
Содержание проектирования баз данных и этапность
![]() Замысел проектирования основывается на какой-либо сформулированной общественной потребности. У этой потребности есть среда её возникновения и целевая аудитория потребителей, которые будут пользоваться результатом проектирования. Следовательно, процесс проектирования баз данных начинается с изучения данной потребности с точки зрения потребителей и функциональной среды её предполагаемого размещения. То есть, первым этапом становится сбор информации и определение модели предметной области системы, а также – взгляда на неё с точки зрения целевой аудитории. В целом, для определения требований к системе производится определение диапазона действий, а также границ приложений БД.
Замысел проектирования основывается на какой-либо сформулированной общественной потребности. У этой потребности есть среда её возникновения и целевая аудитория потребителей, которые будут пользоваться результатом проектирования. Следовательно, процесс проектирования баз данных начинается с изучения данной потребности с точки зрения потребителей и функциональной среды её предполагаемого размещения. То есть, первым этапом становится сбор информации и определение модели предметной области системы, а также – взгляда на неё с точки зрения целевой аудитории. В целом, для определения требований к системе производится определение диапазона действий, а также границ приложений БД.
Далее проектировщик, уже имеющий определённые представления о том, что ему нужно создать, уточняет предположительно решаемые приложением задачи, формирует их список (особенно, если в проектной разработке большая и сложная БД), уточняет последовательность решения задач и производит анализ данных. Такой процесс – тоже этапная проектная работа, но обычно в структуре проектирования эти шаги поглощаются этапом концептуального проектирования – этапом выделения объектов, атрибутов, связей.
Создание концептуальной (информационной модели) предполагает предварительное формирование концептуальных требований пользователей, включая требования в отношении приложений, которые могут и не быть сразу реализованным, но учёт которых позволит в будущем повысить функциональность системы. Имея дело с представлениями объектов-абстракций множества (без указания способов физического хранения) и их взаимосвязями, концептуальная модель содержательно соответствует модели предметной области. Поэтому в литературе первый этап проектирования БД называется инфологическим проектированием.
Далее отдельным этапом (либо дополнением к предыдущему) следует этап формирования требований к операционной обстановке, где оцениваются требования к вычислительным ресурсам, способным обеспечить функционирование системы. Соответственно, чем больше объем проектируемой БД, чем выше пользовательская активность и интенсивность обращений, тем выше требования предъявляются к ресурсам: к конфигурации компьютера к типу и версии операционной системы. Например, многопользовательский режим работы будущей базы данных требует сетевого подключения с использованием операционной системы, соответствующей многозадачности.
Следующим этапом проектировщик должен выбрать систему управления базой данных (СУБД), а также инструментальные средства программного характера. После этого концептуальную модель необходимо перенести в совместимую с выбранной системой управления модель данных. Но нередко это сопряжено с внесением поправок и изменений в концептуальную модель, поскольку не всегда взаимосвязи объектов между собой, отражённые концептуальной моделью, могут быть реализованы средствами данной СУБД.
Это обстоятельство определяет возникновение следующего этапа – появления обеспеченной средствами конкретной СУБД концептуальной модели. Данный шаг соответствует этапу логического проектирования (создания логической модели).
https://youtube.com/watch?v=bwf_vTwwBUg
Наконец, финальным этапом проектирования БД становится физическое проектирование – этап увязки логической структуры и физической среды хранения.
Таким образом, основные этапы проектирования в детализированном виде представлены этапами:
- инфологического проектирования,
- формирования требований к операционной обстановке
- выбора системы управления и программных средств БД,
- логического проектирования,
- физического проектирования
Ключевые из них ниже будут рассмотрены подробнее.![]()
Признаки БД, чем отличаются от электронных таблиц
Любая база данных обладает набором стандартных признаков. Основными из них являются:
- хранение и обработка в вычислительной системе;
- логическая структура;
- наличие схемы или метаданных, которые описывают логическую структуру базы в формальном виде.
Примечание
Первый признак соблюдается строго, остальные могут трактоваться по-разному и иметь неодинаковые степени оценки. Согласно общепринятой практике, к базам данных не относят файловые архивы, интернет-порталы или электронные таблицы.
Рассмотреть базу данных целесообразно на примере Access. Это специальное приложение, в котором хранятся упорядоченные данные, что допускает применение и других приложений (к примеру, Excel). В обоих случаях информация представлена в табличном виде.
Excel включает особые средства, позволяющие работать с упорядоченными данными, позволяет формировать простые базы данных. При внешнем сходстве приложения обладают рядом отличий:
- Excel не предусматривает установку реляционных связей между таблицами. Благодаря связям в Access, исключается ненужное дублирование информации и ошибки при обработке данных. Также допускается совместное использование данных из разных таблиц.
- Access обеспечивает хранение в таблицах нескольких миллионов записей. При этом скорость их обработки сохраняется на высоком уровне.
- Access включает возможность организации одновременной работы с базой данных нескольких десятков пользователей, которые в реальном времени могут видеть изменения, выполненные другими пользователями.
- Данные в Access сохраняются автоматически после завершения редактирования текущей записи. В случае Excel для этого нужно запустить команду «Сохранить».
- Таблицы в Access характеризуются заранее предопределенной жесткой структурой. Невозможно в один столбец записать разные типы данных или форматировать отдельные ячейки.
- Прямо в таблице базы данных Access нельзя выполнять вычисления, подобные действия реализуются с применением запросов.
Вывод: Excel целесообразно использовать для создания компактных баз данных, которые могут поместиться на одном рабочем листе. Excel обладает рядом значительных ограничений для ведения полноценной базы данных, но может успешно использоваться для анализа данных благодаря достаточному математическому аппарату.
Определение атрибутов
Атрибут представляет свойство, описывающее сущность. Атрибуты часто бывают числом, датой или текстом. Все данные, хранящиеся в атрибуте, должны иметь одинаковый тип и обладать одинаковыми свойствами.
В физической модели атрибуты называют колонками.
После определения сущностей необходимо определить все атрибуты этих сущностей.
На диаграммах атрибуты обычно перечисляются внутри прямоугольника сущности. На рисунке вы найдете пример базы данных «Дома», только теперь для сущностей из этой базы определены некоторые атрибуты.
Для каждого атрибута определяется тип данных, их размер, допустимые значения и любые другие правила. К их числу относятся правила обязательности заполнения, изменяемости и уникальности.
Правило обязательности заполнения определяет, является ли атрибут обязательной частью сущности. Если атрибут является необязательной частью сущности, то он может принимать NULL-значение, иначе — нет.
Также вы должны определить, является ли атрибут изменяемым. Значения некоторых атрибутов не могут измениться после создания записи.
И, наконец, вам нужно определить, является ли атрибут уникальным. Если это так, то значения атрибута не могут повторяться.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры:
— название;
— тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Каковы преимущества использования многозначного поля поиска в Access?
Самая важная вещь об использовании поля для несколько ценности должны иметь несколько связанных данных из одного места , это само по себе является преимуществом. Однако это не единственное преимущество полей такого типа. Среди прочего, он предлагает идеальную структуру для разработки баз данных, которые затем можно использовать в Windows SharePoint Services .
Этот инструмент Windows использует тип многозначных полей поиска. Пока вы собираетесь переместить таблицу или хотите связать ее в одном из ее списков, совместимость будет идеальной . De плюс, если вам нужно ввести список выбора небольшого размера в вашей базе данных лучшим решением будет поле с несколькими значениями. Тем более, что вы сможете использовать эту функцию, не обладая глубокими знаниями программирования.
У вас также будет небольшая связь между данными без необходимости обучения более сложной базы данных. Cela signifie que у вас будет научный сотрудник который проведет вас через процесс без осложнений, так что создание и использование многозначного столбца станет очень простой задачей.
База данных: назначение, понятие, классификация
В нашей статье мы не будем углубляться в математические теории и законы, описывающие базы данных, т. к. подробности всегда можно узнать из специализированной литературы. Но принципы работы БД, особенности управления, терминологию, устройство, назначение, а также такое понятие, как классификация баз данных, сегодня должен знать каждый, кто так или иначе сталкивается с ИТ-сферой, а уж тем более в ней работает.
Итак, самое простое определение баз данных звучит следующим образом: база данных — это упорядоченное хранение информации в систематизированном виде. При этом виды упорядочивания, хранения, систематизации и управления могут быть разные. И каждый из них отвечает определённым требованиям либо предназначен для выполнения определённых действий.
Правило 1: Какова природа приложения (OLTP или OLAP)?
Когда вы начинаете разработку базы данных, первое, что нужно определить — природа приложения, которое вы разрабатываете: будет оно транзакционное или аналитическое? Многие разработчики находят применение трем нормальным формам не задумываясь о характере приложения, а затем у них возникают вопросы о том, как получить информацию о производительности и настройке. Как уже сказано выше, есть два вида приложений: основанные на транзакциях и аналитические. Давайте разберемся, что это за типы.
Транзакционный: в этом типе приложения ваш конечный пользователь больше интересуется четырьмя функциями CRUD: созданием, чтением, обновлением и удалением записей. Официальное название такой базы данных — OLTP.
Аналитический: в таких приложениях ваш конечный пользователь больше заинтересован в анализе, отчетности, прогнозировании и т. д. Эти типы баз данных имеют меньшее количество вставок и обновлений. Основная цель здесь — собрать и проанализировать данные как можно быстрее. Официальное название такой базы данных — OLAP.
Если вы считаете, что вставки, обновления и удаления будут использоваться чаще, то создайте нормализованный дизайн таблицы, или же создайте плоскую денормализованную структуру базы данных.
Ниже приведена простая диаграмма, показывающая, как имена и адрес в левой части составляют простую нормализованную таблицу. С помощью денормализованной структуры мы создали структуру плоской таблицы.
Логическое проектирование БД
Логическая структура БД должна соответствовать логической модели предметной области и учитывать связь модели данных с поддерживаемой СУБД
Поэтому этап начинается с выбора модели данных, где важно учесть её простоту и наглядность
Предпочтительнее, когда естественная структура данных совпадает с представляющей её моделью. Так, например, если в данные представлены в виде иерархической структуры, то и модель лучше выбирать иерархическую. Однако на практике такой выбор чаще определяется системой управления БД, а не моделью данных. Поэтому концептуальная модель фактически транслируется в такую модель данных, которая совместима с выбранной системой управления БД.
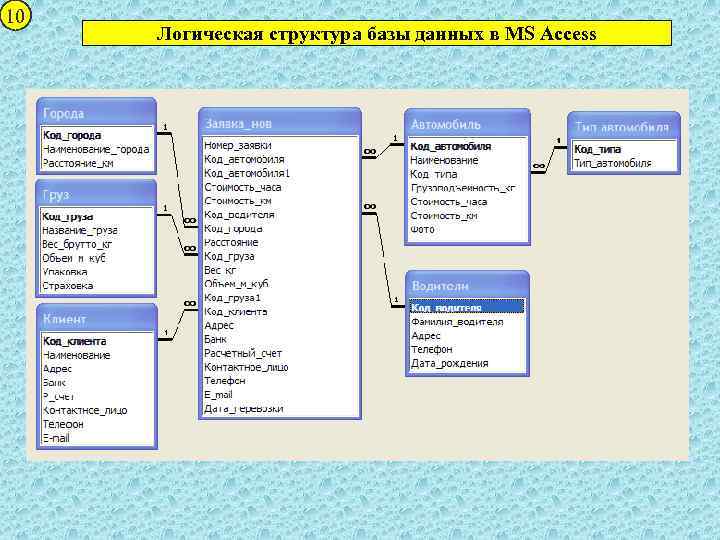
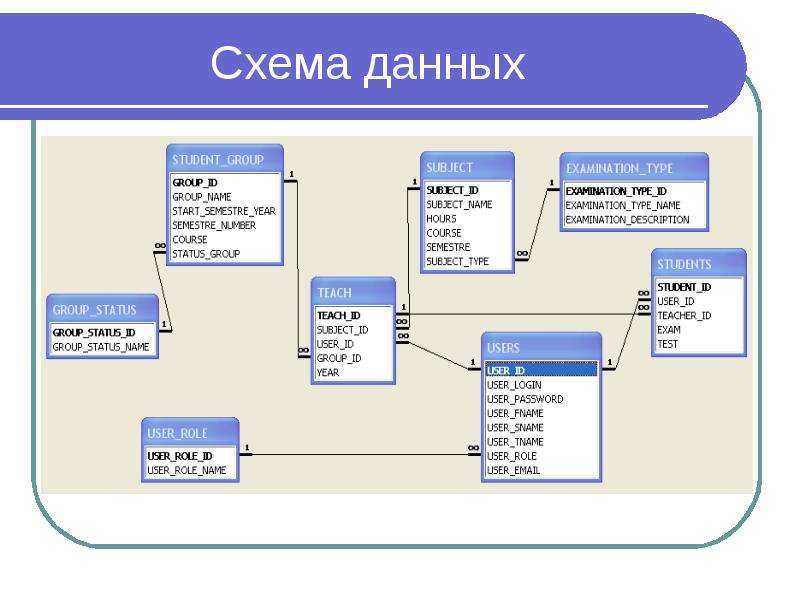
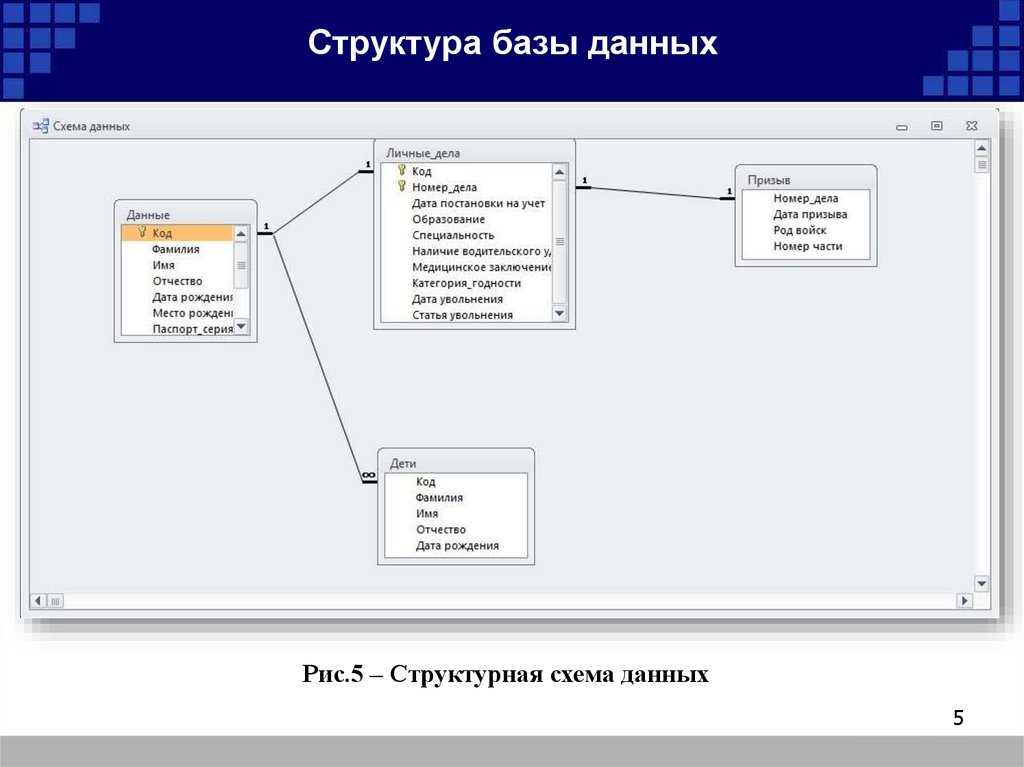
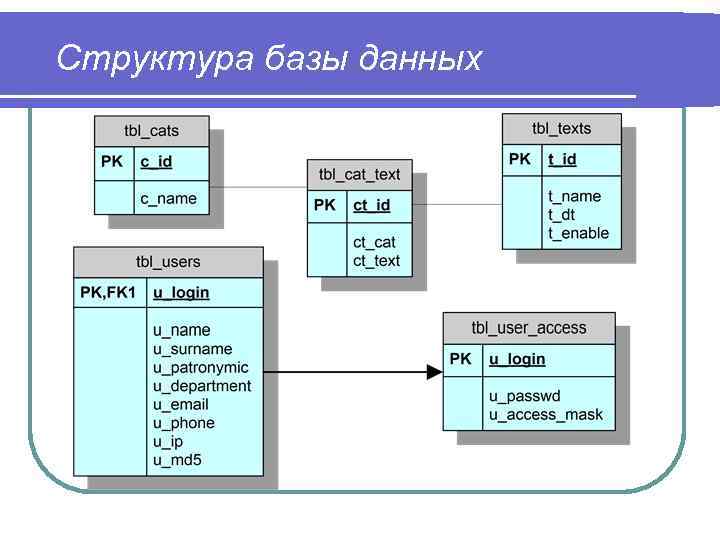
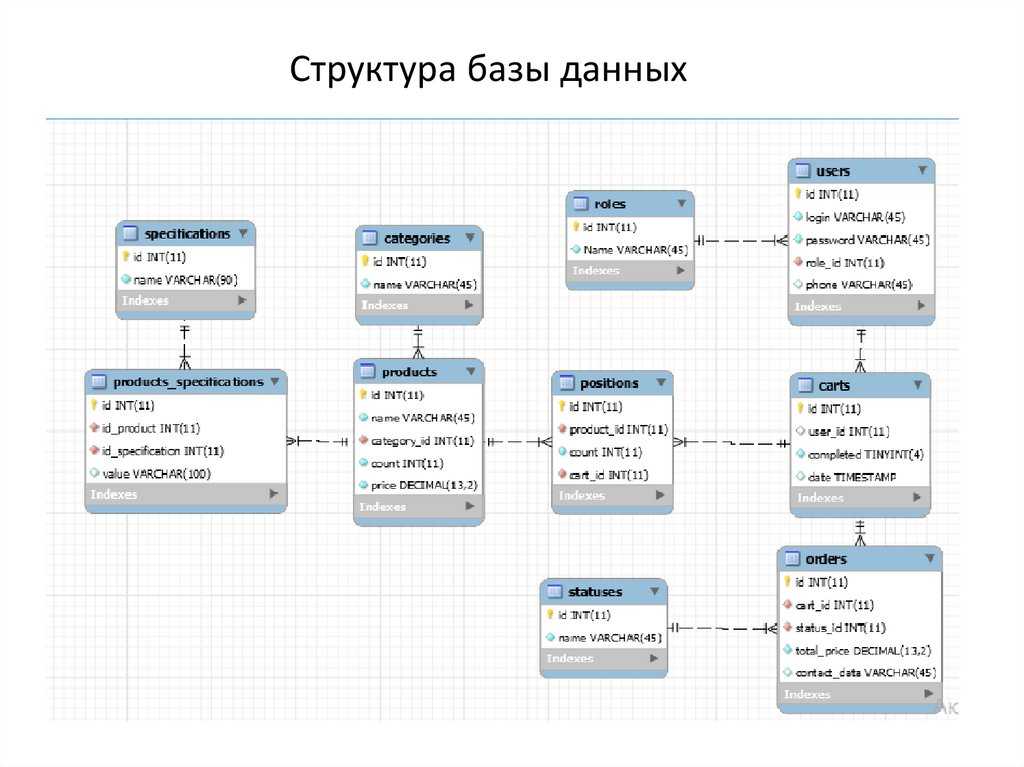
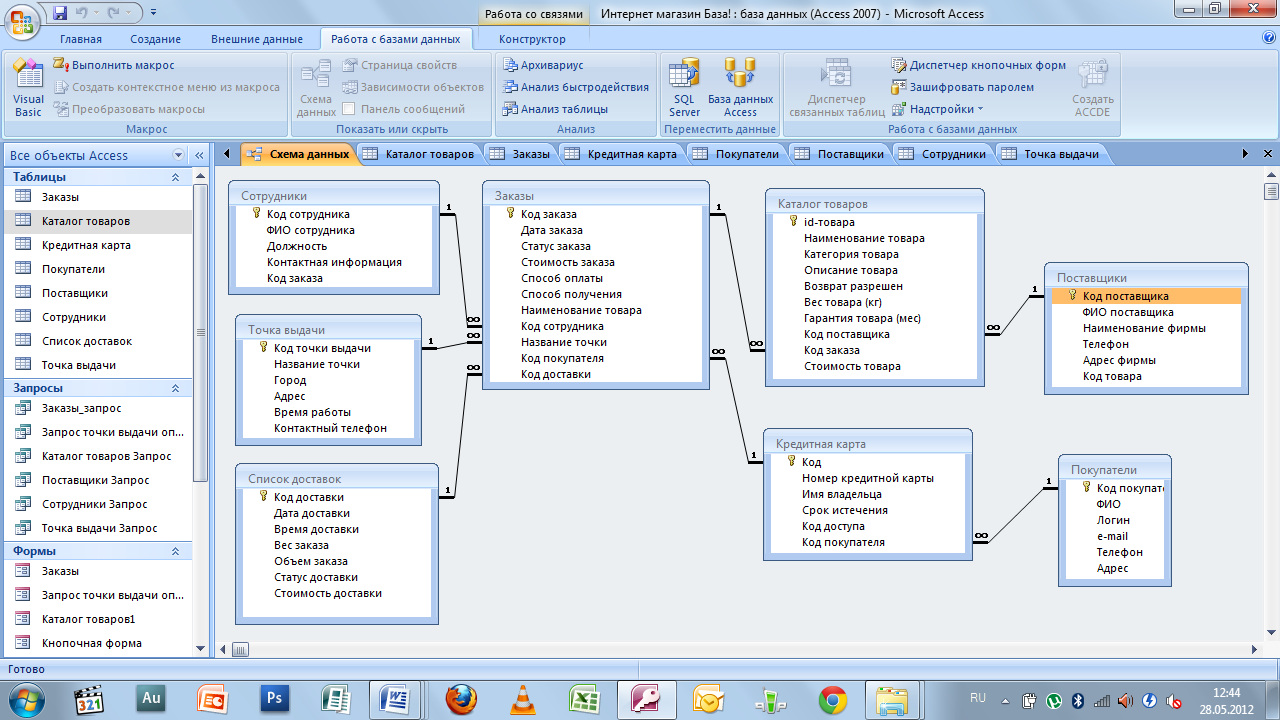
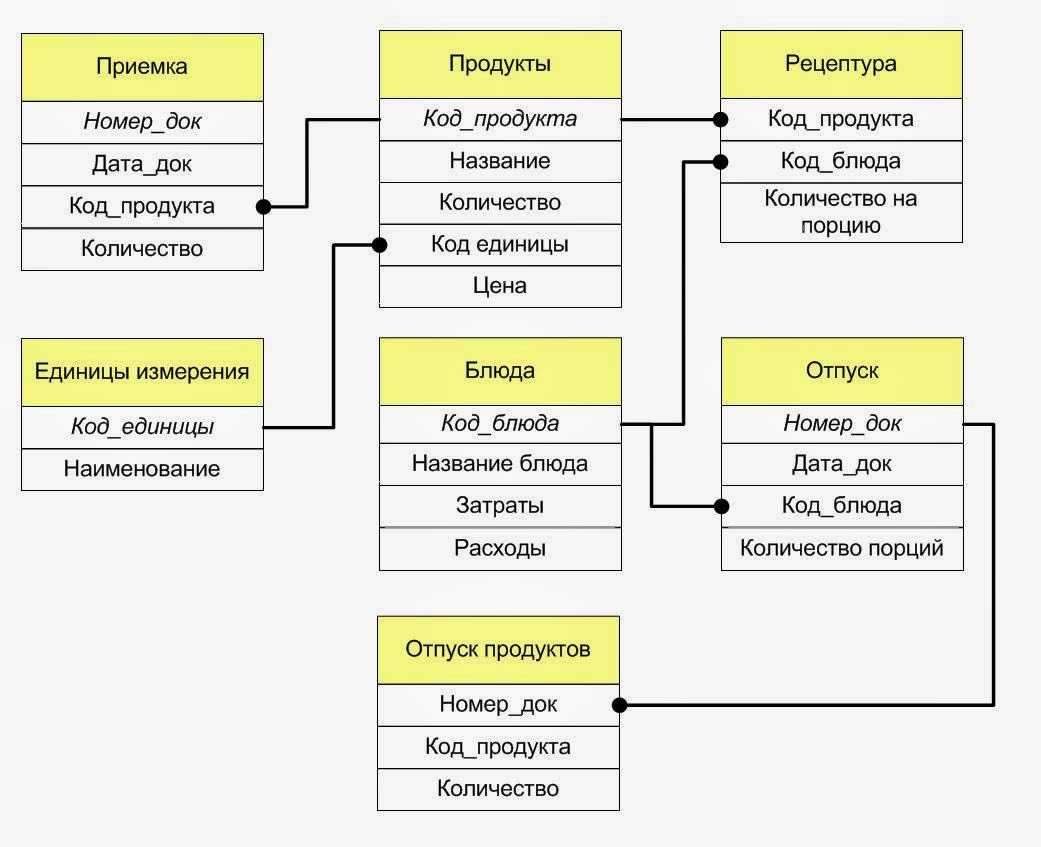
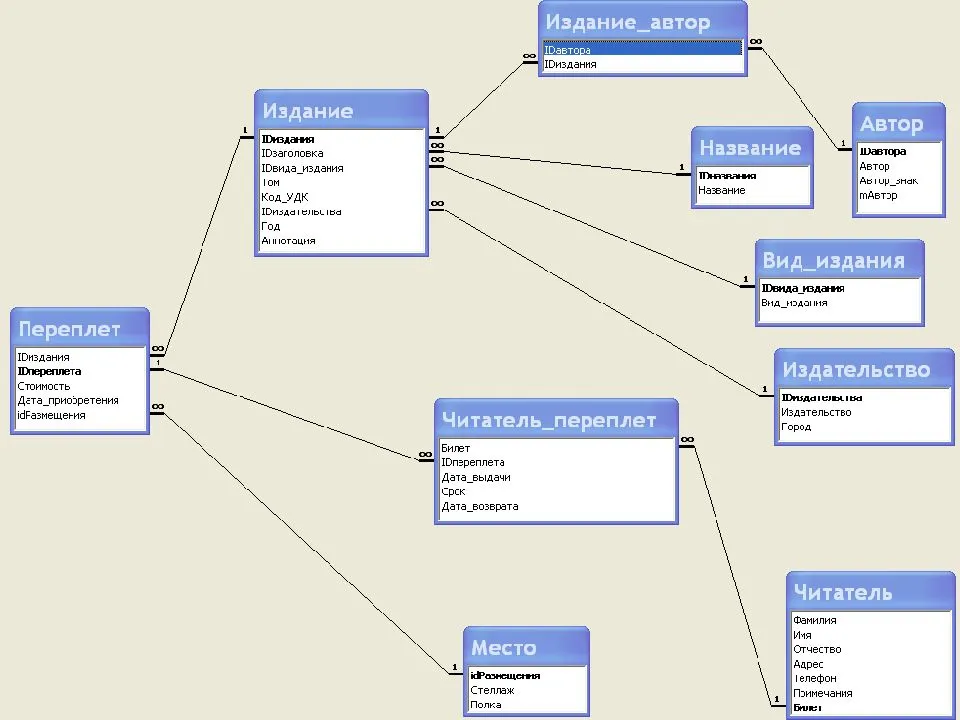
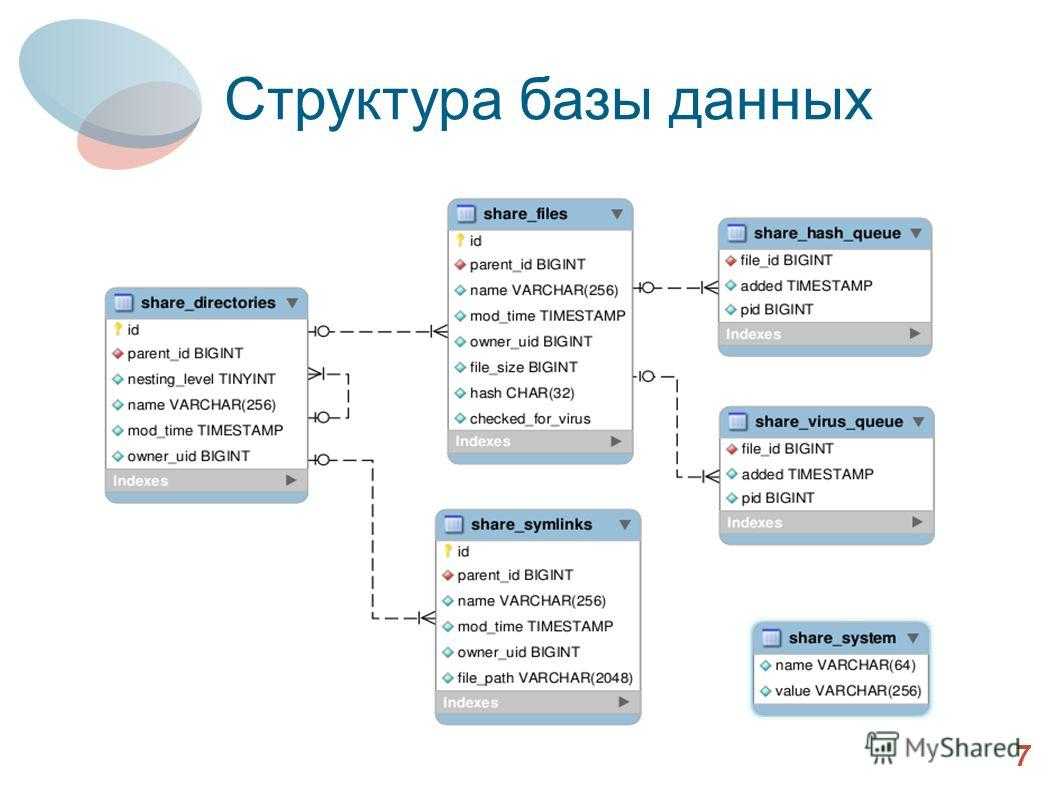
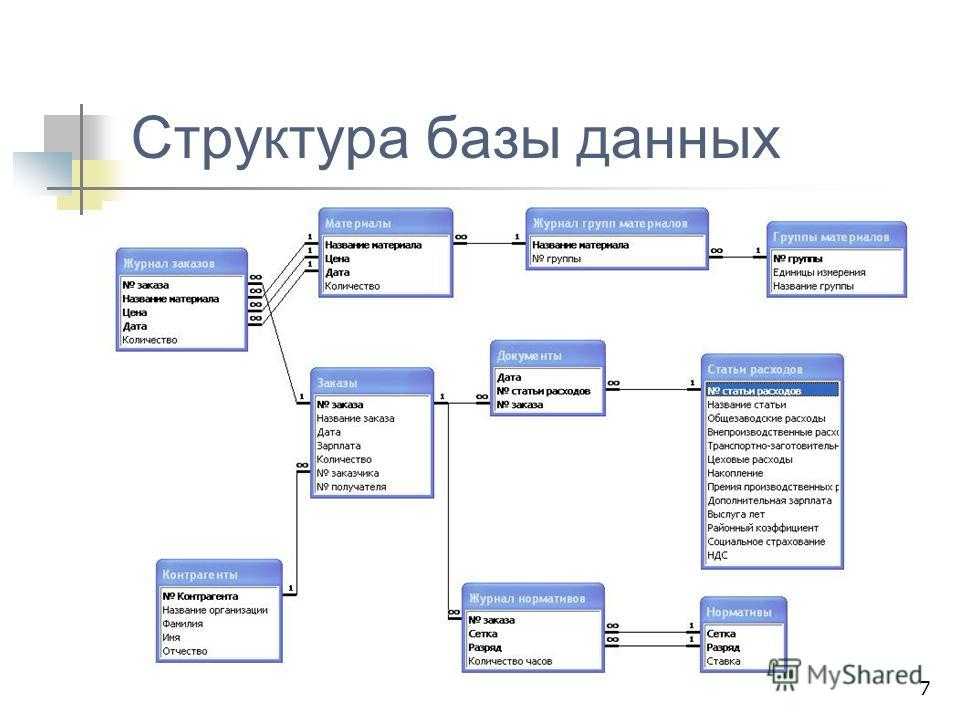
Здесь тоже находит отражение природа проектирования, которая допускает возможность (или необходимость) вернуться к концептуальной модели для её изменения в случае, если отражённые там взаимосвязи между объектами (или атрибуты объектов) не удастся реализовать средствами выбранной СУБД.
По завершению этапа должны быть сформированы схемы баз данных обоих уровней архитектуры (концептуального и внешнего), созданные на языке определения данных, поддерживаемых выбранной СУБД.
![]() Схемы базы данных формируются с помощью одного из двух разнонаправленных подходов:
Схемы базы данных формируются с помощью одного из двух разнонаправленных подходов:
- либо с помощью восходящего подхода, когда работа идёт с нижних уровней определения атрибутов, сгруппированных в отношения, представляющие объекты, на основе существующих между атрибутами связей;
- либо с помощью обратного, нисходящего, подхода, применяемого при значительном (до сотен и тысяч) увеличении числа атрибутов.
Второй подход предполагает определение ряда высокоуровневых сущностей и их взаимосвязей с последующей детализацией до нужного уровня, что и отражает, например, модель, созданная на основе метода «сущность-связь». Но на практике оба подхода, как правило, комбинируются.
Выдержки из книги Чистый код
Недавно я прочитал книгу «Чистый код» Роберта Мартина (Robert Cecil Martin). В ней описываются принципы организации и форматирование исходного кода программы так, чтобы в дальнейшем было легко поддерживать такой код.
Эта книга является библией для многих программистов, но вот в среде программистов 1С, к сожалению, не очень распространено чтение подобной фундаментальной литературы.
Книга более 400 страниц и так много порой лениво читать, да и времени всегда не хватает. По этому я решил выделить в виде цитирования по разделам самые важные моменты. А также снабдил текст своими примерами кода.
Анализ нормальных форм
В базе данных создаваемой информационной системы все таблицы должны находиться в третьей нормальной форме.
Все 9 таблиц базы данных находятся по меньшей мере в первой нормальной форме, так как:
- определены все ключевые атрибуты и ни одно из ключевых полей не пусто;
- ни одна из строк не содержит ни в одном своем поле более одного значения (атомарность);
- все атрибуты зависят от первичного ключа.
Чтобы избежать невыполнения требований второй нормальной формы в таблице AVAILABILITY, создан первичный ключ этой таблицы, а ключи, связывающую эту таблицу с таблицами PHARMACY и PREPARATION, сделаны внешними ключами, сочетание значений которых должно быть уникальным. Таким образом, невозможна функциональная зависимость неключевого атрибута от части первичного ключа – идентификатора аптеки или идентификатора препарата.
Следовательно, все таблицы находятся и во второй нормальной форме.
Во всех таблицах не обнаружено и транзитивной зависимости – функциональной зависимости одного неключевого атрибута от другого неключевого атрибута. Следовательно, все 9 таблиц базы данных находятся в третьей нормальной форме.
SQLite
Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Структура базы данных: построение блоков
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.
![]()
Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:
![]()
При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ (PK) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете над приложениями OLTP, избавление от производных столбцов было бы хорошей мыслью, если только не существует веской причины для повышения производительности. В случае работы с OLAP, где нам нужно производить много сумм и вычислений, эти поля необходимы для повышения производительности.
На приведенном выше рисунке вы можете увидеть, как среднее поле зависит от меток и объекта. Это также одна из форм избыточности. Подумайте, действительно ли нужны поля, полученные из других полей?
Это правило также выражено в 3-й нормальной форме:«Ни один столбец не должен зависеть от других столбцов непервичного ключа». Не стоит применять это правило вслепую, так как не всегда избыточные данные плохие. Если избыточные данные являются расчетными данными, проанализируйте ситуацию, а затем решите, хотите ли вы реализовать третью нормальную форму.
§ 2. Работа с таблицами базы данных
2.3. Связывание таблиц базы данных
|
Связи между таблицами многотабличной БД позволяют обеспечить объединение данных нескольких таблиц. Логическая структура базы данных (таблицы и связи между ними) запоминается в Схеме данных. Связь между таблицами БД осуществляется путем сопоставления данных в полях, по которым связываются таблицы, — полях связи . Перед созданием связей необходимо закрыть все таблицы. Создавать или изменять связи между открытыми таблицами нельзя. Виды связей: 1. Один ко многим. Каждой записи в одной таблице могут соответствовать несколько записей в другой таблице. 2. Многие ко многим. Каждой записи в одной таблице могут соответствовать несколько записей в другой таблице и наоборот. 3. Один к одному. Каждой записи в одной таблице может соответствовать только одна запись в другой таблице. Обычно это связь между двумя ключевыми полями. При установлении связи между таблицами поля связи не обязательно должны иметь одинаковые названия. Однако у них должен быть один и тот же тип данных. Исключением является случай, когда ключевое поле относится к типу Счетчик. Поле типа Счетчик можно связать с полем числового типа, если формат данных в этих полях совпадает. Это же правило действует в случае, если оба связываемых поля являются числовыми. Если после установления связи открыть таблицу, от которой идет связь, то в открывшемся окне видны знаки , расположенные в левой части записей . Их присутствие говорит о наличии связи ключевого поля таблицы «Города» с другой таблицей. После щелчка на знаке откроется вложенная таблица, содержащая те записи таблицы, значение поля которых равно величине одноименного поля записи таблицы «Города». |
Пример 2.17. Создание связи. 1. На вкладке Работа с базами данных выбрать кнопку Схема данных: Появится диалоговое окно: 2. В окне дважды щелкнуть по названиям таблиц, которые необходимо связать, или щелкнуть по названию таблицы и нажать кнопку Добавить. 3. Закрыть окно Добавление таблицы. 4. Перетащить поле связи из одной таблицы на поле связи в другой. Часто связывают ключевое поле (выделенное полужирным) одной таблицы с аналогичным полем другой таблицы. Появится окно Изменение связей: Убедиться, что в каждом из столбцов этого окна отображаются названия нужных полей. При необходимости их можно изменить. 5. Задать параметры связи: 6. Нажать кнопку . 7. Результат: Пример 2.18. Просмотр данных в связанных таблицах. |
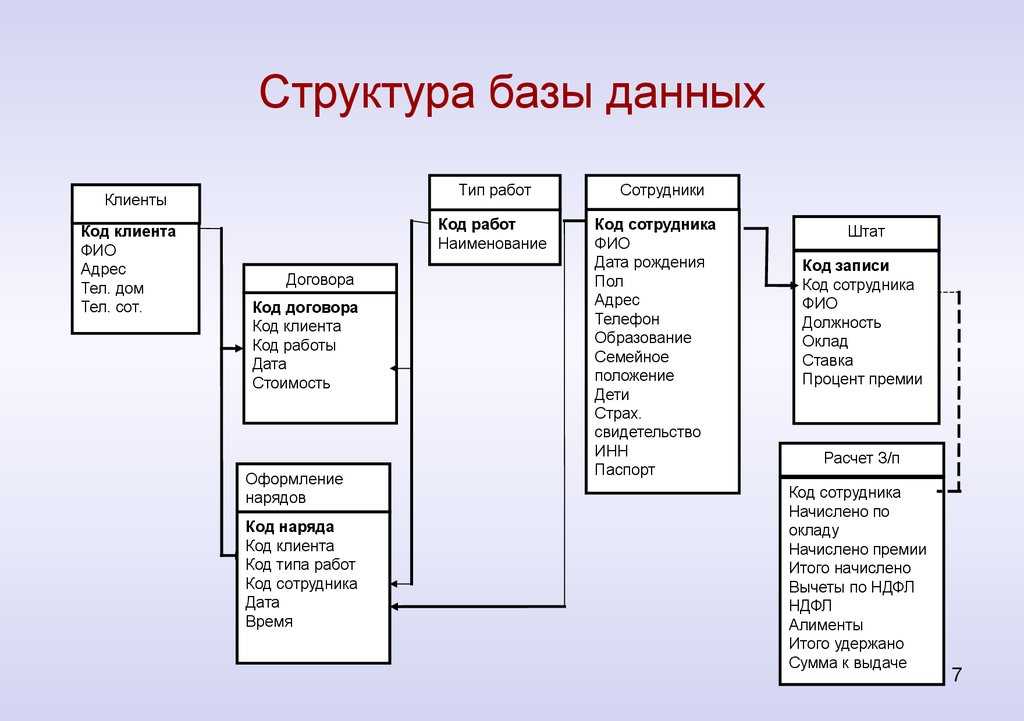
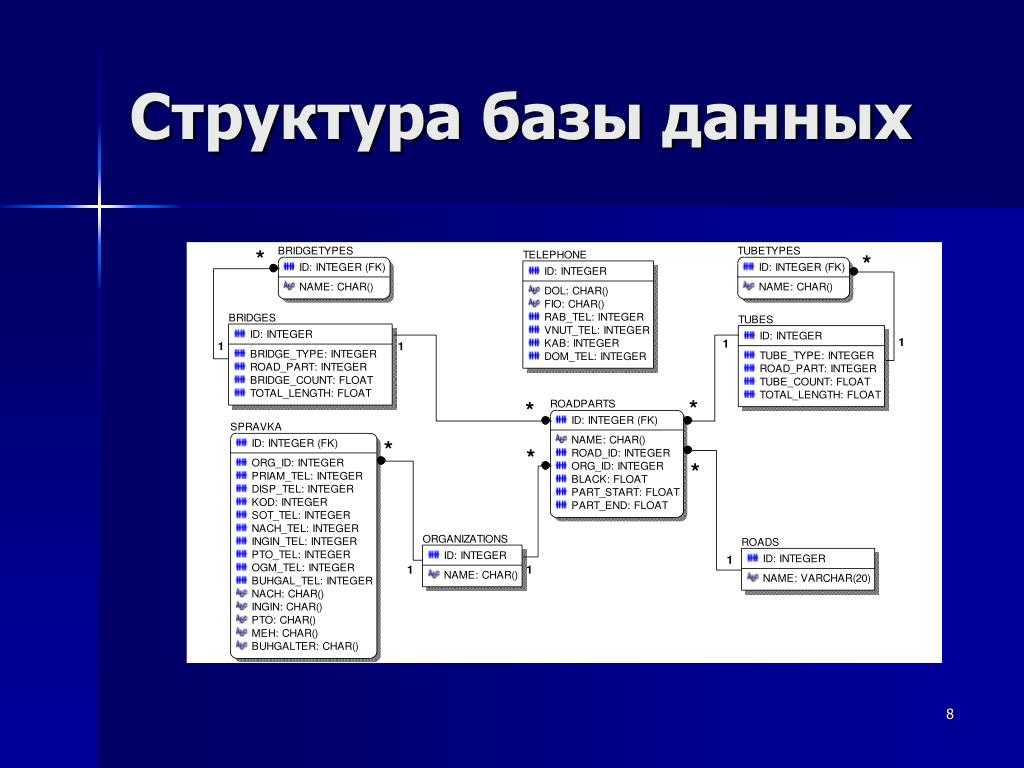
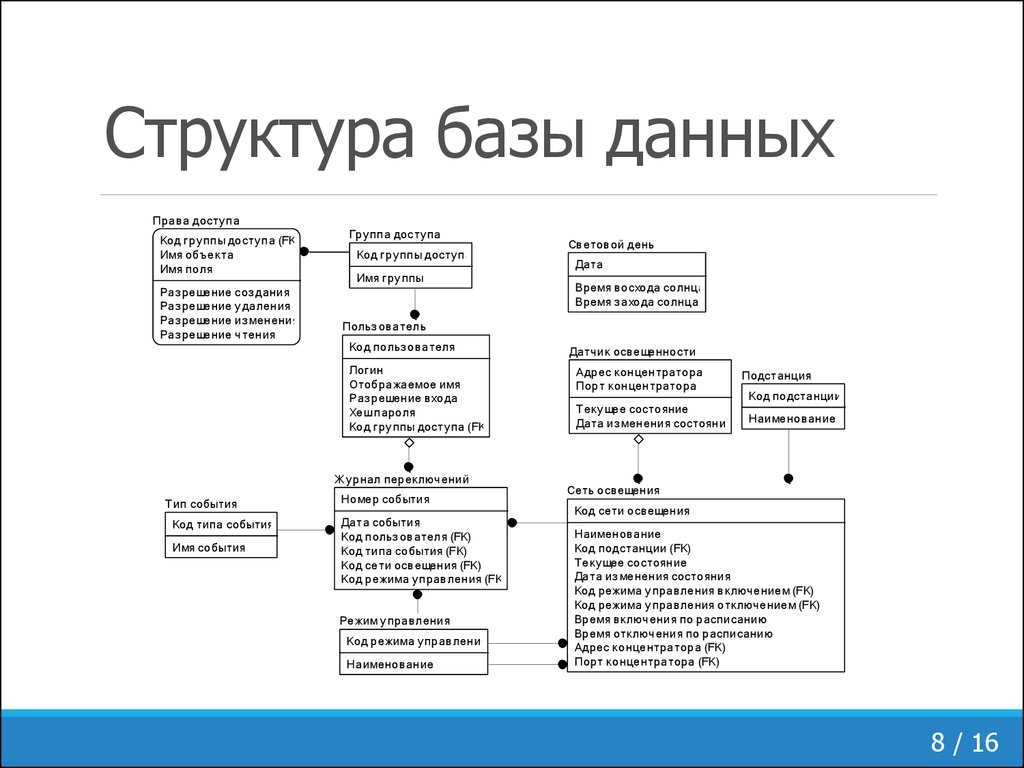
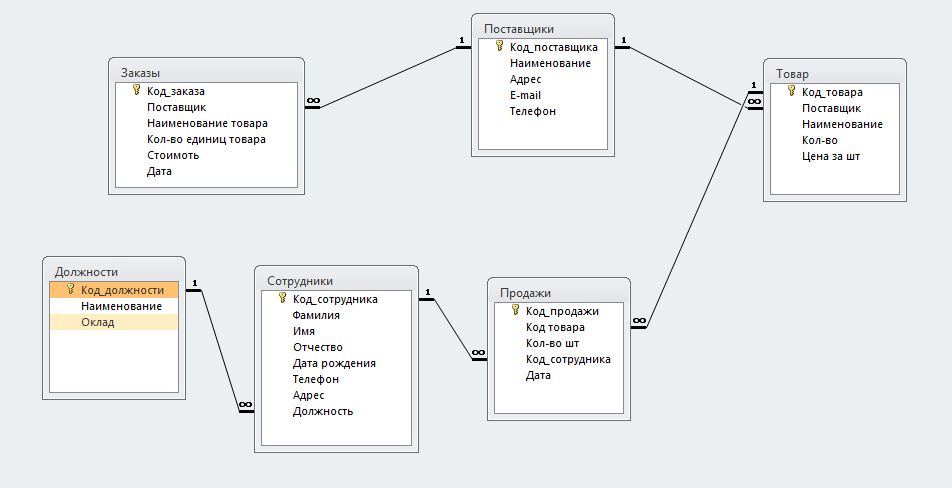
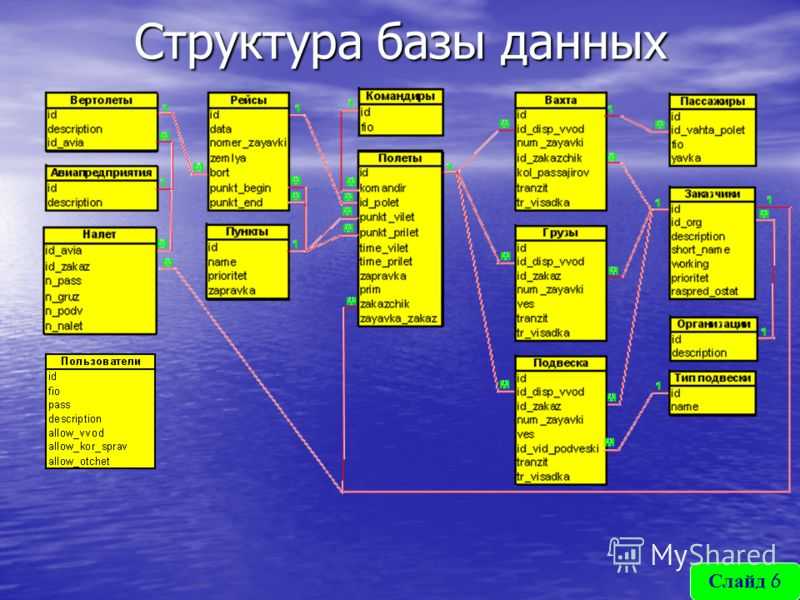
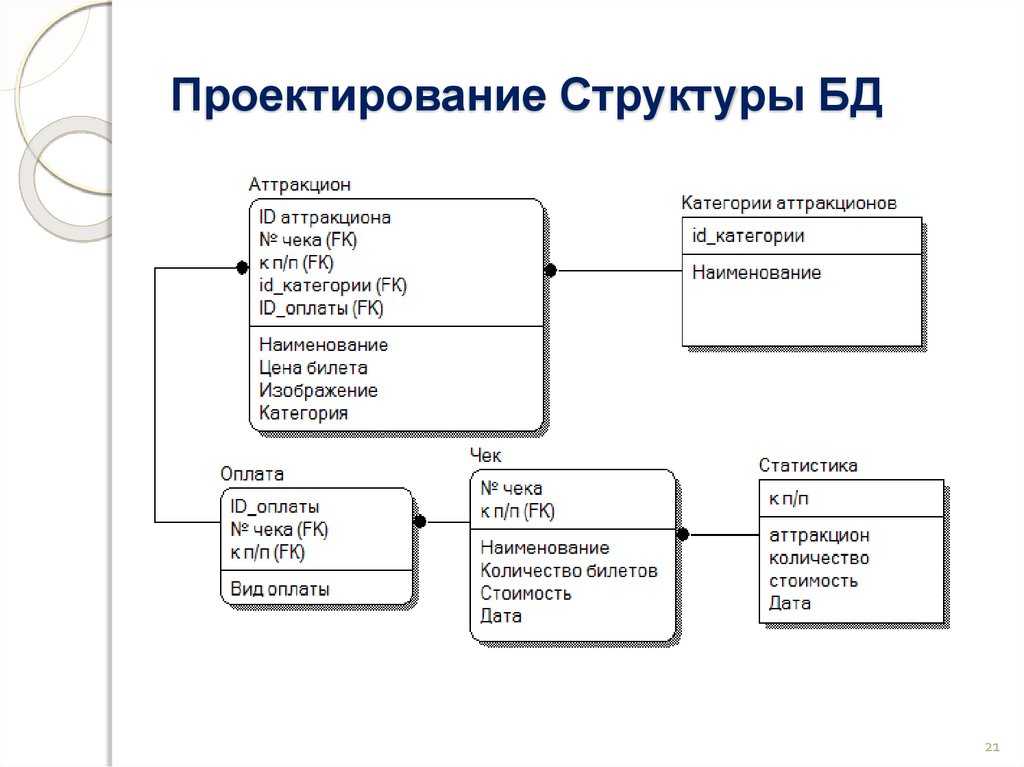
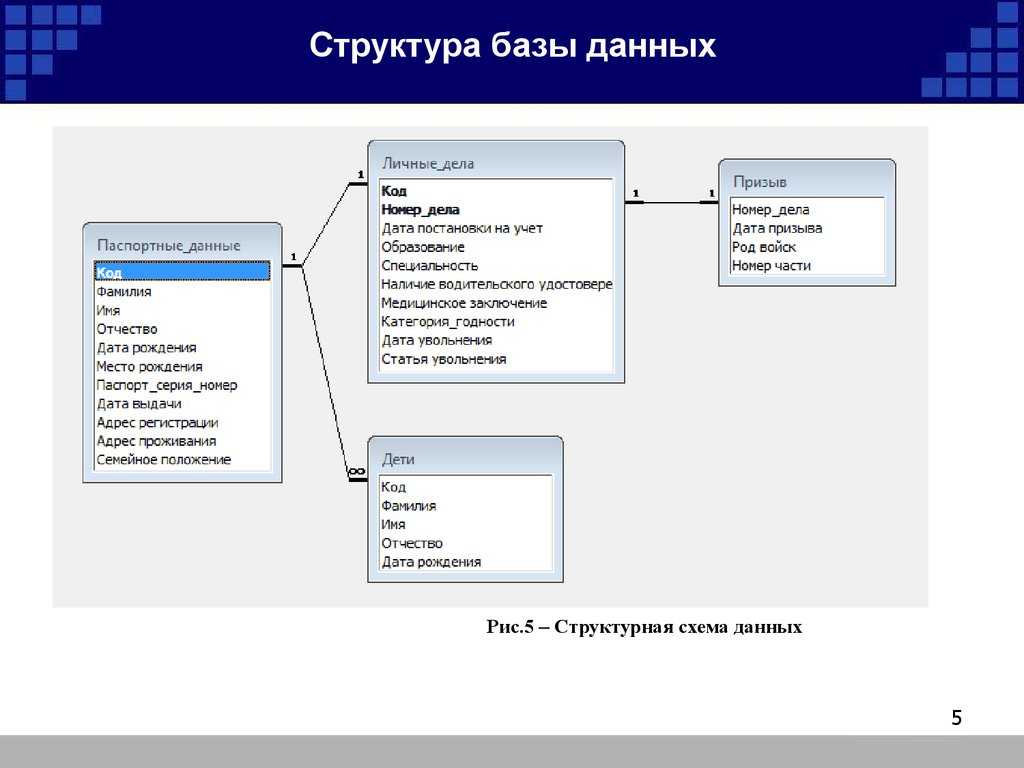
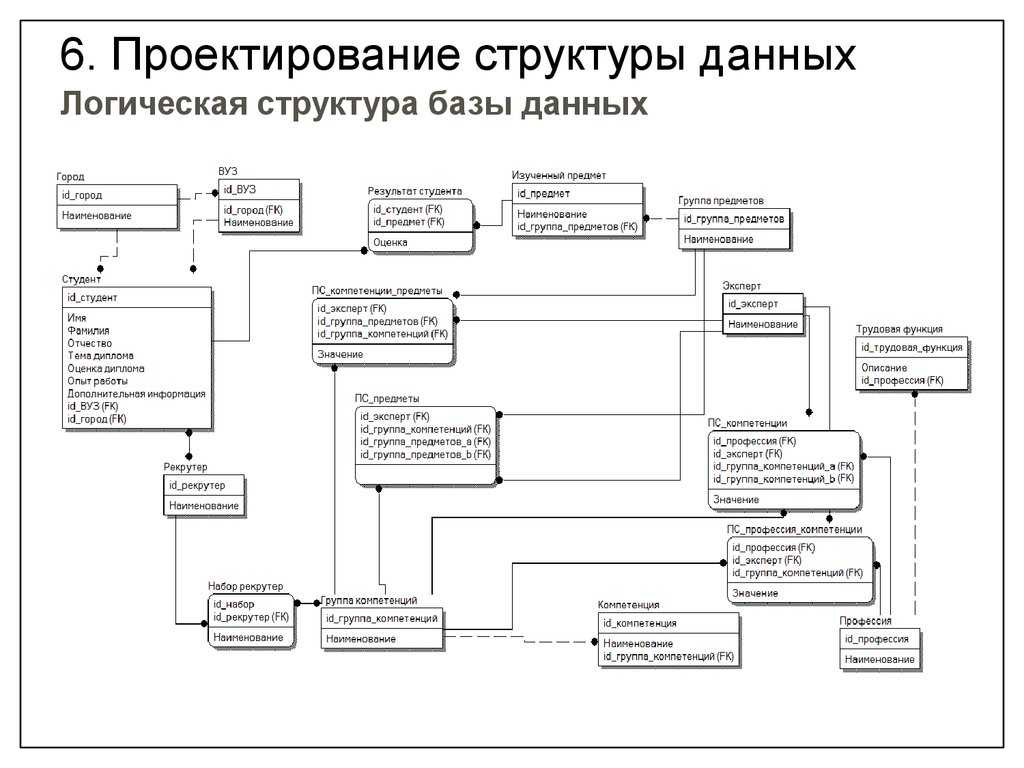
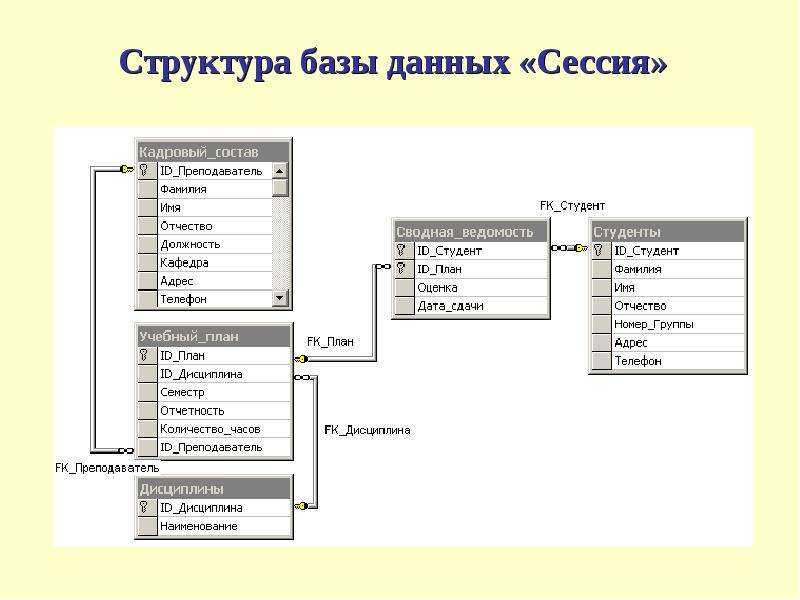
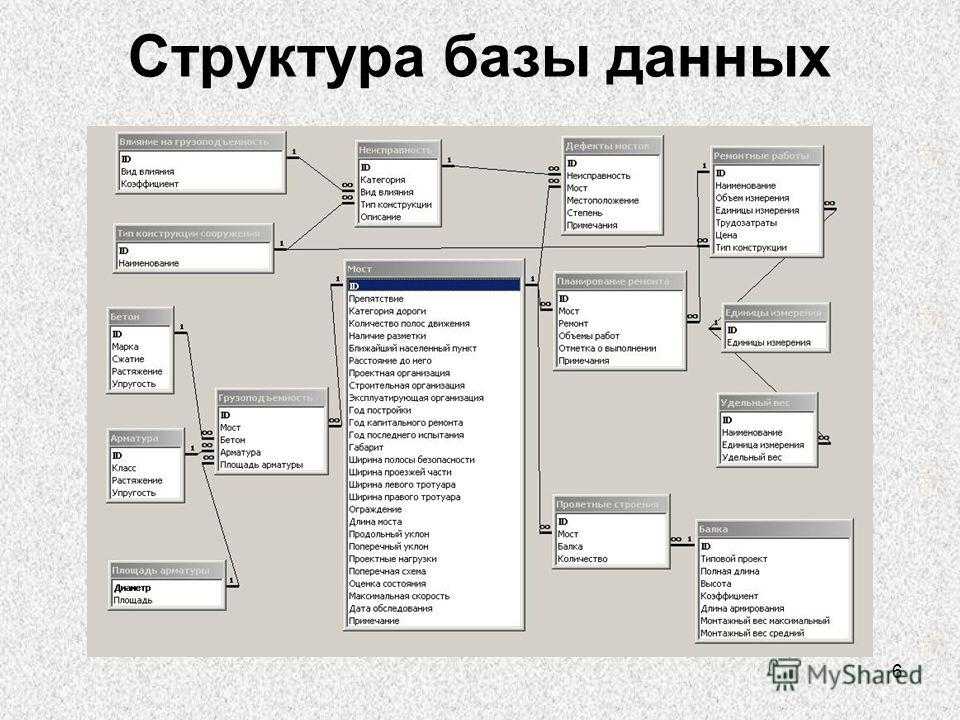
Инфологическое проектирование
Идентификация сущностей составляет смысловую основу инфологического проектирования. Сущность здесь – это такой объект (абстрактный или конкретный), информация о котором будет накапливаться в системе. В инфологической модели предметной области в понятных пользователю терминах, которые не зависят от конкретной реализации БД, описывается структура и динамические свойства предметной области. Но термины, при этом берутся в типовых масштабах. То есть, описание выражается не через отдельные объекты предметной области и их взаимосвязи, а через:
- описание типов объектов,
- ограничения целостности, связанные с описанным типом,
- процессы, приводящие к эволюции предметной области – переходу её в другое состояние.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
- Функциональный подход отталкивается от поставленных задач. Функциональным он называется, потому что применяется, если известны функции и задачи лиц, которые с помощью проектируемой базы данных будут обслуживать свои информационные потребности.
- Предметный подход во главу угла ставит сведения об информации, которая будет содержаться в базе данных, при том, что структура запросов может не быть определена. В этом случае в исследованиях предметной области ориентируются на её максимально адекватное отображение в базе данных в контексте полного спектра предполагаемых информационных запросов.
- Комплексный подход по методу «сущность-связь» объединяет достоинства двух предыдущих. Метод сводится к разделению всей предметной области на локальные части, которые моделируются по отдельности, а затем вновь объединяются в цельную область.
Поскольку использование метода «сущность-связь» является комбинированным способом проектирования на данном этапе, он чаще других становится приоритетным.
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
https://youtube.com/watch?v=DafbjpQ-eu0
Зависимость сущностей отражается в разделении их на сильные (базовые, родительские) и слабые (дочерние). Сильная сущность (например, читатель в библиотеке) может существовать в БД сама по себе, а слабая сущность (например, абонемент этого читателя) «привязывается» к сильной и отдельно не существует.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений.При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа, бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
Типы схемы базы данных
Существует два основных типа схемы базы данных, которые определяют разные части схемы: логическую и физическую.
Логический
Схема логической базы данных представляет, как данные организованы в виде таблиц. Он также объясняет, как атрибуты из таблиц связаны друг с другом. В разных схемах используется разный синтаксис для определения логической архитектуры и ограничений.
Чтобы создать логическую схему базы данных, мы используем инструменты для иллюстрации отношений между компонентами ваших данных. Это называется моделированием сущности-отношения (моделирование ER). Он определяет отношения между типами сущностей.
Схема ниже представляет собой очень простую модель ER, которая показывает логический поток в базовом коммерческом приложении. Он объясняет продукт покупателю, который его покупает.
![]()
Идентификаторы в каждом из трех верхних кружков указывают первичный ключ объекта. Это идентификатор, который однозначно определяет запись в документе или таблице. FK на схеме — это внешний ключ. Это то, что связывает отношения от одной таблицы к другой.
- Первичный ключ: идентифицировать запись в таблице
- Внешний ключ: первичный ключ для другой таблицы
Модели сущностей-отношений могут быть созданы всевозможными способами, и существуют онлайн-инструменты, которые помогают в построении диаграмм, таблиц и даже SQL для создания вашей базы данных из существующей модели ER. Это поможет создать физическое представление схемы вашей базы данных.
Физический
Схема физической базы данных представляет, как данные хранятся на диске. Другими словами, это реальный код, который будет использоваться для создания структуры вашей базы данных. Например, в MongoDB с мангустом это примет форму модели мангуста. В MySQL вы будете использовать SQL для создания базы данных с таблицами.
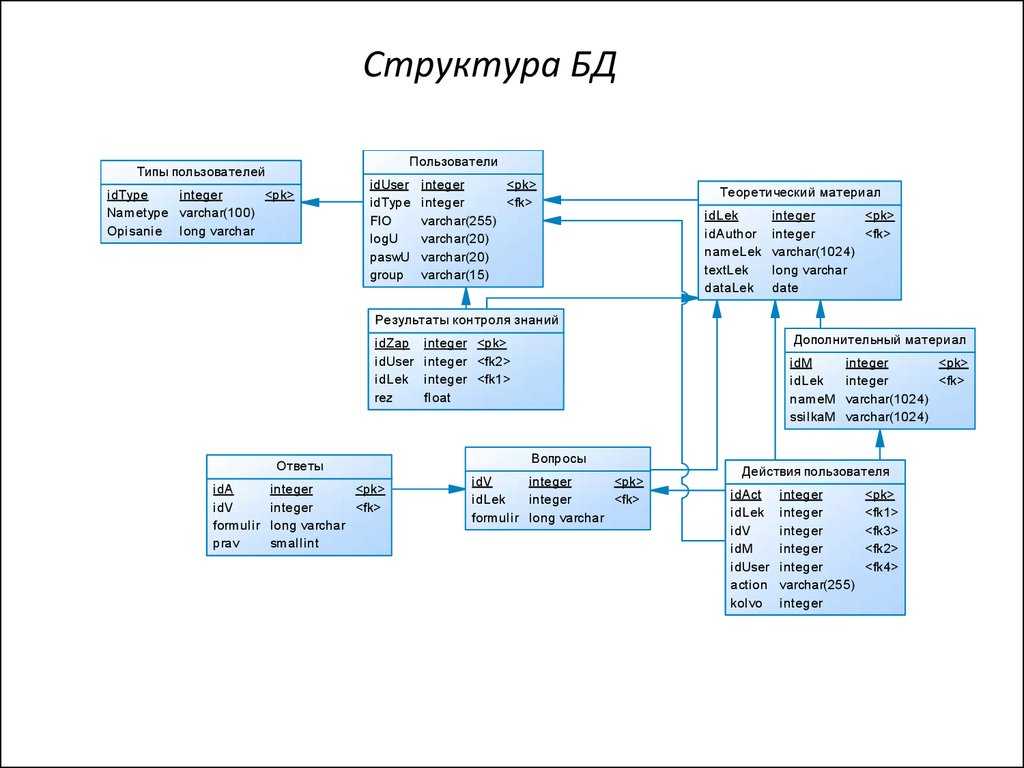
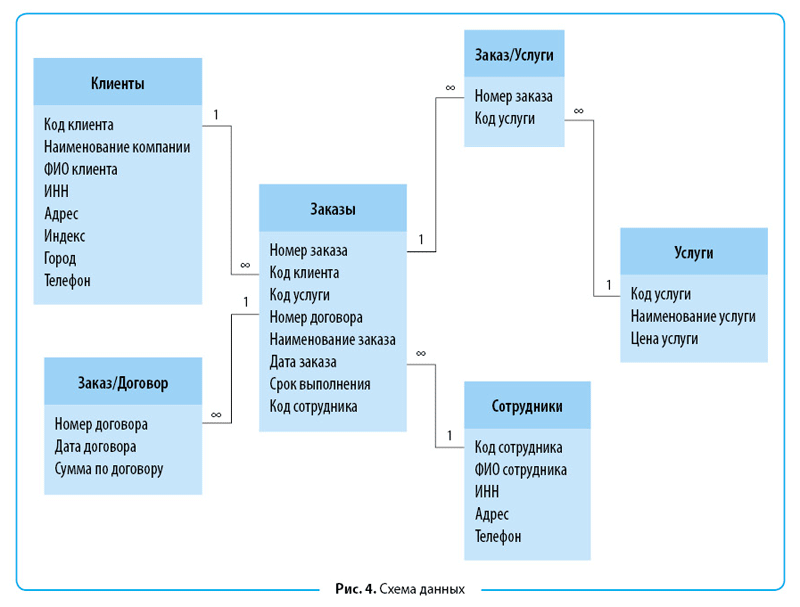
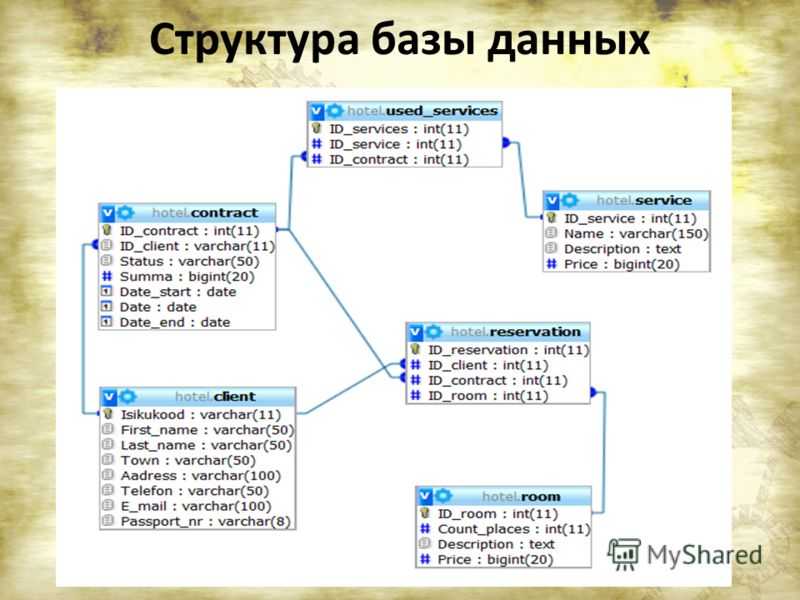
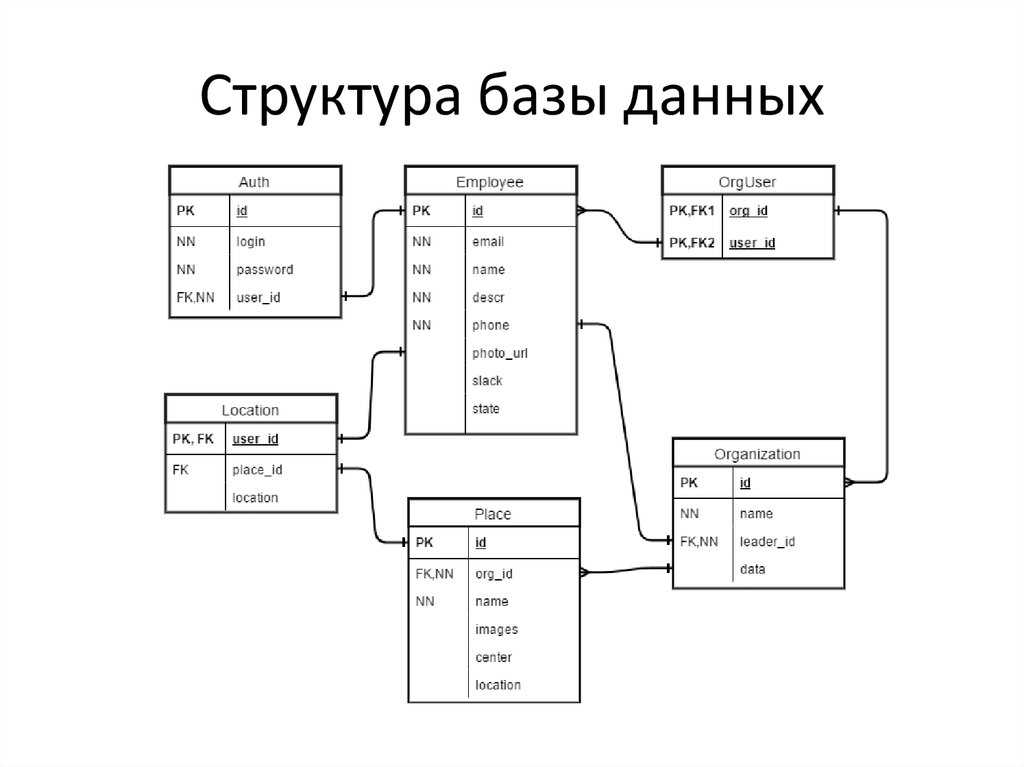
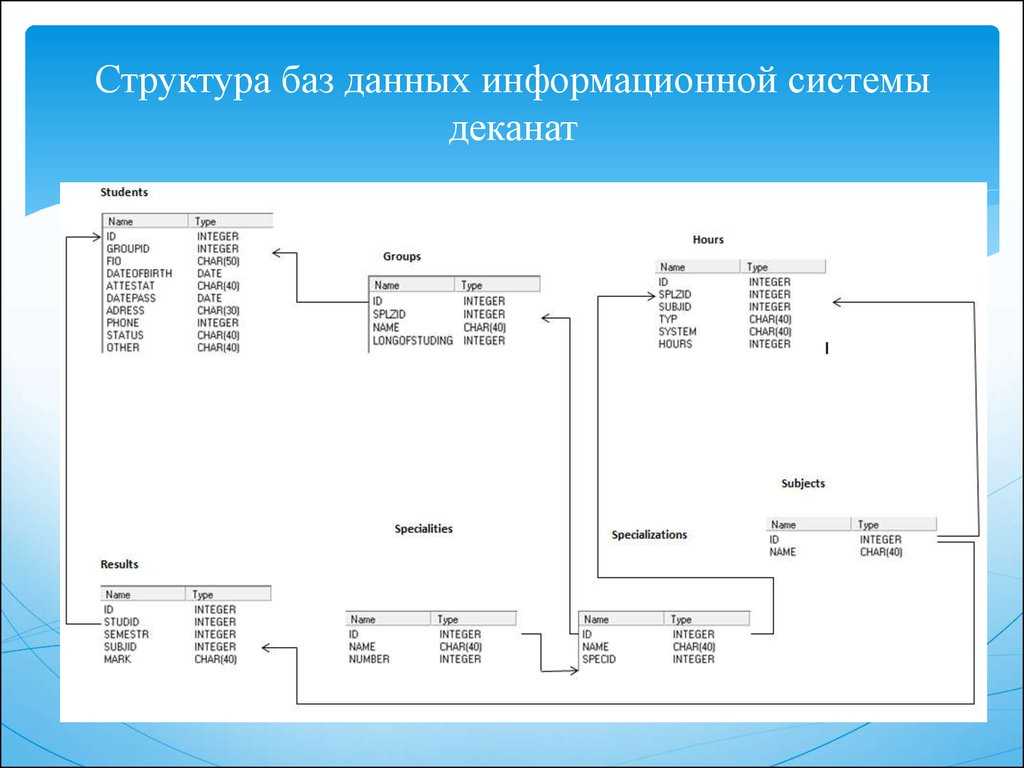
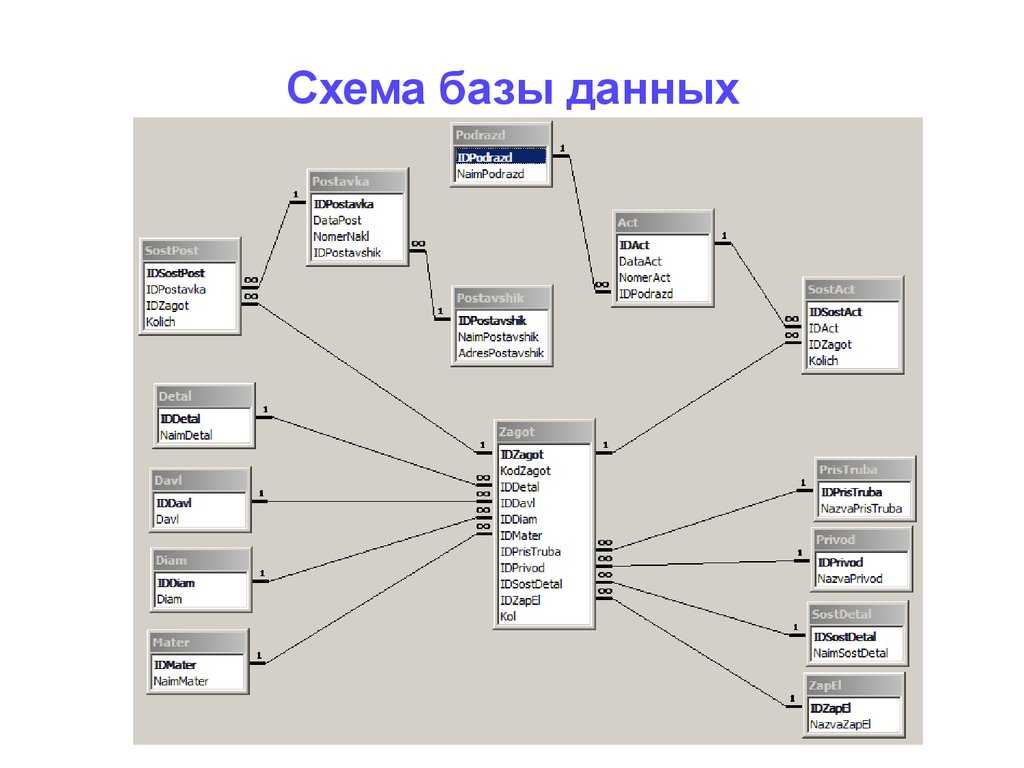

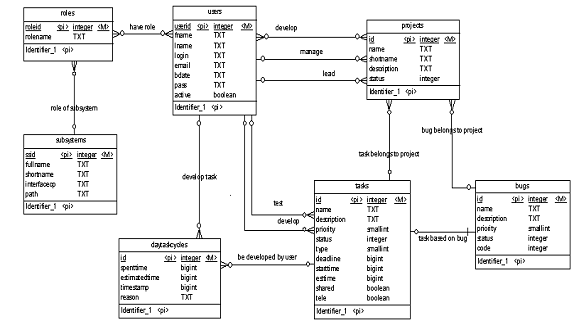
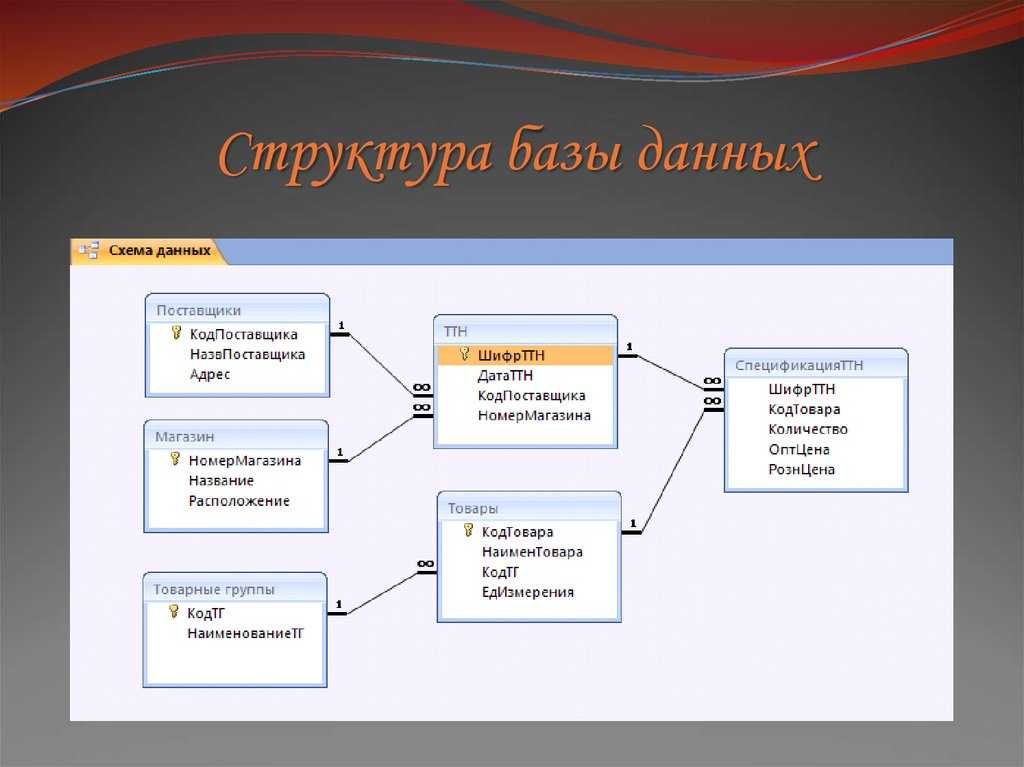
По сравнению с логической схемой она включает имена таблиц базы данных, имена столбцов и типы данных.
Теперь, когда мы знакомы с основами схемы базы данных, давайте рассмотрим несколько примеров. Мы рассмотрим наиболее распространенные примеры, с которыми вы можете столкнуться.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
Как работает серверный вызов в 1С Промо
Клиент-серверная архитектура заложена в платформе изначально — со времен «1С:Предприятие 8.0». Однако при разработке на 8.0 и 8.1 о разделении кода на клиентскую и серверную часть можно было не заботиться, поскольку на клиенте (на толстом клиенте) был доступен тот же функционал, что и на сервере. Всё изменилось с выходом платформы «1С:Предприятие 8.2», когда появился тонкий клиент. Теперь на клиенте доступен один функционал, на сервере — другой. Клиент и сервер «общаются» между собой с помощью серверного вызова. Конечно, это усложнило процесс разработки, но с другой стороны – можно создавать более оптимальные (быстрые) решения, поскольку все сложные задачи выполняются на сервере.



