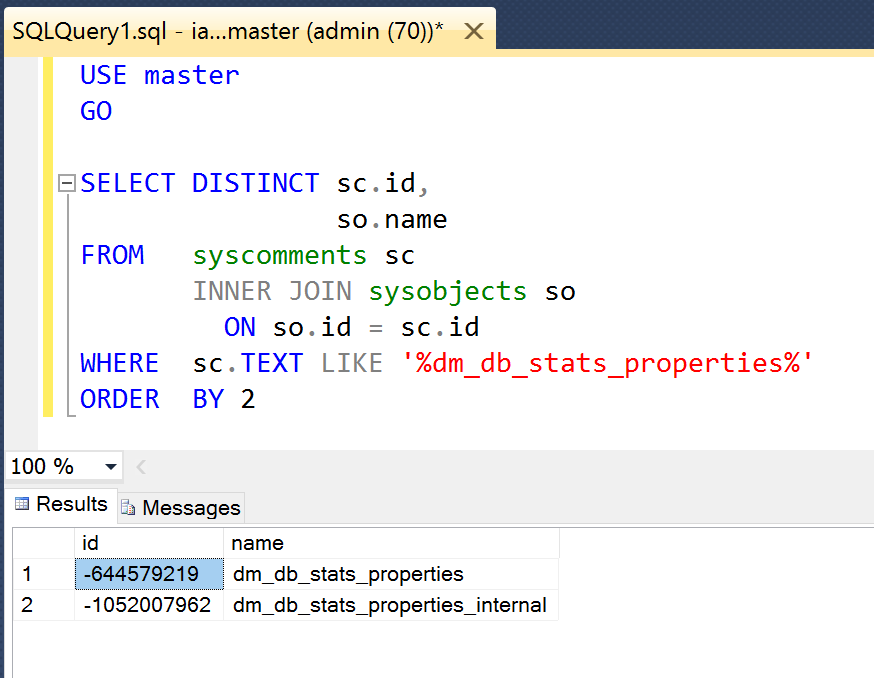
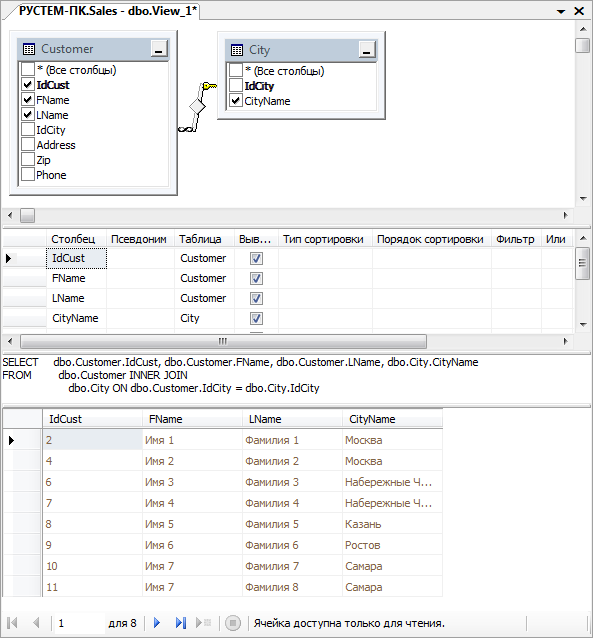
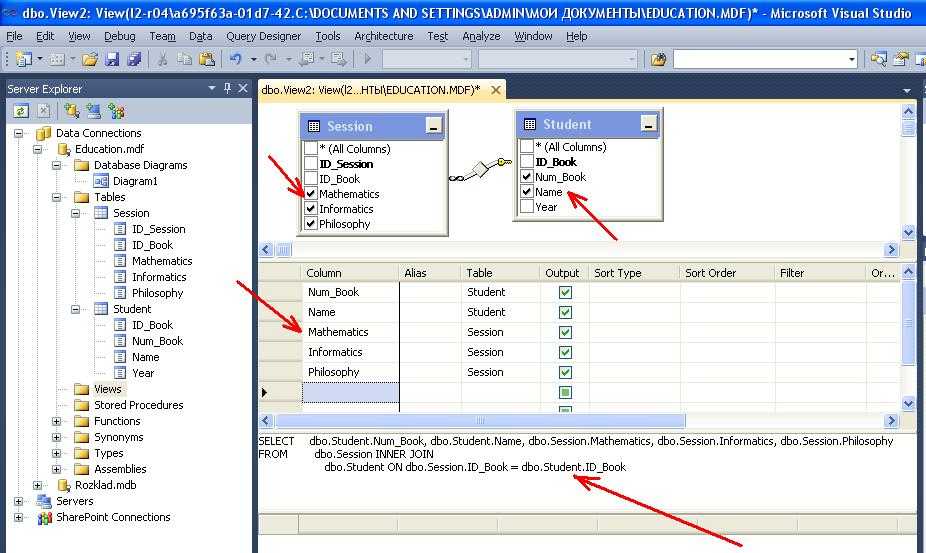
Как создать представление VIEWS?
Теперь давайте поговорим о том, как создавать эти самые вьюшки. Во-первых, сразу скажу, что для этого необходимы знания SQL (для построения сложных запросов). Во-вторых, Вы за ранее должны определиться, что Вам необходимо вывести в результате того или иного запроса. Рассматривать процесс создания представления путем нажатия кнопок мы не будем, так это достаточно просто. Мы рассмотрим создание VIEWS с использованием языка SQL (хотя и это тоже просто).
Например, в PostgreSQL запрос создания представления будет выглядеть так:
CREATE VIEW MyView
AS
SELECT id, name, org
FROM work.TableName
где,
- CREATE VIEW – команда создания представления;
- MyView – название Вашей будущей вьюшки;
- SELECT id, name, org FROM work.TableName – запрос на выборку.
Здесь мы использовали простой запрос на выборку, Вы в свою очередь можете писать любой запрос, даже с объединением нескольких таблиц и условий к ним.
Полный синтаксис команды CREATE VIEW (в PostgreSQL) выглядит следующим образом:
CREATE
VIEW view_name
AS select_statement
CHECK OPTION]
После того, как Вы создали представление, Вы можете к нему обращаться. А данные, которые будет выводить вьюшка, будут изменяться в зависимости от изменений данных в исходных таблицах, так как данные во вьюшке формируются при обращении к этому представлению. Исходя из этого, можно сделать вывод, что данные, которые выводит вьюшка, будут всегда актуальные.
У меня все, надеюсь, теперь у Вас есть представление о том, что такое VIEWS, пока!
Нравится19Не нравится3
Описание проекта
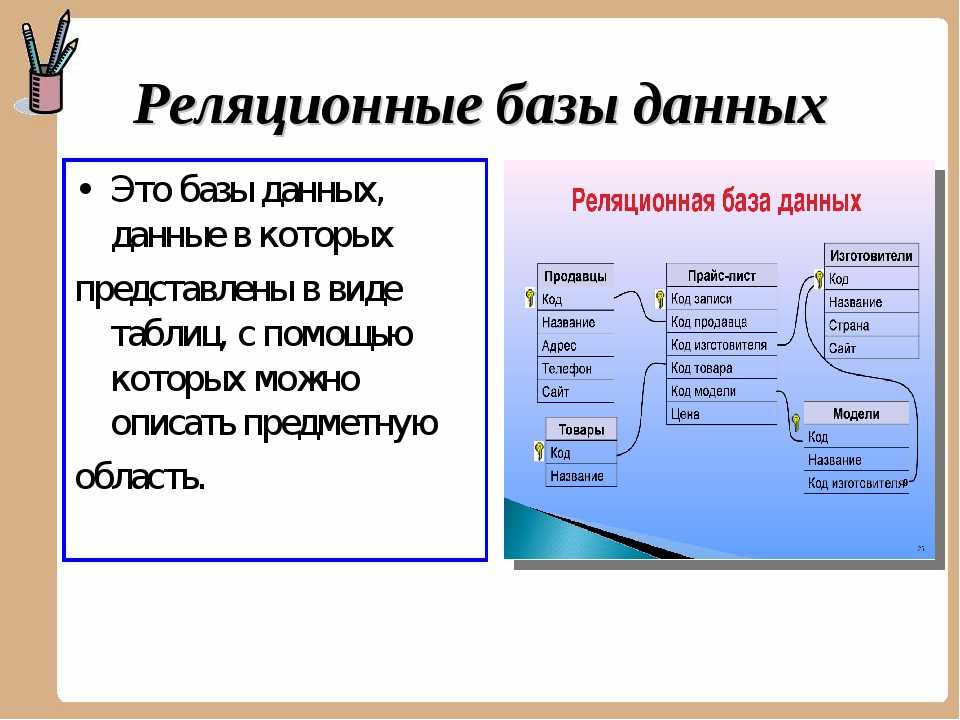
Суть проекта MOVIELISTA — упрощенная модель хранения данных сервиса IMDb с добавлением элементов социальной сети и акцентом на составление списков.
Всё начинается с самых простых, редко изменяющихся данных: список стран, кинокомпаний, жанров, всевозможных профессий/позиций в производственном процессе и список типов экранных сущностей (так как это могут не только фильмы, но и, например, сериалы, в базе они называются абстрактно titles).
TITLES
Дополнительные характеристики:
- Тип (фильм, сериал, анимация, короткометражка и тд)
- Постер
- Теглайн
- Синопсис
- Дата выхода
- Возрастное ограничение
- Состав съемочной группы
- Компания-производитель (может быть несколько)
- Страна (может быть несколько)
- Жанр (может быть несколько)
USERS
Главная движущая сила сервиса – это, естественно, пользователи Их регистрационные данные (таблица users):
- Username
- Номер телефона
- Пароль
Дополнительная информация, которую пользователь может предоставить, заполнив свой профиль:
- Аватар
- Имя
- Фамилия
- Дата рождения
- Страна
- О себе
- Приватность аккаунта
Самое интересное кроется в возможностях пользователя, которые в MovieLista достаточно обширны.
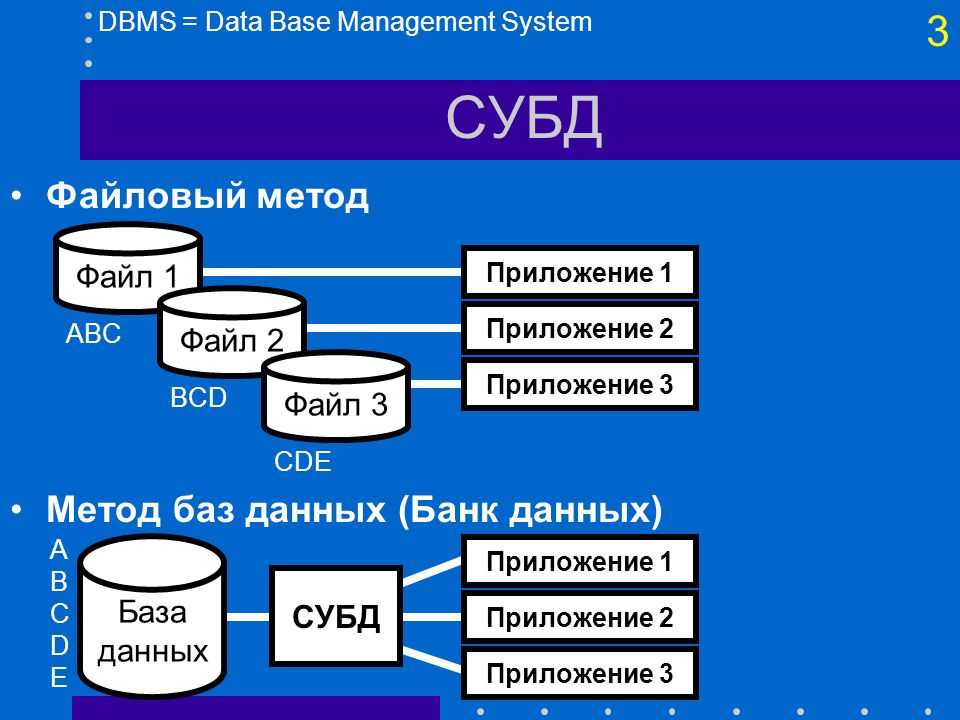
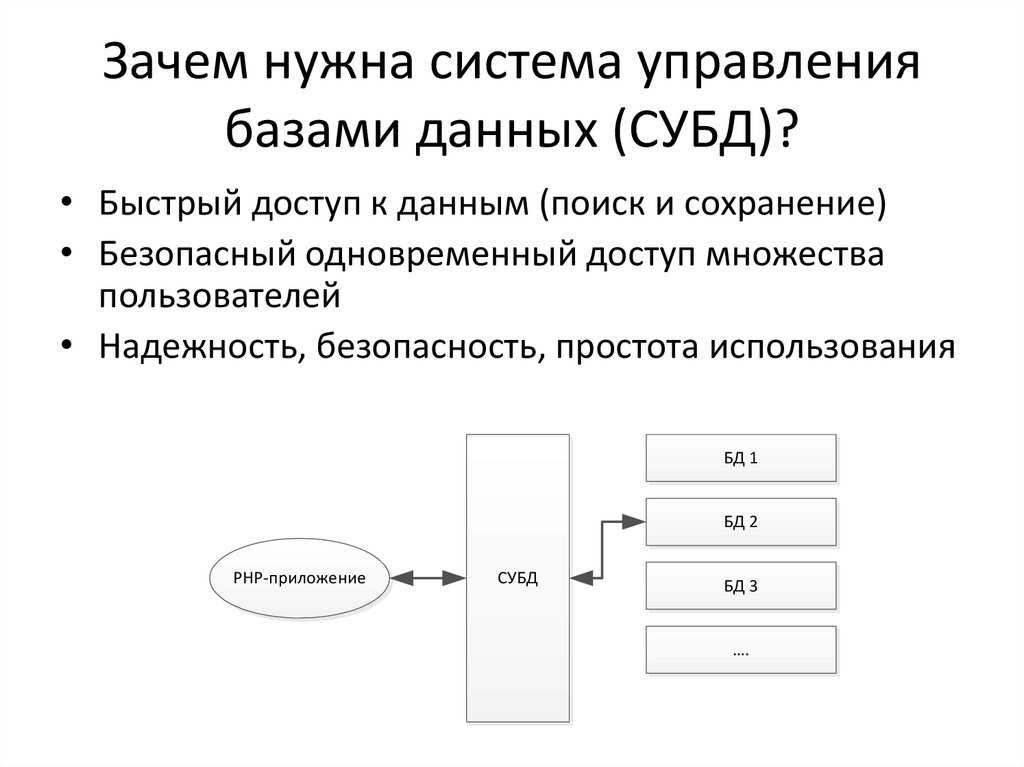
# Benefits of MySQL views
A view in MySQL stores the result of a query in a table-like structure.
You’re able to query this view just like you would query a normal table.
The power of views is twofold:
- Complex queries with joins and unions can be represented as a queryable table on their own.
- MySQL is generally smarter than us when it comes to querying data.
Compared to using collections or array functions in PHP, there’s a big performance gain.
There’s also a caveat to using views though.
Depending on the kind of query, MySQL will need to construct an «in memory» table representing the view, at runtime.
This operation is called table materialization and happens when using certain keywords like , or aggregated functions.
The takeaway is that views might actually hurt query performance,
depending on the kind of query you’re executing.
As with all things, views are a good solution for some problems, but a terrible idea for others.
Use them wisely, and read up on their restrictions here.


![Sql [айти бубен]](https://luxe-host.ru/wp-content/uploads/6/e/e/6ee3155e750f2ee3718cb030a3944a47.jpeg)

Описание структуры статьи IMRAD и ее вариаций
Классическая структура статьи IMRAD – это Introduction – Materials and Methods – Results – Discussion. Она указывает на образец или общепринятый формат, а не на полный список заголовков или компонентов исследовательских работ, так как обязательными элементами статьи еще являются: Title (Название), Authors (Авторы), Keywords (Ключевые слова), Abstract (Аннотация), Conclusions (Выводы) и References (Список литературы). Кроме того, некоторые статьи включают Acknowledgеments (Благодарности) и Appendices (Приложения).
Во «Введении» обычно обозначается объем и цель исследования в свете современных знаний по исследуемому вопросу; «Материалы и методы» описывают то, как было проведено исследование; раздел «Результаты» сообщает о том, что было найдено в исследовании; а раздел «Обсуждение» объясняет значение и значимость результатов и дает необходимые рекомендации для изучения данной темы в дальнейших исследованиях. В любом случае рукопись должна быть подготовлена в соответствии с инструкциями для авторов конкретного журнала.
Важно помнить, что не существует стандартного или единого стиля, которому следуют абсолютно все журналы. У каждого журнала свой стиль, но у каждого разработаны собственные Инструкции для авторов
После того, как вы выберете журнал, в который хотите отправить свою рукопись, следуйте инструкциям для авторов (Instructions to Authors), которые обычно можно найти в каждом выпуске журнала или на сайте журнала.
Некоторые авторы могут сомневаться в логике некоторых из этих инструкций, но спорить с журналом или жаловаться на его инструкции бесполезно. Помните, что авторы вправе свободно выбирать из ряда журналов, в которых можно публиковать свои статьи.
Вариации формата IMRAD
Так в некоторых журналах общепринятые разделы по структуре IMRAD могут быть представлены и/или подкреплены другими; например, Theory (Теория) вместо Materials and Methods. Другие модификации подразумевают объединение разделов Results и Discussion в один раздел и включение Conclusions (Выводы) в качестве последней части раздела Discussion.
Недавняя тенденция состоит в том, чтобы давать только основные аспекты статьи и публиковать все дополнительные или «менее важные» аспекты в качестве Supplemental Materials (Дополнительных материалов) на сайте журнала.
У обзорных статей нет раздела Results and Discussion, в них обычно используются другие заголовки вместо заголовков IMRAD. Термин IMRAD обозначает шаблон или формат, который значит намного больше, чем слова, охватываемые аббревиатурой. Благодаря тому, что Американский национальный институт стандартов (ANSI) принял этот термин в качестве стандарта, сначала в 1972 году, а затем в 1979 году (ANSI 1979), ему отдают предпочтение большинство исследовательских журналов.
Итак, давайте подробно разберем каждый раздел хорошей научной статьи.
Вилки проекта
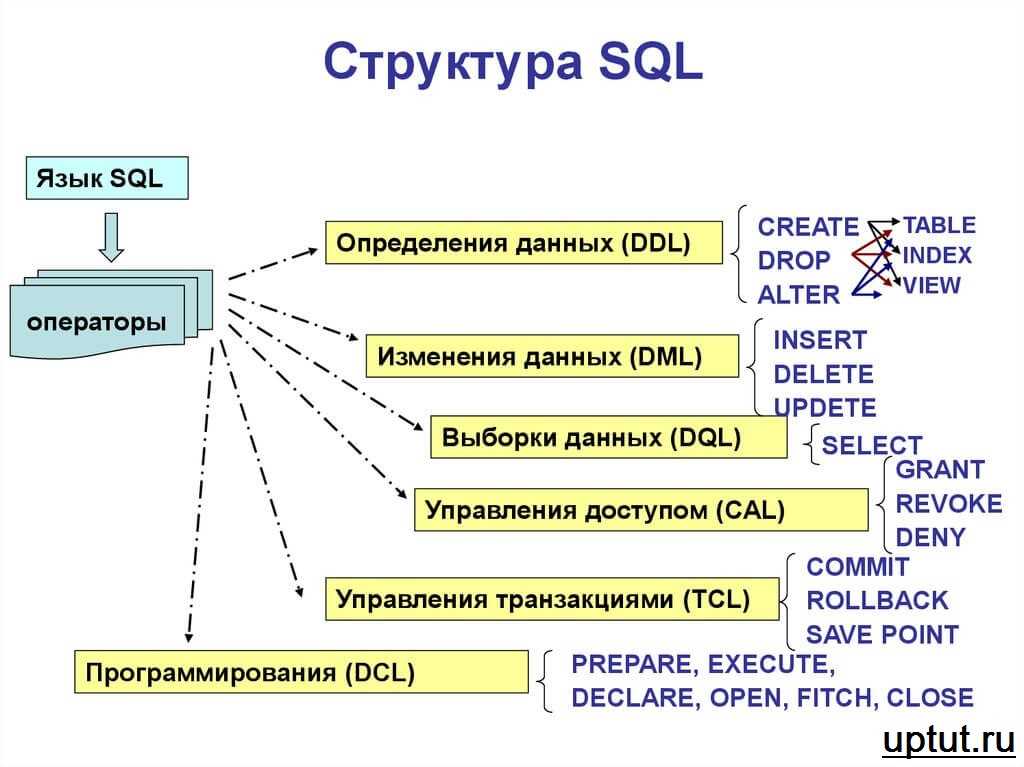
Существует множество форков MySQL , включая следующие.
Текущий
- MariaDB
- MariaDB — это разработанная сообществом ветвь системы управления реляционными базами данных MySQL, предназначенная для бесплатного использования под лицензией GNU GPL. Разветвление было инициировано первоначальными разработчиками MySQL, которые разделили его из-за опасений по поводу его приобретения Oracle.
- Сервер Percona для MySQL
- Percona Server для MySQL , созданный Percona , нацелен на сохранение тесной совместимости с официальными выпусками MySQL. В Percona Server для MySQL также включен XtraDB , ответвление Percona для механизма хранения InnoDB .
Заброшенный
- Морось
- Drizzle была бесплатной системой управления реляционными базами данных (СУБД) с открытым исходным кодом, которая была разветвлена из ныне несуществующей ветки разработки 6.0 СУБД MySQL. Как и MySQL, Drizzle имеет архитектуру клиент / сервер и использует SQL в качестве основного командного языка . Drizzle распространялся под версией 2 и 3 Стандартной общественной лицензии GNU (GPL) с частями, включая драйверы протокола и репликацию сообщений по лицензии BSD .
- WebScaleSQL
- WebScaleSQL — это программная ветвь MySQL 5.6, о которой 27 марта 2014 года объявили Facebook, Google, LinkedIn и Twitter как совместные усилия по обеспечению централизованной структуры разработки для расширения MySQL с помощью новых функций, характерных для его крупномасштабных развертываний, таких как создание больших реплицированных баз данных, работающих на фермах серверов. Таким образом, WebScaleSQL открыла путь к дедупликации усилий, которые каждая компания вкладывала в поддержку своей собственной ветви MySQL, и к объединению большего числа разработчиков. Объединив усилия этих компаний и включив в MySQL различные изменения и новые функции, WebScaleSQL нацелен на поддержку развертывания MySQL в крупномасштабных средах. Исходный код проекта лицензирован в соответствии с версией 2 Стандартной общественной лицензии GNU и размещен на GitHub .
- OurDelta
- Дистрибутив OurDelta, созданный австралийской компанией Open Query (позже приобретенной Catalyst IT Australia), имел две версии: 5.0, которая была основана на MySQL, и 5.1, которая была основана на MariaDB. В него вошли патчи, разработанные Open Query и другими известными членами сообщества MySQL, включая Джереми Коула и Google. После того, как патчи были включены в основную ветку MariaDB, цели OurDelta были достигнуты, и OurDelta передала свой набор инструментов для сборки и упаковки Monty Program (теперь MariaDB Corp).
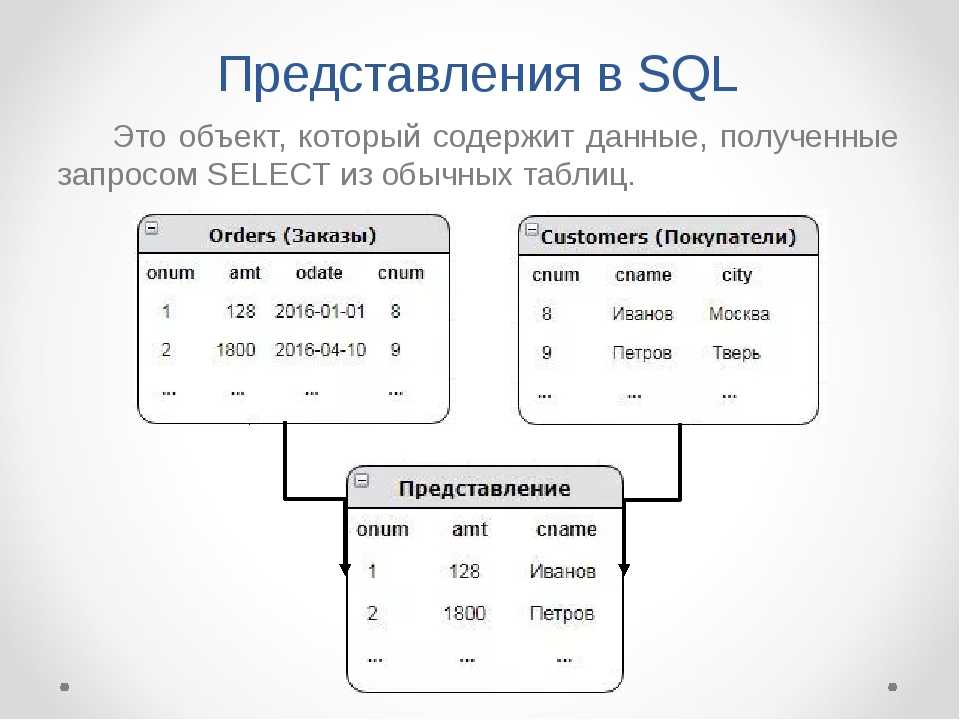
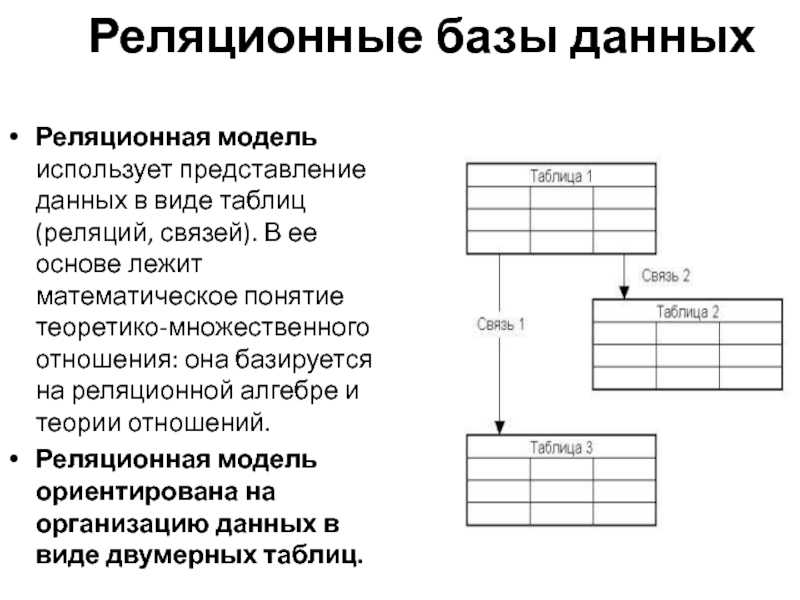
Представления
Последнее обновление: 14.08.2017
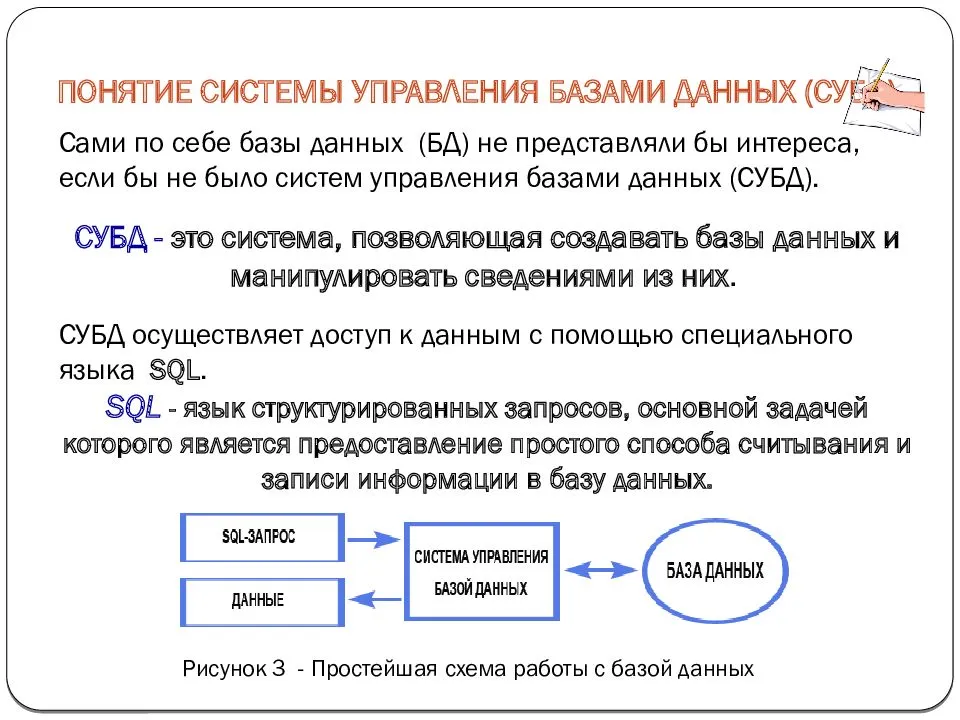
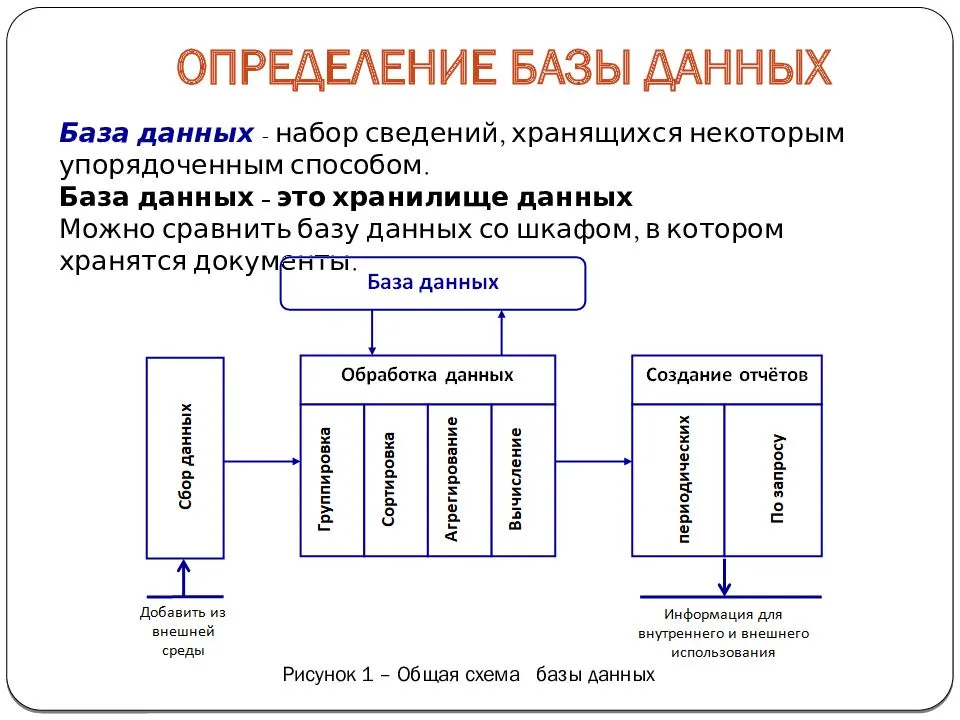
Представления или Views представляют виртуальные таблицы. Но в отличии от обычных стандартных таблиц в базе данных представления
содержат запросы, которые динамически извлекают используемые данные.
Представления дают нам ряд преимуществ. Они упрощают комплексные SQL-операции. Они защищают данные, так как представления могут дать доступ к
части таблицы, а не ко всей таблице. Представления также позволяют возвращать отформатированные значения из таблиц в нужной и
удобной форме.
Для создания представления используется команда CREATE VIEW, которая имеет следующую форму:
CREATE VIEW название_представления AS выражение_SELECT
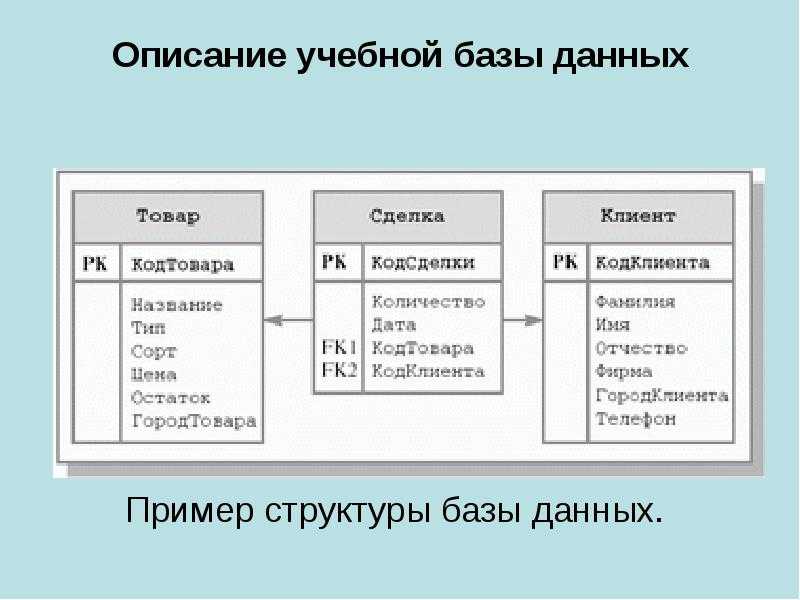
Например, пусть у нас есть три связанных таблицы:
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
CREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(30) NOT NULL
);
CREATE TABLE Orders
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE,
CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE,
CreatedAt DATE NOT NULL,
ProductCount INT DEFAULT 1,
Price MONEY NOT NULL
);
Теперь добавим в базу данных, в которой содержатся данные таблицы, следующее представление:
CREATE VIEW OrdersProductsCustomers AS SELECT Orders.CreatedAt AS OrderDate, Customers.FirstName AS Customer, Products.ProductName As Product FROM Orders INNER JOIN Products ON Orders.ProductId = Products.Id INNER JOIN Customers ON Orders.CustomerId = Customers.Id
То есть данное представление фактически будет возвращать сводные данные из трех таблиц. И после его создания мы сможем его увидеть в
узле Views у выбранной базы данных в SQL Server Management Studio:
Теперь используем созданное выше представление для получения данных:
SELECT * FROM OrdersProductsCustomers
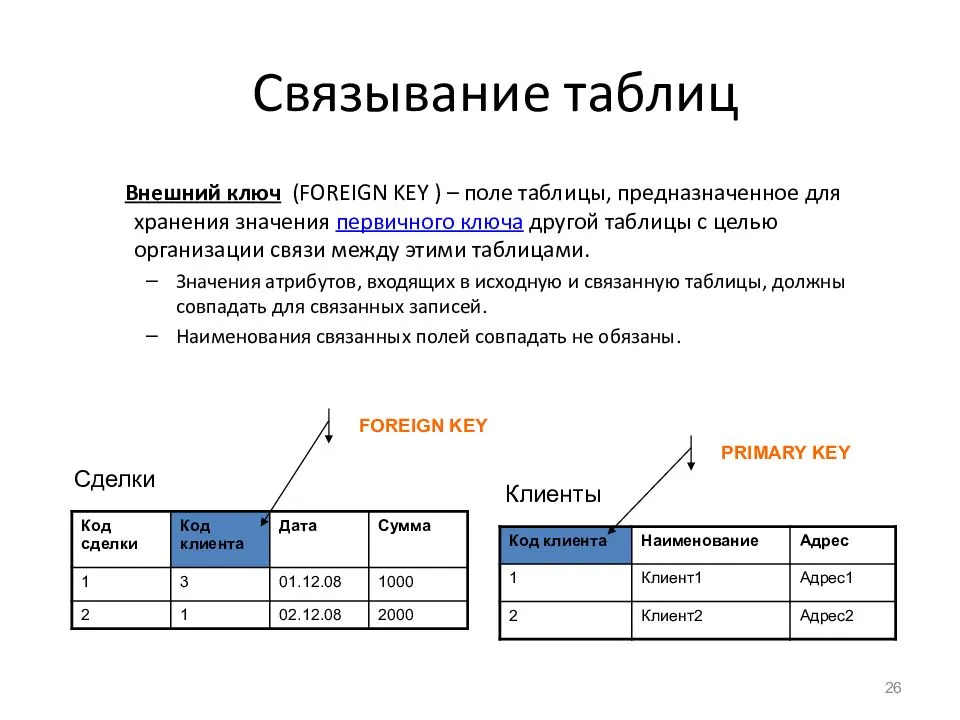
При создании представлений следует учитывать, что представления, как и таблицы, должны иметь уникальные имена в рамках той же базы данных.
Представления могут иметь не более 1024 столбцов и могут обращаться не более чем к 256 таблицам.
Также можно создавать представления на основе других представлений. Такие представления еще называют вложенными (nested views). Однако уровень вложенности не может быть больще 32-х.





Команда SELECT, используемая в представлении, не может включать выражения INTO
или ORDER BY (за исключением тех случаев, когда также применяется выражение TOP или OFFSET).
Если же необходима сортировка данных в представлении, то выражение ORDER BY применяется в команде SELECT, которая извлекает данные из представления.
Также при создании представления можно определить набор его столбцов:
CREATE VIEW OrdersProductsCustomers2 (OrderDate, Customer,Product) AS SELECT Orders.CreatedAt, Customers.FirstName, Products.ProductName FROM Orders INNER JOIN Products ON Orders.ProductId = Products.Id INNER JOIN Customers ON Orders.CustomerId = Customers.Id
Изменение представления
Для изменения представления используется команда ALTER VIEW. Эта команда имеет практически тот же самый синтаксис, что и CREATE VIEW:
ALTER VIEW название_представления AS выражение_SELECT
Например, изменим выше созданное представление OrdersProductsCustomers:
ALTER VIEW OrdersProductsCustomers AS SELECT Orders.CreatedAt AS OrderDate, Customers.FirstName AS Customer, Products.ProductName AS Product, Products.Manufacturer AS Manufacturer FROM Orders INNER JOIN Products ON Orders.ProductId = Products.Id INNER JOIN Customers ON Orders.CustomerId = Customers.Id
Удаление представления
Для удаления представления вызывается команда DROP VIEW:
DROP VIEW OrdersProductsCustomers
Также стоит отметить, что при удалении таблиц также следует удалить и представления, которые используют эти таблицы.
НазадВперед
Преимущества MariaDB перед MySQL
В MariaDB добавлены оптимизации, которые повышают производительность СУБД по сравнению с оригинальным MySQL.
Представления
В части производительности представлений в MariaDB проделана существенная оптимизация. «Представления» — это, по сути, виртуальные таблицы базы данных, к которым можно обращаться, как к обычным таблицам базы данных. В MySQL при запросе к представлению запрашиваются все таблицы, связанные с этим представлением, независимо от того, что для запроса могут не потребоваться некоторые представления. В отличие от MySQL, в MariaDB, запрашиваются только те таблицы, которые необходимы для запроса.
Колоночное хранилище
MariaDB предоставляет еще одно мощное улучшение производительности, достигаемое с помощью нового типа таблиц, представленных не в форме построчного хранилища, а в форме колоночного хранилища. Колоночные хранилища часто используются в аналитике больших данных. MariaDB позволяет масштабировать хранилище данных до петабайтного размера, обспечивая линейное повышение производительности запросов к хранимых данным при добавлении новых серверов.
![]()
Более высокая производительность на SSD
MariaDB предоставляет механизм хранения MyRocks, который позволяет хранить данные в RocksDB. RocksDB — это встраиваемая база данных, которая была разработана для повышения производительности обработки данных, хранимых на SSD-накопителях.
Сегментированный кеш ключей
MariaDB представляет еще одно улучшение производительности — сегментированный кеш ключей. В типичном кеше различные потоки конкурируют за блокировку кэшированной записи. Когда несколько потоков конкурируют за мьютекс, только один из них может получить его, в то время как другим приходится ждать освобождения блокировки перед выполнением операции. Это приводит к задержкам выполнения в этих потоках, замедляя производительность базы данных. В случае сегментированного кэша ключей потоку не нужно блокировать всю страницу, но он может блокировать только тот сегмент, к которому относится страница. Это помогает нескольким потокам работать параллельно, увеличивая параллелизм в приложении, что приводит к повышению производительности базы данных.
Виртуальные столбцы таблицы
Интересная функция, которую поддерживает MariaDB — это виртуальные столбцы. Эти столбцы способны выполнять вычисления на уровне базы данных. Это позволяет перенести типовые вычисления с приложений в сервер СУБД. Эта функция не доступна в MySQL.
Параллельное выполнение запросов
Одна из последних версий MariaDB — 10.0 допускает параллельное выполнение нескольких запросов. Идея состоит в том, что некоторые запросы от Master могут быть переданы на выполнение на ведомые серверы (slave). Этот параллелизм в выполнении запросов, безусловно, обеспечивает MariaDB преимущество над MySQL.
Пул потоков
MariaDB также представляет новую концепцию под названием «Thread Pooling». Ранее, когда требовалось несколько соединений с базой данных, для каждого соединения открывался поток, что приводило к архитектуре «один поток на соединение». С использованием «Thread Pooling» исспользуется пул потоков, которые могут повторно использоваться. Таким образом, новый поток не нужно открывать для каждого нового запроса на подключение, что приводит к более быстрым результатам запроса. Эта функция доступна в коммерческой версии MySQL, но, к сожалению, недоступна в версии для сообщества.
Бэкенды хранения данных
MariaDB предоставляет несколько мощных механизмов хранения, которые не доступны в MySQL. Например, XtraDB, Aria и т. д. Чтобы настроить эти механизмы хранения для MySQL, вам необходимо установить их вручную.



Совместимость
Команда MariaDB гарантирует, что MariaDB сможет заменить MySQL в существующих приложениях. Фактически для каждой версии MySQL они выпускают тот же номер версии MariaDB, чтобы указать, что MariaDB обычно совместима с соответствующей версией MySQL. Это открывает возможность беспрепятственного перехода на MariaDB без каких-либо изменений в кодовой базе приложения.