
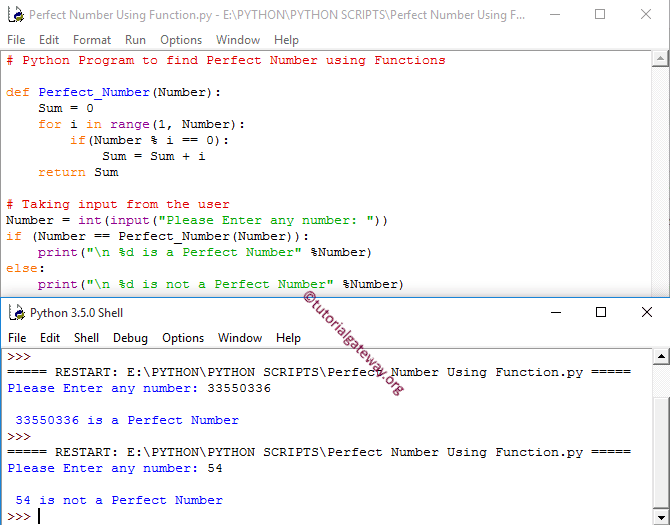
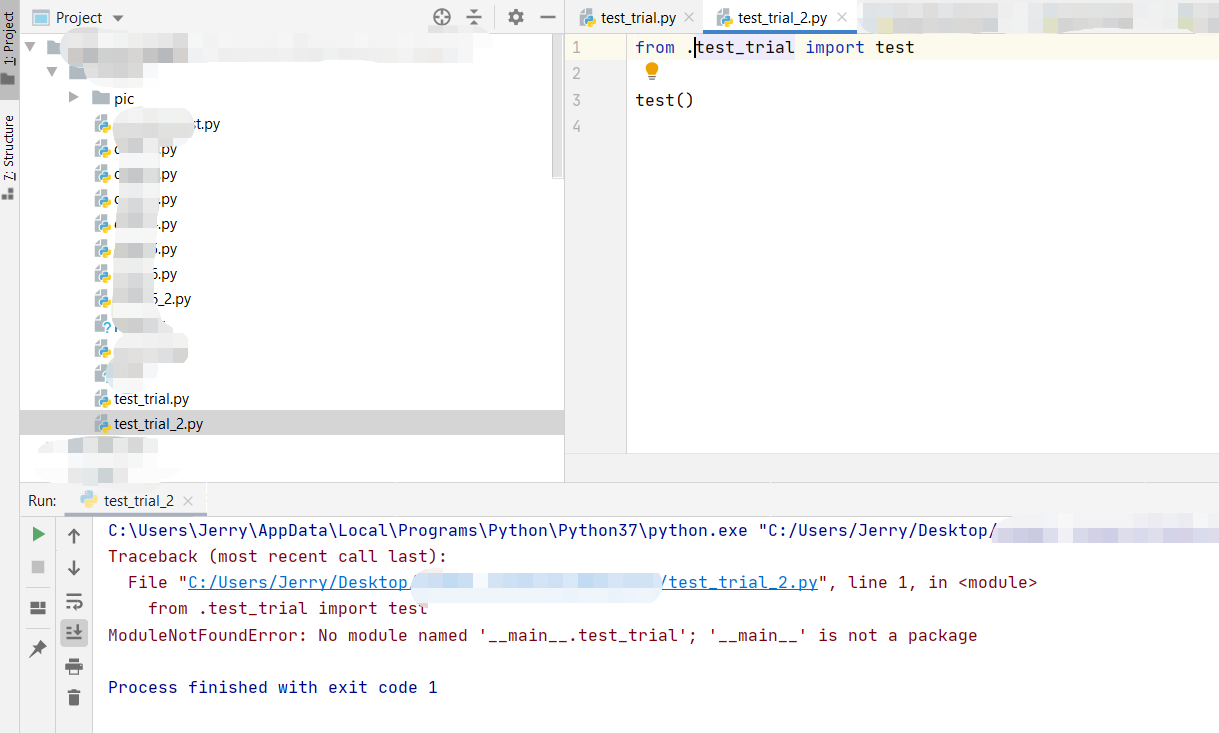
Использование официальной библиотеки для импорта данных из Google BiqQuery
![]()
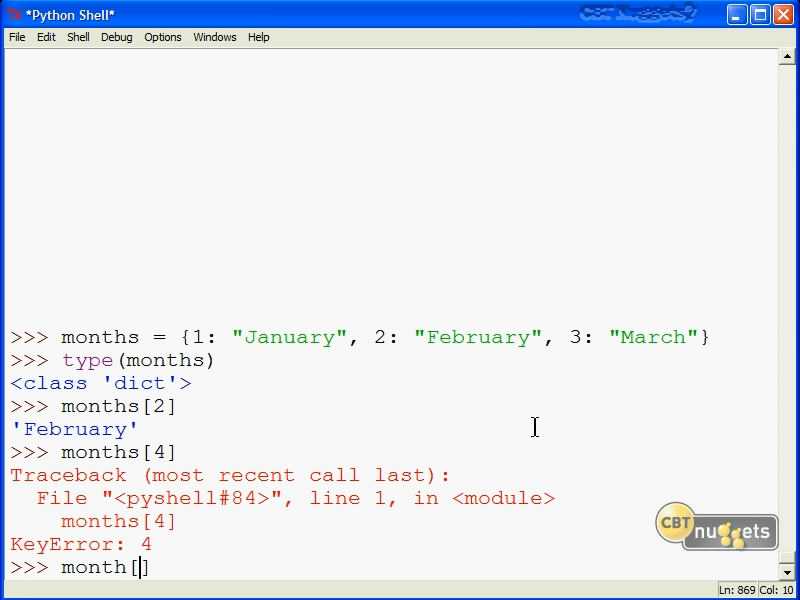
Как видно, по простоте синтаксиса, официальная библиотека мало чем отличается от использования pandas-gbq. При этом я заметил, что некоторые функции (например, date_trunc) не работают через pandas-gbq. Так что я предпочитаю использовать официальное Python SDK для Google BigQuery.
Чтобы импортировать данные из датафрейма в BigQuery, нужно установить pyarrow. Эта библиотека обеспечит унификацию данных в памяти, чтобы dataframe соответствовал структуре данных, нужных для загрузки в BigQuery.
Проверим, что наш датафрейм загрузился в BigQuery:
![]()
Прелесть использования нативного SDK вместо pandas_gbq в том, что можно управлять сущностями в BigQuery, например, создавать датасеты, редактировать таблицы (схемы, описания), создавать новые view и т. д. В общем, если pandas_gbq — это скорее про чтение и запись dataframe, то нативное SDK позволяет управлять всей внутренней кухней
Ниже привожу простой пример, как можно изменить описание таблицы:
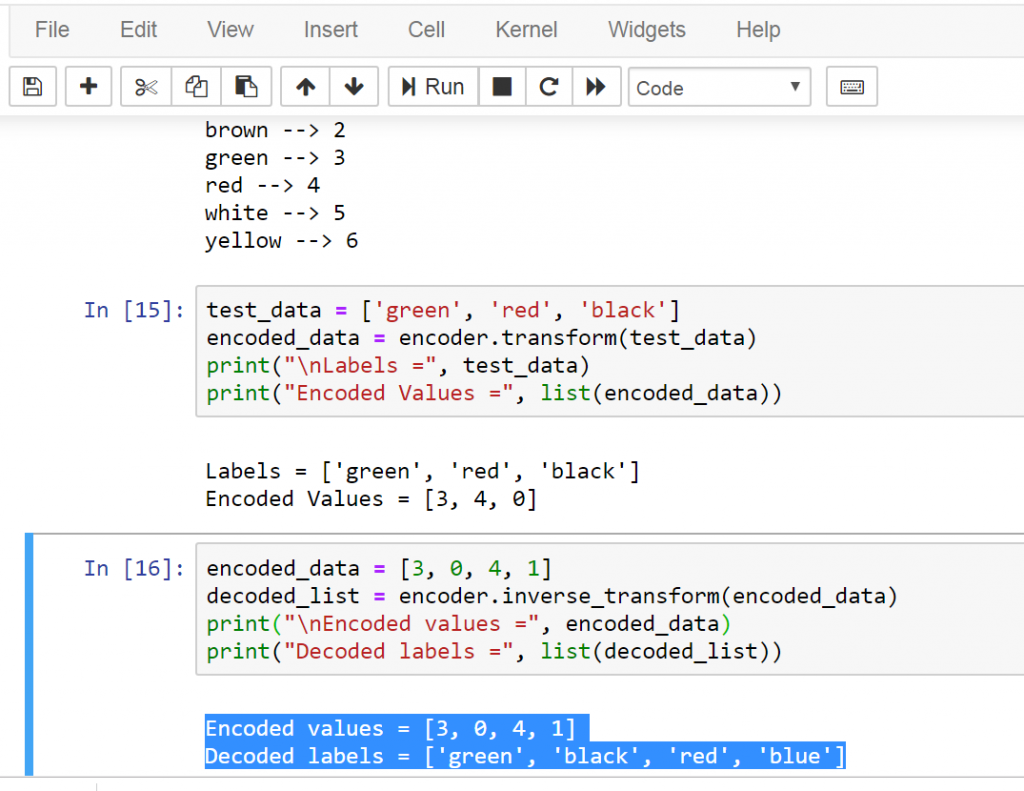
Также с помощью нативного Python-SDK можно вывести все поля из схемы таблицы, отобразить количество строк в таблице
![]()
Если таблица уже создана, то в результате новой передачи датафрейма в существующую таблицу будут добавлены строки
![]()
Что такое файл CSV? ↑
Структура файла CSV определяется его именем. Обычно, в файлах CSV для разделения каждого конкретного значения данных используется запятая. Вот как выглядит эта структура:
column 1 name,column 2 name,column 3 name first row data 1,first row data 2,first row data 3 second row data 1,second row data 2,second row data 3 ...
Обратите внимание, как каждая часть данных разделена запятой. Обычно первая строка идентифицирует каждую часть данных — другими словами, имя столбца данных
Каждая последующая строка после этого является фактическими данными и ограничена только ограничениями размера файла.
Обычно символ-разделитель называется разделителем, и используется не только запятая. Другие популярные разделители включают символы табуляции (), двоеточия () и точки с запятой (). Для правильного анализа CSV-файла нам необходимо знать, какой разделитель используется.
Откуда берутся файлы CSV?
Файлы CSV обычно создаются программами, которые обрабатывают большие объемы данных. Это удобный способ экспортировать данные из электронных таблиц и баз данных, а также импортировать или использовать их в других программах. Например, вы можете экспортировать результаты программы интеллектуального анализа данных в файл CSV, а затем импортировать их в электронную таблицу для анализа данных, создавать графики для презентации или готовить отчет к публикации.
С файлами CSV очень легко работать программно. Любой язык, поддерживающий ввод текстовых файлов и манипуляции со строками (например, Python), может напрямую работать с файлами CSV.
Сортировка по значениям
Метод sort_values() используется для сортировки DataFrame по значениям.
Он принимает параметр «by», в котором нам нужно ввести имя столбца, по которому значения должны быть отсортированы.
Пример:
import pandas
import numpy
input = {'Name':pandas.Series(),
'Marks':pandas.Series(),
'Roll_num':pandas.Series()
}
data_frame = pandas.DataFrame(input, index=)
print("Unsorted data frame:\n")
print(data_frame)
sorted_df=data_frame.sort_values(by='Marks')
print("Sorted data frame:\n")
print(sorted_df)
Выход:
Unsorted data frame:
Name Marks Roll_num
0 John 44 1
2 Caret 75 3
1 Bran 48 2
4 Sam 99 5
3 Joha 33 4
Sorted data frame:
Name Marks Roll_num
3 Joha 33 4
0 John 44 1
1 Bran 48 2
2 Caret 75 3
4 Sam 99 5
# Стандарт UTC
Есть несколько стандартов измерения и записи времени. Раньше в основном придерживались (англ. «Greenwich Mean Time», среднее время по гринвичскому меридиану). Позже прежний всемирный формат был отменен и приняли новый, определяемый атомными часами. Это — «coordinated universal time» — всемирное координированное время.
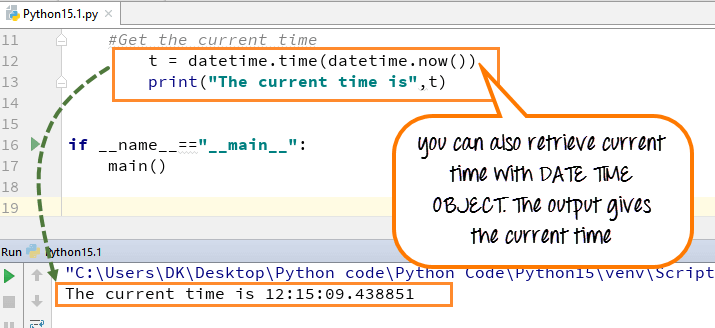
У каждой переменной типа данных можно вызвать метод (англ. now «сейчас»). Он вернёт текущий момент времени по с эталонной точностью до микросекунд.
12345
Более того, метод настолько хитрый, что для его вызова необязательно явно создавать объект типа . Можно просто написать:
1
Для получения времени другого часового пояса, есть тип (от англ. delta, «промежуток»), в котором можно сохранить определенный промежуток времени. Этот тип тоже живёт в библиотеке dt. А объект такого типа создаётся функцией :
1234
И прибавляем его к значению времени по UTC:
1234
В аргументах функции среди прочего можно указывать (дни), (часы), (минуты), (секунды), (микросекунды).
Пример: Победитель Гран-при Австралии чемпионата мира Формулы-1 2019 года, Вале Боттас проехал свой самый быстрый круг за 1 минуту 25 секунд и 273250 микросекунд. Второй результат показал Льюис Хэмилтон с разницей в 208860 микросекунд. Вычислим время самого быстрого круга Хэмилтона.
12345
Работа с часовыми поясами
При работе с часовыми поясами обработка даты и времени становится более сложной. Все вышеупомянутые примеры, которые мы обсуждали, являются наивными объектами datetime, то есть эти объекты не содержат данных, связанных с часовым поясом. У объекта datetime есть одна переменная, которая содержит информацию о часовом поясе, tzinfo.
import datetime as dt dtime = dt.datetime.now() print(dtime) print(dtime.tzinfo)
Этот код напечатает:
$ python3 datetime-tzinfo-1.py 2018-06-29 22:16:36.132767 None
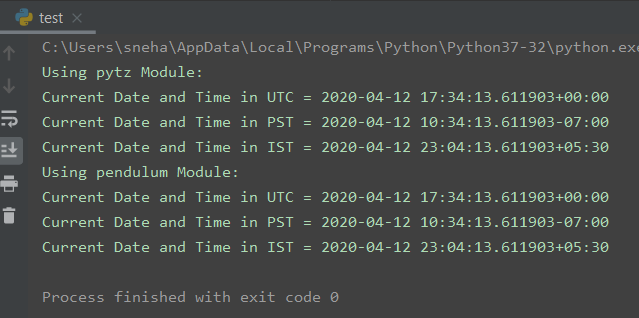
Вывод tzinfo – None, поскольку это объект datetime. Для преобразования часового пояса для Python доступна библиотека pytz. Теперь давайте воспользуемся библиотекой, чтобы преобразовать указанную выше метку времени в UTC.
import datetime as dt import pytz dtime = dt.datetime.now(pytz.utc) print(dtime) print(dtime.tzinfo)
Вывод:
$ python3 datetime-tzinfo-2.py 2018-06-29 17:08:00.586525+00:00 UTC
+00: 00 – разница между отображаемым временем и временем UTC. В этом примере значение tzinfo также совпадает с UTC, отсюда смещение 00:00. В этом случае объект datetime является объектом с учетом часового пояса.
Точно так же мы можем преобразовать строки даты и времени в любой другой часовой пояс. Например, мы можем преобразовать строку «2018-06-29 17: 08: 00.586525 + 00: 00» в часовой пояс «America / New_York», как показано ниже:
import datetime as dt
import pytz
date_time_str = '2018-06-29 17:08:00'
date_time_obj = dt.datetime.strptime(date_time_str, '%Y-%m-%d %H:%M:%S')
timezone = pytz.timezone('America/New_York')
timezone_date_time_obj = timezone.localize(date_time_obj)
print(timezone_date_time_obj)
print(timezone_date_time_obj.tzinfo)
Выход:
$ python3 datetime-tzinfo-3.py 2018-06-29 17:08:00-04:00 America/New_York
Сначала мы преобразовали строку в объект datetime, date_time_obj. Затем мы преобразовали его в объект datetime с включенным часовым поясом, timezone_date_time_obj. Поскольку мы установили часовой пояс, как «America и New_York», время вывода показывает, что он на 4 часа отстает от времени UTC. Вы можете проверить эту страницу Википедии, чтобы найти полный список доступных часовых поясов.
Операции с текстовыми данными в Pandas
Строковые функции Python можно применять к DataFrame.
Ниже приводится список наиболее часто используемых строковых функций в DataFrame:
| Функция |
| lower(): преобразует строку в DataFrame в нижний регистр. |
| upper(): преобразует строку в DataFrame в верхний регистр. |
| len(): возвращает длину строки. |
| strip(): обрезает пробелы с обеих сторон ввода в DataFrame. |
| split (»): разбивает строку с шаблоном ввода. |
| contains (pattern): возвращает истину, если переданная подстрока присутствует во входном элементе DataFrame. |
| replace (x, y): меняет значения x и y. |
| startwith (шаблон): возвращает истину, если входной элемент начинается с предоставленного аргумента. |
| endwith (pattern): возвращает истину, если входной элемент заканчивается предоставленным аргументом. |
| swapcase: меняет верхний регистр на нижний и наоборот. |
| islower(): возвращает логическое значение и проверяет, все ли символы ввода в нижнем регистре или нет. |
| isupper(): возвращает логическое значение и проверяет, все ли символы ввода находятся в верхнем регистре или нет. |
Пример:
import pandas
import numpy
input = pandas.Series()
print("Converting the DataFrame to lower case....\n")
print(input.str.lower())
print("Converting the DataFrame to Upper Case.....\n")
print(input.str.upper())
print("Displaying the length of data element in each row.....\n")
print(input.str.len())
print("Replacing 'a' with '@'.....\n")
print(input.str.replace('a','@'))
Выход:
Converting the DataFrame to lower case.... 0 john 1 bran 2 caret 3 joha 4 sam dtype: object Converting the DataFrame to Upper Case..... 0 JOHN 1 BRAN 2 CARET 3 JOHA 4 SAM dtype: object Displaying the length of data element in each row..... 0 4 1 4 2 5 3 4 4 3 dtype: int64 Replacing 'a' with '@'..... 0 John 1 Br@n 2 C@ret 3 Joh@ 4 S@m dtype: object
Исследуем данные: методы и атрибуты
Кроме методов, у датафреймов есть неотъемлемые свойства, которые называются атрибутами. В отличие от методов, они вызываются без скобок в конце.
Как видим, можно посмотреть каждую колонку отдельно. И уже к этой колонке применить метод:
Вывод будет таким:
Метод .describe(), применённый к колонке salary таблицы trips_df, показал нам следующее.


count — количество строк: 1 000.
mean — средний доход составляет 111 935 рублей. Неплохо!
std — под этим сокращением скрыто так называемое стандартное (среднеквадратичное) отклонение, которое показывает величину разброса значений. В нашем случае оно довольно большое, почти 55 000 рублей. Это означает, что доходы у людей в таблице очень разные.
min — минимальное значение доходов из таблицы. Ноль значит, что есть как минимум один человек с нулевым доходом.
В математической статистике процентиль, или перцентиль (ударение на последний слог), — это, если по-простому, пара чисел. Первое из них — процентная доля тех значений рассматриваемой величины, которые не превышают второго числа. Например, фраза «двадцать пятый процентиль доходов туристов составляет 68 000 рублей в месяц» означает, что у 25% наших туристов доход не превышает этой суммы. А у остальных, что очевидно, доход больше.
25% — вот он, тот самый двадцать пятый процентиль. Часто его ещё называют «нижний квартиль».
50% — пятидесятый процентиль, или медиана. В примере она равна 99000, и это значит, что одна половина людей из таблицы получает меньше этой суммы, а другая — больше.
75% — семьдесят пятый процентиль, который также часто называют «верхний квартиль». Означает, что у 75% людей доход меньше 161 000 рублей, а у оставшихся 25% — больше.
max — здесь всё понятно. В нашей таблице есть как минимум один человек с доходом 250 000 рублей в месяц — наверняка это какой-нибудь дата-сайентист: -).
Name: salary, dtype: float64 — служебная информация: название колонки и тип данных в ней.
Использование pandas-gbq для импорта данных из Google BiqQuery
Я решил рассмотреть основы работы с Google BigQuery с помощью Python на примере публичных датасетов. В качестве интересного примера возьмем датасет с данными о вопросах на сервисе Stackoverflow.
Дальше немного поиграем с обработкой данных. Выделим из даты месяц и год.
![]()
Cгруппируем данные по годам и месяцам и запишем полученные данные в датафрейм stats.
Посчитаем суммарное количество вопросов в год, а также среднее количество запросов в месяц для каждого года, начиная с января 2013 и по август 2018 (последний полный месяц, который был в датасете на момент написания статьи). Запишем полученные данные в новый датафрейм year_stats
Так как 2018 год в наших данных неполный, то мы можем посчитать оценочное количество вопросов, которое ожидается в 2018 году.
![]()
На основе данных от StackOverflow можно сказать, что популярность pandas из года в год растет хорошими темпами ![]()
Формат datetime
Представление даты и времени может отличатся в разных странах, организациях и т. д. В США, например, чаще всего используется формат «мм/дд/гггг», тогда как в Великобритании более распространен формат «дд/мм/гггг».
В Python для работы с форматами есть методы и .
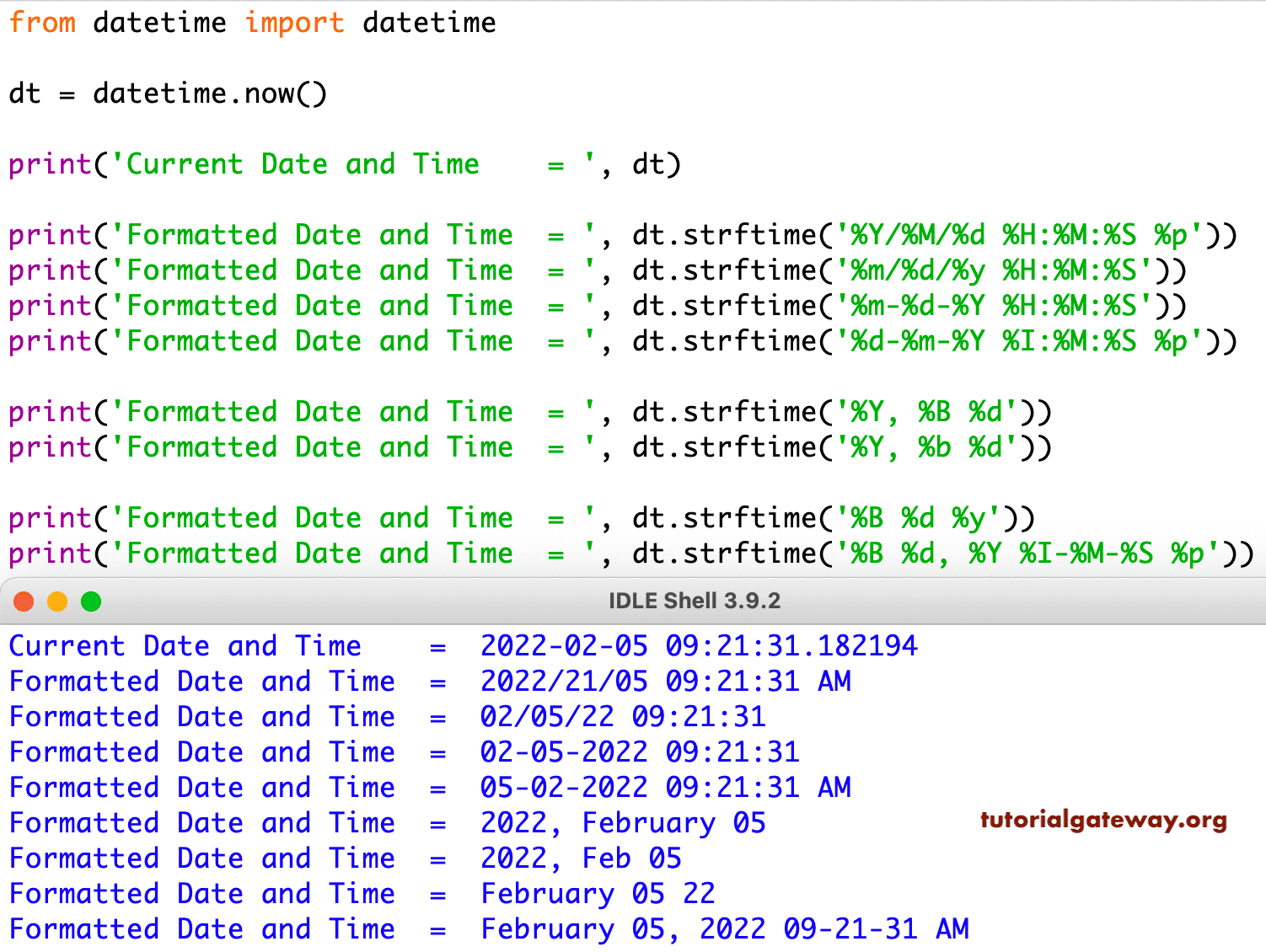
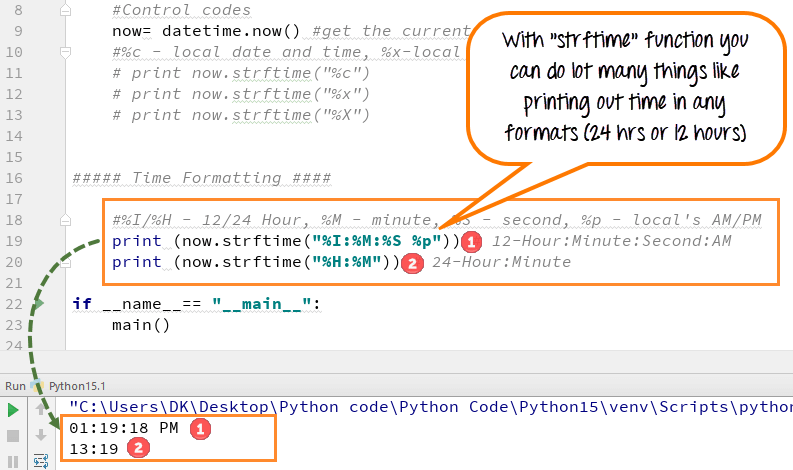
Python strftime() — преобразование объекта datetime в строку
Метод определен в классах , и . Он создает форматированную строку из заданного объекта , или .
Пример 16: форматирование даты с использованием метода strftime().
from datetime import datetime
now = datetime.now()
t = now.strftime("%H:%M:%S")
print("time:", t)
s1 = now.strftime("%m/%d/%Y, %H:%M:%S")
# mm/dd/YY H:M:S format
print("s1:", s1)
s2 = now.strftime("%d/%m/%Y, %H:%M:%S")
# dd/mm/YY H:M:S format
print("s2:", s2)
Когда вы запустите программу, результат будет примерно таким:
Здесь , , , и т. д. — коды для определения формата. Метод принимает один или несколько кодов и возвращает отформатированную строку на его основе.
В приведенной выше программе переменные , и являются строками.
Основные коды для определения формата:
- — год
- — месяц
- — день
- — час
- — минута
- — секунда
Python strptime()- преобразование строки в объект datetime
Метод создает объект datetime из заданной строки (представляющей дату и время).
Пример 17: метод strptime().
from datetime import datetime
date_string = "21 June, 2018"
print("date_string =", date_string)
date_object = datetime.strptime(date_string, "%d %B, %Y")
print("date_object =", date_object)
Когда вы запустите программу, вывод будет следующим:
Метод принимает два аргумента:
- строка, представляющая дату и время.
- формат, определяющий, каким образом части даты и времени расположены в переданной строке.
Кстати, коды , и используются для обозначения дня, месяца (название месяца в полном виде) и года соответственно.
Как создать простой aware-объект datetime, учитывающий часовой пояс
import datetime dt_now = datetime.datetime.utcnow() print(dt_now)
Один из недостатков библиотеки datetime Python — отсутствие поддержки часовых поясов. В случае, когда нужно учитывать часовой пояс, используется другая библиотека – . В первой строке кода эту библиотеку также нужно импортировать. Предположим, что нам необходимо задать время в столице Кении — Найроби:
import pytz
import datetime
tz_nairobi = pytz.timezone("Africa/Nairobi")
dt_nairobi =datetime.datetime.now(tz_nairobi)
print(dt_nairobi)
Консоль выведет:
А вот так высчитывается время в Праге:
import pytz
import datetime
tz_praha = pytz.timezone("Europe/Prague")
dt_praha = datetime.datetime.now(tz_praha)
print(dt_praha)
Результат:
Структура данных DataFrame
DataFrame – это двухмерные структуры помеченных данных, столбцы которых могут содержать разные типы данных.
Данные DataFrame похожи на электронную таблицу или таблицу SQL. В целом DataFrame – самый распространённый объект при работе с pandas.
Чтобы понять, как работает DataFrame, создайте две структуры Series и передайте их DataFrame. Первая структура Series – это avg_ocean_depth (из вышеприведённого примера), а вторая структура будет называться max_ocean_depth и содержать данные о максимальной глубине каждого океана в метрах. Откройте файл ocean.py и добавьте в него:
Структуры Series готовы. Теперь добавьте в конец файла DataFrame (под max_ocean_depth). В данном примере обе структуры Series имеют одинаковые метки индексов; если бы структуры Series имели разные метки индексов, пропущенные значения были бы помечены как NaN.
В массив можно добавить метки столбцов, которые объявлены как ключи переменных Series. Чтобы увидеть DataFrame, отобразите данные:
В результате на экране появится два столбца с соответствующими заголовками, числовые данные справа и метки из словаря (ключи) слева.
Сортировка данных в DataFrame
Вы можете сортировать данные в DataFrame с помощью функции DataFrame.sort_values(by=…).
Для примера используем логический параметр ascending, который может быть истинным или ложным (True или False). Параметр ascending можно передать функции, а descending – нельзя.
Теперь в выводе значения расположены в порядке возрастания.
DataFrame и статистический анализ
Пакет pandas позволяет собирать общие статистические данные с помощью функции DataFrame.describe().

Без дополнительных параметров функция DataFrame.describe() предоставит следующую информацию для числовых типов данных:
|
Вывод |
Что это значит? |
| count | Подсчёт частоты того или иного события (сколько раз произошло событие?). |
| mean | Среднее значение. |
| std | Стандартное отклонение (числовое значение, которое отображает изменение пределов данных). |
| min | Наименьшее число в наборе данных. |
| 25% | 25-й процентиль. |
| 50% | 50-й процентиль. |
| 75% | 75-й процентиль. |
| max | Максимальное число в наборе данных. |
Запросите статистику структуры ocean_depths с помощью функции describe().
На экране появятся данные:
Обработка пропущенных значений
Пропущенные значения часто встречаются при работе с данными. Пакет pandas предоставляет множество способов обработки пропущенных данных (данных null), то есть тех данных, которые были пропущены по той или иной причине. В pandas такие данные называются данными NA и отображаются как NaN.
Рассмотрим некоторые функции работы с пропущенными данными (например, сброс и заполнение). Для сброса используется функция DataFrame.dropna(), а для заполнения – DataFrame.fillna().
Создайте файл user_data.py, добавьте в него данные с пропущенными значениями и превратите в DataFrame:
Теперь отобразите данные:
В них присутствует несколько пропущенных значений.
Попробуйте сбросить пропущенные значения. Добавьте в файл опцию:
Поскольку в файле всего одна строка не содержит пропущенных значений, на экране появится довольно маленький набор данных:
Пропущенные значения можно заполнить любыми значениями, например, вставить 0. Это делается с помощью DataFrame.fillna(0).
Удалите или закомментируйте последнюю строку в файле и добавьте в него такую строку:
Снова запустите программу. На экране появится:
Теперь на экране отображаются все строки, а пропущенные значения NaN заменены нулем.
Arrow
Arrow – еще одна библиотека для работы с datetime в Python. И, как и раньше с Maya, он также автоматически определяет формат даты и времени. После интерпретации он возвращает объект даты и времени в Python из объекта стрелки.
Давайте попробуем это с той же примерной строкой, которую мы использовали для Maya:
import arrow
dt = arrow.get('2018-04-29T17:45:25Z')
print(dt.date())
print(dt.time())
print(dt.tzinfo)
Вывод:
$ python3 arrow-1.py 2018-04-29 17:45:25 tzutc()
А вот как можно использовать стрелку для преобразования часовых поясов с помощью метода to:
import arrow
dt = arrow.get('2018-04-29T17:45:25Z').to('America/New_York')
print(dt)
print(dt.date())
print(dt.time())
Вывод:
$ python3 arrow-2.py 2018-04-29T13:45:25-04:00 2018-04-29 13:45:25
Как видите, строка даты и времени преобразована в регион «Америка и Нью-Йорк».
Теперь давайте снова воспользуемся тем же набором строк, который мы использовали выше:
import arrow
date_array = [
'2018-06-29 08:15:27.243860',
#'Jun 28 2018 7:40AM',
#'Jun 28 2018 at 7:40AM',
#'September 18, 2017, 22:19:55',
#'Sun, 05/12/1999, 12:30PM',
#'Mon, 21 March, 2015',
'2018-03-12T10:12:45Z',
'2018-06-29 17:08:00.586525+00:00',
'2018-06-29 17:08:00.586525+05:00',
#'Tuesday , 6th September, 2017 at 4:30pm'
]
for date in date_array:
dt = arrow.get(date)
print('Parsing: ' + date)
print(dt)
print(dt.date())
print(dt.time())
print(dt.tzinfo)
Этот код завершится ошибкой для закомментированных строк даты и времени, что составляет более половины наших примеров. Результатом для других строк будет:
$ python3 arrow-3.py Parsing: 2018-06-29 08:15:27.243860 2018-06-29T08:15:27.243860+00:00 2018-06-29 08:15:27.243860 tzutc() Parsing: 2018-03-12T10:12:45Z 2018-03-12T10:12:45+00:00 2018-03-12 10:12:45 tzutc() Parsing: 2018-06-29 17:08:00.586525+00:00 2018-06-29T17:08:00.586525+00:00 2018-06-29 17:08:00.586525 tzoffset(None, 0) Parsing: 2018-06-29 17:08:00.586525+05:00 2018-06-29T17:08:00.586525+05:00 2018-06-29 17:08:00.586525 tzoffset(None, 18000)
Чтобы правильно проанализировать строки даты и времени, вам необходимо передать соответствующие токены формата, чтобы дать библиотеке подсказки относительно того, как их анализировать. Например, «MMM» для названия месяцев, например «Jan, Feb, Mar» и т.д. вы можете проверить это руководство для всех доступных токенов.
Модуль datetime
В базовом функционале Питона нет отдельного типа данных, отвечающего за дату и время. Необходимо импортировать модуль, который называется datetime.
Первая особенность, про которую стоит сказать, datetime — это не только название модуля, но и название одного из классов внутри этого модуля. Помимо класса datetime, нас будет интересовать ещё один класс — timedelta.
![]()
Перейдем к практике.
Откроем ноутбук к этому занятию⧉
Импорт модуля и класса datetime
Самый простой способ — импортировать весь модуль datetime.
|
1 |
# импортируем весь модуль importdatetime |
Далее предположим, что мы хотим воспользоваться функцией now(), которая находится внутри класса datetime. Функция now() выводит текущие дату и время.
|
1 |
# чтобы получить доступ к функции now(), сначала обратимся к модулю, потом к классу print(datetime.datetime.now()) |
| 1 | 2021-11-18 09:33:28.140594 |
Как вы видите, это не очень удобно. Можно импортировать только класс datetime и обращаться непосредственно к нему.
|
1 |
fromdatetimeimportdatetime print(datetime.now()) |
| 1 | 2021-11-18093330.586757 |
Объект datetime и функция now()
Теперь поговорим подробнее про то, что выводит функция now().
|
1 |
# поместим созданный с помощью функции now() объект datetime в переменную cur_dt cur_dt=datetime.now() print(cur_dt) |
| 1 | 2021-11-18 09:33:32.412999 |
На выходе мы получаем текущие дату и время по UTC⧉, потому что серверы Google Colab настроены именно на это время (московское время, например, отличается на +3 часа). Сам вывод состоит из следующих компонентов.
![]()
Мы можем обратиться к каждому из этих компонентов по отдельности.
|
1 |
# с помощью соответствующих атрибутов выведем каждый из компонентов объекта print(cur_dt.year,cur_dt.month,cur_dt.day,cur_dt.hour,cur_dt.minute,cur_dt.second,cur_dt.microsecond) |
| 1 | 2021 11 18 9 33 32 412999 |
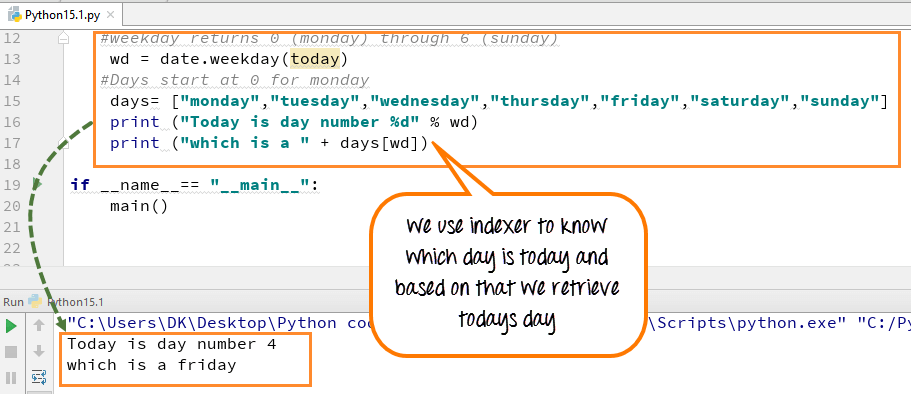
Мы также можем посмотреть на день недели, причем в двух форматах. Метод .weekday() считает, что неделя начинается с нуля, метод .isoweekday(), что с единицы.
![]()
Так как 18 ноября 2021 года — это четверг, то применив эти методы, мы должны получить цифры три и четыре соответственно.
| 1 | print(cur_dt.weekday(),cur_dt.isoweekday()) |
| 1 | 3 4 |
Разумеется, когда вы будете самостоятельно исполнять код в ноутбуке, будут выведены текущие дата и время сервера Google.
Объект datetime, полученный из функции now(), не содержит данных о часовом поясе.
|
1 |
# посмотрим на часовой пояс с помощью атрибута tzinfo print(cur_dt.tzinfo) |
| 1 | None |
Для того чтобы добавить такую информацию и вывести, например, другой часовой пояс, нам нужно воспользоваться модулем pytz.
|
1 |
importpytz dt_moscow=datetime.now(pytz.timezone(‘Europe/Moscow’)) print(dt_moscow) |
| 1 | 2021-11-18 12:33:33.682674+03:00 |
Посмотрим, не появился ли часовой пояс.
| 1 | print(dt_moscow.tzinfo) |
| 1 | Europe/Moscow |
Timestamp
До сих пор мы работали с привычным для нас делением на годы, месяцы, дни, часы, минуты и секунды. При этом компьютеры используют так называемое время Unix, которое отсчитывается в секундах c первого января 1970 года. Для отображения даты и времени в таком формате в Питоне есть объект timestamp (по-английски — «временная отметка»).
|
1 |
# получим timestamp текущего времени с помощью метода .timestamp() timestamp=datetime.now().timestamp() |
Посмотрим, сколько секунд и микросекунд прошло с 01.01.1970 и до момента исполнения кода.
| 1 | print(timestamp) |
| 1 | 1637233979.128056 |
Не составляет труда вернуть timestamp обратно в привычный формат.
|
1 |
# для этого воспользуемся методом .fromtimestamp() print(datetime.fromtimestamp(timestamp)) |
| 1 | 2021-11-18 11:12:59.128056 |
Создание объекта datetime вручную
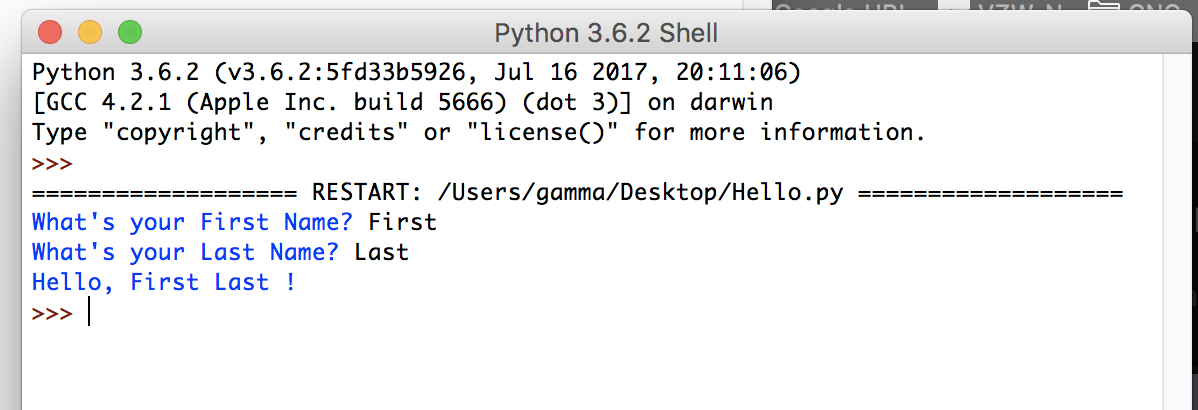
Дату и время не обязательно получать из функции now(). Мы вполне можем передать объекту datetime наши собственные параметры, например, день рождения Питона.
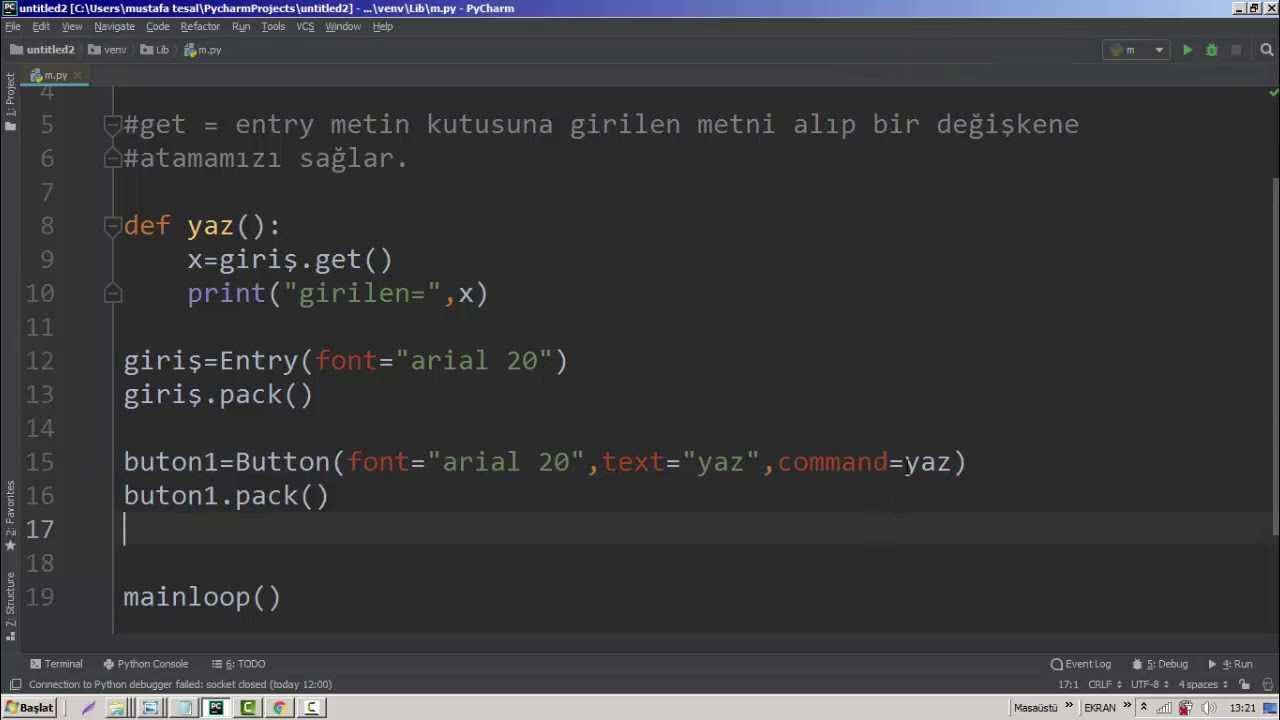
|
1 |
# передадим объекту datetime 20 февраля 1991 года hb=datetime(1991,2,20) print(hb) |
| 1 | 1991-02-20 00:00:00 |
Обратите внимание, мы ввели только год, месяц и день. Это обязательные параметры
Остальные параметры можно не вводить, в этом случае они заполнятся нулями.
Из этого объекта мы также можем извлечь компоненты (год, месяц, число и т.д.) и создать timestamp.
|
1 |
# извлечем год с помощью атрибута year print(hb.year) |
| 1 | 1991 |
|
1 |
# и создадим timestamp print(datetime.timestamp(hb)) |
| 1 | 667008000.0 |
Что нужно?
Изначально надо иметь версию Python хотя бы 3,7. Можно более новую. Помимо этого, должны быть установлены numpy, Pandas.
Далее надо подключиться к серверу. Если его нет, то можно создать локальный сервер, после чего запустить Jupyter. После этого открыть браузер, который подходит вам больше всего и открыть Jupyter Notebook. Далее создается ноутбук с названием pandas_tutorial_1.
Далее надо импортировать numpy, pandas в Jupyter Notebook с использованием двух строчек кода.
import numpy as np import pandas as pd
Теперь все настроено. Поэтому переходим к руководству по этой библиотеке. Начнем с вопроса, как правильно осуществлять открытие файлов с информацией с помощью этой библиотеки.
Сбор данных
Наука о данных включает в себя обработку данных, чтобы данные могли хорошо работать с алгоритмами данных. Data Wrangling – это процесс обработки данных, такой как слияние, группировка и конкатенация.
Библиотека Pandas предоставляет полезные функции, такие как merge(), groupby() и concat() для поддержки задач Data Wrangling.
import pandas as pd
d = {
'Employee_id': ,
'Employee_name':
}
df1 = pd.DataFrame(d, columns=)
print(df1)
![]()
import pandas as pd
data = {
'Employee_id': ,
'Employee_name':
}
df2 = pd.DataFrame(data, columns=)
print(df2)
а. merge()
print(pd.merge(df1, df2, on='Employee_id'))
![]()
Мы видим, что функция merge() возвращает строки из обоих DataFrames, имеющих то же значение столбца, которое использовалось при слиянии.
b. Группировка
import pandas as pd
import numpy as np
data = {
'Employee_id': ,
'Employee_name':
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Поле «Employee_name» со значением «Meera» сгруппировано по столбцу «Employee_name». Пример вывода приведен ниже:
Подведем итог
Сегодня мы посмотрели на возможности Питона по работе с датой и временем. В частности, узнали про классы datetime и timedelta модуля datetime и научились работать с объектами этих классов:
- Мы рассмотрели структуру объекта datetime
- Узнали про функцию now()
- Научились извлекать timestamp и вручную создавать объект datetime
- Посмотрели, как преобразовывать строку в объект datetime и наоборот
- Изучили возможности сравнения дат, вычисления промежутка между датами и выполнили несложную арифметику дат с помощью объекта timedelta
- Наконец, мы познакомились с конструкцией try/except и оператором pass и применили их к обработке различных форматов дат
Вопросы для закрепления
С какими классами модуля datetime мы познакомились на этом занятии?
Посмотреть правильный ответ
Ответ: классом datetime и классом timedelta
Чему соответствует формат ‘%c’?
Посмотреть правильный ответ
Ответ: формат ‘%c’ выводит полную дату и время, например: Sun Nov 21 10:38:12 2021
Как еще в библиотеке Pandas мы можем превратить столбец в индекс и затем преобразовать в объект datetime? Подсказка: обратитесь к лекции по временным рядам.
Посмотреть правильный ответ
Ответ: мы можем последовательно применить .set_index() и pd.to_datetime()
В ноутбуке к лекции приведены ⧉.
На следующем занятии мы поговорим про функции в Питоне.



