Функция SQL MIN
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает
минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3.
База данных и таблица —
те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42.
Для этого пишем следующий запрос:
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения
. В этом и некоторых
других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о
подразделениях фирмы:
![]()
Пример 4.
К таблице Staff добавляется таблица Org, содержащая данные
о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе,
расположенном в Бостоне.
Использование запросов в PHP
Подключаемся к базе данных:
mysql_connect («localhost», «login», «password») or die («MySQL connect error»);
mysql_select_db («db_name»);
mysql_query(«SET NAMES «utf8″»);
* где подключение выполняется к базе на локальном сервере (localhost
); учетные данные для подключения — login
и password
(соответственно, логин и пароль); в качестве базы используется db_name
; используемая кодировка UTF-8
.
Также можно создать постоянное подключение:
mysql_pconnect («localhost», «login», «password») or die («MySQL connect error»);
* однако есть вероятность достигнуть максимально разрешенного лимита хостинга. Данным способом стоит пользоваться на собственных серверах, где мы сами можем контролировать ситуацию.
Завершить подключение:
* в PHP выполняется автоматически, кроме постоянных подключений (mysql_pconnect).
Запрос к MySQL (Mariadb) в PHP делается функцией mysql_query(), а извлечение данных из запроса — mysql_fetch_array():
$result = mysql_query(«SELECT * FROM users»);
while ($mass = mysql_fetch_array($result)) {
echo $mass . «»;
}
* в данном примере выполнен запрос к таблице users
. Результат запроса помещен в переменную $result
. Далее используется цикл while
, каждая итерация которого извлекает массив данных и помещает его в переменную $mass
— в каждой итерации мы работаем с одной строкой базы данных.
Используемая функция mysql_fetch_array() возвращает ассоциативный массив, с которым удобно работать, но есть еще альтернатива — mysql_fetch_row(), которая возвращает обычный нумерованный массив.
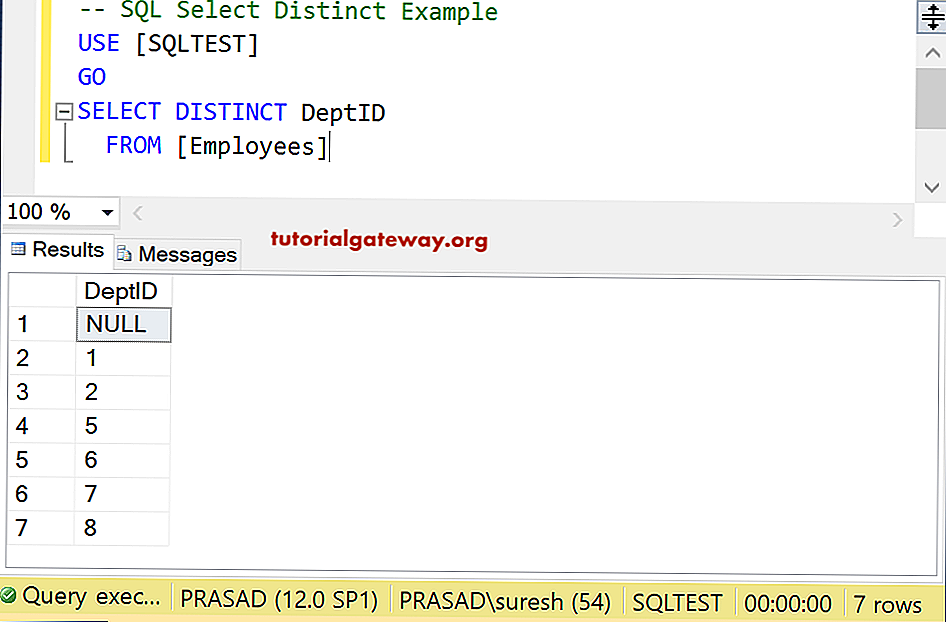
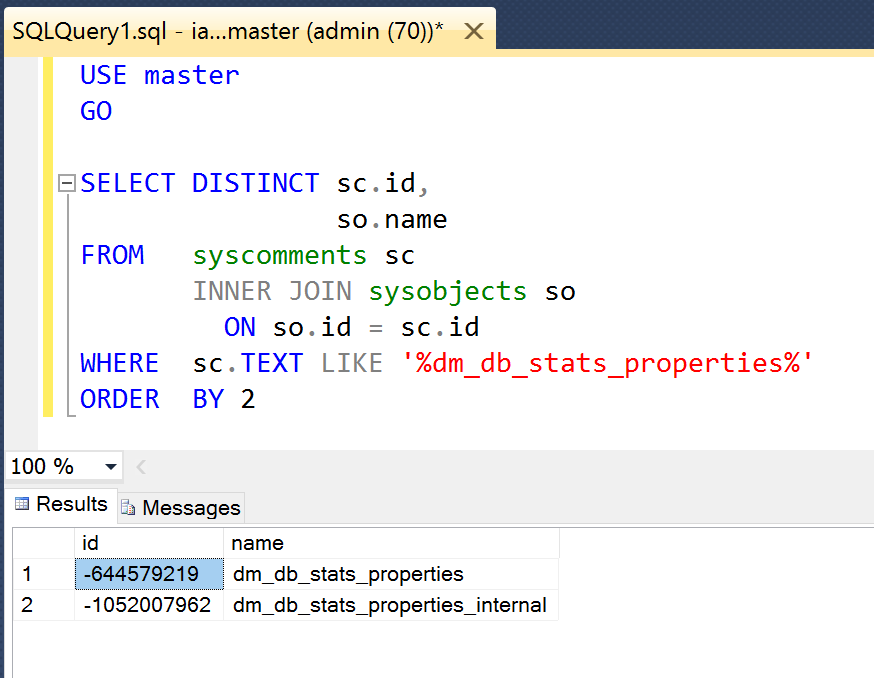
Пример — поиск уникальных значений в столбце
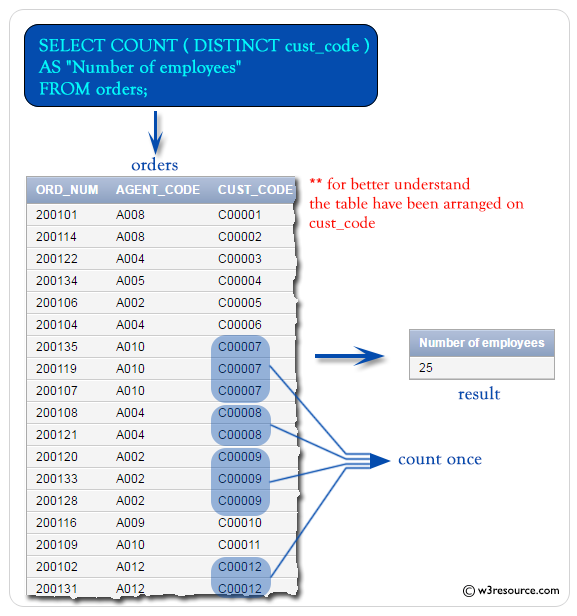
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Давайте найдем все уникальные значения в таблице suppliers. Введите следующий SQL оператор:
PgSQL
SELECT DISTINCT state
FROM suppliers
ORDER BY state;
|
1 |
SELECTDISTINCTstate FROMsuppliers ORDERBYstate; |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| state |
|---|
| Russia |
| Ile de France |
| Pennsylvania |
| California |
| Washington |
| Michigan |
В этом примере возвращаются все уникальные значения состояния из таблицы поставщиков и удаляются все дубликаты из набора результатов. Как видите, штат Калифорния в наборе результатов отображается только один раз, а не четыре раза.
JPQL Запрос
Мы хотим получить список топиков вместе с комментариями единым запросом. Для этого используем ключевые слова LEFT JOIN FETCH:
public interface TopicRepository extends JpaRepository<Topic, Long> {
@Query("select t from Topic t left join fetch t.comments")
List<Topic> getTopicsWithComments();
}
Но возникает проблема: если выполнить JOIN между сущностью и ее коллекцией, то в возвращаемом списке будут дубликаты.
Наш JPQL -запрос преобразуется в следующий SQL с LEFT OUTER JOIN:
select topic0_.id as id1_1_0_, comments1_.id as id1_0_1_, topic0_.title as title2_1_0_, comments1_.text as text2_0_1_,
comments1_.topic_id as topic_id3_0_1_, comments1_.topic_id as topic_id3_0_0__, comments1_.id as id1_0_0__
from topic topic0_ left outer join comment comments1_
on topic0_.id=comments1_.topic_id
Об SQL LEFT OUTER JOIN
LEFT OUTER JOIN значит:
- Декартово произведение множеств строк топиков и строк комментариев — это всевозможные комбинации каждого топика с каждым комментарием (иначе говоря CROSS JOIN).
- Применение к полученным комбинациям логического условия в ON — topic.id=comment.topic_id. Оставляем только те комбинации (строки), где условие выполняется.
- Добавляем невключенные в итоговый результат топики с нулевым числом комментариев (потому что указано ключевое слово LEFT), поля комментариев для этих строк заполняем null.
Данные, результат запроса, а также зачем нужен DISTINCT
Изначально мы заполнили базу тремя топиками, и к первому добавили три комментария:
insert into topic (id, title) values (-1,'title1'); insert into topic (id, title) values (-2,'duplicated title'); insert into topic (id, title) values (-3,'duplicated title'); insert into comment (id, text, topic_id) values (-4, 'text1', -1); insert into comment (id, text, topic_id) values (-5, 'text2', -1); insert into comment (id, text, topic_id) values (-6, 'text3', -1);
В результате LEFT JOIN получаем 5 строк:
-1 title1 -4 text1 -1 -1 title1 -5 text2 -1 -1 title1 -6 text3 -1 -2 duplicated title null null null -3 duplicated title null null null
В них первый топик встречается трижды (он скомбинирован с тремя комментариями).
И без ключевого слова DISTINCT в результирующий List<Topic> пойдет 5 топиков (топик с id=-1 будет встречаться трижды со своими тремя комментариями)! Чтобы убрать дубликаты, надо использовать ключевое слово DISTINCT.
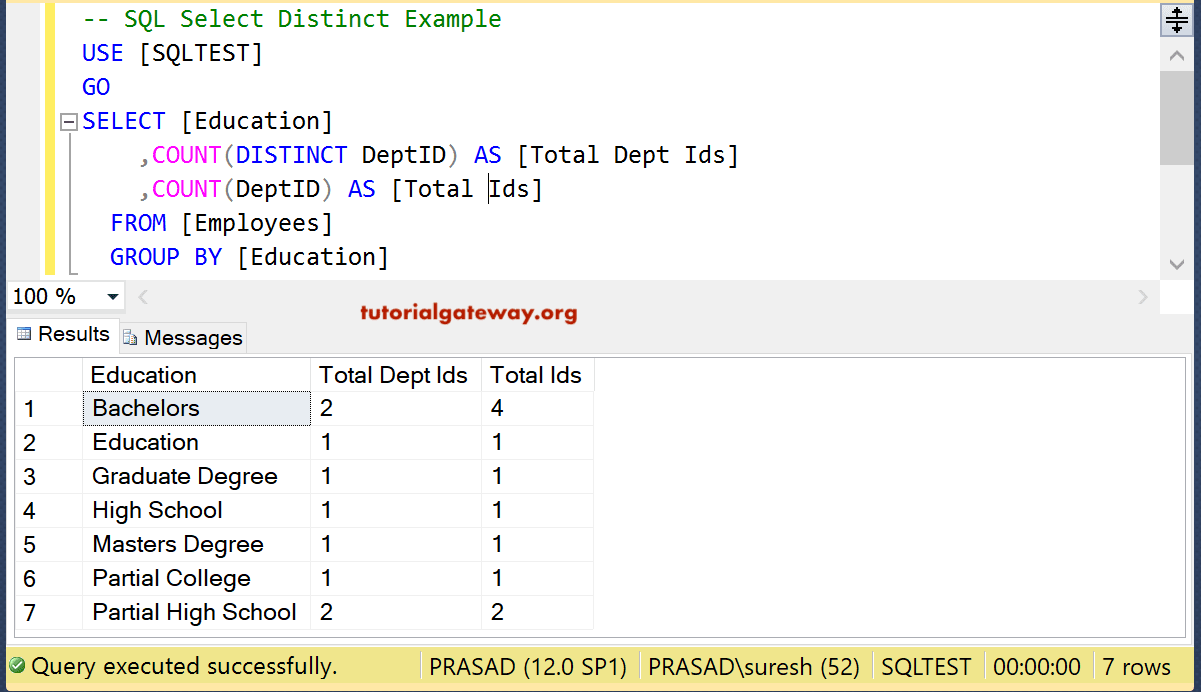
DISTINCT или GROUP BY в MySQL
В MySQL DISTINCT наследует поведение от GROUP BY. Если вы используете выражение GROUP BY без агрегатной функции, то оно будет выполнять роль ключевого слова DISTINCT.
Единственное отличие между ними заключается в следующем:
- GROUP BY сначала сортирует данные, а затем осуществляет группировку;
- Ключевое слово DISTINCTне выполняет сортировки.
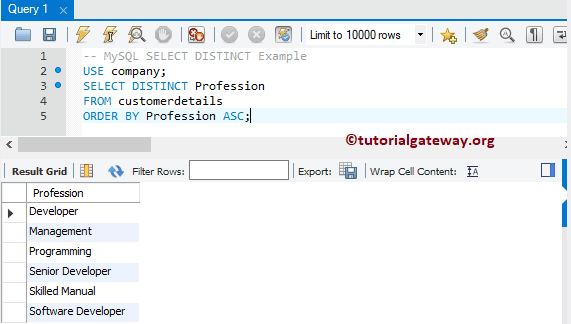
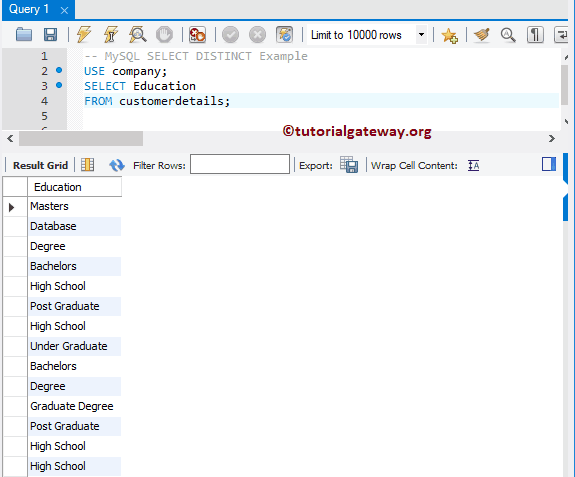
Если вы используете ключевое слово DISTINCT вместе с выражением ORDER BY, то получите тот же результат, что и при применении GROUP BY. Следующий запрос возвращает уникальные значения столбца profession из таблицы customerdetails:
-- MySQL SELECT DISTINCT Example USE company; SELECT DISTINCT Profession FROM customerdetails;
Результат:
![]()
Уберём ключевое слово DISTINCT и используем выражение GROUP BY:
-- MySQL SELECT DISTINCT Example USE company; SELECT Profession FROM customerdetails GROUP BY Profession;
Как видите, запрос возвращает тот же результат, но в другом порядке:
![]()
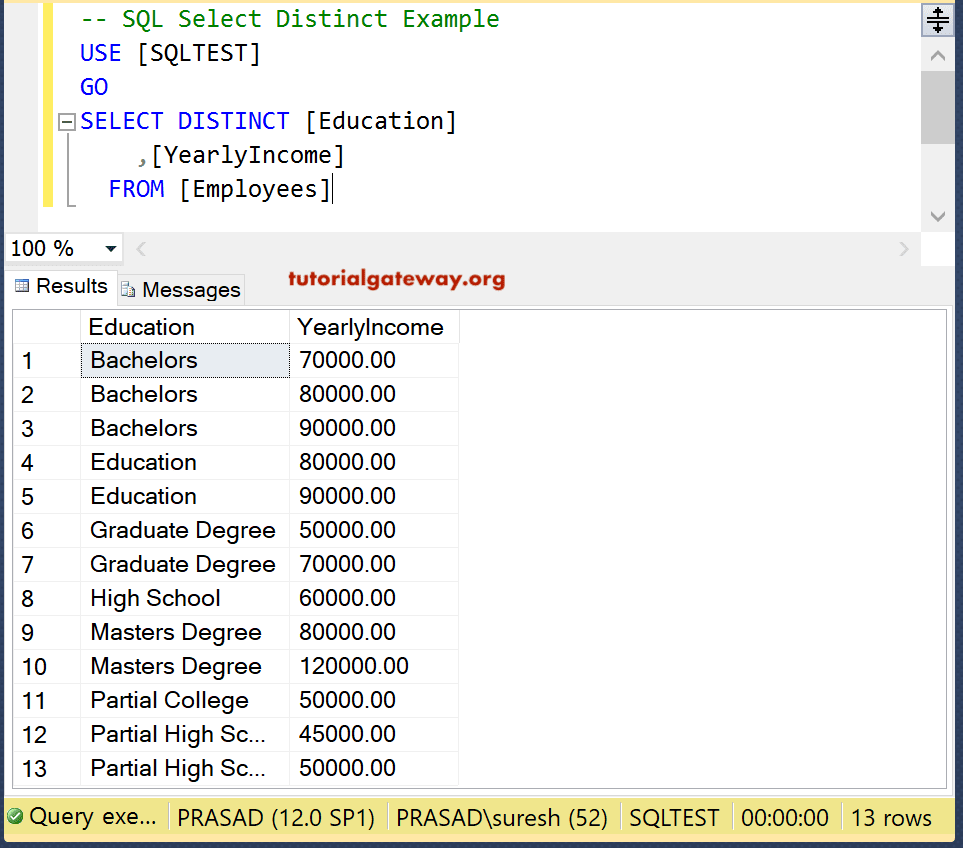
В этом MySQL SELECT DISTINCT примере я использую выражение ORDER BY:
-- MySQL SELECT DISTINCT Example USE company; SELECT DISTINCT Profession FROM customerdetails ORDER BY Profession ASC;
Результат тот же, что и при использовании GROUP BY:
![]()
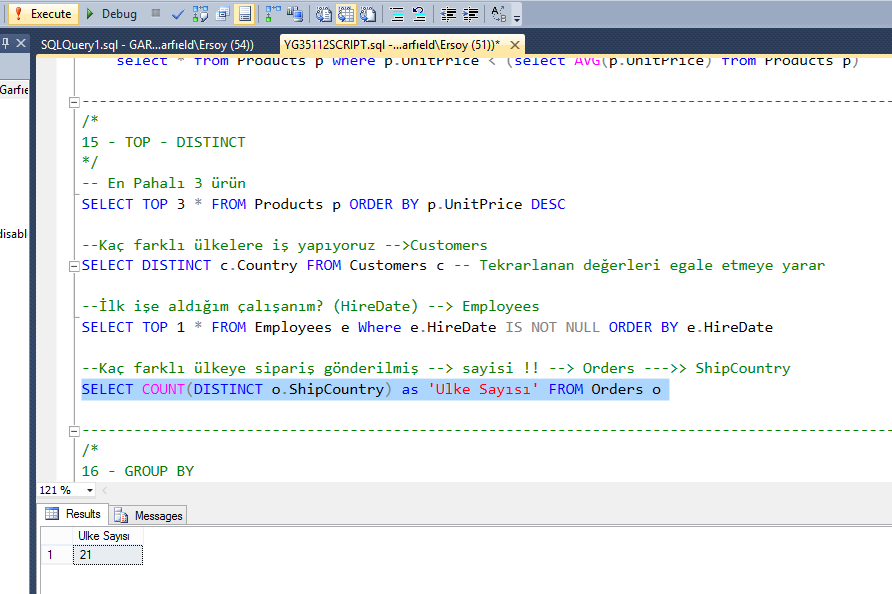
Сложные запросы к базе данных MySQL
SELECT id,name,country FROM users,admins WHERE TO_DAYS(NOW()) — TO_DAYS(registration_date)
Данный сложный запрос ВЫБИРАЕТ колонки id,name,country
В ТАБЛИЦАХ users,admins
ГДЕ registration_date
(дата) не старше 14
дней И activation
НЕ РАВНО , СОРТИРОВАТЬ по registration_date
в обратном порядке (новое в начале).
UPDATE users SET age = «18+» WHERE age = (SELECT age FROM users WHERE male = «man»);
Выше указан пример так называемого запроса в запросе
в SQL. Обновить возраст среди пользователей на 18+, где пол — мужской. Подобные варианты запроса не рекомендую. По личному опыту скажу, лучше создать несколько отдельных — они будут прорабатываться быстрее.



зависимый подзапрос
Для каждой строки таблицы считаем количество строк с тем же идентификатором пользователя (user_id) и большей датой добавления (date_added). Если количество таких строк меньше 3, значит рассматриваемая строка и есть нужная нам строка, т.е. входит в группу трёх последних сообщений пользователя.
select t1.* from posts t1where (select count(*) from posts t2 where t1.user_id=t2.user_id and t2.date_added > t1.date_added) < 3;
Эффективность запроса ухудшается по мере роста числа сообщений у пользователя. Нельзя ограничится рассмотрением только нескольких записей каждого пользователя, необходимо проверить все сообщения и для каждого из них подсчитать точное кол-во более поздних. Кроме того метод неприменим для выборки нескольких случайных строк из группы.
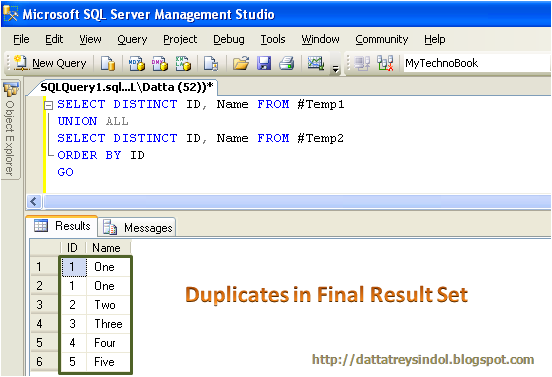
SQL-Урок 11. Выборка уникальных данных (SELECT DISTINCT)
Оператор SQL DISTINCT используется для указания на то, что следует работать только с уникальными значениями столбца.
Оператор SQL DISTINCT нашел широкое применение в операторе SQL SELECT, для выборки уникальных значений. Так же используется в агрегатных функциях.
Все примеры будут по этой таблице workers, если не сказано иное:
| id | name | age | salary |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
Давайте выберем все уникальные значения зарплат из таблицы workers:
SQL запрос выберет следующие строки:
| salary |
|---|
| 400 |
| 500 |
| 1000 |
Давайте подсчитаем все уникальные значения зарплат из таблицы workers (их будет 3 штуки: 400, 500 и 1000):
SQL запрос выберет следующие строки:
| count |
|---|
| 3 |
Давайте подсчитаем одновременно все уникальные значения зарплат и уникальные значения возрастов и запишем их в разные поля:
SQL запрос выберет следующие строки:
| salary_count | age_count |
|---|---|
| 3 | 5 |
оконные функции
Начиная с MariaDB 10.2 / MySQL 8 добавлена поддержка оконных функций. С помощью row_number() можно для каждого пользователя сделать отдельную нумерацию сообщений в порядке убывания даты. После чего выбрать те записи, у которых № меньше или равен 3.
select post_id, user_id, date_added, post_text from (select posts.*,
row_number() over (partition by user_id order by date_added desc) ifrom posts) t where i <= 3;
Производительность — двойное сканирование таблицы: сначала для нумерации (нет возможности ограничиться нумерацией только нескольких строк из группы), потом отбросить не удовлетворяющие условию where i <= 3.
Для случайных сообщений пользователя достаточно заменить сортировку по убыванию даты order by date_added desc на случайную — order by rand().
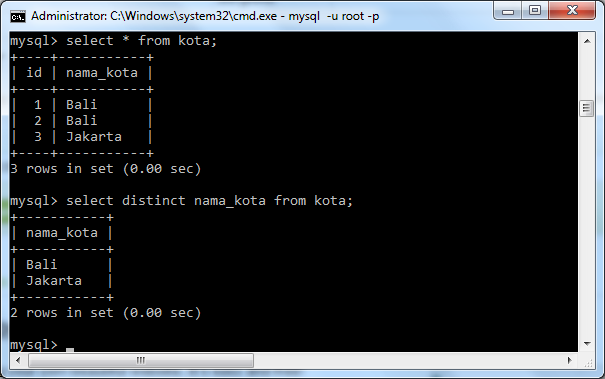
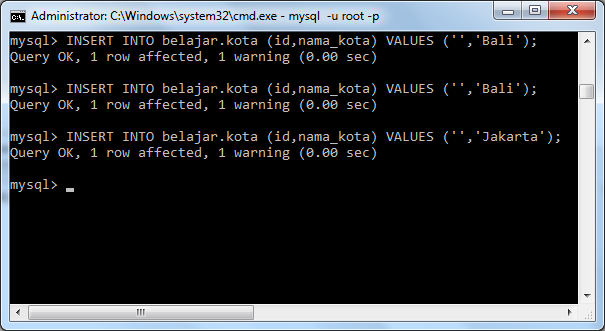
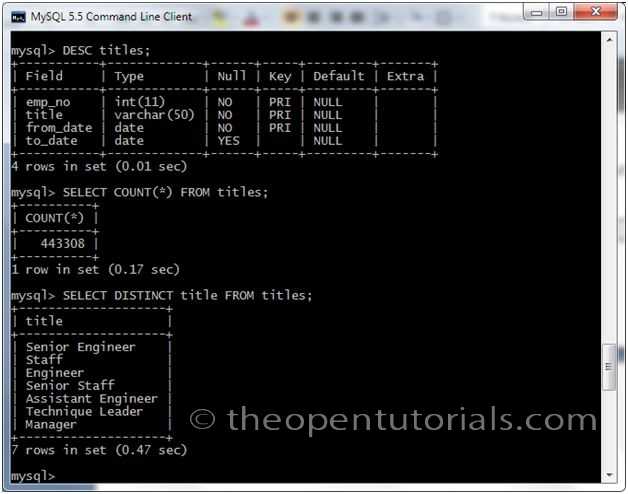
Пример DISTINCT-запроса в MySQL – командная строка
Теперь я покажу, как отобразить уникальные записи с помощью SELECT DISTINCT MySQL в командной строки. В этом случае мы выбираем записи с уникальными значениями столбцов education и profession из таблицы customerdetails :
![]()
Данная публикация представляет собой перевод статьи « MySQL Distinct » , подготовленной дружной командой проекта Интернет-технологии.ру
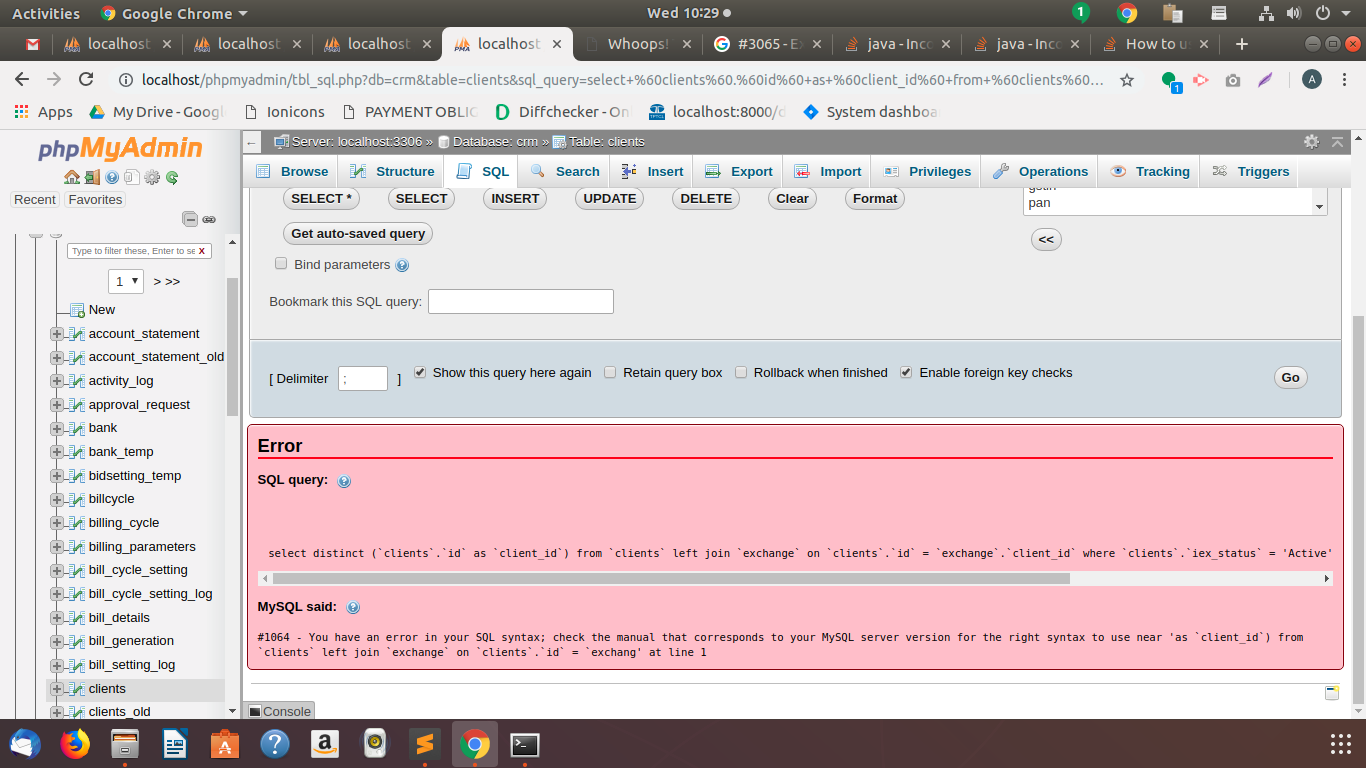
Ищу способ выбрать только строки с уникальными адресами электронной почты, но также мне нужны другие данные поля.
В настоящее время есть это:
Который сводит мои результаты с 9208 до 7848, так что работает нормально.
У меня есть 3 или 4 таблицы с примерно 10000 строками в каждой, и мы сейчас собираемся создать одну таблицу «клиентов». Я делаю скрипт для «импорта» всех этих строк в таблицу клиентов.
Строки, которые мне нужны, например, «имя пользователя», «номер», «название» и т. д.
Они не должны быть уникальными, просто электронная почта.
Но это вернуло больше строк, чем раньше, как мне это сделать?
Пример DISTINCT-запроса в MySQL – условие WHERE
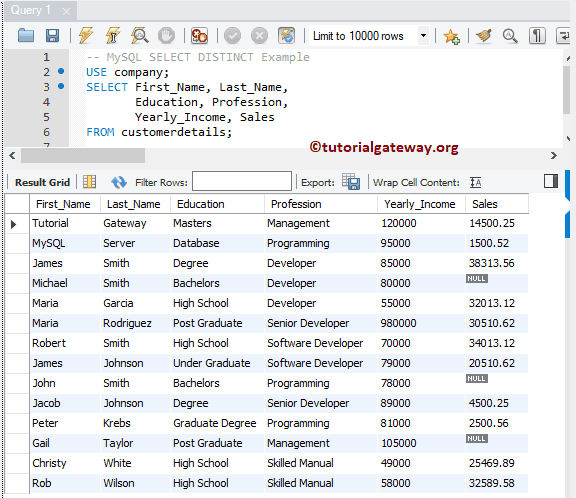
В этом MySQL DISTINCT примере мы покажем, как его использовать вместе с условием WHERE . Следующее выражение возвратит уникальные значения столбцов education и profession из таблицы customers , в которых годовой доход больше или равен 85000 :
![]()
Несмотря на то, что существует 13 уникальных записей с комбинациями столбцов education и profession , 10 записей не соответствуют условию WHERE . Поэтому на скриншоте показано только 5 записей.
Замечание : Выражение DISTINCT в MySQL воспринимает NULL как допустимое уникальное значение. Поэтому используйте любое NOT NULL условие или функцию, чтобы избавиться от этих значений.
SELECT для выбора столбцов таблицы
Запрос с оператором SELECT для выбора всех столбцов таблицы имеет следующий синтаксис:
SELECT * FROM ИМЯ_ТАБЛИЦЫ
То есть для выбора всех столбцов таблицы после слова SELECT нужно ставить звёздочку.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Работать будем с базой данных фирмы — Company1. Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными —
в файле по этой ссылке.
Пример 1. Итак, есть база данных фирмы — Company1. В ней есть таблица
Org (Структура фирмы) и Staff (Сотрудники). Требуется выбрать из таблиц все столбцы. Соответствующий
запрос для выбора всех столбцов из таблицы Org выглядит следующим образом (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT * FROM Org
Этот запрос вернёт следующее (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
![]()
Запрос для выбора всех столбцов из таблицы Staff выглядит следующим образом (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT * FROM Staff
Этот запрос вернёт следующее:
![]()
Для выбора определённых столбцов таблицы нам потребуется вместо звёздочки перечислить через запятую названия
всех столбцов, которые требуется выбрать:
SELECT ВЫБИРАЕМЫЕ_СТОЛБЦЫ FROM ИМЯ_ТАБЛИЦЫ
Пример 2. Пусть требуется из таблицы Org выбрать столбцы Depnumb и
Deptname, в которых содержатся данные соответственно о номерах отделов фирмы и об их названиях. Запрос для получения такой
выборки будет следующим (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Deptnumb, Deptname, FROM Org
А из таблицы Staff нужно выбрать столбцы Dept, Name, Job, в которых содержатся
соответственно данные о номере отдела, в котором трудится сотрудник, его имени и должности (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT Dept, Name, Job FROM Staff
Пример DISTINCT-запроса в MySQL – условие WHERE
В этом MySQL DISTINCT примере мы покажем, как его использовать вместе с условием WHERE. Следующее выражение возвратит уникальные значения столбцов education и profession из таблицы customers, в которых годовой доход больше или равен 85000:
-- MySQL SELECT DISTINCT Example USE company; SELECT DISTINCT Education, Profession FROM customerdetails WHERE Yearly_Income > 85000;
![]()
Несмотря на то, что существует 13 уникальных записей с комбинациями столбцов education и profession, 10 записей не соответствуют условию WHERE. Поэтому на скриншоте показано только 5 записей.
Замечание: Выражение DISTINCT в MySQL воспринимает NULL как допустимое уникальное значение. Поэтому используйте любое NOT NULL условие или функцию, чтобы избавиться от этих значений.
Pets Sample Dataset
I truly believe that every pet deserves a loving home. That is why we rescued
both a Female
Terrier
mix (dog) named Ella and a Male
Siberian (cat) named Ziggy from local animal shelters. Our tiny example
PETS table will have 6 records in which data reflect the images seen below.
The images were taken from Oxford Pets Dataset which can be used by Machine Learning
Algorithms to classifying images as either cat or dog. In short, just want
to make my PETS table more interesting with pictures!
![]()
The T-SQL syntax uses a
table value constructor to create a derived table. The selected data is
inserted into
called #PETS that stays in scope until
the query window until the session is closed. The following query can be re-executed
anytime since the table is deleted and recreated each time.
-- Drop existing table
DROP TABLE IF EXISTS #PETS
-- Create very simple table
SELECT
PETS.*
INTO
#PETS
FROM
(
VALUES
('CAT','SAMMY','ABYSSINIAN','MALE', 2.5),
('DOG','HENRY','AMERICAN BULLDOG','MALE', 1.3),
('CAT','LUCY','BOMBAY','FEMALE', 4.0),
('DOG','CLEO', 'AMERICAN PITBULL','FEMALE', 6.9),
('CAT','BELLA','PERSIAN','FEMALE', 8.7),
('DOG','ZAC','BASSET HOUND','MALE', 4.0)
) AS
PETS
(
PET_TYPE,
PET_NAME,
PET_BREED,
PET_GENDER,
PET_AGE
);
GO
-- Show the data
SELECT * FROM #PETS;
GO
The image below shows the output from SELECT statement. Now that we have
a simple test table, we can start talking about the SQL SELECT DISTINCT clause.
![]()
COUNT (if(выражение))
Для большего акцента вы должны объединить COUNT() с функциями управления потоком. Для начала, для части выражения, используемого в методе COUNT(), вы можете использовать функцию IF(). Это может быть очень полезно для быстрой разбивки информации в базе данных. Мы будем подсчитывать количество строк с разными возрастными условиями и разделять их на три разных столбца, которые можно назвать категориями. Во-первых, COUNT(IF) будет подсчитывать строки, возраст которых меньше 20, и сохранять это количество в новом столбце с именем «Teenage». Второй COUNT(IF) подсчитывает строки с возрастом от 20 до 30, сохраняя его в столбце «Young». В-третьих, последний подсчитывает строки старше 30 лет и сохраняет их в столбце «Mature».
>> SELECT COUNT(IF(Age < 20,1,NULL)) ‘Teenage’, COUNT(IF(Age BETWEEN 20 AND 30,1,NULL)) ‘Young’, COUNT(IF(Age > 30,1,NULL)) ‘Mature’ FROM data.social;
Функция SQL MAX
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда
требуется определить максимальное значение среди всех значений столбца.
Пример 5.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42.
Для этого пишем следующий запрос:
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения
.
Пример 6.
Вновь работаем с двумя таблицами — Staff и Org.
Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе,
относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц)
.
Пример — поиск уникальных значений в столбце
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Давайте найдем все уникальные значения в таблице suppliers . Введите следующий SQL оператор:
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| state |
|---|
| Russia |
| Ile de France |
| Pennsylvania |
| California |
| Washington |
| Michigan |
В этом примере возвращаются все уникальные значения состояния из таблицы поставщиков и удаляются все дубликаты из набора результатов. Как видите, штат Калифорния в наборе результатов отображается только один раз, а не четыре раза.
Оператор SELECT sql
SQL-запрос Select предназначен для обычной выборки из базы данных. Т.е. если нам необходимо просто получить данные, не делая с ними никакой обработки и не внося изменений в базу данных, то можно смело использовать данный запмагарос.
Синтаксис оператора SELECT
Рассмотрим примеры sql запросов select:
Пример : если вы создали локальную базу данных и заполнили таблицы, как в рассмотренном ранее уроке (или же воспользовались сервисом sqlFiddle), то выполним следующий пример.
Необходимо выбрать все записи из таблицы
SELECT * FROM teachers; |
Задание 1_1. . Вывести все поля из таблицы Группы.
SELECT name, zarplata FROM teachers; |
Выберет все значения полей и в том же порядке (сначала , затем )
Задание 1_2. . Получить информацию только о фамилии и годе рождения из таблицы
Сортировка в SQL
SELECT name, zarplata, premia FROM teachers ORDER BY name; |
Выберет значения полей , , и отсортирует по полю (по алфавиту)
Пример: БД «Компьютерный магазин». Выбрать данные о скорости и памяти компьютеров. Требуется упорядочить результирующий набор по скорости процессора в порядке возрастания.
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC |
Или
SELECT `Скорость`,`Память` FROM `pc` ORDER BY 1 ASC |
Результат:
Сортировку можно выполнять по двум полям:
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC, `Память` ASC |
Задание sql select 1_1. База данных : Получить информацию только о скорости процессора и объеме оперативной памяти компьютеров.
Задание sql select 1_2. База данных : Требуется упорядочить результирующий набор по объему оперативной памяти в порядке убывания.
SELECT name, zarplata, premia FROM teachers ORDER BY name DESC; |
Выберет значения полей , , и отсортирует по полю по убыванию
Задание 1_3. . Вывести информацию о фамилиях и годах рождения. Упорядочить результирующий набор по году рождения в порядке убывания.
Удаление повторяющихся значений в SQL
Пример БД «Институт»: требуется узнать возможные варианты размера премий. Если не использовать , в результате будет выдаваться два одинаковых значения. Удалить в sql повторяющиеся значения можно при введении — в результате дублирующиеся значения не повторяются.



-
SELECT premia FROM teachers;
-
SELECT DISTINCT premia FROM teachers;
Рассмотрим другой пример из базы данных «Компьютерный магазин»:
Пример: База данных «Компьютерный магазин»: требуется получить информацию только о скорости процессора и объеме оперативной памяти компьютеров
SELECT Скорость, Память FROM PC; |
Результат:
В таблице первичным ключом является поле . Поскольку это поле отсутствует в запросе, в приведенном выше результирующем наборе имеются дубликаты строк.
Когда требуется получить уникальные строки (например, нас интересуют только различные комбинации скорости процессора и объема памяти, а не характеристики всех имеющихся компьютеров), то нужно использовать :
SELECT DISTINCT Скорость, Память FROM PC; |
Результат:
Задание sql select 1_3. База данных : Из таблицы выбрать различные страны-производители.
Задание sql select 1_1. БД «Институт» Выполните запрос на выборку и из таблицы учителей. Отсортируйте фамилии учителей по убыванию
Задание sql select 1_2. БД «Институт» Выведите возможные варианты длины курсов () из таблицы курсов (), удалив повторяющиеся значения
Задание 1_4. . Из таблицы личные данные вывести поля и . Получить уникальные строки
Модель
Допустим у нас есть топик с комментариями в отношении OneToMany:
![]() OneToMany и ManyToOne
OneToMany и ManyToOne
Класс Topic:
@Data
@NoArgsConstructor
@Entity
public class Topic {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String title;
@OneToMany(mappedBy = "topic", cascade = CascadeType.ALL, orphanRemoval = true)
private Set<Comment> comments=new HashSet<>();
...
}
Класс Comment:
@NoArgsConstructor
@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String text;
@ManyToOne(fetch = FetchType.LAZY)
private Topic topic;
public Comment(String text) {
this.text = text;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (!(o instanceof Comment)) return false;
return id != null && id.equals(((Comment) o).getId());
}
@Override
public int hashCode() {
return 31;
}
}
Вывод данных из нескольких таблиц
Если у вас есть несколько связанных таблиц, то с помощью вы можете выводить их данные составляя из них одну таблицу.
Например мы имеем таблицу с книгами — books и их заказами — orders.
Выведем колонки id, book_id и status для таблицы orders.
Имея идентификаторы записей таблицы books в колонке book_id, мы можем соотнести их с колонкой id в таблице books с помощью команды . В результате мы можем узнать статус заказа для каждой книги.
Выведем колонки title, author, price из таблицы books и колонку status из таблицы orders.
Вывести колонки с одинаковыми именами, например id, в данном случае не получится, т.к. они имеются в обоих таблицах.
Заключение
Сводная таблица, показывающая среднее время выполнения изложенных выше способов для нахождения трёх последних и трёх случайных сообщений каждого пользователя на тестовых данных в 16000 строк, равномерно распределенных среди count(distinct user_id) = 20.
| время, с | ||
| 3 последних | 3 случайных | |
| 1. зависимый подзапрос | 10.8 | — |
| 2. join + group by | 11 | — |
| 3. group_concat() | 0.06 | 0.03 |
| 3. модифицированный вариант + WITH | 0.03 | 0.016 |
| 3. модифицированный вариант без WITH | 0.08 | — |
| 4. row_number() | 0.15 | 0.17 |
| 5. пользовательские переменные | 0.13 | 0.14 |
| 6. LATERAL | 0.005 | 0.03 |
Если ваша СУБД поддерживает подзапросы lateral, то используйте их. Вообще, каждый раз, когда есть необходимость «для каждого значения выбрать …» — возможно вы сможете эффективно решить задачу, используя LATERAL производные таблицы. Подробнее об этой функциональности можно прочитать в статье В MySQL 8.0.14 добавлена поддержка производных таблиц типа LATERAL.
Неожиданно высокую эффективность показал третий способ, особенно для выборки случайных строк из группы. Неожиданно, потому что как правило рекомендуют использовать второй и четвертый (для MySQL до недавнего времени его реализацию через переменные, т.е. пятый) способы.
Также не забывайте про вариант реализации lateral во внешнем приложении: сначала выбираем список идентификаторов групп, потом в цикле отдельными запросами находим нужные строки для каждой группы. Порой встречается ошибочное мнение, что это ламерский подход и правильно решать задачу в один запрос к базе. По эффективности множество «простых» запросов, выбирающих по индексу нужные строки, лучше одного «сложного», который многократно сканирует всю таблицу. Разумеется это справедливо, когда в группах много элементов, и нужно вернуть лишь малую часть, иначе накладные расходы могут превысить выигрыш от снижения количества прочитанных строк.
P.S.При выборе подходящего варианта проводите тестирование в своем окружении.
Если после прочтения статьи ваш вопрос остался нерешенным, задавайте его на форуме SQLinfo.
Все права на данную статью принадлежат порталу SQLInfo.ru. Перепечатка в интернет-изданиях разрешается только с указанием автора и прямой ссылки на оригинальную статью. Перепечатка в бумажных изданиях допускается только с разрешения редакции.