
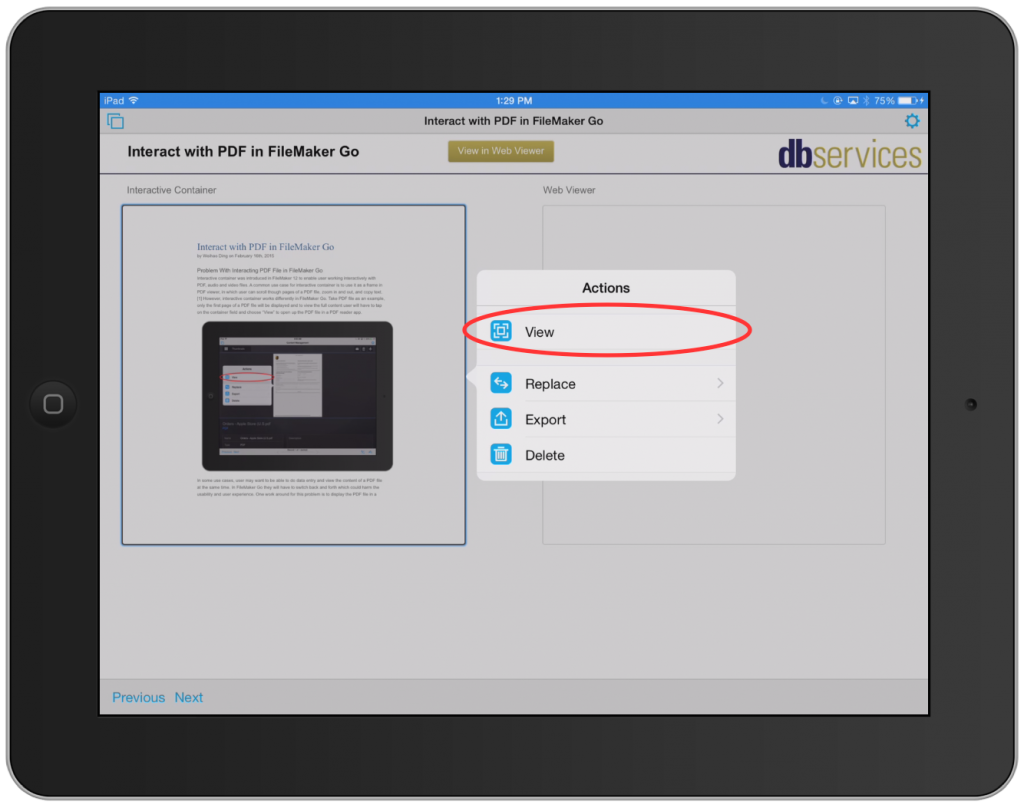
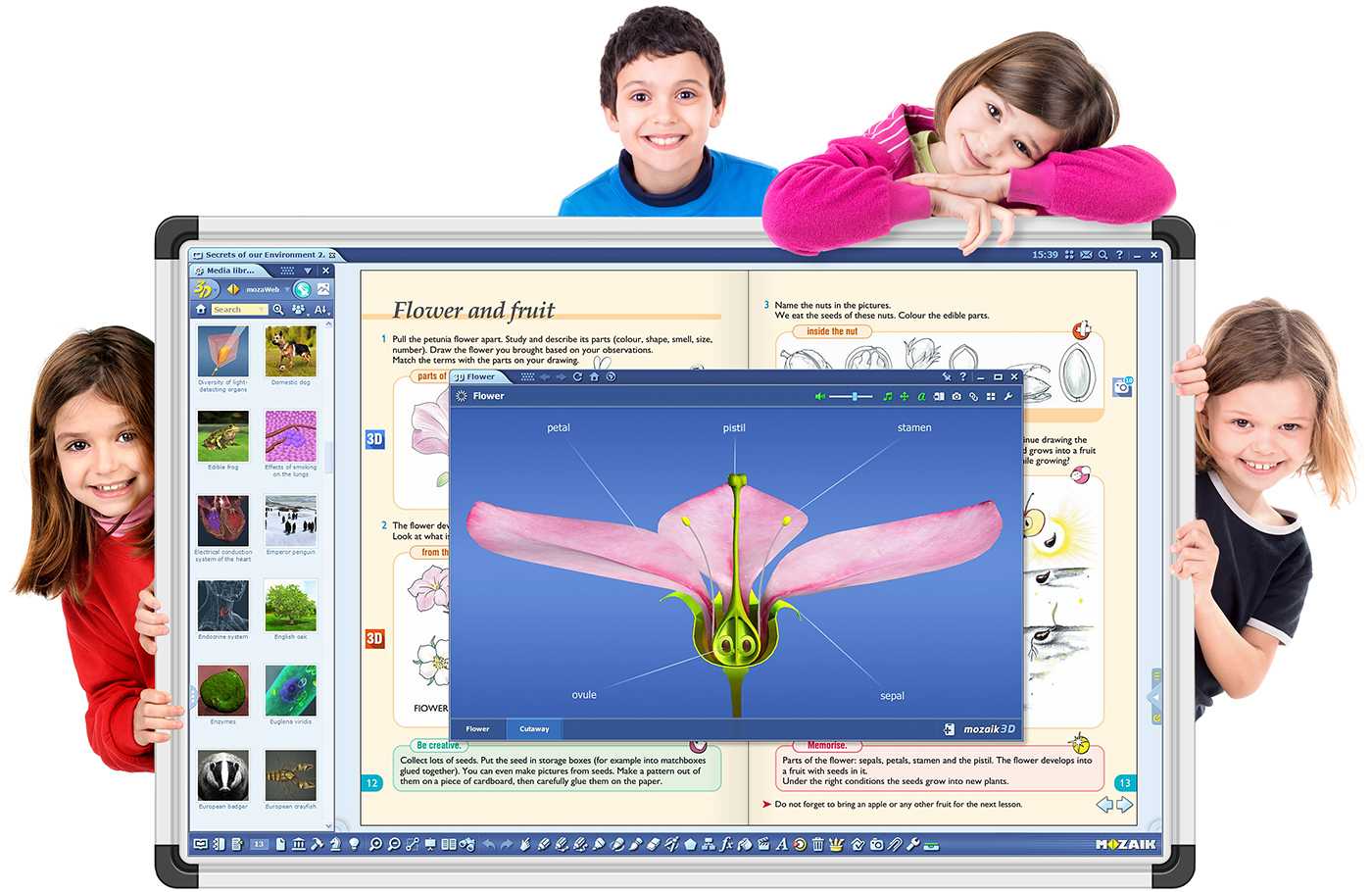
Как записать Java в файл построчно
Каждый раз при компиляции данного кода в консоли будет перезаписываться одна и та же запись. Как сделать так, чтобы при запуске программы в файл записывалась новая информация построчно? Для этого в первую очередь нужно написать ключевое слово true вторым параметром при создании FileWriter:
BufferedWriter writer = new BufferedWriter(new FileWriter(myFile, true));
Каждый раз при компиляции программа будет записывать в файл строку, которая находится в методе write(), без переноса на следующую строку. В нашем случае получилось так:
пример записи в Java пример записи в Java пример записи в Java
Простой способ переноса строки — это добавление оператора /n к строковому аргументу метода write(), однако такой способ не будет работать в разных операционных системах. Для того чтобы записать файл построчно на различных платформах, нужно использовать метод line.separator класса System. В следующем примере видно, как этот метод записать в переменную lineSeparator, которую потом можно использовать в строковом аргументе метода write():
String lineSeparator = System.getProperty(«line.separator»);
Окончательно код будет выглядеть так, как показано ниже.
![]()
Результат выполнения данного кода будет следующим: в файле text.txt при троекратном запуске программы появятся строки «пример записи в Java».
https://youtube.com/watch?v=gbP_nrABqEc
Запись бинарной информации в файл
Если вам требуется записать не текстовые данные, а бинарные данные, используйте следующий пример. В качестве бинарных данных может выступать любой массив байтов (например, байтовое представление картинки или любого другого файла).
// запись в файл бинарной информации (файл перезаписывается) byte[] data = «Бинарные данные».getBytes(); Path fileB = Paths.get(«output.bin»); Files.write(fileB, data);
Для того, чтобы добавить информацию в конец файла, не перезаписывая его полностью, ипользуйте этот код:
// запись в файл бинарной информации (информация добавляется в конец файла) byte[] data2 = «Бинарные данные».getBytes(); Path fileB2 = Paths.get(«output.bin»); Files.write(fileB2, data, StandardOpenOption.APPEND);
Запись текста в файл (Java 6)
Этот код запишет данные в файл (причём если файл существует, данные в нём будут перезаписаны).
// если файл существует, он перезатрётся PrintWriter writer = new PrintWriter(«output.txt», «UTF-8»); writer.println(«Первая строка»); writer.println(«Вторая строка»); writer.close();
Если вам нужно дописать текст в конец файла, используйте следующий код:
// здесь мы допишем информацию в конец файла, если он уже существует PrintWriter writer2 = new PrintWriter((new FileWriter(«output.txt», true))); writer2.println(«Третья строка»); writer2.close();
Для записи бинарных данных в файл в Java 6 используйте следующий код (информация в файле перезапишется):
// запись в файл бинарной информации (файл перезаписывается) OutputStream os = new FileOutputStream(«output.bin»); byte[] data = «какие-то бинарные данные».getBytes(); os.write(data); os.close();
Для добавления бинарных в конец файла в Java используйте следующий код:
// запись в файл бинарной информации (информация добавляется в конец файла) OutputStream osB = new FileOutputStream(«output.bin», true); byte[] dataB = «какие-то бинарные данные».getBytes(); osB.write(dataB); osB.close();
Многостраничные документы
Пакет PyFPDF включает в себя поддержку многостраничных документов по умолчанию. Добавив достаточное количество клеток в странице, автоматически будет создана новая страница, так что вы сможете продолжать ваш новый текст. Вот простой пример:
Python
# multipage_simple.py
from fpdf import FPDF
def multipage_simple():
pdf = FPDF()
pdf.set_font(«Arial», size=12)
pdf.add_page()
line_no = 1
for i in range(100):
pdf.cell(0, 10, txt=»Line #{}».format(line_no), ln=1)
line_no += 1
pdf.output(«multipage_simple.pdf»)
if __name__ == ‘__main__’:
multipage_simple()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# multipage_simple.py fromfpdf importFPDF defmultipage_simple() pdf=FPDF() pdf.set_font(«Arial»,size=12) pdf.add_page() line_no=1 foriinrange(100) pdf.cell(,10,txt=»Line #{}».format(line_no),ln=1) line_no+=1 pdf.output(«multipage_simple.pdf») if__name__==’__main__’ multipage_simple() |
Все, что здесь происходит – это создание 100 строк текста с помощью функции range. Когда я запустил этот код, то получил 4 страницы текста.
Как интерпретировать PDF-файлы
Существует несколько основных методов извлечения текста из PDF файлов в .NET:
- Microsoft IFilter interface и Adobe IFilter implementation;
- iTextSharp;
- PDFBox.
Эти методы PDF-интерпретации неидеальны. Ниже подробно рассмотрим каждый из них.
Для того, чтобы разобрать PDF-файлы с помощью IFilter, Вам понадобится:
Пример кода:
using IFilter;
// …
public static string ExtractTextFromPdf(string path) {
return DefaultParser.Extract(path);
}
Загружаем пример проекта:
Недостатки:
1. Использование ненадежного COM Interop. Он обрабатывает интерфейс IFilter (сочетание IFilter COM и Adobe PDF IFilter может быть проблематичным).
2. Раздельная установка Adobe IFilter на целевой системе. Неудобно распространять индексное решение другим пользователям.
3. Нужно использовать имя файла «filtdump.exe» для Вашего приложения с последним PDF IFilter, прилагающимся к Acrobat Reader.
2. Разбор PDF с помощью iTextSharp
Пример кода:
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
// …
public static string ExtractTextFromPdf(string path)
{
using (PdfReader reader = new PdfReader(path))
{
StringBuilder text = new StringBuilder();
for (int i = 1; i <= reader.NumberOfPages; i++)
{
text.Append(PdfTextExtractor.GetTextFromPage(reader, i));
}
return text.ToString();
}
}
Загружаем пример проекта:
Вы можете использовать LocationTextExtractionStrategy, чтобы получить более высокую точность.
public static string ExtractTextFromPdf(string path)
{
ITextExtractionStrategy its = new iTextSharp.text.pdf.parser.LocationTextExtractionStrategy();




using (PdfReader reader = new PdfReader(path))
{
StringBuilder text = new StringBuilder();
for (int i = 1; i <= reader.NumberOfPages; i++)
{
string thePage = PdfTextExtractor.GetTextFromPage(reader, i, its);
string[] theLines = thePage.Split(‘\n’);
foreach(var theLine in theLines)
{
text.AppendLine(theLine);
}
}
return text.ToString();
}
}
Видео курсы по схожей тематике:
![]()
C# Starter (EN)
Abdul Rashid Hamid
![]()
Платформа Managed Extensibility Framework (MEF)
Давид Бояров
![]()
C# Стартовый. Ускоренный курс
Александр Шевчук
Недостатки iTextSharp:
Лицензирование, если Вы недовольны AGPL лицензией.
3. Разбор PDF с помощью PDFBox
Для использования PDFBox в .NET требуется:
1. Добавление ссылок:
- IKVM.OpenJDK.Core.dll
- IKVM.OpenJDK.SwingAWT.dll
- pdfbox-1.8.7.dll
2. Копирование таких файлов каталога Bin:
- commons-logging.dll
- fontbox-1.8.7.dll
- IKVM.OpenJDK.Text.dll
- IKVM.OpenJDK.Util.dll
- IKVM.Runtime.dll
Использование PDFBox для разбора файлов PDF достаточно простое:
using org.apache.pdfbox.pdmodel;
using org.apache.pdfbox.util;
// …
private static string ExtractTextFromPdf(string path)
{
PDDocument doc = null;
try {
doc = PDDocument.load(path)
PDFTextStripper stripper = new PDFTextStripper();
return stripper.getText(doc);
}
finally {
if (doc != null) {
doc.close();
}
}
}
Бесплатные вебинары по схожей тематике:
![]()
Шахматная IT Арена для программистов. I тур. Доска, фигуры и ходы.
Евгений Волосатов
![]()
Шахматная IT Арена для программистов. III тур — Проходная пешка и рокировка
Евгений Волосатов
![]()
Создание 2D игры «Гонки» на C# + WPF.
Ярослав Меньшиков
Загружаем пример проекта:
Размер требуемой сборки составит почти 18 Мбайт:
- IKVM.OpenJDK.Core.dll (4 MB)
- IKVM.OpenJDK.SwingAWT.dll (6 MB)
- pdfbox-1.8.7.dll (4 MB)
- commons-logging.dll (82 kB)
- fontbox-1.8.7.dll (180 kB)
- IKVM.OpenJDK.Text.dll (800 kB)
- IKVM.OpenJDK.Util.dll (2 MB)
- IKVM.Runtime.dll (1 MB)
Недостатки:
1. IKVM.NET Dependencies (18 MB).
2. Скорость (особенно скорость IKVM.NET).






Лейла Холманн
jPDFWriter
Наше программное обеспечение jPDFWriter — это библиотека Java, которая может создавать документы PDF. jPDFWriter можно использовать бесплатно в коммерческих целях, лицензионные сборы отсутствуют.
jPDFWriter может создавать файлы PDF двумя способами:
-
PDF-файлы могут быть созданы напрямую с помощью очень простого API jPDFWriter. Просто создайте объект PDFDocument, создайте столько объектов PDFPage, сколько необходимо, нарисуйте на страницах строки, графику или любые другие элементы, поддерживаемые Java а затем сохраните документ.
-
jPDFWriter также расширяет стандартный Java так что вы можете создавать PDF-файлы так же, как вы печатаете на физическом принтере. Это позволяет повторно использовать существующий код печати и приложение во время выполнения решает, отправлять ли выходные данные на принтер или в файл PDF.
Synopse PDF Engine
- Стоимость: Free
- Лицензия: MPL/GPL/LGPL tri-license.
- Поддерживаемые версии Delphi: 5-XE3
Возможности, заявленные разработчиками:
- Чистый Delphi-код без использования сторонних DLL
- Маленький размер, создаваемых pdf-файлов
- Быстрая генерация pdf с минимальным использованием памяти
- Доступ к TCanvas для рисования линий, кривых, текста и т.д.
- Поддержка Unicode
- Создание PDF/A-1 файлов.
При работе с Synopse PDF Engine ничего устанавливать не требуется – достаточно указать в проекте путь к модулям Synopse и подключить модуль synpdf.pas в uses.
Пример использования:
var
lPdf TPdfDocument;
begin
lPdf = TPdfDocument.Create;//создали документ
try
lPdf.Info.Author = 'Tester';//задали автора
lPdf.Info.CreationDate = Now;//задали дату создания документа
lPdf.DefaultPaperSize = psA4;//указали формат страниц (А4)
lPDF.AddPage;//добавили страницу в документ
lPDF.Canvas.SetFont('Helvetica',10.0,);//указали параметры шрифта
{записываем текст в документ}
lPdf.Canvas.BeginText;
try
lPdf.Canvas.TextOut(, 700, 'Это текст в PDF-документе...');
lPdf.Canvas.TextOut(, 686, 'Это текст на другой строке в PDF-документе...');
finally
lPdf.Canvas.EndText;
end;
//сохраняем полученный файл
lPdf.SaveToFile('c:\temp\test.pdf');
finally
lPdf.Free;
end;
end;
В результате выполнения этого кода у меня получился PDF-документ вот с таким содержимым:
Пример PDF-документа
Как видно на рисунке, при вводе в PDF юникодного текста возможно появление каких-то непонятных символов.
Что касается печати PDF из HTML-страниц, то, судя по описанию возможностей Synopse PDF Engine на официальном сайте, сделать это возможно, но с использованием других компонентов из набора Synopse. Поэтому я отложил Synopse PDF Engine в сторонку (может потом пригодиться) и начал искать другие решения.
Java PDFBox write text
In the following example, we create a PDF document and write some text into
it.
JavaPdfBoxWriteText.java
package com.zetcode;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
public class JavaPdfBoxWriteText {
public static void main(String[] args) throws IOException {
try (PDDocument doc = new PDDocument()) {
PDPage myPage = new PDPage();
doc.addPage(myPage);
try (PDPageContentStream cont = new PDPageContentStream(doc, myPage)) {
cont.beginText();
cont.setFont(PDType1Font.TIMES_ROMAN, 12);
cont.setLeading(14.5f);
cont.newLineAtOffset(25, 700);
String line1 = "World War II (often abbreviated to WWII or WW2), "
+ "also known as the Second World War,";
cont.showText(line1);
cont.newLine();
String line2 = "was a global war that lasted from 1939 to 1945, "
+ "although related conflicts began earlier.";
cont.showText(line2);
cont.newLine();
String line3 = "It involved the vast majority of the world's "
+ "countries—including all of the great powers—";
cont.showText(line3);
cont.newLine();
String line4 = "eventually forming two opposing military "
+ "alliances: the Allies and the Axis.";
cont.showText(line4);
cont.newLine();
cont.endText();
}
doc.save("src/main/resources/wwii.pdf");
}
}
}
The example writes four lines into a PDF document.
try (PDDocument doc = new PDDocument()) {
A new is created. By default, the document
has an A4 format.
PDPage myPage = new PDPage(); doc.addPage(myPage);
A new page is created and added to the document.
try (PDPageContentStream cont = new PDPageContentStream(doc, myPage)) {
To write to a PDF page, we have to create a object.
cont.beginText(); ... cont.endText();
Text is written betweeen and methods.
cont.setFont(PDType1Font.TIMES_ROMAN, 12); cont.setLeading(14.5f);
We set the font and text leading.
cont.newLineAtOffset(25, 700);
We start a new line of text with method.
The origin of a page is at the bottom-left corner.
String line1 = "World War II (often abbreviated to WWII or WW2), "
+ "also known as the Second World War,";
cont.showText(line1);
The text is written with method.
cont.newLine();
With the method, we move to the start of the next line of text.
Example
This example demonstrates how to add contents to a page in a document. Here, we will create a Java program to load the PDF document named my_doc.pdf, which is saved in the path C:/PdfBox_Examples/, and add some text to it. Save this code in a file with name AddingContent.java.
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
public class AddingContent {
public static void main (String args[]) throws IOException {
//Loading an existing document
File file = new File("C:/PdfBox_Examples/my_doc.pdf");
PDDocument document = PDDocument.load(file);
//Retrieving the pages of the document
PDPage page = document.getPage(1);
PDPageContentStream contentStream = new PDPageContentStream(document, page);
//Begin the Content stream
contentStream.beginText();
//Setting the font to the Content stream
contentStream.setFont(PDType1Font.TIMES_ROMAN, 12);
//Setting the position for the line
contentStream.newLineAtOffset(25, 500);
String text = "This is the sample document and we are adding content to it.";
//Adding text in the form of string
contentStream.showText(text);
//Ending the content stream
contentStream.endText();
System.out.println("Content added");
//Closing the content stream
contentStream.close();
//Saving the document
document.save(new File("C:/PdfBox_Examples/new.pdf"));
//Closing the document
document.close();
}
}
Compile and execute the saved Java file from the command prompt using the following commands.
javac AddingContent.java java AddingContent
Upon execution, the above program adds the given text to the document and displays the following message.
Content added
If you verify the PDF Document new.pdf in the specified path, you can observe that the given content is added to the document as shown below.
![]()
Previous Page
Print Page
Next Page
Методы класса File
Методы могут помочь узнать данные о файлах: размер или дату последних изменений, к какому типу относится. Также с их помощью можно удалить элемент.
Вот распространенные методы:
- boolean createNewFile(): создает новый пустой файл. Если файл не будет создан, тогда выводится false.
- boolean delete(): удаляет каталог или файл.
- boolean exists(): проверяет, существует ли указанный файл или каталог.
- boolean equals(Object obj): проверяет, совпадает ли имя пути с заданным объектом.
- String getName(): выводит название файла или каталога.
- String getParent(): выводит название каталога-родителя.
- boolean isDirectory(): передает абстрактный путь, true — если путь указывает на каталог.
- boolean isFile(): выводит true, если путь указывает на файл.
- boolean isHidden(): проверяет, скрыт файл или нет (если да — выводит true, если нет — false).
- String[] list(): генерация списка строк со всеми именами файлов в каталоге.
- File[] listFiles(): формирование массива и его возврат.
- long length(): предоставляет данные о длине файла.
- URI toURI(): будет создан URI файла.
- boolean setReadable (boolean readable, boolean ownerOnly): устанавливает, кто может читать файл. К примеру, только владелец (owner).
- boolean setReadOnly(): указывает на файл или каталог, для которых возможно только чтение.
PDFtoolkit VCL v4.0.1.293
Про эту библиотеку компонентов от Gnostice имеется довольно много положительных отзывов в Сети.
По возможностям PDFtoolkit практически 1 в 1 соответствует PDF Creator Pilot, т.е. умеет “склеивать” PDF-ки, распознавать текст, вставлять ссылки, проводить поиск в документах и т.д. Но, в отличие от PDF Creator Pilot, PDFtoolkit во-первых, представляет из себя набор визуальных и невизуальных компонентов для работы с PDF, а во-вторых, предназначен для работы с уже созданными документами. В комплекте поставляется небольшой вьювер PDF-ок, невизуальный компонент для работы с PDF, визуальный компонент для организации поиска в PDF-документах и т.д.
Работа с PDFtoolkit довольна простая, например, ниже представлен код вставки простенького HTML-кода в PDF-документ:
gtPDFDocument1 = TgtPDFDocument.Create(Nil);
try
//Загружаем документ
gtPDFDocument1.LoadFromFile('sample_doc.pdf');
//проверяем, что документ успешно загружен
if gtPDFDocument1.IsLoaded then
begin
gtPDFDocument1.TextOut(
'<i>Привет, <b>Мир!</b></i>',
IntToStr(gtPDFDocument1.PageCount),//диапазон страниц в который будет вставлен текст
gtPDFDocument1.GetPageSize(gtPDFDocument1.PageCount, muPixels).Width2,//вставляем текст в центр страницы
gtPDFDocument1.GetPagesize(gtPDFDocument1.PageCount, muPixels).Height2);
{сохраняем документ}
gtPDFDocument1.SaveToFile('modified_doc.pdf');
end;
finally
gtPDFDocument1.Free
end;
Конечно, применительно к моей задаче PDFtoolkit оказывается практически бесполезным, т.к. меня интересует именно создание с нуля PDF-ки, но для тех, кто пишет собственный вьювер PDF-ок, думаю, эта библиотека должна подойти более чем.
Итак, что имеем в итоге. Есть 5 различных решений для создания и работы с PDF-документами в Delphi. Каждое решение имеет как свои достоинства (бесплатность, “навороченность”), так и недостатки (конская стоимость, проблемы с юникодом и т.д.). Применительно к моей задаче надо всеми решениями придётся “работать напильником”. С другой стороны, в Сети есть куча платных и бесплатных сервисов для генерации PDF, но, памятуя о том, что такие сервисы имеют свойство вдруг брать и умирать, то как-то не тянет с ними связываться. Есть, конечно, ещё одно решение – самописное и не совсем в тему Delphi, но об этом как-нибудь в следующий раз, а пока пойду подумаю что же делать с клиентом для DelphiFeeds
![]()
До встречи в онлайне!
5
1
голос
Рейтинг статьи
Java PDFBox document information
PDF documents can contain information describing the document itself or certain objects
within the document such as the author of the document or it’s creation date.
Basic information can be set and retrieved using the object.
JavaPdfBoxDocumentInformation.java
package com.zetcode;
import java.io.IOException;
import java.util.Calendar;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentInformation;
import org.apache.pdfbox.pdmodel.PDPage;
public class JavaPdfBoxDocumentInformation {
public static void main(String[] args) throws IOException {
try (PDDocument doc = new PDDocument()) {
PDPage myPage = new PDPage();
doc.addPage(myPage);
PDDocumentInformation pdi = doc.getDocumentInformation();
pdi.setAuthor("Jan Bodnar");
pdi.setTitle("World war II");
pdi.setCreator("Java code");
Calendar date = Calendar.getInstance();
pdi.setCreationDate(date);
pdi.setModificationDate(date);
pdi.setKeywords("World war II, conflict, Allies, Axis powers");
doc.save("src/main/resources/mydoc.pdf");
}
}
}
The example creates some document information metadata. The information can be seen
in the properties of the PDF document in a PDF viewer.
PDDocumentInformation pdi = doc.getDocumentInformation();
We get the object.
pdi.setAuthor("Jan Bodnar");
pdi.setTitle("World war II");
pdi.setCreator("Java code");
We set some metadata information.
IText создает PDF
вставить текст в PDF
Во-первых, пример вставляет текст «Hello World» в файл PDF.
Использование библиотеки iText для создания PDF-файла основано на работе объекта интерфейса Elements в документе.Наименьший элемент, добавленный в документ, — это фрагмент, представляющий собой строку с форматом шрифта. Кроме того, блок используется для объединения других элементов, таких как абзацы, главы и т. Д., И, наконец, для формирования документа.
Вставить изображение
iText предоставляет простой способ вставки изображений в документы. Просто создайте пример изображения и добавьте в документ:
Вставить таблицу
Вставка таблицы в формате PDF является нашим общим требованием. К счастью, iText предоставляет эти функции по умолчанию. Первое, что нам нужно сделать, — это создать объект PdfTable и указать количество столбцов таблицы в конструкторе. Теперь мы можем добавить новые ячейки во вновь созданную таблицу, вызвав метод addCell. Пока все необходимые ячейки определены, iText будет создавать строки таблицы, что означает, что если вы создадите таблицу с 3 столбцами и добавите в нее 8 ячеек, будут отображаться только 2 строки, каждая с 3 строками Cell. Пожалуйста, смотрите пример:
Мы создаем новую таблицу с тремя столбцами и тремя строками.Первая строка служит заголовком таблицы с разными цветами фона и шириной границ:
Вторая строка состоит из трех ячеек без дополнительных стилей и содержит другой текст:
Клетки могут отображать не только текст, но и изображения. Кроме того, каждая ячейка имеет свой стиль, и в следующих примерах используется горизонтальное и вертикальное выравнивание:
шифрование файлов
Чтобы использовать библиотеку iText для реализации контроля разрешений, вам нужен созданный PDF-документ. В приведенном ниже примере мы нацелены на файл iTextHelloWorld.pdf, созданный ранее. Сначала мы используем PdfReader для загрузки pdf-файла, а затем создаем объект PdfStamper для добавления дополнительного содержимого в pdf, такого как метаданные, шифрование и т. Д.:
В приведенном выше примере мы использовали два пароля для шифрования файла: пароль доступа пользователя доступен только для чтения и не может быть напечатан. Пароль владельца — это главный пароль, обеспечивающий полный доступ. Если вы хотите, чтобы пользователь распечатал pdf, измените значение «0» третьего параметра метода setEncryption на «PdfWriter.ALLOW_PRINTING».
Конечно, мы также можем смешивать различные комбинации разрешений:
Следует напомнить, что использование iText для установки прав доступа также создаст временный pdf-файл, который следует удалить, иначе он будет полностью доступен любому.
Getting iText
You can either download iText jar from its home page http://www.lowagie.com/iText/download.html
iText core: iText-5.5.13.jar
or you can also download from the Maven repository by adding iText dependency on your pom.xml file.
iText Maven Dependency
|
1 2 3 4 5 6 |
iText Gradle Dependency
|
1 2 |
iText JARS :C:\m2\repository\com\lowagie\itext\4.2.1\itext-4.2.1.jarC:\m2\repository\org\bouncycastle\bctsp-jdk14\1.38\bctsp-jdk14-1.38.jarC:\m2\repository\org\bouncycastle\bcprov-jdk14\1.38\bcprov-jdk14-1.38.jarC:\m2\repository\org\bouncycastle\bcmail-jdk14\1.38\bcmail-jdk14-1.38.jarC:\m2\repository\jfree\jfreechart\1.0.12\jfreechart-1.0.12.jarC:\m2\repository\jfree\jcommon\1.0.15\jcommon-1.0.15.jarC:\m2\repository\org\swinglabs\pdf-renderer\1.0.5\pdf-renderer-1.0.5.jar




PDF Creator Pilot
Библиотека стоимостью почти как Delphi XE3 Professional…Ну да ладно, посмотрим, что представляет из себя эта библиотечка.
Возможности, заявленные разработчиками:
- Расширенный набор методов и свойств для легкого создания PDF;
- Чтение и слияние существующих PDF-документов;
- Добавление и удаление страниц PDF-документа;
- Поддержка юникода;
- Создание водяных знаков для каждой страницы;
- Добавление эскизов для PDF-документа;
- Использование и встраивание шрифтов (TrueType, OpenType, Type1 и т.д.);
- Создание интерактивных PDF-документов, используя JavaScript и гиперссылки;
- Поддержка интерактивных элементов AcroForm: текстовые поля ввода, кнопки, радио-кнопки, выпадающие списки, флажки;
- шифрование и защита паролем созданных PDF-документов;
- Создания и управление содержанием документа;
- Доступ к HDC для рисования на PDF-страницах с помощью WinAPI функций.
- Использование изображений в различных форматах (JPEG, TIFF, PNG, BMP, GIF);
- Создание и использование аннотаций;
- Создание PDF-документов на диске или в памяти;
- Извлечения текста из PDF документов;
В общем, довольно внушительный список возможностей. Посмотрим как некоторые из этих возможностей работают на практике. Скачиваем демонстрационную версию, устанавливаем.
После установки запускаем Delphi (в моем случае – это Delphi XE3) и переходим в меню:
Component – Import Component – Import Type Library
В списке ищем библиотеку PDFCreatorPilot:
![]()
Импортируем, создаем новый проект и подключаем в uses модуль PDFCreatorPilotLib_TLB.
Теперь можем протестировать работу библиотеки на каком-нибудь живом примере. Вначале попробуем сгенерировать документ с простым текстом:
procedure TForm1.Button1Click(Sender TObject);
var
fnt integer;
begin
{ initialization }
PDF = TPDFDocument4.Create(nil);
PDF.SetLicenseData('demo', 'demo');
fnt = pdf.AddFont('Verdana', false, false, false, false, fcANSI);
PDF.UseFont(fnt, 14);
PDF.ShowTextAt(20, 40, 'HELLO, PDF!');
{ save }
PDF.SaveToFile('HelloPDF.pdf', true);
PDF.Destroy;
end;
Запускаем приложение и смотрим на созданный PDF-документ:
![]()
Документ, созданный с помощью PDF Creator Pilot
Теперь попробуем записать русский текст в файл:
procedure TForm1.Button1Click(Sender TObject);
begin
{ initialization }
{...}
PDF.ShowTextAt(20, 40, 'Привет, PDF!');
{ save }
{...}
end;
![]()
Может где-то в свойствах класса надо что-то настроить, вызвать какой-нибудь метод, который включит-таки поддержку юникода, НО за такие бабки хотелось бы получить библиотеку, которая заработает сразу “из коробки” без всяких заморочек с настройками и подкрутками…Кстати, метод для вставки ссылки (AddHyperLink) тоже не сработал – документ остался девственно чист несмотря на то, что ссылка якобы вставилась. Но, надо отдать должное, попытка вставить в новый документ уже ранее созданную PDF-ку – сработал на ура – документ вставился на новую страничку как надо, без косяков.
Что такое файл в Java?
Файл – это не что иное, как простое хранилище данных на языке Java. Файловая система может реализовывать ограничения для определенных операций, таких как чтение, запись и выполнение. Эти ограничения известны как права доступа.
При чтении файла в Java мы должны знать класс файлов Java. Класс Java File представляет файлы и имена каталогов в абстрактной манере. Класс File имеет несколько методов для работы с каталогами и файлами, таких как создание новых каталогов или файлов, удаление и переименование каталогов или файлов и т. д. Объект File представляет фактический файл / каталог на диске.
Теперь давайте разберемся с различными методами создания файла.
Java PDFBox reading metadata
In the next example, we read metadata from a PDF document.
JavaPdfBoxMetadataRead.java
package com.zetcode;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentCatalog;
import org.apache.pdfbox.pdmodel.common.PDMetadata;
public class JavaPdfBoxMetadataRead {
public static void main(String[] args) throws IOException {
File myFile = new File("src/main/resources/sinatra.pdf");
try (PDDocument doc = PDDocument.load(myFile)) {
PDDocumentCatalog catalog = doc.getDocumentCatalog();
PDMetadata metadata = catalog.getMetadata();
if (metadata == null) {
System.err.println("No metadata in document");
System.exit(1);
}
try (InputStream is = metadata.createInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr)) {
br.lines().forEach(System.out::println);
}
}
}
}
The example reads metadata from a PDF document and prints it to the console.
PDDocumentCatalog catalog = doc.getDocumentCatalog(); PDMetadata metadata = catalog.getMetadata();
We retrieve from the .
if (metadata == null) {
System.err.println("No metadata in document");
System.exit(1);
}
The document may not contain metadata; therefore, we do some simple checking.
try (InputStream is = metadata.createInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr)) {
br.lines().forEach(System.out::println);
}
The creates an input stream to the document’s
metadata. We read the data from this stream and print it to the terminal.
In this tutorial, we have shown how to work with PDF files in Java using PDFBox library.
List .
Adding annotations and content
![]()
Figure 5.1: an updated form
Where it says , we’ll add the annotation, the extra text, and the extra check box.
Just like in chapter 4, we add the annotation to a page obtained from the instance:
If we want to add content to a content stream, we need to create a object. We can do this using a object as a parameter for the constructor:
The code to add the text is similar to what we did in chapter 2. Whether you’re creating a document from scratch, or adding content to an existing document, has no impact on the instructions we use. The same goes for adding fields to a instance:
Now that we’ve added an extra field, we might want to change the reset action:
Let’s see if we can also change some of the visual aspects of the form fields.



