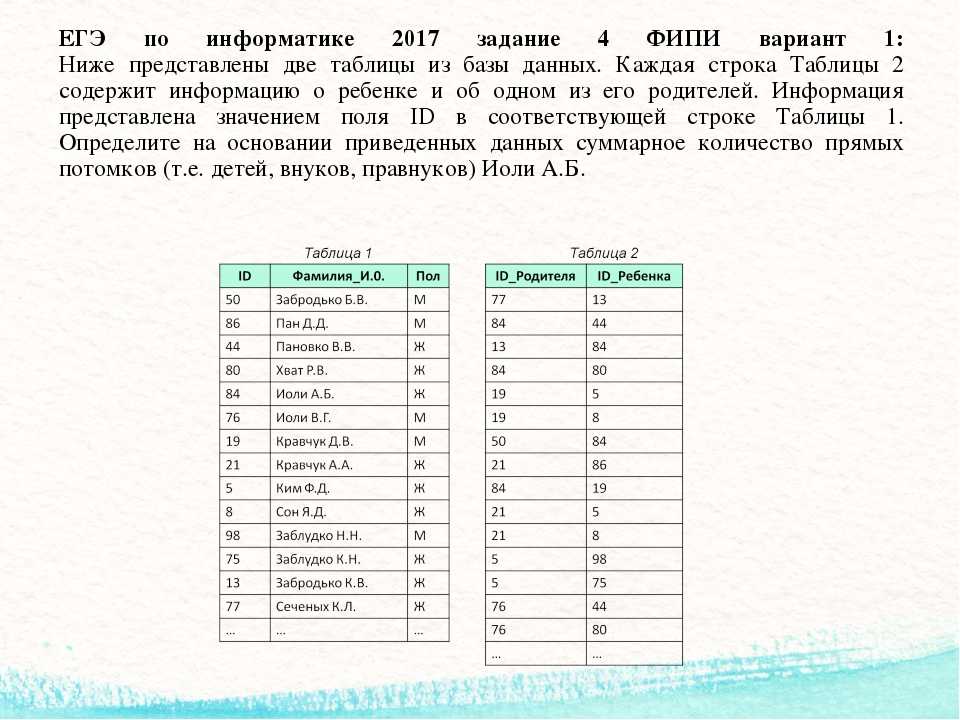
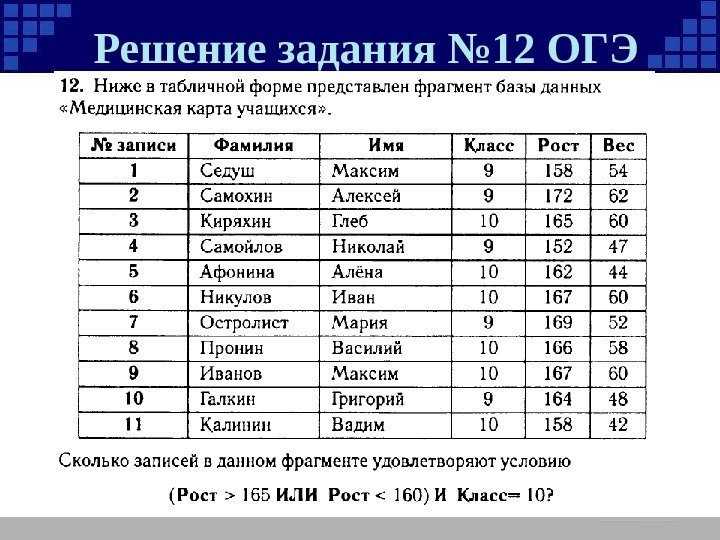
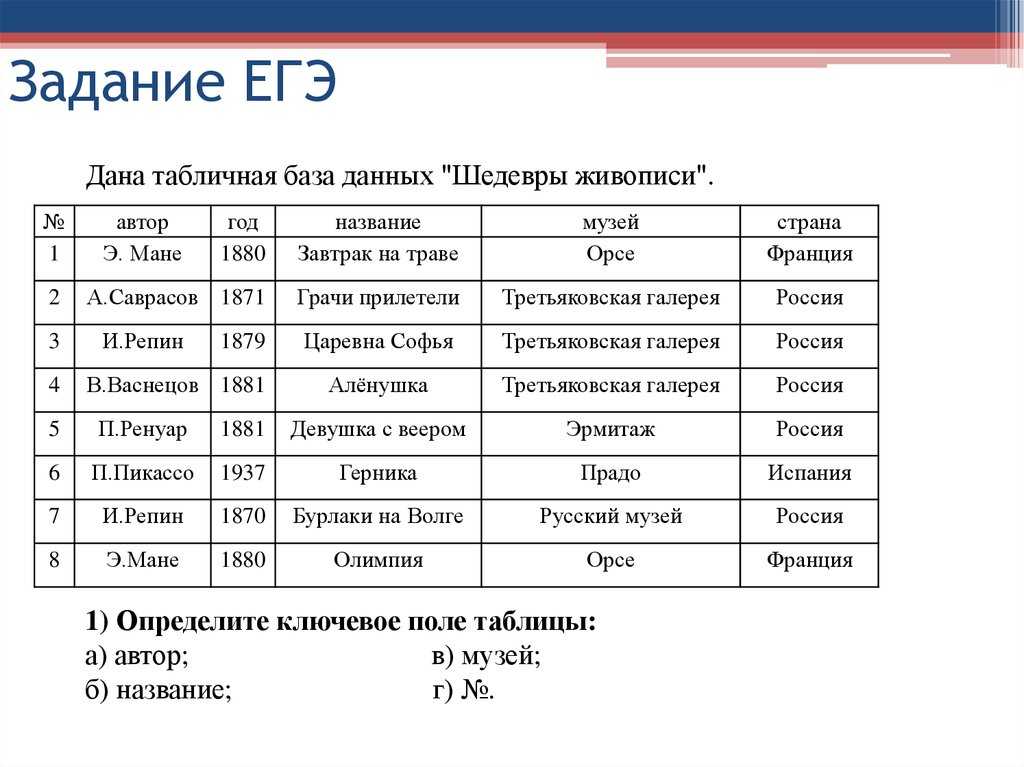
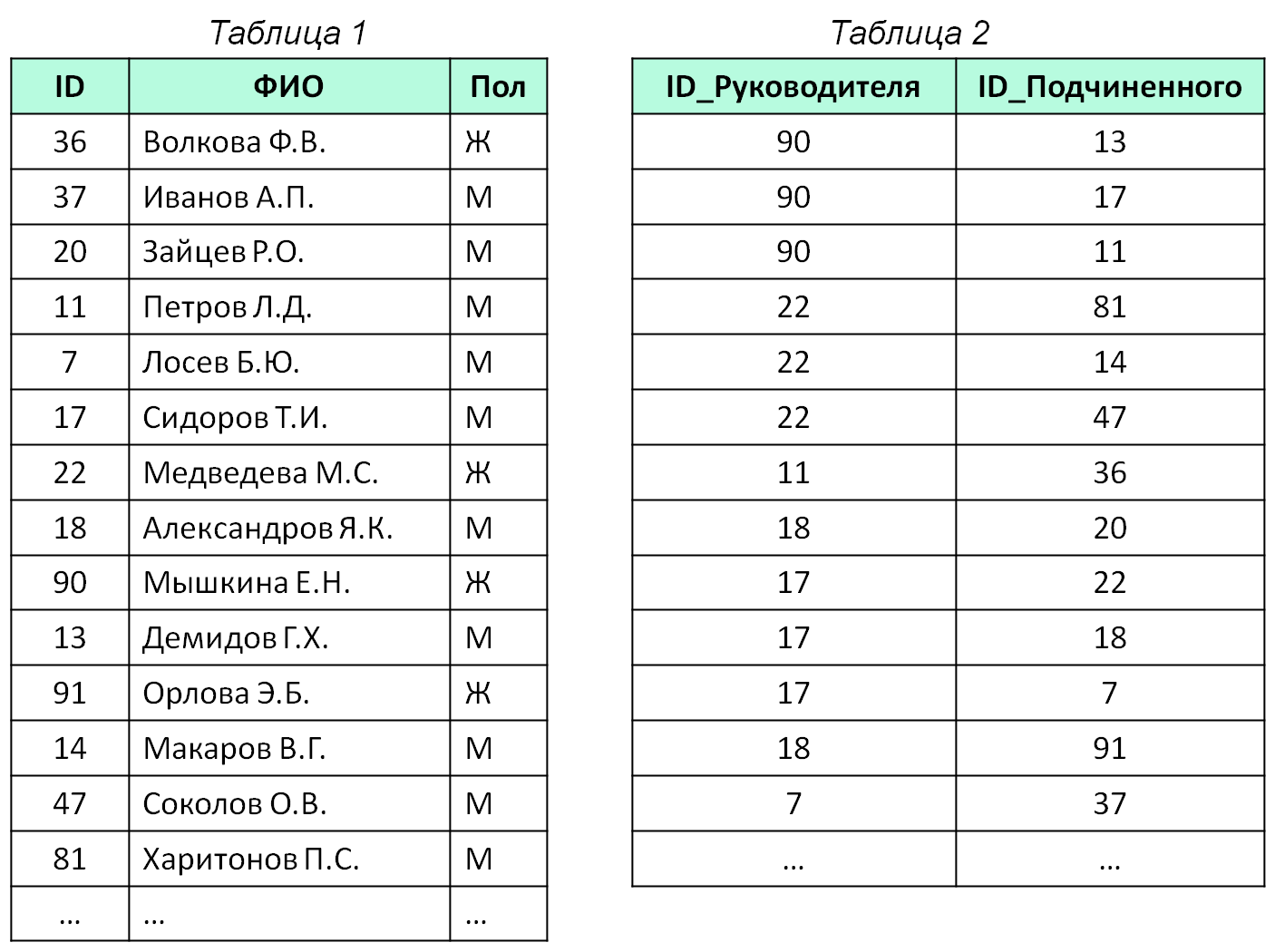
Обработка исключений в PL/SQL
PL/SQL перехватывает ошибки и реагирует на них при помощи так называемых обработчиков исключений. Механизм функционирования обработчиков исключений позволяет четко отделить код обработки ошибок от исполняемых операторов, дает возможность реализовать обработку ошибок, управляемую событиями, отказавшись от устаревшей линейной модели программирования.
Независимо от того, как и по какой причине было инициировано конкретное исключение, оно обрабатывается одним и тем же обработчиком в разделе исключений.
Любая ошибка может быть обработана только одним обработчиком.
Для обработки исключений в блоке PL/SQL предназначается необязательный раздел EXCEPTION
BEGIN
операторы
EXCEPTION
WHEN THEN …..;
WHEN THEN …..;
…
WHEN THEN …..;
WHEN OTHERS THEN …..;
END;
Если в исполняемом блоке PL/SQL инициируется исключение, то выполнение блока прерывается и управление передается в раздел обработки исключений (если таковой имеется). После обработки исключения возврат в исполняемый блок уже невозможен, поэтому управление передается в родительский блок.
Обработчик WHEN OTHERS должен быть последним обработчиком в блоке, иначе возникнет ошибка компиляции. Этот обработчик не является обязательным. Если он отсутствует, то все необработанные исключения передадутся в родительский блок, либо в вызывающую хост-систему.
В одном предложении WHEN, можно объединить несколько исключений, используя оператор OR:
WHEN invalid_company_id OR negative_balance THEN
Также в одном о6ра6отчике можно ком6инировать имена пользовательских и системных исключений:
WHEN balance_too_low OR zero_divide OR dbms_ldap.invalid_session THEN
Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имею отношение «один к одному» с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же, как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов – Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
Команда EXECUTE в T-SQL
EXECUTE (сокращенно EXEC) – команда для запуска хранимых процедур и SQL инструкций в виде текстовых строк.
Перед тем как переходить к примерам, следует отметить, что использование динамического кода с использованием команды EXEC – это не безопасно! Дело в том, что для того чтобы сформировать динамическую SQL инструкцию, необходимо использовать переменные для динамически изменяющихся значений. Так вот, если эти значения будут приходить от клиентского приложения, т.е. от пользователя, злоумышленники могут передать и, соответственно, внедрить в нашу инструкцию вредоносный код в виде текста, а мы его просто исполним в БД, думая, что нам передали обычные параметры. Поэтому все такие значения следует очень хорошо проверять, перед тем как подставлять в инструкцию.
Пример использования EXEC в T-SQL
Сейчас мы с Вами сформируем динамический SQL запрос, текст которого мы сохраним в переменной, и затем выполним его с помощью команды EXEC.
Текст запроса будет храниться в переменной @SQL_QUERY, в переменной @Var1 будет храниться значение, которое мы будем подставлять в наш запрос, для того чтобы этот запрос стал динамическим (в нашем случае мы вручную присвоим статическое значение в переменную, хотя это значение можно узнавать, например, с помощью запроса или каких-то вычислений).
Для формирования строки мы будет использовать конкатенацию строк, а именно оператор + (плюс), только стоит понимать, что в этом случае выражения, участвующие в операции, должны иметь текстовый тип данных. Переменная @Var1 у нас будет иметь тип данных INT, поэтому, чтобы соединить ее со строкой, мы предварительно преобразуем ее значение к типу данных VARCHAR.
Для наглядности того, какой именно SQL запрос у нас получился, мы просто посмотрим, что у нас хранится в переменной @SQL_QUERY инструкцией SELECT.
--Объявляем переменные DECLARE @SQL_QUERY VARCHAR(200), @Var1 INT; --Присваиваем значение переменным SET @Var1 = 1; --Формируем SQL инструкцию SET @SQL_QUERY = 'SELECT * FROM TestTable WHERE ProductID = ' + CAST(@Var1 AS VARCHAR(10)); --Смотрим на итоговую строку SELECT @SQL_QUERY AS --Выполняем текстовую строку как SQL инструкцию EXEC (@SQL_QUERY)
![]()
Хранимая процедура sp_executesql в T-SQL
sp_executesql – это системная хранимая процедура Microsoft SQL Server, которая выполняет SQL инструкции. Эти инструкции могут содержать параметры, тем самым делая их динамическими.
Процедура sp_executesql имеет несколько параметров, первым параметром указывается текст SQL инструкции, вторым объявляются переменные, третий и все последующие — это передача значений для переменных в процедуру и, соответственно, подстановка в нашу инструкцию.
Все параметры процедуры sp_executesql необходимо передавать в формате Unicode (тип данных строк должен быть NVARCHAR).
Пример использования sp_executesql в T-SQL
В этом примере итоговый результат у нас будет точно таким же, как и в примере с EXEC, только динамические значения, у нас это переменная @Var1, мы объявим и передадим в виде параметров хранимой процедуры sp_executesql.
--Объявляем переменные
DECLARE @SQL_QUERY NVARCHAR(200);
--Формируем SQL инструкцию
SELECT @SQL_QUERY = N'SELECT * FROM TestTable WHERE ProductID = @Var1;';
--Смотрим на итоговую строку
SELECT @SQL_QUERY AS
--Выполняем текстовую строку как SQL инструкцию
EXEC sp_executesql @SQL_QUERY,--Текст SQL инструкции
N'@Var1 AS INT', --Объявление переменной @Var1
@Var1 = 1 --Передаем значение для переменной @Var1
![]()
У меня на этом все, надеюсь, материал был Вам интересен и полезен, если Вас интересуют другие возможности языка T-SQL, то рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения специально для начинающих, пока!
Нравится21Не нравится1
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы и сохраняют результат в индексе. Когда конструкция WHERE содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER
Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции, поскольку база данных создаст его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Что такое встроенный SQL?
Запросы встроенного или статического SQL – это те инструкции, которые не изменяются во время выполнения или во время выполнения и могут быть жестко закодированы (где данные или параметры не могут быть изменены) в различных приложениях.
Встроенное приложение SQL
Рассмотрим пример встроенного приложения, в котором операторы в основном встроены в исходные файлы C++, где препроцессор переводит операторы в вызовы библиотеки времени выполнения. Он переносится в другие среды и предоставляет те же функции для каждой операционной среды.
![]()
Приложение встроенного SQL состоит из операторов SQL, и эти операторы перед компиляцией преобразуются в код C или C++. Как видно на диаграмме, приложение во время выполнения использует библиотеку интерфейса SAP IQ, которая известна как DBLIB и используется для связи с серверами баз данных. DBLIB – это библиотека динамической компоновки (DLL), которая может использоваться на всех основных платформах.
Что такое динамический SQL?
Как видно из названия, это метод, который позволяет профессионалам создавать операторы SQL, которые можно динамически изменять во время выполнения. Динамический запрос – это оператор, который может быть создан во время выполнения или во время выполнения; например, приложение может позволять пользователям запускать свои собственные запросы при исполнении.
Сортировка по нескольким столбцам в Excel
Отсортируем базу данных клиентов в соответствии с двумя критериями:
- Наименование городов в алфавитном порядке.
- Возраст клиентов от младших до старших.
Выполним сортировку по отдельным столбцам таблицы:
- Перейдите курсором клавиатуры на любую ячейку таблицы и выберите инструмент: «Данные»-«Сортировка и фильтр»-«Сортировка».
- В появившемся диалоговом окне укажите параметры сортировки так, как указано ниже на рисунке и нажмите на кнопку «Добавить уровень».
- Заполните параметры второго уровня как ниже на рисунке и нажмите ОК.
![]()
В результате таблица Excel отсортирована по нескольким критериям.
![]()
Чем выше уровень параметров сортировки, тем выше его приоритет.
Примечание. В Excel начиная с версии 2010-го года, количество уровней может быть столько, сколько столбцов в таблице. В старших версиях Excel разрешалось только 3 уровня.
Фильтр
Кроме того, в программе Microsoft Excel существует функция фильтра данных. Она позволяет оставить видимыми только те данные, которые вы посчитаете нужными, а остальные скрыть. При необходимости, скрытые данные всегда можно будет вернуть в видимый режим.
Чтобы воспользоваться данной функцией, становимся на любую ячейку в таблице (а желательно в шапке), опять жмем на кнопку «Сортировка и фильтр» в блоке инструментов «Редактирование». Но, на этот раз в появившемся меню выбираем пункт «Фильтр». Можно также вместо этих действий просто нажать сочетание клавиш Ctrl+Shift+L.
![]()
Как видим, в ячейках с наименованием всех столбцов появился значок в виде квадрата, в который вписан перевернутый вниз треугольник.
![]()
Кликаем по этому значку в том столбце, по данным которого мы собираемся проводить фильтрацию. В нашем случае, мы решили провести фильтрацию по имени. Например, нам нужно оставить данные только работника Николаева. Поэтому, снимаем галочки с имен всех остальных работников.
![]()
Когда процедура выполнена, жмем на кнопку «OK».
![]()
Как видим, в таблице остались только строки с именем работника Николаева.
![]()
Усложним задачу, и оставим в таблице только данные, которые относятся к Николаеву за III квартал 2016 года. Для этого, кликаем по значку в ячейке «Дата». В открывшемся списке, снимаем галочки с месяцев «Май», «Июнь» и «Октябрь», так как они не относятся к третьему кварталу, и жмем на кнопку «OK».

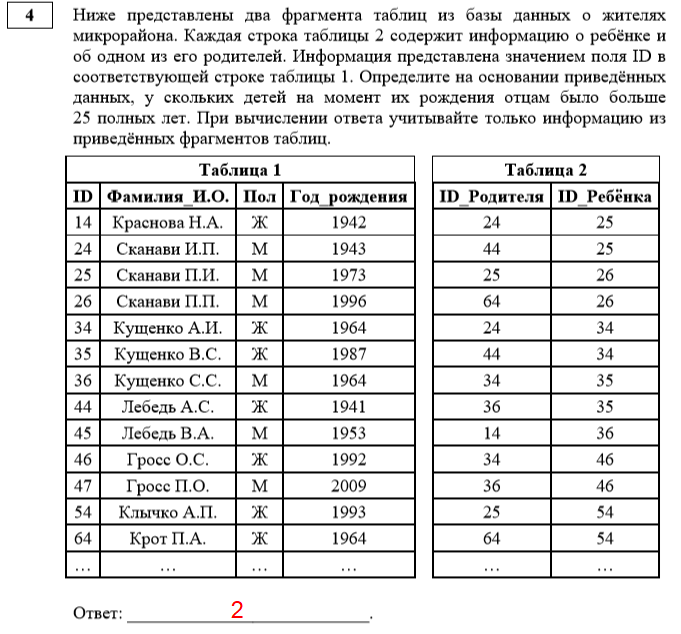

![]()
Как видим, остались только нужные нам данные.
![]()
Для того, чтобы удалить фильтр по конкретному столбцу, и показать скрытые данные, опять кликаем по значку, расположенному в ячейке с заглавием данного столбца. В раскрывшемся меню кликаем по пункту «Удалить фильтр с…».
![]()
Если же вы хотите сбросить фильтр в целом по таблице, тогда нужно нажать кнопку «Сортировка и фильтр» на ленте, и выбрать пункт «Очистить».
![]()
Если нужно полностью удалить фильтр, то, как и при его запуске, в этом же меню следует выбрать пункт «Фильтр», или набрать сочетание клавиш на клавиатуре Ctrl+Shift+L.
![]()
Кроме того, следует заметить, что после того, как мы включили функцию «Фильтр», то при нажатии на соответствующий значок в ячейках шапки таблицы, в появившемся меню становятся доступны функции сортировки, о которых мы говорили выше: «Сортировка от А до Я», «Сортировка от Я до А», и «Сортировка по цвету».
![]()
2 ответа
Лучший ответ
Что ты можешь сделать
Поскольку статический оператор поворота может быть преобразован в функцию, которая содержит два соответствующих параметра
В котором вспомогательный запрос, в котором четко выделены столбцы , используется для определения строки ( для ), которая должна быть объединена с основной строкой SQL, чтобы быть используется внутри курсора, который возвращает значение типа .
И вызывается
Из консоли разработчика SQL.
Демонстрация со сгенерированными операторами SQL
Если порядок столбцов в списке SELECT имеет значение, используйте приведенный ниже код для создания функции
1
Barbaros Özhan
17 Ноя 2020 в 12:17
Это довольно частый вопрос по той простой причине, что ответ — «нет».
При использовании базы данных Oracle каждый оператор SELECT должен иметь фиксированную и известную «форму» (количество столбцов, их имена и их типы данных). В последних версиях есть «полиморфные табличные функции», которые, кажется, нарушают это правило, но на самом деле это не так: «форма» вычисляется при синтаксическом анализе оператора, поэтому она фиксируется и известна до начала выполнения.
Вам не нужен «полиморфный» (изменение формы во время синтаксического анализа), вы хотите действительно «динамический» (изменение формы во время выполнения на основе данных). Oracle этого не делает.
Самое близкое, что вы можете получить с помощью одного оператора SQL, — это вывести ровно один столбец, содержащий XML или JSON. Затем программа, вызывающая базу данных, будет отвечать за преобразование этого результата в строки и столбцы.
Другой альтернативой является выполнение одного SELECT для получения имен столбцов и генерации второго SELECT для получения желаемого результата. Я написал функцию, которая поможет в этом:
https://stewashton.wordpress.com/2018/05/30 / Superior-pivot-function /
Я не собираюсь демонстрировать какие-либо из этих альтернатив, потому что они не дают прямого ответа на ваш вопрос. На ваш вопрос нет прямого ответа.
Stew Ashton
17 Ноя 2020 в 08:28
Что применять для ввода команд: SVRMGR30, SQL Plus или SQL Worksheet ?
Указанные
в заголовке утилиты предназначены для ввода команд SQL (DMLи DDL),
запуска скриптов, просмотра ошибок выполнения команд и ввода других команд,
необходимых для управления БД. Следует отметить, что большинство «ручных»
действий (т.е. выполняемых фактически в режиме командной строки), можно проще,
нагляднее и быстрее осуществить в диалоговом режиме с помощью утилит пакета OracleEnterpriseManagerи других. В то же время,
наиболее «тонкое» управление БД, также как и самую исчерпывающую информацию
(находящуюся в Словаре БД, состоящим из многих групп таблиц и представлений),
можно получить только в режиме командной строки.
Ниже вкратце перечислены лишь некоторые достоинства и
недостатки описываемых утилит, что позволит гибко подойти к их выбору в
конкретной ситуации.
·SVRMGR30. Главное удобство – можно пользоваться на сервере NovellNetware. Имеется также удобная команда showparametersдля
просмотра конфигурационных параметров. Удобна для запуска больших скриптов
(например, генерации БД или запроса к большой таблице), т.к. не имеет буфера
для хранения исполненных команд. Недостатки – обычные недостатки утилит
командной строки, где все действия нужно определять вводом команд. Но это также
является мощным достоинством – эту утилиту можно использовать в командных
файлах (BATи NCF), что позволяет набор однотипных действий выполнить
одним нажатием клавиши. Впрочем, был обнаружен более существенный недостаток – выполняемый
в этой утилите скрипт ломался на комментариях более 1000 символов (в OracleSQL*Plusвсе
прошло нормально). Следовательно, и слишком длинные SQL-выражения (часто
встречающиеся в insertи update) также
не пройдут.
·OracleSQL*Plus. Главные удобства: имеется везде; можно использовать для запуска
больших скриптов (т.к. буфер ограничен); выводит после соединения версию БД. Неудобства:
никаких удобств (нельзя «ползать» по вводимой строке для ее правки; нельзя повторить
предыдущий ввод и т.д.). Еще один недостаток – при соединении нельзя указывать asdba (как в OracleSQLWorksheet) – для этого нужно явно вводить команду (как и вообще
последующие команды connect). И еще неудобство
– по умолчанию длинные строки переносятся (в отличие от OracleSQLWorksheet).
Впрочем, при определенном навыке, работа с OracleSQL*Plus перестает казаться неудобной.
·OracleSQLWorksheet.
Это наиболее удобный «командный» пульт. Имеет неограниченный буфер выполненных
команд и их результатов, имеет историю команд (Ctrl-P – ввод предыдущей комнды, Ctrl-N – ввод следующей команды), позволяет редактировать
вводимую строку. Запуск команды осуществляется кнопкой с молнией или клавишей Ctrl-Enter (в SVRMGR30 и OracleSQL*Plusнадо
было вводить «;», затем нажимать Enter).
Имеется также кнопка для соединения с БД. Утилитой можно пользоваться только на
клиенте, где установлен пакет OEM. Главный недостаток (запомните!) – нельзя
использовать для запуска больших скриптов (например, генерации Словаря БД),
т.к. при заполнении буфера происходит пропорциональное замедление обработки
следующих команд. Если Вам не повезет и в голову придет идея запустить скрипт
генерации БД (да еще без спулинга), то через несколько часов Вы все равно
снимите эту задачу, а потом потратите не известно сколько времени, чтобы
понять, что было создано, а что еще нет (и что надо удалять и заново
пересоздавать). Еще один недостаток – если скрипт большой или запрос
выполняется долго, а Вы переключились в другое окно, то, вернувшись, кроме
песочных часов можете обнаружить белый экран. В OracleSQL*Plusтакая
проблема возникает реже — Вы почти всегда видите весело бегущие строчки. Так
что — да здравствует неудобный OracleSQL*Plus. А если и он немеет – посмотрите, не «отвалилась» ли
сетка. Такое, к сожалению,
часто бывает.
Performance Home
Average Runnable Process
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
Average Active Sessions
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
| № | Класс события ожидания | Описание |
|---|---|---|
| 1 | Cluster | События ожидания, связанные с управлением кластером RAC (Real Cluster Application) |
| 2 | Queueing | Содержит события, которые показывают задержки получения дополнительных данных в канальной среде. Время, затраченное в этих ожиданиях, указывает на неэффективность или другие проблемы в канале, что влияет на такие функции Oracle, как Oracle Streams, параллельные запросы или PL/SQL пакеты DBMS_PIPE |
| 3 | Network | Сетевые события ожидания, включая события, возникающие во время обмена сообщениями по сети |
| 4 | Administrative | Ожидание выполнения DBA-команд, например пересоздание индекса |
| 5 | Configuration | Ожидания, вызванные неправильной конфигурацией ресурсов базы данных или экземпляра (например, недостаточный размер лог-файла) |
| 6 | Commit | События ожидания фиксации. Включает в себя одно-единственное событие ожидания log file sync (событие ожидания синхронизации файлов журналов), которое вызывают выполняемые в базе данных операции фиксации |
| 7 | Application | События ожидания, возникающие из-за кода приложения |
| 8 | Concurency | Ожидает внутренних ресурсов базы данных |
| 9 | System I/O | События ожидания системного ввода-вывода. Включает в себя события ожидания, связанные с фоновыми процессами ввода-вывода, в том числе событие db file parallel write (событие ожидания выполнения параллельной записи в файлы базы данных), которого ожидает фоновый процесс записи в базу данных, и события, связанные с чтением и записью в архивные журналы и журналы повторного выполнения |
| 10 | User I/O | События ожидания пользовательского ввода-вывода. Включает в себя события ожидания, связанные с пользовательскими процессами ввода-вывода, в том числе db file sequential read (событие ожидания выполнения последовательного чтения из файлов базы данных) и db file scattered read (событие ожидания выполнения чтения из файлов базы данных «вразброс») |
| 11 | Scheduler | События ожидания планировщика, включает в себя события ожидания, связанные с работой приложения Resource Manager (диспетчер ресурсов) |
| 12 | Other | Другие события ожидания, включает в себя разнородные события ожидания |
I/O
I/O Function
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
Некоторые рекомендации по настройке объектов БД
1.Рекомендуемые
параметры для таблиц
|
Параметр |
По умолчанию |
Общая рекомендация |
Для относи-тельно |
Для таблиц с |
|
PCTFREE |
10% |
5-20% (15) |
5 или меньше (но не 0) |
Более 10 |
|
PCTUSED |
40% |
55-90% (60) |
65 или даже 80 |
Даже 20 |
|
PCTINCREASE |
50% |
0% |
||
|
INITIAL |
10240 или 20480 |
Все даннае должны помещаться в 1 экстенте с небольшим |
||
|
NEXT |
10240 или 20480 |
От 25% до размера INITIAL |
ПРИМЕЧАНИЕ.
Должно
выполняться всегда следующее: PCTFREE + PCTUSED < 100
2.Рекомендации по количеству
сегментов отката:
·желательно на 5 пользователей 1 RBS;
·обязательно MINEXTENTS не менее 2 и PCTINCREASE не может быть указан
·Если количество одновременных
транзакций
·меньше 16 — использовать 4 RBS
·16-32 — использовать 8
RBS
·более 32 использовать 1 RBS
на 4 транзакции, но меньше 50
3.Для определения, имеется ли
конкуренция за сегменты отката, введите запрос:
select R.NAME,
S.GETS, S.WAITS


from V$ROLLSTAT
S, V$ROLLNAME R where S.USN=R.USN
Возможен такой результат запроса:
NAMEGETSWAITS
—————————— ———-
———-
SYSTEM
105 0
RB1
161 0
…
Если
WAITSGETS >= 2 — нужно сделать больше RBS
4.Другие настройки
·Для определения, имеется ли
конкуренция за ввод-вывод, введите запрос:
select
D.NAME,F.PHYRDS,F.PHYWRTS
from V$DATAFILE
D, V$FILESTAT F
where
D.FILE#=F.FILE#
Возможен такой результат запроса:
NAMEPHYRDSPHYWRTS
—————————————-
———- ———-
D:\ORAWIN95\DATABASE\SYS1ORCL.ORA
648 34
D:\ORAWIN95\DATABASE\USR1ORCL.ORA
0 0
D:\ORAWIN95\DATABASE\RBS1ORCL.ORA
65 75
D:\ORAWIN95\DATABASE\TMP1ORCL.ORA
0 0
D:\ORAWIN95\DATABASE\PLIS1.ORA
6 31
·Для определения степени
фрагментации, введите запрос:
select
TABLESPACE_NAME, sum(BYTES), max(BYTES),
COUNT(TABLESPACE_NAME)
from
DBA_FREE_SPACE GROUP BY TABLESPACE_NAME
order by
TABLESPACE_NAME
Если count(TABLESPACE_NAME) >10 -15, то необходима
дефрагментация
·Для определения, происходит ли
чрезмерное динамическое расширение, введите запрос:
select OWNER,
SEGMENT_NAME, SUM(EXTENTS)
from DBA_SEGMENTS
where
SEGMENT_TYPE in (‘TABLE’,’INDEX’)
group by OWNER,
SEGMENT_NAME
order by OWNER,
SEGMENT_NAME
Типичные операции с запросами и курсорами
Независимо от типа курсора процесс выполнения команд SQL всегда состоит из одних и тех же действий. В одних случаях PL/SQL производит их автоматически, а в других, как, например, при использовании явного курсора, они явно организуются программистом.
- Разбор. Первым шагом при обработке команды SQL должен быть ее разбор (синтаксический анализ), то есть проверка ее корректности и формирование плана выполнения (с применением оптимизации по синтаксису или по стоимости в зависимости от того, какое значение параметра 0PTIMIZER_M0DE задал администратор базы данных).
- Привязка. Привязкой называется установление соответствия между значениями программы и параметрами команды SQL. Для статического SQL привязка производится ядром PL/SQL . Привязка параметров в динамическом SQL выполняется явно с использованием переменных привязки.
- Открытие. При открытии курсора определяется результирующий набор строк команд SQL, для чего используются переменные привязки. Указатель активной или текущей строки указывает на первую строку результирующего набора. Иногда явное открытие курсора не требуется; ядро PL/SQL выполняет эту операцию автоматически (так происходит в случае применения неявных курсоров и встроенного динамического SQL ).
- Выполнение. На этой стадии команда выполняется ядром SQL .
- Выборка. Выборка очередной строки из результирующего набора строк курсора осуществляется командой FETCH . После каждой выборки PL/SQL перемещает указатель на одну строку вперед. Работая с явными курсорами, помните, что и после завершения перебора всех строк можно снова и снова выполнять команду FETCH , но PL/SQL ничего не будет делать (и не станет инициировать исключение) — для выявления этого условия следует использовать атрибуты курсора.
- Закрытие. Операция закрывает курсор и освобождает используемую им память. Закрытый курсор уже не содержит результирующий набор строк. Иногда явное закрытие курсора не требуется, последовательность PL/SQL делает это автоматически (для неявных курсоров и встроенного динамического SQL ).
На рис. 1 показано, как некоторые из этих операций используются для выборки информации из базы данных в программу PL/SQL .
![]()
Рис. 1. Упрощенная схема выборки данных с использованием курсора