
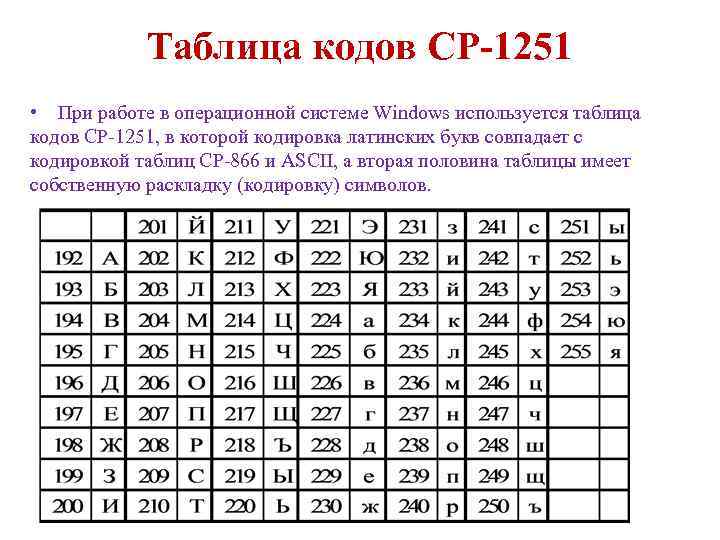
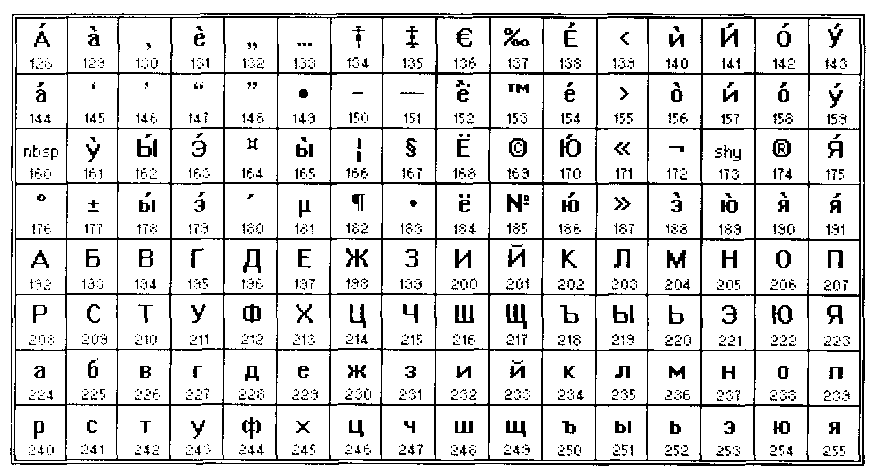
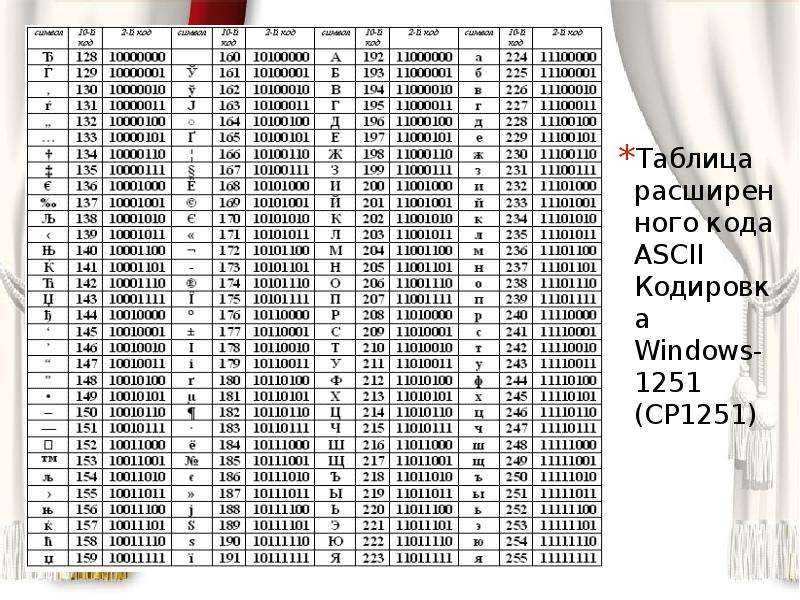
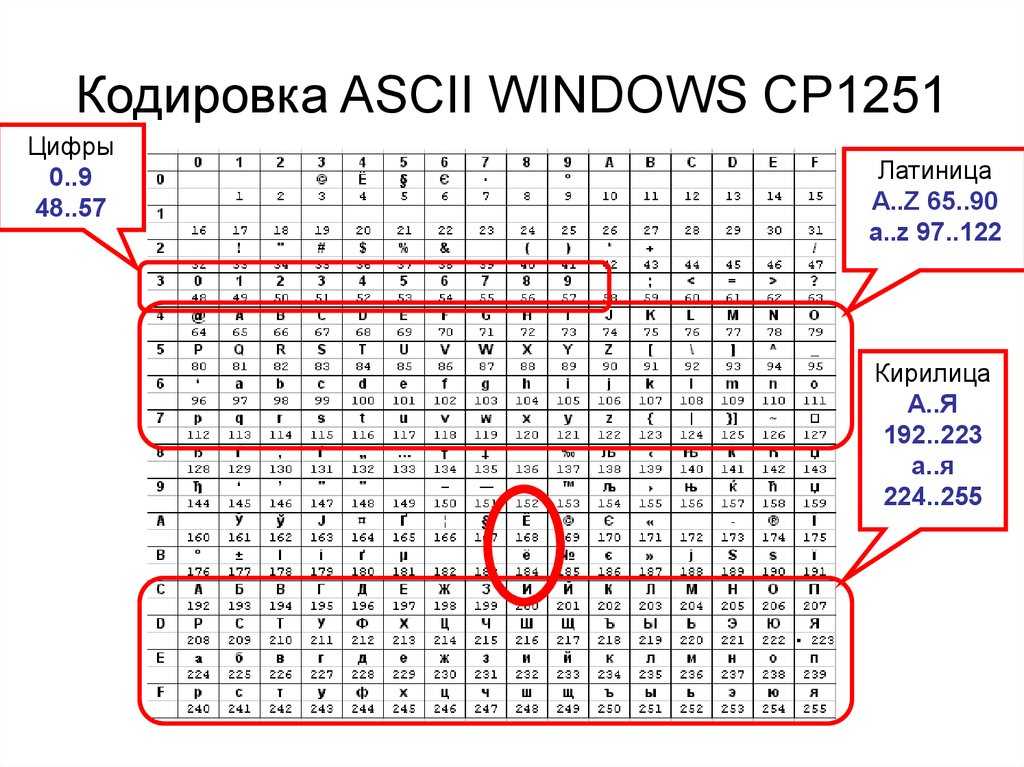
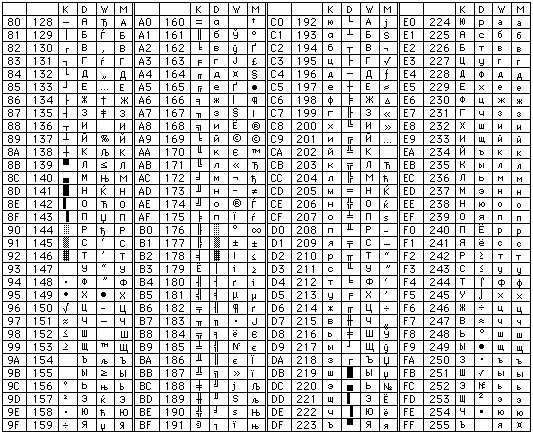
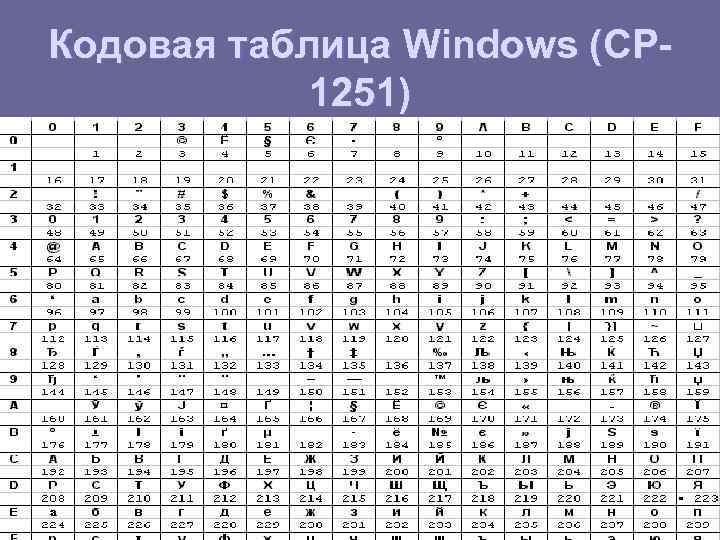
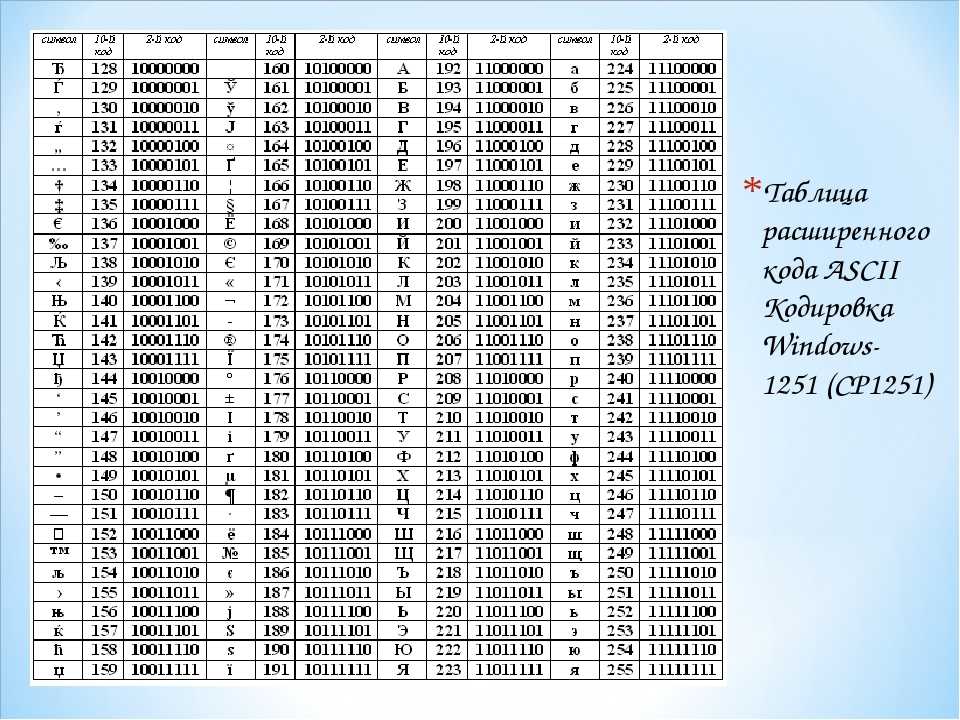
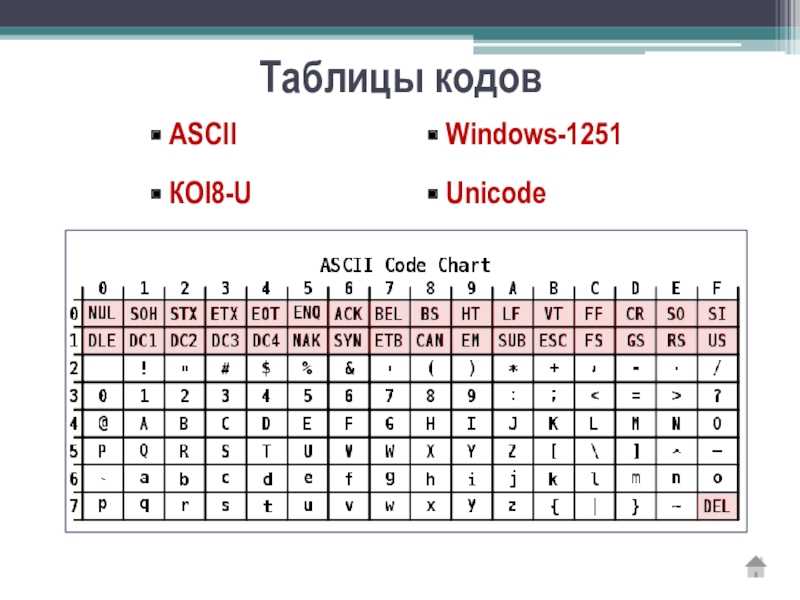
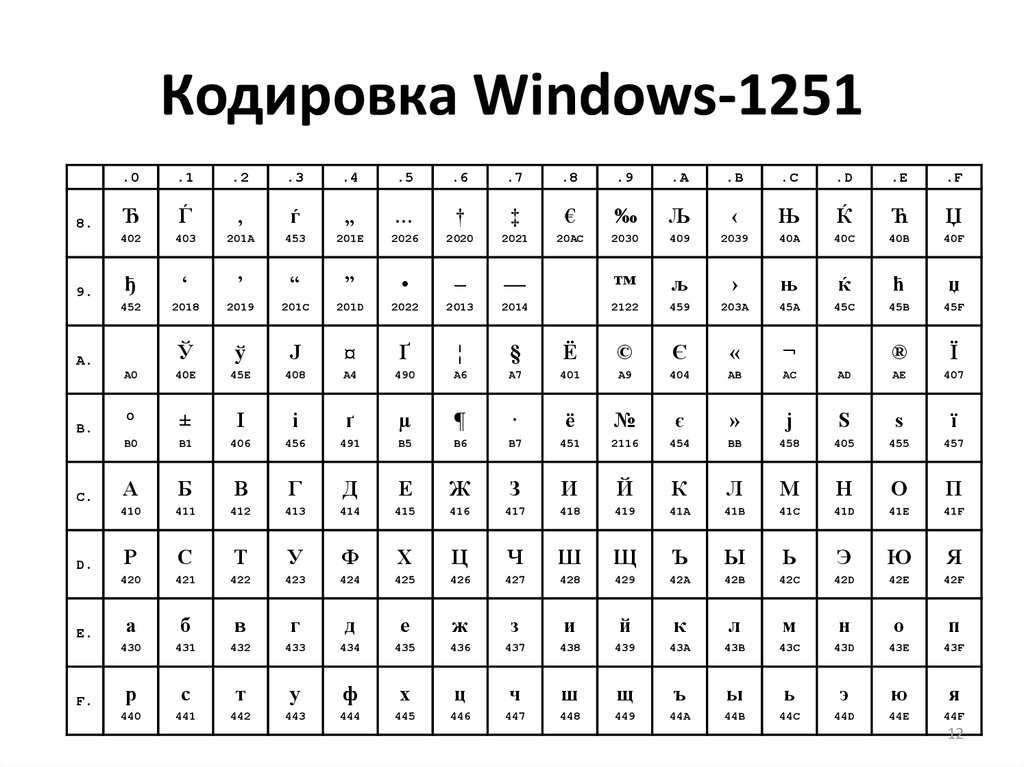
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
https://youtube.com/watch?v=OG9gsFvGtSE
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
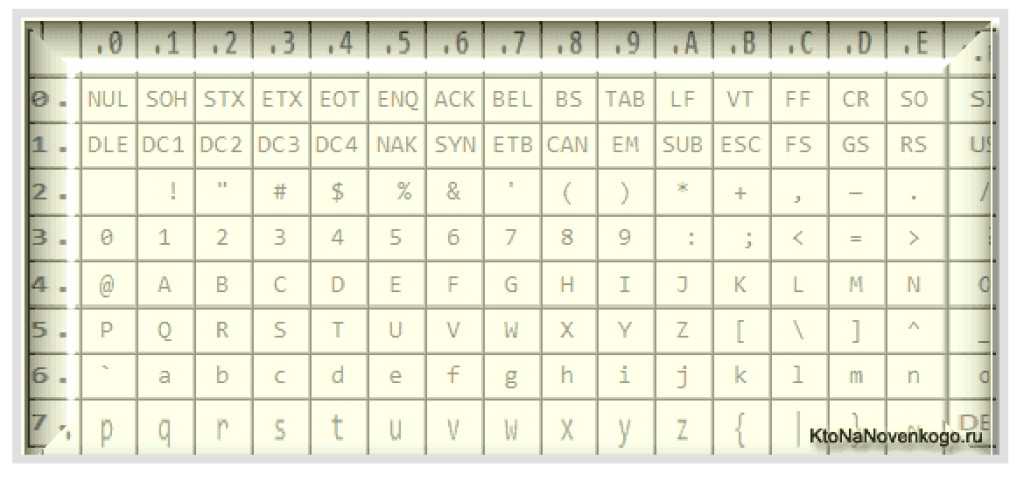
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00
Null, пустой
SOH, 01
Start Of Heading, начало заголовка
STX, 02
Start of TeXt, начало текста
ETX, 03
End of TeXt, конец текста
EOT, 04
End of Transmission, конец передачи
ENQ, 05
Enquire. Прошу подтверждения
ACK, 06
Acknowledgement. Подтверждаю
BEL, 07
Bell, звонок
BS, 08
Backspace, возврат на один символ назад
TAB, 09
Tab, горизонтальная табуляция
LF, 0A
Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B
Vertical Tab, вертикальная табуляция
FF, 0C
Form Feed, прогон страницы, новая страница
CR, 0D
Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E
Shift Out, изменить цвет красящей ленты в печатающем устройстве
SI, 0F
Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно
DLE, 10
Data Link Escape, переключение канала на передачу данных
DC1, 11 DC2, 12DC3, 13DC4, 14
Device Control, символы управления устройствами
NAK, 15
Negative Acknowledgment, не подтверждаю
SYN, 16
Synchronization. Символ синхронизации
ETB, 17
End of Text Block, конец текстового блока
CAN, 18
Cancel, отмена переданного ранее
EM, 19
End of Medium, конец носителя данных
SUB, 1A
Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче
ESC, 1B
Escape Управляющая последовательность
FS, 1C
File Separator, разделитель файлов
GS, 1D
Group Separator, разделитель групп
RS, 1E
Record Separator, разделитель записей
US, 1F
Unit Separator, разделитель юнитов
DEL, 7F
Delete, стереть последний символ.
Приход новой власти
Спасательным кругом оказался новый стандарт кодирования алфавитов – Unicode. Все его кодировки имеют в названии UTF, а после через дефис количество битов для 1-го символа.
Так вот, продвинутые умы того времени скооперировались и создали UTF-32. Конечно это решило проблему нехватки места для тех же объемных иероглифов, однако вызвало другую – размер файлов увеличивался в 4 раза.
После выделяемая память уменьшилась до 16 бит. И наконец дошла до 8.
UTF-8 является стандартом, который не использует фиксированный размер битов для одного символа и в этом ее огромное преимущество: использование переменной длины.
Благодаря этому латиница и другие простые символы кодируются 1-м байтом, как и в ASCII. А вот «тяжелые» знаки могут быть представлены от одного и до шести байт последовательно. Стоит отметить, что помимо алфавитов, в таблицах Юникода можно найти всевозможные закорючки, смайлы, греческие буквы, цветы и другие нестандартные элементы.
Вот мы и разобрали, почему UTF-8 стала лидером.
Как определить кодировку на сайте
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
Отчет о технических данных
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры


AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Таблица кодов символов кирилицы UTF-8
Область UTF-8 с кодами от U+0000 до U+0500 — это базовая область символов кирилицы.
Если Вы хотите какой-либо из этих знаков отобразить в HTML-документе, Вы можете использовать шестнадцатеричное (Hex) значение ( &#x + код + или десятичное (Dec) значение ( &# + код + из таблицы кодов.
В следующем примере видно как можно отобразить заглавную букву Ё, используя символы кодировки UTF-8:
Таблица кодов символов кирилицы UTF-8 от U+0400 до U+0500
Символ
Dec
Hex
Символ
Dec
Hex
Ѐ
1024
0400
Ҁ
1152
0480
Ё
1025
0401
ҁ
1153
0481
Ђ
1026
0402
҂
1154
0482
Ѓ
1027
0403
о҃
1155
0483
Є
1028
0404
о҄
1156
0484
Ѕ
1029
0405
о҅
1157
0485
І
1030
0406
о҆
1158
0486
Ї
1031
0407
о҇
1159
0487
Ј
1032
0408
о҈
1160
0488
Љ
1033
0409
о҉
1161
0489
Њ
1034
040A
Ҋ
1162
048A
Ћ
1035
040B
ҋ
1163
048B
Ќ
1036
040C
Ҍ
1164
048C
Ѝ
1037
040D
ҍ
1165
048D
Ў
1038
040E
Ҏ
1166
048E
Џ
1039
040F
ҏ
1167
048F
А
1040
0410
Ґ
1168
0490
Б
1041
0411
ґ
1169
0491
В
1042
0412
Ғ
1170
0492
Г
1043
0413
ғ
1171
0493
Д
1044
0414
Ҕ
1172
0494
Е
1045
0415
ҕ
1173
0495
Ж
1046
0416
Җ
1174
0496
З
1047
0417
җ
1175
0497
И
1048
0418
Ҙ
1176
0498
Й
1049
0419
ҙ
1177
0499
К
1050
041A
Қ
1178
049A
Л
1051
041B
қ
1179
049B
М
1052
041C
Ҝ
1180
049C
Н
1053
041D
ҝ
1181
049D
О
1054
041E
Ҟ
1182
049E
П
1055
041F
ҟ
1183
049F
Р
1056
0420
Ҡ
1184
04A0
С
1057
0421
ҡ
1185
04A1
Т
1058
0422
Ң
1186
04A2
У
1059
0423
ң
1187
04A3
Ф
1060
0424
Ҥ
1188
04A4
Х
1061
0425
ҥ
1189
04A5
Ц
1062
0426
Ҧ
1190
04A6
Ч
1063
0427
ҧ
1191
04A7
Ш
1064
0428
Ҩ
1192
04A8
Щ
1065
0429
ҩ
1193
04A9
Ъ
1066
042A
Ҫ
1194
04AA
Ы
1067
042B
ҫ
1195
04AB
Ь
1068
042C
Ҭ
1196
04AC
Э
1069
042D
ҭ
1197
04AD
Ю
1070
042E
Ү
1198
04AE
Я
1071
042F
ү
1199
04AF
а
1072
0430
Ұ
1200
04B0
б
1073
0431
ұ
1201
04B1
в
1074
0432
Ҳ
1202
04B2
г
1075
0433
ҳ
1203
04B3
д
1076
0434
Ҵ
1204
04B4
е
1077
0435
ҵ
1205
04B5
ж
1078
0436
Ҷ
1206
04B6
з
1079
0437
ҷ
1207
04B7
и
1080
0438
Ҹ
1208
04B8
й
1081
0439
ҹ
1209
04B9
к
1082
043A
Һ
1210
04BA
л
1083
043B
һ
1211
04BB
м
1084
043C
Ҽ
1212
04BC
н
1085
043D
Ҿ
1214
04BE
о
1086
043E
ҿ
1215
04BF
п
1087
043F
Ӏ
1216
04C0
р
1088
0440
Ӂ
1217
04C1
с
1089
0441
ӂ
1218
04C2
т
1090
0442
Ӄ
1219
04C3
у
1091
0443
ӄ
1220
04C4
ф
1092
0444
Ӆ
1221
04C5
х
1093
0445
ӆ
1222
04C6
ц
1094
0446
Ӈ
1223
04C7
ч
1095
0447
ӈ
1224
04C8
ш
1096
0448
Ӊ
1225
04C9
щ
1097
0449
ӊ
1226
04CA
ъ
1098
044A
Ӌ
1227
04CB
ы
1099
044B
ӌ
1228
04CC
ь
1100
044C
Ӎ
1229
04CD
э
1101
044D
ӎ
1230
04CE
ю
1102
044E
ӏ
1231
04CF
я
1103
044F
Ӑ
1232
04D0
ѐ
1104
0450
ӑ
1233
04D1
ё
1105
0451
Ӓ
1234
04D2
ђ
1106
0452
ӓ
1235
04D3
ѓ
1107
0453
Ӕ
1236
04D4
є
1108
0454
ӕ
1237
04D5
ѕ
1109
0455
Ӗ
1238
04D6
і
1110
0456
ӗ
1239
04D7
ї
1111
0457
Ә
1240
04D8
ј
1112
0458
ә
1241
04D9
љ
1113
0459
Ӛ
1242
04DA
њ
1114
045A
ӛ
1243
04DB
ћ
1115
045B
Ӝ
1244
04DC
ќ
1116
045C
ӝ
1245
04DD
ѝ
1117
045D
Ӟ
1246
04DE
ў
1118
045E
ӟ
1247
04DF
џ
1119
045F
Ӡ
1248
04E0
Ѡ
1120
0460
ӡ
1249
04E1
ѡ
1121
0461
Ӣ
1250
04E2
Ѣ
1122
0462
ӣ
1251
04E3
ѣ
1123
0463
Ӥ
1252
04E4
Ѥ
1124
0464
ӥ
1253
04E5
ѥ
1125
0465
Ӧ
1254
04E6
Ѧ
1126
0466
ӧ
1255
04E7
ѧ
1127
0467
Ө
1256
04E8
Ѩ
1128
0468
ө
1257
04E9
ѩ
1129
0469
Ӫ
1258
04EA
Ѫ
1130
046A
ӫ
1259
04EB
ѫ
1131
046B
Ӭ
1260
04EC
Ѭ
1132
046C
ӭ
1261
04ED
ѭ
1133
046D
Ӯ
1262
04EE
Ѯ
1134
046E
ӯ
1263
04EF
ѯ
1135
046F
Ӱ
1264
04F0
Ѱ
1136
0470
ӱ
1265
04F1
ѱ
1137
0471
Ӳ
1266
04F2
Ѳ
1138
0472
ӳ
1267
04F3
ѳ
1139
0473
Ӵ
1268
04F4
Ѵ
1140
0474
ӵ
1269
04F5
ѵ
1141
0475
Ӷ
1270
04F6
Ѷ
1142
0476
ӷ
1271
04F7
ѷ
1143
0477
Ӹ
1272
04F8
Ѹ
1144
0478
ӹ
1273
04F9
ѹ
1145
0479
Ӻ
1274
04FA
Ѻ
1146
047A
ӻ
1275
04FB
ѻ
1147
047B
Ӽ
1276
04FC
Ѽ
1148
047C
ӽ
1277
04FD
ѽ
1149
047D
Ӿ
1278
04FE
Ѿ
1150
047E
ӿ
1279
04FF
ѿ
1151
047F
Ԁ
1280
0500
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
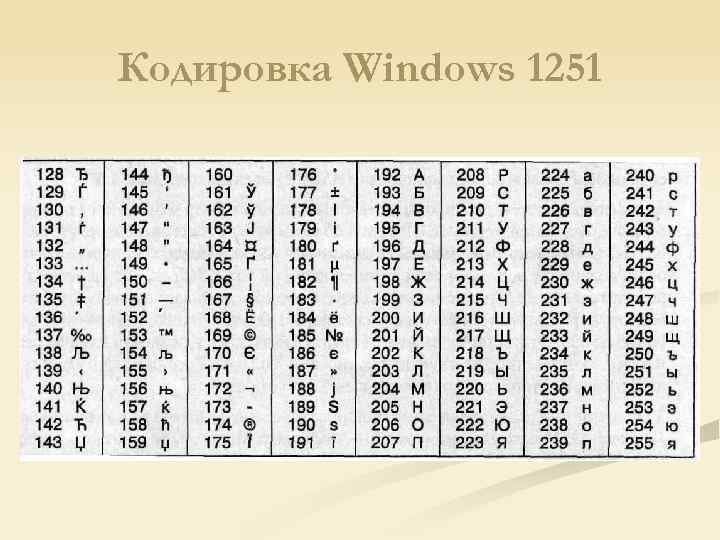
Таблица кодов символов Windows-1251
за что отвечает и как работает
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)
Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
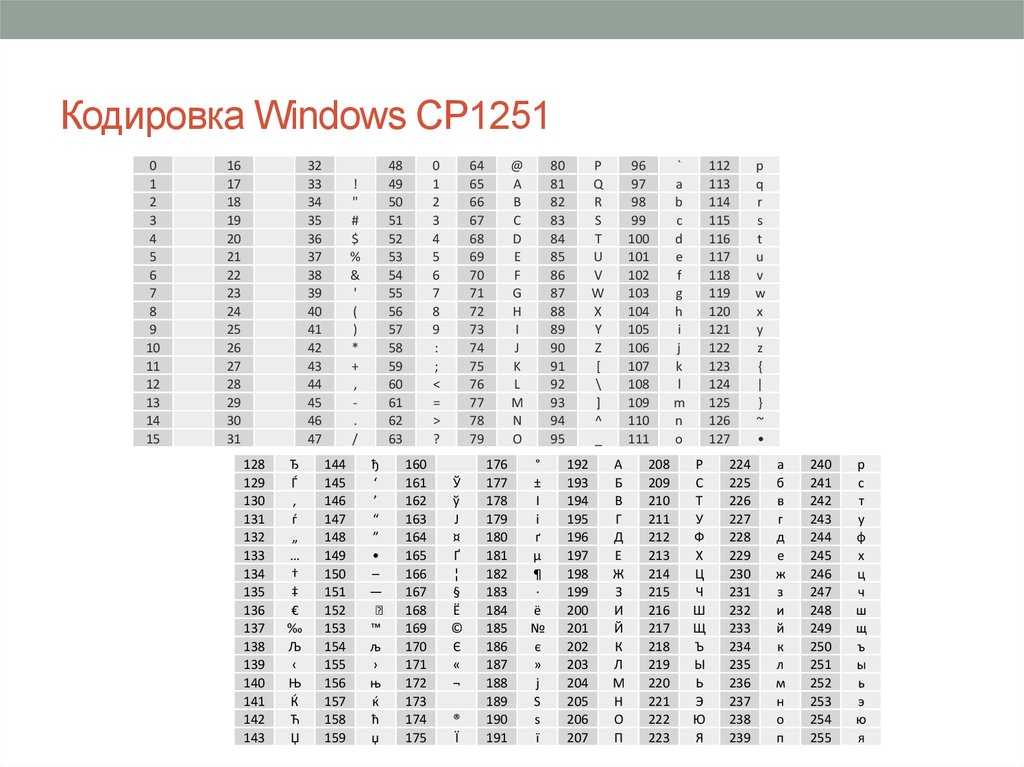
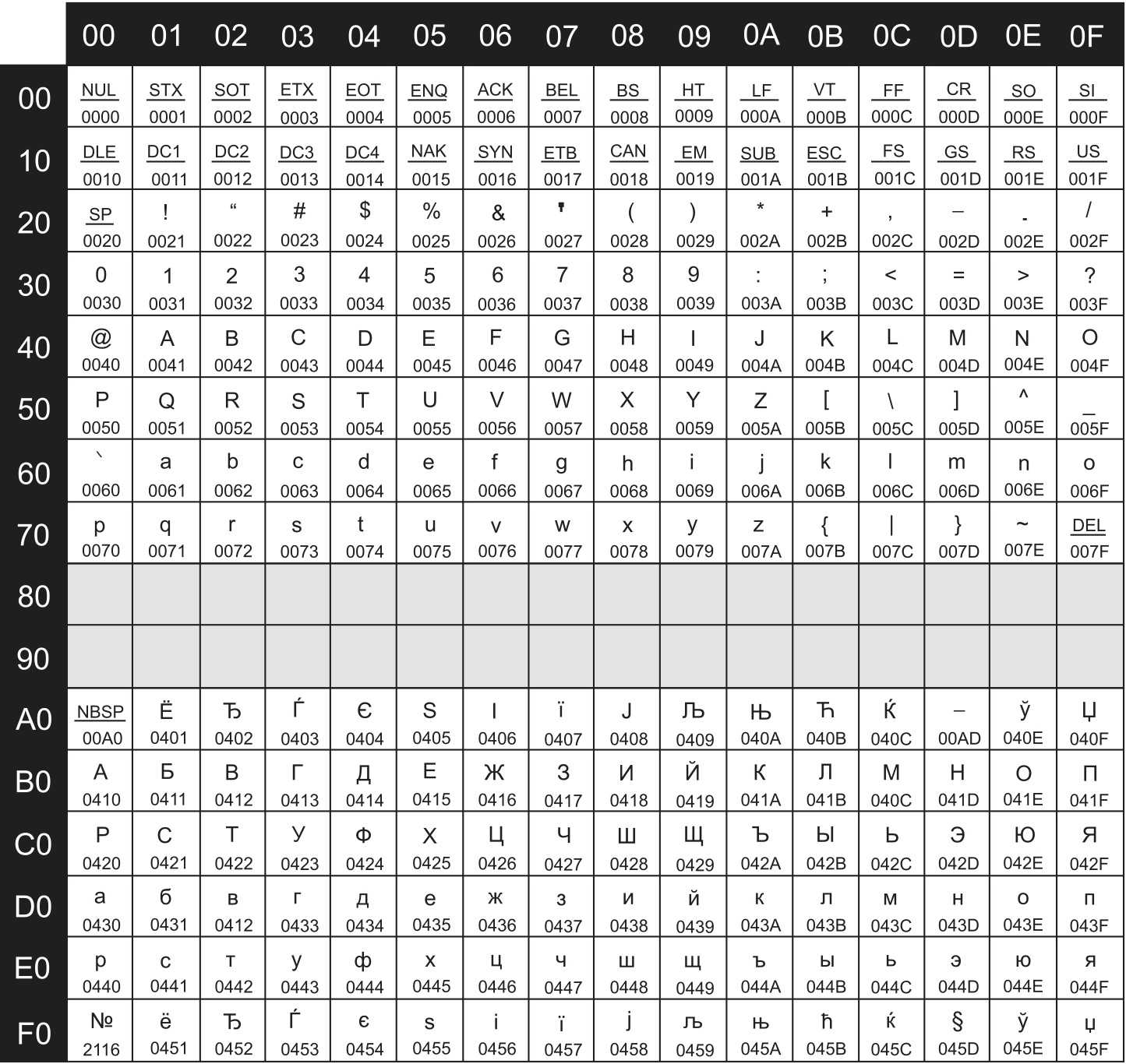
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.
Что делать, если слетела кодировка командной строки?
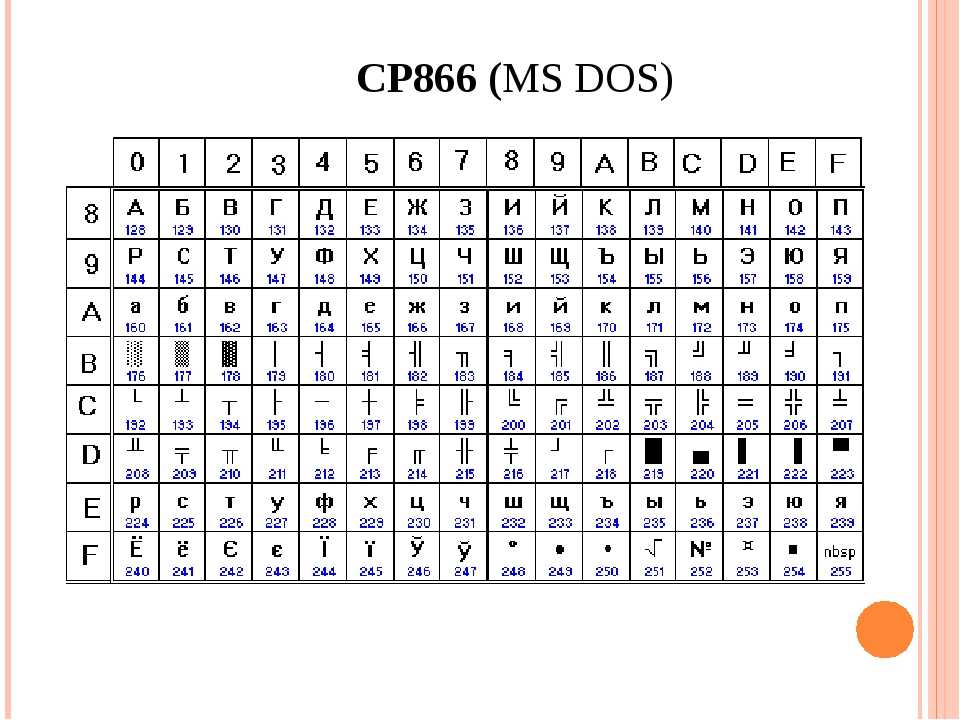
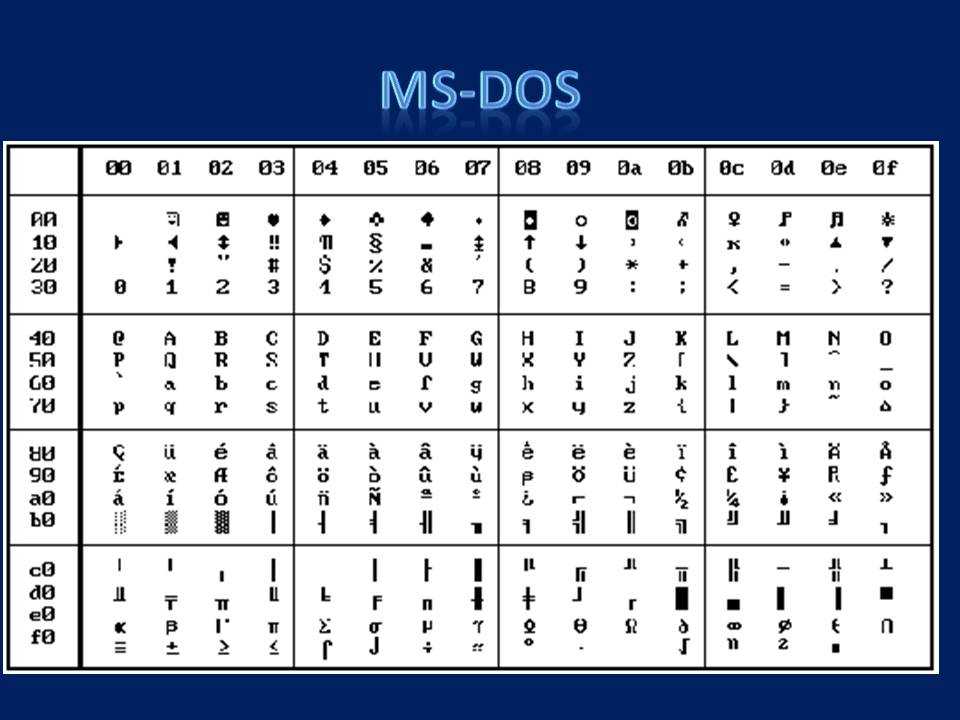
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.
- Перейдите по ветке HKEY_CURRENT_USER\Console и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).
- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.
Как установить кодировку сайта
Вы открыли сайт, но вместо текста видите непонятные закорючки, иностранные символы или цифры. Чтобы привести страницу к обычному виду, нужно вручную задать используемую кодировку.
- Mozilla Firefox
- Заходим в меню – три горизонтальные полосы справа.
- Выбираем категорию «Еще».
- Далее раздел «Кодировка текста».
- Выбираем необходимую опцию.
Opera
- Заходим настройки.
- Выбираем «Веб-сайты».
- Переходим в блок «Отображение».
- Далее – «Настроить шрифты».
- В конце выбираете кодировку.
Google Chrome
- Перейдите в меню – три точки справа вверху.
- Выберите пункт «Дополнительные инструменты».
- Откройте раздел «Кодировка».
- Откроется окно с выбором различных кодировок.
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++».
После запуска «Notepad++» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки > Кодировки > Кириллица > OEM-866»
![]()
и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.
![]()
Как видим, текст на Русском в CMD отобразился, как положено.
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.
![]()
Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
![]()
![]()
![]()
![]()
![]()
Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.
Способ 2: применение Мастера текстов
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.



![]()
Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».
![]()
![]()
Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
![]()
![]()
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».
![]()
![]()
![]()
Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.
![]()
![]()
![]()
![]()
Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.
![]()
![]()
Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
Источник
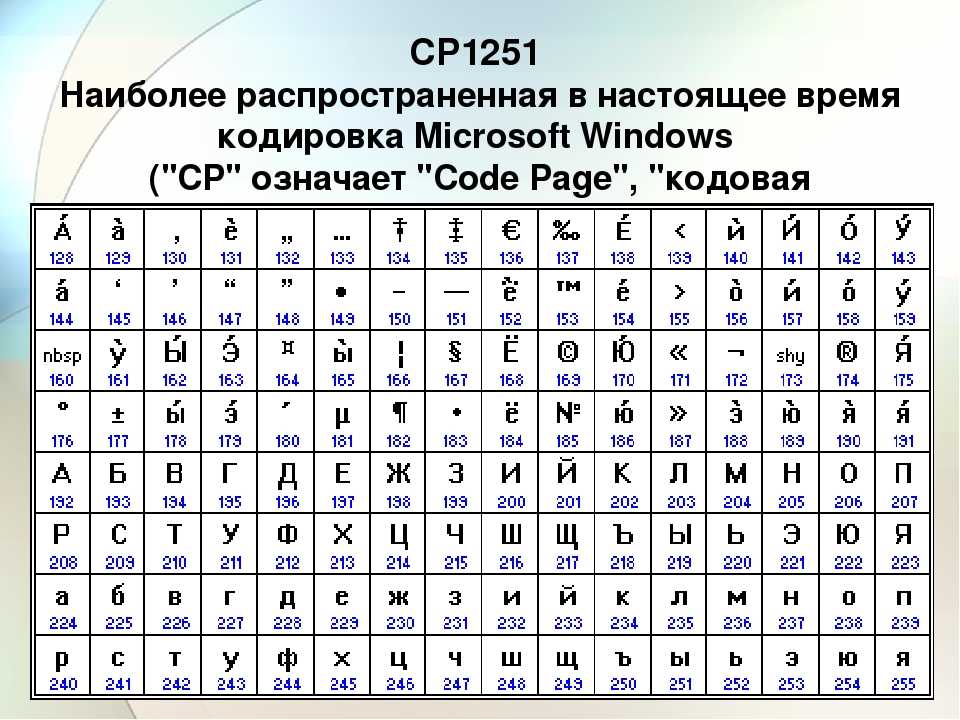
Кодировка windows 1251 в сайтостроении
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft:
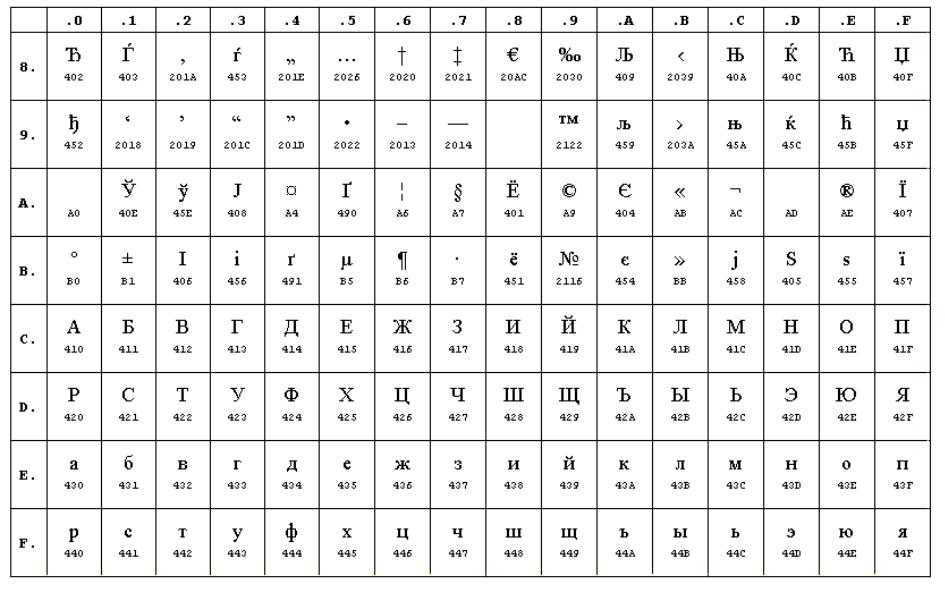
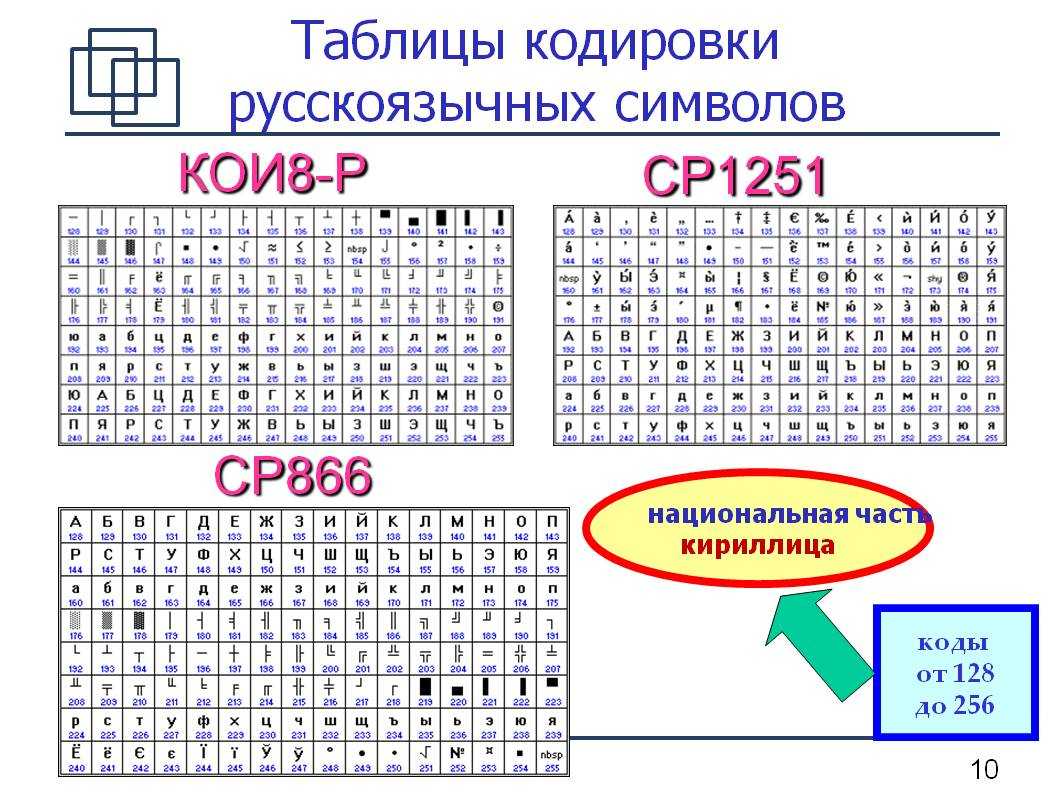
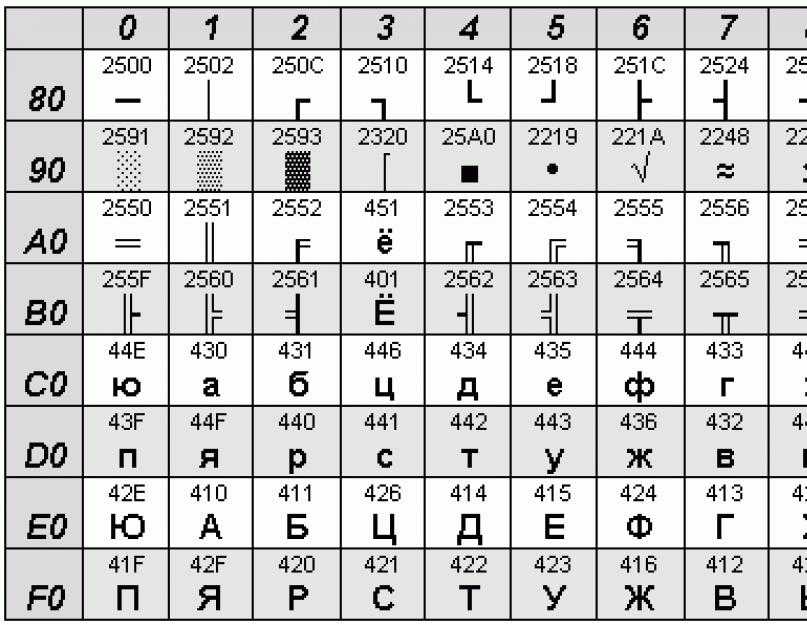
Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866). Однако у 1251-кодировки имеются и весомые недостатки:
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8, CP866.
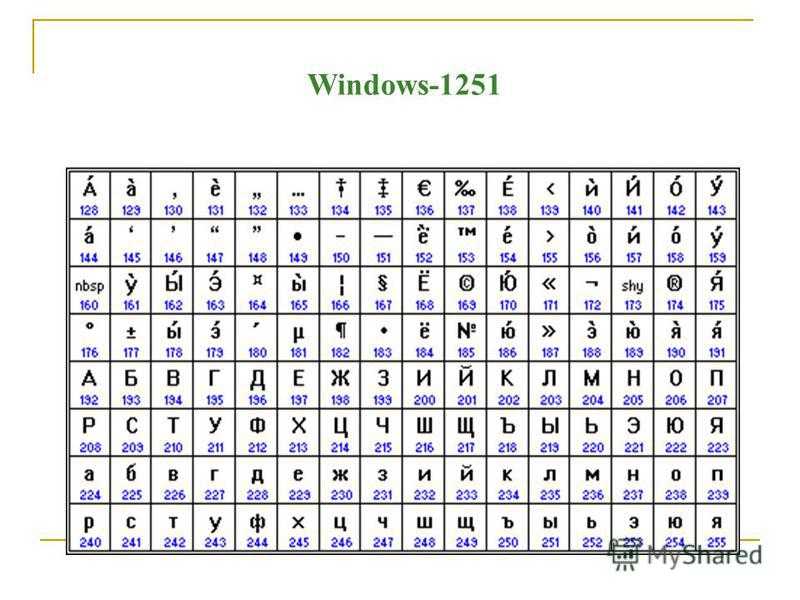
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде):
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:
Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:
Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка
Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
Ввод специальных символов в документах системы windows
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.



Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
Ввод и вывод на консоль
В качестве единственного параметра обеим функциям передается номер кодовой страницы. В нашем случае (кириллица) — это 1251.
Этот способ работает и для Windows XP, и для Windows 7. Опробовано с Dev-C++ 5.6.3 (компилятор TDM-GCC 4.8.1 32-bit) и MS Visual Studio 2012.
Следующая тестовая программа демонстрирует вывод кириллицы на консоль, ввод кириллической строки с консоли, контрольный вывод введенной строки, сравнение введенной строки с эталонной и вывод введенной строки в файл.
Исходный текст в кодировке cp1251:
Эта программа также удобна для экспериментов с различными кодовыми таблицами и их сочетаниями.
Для практических целей можно использовать шаблон:
Здесь я намеренно оставил закомментированный вызов . На ввод-вывод кириллицы он уже не влияет, но может потребоваться для других национальных настроек (разделитель дробной части числа, формат даты, времени и пр.)



