
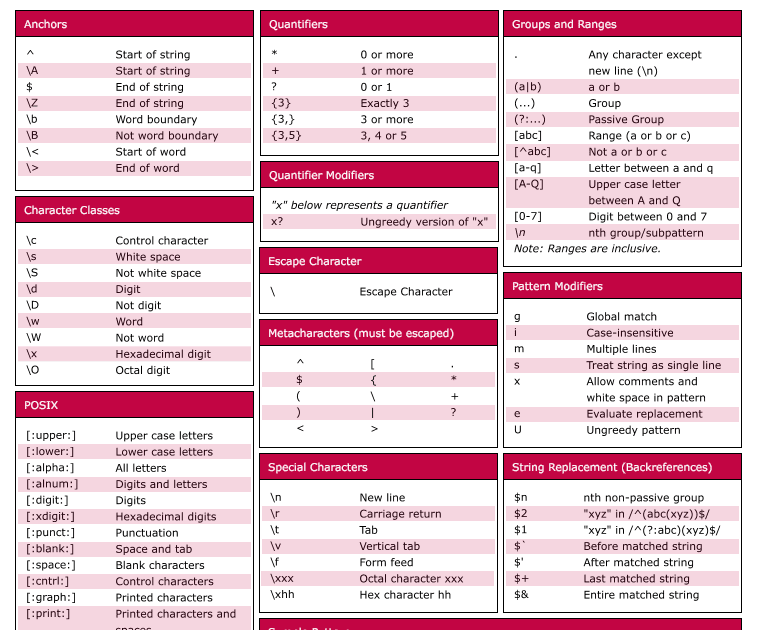
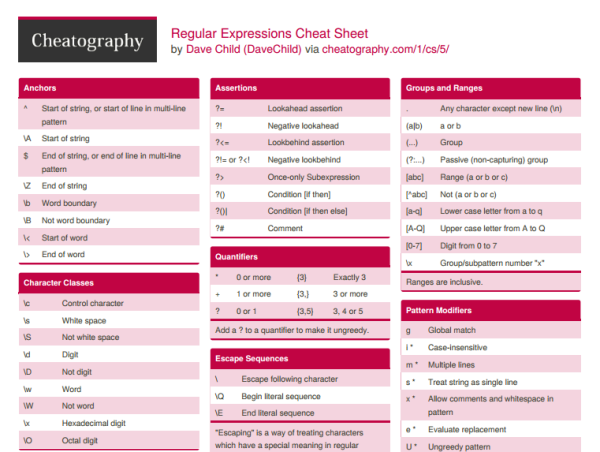
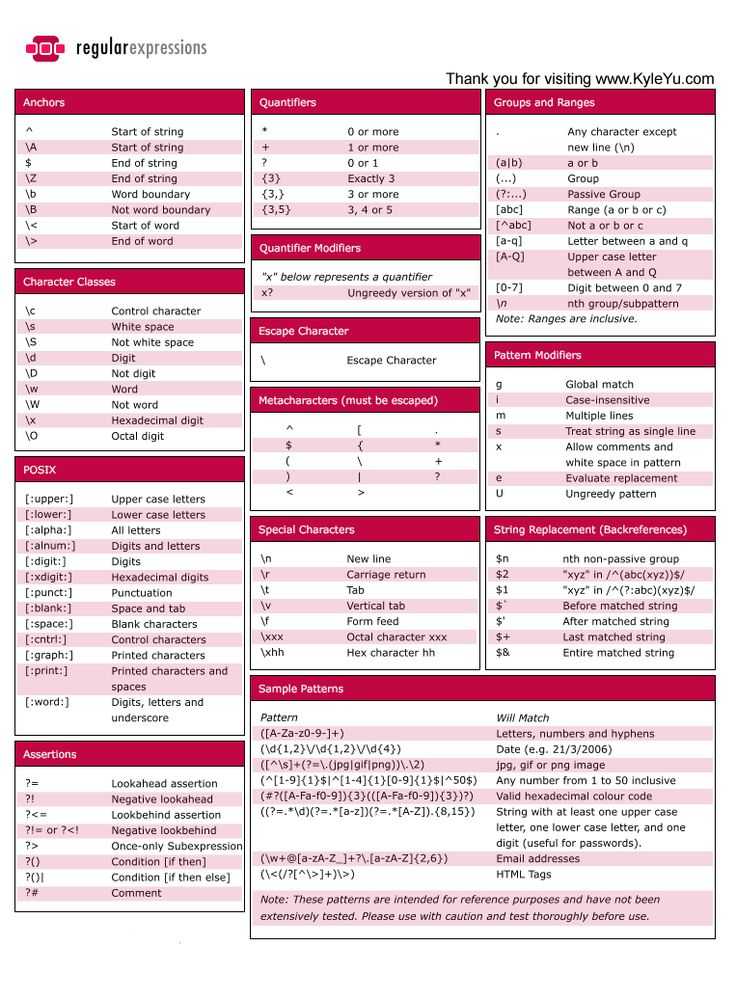
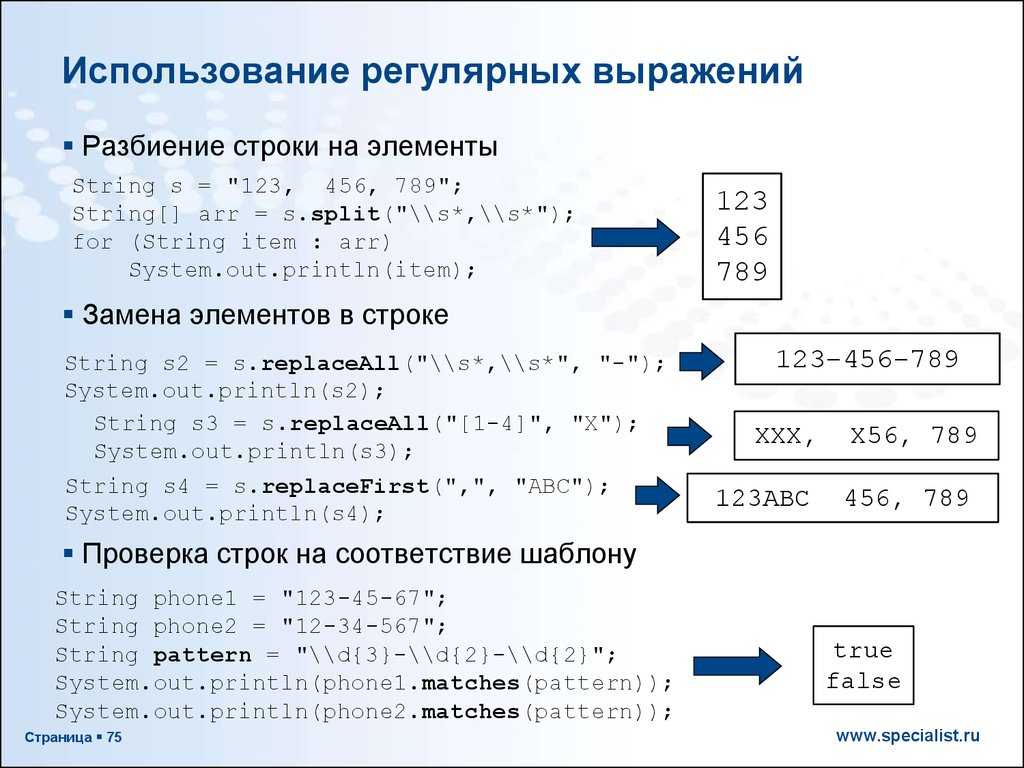
LL(1)-грамматики
LL(k)-грамматики — грамматики, в которых мы можем определить правило для
раскрытия нетерминала по первым символам входной цепочки.
Дано: цепочка терминальных символов и нетерминальный символ. Требуется определить,
по какому правилу нужно раскрыть нетерминальный символ, чтобы получить префикс
этой цепочки. Для LL(k)-грамматик это можно сделать, зная первые k символов.
Чаще всего рассматриваются LL(1)-грамматики, где раскрытие определяется по первому
символу.
Пример: не-LL(k)-грамматика:
Если имеем строку и нетерминал , то мы не знаем, по какому
правилу нужно раскрывать . Поскольку в начале строки может быть сколько
угодно сомножителей, в общем случае, чтобы выбрать правило раскрытия для
(т.е. или ), нужно прочитать неизвестное количество входных
знаков. А для LL(k)-грамматики k должно быть конечно и фиксировано.
Пример: LL(1)-грамматика для тех же арифметических выражений:
здесь — пустая строка. В данной грамматике мы всегда можем определить
применимое правило. Например, для правило только одно, его используем.
Для : если строка начинается на , то выбираем вторую ветку ,
иначе выбираем первую . Для : знак выбирает первую ветку, знак
— вторую.
Пример не-LL(1)-грамматики:
Для строки и нетерминала мы не можем определить раскрытие по первому
символу, т.к. допустимо и то, и другое правило. Язык включает в себя две строки:
и . По первому символу невозможно определить правило для .
Однако, это грамматика LL(2). По первым двум символам определить раскрытие можно.
Также грамматика не LL(1) если разные правила начинаются с одинаковых символов:
Грамматика не LL(1), если в правилах имеем т.н. левую рекурсию:
Преимущество LL(1)-грамматик — для них сравнительно легко написать синтаксический
анализатор методом рекурсивного спуска.
Ответ 4
Позвольте мне дать неофициальное объяснение.
POSIX — это набор стандартов, который пытается отличить UNIX и UNIX-подобные системы от тех, которые с ними несовместимы. Он был создан правительством США в целях закупок. Идея заключалась в том, что федеральные закупки США нуждались в способе юридического определения требований для различного рода предложений и контрактов таким образом, который можно было бы использовать для исключения систем, на которые данная существующая кодовая база или штат программистов НЕ переносится.
Поскольку POSIX был написан постфактум… для описания слабо похожего набора конкурирующих систем… он НЕ был написан таким образом, чтобы его можно было реализовать. Так, например, NT от Microsoft была написана с достаточным соответствием POSIX, чтобы претендовать на некоторые предложения… хотя подсистема POSIX была по существу бесполезна с точки зрения практической переносимости и совместимости с системами UNIX. На протяжении десятилетий были написаны и другие стандарты для UNIX. Такие, как SPEC1170 (определял одиннадцать сотен семьдесят вызовов функций, которые должны были быть реализованы совместимо), и различные воплощения SUS (Single UNIX Specification). По большей части эти стандарты были неадекватны для любого практического технического применения. Они существуют в основном для споров, юридических препирательств и других неблагоприятных причин.
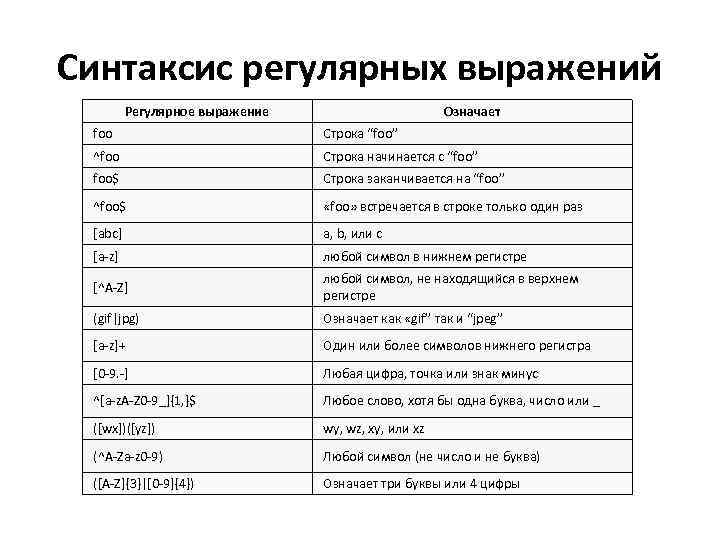
Сводка по грамматике
В следующей таблице приведены возможности, доступные в различных грамматиках регулярных выражений:
| Элемент | basic | extended | ECMAScript | grep | egrep | awk |
|---|---|---|---|---|---|---|
| чередование с помощью | + | + | + | + | ||
| чередование с помощью | + | + | ||||
| привязка | + | + | + | + | + | + |
| обратная ссылка | + | + | + | |||
| выражение в квадратных скобках | + | + | + | + | + | + |
| Группа записи с помощью | + | + | + | + | ||
| Группа записи с помощью | + | + | ||||
| управляющая escape-последовательность | + | |||||
| escape-символ DSW | + | |||||
| escape-выражение формата файлов | + | + | ||||
| шестнадцатеричная escape-последовательность | + | |||||
| escape-последовательность удостоверения | + | + | + | + | + | + |
| отрицательное утверждение | + | |||||
| отрицательное утверждение границы слова | + | |||||
| группа незахвата | + | |||||
| «нежадное» повторение | + | |||||
| восьмеричная escape-последовательность | + | |||||
| обычный символ | + | + | + | + | + | + |
| положительное утверждение | + | |||||
| повторение с помощью | + | + | + | + | ||
| повторение с помощью | + | + | ||||
| повторение с помощью | + | + | + | + | + | + |
| повторение с помощью и | + | + | + | + | ||
| escape-последовательность Юникода | + | |||||
| знак подстановки | + | + | + | + | + | + |
| утверждение границы слова | + |
Возможности
Набор утилит (включая редактор sed и фильтр grep), поставляемых в дистрибутивах UNIX, одним из первых способствовал популяризации регулярных выражений для обработки текстов. Многие современные языки программирования имеют встроенную поддержку регулярных выражений. Среди них ActionScript, Perl, Java,PHP, JavaScript, языки платформы .NET Framework, Python, Tcl, Ruby, Lua, Gambas, C++ (стандарт 2011 года), Delphi, D, Haxe и другие.
Регулярные выражения используются некоторыми текстовыми редакторами и утилитами для поиска и подстановки текста. Например, при помощи регулярных выражений можно задать шаблоны, позволяющие:
- найти все последовательности символов «кот» в любом контексте, как то: «кот», «котлета», «терракотовый»;
- найти отдельно стоящее слово «кот» и заменить его на «кошка»;
- найти слово «кот», которому предшествует слово «персидский» или «чеширский»;
- убрать из текста все предложения, в которых упоминается слово кот или кошка.
Регулярные выражения позволяют задавать и гораздо более сложные шаблоны поиска или замены.
Результатом работы с регулярным выражением может быть:
- проверка наличия искомого образца в заданном тексте;
- определение подстроки текста, которая сопоставляется образцу;
- определение групп символов, соответствующих отдельным частям образца.
Если регулярное выражение используется для замены текста, то результатом работы будет новая текстовая строка, представляющая из себя исходный текст, из которого удалены найденные подстроки (сопоставленные образцу), а вместо них подставлены строки замены (возможно, модифицированные запомненными при разборе группами символов из исходного текста). Частным случаем модификации текста является удаление всех вхождений найденного образца — для чего строка замены указывается пустой.
Описания синтаксиса языков семейства Си
Си (англ. C) — стандартизированный процедурный язык программирования, разработанный в начале 1970-х годов сотрудниками Bell Labs Кеном Томпсоном и Денисом Ритчи как развитие языка Би. Си был создан для использования в операционной системе UNIX. С тех пор он был портирован на многие другие операционные системы и стал одним из самых используемых языков программирования. Си ценят за его эффективность; он является самым популярным языком для создания системного программного обеспечения. Его также часто используют для создания прикладных программ. Несмотря на то, что Си не разрабатывался для новичков, он активно используется для обучения программированию. В дальнейшем синтаксис языка Си стал основой для многих других языков.
Для языка Си характерны лаконичность, современный набор конструкций управления потоком выполнения, структур данных и обширный набор операций.
В знаменитой книге Б. Кернигана и Д. Ритчи описание синтаксиса языка Си дано
в нотации, которая эквивалентна БНФ, но использует другие соглашения об обозначениях терминалов и нетерминалов, альтернативных правых частей правил,
необязательных конструкций.
Нетерминалы записываются курсивом, терминалы — прямым шрифтом. Альтернативные части правил выписываются в столбик по одному в строке или помечаются
словами «one of» (один из). Необязательные части сопровождаются подстрочным
индексом «opt (от optional) — необязательный; «необ» — в некоторых русских пере-
водах). Левая часть правила записывается отдельной строкой с отступом влево.
Вот пример определений конструкций языка Си:
составной оператор
{список описанийopt список операторовopt }
список операторов
оператор
оператор список операторов
Как видим, из-за отсутствия явного способа выражения повторений, определе-
ния изобилуют рекурсией.
Аналогичная нотация с минимальными изменениями использована для описа-
ния синтаксиса языков-потомков Си: Си++, Ява, Си#. Вот выдержка из стандарта
ЕСМА-334 на язык Си#:
block:
{Statement-listopt}
statement-list:
statement
statement-list statement
Специального названия эта нотация, судя по всему, не имеет. И представляется, как минимум, странной. Она неудобна не только для чтения, но и для обработки на компьютере. Ее использование при описании новых языков трудно объяснить чем-либо, кроме дурно понятой необходимости следовать традициям.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
В теории формальных языков
Основная статья: Регулярный язык
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно. Определены следующие константы:
- (пустое множество) ∅;
- (пустая строка) ε обозначает строку, не содержащую ни одного символа; эквивалентно «»;
- (символьный литерал) «a», где a — символ используемого алфавита;
- (множество) из символов, либо из других множеств;
и следующие операции:
- (сцепление, конкатенация) RS обозначает множество {αβ | α ∈ R & β ∈ S}, например: {«boy», «girl»}{«friend», «cott»} = {«boyfriend», «girlfriend», «boycott», «girlcott»};
- (дизъюнкция, чередование) R|S обозначает объединение R и S, например: {«ab», «c»}|{«ab», «d», «ef»} = {«ab», «c», «d», «ef»};
- (замыкание Клини, звезда Клини) R* обозначает минимальное надмножество множества R, которое содержит ε и замкнуто относительно конкатенации (это есть множество всех строк, полученных конкатенацией нуля или более строк из R, например: {«Run», «Forrest»}* = {ε, «Run», «Forrest», «RunRun», «RunForrest», «ForrestRun», «ForrestForrest», «RunRunRun», «RunRunForrest», «RunForrestRun», …}).
Регулярные выражения, входящие в современные языки программирования (в частности, PCRE), имеют больше возможностей, чем то, что называется регулярными выражениями в теории формальных языков; в частности, в них есть нумерованные обратные ссылки. Это позволяет им разбирать строки, описываемые не только регулярными грамматиками, но и более сложными, в частности, контекстно-свободными грамматиками.








Принципы
В первую очередь, рассмотрим несколько принципов поиска по шаблону с помощью РВ.
Для указания шаблона вы должны использовать форму записи, которую может
обработать компьютер. Эта форма записи, или язык, в нашем случае — синтаксис
РВ.
Язык РВ состоит из литералов и метасимволов (В оригинальной
статье говорится «symbols and operators». — Прим. перев.). Литералы — это обычный
текст, являющийся частью шаблона. Для описания отношений между литералами
применяются следующие метасимволы (от имеющих наивысший приоритет к имеющим
наименьший):
- Квантификаторы (closure): строка одинаковых литералов, длина которой может
меняться, либо литерал, появление которого не обязательно.
(Одна из важнейших составляющих поиска по шаблону.) - Конкатенация (concatenation): Если в шаблоне два литерала, идущих друг
за другом, то и в тексте будет осуществлён поиск символов, идущих друг за другом. - Объединение (конструкция выбора, alteration): Один из литералов, между которыми
осуществляется выбор должен находиться в тексте, сравниваемом с шаблоном.
В дополнение к вышеперечисленному, использование скобок позволяет влиять
на последовательность обработки элементов РВ.
В большинстве реализаций обработчиков РВ, квантификаторы включают:
- звёздочку (*), означающую повторение литерала нуль или более раз
- плюс (+), означающий повторение литерала один или более раз
- знак вопроса (?), означающий, что наличие того или иного литерала возможно, но
не является обязательным условием совпадения шаблона с текстом
Примеры: A* совпадает с пустой строкой, «A», «AA», «AAA» и т. д.,
A+ совпадает с «A», «AA», «AAA» и т. д. A? совпадает с пустой строкой
или «A».
Для задания конкатенации нет необходимости использовать метасимволы.
Строка, содержащая идущие друг за другом символы, является конкатенацией.
Регулярное выражение ABC, например, совпадёт со строкой «ABC».
Объединение (конструкция выбора, alteration) задаётся с помощью символа
«|» между двумя РВ. A|B совпадает либо с «A», либо с «B».
В обработчиках расширенных РВ (Extended Regular Expressions) используются несколько
дополнительных метасимволов для более эффективного задания сложных шаблонов.
Но данная статья является не более, чем коротким введением в синтаксические возможности
РВ и не включает рассмотрения этих метасимволов.
История развития стандарта POSIX[2]
Первая версия спецификации IEEE Std 1003.1 была опубликована в 1988 г. В последующем многочисленные редакции IEEE Std 1003.1 были приняты как международные стандарты.
Этапы развития POSIX:
| Год | Этап |
|---|---|
| 1990 г. | Редакция, выпущенная в 1988 г., была переработана и стала основой для дальнейших редакций и дополнений. Она была одобрена как международный стандарт ISO/IEC 9945-1:1990. |
| 1993 г. | Выходит редакция 1003.1b-1993. |
| 1995 г. | Опубликована редакция 1003.1c-1995 (входит как часть в стандарт ANSI/IEEE POSIX 1003.1-1995). |
| 1996 г. | Внесены изменения IEEE Std 1003.1b-1993, IEEE Std 1003.1c-1995 и 1003.1i-1995, однако основная часть документа осталась неизменной. В 1996 г. редакция IEEE Std 1003.1 также была одобрена как международный стандарт ISO/IEC 9945-1:1996. |
| 1998 г. | Появился первый стандарт для «реального времени» – IEEE Std 1003.13-1998. Это расширение стандарта POSIX для встраиваемых приложений реального времени. |
| 1999 г. | Принято решение внести в основной текст стандарта первые за последние 10 лет существенные изменения, включая объединение со стандартом 1003.2 (Shell и утилиты), так как к тому моменты это были отдельные стандарты. PASC решил закончить изменения базового текста после завершения работы над стандартами IEEE 1003.1a, 1003.1d, 1003.1g, 1003.1j, 1003.1q и 1003.2b. |
| 2001 г. | Опубликована новая редакция IEEE Std 1003.1. Также было принято решение о приведении остальных проектов в соответствие с новым документом. |
| 2003 г. | 31 марта опубликована новая редакция стандарта 1003.1. |
| 2004 г. | Последняя на сегодняшний день редакция стандарта 1003.1 была опубликована 30 апреля и выпущена под эгидой Austin Common Standards Revision Group. В нее внесены изменения, касающиеся редакции стандарта 2001 г. Формально редакция 2004 г. известна как IEEE Std 1003.1, 2004 Edition, The Open Group Technical Standard Base Specifications, Issue 6 и включает IEEE Std 1003.1-2001, IEEE Std 1003.1-2001/Cor 1-2002 и IEEE Std 1003.1-2001/Cor 2-2004. |
Метод рекурсивного спуска
Метод рекурсивного спуска — способ написания синтаксических анализаторов
для LL(1)-грамматик на алгоритмических языках программирования. Для каждого
нетерминала грамматики записывается процедура, тело которой выводится из правил
для данного нетерминала.
Построенный синтаксический анализатор выдаёт сообщение о принадлежности
входной строки к заданному языку.
Написание синтаксического анализатора состоит из этапов:
- Составление LL(1)-грамматики для данного языка программирования.
- Формальное выведение парсера из правил грамматики. Парсер либо молча принимает
строку, либо выводит сообщение об ошибке. - Наполнение парсера семантическими действиями — построение дерева разбора,
выполнение проверок на корректность типов операций, возможно даже, вычисление
результата в процессе разбора.
Вспомогательная структура данных — поток (stream).
У потока есть возможность получить текущий символ без продвижения
вперёд, получить символ и удалить из потока .
Пример реализации потока: stream.scm.
Все функции, соответствующие нетерминалам, принимают поток, первым символом которого
должен быть первый символ раскрытия нетерминала, и функцию ошибки, которая вызывается,
чтобы прервать разбор. При успешном разборе функция поглощает из входного потока
все токены, соответствующие раскрытию данного нетерминала.
(define (nterm stream error) …)
Пусть — некоторая строка символов грамматики (терминальных и нетерминальных).
Обозначим — множество терминальных символов, с которого может начинаться
строка токенов, полученная из раскрытием всех нетерминалов. Если строка может
быть пустой, то также входит в .
Построим множество для правил грамматики арифметических выражений:
Пусть правило имеет вид
Если среди альтернатив есть такая , что , то она должна
быть последней.
Функция для нетерминала имеет вид, если не содержит :
(define (nterm stream error)
(cond (( (peek stream) ∈ FIRST ) PARSE )
…
(( (peek stream) ∈ FIRST ) PARSE )
…
(( (peek stream) ∈ FIRST ) PARSE )
(else (error #f))))
Если содержит , то функция имеет вид
(define (nterm stream error)
(cond (( (peek stream) ∈ FIRST ) PARSE )
…
(( (peek stream) ∈ FIRST ) PARSE )
…
(( (peek stream) ∈ FIRST ) PARSE )
(else PARSE)))
Функция описывает последовательность команд для разбора
правой части правила :
где функция имеет вид
(define (expect stream term error)
(if (equal? (peek stream) term)
(next stream)
(error #f)))
Разбор начинается с создания потока и сохранения точки возврата.
После успешного разбора аксиомы в потоке должен располагаться символ
конца потока.
(define (parse tokens)
;; Создаём поток
(define stream (make-stream tokens))
;; Создаём точку возврата
(call-with-current-continuation
(lambda (error)
;; разбираем аксиому
(axiom stream error)
;; в конце должен остаться признак конца потока
(equal? (peek stream) #f))))
Практические советы:
- В конец списка символов, которые потребляет лексический анализатор, в конец
списка токенов, которые потребляет синтаксический анализатор, нужно
обязательно добавлять признак конца ввода (EOF, end-of-file). - На практике язык разделяют на два «слоя»: лексику и синтаксис. Лексика языка
определяет набор «слов», лексем, на которые бьётся программа, по лексемам
создаются токены, которые группируются в синтаксическое дерево. Смысл
в том, что раздельное описание лексики и синтаксиса гораздо проще, чем писать
грамматику для всего сразу. - Удобно определить тип «поток», как описано выше.
- Для прерывания разбора при ошибке рекомендуется использовать продолжение.
Имитация работы автомата
После компиляции шаблона мы можем запустить на исполнение сгенерированный код
и, таким образом, имитировать работу автомата.
Алгоритм поиска реализуется в методе .
Ранее уже отмечалось, что автомат выбирает
правильный ответ, но это с теоретической точки зрения.
Компьютерная имитация недетерминированного конечного
автомата должна включать испытание каждого возможного прохода
через этот автомат. Седжвик (/3/) реализовал интересный алгоритм
для решения этой задачи. Наш алгоритм будет основываться на этом
подходе.
Система Седжвика имеет ряд недостатков при практическом применении.
Во-первых, её грамматика нуждается в наличии символа (character) после квантификатора,
иначе она не может его найти. Но эта проблема быстро решается
написанием заплатки к программе — и наша реализация
уже содержит исправленный код. Вторая проблема несколько более сложна.
Реализация Седжвика завершает работу после первого совпадения.
Это значит, что поиск самой длинной, удовлетворяющей шаблону, строки
не производится. К примеру, если вы ищите «a*a» в «xxaaaaaxx», будет
найдена только «a» вместо «aaaaa». В нашей реализации будет исправлен и
этот недостаток.
Идея о том, что программа может угадать правильный путь звучит невероятно.
Основа такого программного обеспечения заключается в проверке
всех возможных путей, за исключением крайнего, верно совпадающего.
Параллельное выполнение имеет здесь решающее значение.
Каждый переход автомата будет протестирован и, в случае
несовпадения с шаблоном, удалён. Это несколько «усложнённый» путь.
Каждый возможный переход тестируется одновременно с другими и
удаляется при несовпадении с символом, обрабатываемым в текущий момент
поиска по тексту.
Базовой для данного алгоритма является очередь с двусторонним доступом
(deque, double-ended queue). Это гибрид между стэком и буфером.
С такой структурой данных можно не только взаимодействовать
через команды push и pop (по принципу Last In First Out),
но и средствами команды put. Иными словами, данные
в эту структуру могут добавляться не только сверху, но и снизу.
Поведение очереди с двусторонним доступом важно для
нашего алгоритма. Данная очередь разделяется на две части:
- верхняя часть для символа, обрабатываемого в данный момент при поиске в тексте
- нижняя часть для следующего символа
Следующие значения нулевых состояний (см. раздел Автомат.
— Прим. перев.) хранятся в верхней части очереди, так как реализуется структура,
необходимая для выявления совпадения с текущим символом.
Последующие значения ненулевых состояний (the_char != ‘\0’)
размещаются в нижней части очереди, указывая на последующий
символ. Также хранится специальное значение next_char(-1),
указывающее на то, что будет обработан следующий символ из текста.






Основной цикл, в процессе имитации работы автомата, получает
значение состояния из очереди и проверяет условия. Если
символ в the_char совпадает с проверяемым на данный момент
символом из текста, индексы следующих состояний (next1 и next2)
будут помещены в конец очереди. Если прочитанное состояние — нулевое,
следующие индексы будут размещены в начало очереди. Если состояние
равно next_char(-1), будет обработан следующий символ в исследуемом тексте.
В таком случае, next_char размещается в конце очереди.
Цикл будет завершён если достигнут конец текста или очередь пуста.
Очередь пуста при отсутствии каких-либо непроверенных частей шаблона.
До сего момента, описание похоже на предлагаемый Седжвиком подход,
однако, разница в том, что когда состояние становится нулевым, цикл не завершится.
Будет найдено и сохранено совпадение, но цикл продолжит выполнение! Поиск
возможных совпадений будет производится до конца.
После завершения цикла возвращается крайнее совпадение. Если же совпадений
с шаблоном не найдено, — позиция, с которой начинается поиск, минус один.
Рекомендуемая литература
-
Серебряков В. А., Галочкин М. П., Гончар Д. Р., Фуругян М. Г. Теория и
реализация языков программирования: Учебное пособие. М.: МЗ-Пресс, 2003. 345 с. -
Фридл Дж. Регулярные выражения. Библиотека программиста. СПб.: Питер, 2001. 352 с.
-
Царьков В. Б.
Теория и методика построения регулярных выражений. Проблема самообразования. 2010.
URL: (дата обращения 20.07.2010). -
Cox R. Implementing Regular Expressions. 2007. URL:
(дата обращения 20.07.2010).
Если ваша фирма не обладает штатом квалифицированных программистов, вы можете прибегнуть к услугам
IT аутсорсинга. На сегодняшний день одно из самых
эффективных средств обеспечения бизнес-процессов на Вашем предприятии. Во-первых, аутсорсинг
позволяет снизить расходы на содержание штата технических сотрудников и устранить проблему поиска
квалифицированных кадров. А во-вторых, вместо нескольких человек Вы получаете целую команду
высококлассных специалистов, готовых качественно и быстро решить любые Ваши задачи, независимо
от направленности и сложности.
Задачи
- содействовать облегчению переноса кода прикладных программ на иные платформы;
- способствовать определению и унификации интерфейсов заранее при проектировании, а не в процессе их реализации;
- сохранять по возможности и учитывать все главные, созданные ранее и используемые прикладные программы;
- определять необходимый минимум интерфейсов прикладных программ, для ускорения создания, одобрения и утверждения документов;
- развивать стандарты в направлении обеспечения коммуникационных сетей, распределенной обработки данных и защиты информации;
- рекомендовать ограничение использования бинарного (объектного) кода для приложений в простых системах.
Лексический анализ
Грамматика для стадии лексического анализа описывается, как правило, без
рекурсии (имеется ввиду, без нехвостовой рекурсии), т.к. лексическая структура
языка не требует вложенных конструкций.
Назначение лексического анализа: разбивает исходный текст на последовательность
токенов, которые синтаксический анализ будет группировать в дерево. Либо,
если исходный текст не соответствует грамматике — выдача сообщения (сообщений)
об ошибке.
Входные данные: строка символов (или список символов), выходные:
последовательность токенов. Можно сказать, что дерево разбора для грамматики
лексем вырожденное — рекурсия есть только по правой ветке ().
Мы будем его реализовывать методом рекурсивного спуска.
Oracle SQL and POSIX Regular Expression Standard
Oracle SQL implementation of regular expressions conforms to these standards:
-
IEEE Portable Operating System Interface (POSIX) standard draft 1003.2/D11.2
Oracle SQL follows exactly the syntax and matching semantics for regular expression operators as defined in the POSIX standard for matching ASCII (English language) data. You can find the POSIX standard draft at this URL:
http://www.opengroup.org/onlinepubs/007908799/xbd/re.html
For more information, see .
-
Unicode Regular Expression Guidelines of the Unicode Consortium
Oracle SQL extends regular expression support beyond the POSIX standard in these ways:
Ответ 1
POSIX — это семейство стандартов, разработанных IEEE для уточнения и унификации интерфейсов прикладного программирования (и вспомогательных вопросов, таких как утилиты командной строки), предоставляемых операционными системами Unix. Когда вы пишете свои программы, опираясь на стандарты POSIX, вы можете быть уверены, что сможете легко переносить их среди большого семейства производных Unix (включая Linux, но не ограничиваясь им!); если и когда вы используете какой-то API Linux, который не стандартизован как часть Posix, вам будет труднее, если и когда вы захотите перенести эту программу или библиотеку на другие Unix системы (например, MacOSX) в будущем.
Форма Бэкуса-Наура (БНФ)
Форма Бэкуса-Наура (БНФ) была впервые применена при описании Алгола-60.
БНФ совпадает по сути с нотацией КС-грамматик, отличаясь лишь обозначениями.
Предусмотрены следующие метасимволы:
<> — служат для выделения нетерминалов — понятий языка. | — «или». Разделяет альтернативные правые части правил. — «есть по определению». Заменяет стрелку, используемую при записи продукций КС-грамматик.
Терминальные символы записываются как есть, никаких специальных способов их выделения не предусмотрено.
Вот пример определений на БНФ, взятый из спецификации Алгола-60 — «Модифицированного сообщения»:
<простое арифметическое выражение> ::= <терм> 1 Окак операции типа сложения> <терм> | <простое арифметическое выражение> <знак операции типа сложения> <терм> <знак операции типа сложения> ::= + | -
Как видим, для выражения повторений используется рекурсия, причем повсеместно — левая.
БНФ использована Н. Виртом при описании языка Паскаль. Хотя в нотацию
были добавлены метаскобки {и}, обозначающие повторение, применены они лишь
в отдельных случаях, в то время как, например, грамматика выражений леворекурсивна.
Автомат
Для поиска шаблона, заданного РВ, вы не можете сравнивать
каждый символ шаблона с каждым символом текста.
Квантификаторы и объединение вызывают к жизни такое количество путей
срабатывания сложных шаблонов, что использование «обычного» алгоритма невозможно.
Должен быть применен более действенный подход.
Лучший путь — построить автомат и смоделировать его работу. Для описания
поискового шаблона, заданного регулярным выражением, вы можете использовать
недетерминированный и детерминированный конечные автоматы.
Автомат может переходить в несколько состояний. Он может переходить из одного
состояния в другое, в зависимости от события, которое поступило ему на вход,
в нашем случае, — очередной входной символ. Здесь же видна разница между
детерминированными и недетерминированными конечными автоматами. Детерминированный
автомат может принять только состояние в ответ на определённый символ,
а недетерминированный автомат может перейти в одно из
состояний в ответ на один и тот же входной символ.
Оба типа автоматов допустимо использовать для задания любого
РВ. Каждый из этих типов автоматов имеет
достоинства и недостатки. Для всех, кто хочет знать больше об этих
автоматах в их связи с РВ, может быть рекомендована книга /1/.
В нашей реализации мы будем использовать недетерминированный автомат.
Это наиболее востребованная стратегия реализации алгоритма обработки
РВ. Более того, сконструировать недетерминированный
автомат по РВ несколько проще, чем детерминированный.
На Рисунке 1 показана диаграмма переходов недетерминированного конечного
автомата для шаблона a*(cb|c*)d. Она содержит все типы операций
над регулярными множествами: итерацию, конкатенацию, объединение.
Заметьте, что скобка, содержащая объединение, является
литералом для операции конкатенации. Начальное состояние представлено
прямоугольником в левой части рисунка. Допускающее состояние
автомата показано в правой части рисунка в виде прямоугольника,
перечёркнутого по диагонали.
![]()
Рисунок 1. Недетерминированный конечный автомат для шаблона a*(cd|c*)d
Этот пример очень хорошо демонстрирует
проблемы обработки шаблонов. В состоянии под номером 7
не ясно какое состояние будет следующим для
входного символа «c». Состояния 4 и 9 — возможные варианты.
Автомат должен выбрать правильный путь.
Если на предмет совпадения с шаблоном
должна быть исследована строка, содержащая текст «aaccd»,
автомат стартует из состояния номер 0 — начального состояния.
Следующее состояние, номер 2, является .
Первый символ на входе — «a». Автомат переходит в состояние под
номером 1, это единственный путь. После успешного
совпадения части шаблона с символом «a» будет прочитан очередной символ
и автомат снова перейдёт в состояние 2. Для следующего входного
символа, тоже «a», крайние два перехода повторяются.
После этого, единственный допустимый путь — переход в состояние под
номером 3 и 7.
Мы оказались в состоянии, которое может вызвать проблемы.
Следующий символ на входе — «c». Здесь мы видим силу автомата.
Он может догадаться, что правильный путь будет через состояние
номер 9, но не 4. Это — душа недетерминированной стратегии: возможные
решения находятся. Они не описываются алгоритмом, работающим «шаг за шагом».
Разумеется, в реальном мире программирования мы должны перебирать
все возможные пути. Однако, о практической стороне дела поговорим несколько позже.


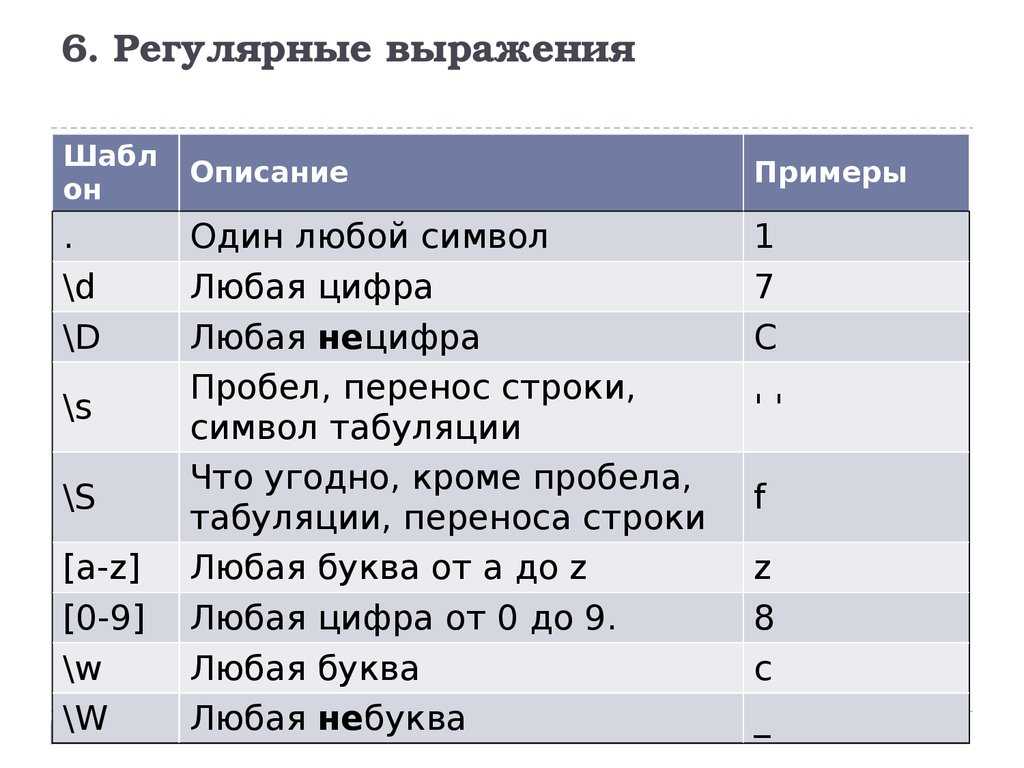






После достижения состояния под номером 9, автомат осуществляет
переход из 9 в 8 (первое «c» на входе), в 9, в 8 (второе «c» на входе),
10 и 11 (совпадение с «d») в допускающее состояние под номером 12.
Допускающее состояние достигнуто, следовательно, текст «aaccd» совпадает с
шаблоном «a*(cb|c*)d».
Разработка
Механизм обработки РВ может
быть разделен на две части: компилятор, генерирующий автомат
по заданному шаблону и интерпретатор или эмулятор, имитирующий
автомат и осуществляющий поиск по шаблону.
Сердцем компилятора является синтаксический анализатор (parser),
основанный на следующей контекстно-свободной грамматике:
Эта EBNF диаграмма (=Extended Backus-Naur Form — Расширенная форма Бакуса-Наура)
описывает (сокращённую) грамматику РВ. В рамках данной статьи
невозможно объяснить, что такое контекстно-свободная грамматика или, например, EBNF.
Поэтому, если вы не знакомы с этими темами, рекомендую почитать /1/ и /3/, например.
(Краткое, но ёмкое введение в систему обозначений EBNF на русском языке, может
быть найдено в свободной энциклопедии Wikipedia. — Прим. перев.)
В нашем примере механизма обработки РВ мы реализуем базовые операции
над регулярными множествами, в частности, и . Такие
квантификаторы как и мы не будем применять. Но
с помощью Рисунка 2 вам не составит проблем самим их реализовать.
Все функции РВ будут инкапсулированы в класс объектов под названием
. Этот класс будет содержать компилятор и интерпретатор/эмулятор.
Пользователю будут предоставлены только два конструктора, один перегруженный оператор и четыре
метода для компиляции, поиска и обработки ошибок.
Шаблон может быть задан через вызов конструктора ,
через использование оператора присваивания или метода .
Если является объектом , следующие строки зададут шаблон «a*(cb|c*)d»:
или
или
Для поиска в текcте предлагается использовать
методы и . Разница между ними в том, что
ожидает, как дополнительный параметр, ссылку на переменную
типа unsigned integer. В этой переменной возвращается длина совпавшей с
шаблоном подстроки
Обратите внимание, что при использовании квантификаторов
и конструкции выбора, длина найденной подстроки может изменяться, например,
совпадает с и т. д
В таких программах как вам не потребуется такая дополнительная информация.
Здесь можно использовать вместо . Этот
метод обрабатывает входную последовательность, вызывая
с «фиктивной» переменной.
![]()
Рисунок 2. Автоматы, реализующие поведение квантификаторов
Обработка ошибок полностью основана на обработке исключений. В случае, если
компилятор обнаруживает синтаксическую ошибку в обрабатываемом РВ,
он выдаст ошибку типа . Вы можете поймать это исключение в вашей программе
и вызвать метод , возвращающий
позицию символа, при обработке которого произошла ошибка. Это может выглядеть следующим
образом:
try {
re.compile("a*(cb|c*)d");
} catch(xsyntax &X) {
cout < "error near character position "
<
X.getErrorPos() < endl;
}
Другая ошибка, которая может произойти — нехватка памяти. Такая ошибка —
вызванная использованием очередного метасимвола (caused by the new operator) —
обрабатывается различными компиляторами C++ неодинаково. gcc, к примеру,
реагирует на такую ошибку, завершая работу. Некоторые компиляторы
генерируют исключения. Другие вовсе ничего не делают и ожидают
пока появятся дополнительные ошибки, которых не приходится долго ждать
в рассматриваемом случае. Обычно, в каждом ANSI C++ компиляторе,
данная проблема решается использованием функции
(объявлена в new.h) для установки режима обработки ошибки.
В большинстве случаев я пишу маленькую подпрограмму для генерации исключения,
с указанием типа ошибки, и использую данную подпрограмму
в качестве обработчика очередного метасимвола. Это, между
прочим, — простое решение при программировании переносимого
обработчика ошибок, которого можно использовать вместе со всеми
ANSI C++ компиляторами и с любой операционной системой.
Для удаления экземпляра объекта
при возникновении ошибки и генерации исключения, в
содержится метод под названием .
Вызов данного метода важен, так как ошибка оставляет компилятор и
эмулятор (части механизма обработки регулярного выражения — Прим. перев.)
в неопределённом состоянии, которое может вызвать фатальные ошибки при
вызове других методов.



