Как сохранить страницу в PDF в Firefox
Подобным способом в Mozilla Firefox выполняется сохранение веб-страницы в файл формата PDF.
Пройдите следующее:
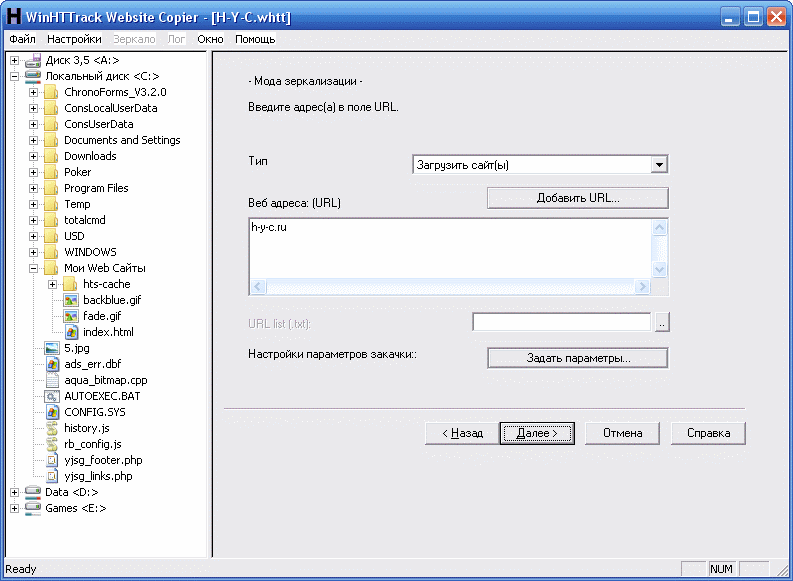
- В окне открытого сайта в браузере Mozilla Firefox нажмите на кнопку «Открыть меню приложения».
- В открывшемся контекстном меню щелкните по пункту «Печать…».
- В свойствах печати, в опции «Получать» установите «Сохранить в PDF».
- Если потребовалось, измените настройки печати.
- Нажмите на кнопку «Сохранить».
- В окне «Сохранить как», в поле «Тип файла:» выбран формат — PDF.
- Нажимайте на кнопку «Сохранить», чтобы получить готовый файл на своем компьютере.
Как скопировать веб-страницу если там установлена защита от копирования
Инструкция по загрузке страницы
Сам способ довольно прост. Он не требует особых технических знаний, но весьма любопытен в своих результатах:
- Открываем нужную страницу.
- Разворачиваем «Настройки» браузера.
- Выбираем пункт «Сохранить как…».
- Указываем место сохранения и название файла.
- Проверяем результат.
Не имеет смысла загружать подобным образом страницы с некоторых ресурсов (например, Youtube). А вот сохранить, например, рецепт блюда вполне реально. Да и от исходного кода страницы зависит очень много. Написанная на PHP страница после сохранения и открытия будет выдавать «белый экран».
Как выглядит загруженная страница?
При нормальных условиях загруженная страница выглядит, как точная копия оригинала с неактивными ссылками. Используется такой же способ хранения разметки, как и обычный. Также, следует отметить, что сохраняются все изображения со страницы.
В результате сохранения на жёстком диске создаются:
- документ выбранного расширения (зачастую .html);
- папка с названием, аналогичным документу.
В документе, который теперь можно редактировать, хранится html разметка документа. А вот папка является хранилищем для картинок. Без неё в документе будут фигурировать огромные пробелы, вызывающие недоумение.
Важно понимать, что при перемещении или смене названия папки картинки тоже пропадут. Потому что в html-документе прописывается название папки при сохранении
После загрузки менять даже расположение файла и папки категорически не рекомендуется.
Как сохранить страницу и картинку из интернета в браузере Mozilla Firefox
В браузере Mozilla Firefox найдите сверху раздел меню «Файл».Нажмите на него. В открывшейся вкладке найдите и нажмите на пункт «Сохранить как…»:
Указать место, куда нужно сохранить файл.В «Тип файла» укажите, как бы вы хотели сохранить страницу:
Нажмите «Сохранить».Если вы не можете найти раздел меню «Файл», значит нужно его включить. Для этого выполните такие действия:кликните правой кнопкой мыши по пустому полю вверху браузера. Появится меню. Выберите в том меню пункт «Панель меню».
Как сохранить текст из интернета?
Это самый примитивный, но работающий способ сохранения текста с интернета.Итак, выделите мышкой текст, который нужно сохранить.После того, как вы выделили текст, нажмите на клавиатуре сочетание клавиш «Ctrl» + «С» — копировать.Откройте любой текстовый редактор: блокнот, Microsoft Word или WordPad.Нажмите сочетание клавиш на клавиатуре «Ctrl» + «V» — вставить.
Таким способом можно не только сохранять тексты в интернете, но и картинки.
Как сохранить видео из интернета?
Как-то давно я писал в своем блоге о том, как сохранить видео из YouTube. Давайте, теперь я расскажу, как сохранить видео из интернета, точнее с сайта. Принцип действия тот же, что при скачивании видео с ютюба. Ладно, не буду болтать лишнего, приступим к делу.
Нажмите правой кнопки мыши по видео, которое размещено на сайте. В открывшейся вкладке нажмите на «Скопировать URL (Copy video URL)».
Теперь открывайте новую вкладку браузера и нажатием клавиш на клавиатуре «Ctrl» + «V» вставьте адрес видео в адресную строку.
Вам только осталось в самом начале адреса добавить две английские буквы «ss».
Например:было так — https://youtube.com/куча символова стало во так — https://ssyoutube.com/куча символов
И все, качаем с хостинга.Это все. Надеюсь, статья о том, как сохранить страницу или видео с интернета была вам полезной. Если была, жмите снизу на кнопки социальных сетей.
Метаданные html страницы
Служебная информация, которая располагается в шапке страницы и задает ее параметры, называется метаданными. HTML-теги, которые задают метаданные, называются метатегами. В нашей небольшой страничке метаданными являются следующие строки кода:
Прежде всего, это тег «title», который задает название WEB-страницы. Это название отображается в заголовке окна WEB-браузера. Кроме того содержимое тега «title» используется поисковиками для указания ссылки на данный документ в результатах поиска по ключевым словам. Поэтому старайтесь задавать интересный заголовок, содержащий ключевые слова, чтобы привлечь больше посетителей.
Следующий метатег «meta» сообщает браузеру кодировку нашего документа. В данном случае мы создали нашу web-страницу в кодировке utf-8. Информацию о кодировке мы передали браузеру с помощью атрибута «content» тега «meta».
Очень важно задавать кодировку, чтобы браузер корректно отображал содержимое нашей страницы. Если вы заметили, то тег meta не имеет закрывающего тега
Это так называемый одиночный тег, или элемент состоящий из одного открывающего тега. Вообще с помощью тега meta можно задавать множество параметров важных как для браузера, так и для поисковиков.
Обычный способ
Перед сохранением интернет-страницы следует перейти на неё. То есть обозреватель сохранит полностью всё, что там находится: картинки, текст, анимацию. Вся информация будет распределена в папке. Однако сам файл с расширением html будет выведен отдельно.
Сохранить страницу можно несколькими способами.
- Нажмите одновременно кнопки Ctrl + S.
- Жмем правой кнопкой мыши на любую часть веб-страницы. Из списка выбираем «Сохранить как…».
- При сохранении указывается путь и подтверждается.
- Открывается меню и нажимаем «Сохранить как…».
Чтобы сохранить полностью все данные, следует выбрать в поле «Тип файла» пункт «Веб-страница полностью».
![]()
Способы сохранения страницы сайта в популярных браузерах
В каждый интернет браузер встроена функция сохранения веб страницы на компьютер. Рассмотрим, на примере, как сохранить страницу сайта в браузере Opera.
Переходим в браузере Opera на страницу, которую вы хотите сохранить. В верхнем левом углу браузера отображается кнопка «Opera», при переходе на которую всплывает меню. В выпадающем меню после нажатия на вкладку «Страница» высветится пункт «Сохранить как…». Есть и более простой способ, нажав комбинацию клавиш Ctrl+S.
После нажатие на этот пункт будет предложено указать место на диске, где вы хотите сохранить файл, и выбрать его тип. По умолчанию страница сайта сохраняется в формате «Веб-архив (единственный файл)» с расширением mht. Этот формат очень удобен, ведь все элементы сайта, в том числе картинки, будут сохранены полностью и находиться в одном файле. Кроме Оперы в таком формате ещё сохраняет браузер Internet Explorer.
При сохранении как «HTML с изображениями», кроме файла с таким расширением, на компьютере создастся отдельный каталог с картинками и прочими элементами. Несмотря на то, что страница будет сохранена полностью, это не столь удобно. Ведь при копировании на флешку, порой для каталога с «увесистыми» картинками может не хватить места, и тогда сохраненный сайт откроется в виде одного текста, что не очень удобно при просмотре.
Если вам картинки не важны, есть возможность полностью сохранить её на компьютер в текстовом формате с расширением txt.
Процесс сохранения в других браузерах аналогичен, но есть некоторые нюансы. Так в браузере Google Chrome, пункт «Сохранить страницу как…» находится в меню настроек и управления (квадрат в верхнем правом углу с тремя линиями). Кроме того, Chrome не поддерживает сохранение в текстовом и архивном файле. В браузерах Mozilla Firefox и Internet Explorer пункт «Сохранить как…» появляется в выпадающем меню при нажатии на кнопку «Файл».
Строчные боксы (inline box)
Строчные боксы предназначены для представления текстового контента. Они располагаются горизонтально, как строки текста. При этом если inline box не помещается в текущую строку, то он переносится (то, что не поместилось) на следующую строку.
Строчным боксам нельзя задать ширину (width) и высоту (height), т.к. их размеры браузер вычисляют самостоятельно.
Изменить высоту этих inline boxes можно с помощью CSS свойства (высота линии).
Задание отступов в строчных боксах с помощью и выполняется очень редко, особенно это касается боксов, содержимое которых размещается на нескольких строках. Это связано с тем, что и в этом случае не работают. Для остальных строчных боксов, т.е. у которых содержимое располагается на одной строке, можно использовать различные отступы ( и ) за исключением и .
Обратите внимание, что боксы генерируются из HTML элементов, при этом тип бокса зависит от его вычисленного значения CSS свойства. При этом один и тот же элемент в зависимости его от конечного значения CSS свойства может генерироваться как inline box, так и block box
Когда создаёте HTML 5 документ применяйте элементы в соответствии с их назначением (смыслом)
При выборе элемента не придавайте важность CSS свойству , которое он имеет по умолчанию. Данное значение свойства всегда можно переназначить с помощью CSS
Использование сброса CSS
Каждый браузер имеет свои собственные стили по умолчанию для различных элементов. То, как Google Chrome отображает заголовки, абзацы, списки и так далее, может отличаться от того, как это делает Internet Explorer. Для обеспечения совместимости с разными браузерами стал широко использоваться сброс CSS.
Сброс CSS берёт все основные элементы HTML с заданным стилем и обеспечивает единый стиль для всех браузеров. Эти сбросы обычно включают в себя удаление размеров, отступов, полей или дополнительные стили понижающие эти значения. Поскольку каскадирование CSS работает сверху вниз (скоро об этом узнаете) — наш сброс должен быть в самом верху нашего стиля. Это гарантирует, что эти стили прочитаются первыми и все разные браузеры станут работать с общей точки отсчёта.
Есть куча разных сбросов CSS доступных для применения, у всех них есть свои сильные стороны. Один из самых популярных от Эрика Мейера, его сброс CSS адаптирован для включения новых элементов HTML5.
Если вы чувствуете себя немного авантюристом, есть также Normalize.css, созданный Николасом Галлахером. Normalize.css фокусируется не на использовании жёсткого сброса для всех основных элементов, но вместо этого на установлении общих стилей для этих элементов. Это требует более глубокого понимания CSS, а также знания того, что вы хотели бы получить от стилей.
Кроссбраузерность и тестирование
Как упоминалось ранее, разные браузеры отображают элементы по-своему
Важно признать значение кроссбраузерности и тестирования. Сайты не должны выглядеть исключительно одинаково во всех браузерах, но должны быть близки
Какие браузеры вы хотите поддерживать и в какой степени — это решение вы должны будете сделать на основе того, что лучше для вашего сайта.
Существует несколько вещей, на которые следует обращать внимание при написании CSS. Хорошей новостью является то, что это всё по силам и нужно немного терпения чтобы это освоить
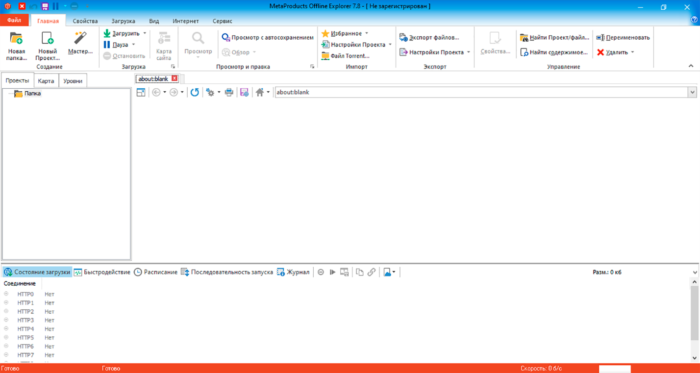
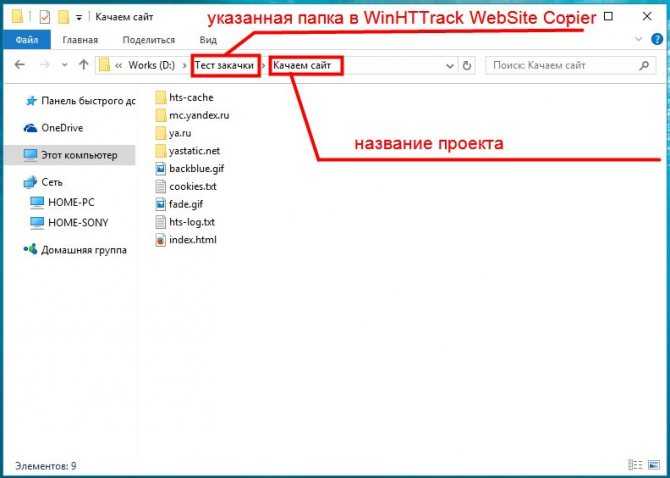
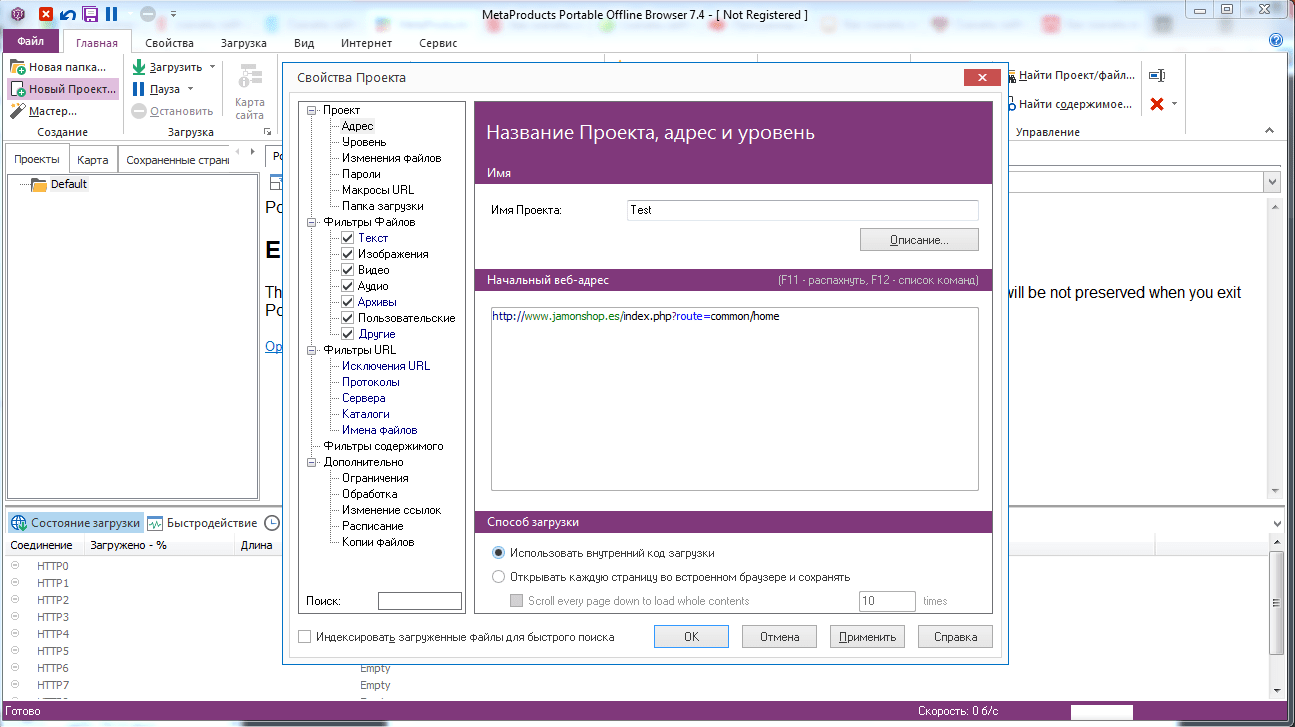
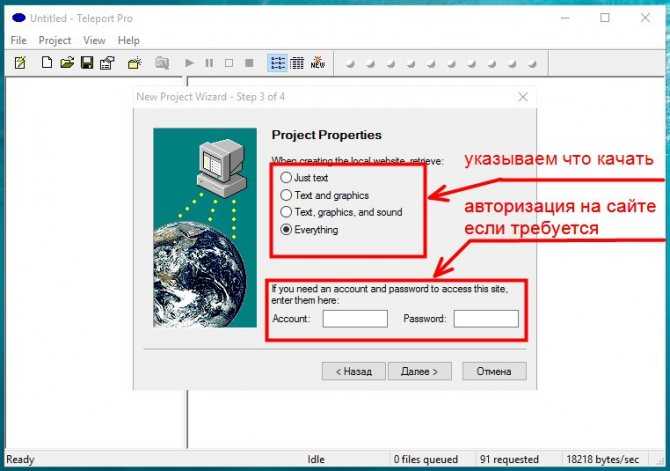
Варианты сохранения данных веб-страницы в документ формата PDF
Интернет — это один из основных современных информационных ресурсов, откуда пользователи черпают информацию. Там размещены все последние новости, зарегистрировано множество ресурсов, которые призваны развлекать, поучать и даже иногда развращать пользователей.
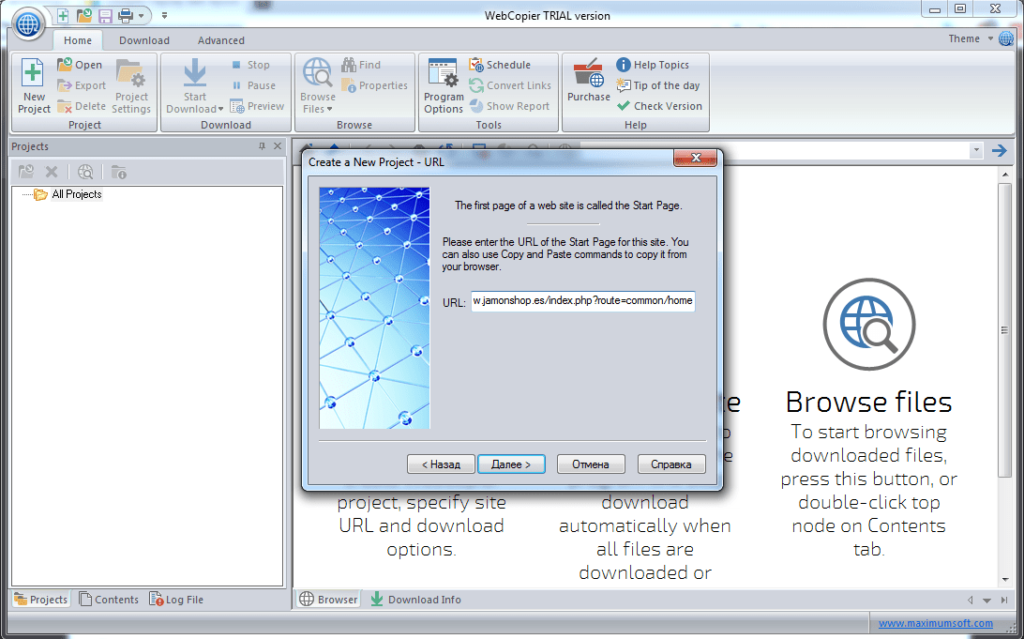
![]()
Существует много способов преобразования html-страниц в PDF
Представление информации в формате PDF
Зачастую, многие люди пытаются сохранить на компьютер себе информацию и впоследствии использовать её в своих целях (чтение, печать, изменение). Формат, в котором информация представлена удобно и с помощью дополнительного ПО доступна к редактированию — PDF. В этом формате веб-страницу в полном объёме либо частично можно сохранить к себе на компьютер. В зависимости от браузера это можно делать либо с помощью плагинов, которые могут быть уже интегрированы в браузер, либо с помощью дополнительных конвертеров.
Рассмотрим несколько вариантов для наиболее популярных браузеров.
Принцип работы в Google Chrome
На сегодняшний день Google Chrome является одним из популярных интернет-браузеров. Положительный момент в использовании этого программного обеспечения заключается в наличии интегрированных плагинов. В нашем случае — это функция сохранять содержимое веб-ресурса сразу в формат PDF.
Чтобы активировать эту опцию, нужно открыть требуемую страницу, нажать либо сочетание клавиш CTRL + P или же следующую последовательность: управление Google Chrome — Печать. В результате откроется диалоговое окно, в котором будет предложено выбрать нужное устройство для печати. Однако, среди предложенных вариантов вместо принтера выбирается опция «Сохранить как PDF» и выбрать нужное место для хранения файла.
![]()
Принцип сохранения веб-ресурсов в браузере Mozilla Firefox
Отличие браузера Mozilla Firefox от браузера Google Chrome состоит в том, что Mozilla не имеет в своём распоряжении каких-то «родных» надстроек. Соответственно и нет возможности напрямую сохранить страницу без каких-то дополнительных манипуляций и инсталляций. Благо для этого браузера есть плагин, который можно найти в свободном доступе и установить себе на рабочую станцию. Называется он Printpdf. Он благополучно добавляется в интернет-браузер и после доступен в использовании после перезагрузки Mozilla Firefox.
Чтобы сохранить веб-страницу с помощью этой надстройки, нужно выбрать в браузере меню «Файл»/«File» и далее выбрать пункт «Сохранить как PDF»/ «Print to PDF». Плагин Printpdf можно настроить таким образом, чтобы он сохранял отдельно любой блок сайта. Это производится в меню «Инструмент» — «Дополнения».
![]()
Сохраняем веб-ресурс через браузер Opera
Opera также является все ещё популярной программой, пусть и требующей повышенного объёма внутренних ресурсов компьютера (оперативной и видеопамяти). С каждым днём новые расширения появляются практически для каждого браузера. Opera не стала исключением. Надстройка Web to PDF является бесплатным конвертером, который также можно легко добавить в своё приложение и активно использовать. После добавления и перезагрузки на верхней рабочей панели появится кнопка, нажав на которую открытая веб-страница сохранится в нужном формате.
![]()
Работа с Microsoft Internet Explorer
Как же можно обойти стороной «старину» Explorer-а. Для него также в последнее время начали появляться новые доработки и плагины, но ничего подобного ещё не предусмотрено для сохранения в формате PDF. Но помочь в вопросе того, как сохранить страницу в pdf, легко поможет универсальных конвертер документов UDP. Это сторонняя утилита, которая воспринимается системой как принтер, но сохраняет веб-ресурсы в нужном формате. Работает она благополучно со всеми браузерами, в том числе и с Internet Explorer. Конечно, существует и масса других конвертеров, которые преобразуют документы в различные форматы, но именно UDP считается более совершенным и наиболее простым в работе. Сама программная составляющая совершенно не требовательна к ресурсам и вызывается операционной системой только во время преобразования.
https://youtube.com/watch?v=oyfUra-8-ek
Подытожив вышеизложенное, можно сказать, что буквально все популярные браузеры без особых проблем поддерживают функцию сохранения содержимого веб-ресурса с помощью различных прикладных программ. Эта функция делает работу браузеров более продуктивной и полезной для пользователя.
Поддержка веб-хранилища браузерами
Веб-хранилище является одной из наиболее поддерживаемой возможностью HTML5, с хорошим уровнем поддержки в каждом основном браузере. В таблице ниже приведены минимальные версии основных браузеров, поддерживающих веб-хранилище:
| Браузер | IE | Firefox | Chrome | Safari | Opera | Safari iOS | Android |
| Минимальная версия | 8 | 3.5 | 5 | 4 | 10.5 | 2 | 2 |
Все эти браузеры предоставляют возможность локального хранилища и хранилища данных сеанса. Но для поддержки события onStorage требуются более поздние версии браузеров, например IE 9, Firefox 4 или Chrome 6.
Самой проблемной является версия IE 7, которая не поддерживает веб-хранилище вообще. В качестве обходного решения можно эмулировать веб-хранилище посредством файлов cookies. Это не совсем идеальное решение, но оно работает. Хотя официального сценария для закрытия этого пробела не существует, несколько хороших отправных точек можно найти на странице HTML5 Cross Browser (в разделе «Web Storage»).
Поворотный момент
Вероятно, дальнейшее содержание заметки читателю представляется очевидным: сейчас нам предложат собственный велосипед, который, конечно, окажется на голову выше любого существующего аналога. Как бы да, но не совсем. Я действительно не выдержал мытарств с myBase и TagSpaces и набросал собственный менеджер документов, ссылку на который приведу ближе к концу. Однако этот мелкий проект для личных нужд сам по себе не заслуживал бы отдельной статьи; я пишу в большей степени потому, что мне показалось интересным поделиться опытом, полученным в процессе работы, и целым рядом неприятных сюрпризов, на которые я никак не рассчитывал.
Логика работы объекта XMLHttpRequest
В первой строке мы создаём анонимную функцию и помещаем её в переменную «inBody«. Название переменной описывает решаемую задачу — дословно «вТело«. То есть результатом выполнения этой функции будет интеграция содержимого файла text.html внутрь элемента <body> загруженной странице index.html на клиенте (в браузере)
Со второй строки начинается тело функции. С помощью конструктора объектов мы создаём новый объект XMLHttpRequest и помещаем его в локальную переменную «xhr«. Название переменной означает сокращённую запись от первых трёх букв — XMLHttpRequest (XHR). Т.к. область видимости ограничена родительской функцией, то можно использовать подобное название без опасений. В рабочих проектах не рекомендую использовать глобальные переменные с именем XHR, т. к. на практике такое имя применяется в основном к объектам XMLHttpRequest.
Третья строка запускает метод open() объекта XMLHttpRequest. В этом методе задаётся HTTP-метод запроса и URL-адрес запроса. В нашем случае мы хотим получить содержимое файла по адресу «text.html», который находится в той же директории, что и загруженный в браузер index.html. Получать содержимое мы будем методом «GET» протокола HTTP.
Четвёртая строка описывает логику работы обработчика события onload. Пользовательский агент ДОЛЖЕН отправить событие load, когда реализация DOM завершит загрузку ресурса (такого как документ) и любых зависимых ресурсов (таких как изображения, таблицы стилей или сценарии). То есть обработчиком события onload мы ловим срабатывание типа события load и полученные ресурсы мы достаём при помощи атрибута ответа объекта XMLHttpRequest.
Пятой строкой мы выводим в консоль результат ответа сервера. Она необходима для разработки. Она не обязательна
ВНИМАНИЕ! Содержимое ответа по-умолчанию имеет тип данных — string (строка). Это стандарт клиент-серверного взаимодействия. Все данные передаются по сети в виде «строковых данных»
Так всегда происходит — это норма. Если вы точно знаете каким образом строка будет оформлена, тогда вы можете воспользоваться атрибутом ответа и в этом случае содержимое ответа будет одним из:
Все данные передаются по сети в виде «строковых данных». Так всегда происходит — это норма. Если вы точно знаете каким образом строка будет оформлена, тогда вы можете воспользоваться атрибутом ответа и в этом случае содержимое ответа будет одним из:
- пустая строка (по умолчанию),
- arraybuffer
- blob
- document
- json
- text
В шестой строке мы присваиваем элементу <body> внутренне содержимое пришедшее из файла на сервере. Это содержимое будет заключено между открывающим <body> и закрывающим </body>. XMLHttpRequest имеет связанный ответ response.
Восьмая строка инициирует запрос на сервер методом send() и отправляет его.
На десятой строке мы вызываем функцию «inBody»
Как сохранить страницу сайта в PDF
Этот способ хорош тем, что на компьютер сохраняется только один файл, без папки. Но для его открытия должна быть установлена специальная программа для чтения pdf файлов. Это популярный формат, поэтому часто такая программа уже есть.
Инструкция по сохранению
1. Щелкните по пустому месту страницы правой кнопкой мышки. Из списка выберите «Печать…». Или нажмите сочетание клавиш Ctrl+P (англ.)
![]()
2. В графе «Принтер» щелкните по «Изменить».
![]()
3. Из списка выберите «Сохранить как PDF».
![]()
В браузерах Mozilla Firefox и Internet Explorer окошко выглядит иначе. Но принцип тот же: из списка с принтерами нужно выбрать тот пункт, в котором будет аббревиатура «PDF».
4. Нажмите на «Сохранить».
![]()
Ну, а дальше в окошке выбираем место в компьютере, куда нужно записать файл, и нажимаем «Сохранить». То есть выполняем пункты 2 и 3 первой инструкции.
P.S.
А еще есть такая штука как «Закладки». Это что-то вроде записной книжки в самом браузере (программе для интернета). Туда можно очень быстро записать любую страницу, но открываться она будет только при наличии интернета. Подробнее об этом читайте здесь.