
Что такое принятие решений и решение проблем
Каждый день мы принимаем сотни решений, которые влияют на нашу жизнь: по разным оценкам только относительно еды их количество доходит до 225 в день. Решения часто оказываются неудачными, нам приходится работать с их последствиями и принимать новые решения. По данным Росстата за 2019 год, в России на 1 000 браков пришлось 653 развода, а за последние 15 лет индустрия сведения татуировок выросла на 440%.
Неэффективные, неуместные, необоснованные решения в бизнесе и управлении встречаются не реже, чем в бытовых ситуациях. Пять лет назад Мировой Экономический Форум в Давосе сделал прогноз, какие компетенции будут определять профессионала будущего в 2020 году. Сейчас это будущее уже наступило. Компетенции, связанные с принятием решений, остаются в ТОП-10 самых важных навыков, а решение сложных проблем занимает лидирующую позицию.
Прогноз 2016 года о самых востребованных навыках будущего — в 2020 году
(Фото: World Economic Forum)
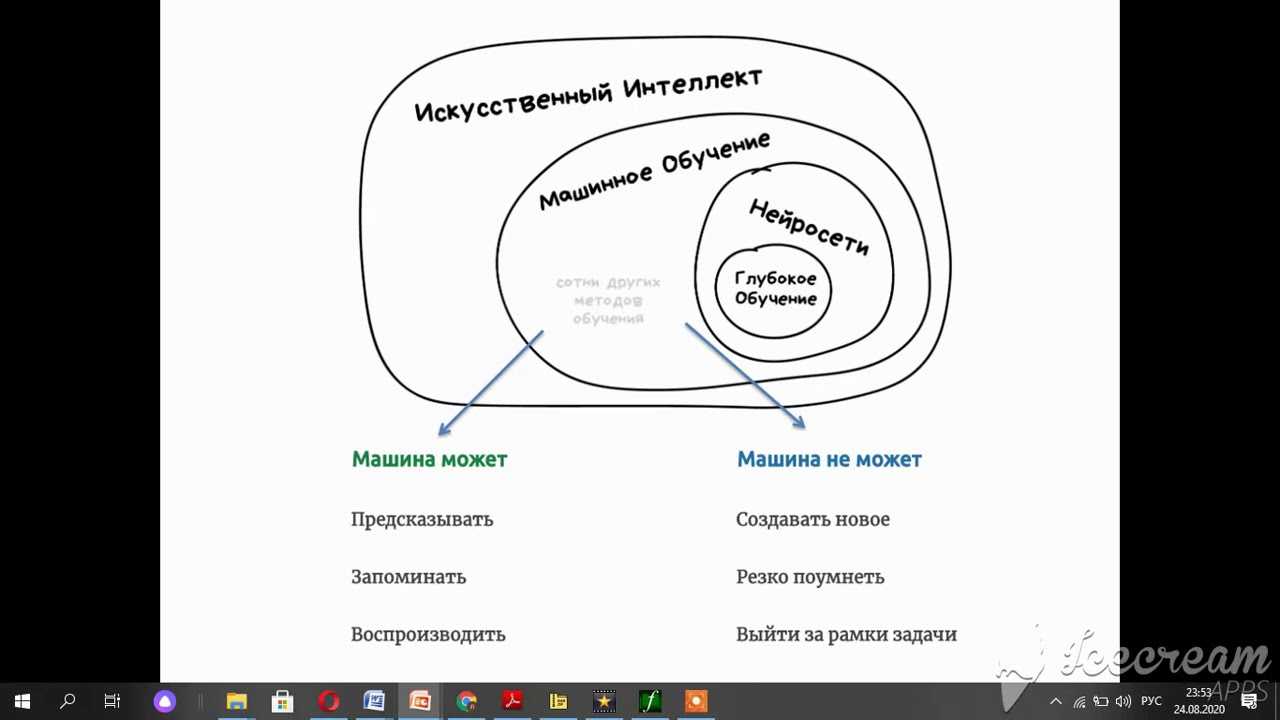
Решение проблем и принятие решений часто смешивают или используют как синонимы. Корректно их разделять, при этом рассматривать в одном «семействе» компетенций РППР (PSDM) — Решение Проблем и Принятие Решений (Problem Solving & Decision Making).
К PSDM обычно относят:
- Системное мышление.
- Стратегическое мышление.
- Критический анализ информации.
- Осознанность в принятии решений.
- Взаимодействие со стейкхолдерами.
- Креативный подход к решению проблем.
- Лидерство в условиях неопределенности.
- Стимулирование организационных изменений.
Большинство компаний, которые я консультирую, добавляют хотя бы два-три навыка из этого списка в модели корпоративных компетенций или эталонные профили должности. При этом чем выше управленческая позиция, тем серьезнее требования бизнеса и меняющегося ландшафта к уровню этих компетенций. Здесь есть две новости: хорошая и не очень.
Хорошая новость в том, что научные сообщества давно изучают PSDM с разных сторон. Например, Ариэль Рубинштейн развил концепцию Герберта Саймона о нашей ограниченной рациональности и рассмотрел наши решения в русле институциональной экономики и теории игр. Психологи-когнитивисты Дэниел Канеман, лауреат Нобелевской премии по экономике в 2002 году и Амос Тверски описали, как мы ищем «короткие» пути в решении сложных задач, но попадаем в ловушки и предубеждения. А социолог Барри Шварц в книге «Парадокс выбора» объяснил, почему большой выбор затрудняет принятие решений и приводит к ощущению неудовлетворенности.
Новость, которая не очень. Ни исследовательское, ни бизнес-сообщество до сих пор не решили, что именно считать решением: взгляды на природу решений разные, а единого определения — нет.
Ожидание: максимизируйте время простоя #
Цель: максимально увеличьте время простоя, чтобы повысить вероятность того, что страница ответит на ввод пользователя в течение 50 мс.
Принципы:
-
Используйте время простоя для завершения отложенной работы. Например, при начальной загрузки страницы загрузите как можно меньше данных, а затем используйте время простоя для загрузки остальных.
-
Выполняйте работу во время простоя не более 50 мс. Превысив этот интервал, вы рискуете помешать приложению реагировать на ввод пользователя в течение 50 мс.
-
Если пользователь взаимодействует со страницей во время простоя, взаимодействие с пользователем всегда должно иметь наивысший приоритет и прерывать работу во время простоя.
Каскадная модель (Линейная последовательная модель жизненного цикла ПО)
Каскадная модель (Waterfall Model) является одной из наиболее старых моделей, которую можно применять не только для разработки или тестирования ПО, но также практически для любого другого проекта. Его базовым принципом является последовательный порядок выполнения задач. Это значит, что мы можем переходить к следующему шагу разработки или тестирования только после того, как предыдущий был успешно завершен. Эта модель подходит для небольших проектов и применима только в том случае, если все требования точно определены. Главными достоинствами этой методологии являются экономическая эффективность, простота использования и управления документацией.
Процесс тестирования ПО начинается после завершения процесса разработки. На этой стадии все необходимые тесты переносятся с юнитов на системное тестирование для того, чтобы контролировать работу компонентов как по отдельности, так и в комплексе.
![]()
Помимо упомянутых выше достоинств, данный подход к тестированию также имеет и свои недостатки. Всегда существует вероятность обнаружения критических ошибок в процессе тестирования. Это может привести к необходимости полностью изменить один из компонентов системы или даже всю логику проекта. Но подобная задача невозможна в случае каскадной модели, поскольку возвращение на предыдущий шаг в этой методологии запрещено.
Узнайте больше о каскадной модели из предыдущей статьи.
RPA представляет собой простую и дешевую альтернативу традиционной интеграции приложений (EAI)
Научить робота, который будет имитировать деятельность пользователя в системе, оказывается быстрее, чем обращаться к ее данным или функциям через программные интерфейсы. А если речь идет о системах старых или самописных, то у них интерфейса может не быть в принципе. Тогда RPA становится «палочкой-выручалочкой».
Однако реальность бывает не столь радужна: на практике настройка робота все же требует программистской квалификации. Кроме того, получившийся сценарий оказывается «хрупким»: в случае изменения внешнего вида приложения робот не ищет элемент, и сценарий дает сбой. Особенно это характерно для облачных приложений, версии которых производитель обновляет по собственному усмотрению.
Поэтому RPA не заменяет традиционные методы интеграции. Однако удачно их дополняет, позволяя быстро интегрировать процесс, чтобы запустить его в эксплуатацию. Это позволяет решить тем самым бизнес-задачу, и уже затем по мере необходимости заменять RPA-интеграцию на более надежные вызовы программных интерфейсов.
![]()
Примеры: UiPath, WorkFusion.
Мы рассмотрели сложившиеся классы процессно-ориентированного ПО. Вследующей статье «О выборе процессно-ориентированного программного обеспечения» мы перейдем к вопросам :
- как определить, какой из них в наибольшей степени соответствует потребностям вашей организации;
- как организовать выбор конкретного программного продукта.
Шаг третий: оценка — что определяет успех? Достаточно ли хороша модель машинного обучения с точностью 95 %?
Допустим, вы определили задачу своего бизнеса в терминах машинного обучения и у вас есть данные. Теперь нужно выяснить, что определяет успех.
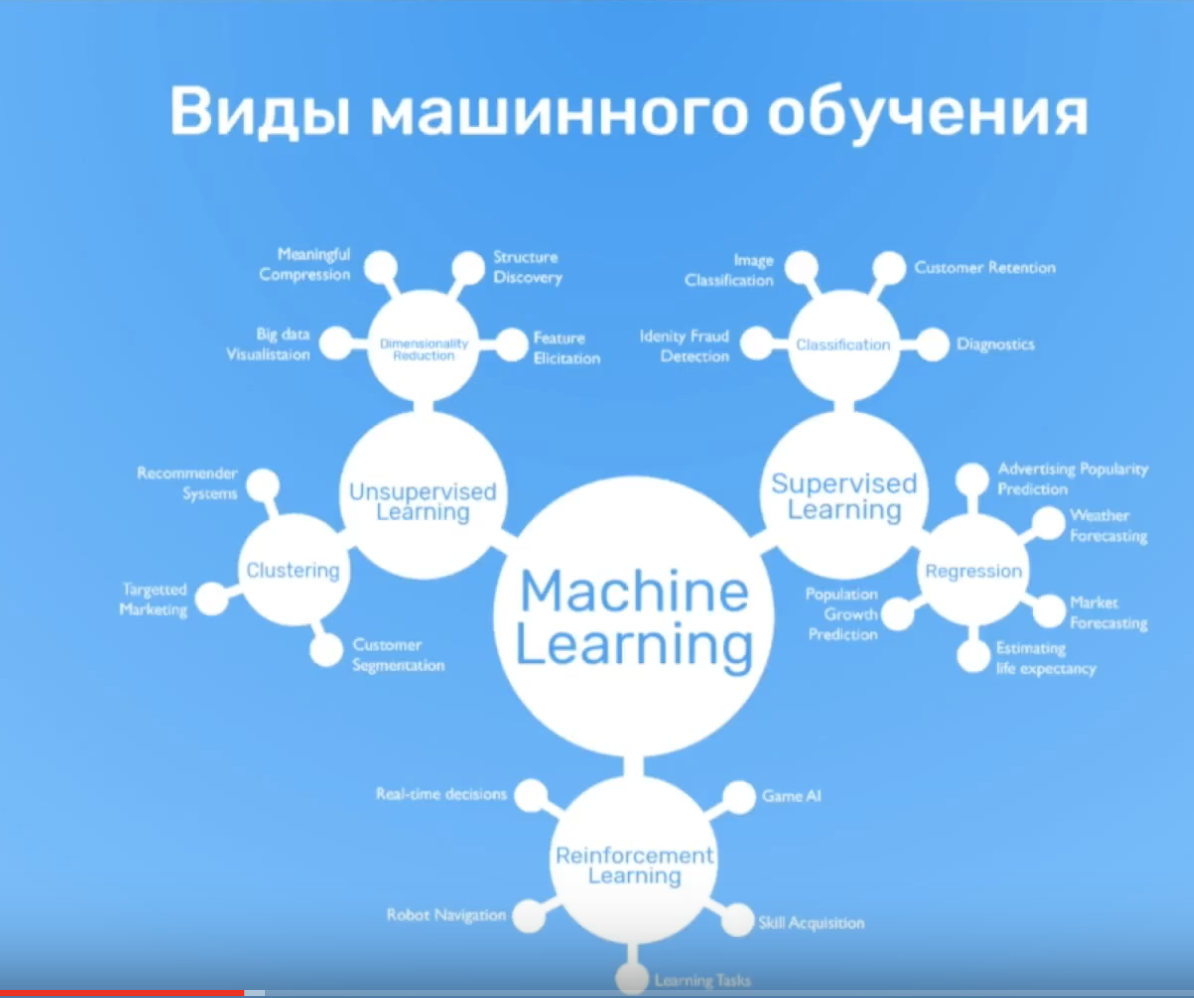
Существуют различные метрики оценки для задач классификации, регрессии и рекомендаций. Какую из них вы выберете, будет зависеть от вашей цели.
Перефразируем.
«Чтобы этот проект был успешным, модель должна быть точной более чем на 95 % в том, что кто-то виноват в аварии или нет.»
Модель с точностью 95 % может показаться довольно хорошей для предсказания виноватого в страховом иске. Но для прогнозирования сердечно-сосудистых заболеваний вы, вероятно, захотите более точных результатов.
Есть и другие вещи, которые нужно принять во внимание при классификации задач
- Ложное отрицательное срабатывание — модель прогнозирует отрицательный вариант, а на самом деле он положительный. В некоторых случаях, таких как прогнозирование спама в электронной почте, ложные срабатывания не так уж и страшны. Но будет гораздо хуже, если система компьютерного зрения для автомобилей с автопилотом не распознает пешехода, когда на самом деле он есть.
- Ложное положительное срабатывание — модель предсказывает положительный вариант, а на самом он отрицательный. Если человеку предскажут болезнь сердца, от которой он на самом деле не страдает, может показаться не таким уж страшным. Лучше перестраховаться, верно? Нет, если это отрицательно влияет на образ жизни человека или устанавливает для него план лечения, в котором он не нуждается.
- Истинное отрицательное срабатывание — модель прогнозирует отрицательный вариант, который на самом деле таковым и является. Это хорошо.
- Истинное положительное срабатывание — модель предсказывает положительный вариант, который на самом деле таковым и является. Это тоже хорошо.
- Точность — какая доля положительных прогнозов была правильной? Модель, которая не даёт ложных срабатываний, имеет точность 1.0.
- Полнота — какая доля фактических положительных вариантов была предсказана правильно? Модель, которая не даёт ложных отрицательных вариантов, имеет отзыв 1.0.
- Оценка F1 — сочетание точности и полноты. Чем ближе к 1.0, тем лучше.
- Кривая рабочих характеристик приёмника (ROC) и площадь под этой кривой (AUC) — кривая ROC представляет собой график, сравнивающий соотношение истинных положительных и ложных положительных вариантов. Метрика AUC — это площадь под кривой ROC. Модель, чьи прогнозы на 100 % неверны, имеет AUC 0.0, а модель, чьи прогнозы являются 100 % правильными, имеет AUC 1.0.
Для задач регрессии (где необходимо предсказать число), допустим, если вы хотите минимизировать разницу между тем, что предсказывает ваша модель, и тем, что является фактическим значением. Если вы пытаетесь предсказать цену, по которой дом будет продаваться, вы захотите, чтобы ваша модель максимально приблизилась к фактической цене. Для этого используйте MAE или RMSE.



Средняя абсолютная ошибка (MAE) — средняя разница между предсказаниями вашей модели и фактическими числами.
Среднеквадратичная ошибка (RMSE) — квадратный корень из среднего квадратов разностей между предсказаниями вашей модели и фактическими числами.
Проблемы с рекомендациями сложнее проверить экспериментально. Один из способов сделать это — взять часть ваших данных и спрятать их. Когда ваша модель построена, используйте её, чтобы предсказать рекомендации для скрытых данных и посмотреть, как они выстраиваются.
Однако традиционные метрики классификации не лучший вариант для задач с рекомендациями. Точность и полнота не имеют понятия порядка.
Если ваша модель машинного обучения вернула список из 10 рекомендаций, которые будут показаны клиенту на вашем веб-сайте, вы бы хотели, чтобы лучшие из них отображались первыми, верно?
— то же, что и обычная точность, однако вы выбираете отсечение k вариантов. Например, точность 5 означает, что вам важны только 5 лучших рекомендаций. У вас может быть 10 000 продуктов, но вы не можете рекомендовать их всем своим клиентам.
Для начала у вас может не быть точной цифры для каждого из них
Но зная, на какие метрики вы должны обращать внимание, вы получите представление о том, как оценить ваш проект машинного обучения
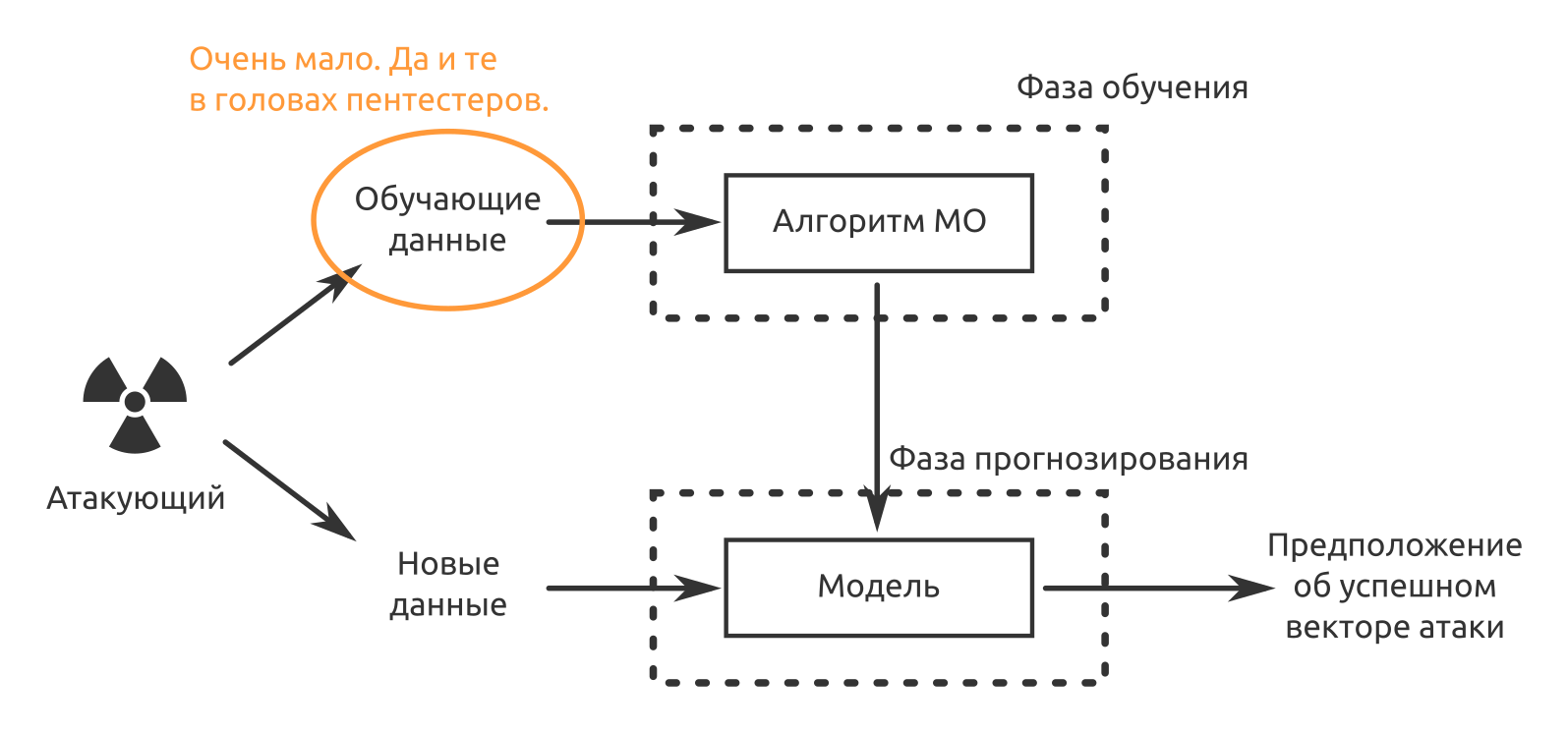
Уделяйте особенное внимание данным
Каждая модель МО обучена на данных
Поэтому на протяжении всей статьи Лоунс постоянно подчеркивает, как важно следить за их качеством. Это касается не только сбора и подготовки, но и обучения и тестирования моделей
Никакие вычислительные мощности и продвинутые технологии не помогут, если данные получены из ненадежного источника и собраны некорректным способом. И нужно проводить собственную тщательную проверку, чтобы проверить происхождение и качество данных. «Не стоит предполагать, что, поскольку набор данных использовался в ряде работ, он хорошего качества», — пишет Лоунс.
У датасета могут быть самые разные проблемы, из-за которых модель будет обучаться неверно. Во время пандемии коронавируса исследователи массово разрабатывали алгоритмы для обнаружения коронавируса, однако результаты были неутешительными.
Например, если вы работаете над проблемой классификации, и в наборе данных слишком много примеров одного класса и очень мало — другого, то в итоге обученная модель может относить все входные данные ко второй категории. В этом случает датасет пострадает из-за «дисбаланса классов».
Хотя его можно довольно быстро обнаружить с помощью методов исследования данных, найти другие проблемы будет труднее. Например, если все фотографии в наборе данных были сделаны при солнечном свете, модель будет плохо работать с темными снимками.
![]()
Фото в тексте: Unsplash
Еще более специфический пример — оборудование, которое используется для сбора данных. Например, если все снимки сделаны на одну камеру, модель может научиться определять уникальный визуальный след этой камеры и плохо работать на прочих фотографиях. Наборы данных для машинного обучения могут иметь самые разнообразные искажения.
Важно не только качество, но и количество. Стоит убедиться, что доступно достаточно данных
«Если сигнал сильный, то вам хватит меньше данных, если он слабый, то нужно больше данных», — пишет Лоунс.
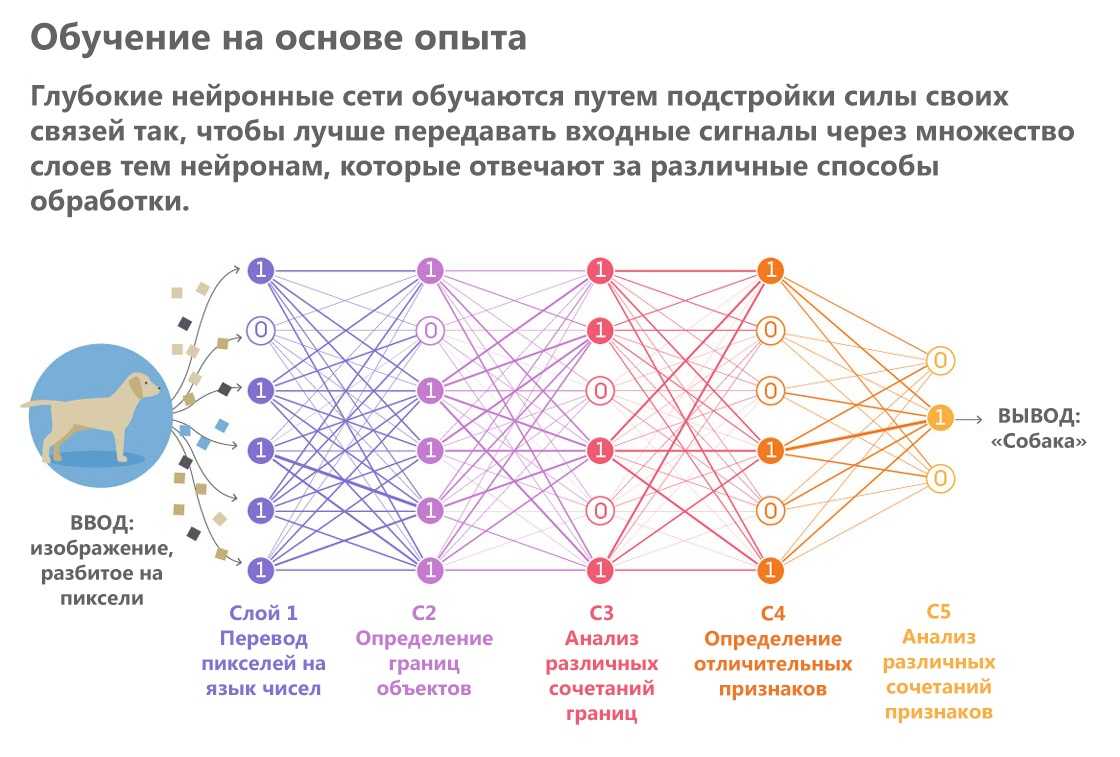
В некоторых областях недостаток данных можно компенсировать с помощью таких методов, как перекрестная проверка и приращение данных. Но в целом стоит осознавать, что чем сложнее модель, тем больше данных для обучения понадобится. Например, нескольких сотен примеров может быть достаточно для простой регрессионной модели с несколькими параметрами. Но если требуется создать глубокую нейросеть с миллионами параметров, понадобится гораздо больше обучающих данных.
Также Лоунс указывает на необходимость четко разделять данные для обучения и тестирования. Инженеры по машинному обучению обычно выделяют часть датасета для тестирования обученной модели. Но иногда данные утекают во время обучения, и в результате получаются модели машинного обучения, которые не обобщаются на данных из реального мира.
В более сложных сценариях понадобится «набор валидационных данных», который поможет провести финальную оценку модели. Например, перекрестная проверка или ансамблевое обучение не дадут точную оценку моделей. В этом случае будет полезен набор валидационных данных.
«Если у вас достаточно данных, лучше оставить их в стороне и использовать только один раз, чтобы дать объективную оценку выбранной в итоге модели», — пишет Лоунс.
Недостатки и преимущества PBL
Выбор подхода для проектирования образовательного опыта должен прежде всего основываться на целях и задачах курса, его программы, аудитории, контекста. PBL отлично работает для практико-ориентированных программ, но его можно, а иногда и нужно сочетать и с другими подходами — например, опытно-ориентированным обучением.
Полный переход на PBL также невозможен. Исследователи и практики подчёркивают, что без стандартной базы знаний работа с аутентичными задачами просто не принесёт нужного результата. Об этом говорят и сами учащиеся. Например, студент медицинского факультета Университета Британской Колумбии Эндрю Прован отмечал:
«Идеализированное проблемно-ориентированное обучение и реальное — на деле совершенно разные вещи. Если первое занятие по этой модели проходит утром в понедельник, то у студентов нет необходимого теоретического материала по предмету, и они с трудом понимают, что делать с их кейсом. Вы могли бы сказать: „Но в реальном мире у докторов тоже нет никакого представления о том, что происходит с новым пациентом!“ Это правда. Но в реальном мире у докторов уже есть хорошая база знаний, которой они могут воспользоваться».
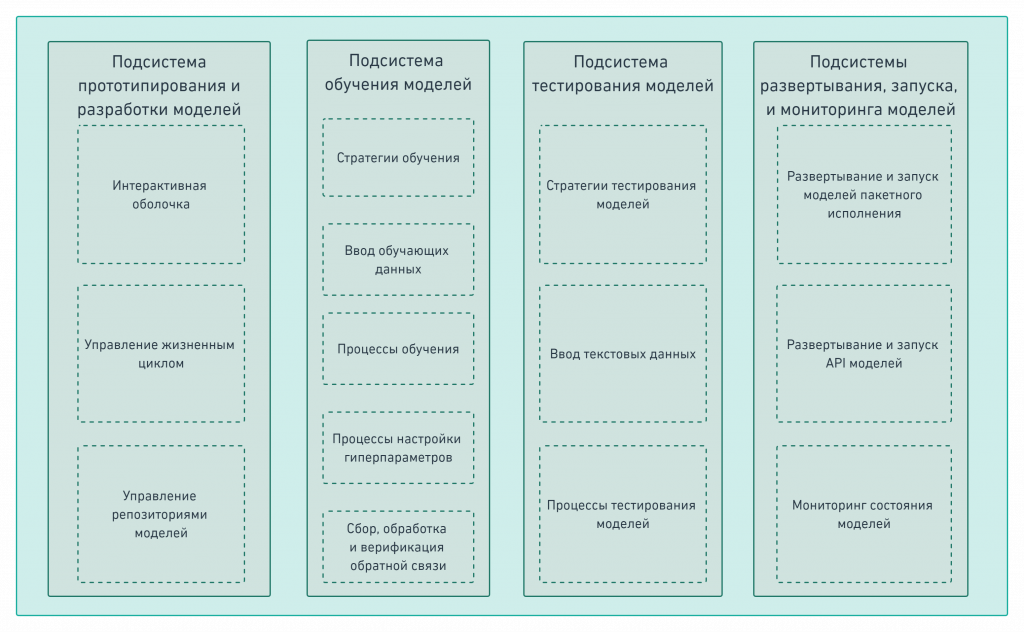
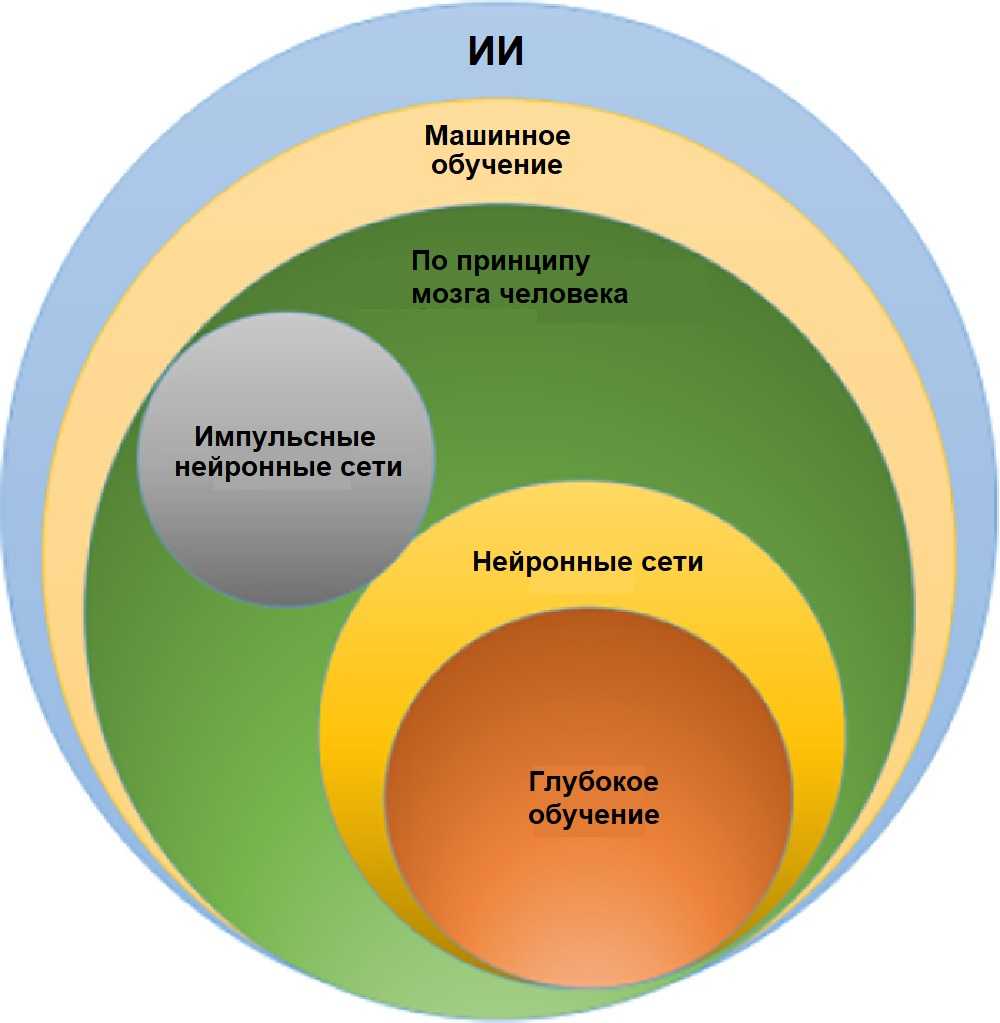
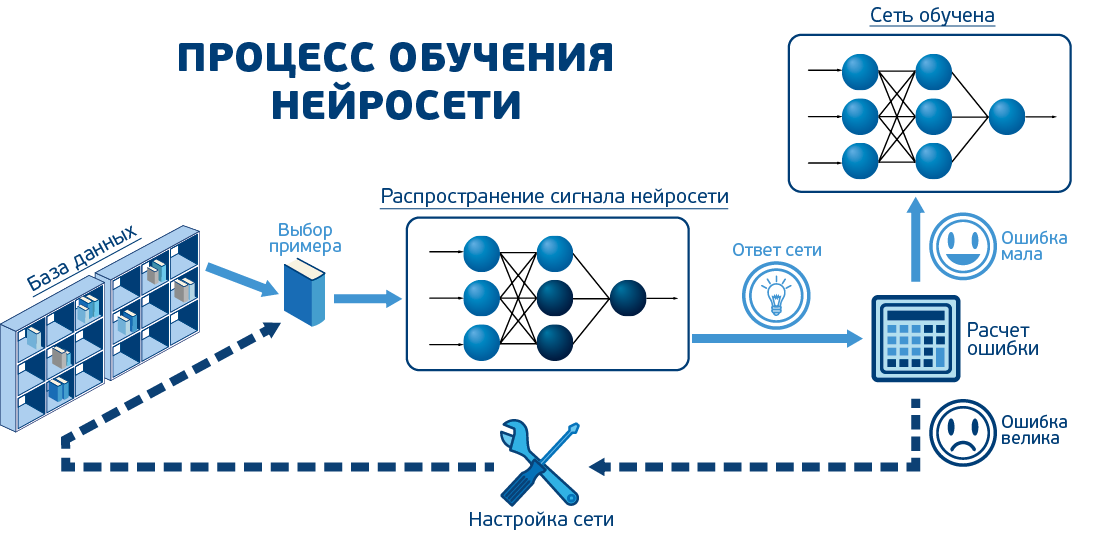
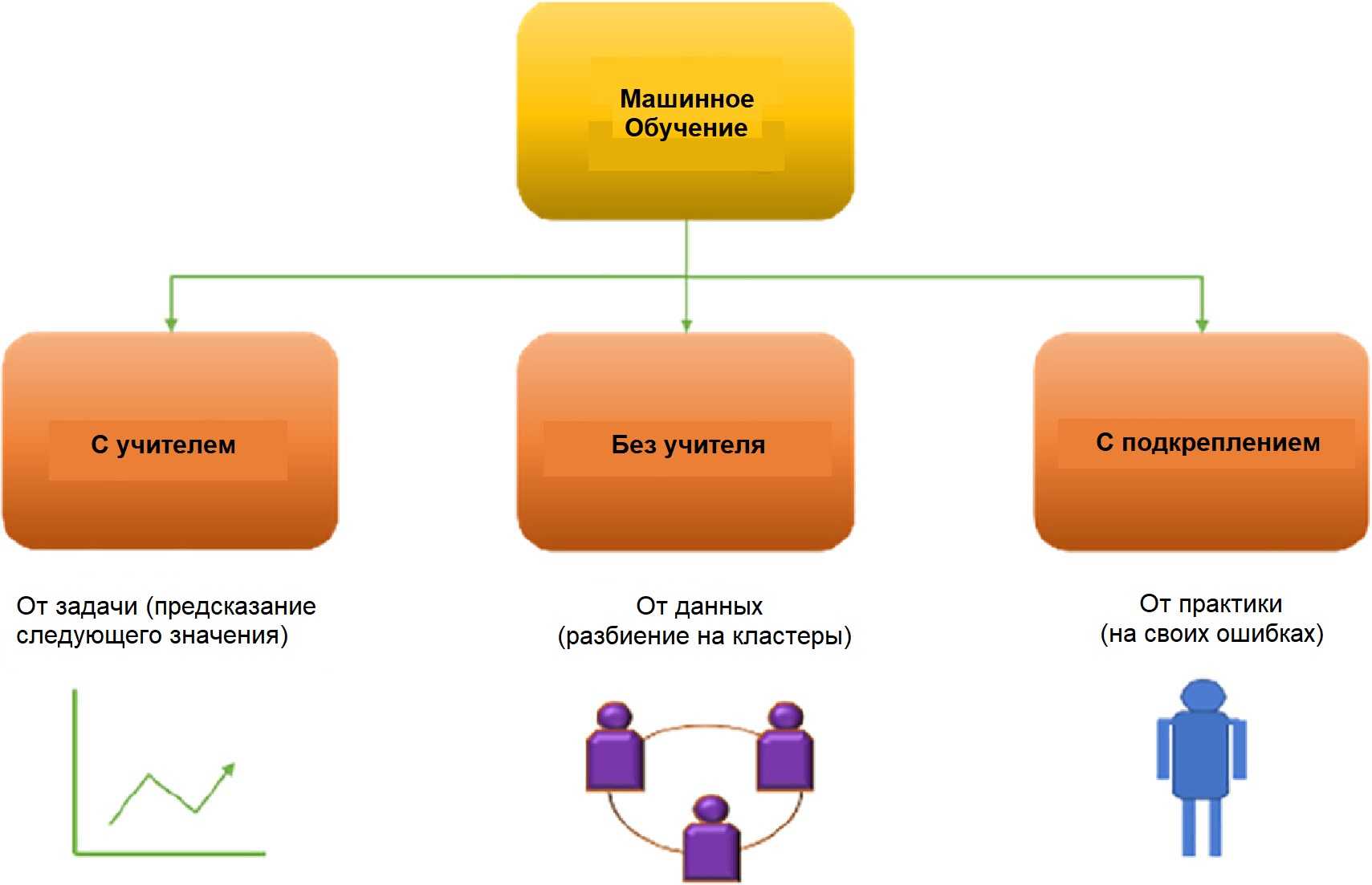

Перенести этот пример можно на любые другие специальности. Он хорошо показывает и сложности проектирования курса для PBL: учебные задачи надо адаптировать под уровень учащихся, чтобы они были посильными для них, и поначалу предоставить максимум инструментов для решения. Кроме того, подготовленные материалы необходимо вовремя актуализировать, поскольку в противном случае они просто перестанут отражать реальные запросы рынка труда.
При этом у PBL есть и ряд существенных преимуществ. Обучение на основе проблем или задач позволяет:
- упростить вход в будущую профессию и на деле показать, как применяются те или иные навыки,
- познакомить с реальной стороной выбранной специальности;
- развивать мягкие навыки, критически необходимые в современном мире.
И пусть создание курсов по любой методике PBL может быть тяжёлым процессом для методистов и значительной перестройкой для педагогов, результат часто стоит того: грамотно выстроенное обучение поможет подготовить квалифицированных специалистов, которые не боятся сделать новые шаги в профессии.
Понимайте конечную цель и ее требования
Четкое понимание задач модели машинного обучения может значительно повлиять на ее разработку. Если проект ведется только в научных целях, вероятно, вы не ограничены в типах данных или алгоритмах машинного обучения, которые вы можете использовать. Но не вся научная работа останется в стенах лабораторий.
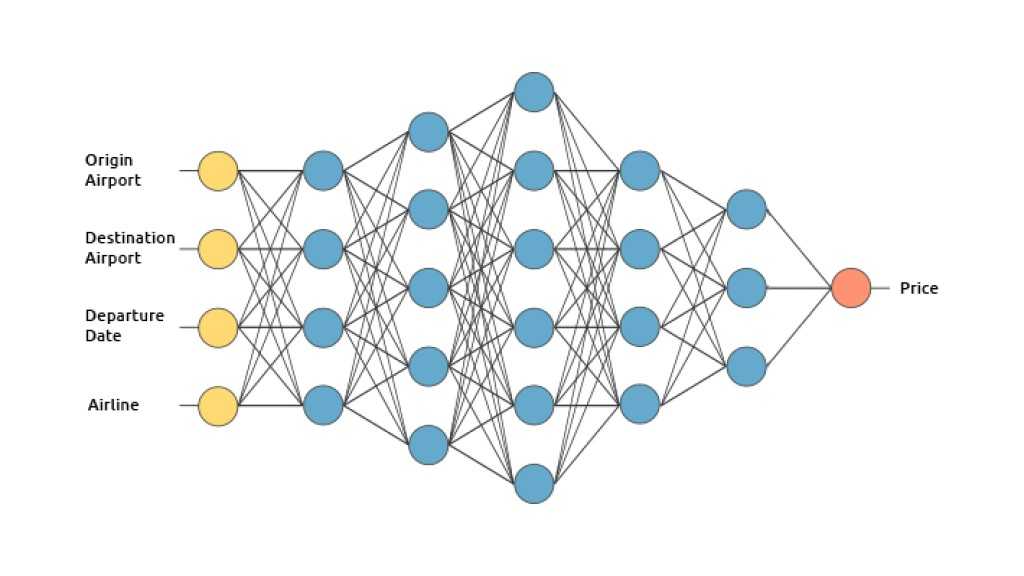
Например, если модель будет использоваться в приложении, которое работает на устройствах пользователей, а не на больших кластерах серверов, не стоит использовать крупные нейросети, которые требуют больших объемов данных и места для хранения. Придется разработать такую модель, которая сможет работать в средах с ограниченными ресурсами.
Еще одна проблема, с которой может столкнуться исследователь, — это объяснимость. В некоторых сферах, например финансах или здравоохранении, разработчики по закону обязаны объяснять, как алгоритм принимает решения, если пользователь этого потребует. В таких случаях использование модели «черного ящика» может оказаться невозможным.
Например, даже если глубокая нейронная сеть может дать вам преимущество в производительности, ее недостаточная интерпретируемость может сделать ее бесполезной. Вместо этого лучше использовать более прозрачную модель, например дерево решений. Потенциальная польза здесь перевесит снижение производительности. В качестве альтернативы, если глубокое обучение необходимо для конкретного случая, нужно изучить методы, которые могут обеспечить надежную интерпретацию активаций в нейросети.
Не каждый инженер по машинному обучению точно знает о требованиях конкретной модели
Поэтому важно поговорить с экспертами по предметной области, потому что они могут помочь направить вас в правильном направлении и определить, решаете ли вы соответствующую проблему или нет
Например, если созданная нейросеть очень точно помечает мошеннические банковские транзакции, но не объясняет свой выбор, финансовые учреждения не смогут ее использовать.
Производительность
Оба фреймворка основаны на интерпретируемых скриптовых языках. Это приводит к почти одинаковой производительности. Ранние версии Ruby, такие как 1.8 или 1.9.x, были низко производительными. В те дни Twitter перешел с Ruby on Rails на Scala, заявив, что «Twitter Search теперь стал в 3 раза быстрее». Но имейте в виду, что большинство компаний вряд ли достигнут такого же объема трафика, как Twitter.
Обычно Python считается немного быстрее Ruby. Некоторые люди могут спорить и ссылаться на сравнительное сравнение времени выполнения. Тесты показывают идентичные результаты с точки зрения производительности. Однако даже эксперты Ruby признают, что язык медленный. Хорошей новостью является то, что каждая новая версия языков программирования повышает производительность.
Трехуровневая и n-уровневая системы
Так выглядит трехуровневая архитектура
Такие архитектуры обладают высокой масштабируемостью как по горизонтали, так и по вертикали. Реализация n-уровневой системы, как правило, обходится дороже, но обеспечивает высокую производительность. Поэтому она обычно применяется в крупных и комплексных программных решениях.
Этот подход можно сочетать с современной сервис-ориентированной архитектурой, чтобы создавать сложнейшие модели. Поскольку реализация может оказаться дорогостоящей с точки зрения времени и ресурсов, рекомендуется использовать его для сложных ПО, требующих производительности и масштабируемости.
Сервис-ориентированная архитектура (SOA)
Эта архитектурная модель состоит из компонентов и приложений, которые связываются друг с другом с помощью четко определенных сервисов.
Она состоит из 5 элементов:
- сервисы (Services);
- сервисная шина (Service Bus);
- сервисный репозиторий (Service Repository );
- безопасность SOA (SOA Security);
- управление SOA (SOA Governance).
Клиент отправляет запрос с использованием стандартного протокола и формата данных по сети. Этот запрос обрабатывается ESB (enterprise service bus — сервисная шина предприятия), которая считается сердцем сервис-ориентированной архитектуры и отвечает за оркестровку и маршрутизацию. С помощью сервисного репозитория ESB направляет запрос в специальный сервис, который может взаимодействовать с другими сервисами и базами данных, чтобы составить полезную нагрузку (данные) ответа.
Полный вызов ответа на запрос согласуется с правилами управления и безопасности SOA для выполнения безопасной и корректной транзакции.
Как правило, сервисы делятся на два вида.
- Атомарные сервисы (Atomic services) предоставляют функциональности, которые не подлежат дальнейшей декомпозиции.
- Композиционные сервисы (Composite services) сочетают в себе несколько атомарных сервисов, чтобы предоставлять сложную составную функциональность.
«Медленно»
Что значит «медленно»? Поменять что-то в DOM – медленно? Как насчет тэга <script> в секции <head>? Анимация на JavaScript работает медленнее, чем на CSS, правильно? Если операция занимает 20 миллисекунд, это медленно? А если 0,5 секунды? А если 10 секунд?
Хотя разные операции требуют разного времени, чтобы быть выполненными, трудно объективно сказать, насколько это быстро или медленно
Важно обращать внимание на контекст, в котором это происходит
Например, разные части кода: одна — работающая в то время, когда на экране ничего не происходит, и другая — в момент игрового цикла, когда игрок ожидает определенную реакцию на свои действия, будут иметь разные требования к производительности. Пользователи вашего сайта или приложения будут иметь разные ожидания в отношении производительности для разных контекстов их использования.


Как и в любом аспекте UX, то, как пользователи воспринимают, является самым главным. Первая «заповедь» работы в Google звучит как «интересы пользователя – в первую очередь, и все остальное придет».
Поэтому оценивать «медленно» ли выполняется какое-то действие – бессмысленно. Нужно выяснить «что чувствует пользователь, когда он взаимодействует с чем-то, что мы сделали?»
Влияние бизнеса на RAIL
Иногда приходится создавать бизнес-кейсы для менеджеров, заинтересованных сторон и клиентов. При этом производительность является лишь частью пользовательского опыта, который мы разрабатываем.
К счастью, многие крупные компании предоставляют цифры, на которые можно ориентироваться:
- Google: на 2% медленнее = на 2% меньше поисковых запросов на пользователя.
- Yahoo: на 400 миллисекунд быстрее = на 9% больше трафика
- AOL: более быстрые страницы = больше просмотров страниц
- Amazon: на 100 миллисекунд быстрее = на 1% больше доход.
- Aberdeen Group: на 1 секунду медленнее = на 11% меньше просмотров страниц, на 7% ниже конверсия.
- Google использует скорость сайта в качестве фактора ранжирования.
Почему именно лидеры Lean-Agile?
Менеджеры, управляющие и другие лидеры организации несут ответственность за внедрение, успех и постоянное совершенствование разработки Lean-Agile и компетенций, которые приводят к гибкости бизнеса. Только они имеют право изменять и постоянно совершенствовать системы, регулирующие порядок выполнения работ. Более того, только эти лидеры могут создать среду, которая поощряет высокопроизводительные Agile-команды к процветанию и созданию ценности. Поэтому лидеры должны осваивать и моделировать более рациональные способы мышления и действий, чтобы члены команды учились с помощью их примера, наставничества и поддержки.
Стать бережливым предприятием отнюдь не легко и просто. Как описано ниже, гибкость бизнеса требует нового подхода к лидерству. Все начинается с того, что лидеры демонстрируют поведение, которое будет вдохновлять и мотивировать организацию стремиться работать эффективнее. Они подают пример, обучая, расширяя возможности и вовлекая отдельных лиц и команды в достижение их наивысшего потенциала с помощью принципов Lean и Agile.
Словом, одних знаний недостаточно. Лидеры Lean-Agile должны не просто поддерживать трансформацию: они должны активно управлять изменениями, участвуя и руководя деятельностью, необходимой для понимания и постоянного улучшения потока ценности через предприятие. Лидеры Lean-Agile:
- Организовывают и перестраивают работу вокруг создания ценности.
- Выявляют очереди и чрезмерно большое количество незавершенной работы.
- Постоянно сосредоточены на исключении потерь и задержек.
- Устраняют бессмысленные ограничения и регламенты.
- Вдохновляют и мотивируют остальных.
- Создают культуру неустанного совершенствования.
- Предоставляют командам пространство для инноваций.
Помогая лидерам развиваться по трем различным направлениям, как показано на рисунке 1, организации могут сделать бережливое и гибкое лидерство основной компетенцией:
![]() Рисунок 1. Аспекты Lean-Agile лидерства
Рисунок 1. Аспекты Lean-Agile лидерства
Эти аспекты представляют собой:
- Служить примером – лидеры приобретают заслуженный авторитет путем моделирования желаемого поведения для других, вдохновляя их на то, чтобы следовать примеру лидера в своем собственном пути развития.
- Мышление и принципы – через внедрение разработки Lean-Agile в свои убеждения, решения, реакции и действия, лидеры моделируют негласные установленные стандарты во всей организации.
- Управление изменениями – лидеры не просто поддерживают трансформацию, а именно руководят ею, создавая особую среду, подготавливая людей и предоставляя необходимые ресурсы для достижения желаемых результатов.
В последующих разделах более подробно рассматривается каждый из этих аспектов.
Использование событий для поддержания согласованности данных
В современном приложении есть различные ограничения по транзакциям, которые делают его сложным для поддержания согласованности данных в сервисах. Каждый сервис имеет свои собственные данные, но использование распределенных транзакций не является жизнеспособным вариантом. Кроме того, многие приложения используют NoSQL-базы, которые не поддерживают даже обычные локальные транзакции, не говоря уже о распределенных. Следовательно, современное приложение должно использовать управляемую событиями модель транзакции, известную как «согласованность в конечном счете» (Eventually Consistent).
Что такое событие (Event)?
Как гласит словарь Merriam-Webster (и Капитан Очевидность), «событие» — это то, что происходит (случается):
![]()
В этой статье мы определяем событие предметной области (Domain Event) как то, что произошло с агрегатом. Событие обычно представляет собой изменение состояния. Рассмотрим, например, агрегат Заказ. События, изменяющие его состояние, включают в себя Заказ создан, Заказ отменен, Заказ отправлен. События могут представлять собой попытки нарушить бизнес-правила, например, кредитный лимит Клиента.
Использование событийно-ориентированной (Event-Driven) архитектуры
Сервисы используют события для обеспечения согласованности между агрегатами следующим образом: агрегат публикует событие всякий раз, когда происходит что-то заметное. Например, его состояние меняется, или есть попытка нарушения бизнес-правила. Другие агрегаты подписываются на событие и реагируют на него путем обновления своего собственного состояния.
- АгрегатЗаказ, который создается со статусом NEW, публикует событие OrderCreated.
- АгрегатКлиентполучает уведомление о событии OrderCreated, резервирует кредит для заказа и публикует событие CreditReserved.
- АгрегатЗаказполучает уведомление о событии CreditReserved и меняет свой статус на УТВЕРЖДЕН.
Если кредитная проверка терпит неудачу из-за нехватки средств, агрегат Клиентпубликует событие CreditLimitExceeded. Это событие не отражает изменения состояния, а представляет собой неудачную попытку нарушить бизнес-правила. Агрегат Заказполучает уведомление об этом событии и меняет свое состояние на ОТМЕНЕН.



