
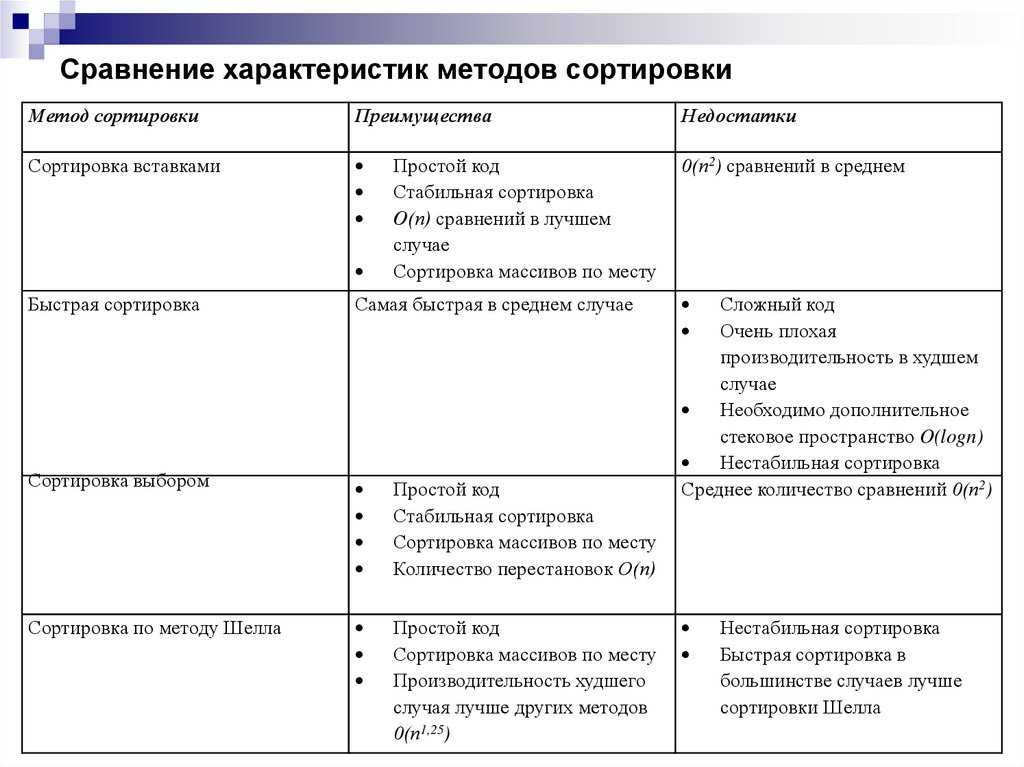
Функции сортировки массивов в PHP
В PHP 8 есть следующие функции для сортировки массива.
| Имя функции | Сортировать по порядку |
| Сортировать() | По возрастанию |
| rsort () | В порядке убывания |
| asort () | Ассоциативные массивы в порядке возрастания по значению |
| ksort () | Ассоциативные массивы в порядке возрастания по ключу |
| arsort () | По убыванию по значению |
| krsort () | По убыванию по ключу |
Таблица функций сортировки массивов в PHP
1. Сортировка (массив, тип_сортировки)
Функция сортировки упорядочивает элементы массива в порядке возрастания (от меньшего к большему). Если массив содержит только один элемент, он вернет тот же массив. Возвращает истину в случае успеха и ложь в случае неудачи.
Например
2. rSort (массив, тип_сортировки)
rSort является обратной функцией сортировки. Он упорядочивает элементы массива в порядке убывания (от большего к меньшему). Если массив содержит только один элемент, он возвращает тот же массив.
3. asort (массив, тип_сортировки)
Функция asort упорядочивает элементы ассоциативного массива в порядке возрастания в соответствии со значением ключей. Если массив состоит из одной пары ключ и значение, он возвращает тот же массив.
Например
4. ksort (массив, тип_сортировки)
Функция ksort также упорядочивает элементы ассоциативного массива в порядке возрастания, но в соответствии с ключами. Если массив состоит из одной пары ключ и значение, он возвращает тот же массив.
Например
Второй параметр в функциях сортировки — sort_type. Доступны следующие варианты. Параметры решают, как сравнивать элементы массива.
5. arsort (массив, тип_сортировки)
Функция asort упорядочивает элементы ассоциативного массива в порядке убывания значений. Если массив состоит из одной пары ключ и значение, он возвращает тот же массив.
Например
6. krsort (массив, sort_type)
Функция krsort также упорядочивает элементы ассоциативного массива в порядке убывания, но в соответствии с ключами. Если массив состоит из одной пары ключ и значение, он возвращает тот же массив.
Например
Второй параметр в функциях сортировки — sort_type. Доступны следующие варианты. Параметры решают, как сравнивать элементы массива.
| Тип сортировки | Описание |
| 0 = СОРТИРОВКА_ОБЫЧНАЯ | Дефолт. Сравнивайте предметы как обычно (не меняйте типы) |
| 1 = СОРТИРОВКА_ЧИСЛА | Сравнить товары численно |
| 2 = SORT_STRING | Сравнить элементы как строки |
| 3 = SORT_LOCALE_STRING | Сравнить элементы в виде строк на основе текущего языкового стандарта |
| 4 = СОРТ_НАТУРАЛЬНЫЙ | Сравните элементы в виде строк, используя естественный порядок |
| 5 = SORT_FLAG_CASE |
Параметры сортировки массивов в функциях sort и rsort
Помимо этих основных и встроенных функций сортировки массивов, пользователь также может определить свою собственную функцию сортировки в PHP. Итак, в этом разделе вы узнаете о функциях usort, uasort и uksort в PHP.
usort (массив, my_sorting_function)
Функция usort принимает два параметра. Первый параметр — это массив для сортировки, а второй параметр — определяемая пользователем функция для сортировки.
Например
uasort (массив, user_define_function)
Сортируйте массив или ассоциативный массив в соответствии с функцией, определяемой пользователем. Функция uasort выполняет сортировку по значению ассоциативного массива. Для ключей у нас есть функция uksort, которая приведена ниже.
Например
uksort (массив, определенная_пользовательская функция)
Отсортируйте ассоциативный массив с помощью пользовательской функции. uksort производит сортировку по ключам ассоциативного массива.
Например
🔸 Сводка метода сортировки ()
- Метод позволяет сортировать список в порядке возрастания или убывания.
- Требуется два аргумента только ключевых слов: и Отказ
- Определяет, отсортирован ли список в порядке возрастания или убывания.
- Это функция, которая генерирует промежуточное значение для каждого элемента, и это значение используется для выполнения сравнений во время процесса сортировки.
- Метод мутирует список, вызывая постоянные изменения. Вы должны быть очень осторожны и использовать его только, если вам не нужна оригинальная версия списка.
Я действительно надеюсь, что вам понравилась моя статья и обнаружила, что это полезно. Теперь вы можете работать с Метод в ваших проектах Python. Проверьте мои онлайн-курсы Отказ Следуй за мной на Отказ ️.
Построение массива из коллекции
5.1. Пример списка ссылок
Давайте рассмотрим использование универсальных массивов в API коллекций Java, где мы создадим новый массив из коллекции.
Сначала давайте создадим новый Связанный список с аргументом типа Строка и добавим в него элементы:
List items = new LinkedList();
items.add("first item");
items.add("second item");
Во-вторых, давайте построим массив элементов, которые мы только что добавили:
String[] itemsAsArray = items.toArray(new String);
Чтобы построить наш массив, Список . Метод toArray требует ввода массива. Он использует этот массив исключительно для получения информации о типе для создания возвращаемого массива нужного типа.
В приведенном выше примере мы использовали новую строку в качестве входного массива для построения результирующего массива String .
5.2. Реализация LinkedList.toArray
Давайте заглянем внутрь LinkedList.toArray , чтобы увидеть, как это реализовано в Java JDK.
Во-первых, давайте посмотрим на сигнатуру метода:
public T[] toArray(T[] a)
Во-вторых, давайте посмотрим, как при необходимости создается новый массив:
a = (T[])java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size);
Обратите внимание, как он использует Массив#newInstance для создания нового массива, как в нашем примере стека ранее. Кроме того, обратите внимание, как параметр a используется для указания типа Массив#Новая установка
Наконец, результат из массива#newInstance преобразуется в T[] для создания универсального массива.
Приложения [ править ]
Массивы используются для реализации математических векторов и матриц , а также других видов прямоугольных таблиц. Многие базы данных , большие и малые, состоят из (или включают) одномерных массивов, элементами которых являются записи .
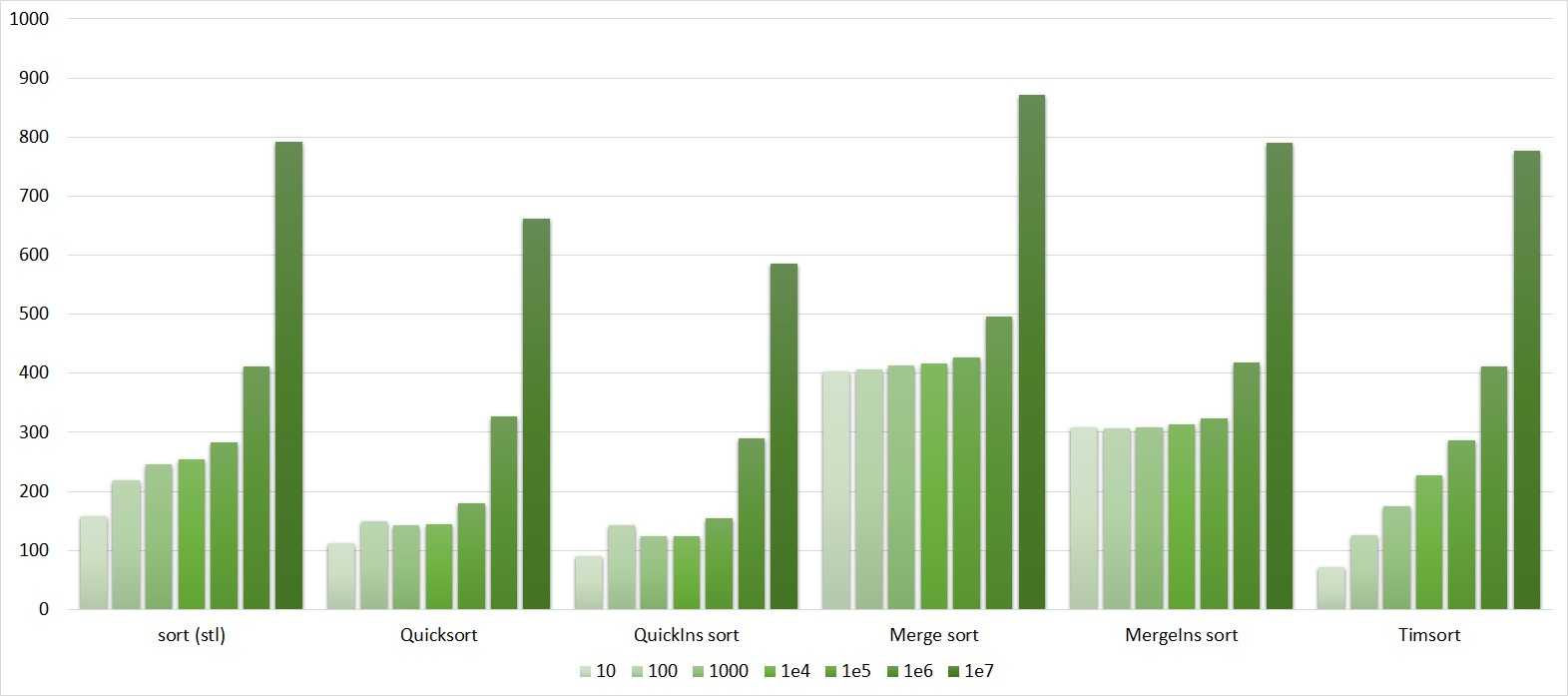
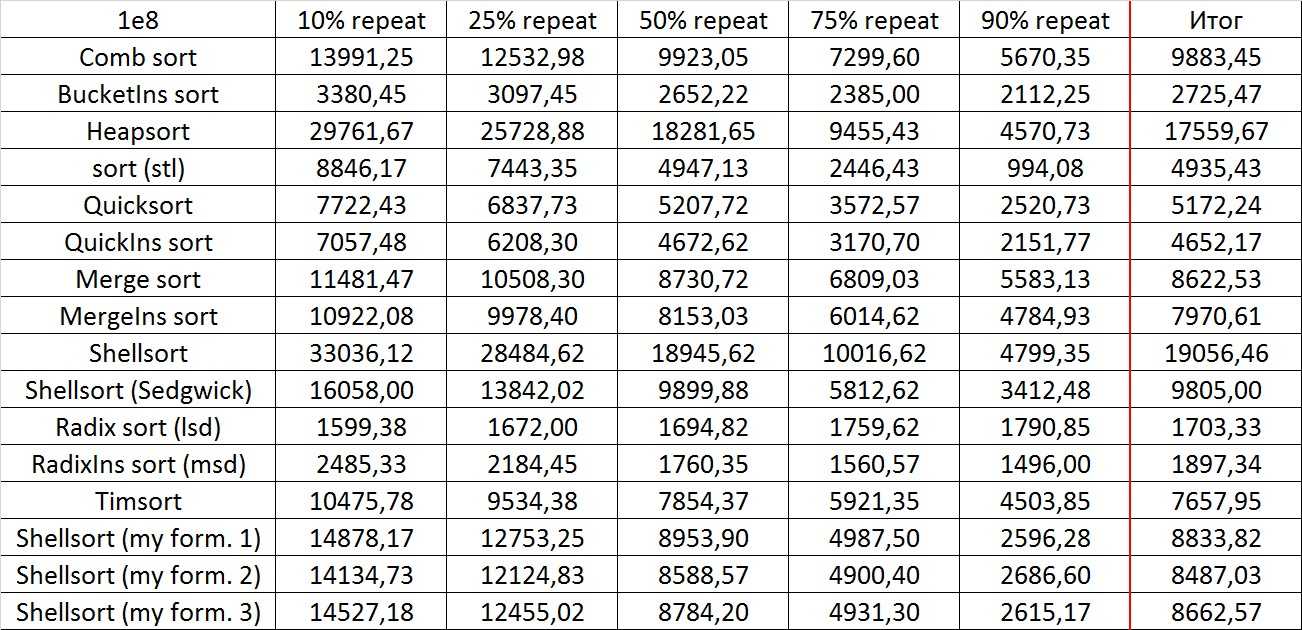
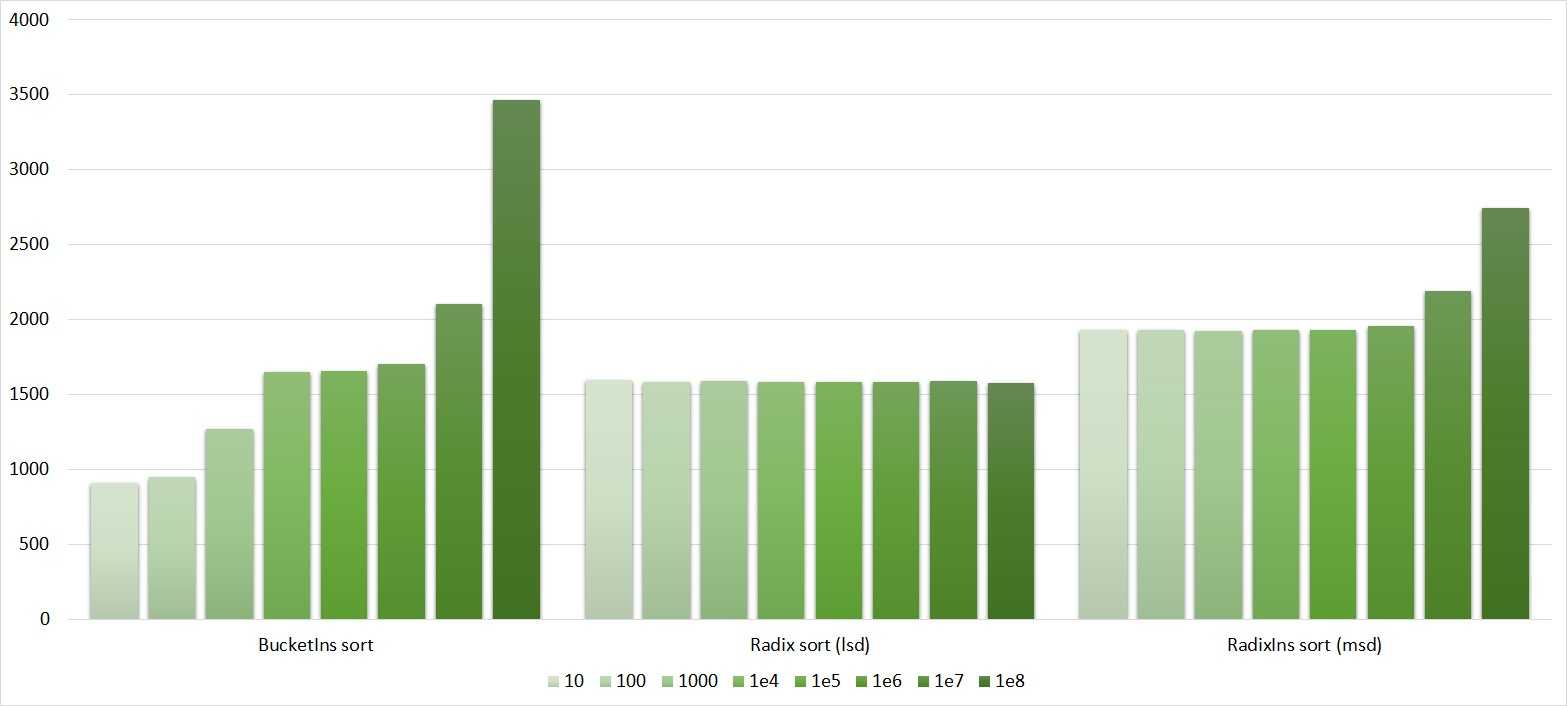
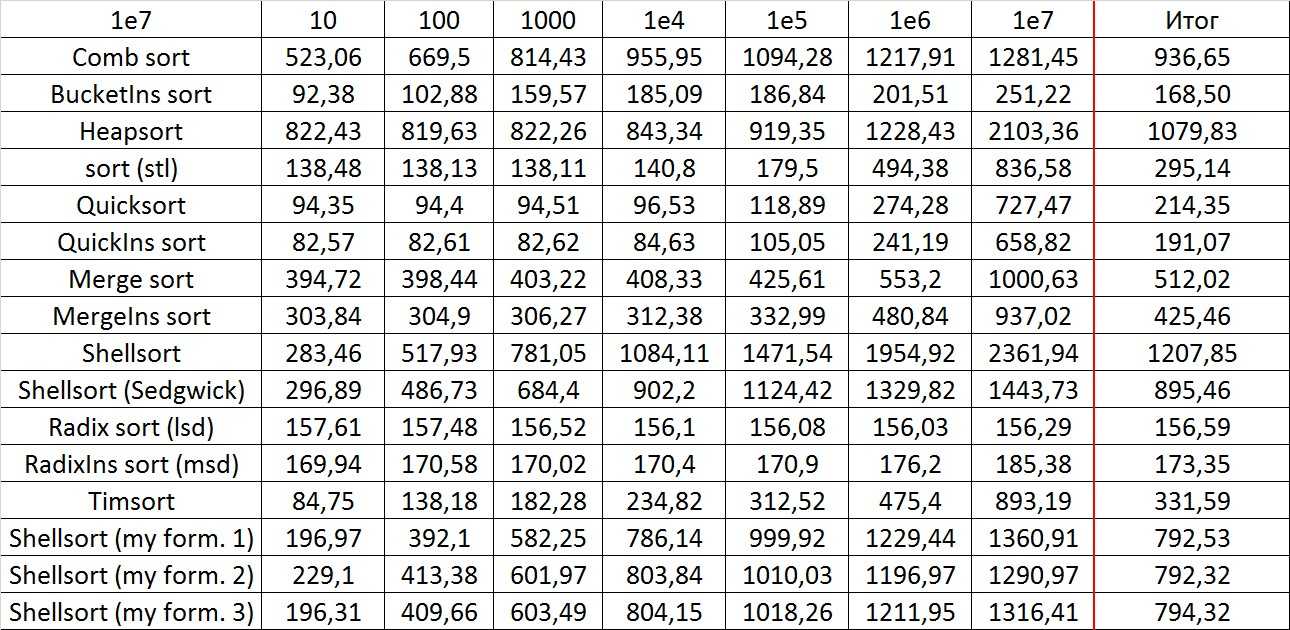
Массивы используются для реализации других структур данных, таких как списки, отвалы , хэш — таблица , двусторонние очереди , очередь , стеки , строки и VLists. Реализации других структур данных на основе массивов часто просты и занимают мало места ( неявные структуры данных ), требуют небольших накладных расходов на пространство , но могут иметь низкую сложность пространства, особенно при модификации, по сравнению с древовидными структурами данных (сравните отсортированный массив с дерево поиска ).
Один или несколько больших массивов иногда используются для имитации распределения динамической памяти в программе , особенно выделения пула памяти . Исторически сложилось так, что иногда это был единственный способ перенести «динамическую память».
Массивы могут использоваться для определения частичного или полного потока управления в программах в качестве компактной альтернативы (иначе повторяющимся) множественным операторам. В этом контексте они известны как управляющие таблицы и используются вместе со специально созданным интерпретатором, поток управления которого изменяется в соответствии со значениями, содержащимися в массиве. Массив может содержать указатели подпрограмм (или относительные номера подпрограмм, на которые могут воздействовать операторы SWITCH ), которые определяют путь выполнения.
🔹 Мутация и риски
Как и обещал, давайте посмотрим, как процесс мутации работает за кулисами:
Когда вы определяете список в Python, как это:
a =
Вы создаете объект в определенном месте памяти. Это местоположение называется «адресом памяти» объекта, представленного уникальным целым числом, называемым ID Отказ
Вы можете подумать о идентификаторе как «тег», используемый для определения определенного места в памяти:
Вы можете получить доступ к идентификатору списка, используя Функция, передавая список в качестве аргумента:
>>> a = >>> id(a) 60501512
Когда ты Мутате Список, вы меняете его непосредственно в память. Вы можете спросить, почему это так рискованно?
Это рискованно, потому что это влияет на каждую единую строку кода, которая использует список после мутации, поэтому вы можете писать код для работы со списком, который полностью отличается от фактического списка, который существует в памяти после мутации.
Вот почему вы должны быть очень осторожны с методами, которые вызывают мутацию.
В частности, Метод Мутации список. Это пример своего эффекта:
Вот пример:
# Define a list >>> a = # Check its id >>> id(a) 67091624 # Sort the list using .sort() >>> a.sort() # Check its id (it's the same, so the list is the same object in memory) >>> id(a) 67091624 # Now the list is sorted. It has been mutated! >>> a
Список был мутирован после звонка Отказ
Каждая отдельная строка кода, которая работает со списком После того, как мутация произошла, будет использовать новую, отсортированную версию списка. Если это было не то, что вы предполагаете, вы не понимаете, что другие части вашей программы работают с новой версией списка.
Вот еще один пример рисков мутации в рамках функции:
# List >>> a = # Function that prints the elements of the list in ascending order. >>> def print_sorted(x): x.sort() for elem in x: print(elem) # Call the function passing 'a' as argument >>> print_sorted(a) 1 3 5 7 # Oops! The original list was mutated. >>> a
Список Это было передано как аргумент мутировал, даже если это не то, что вы предполагали, когда вы изначально написали функцию.
Совет: Если функция мутирует аргумент, он должен быть четко указан, чтобы избежать внедрения ошибок в другие части вашей программы.
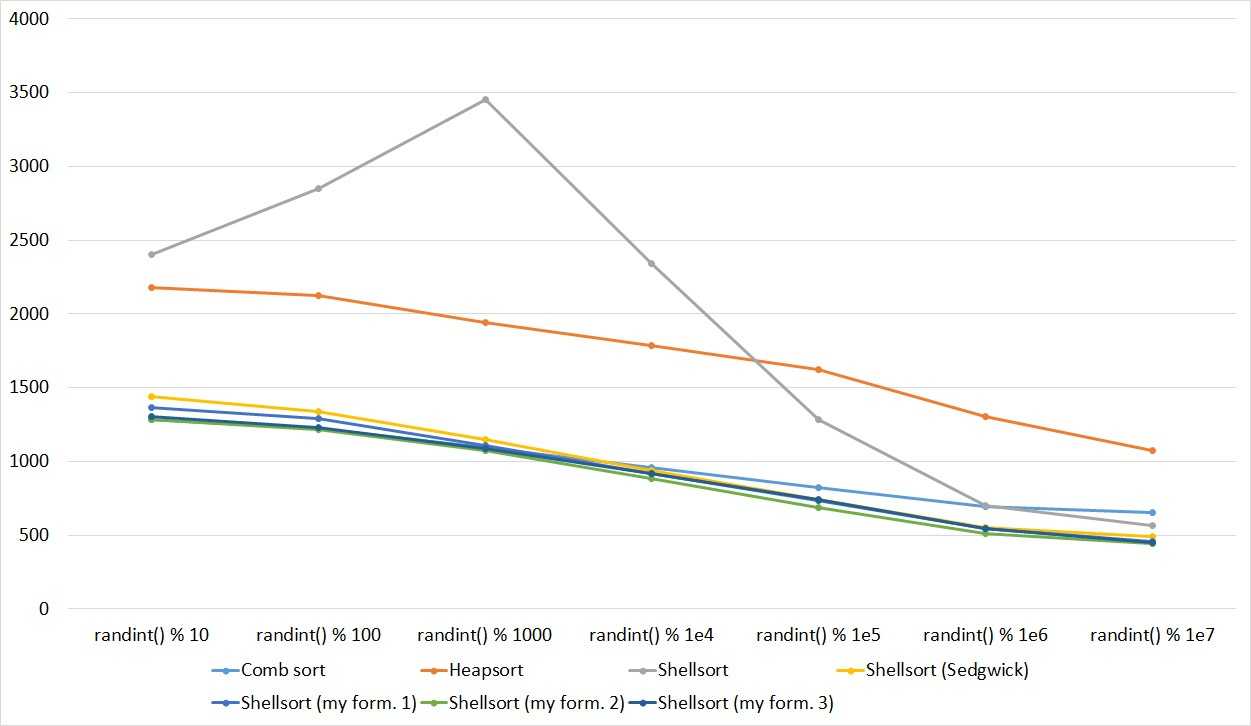
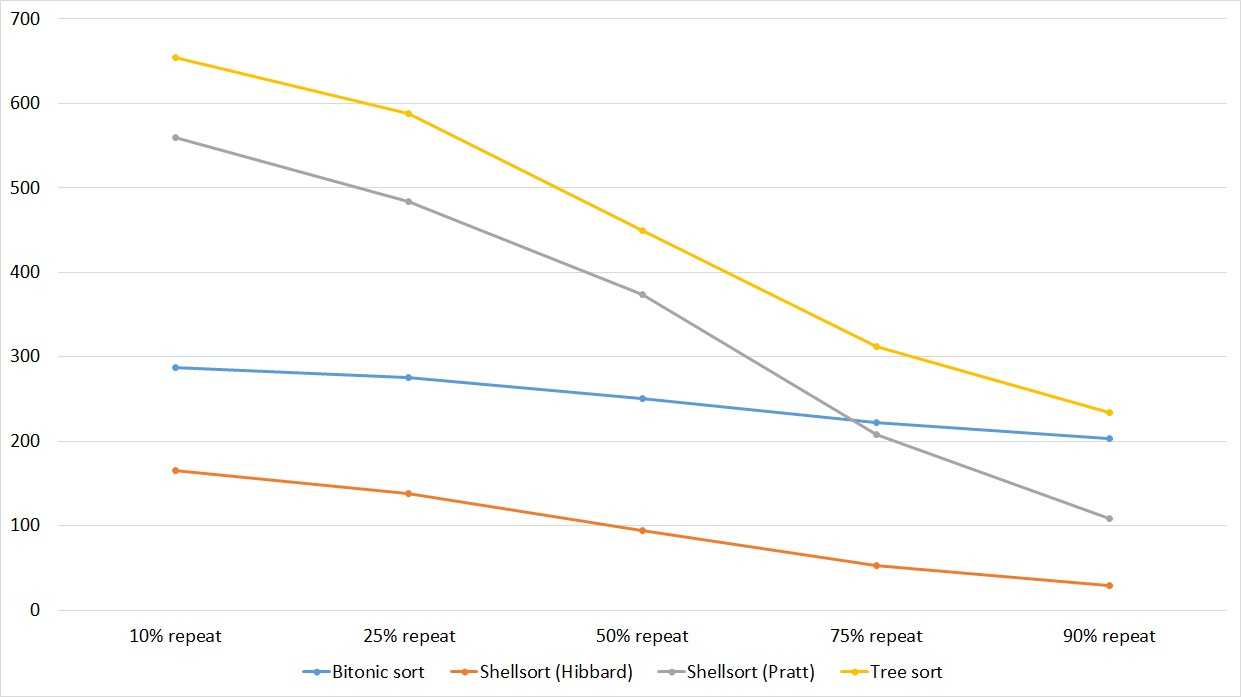
Пирамидальная сортировка
Также известна как сортировка кучей. Этот популярный алгоритм, как и сортировки вставками или выборкой, сегментирует список на две части: отсортированную и неотсортированную. Алгоритм преобразует второй сегмент списка в структуру данных «куча» (heap), чтобы можно было эффективно определить самый большой элемент.
Алгоритм
Сначала преобразуем список в Max Heap — бинарное дерево, где самый большой элемент является вершиной дерева. Затем помещаем этот элемент в конец списка. После перестраиваем Max Heap и снова помещаем новый наибольший элемент уже перед последним элементом в списке.
Этот процесс построения кучи повторяется, пока все вершины дерева не будут удалены.
Методы find(), findIndex() и indexOf()
Методы массивов , и легко перепутать друг с другом. Ниже даны пояснения, помогающие понять их особенности.
Метод возвращает первый элемент массива, соответствующий заданному критерию. Этот метод, найдя первый подходящий элемент, не продолжает поиск по массиву.
![]()
Обратите внимание на то, что в нашем примере заданному критерию соответствуют все элементы массива, следующие за тем, который содержит число 5, но возвращается лишь первый подходящий элемент. Этот метод весьма полезен в ситуациях, в которых, пользуясь для перебора и анализа массивов циклами , такие циклы, при обнаружении в массиве нужного элемента, прерывают, используя инструкцию
Метод очень похож на , но он, вместо того, чтобы возвращать первый подходящий элемент массива, возвращает индекс такого элемента. Для того чтобы лучше понять этот метод — взгляните на следующий пример, в котором используется массив строковых значений.
![]()
Метод очень похож на метод , но он принимает в качестве аргумента не функцию, а обычное значение. Использовать его можно в том случае, если при поиске нужного элемента массива не нужна сложная логика.
![]()
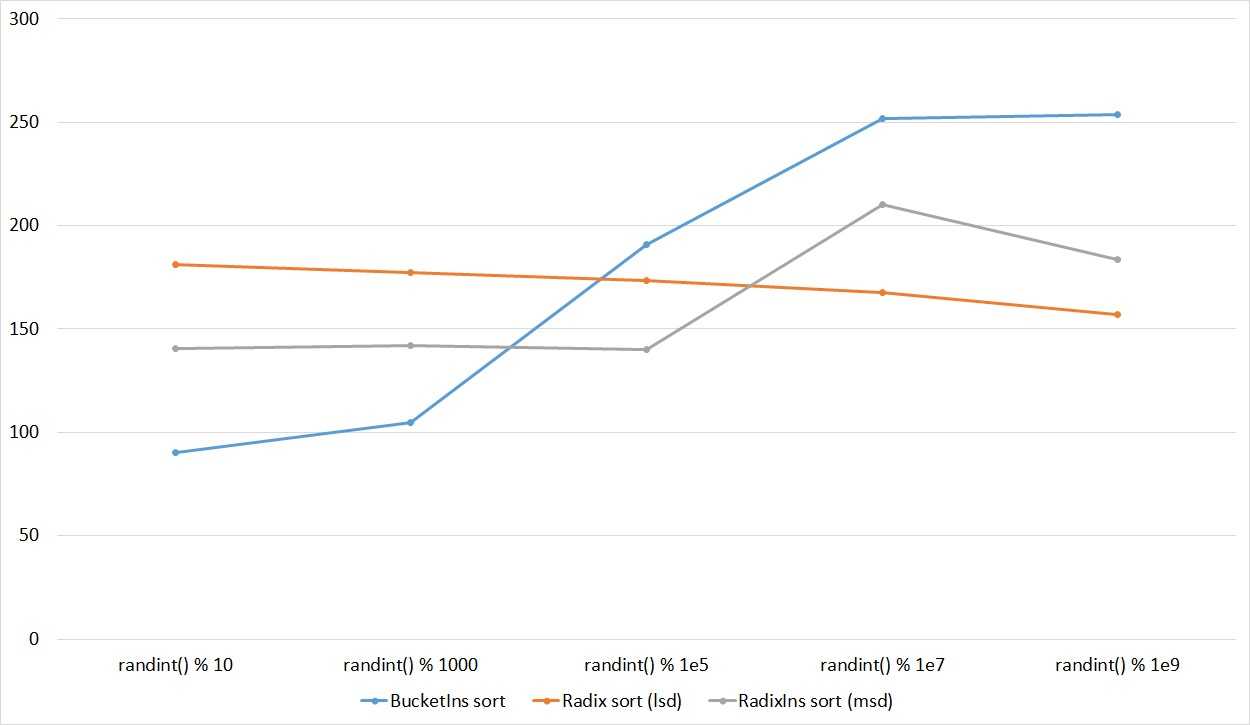
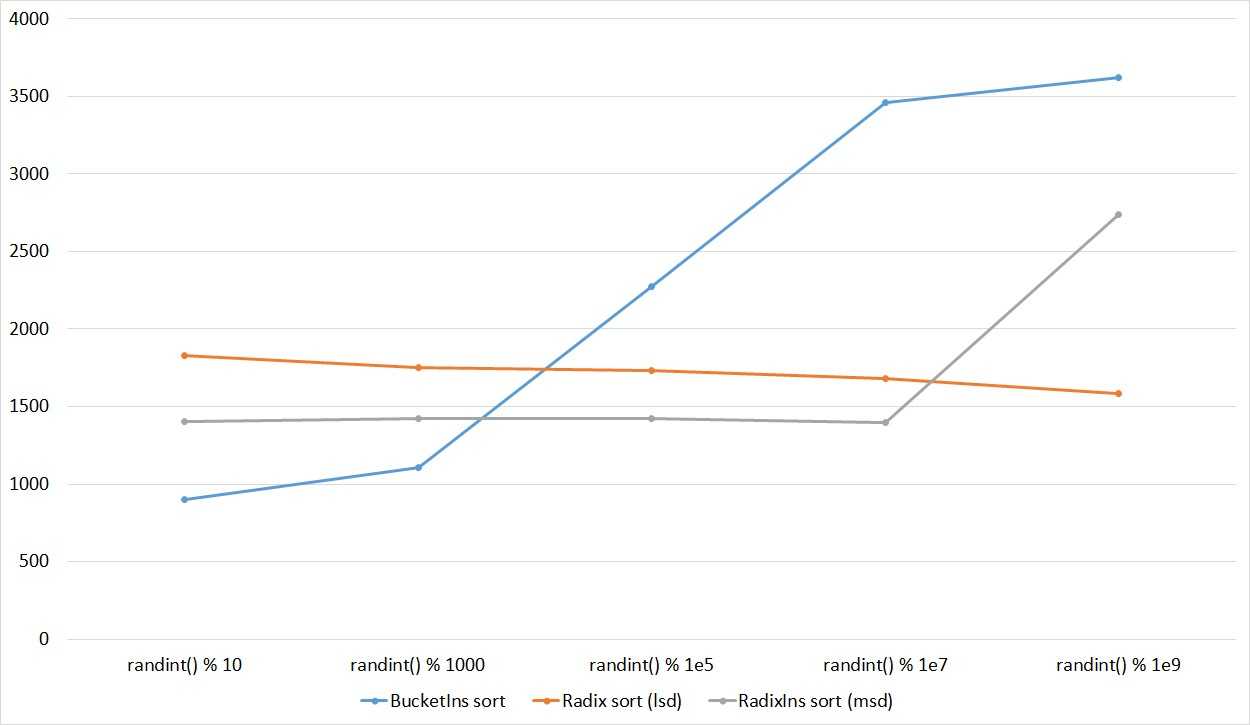
Экономим место
Вернёмся к функции . В текущей реализации эта функция требует \(n\) дополнительной памяти, потому что результат пишется в совершенно новый массив
Впрочем, если обратить внимание на функцию , результат хорошо бы получить на месте исходных массивов. Попробуем сократить аппетиты функции , при учёте того, что сливаемые массивы идут в памяти друг за другом
Пусть даны два массива \(A\) и \(B\), являющиеся по сути двумя подмассивами одного большего массива, идущие друг за другом. А также дан пустой участок памяти, размером \(|A|\). Тогда несложно видеть, что, скопировав \(A\) в свободный участок памяти, можно записать ответ поверх начального местоположения \(A\) и \(B\). Для этого воспользуемся тремя указателями: — текущая голова копии \(A\), — текущая голова массива \(B\) и — указатель на конец результата слияния.
Слияние с n/2 дополнительной памяти. Исходное положение
При этом очевидно, что указатель «догонит» указатель только тогда, когда указатель исчерпает весь массив \(A\). Также несложно адоптировать этот алгоритм для переноса в дополнительную память массива \(B\). Что, кстати сказать, будет выгоднее для нашей реализации Bottom-Up ().
Итак, пусть — массив, в котором располагаются элементы массива \(A\), а затем элементы массива \(B\). — индекс первого элемента массива \(B\). И — пустой массив, размера \(B\).
А можно вообще без дополнительной памяти?
Слияние без дополнительной памяти сделать не получится, а вот всю сортировку целиком можно, хотя и не нужно (сложность будет всё также \(O(n\log n)\), вот только откидываемый скалярный коэффициент будет слишком большой). Для начала стоит отметить, что для слияния массивов разной длинны описанным выше способом объём дополнительной памяти требуется соразмерно меньшему из сливаемых массивов. Кроме того, если заменить все операции на обмены, то нетрудно видеть, что можно сохранить данные в дополнительной памяти (потеряв при этом их порядок). То есть, при перемещении \(A\) в дополнительную память данные из дополнительной памяти оказываются на месте \(A\) (\(a_i \leftrightarrow c_i\)). А при слиянии элементы из дополнительной памяти будут обмениваться с элементами \(A\) и \(B\), но в итоге вернутся в дополнительную память. Таким образом мы можем использовать часть оригинального массива как дополнительную память при сортировке другой его части. Не стоит забывать, что порядок всё же теряется, поэтому поступим следующим образом:


- отсортируем правую половину массива, воспользовавшись левой как дополнительной памятью;
- отсортируем левую неотсортированной части, воспользовавшись правой половиной неотсортированной части;
- сольём отсортированные части, записывая результат поверх неотсортированной части;
- повторим шаги 2 и 3 до тех пор, пока в неотсортированной части не останется одноэлементный массив, который мы сольём с остатком при помощи алгоритма вставки.
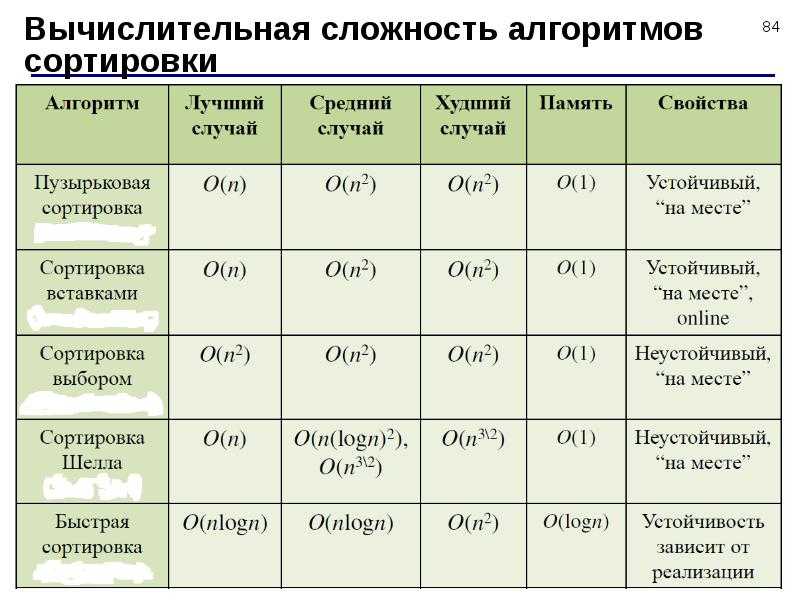
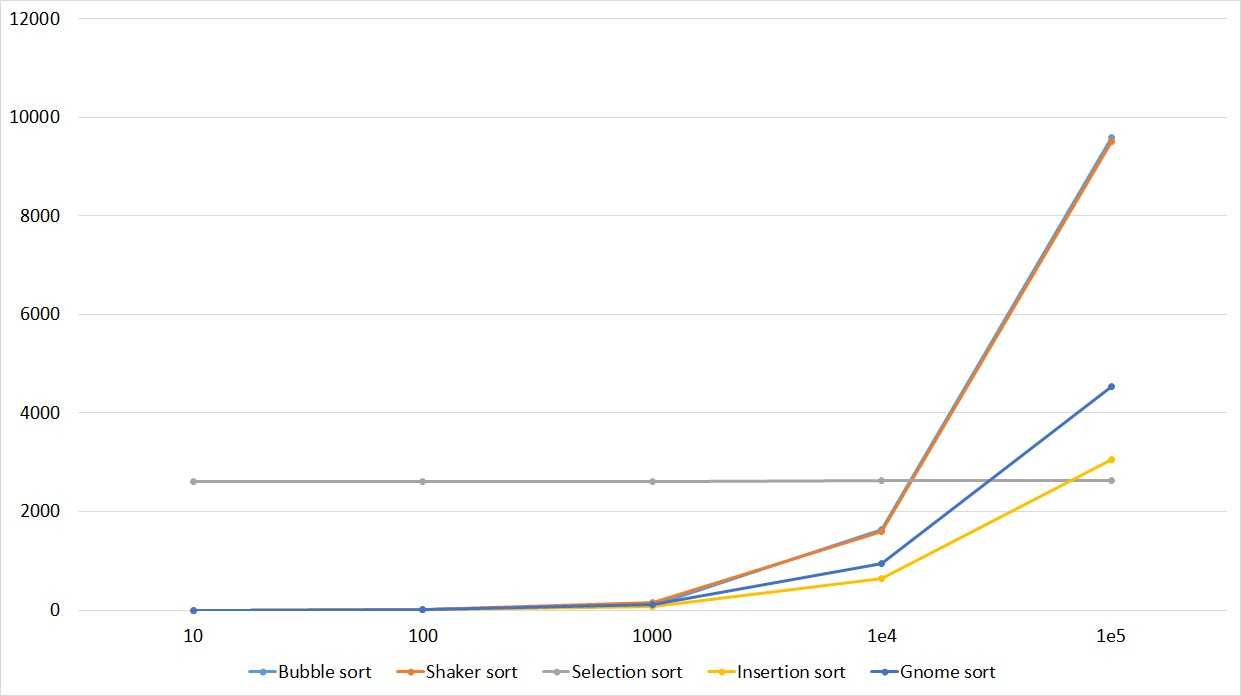
Пузырьковая сортировка
Этот простой алгоритм выполняет итерации по списку, сравнивая элементы попарно и меняя их местами, пока более крупные элементы не «всплывут» в начало списка, а более мелкие не останутся на «дне».
Алгоритм
Сначала сравниваются первые два элемента списка. Если первый элемент больше, они меняются местами. Если они уже в нужном порядке, оставляем их как есть. Затем переходим к следующей паре элементов, сравниваем их значения и меняем местами при необходимости. Этот процесс продолжается до последней пары элементов в списке.
При достижении конца списка процесс повторяется заново для каждого элемента. Это крайне неэффективно, если в массиве нужно сделать, например, только один обмен. Алгоритм повторяется n² раз, даже если список уже отсортирован.
Руководитель направления бизнес анализа
МТС, Москва, По итогам собеседования
tproger.ru
Вакансии на tproger.ru
Для оптимизации алгоритма нужно знать, когда его остановить, то есть когда список отсортирован.
Чтобы остановить алгоритм по окончании сортировки, нужно ввести переменную-флаг. Когда значения меняются местами, устанавливаем флаг в значение , чтобы повторить процесс сортировки. Если перестановок не произошло, флаг остаётся и алгоритм останавливается.
Реализация
Алгоритм работает в цикле и прерывается, когда элементы ни разу не меняются местами. Вначале присваиваем значение , чтобы алгоритм запустился хотя бы один раз.
Время сортировки
Если взять самый худший случай (изначально список отсортирован по убыванию), затраты времени будут равны O(n²), где n — количество элементов списка.
Методы push(), pop(), shift() и unshift()
Методы , , и применяются для добавления в массивы новых элементов и для извлечения из массивов уже имеющихся в них элементов. При этом работа производится с элементами, находящимися в начале или в конце массива.
Метод позволяет добавлять элементы в конец массива. Он модифицирует массив, и, после завершения работы, возвращает элемент, добавленный в массив.
![]()
Метод удаляет из массива последний элемент. Он модифицирует массив и возвращает удалённый из него элемент.
![]()
Метод удаляет из массива первый элемент и возвращает его. Он тоже модифицирует массив, для которого его вызывают.
![]()
Метод добавляет один или большее количество элементов в начало массива. Он, опять же, модифицирует массив. При этом, в отличие от трёх других рассмотренных здесь методов, он возвращает новую длину массива.
![]()
Размер [ править ]
Размерность массива — это количество индексов, необходимых для выбора элемента. Таким образом, если массив рассматривается как функция на множестве возможных комбинаций индексов, это измерение пространства, в котором его домен является дискретным подмножеством. Таким образом, одномерный массив — это список данных, двумерный массив — это прямоугольник данных, трехмерный массив — это блок данных и т. Д.
Это не следует путать с размерностью набора всех матриц с заданным доменом, то есть с количеством элементов в массиве. Например, массив с 5 строками и 4 столбцами является двумерным, но такие матрицы образуют 20-мерное пространство. Точно так же трехмерный вектор может быть представлен одномерным массивом размера три.
Создание универсального массива
Для нашего примера давайте рассмотрим ограниченную структуру данных стека MyStack , где емкость фиксирована до определенного размера. Кроме того, поскольку мы хотели бы, чтобы стек работал с любым типом, разумным выбором реализации был бы универсальный массив.
Во-первых, давайте создадим поле для хранения элементов нашего стека, которое представляет собой универсальный массив типа E :
private E[] elements;
Во-вторых, давайте добавим конструктор:
public MyStack(Class clazz, int capacity) {
elements = (E[]) Array.newInstance(clazz, capacity);
}
Обратите внимание, как мы используем java.lang.reflect.Массив#newInstance для инициализации нашего универсального массива , для которого требуется два параметра. Первый параметр указывает тип объекта внутри нового массива
Второй параметр указывает, сколько места необходимо создать для массива. Поскольку результат Array#newInstance имеет тип Объект , нам нужно привести его к E [] , чтобы создать наш универсальный массив.
Мы также должны отметить соглашение об именовании параметра типа clazz , а не class, , которое является зарезервированным словом в Java.
Соображения При Использовании Универсальных Массивов
Важное различие между массивами и универсальными моделями заключается в том, как они обеспечивают проверку типов. В частности, массивы хранят и проверяют информацию о типе во время выполнения
Универсальные, однако, проверяют наличие ошибок типа во время компиляции и не имеют информации о типе во время выполнения.
Синтаксис Java предполагает, что мы могли бы создать новый универсальный массив:
T[] elements = new T;
Но если бы мы попытались это сделать, то получили бы ошибку компиляции.
Чтобы понять, почему, давайте рассмотрим следующее:
public T[] getArray(int size) {
T[] genericArray = new T; // suppose this is allowed
return genericArray;
}
Поскольку несвязанный универсальный тип T преобразуется в Объект, наш метод во время выполнения будет:
public Object[] getArray(int size) {
Object[] genericArray = new Object;
return genericArray;
}
Затем, если мы вызовем наш метод и сохраним результат в массиве String :
String[] myArray = getArray(5);
Код будет скомпилирован нормально, но во время выполнения произойдет сбой с ClassCastException . Это связано с тем, что мы только что присвоили Объекту[] ссылку String [] . В частности, неявное приведение компилятором не сможет преобразовать Объект[] в наш требуемый тип Строка[] .
Хотя мы не можем инициализировать универсальные массивы напрямую, все же можно выполнить эквивалентную операцию, если вызывающий код предоставляет точный тип информации.
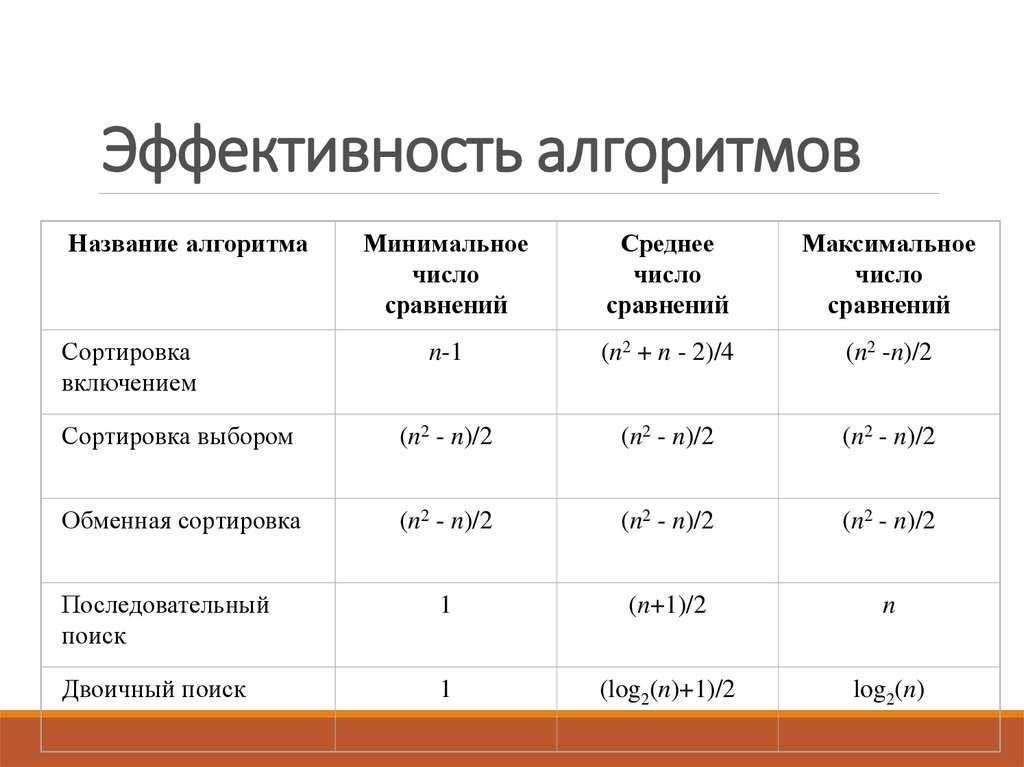
Модель RAM (Random Access Machine)
Каждое вычислительное устройство имеет свои особенности, которые могут влиять на длительность вычисления
Обычно при разработке алгоритма не берутся во внимание такие детали, как размер кэша процессора или тип многозадачности, реализуемый операционной системой. Анализ алгоритмов проводят на модели абстрактного вычислителя, называемого машиной с произвольным доступом к памяти (RAM)
Модель состоит из памяти и процессора, которые работают следующим образом:
- память состоит из ячеек, каждая из которых имеет адрес и может хранить один элемент данных;
- каждое обращение к памяти занимает одну единицу времени, независимо от номера адресуемой ячейки;
- количество памяти достаточно для выполнения любого алгоритма;
- процессор выполняет любую элементарную операцию (основные логические и арифметические операции, чтение из памяти, запись в память, вызов подпрограммы и т.п.) за один временной шаг;
- циклы и функции не считаются элементарными операциями.
Несмотря на то, что такая модель далека от реального компьютера, она замечательно подходит для анализа алгоритмов. После того, как алгоритм будет реализован для конкретной ЭВМ, вы можете заняться профилированием и низкоуровневой оптимизацией, но это будет уже оптимизация кода, а не алгоритма.
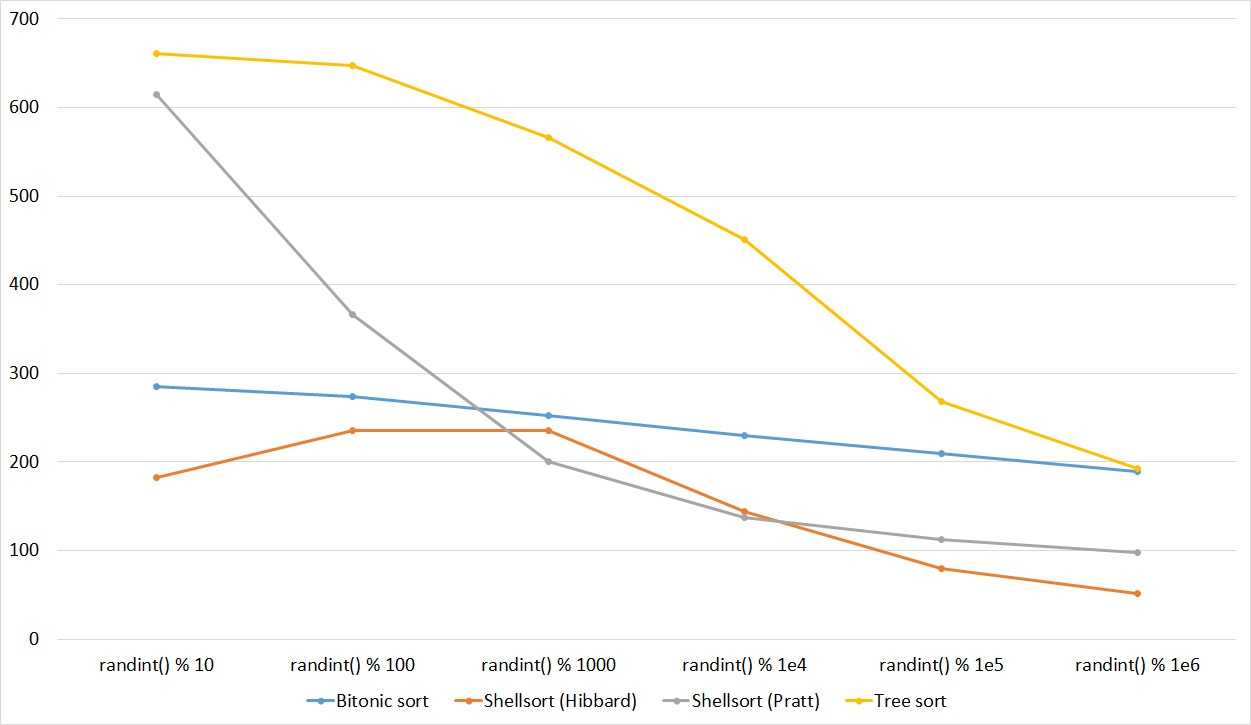
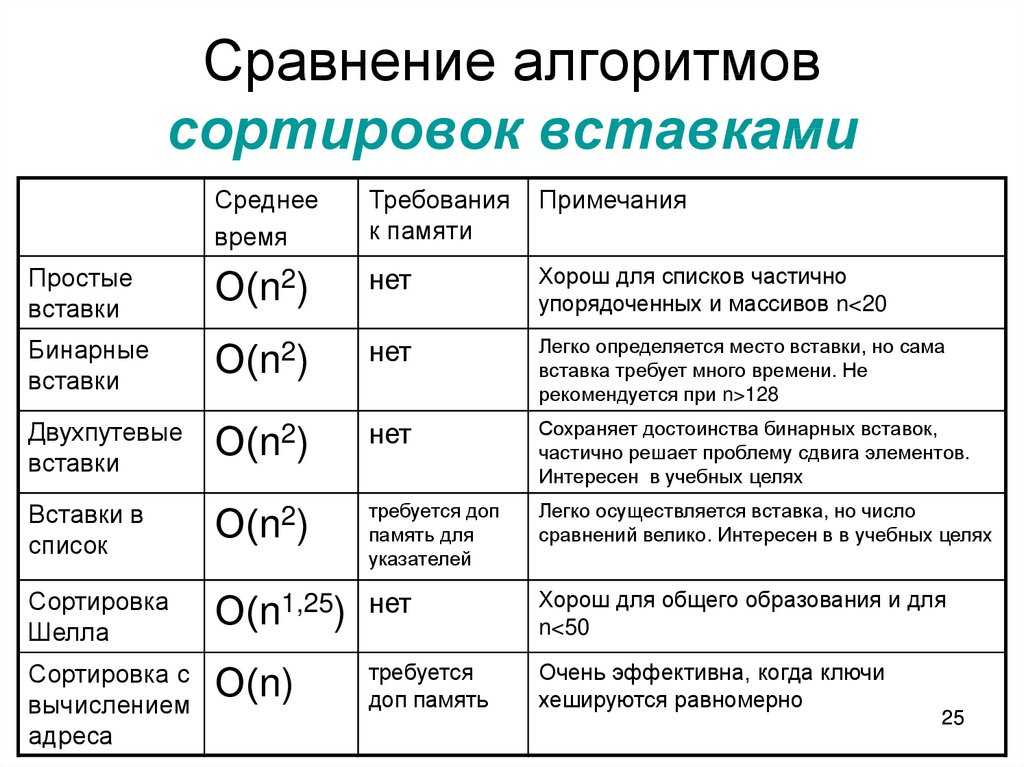

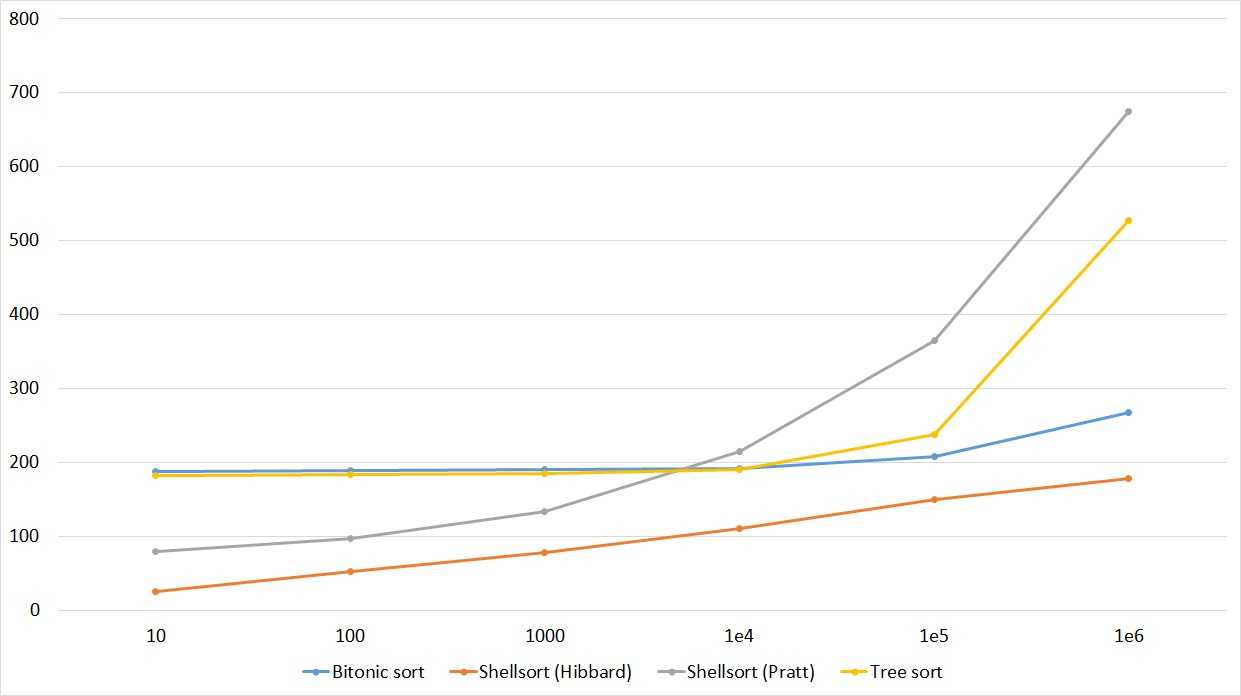
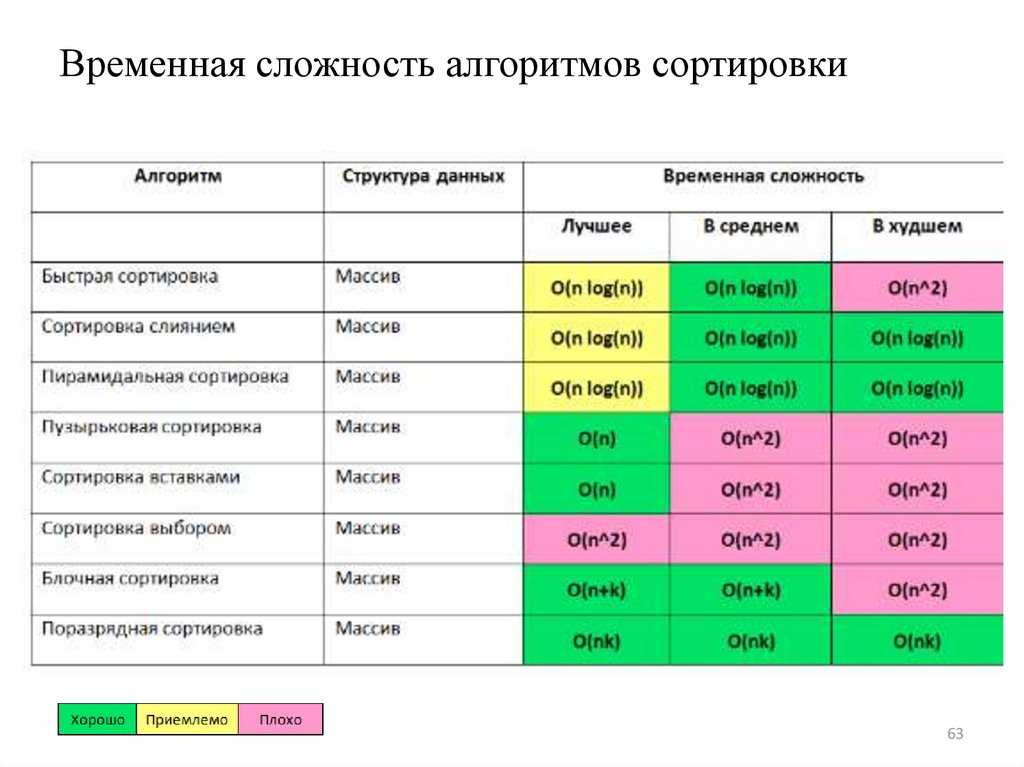
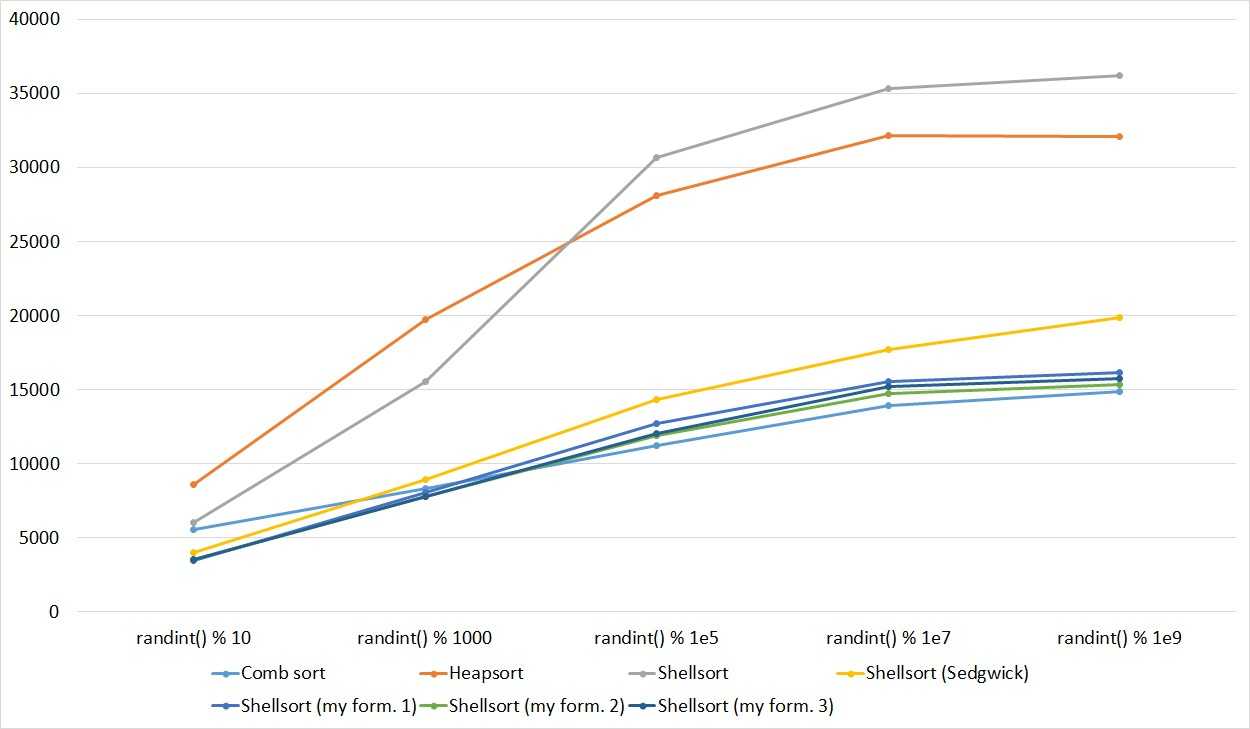
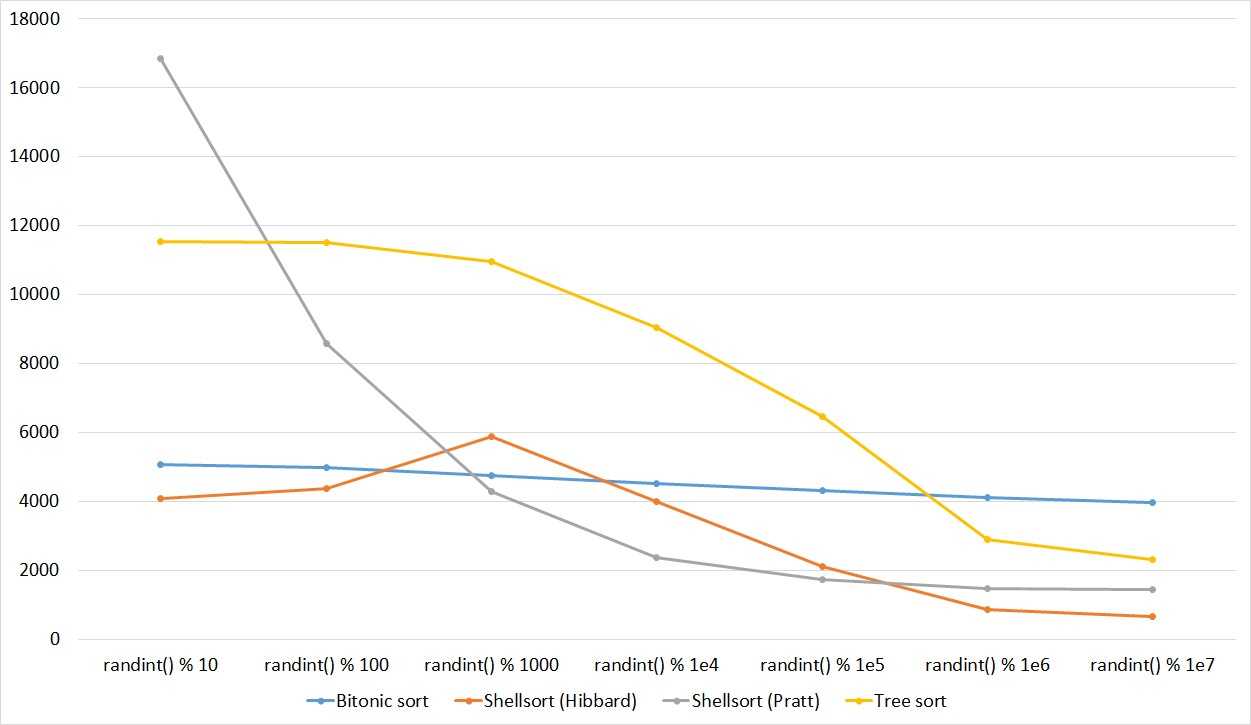
Встроенные функции сортировки на Python
Иногда полезно знать перечисленные выше алгоритмы, но в большинстве случаев разработчик, скорее всего, будет использовать функции сортировки, уже предоставленные в языке программирования.
Отсортировать содержимое списка можно с помощью стандартного метода :
Или можно использовать функцию для создания нового отсортированного списка, оставив входной список нетронутым:
Оба эти метода сортируют в порядке возрастания, но можно изменить порядок, установив для флага значение :
В отличие от других алгоритмов, обе функции в Python могут сортировать также списки кортежей и классов. Функция может сортировать любую последовательность, которая включает списки, строки, кортежи, словари, наборы и пользовательские итераторы, которые вы можете создать.
Функции в Python реализуют алгоритм Tim Sort, основанный на сортировке слиянием и сортировке вставкой.
Ассоциативные массивы в PHP
Чтобы обратиться к нужному элементу этого массива, мы должны написать в квадратных скобках ключ этого элемента. Как вы знаете, в массивах PHP сам определяет ключи для элементов — это их порядковые номера. Но иногда это может оказаться неудобным: например, мы хотим вывести на экран название первого дня недели, а должны писать в квадратных скобках цифру 0 .
Логичнее и удобнее было бы все-таки для первого дня недели писать ключ 1 , как привыкли мы в жизни. Для этого используются массивы. Они имеют следующий синтаксис: имя ключа, затем идет стрелка => , а потом значение. Давайте укажем явные ключи для нашего массива дней:
После добавления наших ключей обратиться к понедельнику можно уже по ключу 1 , а не 0 . Сделаем это:
Создайте массив с ключами 1 , 2 и 3 и значениями ‘a’ , ‘b’ и ‘c’ . Выведите на экран все его элементы.
Хитрость с ключами
Не очень удобно расставлять ключи всем элементам для того, чтобы нумерация началась не с нуля, а с единицы. К счастью, на самом деле достаточно первому элементу поставить ключ 1 и дальше PHP сам автоматически расставит ключи по порядку.
Составьте массив с названиями месяцев. Пусть в нем январь имеет ключ 1 .
Строковые ключи
Ключи не обязательно должны быть числами, они могут быть и строками. Сделаем, к примеру, массив, в котором ключами будут имена работников, а элементами — их зарплаты:
Узнаем зарплату первого работника:
Создайте массив $user с ключами ‘name’ , ‘surname’ , ‘patronymic’ и какими-то произвольными значениями. Выведите на экран фамилию, имя и отчество через пробел.
Создайте массив $date с ключами ‘year’ , ‘month’ и ‘day’ и значениями, соответствующими текущему дню. Выведите созданную дату на экран в формате год-месяц-день.



