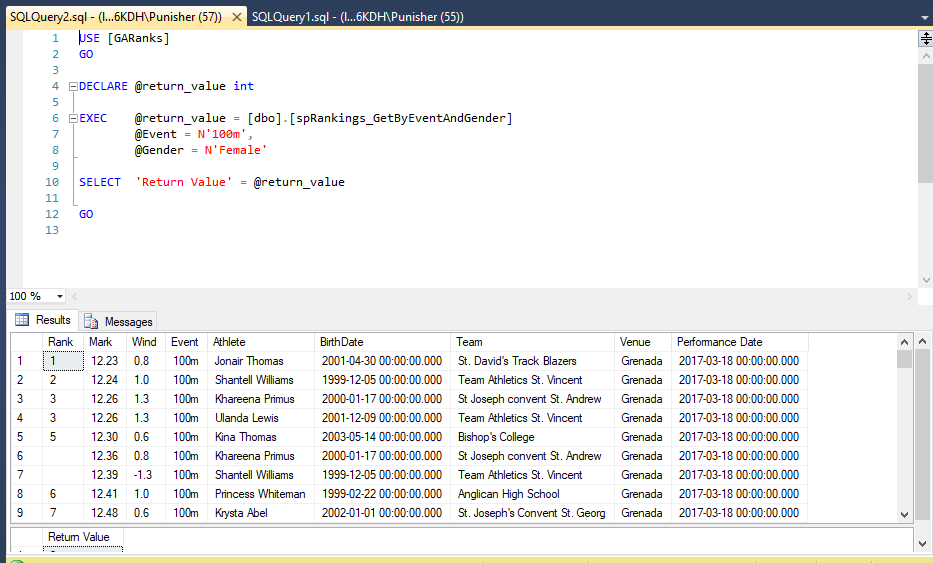
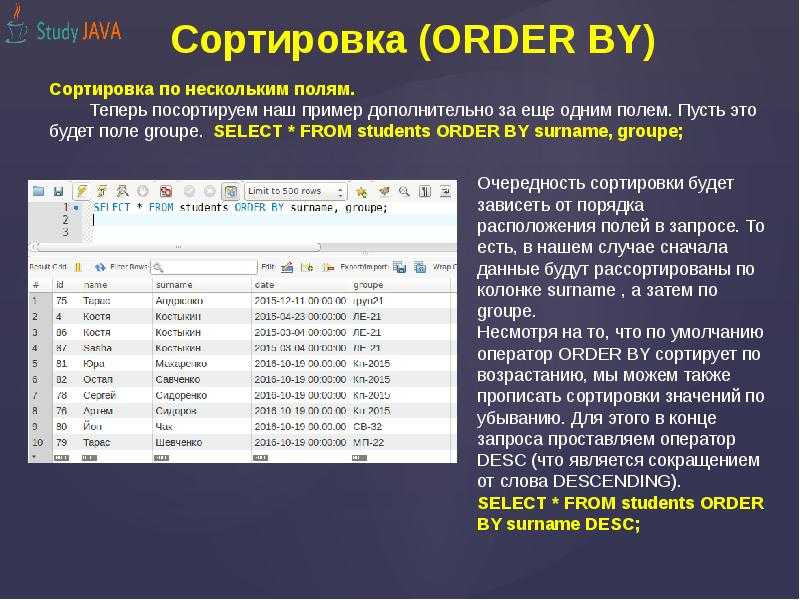
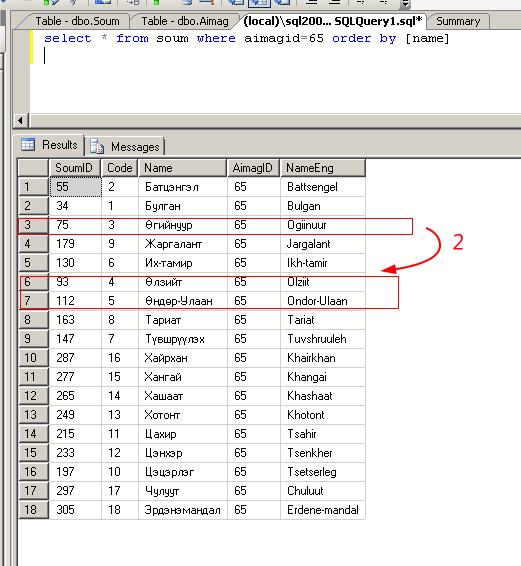
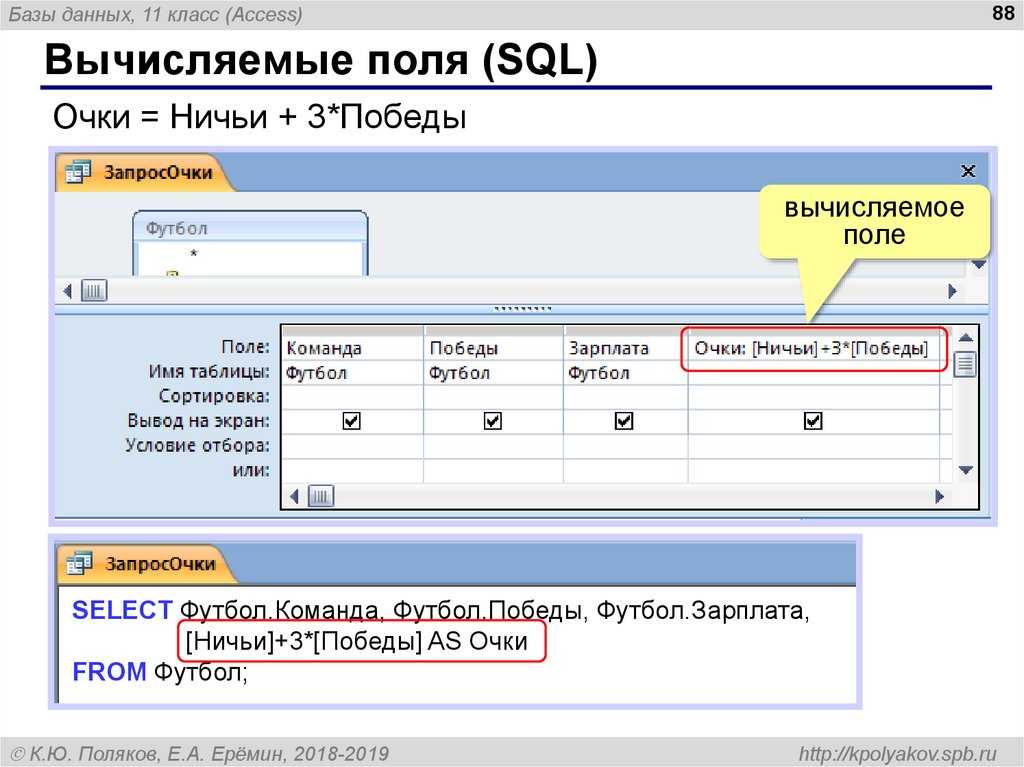
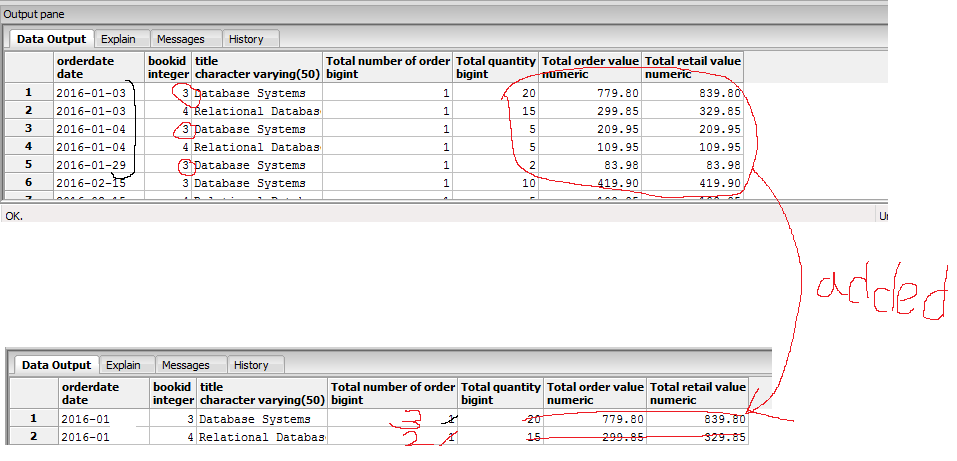
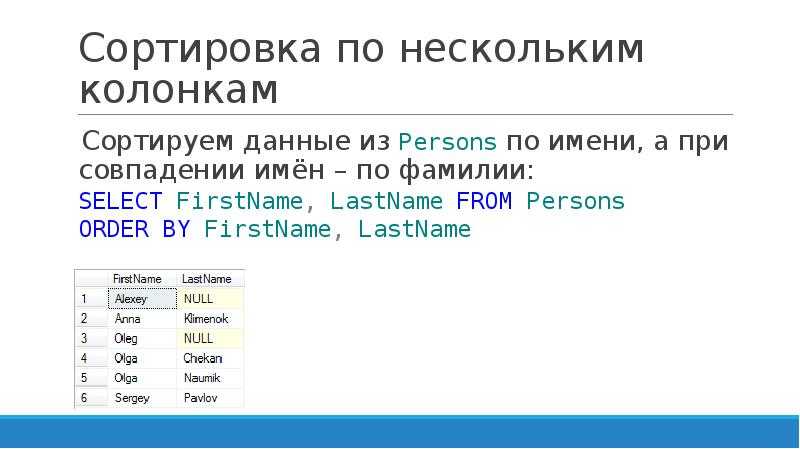
Задания для самоподготовки
1. Используя
сортировку, найдите первые три наименьшие значения в списке:
a=
Сам список
должен оставаться неизменным.
2. Отсортируйте
список:
digs
= (-10, 0, 7, -2, 3, 6, -8)
так, чтобы
сначала шли отрицательные числа, а затем, положительные.
3. Пусть имеется
словарь:
{‘+7’:
2345678901, ‘+4’: 3456789012, ‘+5’: 5678901234, ‘+12’: 78901234}
Необходимо
вывести телефонные номера по убыванию чисел, указанных в ключах, то есть, в
порядке:
+4, +5, +7, +12
Видео по теме
#1. Первое знакомство с Python Установка на компьютер
#2. Варианты исполнения команд. Переходим в PyCharm
#3. Переменные, оператор присваивания, функции type и id
#4. Числовые типы, арифметические операции
#5. Математические функции и работа с модулем math
#6. Функции print() и input(). Преобразование строк в числа int() и float()
#7. Логический тип bool. Операторы сравнения и операторы and, or, not
#8. Введение в строки. Базовые операции над строками
#9. Знакомство с индексами и срезами строк
#10. Основные методы строк
#11. Спецсимволы, экранирование символов, row-строки
#12. Форматирование строк: метод format и F-строки
#13. Списки — операторы и функции работы с ними
#14. Срезы списков и сравнение списков
#15. Основные методы списков
#16. Вложенные списки, многомерные списки
#17. Условный оператор if. Конструкция if-else
#18. Вложенные условия и множественный выбор. Конструкция if-elif-else
#19. Тернарный условный оператор. Вложенное тернарное условие
#20. Оператор цикла while
#21. Операторы циклов break, continue и else
#22. Оператор цикла for. Функция range()
#23. Примеры работы оператора цикла for. Функция enumerate()
#24. Итератор и итерируемые объекты. Функции iter() и next()
#25. Вложенные циклы. Примеры задач с вложенными циклами
#26. Треугольник Паскаля как пример работы вложенных циклов
#27. Генераторы списков (List comprehensions)
#28. Вложенные генераторы списков
#29. Введение в словари (dict). Базовые операции над словарями
#30. Методы словаря, перебор элементов словаря в цикле
#31. Кортежи (tuple) и их методы
#32. Множества (set) и их методы
#33. Операции над множествами, сравнение множеств
#34. Генераторы множеств и генераторы словарей
#35. Функции: первое знакомство, определение def и их вызов
#36. Оператор return в функциях. Функциональное программирование


#37. Алгоритм Евклида для нахождения НОД
#38. Именованные аргументы. Фактические и формальные параметры
#39. Функции с произвольным числом параметров *args и **kwargs
#40. Операторы * и ** для упаковки и распаковки коллекций
#41. Рекурсивные функции
#42. Анонимные (lambda) функции
#43. Области видимости переменных. Ключевые слова global и nonlocal
#44. Замыкания в Python
#45. Введение в декораторы функций
#46. Декораторы с параметрами. Сохранение свойств декорируемых функций
#47. Импорт стандартных модулей. Команды import и from
#48. Импорт собственных модулей
#49. Установка сторонних модулей (pip install). Пакетная установка
#50. Пакеты (package) в Python. Вложенные пакеты
#51. Функция open. Чтение данных из файла
#52. Исключение FileNotFoundError и менеджер контекста (with) для файлов
#53. Запись данных в файл в текстовом и бинарном режимах
#54. Выражения генераторы
#55. Функция-генератор. Оператор yield
#56. Функция map. Примеры ее использования
#57. Функция filter для отбора значений итерируемых объектов
#58. Функция zip. Примеры использования
#59. Сортировка с помощью метода sort и функции sorted
#60. Аргумент key для сортировки коллекций по ключу
#61. Функции isinstance и type для проверки типов данных
#62. Функции all и any. Примеры их использования
#63. Расширенное представление чисел. Системы счисления
#64. Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операторы
#65. Модуль random стандартной библиотеки
Быстрая сортировка или сортировка Хоара
Массив делится на две части относительно опорного элемента. В одну часть помещаются все элементы, величина которых меньше значения опорного элемента, а в правую часть — элементы со значением больше опорного.
Наиболее удачным для сортировки считается разбиение массива на примерно одинаковое количество элементов. Если длина одной из частей превышает один элемент, то ее рекурсивно сортируем, повторно применяя алгоритм на каждом из отрезков.
import random
a =
def quick_sort(a):
if len(a) > 1:
x = a # случайное пороговое значение (для разделения на малые и большие)
low =
eq =
hi =
a = quick_sort(low) + eq + quick_sort(hi)
return a
a = quick_sort(a)
print(a)
![]()
Селективность индексов
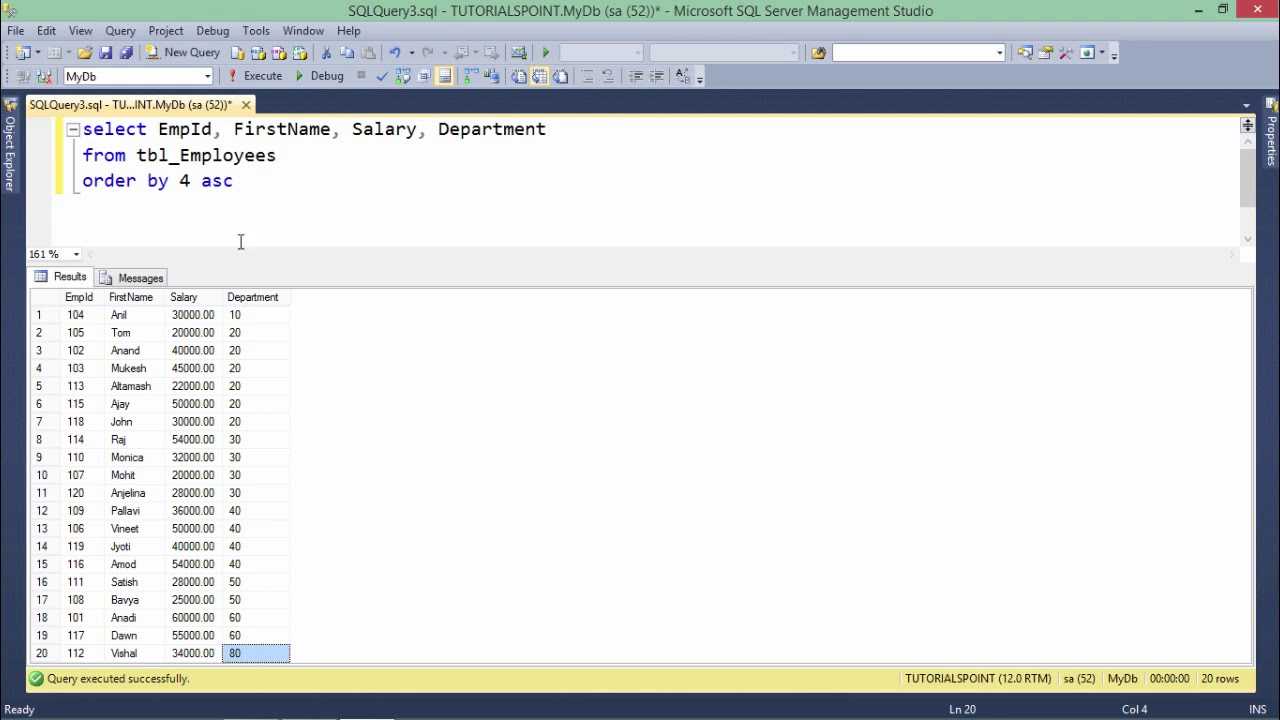
Вернемся к запросу:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
- age, gender
- gender, age
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
mysql> select age, count(*) from users group by age;
+------+----------+ | age | count(*) | +------+----------+ | 15 | 160 | | 16 | 250 | | ... | | 76 | 210 | | 85 | 230 | +------+----------+
68 rows in set (0.00 sec)
mysql> select gender, count(*) from users group by gender;
+--------+----------+ | gender | count(*) | +--------+----------+ | female | 8740 | | male | 4500 | +--------+----------+ 2 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
- Любое значение колонки age обычно содержит около 200 записей.
- Любое значение колонки gender – около 6000 записей.
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало – селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
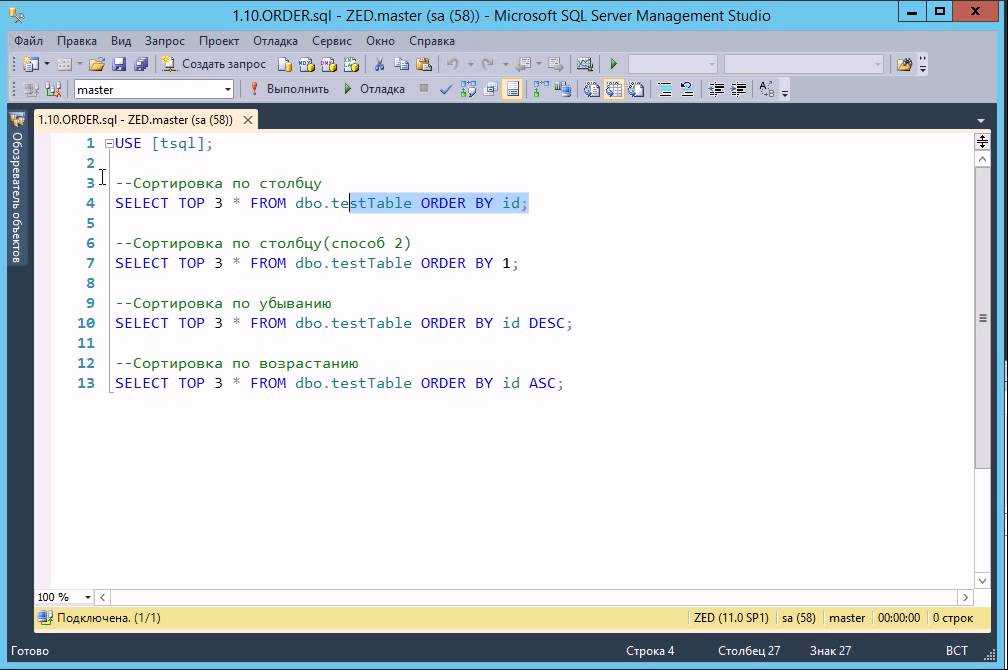
Простая сортировка данных
Сортировка является одним из самых удобных инструментов при работе в программе Microsoft Excel. С помощью неё, можно расположить строчки таблицы в алфавитном порядке, согласно данным, которые находятся в ячейках столбцов.
Сортировку данных в программе Microsoft Excel можно выполнять, воспользовавшись кнопкой «Сортировка и фильтр», которая размещена во вкладке «Главная» на ленте в блоке инструментов «Редактирование». Но, прежде, нам нужно кликнуть по любой ячейке того столбца, по которому мы собираемся выполнить сортировку.
Например, в предложенной ниже таблице следует отсортировать сотрудников по алфавиту. Становимся в любую ячейку столбца «Имя», и жмем на кнопку «Сортировка и фильтр». Чтобы имена упорядочить по алфавиту, из появившегося списка выбираем пункт «Сортировка от А до Я».
![]()
Как видим, все данные в таблице разместились, согласно алфавитному списку фамилий.
![]()
Для того, чтобы выполнить сортировку в обратном порядке, в том же меню выбираем кнопку Сортировка от Я до А».
![]()
Список перестраивается в обратном порядке.
![]()
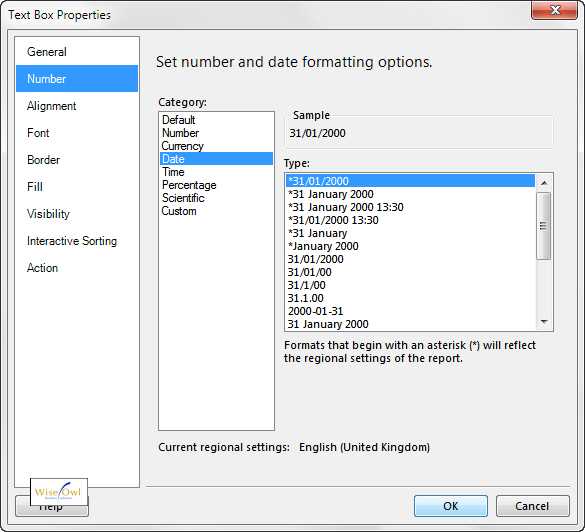
Нужно отметить, что подобный вид сортировки указывается только при текстовом формате данных. Например, при числовом формате указывается сортировка «От минимального к максимальному» (и, наоборот), а при формате даты – «От старых к новым» (и, наоборот).

![]()
Using MySQL ORDER BY clause to sort data using a custom list
The function has the following syntax:
The function returns the position of the str in the str1, str2, … list. If the str is not in the list, the function returns 0. For example, the following query returns 1 because the position of the string ‘A’ is the first position on the list , , and :
Output:
And the following example returns 2:
Output:
Let’s take a more practical example.
See the following table from the sample database.
Suppose that you want to sort the sales orders based on their statuses in the following order:
- In Process
- On Hold
- Canceled
- Resolved
- Disputed
- Shipped
To do this, you can use the function to map each order status to a number and sort the result by the result of the function:
Настраиваемая сортировка
Но, как видим, при указанных видах сортировки по одному значению, данные, содержащие имена одного и того же человека, выстраиваются внутри диапазона в произвольном порядке.
А, что делать, если мы хотим отсортировать имена по алфавиту, но например, при совпадении имени сделать так, чтобы данные располагались по дате? Для этого, а также для использования некоторых других возможностей, все в том же меню «Сортировка и фильтр», нам нужно перейти в пункт «Настраиваемая сортировка…».
![]()
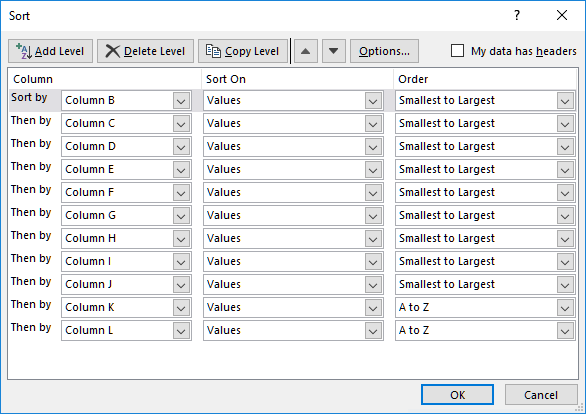
После этого, открывается окно настроек сортировки
Если в вашей таблице есть заголовки, то обратите внимание, чтобы в данном окне обязательно стояла галочка около параметра «Мои данные содержат заголовки»
![]()
В поле «Столбец» указываем наименование столбца, по которому будет выполняться сортировка. В нашем случае, это столбец «Имя». В поле «Сортировка» указывается, по какому именно типу контента будет производиться сортировка. Существует четыре варианта:
- Значения;
- Цвет ячейки;
- Цвет шрифта;
- Значок ячейки.
Но, в подавляющем большинстве случаев, используется пункт «Значения». Он и выставлен по умолчанию. В нашем случае, мы тоже будем использовать именно этот пункт.
В графе «Порядок» нам нужно указать, в каком порядке будут располагаться данные: «От А до Я» или наоборот. Выбираем значение «От А до Я».
![]()
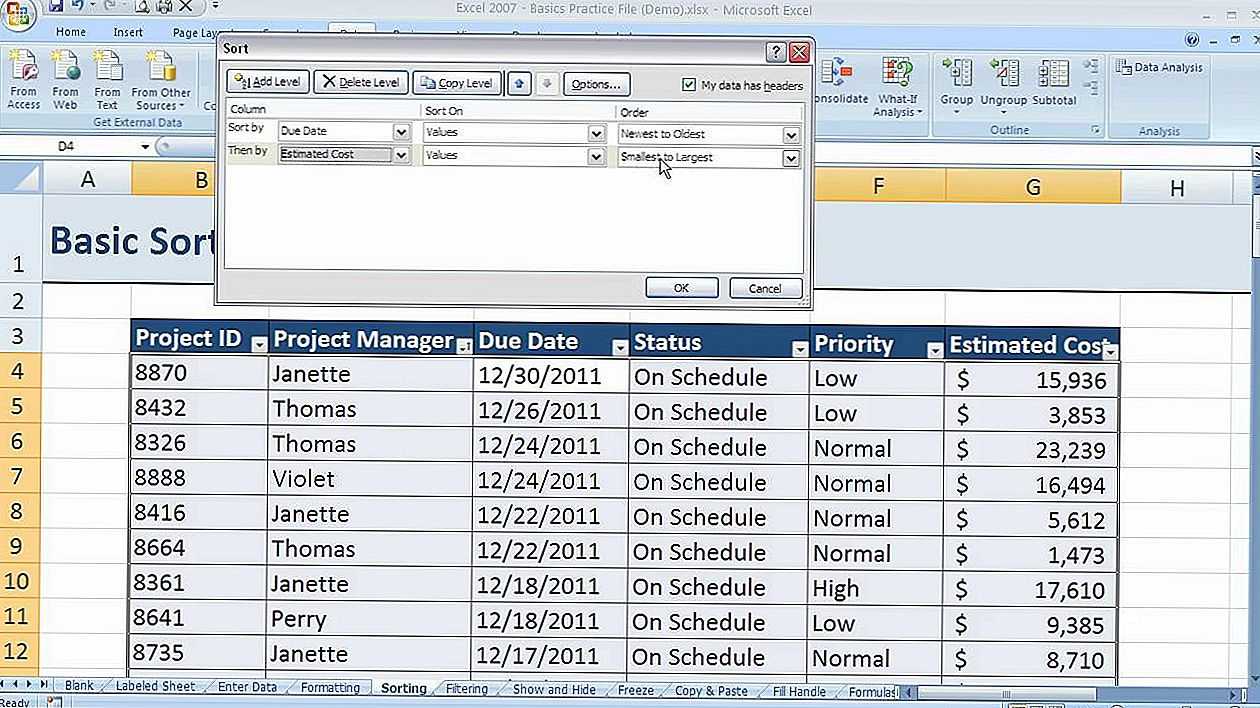
Итак, мы настроили сортировку по одному из столбцов. Для того, чтобы настроить сортировку по другому столбцу, жмем на кнопку «Добавить уровень».
![]()
Появляется ещё один набор полей, который следует заполнить уже для сортировки по другому столбцу. В нашем случае, по столбцу «Дата». Так как в данных ячеек установлен формат даты, то в поле «Порядок» мы устанавливаем значения не «От А до Я», а «От старых к новым», или «От новых к старым».
Таким же образом, в этом окне можно настроить, при необходимости, и сортировку по другим столбцам в порядке приоритета. Когда все настройки выполнены, жмем на кнопку «OK».
![]()
Как видим, теперь в нашей таблице все данные отсортированы, в первую очередь, по именам сотрудника, а затем, по датам выплат.
![]()
Но, это ещё не все возможности настраиваемой сортировки. При желании, в этом окне можно настроить сортировку не по столбцам, а по строкам. Для этого, кликаем по кнопке «Параметры».
![]()
В открывшемся окне параметров сортировки, переводим переключатель из позиции «Строки диапазона» в позицию «Столбцы диапазона». Жмем на кнопку «OK».
![]()
Теперь, по аналогии с предыдущим примером, можно вписывать данные для сортировки. Вводим данные, и жмем на кнопку «OK».
![]()
Как видим, после этого, столбцы поменялись местами, согласно введенным параметрам.
![]()
Конечно, для нашей таблицы, взятой для примера, применение сортировки с изменением места расположения столбцов не несет особенной пользы, но для некоторых других таблиц подобный вид сортировки может быть очень уместным.
Сортировка слиянием
Данный метод является рекурсивным, так как повторяется для частей массива. Сортировка слиянием происходит в несколько этапов. Исходный массив делится на два подмассива, после чего каждый из этих подмассивов сортируется отдельно. Затем оба отсортированных подмассива объединяются в один, сравнивая по одному числу.
Вот как это выглядит на практике. Предположим, у нас есть массив: . Делим его на две части и . Первую часть будем сортировать, разбив снова на две части: и. Сортируем левую часть – числа остались на своих местах — . Сортируем правую часть — . Объединяем их в единую часть.
Смотрим на первые цифры – два меньше четырех, значит, записываем ее в массив. Снова сравниваем первые цифры – четыре меньше шести, поэтому дописываем в массив . И снова сравниваем оставшиеся первые числа — шесть меньше восьми, стало быть дописываем шесть —. И последний элемента массива: . Переходим ко второй части массива и также делим его на и . Сортируем обе части и соединяем их. Получается . Теперь нужно объединить два отсортированных массива и.
Смотрим по крайним левым цифрам: , записываем единицу как первый элемент результирующего массива. Теперь сравниваем по первым цифрам оставшихся массивов и , значит второй элемент результирующего массива будет два. Снова смотрим на то, что осталось и нужно отсортировать. Имеем и .
Сравниваем первые цифры – , значит, следующий элемент результирующего массива – тройка. Следующая итерация сравнения и дает нам четыре. Затем и получаем пятерку, шестерку, семерку и восьмерку. И наш отсортированный массив выглядит как
Реализуем этот рекурсивный алгоритм на языке Python:
A =
def merge_sort(A):
if len(A) == 1 or len(A) == 0:
return A
L, R = A[:len(A) // 2], A[len(A) // 2:]
merge_sort(L)
merge_sort(R)
n = m = k = 0
C = * (len(L) + len(R))
while n < len(L) and m < len(R):
if L <= R:
C = L
n += 1
else:
C = R
m += 1
k += 1
while n < len(L):
C = L
n += 1
k += 1
while m < len(R):
C = R
m += 1
k += 1
for i in range(len(A)):
A = C
return A
print('Исходный массив:', A)
noviyspisok = merge_sort(A).copy()
print('Результат сортировки:', noviyspisok)
После запуска имеем на выходе отсортированный массив:
Исходный массив: Результат сортировки:
Сортировка с учетом типа данных
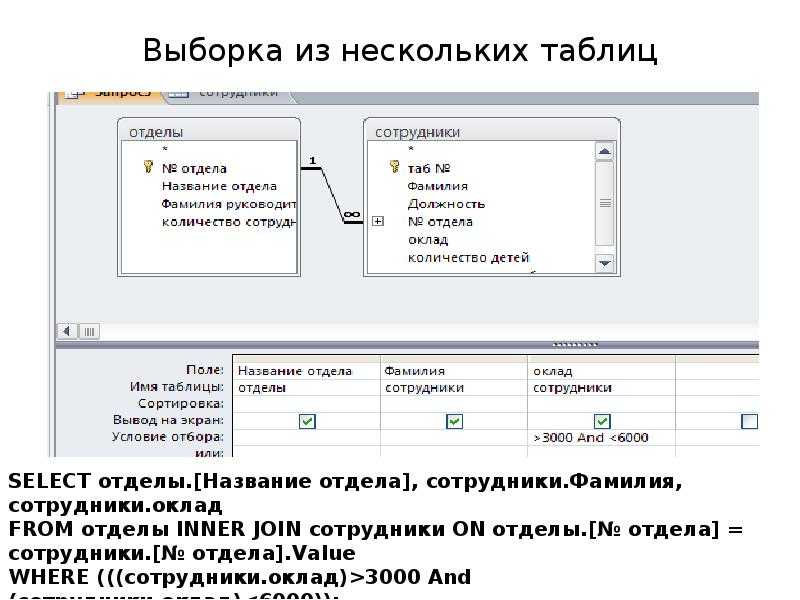
Представьте, что у вас есть две таблицы. Первая содержит какие-нибудь записи (статьи, новости, товары и т.п.), а вторая – метаданные для этих записей. Метаданные могут содержать какую угодно информацию, например, рейтинг новости или цвет товара.
При этом таблицы будут иметь приблизительно следующую структуру.
![]()
Подобные решения используются во многих CMS, т.к. авторы не знают какие именно метаданные будет использовать разработчик сайта и предоставляют ему возможность создавать их в неограниченном количестве.
Но что произойдет если мы попытаемся выполнить сортировку по метаданным?
Такую сортировку можно выполнить с помощью следующего запроса
SELECT * FROM articles AS a LEFT JOIN metadata AS m ON a.a_id=m.m_article_id WHERE m.m_name="color"
Этот запрос выведет все записи из таблицы для которых создано мета-поле .
Очевидно, что тип поля должен быть текстовым, т.к. заранее неизвестно что будет храниться в метаданных.
При этом числовые данные будут отсортированы не правильно. Дело в том, что сравнивает значения с учетом типа поля и, например, при сортировке по возрастанию вы получите следующий ряд значений: «1», «10», «2», «3» и т.д.
Т.е. при выполнении такого запроса нужно указать, что поле необходимо считать числовым. Делается это следующим образом.
SELECT * FROM metadata ORDER BY (m_value+0)
Обратная операция (сортировка числового поля по правилам текстового) записывается немного сложнее.
SELECT left(a_id, 20) AS id_str FROM articles ORDER BY id_str
Функция возвращает строку, содержащую первые символов из строки, указанной в первом параметре. Количество символов (N) задается во втором параметре. В данном случае будут выбраны первые 20 символов (достаточно чтобы преобразовать 8-байтное целое число в строку). Т.е. движок MySQL выполнит сортировку по строке, полученной из значения числового поля.
Хочу предупредить, что несмотря на то, что данные методы могут быть удобны в ряде ситуаций, их использование приводит к снижению скорости выполнения SQL запросов. Поэтому злоупотреблять ими не стоит. С другой стороны, сортировка с помощью PHP (или любого другого языка) также займет какое-то время.
Подготовка набора данных
В этом руководстве мы будем работать с набором данных об экономии топлива, составленным Агентством по охране окружающей среды США(EPA) для автомобилей, выпущенных в период с 1984 по 2021 год.
Набор данных Агентства по охране окружающей среды идеально подходит для понимания сортировки, поскольку в нем много информации различного типа, от числовых до текстовых, в зависимости от которых пользователь может выполнять сортировку. Всего этот набор данных содержит восемьдесят три столбца.
Прежде чем приступить к анализу и сортировке набора данных, пользователю необходимо установить библиотеку Pandas. Версия библиотеки pandas должна быть 1.2.0, а версия Python должна быть выше 3.7.1.
Для целей анализа пользователь будет просматривать данные о милях на галлон (MPG) для транспортных средств по модели, году выпуска, марке и другим атрибутам. Пользователь сможет указать, какие столбцы включить в свой DataFrame. Для этой статьи нам понадобится только подмножество доступных столбцов.
В следующем примере мы передали команды для чтения значимых столбцов набора данных об экономии топлива в DataFrame, и он также отобразит первые пять строк нового DataFrame.
Пример:
import pandas as pd
column_subset =
df = pd.read_csv(
"https://www.fueleconomy.gov/feg/epadata/vehicles.csv",
usecols = column_subset,
nrows = 100
)
df.head()
Вывод:
![]()
Пользователи могут загрузить набор данных в DataFrame, вызвав функцию .read_csv() с URL-адресом набора данных. Мы сузили результат столбца для более быстрого вывода с низким использованием памяти. Чтобы дополнительно ограничить потребление памяти и получить быстрый предварительный просмотр данных, пользователи также могут указать количество строк, которые они хотят загрузить, с помощью команды «nrows».
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе
![]()
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
mysql> show table status;
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ ... | users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ 18 rows in set (0.06 sec)
Комментарии ( 9 ):
Спасибо! Как раз то что нужно
Где-то читал, что вложенные запросы затормаживают быстродействие баз данных.
Затормаживают, но выхода нет. Через PHP сортировка будет гораздо медленнее.
А разве нельзя в ORDER BY указывать несколько полей поочередно? Это ведь работает гораздо быстрее SELECT * FROM `table` ORDER BY `date`, `price`
Вы попробуйте это сделать и увидите, что будет совсем другой результат.
Только что попробовал, работает как надо. Если необходимо могу привести пример. http://www.spravkaweb.ru/mysql/sql/select >>Данные также можно отсортировать по нескольким столбцам. Для этого надо названия столбцов указать через запятую. Это может пригодиться, например, если в столбце, по которому производится сортировка, есть несколько одинаковых значений. >>Сначала данные сортируются по первому столбцу field1. Затем, если в первом столбце есть несколько одинаковых значений, выполняется дополнительная сортировка по второму столбцу (внутри группы с одинаковыми значениями в первом столбце).


Разницу можете посмотреть здесь: http://myrusakov.ru/sql-double-order.html
аааа, врулил. Извиняюсь, не внимательно прочитал первый абзац)
Синтаксис
Синтаксис оператора ORDER BY в MySQL:
SELECT expressions
FROM tables
ORDER BY expression ;
Параметры или аргументы
expressions — столбцы или вычисления, которые вы хотите получить.
tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в операторе FROM.
WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.ASC — необязательный. Сортирует результирующий набор по expression в порядке возрастания (по умолчанию, если атрибут не указан).DESC — необязательный. Сортирует результирующий набор по expression в порядке убывания.
Использование OFFSET и FETCH для ограничения числа возвращаемых строк
Для разбиения на страницы и ограничения числа строк, передаваемых клиентскому приложению, рекомендуется пользоваться предложениями OFFSET и FETCH, а не предложением TOP.
Применение в качестве решения для разбиения на страницы предложений OFFSET и FETCH потребует однократного выполнения запроса для каждой «страницы» данных, возвращаемых клиентскому приложению. Например, чтобы вернуть результаты запроса блоками по 10 строк, необходимо выполнить запрос для получения строк с 1 по 10, затем еще раз для получения строк с 11 по 20 и так далее. Каждый запрос выполняется независимо и никаким образом не связан с другими запросами. Это означает, что в отличие от использования курсора, где запрос выполняется всего один раз, а текущее состояние хранится на сервере, за отслеживание состояния отвечает клиентское приложение. Чтобы добиться стабильных результатов между запросами с предложениями OFFSET и FETCH, должны выполняться следующие условия.
-
Базовые данные, используемые запросом, должны быть неизменными. Иными словами, либо строки, обработанные запросом, не должны обновляться, либо все запросы страниц выполняемого запроса должны выполняться в одной транзакции, использующей моментальный снимок или сериализуемую изоляцию транзакции. Дополнительные сведения об уровнях изоляции транзакции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
-
Предложение ORDER BY содержит столбец или сочетание столбцов, которые гарантированно уникальны.
См. пример «Выполнение нескольких запросов в одной транзакции» в подразделе «Примеры» ниже в этом разделе.
Если согласованность планов выполнения важна для решения разбиения на страницы, подумайте над использованием указания запросов OPTIMIZE FOR для параметров OFFSET и FETCH. См. пункт «Указание выражений для значений OFFSET и FETCH» в подразделе «Примеры» ниже в этом разделе. Дополнительные сведения об OPTIMZE FOR см. в статье Указания запросов (Transact-SQL).
Расширенный фильтр
Расширенный фильтр предоставляет дополнительные возможности. Он позволяет объединить несколько условий, расположить результат в другой части листа или на другом листе и др.
Задание условий фильтрации
![]()
![]()
- В диалоговом окне Расширенный фильтр выбрать вариант записи результатов: фильтровать список на месте или скопировать результат в другое место .
![]()
- Указать Исходный диапазон , выделяя исходную таблицу вместе с заголовками столбцов.
- Указать Диапазон условий , отметив курсором диапазон условий, включая ячейки с заголовками столбцов.
- Указать при необходимости место с результатами в поле Поместить результат в диапазон , отметив курсором ячейку диапазона для размещения результатов фильтрации.
- Если нужно исключить повторяющиеся записи, поставить флажок в строке Только уникальные записи .
Работа в Excel c фильтром и сортировкой
Чтобы выполнить сортировку Excel можно воспользоваться несколькими простыми способами. Сначала рассмотрим самый простой.
- Заполните таблицу как на рисунке:
- Перейдите на любую ячейку столбца F.
- Выберите инструмент: «Главная»-«Редактирование»-«Сортировка и фильтр»-«Сортировка от А до Я».
![]()
- Перейдите на любую ячейку таблицы с данными.
- Выберите инструмент: «Главная»-«Редактирование»-«Сортировка и фильтр»-«Фильтр»
- Щелкните по выпадающему списку опций в заголовке «Город» таблицы и выберите опцию «Сортировка от А до Я».
![]()
Первый способ более простой, но он может выполнить сортировку только по одному столбцу (критерию). Для сортировки по нескольким столбцам следует использовать «Способ 2».
Полезный совет! В таблицах рекомендуется всегда использовать столбец с номерами строк. Он позволит всегда вернуться к первоначальному расположению строк после нескольких сортировок. Для этого достаточно выполнить сортировку этого столбца (например, №п/п).
Следует помнить, что сортировка выполняется над данными таблицы без пустых строк. Если нужно отсортировать только часть данных таблицы, тогда следует выделить это диапазон непосредственно перед сортировкой. Но такое фрагментированное сортирование данных очень редко имеет смысл и легко приводит к ошибкам.
Деталь реализации
Если кроме указан также не слишком большой LIMIT, то расходуется меньше оперативки. Иначе расходуется количество памяти, пропорциональное количеству данных для сортировки. При распределённой обработке запроса, если отсутствует GROUP BY, сортировка частично делается на удалённых серверах, а на сервере-инициаторе запроса производится слияние результатов. Таким образом, при распределённой сортировке, может сортироваться объём данных, превышающий размер памяти на одном сервере.
Существует возможность выполнять сортировку во внешней памяти (с созданием временных файлов на диске), если оперативной памяти не хватает. Для этого предназначена настройка . Если она выставлена в 0 (по умолчанию), то внешняя сортировка выключена. Если она включена, то при достижении объёмом данных для сортировки указанного количества байт, накопленные данные будут отсортированы и сброшены во временный файл. После того, как все данные будут прочитаны, будет произведено слияние всех сортированных файлов и выдача результата. Файлы записываются в директорию (по умолчанию, может быть изменено с помощью параметра ) в конфиге.
На выполнение запроса может расходоваться больше памяти, чем . Поэтому, значение этой настройки должно быть существенно меньше, чем . Для примера, если на вашем сервере 128 GB оперативки, и вам нужно выполнить один запрос, то выставите в 100 GB, а в 80 GB.
Внешняя сортировка работает существенно менее эффективно, чем сортировка в оперативке.
Сортировка выбором
Алгоритм сортировки выбором заключается в том, что мы делим список на две части — сортированный и несортированный. После этого мы находим минимальное значение во второй части и передвигаем это значение в начало массива.
Далее снова делим массив на две части — отсортированную и не сортированную, после чего снова в неотсортированной части ищем минимальное значение и сдвигаем его на место второго элемента первой части. Повторяем итерации до тех пор, пока не отсортируем весь массив. При первой итерации сортировки первая часть считается пустой, а вторая содержит весь список. Реализуем данный алгоритм в Python:
def selection_sort(massiv):
for num in range(len(massiv)):
min_value = num
for item in range(num, len(massiv)):
if massiv > massiv:
min_value = item
print("После очередной итерации:", massiv)
massiv, massiv = massiv, massiv
return (massiv)
massiv =
print("Исходный массив", massiv)
resultat = selection_sort(massiv)
print("Результат", resultat)
![]()
Как работать с осью DataFrame
Когда пользователь использует .sort_index() без передачи какого-либо явного аргумента, по умолчанию используется аргумент axis = 0. Ось DataFrame относится как к индексу (axis = 0), так и к столбцам (axis = 1). Пользователь может использовать как ось для выбора и индексации данных в DataFrame, так и для сортировки данных.
Использование меток столбцов
Мы также можем использовать метки столбцов в качестве ключа сортировки DataFrame для функции sort_index.
Давайте установим ось на 1 для сортировки столбцов нашего DataFrame на основе имен столбцов.
Пример:
df.sort_index(axis = 1)
Вывод:
![]()
Столбцы DataFrame сортируются слева направо в возрастающем алфавитном порядке. Теперь предположим, что мы хотим отсортировать столбцы в порядке убывания, тогда нам просто нужно установить возрастающее значение равным False.
Пример:
df.sort_index(axis = 1, ascending = False)
Вывод:
![]()
Используя axis = 1 в функции .sort_index(), мы отсортировали столбцы нашего DataFrame как в порядке возрастания, так и в порядке убывания. Это может быть более полезным в других наборах данных, в которых метки столбцов соответствуют месяцам года. В этом случае упорядочивание наших данных в порядке возрастания или убывания по месяцам будет иметь смысл.