
Вопрос 1. Как понять какие таблицы не используются?
Вручную анализировать код для 800 таблиц очень долго и сложно. Поэтому такой вариант сразу отпадает. Нужен автоматический вариант.
SQL Server хранит статистику использования(обращений) к таблицам с момента последней перезагрузки. Выполним запрос TSQL:
SELECT sqlserver_start_time AS LastSQLServiceRestart FROM sys.dm_os_sys_info
У нас сервер не перезагружался больше 6 месяцев Т.е. прошло достаточно много времени, чтобы сделать выводы о не используемости таблиц. Список должен быть предварительно проверен т.к есть некоторая функциональность, которая все таки существует в системе, но никто ей не пользуется.
TSQL запрос возвращает имя таблицы, количество строк в таблице, дату создания и дату последнего изменения.
with UnUsedTables (TableName , TotalRowCount, CreatedDate , LastModifiedDate )
AS (
SELECT DBTable.name AS TableName
,PS.row_count AS TotalRowCount
,DBTable.create_date AS CreatedDate
,DBTable.modify_date AS LastModifiedDate
FROM sys.all_objects DBTable
JOIN sys.dm_db_partition_stats PS ON OBJECT_NAME(PS.object_id)=DBTable.name
WHERE DBTable.type ='U'
AND NOT EXISTS (SELECT OBJECT_ID
FROM sys.dm_db_index_usage_stats
WHERE OBJECT_ID = DBTable.object_id )
)
-- Select data from the CTE
SELECT TableName , TotalRowCount, CreatedDate , LastModifiedDate
FROM UnUsedTables
ORDER BY TotalRowCount ASC
Полученный список таблиц сразу анализируем и предварительно отфильтровываем по дате создания, дате последнего использования и количестве строк.
Затем список копируем в Google Таблиц и даем доступ всем разработчикам, чтобы все могли его проверить и высказать свои замечания и предложения. После всех согласований формируем конечный список таблиц под удаление, а также утверждаем окончательный список у ответственных лиц. Полученный список сохраняем в документ Excel, так будет удобнее его обрабатывать.
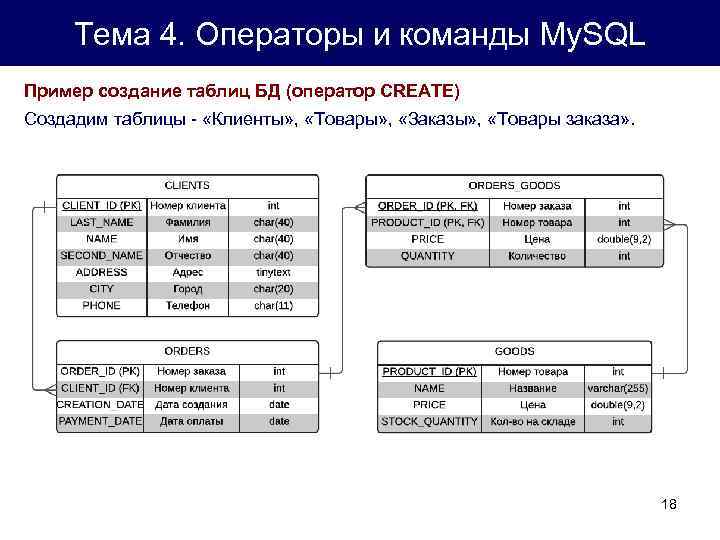
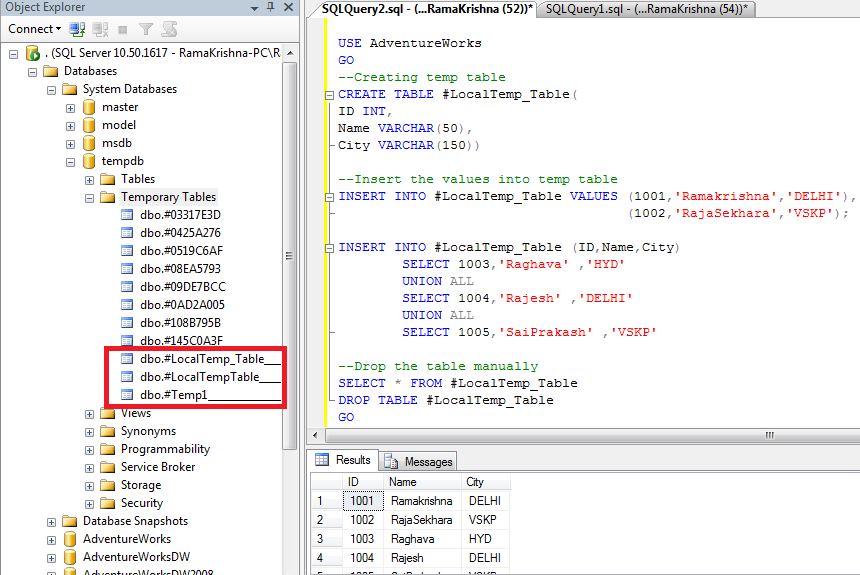
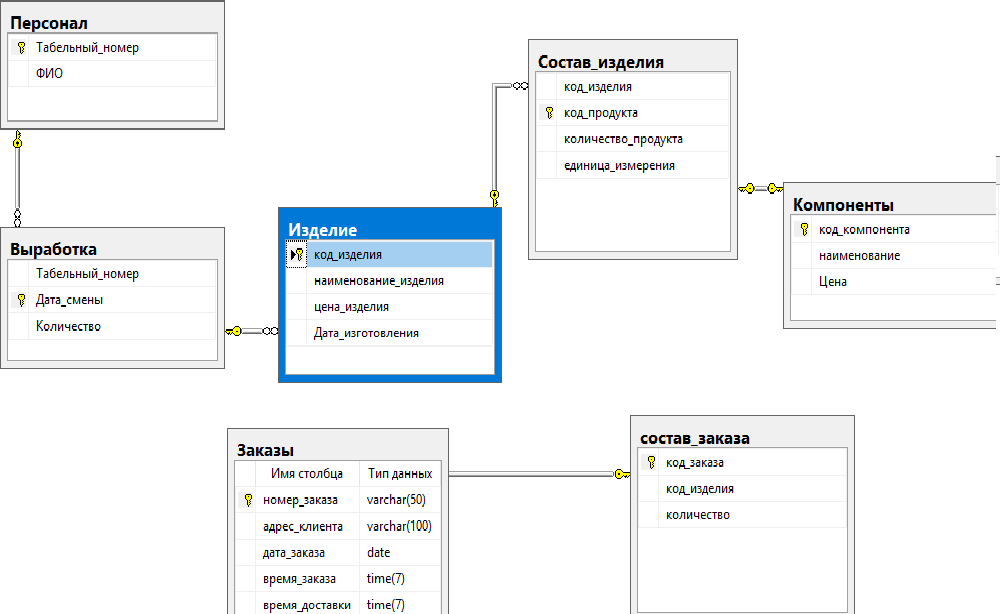
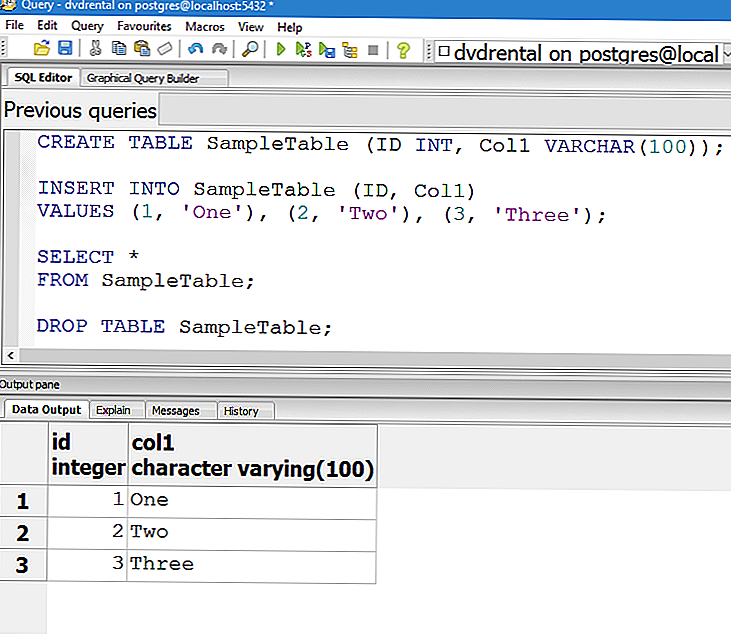
Пишем SQL запрос для создания таблицы базы данных
Суммируем все исходные данные и получаем такой SQL запрос:
/*Таблица пользователей clients*/ create table clients ( /*client_id будет первичный ключ (обязательно целое число) с автоинкрементом (+1), который никогда не будет равен нулю*/ client_id integer not null auto_increment primary key, client_customer varchar(13), /*имя */ client_surclient varchar(22), /*фамилия */ client_login varchar(21), /*логин*/ client_passwd varchar(7), /*пароль*/ client_email varchar(44) /*email*/ client_telefon varchar(26) /*телефон*/ );
Примечание: SQL запрос для создания таблицы создаем в текстовом редакторе типа Notepad++. В скобках ограничиваем длину поля, может быть от 1 до 255.
Итоги статьи
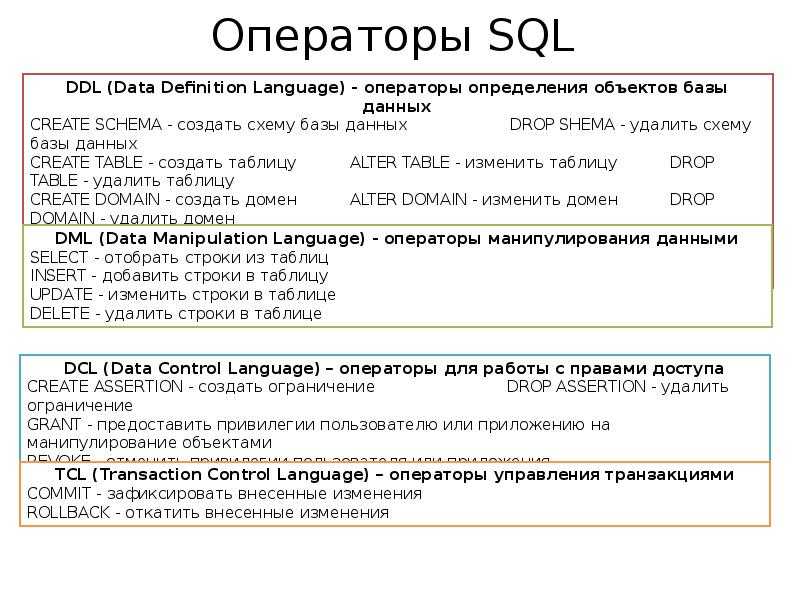
- В этой статье мы познакомились с первым оператором SQL языка CREATE TABLE
- Создали SQL запрос для создания одной (первой) таблицы базы данных с первичным ключом.
WebOnTo.ru
Инструкция CREATE TABLE: базовая форма
Инструкция CREATE TABLE создает новую таблицу базы данных со всеми соответствующими столбцами требуемого типа данных. Далее приводится базовая форма инструкции CREATE TABLE:
Соглашения по синтаксису
Параметр table_name — имя создаваемой базовой таблицы. Максимальное количество таблиц, которое может содержать одна база данных, ограничивается количеством объектов базы данных, число которых не может быть более 2 миллиардов, включая таблицы, представления, хранимые процедуры, триггеры и ограничения. В параметрах col_name1, col_name2, … указываются имена столбцов таблицы, а в параметрах type1, type2, … — типы данных соответствующих столбцов.
Имя объекта базы данных может обычно состоять из четырех частей, в форме:
]]object_name
Здесь object_name — это имя объекта базы данных, schema_name — имя схемы, к которой принадлежит объект, а server_name и db_name — имена сервера и базы данных, к которым принадлежит объект. Имена таблиц, сгруппированные с именем схемы, должны быть однозначными в рамках базы данных. Подобным образом имена столбцов должны быть однозначными в рамках таблицы.
Рассмотрим теперь ограничение, связанное с присутствием или отсутствием значений NULL в столбце. Если для столбца не указано, что значения NULL разрешены (NOT NULL), то данный столбец не может содержать значения NULL, и при попытке вставить такое значение система возвратит сообщение об ошибке.
Как уже упоминалось, объект базы данных (в данном случае таблица) всегда создается в схеме базы данных. Пользователь может создавать таблицы только в такой схеме, для которой у него есть полномочия на выполнение инструкции ALTER. Любой пользователь с ролью sysadmin, db_ddladmin или db_owner может создавать таблицы в любой схеме.
Создатель таблицы не обязательно должен быть ее владельцем. Это означает, что один пользователь может создавать таблицы, которые принадлежат другим пользователям. Подобным образом таблица, создаваемая с помощью инструкции CREATE TABLE, не обязательно должна принадлежать к текущей базе данных, если в префиксе имени таблицы указать другую (существующую) базу данных и имя схемы.
Схема, к которой принадлежит таблица, может иметь два возможных имени по умолчанию. Если таблица указывается без явного имени схемы, то система выполняет поиск имени таблицы в соответствующей схеме по умолчанию. Если имя объекта найти в схеме по умолчанию не удается, то система выполняет поиск в схеме dbo. Имена таблиц всегда следует указывать вместе с именем соответствующей схемы. Это позволит избежать возможных неопределенностей.
В примере ниже показано создание всех таблиц базы данных SampleDb. (База данных SampleDb должна быть установлена в качестве текущей базы данных.)
Кроме типа данных и наличия значения NULL, в спецификации столбца можно указать следующие параметры:
-
предложение DEFAULT;
-
свойство IDENTITY.
Предложение DEFAULT в спецификации столбца указывает значение столбца по умолчанию, т.е. когда в таблицу вставляется новая строка, ячейка этого столбца будет содержать указанное значение, которое останется в ячейке, если в нее не будет введено другое значение. В качестве значения по умолчанию можно использовать константу, например одну из системных функций, таких как, USER, CURRENT_USER, SESSION_USER, SYSTEM_USER, CURRENT_TIMESTAMP и NULL.
Столбец идентификаторов, создаваемый указанием свойства IDENTITY, может иметь только целочисленные значения, которые системой присваиваются обычно неявно. Каждое следующее значение, вставляемое в такой столбец, вычисляется, увеличивая последнее, вставленное в этот столбец, значение. Поэтому определение столбца со свойством IDENTITY содержит (явно или неявно) начальное значение и шаг инкремента (такой столбец еще называют столбцом с автоинкрементом).
Ниже показан пример использования этих инструкций:
Исходные данные
База создана, поэтому можно подумать о её структуре. Планируется создание двух таблиц:
1. Goods – table с информацией о товарах. Будет содержать несколько столбцов:
— ProductId. Представляет собой идентификатор товара. Значение не должно быть NULL. Также здесь будет первичный ключ;
— Category. Это ссылка на категорию товара. Не NULL. Если товар не распределён в нужную категорию, ему присваивается категория по умолчанию («Не указана», «Не определена»);
— ProductName. В этом столбце будет наименование товара. Не NULL;
— Price. Речь идёт о стоимости. Если цена ещё не определена, возможен NULL.
2. Categories — вторая table. В ней будет описание категорий реализуемых товаров, представленное двумя столбцами:
— CategoryId. Представляет собой идентификатор категории. Не NULL, первичный ключ;
— CategoryName. Название категории, не NULL.
Для того чтобы нельзя было внести товар с несуществующей категорией, будет добавлено ограничение внешнего ключа.
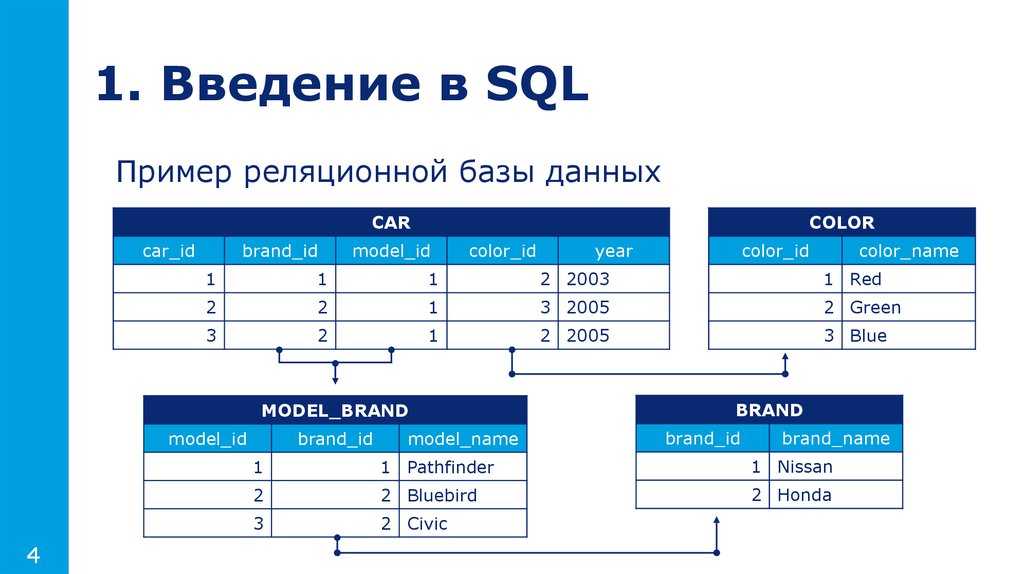
Устройство реляционной базы данных – таблицы, строки, столбцы
Множество это набор уникальных значений, которые закрыты от других множеств (ограничение), не упорядочены (до любого значения можно добраться, не затрагивая другие значения) и уникальны.
Атрибут множества, это название столбца в таблице БД. Математически, атрибут это множество, названий столбцов. Каждое название столбца уникально и неупорядочено. То есть, мы можем «добраться» до уникального названия столбца не затрагивая другие столбцы.
Очень важна уникальность атрибутов (названий столбцов) в рамках базы данных. Достигается уникальность столбцов, добавлением в его названия имя таблицы данных.
О неупорядоченности атрибутов
Математически, множество атрибутов: B.4, B.89, B.55, B.3, B.99, точно такое же, как множество: B.89, B.55, B.4, B.99, B.3. Но на практике, мы не можем вызывать столбцы по названию в произвольном порядке. Для упорядочивания вызова и нужен структурный язык. Для реляционных баз данных структурный язык это язык: SQL. В нем упорядоченный вызов столбцов поатрибутам выглядит так:
SELECT B.4, B.89, B.55, B.3, B.99 FROM B
Или
SELECT B.89, B.55, B.4, B.99, B.3 FROM B
PHP и MySQL
Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта — это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий:
- Соединяемся с БД при помощи команды mysql_connect();
- Используя mysql_select_db() выбираем нужную БД;
- Обрабатываем запрос при помощи mysql_fetch_array();
- Закрываем соединение командой mysql_close().
Важно! Работать с БД не сложно. Главное — правильно написать запрос
Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера «SQL для простых смертных
». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги.
![]()
Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс «Создание и раскрутка сайта
».
![]()
Символьные типы данных
Существует два общих вида символьных типов данных. Строки могут представляться однобайтовыми символами или же символами в кодировке Unicode. (В кодировке Unicode для представления одного символа применяется несколько байтов.) Кроме этого, строки могут быть разной длины. В таблице ниже перечислены категории символьных типов данных с их кратким описанием.




| Тип данных | Описание |
|---|---|
| CHAR |
Применяется для представления строк фиксированной длины, состоящих из n однобайтовых символов. Максимальное значение n равно 8000. CHARACTER(n) — альтернативная эквивалентная форма CHAR(n). Если n явно не указано, то его значение полагается равным 1. |
| VARCHAR |
Используется для представления строки однобайтовых символов переменной длины (0 < n < 8 000). В отличие от типа данных CHAR, количество байтов для хранения значений типа данных VARCHAR равно их действительной длине. Этот тип данных имеет два синонима: CHAR VARYING и CHARACTER VARYING. |
| NCHAR |
Используется для хранения строк фиксированной длины, состоящих из символов в кодировке Unicode. Основная разница между типами данных CHAR и NCHAR состоит в том, что для хранения каждого символа строки типа NCHAR требуется 2 байта, а строки типа CHAR — 1 байт. Поэтому строка типа данных NCHAR может содержать самое большее 4000 символов. Тип NCHAR можно использовать для хранения, например, символов русского алфавита, т.к. однобайтовые кодировки не позволяют делать этого. |
| NVARCHAR |
Используется для хранения строк переменной длины, состоящих из символов в кодировке Unicode. Для хранения каждого символа строки типа NVARCHAR требуется 2 байта, поэтому строка типа данных NVARCHAR может содержать самое большее 4000 символов. |
Тип данных VARCHAR идентичен типу данных CHAR, за исключением одного различия: если содержимое строки CHAR(n) короче, чем n символов, остаток строки заполняется пробелами. А количество байтов, занимаемых строкой типа VARCHAR, всегда равно количеству символов в ней.
Создание таблицы с помощью языка C# ADO.NET
C#
using System;
using System.Data.SqlClient;
namespace CreateTable
{
class Program
{
static void Main(string[] args)
{
SqlConnection con = new SqlConnection(@»Data Source=.\SQLEXPRESS;Initial Catalog=ComputerShop;Integrated Security=True»);
string query =
@»CREATE TABLE dbo.Products
(
ID int IDENTITY(1,1) NOT NULL,
Name nvarchar(50) NULL,
Price nvarchar(50) NULL,
Date datetime NULL,
CONSTRAINT pk_id PRIMARY KEY (ID)
);»;
SqlCommand cmd = new SqlCommand(query, con);
try
{
con.Open();
cmd.ExecuteNonQuery();
Console.WriteLine(«Table Created Successfully»);
}
catch(SqlException e)
{
Console.WriteLine(«Error Generated. Details: » + e.ToString());
}
finally
{
con.Close();
Console.ReadKey();
}
}
}
}
|
1 |
usingSystem; usingSystem.Data.SqlClient; namespaceCreateTable { classProgram { staticvoidMain(stringargs) { SqlConnection con=newSqlConnection(@»Data Source=.\SQLEXPRESS;Initial Catalog=ComputerShop;Integrated Security=True»); stringquery= @»CREATE TABLE dbo.Products ( );»; SqlCommand cmd=newSqlCommand(query,con); try { con.Open(); cmd.ExecuteNonQuery(); Console.WriteLine(«Table Created Successfully»); } catch(SqlExceptione) { Console.WriteLine(«Error Generated. Details: «+e.ToString()); } finally { con.Close(); Console.ReadKey(); } } } } |
11
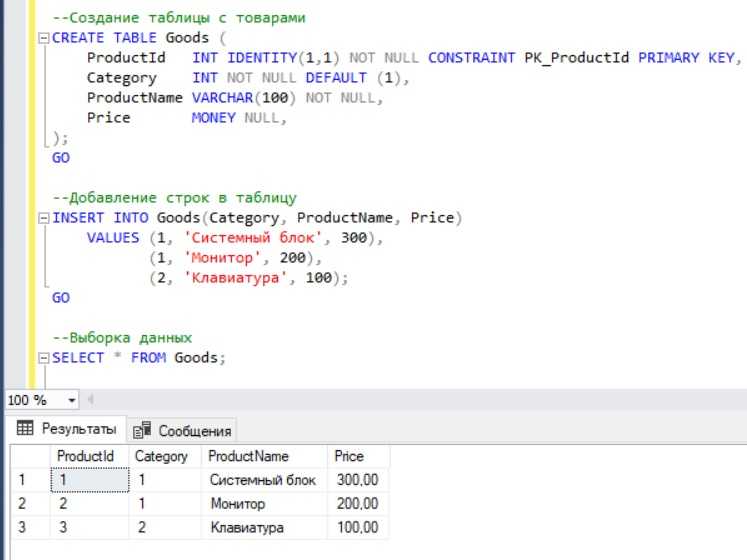
Исходные данные
База создана, поэтому можно подумать о её структуре. Планируется создание двух таблиц: 1. Goods – table с информацией о товарах. Будет содержать несколько столбцов: — ProductId. Представляет собой идентификатор товара. Значение не должно быть NULL. Также здесь будет первичный ключ; — Category. Это ссылка на категорию товара. Не NULL. Если товар не распределён в нужную категорию, ему присваивается категория по умолчанию («Не указана», «Не определена»); — ProductName. В этом столбце будет наименование товара. Не NULL; — Price. Речь идёт о стоимости. Если цена ещё не определена, возможен NULL. 2. Categories — вторая table. В ней будет описание категорий реализуемых товаров, представленное двумя столбцами: — CategoryId. Представляет собой идентификатор категории. Не NULL, первичный ключ; — CategoryName. Название категории, не NULL.
Для того чтобы нельзя было внести товар с несуществующей категорией, будет добавлено ограничение внешнего ключа.
![]()
Команда SELECT DISTINCT
В отличие от обычного , позволяет выводить только уникальные (не повторяющиеся) данные из таблицы БД.
Синтаксис запроса для вывода уникальных данных из таблицы
SELECT DISTINCT column1, column2, … , columnN FROM table_name;
| 1 | SELECTDISTINCTcolumn1,column2,…,columnNFROMtable_name; |
В предыдущем примере у нас много раз повторяются данные из колонки author, если мы хотим узнать какие авторы у нас есть без повторов, то воспользуемся следующим запросом.
SELECT DISTINCT author FROM books;
| 1 | SELECTDISTINCTauthorFROMbooks; |
В результате получим вывод 6 строк с уникальными именами авторов книг вместо 10.
Для подсчета уникальных записей можно воспользоваться функцией .
Наполнение таблицы строками
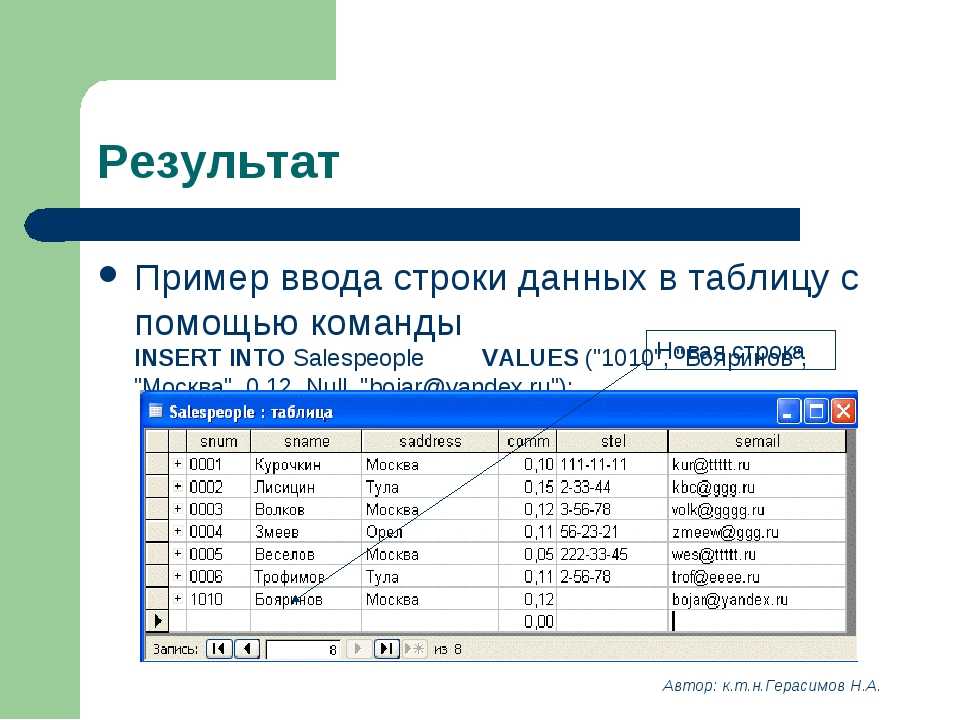
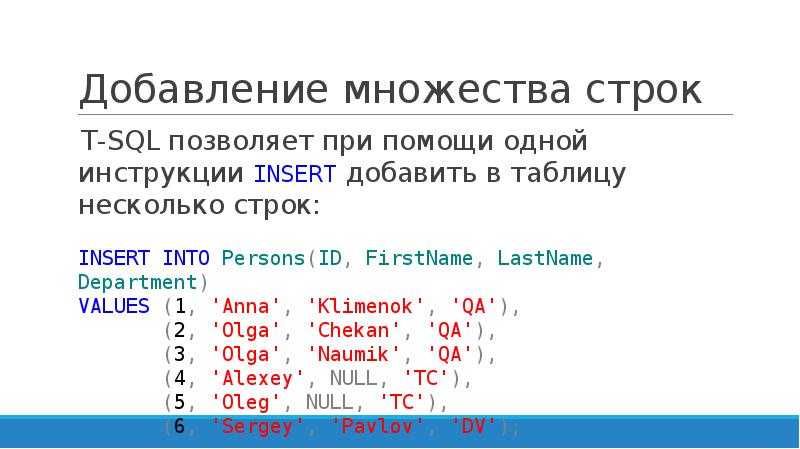
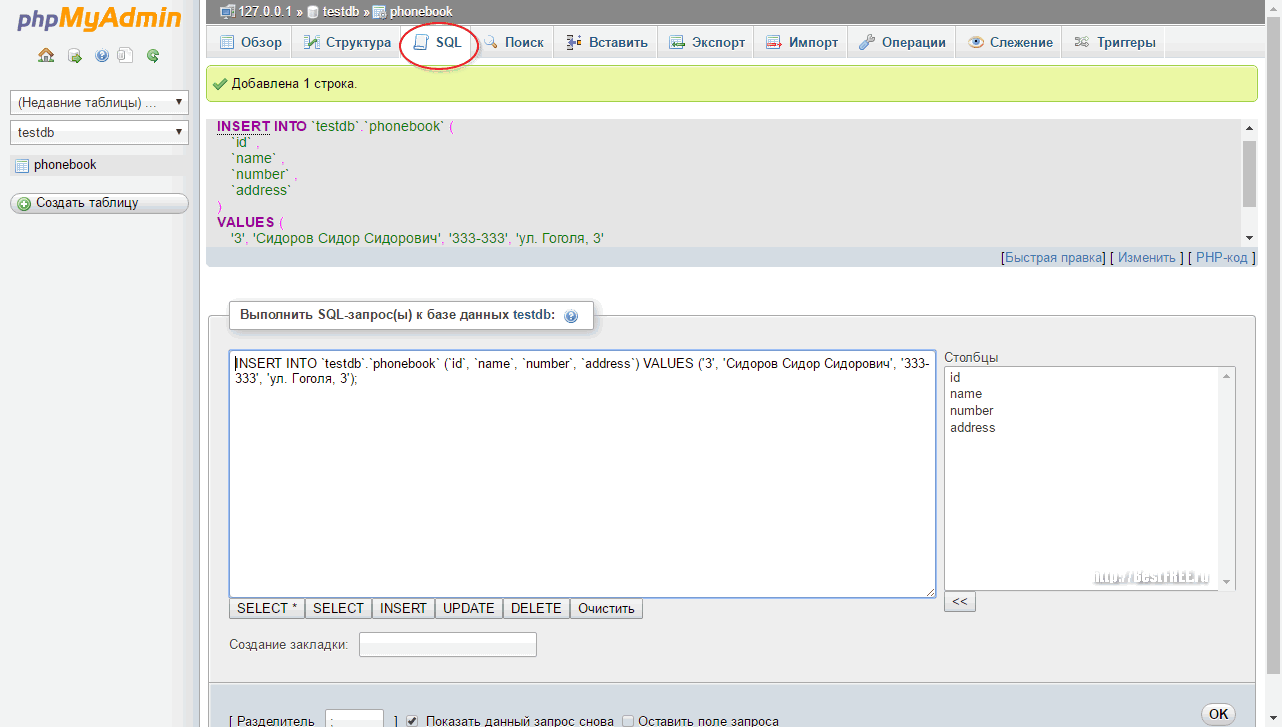
Строки вставляются в таблицу с помощью команды SQL INSERT INTO <имя таблицы> (перечисляем поля)VALUES (перечисляем значения). При этом можно вставлять по одной строке или по несколько. Вставим три строки в нашу таблицу users:
# INSERT INTO users (fio, company, phone, email)
VALUES ('Иванов Иван Алексеевич', 'ООО "Ромашка"', '89057362761', 'ivanov@mail.ru'),
('Донченко Иван Андреевич', 'ООО "Ромашка"', '89038276494', 'dota@yandex.ru'),
('Девин Алексей Владимирович', 'ООО "Начало"', '89069384782', 'test@yandex.ru');
При вставке строковых значений, строка всегда берётся в одинарные кавычки.
Подстановочные знаки
Подстановочный знак совпадает с любой последовательностью из нуля или более символов. Ниже приведена измененная версия предыдущего запроса, в которой используется шаблон, содержащий знак процента.
Оператор указывает SQL, что необходимо сравнивать содержимое столбца с шаблоном «Smith% Corp.». Этому шаблону соответствуют все перечисленные ниже имена.
Smith Corp.
Smithsen Corp.
Smithson Corp.
Smithsonian Corp.
А вот эти имена данному шаблону не соответствуют.
SmithCorp
Smithson Inc.
Подстановочный знак (символ подчеркивания) совпадает с любым отдельным символом. Например, если вы уверены, что название компании либо «Smithson», либо «Smithsen», то можете воспользоваться следующим запросом.
В таком случае шаблону будет соответствовать любое из представленных ниже имен.
Smithson Corp.
Smithsen Corp.
Smithsun Corp.
А вот ни одно из следующих ему соответствовать не будет.
Smithsoon Corp.
Smithsn Corp.
Подстановочные знаки можно помещать в любое место строки шаблона, и в одной строке может содержаться несколько подстановочных знаков. Следующий запрос допускает как написание «Smithson» и «Smithsen», так и любое другое окончание названия компании, включая «Corp.», «Inc.» или какое-то другое.
С помощью формы можно находить строки, которые не соответствуют шаблону. Проверку можно применять только к столбцам, имеющим строковый тип данных. Если в столбце содержится значение , то результатом проверки будет .
Вероятно, вы уже встречались с проверкой на соответствие шаблону в операционных системах, имеющих интерфейс командной строки (таких, как Unix). Обычно в этих системах звездочка () используется для тех же целей, что и символ процента () в SQL, а вопросительный знак () соответствует символу подчеркивания () в SQL, но в целом возможности работы с шаблонами строк в них такие же.
Простые SELECT (выбрать) запросы к базе данных MySQL
SELECT
1. Выбирает ВСЕ данные в таблице tbl_name.
SELECT * FROM tbl_name;
2. Выведет количество записей в таблице tbl_name.




SELECT count(*) FROM tbl_name;
3. Выбирает (SELECT) из(FROM) таблицы tbl_name лимит (LIMIT) 3 записи, начиная с 2.
SELECT * FROM tbl_name LIMIT 2,3;
4. Выбирает (SELECT) ВСЕ (*) записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id по порядку.
SELECT * FROM tbl_name ORDER BY id;
5. Выбирает (SELECT) ВСЕ записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id в ОБРАТНОМ порядке.
SELECT * FROM tbl_name ORDER BY id DESC;
6. Выбирает (SELECT
) ВСЕ (*) записи из (FROM
) таблицы users
и сортирует их (ORDER BY
) по полю id
в порядке возрастания, лимит (LIMIT
) первые 5 записей.
SELECT * FROM users ORDER BY id LIMIT 5;
7. Выбирает все записи из таблицы users
, где поле fname
соответствует значению Gena
.
SELECT * FROM users WHERE fname=»Gena»;
8. Выбирает все записи из таблицы users
, где значение поля fname
начинается с Ge
.
SELECT * FROM users WHERE fname LIKE «Ge%»;
9. Выбирает все записи из таблицы users
, где fname
заканчивается на na
, и упорядочивает записи в порядке возрастания значения id
.
SELECT * FROM users WHERE fname LIKE «%na» ORDER BY id;
10. Выбирает все данные из колонок fname
, lname
из таблице users
.
SELECT fname, lname FROM users;
11.
Допустим у Вас в таблице пользовательских данных есть страна. Так вот если Вы хотите вывести ТОЛЬКО список встречающихся значений (чтобы, например, Россия не выводилось 20 раз, а только один), то используем DISTINCT. Выведет, из массы повторяющихся значений Россия, Украина, Беларусь. Таким образом, из таблицы users
колонки country
будут выведены ВСЕ УНИКАЛЬНЫЕ значения
SELECT DISTINCT country FROM users;
12. Выбирает ВСЕ данные строк из таблицы users
где age
имеет значения 18,19 и 21.
SELECT * FROM users WHERE age IN (18,19,21);
13.
Выбирает МАКСИМАЛЬНОЕ значение age
в таблице users
. То есть если у Вас в таблице самое большее значение age
(с англ. возраст) равно 55, то результатом запроса будет 55.
SELECT max(age) FROM users;
14. Выберет данные из таблицы users
по полям name
и age
ГДЕ age
принимает самое маленькое значение.
SELECT name, min(age) FROM users;
15. Выберет данные из таблицы users
по полю name
ГДЕ id
НЕ РАВЕН 2.
SELECT name FROM users WHERE id!=»2″;
Добавление нового столбца
SQL-скрипт
C#
ALTER TABLE Accessories
ADD Stock nvarchar(50)
|
1 |
ALTER TABLE Accessories ADD Stock nvarchar(50) |
Выполненим выше сценария SQL с использованием c# ado.net создадим новую таблицу в Accessories Table в таблице.
C#
using System;
using System.Data.SqlClient;
namespace CreateColumn
{
class Program
{
static void Main(string[] args)
{
SqlConnection con = new SqlConnection(@»Data Source=.\SQLEXPRESS;Initial Catalog=ComputerShop;Integrated Security=True»);
string query =
@»ALTER TABLE Accessories
ADD Stock nvarchar(50);»;
SqlCommand cmd = new SqlCommand(query, con);
try
{
con.Open();
cmd.ExecuteNonQuery();
Console.WriteLine(«Column Created Successfully»);
}
catch(SqlException e)
{
Console.WriteLine(«Error Generated. Details: » + e.ToString());
}
finally
{
con.Close();
Console.ReadKey();
}
}
}
}
|
1 |
usingSystem; usingSystem.Data.SqlClient; namespaceCreateColumn { classProgram { staticvoidMain(stringargs) { SqlConnection con=newSqlConnection(@»Data Source=.\SQLEXPRESS;Initial Catalog=ComputerShop;Integrated Security=True»); stringquery= @»ALTER TABLE Accessories ADD Stock nvarchar(50);»; SqlCommand cmd=newSqlCommand(query,con); try { con.Open(); cmd.ExecuteNonQuery(); Console.WriteLine(«Column Created Successfully»); } catch(SqlExceptione) { Console.WriteLine(«Error Generated. Details: «+e.ToString()); } finally { con.Close(); Console.ReadKey(); } } } } |
Типы данных в MySQL
В следующей таблице приведены наиболее часто используемые типы данных, поддерживаемые MySQL.
| INT | Хранит числовые значения в диапазоне от -2147483648 до 2147483647. |
| DECIMAL | Хранит десятичные значения. |
| CHAR | Хранит строки фиксированной длины с максимальным размером 255 символов. |
| VARCHAR | Хранит строки переменной длины с максимальным размером 65 535 символов. |
| TEXT | Хранит строки с максимальным размером 65 535 символов. |
| DATE | Сохраняет значения даты в формате ГГГГ-ММ-ДД. |
| DATETIME | Сохраняет объединенные значения даты/времени в формате ГГГГ-ММ-ДД ЧЧ: ММ: СС. |
| TIMESTAMP | Хранит значения меток времени. Значения TIMESTAMP хранятся в виде количества секунд с начала эпохи Unix (1970-01-01 00:00:01 UTC). |
Существует несколько дополнительных ограничений (также называемых модификаторами), которые установлены для столбцов таблицы в предыдущем выражении. Ограничения определяют правила, касающиеся значений, разрешенных в столбцах.
- Ограничение NOT NULL гарантирует, что поле не может принять значение NULL.
- Ограничение PRIMARY KEY помечает соответствующее поле как первичный ключ таблицы.
- Атрибут AUTO_INCREMENT является расширением MySQL для стандартного SQL, который сообщает MySQL, что нужно автоматически присваивать значение этому полю, если оно не указано, путем увеличения предыдущего значения на 1. Доступно только для числовых полей.
- Ограничение UNIQUE гарантирует, что каждая строка для столбца должна иметь уникальное значение.
Пробелы в именах объектов базы данных
У тебя может возникнуть вопрос – а что, а можно создавать имена таблица или колонок из нескольких слов и как тогда MySQL будет работать с пробелами? Создавать объекты с пробелами можно, но в этом случае имя нужно окружить специальными символами, которые зависят от базы данных, в MySQL это символ ` который находится слева от цифры 1 на большинстве клавиш.
Так что теоретически наш запрос может выглядеть так:
SELECT `Adress id`, Name FROM `Address Table`
Обратите внимание, что колонка Address id содержит пробел, поэтому вначале и в конце стоит символ `. У колонки Name нет пробелов, поэтому ничего добавлять не нужно
У имени таблицы так же есть пробел.
Если в имени объекта есть пробел, то ` является обязательным, если пробела нет, то можно поставить, а можно и опустить. Это значит, следующие запросы одинаково корректны:
SELECT `cityname` FROM `city`; SELECT cityname FROM `city`; SELECT `cityname` FROM city; SELECT cityname FROM city;
Все они корректны и все будут работать.
Хотя все примеры мы рассматриваем и тестируем под MySQL, почти все они будут работать и в других базах данных, но вот разделитель в разных базах может отличаться. В MS SQL Server это квадратные скобки:
SELECT FROM ;
Очень часто программисты стараются создавать таблицы и колонки без пробелов, поэтому не так часто можно увидеть запросы, в которых используются символы, которыми окружаются имена объектов.
SELECT и ORDER BY — сортировка (упорядочение) строк
Разобранные до сих пор запросы SQL SELECT возвращали строки, которые могли быть расположены в любой последовательности.
Однако часто требуется отсортировать строки по порядку номеров, алфавиту и другим признакам. Для этого
служит ключевое словосочетание ORDER BY. Такие запросы имеют следующий синтаксис:
Пример 15.
Пусть требуетя выбрать из таблицы Staff сотрудников,
работающих в отделе с номером 84 и отсортировать (упорядочить) записи по числу отработанных лет в
возрастающем порядке:
Слово ASC указывает, что порядок сортировки — возрастающий. Это слово не обязательно,
так как возрастающий порядок сортировки применяется по умолчанию. Результат выполнения запроса:
![]()
Пример 16.
Пусть требуетя выбрать те же данные, что и в предыдущем
примере, но отсортировать (упорядочить) записи по числу отработанных лет в
убывающем порядке.
Синтаксис:
* где fields1
— поля для выборки через запятую, также можно указать все поля знаком *; table
— имя таблицы, из которой вытаскиваем данные; conditions
— условия выборки; fields2
— поле или поля через запятую, по которым выполнить сортировку; count
— количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
Простые примеры использования select
1. Обычная выборка данных:
> SELECT * FROM users
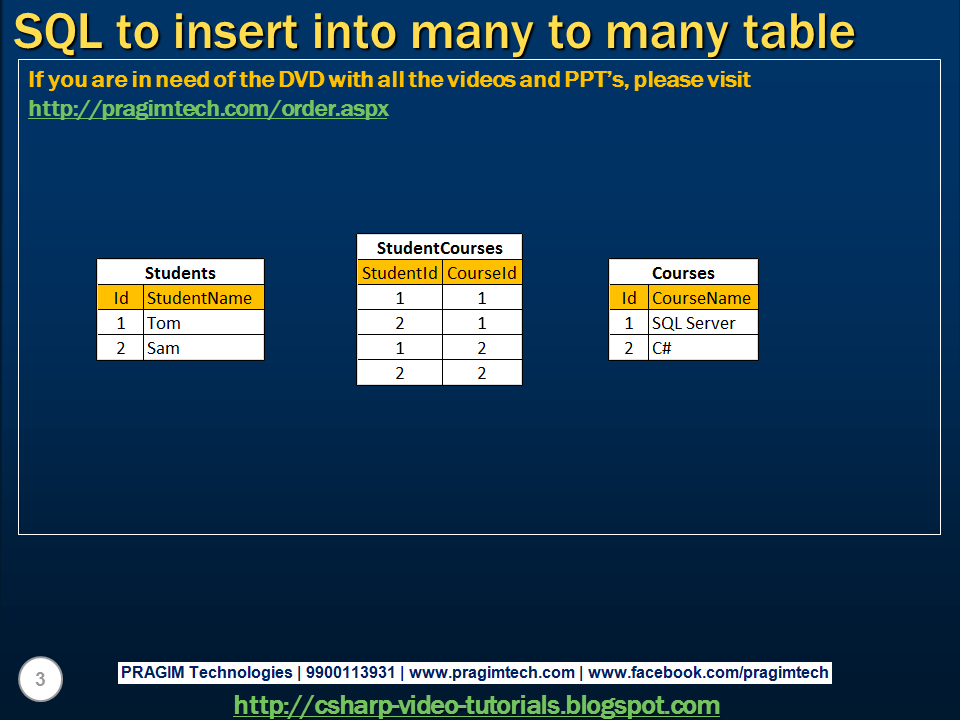
2. Выборка данных с объединением двух таблиц (JOIN):
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users
и users_rights
. Объединяются они по полям user_id
(в таблице users_rights) и id
(users). Извлекается поле name из первой таблицы и все поля из второй.

3. Выборка с интервалом по времени и/или дате
а) известна точка начала и определенный временной интервал:
* будут выбраны данные за последний час (поле date
).
б) известны дата начала и дата окончания:
25.10.2017
и 25.11.2017
.
в) известны даты начала и окончания + время:
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут
и 25.04.2018 15 часов 33 минуты и 9 секунд
.
г) вытаскиваем данные за определенные месяц и год:
* извлечем данные, где в поле date
присутствуют значения для апреля 2018
года.
4. Выборка максимального, минимального и среднего значения:
> SELECT max(area), min(area), avg(area) FROM country
* max
— максимальное значение; min
— минимальное; avg
— среднее.
5. Использование длины строки:
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT):
* из таблицы users
извлекаются данные по полю id
, все они помещаются в одну строку, значения разделяются запятыми
.
2. Группировка данных по двум и более полям:
> SELECT * FROM users GROUP BY CONCAT(title, «::», birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title
и birth
. Перед группировкой мы делаем объединение полей в одну строку с разделителем ::
.
3. Объединение результатов из двух таблиц (UNION):
> (SELECT id, fio, address, «Пользователи» as type FROM users)
UNION
(SELECT id, fio, address, «Покупатели» as type FROM customers)
* в данном примере идет выборка данных из таблиц users
и customers
.
4. Выборка средних значений, сгруппированных за каждый час:
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, «%Y-%m-%d %H») as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, «%Y-%m-%d %H»)
* здесь мы извлекаем среднее значение поля temperature
из таблицы archive
и группируем по полю datetimeupdate
(с разделением времени за каждый час).



