях вы можете попытаться либо свести к минимуму количество строк для обработки или предварительного расчета этих значений
Здесь вы снова убеждаетесь в том, как важно знать, как можно больше о структуре своих данных, о цели запроса … когда вы принимаете решения о том, какой запрос использовать!
Также в тех случаях, когда столбец используется в вычислениях или в скалярной функции, индекс не используется. Возможное решение проблемы состоит в том, чтобы просто изолировать конкретный столбец, чтобы он больше не являлся частью операции вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name FROM Drivers WHERE year + 10 = 1980;
Это выглядит причудливо, да? Попробуйте вместо этого пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name FROM Drivers WHERE year = 1970;
Добавление целых строк
Как видно из названия, оператор INSERT используется для вставки (добавления) строк в таблицу базы данных. Добавление можно осуществить несколькими способами:
- — добавить одну полную строку
- — добавить часть строки
- — добавить результаты запроса.
Итак, чтобы добавить новую строку в таблицу, нам необходимо указать название таблицы, перечислить названия колонок и указать значение для каждой колонки с помощью конструкции INSERT INTO название_таблицы (поле1, поле2 … ) VALUES (значение1, значение2 …). Рассмотрим на примере.
INSERT INTO Sellers (ID, Address, City, Seller_name, Country) VALUES (‘6’, ‘1st Street’, ‘Los Angeles’, ‘Harry Monroe’, ‘USA’)
Также можно изменять порядок указания названий колонок, однако одновременно нужно менять и порядок значений в параметре VALUES.
2. Добавление части строк
В предыдущем примере при использовании оператора INSERT мы явно отмечали имена столбцов таблицы. Используя данный синтаксис, мы можем пропустить некоторые столбцы. Это значит, что вы вводите значение для одних столбцов но не предлагаете их для других. Например:
INSERT INTO Sellers (ID, City, Seller_name) VALUES (‘6’, ‘Los Angeles’, ‘Harry Monroe’)
В данном примере мы не указали значение для двух столбцов Address и Country . Вы можете исключать некоторые столбцы из оператора INSERT INTO, если это позволяет производить определение таблицы. В этом случае должно соблюдаться одно из условий: этот столбец определен как допускающий значение NULL (отсутствие какого-либо значения) или в определение таблицы указанное значение по умолчанию. Это означает, что, если не указано никакое значение, будет использовано значение по умолчанию. Если вы пропускаете столбец таблицы, которая не допускает появления в своих строках значений NULL и не имеет значения, определенного для использования по умолчанию, СУБД выдаст сообщение об ошибке, и это строка не будет добавлена.





3. Добавление отобранных данных
В предыдущей примерах мы вставляли данные в таблицы, прописывая их вручную в запросе. Однако оператор INSERT INTO позволяет автоматизировать этот процесс, если мы хотим вставлять данные из другой таблицы. Для этого в SQL существует такая кострукция как INSERT INTO … SELECT … . Данная конструкция позволяет одновременно выбирать данные из одной таблицы, и вставить их в другую. Предположим мы имеем еще одну таблицу Sellers_EU с перечнем продавцов нашего товара в Европе и нам нужно их добавить в общую таблицу Sellers. Структура этих таблиц одинакова (то же количество колонок и те же их названия), однако другие данные. Для этого мы можем прописать следующий запрос:
INSERT INTO Sellers (ID, Address, City, Seller_name, Country) SELECT ID, Address, City, Seller_name, Country FROM Sellers_EU
Нужно обратить внимание, чтобы значение внутренних ключей не повторялись (поле ID), в противном случае произойдет ошибка. Оператор SELECT также может включать предложения WHERE для фильтрации данных
Также следует отметить, что СУБД не обращает внимания на названия колонок, которые содержатся в операторе SELECT, для нее важно только порядок их расположения. Поэтому данные в первом указанном столбце, что были выбраны из-за SELECT, будут в любом случае заполнены в первый столбец таблицы Sellers, указанной после оператора INSERT INTO, независимо от названия поля
4. Копирование данных из одной таблицы в другую
Часто при работе с базами данных возникает необходимость в создании копий любых таблиц, с целью резервирования или модификации. Чтобы сделать полную копию таблицы в SQL предусмотрен отдельный оператор SELECT INTO. Например, нам нужно создать копию таблицы Sellers, нужно будет прописать запрос следующим образом:
SELECT * INTO Sellers_new FROM Sellers
В отличие от предыдущей конструкции INSERT INTO … SELECT … , когда данные добавляются в существующую таблицу, конструкция SELECT … INTO … FROM … копирует данные в новую таблицу. Также можно сказать, что первая конструкция импортирует данные, а вторая — экспортирует. При использовании конструкции SELECT … INTO … FROM … следует учитывать следующее:
- — можно использовать любые предложения в операторе SELECT, такие как GROUP BY и HAVING
- — для добавления данных из нескольких таблиц можно использовать объединение
- — данные возможно добавить только одну таблицу, независимо от того, из скольких таблиц они были взяты.
Сложные SQL Queries
Кроме стандартных, часто используются сложные SQL запросы, которые представляют собой комбинацию простых. При выполнении простых запросов промежуточные результаты группируются в соответствующие таблицы данных. Сложный SQL запрос в свою очередь уже манипулирует промежуточными результатами, которые были получены с помощью простых.
Сложные SQL запросы формируются различными способами:
- Один запрос (подзапрос) помещается в иной (внешний), который является основным.
- Реляционные операторы получаются путем использования разных операторов объединения промежуточных результатов, полученных в результате выполнения простых подзапросов.
Совет 4: используйте SET NOCOUNT ON
При выполнении операций , , и , используйте . SQL всегда возвращает соответствующее количество строк для таких операций, поэтому, когда у вас есть сложные запросы с большим количеством соединений, это может повлиять на производительность.
С SQL не будет подсчитывать затронутые строки и улучшить производительность.
В следующем примере мы предотвращаем отображение сообщения о количестве затронутых строк.
USE AdventureWorks2012; GO SET NOCOUNT OFF; GO -- Display the count message. SELECT TOP(5)LastName FROM Person.Person WHERE LastName LIKE 'A%'; GO -- SET NOCOUNT to ON to no longer display the count message. SET NOCOUNT ON; GO SELECT TOP(5) LastName FROM Person.Person WHERE LastName LIKE 'A%'; GO -- Reset SET NOCOUNT to OFF SET NOCOUNT OFF; GO
Заключение
В этой статье я познакомил вас с ключевым словом , рассказал о том, что означают данные, которые выводятся в результате его работы и как вы можете их использовать для оптимизации запросов. Использовать в реальном приложении это будет более полезно, чем на демонстрационной базе данных из этой статьи. Почти всегда вы будете объединять несколько таблиц вместе, и использовать
Простое добавление индексов нескольким полям обычно не приносит выгоды, поэтому в процессе составления запросов особое внимание надо уделять самим запросам
Перевод – Земсков Матвей
Оригинал статьи: http://phpmaster.com/using-explain-to-write-better-mysql-queries/
Заключение
В следующей статье будут рассмотрены способы борьбы с неэффективным расходованием оперативной памяти и процессорных ресурсов SQL-сервером с помощью автоматической и ручной параметризации запросов.
Материалы, использованные при написании статьи:
- Справочные материалы по используемым в статье динамическим представлениям — Динамические административные представления и функции, связанные с выполнением (Transact-SQL)
- Обработка инструкций SQL
- Кэширование и повторное использование плана выполнения
- Plan Cache Internals
- SQL Server Execution Plans
- Same query, different execution plans
- Multiple Plans for an «Identical» Query



