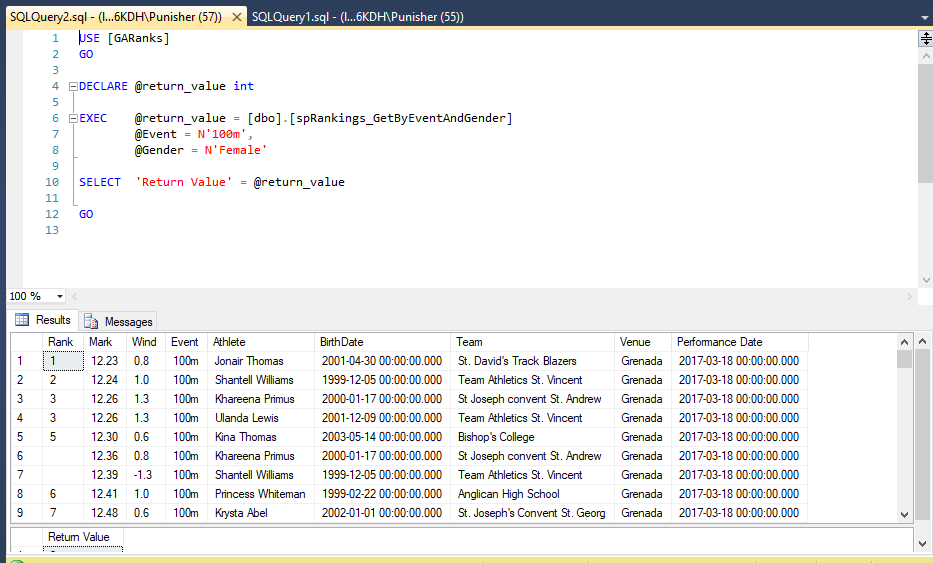
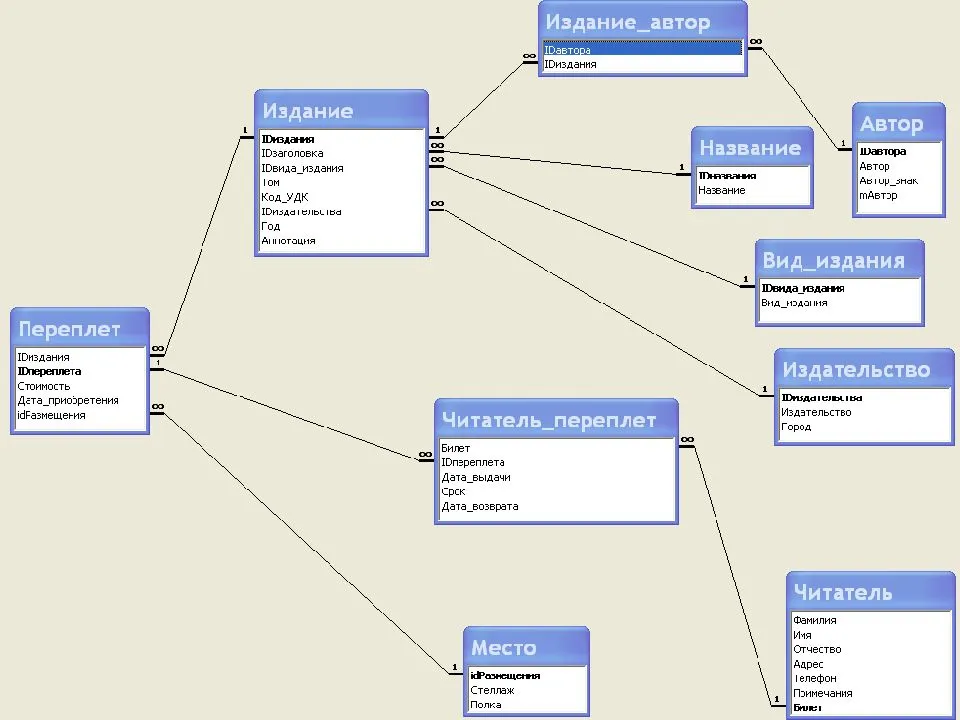
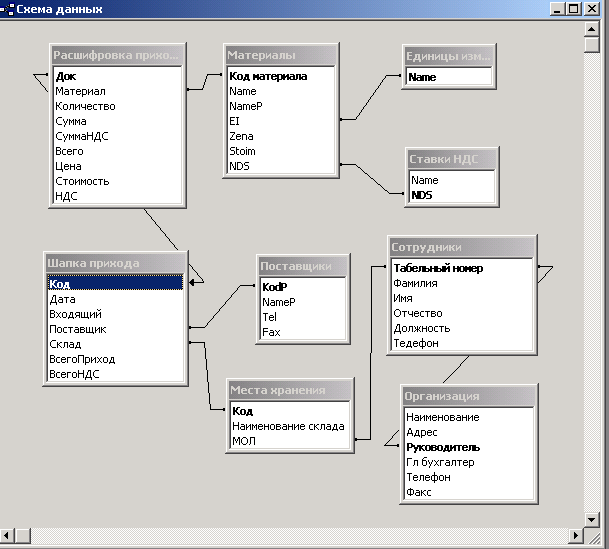
Проектирование базы данных
На текущей стадии необходимо определить, какие сущности, следовательно, информационные объекты, должна содержать в себе база данных, а также с использованием каких атрибутов будет описываться каждая сущность. После формулируется структура реляционных таблиц с указанием свойств полей и связей между таблицами. Следовательно:
- Учреждается общий список полей, которые отражают атрибуты таблиц базы данных;
- Поля общего списка следует распределить по базовым таблицам;
- Согласно свойствам данных определяют свойства каждого поля в частности;
- В каждой таблице выделяется ключевое поле;
- Выявляют связи между таблицами.
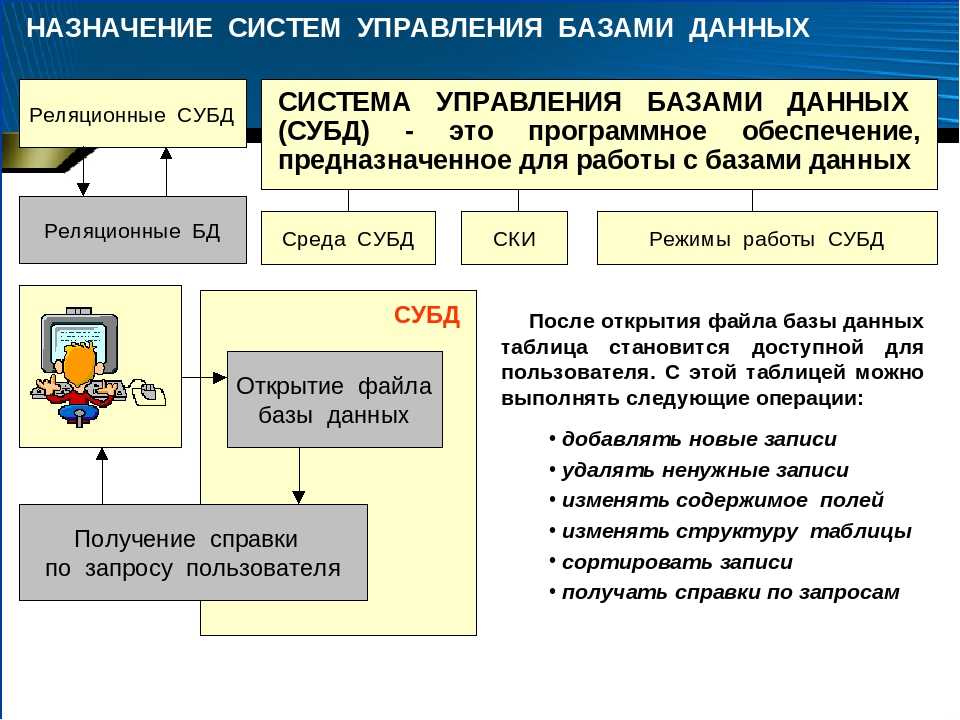
Уровни моделирования реляционной базы данных
Внешний уровень – уровень представления базы данных с точки зрения пользователя.Концептуальный – описывает какие данные хранятся в базе данных, а также, какие связи имеются между этими данными.Внутренний – описывает физическое представление базы данных в компьютере, то есть отвечает на вопрос, как информация хранится в базе данных.
Вводятся следующие понятия:
- Модель предметной области – знания о предметной области, описанные с помощью некоторого формального общепринятого способа.
- Логическая (концептуальная) модель данных – является органической составляющей модели предметной области, описывает понятия предметной области в реляционных терминах данных.
- Физическая модель данных – описывает данные средствами конкретной реляционной СУБД.
- База данных и приложение – средства, реализованные на конкретной программно-аппаратной основе.
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
СУБД временных рядов
Эта СУБД оптимизирована для хранения данных с метками времени или данных временных рядов. Данные временных рядов содержат измерения или события, которые отслеживаются, собираются или объединяются за определенный период времени.
Это данные с датчиков отслеживания движения, метрики JVM из приложений на Java, данные о рыночной торговле, сетевые данные, ответы от API, время безотказной работы процесса и т. д.
Данные хранятся с метками времени — это ключевая особенность — и индексируются и записываются так, чтобы данные этого временного ряда запрашивались намного быстрее, чем при использовании в классической реляционной БД.
Самые известные СУБД временных рядов:
- InfluxDB;
- Kdb+;
- Prometheus;
- TimescaleDB;
- QuestDB;
- AWS Timestream;
- OpenTSDB;
- GridDB.
Когда следует выбирать СУБД временных рядов?
Основная область применения таких СУБД — мониторинг, обработка телеметрии и финансовые системы.
Когда не следует выбирать СУБД временных рядов?
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
На чем основан данный рейтинг
В одной из прошлых статей – ТОП 7 популярных языков программирования, за основу мы брали достаточно много различных источников, но если говорить про базы данных, то таких источников гораздо меньше. Однако все равно существуют официальные рейтинги и другие аналитические данные, которые показывают популярность СУБД.

Некоторые рейтинги основываются на частоте упоминаний в запросах поисковых систем, т.е. если люди чаще ищут информацию по БД в интернете, значит, можно сделать вывод, что эта база данных пользуется популярностью. А некоторые ориентируются на количество заданных вопросов по конкретной базе на специализированных форумах, т.е. если больше вопросов задают по работе с какой-то конкретной базой данных, значит ее используют много людей, и она популярна.
В любом случае такие рейтинги, как, впрочем, и рейтинги языков программирования, не отражают точную фактическую популярность той или иной СУБД, так как основываются на каком-то одном показателе. И как результат, рейтинги просто противоречат друг другу.
Однако если проанализировать все источники, то можно определить несколько баз данных, которые наиболее часто встречаются в топе каждого рейтинга, тем более что состав ТОПа баз данных во всех рейтингах примерно одинаковый, только места у СУБД разные.
На основе всех этих источников можно сделать вывод, что определённые базы данных действительно являются популярными по всем показателям, а не только по какому-то одному.
Таким образом, чтобы упростить Вам задачу в анализе всей необходимой информации, в этом материале представлен ТОП 5 СУБД, который основан на данных всех популярных официальных рейтингов и показателей за предыдущий год.
Источники данных (официальные показатели и рейтинги СУБД):
- PYPL (PopularitY of Programming Language) – рейтинг основывается на данных поисковой системы Google;
- Stack Overflow – основывается на количестве вопросов, связанных с базой данных;
-
DB-Engines – данный рейтинг основывается на многих показателях:
- Данные поисковых систем Google, Bing и Yandex;
- Количество вопросов на Stack Overflow и DBA Stack Exchange;
- Количество предложений о работе на Indeed и Simply Hired, в которых упоминается система;
- Количество профилей в профессиональных сетях LinkedIn и Upwork, в которых упоминается система;
- Количество упоминаний в Twitter.
- Кроме все прочего учитывались данные компании РУССОФТ, которая проводила специальные опросы софтверных компаний об используемых инструментах программирования, и в частности СУБД.
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа — Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится «дорого» в реляционных СУБД, и нужно применять «продвинутую магию» что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
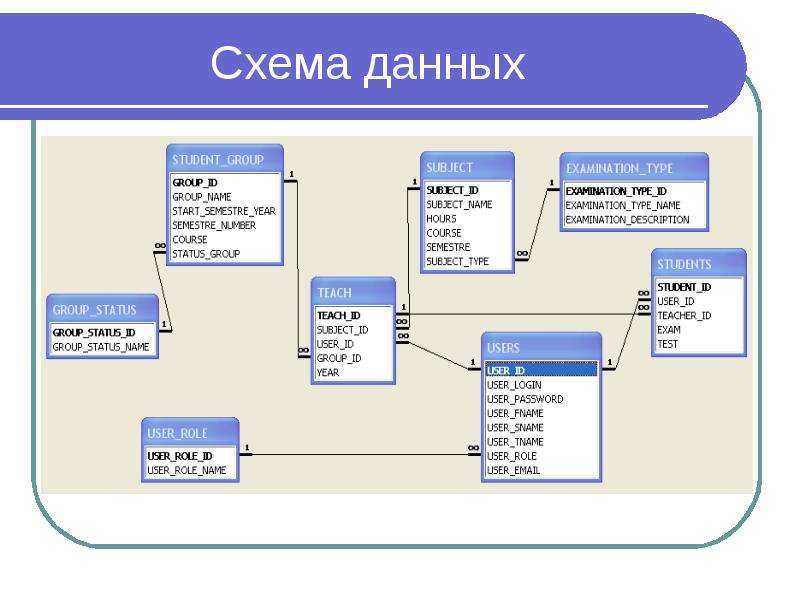
Реляционные базы данных
Реляционная модель базы данных состоит из трех частей:Структурная часть – описывает, какие объекты рассматриваются реляционной моделью. Реляционная база данных состоит из набора отношений. Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.Целостная часть – описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.Манипуляционная часть – описывает два эквивалентных способа манипулирования реляционными данными – реляционную алгебру и реляционное исчисление.
Термины реляционных баз данных.
| Реляционный термин | Описание |
| Отношение | Таблица |
| Заголовок отношения | Заголовок таблицы |
| Тело отношения | Тело таблицы |
| Атрибут отношения | Наименование столбца (поля) таблицы |
| Кортеж отношения | Строка (запись) таблицы |
| Степень отношения | Количество столбцов таблицы |
| Мощность (кардинальность) отношения |
Количество строк таблицы |
| Домен | Базовый или пользовательский тип данных |
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).Логический ключ – представляет собой значение, определяющее запись естественным образом.Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
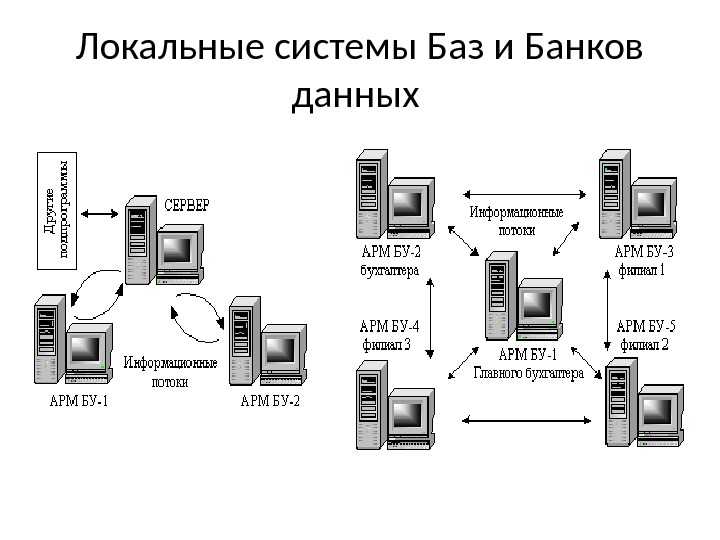
СУБД крупных ЭВМ
![]()
Данный этап развития связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и различных моделях фирмы Hewlett Packard. В таком случае информация хранилась во внешней памяти центральной ЭВМ. Пользователями баз данных были фактически задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, оперативной памятью, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках программирования и запускались как обычные числовые программы. Особенности данного этапа:
- Все СУБД базируются на мощных мультипрограммных ОС (Unix и др.).
- Поддерживается работа с централизованной БД в режиме распределенного доступа. Функции управления распределением ресурсов выполняются операционной системой.
- Поддерживаются языки низкого манипулирования данными, ориентированные на навигационные методы доступа к данным. Значительная роль отводится администрированию данных.
- Проводятся серьезные работы по обоснованию и формализации реляционной модели данных. Была создана первая система (System R), реализующая идеологию реляционной модели данных.
- Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
- Большой поток публикаций по всем вопросам теории БД. Результаты научных исследований активно внедряются в коммерческие СУБД.
- Появляются первые языки высокого уровня для работы с реляционной моделью данных (SQL), однако отсутствуют стандарты для этих языков.
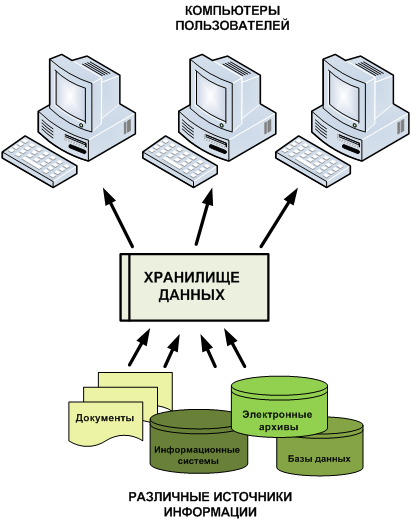
Понятия базы и банка данных
Под базой данных (БД) понимают совокупность организованных определенным образом данных, хранящихся вместе упорядоченно. При этом БД должна быть обеспечена:
- быстрым доступом;
- поддержкой актуальности состояния;
- рациональным взаимодействием между данными.
![]() Понятия базы и банка данных
Понятия базы и банка данных
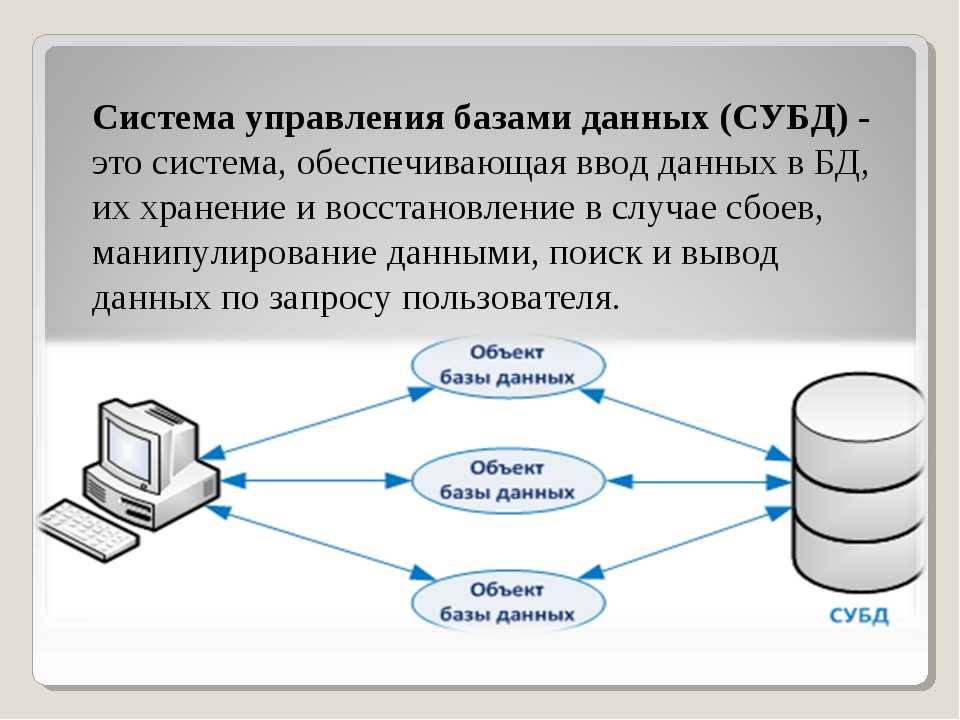
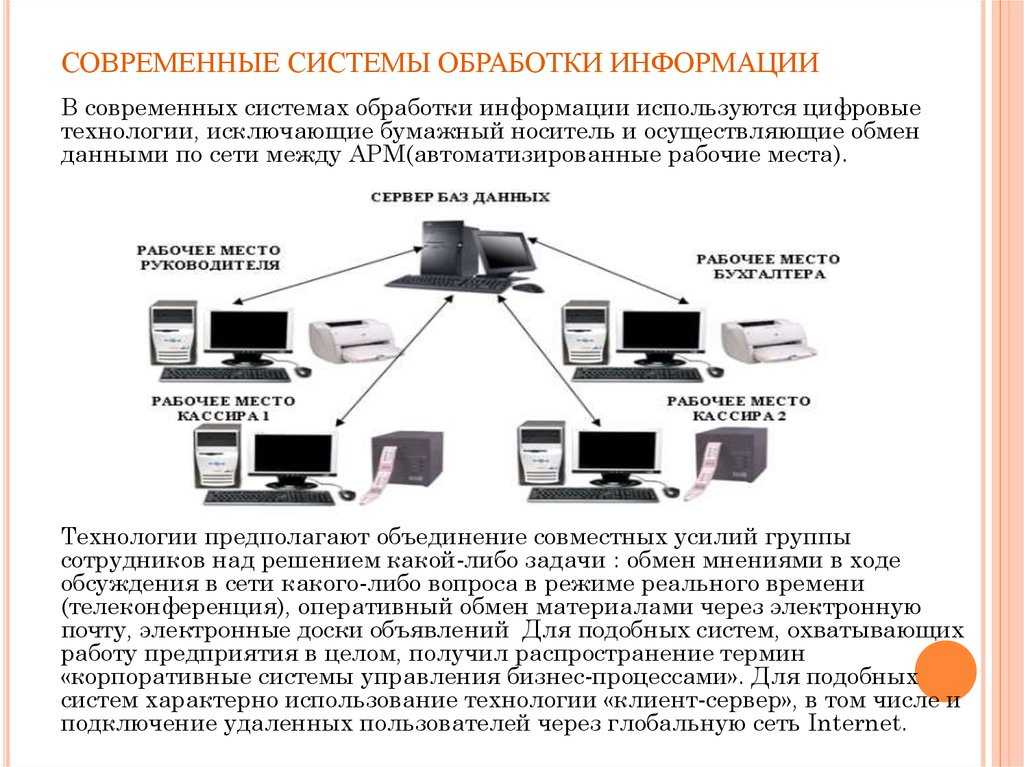
База данных в свою очередь входит в состав банка данных (БнД), который представляет собой структурированную и автоматизированную систему. Она обеспечивает хранение информации, а также ее накопление, поиск и выдачу с помощью программных и технических средств. Помимо БД в состав банка данных входят программно-информационные продукты общего или специального назначения, позволяющее реализовывать хранение и использование информации — СУБД — система управления базой данных.
Исходя из определений БД и БнД следует, что информация, хранимая и используемая в виде баз данных, должна быть сконцентрирована в едином хранилище и иметь возможность доступа для пользователей.
Организация информационных методик для компьютеров связана с технологиями БД и БнД. К автоматизированной системе базы данных предъявляют определенные требования:
- удобный доступ к информации;
- мониторинг данных с последующим удалением лишней и двойственной по значению информации;
- обеспечение безопасности хранения данных;
- обеспечение защищенности данных;
- возможность коллективного использования данных для решения каких-либо задач предприятия;
- независимость сведений от внешних воздействий, связанных с развитием информационного обеспечения автоматизированных систем баз данных;
- использование данных должно иметь организационную структуру.
Соблюдение таких требований позволяет добиться высокой результативности в работе пользователя с большими объемами данных.
База данных должна менять информацию в случае перемены состояния той предметной области, которую она отображает. Для того чтобы работа пользователей с большим количеством информации давала максимально эффективный результат, данные в базе должны объединяться в однородную единую систему.
Бесплатный онлайн-интенсив
Ваш Путь в IT начинается здесь
Подробнее
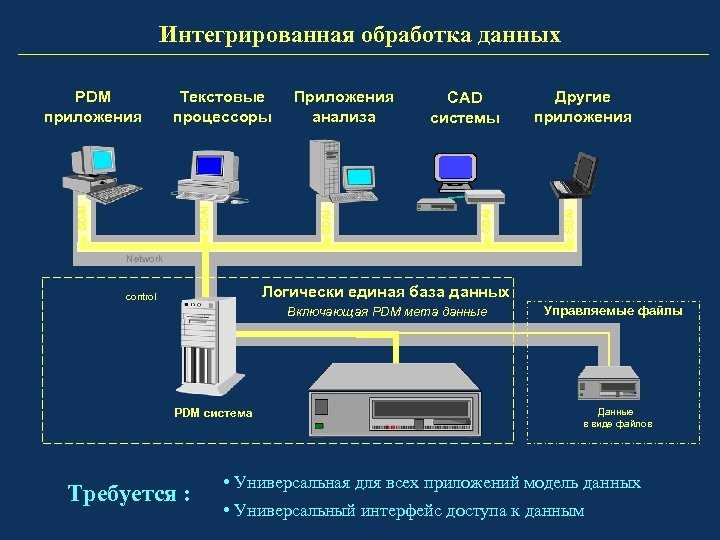
Банк данных, помимо ключевых элементов в виде БД и СУБД, содержит и другие составляющие:
- техническая основа — ЭВМ, технологии и продукты;
- языковые средства — языки программирования, запросов, описания данных и т. п.;
- методические средства — рекомендации и регламенты по созданию и работе с БнД.
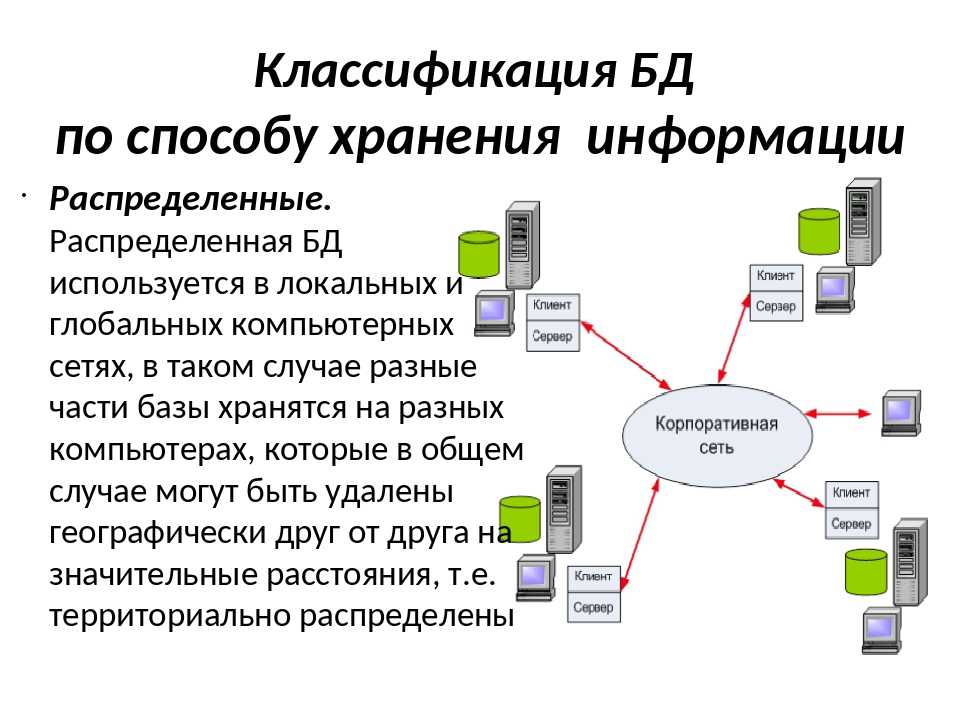
Размещение банка и базы данных возможно на одном или нескольких компьютерах. Если несколько единиц ЭВМ связаны локальными сетями в общую систему, то данные одного пользователя будут открыты другим и наоборот. В случае, когда БД и БнД находятся на одном ПК, то их называют локальными. Если на нескольких – то распределенными, при этом их соединяют сети ПЭВМ.
![Выбор субд [курсовая №32036]](https://luxe-host.ru/wp-content/uploads/0/f/5/0f5a300b40a1ca7c299087ff3122654f.png)

Распределенные БД и БнД важны для более удобного доступа большому числу пользователей при аботе с крупными потоками информации. Особенно, если местоположение таких пользователей географически разрозненно, или они находятся в разных структурных подразделениях.
Для того чтобы данные поместить в БД, необходимо составить предварительную логическую модель. Ее роль заключается в структуризации различной информации по содержанию, связям, объему, динамики. Полученные модели должны быть удобны в использовании для всех предполагаемых пользователей.
При создании логической модели важно понимать какие объекты, процессы или совокупность свойств предметной области представляют интерес для пользователей. Например, объектами предметной области могут быть вкладчики, банки, предприятия и т
д.
Система управления базой данных отвечает за автоматизацию работы БД, которая, в свою очередь, управляет определенной моделью структурирования информации. Для создания логической модели применяют один из способов моделирования: иерархический, сетевой или реляционный.
Список литературы по теме:
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. C. J. Date Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с.
Файловая система NTFS Что такое информация?
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.
Постановка задачи
На этой стадии формулируется цель формирования базы данных, уточняется предметная область, представляются виды работ, которые будут осуществлены в текущей базе данных, к примеру, отбор, изменение информации, печать отчёта. Также определяются потенциальные пользователи.
При этом в постановке задачи участвуют не только специалисты по базам данных, но и эксперты в той предметной области, в которой она будет существовать. Чем шире будет круг знаний специалиста-предметника о принципах формирования базы данных, тем эффективнее будет его взаимодействие с экспертом в области информационных технологий и тем выше будет качество итогового продукта.
Список литературы
- Голицына О. Л., Максимов Н. В., Попов И. И. Базы данных: учебное пособие. — М.: ФОРУМ: ИНФРА-М, 2011. — 400 с.
- Диго С. М. Базы данных: проектирование и использование: учебник для вузов. — М.: Финансы и статистика, 2011. — 592 с.
- Дейт К.Дж., Дарвен Хью. Основы будущих систем баз данных: Третий манифест. — Издательство Янус-К, 2012. – 656 с.
- Дейт К. Дж. Введение в системы баз данных (седьмое издание). Вильямс, 2011 — 1072 с.
- Илюшечкин В. М. Основы проектирования и использования баз данных: учеб. пособие. — М.: Высшее образование, 2012. — 213 с.
- Инструменты для создания тиражируемых приложений «1С: Предприятия 8.2». Серия «1С: Профессиональная разработка» (артикул 4601546090706 2012 г.
- Каленик А. И. Использование новых возможностей Microsoft SQL Server 2012. — М.: «Русская редакция», 2012. — 334 с.
- Когаловский М.Р. Энциклопедия технологий баз данных. М.: Финансы и статистика, 2009. –800 c.
- Когаловский М.Р. Теория реляционных баз данных. М.: Финансы и статистика, 2011. –500 c.
- Кодд Е.Ф. Перевод: Когаловский М.Р. Реляционная модель данных для больших совместно используемых банков данных. М.: Финансы и статистика, 2011 – c.48
- Кодд Е.Ф. Перевод: Когаловский М.Р. Реляционная модель данных для больших совместно используемых банков данных. М.: Финансы и статистика, 2011 – c.76
- Кодд Е.Ф. Перевод: Когаловский М.Р. Реляционная модель данных для больших совместно используемых банков данных. М.: Финансы и статистика, 2011 – c.112
- Кодд Е.Ф. Перевод: Когаловский М.Р. Реляционная модель данных для больших совместно используемых банков данных. М.: Финансы и статистика, 2011 – c. 256
- Коннолли Т., Бегг К. Базы данных: проектирование, реализация и сопровождение. Издательство: Диалектика, 2012 – с.24.
- Коннолли Т., Бегг К. Базы данных: проектирование, реализация и сопровождение. Издательство: Диалектика, 2011 – с.36.
- Крёнке Д. Теория и практика построения баз данных. — М.: Питер, 2009. — 800 с.
- Крёнке Д. Практический опыт программирования в реляционных базах данных. — М.: Питер, 2011. — 400 с.
- Кузин А.В. Базы данных: учебное пособие для вузов. — М.: Академия, 2012. — 30 с.
- Кузин А.В. Базы данных: учебное пособие для вузов. — М.: Академия, 2012. — 54 с.
- Кузнецов С. Д. Основы баз данных: курс лекций: учеб. пособие для студентов, обучающихся по специальностям в обл. информ. технологий. — М.: Интернет — университет информационных технологий, 2011. — 488 с.
- Полякова Л. Н. Основы SQL: Курс лекций. Учебное пособие. — М.: Интернет — университет информационных технологий, 2011. — 368 с.
- Профессиональная разработка в системе 1С:Предприятие 8″ (+DVD-ROM). Издание 2 (артикул 4601546101853). 2013 г.
- Роберт Дж. Мюллер. Базы данных и UML. — М.: Лори, 2008. — 420 с.
- Роберт Дж. Мюллер. Реляционные базы данных. — М.: Лори, 2011. — 420 с.
- Райордан Ребекка М. Основы реляционных баз данных. Базовый курс: Теория и практика. — М.: Русская Редакция, 2011 – 384 с.
- Райордан Ребекка М. Аналитические системы транзакций. Базовый курс: Теория и практика. — М.: Русская Редакция, 2012 – 400 с.
- Разработка сложных отчетов в «1С:Предприятии 8.2″. Система компоновки данных». Издание 2 (+ CD) (артикул 4601546097569). 2013 г.
- Решение специальных прикладных задач в «1С:Предприятии 8.2». Серия «1С:Профессиональная разработка» (артикул 4601546092694) 2014 г.
- Хомоненко А. Д., Цыганков В. М., Мальцев М. Г. Базы данных: Учебник для высших учебных заведений. — М.: Бином-Пресс, 2012. — 736 с.
- Чубукова И. А. Data Mining: Учебное пособие. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2009. — 382 с.
- Чубукова И. А. Создание реляционных баз данных: Учебное пособие. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2011. — 382 с.
- Роль мотивации в поведении организации (Теоретические аспекты мотивации персонала организации)
- Сущность, понятие, классификация затрат на предприятии
- Характеристика деятельности Федерального казначейства
- Алгоритмизация и алгоритмы
- Учет наличных денежных средств в кассе предприятия (ООО «Снежинка»)
- Основные понятия операционной системы
- Выбор стиля руководства организации и рекомендации по совершенствованию
- Классификация языков программирования. Критерии выбора среды и языка разработки программ
- Понятие конкурентоспособности в коммерческой деятельности
- Разработка регламента выполнения процесса “Складской учет”.
- Особенности функционирования и совершенствования системы мотивации персонала в банковской сфере
- Страхование и его государственное регулирование
Объектно-ориентированная СУБД
Эта СУБД предназначена для хранения и обработки объектов. Как и в ООП (объектно-ориентированном программировании), у этих объектов в СУБД есть свойства и методы. И они тоже реализуют инкапсуляцию и полиморфизм.
Главная цель применения объектно-ориентированной СУБД — облегчить жизнь разработчикам, использующим модель объектного программирования. Им не придется преобразовывать объекты в таблицы и строки со связями и обратно.
Самые известные объектно-ориентированные СУБД:
- MongoDB Realm;
- InterSystems Caché;
- ObjectStore;
- Actian NoSQL DB;
- Objectivity/DB.
Когда следует выбирать объектно-ориентированную СУБД?
Вообще-то не доводилось видеть много успешных реализаций с такими СУБД. Объектно-ориентированные базы данных обычно рекомендуется использовать при 1) высокопроизводительных манипуляциях с объектами, имеющими сложную структуру.
В то же время разработка 2) предполагает применение объектно-ориентированных языков программирования. Объектно-ориентированные БД распространены в системах реального времени, архитектуре и инженерии для 3D-моделирования, телекоммуникациях и научных продуктах, молекулярной науке и астрономии.
Когда не следует выбирать объектно-ориентированную СУБД?
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Поисковая СУБД
Этот тип СУБД используется для осуществления полнотекстового поиска. А также поиска по различным данным, например из других БД, электронной почты, RSS-канала, текста, JSON, XML, CSV и даже PDF и документам MS Office.
Поисковая СУБД имеет собственные оптимизированные подходы к индексированию данных, в том числе использование так называемых инвертированных и фасетных индексов для поиска почти в реальном времени.
Различные СУБД этого типа применяют разные языки запросов.
Самые известные поисковые СУБД:
- Apache Solr;
- Elasticsearch;
- Splunk.
Когда следует выбирать поисковую СУБД?
Идеальные примеры — подходящие для быстрого полнотекстового поиска в различных источниках данных системы сбора и поиска по журналам структурированных, полуструктурированных и неструктурированных данных.
Когда не следует выбирать поисковую СУБД?