
3 ответа
Лучший ответ
Вот чего вы хотите достичь:
Поскольку вы используете один объект-потребитель, вам не нужно заботиться о синхронизации операций записи файлов file1 и file2. Однако вам необходимо синхронизировать операцию / метод, в которых ваши потоки будут сбрасывать результат в коллекцию потребителя. Вы можете использовать ConcurrentHashMap для сбора результатов из разных потоков в вашем потребительском классе, который является потокобезопасным.
Кроме того, поскольку вы собираетесь читать строки из DB1 и DB2 на основе уникального идентификатора, блокировка уровня строки не должна происходить, пока несколько потоков пытаются получить доступ. Если это не так и 2 потока пытаются прочитать строку с одинаковым идентификатором, может произойти конфликт.
1
csk
3 Май 2016 в 12:33
Я не могу найти ни одного. Но, конечно, я могу комментировать только на основе вашего высокоуровневого описания вашего алгоритма. Будут правильные и неправильные способы реализовать это.
1
Обратите внимание, что узкими местами для этого приложения, вероятно, будут:
- эффективная пропускная способность ваших запросов DynamoDB
- скорость, с которой вы можете записать результаты в файл
(Вероятно, первое будет преобладать.) Поскольку оба будут ограничены «внешними» факторами (например, дисковым вводом-выводом, сетью, нагрузкой на процессоры базы данных), вам, скорее всего, потребуется «настроить» количество рабочих потоков. ты используешь.
1 — Я полагаю, вы имеете в виду тот, который имеет лучшую пропускную способность.
Stephen C
3 Май 2016 в 12:18
Если я правильно понимаю, вам нужны 2 потока, каждый из которых запрашивает таблицу db и публикует результаты в файле. См. Ниже.
Краткий пример
Звоните с помощью
Это должно работать нормально, пока вы не редактируете идентификаторы, пока читаете их в одном из этих потоков.
Использование синхронизированных
Это блокирует метод для одного потока, например, при записи в один и тот же файл это необходимо, поскольку потоки будут перехватывать друг друга.
Вызовите это как обычный метод в ваших потоках. Это НЕ гарантирует порядок, в котором потоки обращаются к этим методам, в этом примере он первым пришел первым.
1
namlik
3 Май 2016 в 12:31
Работа с выражениями типа Boolean
Булевское значение является примитивным типом данных и может принимать только два значения: true или false. Булевские выражения позволяют рассматривать несколько условий в одном программном решении. Для определения истинности или ложности условий булевские выражения чаще всего используют следующие операторы:
-
&& – логический оператор «И»
-
|| – логический оператор «ИЛИ»
-
! – логический оператор «НЕ»
-
^ – логический оператор «исключающее ИЛИ»
Например, в программе, определяющей оплату за сверхурочные часы, приложение должно в начале проверить, не превысило ли общее количество наработанных часов в неделю по заданному виду деятельности лимит в 40 часов.
В задаче поставленной ранее указывается, что если было наработано более 40 часов, а в качестве вида деятельности указаны или продавец или заведующий складом, то должно вывестись сообщение «Служащий получает оплату за сверхурочную работу». В противном случае выводится сообщение «Служащий получает стандартную зарплату».
В начале программного кода можно объявить булевские переменные, после чего использовать их в булевских выражениях для проверки поставленных условий:
В представленном выше примере первая булевская переменная isSaturday принимает значение true только, если возвращается строка Saturday. Вторая переменная isDayLight определяет условие дневного времени и возвращает значение true только в определенные часы.
Где применяется Java?
Java — это язык широкого назначения. Его основной принцип: «Пиши один раз, запускай где угодно», или WORA (Write Once, Run Anywhere). Это значит, что скомпилированный (преобразованный в машинный код) Java-код можно можно запустить на всех поддерживающих Java платформах без необходимости повторной компиляции.
Java-приложения обычно компилируются в байт-код (набор инструкций, выполняемый виртуальной машиной Java). JVM устанавливается на платформу, на которой предстоит выполнение Java-программы. На Windows, к примеру, ее нужно устанавливать самостоятельно, а на Android JVM уже вшита.
Достоинство такого способа выполнения программ — это независимость байт-кода от операционной системы, что и позволяет выполнять Java-приложения на таком большом количестве устройств.
Сейчас Java остается универсальным языком программирования, который используют компании разного масштаба в своих продуктах. Вот где он применяется:
Android. Несмотря на популяризацию Kotlin в последнее время, на Java написано огромное количество приложений для платформы Android.
Серверные приложения. Часто на Java пишутся приложения, не имеющие интерфейса. Они используются для получения, обработки и передачи данных на сервере.
Десктопные приложения. В том числе и много IDE (интегрированная среда разработки — комплекс программных средств, используемый для разработки ПО) разработаны на Java — например, IntelliJ IDEA, Eclipse, Netbeans.
Веб-приложения. Например, большое количество RESTful-сервисов (REST — стиль архитектуры программного обеспечения для распределенных систем) и сервлетов (интерфейс Java, реализация которого расширяет функциональные возможности сервера) было создано с использованием Java.
Встраиваемые системы. От банкоматов, платежных терминалов и станков с ЧПУ до бытовой техники — Java может использоваться практически везде, как и обещали его создатели.
Большие данные. Java не доминирует в этой области, но применяться может.
О потоках и их истоках
Чтобы понять многопоточность, сначала вникнем, что такое процесс. Процесс – это часть виртуальной памяти и ресурсов, которую ОС выделяет для выполнения программы. Если открыть несколько экземпляров одного приложения, под каждый система выделит по процессу. В современных браузерах за каждую вкладку может отвечать отдельный процесс.
Вы наверняка сталкивались с «Диспетчером задач» Windows (в Linux это — «Системный монитор») и знаете, что лишние запущенные процессы грузят систему, а самые «тяжёлые» из них часто зависают, так что их приходится завершать принудительно.
Но пользователи любят многозадачность: хлебом не корми — дай открыть с десяток окон и попрыгать туда-сюда. Налицо дилемма: нужно обеспечить одновременную работу приложений и при этом снизить нагрузку на систему, чтобы она не тормозила. Допустим, «железу» не угнаться за потребностями владельцев — нужно решать вопрос на программном уровне.
Мы хотим, чтобы в единицу времени процессор успевал выполнить больше команд и обработать больше данных. То есть нам надо уместить в каждом кванте времени больше выполненного кода. Представьте единицу выполнения кода в виде объекта — это и есть поток.
К сложному делу легче подступиться, если разбить его на несколько простых. Так и при работе с памятью: «тяжёлый» процесс делят на потоки, которые занимают меньше ресурсов и скорее доносят код до вычислителя (как именно — см. ниже).
У каждого приложения есть как минимум один процесс, а у каждого процесса — минимум один поток, который называют главным и из которого при необходимости запускают новые.
Разница между потоками и процессами
-
Потоки используют память, выделенную под процесс, а процессы требуют себе отдельное место в памяти. Поэтому потоки создаются и завершаются быстрее: системе не нужно каждый раз выделять им новое адресное пространство, а потом высвобождать его.
-
Процессы работают каждый со своими данными — обмениваться чем-то они могут только через механизм межпроцессного взаимодействия. Потоки обращаются к данным и ресурсам друг друга напрямую: что изменил один — сразу доступно всем. Поток может контролировать «собратьев» по процессу, в то время как процесс контролирует исключительно своих «дочек». Поэтому переключаться между потоками быстрее и коммуникация между ними организована проще.
Какой отсюда вывод? Если вам нужно как можно быстрее обработать большой объём данных, разбейте его на куски, которые можно обрабатывать отдельными потоками, а затем соберите результат воедино. Это лучше, чем плодить жадные до ресурсов процессы.
Но почему такое популярное приложение как Firefox идёт по пути создания нескольких процессов? Потому что именно для браузера изолированная работа вкладок — это надёжно и гибко. Если с одним процессом что-то не так, не обязательно завершать программу целиком — есть возможность сохранить хотя бы часть данных.
Определение многопоточности
Многопоточность Java – это поддержка одновременной работы более одного потока. В процессе выполнения приложения некоторые «операции» осуществляются параллельно друг другу, да еще и в «фоновом» режиме. Наглядные примеры:
- сигнальная обработка;
- операции с памятью;
- управление системой устройства/софта.
Приложение примет только первый поток. За счет многопоточности осуществляется одновременный прием и обработка нескольких потоков в рамках одной и той же утилиты.
Важно: многопоточность не имеет места с процессорами одноядерного типа. Там время процессорного характера делится между несколькими процессами и «открытыми» потоками
Создать поток Java
Мы можем создать новый поток Java двумя способами, как описано ниже:
Класс потока
Мы можем создать новый объект Thread, расширив класс Thread. Чтобы инициировать выполнение потока, мы можем использовать метод start (). После выполнения методов start () он автоматически вызывает метод run (), который мы определяем при расширении класса Thread. Обычно мы создаем поток, используя класс Thread, когда хотим реализовать только функциональность Thread.
Пример
В приведенном ниже примере показано, как создать поток Java с помощью класса Thread. Здесь мы создаем 2 потока и вызываем их с помощью метода start (). Когда поток выполняет метод start (), он автоматически вызывает метод run ().
public class ThreadDemo extends Thread {
public void run() {
System.out.println("Thread " + Thread.currentThread().getId() + " running");
}
public static void main(String[] args) {
ThreadDemo t = new ThreadDemo();
ThreadDemo t1 = new ThreadDemo();
t.start();
t1.start();
}
}
Thread 12 running Thread 13 running
Запускаемый интерфейс
Другой метод создания нового потока — реализация интерфейса Runnable. В этом интерфейсе есть только 1 общедоступный метод run (), который нам нужно реализовать в классе, создающем поток. Метод run () выполняется автоматически, когда мы вызываем метод start () с использованием объекта потока. Обычно мы создаем новый поток с помощью интерфейса Runnable, когда хотим реализовать больше функций, кроме потока.
Пример
В этом примере показано, как создать поток Java путем реализации интерфейса Runnable, в котором нам нужно переопределить метод run ().
public class ThreadRunnableDemo implements Runnable{
public static void main(String[] args) {
ThreadRunnableDemo tr = new ThreadRunnableDemo();
Thread t = new Thread(tr);
t.start();
}
@Override
public void run() {
System.out.println("Thread " + Thread.currentThread().getId() + " running");
}
}
Thread 12 running
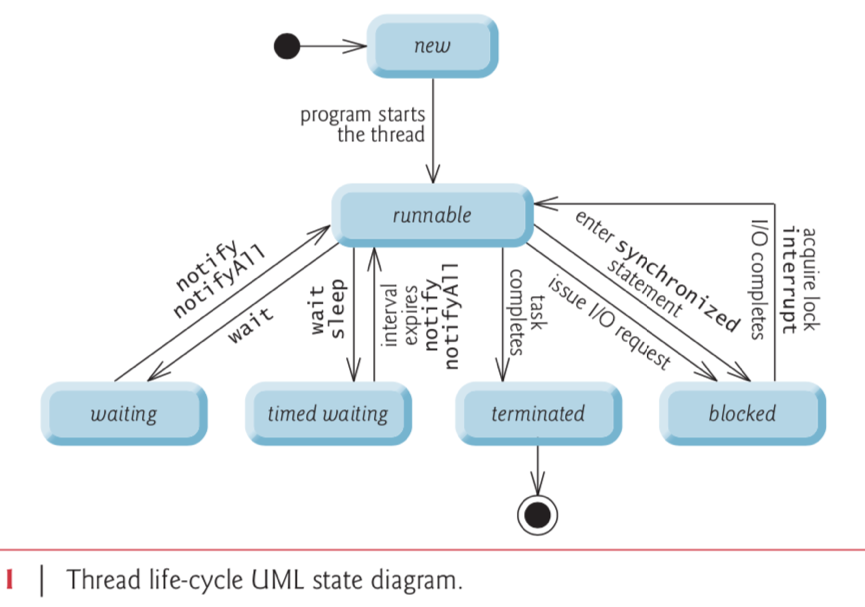
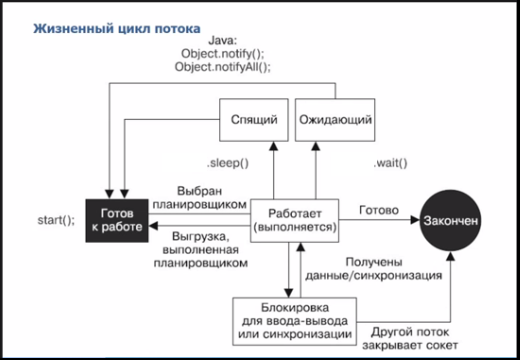
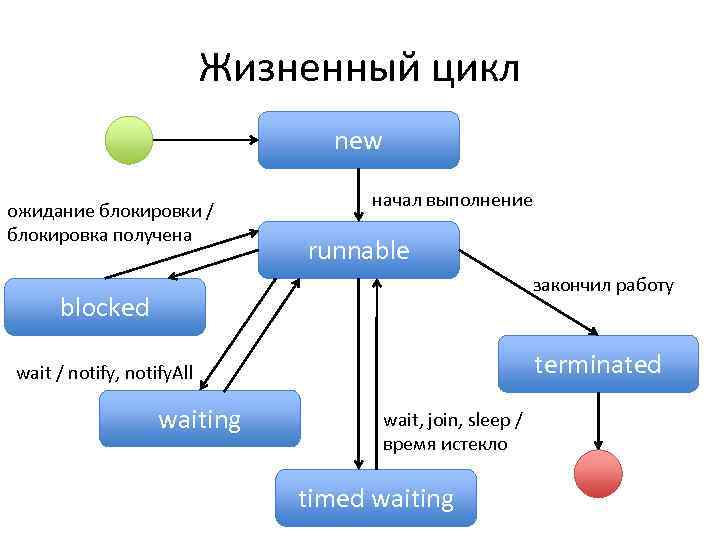
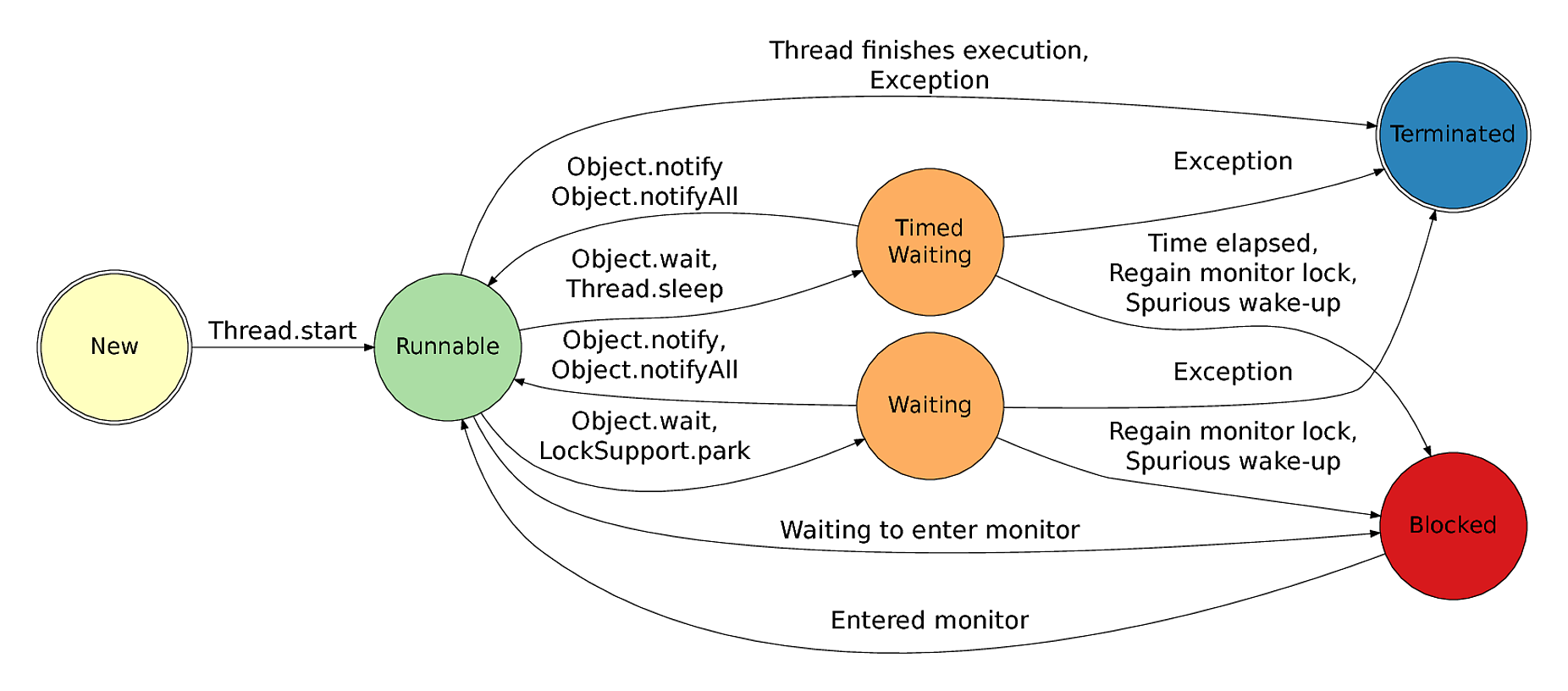
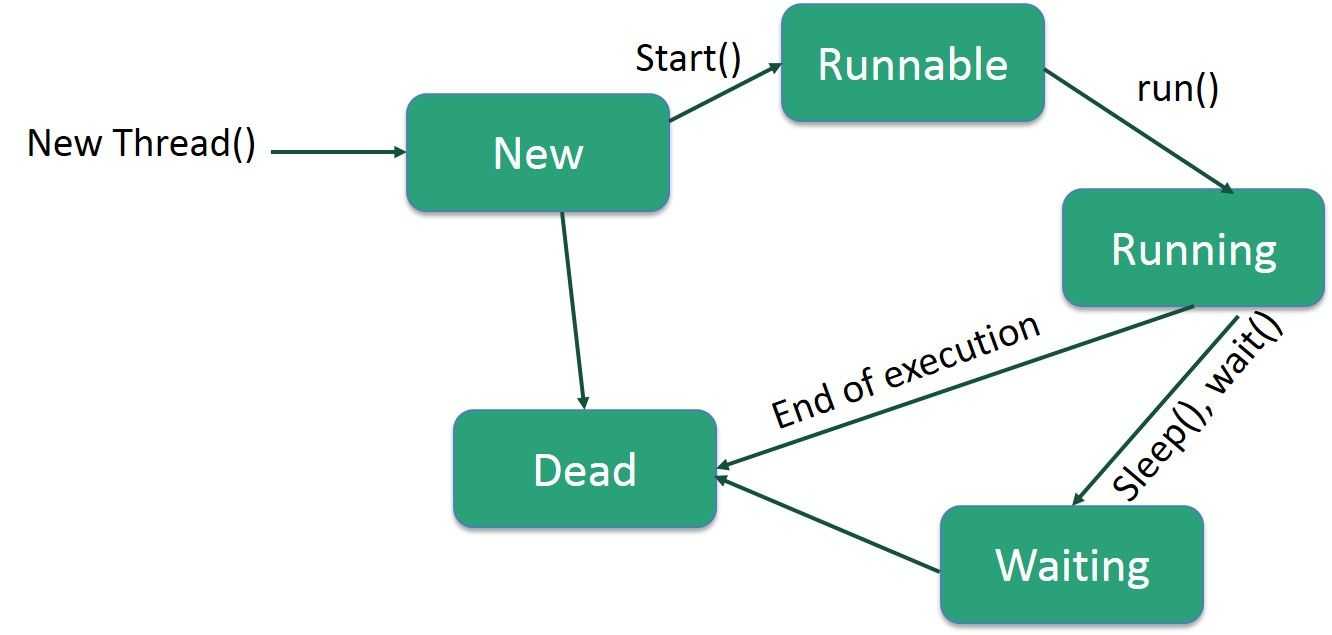
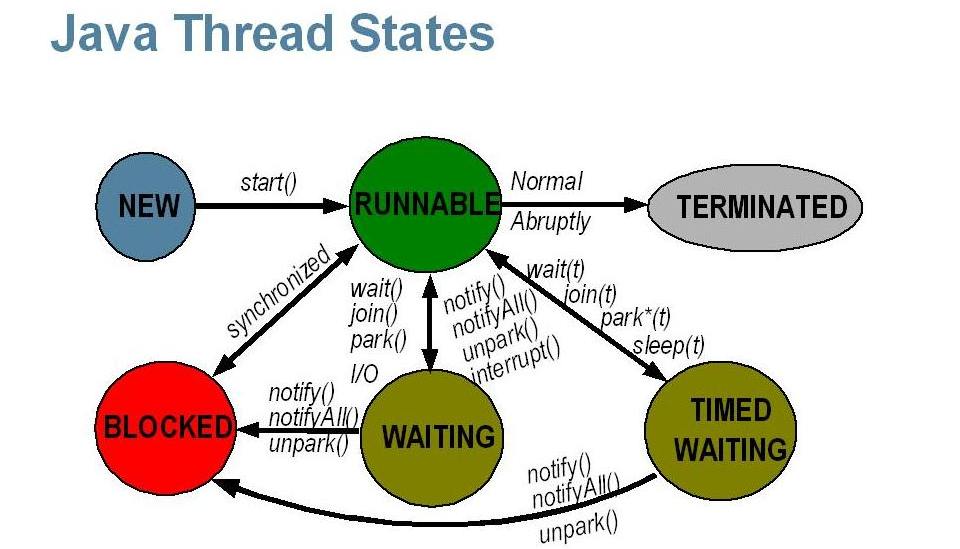
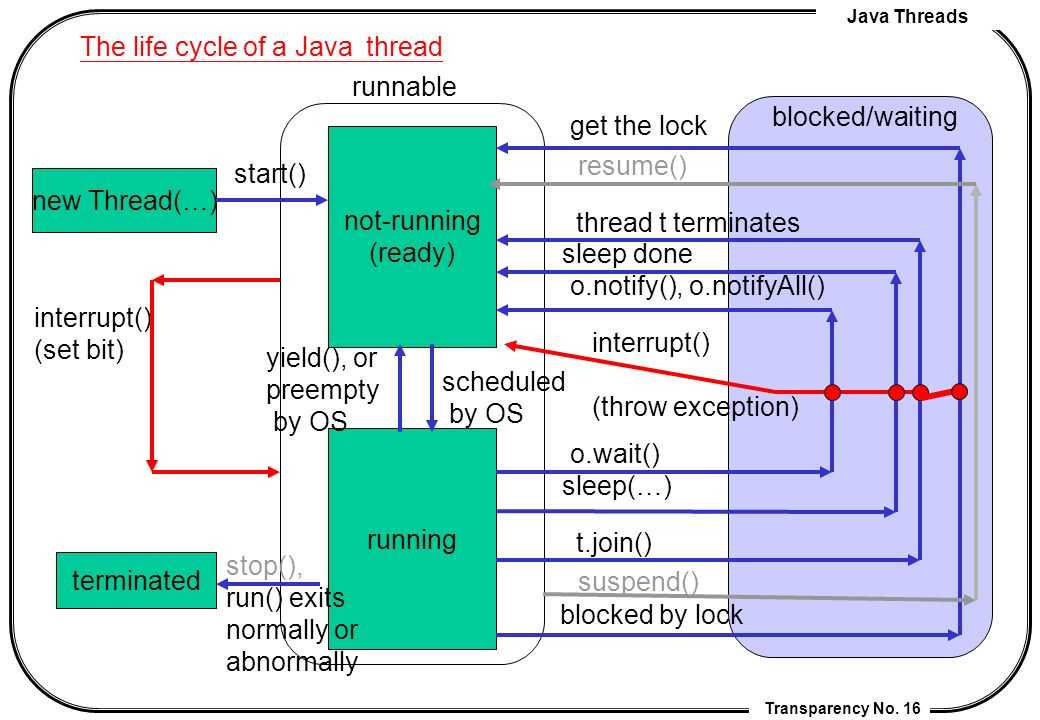
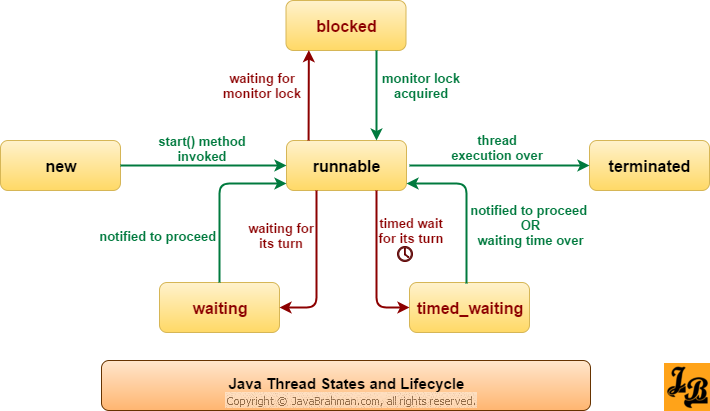
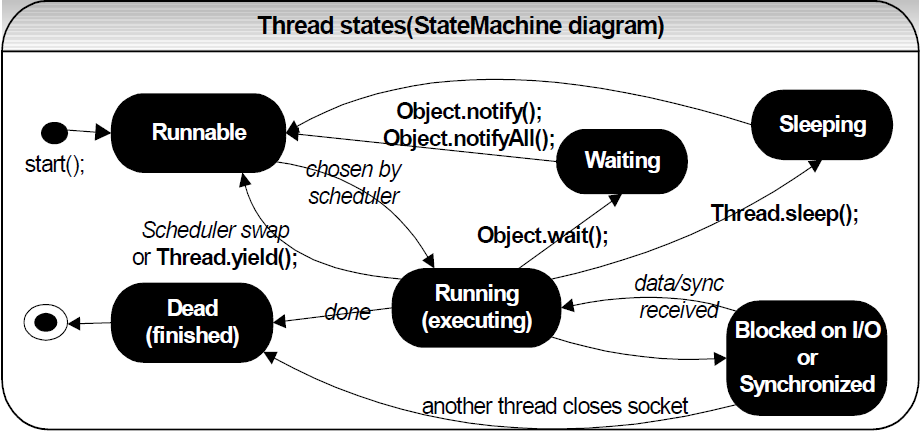
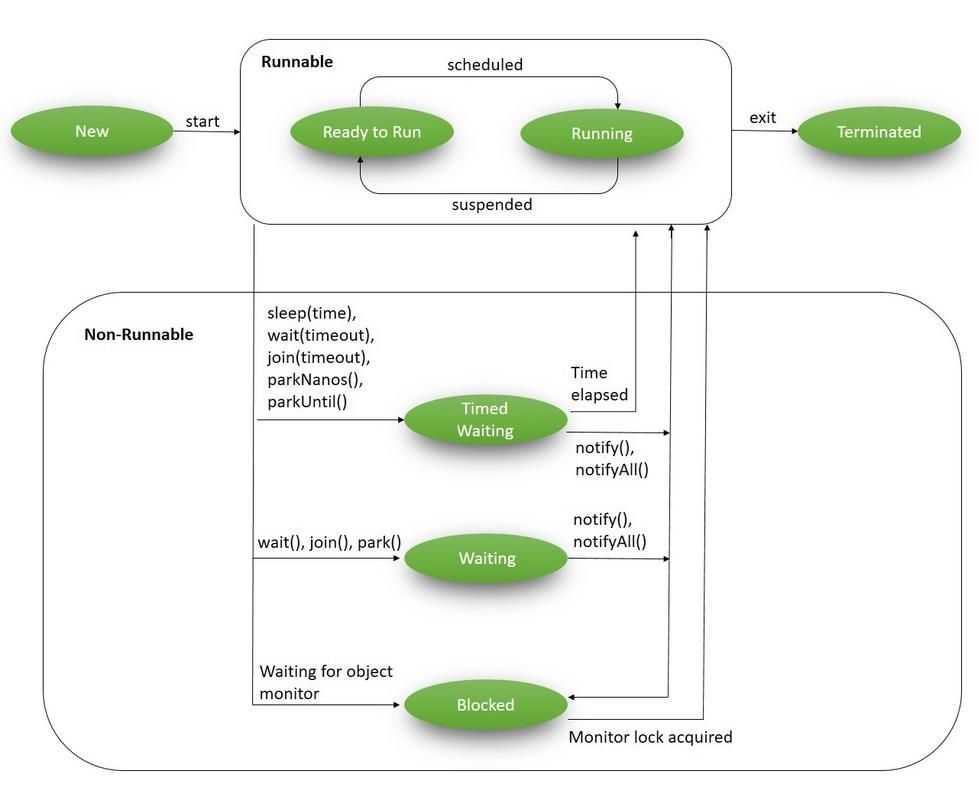
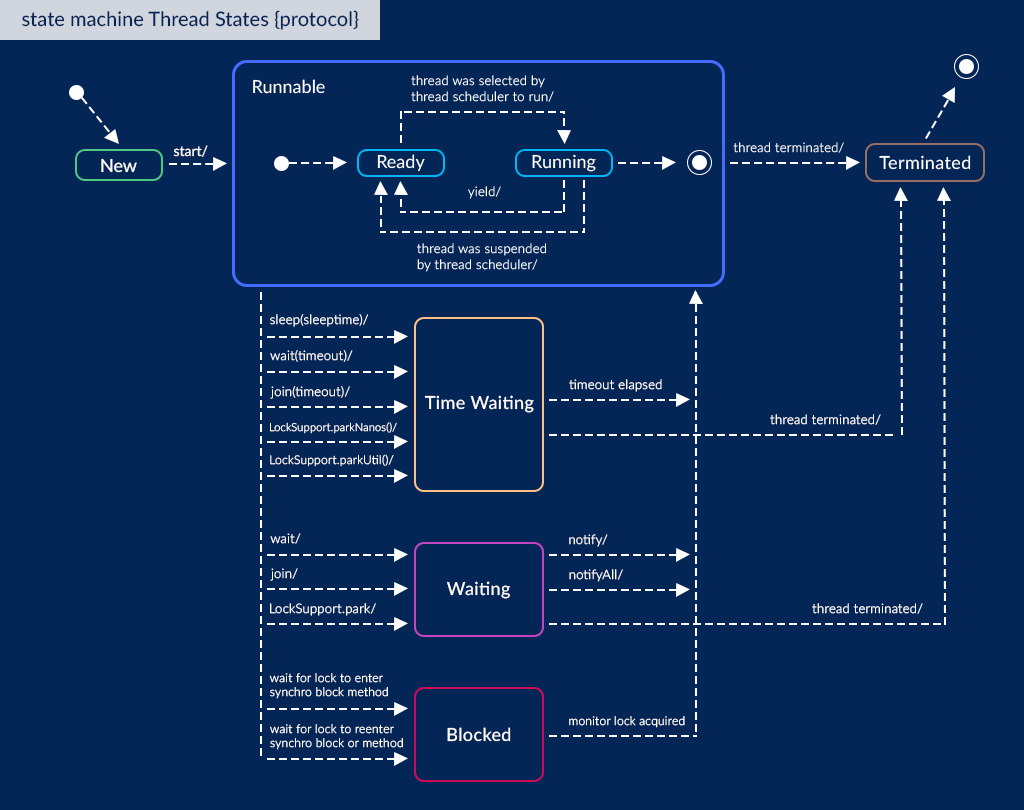
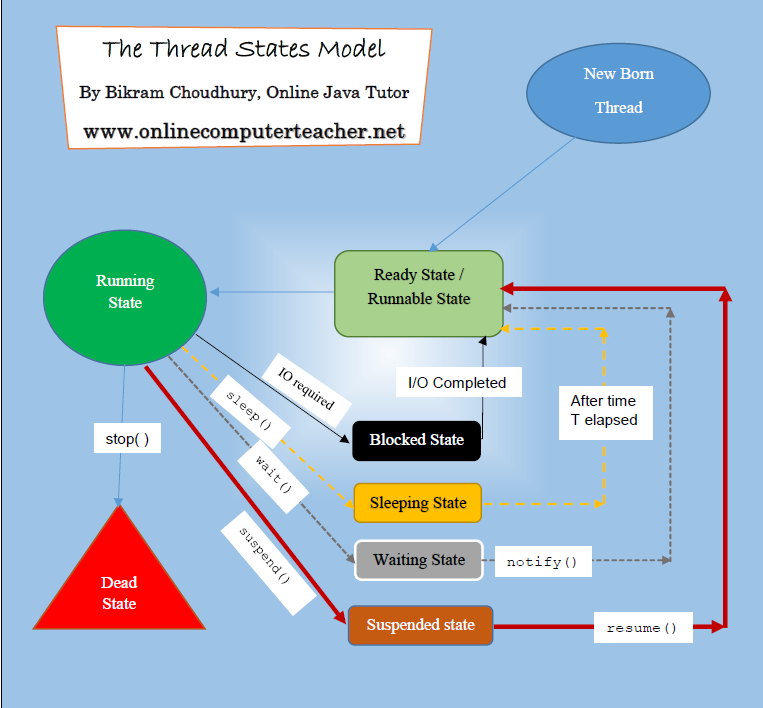
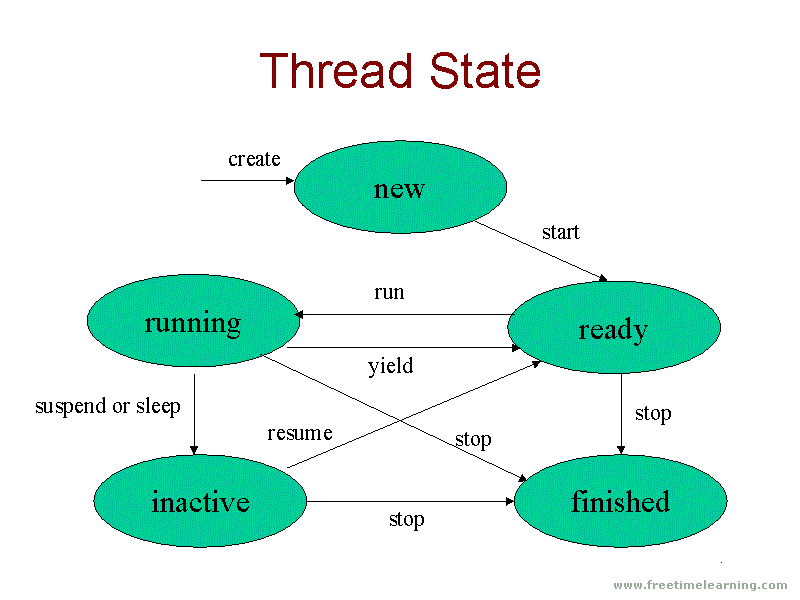
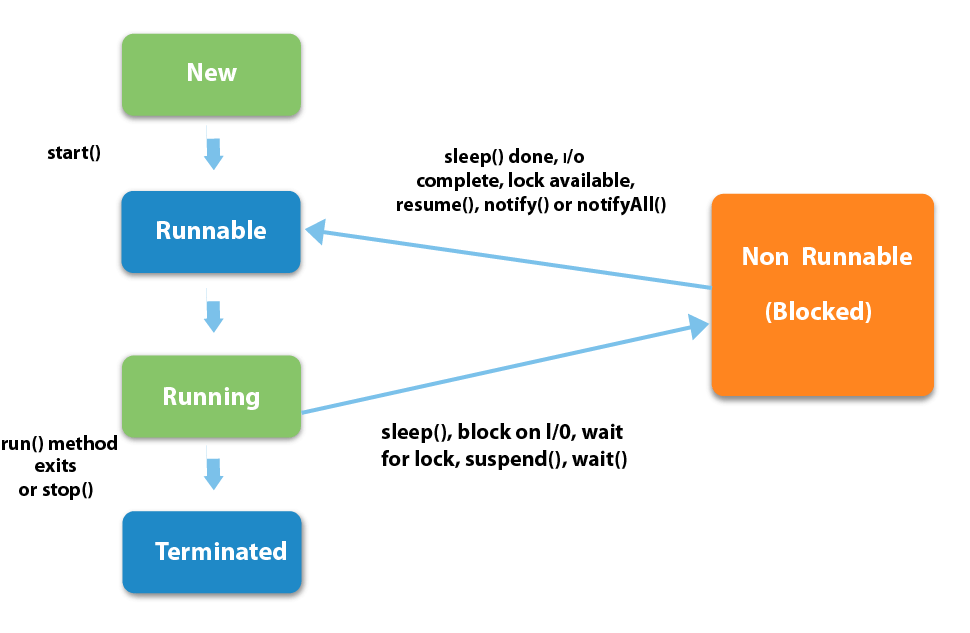
Поток жизненного цикла в Java
Жизненный цикл потока:
Существуют различные этапы жизненного цикла потока, как показано на диаграмме выше:
Некоторые из часто используемых методов для потоков:
Пример: в этом примере мы собираемся создать поток и исследовать встроенные методы, доступные для потоков.
package demotest;
public class thread_example1 implements Runnable {
@Override
public void run() {
}
public static void main(String[] args) {
Thread guruthread1 = new Thread();
guruthread1.start();
try {
guruthread1.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
guruthread1.setPriority(1);
int gurupriority = guruthread1.getPriority();
System.out.println(gurupriority);
System.out.println("Thread Running");
}
}
Пояснение к коду:
- Строка кода 2: Мы создаем класс “thread_Example1”, который реализует интерфейс Runnable (он должен быть реализован любым классом, экземпляры которого предназначены для выполнения потоком.)
- Строка кода 4: переопределяет метод run интерфейса runnable, так как этот метод является обязательным
- Строка кода 6: Здесь мы определили основной метод, в котором мы начнем выполнение потока.
- Строка кода 7: Здесь мы создаем новое имя потока как «guruthread1», создавая новый класс потока.
- Строка кода 8: мы будем использовать метод «start» потока, используя экземпляр «guruthread1». Здесь поток начнет выполняться.
- Строка кода 10: Здесь мы используем метод «сна» потока, используя экземпляр «guruthread1». Следовательно, поток будет спать в течение 1000 миллисекунд.
- Код 9-14: Здесь мы поместили спящий метод в блок try catch, поскольку существует проверенное исключение, которое возникает, т.е. исключение Interrupted.
- Строка кода 15: устанавливаем приоритет потока в 1 от того, какой приоритет был
- Строка кода 16: получаем приоритет потока, используя getPriority()
- Строка кода 17: печатаем значение, полученное из getPriority
- Строка кода 18: пишем текст, запущенный потоком.
Когда вы выполните приведенный выше код, вы получите следующий вывод:
Вывод:
5 – это приоритет Thread, а Thread Running – текст, который является выводом нашего кода.
Пример многопоточности в Java: пинг-понг мьютексами
Если вы думаете, что сейчас будет что-то страшное — выдохните. Работу с объектами синхронизации мы рассмотрим почти в игровой форме: два потока будут перебрасываться mutex’ом. Но по сути вы увидите реальное приложение, где в один момент времени только один поток может обрабатывать общедоступные данные.
Сначала создадим класс, наследующий свойства уже известного нам Thread, и напишем метод «удара по мячу» (kickBall):
Теперь позаботимся о мячике. Будет он у нас не простой, а памятливый: чтоб мог рассказать, кто по нему ударил, с какой стороны и сколько раз. Для этого используем mutex: он будет собирать информацию о работе каждого из потоков — это позволит изолированным потокам общаться друг с другом. После 15-го удара выведем мяч из игры, чтоб его сильно не травмировать.
А теперь на сцену выходят два потока-игрока. Назовём их, не мудрствуя лукаво, Пинг и Понг:
«Полный стадион народа — время начинать матч». Объявим об открытии встречи официально — в главном классе приложения:
Как видите, ничего зубодробительного здесь нет. Это пока только введение в многопоточность, но вы уже представляете, как это работает, и можете экспериментировать — ограничивать длительность игры не числом ударов, а по времени, например. Мы ещё вернёмся к теме многопоточности — рассмотрим пакет java.util.concurrent, библиотеку Akka и механизм volatile. А еще поговорим о реализации многопоточности на Python.
Историческая справка
Чтобы понять сложность разработки многопоточных приложений, нужно окунуться в историю. И так, на заре компьютерной эры, когда были изобретены микропроцессоры, разработчики писали последовательный код. Не уверен, что в то время кто-то вообще мог думать о параллельных вычислениях. Последовательная модель интуитивно понятна, команды выполняются на одном процессоре одна за другой. Скорость выполнения программ оставляла желать лучшего и для ее улучшения был выбран путь – увеличение количества транзисторов на интегральной схеме одного процессора. Возможно вы слышали Закон Мура – основателя компании Intel. Он предсказал удвоение количества транзисторов каждые два года. Мур оказался прав, с каждым годом процессоры становились все быстрее и быстрее. Написанные последовательные программы сами по себе начинали работать быстрее, без изменений в коде! Представляете, вы не пишите код, а ваша программа начинает работать все быстрее и быстрее год за годом. Фантастика! Ближе к 2000-м годам стало понятно, что экспоненциальный рост количества транзисторов заканчивается и скоро упрется в физические ограничения материалов, из которых их и делают. Следующее архитектурное решение повлияло на судьбы многих языков программирования, людей, систем и, в частности, стало возможным написание этой статьи. В замен одноядерных систем стали появляться многоядерные, которые и открыли дорогу многопоточному, параллельному программированию. С этого момента, для ускорение программ и вычислений, стало необходимым задействовать все доступные процессоры, а это возможно только при делении задачи на отдельные части и их параллельное выполнение на разных процессорах. На первый план вышли языки, исторически заточенные под многоядерную и распределенную работу. Одним из мастодонтов стал Earlang. Другим языкам, в том числе Java, пришлось адаптироваться и превращаться из последовательного языка в параллельный. Возможно поэтому многопоточность в Java является очень тяжелой темой для понимания и изучения. Свой отпечаток на написание параллельных программ оставляет наш последовательный образ мышления людей как биологического вида. Люди – однопоточные. Сделаю небольшую ремарку. В эпоху одноядерных процессоров так же было возможно “параллельное” выполнение за счет работы потоков операционной системы. Каждый процесс имеет свое адресное пространство и представляет собой выполняемую программу. Таких процессов может быть много, и в одноядерной системе, действительно, создается иллюзия параллельного выполнения, но на самом деле, процессор осуществляет выполнения только одного процесса в единицу времени. Для выполнения другого процесса, процессор осуществляет прерывания текущего процесса и запускает следующий. В глазах пользователя это происходит настолько быстро, и кажется, что программа работает параллельно, но на самом деле – она последовательна.
Компоненты в пакете Java Concurrent
Далее мы увидим, какие основные компоненты входят в состав Параллельный пакет Java
душеприказчик
Интерфейс исполнителя выполняет конкретную задачу. В зависимости от реализации он решает, выполнять ли задачу в новом потоке или в текущем потоке.
ИсполнительСервис
ИсполнительСервис используется для асинхронной обработки. В зависимости от доступности потока он планирует отправленную задачу. Мы используем интерфейс Runnable для планирования задачи.
ScheduleExecutorService
ЗапланированныйExecutorService планирует задачи периодически без каких-либо задержек. Это означает, что он выполняет задачи мгновенно. Мы можем использовать интерфейсы Runnable и Callable для определения задачи.
Будущее
Будущее предоставляет результат асинхронных задач. Мы можем использовать этот интерфейс для получения вычисленного результата, чтобы проверить, выполнена ли задача или нет.
Защелка
Защелка — служебный класс, который является частью пакета JDK 5, который заставляет потоки ждать завершения некоторых других операций. Обычно он имеет счетчик, который представляет собой целое число, которое автоматически уменьшается по мере завершения выполнения каждым зависимым потоком. Когда значение счетчика равно 0, он освобождает все потоки.
циклическийбарьер
циклическийбарьер похож на CountDownLatch, за исключением того, что он позволяет нескольким потокам ожидать и поддерживает возможность повторного использования. Мы можем определить задачу с помощью интерфейса Runnable.
семафор
семафор используется для блокировки доступа потока к критическим разделам. Прежде чем поток войдет в критическую секцию, он проверяет, есть ли у семафора разрешение или нет. Если есть разрешение, оно позволяет потоку войти, иначе он не войдет. Он содержит метод проверки количества доступных разрешений. Семафоры также могут использоваться для сигнализации потока.
- Подсчет семафора: этот тип семафора может подсчитывать количество сигналов, отправленных с помощью метод.
- Ограниченный семафор: это семафор, у которого есть верхняя граница количества сигналов, которые он может хранить.
Блокировка очереди
Блокировка очереди полезен в асинхронных сценариях, где существует проблема производитель-потребитель, которая является серьезной проблемой в среде многопоточности Java.
ЗадержкаОчередь
ЗадержкаОчередь это BlockingQueue бесконечного размера. Это приводит к задержке опроса элемента, что означает, что самый верхний элемент в очереди, который является элементом головы, будет удален только в последнем.
Волосы
Блокировка гарантирует, что только текущий выполняющийся поток имеет доступ к общему ресурсу, и блокирует доступ к нему других потоков до тех пор, пока текущий поток не освободит ресурс. Это в основном используется для синхронизации, и мы можем использовать его методы, такие как lock () и unlock (), в отдельных методах.
фазовращатель
Phaser также является гибким барьером, который блокирует выполнение нескольких потоков. Он выполняет несколько потоков динамически на отдельных этапах.
Thread
Начиная с версии Java 1.0 в пакете java.lang есть специальный класс, который позволяет создавать новые потоки (или треды) – Thread. Этот класс реализует интерфейс Runnable – специальный интерфейс, который является функциональным, начиная с версии Java 8, и содержит один метод, в котором должна быть описана задача потока – то что он будет делать:
public abstract void run();
| 1 | publicabstractvoidrun(); |
Так как Thread – это класс, то и работа c ним осуществляется как и с другими классами. Чтобы создать поток, необходимо создать экземпляр класса с помощью конструктора. В классе Thread их целых 8 публичных! Чтобы запустить поток у экземпляра нужно вызвать метод start(). Здесь мы можем заметить некое противоречие: мы реализуем интерфейс Runnable, переопределяя метод run(). Почему мы вызываем вместо него start()? Дело в том, что вызвать метод run() у экземпляра Thread можно, но тогда код, который содержится в этом методе выполнится в текущем потоке, новый не будет создан. Вызывая метод start() мы гарантировано выполним код run() в новом потоке! Рассмотрим короткий пример: создадим три потока, но у одного вызовем метод run(), а у других start():
public static void main(String[] args) {
Runnable task = () -> System.out.println(«Sit in Niva » + Thread.currentThread().getName());
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
Thread t3 = new Thread(task);
t1.run();
t2.start();
t3.start();
}
//Результат
Sit in Niva main
Sit in Niva Thread-1
Sit in Niva Thread-2
|
1 |
publicstaticvoidmain(Stringargs){ Runnable task=()->System.out.println(«Sit in Niva «+Thread.currentThread().getName()); Thread t1=newThread(task); Thread t2=newThread(task); Thread t3=newThread(task); t1.run(); t2.start(); t3.start(); } //Результат Sit inNiva main Sit inNiva Thread-1 Sit inNiva Thread-2 |
Как вы видите, первый вызов осуществился в потоке main(), а остальные два каждый в своем потоке. Стоит отметить, что результат работы не является детерминированным, т.е. вы можете получить совсем другой вывод на консоль при повторном запуске, так как потоки выполняются одновременно.
У каждого потока есть приоритет. Потоки с высоким приоритетом имеют преимущество над потоками с низким в глазах профилировщика потоков. Но это не значит, что потоки с низким приоритетом никогда не выполнятся. Технически завязываться на приоритет не всегда верно, т.к. на разных операционных системах реализованы разные механизмы параллельного выполнения потоков. Так же поток может быть помечен как демон. Это фоновый поток, который подходит для выполнения некоторых служебных задач. Целостность данных не гарантируется, т.к. все потоки-демоны прекращают свою работу, когда все другие потоки НЕ-демоны завершили свою работу. Поток, который завершил свою работу, нельзя запустить повторно.
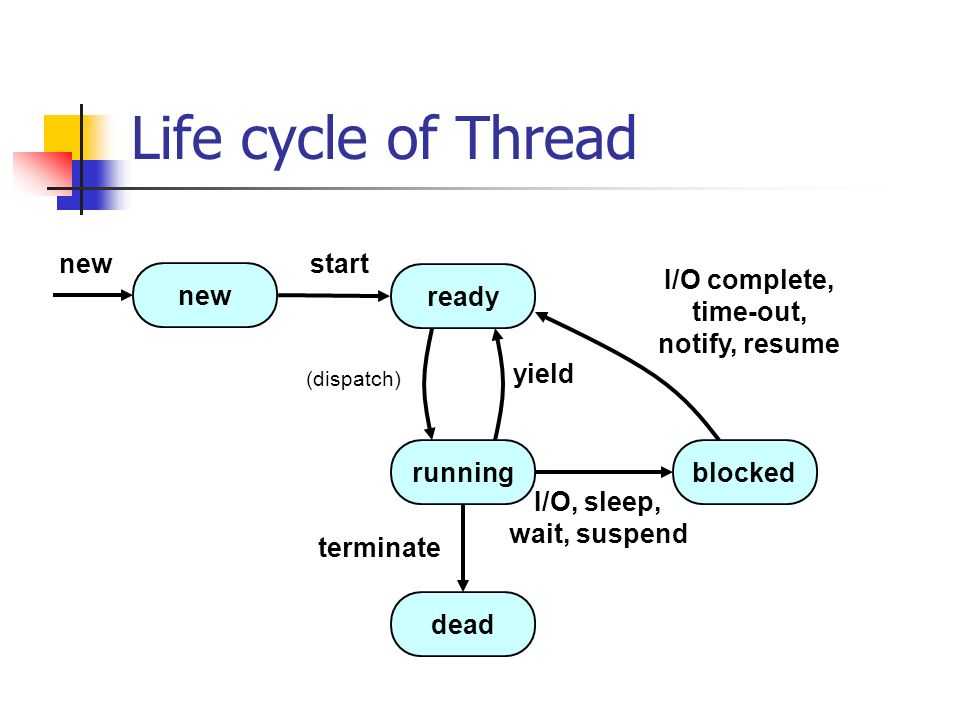
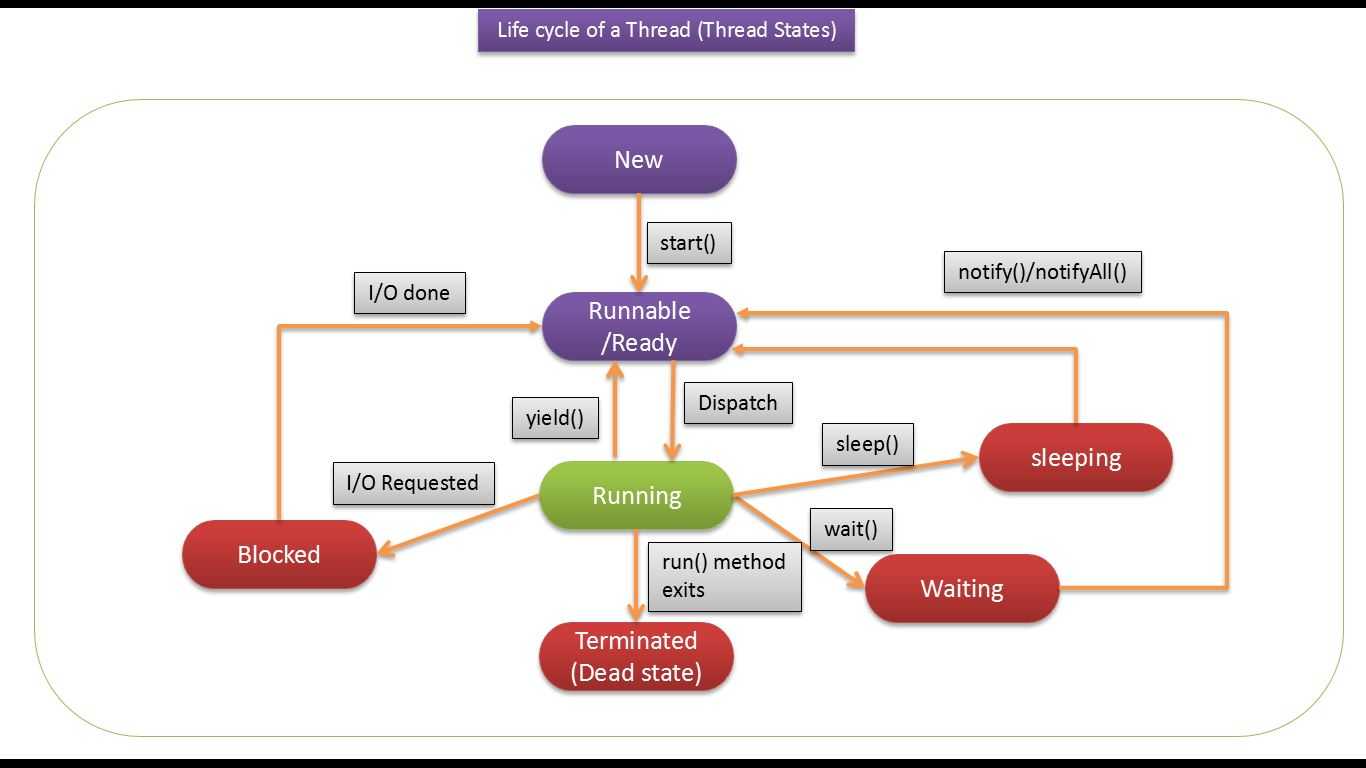
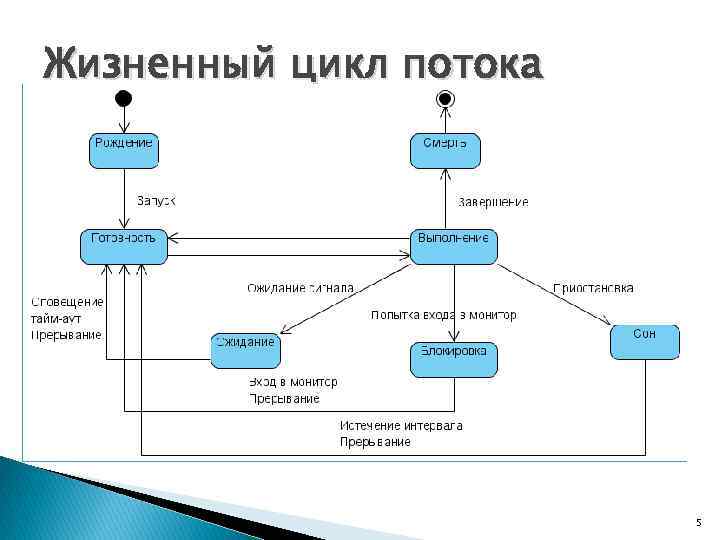
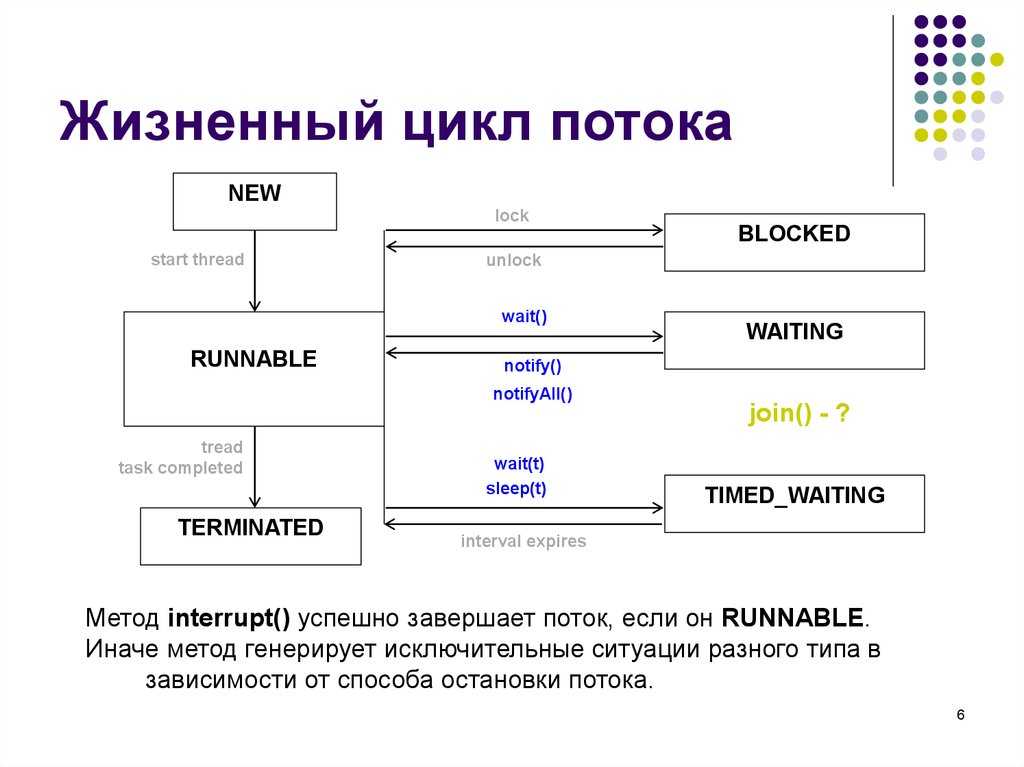
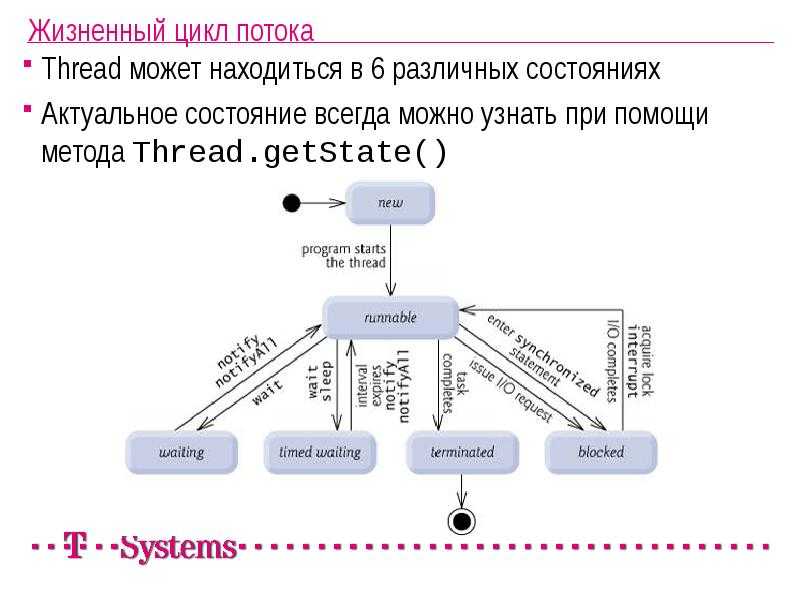
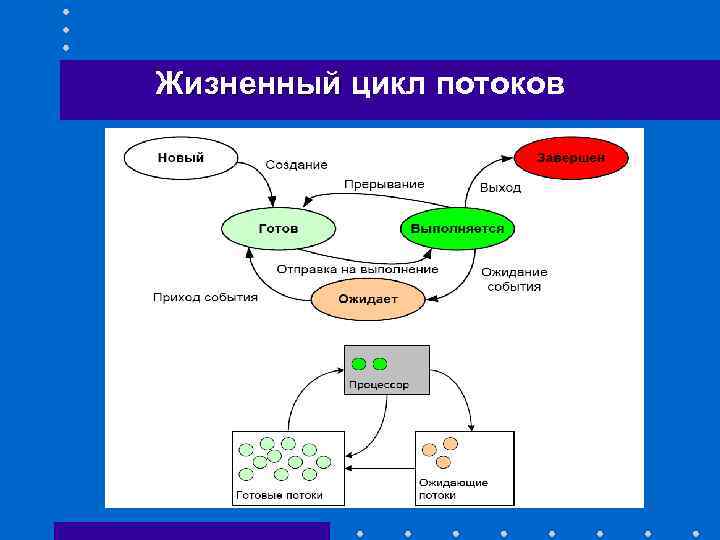
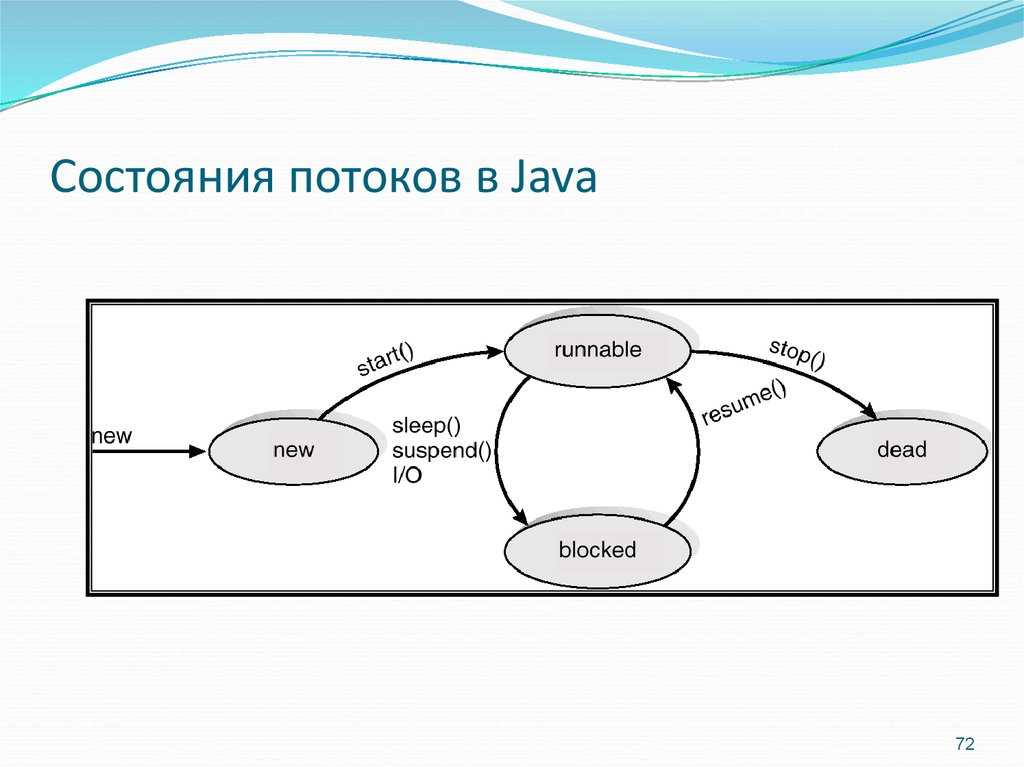
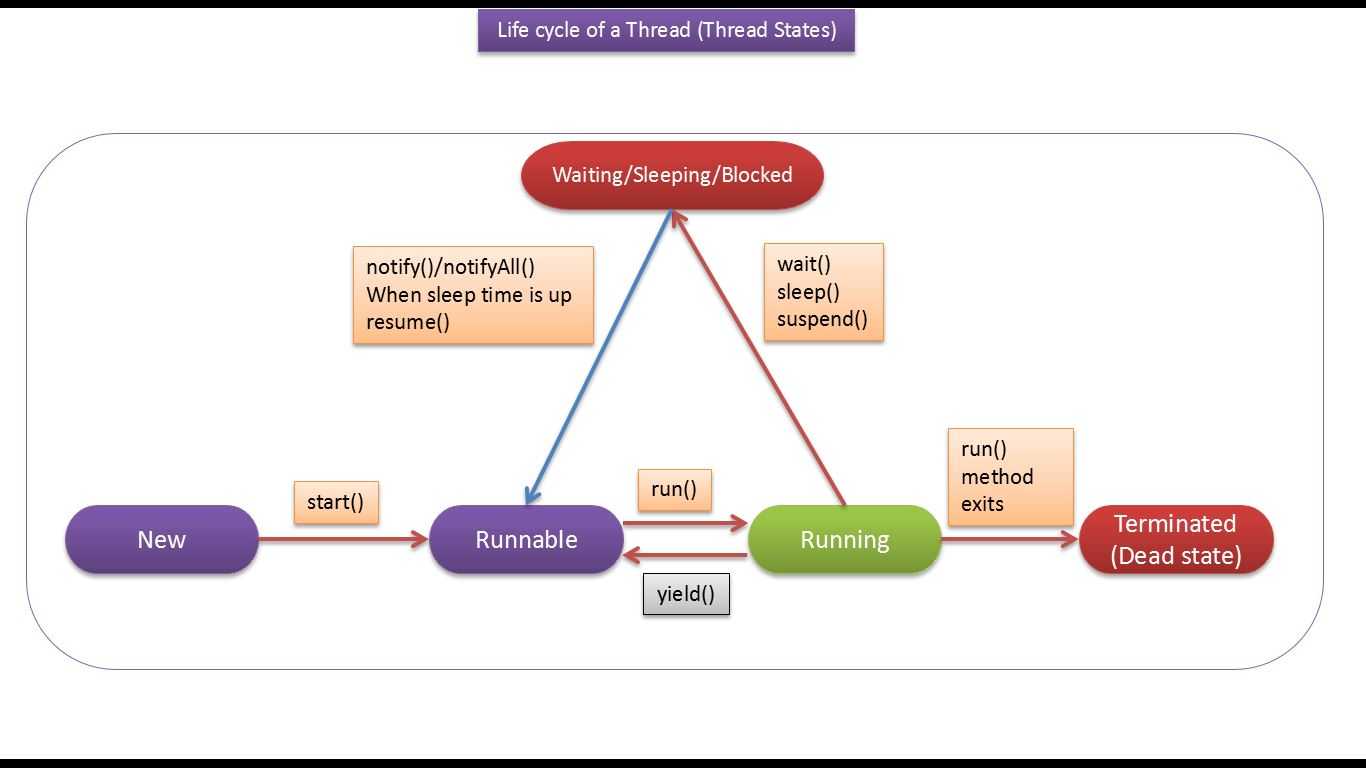
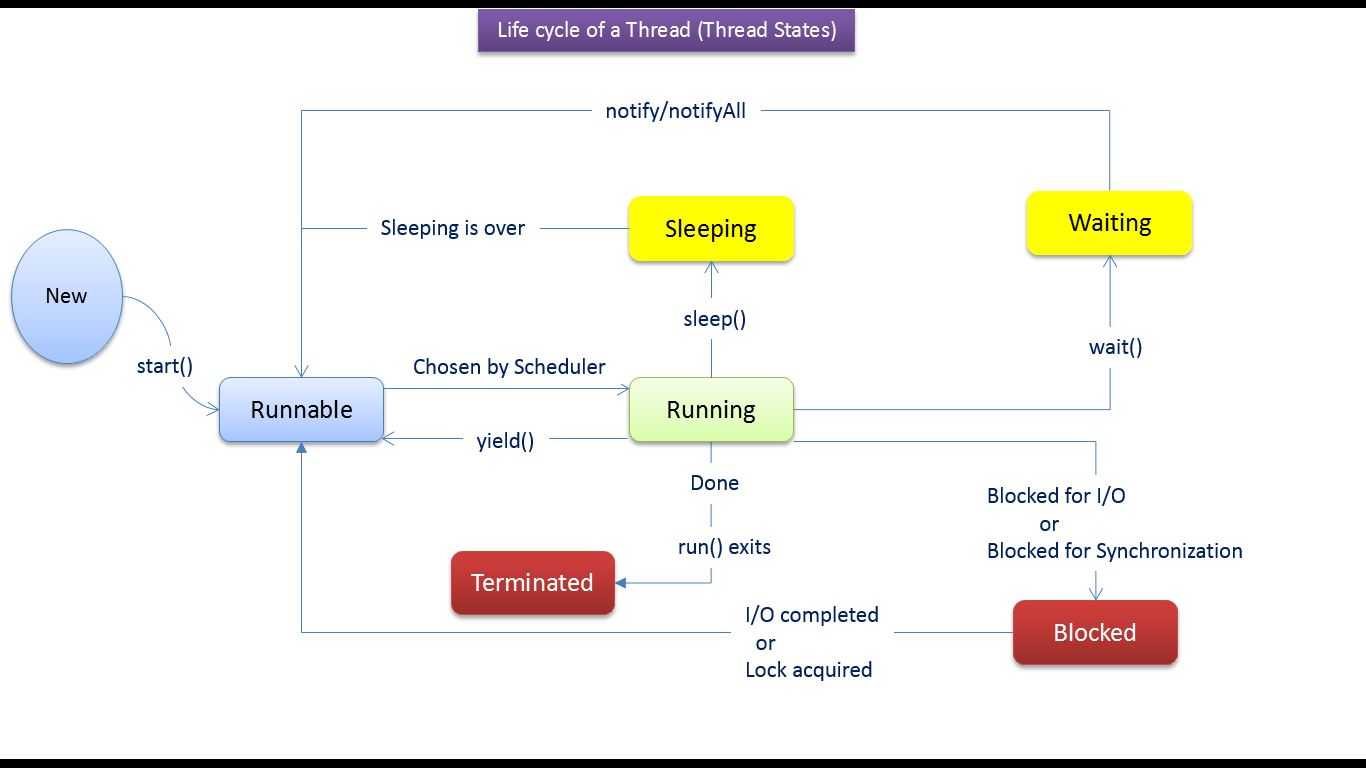
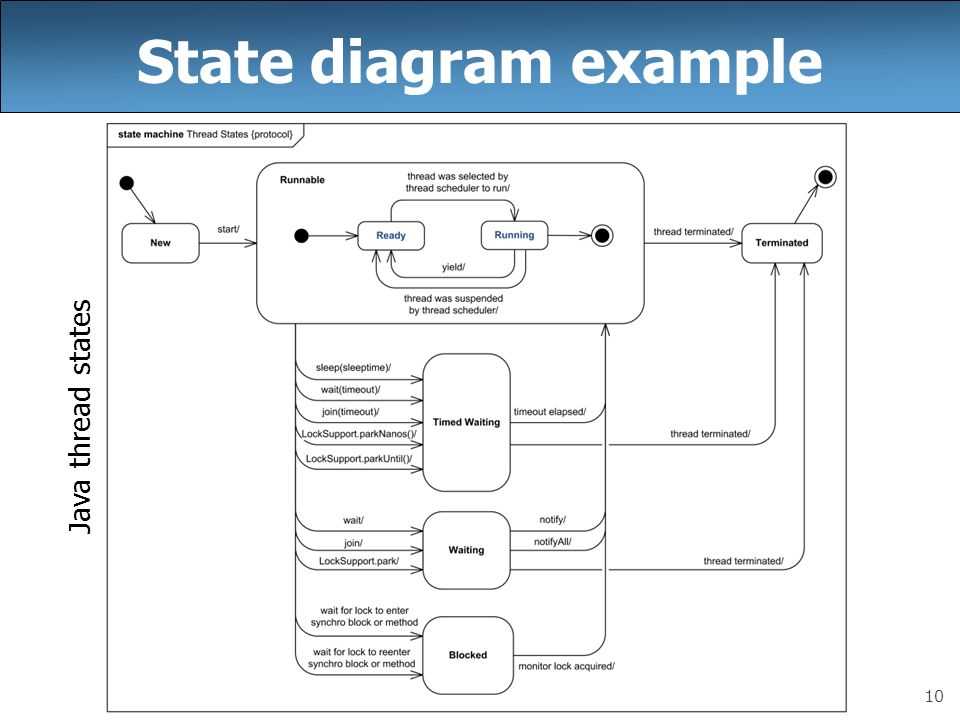
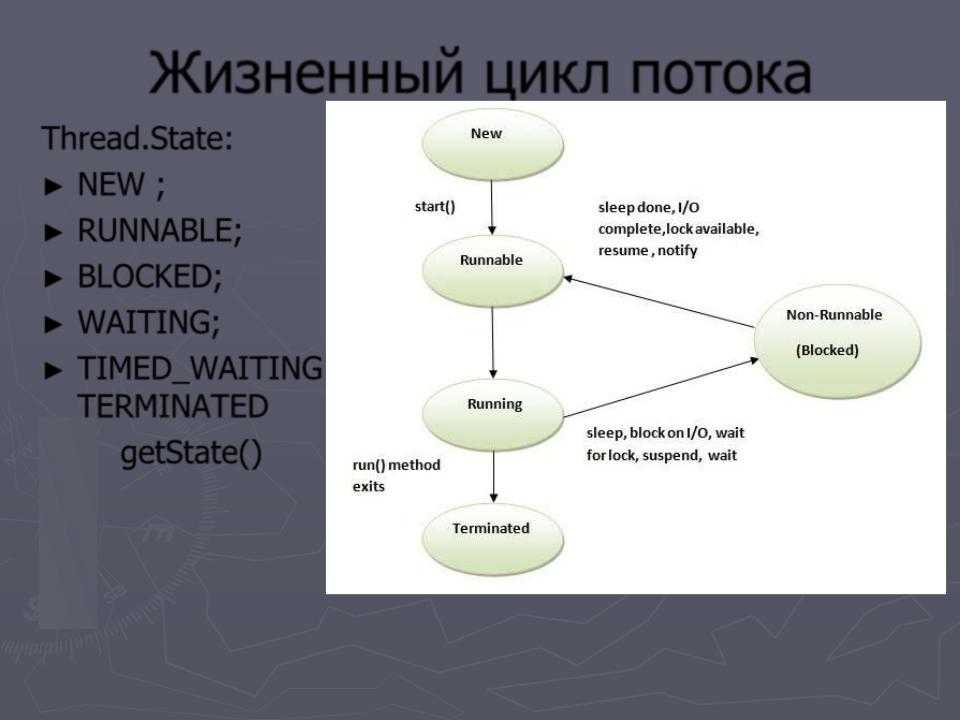
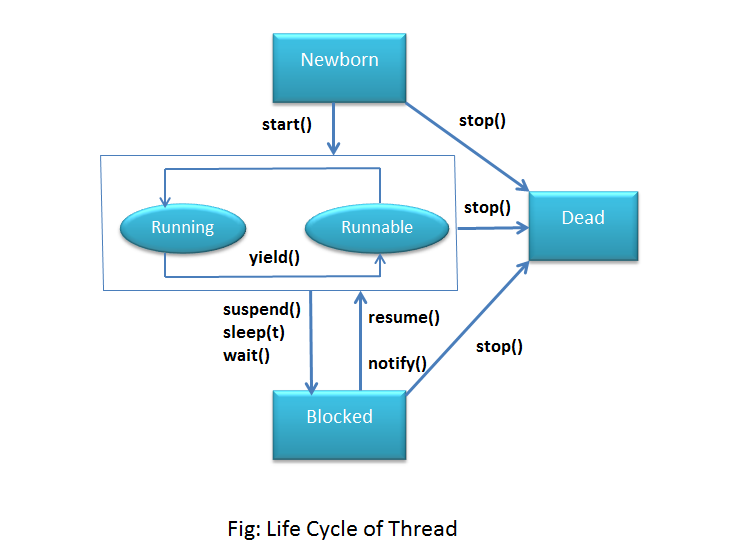
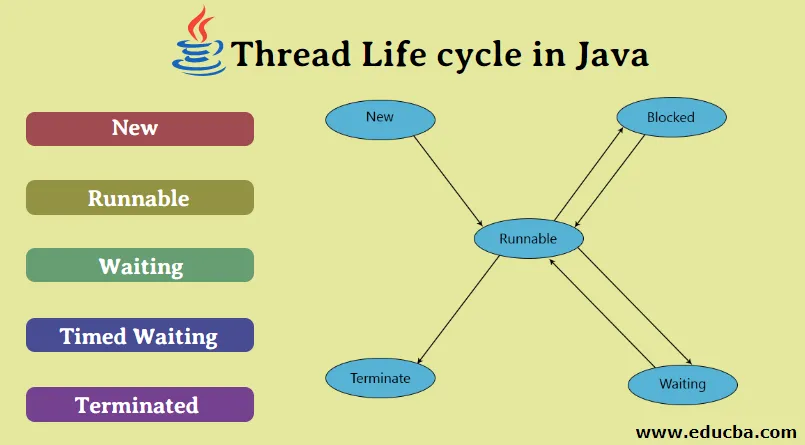
Жизненный цикл потока в Java
Жизненный цикл потока:
![]()
Как показано на диаграмме выше, существуют различные этапы жизненного цикла потока:
- Новый
- Работоспособен
- Бег
- Ожидающий
- мертв
- Новое: на этом этапе поток создается с использованием класса «Thread class». Он остается в этом состоянии до тех пор, пока программа не запустит поток. Он также известен как прирожденная нить.
- Runnable: на этой странице экземпляр потока вызывается с помощью метода start. Управление потоком передается планировщику для завершения выполнения. Запускать ли поток зависит от планировщика.
- Выполняется: когда поток начинает выполняться, состояние изменяется на состояние «выполняется». Планировщик выбирает один поток из пула потоков, и он начинает выполнение в приложении.
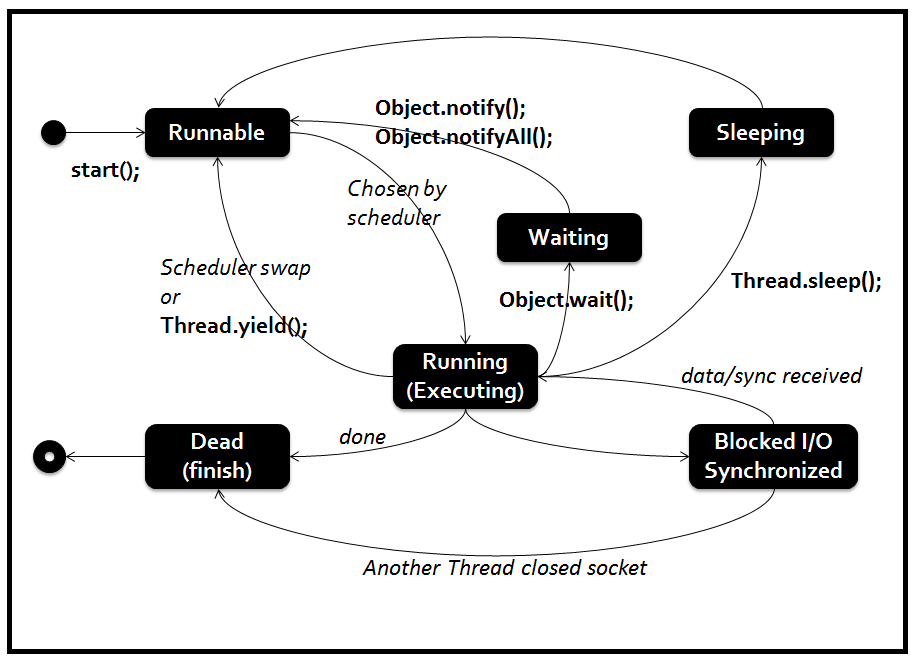
- Ожидание: это состояние, когда поток должен ждать. Поскольку в приложении выполняется несколько потоков, существует необходимость в синхронизации между потоками. Следовательно, один поток должен ждать, пока другой поток не будет выполнен. Поэтому это состояние называется состоянием ожидания.
- Мертвый: это состояние, когда поток завершен. Поток находится в рабочем состоянии, и как только он завершил обработку, он находится в «мертвом состоянии».
Некоторые из наиболее часто используемых методов для потоков:
| Методика | Описание |
|---|---|
| Начните() | Этот метод запускает выполнение потока, а JVM вызывает метод run () в потоке. |
| Сон (целое число миллисекунд) | Этот метод переводит поток в спящий режим, поэтому выполнение потока приостанавливается на заданные миллисекунды, после чего поток снова начинает выполняться. Это помогает в синхронизации потоков. |
| getName () | Возвращает имя потока. |
| setPriority (int newpriority) | Это изменяет приоритет потока. |
| урожай () | Это вызывает остановку текущего потока и выполнение других потоков. |
Пример: В этом примере мы собираемся создать поток и изучить встроенные методы, доступные для потоков.
демотест пакета;открытый класс thread_example1 реализует Runnable {@Overridepublic void run () {}public static void main (String [] args) {Тема guruthread1 = новая тема ();guruthread1.start ();пытаться {guruthread1.sleep (1000);} catch (InterruptedException e) {// TODO Автоматически сгенерированный блок catche.printStackTrace ();}guruthread1.setPriority (1);int gurupriority = guruthread1.getPriority ();System.out.println (приоритетность);System.out.println («Выполнение потока»);}}
Расшифровка кода:
- Строка кода 2: мы создаем класс thread_Example1, который реализует интерфейс Runnable (он должен быть реализован любым классом, экземпляры которого предназначены для выполнения потоком).
- Строка кода 4: он переопределяет метод запуска исполняемого интерфейса, поскольку он является обязательным для переопределения этого метода.
- Строка кода 6: Здесь мы определили основной метод, с помощью которого мы начнем выполнение потока.
- Строка кода 7: Здесь мы создаем новое имя потока как «guruthread1», создавая экземпляр нового класса потока.
- Строка кода 8: мы будем использовать метод «start» потока, используя экземпляр «guruthread1». Здесь поток начнет выполняться.
- Строка кода 10: Здесь мы используем метод «сна» потока с использованием экземпляра «guruthread1». Следовательно, поток будет спать 1000 миллисекунд.
- Код 9-14: Здесь мы поместили метод сна в блок try catch, поскольку происходит проверенное исключение, то есть прерванное исключение.
- Строка кода 15: Здесь мы устанавливаем приоритет потока равным 1, независимо от того, какой приоритет он был
- Строка кода 16: Здесь мы получаем приоритет потока с помощью getPriority ()
- Строка кода 17: Здесь мы печатаем значение, полученное из getPriority
- Строка кода 18: Здесь мы пишем текст, который выполняется потоком.
Когда вы выполните приведенный выше код, вы получите следующий результат:
Выход:
5 — это приоритет потока, а выполнение потока — это текст, который является выводом нашего кода.
Символьные потоки
Потоки байтов в Java позволяют произвести ввод и вывод 8-битных байтов, в то время как потоки символов используются для ввода и вывода 16-битного юникода. Не смотря на множество классов, связанных с потоками символов, наиболее распространено использование следующих классов: FileReader и FileWriter. Не смотря на тот факт, что внутренний FileReader использует FileInputStream, и FileWriter использует FileOutputStream, основное различие состоит в том, что FileReader производит считывание двух байтов в конкретный момент времени, в то время как FileWriter производит запись двух байтов за то же время.
Мы можем переформулировать представленный выше пример, в котором два данных класса используются для копирования файла ввода (с символами юникода) в файл вывода.
Примечание по примеру: чтобы скопировать файл, необходимо в папке проекта создать файл file.txt с любым или пустым содержимым.
Пример
Теперь рассмотрим файл file.txt со следующим содержимым:
В качестве следующего шага необходимо скомпилировать программу и выполнить ее, что позволит создать файл copied_file.txt с тем же содержимым, что имеется в file.txt. Таким образом, разместим обозначенный код в файле FileCopy.java и выполним следующее действие:



